Patent application title: PROCESS FOR THE PRODUCTION OF CELLS WHICH ARE CAPABLE OF CONVERTING ARABINOSE
Inventors:
Paul Klaassen (Dordrecht, NL)
Paul Klaassen (Dordrecht, NL)
Bianca Elisabeth Maria Gielesen (Maassluis, NL)
Wilbert Herman Marie Heijne (Dordrecht, NL)
Wilbert Herman Marie Heijne (Dordrecht, NL)
Gijsberdina Pieternella Van Suylekom (Gravenmoer, NL)
Assignees:
DSM IP ASSETS
IPC8 Class: AC12N119FI
USPC Class:
435 611
Class name: Measuring or testing process involving enzymes or micro-organisms; composition or test strip therefore; processes of forming such composition or test strip involving nucleic acid nucleic acid based assay involving a hybridization step with a nucleic acid probe, involving a single nucleotide polymorphism (snp), involving pharmacogenetics, involving genotyping, involving haplotyping, or involving detection of dna methylation gene expression
Publication date: 2013-02-14
Patent application number: 20130040297
Abstract:
The invention relates to a process for the production of cells which are
capable of converting arabinose, comprising the following steps: a)
Introducing into a host strain that cannot convert arabinose, the genes
AraA, araB and araD, this cell is designated as constructed cell; b)
Subjecting the constructed cell to adaptive evolution until a cell that
converts arabinose is obtained, c) Optionally, subjecting the first
arabinose converting cell to adaptive evolution to improve the arabinose
conversion; the cell produced in step b) or c) is designated as first
arabinose converting cell; d) Analysing the full genome or part of the
genome of the first arabinose converting cell and that of the constructed
cell; e) Identifying single nucleotide polymorphisms (SNP's) in the first
arabinose converting cell; and f) Using the information of the SNP's in
rational design of a cell capable of converting arabinose; g)
Construction of the cell capable of converting arabinose designed in step
f).Claims:
1. A process for producing cells which are capable of converting
arabinose, comprising: a) Introducing into a host strain that cannot
convert arabinose, genes araA, araB and araD, to form a constructed cell;
b) Subjecting the constructed cell to adaptive evolution until a first
arabinose converting cell that converts arabinose is obtained, c)
Optionally, subjecting the first arabinose converting cell to adaptive
evolution to improve the arabinose conversion; said cell produced in step
b) or c) is designated as first arabinose converting cell; d) Analysing a
full genome or part of a genome of said first arabinose converting cell
and that of said constructed cell; e) Identifying single nucleotide
polymorphisms (SNP's) in said first arabinose converting cell; and f)
Using information of said SNP's in rational design of a cell capable of
converting arabinose; g) Constructing said cell capable of converting
arabinose designed in f).
2. The process according to claim 1, wherein in e), f) and/or g) at least one technique of phenotyping is used in combination with at least one technique of genotyping.
3. The process according to claim 1, wherein, in said process, a yeast cell capable of converting arabinose has a chromosome that is amplified compared to the host strain, wherein the amplified chromosome has the same number as the chromosome in which the araA, araB and araD genes were introduced in the host strain.
4. The process according to claim 3, wherein said amplified chromosome is chromosome VII.
5. A yeast cell having araA, araB and araD genes wherein chromosome VII has a size of from 1300 to 1600 Kb as determined by electrophoresis, with the exclusion of a yeast cell BIE201.
6. The yeast cell according to claim 5, wherein a copy number of the araA, araB and araD genes is from three to five each.
7. The yeast cell according to claim 6, comprising at least one single nucleotide polymorphism selected from the group consisting of mutations G1363T in the SSY1 gene, A512T in YJR154w gene, A1186G in CEP3 gene, and A436C in GAL80 gene.
8. The yeast cell according to claim 7, comprising a single polymorphism A436C in GAL80 gene.
9. The yeast cell according to claim 8, comprising a single nucleotide polymorphism A1186G in CEP3 gene.
10. A polypeptide belonging to the group consisting of the polypeptides: a. A polypeptide comprising the sequence encoded by polynucleotide SEQ ID NO: 14 having a substitution E455stop in SSY1 and variant polypeptides thereof wherein at least one of other positions have mutation of an aminoacid with another aminoacid that is an existing aminoacid in AA trans superfamily; b. A polypeptide comprising the sequence encoded by the polynucleotide SEQ ID NO: 16 having a substitution D171G in YJR154w and variant polypeptides thereof wherein at least one of other positions have mutation of an aminoacid with another aminoacid that is an existing conserved aminoacid in PhyH superfamily; c. A polypeptide comprising the sequence encoded by the polynucleotide SEQ ID NO: 18 comprising a substitution S396G in CEP3; d. A polypeptide comprising the sequence encoded by SEQ ID NO: 20 comprising a substitution T146P in GAL80; and variant polypeptides thereof, wherein at least one of other positions may have mutation of an aminoacid with an aminoacid that is an existing conserved aminoacid in NADB Rossmann superfamily.
11. A process for producing at least one fermentation product from a sugar composition comprising glucose, galactose, arabinose and xylose, said process comprising fermenting said sugar composition with a yeast cell according to claim 5.
12. The process according to claim 11, wherein said sugar composition is produced from lignocellulosic material by: a) pretreatment of at least one lignocellulosic material to produce pretreated lignocellulosic material; b) enzymatic treatment of said pretreated lignocellulosic material to produce said sugar composition.
13. The process according to claim 11, wherein said fermentation is anaerobic.
14. The process according to claim 11, wherein said fermentation product is selected from the group consisting of ethanol, n-butanol, isobutanol, lactic acid, 3-hydroxy-propionic acid, acrylic acid, acetic acid, succinic acid, fumaric acid, malic acid, itaconic acid, maleic acid, citric acid, adipic acid, an amino acid, such as lysine, methionine, tryptophan, threonine, and aspartic acid, 1,3-propane-diol, ethylene, glycerol, a β-lactam antibiotic and a cephalosporin, vitamins, pharmaceuticals, animal feed supplements, specialty chemicals, chemical feedstocks, plastics, solvents, fuels, biofuels and biogas or organic polymers, and an industrial enzyme, a protease, a cellulase, an amylase, a glucanase, a lactase, a lipase, a lyase, an oxidoreductase, a transferase or a xylanase.
Description:
FIELD OF THE INVENTION
[0001] The invention relates to a process for the production of cells which are capable of converting arabinose. The invention also relates to cells that may be produced by the process. The invention further relates to a process in which such cells are used for the production of a fermentation product, such as ethanol.
BACKGROUND OF THE INVENTION
[0002] Large-scale consumption of traditional, fossil fuels (petroleum-based fuels) in recent decades has contributed to high levels of pollution. This, along with the realisation that the world stock of fossil fuels is not limited and a growing environmental awareness, has stimulated new initiatives to investigate the feasibility of alternative fuels such as ethanol, which is a particulate-free burning fuel source that releases less CO2 than unleaded gasoline on a per litre basis. Although biomass-derived ethanol may be produced by the fermentation of hexose sugars obtained from many different sources, the substrates typically used for commercial scale production of fuel alcohol, such as cane sugar and corn starch, are expensive. Increases in the production of fuel ethanol will therefore require the use of lower-cost feedstocks. Currently, only lignocellulosic feedstock derived from plant biomass is available in sufficient quantities to substitute the crops currently used for ethanol production. In most lignocellulosic material, the second-most-common sugar, next to C6 sugar also contain considerable amounts of C5 sugars, including arabinose. Thus, for an economically feasible fuel production process, both hexose and pentose sugars must be fermented to form ethanol. The yeast Saccharomyces cerevisiae is robust and well adapted for ethanol production, but it is unable toconvert arabinose. Also, no naturally-occurring organisms are known which can ferment xylose to ethanol with both a high ethanol yield and a high ethanol productivity. There is therefore a need for an organism possessing these properties so as to enable the commercially-viable production of ethanol from lignocellulosic feedstocks.
SUMMARY OF THE INVENTION
[0003] An object of the invention is to provide a cell, in particular a yeast cell that is capable of converting arabinose.
[0004] This object is attained according to the invention that provides a process for the production of cells which are capable of converting arabinose, comprising the following steps: [0005] a) Introducing into a host strain that cannot convert arabinose, the genes araA, araB and araD, this cell is designated as constructed cell; [0006] b) Subjecting the constructed cell to adaptive evolution until a cell that converts arabinose is obtained, [0007] c) Optionally, subjecting the first arabinose converting cell to adaptive evolution to improve the arabinose conversion; the cell produced in step b) or c) is designated as first arabinose converting cell; [0008] d) Analysing the full genome or part of the genome of the first arabinose converting cell and that of the constructed cell; [0009] e) Identifying single nucleotide polymorphisms (SNP's) in the first arabinose converting cell; and [0010] f) Using the information of the SNP's in rational design of a cell capable of converting arabinose; [0011] g) Construction of the cell capable of converting arabinose designed in step f).
[0012] The invention further provides a yeast cell having araA, araB and araD genes wherein chromosome VII has a size of from 1300 to 1600 Kb as determined by electrophoresis, with the exclusion of yeast cell BIE201.
[0013] The invention further relates to a polypeptide belonging to the group consisting of the polypeptides: [0014] a. A polypeptide having a sequence encoded by polynucleotide SEQ ID NO: 14 having a substitution E455stop in SSY1 and variant polypeptides thereof wherein one or more of the other positions have mutation of an aminoacid with another aminoacid that is an existing aminoacid in the AA trans superfamily; [0015] b. A polypeptide having having the sequence encoded by the polynucleotide SEQ ID NO: 16 having a substitution D171G in YJR154w and variant polypeptides thereof wherein one or more of the other positions have mutation of the aminoacid with another aminoacid that is an existing conserved aminoacid in the PhyH superfamily; [0016] c. A polypeptide having the sequence encoded by the polynucleotide SEQ ID NO: 18 having a substitution S396G in CEP3; [0017] d. A polypeptide having the sequence encoded by SEQ ID NO: 20 having a substitution T146P in GAL80 and variant polypeptides thereof wherein one or more of the other positions may have mutation of the aminoacid with an aminoacid that is an existing conserved aminoacid in the NADB Rossmann superfamily.
BRIEF DESCRIPTION OF THE DRAWINGS
[0018] FIG. 1 sets out a physical map of vector pPWT006.
[0019] FIG. 2 sets out a physical map of plasmid pPWT018, the sequence of which is given in SEQ ID NO: 1.
[0020] FIG. 3 sets out an Autoradiogram showing the results of a hybridization experiment showing the correct integration of one copy of the plasmid pPWT080 in CEN.PK113-7D;
[0021] FIG. 4 sets out a physical map of plasmid pPWT080, the sequence of which is given in SEQ ID NO: 8.
[0022] FIG. 5 sets out an aerobic growth curve of reference strain BIE104A2P1 on 2% arabinose as sole carbon source,
[0023] FIG. 6 sets out an anaerobic growth curve of BIE104A2P1c on 2% arabinose as sole carbon source,
[0024] FIG. 7 sets out growth curve (sugar-, ethanol- and glycerol concentrations OD600 and CO2 produced (ml/hr, second axis) for BIE104 precultured on 2% glucose, and grown on Verduyn medium with 5% glucose, 5% xylose, 3.5% arabinose and 1% galactose, All % in w/w.
[0025] FIG. 8 sets out growth curve (sugar-, ethanol- and glycerol concentrations, OD600 and CO2 produced (ml/hr, second axis) for BIE104A2P1c precultured on 2% glucose, and grown on Verduyn medium with 5% glucose, 5% xylose, 3.5% arabinose and 1% galactose.
[0026] FIG. 9 sets out growth curve (sugar-, ethanol- and glycerol concentrations OD600 and CO2 produced (ml/hr, second axis) for BIE201 precultured on 2% glucose, and grown on Verduyn medium with 5% glucose, 5% xylose, 3.5% arabinose and 1% galactose, All % in w/w.
[0027] FIG. 10 sets out a schematic overview of crossing
[0028] FIG. 11 sets out an example of "Normalized Melting Curves" (melting curves; top panel) and a "Normalized melting Peaks" curve (lower panel). The latter is derived from the first graph and is showing the change in fluorescence signal as a function of the temperature. Strains BIE104A2P1 and BIE201 are displayed. The gene tested in this figure is YJR154w. The difference in melting temperature of the probe is clear between the two strains tested, BIE201 and BIE104A2P1.
[0029] FIG. 12 sets out a schematic representation (coverage plot) of chromosome VII in strain BIE201. The read depth is set out as a function of the position along the chromosome. Some parts of chromosome VII are present in multiple copies, i.e. two or three times overrepresented.
[0030] FIG. 13 sets out a CHEF gel, stained with ethidium bromide. Chromosomes were separated on their size using the CHEF technique. Strains analyzed are BIE104 (untransformed yeast cell), BIE104A2P1a (primary transformant unable to consume arabinose, synonym of BIE104A2P1), BIE104A2P1c, a strain derived from BIE104A2P1 by adaptive evolution, which is able to grow on arabinose, and strain BIE201, derived from BIE104A2P1c by adaptive evolution, which can grow on arabinose under anaerobic conditions. Shifts in chromosomes are observed (see text). Strain YNN295 is a marker strain (Bio-Rad).
[0031] FIG. 14 sets out a CHEF gel, blotted and hybridized with the araA probe.
[0032] Chromosomes were separated on their size using the CHEF technique. Strains analyzed are BIE104 (untransformed yeast cell), BIE104A2P1a (primary transformant unable to consume arabinose, synonym of BIE104A2P1), BIE104A2P1c, a strain derived from BIE104A2P1 by adaptive evolution, which is able to grow on arabinose, and strain BIE201, derived from BIE104A2P1c by adaptive evolution, which can grow on arabinose under anaerobic conditions. Shifts in chromosomes are observed (see text). Strain YNN295 is a marker strain (Bio-Rad), used as a reference for the size of the chromosomes.
[0033] FIG. 15 sets out a CHEF gel, blotted and hybridized with the ACT1 probe. Chromosomes were separated on their size using the CHEF technique. Strains analyzed are BIE104 (untransformed yeast cell), BIE104A2P1a (primary transformant unable to consume arabinose, synonym of BIE104A2P1), BIE104A2P1c, a strain derived from BIE104A2P1 by adaptive evolution, which is able to grow on arabinose, and strain BIE201, derived from BIE104A2P1c by adaptive evolution, which can grow on arabinose under anaerobic conditions. Shifts in chromosomes are observed (see text). Strain YNN295 is a marker strain (Bio-Rad), used as a reference for the size of the chromosomes.
[0034] FIG. 16 sets out a CHEF gel, blotted and hybridized with the PNC1 probe. Chromosomes were separated on their size using the CHEF technique. Strains analyzed are BIE104 (untransformed yeast cell), BIE104A2P1a (primary transformant unable to consume arabinose, synonym of BIE104A2P1), BIE104A2P1c, a strain derived from BIE104A2P1 by adaptive evolution, which is able to grow on arabinose, and strain BIE201, derived from BIE104A2P1c by adaptive evolution, which can grow on arabinose under anaerobic conditions. Shifts in chromosomes are observed (see text). Strain YNN295 is a marker strain (Bio-Rad), used as a reference for the size of the chromosomes.
[0035] FIG. 17 sets out a CHEF gel, blotted and hybridized with the HSF1 probe. Chromosomes were separated on their size using the CHEF technique. Strains analyzed are BIE104 (untransformed yeast cell), BIE104A2P1a (primary transformant unable to consume arabinose, synonym of BIE104A2P1), BIE104A2P1c, a strain derived from BIE104A2P1 by adaptive evolution, which is able to grow on arabinose, and strain BIE201, derived from BIE104A2P1c by adaptive evolution, which can grow on arabinose under anaerobic conditions. Shifts in chromosomes are observed (see text). Strain YNN295 is a marker strain (Bio-Rad), used as a reference for the size of the chromosomes.
[0036] FIG. 18 sets out a CHEF gel, blotted and hybridized with the YGRO31w probe. Chromosomes were separated on their size using the CHEF technique. Strains analyzed are BIE104 (untransformed yeast cell), BIE104A2P1a (primary transformant unable to consume arabinose, synonym of BIE104A2P1), BIE104A2P1c, a strain derived from BIE104A2P1 by adaptive evolution, which is able to grow on arabinose, and strain BIE201, derived from BIE104A2P1c by adaptive evolution, which can grow on arabinose under anaerobic conditions. Shifts in chromosomes are observed (see text). Strain YNN295 is a marker strain (Bio-Rad), used as a reference for the size of the chromosomes.
[0037] FIG. 19 sets out an example of ten dissected asci from the cross BIE104A2P1×BIE201. The asci were dissected with a Singer Micromanipulator. Each ascus consists of four ascospores. These ascospores are separated from each other and are put on the agar plate at distinctive distances. In theory, four haploid spore isolates can give rise to four individual colonies. The four colonies in a "column" originate from one ascus.
[0038] FIG. 20 illustrates the performance of strain BIE252 in the BAM (Biological Activity Monitor, Halotec, The Netherlands). The strain was precultured in Verduyn medium 2% glucose. Application in the BAM was done on Verduyn medium supplemented with 5% glucose, 5% xylose, 3.5% arabinose, 1% galactose and 0.5% mannose, pH4.2, under anaerobic conditions.
[0039] FIG. 21 illustrates the performance of strain BIE252ΔGAL80 in the BAM. The strain was precultured in Verduyn medium 2% glucose. Application in the BAM was done on Verduyn medium supplemented with 5% glucose, 5% xylose, 3.5% arabinose, 1% galactose and 0.5% mannose, pH4.2, under anaerobic conditions.
[0040] FIG. 22 sets out a schematic view of the double crossover integration of the complete adipic acid pathway into the genome.
[0041] FIG. 23 sets out a resulting chromatogram of an adipic acid standard and a sample measured with the analysis method.
[0042] FIG. 24 sets out a physical map of plasmid pGBS416ARABD
BRIEF DESCRIPTION OF THE SEQUENCE LISTING
[0043] SEQ ID NO: 1 sets out the sequence of pPWT018;
[0044] SEQ ID NO: 2 sets out the sequence of a primer for checking integration of pPWT018;
[0045] SEQ ID NO: 3 sets out a primer for checking integration of pPWT018 (with SEQ ID NO: 2) and for checking copy number pPWT018 (with SEQ ID NO: 4);
[0046] SEQ ID NO: 4 sets out the sequence for a primer for checking copy number pPWT018;
[0047] SEQ ID NO: 4 sets out the sequence for a primer for checking presence of pPWT018 in genome in combination with SEQ ID NO: 4;
[0048] SEQ ID NO: 6 sets out the sequence for a forward primer for generating the SIT2 probe;
[0049] SEQ ID NO: 7 sets out the sequence for a reverse primer for generating the SIT2 probe;
[0050] SEQ ID NO: 8 sets out the sequence for plasmid pPWT080;
[0051] SEQ ID NO: 9 sets out the sequence for a forward primer for checking correct integration of pPWT080 at the 3'-end of the GRE3-locus (with SEQ ID NO: 10) and for checking the copy number of plasmid pPWT080 (with SEQ ID NO: 11);
[0052] SEQ ID NO: 10 sets out the sequence for a reverse primer for checking correct integration of pPWT080 at the 3'-end of the GRE3-locus;
[0053] SEQ ID NO: 11 sets out the sequence for a reverse primer for checking the copy number of plasmid pPWT080 (with SEQ ID NO: 10);
[0054] SEQ ID NO: 12 sets out the sequence for a forward primer for generating an RKI1-probe;
[0055] SEQ ID NO: 13 sets out the sequence for a reverse primer for generating an RKI1-probe;
[0056] SEQ ID NO: 14 sets out the sequence for the sequence of the SSY1-gene in wild type strain BIE104;
[0057] SEQ ID NO: 15 sets out the sequence for the SSY1-gene in strains BIE104A2P1c and BIE201;
[0058] SEQ ID NO: 16 sets out the sequence for the YJR154w-gene in wild type strain BIE104;
[0059] SEQ ID NO: 17 sets out the sequence the YJR154w-gene in strains BIE104A2P1c and BIE201;
[0060] SEQ ID NO: 18 sets out the sequence the CEP3-gene in wild type strain BIE104;
[0061] SEQ ID NO: 19 sets out the sequence the CEP3-gene in strains BIE104A2P1c and BIE201;
[0062] SEQ ID NO: 20 sets out the sequence the YPL277c-gene in wild type strain BIE104;
[0063] SEQ ID NO: 21 sets out the sequence the YPL277c-gene in strains BIE104A2P1c and BIE201;
[0064] SEQ ID NO: 22 sets out the sequence for the GAL80-gene in wild type strain BIE104;
[0065] SEQ ID NO: 23 sets out the sequence the GAL80-gene in strain BIE201;
[0066] SEQ ID NO 24 sets out the sequence of forward primer SSY1;
[0067] SEQ ID NO 25 sets out the sequence of reverse primer SSY1;
[0068] SEQ ID NO 26 sets out the sequence of forward primer YJR154w;
[0069] SEQ ID NO 27 sets out the sequence of reverse primer YJR154w;
[0070] SEQ ID NO 28 sets out the sequence of forward primer CEP3;
[0071] SEQ ID NO 29 sets out the sequence of reverse primer CEP3;
[0072] SEQ ID NO 30 sets out the sequence of forward primer YPL277c;
[0073] SEQ ID NO 31 sets out the sequence of reverse primer YPL277c;
[0074] SEQ ID NO 32 sets out the sequence of forward primer GAL80;
[0075] SEQ ID NO 33 sets out the sequence of reverse primer GAL80;
[0076] SEQ ID NO 34 sets out the sequence of Hi-Res probe SSY1;
[0077] SEQ ID NO 35 sets out the sequence of Hi-Res probe YJR154w;
[0078] SEQ ID NO 36 sets out the sequence of Hi-Res probe CEP3;
[0079] SEQ ID NO 37 sets out the sequence of Hi-Res probe YPL277c;
[0080] SEQ ID NO 38 sets out the sequence of Hi-Res probe GAL80;
[0081] SEQ ID NO 39 sets out the sequence of forward primer YGL057c;
[0082] SEQ ID NO 40 sets out the sequence of reverse primer YGL057c;
[0083] SEQ ID NO 41 sets out the sequence of forward primer SDS23;
[0084] SEQ ID NO 42 sets out the sequence of reverse primer SDS23;
[0085] SEQ ID NO 43 sets out the sequence of forward primer ACT1;
[0086] SEQ ID NO 44 sets out the sequence of reverse primer ACT1;
[0087] SEQ ID NO 45 sets out the sequence of forward primer araA;
[0088] SEQ ID NO 46 sets out the sequence of reverse primer araA;
[0089] SEQ ID NO 47 sets out the sequence of forward primer ACT1;
[0090] SEQ ID NO 48 sets out the sequence of reverse primer ACT1;
[0091] SEQ ID NO 49 sets out the sequence of forward primer PNC1;
[0092] SEQ ID NO 50 sets out the sequence of reverse primer PNC1;
[0093] SEQ ID NO 51 sets out the sequence of forward primer HSF1;
[0094] SEQ ID NO 52 sets out the sequence of reverse primer HSF1;
[0095] SEQ ID NO 53 sets out the sequence of forward primer YGRO31w;
[0096] SEQ ID NO 54 sets out the sequence of reverse primer YGRO31w;
[0097] SEQ ID NO 55 sets out the sequence of forward primer (matA, matα);
[0098] SEQ ID NO 56 sets out the sequence of reverse primer matA;
[0099] SEQ ID NO 57 sets out the sequence of reverse primer matα (alpha);
[0100] SEQ ID NO 58 sets out the sequence of forward primer GAL80::kanMX;
[0101] SEQ ID NO 59 sets out the sequence of reverse primer GAL80::kanMX;
[0102] SEQ ID NO 60 sets out the sequence of Forward primer for amplification of the INT1LF;
[0103] SEQ ID NO 61 sets out the sequence of Reverse primer for the amplification of INT1LF with a 50 by flank overlapping Adi21 expression cassette;
[0104] SEQ ID NO 62 sets out the sequence of Forward primer for amplification of the Adi21 expression cassette with 50 by flank INT1LF;
[0105] SEQ ID NO 63 sets out the sequence of Reverse primer for the amplification of the Adi21 expression cassette
[0106] SEQ ID NO 64 sets out the sequence of Forward primer for the amplification of the Adi22 expression cassette;
[0107] SEQ ID NO 65 sets out the sequence of Reverse primer for the amplification of the Adi22 expression cassette;
[0108] SEQ ID NO 66 sets out the sequence of Forward primer for the amplification of the Adi23 expression cassette;
[0109] SEQ ID NO 67 sets out the sequence of Reverse primer for the amplification of the Adi23 expression cassette;
[0110] SEQ ID NO 68 sets out the sequence of Forward primer for the amplification of the kanMX marker from pUG7 with 50 by flank overlapping with Adi23;
[0111] SEQ ID NO 69 sets out the sequence of Reverse primer for the amplification of the kanMX marker from pUG7 with 50 by flank overlapping with Adi8;
[0112] SEQ ID NO 70 sets out the sequence of Forward primer for the amplification of the Adi8 expression cassette with 25 by flank overlap with kanMX of pUG7;
[0113] SEQ ID NO 71 sets out the sequence of Reverse primer Adi8 expression cassette;
[0114] SEQ ID NO 72 sets out the sequence of Forward primer for the amplification of the Adi24 expression cassette;
[0115] SEQ ID NO 73 sets out the sequence of Reverse primer for the amplification of the Adi24 expression cassette;
[0116] SEQ ID NO 74 sets out the sequence of Forward primer for the amplification of the Adi25 expression cassette;
[0117] SEQ ID NO 75 sets out the sequence of Reverse primer for the amplification of the Adi25 expression cassette with 50 by overlap with SucC;
[0118] SEQ ID NO 76 sets out the sequence of Forward primer for the amplification of the SucC with 50 by overlap with Adi25;
[0119] SEQ ID NO 77 sets out the sequence of Reverse primer for the amplification of the SucC expression cassette;
[0120] SEQ ID NO 78 sets out the sequence of Forward primer for the amplification of the SucD expression cassette;
[0121] SEQ ID NO 79 sets out the sequence of Reverse primer for the amplification of the SucD expression cassette;
[0122] SEQ ID NO 80 sets out the sequence of Forward primer for the amplification of the acdh67 expression cassette;
[0123] SEQ ID NO 81 sets out the sequence of Reverse primer for the amplification of the acdh67 construct with 50 by flank overlapping with INTRF;
[0124] SEQ ID NO 82 sets out the sequence of Forward primer for the amplification of the INT1LF site on yeast genome;
[0125] SEQ ID NO 83 sets out the sequence of Reverse primer for the amplification of the INT1LF site on yeast genome;
[0126] SEQ ID NO 84 sets out the sequence of ADI21 PCR fragment;
[0127] SEQ ID NO 85 sets out the sequence of ADI22 PCR fragment;
[0128] SEQ ID NO 86 sets out the sequence of ADI23 PCR fragment;
[0129] SEQ ID NO 87 sets out the sequence of ADI8 PCR fragment;
[0130] SEQ ID NO 88 sets out the sequence of ADI24 PCR fragment;
[0131] SEQ ID NO 89 sets out the sequence of ADI25 PCR fragment;
[0132] SEQ ID NO 90 sets out the sequence of SUCC PCR fragment;
[0133] SEQ ID NO 91 sets out the sequence of SUCD PCR fragment;
[0134] SEQ ID NO 92 sets out the sequence of ACDH67 PCR fragment;
[0135] SEQ ID NO 93 sets out the sequence of KANMX marker fragment;
[0136] SEQ ID NO 94 sets out the sequence of INT1LF PCR fragment;
[0137] SEQ ID NO 95 sets out the sequence of INT1RF PCR fragment;
[0138] SEQ ID NO 96 sets out the sequence of forward primer araABD cassette;
[0139] SEQ ID NO 97 sets out the sequence of reverse primer araABD cassette
[0140] SEQ ID NO 98 sets out the sequence of forward primer Ty1::araABD;
[0141] SEQ ID NO 99 sets out the sequence of reverse primer TY1::araABD;
[0142] SEQ ID NO 100 sets out the sequence of forward primer Ty1::kanMX;
[0143] SEQ ID NO 101 sets out the sequence of reverse primer Ty1::kanMX.
DETAILED DESCRIPTION OF THE INVENTION
[0144] Throughout the present specification and the accompanying claims, the words "comprise" and "include" and variations such as "comprises", "comprising", "includes" and "including" are to be interpreted inclusively. That is, these words are intended to convey the possible inclusion of other elements or integers not specifically recited, where the context allows.
[0145] The articles "a" and "an" are used herein to refer to one or to more than one (i.e. to one or at least one) of the grammatical object of the article. By way of example, "an element" may mean one element or more than one element.
[0146] The various embodiments of the invention described herein may be cross-combined. The invention provides a process for the production of cells which are capable of converting arabinose, comprising the steps a) to g) these will be described here in more detail:
[0147] Step a) Introducing into a host strain that cannot convert arabinose, the genes araA, araB and araD, this cell is designated as constructed cell [0148] Step a) will be described below in detail in the description as well as being illustrated by the examples.
[0149] Steps b) and c) Subjecting the constructed cell to adaptive evolution until a cell that converts arabinose is obtained, Optionally, subjecting the first arabinose converting cell to adaptive evolution to improve the arabinose conversion; the cell produced in step b) or c) is designated as first arabinose converting cell; [0150] Steps b) and c) will be described below in detail in the description under adaptive evolution as well as being illustrated by the examples.
[0151] Step d) Analysing the full genome or part of the genome of the first arabinose converting cell and that of the constructed cell;
[0152] This step d) may be executed using common techniques of genome resequencing
[0153] Step e) Identifying single nucleotide polymorphisms (SNP's) in the first arabinose converting cell;
[0154] By looking at the differences between the first arabinose converting cell and that of the constructed cell
[0155] Step f) Using the information of the SNP's in rational design of a cell capable of converting arabinose;
[0156] In step f) the skilled person will know to which SNP's arabinose conversion is attitubed, and with common skill be able to design an improved strain based on that information.
[0157] In steps e), f) and/or g) the skilled person preferably uses techniques of phenotyping, i.e. the identification of cells with desired traits and in combination with techniques of genotyping, i.e. the identification of candidate genes associated with the chosen traits.
[0158] Examples of techniques for phenotyping are growth experiments, in shake flasks or fementors, in the presence of single sugars or sugar mixtures. Also growth assays on solid agar media can be applied. However, other suitable known methods may be used.
[0159] Examples of techniques for genotyping are re-sequencing techniques, such as Solexa and the like, quatitative PCR (Q-PCR), Southern blotting. However other suitable known methods may be used.
[0160] Step g) Construction of the cell capable of converting arabinose designed in step f). In step g) all common techniques of construction of new strains may be used. In one embodiment, different strains (parents) are combined in order to combine advantageous properties of the parents. For example a crossing technique may be used involving the strain of step b) or c) which is crossed with a strain that does not have all SNP's present in the strains of step b) or c).
[0161] For example, a haploid yeast strain, transformed with genes necessary for or enhancing the ability to ferment arabinose (designated all together as ARA) was enhanced by a process called adaptive evolution. During the adaptive evolution process, three mutations have been introduced into the genome, designated mut1, mut2 and mut3. The genotype of such a yeast strain could be written as mut1 mut2 mut3 ARA.
[0162] Such a yeast strain may be crossed with another haploid yeast strain, also consisting of the genes needed for arabinose transformation, but yet unable to do so, because it lacks extra mutations to do so. However, this strain may have another beneficial property, such as tolerance to inhibitors. This property is designated as ABC. Such a process is illustrated in FIG. 10.
[0163] In an embodiment, in the above process, the yeast cell capable of converting arabinose has a chromosome that is amplified compared to the host strain, wherein the amplified chromosome has the same number as the chromosome in which the araA, araB and araD genes were introduced in the host strain. In an embodiment the amplified chromosome is chromosome VII. In an embodiment, in the yeast cell parts of chromosome VII, surrounding the centromere, are amplified (as compared to the host strain). In an embodiment, a region on the left arm of chromosome VII was amplified three times. In an embodiment, part of the right arm of chromosome VII was amplified twice, and an adjacent part was amplified three times (see FIG. 12).
[0164] The part on the right arm of chromosome VII that was amplified three times contains the arabinose expression cassette, i.e. the genes araA, araB and araD under control of strong constitutive promoters.
[0165] The invention further relates to a yeast cell having araA, araB and araD genes wherein chromosome VII has a size of from 1300 to 1600 Kb as determined by electrophoresis, with the exclusion of a yeast cell BIE201. Strain BIE201 has been disclosed in WO2011003893.
[0166] BIE201 has all the single nucleotide polymorphisms G1363T in the SSY1 gene, A512T in YJR154w gene, A1186G in CEP3 gene, and A436C in GAL80 gene.
[0167] In an embodiment, in the yeast cell, the copy number of the araA, araB and araD genes is two to ten, in an embodiment two to eight or three to five each. The copy number of the araA, araB and araD genes may be 2, 3, 4, 5, 6, 7, 8, 9, or 10. The copy number may be determined with methods known to the skilled person, Suitable methods are illustrated in the examples, and results are e.g. shown in FIG. 12
[0168] In an embodiment, the yeast cell one or more, but not all, of the single nucleotide polymorphism chosen from the group consisting of mutations G1363T in the SSY1 gene, A512T in YJR154w gene, A1186G in CEP3 gene, and A436C in GAL80 gene. In an embodiment, the yeast cell has a single polymorphism A436C in GAL80 gene. In an embodiment, the yeast cell has a single polymorphism A1186G in CEP3 gene.
[0169] Sexual Conjugation
[0170] Mating in yeast which is mediated by diffusible molecules, pheromones, can be readily demonstrated (Manney, Duntze & Betz 1981). When cells of opposite mating type are mixed on the surface of agar growth medium in a petri dish, changes become apparent within two to three hours. As each type of cell secretes its pheromone into the medium, it responds to the one produced by the opposite type (MacKay & Manney 1974). They each respond by differentiating into a specialized functional form, a gamete. The cells stop dividing and change their shape. They elongate and become pear-shaped. These distinctive cells have been termed "shmoos". Cells of opposite mating types that are in contact or close proximity join at the surface and fuse together forming a characteristic "peanut" shape with a central constriction, i.e. two shmoos fused at their small ends. The two haploid nuclei within each joined pair fuse into a diploid nucleus, forming a true zygote. The diploid promptly buds at the constriction, forming a characteristic "clover leaf" figure. One can easily observe all of these stages under the microscope.
[0171] The mating pheromones that are secreted by haploid cells are small peptide molecules that diffuse through agar (Betz, Manney & Duntze 1981). Consequently, their existence and their effects on cells of the opposite mating types are easy to demonstrate. If cells of the mating type a (alpha) are grown overnight on agar medium, a high concentration of the pheromone accumulates in the agar surrounding the growth. If cells of the mating type a (matA or matα) are placed on this agar, they begin to undergo the "shmoo" transformation within a couple of hours. The same effect can be demonstrated in a liquid medium in which mating type a (alpha) cells have been grown.
[0172] Meiosis
[0173] Shmoos are the gametes in yeast. They differentiate from normal vegetative haploid cells only when a cell of the opposite mating type is present. In a like manner, any diploid cell can go through meiosis forming haploids which have the potential to become gametes (Esposito & Klapholz 1981; Fowell 1969). Meiosis is part of the process of sporulation which is initiated when diploid cells are transferred to a nutritionally unbalanced medium, but the changes become apparent under the microscope only after three to five days when the asci become quite distinctive. Theoretically, all asci should contain four spores but in practice, some contain only two or three. The ascus has a characteristic shape. Treating the sporulation mixture with a readily available crude preparation of digestive enzymes (e.g. Zymolyase, Glusulase) will remove the wall of the ascus, liberating the spores. When the spores, either within the ascus or after being liberated, are returned to a nutritionally adequate environment, they germinate and undergo vegetative growth in a stable haploid phase. Haploid strains occur in two mating types, called a and α (alpha). Within each ascus, two spores are normally mating-type a (matA) and the other two are a (matα (alpha)). When a cell of one mating type encounters one of the other mating type, they initiate a series of events that leads to conjugation (See Sexual Conjugation). The result is a diploid cell, which grows by mitotic cell division in a stable diploid phase. If one merely transfers a sporulated cell culture to growth medium the result is a mixed population of haploid strains and new diploid strains which are analogous to the progeny from a cross between diploid higher organisms.
[0174] Normally, yeast geneticists isolate the spores, either randomly or by micromanipulation, to prevent the haploid strains from mating and forming the next generation of diploid strains. This degree of control and the ability to observe the genetic traits in the haploid phase makes genetic analysis in yeast powerful and efficient.
[0175] Adaptation
[0176] Adaptation is the evolutionary process whereby a population becomes better suited (adapted) to its habitat or habitats. This process takes place over several to many generations, and is one of the basic phenomena of biology.
[0177] The term adaptation may also refer to a feature which is especially important for an organism's survival. Such adaptations are produced in a variable population by the better suited forms reproducing more successfully, by natural selection.
[0178] Changes in environmental conditions alter the outcome of natural selection, affecting the selective benefits of subsequent adaptations that improve an organism's fitness under the new conditions. In the case of an extreme environmental change, the appearance and fixation of beneficial adaptations can be essential for survival. A large number of different factors, such as e.g. nutrient availability, temperature, the availability of oxygen, etcetera, can drive adaptive evolution.
[0179] Fitness
[0180] There is a clear relationship between adaptedness (the degree to which an organism is able to live and reproduce in a given set of habitats) and fitness. Fitness is an estimate and a predictor of the rate of natural selection. By the application of natural selection, the relative frequencies of alternative phenotypes will vary in time, if they are heritable.
[0181] Genetic Changes
[0182] When natural selection acts on the genetic variability of the population, genetic changes are the underlying mechanism. By this means, the population adapts genetically to its circumstances. Genetic changes may result in visible structures, or may adjust the physiological activity of the organism in a way that suits the changed habitat.
[0183] It may occur that habitats frequently change. Therefore, it follows that the process of adaptation is never finally complete. In time, it may happen that the environment changes gradually, and the species comes to fit its surroundings better and better. On the other hand, it may happen that changes in the environment occur relatively rapidly, and then the species becomes less and less well adapted. Adaptation is a genetic process, which goes on all the time to some extent, also when the population does not change the habitat or environment.
[0184] Single nucleotides in a DNA sequence may be changed (substitution), removed (deletions) or added (insertion). Insertion or deletion SNPs (InDels) may shift the translational frame.
[0185] Single nucleotide polymorphisms may fall within coding sequences of genes (Open Reading Frames or ORFS), non-coding regions of genes (like promoter sequences, terminator sequences and the like), or in the intergenic regions between genes. SNPs within a coding sequence will not necessarily change the amino acid sequence of the corresponding protein that is produced after transcription and translation, due to degeneracy of the genetic code. A SNP in which both forms lead to the same polypeptide sequence is termed synonymous (a silent mutation). If a different polypeptide sequence is produced they are nonsynonymous. A nonsynonymous change may either be missense or nonsense. A missense change results in a different amino acid in the corresponding polypeptide, while a nonsense change results in a premature stop codon, sometimes leading to the formation of a truncated protein.
[0186] SNPs that are not in protein-coding regions may still have consequences for gene expression, for instance by a changed transcription factor binding or stability of the corresponding mRNA.
[0187] The changes that may occur in the DNA are not necessarily limited to the change (substitution, deletion or insertion) of a single nucleotide, but may also comprise a change of two or more nucleotides (Small Nuclear Variations).
[0188] In addition, chromosomal translocations may occur. A chromosome translocation is a chromosome abnormality caused by rearrangement of parts between nonhomologous chromosomes.
[0189] In particular, according to the invention SNP are created in the following reading frames: SSY1, CEP3 and GAL80.
[0190] SSY1 is herein a component of the SPS plasma membrane amino acid sensor system (Ssy1p-Ptr3p-Ssy5p), which senses external amino acid concentration and transmits intracellular signals that result in regulation of expression of amino acid permease genes.
[0191] CEP3 is herein an essential kinetochore protein, component of the CBF3 complex that binds the CDEIII region of the centromere; contains an N-terminal Zn2Cys6 type zinc finger domain, a C-terminal acidic domain, and a putative coiled coil dimerization domain. GAL80 is herein a transcriptional regulator involved in the repression of GAL genes in the absence of galactose. Typically it inhibits transcriptional activation by Gal4p and inhibition is relieved by Gal3p or Gal1p binding.
[0192] According to the invention, SNP's in the genes SSY1, CEP3 and GAL80 have been shown to be important for the cell to be able to ferment a mixed sugar composition. BLAST searches were conducted for the SNP's found in these genes.
[0193] An overview of the SNP that were identified is given in table 1:
TABLE-US-00001 TABLE 1 Overview of SNP's of the invention Nucleotide mutation Amino acid mutation Gene position in ORF* position in protein SSY1 G1363T E455stop YJR154w A512G D171G CEP3 A1186G S396G GAL80 A436C T146P *the A of the start codon ATG is the first nucleotide position
[0194] A blast of the genes containing the SNP resulted in the following data:
[0195] Ssy1p (Member of the AA Trans Superfamily)
[0196] Component of the SPS plasma membrane amino acid sensor system (Ssy1p-Ptr3p-Ssy5p), which senses external amino acid concentration and transmits intracellular signals that result in regulation of expression of amino acid permease genes [Saccharomyces cerevisiae]
TABLE-US-00002 Ssy1p S. cerevisiae JAY291 852 aa 99% identity Ssy1p S. cerevisiae YJM789 852 aa 99% identity YDR160w-like protein S. cerevisiae AWRI1631 791 aa 99% identity ZYRO0F13838p Z. rouxii CBS 732 836 aa 56% identity hypothetical protein C. glabrata CBS 138 853 aa 53% identity KLTH0G11726p Lachancea 824 aa 46% identity thermotolerans
[0197] Shorter protein found in S. cerevisiae BIE201 is a unique feature.
[0198] YJR154w (Member of the PhyH Superfamily)
[0199] Putative protein of unknown function; green fluorescent protein (GFP)-fusion protein localizes to the cytoplasm [Saccharomyces cerevisiae]
TABLE-US-00003 YJR154w S. cerevisiae JAY291 346 aa 100% identity conserved protein S. cerevisiae YJM789 346 aa 99% identity putative pimeloyl- S. cerevisiae 346 aa 71% identity CoA synth. YJR154Wp-like S. cerevisiae AWRI1631 227 aa 99% identity protein KLTH0E09900p Lachancea thermotolerans 340 aa 48% identity
[0200] In all these proteins, the D-residue at position 171 (or equivalent position based on the BLAST results) is conserved.
[0201] CEP3 (GAL4-Like Zn2Cys6 Binuclear Cluster DNA-Binding Domain; Found in Transcription Regulators like GAL4)
[0202] Centromere DNA-binding protein complex CBF3 subunit B
TABLE-US-00004 CEP3 S. cerevisiae JAY291 608 aa 100% identity ZYRO0A07260p Z. rouxii CBS 732 596 aa 46% identity unnamed protein Candida glabrata CBS138 611 aa 44% identity product AFL200Wp A. gossypii ATCC 10895 596 aa 41% identity
[0203] In all these proteins, the S-residue at position 396 (or equivalent position based on the BLAST results) is conserved.
[0204] GAL80 (Member of the NADB Rossmann Superfamily)
[0205] Galactose/lactose metabolism regulatory protein GAL80
TABLE-US-00005 transcriptional regulator S. cerevisiae 435 aa 100% identity YJM789 GAL80p S. kudriavzevii 435 aa 89% identity protein Kpol_1059p5 V. polyspora 429 aa 73% identity DSM 70294 ZYRO0G04664p Z. rouxii CBS 732 437 aa 67% identity KLTH0C02838p L. thermotolerans 424 aa 64% identity KIGAL80 protein Kluyveromyces 457 aa 58% identity lactis NECHADRAFT_86878 N. haematococca 367 aa 30% identity mpVI 77-13-4
[0206] In all these proteins, the T-residue at position 146 (or equivalent position based on the BLAST results) is conserved.
[0207] The Sugar Composition
[0208] The sugar composition according to the invention comprises glucose, arabinose and xylose. Any sugar composition may be used in the invention that suffices those criteria. Optional sugars in the sugar composition are galactose and rhamnose. In a preferred embodiment, the sugar composition is a hydrolysate of one or more lignocellulosic material. Lignocelllulose herein includes hemicellulose and hemicellulose parts of biomass. Also lignocellulose includes lignocellulosic fractions of biomass. Suitable lignocellulosic materials may be found in the following list: orchard primings, chaparral, mill waste, urban wood waste, municipal waste, logging waste, forest thinnings, short-rotation woody crops, industrial waste, wheat straw, oat straw, rice straw, barley straw, rye straw, flax straw, soy hulls, rice hulls, rice straw, corn gluten feed, oat hulls, sugar cane, corn stover, corn stalks, corn cobs, corn husks, switch grass, miscanthus, sweet sorghum, canola stems, soybean stems, prairie grass, gamagrass, foxtail; sugar beet pulp, citrus fruit pulp, seed hulls, cellulosic animal wastes, lawn clippings, cotton, seaweed, trees, softwood, hardwood, poplar, pine, shrubs, grasses, wheat, wheat straw, sugar cane bagasse, corn, corn husks, corn hobs, corn kernel, fiber from kernels, products and by-products from wet or dry milling of grains, municipal solid waste, waste paper, yard waste, herbaceous material, agricultural residues, forestry residues, municipal solid waste, waste paper, pulp, paper mill residues, branches, bushes, canes, corn, corn husks, an energy crop, forest, a fruit, a flower, a grain, a grass, a herbaceous crop, a leaf, bark, a needle, a log, a root, a sapling, a shrub, switch grass, a tree, a vegetable, fruit peel, a vine, sugar beet pulp, wheat midlings, oat hulls, hard or soft wood, organic waste material generated from an agricultural process, forestry wood waste, or a combination of any two or more thereof.
[0209] An overview of some suitable sugar compositions derived from lignocellulose and the sugar composition of their hydrolysates is given in table 1. The listed lignocelluloses include: corn cobs, corn fiber, rice hulls, melon shells, sugar beet pulp, wheat straw, sugar cane bagasse, wood, grass and olive pressings.
TABLE-US-00006 TABLE 1 Overview of sugar compositions from lignocellulosic materials. Lignocellulosic %. material Gal Xyl Ara Man Glu Rham Sum Gal. Lit. Corn cob a 10 286 36 227 11 570 1.7 (1) Corn cob b 131 228 160 144 663 19.8 (1) Rice hulls a 9 122 24 18 234 10 417 2.2 (1) Rice hulls b 8 120 28 209 12 378 2.2 (1) Melon Shells 6 120 11 208 16 361 1.7 (1) Sugar beet pulp 51 17 209 11 211 24 523 9.8 (2) Whea straw Idaho 15 249 36 396 696 2.2 (3) Corn fiber 36 176 113 372 697 5.2 (4) Cane Bagasse 14 180 24 5 391 614 2.3 (5) Corn stover 19 209 29 370 626 (6) Athel (wood) 5 118 7 3 493 625 0.7 (7) Eucalyptus (wood) 22 105 8 3 445 583 3.8 (7) CWR (grass) 8 165 33 340 546 1.4 (7) JTW (grass) 7 169 28 311 515 1.3 (7) MSW 4 24 5 20 440 493 0.9 (7) Reed Canary Grass 16 117 30 6 209 1 379 4.2 (8) Veg Reed Canary Grass 13 163 28 6 265 1 476 2.7 (9) Seed Olive pressing residu 15 111 24 8 329 487 3.1 (9) Gal = galactose, Xyl = xylose, Ara = arabinose, Man = mannose, Glu = glutamate, Rham = rhamnose. The percentage galactose (% Gal) and literature source is given.
[0210] It is clear from table 1 that in these lignocelluloses a high amount of sugar is presence in de form of glucose, xylose, arabinose and galactose. The conversion of glucose, xylose, arabinose and galactose to fermentation product is thus of great economic importance. Also rhamnose is present in some lignocellulose materials be it in lower amounts than the previously mentioned sugars. Advantageously therefore also rhamnose is converted by the mixed sugar cell.
[0211] Pretreatment and Enzymatic Hydrolysis
[0212] Pretreatment and enzymatic hydrolysis may be needed to release sugars that may be fermented according to the invention from the lignocellulosic (including hemicellulosic) material. These steps may be executed with conventional methods.
[0213] The Mixed Sugar Cell
[0214] The mixed sugar cell comprising the genes araA, araB and araD integrated into the mixed suger cell genome as defined hereafter. It is able to ferment glucose, arabinose, xylose, galactose and mannose. In one embodiment of the invention the mixed sugar cell is able to ferment one or more additional sugar, preferably C5 and/or C6 sugar. In an embodiment of the invention the mixed sugar cell comprises one or more of: a xylA-gene and/or XKS1-gene, to allow the mixed sugar cell to ferment xylose; deletion of the aldose reductase (GRE3) gene; overexpression of PPP-genes TAL1, TKL1, RPE1 and RKI1 to allow the increase of the flux through the pentose phosphate pass-way in the cell.
[0215] Construction of the Mixed Sugar Strain
[0216] The genes may be introduced in the mixed sugar cell by introduction into a host cell: [0217] a) a cluster consisting of PPP-genes TAL1, TKL1, RPE1 and RKI1, under control of strong promoters; [0218] b) a cluster consisting of a xylA-gene and a XKS1-gene both under control of constitutive promoters, [0219] c) a cluster consisting of the genes araA, araB and araD and/or a cluster of xylA-gene and/or the XKS1-gene; and [0220] d) deletion of an aldose reductase gene and adaptive evolution to produce the mixed sugar cell. The above cell may be constructed using recombinant expression techniques.
[0221] Recombinant Expression
[0222] The cell of the invention is a recombinant cell. That is to say, a cell of the invention comprises, or is transformed with or is genetically modified with a nucleotide sequence that does not naturally occur in the cell in question.
[0223] Techniques for the recombinant expression of enzymes in a cell, as well as for the additional genetic modifications of a cell of the invention are well known to those skilled in the art. Typically such techniques involve transformation of a cell with nucleic acid construct comprising the relevant sequence. Such methods are, for example, known from standard handbooks, such as Sambrook and Russel (2001) "Molecular Cloning: A Laboratory Manual (3rd edition), Cold Spring Harbor Laboratory, Cold Spring Harbor Laboratory Press, or F. Ausubel et al., eds., "Current protocols in molecular biology", Green Publishing and Wiley Interscience, New York (1987). Methods for transformation and genetic modification of fungal host cells are known from e.g. EP-A- 0635 574, WO 98/46772, WO 99/60102, WO 00/37671, W090/14423, EP-A-0481008, EP-A-0635574 and U.S. Pat. No. 6,265,186.
[0224] Typically, the nucleic acid construct may be a plasmid, for instance a low copy plasmid or a high copy plasmid. The cell according to the present invention may comprise a single or multiple copies of the nucleotide sequence encoding a enzyme, for instance by multiple copies of a nucleotide construct or by use of construct which has multiple copies of the enzyme sequence.
[0225] The nucleic acid construct may be maintained episomally and thus comprise a sequence for autonomous replication, such as an autosomal replication sequence sequence. A suitable episomal nucleic acid construct may e.g. be based on the yeast 2μ or pKD1 plasmids (Gleer et al., 1991, Biotechnology 9: 968-975), or the AMA plasmids (Fierro et al., 1995, Curr Genet. 29:482-489). Alternatively, each nucleic acid construct may be integrated in one or more copies into the genome of the cell. Integration into the cell's genome may occur at random by non-homologous recombination but preferably, the nucleic acid construct may be integrated into the cell's genome by homologous recombination as is well known in the art (see e.g. WO90/14423, EP-A-0481008, EP-A-0635 574 and U.S. Pat. No. 6,265,186).
[0226] Most episomal or 2μ plasmids are relatively unstable, being lost in approximately 10-2 or more cells after each generation. Even under conditions of selective growth, only 60% to 95% of the cells retain the episomal plasmid. The copy number of most episomal plasmids ranges from 10-40 per cell of cir+ hosts. However, the plasmids are not equally distributed among the cells, and there is a high variance in the copy number per cell in populations. Strains transformed with integrative plasmids are extremely stable, even in the absence of selective pressure. However, plasmid loss can occur at approximately 10-3 to 10-4 frequencies by homologous recombination between tandemly repeated DNA, leading to looping out of the vector sequence. Preferably, the vector design in the case of stable integration is thus, that upon loss of the selection marker genes (which also occurs by intramolecular, homologous recombination) that looping out of the integrated construct is no longer possible. Preferably the genes are thus stably integrated. Stable integration is herein defined as integration into the genome, wherein looping out of the integrated construct is no longer possible. Preferably selection markers are absent. Typically, the enzyme encoding sequence will be operably linked to one or more nucleic acid sequences, capable of providing for or aiding the transcription and/or translation of the enzyme sequence.
[0227] The term "operably linked" refers to a juxtaposition wherein the components described are in a relationship permitting them to function in their intended manner. For instance, a promoter or enhancer is operably linked to a coding sequence the said promoter or enhancer affects the transcription of the coding sequence.
[0228] As used herein, the term "promoter" refers to a nucleic acid fragment that functions to control the transcription of one or more genes, located upstream with respect to the direction of transcription of the transcription initiation site of the gene, and is structurally identified by the presence of a binding site for DNA-dependent RNA polymerase, transcription initiation sites and any other DNA sequences known to one of skilled in the art. A "constitutive" promoter is a promoter that is active under most environmental and developmental conditions. An "inducible" promoter is a promoter that is active under environmental or developmental regulation.
[0229] The promoter that could be used to achieve the expression of a nucleotide sequence coding for an enzyme according to the present invention, may be not native to the nucleotide sequence coding for the enzyme to be expressed, i.e. a promoter that is heterologous to the nucleotide sequence (coding sequence) to which it is operably linked. The promoter may, however, be homologous, i.e. endogenous, to the host cell.
[0230] Promotors are widely available and known to the skilled person. Suitable examples of such promoters include e.g. promoters from glycolytic genes, such as the phosphofructokinase (PFK), triose phosphate isomerase (TPI), glyceraldehyde-3-phosphate dehydrogenase (GPD, TDH3 or GAPDH), pyruvate kinase (PYK), phosphoglycerate kinase (PGK) promoters from yeasts or filamentous fungi; more details about such promoters from yeast may be found in (WO 93/03159). Other useful promoters are ribosomal protein encoding gene promoters, the lactase gene promoter (LAC4), alcohol dehydrogenase promoters (ADHI, ADH4, and the like), and the enolase promoter (ENO). Other promoters, both constitutive and inducible, and enhancers or upstream activating sequences will be known to those of skill in the art. The promoters used in the host cells of the invention may be modified, if desired, to affect their control characteristics. Suitable promoters in this context include both constitutive and inducible natural promoters as well as engineered promoters, which are well known to the person skilled in the art. Suitable promoters in eukaryotic host cells may be GAL7, GAL10, or GAL1, CYC1, HIS3, ADH1, PGL, PH05, GAPDH, ADC1, TRP1, URA3, LEU2, ENO1, TPI1, and AOX1. Other suitable promoters include PDC1, GPD1, PGK1, TEF1, and TDH3.
[0231] In a cell of the invention, the 3'-end of the nucleotide acid sequence encoding enzyme preferably is operably linked to a transcription terminator sequence. Preferably the terminator sequence is operable in a host cell of choice, such as e.g. the yeast species of choice. In any case the choice of the terminator is not critical; it may e.g. be from any yeast gene, although terminators may sometimes work if from a non-yeast, eukaryotic, gene. Usually a nucleotide sequence encoding the enzyme comprises a terminator. Preferably, such terminators are combined with mutations that prevent nonsense mediated mRNA decay in the host cell of the invention (see for example: Shirley et al., 2002, Genetics 161:1465-1482).
[0232] The transcription termination sequence further preferably comprises a polyadenylation signal.
[0233] Optionally, a selectable marker may be present in a nucleic acid construct suitable for use in the invention. As used herein, the term "marker" refers to a gene encoding a trait or a phenotype which permits the selection of, or the screening for, a host cell containing the marker. The marker gene may be an antibiotic resistance gene whereby the appropriate antibiotic can be used to select for transformed cells from among cells that are not transformed. Examples of suitable antibiotic resistance markers include e.g. dihydrofolate reductase, hygromycin-B-phosphotransferase, 3'-O-phosphotransferase II (kanamycin, neomycin and G418 resistance). Antibiotic resistance markers may be most convenient for the transformation of polyploid host cells, Also non-antibiotic resistance markers may be used, such as auxotrophic markers (URA3, TRPI, LEU2) or the S. pombe TPI gene (described by Russell P R, 1985, Gene 40: 125-130). In a preferred embodiment the host cells transformed with the nucleic acid constructs are marker gene free. Methods for constructing recombinant marker gene free microbial host cells are disclosed in EP-A-O 635 574 and are based on the use of bidirectional markers such as the A. nidulans amdS (acetamidase) gene or the yeast URA3 and LYS2 genes. Alternatively, a screenable marker such as Green Fluorescent Protein, lacL, luciferase, chloramphenicol acetyltransferase, beta-glucuronidase may be incorporated into the nucleic acid constructs of the invention allowing to screen for transformed cells.
[0234] Optional further elements that may be present in the nucleic acid constructs suitable for use in the invention include, but are not limited to, one or more leader sequences, enhancers, integration factors, and/or reporter genes, intron sequences, centromers, telomers and/or matrix attachment (MAR) sequences. The nucleic acid constructs of the invention may further comprise a sequence for autonomous replication, such as an ARS sequence.
[0235] The recombination process may thus be executed with known recombination techniques. Various means are known to those skilled in the art for expression and overexpression of enzymes in a cell of the invention. In particular, an enzyme may be overexpressed by increasing the copy number of the gene coding for the enzyme in the host cell, e.g. by integrating additional copies of the gene in the host cell's genome, by expressing the gene from an episomal multicopy expression vector or by introducing a episomal expression vector that comprises multiple copies of the gene.
[0236] Alternatively, overexpression of enzymes in the host cells of the invention may be achieved by using a promoter that is not native to the sequence coding for the enzyme to be overexpressed, i.e. a promoter that is heterologous to the coding sequence to which it is operably linked. Although the promoter preferably is heterologous to the coding sequence to which it is operably linked, it is also preferred that the promoter is homologous, i.e. endogenous to the host cell. Preferably the heterologous promoter is capable of producing a higher steady state level of the transcript comprising the coding sequence (or is capable of producing more transcript molecules, i.e. mRNA molecules, per unit of time) than is the promoter that is native to the coding sequence. Suitable promoters in this context include both constitutive and inducible natural promoters as well as engineered promoters.
[0237] The coding sequence used for overexpression of the enzymes mentioned above may preferably be homologous to the host cell of the invention. However, coding sequences that are heterologous to the host cell of the invention may be used.
[0238] Overexpression of an enzyme, when referring to the production of the enzyme in a genetically modified cell, means that the enzyme is produced at a higher level of specific enzymatic activity as compared to the unmodified host cell under identical conditions. Usually this means that the enzymatically active protein (or proteins in case of multi-subunit enzymes) is produced in greater amounts, or rather at a higher steady state level as compared to the unmodified host cell under identical conditions. Similarly this usually means that the mRNA coding for the enzymatically active protein is produced in greater amounts, or again rather at a higher steady state level as compared to the unmodified host cell under identical conditions. Preferably in a host cell of the invention, an enzyme to be overexpressed is overexpressed by at least a factor of about 1.1, about 1.2, about 1.5, about 2, about 5, about 10 or about 20 as compared to a strain which is genetically identical except for the genetic modification causing the overexpression. It is to be understood that these levels of overexpression may apply to the steady state level of the enzyme's activity, the steady state level of the enzyme's protein as well as to the steady state level of the transcript coding for the enzyme.
The Adaptive Evolution
[0239] The mixed sugar cells are in their preparation subjected to adaptive evolution. A cell of the invention may be adapted to sugar utilisation by selection of mutants, either spontaneous or induced (e.g. by radiation or chemicals), for growth on the desired sugar, preferably as sole carbon source, and more preferably under anaerobic conditions. Selection of mutants may be performed by techniques including serial transfer of cultures as e.g. described by Kuyper et al. (2004, FEMS Yeast Res. 4: 655-664) or by cultivation under selective pressure in a chemostat culture. E.g. in a preferred host cell of the invention at least one of the genetic modifications described above, including modifications obtained by selection of mutants, confer to the host cell the ability to grow on the xylose as carbon source, preferably as sole carbon source, and preferably under anaerobic conditions. Preferably the cell produce essentially no xylitol, e.g. the xylitol produced is below the detection limit or e.g. less than about 5, about 2, about 1, about 0.5, or about 0.3% of the carbon consumed on a molar basis.
[0240] Adaptive evolution is also described e.g. in Wisselink H. W. et al, Applied and Environmental Microbiology August 2007, p. 4881-4891
[0241] In one embodiment of adaptive evolution a regimen consisting of repeated batch cultivation with repeated cycles of consecutive growth in different media is applied, e.g. three media with different compositions (glucose, xylose, and arabinose; xylose and arabinose. See Wisselink et al. (2009) Applied and Environmental Microbiology, February 2009, p. 907-914.
[0242] The Host Cell
[0243] The host cell may be any host cell suitable for production of a useful product. A cell of the invention may be any suitable cell, such as a prokaryotic cell, such as a bacterium, or a eukaryotic cell. Typically, the cell will be a eukaryotic cell, for example a yeast or a filamentous fungus.
[0244] Yeasts are herein defined as eukaryotic microorganisms and include all species of the subdivision Eumycotina (Alexopoulos, C. J.,1962, In : Introductory Mycology, John Wiley & Sons, Inc. , New York) that predominantly grow in unicellular form.
[0245] Yeasts may either grow by budding of a unicellular thallus or may grow by fission of the organism. A preferred yeast as a cell of the invention may belong to the genera Saccharomyces, Kluyveromyces, Candida, Pichia, Schizosaccharomyces, Hansenula, Kloeckera, Schwanniomyces or Yarrowia. Preferably the yeast is one capable of anaerobic fermentation, more preferably one capable of anaerobic alcoholic fermentation.
[0246] Filamentous fungi are herein defined as eukaryotic microorganisms that include all filamentous forms of the subdivision Eumycotina. These fungi are characterized by a vegetative mycelium composed of chitin, cellulose, and other complex polysaccharides. The filamentous fungi of the suitable for use as a cell of the present invention are morphologically, physiologically, and genetically distinct from yeasts. Filamentous fungal cells may be advantageously used since most fungi do not require sterile conditions for propagation and are insensitive to bacteriophage infections. Vegetative growth by filamentous fungi is by hyphal elongation and carbon catabolism of most filamentous fungi is obligately aerobic. Preferred filamentous fungi as a host cell of the invention may belong to the genus Aspergillus, Trichoderma, Humicola, Acremoniurra, Fusarium or Penicillium. More preferably, the filamentous fungal cell may be a Aspergillus niger, Aspergillus oryzae, a Penicillium chrysogenum, or Rhizopus oryzae cell.
[0247] In one embodiment the host cell may be yeast.
[0248] Preferably the host is an industrial host, more preferably an industrial yeast. An industrial host and industrial yeast cell may be defined as follows. The living environments of yeast cells in industrial processes are significantly different from that in the laboratory. Industrial yeast cells must be able to perform well under multiple environmental conditions which may vary during the process. Such variations include change in nutrient sources, pH, ethanol concentration, temperature, oxygen concentration, etc., which together have potential impact on the cellular growth and ethanol production of Saccharomyces cerevisiae. Under adverse industrial conditions, the environmental tolerant strains should allow robust growth and production. Industrial yeast strains are generally more robust towards these changes in environmental conditions which may occur in the applications they are used, such as in the baking industry, brewing industry, wine making and the ethanol industry. Examples of industrial yeast (S. cerevisiae) are Ethanol Red® (Fermentis) Fermiol® (DSM) and Thermosacc® (Lallemand).
[0249] In an embodiment the host is inhibitor tolerant. Inhibitor tolerant host cells may be selected by screening strains for growth on inhibitors containing materials, such as illustrated in Kadar et al, Appl. Biochem. Biotechnol. (2007), Vol. 136-140, 847-858, wherein an inhibitor tolerant S. cerevisiae strain ATCC 26602 was selected.
[0250] Preferably the host cell is industrial and inhibitor tolerant.
[0251] araA, araB and araD Genes
[0252] A cell of the invention is capable of using arabinose. A cell of the invention is therefore, be capable of converting L-arabinose into L-ribulose and/or xylulose 5-phosphate and/or into a desired fermentation product, for example one of those mentioned herein.
[0253] Organisms, for example S. cerevisiae strains, able to produce ethanol from L-arabinose may be produced by modifying a cell introducing the araA (L-arabinose isomerase), araB (L-ribulokinase) and araD (L-ribulose-5-P4-epimerase) genes from a suitable source. Such genes may be introduced into a cell of the invention is order that it is capable of using arabinose. Such an approach is given is described in WO2003/095627. araA, araB and araD genes from Lactobacillus plantanum may be used and are disclosed in WO2008/041840. The araA gene from Bacillus subtilis and the araB and araD genes from Escherichia coli may be used and are disclosed in EP1499708.
[0254] PPP-Genes
[0255] A cell of the invention may comprise one ore more genetic modifications that increases the flux of the pentose phosphate pathway. In particular, the genetic modification(s) may lead to an increased flux through the non-oxidative part pentose phosphate pathway. A genetic modification that causes an increased flux of the non-oxidative part of the pentose phosphate pathway is herein understood to mean a modification that increases the flux by at least a factor of about 1.1, about 1.2, about 1.5, about 2, about 5, about 10 or about 20 as compared to the flux in a strain which is genetically identical except for the genetic modification causing the increased flux. The flux of the non-oxidative part of the pentose phosphate pathway may be measured by growing the modified host on xylose as sole carbon source, determining the specific xylose consumption rate and subtracting the specific xylitol production rate from the specific xylose consumption rate, if any xylitol is produced. However, the flux of the non-oxidative part of the pentose phosphate pathway is proportional with the growth rate on xylose as sole carbon source, preferably with the anaerobic growth rate on xylose as sole carbon source. There is a linear relation between the growth rate on xylose as sole carbon source (μmax) and the flux of the non-oxidative part of the pentose phosphate pathway. The specific xylose consumption rate (Qs) is equal to the growth rate (μ) divided by the yield of biomass on sugar (Yxs) because the yield of biomass on sugar is constant (under a given set of conditions: anaerobic, growth medium, pH, genetic background of the strain, etc.; i.e. Qs=μ/Yxs). Therefore the increased flux of the non-oxidative part of the pentose phosphate pathway may be deduced from the increase in maximum growth rate under these conditions unless transport (uptake is limiting).
[0256] One or more genetic modifications that increase the flux of the pentose phosphate pathway may be introduced in the host cell in various ways. These including e.g. achieving higher steady state activity levels of xylulose kinase and/or one or more of the enzymes of the non-oxidative part pentose phosphate pathway and/or a reduced steady state level of unspecific aldose reductase activity. These changes in steady state activity levels may be effected by selection of mutants (spontaneous or induced by chemicals or radiation) and/or by recombinant DNA technology e.g. by overexpression or inactivation, respectively, of genes encoding the enzymes or factors regulating these genes.
[0257] In a preferred host cell, the genetic modification comprises overexpression of at least one enzyme of the (non-oxidative part) pentose phosphate pathway. Preferably the enzyme is selected from the group consisting of the enzymes encoding for ribulose-5- phosphate isomerase, ribulose-5-phosphate epimerase, transketolase and transaldolase. Various combinations of enzymes of the (non-oxidative part) pentose phosphate pathway may be overexpressed. E.g. the enzymes that are overexpressed may be at least the enzymes ribulose-5-phosphate isomerase and ribulose-5-phosphate epimerase; or at least the enzymes ribulose-5-phosphate isomerase and transketolase; or at least the enzymes ribulose-5-phosphate isomerase and transaldolase; or at least the enzymes ribulose-5-phosphate epimerase and transketolase; or at least the enzymes ribulose-5-phosphate epimerase and transaldolase; or at least the enzymes transketolase and transaldolase; or at least the enzymes ribulose-5-phosphate epimerase, transketolase and transaldolase; or at least the enzymes ribulose-5-phosphate isomerase, transketolase and transaldolase; or at least the enzymes ribulose-5-phosphate isomerase, ribulose-5-phosphate epimerase, and transaldolase; or at least the enzymes ribulose-5-phosphate isomerase, ribulose-5-phosphate epimerase, and transketolase. In one embodiment of the invention each of the enzymes ribulose-5-phosphate isomerase, ribulose-5-phosphate epimerase, transketolase and transaldolase are overexpressed in the host cell. More preferred is a host cell in which the genetic modification comprises at least overexpression of both the enzymes transketolase and transaldolase as such a host cell is already capable of anaerobic growth on xylose. In fact, under some conditions host cells overexpressing only the transketolase and the transaldolase already have the same anaerobic growth rate on xylose as do host cells that overexpress all four of the enzymes, i.e. the ribulose-5-phosphate isomerase, ribulose-5-phosphate epimerase, transketolase and transaldolase. Moreover, host cells overexpressing both of the enzymes ribulose-5-phosphate isomerase and ribulose-5-phosphate epimerase are preferred over host cells overexpressing only the isomerase or only the epimerase as overexpression of only one of these enzymes may produce metabolic imbalances.
[0258] The enzyme "ribulose 5-phosphate epimerase" (EC 5.1.3.1) is herein defined as an enzyme that catalyses the epimerisation of D-xylulose 5-phosphate into D-ribulose 5-phosphate and vice versa. The enzyme is also known as phosphoribulose epimerase; erythrose-4-phosphate isomerase; phosphoketopentose 3-epimerase; xylulose phosphate 3-epimerase; phosphoketopentose epimerase; ribulose 5-phosphate 3- epimerase; D-ribulose phosphate-3-epimerase; D-ribulose 5-phosphate epimerase; D- ribulose-5-P 3-epimerase; D-xylulose-5-phosphate 3-epimerase; pentose-5-phosphate 3-epimerase; or D-ribulose-5-phosphate 3-epimerase. A ribulose 5-phosphate epimerase may be further defined by its amino acid sequence. Likewise a ribulose 5-phosphate epimerase may be defined by a nucleotide sequence encoding the enzyme as well as by a nucleotide sequence hybridising to a reference nucleotide sequence encoding a ribulose 5-phosphate epimerase. The nucleotide sequence encoding for ribulose 5-phosphate epimerase is herein designated RPE1.
[0259] The enzyme "ribulose 5-phosphate isomerase" (EC 5.3.1.6) is herein defined as an enzyme that catalyses direct isomerisation of D-ribose 5-phosphate into D-ribulose 5-phosphate and vice versa. The enzyme is also known as phosphopentosisomerase; phosphoriboisomerase; ribose phosphate isomerase; 5-phosphoribose isomerase; D-ribose 5-phosphate isomerase; D-ribose-5-phosphate ketol-isomerase; or D-ribose-5-phosphate aldose-ketose-isomerase. A ribulose 5-phosphate isomerase may be further defined by its amino acid sequence. Likewise a ribulose 5-phosphate isomerase may be defined by a nucleotide sequence encoding the enzyme as well as by a nucleotide sequence hybridising to a reference nucleotide sequence encoding a ribulose 5-phosphate isomerase. The nucleotide sequence encoding for ribulose 5-phosphate isomerase is herein designated RPI1.
[0260] The enzyme "transketolase" (EC 2.2.1.1) is herein defined as an enzyme that catalyses the reaction: D-ribose 5-phosphate+D-xylulose 5-phosphate<->sedoheptulose 7-phosphate +D-glyceraldehyde 3-phosphate and vice versa. The enzyme is also known as glycolaldehydetransferase or sedoheptulose-7-phosphate:D-glyceraldehyde-3-phosphate glycolaldehydetransferase. A transketolase may be further defined by its amino acid. Likewise a transketolase may be defined by a nucleotide sequence encoding the enzyme as well as by a nucleotide sequence hybridising to a reference nucleotide sequence encoding a transketolase. The nucleotide sequence encoding for transketolase is herein designated TKL1.
[0261] The enzyme "transaldolase" (EC 2.2.1.2) is herein defined as an enzyme that catalyses the reaction: sedoheptulose 7-phosphate+D-glyceraldehyde 3-phosphate<->D-erythrose 4-phosphate+D-fructose 6-phosphate and vice versa. The enzyme is also known as dihydroxyacetonetransferase; dihydroxyacetone synthase; formaldehyde transketolase; or sedoheptulose-7-phosphate :D-glyceraldehyde-3-phosphate glyceronetransferase. A transaldolase may be further defined by its amino acid sequence. Likewise a transaldolase may be defined by a nucleotide sequence encoding the enzyme as well as by a nucleotide sequence hybridising to a reference nucleotide sequence encoding a transaldolase. The nucleotide sequence encoding for transketolase from is herein designated TAL1.
Xylose Isomerase Gene
[0262] The presence of the nucleotide sequence encoding a xylose isomerase confers on the cell the ability to isomerise xylose to xylulose. According to the invention, two to fifteen copies of one or more xylose isomerase gene are introduced into the host cell.
[0263] In one embodiment, the two to fifteen copies of one or more xylose isomerase gene are introduced into the host cell.
[0264] A "xylose isomerase" (EC 5.3.1.5) is herein defined as an enzyme that catalyses the direct isomerisation of D-xylose into D-xylulose and/or vice versa. The enzyme is also known as a D-xylose ketoisomerase. A xylose isomerase herein may also be capable of catalysing the conversion between D-glucose and D-fructose (and accordingly may therefore be referred to as a glucose isomerase). A xylose isomerase herein may require a bivalent cation, such as magnesium, manganese or cobalt as a cofactor.
[0265] Accordingly, a cell of the invention is capable of isomerising xylose to xylulose. The ability of isomerising xylose to xylulose is conferred on the host cell by transformation of the host cell with a nucleic acid construct comprising a nucleotide sequence encoding a defined xylose isomerase. A cell of the invention isomerises xylose into xylulose by the direct isomerisation of xylose to xylulose. This is understood to mean that xylose is isomerised into xylulose in a single reaction catalysed by a xylose isomerase, as opposed to two step conversion of xylose into xylulose via a xylitol intermediate as catalysed by xylose reductase and xylitol dehydrogenase, respectively.
[0266] A unit (U) of xylose isomerase activity may herein be defined as the amount of enzyme producing 1 nmol of xylulose per minute, under conditions as described by Kuyper et al. (2003, FEMS Yeast Res. 4: 69-78). The Xylose isomerise gene may have various origin, such as for example Pyromyces sp. as disclosed in WO2006/009434. Other suitable origins are Bacteroides, in particular Bacteroides unifomis as described in PCT/EP2009/52623, Bacillus, in particular Bacillus stearothermophilus as described in PCT/EP2009/052625, Thermotoga, in particular Thermotoga maritima, as described in PCT/EP2009/052621 and Clostridium, in particular Clostridium cellulolyticum as described in PCT/EP2009/052620.
[0267] XKS1 Gene
[0268] A cell of the invention may comprise one or more genetic modifications that increase the specific xylulose kinase activity. Preferably the genetic modification or modifications causes overexpression of a xylulose kinase, e.g. by overexpression of a nucleotide sequence encoding a xylulose kinase. The gene encoding the xylulose kinase may be endogenous to the host cell or may be a xylulose kinase that is heterologous to the host cell. A nucleotide sequence used for overexpression of xylulose kinase in the host cell of the invention is a nucleotide sequence encoding a polypeptide with xylulose kinase activity.
[0269] The enzyme "xylulose kinase" (EC 2.7.1.17) is herein defined as an enzyme that catalyses the reaction ATP+D-xylulose=ADP+D-xylulose 5-phosphate. The enzyme is also known as a phosphorylating xylulokinase, D-xylulokinase or ATP :D-xylulose 5-phosphotransferase. A xylulose kinase of the invention may be further defined by its amino acid sequence. Likewise a xylulose kinase may be defined by a nucleotide sequence encoding the enzyme as well as by a nucleotide sequence hybridising to a reference nucleotide sequence encoding a xylulose kinase.
[0270] In a cell of the invention, a genetic modification or modifications that increase(s) the specific xylulose kinase activity may be combined with any of the modifications increasing the flux of the pentose phosphate pathway as described above. This is not, however, essential.
[0271] Thus, a host cell of the invention may comprise only a genetic modification or modifications that increase the specific xylulose kinase activity. The various means available in the art for achieving and analysing overexpression of a xylulose kinase in the host cells of the invention are the same as described above for enzymes of the pentose phosphate pathway. Preferably in the host cells of the invention, a xylulose kinase to be overexpressed is overexpressed by at least a factor of about 1.1, about 1.2, about 1.5, about 2, about 5, about 10 or about 20 as compared to a strain which is genetically identical except for the genetic modification(s) causing the overexpression. It is to be understood that these levels of overexpression may apply to the steady state level of the enzyme's activity, the steady state level of the enzyme's protein as well as to the steady state level of the transcript coding for the enzyme.
[0272] Aldose Reductase (GRE3) Gene Deletion
[0273] A cell of the invention may comprise one or more genetic modifications that reduce unspecific aldose reductase activity in the host cell. Preferably, unspecific aldose reductase activity is reduced in the host cell by one or more genetic modifications that reduce the expression of or inactivates a gene encoding an unspecific aldose reductase. Preferably, the genetic modification(s) reduce or inactivate the expression of each endogenous copy of a gene encoding an unspecific aldose reductase in the host cell (herein called GRE3 deletion). Host cells may comprise multiple copies of genes encoding unspecific aldose reductases as a result of di-, poly- or aneu-ploidy, and/or the host cell may contain several different (iso)enzymes with aldose reductase activity that differ in amino acid sequence and that are each encoded by a different gene. Also in such instances preferably the expression of each gene that encodes an unspecific aldose reductase is reduced or inactivated. Preferably, the gene is inactivated by deletion of at least part of the gene or by disruption of the gene, whereby in this context the term gene also includes any non-coding sequence up- or down-stream of the coding sequence, the (partial) deletion or inactivation of which results in a reduction of expression of unspecific aldose reductase activity in the host cell.
[0274] A nucleotide sequence encoding an aldose reductase whose activity is to be reduced in the host cell of the invention is a nucleotide sequence encoding a polypeptide with aldose reductase activity.
[0275] Thus, a host cell of the invention comprising only a genetic modification or modifications that reduce(s) unspecific aldose reductase activity in the host cell is specifically included in the invention.
[0276] The enzyme "aldose reductase" (EC 1.1.1.21) is herein defined as any enzyme that is capable of reducing xylose or xylulose to xylitol. In the context of the present invention an aldose reductase may be any unspecific aldose reductase that is native (endogenous) to a host cell of the invention and that is capable of reducing xylose or xylulose to xylitol. Unspecific aldose reductases catalyse the reaction:
aldose+NAD(P)H+H+alditol+NAD(P)+
[0277] The enzyme has a wide specificity and is also known as aldose reductase; polyol dehydrogenase (NADP+); alditol:NADP oxidoreductase; alditol:NADP+1-oxidoreductase; NADPH-aldopentose reductase; or NADPH-aldose reductase.
[0278] A particular example of such an unspecific aldose reductase that is endogenous to S. cerevisiae and that is encoded by the GRE3 gene (Traff et al., 2001, Appl. Environ. Microbiol. 67: 5668-74). Thus, an aldose reductase of the invention may be further defined by its amino acid sequence. Likewise an aldose reductase may be defined by the nucleotide sequences encoding the enzyme as well as by a nucleotide sequence hybridising to a reference nucleotide sequence encoding an aldose reductase.
[0279] Bioproducts Production
[0280] Over the years suggestions have been made for the introduction of various organisms for the production of bio-ethanol from crop sugars. In practice, however, all major bio-ethanol production processes have continued to use the yeasts of the genus Saccharomyces as ethanol producer. This is due to the many attractive features of Saccharomyces species for industrial processes, i.e., a high acid-, ethanol-and osmo-tolerance, capability of anaerobic growth, and of course its high alcoholic fermentative capacity. Preferred yeast species as host cells include S. cerevisiae, S. bulderi, S. barnetti, S. exiguus, S. uvarum, S. diastaticus, K. lactis, K. marxianus or K fragilis.
[0281] A cell of the invention may be able to convert plant biomass, celluloses, hemicelluloses, pectins, rhamnose, galactose, frucose, maltose, maltodextrines, ribose, ribulose, or starch, starch derivatives, sucrose, lactose and glycerol, for example into fermentable sugars. Accordingly, a cell of the invention may express one or more enzymes such as a cellulase (an endocellulase or an exocellulase), a hemicellulase (an endo- or exo-xylanase or arabinase) necessary for the conversion of cellulose into glucose monomers and hemicellulose into xylose and arabinose monomers, a pectinase able to convert pectins into glucuronic acid and galacturonic acid or an amylase to convert starch into glucose monomers.
[0282] The cell further preferably comprises those enzymatic activities required for conversion of pyruvate to a desired fermentation product, such as ethanol, butanol, lactic acid, 3 -hydroxy- propionic acid, acrylic acid, acetic acid, succinic acid, citric acid, fumaric acid, malic acid, itaconic acid, an amino acid, 1,3- propane-diol, ethylene, glycerol, a β-lactam antibiotic or a cephalosporin.
[0283] A preferred cell of the invention is a cell that is naturally capable of alcoholic fermentation, preferably, anaerobic alcoholic fermentation. A cell of the invention preferably has a high tolerance to ethanol, a high tolerance to low pH (i.e. capable of growth at a pH lower than about 5, about 4, about 3, or about 2.5) and towards organic acids like lactic acid, acetic acid or formic acid and/or sugar degradation products such as furfural and hydroxy- methylfurfural and/or a high tolerance to elevated temperatures.
[0284] Any of the above characteristics or activities of a cell of the invention may be naturally present in the cell or may be introduced or modified by genetic modification.
[0285] A cell of the invention may be a cell suitable for the production of ethanol. A cell of the invention may, however, be suitable for the production of fermentation products other than ethanol. Such non-ethanolic fermentation products include in principle any bulk or fine chemical that is producible by a eukaryotic microorganism such as a yeast or a filamentous fungus.
[0286] Such fermentation products may be, for example, butanol, lactic acid, 3 -hydroxy-propionic acid, acrylic acid, acetic acid, succinic acid, citric acid, malic acid, fumaric acid, itaconic acid, an amino acid, 1,3-propane-diol, ethylene, glycerol, a β-lactam antibiotic or a cephalosporin. A preferred cell of the invention for production of non-ethanolic fermentation products is a host cell that contains a genetic modification that results in decreased alcohol dehydrogenase activity.
[0287] In a further aspect the invention relates to fermentation processes in which the cells of the invention are used for the fermentation of a carbon source comprising a source of xylose, such as xylose. In addition to a source of xylose the carbon source in the fermentation medium may also comprise a source of glucose. The source of xylose or glucose may be xylose or glucose as such or may be any carbohydrate oligo- or polymer comprising xylose or glucose units, such as e.g. lignocellulose, xylans, cellulose, starch and the like. For release of xylose or glucose units from such carbohydrates, appropriate carbohydrases (such as xylanases, glucanases, amylases and the like) may be added to the fermentation medium or may be produced by the cell. In the latter case the cell may be genetically engineered to produce and excrete such carbohydrases. An additional advantage of using oligo- or polymeric sources of glucose is that it enables to maintain a low(er) concentration of free glucose during the fermentation, e.g. by using rate-limiting amounts of the carbohydrases. This, in turn, will prevent repression of systems required for metabolism and transport of non-glucose sugars such as xylose.
[0288] In a preferred process the cell ferments both the xylose and glucose, preferably simultaneously in which case preferably a cell is used which is insensitive to glucose repression to prevent diauxic growth. In addition to a source of xylose (and glucose) as carbon source, the fermentation medium will further comprise the appropriate ingredient required for growth of the cell. Compositions of fermentation media for growth of microorganisms such as yeasts are well known in the art. The fermentation process is a process for the production of a fermentation product such as e.g. ethanol, butanol, lactic acid, 3 -hydroxy-propionic acid, acrylic acid, acetic acid, succinic acid, citric acid, malic acid, fumaric acid, itaconic acid, an amino acid, 1,3-propane-diol, ethylene, glycerol, a β-lactam antibiotic, such as Penicillin G or Penicillin V and fermentative derivatives thereof, and a cephalosporin.
[0289] Bioproducts Production
[0290] Over the years suggestions have been made for the introduction of various organisms for the production of bio-ethanol from crop sugars. In practice, however, all major bio-ethanol production processes have continued to use the yeasts of the genus Saccharomyces as ethanol producer. This is due to the many attractive features of Saccharomyces species for industrial processes, i.e., a high acid-, ethanol-and osmo-tolerance, capability of anaerobic growth, and of course its high alcoholic fermentative capacity. Preferred yeast species as host cells include S. cerevisiae, S. bulderi, S. barnetti, S. exiguus, S. uvarum, S. diastaticus, K. lactis, K. marxianus or K fragilis.
[0291] A mixed sugar cell may be a cell suitable for the production of ethanol. A mixed sugar cell may, however, be suitable for the production of fermentation products other than ethanol. Such non-ethanolic fermentation products include in principle any bulk or fine chemical that is producible by a eukaryotic microorganism such as a yeast or a filamentous fungus.
[0292] A mixed sugar cell may be used for production of non-ethanolic fermentation products is a host cell that contains a genetic modification that results in decreased alcohol dehydrogenase activity.
[0293] In an embodiment the mixed sugar cell may be used in a process wherein sugars originating from lignocellulose are converted into ethanol.
[0294] Liqnocellulose
[0295] Lignocellulose, which may be considered as a potential renewable feedstock, generally comprises the polysaccharides cellulose (glucans) and hemicelluloses (xylans, heteroxylans and xyloglucans). In addition, some hemicellulose may be present as glucomannans, for example in wood-derived feedstocks. The enzymatic hydrolysis of these polysaccharides to soluble sugars, including both monomers and multimers, for example glucose, cellobiose, xylose, arabinose, galactose, fructose, mannose, rhamnose, ribose, galacturonic acid, glucoronic acid and other hexoses and pentoses occurs under the action of different enzymes acting in concert.
[0296] In addition, pectins and other pectic substances such as arabinans may make up considerably proportion of the dry mass of typically cell walls from non-woody plant tissues (about a quarter to half of dry mass may be pectins).
[0297] Pretreatment
[0298] Before enzymatic treatment, the lignocellulosic material may be pretreated. The pretreatment may comprise exposing the lignocellulosic material to an acid, a base, a solvent, heat, a peroxide, ozone, mechanical shredding, grinding, milling or rapid depressurization, or a combination of any two or more thereof. This chemical pretreatment is often combined with heat-pretreatment, e.g. between 150-220° C. for 1 to 30 minutes.
[0299] Enzymatic Hydrolysis
[0300] The pretreated material is commonly subjected to enzymatic hydrolysis to release sugars that may be fermented according to the invention. This may be executed with conventional methods, e.g. contacting with cellulases, for instance cellobiohydrolase(s), endoglucanase(s), beta-glucosidase(s) and optionally other enzymes. The conversion with the cellulases may be executed at ambient temperatures or at higher tempatures, at a reaction time to release sufficient amounts of sugar(s). The result of the enzymatic hydrolysis is hydrolysis product comprising C5/C6 sugars, herein designated as the sugar composition.
[0301] Fermentation
[0302] The fermentation process may be an aerobic or an anaerobic fermentation process. An anaerobic fermentation process is herein defined as a fermentation process run in the absence of oxygen or in which substantially no oxygen is consumed, preferably less than about 5, about 2.5 or about 1 mmol/L/h, more preferably 0 mmol/L/h is consumed (i.e. oxygen consumption is not detectable), and wherein organic molecules serve as both electron donor and electron acceptors. In the absence of oxygen, NADH produced in glycolysis and biomass formation, cannot be oxidised by oxidative phosphorylation. To solve this problem many microorganisms use pyruvate or one of its derivatives as an electron and hydrogen acceptor thereby regenerating NAD+.
[0303] Thus, in a preferred anaerobic fermentation process pyruvate is used as an electron (and hydrogen acceptor) and is reduced to fermentation products such as ethanol, butanol, lactic acid, 3 -hydroxy-propionic acid, acrylic acid, acetic acid, succinic acid, citric acid, malic acid, fumaric acid, an amino acid, 1,3-propane-diol, ethylene, glycerol, a β-lactam antibiotic and a cephalosporin.
[0304] The fermentation process is preferably run at a temperature that is optimal for the cell. Thus, for most yeasts or fungal host cells, the fermentation process is performed at a temperature which is less than about 42° C., preferably less than about 38° C. For yeast or filamentous fungal host cells, the fermentation process is preferably performed at a temperature which is lower than about 35, about 33, about 30 or about 28° C. and at a temperature which is higher than about 20, about 22, or about 25° C.
[0305] The ethanol yield on xylose and/or glucose in the process preferably is at least about 50, about 60, about 70, about 80, about 90, about 95 or about 98%. The ethanol yield is herein defined as a percentage of the theoretical maximum yield.
[0306] The invention also relates to a process for producing a fermentation product.,
[0307] The fermentation processes may be carried out in batch, fed-batch or continuous mode. A separate hydrolysis and fermentation (SHF) process or a simultaneous saccharification and fermentation (SSF) process may also be applied. A combination of these fermentation process modes may also be possible for optimal productivity.
[0308] The fermentation process according to the present invention may be run under aerobic and anaerobic conditions. Preferably, the process is carried out under micro-aerophilic or oxygen limited conditions.
[0309] An anaerobic fermentation process is herein defined as a fermentation process run in the absence of oxygen or in which substantially no oxygen is consumed, preferably less than about 5, about 2.5 or about 1 mmol/L/h, and wherein organic molecules serve as both electron donor and electron acceptors.
[0310] An oxygen-limited fermentation process is a process in which the oxygen consumption is limited by the oxygen transfer from the gas to the liquid. The degree of oxygen limitation is determined by the amount and composition of the ingoing gasflow as well as the actual mixing/mass transfer properties of the fermentation equipment used. Preferably, in a process under oxygen-limited conditions, the rate of oxygen consumption is at least about 5.5, more preferably at least about 6, such as at least 7 mmol/L/h. A process of the invention comprises recovery of the fermentation product.
[0311] Fermentation Product
[0312] The fermentation product of the invention may be any useful product. In one embodiment, it is a product selected from the group consisting of ethanol, n-butanol, isobutanol, lactic acid, 3-hydroxy-propionic acid, acrylic acid, acetic acid, succinic acid, fumaric acid, malic acid, itaconic acid, maleic acid, citric acid, adipic acid, an amino acid, such as lysine, methionine, tryptophan, threonine, and aspartic acid, 1,3-propane-diol, ethylene, glycerol, a β-lactam antibiotic and a cephalosporin, vitamins, pharmaceuticals, animal feed supplements, specialty chemicals, chemical feedstocks, plastics, solvents, fuels, including biofuels and biogas or organic polymers, and an industrial enzyme, such as a protease, a cellulase, an amylase, a glucanase, a lactase, a lipase, a lyase, an oxidoreductases, a transferase or a xylanase. For example the fermentation products may be produced by cells according to the invention, following additionally prior art cell preparation methods and fermentation processes, which examples however should herein not be construed as limiting. For example. n-butanol may be produced by cells as described in WO2008121701 or WO2008086124; lactic acid as described in US2011053231 or US2010137551; 3-hydroxy-propionic acid as described in WO2010010291; acrylic acid as described in WO2009153047. An overview of all kind of fermentation products is and how they can be prepared in yeast is given in Romanos, Mass., et al, "Foreign Gene Expression in Yeast:: a Review", yeast vol. 8: 423-488 (1992), see e.g. table 7. The production of glycerol, 1,3 propane diol, organic acids, and vitamin C (table 2) is described in Negvoigt, E., Microbiol. Mol. Biol. Rev. 72(3) 379-412 (2008). Giddijala, L., et al, BMC Biotechnology 8(29) (2008) describes production of beta-lactams in yeast.
[0313] Recovery of the Fermentation Product
[0314] For the recovery of the fermenation product existing technologies are used. For different fermentation products different recovery processes are appropriate. Existing methods of recovering ethanol from aqueous mixtures commonly use fractionation and adsorption techniques. For example, a beer still can be used to process a fermented product, which contains ethanol in an aqueous mixture, to produce an enriched ethanol-containing mixture that is then subjected to fractionation (e.g., fractional distillation or other like techniques). Next, the fractions containing the highest concentrations of ethanol can be passed through an adsorber to remove most, if not all, of the remaining water from the ethanol.
[0315] The following examples illustrate the invention:
EXAMPLES
[0316] Unless indicated otherwise, the methods described in here are standard biochemical techniques. Examples of suitable general methodology textbooks include Sambrook et al., Molecular Cloning, a Laboratory Manual (1989) and Ausubel et al., Current Protocols in Molecular Biology (1995), John Wiley & Sons, Inc.
[0317] Medium Composition
[0318] Growth experiments: Saccharomyces cerevisiae strains are grown on medium having the following composition: 0.67% (w/v) yeast nitrogen base or synthetic medium (Verduyn et al., Yeast 8:501-517, 1992) and glucose, arabinose, galactose or xylose, or a combination of these substrates, at varying concentrations (see examples for specific details; concentrations in % weight over volume (w/v)). For agar plates the medium is supplemented with 2% (w/v) bacteriological agar.
[0319] Ethanol Production
[0320] Pre-cultures were prepared by inoculating 25 ml Verduyn-medium (Verduyn et al.,
[0321] Yeast 8:501-517, 1992) supplemented with 2% glucose in a 100 ml shake flask with a frozen stock culture or a single colony from agar plate. After incubation at 30° C. in an orbital shaker (280 rpm) for approximately 24 hours, this culture was harvested and used for determination of CO2 evolution and ethanol production experiments.
[0322] Cultivations for ethanol production were performed at 30° C. in 100 ml synthetic model medium (Verduyn-medium (Verduyn et al., Yeast 8:501-517, 1992) with 5% glucose, 5% xylose, 3.5% arabinose and 1% galactose) in the BAM (Biological Activity Monitor, Halotec, The Netherlands). The pH of the medium was adjusted to 4.2 with 2 M NaOH/H2SO4 prior to sterilisation. The synthetic medium for anaerobic cultivation was supplemented with 0.01 g I-1 ergosterol and 0.42 g I-1 Tween 80 dissolved in ethanol (Andreasen and Stier. J. Cell Physiol. 41:23-36, 1953; and Andreasen and Stier. J. Cell Physiol. 43:271-281, 1954). The medium was inoculated at an initial OD600 of approximately 2. Cultures were stirred by a magnetic stirrer. Anaerobic conditions developed rapidly during fermentation as the culture was not aerated. CO2 production was monitored constantly. Sugar conversion and product formation (ethanol, glycerol) was analyzed by NMR. Growth was monitored by following optical density of the culture at 600 nm on a LKB Ultrospec K spectrophotometer.
[0323] Transformation of S. Cerevisiae
[0324] Transformation of S. cerevisiae was done as described by Gietz and Woods (2002; Transformation of the yeast by the LiAc/SS carrier DNA/PEG method. Methods in Enzymology 350: 87-96).
[0325] Colony PCR
[0326] A single colony isolate was picked with a plastic toothpick and resuspended in 50 μl milliQ water. The sample was incubated for 10 minutes at 99° C. 5 μl of the incubated sample was used as a template for the PCR reaction, using Phusion® DNA polymerase (Finnzymes) according to the instructions provided by the supplier.
[0327] PCR Reaction Conditions:
TABLE-US-00007 step 1 3' 98° C. step 2 10'' 98° C. step 3 15'' 58° C. repeat step 2 to 4 for 30 cycles step 4 30'' 72° C. step 5 4' 72° C. step 6 30'' 20° C.
[0328] Chromosomal DNA Isolation
[0329] Yeast cells were grown in YEP-medium containing 2% glucose, in a rotary shaker (overnight, at 30° C. and 280 rpm). 1.5 ml of these cultures were transferred to an Eppendorf tube and centrifuged for 1 minute at maximum speed. The supernatant was decanted and the pellet was resuspended in 200 μl of YCPS (0.1% SB3-14 (Sigma Aldrich, the Netherlands) in 10 mM Tris.HCl pH 7.5; 1 mM EDTA) and 1 μl RNase (20 mg/ml RNase A from bovine pancreas, Sigma, the Netherlands). The cell suspension was incubated for 10 minutes at 65° C. The suspension was centrifuged in an Eppendorf centrifuge for 1 minute at 7000 rpm. The supernatant was discarded. The pellet was carefully dissolved in 200 μl CLS (25 mM EDTA, 2% SDS) and 1 μl RNase A. After incubation at 65° C. for 10 minutes, the suspension was cooled on ice. After addition of 70 μl PPS (10M ammonium acetate) the solutions were thoroughly mixed on a Vortex mixer. After centrifugation (5 minutes in Eppendorf centrifuge at maximum speed), the supernatant was mixed with 200 μl ice-cold isopropanol. The DNA readily precipitated and was pelleted by centrifugation (5 minutes, maximum speed). The pellet was washed with 400 μl ice-cold 70% ethanol. The pellet was dried at room temperature and dissolved in 50 μl TE (10 mM Tris.HCl pH7.5, 1 mM EDTA).
Example 1
Construction of Strain BIE104A2P1
[0330] 1.1 Construction of an Expression Vector Containing the Genes for Arabinose Pathway
[0331] Plasmid pPWT018, as set out in FIG. 2, was constructed as follows: vector pPWT006 (FIG. 1, consisting of a SIT2-locus (Gottlin-Ninfa and Kaback (1986) Molecular and Cell Biology vol. 6, no. 6, 2185-2197) and the markers allowing for selection of transformants on the antibiotic G418 and the ability to grow on acetamide was digested with the restriction enzymes BsiWI and MluI. The kanMX-marker, conferring resistance to G418, was isolated from p427TEF (Dualsystems Biotech) and a fragment containing the amdS-marker has been described in the literature (Swinkels, B. W., Noordermeer, A. C. M. and Renniers, A. C. H. M (1995) The use of the amdS cDNA of Aspergillus nidulans as a dominant, bidirectional selectable marker for yeast transformation. Yeast Volume 11, Issue 1995A, page S579; and US 6051431). The genes encoding arabinose isomerase (araA), L-ribulokinase (araB) and L-ribulose-5-phosphate-4-epimerase (araD) from Lactobacillus plantarum, as disclosed in patent application WO2008/041840, were synthesized by BaseClear (Leiden, the Netherlands). One large fragment was synthesized, harbouring the three arabinose-genes mentioned above, under control of (or operable linked to) strong promoters from S. cerevisiae, i.e. the TDH3-promoter controlling the expression of the araA-gene, the ENO1-promoter controlling the araB-gene and the PGI1-promoter controlling the araD-gene. This fragment was surrounded by the unique restriction enzymes Acc65I and MluI. Cloning of this fragment into pPWT006 digested with MluI and BsiWI, resulted in plasmid pPWT018 (FIG. 2). The sequence of plasmid pPWT018 is set out in SEQ ID 1.
[0332] 1.2 Yeast Transformation
[0333] CEN.PK113-7D (MATa URA3 HIS3 LEU2 TRP1 MAL2-8 SUC2) was transformed with plasmid pPWT018, which was previously linearized with SfiI (New England Biolabs), according to the instructions of the supplier. A synthetic SfiI-site was designed in the 5'-flank of the SIT2-gene (see FIG. 2). Transformation mixtures were plated on YPD-agar (per liter: 10 grams of yeast extract, 20 grams per liter peptone, 20 grams per liter dextrose, 20 grams of agar) containing 100 μg G418 (Sigma Aldrich) per ml. After two to four days, colonies appeared on the plates, whereas the negative control (i.e. no addition of DNA in the transformation experiment) resulted in blank YPD/G418-plates. The integration of plasmid pPWT018 is directed to the SIT2-locus. Transformants were characterized using PCR and Southern blotting techniques.
[0334] PCR reactions, which are indicative for the correct integration of one copy of plasmid pPWT018, were performed with the primers indicated by SEQ ID 2 and 3, and 3 and 4. With the primer pairs of SEQ ID 2 and 3, the correct integration at the SIT2-locus was checked. If plasmid pPWT018 was integrated in multiple copies (head-to-tail integration), the primer pair of SEQ ID 3 and 4 will give a PCR-product. If the latter PCR product is absent, this is indicative for one copy integration of pPWT018. A strain in which one copy of plasmid pPWT018 was integrated in the SIT2-locus was designated BIE104R2.
[0335] 1.3 Marker Rescue
[0336] In order to be able to transform the yeast strain with other constructs using the same selection markers, it is necessary to remove the selectable markers. The design of plasmid pPWT018 was such, that upon integration of pPWT018 in the chromosome, homologous sequences are in close proximity of each other. This design allows the selectable markers to be lost by spontaneous intramolecular recombination of these homologous regions.
[0337] Upon vegetative growth, intramolecular recombination will take place, although at low frequency. The frequency of this recombination depends on the length of the homology and the locus in the genome (unpublished results). Upon sequential transfer of a subfraction of the culture to fresh medium, intramolecular recombinants will accumulate in time.
[0338] To this end, strain BIE104R2 was cultured in YPD-medium (per liter: 10 grams of yeast extract, 20 grams per liter peptone, 20 grams per liter dextrose), starting from a single colony isolate. 25 μl of an overnight culture was used to inoculate fresh YPD medium. After at least five of such serial transfers, the optical density of the culture was determined and cells were diluted to a concentration of approximately 5000 per ml. 100 μl of the cell suspension was plated on Yeast Carbon Base medium (Difco) containing 30 mM KPi (pH 6.8), 0.1% (NH4)2SO4, 40 mM fluoro-acetamide (Amersham) and 1.8% agar (Difco). Cells identical to cells of strain BIE104R2, i.e. without intracellular recombination, still contain the amdS-gene. To those cells, fluoro-acetamide is toxic. These cells will not be able to grow and will not form colonies on a medium containing fluoro-acetamide. However, if intramolecular recombination has occurred, BIE104R2-variants that have lost the selectable markers will be able to grow on the fluoro-acetamide medium, since they are unable to convert fluoro-acetamide into growth inhibiting compounds. Those cells will form colonies on this agar medium.
[0339] The thus obtained fluoro-acetamide resistant colonies were subjected to PCR analysis using primers of SEQ ID 2 and 3, and 4 and 5. Primers of SEQ ID 2 and 3 will give a band if recombination of the selectable markers has taken place as intended. As a result, the cassette with the genes araA, araB and araD under control of the strong yeast promoters have been integrated in the SIT2-locus of the genome of the host strain. In that case, a PCR reaction using primers of SEQ ID 4 and 5 should not result in a PCR product, since primer 4 primes in a region that should be lost due to the recombination. If a band is obtained with the latter primers, this is indicative for the presence of the complete plasmid pPWT018 in the genome, so no recombination has taken place.
[0340] If primers of SEQ ID 2 and 3 do not result in a PCR product, recombination has taken place, but in such a way that the complete plasmid pPWT018 has recombined out of the genome. Not only were the selectable markers lost, but also the arabinose-genes. In fact, wild-type yeast has been retrieved.
[0341] Isolates that showed PCR results in accordance with one copy integration of pPWT018 were subjected to Southern blot analysis. The chromosomal DNA of strains CEN.PK113-7D and the correct recombinants were digested with EcoRI and HindIII (double digestion). A SIT2-probe was prepared with primers of SEQ ID 6 and 7, using pPW018 as a template. The result of the hybridisation experiment is shown in FIG. 3.
[0342] In the wild-type strain, a band of 2.35 kb is observed, which is in accordance with the expected size of the wild-type gene. Upon integration and partial loss by recombination of the plasmid pPWT018, a band of 1.06 kb was expected. Indeed, this band is observed, as shown in FIG. 3 (lane 2).
[0343] One of the strains that showed the correct pattern of bands on the Southern blot (as can be deduced from FIG. 3) is the strain designated as BIE104A2.
[0344] 1.4 Introduction of Four Constitutively Expressed Genes of the Non-Oxidative Pentose Phosphate Pathway
[0345] Saccharomyces cerevisiae BIE104A2, expressing the genes araA, araB and araD constitutively, was transformed with plasmid pPWT080 (FIG. 4). The sequence of plasmid pPWT080 is set out in SEQ ID 8. The procedure for transformation and selection, after selecting a one copy integration transformant, are the same as described above in sections 1.1, 1.2 and 1.3. In short, BIE104A2 was transformed with Sfil-digested pPWT080. Transformation mixtures were plated on YPD-agar (per liter: 10 grams of yeast extract, 20 grams per liter peptone, 20 grams per liter dextrose, 20 grams of agar) containing 100 μg G418 (Sigma Aldrich) per ml.
[0346] After two to four days, colonies appeared on the plates, whereas the negative control (i.e. no addition of DNA in the transformation experiment) resulted in blank YPD/G418-plates.
[0347] The integration of plasmid pPWT080 is directed to the GRE3-locus. Transformants were characterized using PCR and Southern blotting techniques. The correct integration of the plasmid pPWT080 at the GRE3-locus was checked by PCR using primer pairs SEQ ID 9 and SEQ ID10, and the primer pair SEQ ID 9 and SEQ ID 11 was used to detect single or multicopy integration of the plasmid pPWT080. For Southern analysis, a probe was prepared by PCR using SEQ ID 12 and SEQ ID 13, amplifying a part of the RKI1-gene of S. cerevisiae. Next to the native RKI1-gene, an extra signal was obtained resulting from the integration of the plasmid pPWT080 (data not shown)
[0348] A transformant showing correct integration of one copy of plasmid pPWT080, in accordance with the expected hybridisation pattern, was designated BIE104A2F1.
[0349] In order to remove the selection markers introduced by the integration of plasmid pPWT080, strain BIE104A2F1 was cultured in YPD-medium, starting from a colony isolate. 25 μl of an overnight culture was used to inoculate fresh YPD-medium. After five serial transfers, the optical density of the culture was determined and cells were diluted to a concentration of approximately 5000 per ml. 100 μl of the cell suspension was plated on Yeast Carbon Base medium (Difco) containing 30 mM KPi (pH 6.8), 0.1% (NH4)2SO4, 40 mM fluoro-acetamide (Amersham) and 1.8% agar (Difco). Fluoro-acetamide resistant colonies were subjected to PCR analysis using the primers of SEQ ID 9 and SEQ ID 10. In case of correct PCR-profiles, Southern blot analysis was performed in order to verify the correct integration, again using the probe of the RKI1-gene. One of the strains that showed the correct pattern of bands on the Southern blot is the strain designated as BIE104A2P1.
Example 2
Adaptive Evolution in Shake Flask Leading to BIE104A2P1c and BIE201
[0350] 2.1 Adaptive Evolution (Aerobically)
[0351] A single colony isolate of strain BIE104A2P1 was used to inoculate YNB-medium (Difco) supplemented with 2% galactose. The preculture was incubated for approximately 24 hours at 30° C. and 280 rpm. Cells were harvested and inoculated in YNB medium containing 1% galactose and 1% arabinose at a starting OD600 of 0.2 (FIG. 5). Cells were grown at 30° C. and 280 rpm. The optical density at 600 nm was monitored regularly.
[0352] When the optical density reached a value of 5, an aliquot of the culture was transferred to fresh YNB medium containing the same medium. The amount of cells added was such that the starting OD600 of the culture was 0.2. After reaching an OD600 of 5 again, an aliquot of the culture was transferred to YNB medium containing 2% arabinose as sole carbon source (event indicated by (1) in FIG. 5).
[0353] Upon transfer to YNB with 2% arabinose as sole carbon source growth could be observed after approximately two weeks. When the optical density at 600 nm reached a value at least of 1, cells were transferred to a shake flask with fresh YNB-medium supplemented with 2% arabinose at a starting OD600 of 0.2 (FIG. 5, day 28). Sequential transfer was repeated three times, as is set out it in FIG. 5. The resulting strain which was able to grow fast on arabinose was designated BIE104A2P1c.
[0354] 2.2 Adaptive Evolution (Anaerobically)
[0355] After adaptation on growth on arabinose under aerobic conditions, a single colony from strain BIE104A2P1c was inoculated in YNB medium supplemented with 2% glucose. The preculture was incubated for approximately 24 hours at 30° C. and 280 rpm. Cells were harvested and inoculated in YNB medium containing 2% arabinose, with a initial optical density OD600 of 0.2. The flasks were closed with waterlocks, ensuring anaerobic growth conditions after the oxygen was exhausted from the medium and head space. After reaching an OD600 minimum of 3, an aliquot of the culture was transferred to fresh YNB medium containing 2% arabinose (FIG. 6), each time at an initial OD600 value of 0.2. After several transfers the resulting strain was designated BIE104A2P1d (=BIE201).
Example 3
Performance Test of Strains in the BAM Showing that Adaptive Evolution has Led to (Improved) Arabinose Conversion. Co-Fermentation with Galactose
[0356] Single colony isolates of strain BIE104, BIE104A2P1c and BIE201 were used to inoculate YNB-medium (Difco) supplemented with 2% glucose. The precultures were incubated for approximately 24 hours at 30° C. and 280 rpm. Cells were harvested and inoculated in a synthetic model medium (Verduyn et al., Yeast 8:501-517, 1992; 5% glucose, 5% xylose, 3.5% arabinose, 1% galactose) at an initial OD600 of approximately 2 in the BAM. CO2 production was monitored constantly. Sugar conversion and product formation was analyzed by NMR. The data represent the residual amount of sugars at the indicated (glucose, arabinose, galactose and xylose in grams per litre) and the formation of (by-)products (ethanol, glycerol). Growth was monitored by following optical density of the culture at 600nm (FIGS. 7, 8 and 9). The experiment was running for approximately 140 hours.
[0357] The experiments clearly show that reference strain BIE104 converted glucose rapidly, but was not able to convert arabinose, xylose and/or galactose within 140 hours (FIG. 7). However, strain BIE104A2P1c and BIE201 were capable to convert arabinose and galactose (FIGS. 8 and 9, respectively). Galactose and arabinose utilization started immediately after glucose depletion after less than 20 hours. Both sugars were converted simultaneously. However, strain BIE201 which was improved for arabinose growth under anaerobic conditions, consumed both sugars more rapidly (FIG. 9). In all fermentations only glycerol was generated as by-product.
Example 4
Resequencing of the Strains and Identification of SNPs Involved in Arabinose Fermentation
[0358] As can be concluded from examples 1, 2 and 3, mere introduction of the genes encoding enzymes needed for or enhancing the utilization of arabinose is not sufficient to allow growth on arabinose as sole carbon source. As shown in example 2, a process called adaptive evolution is required to select cells that utilize arabinose as sole C-source.
[0359] Presumably, spontaneous mutations (SNPs, for Single Nucleotide Polymorphisms) in the genome are responsible for this phenotypic change. Alternatively, larger variations in the genome (not limited to the substitution, insertion or deletion of a single nucleotide) may have taken place.
[0360] In order to learn which mutations or SNPs are responsible for this phenotypic change, we resequenced the genomic DNA of the transformants, using the art known as Solexa® technology, using the Illumina® Genome Analyzer.
[0361] To this end, chromosomal DNA was isolated from the strains BIE104, primary transformant BIE104A2P1, evolved transformant BIE104A2P1c and further evolved transformant BIE201 from YEP 2% glucose overnight cultures. The DNA was sent to ServiceXS (Leiden, the Netherlands) for resequencing using the Illumina® Genome Analyzer (50 by reads, pair end sequencing).
[0362] Per strain, about 1800 Mb of sequences were obtained, which corresponds to an average genome coverage of 140, which means that on average, every base has been read 140 times.
[0363] Using NextGene software (SoftGenetics LLC, State College, Pa. 16803, USA), the sequencing reads were aligned using the S288c as a template. Mutations (single nucleotide polymorphisms and insertion/deletions up to 30 bp) were detected using NextGene software and summarised in a mutation report. The alignments of the different strains were compared to each other to identify the unique variations between the strains. Every entry of the mutation report was checked manually, in order to rule out the possibility of misalignment of the reads, sequencing errors or mutation calls in areas where the sequencing coverage was too low to support this. False positive mutations were removed from the mutation report.
[0364] The sequence of the primary transformant (BIE104A2P1) was identical to the sequence of wild-type strain BIE104, with the exception of the sequences that were introduced and the sequences that were deleted by the integration of the plasmids and the subsequent removal of the markers by recombination.
[0365] In the evolved transformant, strain BIE104A2P1c, a limited number of SNPs was introduced:
TABLE-US-00008 SSY1 YDR160w G → T introduction stop-codon YJR154w A → G D → G CEP3 YMR168c A → G S → G YPL277c C → T silent
[0366] In the further evolved transformant, strain BIE201, one additional SNP was observed, next to the 4 SNPs mentioned above:
TABLE-US-00009 GAL80 YML051w A → C T → P
[0367] The sequences of the five open reading frames of the genes containing the SNPs, both in the wild type strain BIE104 and in the evolved strains BIE104A2P1c and BIE201, are given in SEQ ID 14, SEQ ID 15 (SSY1), SEQ ID 16, SEQ ID 17 (YJR154w), SEQ ID 18, SEQ ID19 (CEP3), SEQ ID 20, SEQ ID 21 (YPL277c), SEQ ID 22 and SEQ ID 23 (GAL80).
Example 5
Confirmation of the SNPs
[0368] In order to (re)confirm the SNPs that were detected in the example described above, two methods were employed. The first method comprised amplification of the regions containing the SNPs followed by Single read (Sanger) sequencing on a AB13730XL sequencer (outsourced to Baseclear B V, Leiden, the Netherlands). The second method consisted of High Resolution Melting Analysis (Hi-Res).
[0369] 5.1 Single Read Sanger Sequencing
[0370] Genomic DNA isolated from cultures of strains BIE104A2P1 and BIE201 was used as a template for PCR reactions using Phusion® High-Fidelity DNA Polymerase (Finnzymes, Vantaa, Finland). The PCR reactions were performed according to the suggestions made by the supplier. The following primers were used to amplify the following genes, expected to have a SNP.
TABLE-US-00010 TABLE 2 Primers used for amplification of PCR products Gene of interest Forward primer Reverse primer SSY1 (YDR160w) SEQ ID NO 24 SEQ ID NO 25 YJR154w SEQ ID NO 26 SEQ ID NO 27 CEP3 (YMR168c) SEQ ID NO 28 SEQ ID NO 29 YPL277c SEQ ID NO 30 SEQ ID NO 31 GAL80 (YML051w) SEQ ID NO 32 SEQ ID NO 33
[0371] The PCR products were cloned into the pTOPO Blunt II vector (Invitrogen, Carlsbad, USA). The correct clones were selected on basis of restriction enzyme analysis. Correct clones were sent to BaseClear BV (Leiden, the Netherlands) for single stranded Sanger sequencing.
[0372] The TOPO cloning of the CEP3 fragment was not successful. No Sanger sequencing data was obtained for this gene.
[0373] The sequence of YPL277c appeared to be identical to the sequence of the wild-type strain BIE104.
[0374] The Sanger sequencing results confirmed the SNPs in the genes SSY1, YJR154w and GAL80, i.e. the SNPs were the same as described in Example 4.
[0375] 5.2 Hi-Res Analysis
[0376] The Hi-Res technology is commercialized by Idaho Technologies (Salt Lake City, Utah 84108, USA). In short, mutations in PCR products are detected by the presence of heteroduplexes optimally detected by LCGreen® dye. Variations are identified by changes in the shape of the melting profile compared to a reference sample. Hi-Res Melting® (HRM) on the LightScanner® is being used for mutation discovery in numerous research and clinical applications.
[0377] For each SNP, two primers were designed in order to amplify a region of around 100 to 200 by containing the SNP or the wild-type sequence. In addition, a third primer was designed to function as a probe in the experiments which detects the melting profile. The latter primer was designed such that it covers the SNP region and is exactly complimentary to the wild-type sequence. The matching to the SNP sequence is imperfect, i.e. all but one of the nucleotides of the probe are complementary to the region of interest. Mismatched DNA strands will melt earlier than matched DNA strands, which results in different melting curves of wild type and SNP amplicons, which are detected using the LightScanner® (Idaho Technologies, Salt Lake City, Utah, USA).
[0378] The table below summarizes the primer sequences that were used to amplify the gene or ORF of interest, of which the SNP should be verified in strain BIE201.
TABLE-US-00011 TABLE 3 Primers for amplification of PCR products Gene of interest Forward primer Reverse primer SSY1 (YDR160w) SEQ ID NO 24 SEQ ID NO 25 YJR154w SEQ ID NO 26 SEQ ID NO 27 CEP3 (YMR168c) SEQ ID NO 28 SEQ ID NO 29 YPL277c SEQ ID NO 30 SEQ ID NO 31 GAL80 (YML051w) SEQ ID NO 32 SEQ ID NO 33
[0379] The table below summarizes the SEQ ID NOs that have been used to verify the SNPs in strain BIE201 (the probes).
TABLE-US-00012 TABLE 4 Primers used as probes in Hi-Res analysis Gene of interest Probe wild-type sequence SSY1 (YDR160w) SEQ ID NO 34 YJR154w SEQ ID NO 35 CEP3 (YMR168c) SEQ ID NO 36 YPL277c SEQ ID NO 37 GAL80 (YML051w) SEQ ID NO 38
[0380] PCR reactions were carried out using chromosomal DNA of the strains BIE104 (wild type yeast strain) and strain BIE201 (the yeast strain capable of growing anaerobically on arabinose), using primer pairs of SEQ ID NO 24 and 25 (SSY1), 26 and 27 (YJR154w), 28 and 29 (CEP3), 30 and 31 (YPL277c) and 32 and 33 (GAL80), according to the instructions as provided by Idaho Technologies but in the absence of probe. The amplified fragments were checked on a 2% agarose gel for yield and integrity.
[0381] The HiRes analysis was performed as follows, analogous to the protocol provided by Idaho Technologies: 2 μl of probe (5 μM) was added to 10 μl PCR product in a PCR microplate (4titude Framestart 96, black frame, white wells (BiokeO, Leiden, the Netherlands)). After mixing the microplate was spun down. The plate was incubated for 30 seconds at 99° C. and cooled to room temperature (˜20° C.). Subsequently, the melting protocol on the Lightscanner was followed with start temperature of 55° C., end temperature of 94° C. and exposure settings on "auto". After the measurements were complete, data analysis was performed. The temperature boundaries between which the change in fluorescence was analysed were manually set at the temperature interval where the probe was expected to melt from the PCR products.
[0382] An example of a melting curve is shown in FIG. 11. FIG. 11 displays an example of both "Normalized Melting Curves" (melting curves; top panel) and a "Normalized melting Peaks" curve (lower panel). The latter is derived from the first graph and is showing the change in fluorescence signal as a function of the temperature. Strains BIE104A2P1 and BIE201 are displayed. The gene tested in this figure is YJR154w. The difference in melting temperature of the probe is clear between the two strains tested, BIE201 and BIE104A2P1.
[0383] All expected SNPs, except the one in YPL277c, were confirmed. The sequence of this ORF (YPL277c) in BIE201 appeared to be identical to the sequence of the wild-type strain BIE104.
[0384] In summary, in Example 5 the SNPs in the ORFs SSY1 (YDR160w), YJR154w, CEP3 (YMR168c) and GAL80 (YML051w) were confirmed. The SNP that was previously identified (Example 4) in the ORF of YPL277c was falsified using two independent methods.
Example 6
Amplification of Parts of Chromosome VII
[0385] 6.1 Amplification of a Part of Chromosome VII
[0386] As was described in Example 4, resequencing of the wild-type strain BIE104, primary transformant BIE104A2P1, evolved transformant BIE104A2P1c and further evolved strain BIE201 yielded several interesting SNPs.
[0387] Using the coverage plots, which indicate the read depth of every single nucleotide of the genome, we have searched for areas in the genome that were over- or underrepresented. Indeed, we have identified a region on chromosome VII that was overrepresented (see FIG. 12).
[0388] From the read depth, it was concluded that parts of chromosome VII, surrounding the centromere, were amplified. A region on the left arm of chromosome VII was amplified three times. A part of the right arm of chromosome VII was amplified twice, and an adjacent part was amplified three times (see FIG. 12).
[0389] The part on the right arm of chromosome VII that was amplified three times contains the arabinose expression cassette, i.e. the genes araA, araB and araD under control of strong constitutive promoters.
[0390] Firstly, the copy number of several genes was confirmed by Q-PCR. Secondly, it was investigated whether the amplification took place on the same chromosome (duplication cq. triplication) or whether the amplified region was integrated into another chromosome (translocation).
[0391] 6.2 Copy Number Determination by Q-PCR
[0392] In order to verify the amplification of parts of chromosome VII, as indicated by the coverage plot of FIG. 12, Q-PCR experiments were performed. Specifically, this method measures the relative copy number of a gene of interest by comparing it with another gene, with a known copy number.
[0393] To this end, the Bio-Rad iCycler iQ system from Bio-Rad (Bio-Rad Laboratories, Hercules, Calif., USA) was used. The iQ SYBR Green Supermix (Bio-Rad) was used. Experiments were set up as suggested in the manual of the provider.
[0394] From the coverage plot (read depth) it was deduced that genes SDS23 and YGL057c were expected to be part of the amplified region on the left arm of chromosome VII. As a reference single copy gene, the ACT1 gene was chosen.
[0395] The primers for the detection of the genes YGL057c, SDS23 and ACT1 are summarized in the table below.
TABLE-US-00013 TABLE 5 Primers used for amplification in the Q-PCR experiment Gene of interest Forward primer Reverse primer YGL057c SEQ ID NO 39 SEQ ID NO 40 SDS23 SEQ ID NO 41 SEQ ID NO 42 ACT1 SEQ ID NO 43 SEQ ID NO 44
[0396] The Q-PCR conditions were as follows:
[0397] 1) 95° C. for 3 min
[0398] for 40 cycli, steps 2-4
[0399] 2) 95° C. for 10 sec
[0400] 3) 58° C. for 45 sec
[0401] 4) 72° C. for 45 sec
[0402] 5) 65° C. for 10 sec
[0403] 6) Increase of temperature with 0.5° C. per 10 sec to 95° C.
[0404] The melting curve is being determined by starting to measure fluorescence at 65° C. for 10 seconds. The temperature is increased every 10 seconds with 0.5° C., until a temperature of 95° C. is reached. From the reads, the copy number of the gene of interest were calculated and/or estimated. The results are presented in the table below.
TABLE-US-00014 TABLE 6 Relative copy number of selected genes in strains BIE104A2P1 and BIE201 Copy number in Copy number in Gene of interest BIE104A2P1 BIE201 YGL057c 1.2 5.1 SDS23 1.2 4.4 ACT1 1.0 (reference) 1.0 (reference)
[0405] The results corroborate the amplification as was apparent from the read depth analysis in Example 6 (section 6.1). The observed values are higher than the expected copy number of 3.0. The difference may be caused by a number of factors, as previously disclosed by Klein (Klein, D. (2002) TRENDS in Molecular Medicine Vol. 8 No. 6, 257-260).
[0406] 6.3 Analysis of the Nature of the Duplication
[0407] In order to determine whether the amplified regions are located on the same chromosome as the genes are originally located, i.e. chromosome VII, or have been translocated to another chromosome, CHEF electrophoresis (Clamped Homogeneous Electric Fields electrophoresis; CHEF-DR® III Variable Angle System; Bio-Rad, Hercules, Calif. 94547, USA) was applied. Agarose plugs of yeast strains (see below) were prepared using the CHEF Yeast Genomic DNA Plug Kit (BioRad) according to the instructions of the supplier. 1% Agarose gels (Pulse Field Agarose, Bio-Rad) were prepared in 0.5× TBE (Tris-Borate-EDTA) according to the suppliers instructions. Gels were run according to the following settings:
[0408] Block 1 initial time 60 sec [0409] final time 80 sec [0410] ratio 1 [0411] run time 15 hours
[0412] Block 2 initial time 90 sec [0413] final time 120 sec [0414] ratio 1 [0415] run time 9 hours
[0416] As a marker for size determination of the chromosomes, agarose plugs of strain YNN295 (Bio-Rad) were included in the experiment.
[0417] After electrophoresis, gels were stained using ethidiumbromide at a final concentration of 70 pg per litre, for 30 minutes. In FIG. 13, an example of a stained gel is shown.
[0418] After staining, gels were blotted onto Amersham Hybond N+ membranes (GE Healthcare Life Sciences, Diegem, Belgium).
[0419] In order to be able to establish if the amplified genes are located on one chromosome or translocated to other chromosomes, probes were made for hybridization with the blotted membranes. Probes (see table below) were prepared using the PCR DIG Probe Synthesis Kit (Roche, Almere, the Netherlands) according to the instructions of the supplier.
[0420] The following probes were prepared.
TABLE-US-00015 TABLE 7 Primers for amplification of the indicated probes Size Systematic PCR Chro- name Forward Reverse product mo- Probe gene primer primer (bp) some araA SEQ ID NO 45 SEQ ID NO 46 641 VII ACT1 YFL039c SEQ ID NO 47 SEQ ID NO 48 392 VI PNC1 YGL037c SEQ ID NO 49 SEQ ID NO 50 384 VII HSF1 YGL073w SEQ ID NO 51 SEQ ID NO 52 381 VII YGR031w YGR031w SEQ ID NO 53 SEQ ID NO 54 392 VII
[0421] The araA-gene is expected to be amplified three times in BIE104A2P1c and BIE201.
[0422] The ACT1-gene is located on chromosome VI and not expected to be amplified. Hence, this probe serves as a control.
[0423] PNC1 is located on the left arm of chromosome VII and is expected to be amplified three times in BIE104A2P1c and BIE201.
[0424] HSF1 is located on the left arm of chromosome VII and is located upstream of the amplified region. Hence, this gene is expected to be present in the genome as a single gene in the strains tested.
[0425] YGR031w is located on the right arm of chromosome VII. This gene is expected to be present in two copies in the genome of strains BIE104A2P1c and BIE201.
[0426] Membranes were prehybridized in DIG Easy Hyb Buffer (Roche) according to the instructions of the supplier. The probes were denatured at 99° C. for 5 minutes, chilled on ice for 5 minutes, and added to the prehybridized membranes. Hybridization was done overnight at 42° C.
[0427] Washing of the membranes and blocking of the membranes prior to detection of the hybridized probes were done using the DIG Wash and Block Buffer Set (Roche) according to the instructions of the supplier. The detection was done by incubation with anti-dioxygenin-AP Fab fragments (Roche) followed by the addition of detection reagents using the CDP-Star ready-to-use kit (Roche). Detection of the chemiluminiscent signals were performed using the Bio-Rad Chemidoc XRS+ System, using the appropriate settings provided by the Chemidoc apparatus.
[0428] The results are shown in FIGS. 13, 14, 15, 16, 17 and 18.
[0429] From FIG. 13 it can already be inferred that there are differences in the size of the chromosomes in the strain lineage from BIE104 to BIE201. In strain BIE104A2P1(a), the primary transformant, no large differences are observed with respect to the size of the chromosomes when compared to BIE104. In strains BIE104A2P1c and BIE201 however, the size of chromosome VII has increased. In strain BIE104, chromosome VII is close to chromosome XV; in BIE104A2P1c and BIE201 however, the chromosome has increased in size and is almost as large as chromosome IV.
[0430] Hybridization with probes of the genes araA (FIG. 14), PNC1 (FIG. 16) and HSF1 (FIG. 17) projects the same image. This suggests that the amplification has taken place within the same chromosome, i.e. that all amplified regions are still on chromosome VII. If a translocation had occurred, multiple signals were expected, which is not the case. In strain BIE104A2P1(a), a smaller band is observed under the band of chromosome VII, with all three probes. This suggests that a second, smaller version chromosome VII is present. Since the intensity is lower than the larger band, it may be present in only a fraction of the cells. It may also be explained by assuming an electrophoresis artefact.
[0431] The hybridisation with the ACT1 probe (FIG. 15) results in a single band in all strains, as expected, is representing chromosome VI.
[0432] The hybridisation with the YGRO31w (FIG. 18) probe finally, resulted in many bands. Apparently, cross-hybridization occurred, resulting in multiple signals in each strain. Therefore, this result can not be used for the purpose of this experiment.
[0433] Though some differences in intensity are observed between the strains, it is difficult to conclude from these data whether amplification can be shown. Although an increase in the signal intensity may suggest an increase of the copy number of a certain gene, other factors may also influence the signal strength, like the amount of DNA applied on the gel, blotting efficiency, detection saturation, and the like.
[0434] Taken together, the results of Example 6 clearly indicate that the amplification has taken place within chromosome VII. There is no evidence for a translocation of the genetic context of the genes araA, araB and araD (including surrounding sequences) to another chromosome.
Example 7
Phenotypic Validation of the SNPs and Amplification
[0435] In order to validate whether the discovered SNPs and amplification, and if yes to which extent, contribute to the ability to convert arabinose into ethanol by yeast cells (apart from the introduced homologous and heterologous pathways), cross-breeding experiments were performed. To this end, the following experiments were performed: mating type switch of strain BIE201, cross-breeding of the mating type switched BIE201 with the non-evolved parent strain BIE104A2P1, sporulation of the diploid strain followed by dissection of the four ascospores, determination of the ability to utilize arabinose as sole carbon and energy source in the haploid offspring, SNP detection in the haploid offspring using Hi-Res, and analysis of these datasets.
[0436] By crossing the evolved, mating type switched BIE201 with the non-evolved primary transformant BIE104A2P1, a diploid cell is being constructed which is completely homozygous, except for the identified genomic changes (SNPs and amplification). By subsequently sporulating this diploid cell followed by dissection of the ascospores, haploid cells will be obtained which may have none, some or all genomic changes that were introduced during adapted evolution. The distribution of the genomic changes over the four haploid derivatives of one diploid cell is random, although per SNP, DIP or amplification, a 2:2 segregation is expected over the four haploid derivatives. For more theoretical background, see e.g. Mortimer R. K. and Hawthorne D. C. (1975) Genetic Mapping in Yeast. Methods Cell Biol. 11:221-33.
[0437] 7.1 Mating Type Switch of Strain BIE201
[0438] Plasmid pGal-HO (KAN) is a derivative of the plasmid pGAL-HO (Herskowitz, I. and Jensen, R. E. (1991) Methods in Enzymology, 194:132-146). The URA3-marker in pGAL-HO has been replaced by the kanMX marker, by cutting pGAL-HO with EcoRV followed by the ligation of the kanMX fragment from pUG6 (Guldener, U. et al (1996) Nucleic Acids Research 24: 2519-2524). The kanMX marker, allowing for G418 selection in S. cerevisiae, was cut from pUG6 with the restriction enzymes XbaI and XhoI, followed by filling in the overhanging ends with Klenow polymerase. The resulting plasmid is pGal-HO (KAN).
[0439] Strain BIE201 (relevant genotype in relation to this experiment: matA) was transformed according to the method of Gietz and Woods (2002) with the plasmid pGal-HO (KAN). Transformants were selected on YEP/agar-plates containing glucose (2%) and G418 (100 μg/ml). Colonies appeared after two days of incubation at 30° C. Eight colonies were restreaked on fresh YEP/agar-plates with glucose and G418. Two colonies of each transformation were used to inoculate 20 ml YEP-medium containing 1% galactose and 0.1% glucose. After 2 days of incubation at 30° C. and 280 rpm, cells were restreaked on YEPD-plates. Plates were incubated during 2 days at 30° C., and colonies were visible. PCR reactions were performed for the determination of the mating-type using the primers of SEQ ID NO 55 and 56 (for identification of matA cells), and primers of SEQ ID NO 55 and 57 (for identification of matα (alpha) cells).
[0440] Several matα (alpha) variants of BIE201 were obtained. In order to test whether these derivatives have indeed switched their mating type, they were restreaked on fresh YEPD-plates. Also, strain BIE104A2P1 (the primary transformant, relevant genotype in this experiment: matA) was restreaked on a separate fresh YEPD-plate.
[0441] Subsequently, both strains were allowed to mate by mixing a loopful of each strain on a fresh YEPD-agar plate. After 6 hours of incubation at 30° C., mating was scored under the microscope. Some isolates indeed appeared to form zygotes, i.e. structures in which two cells of opposite mating type have fused to form a diploid strain. These BIE201 derivatives indeed changed the mating type to matα (alpha).
[0442] 7.2 Cross-Breeding of the Mating Type Switched BIE201 with the Non-Evolved Parent Strain BIE104A2P1
[0443] The preparations in which the formation of hybrids (zygotes) were observed by microscopy (section 7.1), were plated on YEPD-agar plates. Plates were incubated at 30° C. for two days. The larger colonies were picked and restreaked on fresh YEPD-plates. Subsequently, colony PCR was performed using the primers of SEQ ID NO 55 and 56 and SEQ ID NO 55 and 57. Diploids will form a PCR product with both primer pairs. Several of these colonies were obtained and used to inoculate YEP-medium with 2% glucose (30° C., 280 rpm).
[0444] 7.3 Sporulation of the Diploid Strain and Dissection of the Ascospores
[0445] After overnight growth at 30° C. and 280 rpm, 2.5 ml was transferred to 25 ml 1.5% KAc in tap water (sterilized). Incubation was continued at 30° C. and 280 rpm. Each day, the degree of sporulation was checked microscopically. When the ratio of asci versus vegetative cells was larger than 2, 60 asci were dissected using the Singer MSM System© series 300 (Somerset, UK) apparatus, using the instructions and protocols of the supplier. Dissection was done on YEPD-plates. Plates were incubated for 2 days at 30° C. An example of the result is set out in FIG. 19.
[0446] FIG. 19 shows 10 asci that were dissected. The ascospores from the ascus were separated from each other and put on the agar plate at distinctive distances. Colonies in a "column" (10 columns are shown) originate from one ascus.
[0447] As is apparent from FIG. 19, not all four spores were viable in all cases. In a minority of the cases, only three and sometimes even only two ascospores grew into viable colonies.
[0448] Also, some differences in the colony size were observed between the colonies from one ascospore.
[0449] 7.4 Determination of the Ability to Utilize Arabinose as Sole Carbon and Energy Source in the Haploid Offspring
[0450] All complete sets of haploid derivatives, it is in those cases where four viable spores were obtained from an ascus, were inoculated in YEPD-agar in 96-wells microplates. Controls BIE104A2P1 and BIE201 were included as controls on each microplate in at least twofold. The plates were incubated for 2 days at 30° C. These plates are called the "masterplates".
[0451] 96-Well microplates containing 200 μl Verduyn-medium and 2% glucose were inoculated with colony material from the masterplates, with the aid of a disposable pin tool, which allows the transfer of cell material of all 96 strains in a microplate in one movement.
[0452] The microplate containing the liquid Verduyn medium with 2% glucose was grown for two days at 30° C. and 550 rpm, in an Infors microplate shaker, at 80% humidity.
[0453] Subsequently, 10 μl of the glucose grown microplate cultures were transferred to microplates containing 200 μl Verduyn medium containing 2% arabinose as a carbon source. The incubation in an Infors shaker at 30° C., 550 rpm and 80% humidity lasted for four days. Each day, the growth was monitored by measuring the optical density at 620 nm using a BMG FLUOstar microplate reader (BMG, Offenburg, Germany). The ability to utilize arabinose was expressed by dividing the final optical density after 4 days of incubation on arabinose as sole carbon source by the initial optical density of the same microplate. An example of the results is summarized in table 8.
TABLE-US-00016 TABLE 8 Of each haploid derivative from the dissected asci and the controls BIE104A2P1 and BIE201, the growth (defined as the final optical density at 620 nm divided by the initial optical density at 620 nm) was determined. Haploid strain Growth A1 27 A2 7 A3 5 A4 26 B1 6 B2 29 B3 9 B4 5 BIE201 25 BIE104A2P1a 5 C1 9 C2 11 C3 25 C4 12 D1 17 D2 8 D3 11 D4 15 E1 18 E2 6 E3 9 E4 10 F1 9 F2 8 F3 10 F4 7 G1 9 G2 9 G3 17 G4 32
[0454] From table 8 it is clear that there is, as can be expected, a large difference between the two control strains, BIE104A2P1 and BIE201. BIE104A2P1 reaches a level of 5, which in practice means that no growth was obtained. Though a factor 5 suggests that some growth has occurred, this will most likely be caused by carry over of nutrients (residual glucose, ethanol) from the preculture. Strain BIE201 reaches a growth ratio of 25, which is significantly higher than the strain BIE104A2P1.
[0455] The haploid derivatives display a wide range of growth phenotypes, ranging from low growth (similar to BIE104A2P1) to high levels of growth (similar to and exceeding the level of BIE201). Also, strains with intermediate growth levels were obtained. For instance, in the first ascus, ascus A, resulting in four haploid strains A1, A2, A3 and A4, a 2:2 segregation of the arabinose growth phenotype is obtained. In some other asci, the segregation between low and high growth levels obtained does not follow a 2:2 pattern. For instance, in ascus B, one high level growth phenotype strain is obtained, one with an intermediate level (value of 9), and two haploids that have a low growth phenotype. Similar observations can be done from the haploid strains derived from the other asci.
[0456] 7.5 SNP Detection in the Haploid Offspring using Hi-Res
[0457] 96-Well microplates containing YEP-medium supplemented with 2% glucose were inoculated with colony material from the masterplates (section 7.4). Cells were allowed to grow in an Infors shaker at 30° C., 550 rpm and 80% humidity for 2 days. As controls, strain BIE104A2P1 and BIE201 were included.
[0458] Chromosomal DNA was isolated using the above protocol in a downscaled fashion. The chromosomal DNA served as a template for Hi-Res analysis as described in section 5.2. The Hi-Res analysis allowed the identification of the SNPs in each haploid segregant from the cross BIE201 (matα) X BIE104A2P1 (matA). Likewise, the presence of the amplified regions on chromosome VII were determined according to the methods described in section 6.2. Of each haploid segregant, the genotype with respect to the SNPs and amplification were determined. The results are presented in table 9.
TABLE-US-00017 TABLE 9 Overview of the presence of the SNPs and the amplification in the haploid derivatives of the cross BIE104A2P1 × BIE201. As controls, BIE104A2P1 and BIE201 were included. Haploid strain YJR154w SSY1 CEP3 GAL80 Amplification A1 WT WT WT SNP + A2 SNP SNP SNP WT - A3 WT WT WT WT - A4 WT SNP WT SNP + B1 SNP WT SNP SNP - B2 WT WT WT SNP + B3 WT SNP SNP WT + B4 SNP SNP WT WT - BIE201 SNP SNP SNP SNP + BIE104A2P1a WT WT WT WT - C1 SNP SNP SNP WT - C2 WT WT SNP SNP - C3 WT WT WT SNP + C4 SNP SNP WT WT + D1 WT SNP SNP WT + D2 SNP SNP WT SNP - D3 SNP WT SNP SNP - D4 WT WT WT WT - E1 WT SNP WT WT + E2 WT WT SNP SNP - E3 SNP SNP WT SNP - E4 SNP WT SNP WT + F1 SNP WT WT WT - F2 WT WT SNP SNP - F3 WT SNP SNP WT - F4 SNP SNP WT SNP - G1 SNP SNP WT SNP - G2 WT WT WT WT - G3 WT SNP SNP WT + G4 SNP WT SNP SNP +
[0459] In most asci, a 2:2 segregation of the SNPs and amplification are observed. There are some exceptions to this, which may be caused by e.g. meiotic gene conversion.
[0460] 7.6 Analysis of these Datasets
[0461] Combining the datasets of section 7.4 and 7.5 (tables 8 and 9 respectively), yields the following table, table 10. In table Z however, the results have been sorted from high growth to low growth on arabinose.
TABLE-US-00018 TABLE 10 Overview of the SNPs, the amplification and the growth phenotype of haploid derivatives of the cross BIE104A2P1 × BIE201, and the respective parent strains. Am- Strain YJR154w SSY1 CEP3 GAL80 plification Growth G4 SNP WT SNP SNP + 32 B2 WT WT WT SNP + 29 A1 WT WT WT SNP + 27 A4 WT SNP WT SNP + 26 BIE201 SNP SNP SNP SNP + 25 C3 WT WT WT SNP + 25 E1 WT SNP WT WT + 18 G3 WT SNP SNP WT + 17 D1 WT SNP SNP WT + 17 D4 WT WT WT WT - 15 C4 SNP SNP WT WT + 12 D3 SNP WT SNP SNP - 11 C2 WT WT SNP SNP - 11 E4 SNP WT SNP WT + 10 F3 WT SNP SNP WT - 10 E3 SNP SNP WT SNP - 9 G2 WT WT WT WT - 9 B3 WT SNP SNP WT + 9 G1 SNP SNP WT SNP - 9 C1 SNP SNP SNP WT - 9 F1 SNP WT WT WT - 9 F2 WT WT SNP SNP - 8 D2 SNP SNP WT SNP - 8 F4 SNP SNP WT SNP - 7 A2 SNP SNP SNP WT - 7 B1 SNP WT SNP SNP - 6 E2 WT WT SNP SNP - 6 BIE104A2P1a WT WT WT WT - 5 A3 WT WT WT WT - 5 B4 SNP SNP WT WT - 5
[0462] The results of table 10 strongly suggest that the amplification is the key event determining the ability to grow on arabinose at a relatively high growth rate. Most of the strains having the amplification are located in the top 9 of table 10. Two-third of these strains also have a SNP in the GAL80 gene, suggesting an interaction between the presence of the SNP in the GAL80 gene and the presence of the amplification.
[0463] In order to to determine, statistically, which of the factors are relevant for high growth and whether there are synergistic effects, ANOVA analysis was applied. Though the design is not balanced, based on the statistical testing of the data, it is clear that the presence of the amplification (p<<0.01) has a positive effect on the growth. The results also reveal that a strong interaction between GAL80 SNP and the presence of the amplification (p<<0.01) exists while the other SNPs have no significant effect (p>0.01).
[0464] A median growth of 8.4 is estimated in case of absence of the amplification, while in the presence of the amplification, the median growth is 17.6. A median growth of 8.7 is estimated in case of absence of both the GAL80 SNP and the amplification, while in case both are present, the median growth is 26.8.
[0465] Also, the interaction of the presence of the CEP3 SNP and the presence of the amplification appears to have a synergistic effect, although in a lesser extent than the interaction between the presence of the GAL80 SNP and the amplification.
[0466] In conclusion, the effects and the significance of effects on growth due to the presence of SNPs and/or the amplification could be determined. The amplification has a significant effect on the growth. This effect is increased through combination of the amplification and the GAL80 SNP. A minor interaction effect was detected for the combination of amplification and the CEP3 SNP and the combination of amplification, the GAL80 SNP and the CEP3 SNP.
Example 8
Deletion of GAL80 Leads to an Even Better Arabinose Conversion
[0467] In Example 7 it was shown that the identified SNP in the GAL80 gene has a positive additive effect on the growth on arabinose, if the amplification of a part of chromosome VII is also present.
[0468] GAL80 encodes a transcriptional repressor involved in transcriptional regulation in response to galactose (Timson D J, et al. (2002) Biochem J 363(Pt 3):515-20). In conjunction with Gal4p and Gal3p, Gal80p coordinately regulates the expression of genes containing a GAL upstream activation site in their promoter (UAS-GAL), which includes the GAL metabolic genes GAL1, GAL10, GAL2, and GAL7 (reviewed in Lohr D, et al. (1995) FASEB J 9(9):777-87). Cells null for gal80 constitutively express GAL genes, even in non-inducing media (Torchia T E, et al. (1984) Mol Cell Biol 4(8):1521-7).
[0469] The hypothesis is that the SNP that was identified in the GAL80 gene influences the interaction between Gal80p, Gal3p and Gal4p. Hence, the expression of the galactose metabolic genes, including GAL2 encoding galactose permease, will be changed as well as compared to a yeast cell with a wild type GAL80 allele. Gal2p (galactose permease) is the main sugar transporter for arabinose (Kou et al (1970) J Bacteriol. 103(3):671-678; Becker and Boles (2003) Appl Environ Microbiol. 69(7): 4144-4150).
[0470] Apparently, the SNP in the GAL80 gene has a positive effect on the ability to convert L-arabinose. In order to investigate whether the arabinose growth phenotype could further be improved, the coding sequence of the GAL80 gene was deleted in its entirety, using a PCR-mediated gene replacement strategy.
[0471] 8.1 Disruption of the GAL80 Gene
[0472] Primers of SEQ ID NO 58 and 59 (the forward and reverse primers respectively) were used for amplification of the kanMX-marker from plasmid p427-TEF (Dualsystems Biotech, Schlieren, Switzerland). The flanks of the primers are homologous to the 5'-region and 3'-region of the GAL80 gene. Upon homologous recombination, the ORF of the GAL80 gene will be replaced by the kanMX marker, similar as described by Wach (Wach et al (1994) Yeast 10, 1793-1808). The obtained fragment is designated as the GAL80::kanMX fragment.
[0473] A yeast transformation of strain BIE252 was done with the purified GAL80::kanMX fragment according to the protocol described by Gietz and Woods (2002), Methods in Enzymology 350: 87-96). The construction of strain BIE252 has been described in EP10160622.6. Strain BIE252 is a xylose and arabinose fermenting strain of S. cerevisiae, which is a derivative of BIE201. Strain BIE252 also contains the GAL80 SNP.
[0474] The transformed cells were plated on YEPD-agar containing 100 μg/ml G418 for selection. The plates were incubated at 30° C. until colonies were visible. Plasmid p427-TEF was included as a positive control and yielded many colonies. MilliQ (i.e. no DNA) was included as a negative control and yielded no colonies. The GAL80::kanMX fragment yielded many colonies. Two independent colonies were tested by Southern blotting in order to verify the correct integration (data not shown). A colony with the correct deletion of the GAL80 gene was designated BIE252ΔGAL80.
[0475] 8.2 Effect of GAL80 Gene Replacement on the Performance in the BAM
[0476] A BAM (Biological Activity Monitor; Halotec B V, Veenendaal, the Netherlands) experiment was performed. Single colony isolates of strain BIE252 and strain BIE252ΔGAL80 (a transformant in which the ORF of the GAL80 gene was correctly replaced by the kanMX marker) were used to inoculate Verduyn medium (Verduyn et al., Yeast 8:501-517, 1992) supplemented with 2% glucose. The precultures were incubated for approximately 24 hours at 30° C. and 280 rpm. Cells were harvested and inoculated in a synthetic model medium (Verduyn medium supplemented with 5% glucose, 5% xylose, 3.5% arabinose, 1% galactose and 0.5% mannose, pH 4.2) at a cell density of about 1 gram dry weight per kg of medium. CO2 production was monitored constantly. Sugar conversion and product formation was analyzed by NMR. The data represent the residual amount of sugars at the indicated time points (glucose, arabinose, galactose, mannose and xylose in grams per litre) and the formation of (by-)products (ethanol, glycerol, and the like). Growth was monitored by following optical density of the culture at 600nm. The experiment was running for approximately 72 hours.
[0477] The graphs are displayed in FIG. 20 (BIE252) and 21 (BIE252ΔGAL80).
[0478] The experiments clearly show that reference strain BIE252 converted glucose and mannose rapidly. After glucose depletion (around 10 hours), the conversion of xylose and arabinose commenced. Some galactose was already being fermented around the 10 hours time point, which might be due to the GAL80 SNP in this strain, which would allow (partial) simultaneous utilisation of glucose and galactose. At the end of the experiment, around 72 hours, almost all sugars were converted. An ethanol yield of 0.37 grams of ethanol per gram sugar was obtained.
[0479] Strain BIE252ΔGAL80 exhibits faster sugar conversion ability than strain BIE252. Also in case of this strain, mannose and glucose are converted in the first hours of fermentation. However, as opposed to strain BIE252, in this transformant there is some co-consumption of glucose, galactose and mannose with arabinose and especially xylose. In general, sugar consumption is faster, leading to a more complete use of all available sugars. This is also apparent from the CO2 evolution in time. In case of BIE252, a first peak is observed, which is basically the CO2 formed from glucose and mannose. After reaching a minimum of just above 10 ml/hr (FIG. 20) a second, more flat peak is observed. In case of BIE252ΔGAL80 however (FIG. 21), the second peak appears as a tail of the first peak, due to an intensified co-use of glucose, xylose, arabinose, mannose and galactose, as is apparent from the sugar analysis by NMR. In the parent strain BIE252, the use of the different sugars is more sequential. Hence, the yield of strain BIE252ΔGAL80 is higher at the end of the experiment (72 h): 0.40 grams of ethanol per gram sugar.
[0480] In conclusion, the deletion of the ORF of the GAL80 gene resulted in a further improved performance, as was tested in strain BIE252.
Example 9
Adipic Acid Production in Strain BIE201
[0481] 9.1 Synthetic DNA Fragments Ordered at DNA2.0
[0482] Nine DNA fragments containing the nine open reading frames involved in the adipic acid pathway (see European Patent Application EP11160000.3 filed 28 Mar. 2011) and a S. cerevisiae promoter and terminator for efficient expression were ordered synthetically at DNA2.0 (Menlo Park, Calif. 94025, USA). In some cases homology to an adjacent part of the adipic acid pathway was added to the synthetic fragment for in vivo recombination of the pathway after transformation to BIE201. DNA2.0 delivered the synthetic fragments as cloned inserts in a standard cloning vector. This resulted in the following plasmids (between brackets the abbreviation), pADI141 (Adi21), pADI142 (Adi22), pADI143 (Adi23), pADI199 (Adi8), pADI145 (Adi24), pADI146 (Adi25), pADI149 (SucC), pADI150 (SucD) and pADI200 (Acdh67). Table 11 shows the genes involved in the pathway, the used abbreviations, source, Uniprot code and involvement in the pathway.
TABLE-US-00019 TABLE 11 Overview of the genes in the adipic acid pathway transformed to the BIE201 strain Uniprot Step in Abbreviation Name Source code pathway Adi21 beta-ketodipyl CoA Acinetobacter sp. Q6FBN0 1 thiolase (DcaF) Adi22 beta-hydroxy-adipoyl Acinetobacter sp. Q937T5 2 dehydrogenase(DcaH) Adi23 enoyl-CoA hydratase Acinetobacter sp. Q937T3 3 (DcaE) Adi8 trans-2-enoyl-CoA- Candida Q8WZM3 4 reductase tropicalus Adi24 acyl-CoA transferase Acinetobacter Sp. Q937T0 5 (Dcal) (subunit A) Adi25 acyl-CoA transferase Acinetobacter Sp. Q937S9 5 (Dcal) (subunit B) Acdh67 Acetylating Listeria innocua Q92CP2 Acetyl-CoA Acetaldehyde supply dehydrogenase SucC Succinyl-CoA E. coli P0A836 Succinyl- synthetase subunit A CoA supply SucD Succinyl-CoA E. coli P0AGE9 Succinyl- synthetase subunit B CoA supply
[0483] 9.2 Preparation of PCR Fragments for Transformation to BIE201
[0484] In vivo homologous recombination was used to assemble and integrate the complete adipic acid pathway into BIE201. The necessary homology for recombination of the complete pathway (50-250 bp) was added during synthesis of the synthetic fragment or by adding the sequence to the primers used for amplification of the fragment. Primer sequences are listed in table 12.
TABLE-US-00020 TABLE 12 A list of all primer sequences used in the PCR-reactions to create the fragments for transformation to the BIE201 strain. Primer Short description SEQ ID NO 60 Forward primer for amplification of the INT1LF SEQ ID NO 61 Reverse primer for the amplification of INT1LF with a 50 bp flank overlapping Adi21 expression cassette SEQ ID NO 62 Forward primer for amplification of the Adi21 expression cassette with 50 bp flank INT1LF SEQ ID NO 63 Reverse primer for the amplification of the Adi21 expression cassette SEQ ID NO 64 Forward primer for the amplification of the Adi22 expression cassette SEQ ID NO 65 Reverse primer for the amplification of the Adi22 expression cassette SEQ ID NO 66 Forward primer for the amplification of the Adi23 expression cassette SEQ ID NO 67 Reverse primer for the amplification of the Adi23 expression cassette SEQ ID NO 68 Forward primer for the amplification of the kanMX marker from pUG7 with 50 bp flank overlapping with Adi23 SEQ ID NO 69 Reverse primer for the amplification of the kanMX marker from pUG7 with 50 bp flank overlapping with Adi8 SEQ ID NO 70 Forward primer for the amplification of the Adi8 expression cassette with 25 bp flank overlap with kanMX of pUG7 SEQ ID NO 71 Reverse primer Adi8 expression cassette SEQ ID NO 72 Forward primer for the amplification of the Adi24 expression cassette SEQ ID NO 73 Reverse primer for the amplification of the Adi24 expression cassette SEQ ID NO 74 Forward primer for the amplification of the Adi25 expression cassette SEQ ID NO 75 Reverse primer for the amplification of the Adi25 expression cassette with 50 bp overlap with SucC SEQ ID NO 76 Forward primer for the amplification of the SucC with 50 bp overlap with Adi25 SEQ ID NO 77 Reverse primer for the amplification of the SucC expression cassette SEQ ID NO 78 Forward primer for the amplification of the SucD expression cassette SEQ ID NO 79 Reverse primer for the amplification of the SucD expression cassette SEQ ID NO 80 Forward primer for the amplification of the acdh67 expression cassette SEQ ID NO 81 Reverse primer for the amplification of the acdh67 construct with 50 bp flank overlapping with INTRF SEQ ID NO 82 Forward primer for the amplification of the INT1LF site on yeast genome SEQ ID NO 83 Reverse primer for the amplification of the INT1LF site on yeast genome
[0485] In total 12 fragments (see FIG. 22) were needed to integrate the complete adipic acid pathway into the genome of BIE201, 9 PCR fragments containing the gene expression cassettes belonging to the adipic acid pathway (SEQ ID NO 84-92), one PCR fragment containing the kanMX-marker conferring resistance to G418 (SEQ ID 93) and finally the INT1LF (INTegration Left Flank) and INT1RF (INTegration Right Flank) integration flanks (SED ID NO 94 and SEQ ID NO 95 respectively). All fragments were created with overlapping homology to each neighboring fragment in the pathway and on the outside of the pathway to the INT1LF and INT1RF for integration of the pathway via a double crossover into the genome. The homologous recombination event, complete assembly and integration of the pathway, is shown in a drawing in FIG. 22. The created PCR fragments used in the transformation are listed in table 13. The sequences are included herein as SEQ ID NO 84 until and including SEQ ID NO 95. Table 13 shows information on the used promoters and terminators for the genes and the primers used in the PCR amplification reactions to create the fragments for transformation.
TABLE-US-00021 TABLE 13 Overview of DNA elements used for in vivo recombination/integration of the adipic acid pathway. The promoter-ORF-terminator fragments are referred to as the name of the ORF. The columns 5' and 3' homology indicate with which other fragment(s) homology is shared (see FIG. 22). The `plasmid name` column shows the name of the DNA2.0 plasmid containing the synthetic fragment. 5' homology 3'homology ID# ORF/ Forward Reverse with with plasmid element Promoter element terminator primer primer element element name ADI21 pTPI1 ADI21 tGND2 SEQ ID SEQ ID INT1LF ADI22 pADI141 SEQ ID NO 62 NO 63 NO 84 ADI22 pFBA1 ADI22 tPMA1 SEQ ID SEQ ID ADI21 ADI23 pADI142 SEQ ID NO 64 NO 65 NO 85 ADI23 pADH1 ADI23 tTDH1 SEQ ID SEQ ID ADI22 KANMX pADI143 SEQ ID NO 66 NO 67 NO 86 ADI8 pENO1 ADI8 tPDC1 SEQ ID SEQ ID KANMX ADI24 pADI199 SEQ ID NO 70 NO 71 NO 87 ADI24 pTDH1 ADI24 tADH2 SEQ ID SEQ ID ADI8 ADI25 pADI145 SEQ ID NO 72 NO 73 NO 88 ADI25 pENO2 ADI25 tGPM1 SEQ ID SEQ ID ADI24 SUCC pADI146 SEQ ID NO 74 NO 75 NO 89 SUCC pPDC1 SUCC tGND2 SEQ ID SEQ ID ADI25 SUCD pADI149 SEQ ID NO 76 NO 77 NO 90 SUCD pGPM1 SUCD tADH1 SEQ ID SEQ ID SUCC ACDH67 pADI150 SEQ ID NO 78 NO 79 NO 91 A67 pOYE2 ACDH67 tTPI1 SEQ ID SEQ ID SUCD INT1RF pADI200 SEQ ID NO 80 NO 81 NO 92 INT1LF -- INT1LF -- SEQ ID SEQ ID -- ADI21 -- SEQ ID NO 60 NO 61 NO 94 INT1RF -- INT1RF -- SEQ ID SEQ ID ACDH67 -- -- SEQ ID NO 82 NO 83 NO 95 KANMX -- KANMX -- SEQ ID SEQ ID ADI23 ADI8 pUG7 SEQ ID NO 68 NO 69 NO 93
[0486] All PCR reactions were performed with Phusion® polymerase (Finnzymes) according to the manual. The plasmids ordered at DNA2.0 were used as template for amplifying the 9 adipic acid pathway genes. The kanMX-marker was amplified from a plasmid pUG7 carrying the marker sequence. pUG7 was constructed as follows: the loxP-sites of plasmid pUG6 (Guldener, U. et al (1996) Nucleic Acids Research 24: 2519-2524) were replaced in two steps by cloning linkers containing the modified loxP-sites lox 66 and lox71 (Araki et al (1997) Nucleic Acids Research, 1997, Vol. 25, No. 4, pp 868-872). Restriction analysis and sequencing was done to confirm correct replacement.
[0487] The INT1LF and INT1RF (the left and right flanks, respectively) for integration at the "INT1 locus" were amplified using chromosomal DNA isolated from BIE104 as a template.
[0488] Size of the PCR fragments was checked with standard agarose electrophoresis techniques. PCR amplified DNA fragments were purified and concentrated with the PCR purification kit from Qiagen, according to the manual. DNA concentration was measured using the Nanodrop from Thermo scientific (A260/A280 absorbance).
[0489] 9.3. Yeast Transformation
[0490] Transformation of S. cerevisiae was done as described by Gietz and Woods (2002, Methods in Enzymology 350: 87-96). BIE201 was transformed with 1 μg of each of the 12 amplified and purified PCR fragments. Transformation mixtures were plated on YPD-agar (per liter: 10 grams of yeast extract, 20 grams per liter peptone, 20 grams per liter dextrose, 20 grams of agar) containing 100 μg G418 (Sigma Aldrich) per ml. After two to four days, colonies appeared on the plates, whereas the negative control (i.e. no addition of DNA in the transformation experiment) resulted in blank YPD/G418-plates. From the transformation plate single colonies were transferred to new YPD-agar plates containing 100 μg G418 per ml. The plates were incubated 2 days at 30° C.
[0491] 9.4 Adipic acid Production on Arabinose
[0492] Single colonies of 4 transformants (strains 1, 2 3 and 4) and BIE201 as a control strain were inoculated in duplo in a half deepwell MTP (microplate) containing 200 μl Verduyn medium with 2% arabinose and 0.05% glucose per well. The MTP was incubated 48 hours at 30° C., 550 rpm and 80% humidity in an Infors shaker for microplates. After 48 hours incubation 40 pl of each culture was transferred to two 24-well plates containing 2.5 ml Verduyn medium with 2% arabinose per well. The 24 well plates were covered with a standard MTP lid and incubated for 24 hours at 30° C., 550 rpm and 80% humidity. After the 24 hours incubation the 24 well plates were centrifuged for 10 minutes in Heraeus centrifuge at 2750 g. The supernatant was removed and to each well containing cell pellet, 4.5 ml fresh Verduyn media with 2% arabinose was added. The cell pellet was re-suspended with a pipette. For one plate the standard MTP lid was replaced by an airpore sheet (Qiagen) to improve aeration. For the second 24-well plate it was replaced by a BugStopper® Capmat (Whatman) which creates a micro-aerobic environment. The 24-well plates were incubated in the Infors Microtron incubator for 72 hours at 30° C., 350 rpm and 80% humidity. After incubation the plates were centrifuged for 10 minutes at 2750 g in a Heraeus Centrifuge. Adipic acid concentrations were measured in the supernatant with LC-MS. Results are shown in table 14.
TABLE-US-00022 TABLE 14 Resulting adipic acid concentrations in supernatant produced by the BIE201 transformants after growth on arabinose. Adipic acid concentration Strain Used lid (mg/l) BIE201 Airpore sheets <0.2 BIE201 Airpore sheets <0.2 Strain 2 Airpore sheets 1.4 Strain 2 Airpore sheets 1.4 Strain 3 Airpore sheets 1.2 Strain 3 Airpore sheets 1.3 Strain 4 Airpore sheets 1.6 Strain 4 Airpore sheets 2.0 BIE201 Bugstopper <0.2 BIE201 Bugstopper <0.2 Strain 2 Bugstopper 3.0 Strain 2 Bugstopper 2.4 Strain 3 Bugstopper 1.8 Strain 3 Bugstopper 2.2 Strain 4 Bugstopper 2.5 Strain 4 Bugstopper 2.8
[0493] Strains 2, 3 and 4 produce adipic acid on Verduyn media with arabinose as sole C-source. Under oxygen limited conditions, i.e. with the bugstopper lids, a higher level is obtained as compared to the plates with airpore sheets.
[0494] Reference strain BIE201 grows on arabinose but does not produce adipic acid.
[0495] 9.5 UPLC-MS/MS Analysis (ESI Negative Mode)
[0496] The samples were analysed with a column having the following specifications "Waters Acquity UPLC HSS T3, 1.8 μm, 100 mm*2.1 mm I.D.". Injection volume was 5 μl using a full loop, the flow through the column was 0.250 ml/min and the column temperature was 40° C. Table 15 shows the gradient used for mobile phase A and B. Mobile phase A contains 0.1% formic acid in water and Mobile phase B contains 0.1% formic acid in acetonitril.
TABLE-US-00023 TABLE 15 The gradient used during UPLC-MS/MS analysis of adipic acid concentrations in the supernatant. Time (min.) 0.0 5.0 6.5 7.0 10.0 10.5 15.0 % A 100.0 85.0 85.0 20.0 20.0 100.0 100.0 % B 0.0 15.0 15.0 80.0 80.0 0.0 0.0
[0497] FIG. 23 depicts a MRM chromatogram of a standard containing 10, 5 mg/L adipic acid and a sample produced by strain 3 containing 3 mg/I adipic acid strain 3 production on arabinose with a Bugstopper.
Example 10
Succinic Acid Production
[0498] 10.1 Expression Constructs
[0499] Expression construct pGBS414PPK-3 comprising a phosphoenol pyruvate carboxykinase PCKa (E.C. 4.1.1.49) from Actinobacillus succinogenes, and glycosomal fumarate reductase FRDg (E.C. 1.3.1.6) from Trypanosoma brucei, and an expression construct pGBS415FUM3 comprising a fumarase (E.C. 4.2.1.2.) from Rhizopus oryzae, and a peroxisomal malate dehydrogenase MDH3 (E.C. 1.1.1.37) were made as described previously in WO2009/065778 on p. 19-20, and 22-30 which herein enclosed by reference including the figures and sequence listing.
[0500] Expression construct pGBS416ARAABD comprising the genes araA, araB and araD, derived from Lactobacillus plantarum, were constructed by cloning a PCR product, comprising the araABD expression cassette from plasmid pPWT018, into plasmid pRS416. The PCR fragment was generated using Phusion® DNA polymerase (Finnzymes) and PCR primers defined in here as SEQ ID 96 and SEQ ID 97. The PCR product was cut with the restriction enzymes SalI and NotI, as was plasmid pRS416. After ligation and transformation of E. coli TOP10, the correct recombinants were selected on basis of restriction enzyme analysis. The physical map of plasmid pGBS416ARAABD is set out in FIG. 24.
[0501] 10.2 S. Cerevisiae Strains
[0502] The plasmids pGBS414PPK-3, pGBS415-FUM-3 were transformed into S. cerevisiae strain CEN.PK113-6B (MATA ura3-52 /eu2-112 trp1-289). In addition plasmid pGBS416ARAABD is transformed into this yeast to create prototrophic yeast strains. The expression vectors were transformed into yeast by electroporation. The transformation mixtures were plated on Yeast Nitrogen Base (YNB) w/o AA (Difco)+2% glucose. One such transformant was called SUC595.
[0503] As a control, strain CEN.PK113-6B was transformed with plasmid pGBS416ARAABD only. One such transformant was called SUC600.
[0504] Strains were subjected to adaptive evolution (see Example 2, section 2.1) for growth on arabinose as sole carbon source. In Example 2, YNB-medium containing arabinose was used, while in the Example, Verduyn medium with 2% arabinose was used.
[0505] Isolated single colony isolates from the adaptive evolution shake flasks were characterized for their ability to grow on arabinose as sole carbon source. SUC689, a derivative of SUC595 through adaptive evolution, has a growth rate of 0.1 h-1 on arabinose as sole carbon source. SUC694, a derivative of SUC600 through adaptive evolution, has a growth rate of 0.09 h-1 on arabinose as sole carbon source.
[0506] 10.3 Growth Experiments and Succinic Acid Production
[0507] Single colony isolates of transformants SUC689 and SUC694 were inoculated in 96 wells microplates containing YNB (Difco), 4% galactose and 2% agar. Four independent colonies were inoculated per strain. After growth for 2 days at 30° C., with the aid of a pin tool, colony material was transferred to a 96 wells microplate containing 200 μl pre-culture medium consisting of Verduyn medium (Verduyn et al., 1992, Yeast. July; 8(7):501-17) comprising 4% galactose (w/v) and grown under aerobic conditions in an Infors shaking incubator at 30° C., 550 rpm and 80% humidity. After approximately 48 hours, cells were transferred in duplicate to 24 wells microplates, containing 2.5 ml fresh Verduyn medium supplemented with 4% galactose. After 72 hours of incubation at 30° C., the plates were spun down in a microplate centrifuge, in order to separate the cells from the medium. The supernatant was discarded. The cells were resuspended in 4 ml Verduyn medium comprising 8% arabinose. At two time intervals, 48 hours (microplate 1) and 72 hours (microplate 2), the incubation was stopped by spinning down the cells. The supernatant was used to measure succinic acid levels by NMR as described in section 10.4.
[0508] 10.4 NMR Analysis
[0509] NMR was performed for the determination of organic acids and sugars in broth samples.
[0510] The results are presented in tables 16 and 17.
TABLE-US-00024 TABLE 16 Results of the NMR analysis at time point 48 hours. Strain Arabinose Malic acid Glycerol Succinic acid Ethanol SUC689 18.5 0.4 3.3 0.7 8.4 SUC689 14.5 0.4 4.3 0.8 10.0 SUC689 16.6 0.4 4.3 0.8 9.7 SUC689 14.9 0.4 4.1 0.7 9.1 SUC694 0.7 N.D. N.D. 0.2 18.8 SUC694 0.4 N.D. 0.0 0.2 18.5 SUC694 1.1 N.D. N.D. 0.3 18.4 SUC694 0.7 N.D. N.D. 0.2 17.8 All values are in grams per litre. N.D. means not detected.
TABLE-US-00025 TABLE 17 Results of the NMR analysis at time point 72 hours. Strain Arabinose Malic acid Glycerol Succinic acid Ethanol SUC689 14.0 0.5 3.5 0.7 6.7 SUC689 11.2 0.5 4.3 0.8 6.8 SUC689 13.7 0.5 3.9 0.8 6.0 SUC689 10.3 0.5 3.9 0.7 7.5 SUC694 0.1 N.D. N.D. 0.2 15.6 SUC694 0.1 N.D. N.D. 0.2 15.2 SUC694 0.2 N.D. N.D. 0.2 15.6 SUC694 0.3 N.D. N.D. 0.3 13.6 All values are in grams per litre. N.D. means not detected.
[0511] It is clear from tables 16 and 17 that the amount of succinic acid is higher in case of strain SUC689, as compared to strain SUC694. The latter converts almost all arabinose, and as products mainly biomass and ethanol were formed. In case of strain SUC689, less ethanol is formed, but a significantly higher amount of succinic acid, 3 to 4 times higher as compared to SUC694. Succinic acid yields were calculated and shown in the table below.
TABLE-US-00026 TABLE 18 Succinic acid yields on arabinose as a carbon source. Average succinic acid Average succinic acid yield (gram succinic acid yield (gram succinic acid per gram arabinose) at 48 per gram arabinose) at 72 Strain hours hours SUC689 0.012 0.011 SUC694 0.003 0.003
[0512] In conclusion, succinic acid was produced from arabinose in strain SUC689, which was significantly lower in strain SUC694, the strain not expressing the succinic acid pathway.
Example 11
Introduction of Extra Copies of the araA, araB and araD-Genes
[0513] 11.1 Amplification of the araABD-Cassette
[0514] In order to introduce extra copies of the araA, araB and araD genes into the genome, a PCR reaction is performed using Phusion® DNA polymerase (Finnzymes) with plasmid pPWT018 as a template and the oligonucleotides with SEQ ID 98 and SEQ ID 99 as primers. With these primers, the araABD-cassette is being amplified. The primer design is such that the flanks of the PCR fragment are homologous to the consensus sequence of the delta-sequences of the yeast transposon Ty-1. These sequences can be obtained from NCBI (http://www.ncbi.nlm.nih.gov/) and aligned using a software package allowing to do so, like e.g. Clone Manager 9 Professional Edition (Scientific & Educational Software, Cary, USA).
[0515] The araABD-cassette does not contain a selectable marker with which the integration into the genome can be selected for. In order to estimate transformation frequency, a second control transformation was done with the kanMX-marker. To this end, the kanMX-cassette from plasmid p427TEF (Dualsystems Biotech) was amplified in a PCR reaction using the primers corresponding to SEQ ID NO 100 and SEQ ID NO 101.
[0516] 11.2 Transformation of BIE104A2P1
[0517] BIE104A2P1 is transformed according to the electroporation protocol (as described above) with the fragments comprising either 30 μg of the araABD-cassette (designated Ty1::araABD) or 10 μg of the kanMX-cassette. The kanMX-transformation mixture is plated on YPD-agar (per liter: 10 grams of yeast extract, 20 grams per liter peptone, 20 grams per liter dextrose, 20 grams of agar) containing 100 μg G418 (Sigma Aldrich) per ml. After two to four days, colonies are appearing on the plates, whereas the negative control (i.e. no addition of DNA in the transformation experiment) is resulting in blank YPD/G418-plates. The transformation frequency is higher than 600 colonies per pg of kanMX-cassette.
[0518] The Ty1::araABD transformation mixture is used to inoculate a shake flask containing 100 ml of Verduyn medium, supplemented with 2% arabinose. As a control, the negative control of the transformation (i.e. no addition of DNA in the transformation experiment) is used. The shake flasks were incubated at 30° C. and 280 rpm in an orbital shaker. Growth is followed by measuring the optical density at 600 nm on a regular basis.
[0519] After approximately 25 days, the optical density of the Ty1::araABD shake flask increases, while the growth in the negative control is still absent. At day 25, a flask containing fresh Verduyn medium supplemented with 2% arabinose is inoculated from the Ty1::araABD culture to a start optical density at 600 nm of 0.15. The culture starts to grow on arabinose immediately and rapidly. Since it is likely that the culture consists of a mixture of subcultures, thus consisting of cells with differences in copy number of the Ty1::araABD cassette and in growth rate on arabinose, cells are diluted in milliQ water and are plated on YPD-agar plates in order to get single colony isolates. The single colony isolates are tested for their ability to utilize different carbon sources.
[0520] 11.3 Selection of Better Arabinose Converting Strains
[0521] In order to select a strain which has gained improved growth on arabinose as a sole carbon source without losing its ability to utilize the other important sugars (glucose, and galactose), ten single colony isolates of the adaptive evolution culture are restreaked on YPD-agar. Subsequently, a preculture is done on YPD-medium supplemented with 2% glucose. The ten cultures are incubated overnight at 30° C. and 280° C. Aliquots of each culture are used to inoculate fresh Verduyn medium supplemented with either 2% glucose, or 2% arabinose or 2% galactose, at an initial optical density of 0.15. As controls, strains BIE201, BIE104A2P1 and the mixed population (from which the ten single colony isolates are retrieved) are included in the experiment. Cells are grown at 30° C. and 280 rpm in an orbital shaker. Growth is assessed on basis of optical density measurements at 600 nm.
[0522] The results are showing that both the mixed culture and the ten single colony isolates exhibit a higher final optical density at 600 nm.
[0523] One colony (colony T) is selected on basis of its growth on arabinose as sole carbon source. This colony, if inoculated in Verduyn medium supplemented with 2% arabinose, is showing a higher growth rate than parent strain BIE104A2P1. Its growth rate is comparable to the growth rate of strain BIE201.
[0524] Q-PCR is done on the chromosomal DNA of strains BIE201, BIE104A2P1 and colony T. The copy number of the araABD cassette is determined to be 1 in case of BIE104A2P1, and larger than 2 in case of both colony T and BIE201.
Sequence CWU
1
101118215DNAArtificial Sequencesynthetic plasmid 1ggccaagatg gccgatctgc
atttttcata ataatcctcg gtactttcta caagatcaat 60taaattccaa tcaaaaatcg
tcttttgcaa gattttgaag tcacagtact tttcattttc 120aatgtcaaca gcgccccatt
tgtattgtct tcctttaact ttttcgccct tttcattaaa 180aatgtactca ttagatgcaa
ttatactgaa tggatatttt tgaaaaatat cttgtgttgc 240attcaaaact tcatcgccga
aaaagaaaca tacagggata tcttgtactc ttattatttc 300tctaacttgt gttttgaagt
ttttcaattc ctctttcgtt agcaaatctg atttagcaat 360aaccgggatt aaattcactc
tcttcgctaa ttttttcatt gttacgacgt ctaaagtatc 420aattccctta tttgaaggtc
tcagaaagta caaacaacaa tggactctat tatcaaccat 480ttttgtccta tcaggttgtt
cttcttggaa aatgtacgat cttatttctt catcaatata 540gtttctagac tgcagcccgg
gatccgtcga caagcttgtg gagaggtgac ttcatgaacc 600aagtgtctgt cgatatacaa
caaaaaggaa ccattttcat cttgatggac aacatgtgca 660tcaaaaacct tatcgtaaag
agttcttgga cccttggatg gagtgtaaac catgatttaa 720aacagcaaat aataaaaatc
gatagcgaca aaaactgtca atttcaatat tctttatatt 780tgttgactgc ttagatattt
tgagaaaatt cagcggaaac agcgtgatga gtgagttaag 840ttctgctgtt taaataagta
ttcaactact attgaagccg actcatgaag ccggttacgg 900acaaaaccgg gcaaatttcg
ccggtcccgg aattttcgtt tccgcaataa aagaaccgct 960catcatcata gcgccagggt
agtatactat agaaggtcag actaaactga gtcatctaga 1020gtaatgacgc cttagtagct
tttacatctt cataagaaaa ggaaacttgt agaatggcct 1080ggcgatttgt ttgctttctt
gtgatgaaga aatttcgatg cgattaaccg gcaaaatcag 1140taaaggtatt tcgcggaggc
ggccttcaat catcgaatac tacgtcttaa tatgatgtac 1200tgtggttcat attttcaagt
agtgttagta aatttgtata cgttcatgta agtgtgtatc 1260ttgagtgtct gtatgggcgc
ataaacgtaa gcgagacttc caaatggagc aaacgagaag 1320agatctttaa agtattatag
aagagctggg caggaactat tatgacgtaa agccttgacc 1380ataataaaga cgattctttg
tccctctata caaacatctt gcaaagatac caaatatttt 1440caaatcctac tcaataaaaa
attaatgaat aaattagtgt gtgtgcatta tatatattaa 1500aaattaagaa ttagactaaa
taaagtgttt ctaaaaaaat attaaagttg aaatgtgcgt 1560gttgtgaatt gtgctctatt
agaataatta tgacttgtgt gcgtttcata ttttaaaata 1620ggaaataacc aagaaagaaa
aagtaccatc cagagaaacc aattatatca aatcaaataa 1680aacaaccagc ttcggtgtgt
gtgtgtgtgt gaagctaaga gttgatgcca tttaatctaa 1740aaattttaag gtgtgtgtgt
ggataaaata ttagaatgac aattcgaatt gcgtacctta 1800gtcaaaaaat tagcctttta
attctgctgt aacccgtaca tgcccaaaat agggggcggg 1860ttacacagaa tatataacat
cgtaggtgtc tgggtgaaca gtttattcct ggcatccact 1920aaatataatg gagcccgctt
tttaagctgg catccagaaa aaaaaagaat cccagcacca 1980aaatattgtt ttcttcacca
accatcagtt cataggtcca ttctcttagc gcaactacag 2040agaacagggg cacaaacagg
caaaaaacgg gcacaacctc aatggagtga tgcaacctgc 2100ctggagtaaa tgatgacaca
aggcaattga cccacgcatg tatctatctc attttcttac 2160accttctatt accttctgct
ctctctgatt tggaaaaagc tgaaaaaaaa ggttgaaacc 2220agttccctga aattattccc
ctacttgact aataagtata taaagacggt aggtattgat 2280tgtaattctg taaatctatt
tcttaaactt cttaaattct acttttatag ttagtctttt 2340ttttagtttt aaaacaccaa
gaacttagtt tcgaataaac acacataaac aaacaaaatg 2400ttatcagtac ctgattatga
gttttggttt gttaccggtt cacaacacct ttatggtgaa 2460gaacaattga agtctgttgc
taaggatgcg caagatattg cggataaatt gaatgcaagc 2520ggcaagttac cttataaagt
agtctttaag gatgttatga cgacggctga aagtatcacc 2580aactttatga aagaagttaa
ttacaatgat aaggtagccg gtgttattac ttggatgcac 2640acattctcac cagctaagaa
ctggattcgt ggaactgaac tgttacaaaa accattatta 2700cacttagcaa cgcaatattt
gaataatatt ccatatgcag acattgactt tgattacatg 2760aaccttaacc aaagtgccca
tggcgaccgc gagtatgcct acattaacgc ccggttgcag 2820aaacataata agattgttta
cggctattgg ggcgatgaag atgtgcaaga gcagattgca 2880cgttgggaag acgtcgccgt
agcgtacaat gagagcttta aagttaaggt tgctcgcttt 2940ggcgacacaa tgcgtaatgt
ggccgttact gaaggtgaca aggttgaggc tcaaattaag 3000atgggctgga cagttgacta
ttatggtatc ggtgacttag ttgaagagat caataaggtt 3060tcggatgctg atgttgataa
ggaatacgct gacttggagt ctcggtatga aatggtccaa 3120ggtgataacg atgcggacac
gtataaacat tcagttcggg ttcaattggc acaatatctg 3180ggtattaagc ggttcttaga
aagaggcggt tacacagcct ttaccacgaa ctttgaagat 3240ctttggggga tggagcaatt
acctggtcta gcttcacaat tattaattcg tgatgggtat 3300ggttttggtg ctgaaggtga
ctggaagacg gctgctttag gacgggttat gaagattatg 3360tctcacaaca agcaaaccgc
ctttatggaa gactacacgt tagacttgcg tcatggtcat 3420gaagcgatct taggttcaca
catgttggaa gttgatccgt ctatcgcaag tgataaacca 3480cgggtcgaag ttcatccatt
ggatattggg ggtaaagatg atcctgctcg cctagtattt 3540actggttcag aaggtgaagc
aattgatgtc accgttgccg atttccgtga tgggttcaag 3600atgattagct acgcggtaga
tgcgaataag ccagaagccg aaacacctaa tttaccagtt 3660gctaagcaat tatggacccc
aaagatgggc ttaaagaaag gtgcactaga atggatgcaa 3720gctggtggtg gtcaccacac
gatgctgtcc ttctcgttaa ctgaagaaca aatggaagac 3780tatgcaacca tggttggcat
gactaaggca ttcttaaagt aagtgaattt actttaaatc 3840ttgcatttaa ataaattttc
tttttatagc tttatgactt agtttcaatt tatatactat 3900tttaatgaca ttttcgattc
attgattgaa agctttgtgt tttttcttga tgcgctattg 3960cattgttctt gtctttttcg
ccacatgtaa tatctgtagt agatacctga tacattgtgg 4020atgctgagtg aaattttagt
taataatgga ggcgctctta ataattttgg ggatattggc 4080tttttttttt aaagtttaca
aatgaatttt ttccgccagg atcgtacgcc gcggaaccgc 4140cagatattca ttacttgacg
caaaagcgtt tgaaataatg acgaaaaaga aggaagaaaa 4200aaaaagaaaa ataccgcttc
taggcgggtt atctactgat ccgagcttcc actaggatag 4260cacccaaaca cctgcatatt
tggacgacct ttacttacac caccaaaaac cactttcgcc 4320tctcccgccc ctgataacgt
ccactaattg agcgattacc tgagcggtcc tcttttgttt 4380gcagcatgag acttgcatac
tgcaaatcgt aagtagcaac gtctcaaggt caaaactgta 4440tggaaacctt gtcacctcac
ttaattctag ctagcctacc ctgcaagtca agaggtctcc 4500gtgattccta gccacctcaa
ggtatgcctc tccccggaaa ctgtggcctt ttctggcaca 4560catgatctcc acgatttcaa
catataaata gcttttgata atggcaatat taatcaaatt 4620tattttactt ctttcttgta
acatctctct tgtaatccct tattccttct agctattttt 4680cataaaaaac caagcaactg
cttatcaaca cacaaacact aaatcaaaat gaatttagtt 4740gaaacagccc aagcgattaa
aactggcaaa gtttctttag gaattgagct tggctcaact 4800cgaattaaag ccgttttgat
cacggacgat tttaatacga ttgcttcggg aagttacgtt 4860tgggaaaacc aatttgttga
tggtacttgg acttacgcac ttgaagatgt ctggaccgga 4920attcaacaaa gttatacgca
attagcagca gatgtccgca gtaaatatca catgagtttg 4980aagcatatca atgctattgg
cattagtgcc atgatgcacg gatacctagc atttgatcaa 5040caagcgaaat tattagttcc
gtttcggact tggcgtaata acattacggg gcaagcagca 5100gatgaattga ccgaattatt
tgatttcaac attccacaac ggtggagtat cgcacactta 5160taccaggcaa tcttaaataa
tgaagcgcac gttaaacagg tggacttcat aacaacgctg 5220gctggctatg taacctggaa
attgtcgggt gagaaagttc taggaatcgg tgatgcgtct 5280ggcgttttcc caattgatga
aacgactgac acatacaatc agacgatgtt aaccaagttt 5340agccaacttg acaaagttaa
accgtattca tgggatatcc ggcatatttt accgcgggtt 5400ttaccagcgg gagccattgc
tggaaagtta acggctgccg gggcgagctt acttgatcag 5460agcggcacgc tcgacgctgg
cagtgttatt gcaccgccag aaggggatgc tggaacagga 5520atggtcggta cgaacagcgt
ccgtaaacgc acgggtaaca tctcggtggg aacctcagca 5580ttttcgatga acgttctaga
taaaccattg tctaaagtct atcgcgatat tgatattgtt 5640atgacgccag atgggtcacc
agttgcaatg gtgcatgtta ataattgttc atcagatatt 5700aatgcgtggg caacgatttt
tcatgagttt gcagcccggt tgggaatgga attgaaaccg 5760gatcgattat atgaaacgtt
attcttggaa tcaactcgcg ctgatgcgga tgctggaggg 5820ttggctaatt atagttatca
atccggtgag aatattacta agattcaagc tggtcggccg 5880ctatttgtac ggacaccaaa
cagtaaattt agtttaccga actttatgtt gactcaatta 5940tatgcggcgt tcgcacccct
ccaacttggt atggatattc ttgttaacga agaacatgtt 6000caaacggacg ttatgattgc
acagggtgga ttgttccgaa cgccggtaat tggccaacaa 6060gtattggcca acgcactgaa
cattccgatt actgtaatga gtactgctgg tgaaggcggc 6120ccatggggga tggcagtgtt
agccaacttt gcttgtcggc aaactgcaat gaacctagaa 6180gatttcttag atcaagaagt
ctttaaagag ccagaaagta tgacgttgag tccagaaccg 6240gaacgggtgg ccggatatcg
tgaatttatt caacgttatc aagctggctt accagttgaa 6300gcagcggctg ggcaagcaat
caaatattag agcttttgat taagccttct agtccaaaaa 6360acacgttttt ttgtcattta
tttcattttc ttagaatagt ttagtttatt cattttatag 6420tcacgaatgt tttatgattc
tatatagggt tgcaaacaag catttttcat tttatgttaa 6480aacaatttca ggtttacctt
ttattctgct tgtggtgacg cgggtatccg cccgctcttt 6540tggtcaccca tgtatttaat
tgcataaata attcttaaaa gtggagctag tctatttcta 6600tttacatacc tctcatttct
catttcctcc actagtagag aattttgcca tcggacatgc 6660taccttacgc ttatatctct
cattggaata tcgttttctg attaaaacac ggaagtaaga 6720acttaattcg tttttcgttg
aactatgttg tgccagcgta acattaaaaa agagtgtaca 6780aggccacgtt ctgtcaccgt
cagaaaaata tgtcaatgag gcaagaaccg ggatggtaac 6840aaaaatcacg atctgggtgg
gtgtgggtgt attggattat aggaagccac gcgctcaacc 6900tggaattaca ggaagctggt
aattttttgg gtttgcaatc atcaccatct gcacgttgtt 6960ataatgtccc gtgtctatat
atatccattg acggtattct atttttttgc tattgaaatg 7020agcgtttttt gttactacaa
ttggttttac agacggaatt ttccctattt gtttcgtccc 7080atttttcctt ttctcattgt
tctcatatct taaaaaggtc ctttcttcat aatcaatgct 7140ttcttttact taatatttta
cttgcattca gtgaatttta atacatattc ctctagtctt 7200gcaaaatcga tttagaatca
agataccagc ctaaaaatgc tagaagcatt aaaacaagaa 7260gtttatgagg ctaacatgca
gcttccaaag ctgggcctgg ttacttttac ctggggcaat 7320gtctcgggca ttgaccggga
aaaaggccta ttcgtgatca agccatctgg tgttgattat 7380ggtgaattaa aaccaagcga
tttagtcgtt gttaacttac agggtgaagt ggttgaaggt 7440aaactaaatc cgtctagtga
tacgccgact catacggtgt tatataacgc ttttcctaat 7500attggcggaa ttgtccatac
tcattcgcca tgggcagttg cctatgcagc tgctcaaatg 7560gatgtgccag ctatgaacac
gacccatgct gatacgttct atggtgacgt gccggccgcg 7620gatgcgctga ctaaggaaga
aattgaagca gattatgaag gcaacacggg taaaaccatt 7680gtgaagacgt tccaagaacg
gggcctcgat tatgaagctg taccagcctc attagtcagc 7740cagcacggcc catttgcttg
gggaccaacg ccagctaaag ccgtttacaa tgctaaagtg 7800ttggaagtgg ttgccgaaga
agattatcat actgcgcaat tgacccgtgc aagtagcgaa 7860ttaccacaat atttattaga
taagcattat ttacgtaagc atggtgcaag tgcctattat 7920ggtcaaaata atgcgcattc
taaggatcat gcagttcgca agtaaacaaa tcgctcttaa 7980atatatacct aaagaacatt
aaagctatat tataagcaaa gatacgtaaa ttttgcttat 8040attattatac acatatcata
tttctatatt tttaagattt ggttatataa tgtacgtaat 8100gcaaaggaaa taaattttat
acattattga acagcgtcca agtaactaca ttatgtgcac 8160taatagttta gcgtcgtgaa
gactttattg tgtcgcgaaa agtaaaaatt ttaaaaatta 8220gagcaccttg aacttgcgaa
aaaggttctc atcaactgtt taaaaacgcg tgtcttctgt 8280gtttcagttc agggcttttc
ggaggatgtg aatcgacggc gtactgtcct tgggaacttt 8340gtctacgtat tttcacttcc
tcagcgaatc cagagactat cttgggaaat tcgacaggac 8400agtctgttga caaccgactc
ccttttgact tcataataaa aattcaatga cgcaaaagga 8460attttaggtt tttattattt
atttatttat ttctgttaat tgatcctttt ctttccacta 8520ccaacaacaa aaaagggggg
aaaaagatgt ataatctaaa agacactaat ctgctcttga 8580tatccttatt atgtaatgga
ataactcata taaatgtaaa atagaacttc aaattaatat 8640tataatgata gtcgaggtca
gacacactta taatacatta agtaaagaaa aaaaaatgtc 8700tgtcatcgag gtctcttttg
tgtcgctaac aaaacatcac taaatacgaa gacactttgc 8760atgggaagga tgcagcaaat
ggcaaactaa cgggccattg attggtttac ctcttctatt 8820tgtattacga ccagaaagaa
cgaatggttt tcatcaatga ggtaggaaac gacctaaata 8880taatgtagca tagataaaat
ctttgtactg tatggttgca atgccttctt gattagtatc 8940gaatttcctg aataattttg
ttaatctcat tagccaaact aacgcctcaa cgaatttatc 9000aaactttagt tcttttcctg
ttccatttct gtttataaac tcagcatatt ggtcaaatgt 9060tttctcgcta acttcaaaag
gtattagata tcctagttct tgaagtgagt tatgaaattc 9120gcttacagaa atggtgagcg
atccgttgat atcattgtcc acataaactt ttctccaact 9180tttcactctt ttgtataggg
cgatgaattc tgcctggttg acagtgccaa acctggaagc 9240accaaataaa tttatcagcg
catctactga tgatatacaa aaatgggagt tgtcgtcgtt 9300ttgtagtaag ttctgtagtt
cctcagctgt cagtcggttt ttgcccttta catcatggtt 9360atgaaatagc tgtgtggcca
cttgcatgtc tcgtacatct tctctgctat cgaacgaagc 9420aggtgcaact ttcttcaaga
gttgtgcagg cactgcttga ttgtgaatta ggggaggagg 9480agaggaagct atccgttgag
cggaagtgtt caagttgtta taatgggttg gcgctggagg 9540tataggcctg cctgctggtt
tctgtgcgat aacattatat ctaggatcca caggtgtttt 9600cgtatgtctt ggagaataac
tttggggaga accataggag tggtgaccgt tttctgctct 9660gtttttgtta tattgagttt
gtaagggaat tggagctgag tggactctag tgttgggagt 9720ttgtgcttga gtaaccggta
ccacggctcc tcgctgcaga cctgcgagca gggaaacgct 9780cccctcacag tcgcgttgaa
ttgtccccac gccgcgcccc tgtagagaaa tataaaaggt 9840taggatttgc cactgaggtt
cttctttcat atacttcctt ttaaaatctt gctaggatac 9900agttctcaca tcacatccga
acataaacaa ccatgggtaa ggaaaagact cacgtttcga 9960ggccgcgatt aaattccaac
atggatgctg atttatatgg gtataaatgg gctcgcgata 10020atgtcgggca atcaggtgcg
acaatctatc gattgtatgg gaagcccgat gcgccagagt 10080tgtttctgaa acatggcaaa
ggtagcgttg ccaatgatgt tacagatgag atggtcagac 10140taaactggct gacggaattt
atgcctcttc cgaccatcaa gcattttatc cgtactcctg 10200atgatgcatg gttactcacc
actgcgatcc ccggcaaaac agcattccag gtattagaag 10260aatatcctga ttcaggtgaa
aatattgttg atgcgctggc agtgttcctg cgccggttgc 10320attcgattcc tgtttgtaat
tgtcctttta acagcgatcg cgtatttcgt ctcgctcagg 10380cgcaatcacg aatgaataac
ggtttggttg atgcgagtga ttttgatgac gagcgtaatg 10440gctggcctgt tgaacaagtc
tggaaagaaa tgcataagct tttgccattc tcaccggatt 10500cagtcgtcac tcatggtgat
ttctcacttg ataaccttat ttttgacgag gggaaattaa 10560taggttgtat tgatgttgga
cgagtcggaa tcgcagaccg ataccaggat cttgccatcc 10620tatggaactg cctcggtgag
ttttctcctt cattacagaa acggcttttt caaaaatatg 10680gtattgataa tcctgatatg
aataaattgc agtttcattt gatgctcgat gagtttttct 10740aatcagtact gacaataaaa
agattcttgt tttcaagaac ttgtcatttg tatagttttt 10800ttatattgta gttgttctat
tttaatcaaa tgttagcgtg atttatattt tttttcgcct 10860cgacatcatc tgcccagatg
cgaagttaag tgcgcagaaa gtaatatcat gcgtcaatcg 10920tatgtgaatg ctggtcgcta
tactgctgtc gattcgatac taacgccgcc atccagggta 10980ccatcctttt gttgtttccg
ggtgtacaat atggacttcc tcttttctgg caaccaaacc 11040catacatcgg gattcctata
ataccttcgt tggtctccct aacatgtagg tggcggaggg 11100gagatataca atagaacaga
taccagacaa gacataatgg gctaaacaag actacaccaa 11160ttacactgcc tcattgatgg
tggtacataa cgaactaata ctgtagccct agacttgata 11220gccatcatca tatcgaagtt
tcactaccct ttttccattt gccatctatt gaagtaataa 11280taggcgcatg caacttcttt
tctttttttt tcttttctct ctcccccgtt gttgtctcac 11340catatccgca atgacaaaaa
aaatgatgga agacactaaa ggaaaaaatt aacgacaaag 11400acagcaccaa cagatgtcgt
tgttccagag ctgatgaggg gtatcttcga acacacgaaa 11460ctttttcctt ccttcattca
cgcacactac tctctaatga gcaacggtat acggccttcc 11520ttccagttac ttgaatttga
aataaaaaaa gtttgccgct ttgctatcaa gtataaatag 11580acctgcaatt attaatcttt
tgtttcctcg tcattgttct cgttcccttt cttccttgtt 11640tctttttctg cacaatattt
caagctatac caagcataca atcaactatc tcatatacaa 11700tgcctcaatc ctgggaagaa
ctggccgctg ataagcgcgc ccgcctcgca aaaaccatcc 11760ctgatgaatg gaaagtccag
acgctgcctg cggaagacag cgttattgat ttcccaaaga 11820aatcggggat cctttcagag
gccgaactga agatcacaga ggcctccgct gcagatcttg 11880tgtccaagct ggcggccgga
gagttgacct cggtggaagt tacgctagca ttctgtaaac 11940gggcagcaat cgcccagcag
ttaacaaact gcgcccacga gttcttccct gacgccgctc 12000tcgcgcaggc aagggaactc
gatgaatact acgcaaagca caagagaccc gttggtccac 12060tccatggcct ccccatctct
ctcaaagacc agcttcgagt caagggctac gaaacatcaa 12120tgggctacat ctcatggcta
aacaagtacg acgaagggga ctcggttctg acaaccatgc 12180tccgcaaagc cggtgccgtc
ttctacgtca agacctctgt cccgcagacc ctgatggtct 12240gcgagacagt caacaacatc
atcgggcgca ccgtcaaccc acgcaacaag aactggtcgt 12300gcggcggcag ttctggtggt
gagggtgcga tcgttgggat tcgtggtggc gtcatcggtg 12360taggaacgga tatcggtggc
tcgattcgag tgccggccgc gttcaacttc ctgtacggtc 12420taaggccgag tcatgggcgg
ctgccgtatg caaagatggc gaacagcatg gagggtcagg 12480agacggtgca cagcgttgtc
gggccgatta cgcactctgt tgaggacctc cgcctcttca 12540ccaaatccgt cctcggtcag
gagccatgga aatacgactc caaggtcatc cccatgccct 12600ggcgccagtc cgagtcggac
attattgcct ccaagatcaa gaacggcggg ctcaatatcg 12660gctactacaa cttcgacggc
aatgtccttc cacaccctcc tatcctgcgc ggcgtggaaa 12720ccaccgtcgc cgcactcgcc
aaagccggtc acaccgtgac cccgtggacg ccatacaagc 12780acgatttcgg ccacgatctc
atctcccata tctacgcggc tgacggcagc gccgacgtaa 12840tgcgcgatat cagtgcatcc
ggcgagccgg cgattccaaa tatcaaagac ctactgaacc 12900cgaacatcaa agctgttaac
atgaacgagc tctgggacac gcatctccag aagtggaatt 12960accagatgga gtaccttgag
aaatggcggg aggctgaaga aaaggccggg aaggaactgg 13020acgccatcat cgcgccgatt
acgcctaccg ctgcggtacg gcatgaccag ttccggtact 13080atgggtatgc ctctgtgatc
aacctgctgg atttcacgag cgtggttgtt ccggttacct 13140ttgcggataa gaacatcgat
aagaagaatg agagtttcaa ggcggttagt gagcttgatg 13200ccctcgtgca ggaagagtat
gatccggagg cgtaccatgg ggcaccggtt gcagtgcagg 13260ttatcggacg gagactcagt
gaagagagga cgttggcgat tgcagaggaa gtggggaagt 13320tgctgggaaa tgtggtgact
ccataggtcg agaatttata cttagataag tatgtactta 13380caggtatatt tctatgagat
actgatgtat acatgcatga taatatttaa acggttatta 13440gtgccgattg tcttgtgcga
taatgacgtt cctatcaaag caatacactt accacctatt 13500acatgggcca agaaaatatt
ttcgaacttg tttagaatat tagcacagag tatatgatga 13560tatccgttag attatgcatg
attcattcct acaacttttt cgtagcataa ggattaatta 13620cttggatgcc aataaaaaaa
aaaaacatcg agaaaatttc agcatgctca gaaacaattg 13680cagtgtatca aagtaaaaaa
aagattttcg ctacatgttc cttttgaaga aagaaaatca 13740tggaacatta gatttacaaa
aatttaacca ccgctgatta acgattagac cgttaagcgc 13800acaacaggtt attagtacag
agaaagcatt ctgtggtgtt gccccggact ttcttttgcg 13860acataggtaa atcgaatacc
atcatactat cttttccaat gactccctaa agaaagactc 13920ttcttcgatg ttgtatacgt
tggagcatag ggcaagaatt gtggcttgag atctagatta 13980cgtggaagaa aggtagtaaa
agtagtagta taagtagtaa aaagaggtaa aaagagaaaa 14040ccggctacat actagagaag
cacgtacaca aaaactcata ggcacttcat catacgacag 14100tttcttgatg cattataata
gtgtattaga tattttcaga aatatgcata gaacctcttc 14160ttgcctttac tttttataca
tagaacattg gcagatttac ttacactact ttgtttctac 14220gccatttctt ttgttttcaa
cacttagaca agttgttgag aaccggacta ctaaaaagca 14280atgttcccac tgaaaatcat
gtacctgcag gataataacc ccctaattct gcatcgatcc 14340agtatgtttt tttttctcta
ctcattttta cctgaagata gagcttctaa aacaaaaaaa 14400atcagcgatt acatgcatat
tgtgtgttct agaattgcgg atcaccagat cgccattaca 14460atgtatgcag gcaaatattt
ctcagaatga aaaatagaga aaaggaaacg aaaattctgt 14520aagatgcctt cgaagagatt
tctcgatatg caaggcgtgc atcagggtga tccaaaggaa 14580ctcgagagag agggcgaaag
gcaatttaat gcattgcttc tccattgact tctagttgag 14640cggataagtt cggaaatgta
agtcacagct aatgacaaat ccactttagg tttcgaggca 14700ctatttaggc aaaaagacga
gtggggaaat aacaaacgct caaacatatt agcatatacc 14760ttcaaaaaat gggaatagta
tataaccttc cggttcgtta ataaatcaaa tctttcatct 14820agttctctta agatttcaat
attttgcttt cttgaagaaa gaatctactc tcctccccca 14880ttcgcactgc aaagctagct
tggcactggc cgtcgtttta caacgtcgtg actgggaaaa 14940ccctggcctt acccaactta
atcgccttgc agcacatccc cctttcgcca gctggcgtaa 15000tagcgaagag gcccgcaccg
atcgcccttc ccaacagttg cgcagcctga atggcgaatg 15060ggaaattgta aacgttaata
ttttgttaaa attcgcgtta aatttttgtt aaatcagctc 15120attttttaac caataggccg
aaatcggcaa aatcccttat aaatcaaaag aatagaccga 15180gatagggttg agtgttgttc
cagtttggaa caagagtcca ctattaaaga acgtggactc 15240caacgtcaaa gggcgaaaaa
ccgtctatca gggcgatggc ccactacgtg aaccatcacc 15300ctaatcaagt tttttggggt
cgaggtgccg taaagcacta aatcggaacc ctaaagggag 15360cccccgattt agagcttgac
ggggaaagcc ggcgaacgtg gcgagaaagg aagggaagaa 15420agcgaaagga gcgggcgcta
gggcgctggc aagtgtagcg gtcacgctgc gcgtaaccac 15480cacacccgcc gcgcttaatg
cgccgctaca gggcgcgtca ggtggcactt ttcggggaaa 15540tgtgcgcgga acccctattt
gtttattttt ctaaatacat tcaaatatgt atccgctcat 15600gagacaataa ccctgataaa
tgcttcaata atattgaaaa aggaagagta tgagtattca 15660acatttccgt gtcgccctta
ttcccttttt tgcggcattt tgccttcctg tttttgctca 15720cccagaaacg ctggtgaaag
taaaagatgc tgaagatcag ttgggtgcac gagtgggtta 15780catcgaactg gatctcaaca
gcggtaagat ccttgagagt tttcgccccg aagaacgttt 15840tccaatgatg agcactttta
aagttctgct atgtggcgcg gtattatccc gtattgacgc 15900cgggcaagac caactcggtc
gccgcataca ctattctcag aatgacttgg ttgagtactc 15960accagtcaca gaaaagcatc
ttacggatgg catgacagta agagaattat gcagtgctgc 16020cataaccatg agtgataaca
ctgcggccaa cttacttctg acaacgatcg gaggaccgaa 16080ggagctaacc gcttttttgc
acaacatggg ggatcatgta actcgccttg atcgttggga 16140accggagctg aatgaagcca
taccaaacga cgagcgtgac accacgatgc ctgtagcaat 16200ggcaacaacg ttgcgcaaac
tattaactgg cgaactactt agtctagctt cccggcaaca 16260attaatagac tggatggagg
cggataaagt tgcaggacca cttctgcgct cggcccttcc 16320ggctggctgg tttattgctg
ataaatctgg agccggtgag cgtgggtctc gcggtatcat 16380tgcagcactg gggccagatg
gtaagccctc ccgtatcgta gttatctaca cgacggggag 16440tcaggcaact atggatgaac
gaaatagaca gatcgctgag ataggtgcct cactgattaa 16500gcattggtaa ctgtcagacc
aagtttactc atatatactt tagattgatt taaaacttca 16560tttttaattt aaaaggatct
aggtgaagat cctttttgat aatctcatga ccaaaatccc 16620ttaacgtgag ttttcgttcc
actgagcgtc agaccccgta gaaaagatca aaggatcttc 16680ttgagatcct ttttttctgc
gcgtaatctg ctgcttgcaa acaaaaaaac caccgctacc 16740agcggtggtt tgtttgccgg
atcaagagct accacctctt tttccgaagg taactggctt 16800cagcagagcg cagataccaa
atactgtcct tctagtgtag ccgtagttag gccaccactt 16860caagaactct gtagcaccgc
ctacatacct cgctctgcta atcctgttac cagtggctgc 16920tgccagtggc gataagtcgt
gtcttaccgg gttggactca agacgatagt taccggataa 16980ggcgcagcgg tcgggctgaa
cggggggttc gtgcacacag cccagcttgg agcgaacgac 17040ctacaccgaa ctgagatacc
tacagcgtga gcattgagaa agcgccacgc ttcccgaagg 17100gagaaaggcg gacaggtatc
cggtaagcgg cagggtcgga acaggagagc gcacgaggga 17160gcttccaggg ggaaacgcct
ggtatcttta tagtcctgtc gggtttcgcc acctctgact 17220tgagcgtcga tttttgtgat
gctcgtcagg ggggcggagc ctatggaaaa acgccagcaa 17280cgcggccttt ttacggttcc
tggccttttg ctggcctttt gctcacatgt tctttcctgc 17340gttatcccct gattctgtgg
ataaccgtat taccgccttt gagtgagctg ataccgctcg 17400ccgcagccga acgaccgagc
gcagcgagtc agtgagcgag gaagcggaag agcgcccaat 17460acgcaaaccg cctctccccg
cgcgttggcc gattcattaa tgcagctggc acgacaggtt 17520tcccgactgg aaagcgggca
gtgagcgcaa cgcaattaat gtgagttagc tcactcatta 17580ggcaccccag gctttacact
ttatgcttcc ggctcgtatg ttgtgtggaa ttgtgagcgg 17640ataacaattt cacacaggaa
acagctatga catgattacg aatttaatac gactcacaat 17700agggaattag cttgcgcgaa
attattggct tttttttttt tttaattaat actacctttt 17760gatgtgaacg tttactaaag
tagcactatc tgtggaatgg ctgttggaac tttttccgat 17820taacagcttg tattccaagt
cctgacattc cagttgtaag ttttccaact tgtgattcaa 17880ttgttcaatc tcttggttaa
aattctcttg ttccatgaat aggctctttt tccagtctcg 17940aaattttgaa atttctctgt
tggacagctc gttgaatttt ttcttagctt ctaattgtct 18000agttataaat tcaggatccc
attctgtagc caccttatcc atgaccgttt tattaattat 18060ttcatagcac ttgtaatttt
tgagtttgtt ttcctcgatt tcatcgaagt tcatttcttc 18120ctccaaaaat ttcctttgtt
cttccgttat gtcaacactt ttcgttgtta agcaatctct 18180ggcctttaat agcctagttc
ttagcatttc agatc 18215223DNAArtificial
Sequencesynthetic primer 2tgatcttgta gaaagtaccg agg
23324DNAArtificial Sequencesynthetic primer
3ggaaacagct atgacatgat tacg
24423DNAArtificial Sequencesynthetic primer 4tgcacatgtt gtccatcaag atg
23525DNAArtificial
Sequencesynthetic primer 5ctttgttctt ccgttatgtc aacac
25623DNAArtificial Sequencesynthetic primer
6ttccaagaag aacaacctga tag
23721DNAArtificial Sequencesynthetic primer 7tgatgtgaac gtttactaaa g
21816176DNAArtificial
Sequencesynthetic plasmid 8tcgcgcgttt cggtgatgac ggtgaaaacc tcttgacaca
tgcagctccc ggagacggtc 60acagcttgtc tgtaagcgga tgccgggagc agacaagccc
gtcagggcgc gtcagcgggt 120gttggcgggt gtcggggctg gcttaactat gcggcatcag
agcagattgt actgagagtg 180caccatatgc ggtgtgaaat accgcacaga tgcgtaagga
gaaaataccg catcaggcgc 240cattcgccat tcaggctgcg caactgttgg gaagggcgat
cggtgcgggc ctcttcgcta 300ttacgccagc tggcgaaagg gggatgtgct gcaaggcgat
taagttgggt aacgccaggg 360ttttcccagt cacgacgttg taaaacgacg gccagtaagc
ttgcatgcct gcaggtcgac 420gcggccgcat attttttgta actgtaattt cactcatgca
caagaaaaaa aaaactggat 480taaaagggag cccaaggaaa actcctcagc atatatttag
aagtctcctc agcatatagt 540tgtttgtttt ctttacacat tcactgttta ataaaacttt
tataatattt cattatcgga 600actctagatt ctatacttgt ttcccaattg ggccgatcgg
gccttgctgg tagtaaacgt 660atacgtcata aaagggaaaa gccacatgcg gaagaatttt
atggaaaaaa aaaaaacctc 720gaagttacta cttctagggg gcctatcaag taaattactc
ctggtacact gaagtatata 780agggatatag aagcaaatag ttgtcagtgc aatccttcaa
gacgattggg aaaatactgt 840aggtaccgga gacctaacta catagtgttt aaagattacg
gatatttaac ttacttagaa 900taatgccatt tttttgagtt ataataatcc tacgttagtg
tgagcgggat ttaaactgtg 960aggaccttaa tacattcaga cacttctgcg gtatcaccct
acttattccc ttcgagatta 1020tatctaggaa cccatcaggt tggtggaaga ttacccgttc
taagactttt cagcttcctc 1080tattgatgtt acacctggac accccttttc tggcatccag
tttttaatct tcagtggcat 1140gtgagattct ccgaaattaa ttaaagcaat cacacaattc
tctcggatac cacctcggtt 1200gaaactgaca ggtggtttgt tacgcatgct aatgcaaagg
agcctatata cctttggctc 1260ggctgctgta acagggaata taaagggcag cataatttag
gagtttagtg aacttgcaac 1320atttactatt ttcccttctt acgtaaatat ttttcttttt
aattctaaat caatcttttt 1380caattttttg tttgtattct tttcttgctt aaatctataa
ctacaaaaaa cacatacata 1440aactaaaaat gtctgaacca gctcaaaaga aacaaaaggt
tgctaacaac tctctagaac 1500aattgaaagc ctccggcact gtcgttgttg ccgacactgg
tgatttcggc tctattgcca 1560agtttcaacc tcaagactcc acaactaacc catcattgat
cttggctgct gccaagcaac 1620caacttacgc caagttgatc gatgttgccg tggaatacgg
taagaagcat ggtaagacca 1680ccgaagaaca agtcgaaaat gctgtggaca gattgttagt
cgaattcggt aaggagatct 1740taaagattgt tccaggcaga gtctccaccg aagttgatgc
tagattgtct tttgacactc 1800aagctaccat tgaaaaggct agacatatca ttaaattgtt
tgaacaagaa ggtgtctcca 1860aggaaagagt ccttattaaa attgcttcca cttgggaagg
tattcaagct gccaaagaat 1920tggaagaaaa ggacggtatc cactgtaatt tgactctatt
attctccttc gttcaagcag 1980ttgcctgtgc cgaggcccaa gttactttga tttccccatt
tgttggtaga attctagact 2040ggtacaaatc cagcactggt aaagattaca agggtgaagc
cgacccaggt gttatttccg 2100tcaagaaaat ctacaactac tacaagaagt acggttacaa
gactattgtt atgggtgctt 2160ctttcagaag cactgacgaa atcaaaaact tggctggtgt
tgactatcta acaatttctc 2220cagctttatt ggacaagttg atgaacagta ctgaaccttt
cccaagagtt ttggaccctg 2280tctccgctaa gaaggaagcc ggcgacaaga tttcttacat
cagcgacgaa tctaaattca 2340gattcgactt gaatgaagac gctatggcca ctgaaaaatt
gtccgaaggt atcagaaaat 2400tctctgccga tattgttact ctattcgact tgattgaaaa
gaaagttacc gcttaaggaa 2460gtatctcgga aatattaatt taggccatgt ccttatgcac
gtttcttttg atacttacgg 2520gtacatgtac acaagtatat ctatatatat aaattaatga
aaatccccta tttatatata 2580tgactttaac gagacagaac agttttttat tttttatcct
atttgatgaa tgatacagtt 2640tcttattcac gtgttatacc cacaccaaat ccaatagcaa
taccggccat cacaatcact 2700gtttcggcag cccctaagat cagacaaaac atccggaacc
accttaaatc aacgtcccat 2760atgaatcctt gcagcaaagc cgctcgtacc ggagatatac
aatagaacag ataccagaca 2820agacataatg ggctaaacaa gactacacca attacactgc
ctcattgatg gtggtacata 2880acgaactaat actgtagccc tagacttgat agccatcatc
atatcgaagt ttcactaccc 2940tttttccatt tgccatctat tgaagtaata ataggcgcat
gcaacttctt ttcttttttt 3000ttcttttctc tctcccccgt tgttgtctca ccatatccgc
aatgacaaaa aaatgatgga 3060agacactaaa ggaaaaaatt aacgacaaag acagcaccaa
cagatgtcgt tgttccagag 3120ctgatgaggg gtatctcgaa gcacacgaaa ctttttcctt
ccttcattca cgcacactac 3180tctctaatga gcaacggtat acggccttcc ttccagttac
ttgaatttga aataaaaaaa 3240agtttgctgt cttgctatca agtataaata gacctgcaat
tattaatctt ttgtttcctc 3300gtcattgttc tcgttccctt tcttccttgt ttctttttct
gcacaatatt tcaagctata 3360ccaagcatac aatcaactat ctcatataca atgactcaat
tcactgacat tgataagcta 3420gccgtctcca ccataagaat tttggctgtg gacaccgtat
ccaaggccaa ctcaggtcac 3480ccaggtgctc cattgggtat ggcaccagct gcacacgttc
tatggagtca aatgcgcatg 3540aacccaacca acccagactg gatcaacaga gatagatttg
tcttgtctaa cggtcacgcg 3600gtcgctttgt tgtattctat gctacatttg actggttacg
atctgtctat tgaagacttg 3660aaacagttca gacagttggg ttccagaaca ccaggtcatc
ctgaatttga gttgccaggt 3720gttgaagtta ctaccggtcc attaggtcaa ggtatctcca
acgctgttgg tatggccatg 3780gctcaagcta acctggctgc cacttacaac aagccgggct
ttaccttgtc tgacaactac 3840acctatgttt tcttgggtga cggttgtttg caagaaggta
tttcttcaga agcttcctcc 3900ttggctggtc atttgaaatt gggtaacttg attgccatct
acgatgacaa caagatcact 3960atcgatggtg ctaccagtat ctcattcgat gaagatgttg
ctaagagata cgaagcctac 4020ggttgggaag ttttgtacgt agaaaatggt aacgaagatc
tagccggtat tgccaaggct 4080attgctcaag ctaagttatc caaggacaaa ccaactttga
tcaaaatgac cacaaccatt 4140ggttacggtt ccttgcatgc cggctctcac tctgtgcacg
gtgccccatt gaaagcagat 4200gatgttaaac aactaaagag caaattcggt ttcaacccag
acaagtcctt tgttgttcca 4260caagaagttt acgaccacta ccaaaagaca attttaaagc
caggtgtcga agccaacaac 4320aagtggaaca agttgttcag cgaataccaa aagaaattcc
cagaattagg tgctgaattg 4380gctagaagat tgagcggcca actacccgca aattgggaat
ctaagttgcc aacttacacc 4440gccaaggact ctgccgtggc cactagaaaa ttatcagaaa
ctgttcttga ggatgtttac 4500aatcaattgc cagagttgat tggtggttct gccgatttaa
caccttctaa cttgaccaga 4560tggaaggaag cccttgactt ccaacctcct tcttccggtt
caggtaacta ctctggtaga 4620tacattaggt acggtattag agaacacgct atgggtgcca
taatgaacgg tatttcagct 4680ttcggtgcca actacaaacc atacggtggt actttcttga
acttcgtttc ttatgctgct 4740ggtgccgtta gattgtccgc tttgtctggc cacccagtta
tttgggttgc tacacatgac 4800tctatcggtg tcggtgaaga tggtccaaca catcaaccta
ttgaaacttt agcacacttc 4860agatccctac caaacattca agtttggaga ccagctgatg
gtaacgaagt ttctgccgcc 4920tacaagaact ctttagaatc caagcatact ccaagtatca
ttgctttgtc cagacaaaac 4980ttgccacaat tggaaggtag ctctattgaa agcgcttcta
agggtggtta cgtactacaa 5040gatgttgcta acccagatat tattttagtg gctactggtt
ccgaagtgtc tttgagtgtt 5100gaagctgcta agactttggc cgcaaagaac atcaaggctc
gtgttgtttc tctaccagat 5160ttcttcactt ttgacaaaca acccctagaa tacagactat
cagtcttacc agacaacgtt 5220ccaatcatgt ctgttgaagt tttggctacc acatgttggg
gcaaatacgc tcatcaatcc 5280ttcggtattg acagatttgg tgcctccggt aaggcaccag
aagtcttcaa gttcttcggt 5340ttcaccccag aaggtgttgc tgaaagagct caaaagacca
ttgcattcta taagggtgac 5400aagctaattt ctcctttgaa aaaagctttc taaattctga
tcgtagatca tcagatttga 5460tatgatatta tttgtgaaaa aatgaaataa aactttatac
aacttaaata caactttttt 5520tataaacgat taagcaaaaa aatagtttca aacttttaac
aatattccaa acactcagtc 5580cttttccttc ttatattata ggtgtacgta ttatagaaaa
atttcaatga ttactttttc 5640tttctttttc cttgtaccag cacatggccg agcttgaatg
ttaaaccctt cgagagaatc 5700acaccattca agtataaagc caataaagaa tatcgtacca
gagaattttg ccatcggaca 5760tgctacctta cgcttatatc tctcattgga atatcgtttt
ctgattaaaa cacggaagta 5820agaacttaat tcgtttttcg ttgaactatg ttgtgccagc
gtaacattaa aaaagagtgt 5880acaaggccac gttctgtcac cgtcagaaaa atatgtcaat
gaggcaagaa ccgggatggt 5940aacaaaaatc acgatctggg tgggtgtggg tgtattggat
tataggaagc cacgcgctca 6000acctggaatt acaggaagct ggtaattttt tgggtttgca
atcatcacca tctgcacgtt 6060gttataatgt cccgtgtcta tatatatcca ttgacggtat
tctatttttt tgctattgaa 6120atgagcgttt tttgttacta caattggttt tacagacgga
attttcccta tttgtttcgt 6180cccatttttc cttttctcat tgttctcata tcttaaaaag
gtcctttctt cataatcaat 6240gctttctttt acttaatatt ttacttgcat tcagtgaatt
ttaatacata ttcctctagt 6300cttgcaaaat cgatttagaa tcaagatacc agcctaaaaa
tggtcaaacc aattatagct 6360cccagtatcc ttgcttctga cttcgccaac ttgggttgcg
aatgtcataa ggtcatcaac 6420gccggcgcag attggttaca tatcgatgtc atggacggcc
attttgttcc aaacattact 6480ctgggccaac caattgttac ctccctacgt cgttctgtgc
cacgccctgg cgatgctagc 6540aacacagaaa agaagcccac tgcgttcttc gattgtcaca
tgatggttga aaatcctgaa 6600aaatgggtcg acgattttgc taaatgtggt gctgaccaat
ttacgttcca ctacgaggcc 6660acacaagacc ctttgcattt agttaagttg attaagtcta
agggcatcaa agctgcatgc 6720gccatcaaac ctggtacttc tgttgacgtt ttatttgaac
tagctcctca tttggatatg 6780gctcttgtta tgactgtgga acctgggttt ggaggccaaa
aattcatgga agacatgatg 6840ccaaaagtgg aaactttgag agccaagttc ccccatttga
atatccaagt cgatggtggt 6900ttgggcaagg agaccatccc gaaagccgcc aaagccggtg
ccaacgttat tgtcgctgga 6960accagtgttt tcactgcagc tgacccgcac gatgttatct
ccttcatgaa agaagaagtc 7020tcgaaggaat tgcgttctag agatttgcta gattagttgt
acatatgcgg catttcttat 7080atttatactc tctatactat acgatatggt atttttttct
cgttttgatc tcctaatata 7140cataaaccga gccattccta ctatacaaga tacgtaagtg
cctaactcat gggaaaaatg 7200ggccgcccag ggtggtgcct tgtccgtttt cgatgatcaa
tccctgggat gcagtatcgt 7260caatgacact ccataaggct tccttaacca aagtcaaaga
actcttcttt tcattctctt 7320tcactttctt accgccatct agatcaatat ccatttcgta
ccccgcggaa ccgccagata 7380ttcattactt gacgcaaaag cgtttgaaat aatgacgaaa
aagaaggaag aaaaaaaaag 7440aaaaataccg cttctaggcg ggttatctac tgatccgagc
ttccactagg atagcaccca 7500aacacctgca tatttggacg acctttactt acaccaccaa
aaaccacttt cgcctctccc 7560gcccctgata acgtccacta attgagcgat tacctgagcg
gtcctctttt gtttgcagca 7620tgagacttgc atactgcaaa tcgtaagtag caacgtctca
aggtcaaaac tgtatggaaa 7680ccttgtcacc tcacttaatt ctagctagcc taccctgcaa
gtcaagaggt ctccgtgatt 7740cctagccacc tcaaggtatg cctctccccg gaaactgtgg
ccttttctgg cacacatgat 7800ctccacgatt tcaacatata aatagctttt gataatggca
atattaatca aatttatttt 7860acttctttct tgtaacatct ctcttgtaat cccttattcc
ttctagctat ttttcataaa 7920aaaccaagca actgcttatc aacacacaaa cactaaatca
aaatggctgc cggtgtccca 7980aaaattgatg cgttagaatc tttgggcaat cctttggagg
atgccaagag agctgcagca 8040tacagagcag ttgatgaaaa tttaaaattt gatgatcaca
aaattattgg aattggtagt 8100ggtagcacag tggtttatgt tgccgaaaga attggacaat
atttgcatga ccctaaattt 8160tatgaagtag cgtctaaatt catttgcatt ccaacaggat
tccaatcaag aaacttgatt 8220ttggataaca agttgcaatt aggctccatt gaacagtatc
ctcgcattga tatagcgttt 8280gacggtgctg atgaagtgga tgagaattta caattaatta
aaggtggtgg tgcttgtcta 8340tttcaagaaa aattggttag tactagtgct aaaaccttca
ttgtcgttgc tgattcaaga 8400aaaaagtcac caaaacattt aggtaagaac tggaggcaag
gtgttcccat tgaaattgta 8460ccttcctcat acgtgagggt caagaatgat ctattagaac
aattgcatgc tgaaaaagtt 8520gacatcagac aaggaggttc tgctaaagca ggtcctgttg
taactgacaa taataacttc 8580attatcgatg cggatttcgg tgaaatttcc gatccaagaa
aattgcatag agaaatcaaa 8640ctgttagtgg gcgtggtgga aacaggttta ttcatcgaca
acgcttcaaa agcctacttc 8700ggtaattctg acggtagtgt tgaagttacc gaaaagtgag
cagatcaaag gcaaagacag 8760aaaccgtagt aaaggttgac ttttcacaac agtgtctcca
ttttttatat tgtattatta 8820aagctattta gttatttgga tactgttttt tttccagaag
ttttcttttt agtaaagtac 8880aatccagtaa aaatgaagga tgaacaatcg gtgtatgcag
attcaacacc aataaatgca 8940atgtttattt ctttggaacg tttgtgttgt tcgaaatcca
ggataatcct tcaacaagac 9000cctgtccgga taaggcgtta ctaccgatga cacaccaagc
tcgagtaacg gagcaagaat 9060tgaaggatat ttctgcacta aatgccaaca tcagatttaa
tgatccatgg acctggttgg 9120atggtaaatt ccccactttt gcctgatcca gccagtaaaa
tccatactca acgacgatat 9180gaacaaattt ccctcattcc gatgctgtat atgtgtataa
atttttacat gctcttctgt 9240ttagacacag aacagcttta aataaaatgt tggatatact
ttttctgcct gtggtgtcat 9300ccacgctttt aattcatctc ttgtatggtt gacaatttgg
ctatttttta acagaaccca 9360acggtaattg aaattaaaag ggaaacgagt gggggcgatg
agtgagtgat actaaaatag 9420acaccaagag agcaaagcgg tcccagcggc cgcgaattcg
gcgtaatcat ggtcatagct 9480gtttcctgtg tgaaattgtt atccgctcac aattccacac
aacatacgag ccggaagcat 9540aaagtgtaaa gcctggggtg cctaatgagt gagctaactc
acattaattg cgttgcgctc 9600actgcccgct ttccagtcgg gaaacctgtc gtgccagctg
cattaatgaa tcggccaacg 9660cgcggggaga ggcggtttgc gtattgggcg ctcttccgct
tcctcgctca ctgactcgct 9720gcgctcggtc gttcggctgc ggcgagcggt atcagctcac
tcaaaggcgg taatacggtt 9780atccacagaa tcaggggata acgcaggaaa gaacatgtga
gcaaaaggcc agcaaaaggc 9840caggaaccgt aaaaaggccg cgttgctggc gtttttccat
aggctccgcc cccctgacga 9900gcatcacaaa aatcgacgct caagtcagag gtggcgaaac
ccgacaggac tataaagata 9960ccaggcgttt ccccctggaa gctccctcgt gcgctctcct
gttccgaccc tgccgcttac 10020cggatacctg tccgcctttc tcccttcggg aagcgtggcg
ctttctcaat gctcacgctg 10080taggtatctc agttcggtgt aggtcgttcg ctccaagctg
ggctgtgtgc acgaaccccc 10140cgttcagccc gaccgctgcg ccttatccgg taactatcgt
cttgagtcca acccggtaag 10200acacgactta tcgccactgg cagcagccac tggtaacagg
attagcagag cgaggtatgt 10260aggcggtgct acagagttct tgaagtggtg gcctaactac
ggctacacta gaaggacagt 10320atttggtatc tgcgctctgc tgaagccagt taccttcgga
aaaagagttg gtagctcttg 10380atccggcaaa caaaccaccg ctggtagcgg tggttttttt
gtttgcaagc agcagattac 10440gcgcagaaaa aaaggatctc aagaagatcc tttgatcttt
tctacggggt ctgacgctca 10500gtggaacgaa aactcacgtt aagggatttt ggtcatgaga
ttatcaaaaa ggatcttcac 10560ctagatcctt ttaaattaaa aatgaagttt taaatcaatc
taaagtatat atgagtaaac 10620ttggtctgac agttaccaat gcttaatcag tgaggcacct
atctcagcga tctgtctatt 10680tcgttcatcc atagttgcct gactccccgt cgtgtagata
actacgatac gggagggctt 10740accatctggc cccagtgctg caatgatacc gcgagaccca
cgctcaccgg ctccagattt 10800atcagcaata aaccagccag ccggaagggc cgagcgcaga
agtggtcctg caactttatc 10860cgcctccatc cagtctatta attgttgccg ggaagctaga
gtaagtagtt cgccagttaa 10920tagtttgcgc aacgttgttg ccattgctac aggcatcgtg
gtgtcacgct cgtcgtttgg 10980tatggcttca ttcagctccg gttcccaacg atcaaggcga
gttacatgat cccccatgtt 11040gtgcaaaaaa gcggttagct ccttcggtcc tccgatcgtt
gtcagaagta agttggccgc 11100agtgttatca ctcatggtta tggcagcact gcataattct
cttactgtca tgccatccgt 11160aagatgcttt tctgtgactg gtgagtactc aaccaagtca
ttctgagaat agtgtatgcg 11220gcgaccgagt tgctcttgcc cggcgtcaat acgggataat
accgcgccac atagcagaac 11280tttaaaagtg ctcatcattg gaaaacgttc ttcggggcga
aaactctcaa ggatcttacc 11340gctgttgaga tccagttcga tgtaacccac tcgtgcaccc
aactgatctt cagcatcttt 11400tactttcacc agcgtttctg ggtgagcaaa aacaggaagg
caaaatgccg caaaaaaggg 11460aataagggcg acacggaaat gttgaatact catactcttc
ctttttcaat attattgaag 11520catttatcag ggttattgtc tcatgagcgg atacatattt
gaatgtattt agaaaaataa 11580acaaataggg gttccgcgca catttccccg aaaagtgcca
cctgacgtca actatacaaa 11640tgacaagttc ttgaaaacaa gaatcttttt attgtcagta
ctgattagaa aaactcatcg 11700agcatcaaat gaaactgcaa tttattcata tcaggattat
caataccata tttttgaaaa 11760agccgtttct gtaatgaagg agaaaactca ccgaggcagt
tccataggat ggcaagatcc 11820tggtatcggt ctgcgattcc gactcgtcca acatcaatac
aacctattaa tttcccctcg 11880tcaaaaataa ggttatcaag tgagaaatca ccatgagtga
cgactgaatc cggtgagaat 11940ggcaaaagct tatgcatttc tttccagact tgttcaacag
gccagccatt acgctcgtca 12000tcaaaatcac tcgcatcaac caaaccgtta ttcattcgtg
attgcgcctg agcgagacga 12060aatacgcgat cgctgttaaa aggacaatta caaacaggaa
tcgaatgcaa ccggcgcagg 12120aacactgcca gcgcatcaac aatattttca cctgaatcag
gatattcttc taatacctgg 12180aatgctgttt tgccggggat cgcagtggtg agtaaccatg
catcatcagg agtacggata 12240aaatgcttga tggtcggaag aggcataaat tccgtcagcc
agtttagtct gaccatctca 12300tctgtaacat cattggcaac gctacctttg ccatgtttca
gaaacaactc tggcgcatcg 12360ggcttcccat acaatcgata gattgtcgca cctgattgcc
cgacattatc gcgagcccat 12420ttatacccat ataaatcagc atccatgttg gaatttaatc
gcggcctcga aacgtgagtc 12480ttttccttac ccatggttgt ttatgttcgg atgtgatgtg
agaactgtat cctagcaaga 12540ttttaaaagg aagtatatga aagaagaacc tcagtggcaa
atcctaacct tttatatttc 12600tctacagggg cgcggcgtgg ggacaattca acgcgactgt
gacgcgttct agaacacaca 12660atatgcatgt aatcgctgat tttttttgtt ttagaagctc
tatcttcagg taaaaatgag 12720tagagaaaaa aaaacatact ggatcgatgc agaattaggg
ggttattatc ctgcaggtac 12780atgattttca gtgggaacat tgctttttag tagtccggtt
ctcaacaact tgtctaagtg 12840ttgaaaacaa aagaaatggc gtagaaacaa agtagtgtaa
gtaaatctgc caatgttcta 12900tgtataaaaa gtaaaggcaa gaagaggttc tatgcatatt
tctgaaaata tctaatacac 12960tattataatg catcaagaaa ctgtcgtatg atgaagtgcc
tatgagtttt tgtgtacgtg 13020cttctctagt atgtagccgg ttttctcttt ttacctcttt
ttactactta tactactact 13080tttactacct ttcttccacg taatctagat ctcaagccac
aattcttgcc ctatgctcca 13140acgtatacaa catcgaagaa gagtctttct ttagggagtc
attggaaaag atagtatgat 13200ggtattcgat ttacctatgt cgcaaaagaa agtccggggc
aacaccacag aatgctttct 13260ctgtactaat aacctgttgt gcgcttaacg gtctaatcgt
taatcagcgg tggttaaatt 13320tttgtaaatc taatgttcca tgattttctt tcttcaaaag
gaacatgtag cgaaaatctt 13380ttttttactt tgatacactg caattgtttc tgagcatgct
gaaattttct cgatgttttt 13440tttttttatt ggcatccaag taattaatcc ttatgctacg
aaaaagttgt aggaatgaat 13500catgcataat ctaacggata tcatcatata ctctgtgcta
atattctaaa caagttcgaa 13560aatattttct tggcccatgt aataggtggt aagtgtattg
ctttgatagg aacgtcatta 13620tcgcacaaga caatcggcac taataaccgt ttaaatatta
tcatgcatgt atacatcagt 13680atctcataga aatatacctg taagtacata cttatctaag
tataaattct cgacctatgg 13740agtcaccaca tttcccagca acttccccac ttcctctgca
atcgccaacg tcctctcttc 13800actgagtctc cgtccgataa cctgcactgc aaccggtgcc
ccatggtacg cctccggatc 13860atactcttcc tgcacgaggg catcaagctc actaaccgcc
ttgaaactct cattcttctt 13920atcgatgttc ttatccgcaa aggtaaccgg aacaaccacg
ctcgtgaaat ccagcaggtt 13980gatcacagag gcatacccat agtaccggaa ctggtcatgc
cgtaccgcag cggtaggcgt 14040aatcggcgcg atgatggcgt ccagttcctt cccggccttt
tcttcagcct cccgccattt 14100ctcaaggtac tccatctggt aattccactt ctggagatgc
gtgtcccaga gctcgttcat 14160gttaacagct ttgatgttcg ggttcagtag gtctttgata
tttggaatcg ccggctcgcc 14220ggatgcactg atatcgcgca ttacgtcggc gctgccgtca
gccgcgtaga tatgggagat 14280gagatcgtgg ccgaaatcgt gcttgtatgg cgtccacggg
gtcacggtgt gaccggcttt 14340ggcgagtgcg gcgacggtgg tttccacgcc gcgcaggata
ggagggtgtg gaaggacatt 14400gccgtcgaag ttgtagtagc cgatattgag cccgccgttc
ttgatcttgg aggcaataat 14460gtccgactcg gactggcgcc agggcatggg gatgaccttg
gagtcgtatt tccatggctc 14520ctgaccgagg acggatttgg tgaagaggcg gaggtcctca
acagagtgcg taatcggccc 14580gacaacgctg tgcaccgtct cctgaccctc catgctgttc
gccatctttg catacggcag 14640ccgcccatga ctcggcctta gaccgtacag gaagttgaac
gcggccggca ctcgaatcga 14700gccaccgata tccgttccta caccgatgac gccaccacga
atcccaacga tcgcaccctc 14760accaccagaa ctgccgccgc acgaccagtt cttgttgcgt
gggttgacgg tgcgcccgat 14820gatgttgttg actgtctcgc agaccatcag ggtctgcggg
acagaggtct tgacgtagaa 14880gacggcaccg gctttgcgga gcatggttgt cagaaccgag
tccccttcgt cgtacttgtt 14940tagccatgag atgtagccca ttgatgtttc gtagcccttg
actcgaagct ggtctttgag 15000agagatgggg aggccatgga gtggaccaac gggtctcttg
tgctttgcgt agtattcatc 15060gagttccctt gcctgcgcga gagcggcgtc agggaagaac
tcgtgggcgc agtttgttaa 15120ctgctgggcg attgctgccc gtttacagaa tgctagcgta
acttccaccg aggtcaactc 15180tccggccgcc agcttggaca caagatctgc agcggaggcc
tctgtgatct tcagttcggc 15240ctctgaaagg atccccgatt tctttgggaa atcaataacg
ctgtcttccg caggcagcgt 15300ctggactttc cattcatcag ggatggtttt tgcgaggcgg
gcgcgcttat cagcggccag 15360ttcttcccag gattgaggca ttgtatatga gatagttgat
tgtatgcttg gtatagcttg 15420aaatattgtg cagaaaaaga aacaaggaag aaagggaacg
agaacaatga cgaggaaaca 15480aaagattaat aattgcaggt ctatttatac ttgatagcaa
agcggcaaac tttttttatt 15540tcaaattcaa gtaactggaa ggaaggccgt ataccgttgc
tcattagaga gtagtgtgcg 15600tgaatgaagg aaggaaaaag tttcgtgtgt tcgaagatac
ccctcatcag ctctggaaca 15660acgacatctg ttggtgctgt ctttgtcgtt aattttttcc
tttagtgtct tccatcattt 15720tttttgtcat tgcggatatg gtgagacaac aacgggggag
agagaaaaga aaaaaaaaga 15780aaagaagttg catgcgccta ttattacttc aatagatggc
aaatggaaaa agggtagtga 15840aacttcgata tgatgatggc tatcaagtct agggctacag
tattagttcg ttatgtacca 15900ccatcaatga ggcagtgtaa tttgtgtagt cttgtttagc
ccattatgtc ttgtctggta 15960tctgttctat tgtatatctc ccctccgcca cctacatgtt
agggagacca acgaaggtat 16020tataggaatc ccgatgtatg ggtttggttg ccagaaaaga
ggaagtccat attgtacacc 16080cggaaacaac aaaaggatgg gcccatgacg tctaagaaac
cattattatc atgacattaa 16140cctataaaaa taggcgtatc acgaggccct ttcgtc
16176922DNAArtificial Sequencesynthetic primer
9acgccagggt tttcccagtc ac
221022DNAArtificial Sequencesynthetic primer 10caccaacctg atgggttcct ag
221122DNAArtificial
Sequencesynthetic primer 11caccaacctg atgggttcct ag
221221DNAArtificial Sequencesynthetic primer
12acggtgctga tgaagtggat g
211321DNAArtificial Sequencesynthetic primer 13accacgccca ctaacagttt g
21142559DNASaccharomyces
cerevisiae 14atgagttctg tcaaccaaat atatgaccta tttcccaata agcataatat
ccaatttaca 60gattctcatt cacaggagca tgatacttcg tccagccttg ctaagaatga
tacagacgga 120actataagta taccaggtag tatagacact ggcattttaa agagcattat
tgaggagcaa 180ggttggaatg acgctgagtt atatagaagt tcaatacaaa atcaaagatt
ttttttaacg 240gataaataca ctaaaaagaa gcatttgact atggaggaca tgcttagccc
agaagaagaa 300caaatatatc aggaacctat tcaagatttc caaacatata acaaacgtgt
tcaaagggaa 360tatgagctca gggaaaggat ggaagaattc ttccgtcaaa acaccaaaaa
tgatttacat 420attttaaacg aggattcatt aaatcagcaa tattccccgt taggacctgc
agattatgtt 480ctgcccctcg atagatactc cagaatgaaa cacattgcct caaacttttt
cagaaaaaaa 540cttggtattc ctagaaaact gaaaagaaga agccattata atcccaacgc
agagggccac 600accaaaggga attcttctat attgagttcc actactgatg taattgataa
cgccagctac 660aggaatattg caatagatga aaatgttgac ataacacata aagaacacgc
cattgacgaa 720ataaacgagc agggtgcatc aggtagtgaa tctgttgtgg aaggtggatc
gttattgcat 780gacattgaaa aggttttcaa taggtccagg gcaactagga aataccatat
ccaacggaaa 840ttaaaagtgc gccatattca aatgctttct atcggggctt gctttagtgt
cggattattt 900ttaacctcag ggaaagcctt ttctattgcc gggccatttg gtacactact
tgggtttgga 960ctcacaggta gcatcatttt agccacaatg ctgtcattta cagagttatc
cacccttatt 1020cctgtgtctt ctgggttctc aggactggct tctagatttg tagaggatgc
tttcggattt 1080gcattgggct ggacgtattg gatttcctgt atgcttgctc ttcctgccca
agtttcctca 1140agtacattct atctcagcta ttataataat gtcaatatat caaagggagt
aacagcaggg 1200tttatcacgc tgttttctgc atttagcatt gtagtaaatt tactggatgt
cagcataatg 1260ggtgaaattg tatatgttgc tggaataagc aaagtgataa ttgcaatttt
gatggttttc 1320acgatgatca tcctaaatgc cggacatgga aatgacattc acgaaggagt
cggttttaga 1380tattgggata gctctaaatc tgtccgaaat ttgacctacg ggctatatcg
tccaacattt 1440gacctggctg atgctggcga aggaagcaaa aaaggaattt caggcccaaa
aggccgattt 1500ttagctacgg catcagtaat gctaatttca acatttgcgt ttagcggtgt
tgagatgact 1560tttttagcta gtggggaagc tataaatcca aggaaaacaa ttccttctgc
tacaaaaagg 1620acattttcca ttgtactgat atcttacgtt tttttgattt tttcggtagg
catcaacata 1680tacagtggcg atccaagact actatcatat tttcctggta tttccgaaaa
gaggtatgaa 1740gccattataa aaggcacagg aatggactgg agacttagga ctaattgtcg
cggcggtatt 1800gattataggc agatttcagt aggaacaggt tattctagtc cttgggttgt
tgcattgcag 1860aactttgggc tatgtacttt cgcatctgct tttaacgcaa tactgatatt
tttcactgct 1920acagcaggga tatcctcgtt atttagttgt tcaagaacac tatacgccat
gtctgtacaa 1980cggaaggcac cgccagtttt cgaaatttgc agcaagagag gtgttcctta
tgtttcagtg 2040atattctcct ctttattttc agtcattgct tatattgcag ttgaccaaac
cgcgattgaa 2100aacttcgacg tcttggccaa tgtttctagt gctagtacgt ctattatatg
gatgggattg 2160aatctttcct ttttgcgatt ctattacgcc ctaaaacaaa ggaaggatat
tatatcaaga 2220aatgattcat catacccata taaatcgcca ttccaaccat atctagcgat
ttatggtcta 2280gttggatgtt cattatttgt tatatttatg ggatatccta actttataca
tcatttctgg 2340agtactaaag cttttttttc agcatatggt ggcctgatgt ttttctttat
cagttacaca 2400gcttataagg ttctcggaac gtcaaagatt caaagactag atcagttaga
tatggacagt 2460gggaggaggg aaatggacag aactgactgg accgaacata gccaatattt
gggaacatat 2520agggaaagag cgaagaagtt ggttacctgg ctgatttag
2559152559DNASaccharomyces cerevisiae 15atgagttctg tcaaccaaat
atatgaccta tttcccaata agcataatat ccaatttaca 60gattctcatt cacaggagca
tgatacttcg tccagccttg ctaagaatga tacagacgga 120actataagta taccaggtag
tatagacact ggcattttaa agagcattat tgaggagcaa 180ggttggaatg acgctgagtt
atatagaagt tcaatacaaa atcaaagatt ttttttaacg 240gataaataca ctaaaaagaa
gcatttgact atggaggaca tgcttagccc agaagaagaa 300caaatatatc aggaacctat
tcaagatttc caaacatata acaaacgtgt tcaaagggaa 360tatgagctca gggaaaggat
ggaagaattc ttccgtcaaa acaccaaaaa tgatttacat 420attttaaacg aggattcatt
aaatcagcaa tattccccgt taggacctgc agattatgtt 480ctgcccctcg atagatactc
cagaatgaaa cacattgcct caaacttttt cagaaaaaaa 540cttggtattc ctagaaaact
gaaaagaaga agccattata atcccaacgc agagggccac 600accaaaggga attcttctat
attgagttcc actactgatg taattgataa cgccagctac 660aggaatattg caatagatga
aaatgttgac ataacacata aagaacacgc cattgacgaa 720ataaacgagc agggtgcatc
aggtagtgaa tctgttgtgg aaggtggatc gttattgcat 780gacattgaaa aggttttcaa
taggtccagg gcaactagga aataccatat ccaacggaaa 840ttaaaagtgc gccatattca
aatgctttct atcggggctt gctttagtgt cggattattt 900ttaacctcag ggaaagcctt
ttctattgcc gggccatttg gtacactact tgggtttgga 960ctcacaggta gcatcatttt
agccacaatg ctgtcattta cagagttatc cacccttatt 1020cctgtgtctt ctgggttctc
aggactggct tctagatttg tagaggatgc tttcggattt 1080gcattgggct ggacgtattg
gatttcctgt atgcttgctc ttcctgccca agtttcctca 1140agtacattct atctcagcta
ttataataat gtcaatatat caaagggagt aacagcaggg 1200tttatcacgc tgttttctgc
atttagcatt gtagtaaatt tactggatgt cagcataatg 1260ggtgaaattg tatatgttgc
tggaataagc aaagtgataa ttgcaatttt gatggttttc 1320acgatgatca tcctaaatgc
cggacatgga aatgacattc actaaggagt cggttttaga 1380tattgggata gctctaaatc
tgtccgaaat ttgacctacg ggctatatcg tccaacattt 1440gacctggctg atgctggcga
aggaagcaaa aaaggaattt caggcccaaa aggccgattt 1500ttagctacgg catcagtaat
gctaatttca acatttgcgt ttagcggtgt tgagatgact 1560tttttagcta gtggggaagc
tataaatcca aggaaaacaa ttccttctgc tacaaaaagg 1620acattttcca ttgtactgat
atcttacgtt tttttgattt tttcggtagg catcaacata 1680tacagtggcg atccaagact
actatcatat tttcctggta tttccgaaaa gaggtatgaa 1740gccattataa aaggcacagg
aatggactgg agacttagga ctaattgtcg cggcggtatt 1800gattataggc agatttcagt
aggaacaggt tattctagtc cttgggttgt tgcattgcag 1860aactttgggc tatgtacttt
cgcatctgct tttaacgcaa tactgatatt tttcactgct 1920acagcaggga tatcctcgtt
atttagttgt tcaagaacac tatacgccat gtctgtacaa 1980cggaaggcac cgccagtttt
cgaaatttgc agcaagagag gtgttcctta tgtttcagtg 2040atattctcct ctttattttc
agtcattgct tatattgcag ttgaccaaac cgcgattgaa 2100aacttcgacg tcttggccaa
tgtttctagt gctagtacgt ctattatatg gatgggattg 2160aatctttcct ttttgcgatt
ctattacgcc ctaaaacaaa ggaaggatat tatatcaaga 2220aatgattcat catacccata
taaatcgcca ttccaaccat atctagcgat ttatggtcta 2280gttggatgtt cattatttgt
tatatttatg ggatatccta actttataca tcatttctgg 2340agtactaaag cttttttttc
agcatatggt ggcctgatgt ttttctttat cagttacaca 2400gcttataagg ttctcggaac
gtcaaagatt caaagactag atcagttaga tatggacagt 2460gggaggaggg aaatggacag
aactgactgg accgaacata gccaatattt gggaacatat 2520agggaaagag cgaagaagtt
ggttacctgg ctgatttag 2559161041DNASaccharomyces
cerevisiae 16atgaacacag attcacacaa ccttagtgag ccatacaata taggtggcca
aaaatacatt 60aatatgaaaa aaaaggaaga tcttggcgta tgccagcctg gcttaacgca
aaaggcattc 120acagtcgaag acaagttcga ttacaaagca attattgaaa aaatggaagt
atacggactt 180tgcgtggtca agaattttat agagacctcc agatgtgatg aaatattgaa
agaaatcgaa 240ccgcattttt atagatacga atcatggcaa ggctcaccgt ttcctaagga
aactactgtg 300gcaacgagat cggttttaca ctcatctaca gtcttaaagg atgtggtatg
cgaccgtatg 360ttttgtgata tctcaaaaca ttttttgaat gaagaaaact actttgcggc
gggaaaggtg 420attaataaat gcactagtga tattcaactg aactccggta tagtctacaa
ggttggcgct 480ggtgcaagtg accagggcta ccaccgagaa gatattgttc atcatacgac
ccatcaagca 540tgtgaacgtt tccagtatgg aaccgaaacc atggtagggt taggtgtagc
ttttacagat 600atgaataaag aaaatggctc tacgcgaatg atagtcggtt cacatttgtg
gggtccgcac 660gattcctgtg ggaactttga caagaggatg gaatttcacg ttaatgttgc
aaagggagac 720gcagttctat tcttagggag cctctaccat gcagccagtg caaatcgtac
gtcacaagac 780agagttgctg gatatttttt tatgacaaag agctacttga aaccagagga
aaatcttcac 840ttagggactg atttgcgagt gtttaagggt ttaccattgg aagccttgca
actgttgggg 900ctcggaatta gtgagccatt ttgtggtcac atagattata agagtccagg
acatcttatc 960agttctagtt tgtttgaaaa tgatatcgaa aaggggtact atggagagac
aataagggtg 1020aattatgggt ccacgcaata a
1041171041DNASaccharomyces cerevisiae 17atgaacacag attcacacaa
ccttagtgag ccatacaata taggtggcca aaaatacatt 60aatatgaaaa aaaaggaaga
tcttggcgta tgccagcctg gcttaacgca aaaggcattc 120acagtcgaag acaagttcga
ttacaaagca attattgaaa aaatggaagt atacggactt 180tgcgtggtca agaattttat
agagacctcc agatgtgatg aaatattgaa agaaatcgaa 240ccgcattttt atagatacga
atcatggcaa ggctcaccgt ttcctaagga aactactgtg 300gcaacgagat cggttttaca
ctcatctaca gtcttaaagg atgtggtatg cgaccgtatg 360ttttgtgata tctcaaaaca
ttttttgaat gaagaaaact actttgcggc gggaaaggtg 420attaataaat gcactagtga
tattcaactg aactccggta tagtctacaa ggttggcgct 480ggtgcaagtg accagggcta
ccaccgagaa ggtattgttc atcatacgac ccatcaagca 540tgtgaacgtt tccagtatgg
aaccgaaacc atggtagggt taggtgtagc ttttacagat 600atgaataaag aaaatggctc
tacgcgaatg atagtcggtt cacatttgtg gggtccgcac 660gattcctgtg ggaactttga
caagaggatg gaatttcacg ttaatgttgc aaagggagac 720gcagttctat tcttagggag
cctctaccat gcagccagtg caaatcgtac gtcacaagac 780agagttgctg gatatttttt
tatgacaaag agctacttga aaccagagga aaatcttcac 840ttagggactg atttgcgagt
gtttaagggt ttaccattgg aagccttgca actgttgggg 900ctcggaatta gtgagccatt
ttgtggtcac atagattata agagtccagg acatcttatc 960agttctagtt tgtttgaaaa
tgatatcgaa aaggggtact atggagagac aataagggtg 1020aattatgggt ccacgcaata a
1041181827DNASaccharomyces
cerevisiae 18atgtttaacc gtaccactca actgaaatcc aagcatccct gttccgtgtg
tacgaggcga 60aaagtcaaat gtgatcgtat gataccgtgt ggaaactgca ggaagagagg
acaggactcc 120gaatgtatga aatcaacaaa actaataacg gcttcatctt ccaaggaata
tctccctgac 180ctattgttat tctggcaaaa ttatgaatat tggataacga atattgggct
gtacaaaaca 240aaacaaagag atcttactag aacaccagct aatttggata ctgatactga
agaatgtatg 300ttttggatga attatcttca aaaagaccaa tcattccaat tgatgaactt
tgctatggaa 360aacttaggtg ctttgtattt tggttccatt ggagatatca gtgaattata
tttgagggtg 420gaacagtact gggatagaag ggcagacaag aatcacagtg tagacggcaa
atactgggac 480gcactaatat ggtctgtctt taccatgtgc atttattata tgccagtcga
gaagttagca 540gaaatatttt cagtatatcc tctccatgaa tatttgggta gcaacaaaag
gctcaattgg 600gaagatggta tgcaattagt catgtgccaa aattttgcac gctgctcatt
attccaattg 660aaacaatgtg atttcatggc gcatcccgat ataaggctcg ttcaagcata
tctgatttta 720gccactacaa ctttccccta cgatgaaccg ttgttggcaa attcgctcct
aacacagtgc 780atccatacct ttaaaaattt tcatgtggat gactttagac ctttacttaa
tgatgacccc 840gttgaaagca tcgctaaagt aaccttggga agaatattct atcgcctgtg
tggatgcgat 900tatcttcaat cggggccacg caaaccaatt gcacttcata cagaagtatc
ctccctatta 960caacatgcag catatttgca ggatttgcct aacgttgatg tttacaggga
agaaaacagc 1020acagaggtct tgtattggaa aatcatctca ttagacagag atttagatca
atacttgaac 1080aagagttcta aacctccctt aaaaacattg gatgctataa ggagggagct
cgatattttt 1140caatacaaag tagattcgtt ggaagaagat tttagatcaa ataacagcag
atttcaaaaa 1200tttattgcac tttttcaaat atctactgtt tcctggaaat tgtttaagat
gtatctcatt 1260tattatgata ccgcagattc actactaaag gttatacatt attctaaggt
aatcattagt 1320cttattgtta ataacttcca tgcaaaaagt gagtttttca acagacatcc
gatggtgatg 1380caaaccatta cgcgcgtggt ctctttcatc tccttttacc aaatttttgt
ggaatcggct 1440gctgtcaaac aacttttagt agatctaact gaacttactg caaatctgcc
cacaatattc 1500ggttcaaaac tagataaact agtttacttg accgaaaggc tcagtaaatt
aaaactttta 1560tgggacaagg tacagcttct agattcaggt gattcgtttt accatcctgt
tttcaaaata 1620ctacaaaatg atattaagat aattgagttg aaaaatgatg aaatgttttc
tctcataaaa 1680ggactcgggt ctttggtacc gttgaataag cttagacaag aatcgttgct
tgaggaagag 1740gacgaaaaca atacggaacc aagtgacttc agaactattg tagaagagtt
tcaatccgaa 1800tataacattt ctgacatact ttcctaa
1827191827DNASaccharomyces cerevisiae 19atgtttaacc gtaccactca
actgaaatcc aagcatccct gttccgtgtg tacgaggcga 60aaagtcaaat gtgatcgtat
gataccgtgt ggaaactgca ggaagagagg acaggactcc 120gaatgtatga aatcaacaaa
actaataacg gcttcatctt ccaaggaata tctccctgac 180ctattgttat tctggcaaaa
ttatgaatat tggataacga atattgggct gtacaaaaca 240aaacaaagag atcttactag
aacaccagct aatttggata ctgatactga agaatgtatg 300ttttggatga attatcttca
aaaagaccaa tcattccaat tgatgaactt tgctatggaa 360aacttaggtg ctttgtattt
tggttccatt ggagatatca gtgaattata tttgagggtg 420gaacagtact gggatagaag
ggcagacaag aatcacagtg tagacggcaa atactgggac 480gcactaatat ggtctgtctt
taccatgtgc atttattata tgccagtcga gaagttagca 540gaaatatttt cagtatatcc
tctccatgaa tatttgggta gcaacaaaag gctcaattgg 600gaagatggta tgcaattagt
catgtgccaa aattttgcac gctgctcatt attccaattg 660aaacaatgtg atttcatggc
gcatcccgat ataaggctcg ttcaagcata tctgatttta 720gccactacaa ctttccccta
cgatgaaccg ttgttggcaa attcgctcct aacacagtgc 780atccatacct ttaaaaattt
tcatgtggat gactttagac ctttacttaa tgatgacccc 840gttgaaagca tcgctaaagt
aaccttggga agaatattct atcgcctgtg tggatgcgat 900tatcttcaat cggggccacg
caaaccaatt gcacttcata cagaagtatc ctccctatta 960caacatgcag catatttgca
ggatttgcct aacgttgatg tttacaggga agaaaacagc 1020acagaggtct tgtattggaa
aatcatctca ttagacagag atttagatca atacttgaac 1080aagagttcta aacctccctt
aaaaacattg gatgctataa ggagggagct cgatattttt 1140caatacaaag tagattcgtt
ggaagaagat tttagatcaa ataacggcag atttcaaaaa 1200tttattgcac tttttcaaat
atctactgtt tcctggaaat tgtttaagat gtatctcatt 1260tattatgata ccgcagattc
actactaaag gttatacatt attctaaggt aatcattagt 1320cttattgtta ataacttcca
tgcaaaaagt gagtttttca acagacatcc gatggtgatg 1380caaaccatta cgcgcgtggt
ctctttcatc tccttttacc aaatttttgt ggaatcggct 1440gctgtcaaac aacttttagt
agatctaact gaacttactg caaatctgcc cacaatattc 1500ggttcaaaac tagataaact
agtttacttg accgaaaggc tcagtaaatt aaaactttta 1560tgggacaagg tacagcttct
agattcaggt gattcgtttt accatcctgt tttcaaaata 1620ctacaaaatg atattaagat
aattgagttg aaaaatgatg aaatgttttc tctcataaaa 1680ggactcgggt ctttggtacc
gttgaataag cttagacaag aatcgttgct tgaggaagag 1740gacgaaaaca atacggaacc
aagtgacttc agaactattg tagaagagtt tcaatccgaa 1800tataacattt ctgacatact
ttcctaa 1827201464DNASaccharomyces
cerevisiae 20atgcgattcc atcgtcaagg tatctcagcc atcataggcg tactactcat
tgtactgctt 60ggtttctgtt ggaagttatc tggatcttac ggcatagtat caactgccct
accacacaat 120caatctgcaa ttaaaagcac agacttacct tctatacgat gggataatta
ccatgagttc 180gtcagagaca ttgattttga taacagtacg gctatcttta attccattcg
ggctgcttta 240agacagtctc catcggatat acatcctgtc ggagtatctt attttcccgc
tgtaattccc 300aaaggaactt taatgtacca tgccggatca aaagtgccaa ctaccttcga
atggctagct 360atggaccatg aattcagcta ctctttcggc ttgaggtcac catcctatgg
gagaaaatct 420ttggaaagaa ggcatgggag gttcggcaat ggcaccaacg gtgatcatcc
aaaagggcca 480ccaccaccac caccaccacc agacgaaaaa ggtcggggtt cacaaaaaat
gcttacttat 540agagcagcac gggacctcaa caaatttctc tatcttgatg gggcttctgc
tgcgaaaact 600gactcaggag agatggacac gcagctaatg ttgtcaaatg ttattaaaga
gaaattgaac 660cttacagatg atggtgaaaa cgaacgaatg gccgaacgac tctacgctgc
tagaatatgc 720aaatggggga agccattcgg gcttgacgga attatcaggg tagaggttgg
ctttgaggtc 780gttttgtgtg atttttcggc tgataacgtc gaacttgttt caatgttaga
aatggtccag 840cctaaccagt acctaggctt accagcacct accgtaatat cgaaggaaga
aggttggcct 900ctggatgaaa atggaagcct agttgaagat cagctaacag atgaccaaaa
ggcgattctg 960gaaagagaag atggttggga gaaggctttt tctaatttca acgcagttaa
aagcttcaat 1020cagttgagag cgggtgcagc gcatgacaac ggggagcatc gaatccatat
cgactatagg 1080tacctagtga gcgggataaa caggacgtac attgctcctg atcctaacaa
cagaagatta 1140ctcgatgaag gaatgacatg ggaaaagcaa ttggacatgg tagatgactt
agaaaaggcg 1200ctggaagtcg gatttgatgc cacgcaaagt atggattggc agttagcatt
tgatgagctt 1260gtccttaaat ttgctccatt actaaaatct gttagtaaca tactgaacag
cgatggtgat 1320attaatgagt caattgccat caatgcaaca gcactcacat tgaacttttg
tctaccaata 1380tgtgagccca taccaggcct taaaaacgga tgcagacttt ttgatttggt
catctgctgt 1440cagcgttgtc ggagaaattg ttga
1464211464DNASaccharomyces cerevisiae 21atgcgattcc atcgtcaagg
tatctcagcc atcataggcg tactactcat tgtactgctt 60ggtttctgtt ggaagttatc
tggatcttac ggcatagtat caactgccct accacacaat 120caatctgcaa ttaaaagcac
agacttacct tctatacgat gggataatta ccatgagttt 180gtcagagaca ttgattttga
taacagtacg gctatcttta attccattcg ggctgcttta 240agacagtctc catcggatat
acatcctgtc ggagtatctt attttcccgc tgtaattccc 300aaaggaactt taatgtacca
tgccggatca aaagtgccaa ctaccttcga atggctagct 360atggaccatg aattcagcta
ctctttcggc ttgaggtcac catcctatgg gagaaaatct 420ttggaaagaa ggcatgggag
gttcggcaat ggcaccaacg gtgatcatcc aaaagggcca 480ccaccaccac caccaccacc
agacgaaaaa ggtcggggtt cacaaaaaat gcttacttat 540agagcagcac gggacctcaa
caaatttctc tatcttgatg gggcttctgc tgcgaaaact 600gactcaggag agatggacac
gcagctaatg ttgtcaaatg ttattaaaga gaaattgaac 660cttacagatg atggtgaaaa
cgaacgaatg gccgaacgac tctacgctgc tagaatatgc 720aaatggggga agccattcgg
gcttgacgga attatcaggg tagaggttgg ctttgaggtc 780gttttgtgtg atttttcggc
tgataacgtc gaacttgttt caatgttaga aatggtccag 840cctaaccagt acctaggctt
accagcacct accgtaatat cgaaggaaga aggttggcct 900ctggatgaaa atggaagcct
agttgaagat cagctaacag atgaccaaaa ggcgattctg 960gaaagagaag atggttggga
gaaggctttt tctaatttca acgcagttaa aagcttcaat 1020cagttgagag cgggtgcagc
gcatgacaac ggggagcatc gaatccatat cgactatagg 1080tacctagtga gcgggataaa
caggacgtac attgctcctg atcctaacaa cagaagatta 1140ctcgatgaag gaatgacatg
ggaaaagcaa ttggacatgg tagatgactt agaaaaggcg 1200ctggaagtcg gatttgatgc
cacgcaaagt atggattggc agttagcatt tgatgagctt 1260gtccttaaat ttgctccatt
actaaaatct gttagtaaca tactgaacag cgatggtgat 1320attaatgagt caattgccat
caatgcaaca gcactcacat tgaacttttg tctaccaata 1380tgtgagccca taccaggcct
taaaaacgga tgcagacttt ttgatttggt catctgctgt 1440cagcgttgtc ggagaaattg
ttga 1464221308DNASaccharomyces
cerevisiae 22atggactaca acaagagatc ttcggtctca accgtgccta atgcagctcc
cataagagtc 60ggattcgtcg gtctcaacgc agccaaagga tgggcaatca agacacatta
ccccgccata 120ctgcaactat cgtcacaatt tcaaatcact gccttataca gtccaaaaat
tgagacttct 180attgccacca ttcagcgtct aaaattgagt aatgccactg cttttcccac
tttagagtca 240tttgcatcat cttccactat agatatgata gtgatagcta tccaagtggc
cagccattat 300gaagttgtta tgcctctctt ggaattctcc aaaaataatc cgaacctcaa
gtatcttttc 360gtagaatggg cccttgcatg ttcactagat caagccgaat ccatttataa
ggctgctgct 420gaacgtgggg ttcaaaccat catctcttta caaggtcgta aatcaccata
tattttgaga 480gcaaaagaat taatatctca aggctatatc ggcgacatta attcgatcga
gattgctgga 540aatggcggtt ggtacggcta cgaaaggcct gttaaatcac caaaatacat
ctatgaaatc 600gggaacggtg tagatctggt aaccacaaca tttggtcaca caatcgatat
tttacaatac 660atgacaagtt cgtacttttc caggataaat gcaatggttt tcaataatat
tccagagcaa 720gagctgatag atgagcgtgg taaccgattg ggccagcgag tcccaaagac
agtaccggat 780catcttttat tccaaggcac attgttaaat ggcaatgttc cagtgtcatg
cagtttcaaa 840ggtggcaaac ctaccaaaaa atttaccaaa aatttggtca ttgacattca
cggtaccaag 900ggagatttga aacttgaagg cgatgccggc ttcgcagaaa tttcaaatct
ggtcctttac 960tacagtggaa ctagagcaaa cgacttcccg ctagccaatg gacaacaagc
tcctttagac 1020ccggggtatg atgcaggtaa agaaatcatg gaagtatatc atttacgaaa
ttataatgcc 1080attgtgggta atattcatcg actgtatcaa tctatctctg acttccactt
caatacaaag 1140aaaattcctg aattaccctc acaatttgta atgcaaggtt tcgatttcga
aggctttccc 1200accttgatgg atgctctgat attacacagg ttaatcgaga gcgtttataa
aagtaacatg 1260atgggctcca cattaaacgt tagcaatatc tcgcattata gtttataa
1308231308DNASaccharomyces cerevisiae 23atggactaca acaagagatc
ttcggtctca accgtgccta atgcagctcc cataagagtc 60ggattcgtcg gtctcaacgc
agccaaagga tgggcaatca agacacatta ccccgccata 120ctgcaactat cgtcacaatt
tcaaatcact gccttataca gtccaaaaat tgagacttct 180attgccacca ttcagcgtct
aaaattgagt aatgccactg cttttcccac tttagagtca 240tttgcatcat cttccactat
agatatgata gtgatagcta tccaagtggc cagccattat 300gaagttgtta tgcctctctt
ggaattctcc aaaaataatc cgaacctcaa gtatcttttc 360gtagaatggg cccttgcatg
ttcactagat caagccgaat ccatttataa ggctgctgct 420gaacgtgggg ttcaacccat
catctcttta caaggtcgta aatcaccata tattttgaga 480gcaaaagaat taatatctca
aggctatatc ggcgacatta attcgatcga gattgctgga 540aatggcggtt ggtacggcta
cgaaaggcct gttaaatcac caaaatacat ctatgaaatc 600gggaacggtg tagatctggt
aaccacaaca tttggtcaca caatcgatat tttacaatac 660atgacaagtt cgtacttttc
caggataaat gcaatggttt tcaataatat tccagagcaa 720gagctgatag atgagcgtgg
taaccgattg ggccagcgag tcccaaagac agtaccggat 780catcttttat tccaaggcac
attgttaaat ggcaatgttc cagtgtcatg cagtttcaaa 840ggtggcaaac ctaccaaaaa
atttaccaaa aatttggtca ttgacattca cggtaccaag 900ggagatttga aacttgaagg
cgatgccggc ttcgcagaaa tttcaaatct ggtcctttac 960tacagtggaa ctagagcaaa
cgacttcccg ctagccaatg gacaacaagc tcctttagac 1020ccggggtatg atgcaggtaa
agaaatcatg gaagtatatc atttacgaaa ttataatgcc 1080attgtgggta atattcatcg
actgtatcaa tctatctctg acttccactt caatacaaag 1140aaaattcctg aattaccctc
acaatttgta atgcaaggtt tcgatttcga aggctttccc 1200accttgatgg atgctctgat
attacacagg ttaatcgaga gcgtttataa aagtaacatg 1260atgggctcca cattaaacgt
tagcaatatc tcgcattata gtttataa 13082427DNAArtificial
SequenceSynthetic DNA 24tggatgtcag cataatgggt gaaattg
272519DNAArtificial SequenceSynthetic DNA
25cgccagcatc agccaggtc
192627DNAArtificial SequenceSynthetic DNA 26tctacagtct taaaggatgt ggtatgc
272725DNAArtificial
SequenceSynthetic DNA 27atgcttgatg ggtcgtatga tgaac
252823DNAArtificial SequenceSynthetic DNA
28cattggatgc tataaggagg gag
232924DNAArtificial SequenceSynthetic DNA 29ctttagtagt gaatctgcgg tatc
243027DNAArtificial
SequenceSynthetic DNA 30agcacagact taccttctat acgatgg
273126DNAArtificial SequenceSynthetic DNA
31cagcccgaat ggaattaaag atagcc
263225DNAArtificial SequenceSynthetic DNA 32atgttcacta gatcaagccg aatcc
253322DNAArtificial
SequenceSynthetic DNA 33ccaaccgcca tttccagcaa tc
223431DNAArtificial SequenceSynthetic DNA
34ccggacatgg aaatgacatt cacgaaggag t
313523DNAArtificial SequenceSynthetic DNA 35ccaccgagaa gatattgttc atc
233621DNAArtificial
SequenceSynthetic DNA 36gatcaaataa cagcagattt c
213735DNAArtificial SequenceSynthetic DNA
37gataattacc atgagttcgt cagagacatt gattt
353821DNAArtificial SequenceSynthetic DNA 38cgtggggttc aaaccatcat c
213927DNAArtificial
SequenceSynthetic DNA 39ccccaccttg accacgtttt gcacatc
274028DNAArtificial SequenceSynthetic DNA
40ccccttcaat ccgtcttcga cacataac
284125DNAArtificial SequenceSynthetic DNA 41ggggatggag actgtggttg agaag
254224DNAArtificial
SequenceSynthetic DNA 42gggcatgtcg tcattttgtc tcgg
244321DNAArtificial SequenceSynthetic DNA
43gttacgtcgc cttggacttc g
214421DNAArtificial SequenceSynthetic DNA 44cggcaatacc tgggaacatg g
214523DNAArtificial
SequenceSynthetic DNA 45gaagtctgtt gctaaggatg cgc
234623DNAArtificial SequenceSynthetic DNA
46tcataccgag actccaagtc agc
234721DNAArtificial SequenceSynthetic DNA 47gtaagaagaa ttgcacggtc c
214821DNAArtificial
SequenceSynthetic DNA 48taccttggtg tcttggtcta c
214922DNAArtificial SequenceSynthetic DNA
49gatagagact ggcacaggat tg
225021DNAArtificial SequenceSynthetic DNA 50acaatactcc aaagctacac c
215121DNAArtificial
SequenceSynthetic DNA 51ggttaaatcg cgacaacaca g
215221DNAArtificial SequenceSynthetic DNA
52cgatatcaaa gggcgttagg c
215321DNAArtificial SequenceSynthetic DNA 53cgtgtatctg ctggacctaa g
215421DNAArtificial
SequenceSynthetic DNA 54tcagcgccgt taggagaaac c
215523DNAArtificial SequenceSynthetic DNA
55agtcacatca agatcgttta tgg
235623DNAArtificial SequenceSynthetic DNA 56actccacttc aagtaagagt ttg
235723DNAArtificial
SequenceSynthetic DNA 57gcacggaata tgggactact tcg
235882DNAArtificial SequenceSynthetic DNA
58atggactaca acaagagatc ttcggtctca accgtgccta atgcagctcc cataagagtc
60agacgcgttg aattgtcccc ac
825986DNAArtificial SequenceSynthetic DNA 59catgttactt ttataaacgc
tctcgattaa cctgtgtaat atcagagcat ccatcaaggt 60acaaatgaca agttcttgaa
aacaag 866019DNAArtificial
SequenceSynthetic DNA 60cggcattatt gtgtatggc
196175DNAArtificial SequenceSynthetic DNA
61attttttgga aattaccaaa atcttgttcc cttattcttg gctcatcctt agggtttcaa
60agatccatac ttctc
756271DNAArtificial SequenceSynthetic DNA 62cagttttaaa aagtcagaga
atgtagagaa gtatggatct ttgaaaccct aaggatgagc 60caagaataag g
716326DNAArtificial
SequenceSynthetic DNA 63tggttgccat ctttagagct tccgtg
266419DNAArtificial SequenceSynthetic DNA
64ggatccactg gtagagagc
196520DNAArtificial SequenceSynthetic DNA 65actagtaaac gtgtgtgtgc
206620DNAArtificial
SequenceSynthetic DNA 66atatgaaacg cacacaagtc
206754DNAArtificial SequenceSynthetic DNA
67gaattcgtcg acctgcagcg tacgattctt agtatatata tactgctcaa gggc
546875DNAArtificial SequenceSynthetic DNA 68atttccaaag taattgcatt
tgcccttgag cagtatatat atactaagaa tcgtacgctg 60caggtcgacg aattc
756975DNAArtificial
SequenceSynthetic DNA 69gttaattcca ggattgaaag gaagtgtcga atagtatagt
atgctttcta taggccacta 60gtggatctga tatcg
757056DNAArtificial SequenceSynthetic DNA
70cgatatcaga tccactagtg gcctatagaa agcatactat actattcgac acttcc
567124DNAArtificial SequenceSynthetic DNA 71caagctgctt ttacttagct aaac
247220DNAArtificial
SequenceSynthetic DNA 72ttccctttta cagtgcttcg
207320DNAArtificial SequenceSynthetic DNA
73tgagggtgtg tacattgcag
207423DNAArtificial SequenceSynthetic DNA 74tttactcatc tcatctcatc aag
237570DNAArtificial
SequenceSynthetic DNA 75accctttacg tcctggttgt cccttcccgc cttgatttgg
ccttcatttt tctcaaaatt 60caccaacctc
707671DNAArtificial SequenceSynthetic DNA
76agttacatgc atgatgaata tgcgccatga gaggttggtg aattttgaga aaaatgaagg
60ccaaatcaag g
717724DNAArtificial SequenceSynthetic DNA 77ttttcactat cgggtgagaa tatc
247823DNAArtificial
SequenceSynthetic DNA 78gactatgtga tgccataggc aag
237923DNAArtificial SequenceSynthetic DNA
79gtaaaaaaag catgcacgta tac
238023DNAArtificial SequenceSynthetic DNA 80tctatcttca tcgtcattca ttg
238175DNAArtificial
SequenceSynthetic DNA 81atcttacata gtgtcgggaa caggtcattc taaaaaaagt
aaaataaaat tccaccgcgg 60tggcggccgc tctag
758265DNAArtificial SequenceSynthetic DNA
82ctagagcggc cgccaccgcg gtggaatttt attttacttt ttttagaatg acctgttccc
60gacac
658324DNAArtificial SequenceSynthetic DNA 83cacaagctta ttcttccaaa aatc
24842916DNAArtificial
SequenceSynthetic DNA 84cagttttaaa aagtcagaga atgtagagaa gtatggatct
ttgaaaccct aaggatgagc 60caagaataag ggaacaagat tttggtaatt tccaaaaaat
caatagcatg caggacgtta 120tgaagaagag atctacgtat ggtcatttct tcttcagatt
ccctcatgga gaaagtgcgg 180cagatgtata tgacagagtc gccagtttcc aagagacttt
attcaggcac ttccatgata 240ggcaagagag aagacccaga gatgttgttg tcctagttac
acatggtatt tattccagag 300tattcctgat gaaatggttt agatggacat acgaagagtt
tgaatcgttt accaatgttc 360ctaacgggag cgtaatggtg atggaactgg acgaatccat
caatagatac gtcctgagga 420ccgtgctacc caaatggact gattgtgagg gagacctaac
tacatagtgt ttaaagatta 480cggatattta acttacttag aataatgcca tttttttgag
ttataataat cctacgttag 540tgtgagcggg atttaaactg tgaggacctt aatacattca
gacacttctg cggtatcacc 600ctacttattc ccttcgagat tatatctagg aacccatcag
gttggtggaa gattacccgt 660tctaagactt ttcagcttcc tctattgatg ttacacctgg
acaccccttt tctggcatcc 720agtttttaat cttcagtggc atgtgagatt ctccgaaatt
aattaaagca atcacacaat 780tctctcggat accacctcgg ttgaaactga caggtggttt
gttacgcatg ctaatgcaaa 840ggagcctata tacctttggc tcggctgctg taacagggaa
tataaagggc agcataattt 900aggagtttag tgaacttgca acatttacta ttttcccttc
ttacgtaaat atttttcttt 960ttaattctaa atcaatcttt ttcaattttt tgtttgtatt
cttttcttgc ttaaatctat 1020aactacaaaa aacacataca taaactaaaa atgttgaacg
cttacatcta cgatggtttg 1080agaactccat tcggtagaca tgccggtgaa ttggcttcca
tcagaccaga tgacttggct 1140ggtttagtca tccaaagatt gattgaaaag accggtgttg
ctggtgctga cattgaagat 1200gtcatcttcg gtgacaccaa ccaagctggt gaagattcca
gaaacattgc ccgtcacgct 1260gctttgttgg ctggtttgcc agttaccgtt ccaggtcaaa
ccgtcaacag attatgtgct 1320tctggtttag ctgccatcat tgactctgcc agagccatca
cctgtggtga aggtgactta 1380tacattgctg gtggtgttga atccatgtcc agagctccat
tcgtcatggg taaggctgaa 1440tctgcttact ccagagatgc caagatctac gacaccacca
ttggtaccag attcccaaac 1500aagaagattg ttgctcaata cggtggtcac tccatgccag
aaaccggtga caacgttgct 1560gtcgaatacg gtatctccag agaacaagct gacttattcg
ctgctcaatc tcaagccaag 1620taccaaaagg ctttggaaga aggtttcttt gctggtgaaa
tcactgctgt cgaagtttct 1680caaggtaaga aattgcctcc aaagcaagtc actgaagatg
aacacccaag accatcttcc 1740actttggaag ctctatccaa gttgaagcca ttgttcgaag
gtggtgttgt cactgctggt 1800aacgcttctg gtatcaacga tggtgctgct gctttgttga
ttggttctga agttgccggt 1860caaaagtacg gtttgactcc aatggccaag atcttgtctg
ctgctgctgc tggtgttgaa 1920ccaagaatca tgggtgctgg tccaattgaa gccatcaaga
aggctgttgc cagagctggt 1980ttgactttgg atgacttgga catcattgaa atcaacgaag
cctttgcttc tcaagtcttg 2040tcttgtttga aaggtttggg tattgacttc aacgacccaa
gagtcaaccc aaacggtggt 2100gccattgctg tcggtcaccc attgggtgct tctggtgctc
gtttggcttt gactgttgcc 2160cgtgaattgc aaagaagaaa caagaaatac gctgttgttt
ctctatgtat cggtgtcggt 2220caaggtttgg ctatggttat cgaaaatgta tcataagtaa
ggagttaaag gcaaagtttt 2280ctttactaga gccgttccca caaataatta tacgtatatg
cttcttttcg tttactatat 2340atctatattt acaagccttt attcactgat gcaatttgtt
tccaaatact tttttggaga 2400tctcataact agatatgatg atggcgcaac ttgggcgtat
cttaattact ctggctgcca 2460ggcccgtgta gagggccgca agaccttctg tacgccatat
agtctctaag aacttgaaca 2520tgttactaga cctattgccg cctttcggat cgctattgtt
catcatggat atttgccatc 2580tcgtcttacc gacatcaaaa gggtgtgtgc atatagcagc
tatcatccca cttatgcaac 2640cactggcaaa actgtttata aaatggaccc agtttgcgtc
cttagatgca aatcgagtag 2700aatctagcca tagtctttcc ttgcaaagtt cataggaact
ccaatatatt gcactaaacg 2760ggatccactg gtagagagcg actttgtatg ccccaattgc
gaaacccgcg ttatccttct 2820cgattcttta gtacccgacc aggacaagga aaaggaggtc
gaaacgtttt tgaagaaaca 2880agaggaacta cacggaagct ctaaagatgg caacca
2916853034DNAArtificial SequenceSynthetic DNA
85ggatccactg gtagagagcg actttgtatg ccccaattgc gaaacccgcg ttatccttct
60cgattcttta gtacccgacc aggacaagga aaaggaggtc gaaacgtttt tgaagaaaca
120agaggaacta cacggaagct ctaaagatgg caaccagcca gaaactaaga aaatgaagtt
180gatggttcca actggcaccg ctggcttgaa caacaatacc agccttccaa cttctgtaaa
240taacggcggt acgccagtgc caccagtacc gttacctttc ggtatacctc ctttccccat
300gtttccaatg cccttcatgc ctccaacggc tactatcaca aatcctcatc aagctgacgc
360aagccctaag aaatgaataa caatactgac agtactaaat aattgcctac ttggcttcac
420atacgttgca tacgtcgata tagataataa tgataatgac agcaggatta tcgtaatacg
480taatagttga aaatctcaaa aatgtgtggg tcattacgta aataatgata ggaatgggat
540tcttctattt ttcctttttc cattctagca gccgtcggga aaacgtggca tcctctcttt
600cgggctcaat tggagtcacg ctgccgtgag catcctctct ttccatatct aacaactgag
660cacgtaacca atggaaaagc atgagcttag cgttgctcca aaaaagtatt ggatggttaa
720taccatttgt ctgttctctt ctgactttga ctcctcaaaa aaaaaaaatc tacaatcaac
780agatcgcttc aattacgccc tcacaaaaac ttttttcctt cttcttcgcc cacgttaaat
840tttatccctc atgttgtcta acggatttct gcacttgatt tattataaaa agacaaagac
900ataatacttc tctatcaatt tcagttattg ttcttccttg cgttattctt ctgttcttct
960ttttcttttg tcatatataa ccataaccaa gtaatacata ttcaaaatga cccacccaat
1020caagaagatt gccatcatcg gtgtcggtgt catgggttcc ggtattgctc aaattgctgc
1080tcaatctggt cacatcactt acttatacga tgctaaggct ggtgctgctc aacaagctaa
1140gcaacaattg gccatcactt tccaaaaatt gttggacaag aacaagatca ccactgaata
1200cgctgatgct gctaacgcta acttgttgat tgctaacgaa ttgcacgatt tgaaggactg
1260tgacttgatt gtcgaagcca ttgttgaaag attagatatt aaacaatctt tgatgtccca
1320attggaagcc atcgttccag aaaccaccat cttggcttct aacacctctt ctttgtccat
1380cactgccatt gcttccaact gtaagcatcc agaaagagtt gctggttacc atttcttcaa
1440cccagttcca ttgatgaagg ttgttgaagt catccaaggt ttgaaaactg acccaaagca
1500cattgaaact ttgaaccaat tgtccagagt cttaggtcac agacctgttg ttgccaagga
1560caccccaggt ttcatcatca accacgctgg tagagcttac ggtactgaag ccttgaaaat
1620cttgaatgaa aacgttaccg acatctctga aatcgacaga atcttgcgtg acggtgttgg
1680tttcagaatg ggtccatttg aattgatgga cttgactggt ttagatgtct cccacccagt
1740catggaatcc atttaccatc aatactacga agaagctcgt tacagaccaa actctttgac
1800caagcaaatg ttggaagcta agcaattagg tagaaaggtc ggtcaaggtt tctacgacta
1860cagaaccggt tccaagactg gtgaaacttc tgccaaggtt gctgaaagat tgactttgta
1920cccaaaggtc tggattgctg ctgacttcga agatgacaaa caattgttga tcaactattt
1980gaccacccac aacattcaat tggatgtcgg tgccaagcct caagctgact ctttgtgtct
2040attagcttgt tacggtgaag ataccactca cgctgctttg agattaaacg tcaacccagc
2100tcactctgtt gccattgaca tgttgtacgg tatcgaaaag cacagaactt tgatgccatc
2160tttgatcact gaagtcacct actctcacgc tgctcactcc atcttcaact tggatggtgc
2220catggtttcc actatcggtg aatctattgg tttcgttgct caaagaatct tagctatggt
2280tatcaacttg ggttgtgaca ttgctcaaca agccattgct tctgtcgatg acattaatgc
2340tgctgtccgt ttgggtctag gttacccatt cggtccaatc gaatggggtg atgaaattgg
2400ttccaacaag atcttgttga tcttgaacag aatcactgct ttgacctctg acccaagata
2460cagaccatct ccatggttac aaagaagagt tgctttgaac ttgccattga cctttacgac
2520ctaagtaagc tcctgttgaa gtagcattta atcataattt ttgtcacatt ttaatcaact
2580tgatttttct ggtttaattt ttctaatttt aattttaatt tttttatcaa tgggaactga
2640tacactaaaa agaattagga gccaacaaga ataagccgct tatttcctac tagagtttgc
2700ttaaaatttc atctcgaatt gtcattctaa tattttatcc acacacacac cttaaaattt
2760ttagattaaa tggcatcaac tcttagcttc acacacacac acacaccgaa gctggttgtt
2820ttatttgatt tgatataatt ggtttctctg gatggtactt tttctttctt ggttatttcc
2880tattttaaaa tatgaaacgc acacaagtca taattattct aatagagcac aattcacaac
2940acgcacattt caactttaat atttttttag aaacacttta tttagtctaa ttcttaattt
3000ttaatatata taatgcacac acacgtttac tagt
3034862460DNAArtificial SequenceSynthetic DNA 86atatgaaacg cacacaagtc
ataattattc taatagagca caattcacaa cacgcacatt 60tcaactttaa tattttttta
gaaacacttt atttagtcta attcttaatt tttaatatat 120ataatgcaca cacacgttta
ctagtaaggt gagacgcgca taaccgctag agtactttga 180agaggaaaca gcaatagggt
tgctaccagt ataaatagac aggtacatac aacactggaa 240atggttgtct gtttgagtac
gctttcaatt catttgggtg tgcactttat tatgttacaa 300tatggaaggg aactttacac
ttctcctatg cacatatatt aattaaagtc caatgctagt 360agagaagggg ggtaacaccc
ctccgcgctc ttttccgatt tttttctaaa ccgtggaata 420tttcggttat ccttttgttg
tttccgggtg tacaatatgg acttcctctt ttctggcaac 480caaacccata catcgggatt
cctataatac cttcgttggt ctccctaaca tgtaggtggc 540ggaggggaga tatacaatag
aacagatacc agacaagaca taatgggcta aacaagacta 600caccaattac actgcctcat
tgatggtggt acataacgaa ctaatactgt agccctagac 660ttgatagcca tcatcatatc
gaagtttcac tacccttttt ccatttgcca tctattgaag 720taataatagg cgcatgcaac
ttcttttctt tttttttctt ttctctctcc cccgttgttg 780tctcaccata tccgcaatga
caaaaaaatg atggaagaca ctaaaggaaa aaattaacga 840caaagacagc accaacagat
gtcgttgttc cagagctgat gaggggtatc tcgaagcaca 900cgaaactttt tccttccttc
attcacgcac actactctct aatgagcaac ggtatacggc 960cttccttcca gttacttgaa
tttgaaataa aaaaaagttt gctgtcttgc tatcaagtat 1020aaatagacct gcaattatta
atcttttgtt tcctcgtcat tgttctcgtt ccctttcttc 1080cttgtttctt tttctgcaca
atatttcaag ctataccaag catacaatca actatctcat 1140atacaatgat tccagaccaa
gacaactttg ttgaaatcga cttctccatt gaacaaatcg 1200ctattgtcaa gatcaacaga
ccagcttcca agaacgcttt gaacactgaa gtcagaaagc 1260aattggctca agccttcacc
gaattgtctt tcaacgacca aatcaacgcc attgttttga 1320ctggtggtga agatgttttc
gctgctggtg ctgacttgaa ggaaatggct accgcttctt 1380ccactgacat gttgttgaga
cacactgaac gttactggaa cgccattgct caatgtccaa 1440agccagttat cgctgctgtc
aacggttacg ctttaggtgg tggttgtgaa ttggccatgc 1500acactgacat catcattgct
ggtaaatctg ccacctttgg tcaaccagaa atcaaggtcg 1560gtttgatgcc aggtgctggt
ggtacccaaa gattattcag agctgttggt aaattccacg 1620ctatgagaat gatcatgacc
ggtgtcatgg ttcctgctga agaagcctac ttgattggtt 1680tggtttctca agtcactgaa
gattctcaaa ccattccaac tgccatcaag atggctcaat 1740ctttggccaa gatgccacca
attgctttgc aacaaatcaa ggaagttgct ttgatgtccg 1800aagatgtccc attgaacgct
ggtttgactt tggaaagaaa gtctttccaa ttattattct 1860ccactgaaga taagaacgaa
ggtatcaatg ctttcatcga aaagagaaag ccatcttacc 1920atggaaaata agtaaataaa
gcaatcttga tgaggataat gatttttttt tgaatataca 1980taaatactac cgtttttctg
ctagattttg tgaagacgta aataagtaca tattactttt 2040taagccaaga caagattaag
cattaacttt acccttttct cttctaagtt tcaattctag 2100ttatcactgt ttaaaagtta
tggcgagaac gtcggcggtt aaaatatatt accctgaacg 2160tggtgaattg aagttctagg
atggtttaaa gatttttcct ttttgggaaa taagtaaaca 2220atatattgct gcctttgcaa
aacgcacata cccacaatat gtgactattg gcaaagaacg 2280cattatcctt tgaagaggtg
gatactgata ctaagagagt ctctattccg gctccacttt 2340tagtccagag attacttgtc
ttcttacgta tcagaacaag aaagcatttc caaagtaatt 2400gcatttgccc ttgagcagta
tatatatact aagaatcgta cgctgcaggt cgacgaattc 2460872460DNAArtificial
SequenceSynthetic DNA 87atatgaaacg cacacaagtc ataattattc taatagagca
caattcacaa cacgcacatt 60tcaactttaa tattttttta gaaacacttt atttagtcta
attcttaatt tttaatatat 120ataatgcaca cacacgttta ctagtaaggt gagacgcgca
taaccgctag agtactttga 180agaggaaaca gcaatagggt tgctaccagt ataaatagac
aggtacatac aacactggaa 240atggttgtct gtttgagtac gctttcaatt catttgggtg
tgcactttat tatgttacaa 300tatggaaggg aactttacac ttctcctatg cacatatatt
aattaaagtc caatgctagt 360agagaagggg ggtaacaccc ctccgcgctc ttttccgatt
tttttctaaa ccgtggaata 420tttcggttat ccttttgttg tttccgggtg tacaatatgg
acttcctctt ttctggcaac 480caaacccata catcgggatt cctataatac cttcgttggt
ctccctaaca tgtaggtggc 540ggaggggaga tatacaatag aacagatacc agacaagaca
taatgggcta aacaagacta 600caccaattac actgcctcat tgatggtggt acataacgaa
ctaatactgt agccctagac 660ttgatagcca tcatcatatc gaagtttcac tacccttttt
ccatttgcca tctattgaag 720taataatagg cgcatgcaac ttcttttctt tttttttctt
ttctctctcc cccgttgttg 780tctcaccata tccgcaatga caaaaaaatg atggaagaca
ctaaaggaaa aaattaacga 840caaagacagc accaacagat gtcgttgttc cagagctgat
gaggggtatc tcgaagcaca 900cgaaactttt tccttccttc attcacgcac actactctct
aatgagcaac ggtatacggc 960cttccttcca gttacttgaa tttgaaataa aaaaaagttt
gctgtcttgc tatcaagtat 1020aaatagacct gcaattatta atcttttgtt tcctcgtcat
tgttctcgtt ccctttcttc 1080cttgtttctt tttctgcaca atatttcaag ctataccaag
catacaatca actatctcat 1140atacaatgat tccagaccaa gacaactttg ttgaaatcga
cttctccatt gaacaaatcg 1200ctattgtcaa gatcaacaga ccagcttcca agaacgcttt
gaacactgaa gtcagaaagc 1260aattggctca agccttcacc gaattgtctt tcaacgacca
aatcaacgcc attgttttga 1320ctggtggtga agatgttttc gctgctggtg ctgacttgaa
ggaaatggct accgcttctt 1380ccactgacat gttgttgaga cacactgaac gttactggaa
cgccattgct caatgtccaa 1440agccagttat cgctgctgtc aacggttacg ctttaggtgg
tggttgtgaa ttggccatgc 1500acactgacat catcattgct ggtaaatctg ccacctttgg
tcaaccagaa atcaaggtcg 1560gtttgatgcc aggtgctggt ggtacccaaa gattattcag
agctgttggt aaattccacg 1620ctatgagaat gatcatgacc ggtgtcatgg ttcctgctga
agaagcctac ttgattggtt 1680tggtttctca agtcactgaa gattctcaaa ccattccaac
tgccatcaag atggctcaat 1740ctttggccaa gatgccacca attgctttgc aacaaatcaa
ggaagttgct ttgatgtccg 1800aagatgtccc attgaacgct ggtttgactt tggaaagaaa
gtctttccaa ttattattct 1860ccactgaaga taagaacgaa ggtatcaatg ctttcatcga
aaagagaaag ccatcttacc 1920atggaaaata agtaaataaa gcaatcttga tgaggataat
gatttttttt tgaatataca 1980taaatactac cgtttttctg ctagattttg tgaagacgta
aataagtaca tattactttt 2040taagccaaga caagattaag cattaacttt acccttttct
cttctaagtt tcaattctag 2100ttatcactgt ttaaaagtta tggcgagaac gtcggcggtt
aaaatatatt accctgaacg 2160tggtgaattg aagttctagg atggtttaaa gatttttcct
ttttgggaaa taagtaaaca 2220atatattgct gcctttgcaa aacgcacata cccacaatat
gtgactattg gcaaagaacg 2280cattatcctt tgaagaggtg gatactgata ctaagagagt
ctctattccg gctccacttt 2340tagtccagag attacttgtc ttcttacgta tcagaacaag
aaagcatttc caaagtaatt 2400gcatttgccc ttgagcagta tatatatact aagaatcgta
cgctgcaggt cgacgaattc 2460882168DNAArtificial SequenceSynthetic DNA
88ttccctttta cagtgcttcg gaaaagcaca gcgttgtcca agggaacaat ttttcttcaa
60gttaatgcat aagaaatatc tttttttatg tttagctaag taaaagcagc ttggagtaaa
120aaaaaaaatg agtaaatttc tcgatggatt agtttctcac aggtaacata acaaaaacca
180agaaaagccc gcttctgaaa actacagttg acttgtatgc taaagggcca gactaatggg
240aggagaaaaa gaaacgaatg tatatgctca tttacactct atatcaccat atggaggata
300agttgggctg agcttctgat ccaatttatt ctatccatta gttgctgata tgtcccacca
360gccaacactt gatagtatct actcgccatt cacttccagc agcgccagta gggttgttga
420gcttagtaaa aatgtgcgca ccacaagcct acatgactcc acgtcacatg aaaccacacc
480gtggggcctt gttgcgctag gaataggata tgcgacgaag acgcttctgc ttagtaacca
540caccacattt tcagggggtc gatctgcttg cttcctttac tgtcacgagc ggcccataat
600cgcgcttttt ttttaaaagg cgcgagacag caaacaggaa gctcgggttt caaccttcgg
660agtggtcgca gatctggaga ctggatcttt acaatacagt aaggcaagcc accatctgct
720tcttaggtgc atgcgacggt atccacgtgc agaacaacat agtctgaaga agggggggag
780gagcatgttc attctctgta gcagtaagag cttggtgata atgaccaaaa ctggagtctc
840gaaatcatat aaatagacaa tatattttca cacaatgaga tttgtagtac agttctattc
900tctctcttgc ataaataaga aattcatcaa gaacttggtt tgatatttca ccaacacaca
960caaaaaacag tacttcacta aatttacaca caatgatcaa caaaatcatc aacgacattg
1020aaccaatctt gaaatccatt ccagatggtt ccaccatcat gacttctggt ttcggtacca
1080ctggtcaacc agaagctcta ttagaagcct tgattgactt tgctccaaag gaattgacca
1140tcatcaacaa caatgcttct tctggtccaa acggtttgac tcaattattc actgctggtt
1200tggtcaagaa attgatctgt tcttacccaa agtccatttc ttccactgtt ttcccagatt
1260tgtacagagc tggtaagatt gaattggaat tggttcctca aggtaactta gcttgtcgta
1320tccaagctgc tggtgctggt ttgggtgccg ttttcactcc aactggttac ggtaccaaga
1380ttgctgaagg taaggaaacc agaatcatca acggtaagaa ctacgttttg gaatacccat
1440tggaagctga ttacgctttc atctacgctg acaaggctga cagatggggt aacttgacct
1500acagaaaggc tgccagaaac ttcggtccaa tcatggccaa ggctgccaag accaccattg
1560ctcaagtcaa ccaaaccgtc gaattgggtg atttggaccc agaatgtatc atcactccag
1620gtattttcgt ccaacacgtt gtcagattgg gtgacattaa gtaagtaagg gcgcggatct
1680cttatgtctt tacgatttat agttttcatt atcaagtatg cctatattag tatatagcat
1740ctttagatga cagtgttcga agtttcacga ataaaagata atattctact ttttgctccc
1800accgcgtttg ctagcacgag tgaacaccat ccctcgcctg tgagttgtac ccattcctct
1860aaactgtaga catggtagct tcagcagtgt tcgttatgta cggcatcctc caacaaacag
1920tcggttatag tttgtcctgc tcctctgaat cgtctccctc gatatttctc attttccttc
1980gcatgccagc attgaaatga tcgaagttca atgatgaaac ggtaattctt ctgtcattta
2040ctcatctcat ctcatcaagt tatataattc tatacggatg taatttttca cttttcgtct
2100tgacgtccac cctataattt caattattga accctcacaa atgatgcact gcaatgtaca
2160caccctca
2168892362DNAArtificial SequenceSynthetic DNA 89tttactcatc tcatctcatc
aagttatata attctatacg gatgtaattt ttcacttttc 60gtcttgacgt ccaccctata
atttcaatta ttgaaccctc acaaatgatg cactgcaatg 120tacacaccct caactagtaa
tcctactctt gccgttgcca tccaaaatga gctagaaggt 180ggattaacaa atataatgac
aaatcgttgc ttgtctgact tgattccact acagttacaa 240atatttgaca ttgtatataa
gttttgcaag ttcatcaaat ctatgagagc aaaattatgt 300caactggacc ccgtactata
tgagaaacac aaaagcggga tgatgaaaac actaaacgaa 360ggctatcgta caaacaatgg
cggtcaggaa gatgttggtt accaagaaga tgccgccctg 420gaattaattc agaagctgat
tgaatacatt agcaacgcgt ccagcatttt tcggaagtgt 480ctcataaact ttactcaaga
gttaagtact gaaaaattcg acttttatga tagttcaagt 540gtcgacgctg cgggtataga
aagggttctt tactctatag tacctcctcg ctcagcatct 600gcttcttccc aaagatgaac
gcggcgttat gtcactaacg acgtgcacca acttgcggaa 660agtggaatcc cgttccaaaa
ctggcatcca ctaattgata catctacaca ccgcacgcct 720tttttctgaa gcccactttc
gtggactttg ccatatgcaa aattcatgaa gtgtgatacc 780aagtcagcat acacctcact
agggtagttt ctttggttgt attgatcatt tggttcatcg 840tggttcatta attttttttc
tccattgctt tctggctttg atcttactat catttggatt 900tttgtcgaag gttgtagaat
tgtatgtgac aagtggcacc aagcatatat aaaaaaaaaa 960agcattatct tcctaccaga
gttgattgtt aaaaacgtat ttatagcaaa cgcaattgta 1020attaattctt attttgtatc
ttttcttccc ttgtctcaat cttttatttt tattttattt 1080ttcttttctt agtttctttc
ataacaccaa gcaactaata ctataacata caataataat 1140gaccatccaa aagagatcca
gagaagatat tgccatcatg attgctaagg acattccaga 1200tggttcttac gtcaacttgg
gtattggttt accaactcac gttgctaaat acttgccaaa 1260ggacaaggaa atctttttgc
actctgaaaa cggtgttttg gctttcggtc caccacctgc 1320tgaaggtgaa gaagatcaag
atttggttaa cgctggtaag gaattagtca ctttgttgtc 1380cggtggttgt ttcatgcacc
acggtgactc tttcgacatc atgagaggtg gtcatttgga 1440catctgtgtt atcggtgctt
tccaagttgc tttgaacggt gacttggcta actggcacac 1500tggtaaggat gacgatgttc
cagccgtcgg tggtgctatg gacttggctg tcggtgccaa 1560gagaattttc gtctacatgg
aacacaccac caagaagggt gaaccaaaga tcgtcaagca 1620tttgacctac ccaatcactg
gtgaacaatg tgttgacaga atctacaccg atttgtgtac 1680cattgaattg aaagatggtc
aagcctacgt catcgaaatg gttgacggtt tggacttcga 1740cactttacaa gctctaactg
aatgtccatt gattgaccac tgtacctact cctctttgat 1800ccaattgcga taagtaagtc
tgaagaatga atgatttgat gatttctttt tccctccatt 1860tttcttactg aatatatcaa
tgatatagac ttgtatagtt tattatttca aattaagtag 1920ctatatatag tcaagataac
gtttgtttga cacgattaca ttattcgtcg acatcttttt 1980tcagcctgtc gtggtagcaa
tttgaggagt attattaatt gaataggttc attttgcgct 2040cgcataaaca gttttcgtca
gggacagtat gttggaatga gtggtaatta atggtgacat 2100gacatgttat agcaataacc
ttgatgttta catcgtagtt taatgtacac cccgcgaatt 2160cgttcaagta ggagtgcacc
aattgcaaag ggaaaagctg aatgggcagt tcgaatagta 2220cttaagatta gttaaaagtc
catgattgaa cattgatgtg gtagttacat gcatgatgaa 2280tatgcgccat gagaggttgg
tgaattttga gaaaaatgaa ggccaaatca aggcgggaag 2340ggacaaccag gacgtaaagg
gt 2362902874DNAArtificial
SequenceSynthetic DNA 90agttacatgc atgatgaata tgcgccatga gaggttggtg
aattttgaga aaaatgaagg 60ccaaatcaag gcgggaaggg acaaccagga cgtaaagggt
agcctcccca taacataaac 120tcaataaaat atatagtctt caacttgaaa aaggaacaag
ctcatgcaaa gaggtggtac 180ccgcacgccg aaatgcatgc aagtaaccta ttcaaagtaa
tatctcatac atgtttcatg 240agggtaacaa catgcgactg ggtgagcata tgttccgctg
atgtgatgtg caagataaac 300aagcaagaca gaaactaact tcttcttcat gtaataaaca
caccccgcgt ttatttacct 360atctttaaac ttcaacacct tatatcataa ctaatatttc
ttgagataag cacactgcac 420ccataccttc cttaaaaacg tagcttccag tttttggtgg
ttctggcttc cttcccgatt 480ccgcccgcta aacgcataat tttgttgcct ggtggcattt
gcaaaatgca taacctatgc 540atttaaaaga ttatgtatgg tcttctgact tttcgtgtga
tgaggctcgt ggaaaaaatg 600aataatttat gaatttgaga acaattttgt gttgttacgg
tattttacta tggaataatc 660aatcaattga ggattttatg caaatatcgt ttgaatattt
ttccgaccct ttgagtactt 720ttcttcataa ttgcataata ttgtccgctg cccgtttttc
tgttagacgg tgtcttgatc 780tacttgctat cgttcaacac caccttattt tctaactatt
ttttttttag ctcatttgaa 840tcagcttatg gtgatggcac atttttgcat aaacctagct
gtcctcgttg aacataggaa 900aaaaaaatat ataaacaagg ctctttcact ctccttggaa
tcagatttgg gtttgttccc 960tttattttca tatttcttgt catattcttt tctcaattat
tatcttctac tcataacctc 1020acgcaaaata acacagtcaa atcaatcaaa atgaacttgc
acgaatacca agccaagcaa 1080ttgtttgctc gttacggtct accagctcca gttggttacg
cttgtaccac tccaagagaa 1140gctgaagaag ctgcctccaa gattggtgct ggtccatggg
ttgtcaagtg tcaagtccac 1200gctggtggtc gtggtaaggc tggtggtgtc aaggttgtca
actccaagga agatattaga 1260gctttcgctg aaaactggtt aggtaagaga ttagtcacct
accaaactga cgctaacggt 1320caacctgtta accaaatctt agtcgaagct gccactgaca
ttgccaagga attatacttg 1380ggtgccgttg ttgaccgttc ttccagaaga gttgttttca
tggcttctac tgaaggtggt 1440gttgaaatcg aaaaggttgc tgaagaaact ccacatttga
ttcacaaggt tgctttggac 1500ccattgactg gtccaatgcc ataccaaggt agagaattgg
ccttcaaatt gggtttggaa 1560ggtaagttgg tccaacaatt caccaagatc ttcatgggtt
tggctaccat cttcttggaa 1620agagacttgg ctttgattga aatcaaccca ttagtcatca
ccaagcaagg tgacttgatc 1680tgtttggatg gtaagttggg tgctgacggt aacgctttat
tcagacaacc agatttgaga 1740gaaatgagag atcaatctca agaagatcca agagaagctc
aagctgctca atgggaattg 1800aactacgttg ctttggacgg taacatcggt tgtatggtta
acggtgccgg tttggccatg 1860ggtaccatgg acattgtcaa attgcacggt ggtgaaccag
ctaacttctt ggatgtcggt 1920ggtggtgcca ccaaggaaag agttactgaa gccttcaaga
tcatcttatc tgacgacaag 1980gtcaaggctg tcttggttaa catcttcggt ggtattgtca
gatgtgactt gattgctgat 2040ggtatcatcg gtgctgttgc tgaagttggt gtcaatgtcc
cagttgttgt cagattggaa 2100ggtaacaacg ctgaattggg tgccaagaaa ttggctgact
ctggtttgaa catcattgct 2160gccaagggtt tgaccgatgc tgctcaacaa gttgttgctg
ctgtcgaagg gaaataagta 2220aggagttaaa ggcaaagttt tctttactag agccgttccc
acaaataatt atacgtatat 2280gcttcttttc gtttactata tatctatatt tacaagcctt
tattcactga tgcaatttgt 2340ttccaaatac ttttttggag atctcataac tagatatgat
gatggcgcaa cttgggcgta 2400tcttaattac tctggctgcc aggcccgtgt agagggccgc
aagaccttct gtacgccata 2460tagtctctaa gaacttgaac atgttactag acctattgcc
gcctttcgga tcgctattgt 2520tcatcatgga tatttgccat ctcgtcttac cgacatcaaa
agggtgtgtg catatagcag 2580ctatcatccc acttatgcaa ccactggcaa aactgtttat
aaaatggacc cagtttgcgt 2640ccttagatgc aaatcgagta gaatctagcc atagtctttc
cttgcaaagt tcataggaac 2700tccaatatat tgcactaaac gggatcctgt ggtagaatac
aaaagactat gtgatgccat 2760aggcaagaag ggagactctc actccgagat gggcagcttg
atcgcccagg aattgaattg 2820tattgtggtg gagaaaggtc agtcagataa gatattctca
cccgatagtg aaaa 2874912356DNAArtificial SequenceSynthetic DNA
91gactatgtga tgccataggc aagaagggag actctcactc cgagatgggc agcttgatcg
60cccaggaatt gaattgtatt gtggtggaga aaggtcagtc agataagata ttctcacccg
120atagtgaaaa agacatgttg acgaacagcg aagagggcag caacaagagg gtaggaggcc
180aaggtgatac tttgacagga gctatatcat gcatgcttgc atttagtcgt gcaatgtatg
240actttaagat ttgtgagcag gaagaaaagg gagaatcttc taacgataaa cccttgaaaa
300actgggtaga ctacgctatg ttgagttgct acgcaggctg cacaattaca cgagaatgct
360cccgcgtagg atttaaggct aagggacgtg caatgcagac gacagatcta aatgaccgtg
420tcggtgaagt gttcgccaaa cttttcggtt aacacatgca gtgatgcacg cgcgatggtg
480ctaagttaca tatatatata tatatatata tatatatata tatagccata gtgatgtcta
540agtaaccttt atggtatatt tcttaatgtg gaaagatact agcgcgcgca cccacacact
600agcttcgtct tttcttgaag aaaagaggaa gctcgctaaa tgggattcca ctttccgttc
660cctgccagct catggaaaaa ggttagtgga acgatgaaga ataaaaagag agatccactg
720aggtgaaatt tgagctgaca gcgagtttca tgatcgtgat gaacaatggt aacgagttgt
780ggctgttgcc agggagggtg gttctcaact tttaatgtat ggccaaatcg ctacttgggt
840ttgttatata acaaagaaga aataatgaac tgattctctt cctccttctt gtcctttctt
900aattctgttg taattacctt cctttgtaat tttttttgta attattcttc ttaataatcc
960aaacaaacac acatattaca ataatgtcca tcttgattga caagaacacc aaggtcatct
1020gtcaaggttt caccggttct caaggtactt tccactctga acaagccatt gcttacggta
1080ccaagatggt tggcggtgtc accccaggta agggtggtac cactcacttg ggtttaccag
1140ttttcaacac cgtcagagaa gctgttgctg ccactggtgc taccgcttct gtcatctacg
1200ttccagctcc attctgtaag gattccatct tggaagccat tgatgctggt atcaaattga
1260tcattaccat tactgaaggt atcccaactt tggacatgtt gactgtcaag gtcaaattgg
1320atgaagctgg tgttagaatg attggtccaa actgtccagg tgtcatcact ccaggtgaat
1380gtaagatcgg tattcaacca ggtcacattc acaagccagg taaggttggt atcgtttccc
1440gttctggtac tttgacctac gaagctgtca agcaaaccac tgactacggt ttcggtcaat
1500ctacctgtgt tggtatcggt ggtgacccaa ttccaggttc caacttcatc gacatcttgg
1560aaatgtttga aaaggaccct caaactgaag ccattgtcat gatcggtgaa atcggtggtt
1620ctgctgaaga agaagctgct gcttacatca aggaacacgt taccaagcca gttgttggtt
1680acattgctgg tgttactgct ccaaagggta agagaatggg tcatgccggt gccatcattg
1740ctggtggtaa gggtactgct gatgaaaaat tcgctgcttt ggaagctgct ggtgtcaaga
1800ccgtcagatc tttggctgac atcggtgaag ccttaaagac tgttttgaaa taagtaagcg
1860aatttcttat gatttatgat ttttattatt aaataagtta taaaaaaaat aagtgtatac
1920aaattttaaa gtgactctta ggttttaaaa cgaaaattct tattcttgag taactctttc
1980ctgtaggtca ggttgctttc tcaggtatag catgaggtcg ctcttattga ccacacctct
2040accggcatgc cgagcaaatg cctgcaaatc gctccccatt tcacccaatt gtagatatgc
2100taactccagc aatgagttga tgaatctcgg tgtgtatttt atgtcctcag aggacaacac
2160ctgttgtaat cgttcttcca caccgatcca cagcctagcc ttcagttggg ctctatcttc
2220atcgtcattc attgcatcta ctagcccctt acctgagctt caagacgtta tatcgctttt
2280atgtatcatg atcttatctt gagatatgaa tacataaata tatttactca agtgtatacg
2340tgcatgcttt ttttac
2356923138DNAArtificial SequenceSynthetic DNA 92tctatcttca tcgtcattca
ttgcatctac tagcccctta cctgagcttc aagacgttat 60atcgctttta tgtatcatga
tcttatcttg agatatgaat acataaatat atttactcaa 120gtgtatacgt gcatgctttt
tttacgacta gtacgtctct tgggttgata aacttgtatg 180acatatgttc accgagtttt
gtcatgtcgt catactatac ggcagcggct tgttgctgcc 240gtttaatgaa acagtttttt
tcacgacaag attcttctat tgattattca catatgtatt 300ttaatgaaaa atgagtactt
tataacacaa ccctaatgac aaatgaaaaa gttgattgcc 360atgaactctt aaagcgattt
atgagaacaa ttaattgatt atatatatat atctttgcaa 420ttatgtcgtt tgttgcaaga
tgcttctgaa agtaagtaac tctataagat agataatgct 480acaagacgcc aaacgcaagt
gagtaagaaa taagagctgg caggtcttcg ccggaacact 540atcatcaaaa tcactacaat
ttagcggctt agcacaatac gcgttttcaa cttcctacgc 600tagcgatgac aaaatgtctc
caagaggcgg aacttgcgac ggatgcatgg aaatatctta 660cgtaatgaac ttccgtaatg
aacttccgta attcaagatc tcttagcatc tcttgttcaa 720tcttcagact ctactaagtg
ttcttaccaa ccattggatg ctcattacaa atgaatgaat 780atattgcacg gaacggaagc
ggcatgcttt ttccgtctcg tgtgcttagt aaagcaaaac 840ggagtagaat cggtaagaac
ttcctttttg ggttggaaaa tcattgccat tgtttggaca 900cctttctttt tccgtattgt
tcgagcaccg cgtttctttt tgggtacttg atgaggtagc 960agattcctgg aacgtgcttt
ctctcgaggt aacctgcctt gttcctcctg gtgactttct 1020aaaatataaa aggaaaagca
tatctctagt ttcgagtttt ttcttcatac tttatttcct 1080tatgttaaac ggtccagata
tagaataaat catcatatta agctaaatat agacgataat 1140atagtatcga taatggaatc
tttggaattg gaacaattag tcaagaaggt tttgttggaa 1200aaattggctg aacaaaagga
agttccaacc aagaccacca cccaaggtgc caagtccggt 1260gttttcgata ccgtcgatga
agctgtccaa gctgccgtca ttgctcaaaa ctgttacaag 1320gaaaaatctt tggaagaaag
aagaaacgtt gtcaaggcca tcagagaagc tttataccca 1380gaaatcgaaa ccattgctac
cagagctgtt gctgaaaccg gtatgggtaa tgtcaccgat 1440aaaatcttga agaacacttt
agctatcgaa aagactccag gtgttgaaga cttgtacact 1500gaagttgcta ccggtgacaa
cggtatgact ttatacgaat tatctccata cggtgtcatc 1560ggtgctgttg ctccatctac
caacccaact gaaactttga tctgtaactc catcggtatg 1620ttggctgctg gtaacgccgt
tttctactct cctcacccag gtgccaagaa catctcttta 1680tggttgattg aaaagttgaa
cactatcgtc agagattctt gtggtattga caacttgatt 1740gtcaccgttg ccaagccatc
tatccaagct gctcaagaaa tgatgaacca cccaaaggtt 1800ccattgttgg tcatcactgg
tggtccaggt gttgtcttgc aagctatgca atctggtaag 1860aaggttatcg gtgctggtgc
tggtaaccct ccatccatcg ttgacgaaac cgctaacatt 1920gaaaaggctg ctgctgacat
tgtcgacggt gcttcctttg accataatat cttgtgtatc 1980gctgaaaagt ctgttgttgc
cgttgactcc attgctgact tcttgttgtt ccaaatggaa 2040aagaacggtg ctttgcacgt
cactaaccca tctgacatcc aaaaattgga aaaggttgcc 2100gtcactgaca agggtgtcac
caacaagaaa ttggttggta agtctgccac tgaaatcttg 2160aaagaagctg gtattgcttg
tgatttcacc ccaagattga tcattgtcga aactgaaaag 2220tcccacccat tcgctactgt
tgaattgttg atgccaattg ttccagttgt cagagttcca 2280gacttcgatg aagctttgga
agttgccatt gaattggaac aaggtctaca tcacactgct 2340accatgcact ctcaaaacat
ctccagattg aacaaggctg cccgtgacat gcaaacctcc 2400atctttgtca agaacggtcc
atctttcgct ggtttaggtt tcagaggtga aggttccacc 2460actttcacca ttgctactcc
aactggtgaa ggtactacca ctgcccgtca cttcgctaga 2520agaagaagat gtgtcttgac
tgatggtttc tccattagat aagattaata taattatata 2580aaaatattat cttcttttct
ttatatctag tgttatgtaa aataaattga tgactacgga 2640aagctttttt atattgtttc
tttttcattc tgagccactt aaatttcgtg aatgttcttg 2700taagggacgg tagatttaca
agtgatacaa caaaaagcaa ggcgcttttt ctaataaaaa 2760gaagaaaagc atttaacaat
tgaacacctc tatatcaacg aagaatatta ctttgtctct 2820aaatccttgt aaaatgtgta
cgatctctat atgggttact cataagtgta ccgaagactg 2880cattgaaagt ttatgttttt
tcactggagg cgtcattttc gcgttgagaa gatgttctta 2940tccaaatttc aactgttata
tacaagagca aaaaattgcc aaaaaaaaca acatttattc 3000atttgaaata taaaatttgg
gcttctatat tttaatattg cttttcaatt actgttatta 3060aatctagagc ggccgccacc
gcggtggaat tttattttac tttttttaga atgacctgtt 3120cccgacacta tgtaagat
3138931672DNAArtificial
SequenceSynthetic DNA 93atttccaaag taattgcatt tgcccttgag cagtatatat
atactaagaa tcgtacgctg 60caggtcgacg aattctaccg ttcgtataat gtatgctata
cgaagttata gatctgttta 120gcttgcctcg tccccgccgg gtcacccggc cagcgacatg
gaggcccaga ataccctcct 180tgacagtctt gacgtgcgca gctcaggggc atgatgtgac
tgtcgcccgt acatttagcc 240catacatccc catgtataat catttgcatc catacatttt
gatggccgca cggcgcgaag 300caaaaattac ggctcctcgc tgcagacctg cgagcaggga
aacgctcccc tcacagacgc 360gttgaattgt ccccacgccg cgcccctgta gagaaatata
aaaggttagg atttgccact 420gaggttcttc tttcatatac ttccttttaa aatcttgcta
ggatacagtt ctcacatcac 480atccgaacat aaacaaccat gggtaaggaa aagactcacg
tttcgaggcc gcgattaaat 540tccaacatgg atgctgattt atatgggtat aaatgggctc
gcgataatgt cgggcaatca 600ggtgcgacaa tctatcgatt gtatgggaag cccgatgcgc
cagagttgtt tctgaaacat 660ggcaaaggta gcgttgccaa tgatgttaca gatgagatgg
tcagactaaa ctggctgacg 720gaatttatgc ctcttccgac catcaagcat tttatccgta
ctcctgatga tgcatggtta 780ctcaccactg cgatccccgg caaaacagca ttccaggtat
tagaagaata tcctgattca 840ggtgaaaata ttgttgatgc gctggcagtg ttcctgcgcc
ggttgcattc gattcctgtt 900tgtaattgtc cttttaacag cgatcgcgta tttcgtctcg
ctcaggcgca atcacgaatg 960aataacggtt tggttgatgc gagtgatttt gatgacgagc
gtaatggctg gcctgttgaa 1020caagtctgga aagaaatgca taagcttttg ccattctcac
cggattcagt cgtcactcat 1080ggtgatttct cacttgataa ccttattttt gacgagggga
aattaatagg ttgtattgat 1140gttggacgag tcggaatcgc agaccgatac caggatcttg
ccatcctatg gaactgcctc 1200ggtgagtttt ctccttcatt acagaaacgg ctttttcaaa
aatatggtat tgataatcct 1260gatatgaata aattgcagtt tcatttgatg ctcgatgagt
ttttctaatc agtactgaca 1320ataaaaagat tcttgttttc aagaacttgt catttgtata
gtttttttat attgtagttg 1380ttctatttta atcaaatgtt agcgtgattt atattttttt
tcgcctcgac atcatctgcc 1440cagatgcgaa gttaagtgcg cagaaagtaa tatcatgcgt
caatcgtatg tgaatgctgg 1500tcgctatact gctgtcgatt cgatactaac gccgccatcc
agtgtcgaaa acgagctcat 1560aacttcgtat aatgtatgct atacgaacgg tagaattcga
tatcagatcc actagtggcc 1620tatagaaagc atactatact attcgacact tcctttcaat
cctggaatta ac 167294550DNAArtificial SequenceSynthetic DNA
94cggcattatt gtgtatggct caataatttt ataaaaaaag gaactattgg ttcttagtat
60tttcttgcta gaagacatat tcttaccaat cctttcataa gctaattatg ccatccatat
120agcaagagaa tccggtgggg gcgccatgcc tatccggcgg caacattatt actctggtat
180acgggcgtaa ctccataata tgccaccact tacctttaac atgttcatgg taggtacccc
240acccagccat aaggaaattt tcaaaggcgt tggatcaaaa aataggcctt tatttcatcg
300cgtgattgag gagcataaca tgtttagtga aggtttcttt tggaaaactt cagtcgctca
360ttattagaac cagggaggtc caggctttgc tggtgggaga gaaagcttat gaagctgggg
420ttgcagattt gtcgattggt cgccagtaca cagttttaaa aagtcagaga atgtagagaa
480gtatggatct ttgaaaccct aaggatgagc caagaataag ggaacaagat tttggtaatt
540tccaaaaaat
55095523DNAArtificial SequenceSynthetic DNA 95ctagagcggc cgccaccgcg
gtggaatttt attttacttt ttttagaatg acctgttccc 60gacactatgt aagatctagc
ttttaacata ttatggaaac ctgaaatgta aaatctgaat 120ttttgtatat gtgtttatat
ttgggtagtt cttttgagga aagcatgcat agacttgctg 180tacgaacttt atgtgacttg
tagtgacgct gtttcatgag actttagccc tttgaacata 240ttatcatatc tcagcttgaa
atactataga tttacttttg cagccatttc ttggtgctcc 300aaggttgtgc gtatctatta
cttaatttct gtccttgcca agttttgcag cagggcggtc 360acaagactcc tctgccgtca
ttccttagtc cttcgggaac acacttattt atgtatttgt 420attctacaat tctacggtgc
acaagggttg ggcactgttg agctcagcac gcaactattg 480ctggcatgaa gataagattg
atttttggaa gaataagctt gtg 5239622DNAArtificial
SequenceSynthetic DNA 96tgttcttctt ggaaaatgta cg
229734DNAArtificial SequenceSynthetic DNA
97gattcgcggc cgcctgaact gaaacacaga agac
3498121DNAArtificial SequenceSynthetic DNA 98tttctcatgg tagcgcctgt
gcttcggtta cttctaagga agtccacaca aatcaagatc 60cgttagacgt ttcagcttcc
aaaacagaag aatgtgagat gttcttcttg gaaaatgtac 120g
12199120DNAArtificial
SequenceSynthetic DNA 99gaggtggtac tgaagcaggt tgaggagagg catgatgggg
gttctctgga acagctgatg 60aagcaggtgt tgttgtctgt tgagagttag ccttagtgcc
tgaactgaaa cacagaagac 120100120DNAArtificial SequenceSynthetic DNA
100tttctcatgg tagcgcctgt gcttcggtta cttctaagga agtccacaca aatcaagatc
60cgttagacgt ttcagcttcc aaaacagaag aatgtgagag ctcccctcac agacgcgttg
120101120DNAArtificial SequenceSynthetic DNA 101gaggtggtac tgaagcaggt
tgaggagagg catgatgggg gttctctgga acagctgatg 60aagcaggtgt tgttgtctgt
tgagagttag ccttagtgca aatgacaagt tcttgaaaac 120
User Contributions:
Comment about this patent or add new information about this topic:
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
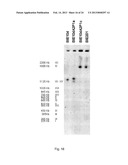 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 | 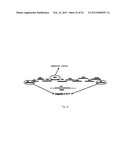 |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 | 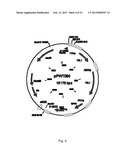 |
 |  |
 |  |
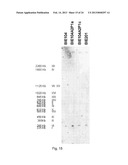 |  |
 |  |
 |  |
 |  |
 |  |
 | 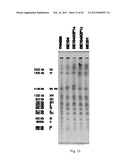 |
 |  |
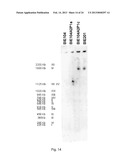 |  |
 | 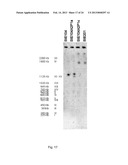 |
 |
| Similar patent applications: | |
| Date | Title |
|---|---|
| 2013-02-21 | Process for the identification and traceability of plant components |
| 2013-02-14 | Production of fatty alcohols with fatty alcohol forming acyl-coa reductases (far) |
| 2013-02-21 | Composition for cancer prognosis prediction comprising anti-tmap/ckap2 antibodies |
| 2012-12-27 | Process for production of l-amino acid |
| 2013-02-14 | Industrial yeast capable of producing ethanol from at least one pentose |
| New patent applications in this class: | |
| Date | Title |
|---|---|
| 2022-05-05 | Photocleavable mass-tags for multiplexed mass spectrometric imaging of tissues using biomolecular probes |
| 2022-05-05 | Macrophage expression in breast cancer |
| 2022-05-05 | Characterizing methylated dna, rna, and proteins in the detection of lung neoplasia |
| 2022-05-05 | Methods for identifying and improving t cell multipotency |
| 2022-05-05 | Sequence analysis using meta-stable nucleic acid molecules |
| New patent applications from these inventors: | |
| Date | Title |
|---|---|
| 2014-01-30 | Polypeptide having carbohydrate degrading activity and uses thereof |
| 2013-09-12 | Polypeptides with permease activity |
| 2013-08-22 | Polypeptide having swollenin activity and uses thereof |
| 2013-04-25 | Polypeptide having beta-glucosidase activity and uses thereof |
| 2013-04-18 | Polypeptide having or assisting in carbohydrate material degrading activity and uses thereof |
| Top Inventors for class "Chemistry: molecular biology and microbiology" | |
| Rank | Inventor's name |
|---|---|
| 1 | Marshall Medoff |
| 2 | Anthony P. Burgard |
| 3 | Mark J. Burk |
| 4 | Robin E. Osterhout |
| 5 | Rangarajan Sampath |