Patent application title: Adding Information or Functionality to a Rendered Document via Association with an Electronic Counterpart
Inventors:
Martin T. King (Vashon Island, WA, US)
Dale L. Grover (Ann Arbor, MI, US)
Clifford A. Kushler (Lynnwood, WA, US)
James Q. Stafford-Fraser (Cambridge, GB)
Assignees:
GOOGLE INC.
IPC8 Class: AG06F1730FI
USPC Class:
707741
Class name: Database and file access preparing data for information retrieval generating an index
Publication date: 2013-12-12
Patent application number: 20130332464
Abstract:
An action plan data structure for one or more selected rendered documents
is described. The data structure contains information specifying an
action to perform automatically in response to a text capture from any of
the selected rendered documents.Claims:
1-20. (canceled)
21. A method, comprising: at an index publication server: receiving a full-text index for determining textual content of a plurality of electronic documents, wherein each electronic document of the plurality of electronic documents corresponds to a respective rendered document; receiving a query that is based on a text capture from at least a portion of a rendered document; determining a first level of query matching between the received query and a first rendered document; determining a second level of query matching between the received query and a second rendered document wherein the first rendered document differs from the second rendered document; retrieving, from the full-text index, a first specified level of matching for the first rendered document; retrieving, from the full-text index, a second specified level of matching for the second rendered document; determining that the first level of query matching exceeds the first specified level of matching; and responsively generating a first query result, for the received query, that identifies the first rendered document; and aggregating a plurality of indications of received queries to generate a profile of documents that have been queried.
22. The method of claim 21, wherein the text capture is obtained by optical scanning.
23. The method of claim 22, further comprising storing an indication that the text capture is obtained by optical scanning.
24. The method of claim 22, wherein the received query contains an indication that the text capture is obtained by optical scanning.
25. The method of claim 24, wherein the first query result is generated for the received query in a manner different than is used for queries not containing the indication.
26. The method of claim 21, wherein the plurality of electronic documents comprises an electronic document for which a paper version exists.
27. The method of claim 21, wherein the plurality of electronic documents comprises an electronic document for which a paper version is known to have been created.
28. The method of claim 21, wherein the plurality of electronic documents comprises an electronic document of a document type for which paper versions are typically created.
29. The method of claim 21, wherein the first query result returns identifications of electronic versions of documents of which paper versions exist.
30. The method of claim 21, wherein the first query result comprises an indication of a location in the first rendered document where the text capture occurs.
31. The method of claim 21, further comprising: receiving a selection of the first rendered document identified in the first query result; and providing controlled access to the first rendered document.
32. The method of claim 31, wherein providing controlled access to first rendered document comprises imposing a pecuniary charge for access to the first rendered document.
33. The method of claim 31, wherein providing controlled access to the first rendered document comprises providing access to the first rendered document when access the first rendered document is approved.
34. The method of claim 21, wherein an index is used to generate at least the first query result, and wherein the index used to generate at least the first query result is the full-text index.
35. The method of claim 34, further comprising: receiving additional indexes; and creating an aggregated index consolidating the full-text index with the additional indexes, wherein the index used to generate at least the first query result is the aggregated index.
36. The method of claim 34, further comprising: creating an aggregated index consolidating the full-text index with index information for one or more public networks, wherein the index used to generate at least the first query result comprises the aggregated index.
37. The method of claim 21, wherein at least one electronic document of the plurality of electronic documents is identified by one or more links between documents available inside a network.
38. The method of claim 21, wherein at least one electronic document of the plurality of electronic documents is identified based on one or more document catalogs.
39. The method of claim 38, wherein at least one document catalog of the one or more document catalogs is a file system directory.
40. The method of claim 38, wherein at least one document catalog of the one or more document catalogs is a document management system catalog.
41. The method of claim 34, wherein using the index based on the full-text index to generate at least the first query result comprises: determining that the first query result is permitted to include an identification of the first rendered document in the first query result.
42. The method of claim 21, wherein the full-text index comprises a plurality of indexes, each index of the plurality of indexes covering a subset of the plurality of electronic documents, such that the first rendered document is covered in a distinguished index, and wherein the method further comprises: determining that one or more requirements for revealing the first rendered document are satisfied; and in response, using the distinguished index to generate the first query result.
43. The method of claim 21, wherein the full-text index comprises a filtered index.
44. The method of claim 34, wherein the received query comprises a contiguous-string query specifying an ordered sequence of query terms, and wherein the method further comprises: using the index based upon the full-text index to determine that each query term in the ordered sequence of query terms is contained in the first rendered document; and determining that the first rendered document satisfies the contiguous-string query.
45. The method of claim 44, wherein the index based upon the full-text index is configured to determine that the first rendered document satisfies the contiguous-string query.
46. The method of claim 21, further comprising: determining that the second level of query matching is less than the second specified level of matching; and responsively determining not to generate, for the received query, a second query result that identifies the second rendered document.
47. A non-transitory computer-readable storage medium having stored thereon instructions that, when executed, cause a computing system to perform operations, comprising: receiving a full-text index for determining textual content of a plurality of electronic documents, wherein each electronic document of the plurality of electronic documents corresponds to a respective rendered document; receiving a query that is based on a text capture from at least a portion of a rendered document; determining a first level of query matching between the full-text query and a first rendered document; determining a second level of query matching between the received query and a second rendered document, wherein the first rendered document differs from the second rendered document; retrieving, from the full-text index, a first specified level of matching for the first rendered document; retrieving, from the full-text index, a second specified level of matching for the second rendered document; determining that the first level of query matching exceeds the first specified level of matching; responsively generating a first query result, for the received query, that identifies the first rendered document; and aggregating a plurality of indications of received queries to generate a profile of documents that have been queried.
48. An index publication server, configured to: receive a full-text index for determining textual content of a plurality of electronic documents, wherein each electronic document of the plurality of electronic documents corresponds to a respective rendered document; receive a query that is based on a text capture from at least a portion of a rendered document; and determine a first level of query matching between the received query and a first rendered document; determine a second level of query matching between the received query and a second rendered document, wherein the first rendered document differs from the second rendered document; retrieve, from the full-text index, a first specified level of matching for the first rendered document; retrieve, from the full-text index, a second specified level of matching for the second rendered document; determine that the first level of query matching exceeds the first specified level of matching; responsively generate a first query result for the received query that identifies the first rendered document; and aggregate a plurality of indications of received queries to generate a profile of documents that have been queried.
49. An index aggregation system, comprising: an index subsystem comprising: a first full-text index; a second full-text index, wherein at least one of the first full-text index or the second full-text index is configured to store a specified level of matching for an electronic document, and wherein the specified level of matching specifies a level of matching that a query for the electronic document has to match the electronic document before existence of the electronic document is revealed; a query subsystem configured to service a plurality of queries by searching at least the first full-text index and the second full-text index to generate a plurality of query results corresponding to the plurality of queries based on the specified levels of matching in the at least one of the first full-text index or the second full-text index and to aggregate a plurality of indications of received queries to generate a profile of documents that have been queried, wherein at least one query of the plurality of queries is based on a text capture from at least a portion of a rendered document, and wherein a query result corresponding to the at least one query is configured to identify the rendered document and at least one electronic document corresponding to the rendered document.
50. The index aggregation system of claim 49, wherein the index aggregation system is configured to identify a preferred index and return results from the preferred index.
51. The index aggregation system of claim 50, wherein the index aggregation system is configured to identify the preferred index based on content of a query.
52. The index aggregation system of claim 49, further comprising: a payment subsystem, configured to receive payments; wherein the query subsystem is further configured to service a first distinguished query after the payment subsystem receives a payment for the first distinguished query.
53. The index aggregation system of claim 49, further comprising: a payment subsystem, configured to receive payments; wherein the query subsystem is further configured to service a second distinguished query before the payment subsystem receives a payment for the second distinguished query.
54. The index aggregation system of claim 49, wherein the index subsystem further comprises a third index.
55. A system, comprising: an index subsystem comprising: a first full-text index; a second full-text index, wherein the first full-text index differs from the second full-text index, wherein at least one of the first full-text index or the second full-text index is configured to store a specified level of matching for an electronic document, and wherein the specified level of matching specifies a level of matching that a query for the electronic document has to match the electronic document before existence of the electronic document is revealed; a query subsystem configured to generate a plurality of query results for a corresponding plurality of queries by searching at least the first and second full-text indices based on the specified levels of matching in the at least one of the first full-text index or the second full-text index and to aggregate a plurality of indications of received queries to generate a profile of documents that have been queried, wherein at least one query of the plurality of queries is based on a text capture from at least a portion of a rendered document, and wherein a query result corresponding to the at least one query is configured to identify the rendered document and at least one electronic document corresponding to the rendered document; and a result subsystem that returns at least some of the plurality of query results based on the specified levels of matching in the at least one of the first full-text index or the second full-text index.
Description:
CROSS-REFERENCE TO RELATED APPLICATIONS
[0001] This application is a continuation of U.S. patent application Ser. No. 12/774,612, published as U.S. Pat. App. Pub. No. 2011/0019020 on Jan. 27, 2011, which is a continuation of U.S. patent application Ser. No. 11/097,828, now U.S. Pat. No. 7,742,953, issued Jun. 22, 2010, which is a Continuation-In-Part of U.S. patent application Ser. No. 11/004,637 filed on Dec. 3, 2004, now U.S. Pat. No. 7,707,039, issued Apr. 27, 2010, which are hereby incorporated by reference in their entirety.
[0002] This application is related to, and incorporates by reference in their entirety, the following U.S. patent applications, each of which was filed on Apr. 1, 2005: U.S. patent application Ser. No. 11/097,961, entitled METHODS AND SYSTEMS FOR INITIATING APPLICATION PROCESSES BY DATA CAPTURE FROM RENDERED DOCUMENTS, published as U.S. Pat. App. Pub. No. 2006/0041484 on Feb. 23, 2006, now abandoned, U.S. patent application Ser. No. 11/097,093, entitled DETERMINING ACTIONS INVOLVING CAPTURED INFORMATION AND ELECTRONIC CONTENT ASSOCIATED WITH RENDERED DOCUMENTS, published as U.S. Pat. App. Pub. No. 2006/0041605 on Feb. 23, 2006, now abandoned, U.S. patent application Ser. No. 11/098,038, entitled CONTENT ACCESS WITH HANDHELD DOCUMENT DATA. CAPTURE DEVICES, now U.S. Pat. No. 7,599,844, issued on Oct. 6, 2009, U.S. patent application Ser. No. 11/098,014, entitled SEARCH ENGINES AND SYSTEMS WITH HANDHELD DOCUMENT DATA CAPTURE DEVICES, now U.S. Pat. No. 8,019,648, issued on Sep. 13, 2011, U.S. patent application Ser. No. 11/097,103, entitled TRIGGERING ACTIONS IN RESPONSE TO OPTICALLY OR ACOUSTICALLY CAPTURING KEYWORDS FROM A RENDERED DOCUMENT, now U.S. Pat. No. 7,596,269, issued on Sep. 29, 2009, U.S. patent application Ser. No. 11/098,043, entitled SEARCHING AND ACCESSING DOCUMENTS ON PRIVATE NETWORKS FOR USE WITH CAPTURES FROM RENDERED DOCUMENTS, published at U.S. Pat. App. Pub. No. 2006/0053097 on Mar. 9, 2006, now abandoned, U.S. patent application Ser. No. 11/097,981, entitled INFORMATION GATHERING SYSTEM AND METHOD, now U.S. Pat. No. 7,606,741, issued Oct. 20, 2009, U.S. patent application Ser. No. 11/097,089, entitled DOCUMENT ENHANCEMENT SYSTEM AND METHOD, now U.S. Pat. No. 8,214,387, issued Jul. 3, 2012, U.S. patent application Ser. No. 11/097,835, entitled PUBLISHING TECHNIQUES FOR ADDING VALUE TO A RENDERED DOCUMENT, now U.S. Pat. No. 7,831,912, issued on Nov. 9, 2010, U.S. patent application Ser. No. 11/098,016, entitled ARCHIVE OF TEXT CAPTURES FROM RENDERED DOCUMENTS, now U.S. Pat. No. 7,421,155, issued on Sep. 2, 2008, U.S. patent application Ser. No. 11/097,833, entitled AGGREGATE ANALYSIS OF TEXT CAPTURES PERFORMED BY MULTIPLE USERS FROM RENDERED DOCUMENTS, published as U.S. Pat. App. Pub. No. 2006/0036462 on Feb. 16, 2006, now pending, U.S. patent application Ser. No. 11/097,836, entitled ESTABLISHING AN INTERACTIVE ENVIRONMENT FOR RENDERED DOCUMENTS, published as U.S. Pat. App. Pub. No. 2006/0041538 on Feb. 23, 2006, now abandoned, U.S. patent application Ser. No. 11/098,042, entitled DATA CAPTURE FROM RENDERED DOCUMENTS USING HANDHELD DEVICE, now U.S. Pat. No. 7,593,605, issued on Sep. 22, 2009, and U.S. patent application Ser. No. 11/096,704, entitled CAPTURING TEXT FROM RENDERED DOCUMENTS USING SUPPLEMENTAL INFORMATION, now U.S. Pat. No. 7,599,580, issued on Oct. 6, 2009.
[0003] This application claims priority to, and incorporates by reference in their entirety, the following U.S. Provisional patent applications: Application No. 60/559,226 filed on Apr. 1, 2004, Application No. 60/558,893 filed on Apr. 1, 2004, Application No. 60/558,968 filed on Apr. 1, 2004, Application No. 60/558,867 filed on Apr. 1, 2004, Application No. 60/559,278 filed on Apr. 1, 2004, Application No. 60/559,279 filed on Apr. 1, 2004, Application No. 60/559,265 filed on Apr. 1, 2004, Application No. 60/559,277 filed on Apr. 1, 2004, Application No. 60/558,969 filed on Apr. 1, 2004, Application No. 60/558,892 filed on Apr. 1, 2004, Application No. 60/558,760 filed on Apr. 1, 2004, Application No. 60/558,717 filed on Apr. 1, 2004, Application No. 60/558,499 filed on Apr. 1, 2004, Application No. 60/558,370 filed on Apr. 1, 2004, Application No. 60/558,789 filed on Apr. 1, 2004, Application No. 60/558,791 filed on Apr. 1, 2004, Application No. 60/558,527 filed on Apr. 1, 2004, Application No. 60/559,125 filed on Apr. 2, 2004, Application No. 60/558,909 filed on Apr. 2, 2004, Application No. 60/559,033 filed on Apr. 2, 2004, Application No. 60/559,127 filed on Apr. 2, 2004, Application No. 60/559,087 filed on Apr. 2, 2004, Application No. 60/559,131 filed on Apr. 2, 2004, Application No. 60/559,766 filed on Apr. 6, 2004, Application No. 60/561,768 filed on Apr. 12, 2004, Application No. 60/563,520 filed on Apr. 19, 2004, Application No. 60/563,485 filed on Apr. 19, 2004, Application No. 60/564,688 filed on Apr. 23, 2004, Application No. 60/564,846 filed on Apr. 23, 2004, Application No. 60/566,667 filed on Apr. 30, 2004, Application No. 60/571,381 filed on May 14, 2004, Application No. 60/571,560 filed on May 14, 2004, Application No. 60/571,715 filed on May 17, 2004, Application No. 60/589,203 filed on Jul. 19, 2004, Application No. 60/589,201 filed on Jul. 19, 2004, Application No. 60/589,202 filed on Jul. 19, 2004, Application No. 60/598,821 filed on Aug. 2, 2004, Application No. 60/602,956 filed on Aug. 18, 2004, Application No. 60/602,925 filed on Aug. 18, 2004, Application No. 60/602,947 filed on Aug. 18, 2004, Application No. 60/602,897 filed on Aug. 18, 2004, Application No. 60/602,896 filed on Aug. 18, 2004, Application No. 60/602,930 filed on Aug. 18, 2004, Application No. 60/602,898 filed on Aug. 18, 2004, Application No. 60/603,466 filed on Aug. 19, 2004, Application No. 60/603,082 filed on Aug. 19, 2004, Application No. 60/603,081 filed on Aug. 19, 2004, Application No. 60/603,498 filed on Aug. 20, 2004, Application No. 60/603,358 filed on Aug. 20, 2004, Application No. 60/604,103 filed on Aug. 23, 2004, Application No. 60/604,098 filed on Aug. 23, 2004, Application No. 60/604,100 filed on Aug. 23, 2004, Application No. 60/604,102 filed on Aug. 23, 2004, Application No. 60/605,229 filed on Aug. 27, 2004, Application No. 60/605,105 filed on Aug. 27, 2004, Application No. 60/613,243 filed on Sep. 27, 2004, Application No. 60/613,628 filed on Sep. 27, 2004, Application No. 60/613,632 filed on Sep. 27, 2004, Application No. 60/613,589 filed on Sep. 27, 2004, Application No. 60/613,242 filed on Sep. 27, 2004, Application No. 60/613,602 filed on Sep. 27, 2004, Application No. 60/613,340 filed on Sep. 27, 2004, Application No. 60/613,634 filed on Sep. 27, 2004, Application No. 60/613,461 filed on Sep. 27, 2004, Application No. 60/613,455 filed on Sep. 27, 2004, Application No. 60/613,460 filed on Sep. 27, 2004, Application No. 60/613,400 filed on Sep. 27, 2004, Application No. 60/613,456 filed on Sep. 27, 2004, Application No. 60/613,341 filed on Sep. 27, 2004, Application No. 60/613,361 filed on Sep. 27, 2004, Application No. 60/613,454 filed on Sep. 27, 2004, Application No. 60/613,339 filed on Sep. 27, 2004, Application No. 60/613,633 filed on Sep. 27, 2004, Application No. 60/615,378 filed on Oct. 1, 2004, Application No. 60/615,112 filed on Oct. 1, 2004, Application No. 60/615,538 filed on Oct. 1, 2004, Application No. 60/617,122 filed on Oct. 7, 2004, Application No. 60/622,906 filed on Oct. 28, 2004, Application No. 60/633,452 filed on Dec. 6, 2004, Application No. 60/633,678 filed on Dec. 6, 2004, Application No. 60/633,486 filed on Dec. 6, 2004, Application No. 60/633,453 filed on Dec. 6, 2004, Application No. 60/634,627 filed on Dec. 9, 2004, Application No. 60/634,739 filed on Dec. 9, 2004, Application No. 60/647,684 filed on Jan. 26, 2005, Application No. 60/648,746 filed on Jan. 31, 2005, Application No. 60/653,372 filed on Feb. 15, 2005, Application No. 60/653,663 filed on Feb. 16, 2005, Application No. 60/653,669 filed on Feb. 16, 2005, Application No. 60/653,899 filed on Feb. 16, 2005, Application No. 60/653,679 filed on Feb. 16, 2005, Application No. 60/653,847 filed on Feb. 16, 2005, Application No. 60/654,379 filed on Feb. 17, 2005, Application No. 60/654,368 filed on Feb. 18, 2005, Application No. 60/654,326 filed on Feb. 18, 2005, Application No. 60/654,196 filed on Feb. 18, 2005, Application No. 60/655,279 filed on Feb. 22, 2005, Application No. 60/655,280 filed on Feb. 22, 2005, Application No. 60/655,987 filed on Feb. 22, 2005, Application No. 60/655,697 filed on Feb. 22, 2005, Application No. 60/655,281 filed on Feb. 22, 2005, and Application No. 60/657,309 filed on Feb. 28, 2005.
TECHNICAL FIELD
[0004] The described technology is directed to the field of document processing. This disclosure relates generally to search and retrieval of electronic materials and, more specifically, to searching and accessing digital content on private networks.
BACKGROUND
[0005] Paper documents have an enduring appeal, as can be seen by the proliferation of paper documents in the computer age. It has never been easier to print and publish paper documents than it is today. Paper documents prevail even though electronic documents are easier to duplicate, transmit, search and edit.
[0006] Given the popularity of paper documents and the advantages of electronic documents, it would be useful to combine the benefits of both.
BRIEF DESCRIPTION OF THE DRAWINGS
[0007] FIG. 1 is a data flow diagram that illustrates the flow of information in one embodiment of the core system.
[0008] FIG. 2 is a component diagram of components included in a typical implementation of the system in the context of a typical operating environment.
[0009] FIG. 3 is a block diagram of an embodiment of a scanner.
[0010] FIG. 4 is a network diagram showing a typical environment in which the facility operates.
[0011] FIG. 5 shows an example embodiment of the system.
[0012] FIG. 6 is a block diagram showing some of the components typically incorporated in at least some of the computer systems and other devices on which the facility executes.
[0013] FIG. 7 is a data flow diagram showing a first manner in which index information is exported by some embodiments of the facility.
[0014] FIG. 8 is a flow diagram showing steps typically performed by the facility in order to export an index from the private network.
[0015] FIG. 9 is a table diagram showing a sample exported index exported by the facility.
[0016] FIG. 10 is a flow diagram showing steps typically performed by the facility in order to import an exported index.
[0017] FIG. 11 is a data structure diagram showing a sample aggregated index generated by the facility.
[0018] FIG. 12 is a flow diagram showing steps typically performed by the facility to service a query.
[0019] FIG. 13 is a data flow diagram showing a second manner in which index information is exported by some embodiments of the facility.
[0020] FIG. 14 is a data flow diagram showing a third manner in which index information is exported by some embodiments of the facility.
DETAILED DESCRIPTION
[0021] Overview
[0022] A software and/or hardware facility for searching for documents available in a private network ("the facility") is described below. In some embodiments, a portion of the facility executing inside a private network crawls or otherwise surveys electronic versions of documents available in the private network to build an index of electronic documents found in the private network. The facility can export the index to an external index aggregation center where the index can be stored and/or aggregated with indexes from other sources. The facility may use individual indexes and/or various aggregated indexes to service queries from users, such as queries each seeking to identify a document based upon a small portion of text optically scanned from a paper version of the document. The search result returned by the facility lists documents satisfying the query, and can be used to access these documents in a variety of ways.
[0023] In some embodiments, the facility can expose an index of private documents to predetermined users. In a private network, the facility (1) identifies electronic versions of documents that are available inside the private network, including a distinguished document; (2) constructs an index covering the identified electronic versions of documents; and (3) exports the constructed index from the private network to an index publication server. At the index publication server, the facility (1) receives the exported index; (2) receives a query via a public network; and (3) verifies that the party submitting the query is authorized to search the index and/or access the query results; and (4) if the party is authorized, generates a query result for the received query that contains the distinguished document.
[0024] Part I--Introduction
1. Nature of the System
[0025] For every paper document that has an electronic counterpart, there exists a discrete amount of information in the paper document that can identify the electronic counterpart. In some embodiments, the system uses a sample of text captured from a paper document, for example using a handheld scanner, to identify and locate an electronic counterpart of the document. In most cases, the amount of text needed by the facility is very small in that a few words of text from a document can often function as an identifier for the paper document and as a link to its electronic counterpart. In addition, the system may use those few words to identify not only the document, but also a location within the document.
[0026] Thus, paper documents and their digital counterparts can be associated in many useful ways using the system discussed herein.
[0027] 1.1. A Quick Overview of the Future
[0028] Once the system has associated a piece of text in a paper document with a particular digital entity has been established, the system is able to build a huge amount of functionality on that association.
[0029] It is increasingly the case that most paper documents have an electronic counterpart that is accessible on the World Wide Web or from some other online database or document corpus, or can be made accessible, such as in response to the payment of a fee or subscription. At the simplest level, then, when a user scans a few words in a paper document, the system can retrieve that electronic document or some part of it, or display it, email it to somebody, purchase it, print it or post it to a web page. As additional examples, scanning a few words of a book that a person is reading over breakfast could cause the audio-book version in the person's car to begin reading from that point when s/he starts driving to work, or scanning the serial number on a printer cartridge could begin the process of ordering a replacement.
[0030] The system implements these and many other examples of "paper/digital integration" without requiring changes to the current processes of writing, printing and publishing documents, giving such conventional rendered documents a whole new layer of digital functionality.
[0031] 1.2. Terminology
[0032] A typical use of the system begins with using an optical scanner to scan text from a paper document, but it is important to note that other methods of capture from other types of document are equally applicable. The system is therefore sometimes described as scanning or capturing text from a rendered document, where those terms are defined as follows:
[0033] A rendered document is a printed document or a document shown on a display or monitor. It is a document that is perceptible to a human, whether in permanent form or on a transitory display.
[0034] Scanning or capturing is the process of systematic examination to obtain information from a rendered document. The process may involve optical capture using a scanner or camera (for example a camera in a cellphone), or it may involve reading aloud from the document into an audio capture device or typing it on a keypad or keyboard. For more examples, see Section 15.
2. Introduction to the System
[0035] This section describes some of the devices, processes and systems that constitute a system for paper/digital integration. In various embodiments, the system builds a wide variety of services and applications on this underlying core that provides the basic functionality.
[0036] 2.1. The Processes
[0037] FIG. 1 is a data flow diagram that illustrates the flow of information in one embodiment of the core system. Other embodiments may not use all of the stages or elements illustrated here, while some will use many more.
[0038] Text from a rendered document is captured 100, typically in optical form by an optical scanner or audio form by a voice recorder, and this image or sound data is then processed 102, for example to remove artifacts of the capture process or to improve the signal-to-noise ratio. A recognition process 104 such as OCR, speech recognition, or autocorrelation then converts the data into a signature, comprised in some embodiments of text, text offsets, or other symbols. Alternatively, the system performs an alternate form of extracting document signature from the rendered document. The signature represents a set of possible text transcriptions in some embodiments. This process may be influenced by feedback from other stages, for example, if the search process and context analysis 110 have identified some candidate documents from which the capture may originate, thus narrowing the possible interpretations of the original capture.
[0039] A post-processing 106 stage may take the output of the recognition process and filter it or perform such other operations upon it as may be useful. Depending upon the embodiment implemented, it may be possible at this stage to deduce some direct actions 107 to be taken immediately without reference to the later stages, such as where a phrase or symbol has been captured which contains sufficient information in itself to convey the user's intent. In these cases no digital counterpart document need be referenced, or even known to the system.
[0040] Typically, however, the next stage will be to construct a query 108 or a set of queries for use in searching. Some aspects of the query construction may depend on the search process used and so cannot be performed until the next stage, but there will typically be some operations, such as the removal of obviously misrecognized or irrelevant characters, which can be performed in advance.
[0041] The query or queries are then passed to the search and context analysis stage 110. Here, the system optionally attempts to identify the document from which the original data was captured. To do so, the system typically uses search indices and search engines 112, knowledge about the user 114 and knowledge about the user's context or the context in which the capture occurred 116. Search engine 112 may employ and/or index information specifically about rendered documents, about their digital counterpart documents, and about documents that have a web (internet) presence). It may write to, as well as read from, many of these sources and, as has been mentioned, it may feed information into other stages of the process, for example by giving the recognition system 104 information about the language, font, rendering and likely next words based on its knowledge of the candidate documents.
[0042] In some circumstances the next stage will be to retrieve 120 a copy of the document or documents that have been identified. The sources of the documents 124 may be directly accessible, for example from a local filing system or database or a web server, or they may need to be contacted via some access service 122 which might enforce authentication, security or payment or may provide other services such as conversion of the document into a desired format.
[0043] Applications of the system may take advantage of the association of extra functionality or data with part or all of a document. For example, advertising applications discussed in Section 10.4 may use an association of particular advertising messages or subjects with portions of a document. This extra associated functionality or data can be thought of as one or more overlays on the document, and is referred to herein as "markup." The next stage of the process 130, then, is to identify any markup relevant to the captured data. Such markup may be provided by the user, the originator, or publisher of the document, or some other party, and may be directly accessible from some source 132 or may be generated by some service 134. In various embodiments, markup can be associated with, and apply to, a rendered document and/or the digital counterpart to a rendered document, or to groups of either or both of these documents.
[0044] Lastly, as a result of the earlier stages, some actions may be taken 140. These may be default actions such as simply recording the information found, they may be dependent on the data or document, or they may be derived from the markup analysis. Sometimes the action will simply be to pass the data to another system. In some cases the various possible actions appropriate to a capture at a specific point in a rendered document will be presented to the user as a menu on an associated display, for example on a local display 332, on a computer display 212 or a mobile phone or PDA display 216. If the user doesn't respond to the menu, the default actions can be taken.
[0045] 2.2. The Components
[0046] FIG. 2 is a component diagram of components included in a typical implementation of the system in the context of a typical operating environment. As illustrated, the operating environment includes one or more optical scanning capture devices 202 or voice capture devices 204. In some embodiments, the same device performs both functions. Each capture device is able to communicate with other parts of the system such as a computer 212 and a mobile station 216 (e.g., a mobile phone or PDA) using either a direct wired or wireless connection, or through the network 220, with which it can communicate using a wired or wireless connection, the latter typically involving a wireless base station 214. In some embodiments, the capture device is integrated in the mobile station, and optionally shares some of the audio and/or optical components used in the device for voice communications and picture-taking.
[0047] Computer 212 may include a memory containing computer executable instructions for processing an order from scanning devices 202 and 204. As an example, an order can include an identifier (such as a serial number of the scanning device 202/204 or an identifier that partially or uniquely identifies the user of the scanner), scanning context information (e.g., time of scan, location of scan, etc.) and/or scanned information (such as a text string) that is used to uniquely identify the document being scanned. In alternative embodiments, the operating environment may include more or less components.
[0048] Also available on the network 220 are search engines 232, document sources 234, user account services 236, markup services 238 and other network services 239. The network 220 may be a corporate intranet, the public Internet, a mobile phone network or some other network, or any interconnection of the above.
[0049] Regardless of the manner by which the devices are coupled to each other, they may all may be operable in accordance with well-known commercial transaction and communication protocols (e.g., Internet Protocol (IP)). In various embodiments, the functions and capabilities of scanning device 202, computer 212, and mobile station 216 may be wholly or partially integrated into one device. Thus, the terms scanning device, computer, and mobile station can refer to the same device depending upon whether the device incorporates functions or capabilities of the scanning device 202, computer 212 and mobile station 216. In addition, some or all of the functions of the search engines 232, document sources 234, user account services 236, markup services 238 and other network services 239 may be implemented on any of the devices and/or other devices not shown.
[0050] 2.3. The Capture Device
[0051] As described above, the capture device may capture text using an optical scanner that captures image data from the rendered document, or using an audio recording device that captures a user's spoken reading of the text, or other methods. Some embodiments of the capture device may also capture images, graphical symbols and icons, etc., including machine readable codes such as barcodes. The device may be exceedingly simple, consisting of little more than the transducer, some storage, and a data interface, relying on other functionality residing elsewhere in the system, or it may be a more full-featured device. For illustration, this section describes a device based around an optical scanner and with a reasonable number of features.
[0052] Scanners are well known devices that capture and digitize images. An offshoot of the photocopier industry, the first scanners were relatively large devices that captured an entire document page at once. Recently, portable optical scanners have been introduced in convenient form factors, such as a pen-shaped handheld device.
[0053] In some embodiments, the portable scanner is used to scan text, graphics, or symbols from rendered documents. The portable scanner has a scanning element that captures text, symbols, graphics, etc, from rendered documents. In addition to documents that have been printed on paper, in some embodiments, rendered documents include documents that have been displayed on a screen such as a CRT monitor or LCD display.
[0054] FIG. 3 is a block diagram of an embodiment of a scanner 302. The scanner 302 comprises an optical scanning head 308 to scan information from rendered documents and convert it to machine-compatible data, and an optical path 306, typically a lens, an aperture or an image conduit to convey the image from the rendered document to the scanning head. The scanning head 308 may incorporate a Charge-Coupled Device (CCD), a Complementary Metal Oxide Semiconductor (CMOS) imaging device, or an optical sensor of another type.
[0055] A microphone 310 and associated circuitry convert the sound of the environment (including spoken words) into machine-compatible signals, and other input facilities exist in the form of buttons, scroll-wheels or other tactile sensors such as touch-pads 314.
[0056] Feedback to the user is possible through a visual display or indicator lights 332, through a loudspeaker or other audio transducer 334 and through a vibrate module 336.
[0057] The scanner 302 comprises logic 326 to interact with the various other components, possibly processing the received signals into different formats and/or interpretations. Logic 326 may be operable to read and write data and program instructions stored in associated storage 330 such as RAM, ROM, flash, or other suitable memory. It may read a time signal from the clock unit 328. The scanner 302 also includes an interface 316 to communicate scanned information and other signals to a network and/or an associated computing device. In some embodiments, the scanner 302 may have an on-board power supply 332. In other embodiments, the scanner 302 may be powered from a tethered connection to another device, such as a Universal Serial Bus (USB) connection.
[0058] As an example of one use of scanner 302, a reader may scan some text from a newspaper article with scanner 302. The text is scanned as a bit-mapped image via the scanning head 308. Logic 326 causes the bit-mapped image to be stored in memory 330 with an associated time-stamp read from the clock unit 328. Logic 326 may also perform optical character recognition (OCR) or other post-scan processing on the bit-mapped image to convert it to text. Logic 326 may optionally extract a signature from the image, for example by performing a convolution-like process to locate repeating occurrences of characters, symbols or objects, and determine the distance or number of other characters, symbols, or objects between these repeated elements. The reader may then upload the bit-mapped image (or text or other signature, if post-scan processing has been performed by logic 326) to an associated computer via interface 316.
[0059] As an example of another use of scanner 302, a reader may capture some text from an article as an audio file by using microphone 310 as an acoustic capture port. Logic 326 causes audio file to be stored in memory 328. Logic 326 may also perform voice recognition or other post-scan processing on the audio file to convert it to text. As above, the reader may then upload the audio file (or text produced by post-scan processing performed by logic 326) to an associated computer via interface 316.
[0060] Part II--Overview of the Areas of the Core System
[0061] As paper-digital integration becomes more common, there are many aspects of existing technologies that can be changed to take better advantage of this integration, or to enable it to be implemented more effectively. This section highlights some of those issues.
3. Search
[0062] Searching a corpus of documents, even so large a corpus as the World Wide Web, has become commonplace for ordinary users, who use a keyboard to construct a search query which is sent to a search engine. This section and the next discuss the aspects of both the construction of a query originated by a capture from a rendered document, and the search engine that handles such a query.
[0063] 3.1. Scan/Speak/Type as Search Query
[0064] Use of the described system typically starts with a few words being captured from a rendered document using any of several methods, including those mentioned in Section 1.2 above. Where the input needs some interpretation to convert it to text, for example in the case of OCR or speech input, there may be end-to-end feedback in the system so that the document corpus can be used to enhance the recognition process. End-to-end feedback can be applied by performing an approximation of the recognition or interpretation, identifying a set of one or more candidate matching documents, and then using information from the possible matches in the candidate documents to further refine or restrict the recognition or interpretation. Candidate documents can be weighted according to their probable relevance (for example, based on then number of other users who have scanned in these documents, or their popularity on the Internet), and these weights can be applied in this iterative recognition process.
[0065] 3.2. Short Phrase Searching
[0066] Because the selective power of a search query based on a few words is greatly enhanced when the relative positions of these words are known, only a small amount of text need be captured for the system to identify the text's location in a corpus. Most commonly, the input text will be a contiguous sequence of words, such as a short phrase.
[0067] 3.2.1. Finding Document and Location in Document from Short Capture
[0068] In addition to locating the document from which a phrase originates, the system can identify the location in that document and can take action based on this knowledge.
[0069] 3.2.2. Other Methods of Finding Location
[0070] The system may also employ other methods of discovering the document and location, such as by using watermarks or other special markings on the rendered document.
[0071] 3.3. Incorporation of Other Factors in Search Query
[0072] In addition to the captured text, other factors (i.e., information about user identity, profile, and context) may form part of the search query, such as the time of the capture, the identity and geographical location of the user, knowledge of the user's habits and recent activities, etc.
[0073] The document identity and other information related to previous captures, especially if they were quite recent, may form part of a search query.
[0074] The identity of the user may be determined from a unique identifier associated with a capturing device, and/or biometric or other supplemental information (speech patterns, fingerprints, etc.).
[0075] 3.4. Knowledge of Nature of Unreliability in Search Query (OCR Errors Etc.)
[0076] The search query can be constructed taking into account the types of errors likely to occur in the particular capture method used. One example of this is an indication of suspected errors in the recognition of specific characters; in this instance a search engine may treat these characters as wildcards, or assign them a lower priority.
[0077] 3.5. Local Caching of Index for Performance/Offline Use
[0078] Sometimes the capturing device may not be in communication with the search engine or corpus at the time of the data capture. For this reason, information helpful to the offline use of the device may be downloaded to the device in advance, or to some entity with which the device can communicate. In some cases, all or a substantial part of an index associated with a corpus may be downloaded. This topic is discussed further in Section 15.3.
[0079] 3.6. Queries, in Whatever Form, May be Recorded and Acted on Later
[0080] If there are likely to be delays or cost associated with communicating a query or receiving the results, this pre-loaded information can improve the performance of the local device, reduce communication costs, and provide helpful and timely user feedback.
[0081] In the situation where no communication is available (the local device is "offline"), the queries may be saved and transmitted to the rest of the system at such a time as communication is restored.
[0082] In these cases it may be important to transmit a timestamp with each query. The time of the capture can be a significant factor in the interpretation of the query. For example, Section 13.1 discusses the importance of the time of capture in relation to earlier captures. It is important to note that the time of capture will not always be the same as the time that the query is executed.
[0083] 3.7. Parallel Searching
[0084] For performance reasons, multiple queries may be launched in response to a single capture, either in sequence or in parallel. Several queries may be sent in response to a single capture, for example as new words are added to the capture, or to query multiple search engines in parallel.
[0085] For example, in some embodiments, the system sends queries to a special index for the current document, to a search engine on a local machine, to a search engine on the corporate network, and to remote search engines on the Internet.
[0086] The results of particular searches may be given higher priority than those from others.
[0087] The response to a given query may indicate that other pending queries are superfluous; these may be cancelled before completion.
4. Paper and Search Engines
[0088] Often it is desirable for a search engine that handles traditional online queries also to handle those originating from rendered documents. Conventional search engines may be enhanced or modified in a number of ways to make them more suitable for use with the described system.
[0089] The search engine and/or other components of the system may create and maintain indices that have different or extra features. The system may modify an incoming paper-originated query or change the way the query is handled in the resulting search, thus distinguishing these paper-originated queries from those coming from queries typed into web browsers and other sources. And the system may take different actions or offer different options when the results are returned by the searches originated from paper as compared to those from other sources. Each of these approaches is discussed below.
[0090] 4.1. Indexing
[0091] Often, the same index can be searched using either paper-originated or traditional queries, but the index may be enhanced for use in the current system in a variety of ways.
[0092] 4.1.1. Knowledge about the Paper Form
[0093] Extra fields can be added to such an index that will help in the case of a paper-based search.
Index Entry Indicating Document Availability in Paper Form
[0094] The first example is a field indicating that the document is known to exist or be distributed in paper form. The system may give such documents higher priority if the query comes from paper.
Knowledge of Popularity Paper Form
[0095] In this example statistical data concerning the popularity of paper documents (and, optionally, concerning sub-regions within these documents)--for example the amount of scanning activity, circulation numbers provided by the publisher or other sources, etc.--is used to give such documents higher priority, to boost the priority of digital counterpart documents (for example, for browser-based queries or web searches), etc.
Knowledge of Rendered Format
[0096] Another important example may be recording information about the layout of a specific rendering of a document.
[0097] For a particular edition of a book, for example, the index may include information about where the line breaks and page breaks occur, which fonts were used, any unusual capitalization.
[0098] The index may also include information about the proximity of other items on the page, such as images, text boxes, tables and advertisements.
Use of Semantic Information in Original
[0099] Lastly, semantic information that can be deduced from the source markup but is not apparent in the paper document, such as the fact that a particular piece of text refers to an item offered for sale, or that a certain paragraph contains program code, may also be recorded in the index.
[0100] 4.1.2. Indexing in the Knowledge of the Capture Method
[0101] A second factor that may modify the nature of the index is the knowledge of the type of capture likely to be used. A search initiated by an optical scan may benefit if the index takes into account characters that are easily confused in the OCR process, or includes some knowledge of the fonts used in the document. Similarly, if the query is from speech recognition, an index based on similar-sounding phonemes may be much more efficiently searched. An additional factor that may affect the use of the index in the described model is the importance of iterative feedback during the recognition process. If the search engine is able to provide feedback from the index as the text is being captured, it can greatly increase the accuracy of the capture.
Indexing Using Offsets
[0102] If the index is likely to be searched using the offset-based/autocorrelation OCR methods described in Section 9, in some embodiments, the system stores the appropriate offset or signature information in an index.
[0103] 4.1.3. Multiple Indices
[0104] Lastly, in the described system, it may be common to conduct searches on many indices. Indices may be maintained on several machines on a corporate network. Partial indices may be downloaded to the capture device, or to a machine close to the capture device. Separate indices may be created for users or groups of users with particular interests, habits or permissions. An index may exist for each file system, each directory, even each file on a user's hard disk. Indexes are published and subscribed to by users and by systems. It will be important, then, to construct indices that can be distributed, updated, merged and separated efficiently.
[0105] 4.2. Handling the Queries
[0106] 4.2.1. Knowing the Capture is from Paper
[0107] A search engine may take different actions when it recognizes that a search query originated from a paper document. The engine might handle the query in a way that is more tolerant to the types of errors likely to appear in certain capture methods, for example.
[0108] It may be able to deduce this from some indicator included in the query (for example a flag indicating the nature of the capture), or it may deduce this from the query itself (for example, it may recognize errors or uncertainties typical of the OCR process).
[0109] Alternatively, queries from a capture device can reach the engine by a different channel or port or type of connection than those from other sources, and can be distinguished in that way. For example, some embodiments of the system will route queries to the search engine by way of a dedicated gateway. Thus, the search engine knows that all queries passing through the dedicated gateway were originated from a paper document.
[0110] 4.2.2. Use of Context
[0111] Section 13 below describes a variety of different factors which are external to the captured text itself, yet which can be a significant aid in identifying a document. These include such things as the history of recent scans, the longer-term reading habits of a particular user, the geographic location of a user and the user's recent use of particular electronic documents. Such factors are referred to herein as "context."
[0112] Some of the context may be handled by the search engine itself, and be reflected in the search results. For example, the search engine may keep track of a user's scanning history, and may also cross-reference this scanning history to conventional keyboard-based queries. In such cases, the search engine maintains and uses more state information about each individual user than do most conventional search engines, and each interaction with a search engine may be considered to extend over several searches and a longer period of time than is typical today.
[0113] Some of the context may be transmitted to the search engine in the search query (Section 3.3), and may possibly be stored at the engine so as to play a part in future queries. Lastly, some of the context will best be handled elsewhere, and so becomes a filter or secondary search applied to the results from the search engine.
Data-Stream Input to Search
[0114] An important input into the search process is the broader context of how the community of users is interacting with the rendered version of the document--for example, which documents are most widely read and by whom. There are analogies with a web search returning the pages that are most frequently linked to, or those that are most frequently selected from past search results. For further discussion of this topic, see Sections 13.4 and 14.2.
[0115] 4.2.3. Document Sub-Regions
[0116] The described system can emit and use not only information about documents as a whole, but also information about sub-regions of documents, even down to individual words. Many existing search engines concentrate simply on locating a document or file that is relevant to a particular query. Those that can work on a finer grain and identify a location within a document will provide a significant benefit for the described system.
[0117] 4.3. Returning the Results
[0118] The search engine may use some of the further information it now maintains to affect the results returned.
[0119] The system may also return certain documents to which the user has access only as a result of being in possession of the paper copy (Section 7.4).
[0120] The search engine may also offer new actions or options appropriate to the described system, beyond simple retrieval of the text.
5. Markup, Annotations and Metadata
[0121] In addition to performing the capture-search-retrieve process, the described system also associates extra functionality with a document, and in particular with specific locations or segments of text within a document. This extra functionality is often, though not exclusively, associated with the rendered document by being associated with its electronic counterpart. As an example, hyperlinks in a web page could have the same functionality when a printout of that web page is scanned. In some cases, the functionality is not defined in the electronic document, but is stored or generated elsewhere.
[0122] This layer of added functionality is referred to herein as "markup."
[0123] 5.1. Overlays, Static and Dynamic
[0124] One way to think of the markup is as an "overlay" on the document, which provides further information about--and may specify actions associated with--the document or some portion of it. The markup may include human-readable content, but is often invisible to a user and/or intended for machine use. Examples include options to be displayed in a popup-menu on a nearby display when a user captures text from a particular area in a rendered document, or audio samples that illustrate the pronunciation of a particular phrase.
[0125] 5.1.1. Several Layers, Possibly from Several Sources
[0126] Any document may have multiple overlays simultaneously, and these may be sourced from a variety of locations. Markup data may be created or supplied by the author of the document, or by the user, or by some other party.
[0127] Markup data may be attached to the electronic document or embedded in it. It may be found in a conventional location (for example, in the same place as the document but with a different filename suffix). Markup data may be included in the search results of the query that located the original document, or may be found by a separate query to the same or another search engine. Markup data may be found using the original captured text and other capture information or contextual information, or it may be found using already-deduced information about the document and location of the capture. Markup data may be found in a location specified in the document, even if the markup itself is not included in the document.
[0128] The markup may be largely static and specific to the document, similar to the way links on a traditional html web page are often embedded as static data within the html document, but markup may also be dynamically generated and/or applied to a large number of documents. An example of dynamic markup is information attached to a document that includes the up-to-date share price of companies mentioned in that document. An example of broadly applied markup is translation information that is automatically available on multiple documents or sections of documents in a particular language.
[0129] 5.1.2. Personal "Plug-in" Layers
[0130] Users may also install, or subscribe to particular sources of, markup data, thus personalizing the system's response to particular captures.
[0131] 5.2. Keywords and Phrases, Trademarks and Logos
[0132] Some elements in documents may have particular "markup" or functionality associated with them based on their own characteristics rather than their location in a particular document. Examples include special marks that are printed in the document purely for the purpose of being scanned, as well as logos and trademarks that can link the user to further information about the organization concerned. The same applies to "keywords" or "key phrases" in the text. Organizations might register particular phrases with which they are associated, or with which they would like to be associated, and attach certain markup to them that would be available wherever that phrase was scanned.
[0133] Any word, phrase, etc. may have associated markup. For example, the system may add certain items to a pop-up menu (e.g., a link to an online bookstore) whenever the user captures the word "book," or the title of a book, or a topic related to books. In some embodiments, of the system, digital counterpart documents or indices are consulted to determine whether a capture occurred near the word "book," or the title of a book, or a topic related to books--and the system behavior is modified in accordance with this proximity to keyword elements. In the preceding example, note that markup enables data captured from non-commercial text or documents to trigger a commercial transaction.
[0134] 5.3. User-Supplied Content
[0135] 5.3.1. User Comments and Annotations, Including Multimedia
[0136] Annotations are another type of electronic information that may be associated with a document. For example, a user can attach an audio file of his/her thoughts about a particular document for later retrieval as voice annotations. As another example of a multimedia annotation, a user may attach photographs of places referred to in the document. The user generally supplies annotations for the document but the system can associate annotations from other sources (for example, other users in a work group may share annotations).
[0137] 5.3.2. Notes from Proof-Reading
[0138] An important example of user-sourced markup is the annotation of paper documents as part of a proofreading, editing or reviewing process.
[0139] 5.4. Third-Party Content
[0140] As mentioned earlier, markup data may often be supplied by third parties, such as by other readers of the document. Online discussions and reviews are a good example, as are community-managed information relating to particular works, volunteer-contributed translations and explanations.
[0141] Another example of third-party markup is that provided by advertisers.
[0142] 5.5. Dynamic Markup Based on Other Users' Data Streams
[0143] By analyzing the data captured from documents by several or all users of the system, markup can be generated based on the activities and interests of a community. An example might be an online bookstore that creates markup or annotations that tell the user, in effect, "People who enjoyed this book also enjoyed . . . " The markup may be less anonymous, and may tell the user which of the people in his/her contact list have also read this document recently. Other examples of datastream analysis are included in Section 14.
[0144] 5.6. Markup Based on External Events and Data Sources
[0145] Markup will often be based on external events and data sources, such as input from a corporate database, information from the public Internet, or statistics gathered by the local operating system.
[0146] Data sources may also be more local, and in particular may provide information about the user's context--his/her identity, location and activities. For example, the system might communicate with the user's mobile phone and offer a markup layer that gives the user the option to send a document to somebody that the user has recently spoken to on the phone.
6. Authentication, Personalization and Security
[0147] In many situations, the identity of the user will be known. Sometimes this will be an "anonymous identity," where the user is identified only by the serial number of the capture device, for example. Typically, however, it is expected that the system will have a much more detailed knowledge of the user, which can be used for personalizing the system and to allow activities and transactions to be performed in the user's name.
[0148] 6.1. User History and "Life Library"
[0149] One of the simplest and yet most useful functions that the system can perform is to keep a record for a user of the text that s/he has captured and any further information related to that capture, including the details of any documents found, the location within that document and any actions taken as a result.
[0150] This stored history is beneficial for both the user and the system.
[0151] 6.1.1. For the User
[0152] The user can be presented with a "Life Library," a record of everything s/he has read and captured. This may be simply for personal interest, but may be used, for example, in a library by an academic who is gathering material for the bibliography of his next paper.
[0153] In some circumstances, the user may wish to make the library public, such as by publishing it on the web in a similar manner to a weblog, so that others may see what s/he is reading and finds of interest.
[0154] Lastly, in situations where the user captures some text and the system cannot immediately act upon the capture (for example, because an electronic version of the document is not yet available) the capture can be stored in the library and can be processed later, either automatically or in response to a user request. A user can also subscribe to new markup services and apply them to previously captured scans.
[0155] 6.1.2. For the System
[0156] A record of a user's past captures is also useful for the system. Many aspects of the system operation can be enhanced by knowing the user's reading habits and history. The simplest example is that any scan made by a user is more likely to come from a document that the user has scanned in the recent past, and in particular if the previous scan was within the last few minutes it is very likely to be from the same document. Similarly, it is more likely that a document is being read in start-to-finish order. Thus, for English documents, it is also more likely that later scans will occur farther down in the document. Such factors can help the system establish the location of the capture in cases of ambiguity, and can also reduce the amount of text that needs to be captured.
[0157] 6.2. Scanner as Payment, Identity and Authentication Device
[0158] Because the capture process generally begins with a device of some sort, typically an optical scanner or voice recorder, this device may be used as a key that identifies the user and authorizes certain actions.
[0159] 6.2.1. Associate Scanner with Phone or Other Account
[0160] The device may be embedded in a mobile phone or in some other way associated with a mobile phone account. For example, a scanner may be associated with a mobile phone account by inserting a SIM card associated with the account into the scanner. Similarly, the device may be embedded in a credit card or other payment card, or have the facility for such a card to be connected to it. The device may therefore be used as a payment token, and financial transactions may be initiated by the capture from the rendered document.
[0161] 6.2.2. Using Scanner Input for Authentication
[0162] The scanner may also be associated with a particular user or account through the process of scanning some token, symbol or text associated with that user or account. In addition, scanner may be used for biometric identification, for example by scanning the fingerprint of the user. In the case of an audio-based capture device, the system may identify the user by matching the voice pattern of the user or by requiring the user to speak a certain password or phrase.
[0163] For example, where a user scans a quote from a book and is offered the option to buy the book from an online retailer, the user can select this option, and is then prompted to scan his/her fingerprint to confirm the transaction.
[0164] See also Sections 15.5 and 15.6.
[0165] 6.2.3. Secure Scanning Device
[0166] When the capture device is used to identify and authenticate the user, and to initiate transactions on behalf of the user, it is important that communications between the device and other parts of the system are secure. It is also important to guard against such situations as another device impersonating a scanner, and so-called "man in the middle" attacks where communications between the device and other components are intercepted.
[0167] Techniques for providing such security are well understood in the art; in various embodiments, the hardware and software in the device and elsewhere in the system are configured to implement such techniques.
7. Publishing Models and Elements
[0168] An advantage of the described system is that there is no need to alter the traditional processes of creating, printing or publishing documents in order to gain many of the system's benefits. There are reasons, though, that the creators or publishers of a document--hereafter simply referred to as the "publishers"--may wish to create functionality to support the described system.
[0169] This section is primarily concerned with the published documents themselves. For information about other related commercial transactions, such as advertising, see Section 10 entitled "P-Commerce."
[0170] 7.1. Electronic Companions to Printed Documents
[0171] The system allows for printed documents to have an associated electronic presence. Conventionally publishers often ship a CD-ROM with a book that contains further digital information, tutorial movies and other multimedia data, sample code or documents, or further reference materials. In addition, some publishers maintain web sites associated with particular publications which provide such materials, as well as information which may be updated after the time of publishing, such as errata, further comments, updated reference materials, bibliographies and further sources of relevant data, and translations into other languages. Online forums allow readers to contribute their comments about the publication.
[0172] The described system allows such materials to be much more closely tied to the rendered document than ever before, and allows the discovery of and interaction with them to be much easier for the user. By capturing a portion of text from the document, the system can automatically connect the user to digital materials associated with the document, and more particularly associated with that specific part of the document. Similarly, the user can be connected to online communities that discuss that section of the text, or to annotations and commentaries by other readers. In the past, such information would typically need to be found by searching for a particular page number or chapter.
[0173] An example application of this is in the area of academic textbooks (Section 17.5).
[0174] 7.2. "Subscriptions" to Printed Documents
[0175] Some publishers may have mailing lists to which readers can subscribe if they wish to be notified of new relevant matter or when a new edition of the book is published. With the described system, the user can register an interest in particular documents or parts of documents more easily, in some cases even before the publisher has considered providing any such functionality. The reader's interest can be fed to the publisher, possibly affecting their decision about when and where to provide updates, further information, new editions or even completely new publications on topics that have proved to be of interest in existing books.
[0176] 7.3. Printed Marks with Special Meaning or Containing Special Data
[0177] Many aspects of the system are enabled simply through the use of the text already existing in a document. If the document is produced in the knowledge that it may be used in conjunction with the system, however, extra functionality can be added by printing extra information in the form of special marks, which may be used to identify the text or a required action more closely, or otherwise enhance the document's interaction with the system. The simplest and most important example is an indication to the reader that the document is definitely accessible through the system. A special icon might be used, for example, to indicate that this document has an online discussion forum associated with it.
[0178] Such symbols may be intended purely for the reader, or they may be recognized by the system when scanned and used to initiate some action. Sufficient data may be encoded in the symbol to identify more than just the symbol: it may also store information, for example about the document, edition, and location of the symbol, which could be recognized and read by the system.
[0179] 7.4. Authorization Through Possession of the Paper Document
[0180] There are some situations where possession of or access to the printed document would entitle the user to certain privileges, for example, the access to an electronic copy of the document or to additional materials. With the described system, such privileges could be granted simply as a result of the user capturing portions of text from the document, or scanning specially printed symbols. In cases where the system needed to ensure that the user was in possession of the entire document, it might prompt the user to scan particular items or phrases from particular pages, e.g. "the second line of page 46."
[0181] 7.5. Documents which Expire
[0182] If the printed document is a gateway to extra materials and functionality, access to such features can also be time-limited. After the expiry date, a user may be required to pay a fee or obtain a newer version of the document to access the features again. The paper document will, of course, still be usable, but will lose some of its enhanced electronic functionality. This may be desirable, for example, because there is profit for the publisher in receiving fees for access to electronic materials, or in requiring the user to purchase new editions from time to time, or because there are disadvantages associated with outdated versions of the printed document remaining in circulation. Coupons are an example of a type of commercial document that can have an expiration date.
[0183] 7.6. Popularity Analysis and Publishing Decisions
[0184] Section 10.5 discusses the use of the system's statistics to influence compensation of authors and pricing of advertisements.
[0185] In some embodiments, the system deduces the popularity of a publication from the activity in the electronic community associated with it as well as from the use of the paper document. These factors may help publishers to make decisions about what they will publish in future. If a chapter in an existing book, for example, turns out to be exceedingly popular, it may be worth expanding into a separate publication.
8. Document Access Services
[0186] An important aspect of the described system is the ability to provide to a user who has access to a rendered copy of a document access to an electronic version of that document. In some cases, a document is freely available on a public network or a private network to which the user has access. The system uses the captured text to identify, locate and retrieve the document, in some cases displaying it on the user's screen or depositing it in their email inbox.
[0187] In some cases, a document will be available in electronic form, but for a variety of reasons may not be accessible to the user. There may not be sufficient connectivity to retrieve the document, the user may not be entitled to retrieve it, there may be a cost associated with gaining access to it, or the document may have been withdrawn and possibly replaced by a new version, to name just a few possibilities. The system typically provides feedback to the user about these situations.
[0188] As mentioned in Section 7.4, the degree or nature of the access granted to a particular user may be different if it is known that the user already has access to a printed copy of the document.
[0189] 8.1. Authenticated Document Access
[0190] Access to the document may be restricted to specific users, or to those meeting particular criteria, or may only be available in certain circumstances, for example when the user is connected to a secure network. Section 6 describes some of the ways in which the credentials of a user and scanner may be established.
[0191] 8.2. Document Purchase--Copyright-Owner Compensation
[0192] Documents that are not freely available to the general public may still be accessible on payment of a fee, often as compensation to the publisher or copyright-holder. The system may implement payment facilities directly or may make use of other payment methods associated with the user, including those described in Section 6.2.
[0193] 8.3. Document Escrow and Proactive Retrieval
[0194] Electronic documents are often transient; the digital source version of a rendered document may be available now but inaccessible in future. The system may retrieve and store the existing version on behalf of the user, even if the user has not requested it, thus guaranteeing its availability should the user request it in future. This also makes it available for the system's use, for example for searching as part of the process of identifying future captures.
[0195] In the event that payment is required for access to the document, a trusted "document escrow" service can retrieve the document on behalf of the user, such as upon payment of a modest fee, with the assurance that the copyright holder will be fully compensated in future if the user should ever request the document from the service.
[0196] Variations on this theme can be implemented if the document is not available in electronic form at the time of capture. The user can authorize the service to submit a request for or make a payment for the document on his/her behalf if the electronic document should become available at a later date.
[0197] 8.4. Association with Other Subscriptions and Accounts
[0198] Sometimes payment may be waived, reduced or satisfied based on the user's existing association with another account or subscription. Subscribers to the printed version of a newspaper might automatically be entitled to retrieve the electronic version, for example.
[0199] In other cases, the association may not be quite so direct: a user may be granted access based on an account established by their employer, or based on their scanning of a printed copy owned by a friend who is a subscriber.
[0200] 8.5. Replacing Photocopying with Scan-and-Print
[0201] The process of capturing text from a paper document, identifying an electronic original, and printing that original, or some portion of that original associated with the capture, forms an alternative to traditional photocopying with many advantages:
[0202] the paper document need not be in the same location as the final printout, and in any case need not be there at the same time
[0203] the wear and damage caused to documents by the photocopying process, especially to old, fragile and valuable documents, can be avoided
[0204] the quality of the copy is typically be much higher
[0205] records may be kept about which documents or portions of documents are the most frequently copied
[0206] payment may be made to the copyright owner as part of the process
[0207] unauthorized copying may be prohibited
[0208] 8.6. Locating Valuable Originals from Photocopies
[0209] When documents are particularly valuable, as in the case of legal instruments or documents that have historical or other particular significance, people may typically work from copies of those documents, often for many years, while the originals are kept in a safe location.
[0210] The described system could be coupled to a database which records the location of an original document, for example in an archiving warehouse, making it easy for somebody with access to a copy to locate the archived original paper document.
9. Text Recognition Technologies
[0211] Optical Character Recognition (OCR) technologies have traditionally focused on images that include a large amount of text, for example from a flat-bed scanner capturing a whole page. OCR technologies often need substantial training and correcting by the user to produce useful text. OCR technologies often require substantial processing power on the machine doing the OCR, and, while many systems use a dictionary, they are generally expected to operate on an effectively infinite vocabulary.
[0212] All of the above traditional characteristics may be improved upon in the described system.
[0213] While this section focuses on OCR, many of the issues discussed map directly onto other recognition technologies, in particular speech recognition. As mentioned in Section 3.1, the process of capturing from paper may be achieved by a user reading the text aloud into a device which captures audio. Those skilled in the art will appreciate that principles discussed here with respect to images, fonts, and text fragments often also apply to audio samples, user speech models and phonemes.
[0214] 9.1. Optimization for Appropriate Devices
[0215] A scanning device for use with the described system will often be small, portable, and low power. The scanning device may capture only a few words at a time, and in some implementations does not even capture a whole character at once, but rather a horizontal slice through the text, many such slices being stitched together to form a recognizable signal from which the text may be deduced. The scanning device may also have very limited processing power or storage so, while in some embodiments it may perform all of the OCR process itself, many embodiments will depend on a connection to a more powerful device, possibly at a later time, to convert the captured signals into text. Lastly, it may have very limited facilities for user interaction, so may need to defer any requests for user input until later, or operate in a "best-guess" mode to a greater degree than is common now.
[0216] 9.2. "Uncertain" OCR
[0217] The primary new characteristic of OCR within the described system is the fact that it will, in general, examine images of text which exists elsewhere and which may be retrieved in digital form. An exact transcription of the text is therefore not always required from the OCR engine. The OCR system may output a set or a matrix of possible matches, in some cases including probability weightings, which can still be used to search for the digital original.
[0218] 9.3. Iterative OCR--Guess, Disambiguate, Guess . . .
[0219] If the device performing the recognition is able to contact the document index at the time of processing, then the OCR process can be informed by the contents of the document corpus as it progresses, potentially offering substantially greater recognition accuracy.
[0220] Such a connection will also allow the device to inform the user when sufficient text has been captured to identify the digital source.
[0221] 9.4. Using Knowledge of Likely Rendering When the system has knowledge of aspects of the likely printed rendering of a document--such as the font typeface used in printing, or the layout of the page, or which sections are in italics--this too can help in the recognition process. (Section 4.1.1)
[0222] 9.5. Font Caching--Determine Font on Host, Download to Client
[0223] As candidate source texts in the document corpus are identified, the font, or a rendering of it, may be downloaded to the device to help with the recognition.
[0224] 9.6. Autocorrelation and Character Offsets
[0225] While component characters of a text fragment may be the most recognized way to represent a fragment of text that may be used as a document signature, other representations of the text may work sufficiently well that the actual text of a text fragment need not be used when attempting to locate the text fragment in a digital document and/or database, or when disambiguating the representation of a text fragment into a readable form. Other representations of text fragments may provide benefits that actual text representations lack. For example, optical character recognition of text fragments is often prone to errors, unlike other representations of captured text fragments that may be used to search for and/or recreate a text fragment without resorting to optical character recognition for the entire fragment. Such methods may be more appropriate for some devices used with the current system.
[0226] Those of ordinary skill in the art and others will appreciate that there are many ways of describing the appearance of text fragments. Such characterizations of text fragments may include, but are not limited to, word lengths, relative word lengths, character heights, character widths, character shapes, character frequencies, token frequencies, and the like. In some embodiments, the offsets between matching text tokens (i.e., the number of intervening tokens plus one) are used to characterize fragments of text.
[0227] Conventional OCR uses knowledge about fonts, letter structure and shape to attempt to determine characters in scanned text. Embodiments of the present invention are different; they employ a variety of methods that use the rendered text itself to assist in the recognition process. These embodiments use characters (or tokens) to "recognize each other." One way to refer to such self-recognition is "template matching," and is similar to "convolution." To perform such self-recognition, the system slides a copy of the text horizontally over itself and notes matching regions of the text images. Prior template matching and convolution techniques encompass a variety of related techniques. These techniques to tokenize and/or recognize characters/tokens will be collectively referred to herein as "autocorrelation," as the text is used to correlate with its own component parts when matching characters/tokens.
[0228] When autocorrelating, complete connected regions that match are of interest. This occurs when characters (or groups of characters) overlay other instances of the same character (or group). Complete connected regions that match automatically provide tokenizing of the text into component tokens. As the two copies of the text are slid past each other, the regions where perfect matching occurs (i.e., all pixels in a vertical slice are matched) are noted. When a character/token matches itself, the horizontal extent of this matching (e.g., the connected matching portion of the text) also matches.
[0229] Note that at this stage there is no need to determine the actual identity of each token (i.e., the particular letter, digit or symbol, or group of these, that corresponds to the token image), only the offset to the next occurrence of the same token in the scanned text. The offset number is the distance (number of tokens) to the next occurrence of the same token. If the token is unique within the text string, the offset is zero (0). The sequence of token offsets thus generated is a signature that can be used to identify the scanned text.
[0230] In some embodiments, the token offsets determined for a string of scanned tokens are compared to an index that indexes a corpus of electronic documents based upon the token offsets of their contents (Section 4.1.2). In other embodiments, the token offsets determined for a string of scanned tokens are converted to text, and compared to a more conventional index that indexes a corpus of electronic documents based upon their contents
[0231] As has been noted earlier, a similar token-correlation process may be applied to speech fragments when the capture process consists of audio samples of spoken words.
[0232] 9.7. Font/Character "Self-Recognition"
[0233] Conventional template-matching OCR compares scanned images to a library of character images. In essence, the alphabet is stored for each font and newly scanned images are compared to the stored images to find matching characters. The process generally has an initial delay until the correct font has been identified. After that, the OCR process is relatively quick because most documents use the same font throughout. Subsequent images can therefore be converted to text by comparison with the most recently identified font library.
[0234] The shapes of characters in most commonly used fonts are related. For example, in most fonts, the letter "c" and the letter "e" are visually related--as are "t" and "f," etc. The OCR process is enhanced by use of this relationship to construct templates for letters that have not been scanned yet. For example, where a reader scans a short string of text from a paper document in a previously unencountered font such that the system does not have a set of image templates with which to compare the scanned images the system can leverage the probable relationship between certain characters to construct the font template library even though it has not yet encountered all of the letters in the alphabet. The system can then use the constructed font template library to recognize subsequent scanned text and to further refine the constructed font library.
[0235] 9.8. Send Anything Unrecognized (Including Graphics) to Server
[0236] When images cannot be machine-transcribed into a form suitable for use in a search process, the images themselves can be saved for later use by the user, for possible manual transcription, or for processing at a later date when different resources may be available to the system.
10. P-Commerce
[0237] Many of the actions made possible by the system result in some commercial transaction taking place. The phrase p-commerce is used herein to describe commercial activities initiated from paper via the system.
[0238] 10.1. Sales of Documents from their Physical Printed Copies
[0239] When a user captures text from a document, the user may be offered that document for purchase either in paper or electronic form. The user may also be offered related documents, such as those quoted or otherwise referred to in the paper document, or those on a similar subject, or those by the same author.
[0240] 10.2. Sales of Anything Else Initiated or Aided by Paper
[0241] The capture of text may be linked to other commercial activities in a variety of ways. The captured text may be in a catalog that is explicitly designed to sell items, in which case the text will be associated fairly directly with the purchase of an item (Section 18.2). The text may also be part of an advertisement, in which case a sale of the item being advertised may ensue.
[0242] In other cases, the user captures other text from which their potential interest in a commercial transaction may be deduced. A reader of a novel set in a particular country, for example, might be interested in a holiday there. Someone reading a review of a new car might be considering purchasing it. The user may capture a particular fragment of text knowing that some commercial opportunity will be presented to them as a result, or it may be a side-effect of their capture activities.
[0243] 10.3. Capture of Labels, Icons, Serial Numbers, Barcodes on an Item Resulting in a Sale
[0244] Sometimes text or symbols are actually printed on an item or its packaging. An example is the serial number or product id often found on a label on the back or underside of a piece of electronic equipment. The system can offer the user a convenient way to purchase one or more of the same items by capturing that text. They may also be offered manuals, support or repair services.
[0245] 10.4. Contextual Advertisements
[0246] In addition to the direct capture of text from an advertisement, the system allows for a new kind of advertising which is not necessarily explicitly in the rendered document, but is nonetheless based on what people are reading.
[0247] 10.4.1. Advertising Based on Scan Context and History
[0248] In a traditional paper publication, advertisements generally consume a large amount of space relative to the text of a newspaper article, and a limited number of them can be placed around a particular article. In the described system, advertising can be associated with individual words or phrases, and can selected according to the particular interest the user has shown by capturing that text and possibly taking into account their history of past scans.
[0249] With the described system, it is possible for a purchase to be tied to a particular printed document and for an advertiser to get significantly more feedback about the effectiveness of their advertising in particular print publications.
[0250] 10.4.2. Advertising Based on User Context and History
[0251] The system may gather a large amount of information about other aspects of a user's context for its own use (Section 13); estimates of the geographical location of the user are a good example. Such data can also be used to tailor the advertising presented to a user of the system.
[0252] 10.5. Models of Compensation
[0253] The system enables some new models of compensation for advertisers and marketers. The publisher of a printed document containing advertisements may receive some income from a purchase that originated from their document. This may be true whether or not the advertisement existed in the original printed form; it may have been added electronically either by the publisher, the advertiser or some third party, and the sources of such advertising may have been subscribed to by the user.
[0254] 10.5.1. Popularity-Based Compensation
[0255] Analysis of the statistics generated by the system can reveal the popularity of certain parts of a publication (Section 14.2). In a newspaper, for example, it might reveal the amount of time readers spend looking at a particular page or article, or the popularity of a particular columnist. In some circumstances, it may be appropriate for an author or publisher to receive compensation based on the activities of the readers rather than on more traditional metrics such as words written or number of copies distributed. An author whose work becomes a frequently read authority on a subject might be considered differently in future contracts from one whose books have sold the same number of copies but are rarely opened. (See also Section 7.6)
[0256] 10.5.2. Popularity-Based Advertising
[0257] Decisions about advertising in a document may also be based on statistics about the readership. The advertising space around the most popular columnists may be sold at a premium rate. Advertisers might even be charged or compensated some time after the document is published based on knowledge about how it was received.
[0258] 10.6. Marketing Based on Life Library
[0259] The "Life Library" or scan history described in Sections 6.1 and 16.1 can be an extremely valuable source of information about the interests and habits of a user. Subject to the appropriate consent and privacy issues, such data can inform offers of goods or services to the user. Even in an anonymous form, the statistics gathered can be exceedingly useful.
[0260] 10.7. Sale/Information at Later Date (when Available)
[0261] Advertising and other opportunities for commercial transactions may not be presented to the user immediately at the time of text capture. For example, the opportunity to purchase a sequel to a novel may not be available at the time the user is reading the novel, but the system may present them with that opportunity when the sequel is published.
[0262] A user may capture data that relates to a purchase or other commercial transaction, but may choose not to initiate and/or complete the transaction at the time the capture is made. In some embodiments, data related to captures is stored in a user's Life Library, and these Life Library entries can remain "active" (i.e., capable of subsequent interactions similar to those available at the time the capture was made). Thus a user may review a capture at some later time, and optionally complete a transaction based on that capture. Because the system can keep track of when and where the original capture occurred, all parties involved in the transaction can be properly compensated. For example, the author who wrote the story--and the publisher who published the story--that appeared next to the advertisement from which the user captured data can be compensated when, six months later, the user visits their Life Library, selects that particular capture from the history, and chooses "Purchase this item at Amazon" from the pop-up menu (which can be similar or identical to the menu optionally presented at the time of the capture).
11. Operating System and Application Integration
[0263] Modern Operating Systems (OSs) and other software packages have many characteristics that can be advantageously exploited for use with the described system, and may also be modified in various ways to provide an even better platform for its use.
[0264] 11.1. Incorporation of Scan and Print-Related Information in Metadata and Indexing
[0265] New and upcoming file systems and their associated databases often have the ability to store a variety of metadata associated with each file. Traditionally, this metadata has included such things as the ID of the user who created the file, the dates of creation, last modification, and last use. Newer file systems allow such extra information as keywords, image characteristics, document sources and user comments to be stored, and in some systems this metadata can be arbitrarily extended. File systems can therefore be used to store information that would be useful in implementing the current system. For example, the date when a given document was last printed can be stored by the file system, as can details about which text from it has been captured from paper using the described system, and when and by whom.
[0266] Operating systems are also starting to incorporate search engine facilities that allow users to find local files more easily. These facilities can be advantageously used by the system. It means that many of the search-related concepts discussed in Sections 3 and 4 apply not just to today's Internet-based and similar search engines, but also to every personal computer.
[0267] In some cases specific software applications will also include support for the system above and beyond the facilities provided by the OS.
[0268] 11.2. OS Support for Capture Devices
[0269] As the use of capture devices such as pen scanners becomes increasingly common, it will become desirable to build support for them into the operating system, in much the same way as support is provided for mice and printers, since the applicability of capture devices extends beyond a single software application. The same will be true for other aspects of the system's operation. Some examples are discussed below. In some embodiments, the entire described system, or the core of it, is provided by the OS. In some embodiments, support for the system is provided by Application Programming Interfaces (APIS) that can be used by other software packages, including those directly implementing aspects of the system.
[0270] 11.2.1. Support for OCR and Other Recognition Technologies
[0271] Most of the methods of capturing text from a rendered document require some recognition software to interpret the source data, typically a scanned image or some spoken words, as text suitable for use in the system. Some OSs include support for speech or handwriting recognition, though it is less common for OSs to include support for OCR, since in the past the use of OCR has typically been limited to a small range of applications.
[0272] As recognition components become part of the OS, they can take better advantage of other facilities provided by the OS. Many systems include spelling dictionaries, grammar analysis tools, internationalization and localization facilities, for example, all of which can be advantageously employed by the described system for its recognition process, especially since they may have been customized for the particular user to include words and phrases that he/she would commonly encounter.
[0273] If the operating system includes full-text indexing facilities, then these can also be used to inform the recognition process, as described in Section 9.3.
[0274] 11.2.2. Action to be Taken on Scans
[0275] If an optical scan or other capture occurs and is presented to the OS, it may have a default action to be taken under those circumstances in the event that no other subsystem claims ownership of the capture. An example of a default action is presenting the user with a choice of alternatives, or submitting the captured text to the OS's built-in search facilities.
[0276] 11.2.3. OS has Default Action for Particular Documents or Document Types
[0277] If the digital source of the rendered document is found, the OS may have a standard action that it will take when that particular document, or a document of that class, is scanned. Applications and other subsystems may register with the OS as potential handlers of particular types of capture, in a similar manner to the announcement by applications of their ability to handle certain file types.
[0278] Markup data associated with a rendered document, or with a capture from a document, can include instructions to the operating system to launch specific applications, pass applications arguments, parameters, or data, etc.
[0279] 11.2.4. Interpretation of Gestures and Mapping into Standard Actions
[0280] In Section 12.1.3 the use of "gestures" is discussed, particularly in the case of optical scanning, where particular movements made with a handheld scanner might represent standard actions such as marking the start and end of a region of text.
[0281] This is analogous to actions such as pressing the shift key on a keyboard while using the cursor keys to select a region of text, or using the wheel on a mouse to scroll a document. Such actions by the user are sufficiently standard that they are interpreted in a system-wide way by the OS, thus ensuring consistent behavior. The same is desirable for scanner gestures and other scanner-related actions.
[0282] 11.2.5. Set Response to Standard (and Non-Standard) Iconic/Text Printed Menu Items
[0283] In a similar way, certain items of text or other symbols may, when scanned, cause standard actions to occur, and the OS may provide a selection of these. An example might be that scanning the text "[print]" in any document would cause the OS to retrieve and print a copy of that document. The OS may also provide a way to register such actions and associate them with particular scans.
[0284] 11.3. Support in System GUI Components for Typical Scan-Initiated Activities
[0285] Most software applications are based substantially on standard Graphical User Interface components provided by the OS.
[0286] Use of these components by developers helps to ensure consistent behavior across multiple packages, for example that pressing the left-cursor key in any text-editing context should move the cursor to the left, without every programmer having to implement the same functionality independently.
[0287] A similar consistency in these components is desirable when the activities are initiated by text-capture or other aspects of the described system. Some examples are given below.
[0288] 11.3.1. Interface to Find Particular Text Content
[0289] A typical use of the system may be for the user to scan an area of a paper document, and for the system to open the electronic counterpart in a software package that is able to display or edit it, and cause that package to scroll to and highlight the scanned text (Section 12.2.1). The first part of this process, finding and opening the electronic document, is typically provided by the OS and is standard across software packages. The second part, however--locating a particular piece of text within a document and causing the package to scroll to it and highlight it--is not yet standardized and is often implemented differently by each package. The availability of a standard API for this functionality could greatly enhance the operation of this aspect of the system.
[0290] 11.3.2. Text Interactions
[0291] Once a piece of text has been located within a document, the system may wish to perform a variety of operations upon that text. As an example, the system may request the surrounding text, so that the user's capture of a few words could result in the system accessing the entire sentence or paragraph containing them. Again, this functionality can be usefully provided by the OS rather than being implemented in every piece of software that handles text.
[0292] 11.3.3. Contextual (Popup) Menus
[0293] Some of the operations that are enabled by the system will require user feedback, and this may be optimally requested within the context of the application handling the data. In some embodiments, the system uses the application pop-up menus traditionally associated with clicking the right mouse button on some text. The system inserts extra options into such menus, and causes them to be displayed as a result of activities such as scanning a paper document.
[0294] 11.4. Web/Network Interfaces
[0295] In today's increasingly networked world, much of the functionality available on individual machines can also be accessed over a network, and the functionality associated with the described system is no exception. As an example, in an office environment, many paper documents received by a user may have been printed by other users' machines on the same corporate network. The system on one computer, in response to a capture, may be able to query those other machines for documents which may correspond to that capture, subject to the appropriate permission controls.
[0296] 11.5. Printing of Document Causes Saving
[0297] An important factor in the integration of paper and digital documents is maintaining as much information as possible about the transitions between the two. In some embodiments, the OS keeps a simple record of when any document was printed and by whom. In some embodiments, the OS takes one or more further actions that would make it better suited for use with the system. Examples include:
[0298] Saving the digital rendered version of every document printed along with information about the source from which it was printed
[0299] Saving a subset of useful information about the printed version--for example, the fonts used and where the line breaks occur--which might aid future scan interpretation
[0300] Saving the version of the source document associated with any printed copy
[0301] Indexing the document automatically at the time of printing and storing the results for future searching
[0302] 11.6. My (Printed/Scanned) Documents
[0303] An OS often maintains certain categories of folders or files that have particular significance. A user's documents may, by convention or design, be found in a "My Documents" folder, for example. Standard file-opening dialogs may automatically include a list of recently opened documents.
[0304] On an OS optimized for use with the described system, such categories may be enhanced or augmented in ways that take into account a user's interaction with paper versions of the stored files. Categories such as "My Printed Documents" or "My Recently-Read Documents" might usefully be identified and incorporated in its operations.
[0305] 11.7. OS-Level Markup Hierarchies
[0306] Since important aspects of the system are typically provided using the "markup" concepts discussed in Section 5, it would clearly be advantageous to have support for such markup provided by the OS in a way that was accessible to multiple applications as well as to the OS itself. In addition, layers of markup may be provided by the OS, based on its own knowledge of documents under its control and the facilities it is able to provide.
[0307] 11.8. Use of OS DRM Facilities
[0308] An increasing number of operating systems support some form of "Digital Rights Management": the ability to control the use of particular data according to the rights granted to a particular user, software entity or machine. It may inhibit unauthorized copying or distribution of a particular document, for example.
12. User Interface
[0309] The user interface of the system may be entirely on a PC, if the capture device is relatively dumb and is connected to it by a cable, or entirely on the device, if it is sophisticated and with significant processing power of its own. In some cases, some functionality resides in each component. Part, or indeed all, of the system's functionality may also be implemented on other devices such as mobile phones or PDAs.
[0310] The descriptions in the following sections are therefore indications of what may be desirable in certain implementations, but they are not necessarily appropriate for all and may be modified in several ways.
[0311] 12.1. On the Capture Device
[0312] With all capture devices, but particularly in the case of an optical scanner, the user's attention will generally be on the device and the paper at the time of scanning. It is very desirable, then, that any input and feedback needed as part of the process of scanning do not require the user's attention to be elsewhere, for example on the screen of a computer, more than is necessary.
[0313] 12.1.1. Feedback on Scanner
[0314] A handheld scanner may have a variety of ways of providing feedback to the user about particular conditions. The most obvious types are direct visual, where the scanner incorporates indicator lights or even a full display, and auditory, where the scanner can make beeps, clicks or other sounds. Important alternatives include tactile feedback, where the scanner can vibrate, buzz, or otherwise stimulate the user's sense of touch, and projected feedback, where it indicates a status by projecting onto the paper anything from a colored spot of light to a sophisticated display.
[0315] Important immediate feedback that may be provided on the device includes:
[0316] feedback on the scanning process--user scanning too fast, at too great an angle, or drifting too high or low on a particular line
[0317] sufficient content--enough has been scanned to be pretty certain of finding a match if one exists--important for disconnected operation
[0318] context known--a source of the text has been located
[0319] unique context known--one unique source of the text has been located
[0320] availability of content--indication of whether the content is freely available to the user, or at a cost
[0321] Many of the user interactions normally associated with the later stages of the system may also take place on the capture device if it has sufficient abilities, for example, to display part or all of a document.
[0322] 12.1.2. Controls on Scanner
[0323] The device may provide a variety of ways for the user to provide input in addition to basic text capture. Even when the device is in close association with a host machine that has input options such as keyboards and mice, it can be disruptive for the user to switch back and forth between manipulating the scanner and using a mouse, for example.
[0324] The handheld scanner may have buttons, scroll/jog-wheels, touch-sensitive surfaces, and/or accelerometers for detecting the movement of the device. Some of these allow a richer set of interactions while still holding the scanner.
[0325] For example, in response to scanning some text, the system presents the user with a set of several possible matching documents. The user uses a scroll-wheel on the side of the scanner is to select one from the list, and clicks a button to confirm the selection.
[0326] 12.1.3. Gestures
[0327] The primary reason for moving a scanner across the paper is to capture text, but some movements may be detected by the device and used to indicate other user intentions. Such movements are referred to herein as "gestures."
[0328] As an example, the user can indicate a large region of text by scanning the first few words in conventional left-to-right order, and the last few in reverse order, i.e. right to left. The user can also indicate the vertical extent of the text of interest by moving the scanner down the page over several lines. A backwards scan might indicate cancellation of the previous scan operation.
[0329] 12.1.4. Online/Offline Behavior
[0330] Many aspects of the system may depend on network connectivity, either between components of the system such as a scanner and a host laptop, or with the outside world in the form of a connection to corporate databases and Internet search. This connectivity may not be present all the time, however, and so there will be occasions when part or all of the system may be considered to be "offline." It is desirable to allow the system to continue to function usefully in those circumstances.
[0331] The device may be used to capture text when it is out of contact with other parts of the system. A very simple device may simply be able to store the image or audio data associated with the capture, ideally with a timestamp indicating when it was captured. The various captures may be uploaded to the rest of the system when the device is next in contact with it, and handled then. The device may also upload other data associated with the captures, for example voice annotations associated with optical scans, or location information.
[0332] More sophisticated devices may be able to perform some or all of the system operations themselves despite being disconnected. Various techniques for improving their ability to do so are discussed in Section 15.3. Often it will be the case that some, but not all, of the desired actions can be performed while offline. For example, the text may be recognized, but identification of the source may depend on a connection to an Internet-based search engine. In some embodiments, the device therefore stores sufficient information about how far each operation has progressed for the rest of the system to proceed efficiently when connectivity is restored.
[0333] The operation of the system will, in general, benefit from immediately available connectivity, but there are some situations in which performing several captures and then processing them as a batch can have advantages. For example, as discussed in Section 13 below, the identification of the source of a particular capture may be greatly enhanced by examining other captures made by the user at approximately the same time. In a fully connected system where live feedback is being provided to the user, the system is only able to use past captures when processing the current one. If the capture is one of a batch stored by the device when offline, however, the system will be able to take into account any data available from later captures as well as earlier ones when doing its analysis.
[0334] 12.2. On a Host Device
[0335] A scanner will often communicate with some other device, such as a PC, PDA, phone or digital camera to perform many of the functions of the system, including more detailed interactions with the user.
[0336] 12.2.1. Activities Performed in Response to a Capture
[0337] When the host device receives a capture, it may initiate a variety of activities. An incomplete list of possible activities performed by the system after locating and electronic counterpart document associated with the capture and a location within that document follows.
[0338] The details of the capture may be stored in the user's history. (Section 6.1)
[0339] The document may be retrieved from local storage or a remote location. (Section 8)
[0340] The operating system's metadata and other records associated with the document may be updated. (Section 11.1)
[0341] Markup associated with the document may be examined to determine the next relevant operations. (Section 5)
[0342] A software application may be started to edit, view or otherwise operate on the document. The choice of application may depend on the source document, or on the contents of the scan, or on some other aspect of the capture. (Section 11.2.2, 11.2.3)
[0343] The application may scroll to, highlight, move the insertion point to, or otherwise indicate the location of the capture. (Section 11.3)
[0344] The precise bounds of the captured text may be modified, for example to select whole words, sentences or paragraphs around the captured text. (Section 11.3.2)
[0345] The user may be given the option to copy the capture text to the clipboard or perform other standard operating system or application-specific operations upon it.
[0346] Annotations may be associated with the document or the captured text. These may come from immediate user input, or may have been captured earlier, for example in the case of voice annotations associated with an optical scan. (Section 19.4)
[0347] Markup may be examined to determine a set of further possible operations for the user to select.
[0348] 12.2.2. Contextual Popup Menus
[0349] Sometimes the appropriate action to be taken by the system will be obvious, but sometimes it will require a choice to be made by the user. One good way to do this is through the use of "popup menus" or, in cases where the content is also being displayed on a screen, with so-called "contextual menus" that appear close to the content. (See Section 11.3.3). In some embodiments, the scanner device projects a popup menu onto the paper document. A user may select from such menus using traditional methods such as a keyboard and mouse, or by using controls on the capture device (Section 12.1.2), gestures (Section 12.1.3), or by interacting with the computer display using the scanner (Section 12.2.4). In some embodiments, the popup menus which can appear as a result of a capture include default items representing actions which occur if the user does not respond--for example, if the user ignores the menu and makes another capture.
[0350] 12.2.3. Feedback on Disambiguation
[0351] When a user starts capturing text, there will initially be several documents or other text locations that it could match. As more text is captured, and other factors are taken into account (Section 13), the number of candidate locations will decrease until the actual location is identified, or further disambiguation is not possible without user input. In some embodiments, the system provides a real-time display of the documents or the locations found, for example in list, thumbnail-image or text-segment form, and for the number of elements in that display to reduce in number as capture continues. In some embodiments, the system displays thumbnails of all candidate documents, where the size or position of the thumbnail is dependent on the probability of it being the correct match.
[0352] When a capture is unambiguously identified, this fact may be emphasized to the user, for example using audio feedback.
[0353] Sometimes the text captured will occur in many documents and will be recognized to be a quotation. The system may indicate this on the screen, for example by grouping documents containing a quoted reference around the original source document.
[0354] 12.2.4. Scanning from Screen
[0355] Some optical scanners may be able to capture text displayed on a screen as well as on paper. Accordingly, the term rendered document is used herein to indicate that printing onto paper is not the only form of rendering, and that the capture of text or symbols for use by the system may be equally valuable when that text is displayed on an electronic display.
[0356] The user of the described system may be required to interact with a computer screen for a variety of other reasons, such as to select from a list of options. It can be inconvenient for the user to put down the scanner and start using the mouse or keyboard. Other sections have described physical controls on the scanner (Section 12.1.2) or gestures (Section 12.1.3) as methods of input which do not require this change of tool, but using the scanner on the screen itself to scan some text or symbol is an important alternative provided by the system.
[0357] In some embodiments, the optics of the scanner allow it to be used in a similar manner to a light-pen, directly sensing its position on the screen without the need for actual scanning of text, possibly with the aid of special hardware or software on the computer.
13. Context Interpretation
[0358] An important aspect of the described system is the use of other factors, beyond the simple capture of a string of text, to help identify the document in use. A capture of a modest amount of text may often identify the document uniquely, but in many situations it will identify a few candidate documents. One solution is to prompt the user to confirm the document being scanned, but a preferable alternative is to make use of other factors to narrow down the possibilities automatically. Such supplemental information can dramatically reduce the amount of text that needs to be captured and/or increase the reliability and speed with which the location in the electronic counterpart can be identified. This extra material is referred to as "context," and it was discussed briefly in Section 4.2.2. We now consider it in more depth.
[0359] 13.1. System and Capture Context
[0360] Perhaps the most important example of such information is the user's capture history.
[0361] It is highly probable that any given capture comes from the same document as the previous one, or from an associated document, especially if the previous capture took place in the last few minutes (Section 6.1.2). Conversely, if the system detects that the font has changed between two scans, it is more likely that they are from different documents.
[0362] Also useful are the user's longer-term capture history and reading habits. These can also be used to develop a model of the user's interests and associations.
[0363] 13.2. User's Real-World Context
[0364] Another example of useful context is the user's geographical location. A user in Paris is much more likely to be reading Le Monde than the Seattle Times, for example. The timing, size and geographical distribution of printed versions of the documents can therefore be important, and can to some degree be deduced from the operation of the system.
[0365] The time of day may also be relevant, for example in the case of a user who always reads one type of publication on the way to work, and a different one at lunchtime or on the train going home.
[0366] 13.3. Related Digital Context
[0367] The user's recent use of electronic documents, including those searched for or retrieved by more conventional means, can also be a helpful indicator.
[0368] In some cases, such as on a corporate network, other factors may be usefully considered:
[0369] Which documents have been printed recently?
[0370] Which documents have been modified recently on the corporate file server?
[0371] Which documents have been emailed recently?
[0372] All of these examples might suggest that a user was more likely to be reading a paper version of those documents. In contrast, if the repository in which a document resides can affirm that the document has never been printed or sent anywhere where it might have been printed, then it can be safely eliminated in any searches originating from paper.
[0373] 13.4. Other Statistics--the Global Context
[0374] Section 14 covers the analysis of the data stream resulting from paper-based searches, but it should be noted here that statistics about the popularity of documents with other readers, about the timing of that popularity, and about the parts of documents most frequently scanned are all examples of further factors which can be beneficial in the search process. The system brings the possibility of Google-type page-ranking to the world of paper.
[0375] See also Section 4.2.2 for some other implications of the use of context for search engines.
14. Data-Stream Analysis
[0376] The use of the system generates an exceedingly valuable data-stream as a side effect. This stream is a record of what users are reading and when, and is in many cases a record of what they find particularly valuable in the things they read. Such data has never really been available before for paper documents.
[0377] Some ways in which this data can be useful for the system, and for the user of the system, are described in Section 6.1. This section concentrates on its use for others. There are, of course, substantial privacy issues to be considered with any distribution of data about what people are reading, but such issues as preserving the anonymity of data are well known to those of skill in the art.
[0378] 14.1. Document Tracking
[0379] When the system knows which documents any given user is reading, it can also deduce who is reading any given document. This allows the tracking of a document through an organization, to allow analysis, for example, of who is reading it and when, how widely it was distributed, how long that distribution took, and who has seen current versions while others are still working from out-of-date copies.
[0380] For published documents that have a wider distribution, the tracking of individual copies is more difficult, but the analysis of the distribution of readership is still possible.
[0381] 14.2. Read Ranking--Popularity of Documents and Sub-Regions
[0382] In situations where users are capturing text or other data that is of particular interest to them, the system can deduce the popularity of certain documents and of particular sub-regions of those documents. This forms a valuable input to the system itself (Section 4.2.2) and an important source of information for authors, publishers and advertisers (Section 7.6, Section 10.5). This data is also useful when integrated in search engines and search indices--for example, to assist in ranking search results for queries coming from rendered documents, and/or to assist in ranking conventional queries typed into a web browser.
[0383] 14.3. Analysis of Users--Building Profiles
[0384] Knowledge of what a user is reading enables the system to create a quite detailed model of the user's interests and activities. This can be useful on an abstract statistical basis--"35% of users who buy this newspaper also read the latest book by that author"--but it can also allow other interactions with the individual user, as discussed below.
[0385] 14.3.1. Social Networking
[0386] One example is connecting one user with others who have related interests. These may be people already known to the user. The system may ask a university professor, "Did you know that your colleague at XYZ University has also just read this paper?" The system may ask a user, "Do you want to be linked up with other people in your neighborhood who are also how reading Jane Eyre?" Such links may be the basis for the automatic formation of book clubs and similar social structures, either in the physical world or online.
[0387] 14.3.2. Marketing
[0388] Section 10.6 has already mentioned the idea of offering products and services to an individual user based on their interactions with the system. Current online booksellers, for example, often make recommendations to a user based on their previous interactions with the bookseller. Such recommendations become much more useful when they are based on interactions with the actual books.
[0389] 14.4. Marketing Based on Other Aspects of the Data-Stream
[0390] We have discussed some of the ways in which the system may influence those publishing documents, those advertising through them, and other sales initiated from paper (Section 10). Some commercial activities may have no direct interaction with the paper documents at all and yet may be influenced by them. For example, the knowledge that people in one community spend more time reading the sports section of the newspaper than they do the financial section might be of interest to somebody setting up a health club.
[0391] 14.5. Types of Data that May be Captured
[0392] In addition to the statistics discussed, such as who is reading which bits of which documents, and when and where, it can be of interest to examine the actual contents of the text captured, regardless of whether or not the document has been located.
[0393] In many situations, the user will also not just be capturing some text, but will be causing some action to occur as a result. It might be emailing a reference to the document to an acquaintance, for example. Even in the absence of information about the identity of the user or the recipient of the email, the knowledge that somebody considered the document worth emailing is very useful.
[0394] In addition to the various methods discussed for deducing the value of a particular document or piece of text, in some circumstances the user will explicitly indicate the value by assigning it a rating.
[0395] Lastly, when a particular set of users are known to form a group, for example when they are known to be employees of a particular company, the aggregated statistics of that group can be used to deduce the importance of a particular document to that group.
15. Device Features and Functions
[0396] A capture device for use with the system needs little more than a way of capturing text from a rendered version of the document. As described earlier (Section 1.2), this capture may be achieved through a variety of methods including taking a photograph of part of the document or typing some words into a mobile phone keypad. This capture may be achieved using a small hand-held optical scanner capable of recording a line or two of text at a time, or an audio capture device such as a voice-recorder into which the user is reading text from the document. The device used may be a combination of these--an optical scanner which could also record voice annotations, for example--and the capturing functionality may be built into some other device such as a mobile phone, PDA, digital camera or portable music player.
[0397] 15.1. Input and Output
[0398] Many of the possibly beneficial additional input and output facilities for such a device have been described in Section 12.1. They include buttons, scroll-wheels and touch-pads for input, and displays, indicator lights, audio and tactile transducers for output. Sometimes the device will incorporate many of these, sometimes very few. Sometimes the capture device will be able to communicate with another device that already has them (Section 15.6), for example using a wireless link, and sometimes the capture functionality will be incorporated into such other device (Section 15.7).
[0399] 15.2. Connectivity
[0400] In some embodiments, the device implements the majority of the system itself. In some embodiments, however, it often communicates with a PC or other computing device and with the wider world using communications facilities.
[0401] Often these communications facilities are in the form of a general-purpose data network such as Ethernet, 802.11 or UWB or a standard peripheral-connecting network such as USB, IEEE-1394 (Firewire), Bluetooth® or infra-red. When a wired connection such as Firewire or USB is used, the device may receive electrical power though the same connection. In some circumstances, the capture device may appear to a connected machine to be a conventional peripheral such as a USB storage device.
[0402] Lastly, the device may in some circumstances "dock" with another device, either to be used in conjunction with that device or for convenient storage.
[0403] 15.3. Caching and Other Online/Offline Functionality
[0404] Sections 3.5 and 12.1.4 have raised the topic of disconnected operation. When a capture device has a limited subset of the total system's functionality, and is not in communication with the other parts of the system, the device can still be useful, though the functionality available will sometimes be reduced. At the simplest level, the device can record the raw image or audio data being captured and this can be processed later. For the user's benefit, however, it can be important to give feedback where possible about whether the data captured is likely to be sufficient for the task in hand, whether it can be recognized or is likely to be recognizable, and whether the source of the data can be identified or is likely to be identifiable later. The user will then know whether their capturing activity is worthwhile. Even when all of the above are unknown, the raw data can still be stored so that, at the very least, the user can refer to them later. The user may be presented with the image of a scan, for example, when the scan cannot be recognized by the OCR process.
[0405] To illustrate some of the range of options available, both a rather minimal optical scanning device and then a much more full-featured one are described below. Many devices occupy a middle ground between the two.
[0406] 15.3.1. The SimpleScanner--a Low-End Offline Example
[0407] The SimpleScanner has a scanning head able to read pixels from the page as it is moved along the length of a line of text. It can detect its movement along the page and record the pixels with some information about the movement. It also has a clock, which allows each scan to be time-stamped. The clock is synchronized with a host device when the SimpleScanner has connectivity. The clock may not represent the actual time of day, but relative times may be determined from it so that the host can deduce the actual time of a scan, or at worst the elapsed time between scans.
[0408] The SimpleScanner does not have sufficient processing power to perform any OCR itself, but it does have some basic knowledge about typical word-lengths, word-spacings, and their relationship to font size. It has some basic indicator lights which tell the user whether the scan is likely to be readable, whether the head is being moved too fast, too slowly or too inaccurately across the paper, and when it determines that sufficient words of a given size are likely to have been scanned for the document to be identified.
[0409] The SimpleScanner has a USB connector and can be plugged into the USB port on a computer, where it will be recharged. To the computer it appears to be a USB storage device on which time-stamped data files have been recorded, and the rest of the system software takes over from this point.
[0410] 15.3.2. The SuperScanner--a High-End Offline Example
[0411] The SuperScanner also depends on connectivity for its full operation, but it has a significant amount of on-board storage and processing which can help it make better judgments about the data captured while offline.
[0412] As it moves along the line of text, the captured pixels are stitched together and passed to an OCR engine that attempts to recognize the text. A number of fonts, including those from the user's most-read publications, have been downloaded to it to help perform this task, as has a dictionary that is synchronized with the user's spelling-checker dictionary on their PC and so contains many of the words they frequently encounter. Also stored on the scanner is a list of words and phrases with the typical frequency of their use--this may be combined with the dictionary. The scanner can use the frequency statistics both to help with the recognition process and also to inform its judgment about when a sufficient quantity of text has been captured; more frequently used phrases are less likely to be useful as the basis for a search query.
[0413] In addition, the full index for the articles in the recent issues of the newspapers and periodicals most commonly read by the user are stored on the device, as are the indices for the books the user has recently purchased from an online bookseller, or from which the user has scanned anything within the last few months. Lastly, the titles of several thousand of the most popular publications which have data available for the system are stored so that, in the absence of other information the user can scan the title and have a good idea as to whether or not captures from a particular work are likely to be retrievable in electronic form later.
[0414] During the scanning process, the system informs user that the captured data has been of sufficient quality and of a sufficient nature to make it probable that the electronic copy can be retrieved when connectivity is restored. Often the system indicates to the user that the scan is known to have been successful and that the context has been recognized in one of the on-board indices, or that the publication concerned is known to be making its data available to the system, so the later retrieval ought to be successful.
[0415] The SuperScanner docks in a cradle connected to a PC's Firewire or USB port, at which point, in addition to the upload of captured data, its various onboard indices and other databases are updated based on recent user activity and new publications. It also has the facility to connect to wireless public networks or to communicate via Bluetooth to a mobile phone and thence with the public network when such facilities are available.
[0416] 15.4. Features for Optical Scanning
[0417] We now consider some of the features that may be particularly desirable in an optical scanner device.
[0418] 15.4.1. Flexible Positioning and Convenient Optics
[0419] One of the reasons for the continuing popularity of paper is the ease of its use in a wide variety of situations where a computer, for example, would be impractical or inconvenient. A device intended to capture a substantial part of a user's interaction with paper should therefore be similarly convenient in use. This has not been the case for scanners in the past; even the smallest hand-held devices have been somewhat unwieldy. Those designed to be in contact with the page have to be held at a precise angle to the paper and moved very carefully along the length of the text to be scanned. This is acceptable when scanning a business report on an office desk, but may be impractical when scanning a phrase from a novel while waiting for a train. Scanners based on camera-type optics that operate at a distance from the paper may similarly be useful in some circumstances.
[0420] Some embodiments of the system use a scanner that scans in contact with the paper, and which, instead of lenses, uses an image conduit a bundle of optical fibers to transmit the image from the page to the optical sensor device. Such a device can be shaped to allow it to be held in a natural position; for example, in some embodiments, the part in contact with the page is wedge-shaped, allowing the user's hand to move more naturally over the page in a movement similar to the use of a highlighter pen. The conduit is either in direct contact with the paper or in close proximity to it, and may have a replaceable transparent tip that can protect the image conduit from possible damage. As has been mentioned in Section 12.2.4, the scanner may be used to scan from a screen as well as from paper, and the material of the tip can be chosen to reduce the likelihood of damage to such displays.
[0421] Lastly, some embodiments of the device will provide feedback to the user during the scanning process which will indicate through the use of light, sound or tactile feedback when the user is scanning too fast, too slow, too unevenly or is drifting too high or low on the scanned line.
[0422] 15.5. Security, Identity, Authentication, Personalization and Billing
[0423] As described in Section 6, the capture device may form an important part of identification and authorization for secure transactions, purchases, and a variety of other operations. It may therefore incorporate, in addition to the circuitry and software required for such a role, various hardware features that can make it more secure, such as a smartcard reader, RFID, or a keypad on which to type a PIN.
[0424] It may also include various biometric sensors to help identify the user. In the case of an optical scanner, for example, the scanning head may also be able to read a fingerprint. For a voice recorder, the voice pattern of the user may be used.
[0425] 15.6. Device Associations
[0426] In some embodiments, the device is able to form an association with other nearby devices to increase either its own or their functionality. In some embodiments, for example, it uses the display of a nearby PC or phone to give more detailed feedback about its operation, or uses their network connectivity. The device may, on the other hand, operate in its role as a security and identification device to authenticate operations performed by the other device. Or it may simply form an association in order to function as a peripheral to that device.
[0427] An interesting aspect of such associations is that they may be initiated and authenticated using the capture facilities of the device. For example, a user wishing to identify themselves securely to a public computer terminal may use the scanning facilities of the device to scan a code or symbol displayed on a particular area of the terminal's screen and so effect a key transfer. An analogous process may be performed using audio signals picked up by a voice-recording device.
[0428] 15.7. Integration with Other Devices
[0429] In some embodiments, the functionality of the capture device is integrated into some other device that is already in use. The integrated devices may be able to share a power supply, data capture and storage capabilities, and network interfaces. Such integration may be done simply for convenience, to reduce cost, or to enable functionality that would not otherwise be available.
[0430] Some examples of devices into which the capture functionality can be integrated include:
[0431] an existing peripheral such as a mouse, a stylus, a USB "webcam" camera, a Bluetooth® headset or a remote control
[0432] another processing/storage device, such as a PDA, an MP3 player, a voice recorder, a digital camera or a mobile phone
[0433] other often-carried items, just for convenience--a watch, a piece of jewelry, a pen, a car key fob
[0434] 15.7.1. Mobile Phone Integration
[0435] As an example of the benefits of integration, we consider the use of a modified mobile phone as the capture device.
[0436] In some embodiments, the phone hardware is not modified to support the system, such as where the text capture can be adequately done through voice recognition, where they can either be processed by the phone itself, or handled by a system at the other end of a telephone call, or stored in the phone's memory for future processing. Many modern phones have the ability to download software that could implement some parts of the system. Such voice capture is likely to be suboptimal in many situations, however, for example when there is substantial background noise, and accurate voice recognition is a difficult task at the best of times. The audio facilities may best be used to capture voice annotations.
[0437] In some embodiments, the camera built into many mobile phones is used to capture an image of the text. The phone display, which would normally act as a viewfinder for the camera, may overlay on the live camera image information about the quality of the image and its suitability for OCR, which segments of text are being captured, and even a transcription of the text if the OCR can be performed on the phone.
[0438] In some embodiments, the phone is modified to add dedicated capture facilities, or to provide such functionality in a clip-on adaptor or a separate Bluetooth-connected peripheral in communication with the phone. Whatever the nature of the capture mechanism, the integration with a modern cellphone has many other advantages. The phone has connectivity with the wider world, which means that queries can be submitted to remote search engines or other parts of the system, and copies of documents may be retrieved for immediate storage or viewing. A phone typically has sufficient processing power for many of the functions of the system to be performed locally, and sufficient storage to capture a reasonable amount of data. The amount of storage can also often be expanded by the user. Phones have reasonably good displays and audio facilities to provide user feedback, and often a vibrate function for tactile feedback. They also have good power supplies.
[0439] Most significantly of all, they are a device that most users are already carrying.
[0440] Part III--Example Applications of the System
[0441] This section lists example uses of the system and applications that may be built on it. This list is intended to be purely illustrative and in no sense exhaustive.
16. Personal Applications
[0442] 16.1. Life Library
[0443] The Life Library (see also Section 6.1.1) is a digital archive of any important documents that the subscriber wishes to save and is a set of embodiments of services of this system. Important books, magazine articles, newspaper clippings, etc., can all be saved in digital form in the Life Library. Additionally, the subscriber's annotations, comments, and notes can be saved with the documents. The Life Library can be accessed via the Internet and World Wide Web.
[0444] The system creates and manages the Life Library document archive for subscribers. The subscriber indicates which documents the subscriber wishes to have saved in his life library by scanning information from the document or by otherwise indicating to the system that the particular document is to be added to the subscriber's Life Library. The scanned information is typically text from the document but can also be a barcode or other code identifying the document. The system accepts the code and uses it to identify the source document. After the document is identified the system can store either a copy of the document in the user's Life Library or a link to a source where the document may be obtained.
[0445] One embodiment of the Life Library system can check whether the subscriber is authorized to obtain the electronic copy. For example, if a reader scans text or an identifier from a copy of an article in the New York Times (NYT) so that the article will be added to the reader's Life Library, the Life Library system will verify with the NYT whether the reader is subscribed to the online version of the NYT; if so, the reader gets a copy of the article stored in his Life Library account; if not, information identifying the document and how to order it is stored in his Life Library account.
[0446] In some embodiments, the system maintains a subscriber profile for each subscriber that includes access privilege information. Document access information can be compiled in several ways, two of which are: 1) the subscriber supplies the document access information to the Life Library system, along with his account names and passwords, etc., or 2) the Life Library service provider queries the publisher with the subscriber's information and the publisher responds by providing access to an electronic copy if the Life Library subscriber is authorized to access the material. If the Life Library subscriber is not authorized to have an electronic copy of the document, the publisher provides a price to the Life Library service provider, which then provides the customer with the option to purchase the electronic document. If so, the Life Library service provider either pays the publisher directly and bills the Life Library customer later or the Life Library service provider immediately bills the customer's credit card for the purchase. The Life Library service provider would get a percentage of the purchase price or a small fixed fee for facilitating the transaction.
[0447] The system can archive the document in the subscriber's personal library and/or any other library to which the subscriber has archival privileges. For example, as a user scans text from a printed document, the Life Library system can identify the rendered document and its electronic counterpart. After the source document is identified, the Life Library system might record information about the source document in the user's personal library and in a group library to which the subscriber has archival privileges. Group libraries are collaborative archives such as a document repository for: a group working together on a project, a group of academic researchers, a group web log, etc.
[0448] The life library can be organized in many ways: chronologically, by topic, by level of the subscriber's interest, by type of publication (newspaper, book, magazine, technical paper, etc.), where read, when read, by ISBN or by Dewey decimal, etc. In one alternative, the system can learn classifications based on how other subscribers have classified the same document. The system can suggest classifications to the user or automatically classify the document for the user.
[0449] In various embodiments, annotations may be inserted directly into the document or may be maintained in a separate file. For example, when a subscriber scans text from a newspaper article, the article is archived in his Life Library with the scanned text highlighted. Alternatively, the article is archived in his Life Library along with an associated annotation file (thus leaving the archived document unmodified). Embodiments of the system can keep a copy of the source document in each subscriber's library, a copy in a master library that many subscribers can access, or link to a copy held by the publisher.
[0450] In some embodiments, the Life Library stores only the user's modifications to the document (e.g., highlights, etc.) and a link to an online version of the document (stored elsewhere). The system or the subscriber merges the changes with the document when the subscriber subsequently retrieves the document.
[0451] If the annotations are kept in a separate file, the source document and the annotation file are provided to the subscriber and the subscriber combines them to create a modified document. Alternatively, the system combines the two files prior to presenting them to the subscriber. In another alternative, the annotation file is an overlay to the document file and can be overlaid on the document by software in the subscriber's computer.
[0452] Subscribers to the Life Library service pay a monthly fee to have the system maintain the subscriber's archive. Alternatively, the subscriber pays a small amount (e.g., a micro-payment) for each document stored in the archive. Alternatively, the subscriber pays to access the subscriber's archive on a per-access fee. Alternatively, subscribers can compile libraries and allow others to access the materials/annotations on a revenue share model with the Life Library service provider and copyright holders. Alternatively, the Life Library service provider receives a payment from the publisher when the Life Library subscriber orders a document (a revenue share model with the publisher, where the Life Library service provider gets a share of the publisher's revenue).
[0453] In some embodiments, the Life Library service provider acts as an intermediary between the subscriber and the copyright holder (or copyright holder's agent, such as the Copyright Clearance Center, a.k.a. CCC) to facilitate billing and payment for copyrighted materials. The Life Library service provider uses the subscriber's billing information and other user account information to provide this intermediation service. Essentially, the Life Library service provider leverages the pre-existing relationship with the subscriber to enable purchase of copyrighted materials on behalf of the subscriber.
[0454] In some embodiments, the Life Library system can store excerpts from documents. For example, when a subscriber scans text from a paper document, the regions around the scanned text are excerpted and placed in the Life Library, rather than the entire document being archived in the life library. This is especially advantageous when the document is long because preserving the circumstances of the original scan prevents the subscriber from re-reading the document to find the interesting portions. Of course, a hyperlink to the entire electronic counterpart of the paper document can be included with the excerpt materials.
[0455] In some embodiments, the system also stores information about the document in the Life Library, such as author, publication title, publication date, publisher, copyright holder (or copyright holder's licensing agent), ISBN, links to public annotations of the document, readrank, etc. Some of this additional information about the document is a form of paper document metadata. Third parties may create public annotation files for access by persons other than themselves, such the general public. Linking to a third party's commentary on a document is advantageous because reading annotation files of other users enhances the subscriber's understanding of the document.
[0456] In some embodiments, the system archives materials by class. This feature allows a Life Library subscriber to quickly store electronic counterparts to an entire class of paper documents without access to each paper document. For example, when the subscriber scans some text from a copy of National Geographic magazine, the system provides the subscriber with the option to archive all back issues of the National Geographic. If the subscriber elects to archive all back issues, the Life Library service provider would then verify with the National Geographic Society whether the subscriber is authorized to do so. If not, the Life Library service provider can mediate the purchase of the right to archive the National Geographic magazine collection.
[0457] 16.2. Life Saver
[0458] A variation on, or enhancement of, the Life Library concept is the "Life Saver," where the system uses the text captured by a user to deduce more about their other activities. The scanning of a menu from a particular restaurant, a program from a particular theater performance, a timetable at a particular railway station, or an article from a local newspaper allows the system to make deductions about the user's location and social activities, and could construct an automatic diary for them, for example as a website. The user would be able to edit and modify the diary, add additional materials such as photographs and, of course, look again at the items scanned.
17. Academic Applications
[0459] Portable scanners supported by the described system have many compelling uses in the academic setting. They can enhance student/teacher interaction and augment the learning experience. Among other uses, students can annotate study materials to suit their unique needs; teachers can monitor classroom performance; and teachers can automatically verify source materials cited in student assignments.
[0460] 17.1. Children's Books
[0461] A child's interaction with a paper document, such as a book, is monitored by a literacy acquisition system that employs a specific set of embodiments of this system. The child uses a portable scanner that communicates with other elements of the literacy acquisition system. In addition to the portable scanner, the literacy acquisition system includes a computer having a display and speakers, and a database accessible by the computer. The scanner is coupled with the computer (hardwired, short range RF, etc.). When the child sees an unknown word in the book, the child scans it with the scanner. In one embodiment, the literacy acquisition system compares the scanned text with the resources in its database to identify the word. The database includes a dictionary, thesaurus, and/or multimedia files (e.g., sound, graphics, etc.). After the word has been identified, the system uses the computer speakers to pronounce the word and its definition to the child. In another embodiment, the word and its definition are displayed by the literacy acquisition system on the computer's monitor. Multimedia files about the scanned word can also be played through the computer's monitor and speakers. For example, if a child reading "Goldilocks and the Three Bears" scanned the word "bear," the system might pronounce the word "bear" and play a short video about bears on the computer's monitor. In this way, the child learns to pronounce the written word and is visually taught what the word means via the multimedia presentation.
[0462] The literacy acquisition system provides immediate auditory and/or visual information to enhance the learning process. The child uses this supplementary information to quickly acquire a deeper understanding of the written material. The system can be used to teach beginning readers to read, to help children acquire a larger vocabulary, etc. This system provides the child with information about words with which the child is unfamiliar or about which the child wants more information.
[0463] 17.2. Literacy Acquisition
[0464] In some embodiments, the system compiles personal dictionaries. If the reader sees a word that is new, interesting, or particularly useful or troublesome, the reader saves it (along with its definition) to a computer file. This computer file becomes the reader's personalized dictionary. This dictionary is generally smaller in size than a general dictionary so can be downloaded to a mobile station or associated device and thus be available even when the system isn't immediately accessible. In some embodiments, the personal dictionary entries include audio files to assist with proper word pronunciation and information identifying the paper document from which the word was scanned.
[0465] In some embodiments, the system creates customized spelling and vocabulary tests for students. For example, as a student reads an assignment, the student may scan unfamiliar words with the portable scanner. The system stores a list of all the words that the student has scanned. Later, the system administers a customized spelling/vocabulary test to the student on an associated monitor (or prints such a test on an associated printer).
[0466] 17.3. Music Teaching
[0467] The arrangement of notes on a musical staff is similar to the arrangement of letters in a line of text. The same scanning device discussed for capturing text in this system can be used to capture music notation, and an analogous process of constructing a search against databases of known musical pieces would allow the piece from which the capture occurred to be identified which can then be retrieved, played, or be the basis for some further action.
[0468] 17.4. Detecting Plagiarism
[0469] Teachers can use the system to detect plagiarism or to verify sources by scanning text from student papers and submitting the scanned text to the system. For example, a teacher who wishes to verify that a quote in a student paper came from the source that the student cited can scan a portion of the quote and compare the title of the document identified by the system with the title of the document cited by the student. Likewise, the system can use scans of text from assignments submitted as the student's original work to reveal if the text was instead copied.
[0470] 17.5. Enhanced Textbook
[0471] In some embodiments, capturing text from an academic textbook links students or staff to more detailed explanations, further exercises, student and staff discussions about the material, related example past exam questions, further reading on the subject, recordings of the lectures on the subject, and so forth. (See also Section 7.1.)
[0472] 17.6. Language Learning
[0473] In some embodiments, the system is used to teach foreign languages. Scanning a Spanish word, for example, might cause the word to be read aloud in Spanish along with its definition in English.
[0474] The system provides immediate auditory and/or visual information to enhance the new language acquisition process. The reader uses this supplementary information to acquire quickly a deeper understanding of the material. The system can be used to teach beginning students to read foreign languages, to help students acquire a larger vocabulary, etc. The system provides information about foreign words with which the reader is unfamiliar or for which the reader wants more information.
[0475] Reader interaction with a paper document, such as a newspaper or book, is monitored by a language skills system. The reader has a portable scanner that communicates with the language skills system. In some embodiments, the language skills system includes a computer having a display and speakers, and a database accessible by the computer. The scanner communicates with the computer (hardwired, short range RF, etc.). When the reader sees an unknown word in an article, the reader scans it with the scanner. The database includes a foreign language dictionary, thesaurus, and/or multimedia files (sound, graphics, etc.). In one embodiment, the system compares the scanned text with the resources in its database to identify the scanned word. After the word has been identified, the system uses the computer speakers to pronounce the word and its definition to the reader. In some embodiments, the word and its definition are both displayed on the computer's monitor. Multimedia files about grammar tips related to the scanned word can also be played through the computer's monitor and speakers. For example, if the words "to speak" are scanned, the system might pronounce the word "hablar," play a short audio clip that demonstrates the proper Spanish pronunciation, and display a complete list of the various conjugations of "hablar." In this way, the student learns to pronounce the written word, is visually taught the spelling of the word via the multimedia presentation, and learns how to conjugate the verb. The system can also present grammar tips about the proper usage of "hablar" along with common phrases.
[0476] In some embodiments, the user scans a word or short phrase from a rendered document in a language other than the user's native language (or some other language that the user knows reasonably well). In some embodiments, the system maintains a prioritized list of the user's "preferred" languages. The system identifies the electronic counterpart of the rendered document, and determines the location of the scan within the document. The system also identifies a second electronic counterpart of the document that has been translated into one of the user's preferred languages, and determines the location in the translated document corresponding to the location of the scan in the original document. When the corresponding location is not known precisely, the system identifies a small region (e.g., a paragraph) that includes the corresponding location of the scanned location. The corresponding translated location is then presented to the user. This provides the user with a precise translation of the particular usage at the scanned location, including any slang or other idiomatic usage that is often difficult to accurately translate on a word-by-word basis.
[0477] 17.7. Gathering Research Materials
[0478] A user researching a particular topic may encounter all sorts of material, both in print and on screen, which they might wish to record as relevant to the topic in some personal archive. The system would enable this process to be automatic as a result of scanning a short phrase in any piece of material, and could also create a bibliography suitable for insertion into a publication on the subject.
18. Commercial Applications
[0479] Obviously, commercial activities could be made out of almost any process discussed in this document, but here we concentrate on a few obvious revenue streams.
[0480] 18.1. Fee-Based Searching and Indexing
[0481] Conventional Internet search engines typically provide free search of electronic documents, and also make no charge to the content providers for including their content in the index. In some embodiments, the system provides for charges to users and/or payments to search engines and/or content providers in connection with the operation and use of the system.
[0482] In some embodiments, subscribers to the system's services pay a fee for searches originating from scans of paper documents. For example, a stockbroker may be reading a Wall Street Journal article about a new product offered by Company X. By scanning the Company X name from the paper document and agreeing to pay the necessary fees, the stockbroker uses the system to search special or proprietary databases to obtain premium information about the company, such as analyst's reports. The system can also make arrangements to have priority indexing of the documents most likely to be read in paper form, for example by making sure all of the newspapers published on a particular day are indexed and available by the time they hit the streets.
[0483] Content providers may pay a fee to be associated with certain terms in search queries submitted from paper documents. For example, in one embodiment, the system chooses a most preferred content provider based on additional context about the provider (the context being, in this case, that the content provider has paid a fee to be moved up the results list). In essence, the search provider is adjusting paper document search results based on pre-existing financial arrangements with a content provider. See also the description of keywords and key phrases in Section 5.2.
[0484] Where access to particular content is to be restricted to certain groups of people (such as clients or employees), such content may be protected by a firewall and thus not generally indexable by third parties. The content provider may nonetheless wish to provide an index to the protected content. In such a case, the content provider can pay a service provider to provide the content provider's index to system subscribers. For example, a law firm may index all of a client's documents. The documents are stored behind the law firm's firewall. However, the law firm wants its employees and the client to have access to the documents through the portable scanner so it provides the index (or a pointer to the index) to the service provider, which in turn searches the law firm's index when employees or clients of the law firm submit paper-scanned search terms via their portable scanners. The law firm can provide a list of employees and/or clients to the service provider's system to enable this function or the system can verify access rights by querying the law firm prior to searching the law firm's index. Note that in the preceding example, the index provided by the law firm is only of that client's documents, not an index of all documents at the law firm. Thus, the service provider can only grant the law firm's clients access to the documents that the law firm indexed for the client.
[0485] There are at least two separate revenue streams that can result from searches originating from paper documents: one revenue stream from the search function, and another from the content delivery function. The search function revenue can be generated from paid subscriptions from the scanner users, but can also be generated on a per-search charge. The content delivery revenue can be shared with the content provider or copyright holder (the service provider can take a percentage of the sale or a fixed fee, such as a micropayment, for each delivery), but also can be generated by a "referral" model in which the system gets a fee or percentage for every item that the subscriber orders from the online catalog and that the system has delivered or contributed to, regardless of whether the service provider intermediates the transaction. In some embodiments, the system service provider receives revenue for all purchases that the subscriber made from the content provider, either for some predetermined period of time or at any subsequent time when a purchase of an identified product is made.
[0486] 18.2. Catalogs
[0487] Consumers may use the portable scanner to make purchases from paper catalogs. The subscriber scans information from the catalog that identifies the catalog. This information is text from the catalog, a bar code, or another identifier of the catalog. The subscriber scans information identifying the products that s/he wishes to purchase. The catalog mailing label may contain a customer identification number that identifies the customer to the catalog vendor. If so, the subscriber can also scan this customer identification number. The system acts as an intermediary between the subscriber and the vendor to facilitate the catalog purchase by providing the customer's selection and customer identification number to the vendor.
[0488] 18.3. Coupons
[0489] A consumer scans paper coupons and saves an electronic copy of the coupon in the scanner, or in a remote device such as a computer, for later retrieval and use. An advantage of electronic storage is that the consumer is freed from the burden of carrying paper coupons. A further advantage is that the electronic coupons may be retrieved from any location. In some embodiments, the system can track coupon expiration dates, alert the consumer about coupons that will expire soon, and/or delete expired coupons from storage. An advantage for the issuer of the coupons is the possibility of receiving more feedback about who is using the coupons and when and where they are captured and used.
19. General Applications
[0490] 19.1. Forms
[0491] The system may be used to auto-populate an electronic document that corresponds to a paper form. A user scans in some text or a barcode that uniquely identifies the paper form. The scanner communicates the identity of the form and information identifying the user to a nearby computer. The nearby computer has an Internet connection. The nearby computer can access a first database of forms and a second database having information about the user of the scanner (such as a service provider's subscriber information database). The nearby computer accesses an electronic version of the paper form from the first database and auto-populates the fields of the form from the user's information obtained from the second database. The nearby computer then emails the completed form to the intended recipient. Alternatively, the computer could print the completed form on a nearby printer.
[0492] Rather than access an external database, in some embodiments, the system has a portable scanner that contains the user's information, such as in an identity module, SIM, or security card. The scanner provides information identifying the form to the nearby PC. The nearby PC accesses the electronic form and queries the scanner for any necessary information to fill out the form.
[0493] 19.2. Business Cards
[0494] The system can be used to automatically populate electronic address books or other contact lists from paper documents. For example, upon receiving a new acquaintance's business card, a user can capture an image of the card with his/her cellular phone. The system will locate an electronic copy of the card, which can be used to update the cellular phone's onboard address book with the new acquaintance's contact information. The electronic copy may contain more information about the new acquaintance than can be squeezed onto a business card. Further, the onboard address book may also store a link to the electronic copy such that any changes to the electronic copy will be automatically updated in the cell phone's address book. In this example, the business card optionally includes a symbol or text that indicates the existence of an electronic copy. If no electronic copy exists, the cellular phone can use OCR and knowledge of standard business card formats to fill out an entry in the address book for the new acquaintance. Symbols may also aid in the process of extracting information directly from the image. For example, a phone icon next to the phone number on the business card can be recognized to determine the location of the phone number.
[0495] 19.3. Proofreading/Editing
[0496] The system can enhance the proofreading and editing process. One way the system can enhance the editing process is by linking the editor's interactions with a paper document to its electronic counterpart. As an editor reads a paper document and scans various parts of the document, the system will make the appropriate annotations or edits to an electronic counterpart of the paper document. For example, if the editor scans a portion of text and makes the "new paragraph" control gesture with the scanner, a computer in communication with the scanner would insert a "new paragraph" break at the location of the scanned text in the electronic copy of the document.
[0497] 19.4. Voice Annotation
[0498] A user can make voice annotations to a document by scanning a portion of text from the document and then making a voice recording that is associated with the scanned text. In some embodiments, the scanner has a microphone to record the user's verbal annotations. After the verbal annotations are recorded, the system identifies the document from which the text was scanned, locates the scanned text within the document, and attaches the voice annotation at that point. In some embodiments, the system converts the speech to text and attaches the annotation as a textual comment.
[0499] In some embodiments, the system keeps annotations separate from the document, with only a reference to the annotation kept with the document. The annotations then become an annotation markup layer to the document for a specific subscriber or group of users.
[0500] In some embodiments, for each capture and associated annotation, the system identifies the document, opens it using a software package, scrolls to the location of the scan and plays the voice annotation. The user can then interact with a document while referring to voice annotations, suggested changes or other comments recorded either by themselves or by somebody else.
[0501] 19.5. Help in Text
[0502] The described system can be used to enhance paper documents with electronic help menus. In some embodiments, a markup layer associated with a paper document contains help menu information for the document. For example, when a user scans text from a certain portion of the document, the system checks the markup associated with the document and presents a help menu to the user. The help menu is presented on a display on the scanner or on an associated nearby display.
[0503] 19.6. Use with Displays
[0504] In some situations, it is advantageous to be able to scan information from a television, computer monitor, or other similar display. In some embodiments, the portable scanner is used to scan information from computer monitors and televisions. In some embodiments, the portable optical scanner has an illumination sensor that is optimized to work with traditional cathode ray tube (CRT) display techniques such as rasterizing, screen blanking, etc.
[0505] A voice capture device which operates by capturing audio of the user reading text from a document will typically work regardless of whether that document is on paper, on a display, or on some other medium.
[0506] 19.6.1. Public Kiosks and Dynamic Session IDs
[0507] One use of the direct scanning of displays is the association of devices as described in Section 15.6. For example, in some embodiments, a public kiosk displays a dynamic session ID on its monitor. The kiosk is connected to a communication network such as the Internet or a corporate intranet. The session ID changes periodically but at least every time that the kiosk is used so that a new session ID is displayed to every user. To use the kiosk, the subscriber scans in the session ID displayed on the kiosk; by scanning the session ID, the user tells the system that he wishes to temporarily associate the kiosk with his scanner for the delivery of content resulting from scans of printed documents or from the kiosk screen itself. The scanner may communicate the Session ID and other information authenticating the scanner (such as a serial number, account number, or other identifying information) directly to the system. For example, the scanner can communicate directly (where "directly" means without passing the message through the kiosk) with the system by sending the session initiation message through the user's cell phone (which is paired with the user's scanner via Bluetooth®) Alternatively, the scanner can establish a wireless link with the kiosk and use the kiosk's communication link by transferring the session initiation information to the kiosk (perhaps via short range RF such as Bluetooth®, etc.); in response, the kiosk sends the session initiation information to the system via its Internet connection.
[0508] The system can prevent others from using a device that is already associated with a scanner during the period (or session) in which the device is associated with the scanner. This feature is useful to prevent others from using a public kiosk before another person's session has ended. As an example of this concept related to use of a computer at an Internet cafe, the user scans a barcode on a monitor of a PC which s/he desires to use; in response, the system sends a session ID to the monitor that it displays; the user initiates the session by scanning the session ID from the monitor (or entering it via a keypad or touch screen or microphone on the portable scanner); and the system associates in its databases the session ID with the serial number (or other identifier that uniquely identifies the user's scanner) of his/her scanner so another scanner cannot scan the session ID and use the monitor during his/her session. The scanner is in communication (through wireless link such as Bluetooth®, a hardwired link such as a docking station, etc.) with a PC associated with the monitor or is in direct (i.e., w/o going through the PC) communication with the system via another means such as a cellular phone, etc.
[0509] Part IV--System Details
[0510] A software and/or hardware facility for searching for documents available in a private network ("the facility") is described. In some embodiments, a portion of the facility executing inside a private network crawls or otherwise surveys electronic versions of documents available in the private network to build one or more indexes of documents of which paper versions might exist. The facility exports one or more indexes to an external index aggregation center where these indexes may be stored and/or aggregated with indexes from other private networks and/or other sources. The facility may use individual indexes and/or various aggregated indexes to service queries from users, such as queries each seeking to identify a document based upon a small portion of text captured from a rendered version of the document. The search result returned by the facility lists documents satisfying the query, and can be used to access these documents in a variety of ways.
[0511] The index aggregator organization may charge a fee for including the index in the aggregated index. Users may be charged a fee to search the aggregated index. The ordering of search results may be modified based on the provider of a particular index purchasing a higher ranking. In other words, if a search of the aggregated index (which includes Index A, Index B, Index C, etc.) returns results from Index A supplied by content provider A and Index B supplied by content provider B, the results from index A might be presented to the searcher before the results from Index B if content provider A has paid a fee for this service. A fee might also be paid by the content provider, publisher, copyright holder, etc., to receive data relating to who searched in various documents, how many such searches occurred, when these searches occurred, the user's physical location when the search was performed, etc.
[0512] In some embodiments, the facility compiles special purpose indexes and stores many separate indexes. For example, a consulting firm could compile an index for each client's documents. The index of a client's documents would only be searchable by the client and the consulting firm's employees. The client and employees from other offices could use a virtual private network ("VPN") to access the index of the client's documents from remote locations. The different classes of indexes could control who can view/access them. Certain indexes could be provided to public search engines, others could be retained for internal use.
[0513] Alternatively, a single index may be published for the firm, with actual access to specific documents or groups of documents controlled at the firm's portal. In some embodiments, such documents are flagged in the exported index, either (1) to prevent caching of these documents on the public search engine server, or (2) to require that copies of these documents cached on the public search engine server are accessible only to users authorized by the firm.
[0514] In one example, a news wire service stores news articles on its private network. The wire service creates an index to its articles with the facility and provides that index to an index aggregator for aggregation. When a user scans text from a wire service article in a particular newspaper, the facility will search the aggregated index and identify the source of the article as the wire service. The facility could then purchase an electronic copy of the article from the wire service on the subscriber's behalf. The wire service would provide a copy of the article from its private network. The facility further arranges for access fees to be paid to the particular newspaper in which the article was scanned (i.e., a particular publisher of the work), a wire service (i.e., a higher-level copyright owner of the work), or both. In this way, the wire service and newspaper can both avoid exposing copyrighted works to unauthorized copying, yet still sell copies to interested readers.
[0515] In some embodiments, the facility may expose portions of the work to the user, and/or allow limited excerpting. In some embodiments, the facility in some cases releases some or all content based upon information indicating that the user already has access to a paper copy of the same work.
[0516] By providing some or all of the indexing and searching functionalities discussed above, the facility enables users to search for private documents that are generally inaccessible to a webcrawler, that otherwise might not be able to be located through a normal web search. This is particularly useful where users are frequently trying to identify the electronic source of a phrase scanned from a printed document. Such scans can also be identified to the system as originating from a paper-document-based query.
[0517] FIG. 4 is a network diagram showing a typical environment in which the facility operates. The environment includes a private network 400, such as a private network belonging to a particular company or organization. The private network includes a number of content storage computer systems, such as content storage computer systems 421-423. These are computer systems that can or do store documents, such as file servers, document management system servers, user computer systems, storage area network gateways, etc. Access to the content storage computer systems and the documents stored thereon from the Internet is regulated by a network access control computer system 411, such as a firewall facility. For example, the network access control computer system may control access based upon user identity, subscription payment status, document identity, etc. The private network also includes a network indexing computer system 412 that periodically surveys the content storage computer systems, using techniques such as link crawling or directory traversal, to compile an index of the documents stored in the private network. This index may be used to search for documents from inside the private network. In some embodiments, the network indexing computer system 412 is a special-purpose network appliance designed, constructed, and sold to support the operation of the facility. In some embodiments, the network indexing computer system is a pre-existing or arbitrarily selected node of the private network on which software for the facility has been installed.
[0518] The network indexing computer system 412 exports the index via the Internet 430 to a search engine computer system 440. The search engine computer system 440 merges the index exported by the network indexing computer system 412 into an aggregated index, together with indexes exported by other private networks and/or index information obtained via other techniques, such as conventional public network indexing techniques. When the search engine computer system 440 receives a search query from a search client computer system 450, it uses the aggregated index containing the information from the exported index to service the query. In some embodiments, the query received from the search client computer system 450 is derived from an optical scan of a printed, displayed, or otherwise rendered document. In some cases, the query contains an adequate portion of text known to come from the document (which may include a document identifier known to be contained in the document) to demonstrate a high probability that the document is in the possession of the user. The query may further identify the location of the user and/or the location of the optical scanner used to perform the optical scan. The query may further include information identifying the user and/or the scanner.
[0519] While various functionalities and data are shown in FIG. 4 as residing on particular computer systems that are arranged in a particular way, those skilled in the art will appreciate that such functionalities and data may be distributed in various other ways across computer systems in different arrangements. In some embodiments, for example, the entire private network 400 is implemented on a single computer system.
[0520] FIG. 5 shows an example embodiment of some aspects of the system. The user makes an optical scan (501) from a rendered document. The data is passed to an image processing/OCR engine (502) which outputs data that can be used as the basis of a query, for example, recognized text. A query processing stage (504) takes this and uses it to create a query or queries suitable for the query engine (506). It may remove characters that are likely to be OCR errors, for example, or assign them a lower priority. It may produce several queries, for example in cases where the content of the scan is not entirely clear. The query engine (506) searches or causes a search to happen on one or more indexes (510) using the queries passed to it, and produces a set of references to the documents it find.
[0521] An index (510) is produced from a set of source documents (512) which may include the electronic counterpart of the rendered document from which the scan occurred. The process of creating the index starts with the gathering (514) of those source documents. In the case where those documents are available on the web, this includes the process of finding and retrieving them from their web server. Markup associated with the documents may be retrieved at the same time. A local cache of the documents and markup (515) may be maintained. These gathered documents are processed (516), for example to remove formatting instructions or to extract the basic text before being passed to the indexing process (518) that produces the index.
[0522] In producing the set of references, the query engine (506) may take into account the real-world context in which the scan occurred using a subsystem (522) that may maintain its own database (524). For example, the geographical location of the user, if known, could be taken into account at this stage, as could information from the gathering process (514) such as the geographical location of the publisher of the documents. The query engine (506) will also typically take into account the `scan context` (532) which includes information, for example, about the other scans the user has made recently, and which font and language they were in. The scan context handling process (532) may also maintain its own database (534).
[0523] The references produced by the query engine (506) will typically include information about the source documents (512) that are relevant to the scan. The response processing stage (508) takes these references and produces output for the user. In the simplest case, this may be a list of document references from which the user may choose. More typically, it will involve the use of the context systems (522, 532) to determine certain aspects of the presentation, such as the prioritization of the options presented to the user or the formatting of the display.
[0524] The response processing stage (508) is also one of the key stages that may make use of markup (542). Such markup may already have been retrieved or generated, may be retrieved or generated at the time of use, may be based on information or rules in an associated database (544). As an example, the response processing stage (508) may request from the markup handling system (542) any markup associated with the documents mentioned in the references. The markup handling system may contact the `gather` system (514) that retrieves any such markup from the original source of the documents or from its own cache. This markup is returned to the response processing system (508) that uses it to determine the options available to the user. It may also make use of information provided by the context handling stages (522, 532). A results document is thus produced and presented to the user.
[0525] If the user makes a selection (509) from the results document, for example to retrieve a particular document, that request may be passed to the access/billing system (552) which is responsible for retrieving said document and/or any associated data and, optionally, charging a fee for doing so. Other actions may be performed depending on the user's selection. Any results, such as the retrieved document, are presented to the user by the results processing stage (562) that may also make use of the markup handling system (542) to identify information relevant to the presentation.
[0526] FIG. 6 is a block diagram showing some of the components typically incorporated in at least some of the computer systems and other devices on which the facility executes. These computer systems and devices 600 may include one or more central processing units ("CPUs") 601 for executing computer programs; a computer memory 602 for storing programs and data--including data structures--while they are being used; a persistent storage device 603, such as a hard drive, for persistently storing programs and data; a computer-readable media drive 604, such as a CD-ROM drive, for reading programs and data stored on a computer-readable medium; a network connection 605 for connecting the computer system to other computer systems, such as via the Internet, to exchange programs and/or data--including data structures; and a handheld document data capture device 606, such as a portable and/or wireless optical scanner, that can be used to capture text and/or symbols from a rendered document. The programs executed by the CPU 601 may include programs associated with the facility and described elsewhere herein, as well as software for recognizing scanned images, such as optical character recognition ("OCR") software. While computer systems configured as described above are typically used to support the operation of the facility, one of ordinary skill in the art will appreciate that the facility may be implemented using devices of various types and configurations, and having various components.
[0527] FIG. 7 is a data flow diagram showing a first manner in which index information is exported by some embodiments of the facility. FIG. 7 shows that the network indexing computer system 412 exports a single exported private network index 701 to the search engine computer system 440. The exported index may contain information about all of the documents identified in the private network by the network indexing computer system, or a predetermined subset. For example, the documents included in the exported index may be filtered to omit sensitive documents. The exported private network index 701 may include information regarding access restrictions associated with one or more of the indexed documents.
[0528] FIG. 8 is a flow diagram showing steps typically performed by the facility in order to export an index from the private network 400. The facility typically performs these steps periodically in the network indexing computer system 412. In step 801, the facility identifies electronic versions of documents available inside the private network 400. In some embodiments, step 801 involves document links spidering techniques, in which the facility traverses links from known documents to discover additional documents. In some embodiments, step 801 involves enumerating the contents of various kinds of document catalogs and hierarchies. For example, in some embodiments the facility enumerates all of the documents stored in a hierarchical file system on a content storage computer system 421-423. In some embodiments, the facility enumerates documents stored in a document repository managed by a document management system installed on one of the content storage computer systems 421-423. Embodiments of the facility use various additional approaches to identifying electronic versions of documents available inside the private network 400.
[0529] In some embodiments, step 801 further includes determining whether one or more paper copies of each identified document have or may have been created. In some embodiments, step 801 further involves reviewing explicit indications that particular documents should be included in or excluded from the indexing, such as indications directly applied to individual documents, or indications collected in a centralized database. In some embodiments, step 801 further includes determining whether certain specific access restrictions apply to one or more of the identified documents. In some embodiments, the facility uses this information to filter the set of electronic documents identified in step 801, and/or to includes explicit indications in the index to this effect.
[0530] In step 802, the facility constructs an index covering the identified electronic versions of documents. Different embodiments of the facility use a variety of indexing techniques, including those that generate indexes capable of supporting phrase searching, offset-based searching, word length based searching, and other search methodologies known or described herein. A sample index constructed by the facility in step 802 is shown in FIG. 9 and discussed below. In some embodiments, the constructed index is exhaustive, in that index information is included in the index irrespective of whether it was included in an earlier-exported index. In some embodiments, the index constructed by the facility is differential, in that it contains only index information that differs from that contained in earlier-exported indexes. In addition to containing newly indexed material, such a differential index may include index information that has changed for previously indexed documents. For example, different access restrictions can be associated with a previously known document. In step 803, the facility exports the index constructed in step 802 to a search engine computer system 440 or other destination. After step 803, these steps conclude.
[0531] FIG. 9 is a table diagram showing a sample exported index exported by the facility. The index 900 is made up of rows-such as rows 901-904--each corresponding to a particular query term and a particular document containing the term. Each row is divided into the following columns: a term column 911 containing the term; a document column 912 containing information usable, either alone or in combination with other information, to retrieve or attempt to retrieve the document; a count column 913 showing the number of occurrences of the term in the document; and an offset column 914 containing offset values indicating the position or positions of the term in the document, such as the word number of the term in the document (as shown), or the character number at which the term begins in the document (not shown).
[0532] For example, the contents of row 901 indicate that the term "diverge" occurs in the document http://www.acmeconsulting.com/documents/01934125 one time, at word number 436. The inclusion of offsets in the exported index is one way in which the facility may enable the search engine computer system to directly support term searching. For example, from the contents of rows 901, 902, and 904, it can be seen that the same document contains the phrase "husbandry trends diverge" beginning at word 434. In some embodiments, however, the offset information is omitted from the exported index in order to limit the extent to which the contents of the document may be derived from the exported index.
[0533] In some embodiments, the index is exported with an index or private network identifier 999--here 4010--that can be used by the search engine computer system 440 to associate the contents of the index with index information for the same private network 400 earlier merged into the aggregated index maintained by the search engine computer system 440.
[0534] Those skilled in the art will recognize that the data shown in FIG. 9 and the data shown in the additional table diagrams discussed hereafter, or similar data, could be stored in a variety of different forms, including being stored in various types of memory devices, in various organizations, in one or more tables or other data structures having various organizations, using various forms of indexing, compression, encryption, etc.
[0535] As one example, the index is stored as a trie--that is, a tree for storing strings in which each node represents a word or a portion of a word, and in which any monotonically-downward traversal represents a string concatenated from the text of the nodes in the order of traversal. In some embodiments, the facility includes in the index it generates additional entries corresponding to keywords that are produced by a scanning and/or recognition error likely to occur when a term appearing in a printed document is optically scanned and recognized.
[0536] FIG. 10 is a flow diagram showing steps typically performed by the facility in order to import an exported index. The facility typically performs these steps in the search engine computer system each time an index is exported from a private network. In step 1001, the facility receives the exported index. In step 1002, the facility merges the exported index into the aggregated index maintained by the facility.
[0537] In some embodiments in which the exported index is exhaustive, step 602 involves using the source index identifiers to replace information presently contained in the aggregated index for the same private network with the index information in the received exported index. In some such embodiments, step 602 involves creating a new aggregated index from the received exported index and the latest version of other index information, such as indexes exported from other private networks.
[0538] In some embodiments, however, rather than exporting an exhaustive index in every index exporting cycle, a private network in some index exporting cycles exports only a differential index identifying changes in the private network since the last index exporting cycle. Where the exported index received in step 602 is such a differential index, the facility typically uses it to augment the index information already contained in the aggregated index for the same private network rather than substituting the index information. A sample aggregated index produced by the facility is shown in FIG. 11 and discussed below. After step 602, the steps conclude. In some embodiments, index information that has changed for specific documents since the last index exporting cycle is updated in the aggregated index in addition to merging new index information.
[0539] FIG. 11 is a data structure diagram showing a sample aggregated index generated by the facility. The aggregated index 1100 is made up of rows--such as rows 1101-1106--each corresponding to a combination of a term and a document containing the term. The contents of a row may come from an exported index received from any private network, or index information obtained or received in a variety of other ways, such as by performing conventional public network exploration techniques. Each row is divided into the following columns: column 1111-1114, which are similar to columns 911-914 shown in FIG. 9; and a source index column 1115, which contains the index identifier included with the exported index that was the source of the index information in the row. For example, it can be seen that rows 1101, 1102, 1105, and 1106 each have the source index identifier 4010, included with exported index 900. The contents of the aggregated index 1100 can be used by the search engine computer system, 440 in response to the phrase query "husbandry trends diverge," to identify position 434 in the document http://www.acmeconsulting.com/documents/01934125 as satisfying the query. In some embodiments, the facility returns the document identifier from the document column 1112 as part of the search result for use in retrieving the document. In some embodiments, the facility uses the document ID in document column 1112, together with other information, such as the source index in the source index column and/or additional information to generate a URL or other identifier for inclusion in the search result that can be used by the user to access the document or attempt to access the document. In some embodiments, a source index column 1115 is replaced with a source index identifier column, which contains a source index identifier that is mapped by a separate table to the index identifier included with the exported index that was the source of the index information in the row. In some embodiments, where the offsets column 1114 is omitted from the aggregated index or emptied, the facility services a phrase query by identifying the documents that contain all of the query terms contained in the phrase, and forwarding to the corresponding private networks a delegated query requesting that the private networks themselves determine whether each of the identified documents satisfy the phrase query. In some embodiments, the exported private index contains information regarding how one or more of the indexed private documents are to be represented in response to a matching public query. For example, a response to a query that matches a document within the private network of firm XYZ may initially appear in a search result identified only as "Confidential document of XYZ."
[0540] Furthermore, the exported index may specify a level at which a query must match a document before the existence of a potential match may be revealed in response to a public query. For example, a firm may wish to only expose the existence of a possible match when a search phrase is matched exactly. Access may be further limited to exact matches for phrases of a minimum length (or, alternatively, minimum "complexity," where complexity takes into account the information-theoretic content of a phrase, and corresponds to the likelihood that the specific phrase would not be generated by any means other than scanning a phrase from a printed version of the referenced document). This allows a firm to effectively limit access to private documents only to those in possession of a printed copy. In another embodiment, once a query has been submitted from an identified user that satisfies the requirements for revealing a matching document, the access requirements for revealing subsequent matches to the same identified user may be reduced.
[0541] FIG. 12 is a flow diagram showing steps typically performed by the facility to service a query. The facility typically performs these steps in the search engine computer system each time a query is received. In step 1201, the facility receives the query. In some embodiments, the received query specifies a query string optically scanned by a user from a paper document. In some embodiments, the received query is automatically created and submitted in response to the act of optically scanning the query string from a paper document. In some embodiments, the query may explicitly specify that its query string was copied from a paper document, either by scanning or by other means, such as keyboard transcription or audio dictation. In step 1202, the facility services the query using the aggregated index. In some embodiments, servicing the query includes, where the query indicates that the query string was obtained from a paper document, generating a query result containing only documents of which paper versions are believed to exist. In some embodiments, servicing the query involves augmenting a profile of documents that have been scanned and queried to reflect the processed query. In some embodiments, servicing the query involves generating a query result identifying, for each document in the query result, a location in the document at which the query string occurs. After step 1202, these steps conclude.
[0542] FIG. 13 is a data flow diagram showing a second manner in which index information is exported by some embodiments of the facility. FIG. 13 shows that the network indexing computer system 412 exports a number of different exported private network indexes 1301 to the search engine computer system 440. In some embodiments, the facility does so in order to enable different groups of users sending queries to the search engine computer system to search across different subsets of the documents available in the private network. For example, where the private network is operated by a consulting firm having three clients, the facility may export four indexes: one index for use in servicing searches from employees from the consulting firm that covers all of the documents available in the private network, and three additional indexes each corresponding to one of the consulting firm's clients, covering only that client's documents, and for use in servicing queries from employees of the client.
[0543] FIG. 14 is a data flow diagram showing a third manner in which index information is exported by some embodiments of the facility. FIG. 14 shows that three different network indexing computer systems--network indexing computer system 412, 1412, and 1413--each contained in a different private network, each export their own private network index--indexes 1401, 1402, and 1403, respectively. At the search engine computer system, the facility merges these exported private network indexes together to form an aggregated index.
[0544] In some embodiments, the exported index associates an indicator with each document entry that indicates whether the document has been published in paper form. In some embodiments, the exported index may further indicate document context such as the geographic areas in which the paper document was distributed
[0545] In some embodiments, the facility can process search queries that originate from information captures from paper documents having electronic counterparts or associated electronic supplemental materials.
CONCLUSION
[0546] It will be appreciated by those skilled in the art that the above-described facility may be straightforwardly adapted or extended in various ways. While the foregoing description makes reference to preferred embodiments, the scope of the invention is defined solely by the claims that follow and the elements recited therein. Furthermore, although the concept of data captures has been discussed primarily in the context of optical scans, the facility can use other types of data capture such as audio capture (e.g., voice entry).
User Contributions:
Comment about this patent or add new information about this topic:
Images included with this patent application:
 | 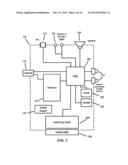 |
 |  |
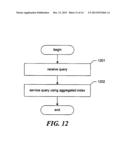 |  |
 |  |
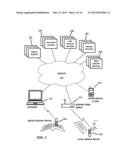 |  |
 |  |
 | 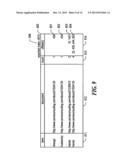 |
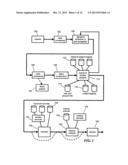 | 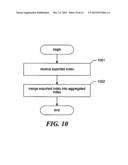 |
| Similar patent applications: | |
| Date | Title |
|---|---|
| 2013-12-19 | Method and system for displaying comments associated with a query |
| 2013-12-19 | Sharing information with other users |
| 2011-10-20 | Providing notice via the internet |
| 2012-05-31 | Information feed update mechanism |
| 2012-06-21 | Tag association with image regions |
| New patent applications in this class: | |
| Date | Title |
|---|---|
| 2022-05-05 | Techniques to generate and store graph models from structured and unstructured data in a cloud-based graph database system |
| 2022-05-05 | Medium recommendation system, table creation system, medium recommendation device, and table creation method |
| 2019-05-16 | Feature generation and storage in a multi-tenant environment |
| 2019-05-16 | Data enrichment and augmentation |
| 2018-01-25 | Big data computing architecture |
| New patent applications from these inventors: | |
| Date | Title |
|---|---|
| 2017-05-18 | Adding value to a rendered document |
| 2016-02-04 | Automatically capturing information such as capturing information using a document-aware device |
| Top Inventors for class "Data processing: database and file management or data structures" | |
| Rank | Inventor's name |
|---|---|
| 1 | International Business Machines Corporation |
| 2 | International Business Machines Corporation |
| 3 | John M. Santosuosso |
| 4 | Robert R. Friedlander |
| 5 | James R. Kraemer |