Patent application title: METHOD AND APPARATUS FOR ROUTING DATA IN AN AUTOMATIC IDENTIFICATION SYSTEM
Inventors:
Sanjay Sarma (Belmont, MA, US)
Daniel W. Engels (Lincoln, MA, US)
Laxmiprasad Putta (Wellesley, MA, US)
Sridhar Ramachandran (Watertown, MA, US)
James L. Waldrop (Somerville, MA, US)
IPC8 Class: AG05B1902FI
USPC Class:
700 7
Class name: Generic control system, apparatus or process plural processors including sequence or logic processor
Publication date: 2010-07-08
Patent application number: 20100174386
Inventors list |
Agents list |
Assignees list |
List by place |
Classification tree browser |
Top 100 Inventors |
Top 100 Agents |
Top 100 Assignees |
Usenet FAQ Index |
Documents |
Other FAQs |
Patent application title: METHOD AND APPARATUS FOR ROUTING DATA IN AN AUTOMATIC IDENTIFICATION SYSTEM
Inventors:
Sanjay Sarma
Daniel W. Engels
Laxmiprasad Putta
Sridhar Ramachandran
James L. Waldrop
Agents:
DANN, DORFMAN, HERRELL & SKILLMAN
Assignees:
Origin: PHILADELPHIA, PA US
IPC8 Class: AG05B1902FI
USPC Class:
700 7
Publication date: 07/08/2010
Patent application number: 20100174386
Abstract:
A system for routing data in an automatic identification system includes
an event management system (EMS), a real-time in-memory data structure
(RIED) coupled to the EMS, the RIED for storing event information
gathered by the EMS and a task management system (TMS) for ensuring that
the RIED is updated by one transaction at a time. With this particular
arrangement, a system for managing a large number of real-time events is
provided. In one embodiment, the control system can be provided in a
distributed hierarchical arrangement. The EMS of each control system can
include filters which limit the amount of information provided to the
next level in the hierarchy. In this manner the hierarchical control
system network acts as a high volume data collector and processor. In
some embodiments a level of the hierarchy can be removed spatially and/or
temporally from an adjacent level in the hierarchy. This approach results
in an intelligent network and also lends itself to scalability. By
including optional filters and queues in the EMS, the EMS can be
configured as desired.Claims:
1. A distributed control system comprising a hierarchy of control systems;
said hierarchy comprising:a. a first level of control systems comprising
a plurality of edge control systems that receive information through an
event management system (EMS), said EMS being configured to provide a
system structured to receive information events from data readers wherein
said readers are capable of receiving information from at least one data
source; andb. a second level comprising at least one second-level control
system; said second-level control system being configured to receive
information from at least two edge control systems, but not directly from
a data reader.
2. The distributed control system of claim 1 wherein said second-level control system and said edge control system comprise a task management system (TMS) that provides data management capabilities to the distributed control system and provides data monitoring using customizable tasks.
3. The distributed control system of claim 1, further comprising at least one third-level control system; said third level control system being configured to receive data from said second level, and said second level being configured to receive data from said first level.
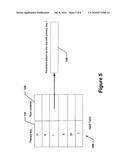
4. The distributed control system of claim 3, wherein the first-level, second-level, and third-level control systems comprise a database that stores data in real time.
5. The distributed control system of claim 1, wherein the data readers are RFID readers and said data source is an RFID tag.
6. The distributed control system of claim 1, wherein the first and second level control systems contain a real time database.
7. The distributed control system of claim 6, wherein the control systems store an in-memory sequence manager; said sequence manager stores sequence numbers associated with snapshots of the database.
8. A method of processing and storing data in a distributed control system comprising the steps ofa. Maintaining a first persistent datum;b. Forwarding data received from a data reader to an edge control system;c. Processing the data at the edge control system;d. Forwarding the data from the edge control system to at least one second-level control system;e. Forwarding data from a second edge control system to at least one second-level control system; andf. Processing data at the at least one second-level control system that was received from at least two edge control systems.
9. The method of claim 8, further comprising the step wherein event data readers communicate with the edge control system through an adapter.
10. The method of claim 9 wherein said adapter sends information to the edge control system through a filter.
11. The method of claim 10, further comprising storing information in an event logger.
12. The method of claim 11, further comprising a step of providing a queuing system that records events read by at least one reader adapter, and posting the recorded events to all of the event loggers registered with the system.
13. The method of claim 8, further comprising the step of saving a snapshot of a database.
Description:
CROSS REFERENCE TO RELATED APPLICATIONS
[0001]This application claims the benefit of provisional application No. 60/444,090 filed Jan. 31, 2003, the disclosure of which is hereby incorporated by reference.
STATEMENT REGARDING FEDERALLY SPONSORED RESEARCH
[0002]Not Applicable.
FIELD OF THE INVENTION
[0003]The present invention relates generally to a network service and related apparatus and more particularly to a service for identifying objects based upon a unique code associated with that object.
BACKGROUND OF THE INVENTION
[0004]As is known in the art, the ability to uniquely identify items, devices, and services (collectively called objects) is essential for many applications including but not limited to security access control, supply chain management and communications. The inability to uniquely identify every object of interest renders many of these applications less effective than is generally desired. One component for unique identification is the association of a unique identifier with the object. The identifier may take many forms, such as a given name or number (e.g., a social security number) or a characteristic of the object (e.g., a fingerprint). Once objects are uniquely identified, it would be desirable to locate data about the object or service using the unique identifier.
[0005]In a world in which every object has an associated electronic product code (EPC) which may be attached or associate to the object with a Radio Frequency Identification (RFID) tag for example, EPC readers (e.g., RFID tag readers) will be picking up a continual stream of EPCs. It has, therefore, been recognized that managing and moving all of this data is a difficult problem and one that must be addressed in an RF ID network. One embodiment of a RFID system is described in co-pending U.S. patent application Ser. No. 09/379,187 filed on Aug. 20, 1999 which claims the benefit of application No. 60/097,254 filed Aug. 20, 1998.
SUMMARY OF THE INVENTION
[0006]In accordance with the present invention, a system for routing data in an automatic identification system includes an event management system (EMS), a real-time in-memory data structure (RIED) coupled to the EMS, the RIED for storing event information gathered by the EMS and a task management system (TMS) for ensuring that the RIED is updated by one transaction at a time. With this particular arrangement, a system for managing a large number of real-time events is provided. In one embodiment, the control system can be provided in a distributed hierarchical arrangement. The EMS of each control system can include filters which limit the amount of information provided to the next level in the hierarchy. In this manner the hierarchical control system network acts as a high volume data collector and processor. In some embodiments a level of the hierarchy can be removed spatially and/or temporally from an adjacent level in the hierarchy. This approach results in an intelligent network and also lends itself to scalability. By including optional filters and queues in the EMS, the EMS can be configured as desired.
BRIEF DESCRIPTION OF THE DRAWINGS
[0007]The invention will be more fully understood from the following detailed description taken in conjunction with the accompanying drawings, in which:
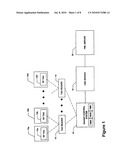
[0008]FIG. 1 is a block diagram of an automatic identification (control) system;
[0009]FIG. 2 is a block diagram of hierarchical control system;
[0010]FIG. 3 is a block diagram of an event management system (EMS);
[0011]FIG. 4 is a series of tables which illustrate a synchronization operation;
[0012]FIG. 5 is a persistent datum Hash table;
[0013]FIG. 6 is a persistent set Hash table;
[0014]FIG. 7 is a table which illustrates a sample persistent datum;
[0015]FIG. 8 is a series of tables which illustrate an update operation; and
[0016]FIG. 9 is a series of tables which illustrate a persistent set along with the results of queries in various snapshots.
DETAILED DESCRIPTION OF THE INVENTION
[0017]Before describing the processing to be performed by an automatic identification (control) system to manage and move data, it should be appreciated that, in an effort to promote clarity, reference is sometimes made herein to certain exemplary embodiments and applications--e.g., supply chain management applications. Such reference should not be taken as limiting the invention to such embodiments and applications. Rather, it should be understood that such examples are intended only as an aid to describing the invention and that the present invention finds use in a wide variety of different applications including but not limited to communications networks, power networks, chemical supply networks, supply chain networks, transportation systems and security.
[0018]Accordingly, those of ordinary skill in the art will appreciate that the description and processing taking place on supply chain systems could equally be taking place on communication systems, transportation systems, security systems or any other type of system. Likewise, reference is sometimes made herein to radio frequency (RF) ID tags. It should be appreciated, however, that the present invention can be used with any type of identifier including but not limited to RF ID tags.
[0019]Likewise the operating environment referred to herein as "Savant" has application to any distributed system and in particular can be used to tie together many events in any sensor network. Thus, control systems can be provided as global infrastructures to track objects by tagging the objects with unique Electronic Product Codes (EPCs) stored, for example, in radio frequency (RF) tags. In a preferred embodiment, the control system is a modular platform which manages EPC data. As will be described herein below, a hierarchical setup of geographically distributed control systems can manage EPC data throughout an enterprise.
[0020]The Savant operating environment described herein utilizes a distributed architecture and is organized in a hierarchy that manages the flow of data. These control systems will be implemented in stores, distribution centers, regional offices, factories, trucks and in cargo planes. Control systems at each level will gather, store and act on information and interact with other control systems. For instance, a control system at a store might inform a distribution center that more product is needed. A control system at the distribution center might inform the store control system that a shipment was dispatched at a specific time. The control system will handle a variety of tasks including but not limited to data smoothing, reader coordination, data forwarding, data storage and task management.
[0021]Referring now to FIG. 1, each of a plurality of objects 10a-10N has an electronic product code (EPC) 12a-12N associated with or "tagged" thereon. In one embodiment, each EPC is unique and is associated with an object via a radio frequency (RF) tag in which case the EPC can be said to be provided as a radio frequency identifier (RFID). It should be appreciated, however, that the EPC may be associated with or disposed on an object by any means known to those of ordinary skill in the art.
[0022]An identification (control) system 1 includes a plurality of tag readers 14 (or more simply "readers") adapted to read the EPCs 12 within a given physical location about the reader 14. The readers 14 identify the EPC in a tag, preferably without manual intervention. For example, in the case in which RF tags are used, the readers 14 can be provided as radio-frequency sensors which can detect all RF IDs within a certain detection range around the reader.
[0023]The readers 14 collect the EPCs and provide the EPCs to a control system 16. In one particular embodiment, the control system is provided as computer system executing an operating environment referred to herein as Savant Control System (or more simply "Savant"). It should be appreciated that the location of the readers 14 are known and thus when the readers transmit EPCs to the control system 16, the control system also has information as to the location of the object associated with the EPC. Thus, the readers 14 are in communication with a processing system executing control system and the readers 14 send control system the EPCs which have been collected.
[0024]The control system acts like a data router and performs operations such as data capturing, data monitoring and data transmission. The control system includes three major modules: an Event Management System (EMS); a Real-time in-memory data structure (RIED); and a Task Management System (TMS).
[0025]The control system 16 is in communication with an Object Name Service (ONS) server 18. The ONS server is described in detail in co-pending application no. ______, filed on even date herewith and entitled "Object Naming Service" assigned attorney docket number MIT-147AUS which application is hereby incorporated herein by reference in its entirety. In operation, the control system sends a query (e.g., over the Internet) to an ONS database, which acts like a reverse telephone directory--it receives a number and produces an address.
[0026]In particular, based upon an object's tag EPC, a object can be associated with networked services. A network service is a remote service provided on a network on the Internet or a Virtual Private Network (VPN) to provide and store information regarding that object. The network may, for example, be provided as an intranet, the Internet, a virtual private network (VPN) or any other type of network. A typical network service could offer product information regarding the object.
[0027]The ONS provides a framework to locate networked services for tagged objects. Specifically, networked services for an object can be identified based. VP on the unique EPC tagged to that object. The ONS framework helps readers, or processing units integrated with the readers, locate these services.
[0028]The ONS server 18 matches the EPC number (which may be the only data stored on an RFID tag) to the address of a server having stored thereon information about the object. In some cases the server may have an extensive amount of information about the object stored thereon. This data is available to, and can be augmented by, control systems around the world. In the exemplary embodiment shown in FIG. 1, the ONS service is used to locate Physical Markup Language (PML) servers 20 associated with an EPC. In one embodiment, the PML server 20 can be provided as a web server that serves information about that object in the Physical Markup Language.
[0029]The PML server 20 uses PML to store comprehensive data about manufacturers' products. The PML server 20 recognizes the incoming EPCs as belonging to a particular object (e.g. cans of SuperCola, Inc.'s Cherry Hydro). Because the system knows the location of the reader which sent the query, the system now also knows which plant produced the cola. If an incident involving a defect or tampering arose for example, this information would make it easy to track the source of the problem and recall the products in question.
[0030]Before describing the ONS server 18 in detail, a general overview is provided. Since only the EPC may be stored on the object tag, computers need some way of matching the EPC to information about the associated item. The Object Name Service (ONS) serves this role. The ONS is an automated networking service similar to the Domain Name Service (DNS) that points computers to sites on the World Wide Web.
[0031]When an interrogator (e.g., reader 14 in FIG. 1) reads an RFID tag (e.g. RF tag 12a in FIG. 1), the EPC read from the tag is passed on to a control system (e.g. the control system 16 described above). The control system can, in turn, communicate with an ONS on a local network or the Internet to find where information on the product is stored. The ONS points the control system to a server where a file about that product is stored. That file can then be retrieved by the control system, and the information about the product in the file can be forwarded to a company's inventory or supply chain applications.
[0032]The Object Name Service handles many more requests than the Web's Domain Name Service. Therefore, companies can maintain ONS servers locally, which will store information for quick retrieval. For example, a computer manufacturer may store ONS data from its current suppliers on its own network, rather than pulling the information off a web site every time a shipment arrives at the assembly plant. The system will also have built-in redundancies. For example, two or more servers will have the same information stored thereon. Thus, if one server with information on a certain product crashes, ONS will be able to point the Control to another server where the same information is stored.
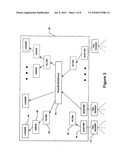
[0033]Referring now to FIG. 2, a Savant control system 16' which may be similar to system 16 described above in conjunction with FIG. 1 is shown. The Savant control system 16' is provided from a plurality of control systems 21a-n, 22a-22n, and 24 arranged in a hierarchical structure. In this particular example a three-level hierarchy is shown with control system 24 corresponding to a root of the hierarchy with control systems 21a-21n corresponding to the outermost (or "leaf" or "edge") control systems in the hierarchy. Those of ordinary skill in the art will appreciate of course that more or fewer than three levels may be used in the hierarchy. The particular number of levels to use in the hierarchy will depend on a number of factors including but not limited to the particular application, physical constraints, cost and the like.
[0034]Control systems 16a-16N generally denoted 16 at the edge of the network (i.e. those control systems attached to readers 14) will smooth data. Not every tag is read every time, and sometimes a tag is read incorrectly. By using algorithms, the control system is able to correct these errors. If the signals from two readers overlap, they may read the same tag, producing duplicate EPCs. One of the control system's jobs is to analyze reads and delete duplicate codes. The information collected by the edge control systems 16 is passed to another control system (e.g., control system 22) further up the hierarchy (data forwarding). At each level 16, 22, 24 the control system has to decide what information needs to be forwarded up or down the chain. For instance, a control system in a cold storage facility might forward only changes in the temperature of stored items. It should be appreciated that while three control system levels are here shown, any number of control system levels can be used.
[0035]Existing databases typically can't handle more than a few hundred transactions per second, so another job of the control systems is to maintain a real-time in-memory event database (RIED). In essence, the system will take the EPC data that is generated in real time and store it intelligently, so that other enterprise applications have access to the information, but databases aren't overloaded.
[0036]All control systems 16, 22, 24, regardless of their level in the hierarchy, include a Task Management System (TMS), which enables them to perform data management and data monitoring using customizable tasks. For example, a control system running in a store might be programmed to alert the stockroom manager when product on the shelves drops below a certain level.
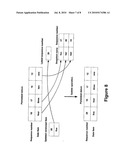
[0037]Referring now to FIG. 3, an event management system (EMS) 28 is shown. The EMS provides a framework to collect, process, and store reads by a tag. The EMS is responsible for several functions including allowing adapters to be written for various types of readers; collecting EPC data from readers in a standard format; allowing filters to be written to smooth or clean EPC data; allowing various loggers to be written, such as database loggers to log EPC data into the database, network loggers to broadcast EPC data to remote servers; and buffering events to enable loggers, filters and adapters to operate without blocking each other.
[0038]The EMS 28 receives events from readers 14 at adapters 30. Reader adapters 30 communicate directly or indirectly with readers and gather information about the events detected by the readers. The reader adapter 30 then writes these events to the reader interface 34 through an optional filter 32.
[0039]The Reader Interface 34 allows reader interface adapters 30 to communicate events detected by the control readers 14. The reader adapters 30 communicate with readers 14 to capture EPC events. The reader adapters 30 are event producers that post the reader events to any event consumer that implements the reader interface 34.
[0040]The reader interface 34 is coupled through optional filters and queues 36, 38 to event loggers 40. Event loggers 40 correspond to various implementations of the reader interface and allow for varied processing of events. For example, one implementation of the reader interface can store the information in the database, another implementation of the reader interface can store the events in a memory data structure, and yet another can broadcast the events to one or more remote servers using Hyper Text Transfer Protocol (HTTP), Java Message Service (JMS) or Simple Object Access Protocol (SOAP) protocols. Event Loggers are also called event consumers, since they consume incoming events in a stream.
[0041]The event queues 38 provide an asynchronous queuing system that handles multiple reader event loggers with synchronous implementations. The queuing system records events read by various reader adapters, and posts these events to all of the reader event loggers registered with the system. Event loggers can register and unregister from the event queue in real time.
[0042]The queuing system increases the throughput of the system using multi-processing. For example, a database event logger, which would consume most of its time in disk reads and writes, will not reduce the speed of a network event logger that posts real-time events to a remote server. Since event queues are neither producers nor consumers of events, they are called event forwarders.
[0043]The event filters 32, 36 handle one incoming event stream and post the events to one or more output streams. Unlike event queues 38, event filters 32, 36 are usually synchronous implementations. Event filters can be added between event producers and event consumers to perform smoothing, coordination or forwarding.
[0044]The above processing units are arranged in a Directed Acyclic Graph (DAG) by the EMS system when it starts up. The EMS starts up each processing unit only after its dependencies have been started up. An EMS configuration file defines this DAG. On startup, the EMS configuration parser loads this file and sets up the processing units as specified in that file.
[0045]Any provider can implement the EMS interfaces and use the implemented EMS unit in the control system. Using the EMS framework, the control system can configure adapters, filters and loggers provided by multiple software vendors, to process tag data.
[0046]RIED is an in-memory database that can be used to store event information gathered by the Event Management System. The RIED system is a high-performance, multi-versioned in-memory database.
[0047]Applications can access RIED using Java Data Base Connectivity (JDBC) or a native Java interface. RIED supports SQL operations such as SELECT, UPDATE, INSERT and DELETE. RIED supports a subset of data manipulation operations defined in SQL92.
[0048]RIED is a relatively simple, high-performance, multi-versioned in-memory database that can be used to store event information gathered by the Event Management System. RIED can maintain "snapshots" of the database at different timestamps. Furthermore, as will be described below, the time taken by RIED to create a new snapshot is a constant-time operation. Old snapshots of observations are required for queries such as counting the inventory, and backing up RIED to the database. RIED is capable of holding multiple read only snapshots of outdated information. For example, the database could hold two outdated snapshots of all observed tags, one at the beginning of the day, and the other at the beginning of the minute
[0049]Typical control system application units perform frequent updates on the event information. For instance, every tag read would be associated with an update operation on the database to register the last read time of that tag. Most in-memory databases are suited for applications that spend more time in queries than in updates. When performing a large query on the in-memory database, such as getting a list of all tags detected by readers, while performing frequent updates, typical databases may perform inefficiently.
[0050]RIED is capable of holding multiple read-only snapshots of outdated information. A snapshot is a copy of the current state of the database that can be queried, but not modified. Consequently, an application scanning over all event data can perform the query on a consistent version of the database, while other routines update the event data.
[0051]RIED transactions are applied sequentially. Specifically, at any time only one transaction operates on the latest state of the database. Every transaction taking place in RIED is assigned a sequence number. A sequence manager maintains the latest sequence number and a list of sequence numbers corresponding to outdated snapshots in the database. Every snapshot can be referenced with a snapshot name. The RIED system is configured with a fixed number of snapshot names during startup.
[0052]As mentioned above, RIED uses versioned data structures for snapshot maintenance. In contrast, conventional existing in-memory database systems do not provide such support for efficient management of persistent information.
[0053]Versioned data structures perform updates on the latest snapshot and queries on all previous snapshots. The multi-versioned database is implemented as follows:
[0054]Suppose the database holds n snapshots (S0, S1 . . . Sn). A sequence manager holds the sequence numbers associated with each snapshot Si as Ti for example. The sequence manager supports the following operations: [0055]a. increment T0: every update operation increases the sequence number of the latest snapshot S0. [0056]b. synchronize Si: every snapshot synchronization operation makes the snapshot Si correspond to the currently latest snapshot. This operation is implemented by setting Ti to T0, which makes the operation a constant-time operation.
[0057]Versioned data structures need not be modified when the sequence manager performs the two above operations. This allows the RIED system to perform updates and state synchronizations in constant time.
[0058]One type of versioned data structure used by the RIED system is known as persistent datum. This data structure maintains the history of a data item for every snapshot. RIED table rows are stored in persistent data items. Each datum holds n items with the sequence numbers associated with them. On any search operation that queries the data item's value for a certain version, the persistent datum returns the data item associated with the latest sequence number smaller than the version's sequence number.
[0059]A valid version of the data item is a version that corresponds to the latest update before some snapshot sequence number Ti. Not all versions maintained in the persistent datum are valid data items. However, any update operation performed on a persistent datum ensures that invalid versions are removed when necessary.
[0060]A second type of versioned data structure used by the REID system is known as persistent set. This data structure maintains the history of a set of data items. RIED table index contents are stored in persistent sets. Specifically, all the primary keys that share the same index column value are stored in one persistent set.
[0061]The persistent set allows query operations to retrieve all items in the set and update operations to add or remove items from the set. As in the persistent datum, the persistent set maintains versions of object membership values that determine if an object is present or absent in a set. Update operations remove unnecessary objects from this set depending on the same validity principle used in persistent datums.
[0062]A third type of versioned data structure used by the REID system is known as a hash table. The hash table is high-speed constant-time search data structure. Hash tables are used to maintain tables as mappings from primary keys to persistent datums containing the row values. They are also used to maintain table indexes. Here the hash table maintains mappings from indexed column values to persistent sets of the corresponding primary keys.
[0063]Transaction management involves support for COMMIT and ROLLBACK operations on transactions. All updates performed by a transaction are stored in a rollback buffer. On a COMMIT operation, all updates enqueued in the rollback buffer are written to the table and table index data structures. On a ROLLBACK operation, this buffer is emptied out.
[0064]The RIED transaction manager supports only one transaction at a time. This means that every transaction blocks other transactions from updating the RIED database. Such a transaction management method is necessary to avoid the high cost of locking and unlocking memory data structures. A typical wait/notify cycle implemented using semaphores can take a few microseconds. This rules out the possibility of performing fine-grained row-level locking in the RIED system.
[0065]Queries made on the latest snapshot of the RIED system will first look at the rollback buffer, and then search the other memory data structures. This behavior ensures that updates made by a transaction are visible within that transaction even before a COMMIT operation. Queries made on older states however will not look at the rollback buffer, thereby ensuring that there are no dirty reads in the system.
[0066]EMS can be implemented as a pure-Java package providing Java interfaces for the above mentioned EMS units. The RIED implementation may also be realized as a pure-Java implementation that uses Another Tool for Language Recognition (ANTLR) to parse the SQL Data Definition Language and the Data Manipulation Language.
[0067]The TMS implementation may also be a Java implementation that provides task scheduling using schedule configuration similar to UNIX crontab.
[0068]Referring now to FIG. 4, to exploit RIED versioning, applications can synchronize a snapshot referenced by its name to the latest state of the database. As shown in FIG. 4, an application synchronizes the state of the snapshot named "foo" to the latest sequence number (28). The figure also illustrates the manner in which the sequence manager maintains the snapshot sequence numbers. Note that after the synchronization of the snapshot "foo", its sequence number is set to 28 which indicates that the snapshot has been synchronized to the latest sequence number.
[0069]Referring now to FIG. 5, every table in RIED is stored in a hash table 100. The primary key 110 of every record in the table 100 is maintained as a key in the hash table. The value associated with the key is a persistent datum holding the contents of the row 120. FIG. 5 illustrates a table stored in this format. Every value stored in the hash table is a persistent datum. FIG. 5 shows the persistent datum 130 for the row with primary key 1.
[0070]Referring now to FIG. 6, each index in RIED is also stored in a hash table 150. The key maintained by the hash table 150 corresponds to a value in the indexed primary key column 160. However, unlike the primary key of a table, an indexed key could be the same for more than one record in the table. For each indexed value, RIED stores the primary keys of the records having that indexed value in a persistent set. FIG. 6 illustrates an index stored in this format. Every value stored in the hash table points to a persistent set of primary keys 170.
[0071]All query paths accessing the rows in a table using a primary key can load the row associated with a given primary key in constant time. Based on the snapshot of the database in which the query is performed, the persistent datum returns the appropriate row. Similarly query paths accessing the rows in a table using an indexed key can load the row associated with a given indexed key in constant time. Based on the snapshot of the database in which the query is performed, the persistent set will return the appropriate set of primary keys that have the given indexed value.
[0072]The persistent datum data structure allows support for certain operations. These operations include the ability to perform a query the latest value of the datum, perform a query the value of the datum at a given sequence number, and update the value of the datum.
[0073]The persistent datum is an array of versioned items. The size of the array is one more than the number of snapshots maintained. Each versioned item in the array holds the sequence number and the value of the data item set at that version number. The sequence number maintained in the versioned item is monotonically non-increasing for increasing indexes.
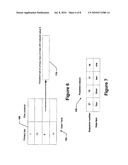
[0074]FIG. 7 shows a sample persistent datum 130. When the latest value of the datum is queried, the first data item held in the item in the array is returned. For the datum shown in FIG. 7 the value "four" will be returned.
[0075]When the value of the datum at a given sequence number is queried, the persistent datum will return the data item corresponding to the first (based on increasing array index) versioned item in the array with the sequence number less than or equal to the given sequence number. For example, in FIG. 7, the data item "two" will be returned as the value of the datum for sequence number 18 since the first sequence number less than or equal to sequence number 18 is sequence number 17, thus the data item for sequence number 17 is returned.
[0076]On an update operation, the persistent datum uses the sequence manager to determine am invalid versioned item. A versioned item is valid if it can be accessed by querying the latest value of the datum, or by querying based on the sequence number of a snapshot defined in the sequence manager. Since the latest value of the datum is the currently updated value, the persistent datum can have at most n valid items before an update, where n is the number of snapshots maintained. The array however holds n+1 items, which means that there at least one invalid versioned item. This item will be overwritten during the update process.
[0077]FIG. 8 illustrates an update operation. The valid items are linked with curved lines to the snapshot for which they are relevant. The invalid item is "two" updated at sequence number 16. After the update operation, this invalid item is removed, and sequence number 28 having data item "five" is inserted into the persistent datum. The updated persistent datum now includes the latest sequence number (28), as shown in FIG. 8.
[0078]All operations on a persistent datum can be performed in constant time, since the number of versions maintained is a constant. Persistent sets are maintained as persistent datums with data items corresponding to additions (ADD) and removals (DEL) from the set. Unlike the persistent datum however, the array maintaining the persistent set keeps growing.
[0079]FIG. 9 illustrates a persistent set along with the results of queries in various snapshots. An update operation causes the addition of versioned data item to the beginning of the array. A query is performed by traversing the array from right to left (in decreasing order of indexes). The set is constructed as ADD and DEL records are encountered. This process stops when a versioned item with sequence number greater than the sequence number specified by the query is encountered.
[0080]On any query, update or versioned query operation, all invalid items in the array are removed. Invalid items in the persistent set occur in pairs of addition and removal records on the same value.
[0081]A pair of invalid items is shown in FIG. 9. The deletion of "one" at sequence number 18 followed by its addition in sequence number 19 cannot be detected by performing queries on any of the snapshots. For example, a query of snapshot foo would be detected by persistent datum sequence number 17, while a query of snapshot bar would be detected by persistent datum sequence numbers 20 and a query of snapshot name baz would be detected by persistent datum sequence number 12. There is no query of the snapshots however that would be detected by persistent datum sequence numbers 19 and 18, therefore they are deemed invalid.
[0082]Having described preferred embodiments of the invention it will now become apparent to those of ordinary skill in the art that other embodiments incorporating these concepts may be used. Additionally, the software included as part of the invention may be embodied in a computer program product that includes a computer useable medium. For example, such a computer usable medium can include a readable memory device, such as a hard drive device, a CD-ROM, a DVD-ROM, or a computer diskette, having computer readable program code segments stored thereon. The computer readable medium can also include a communications link, either optical, wired, or wireless, having program code segments carried thereon as digital or analog signals. Accordingly, it is submitted that that the invention should not be limited to the described embodiments but rather should be limited only by the spirit and scope of the appended claims. All publications and references cited herein are expressly incorporated herein by reference in their entirety.
User Contributions:
comments("1"); ?> comment_form("1"); ?>Inventors list |
Agents list |
Assignees list |
List by place |
Classification tree browser |
Top 100 Inventors |
Top 100 Agents |
Top 100 Assignees |
Usenet FAQ Index |
Documents |
Other FAQs |
User Contributions:
Comment about this patent or add new information about this topic:
Images included with this patent application:
 |  |
 |  |
 |  |
 |  |
 |
| Similar patent applications: | |
| Date | Title |
|---|---|
| 2013-04-25 | Method and system for fulfilling requests in an inventory system |
| 2013-05-23 | Automated identification of shoe parts |
| 2013-07-25 | Action detection and activity classification |
| 2013-08-08 | Building management server and building illumination control method |
| 2010-11-04 | Redundant communication system |
| New patent applications in this class: | |
| Date | Title |
|---|---|
| 2022-05-05 | Control system, support device, and support program |
| 2015-04-16 | Event input module |
| 2015-01-08 | Operating environment parameter regulation in a multi-processor environment |
| 2014-11-13 | Plc communication system |
| 2014-06-12 | Programmable logic controller communication system |
| New patent applications from these inventors: | |
| Date | Title |
|---|---|
| 2011-01-27 | Method and apparatus for routing data in an automatic identification system |
| Top Inventors for class "Data processing: generic control systems or specific applications" | |
| Rank | Inventor's name |
|---|---|
| 1 | Kyung Shik Roh |
| 2 | Lowell L. Wood, Jr. |
| 3 | Mark J. Nixon |
| 4 | Royce A. Levien |
| 5 | Yulun Wang |