Patent application title: COMPOSITIONS AND METHODS FOR 3-HYDROXYPROPIONATE BIO-PRODUCTION FROM BIOMASS
Inventors:
Michael D. Lynch (Boulder, CO, US)
Michael D. Lynch (Boulder, CO, US)
Assignees:
OPX Biotechnologies, Inc.
IPC8 Class: AC07C5704FI
USPC Class:
562598
Class name: Carboxylic acids and salts thereof acyclic unsaturated
Publication date: 2012-02-16
Patent application number: 20120041232
Abstract:
Methods of obtaining mutant nucleic acid sequences that demonstrate
elevated oxaloacetate α-decarboxylase activity are provided.
Compositions, such as genetically modified microorganisms that comprise
such mutant nucleic acid sequences, are described, as are methods to
obtain the same.Claims:
1. A method for producing an acrylic acid-based consumer product, said
method comprising i) combining a carbon source and a microorganism cell
culture to produce 3-hydroxypropionic acid; ii) converting said
3-hydroxypropionic acid to acrylic acid; and iii) processing said acrylic
acid into a consumer product.
2. The method of claim 1, wherein said cell culture comprises a genetically modified microorganism.
3. The method of claim 2, wherein said microorganism is modified for increased tolerance to 3-hydroxypropionic acid.
4. The method of claim 3, wherein said modification modulates one or more components of the chorismate superpathway.
5. The method of claim 2, wherein said microorganism is modified for increased production of 3-hydroxypropionic acid.
6. The method of claim 5, wherein said modification comprises reduction in activity of one or more enzymes selected from pyruvate kinase, phosphofructokinase, lactate dehydrogenase, phosphate acetyltransferase, pyruvate oxidase, pyruvate-formate lyase, and homologs thereof.
7. The method of claim 6, wherein said pyruvate kinase is selected from pykA and pykF, said phosphofructokinase is selected from pfkA and pfkB, said lactate dehydrogenase is selected from ldhA, said phosphate acetyltransferase is selected from pta, said pyruvate oxidase is selected from poxB, said pyruvate-formate lyase is selected from pflB, and homologs thereof.
8. The method of claim 5, wherein said modification comprises increase in activity of one or more enzymes selected from phosphoenolpyruvate carboxykinase, malonyl-CoA reductase, 3-hydroxypropionate dehydrogenase, malonate semialdehyde dehydrogenase A, alpha-ketoglutarate decarboxylase, oxaloacetate alpha-oxo-decarboxylase, and homologs thereof.
9. The method of claim 8, wherein said phosphoenolpyruvate carboxykinase is selected from pck, said malonyl-CoA reductase is selected from mcr, said malonate semialdehyde dehydrogenase A is selected from mmsA, said 3-hydroxypropionic acid acid dehydrogenase is selected from mmsB, said alpha-ketoglutarate decarboxylase is selected from kgd, said oxaloacetate alpha-oxo-decarboxylase is selected from oad, and homologs thereof.
10. The method of claim 8, wherein said modification comprises an increase in activity in a malonyl-CoA reductase enzyme.
11. The method of claim 8, wherein said modification comprises an increase in activity in an oxaloacetate alpha-oxo-decarboxylase enzyme.
12. The method of claim 2, wherein said microorganism is modified for increased tolerance to 3-hydroxypropionic acid, and wherein said microorganism is modified for increased production of 3-hydroxypropionic acid.
13. A method for producing an acrylic acid-based consumer product, said method comprising i) combining a carbon source and a genetically modified microorganism in cell culture to produce 3-hydroxypropionic acid; ii) converting said 3-hydroxypropionic acid to acrylic acid; and iii) processing said acrylic acid into a consumer product; wherein said microorganism is modified for increased production of 3-hydroxypropionic acid via an increase in activity in an oxaloacetate alpha decarboxylase enzyme or homolog thereof.
14. A method for producing acrylic acid, said method comprising i) combining a carbon source and a microorganism cell culture to produce 3-hydroxypropionic acid in a concentration of at least 10 g/L; and ii) converting said 3-hydroxypropionic acid to acrylic acid.
15. The method of claim 14, wherein the combining comprises combining a carbon source and a microorganism cell culture comprising a microorganism genetically modified to increase activity of one or more enzymes selected from phosphoenolpyruvate carboxykinase, malonyl-CoA reductase, malonate semialdehyde dehydrogenase A, 3-HP dehydrogenase, alpha-ketoglutarate decarboxylase, oxaloacetate alpha-oxo-decarboxylase, and homologs thereof.
16. The method of claim 15, wherein said phosphoenolpyruvate carboxykinase is selected from pck, said malonyl-CoA reductase is selected from mcr, said malonate semialdehyde dehydrogenase A is selected from mmsA, said 3-hydroxypropionic acid dehydrogenase is selected from mmsB, said alpha-ketoglutarate decarboxylase is selected from kgd, said oxaloacetate alpha-oxo-decarboxylase is selected from oad, and homologs thereof.
17. The method of claim 14, wherein the combining comprises combining a carbon source and a microorganism cell culture comprising a microorganism genetically modified to increase activity of malonyl-CoA reductase enzyme increasing production of 3-hydroxypropionic acid.
18. The method of claim 14, wherein the combining comprises combining a carbon source and a microorganism cell culture comprising a microorganism genetically modified to increase activity of an oxaloacetate alpha-oxo-decarboxylase enzyme, increasing production of 3-hydroxypropionic acid.
19. Biologically-produced acrylic acid, wherein said acrylic acid is produced according to claim 14.
20. A consumer product produced with acrylic acid according to claim 19.
Description:
RELATED APPLICATIONS
[0001] This application is a continuation application which claims priority under 35 USC 120 to U.S. patent application Ser. No. 12/328,588, filed Dec. 4, 2008, and this application also claims priority under 35 USC 119 to U.S. Provisional Patent Application No. 60/992,290, filed Dec. 4, 2007. Both referenced patent applications are incorporated by reference in their respective entireties herewith.
STATEMENT REGARDING FEDERALLY SPONSORED DEVELOPMENT
[0002] N/A
REFERENCE TO A SEQUENCE LISTING
[0003] An electronically filed sequence listing is provided herewith.
FIELD OF THE INVENTION
[0004] The present invention relates to methods, systems and compositions, including genetically modified microorganisms, i.e., recombinant microorganisms, adapted to exhibit elevated oxaloacetate alpha-oxo decarboxylase activity (also referred to herein as oxaloacetate alpha-decarboxylase activity).
BACKGROUND OF THE INVENTION
[0005] 3-hydroxypropionate ("3-HP", CAS No. 503-66-2) has been identified as a highly attractive potential chemical feedstock for the production of many large market commodity chemicals that are currently derived from petroleum derivatives. For example, commodity products that can be readily produced using 3-HP include acrylic acid, 1,3-propanediol, methyl-acrylate, and acrylamide, as shown in FIG. 1. The sum value of these commodity chemicals is currently estimated to exceed several billions of dollars annually in the US. However, the current petrochemical manufacturing techniques for these commodities adverse impact the environment via the pollutants generated and the energy used in their production. Manufacture of these same commodities via the clean, cost-effective, production of 3-HP from biomass will simultaneously reduce toxic waste and substitute renewable feed stocks for non-renewable resources. In addition to the environmental benefits associated with bio-based production of 3-HP, if the production cost of the derived commodities is substantially reduced relative to petroleum-based production, this would make a biorefining industry not only environmentally beneficial but also a very attractive investment.
[0006] Previous attempts to produce 3-HP via biological pathways provide product titers which have been low and these processes have required the use of expensive, rich media. Both of these factors limit commercial feasibility and profitability. The use of rich media was necessary due to the toxicity of 3-HP when fermented with the more economical minimal media. For example, in wild type E. coli, metabolic activity is significantly inhibited at levels of 3-HP that are 5-10 times lower than the approximate 100 g/L titer needed for economic feasibility using the more economical minimal media. In fact, toxic effects have also been observed in rich media at product titers which are approximately two times lower than desired titers for commercial feasibility (Refer to FIG. 2). Further, the fermentative pathways reported by other investigators have not addressed and resolved the toxicity mechanisms of 3-HP to the host organisms.
[0007] Further to issues related to commodity chemical production, which largely relies on petroleum-based starting materials, there is an increasing need to reduce the domestic usage of petroleum and natural gas. The numerous motivating factors for this increasing need include, but are not limited to: pollutant reduction (such as greenhouse gases), environmental protection, and reducing the dependence on foreign oil. These issues not only impact fuel markets, but also the markets of numerous other products that are currently derived from oil. Biorefining promises the development of efficient biological processes allowing for the conversion of renewable sources of carbon and energy into large volume commodity chemicals.
[0008] A biosynthetic route to 3-HP as a platform chemical would be of benefit to the public, not only in terms of reduced dependence on petroleum, but also by a reduction in the amount of pollutants that are generated by current non-biosynthetic processes. Because 3-HP is not currently used as a building block for the aforementioned commodity chemicals, technical hurdles must be surmounted to achieve low cost biological routes to 3-HP. These hurdles include the development of a new organism that not only has a metabolic pathway enabling the production of 3-HP, but is also tolerant to the toxic effects of 3-HP thus enabling the sustained production of 3-HP at economically desired levels.
[0009] There are numerous motivating factors to reduce the domestic usage of petroleum. These factors include, but are not limited to: 1) the negative environmental impacts of petroleum refining such as production of greenhouse gases and the emission of a wide variety of pollutants; 2) the national security issues that are associated with the current dependence on foreign oil such as price instability and future availability; and 3) the long term economic concerns with the ever-increasing price of crude oil. These issues not only impact fuel markets, but also the multi-billion dollar commodity petro-chemical market
[0010] One potential method to alleviate these issues is the implementation of bioprocessing for the conversion of renewable feed stocks (e.g. agricultural wastes) to large volume commodity chemicals. It has been estimated that such bioprocesses already account for 5% of the 1.2 trillion dollar US chemical market. Furthermore, some experts are projecting that up to 50% of the total US chemical market will ultimately be generated through biological means.
[0011] While the attractiveness of such bioprocesses has been recognized for some time, recent advances in biological engineering, including several bio-refining success stories, have accelerated interest in the large scale production of chemicals through biological routes. However, many challenges still remain for the economical bio-production of commodity chemicals. These challenges include the need to convert biomass into usable feed stocks, the engineering of microbes to produce relevant chemicals at high titers and productivities, the improvement of the microbes' tolerance to the desired product, and the need to minimize the generation of byproducts that might affect downstream processes. Finally, the product must be economically competitive in the marketplace.
[0012] The contributions of bioprocessing are expected to grow in the future as existing biological methods become more efficient and as new bioprocesses are developed. A recent analysis by the U.S. Department of Energy identified a list of the Top Value Added Chemicals from Biomass that are good candidates for biosynthetic production. Eight of the top value added chemicals were organic acids, including 3-hydroxypropionic acid (3-HP). As depicted in FIG. 1, 3-HP is considered to be a platform chemical, capable of yielding valuable derivative commodity chemicals including acrylic acid and acrylic acid polymers, acrylate esters, acrylate polymers (plastics), acrylamide, and 1,3-propanediol. Presently, these high value chemicals are produced from petroleum.
[0013] One method to efficiently generate 3-HP by a bioprocess approach would be the microbial biosynthesis of renewable biomass sugars to 3-HP. According to the DOE Report (Werpy, T.; Petersen, G. Volume 1: Results of Screening for Potential Candidates from Sugars and Synthetic Gas. Oak Ridge, Tenn., U.S. Department of Energy; 2004. Top Value Added Chemicals from Biomass), a number of factors will need to be addressed, including: identifying the appropriate biosynthetic pathway, improving the reactions to reduce other acid co-products, increasing microbial yields and productivities, reducing the unwanted salts, and scale-up and integration of the system. Additionally, as noted above, it is critical to engineer the microbial organism to be tolerant to the potential toxicity of the desired product at commercially significant concentrations.
[0014] The production of acrylic acid from 3-HP is of particular interest because of the high market value of acrylic acid and its numerous derivatives. In 2005, the estimated annual production capacity for acrylic acid was approximately 4.2 million metric tons, which places it among the top 25 organic chemical products. Also, this figure is increasing annually. The demand for acrylic acid may exceed $2 billion by 2010. The primary application of acrylic acid is the synthesis of acrylic esters, such as methyl, butyl or ethyl acrylate. When polymerized, these acrylates are ingredients in numerous consumer products, such as paints, coatings, plastics, adhesives, dispersives and binders for paper, textiles and leather. Acrylates account for 55% of the world demand for acrylic acid products, with butyl acrylate and ethyl acrylate having the highest production volumes. The other key use of the acrylic acid is through polymerization to polyacrylic acid, which is used in hygiene products, detergents, and waste water treatment chemicals. Acrylic acid polymers can also be converted into super absorbent materials (which account for 32% of worldwide acrylic acid demand) or developed into replacement materials for phosphates in detergents. Both of these are fast growing applications for acrylic acid. Today, acrylic acid is made in a two step catalytic oxidation of propylene (a petroleum product) to acrolein, and acrolein to acrylic acid, using a molybdenum/vanadium based catalyst, with optimized yields of approximately 90%. It should be noted that several commercial manufacturers of acrylic acid are exploring the use of propane instead of propylene. The use of propane is projected to be more environmentally friendly by reducing energy consumption during production. However, propane is petroleum based, and while its use is a step in the right direction from an energy consumption standpoint, it does not offer the benefits afforded by the bioprocessing route.
[0015] In addition to acrylic acid, acrylates, and acrylic acid polymers, another emerging high value derivative of 3-HP is 1,3-propanediol (1,3-PD). 1,3-PD has recently been used in carpet fiber production for carpets. Further applications of 1,3-PD are expected to include cosmetics, liquid detergents, and anti-freeze. The market for 1,3-PD is expected to grow rapidly as it becomes more routinely used in commercial products.
[0016] Pursuing a cleaner, renewable carbon source route to commodity chemicals through 3-HP will require downstream optimization of the chemical reactions, depending on the desired end product. 3-HP production through bioprocesses directly, or through reaction routes to the high-value chemical derivatives of 3-HP will provide for large scale manufacture of acrylic acid, as well reduction of environmental pollution, the reduction in dependence on foreign oil, and the improvement in the domestic usage of clean methods of manufacturing. Furthermore, the products produced will be of the same quality but at a competitive cost and purity compared to the current petroleum based product.
[0017] Thus, notwithstanding various advances in the art, there remains a need for methods that identify and/or provide, and compositions directed to recombinant microorganisms that have improved 3-HP production capabilities, so that increased 3-HP titers are achieved.
BRIEF DESCRIPTION OF THE DRAWINGS
[0018] FIG. 1 depicts how biomass derived 3-HP can serve as a chemical feedstock to many major chemical commodities worth billions of dollars. (Adapted from Werpy et al. US Dept. Energy, 2004).
[0019] FIG. 2 depicts 3-hydroxpropionate toxicity in E. coli K12. The minimum concentration of 3-HP that is required to inhibit visible growth after 24 hrs in minimal media is shown for wild type E. coli K12 grown in both minimal media and rich media which contains more complex nutrients.
[0020] FIG. 3 is an overview of SCALEs. (a) Genomic DNA is fragmented to several specific sizes and ligated into vectors creating libraries with defined insert sizes. (b) These libraries are individually transformed into the host cell line used for selections. (c) The pools of transformants are mixed and subjected to selection. Clones bearing inserts with increasing fitness in a given selection have a growth advantage. (d) Enriched plasmids are purified from the selected population, prepared for hybridization, and applied to a microarray. (e) The processed microarray signal is analyzed as a function of genomic sequence position. (f) A nonlinear multi-scale analysis decomposition gives signal not only as a function of position but as a function of scale or library size. (g) Data are visualized and analyzed as a function of genomic position and scale. (for the circular chromosome of E. coli shown, genomic position correlates to position around the circle and scale is represented by color. The height of the peak above the circle correlates to population frequency or fitness of a given scale at a given position.)
[0021] FIGS. 4A-4C-1 depict the SCALEs data identifying the chorismate superpathway as a 3-HP target. (A) Fitness data for positions and scales conferring increased fitness of E. coli in the presence of 3-HP. Genomic position correlates to position around the circle and scale is represented by color (red=500-1000 bp, yellow=1000-2000 bp, green=4000-8000 bp, blue=8000-10000 bp). The height of the peak above the circle correlates to the fitness of a given scale at a given position. Peaks corresponding to genes involved in the chorismate superpathway are numbered. (B) List of genes in the chorismate superpathway identified in (A). (C) The fitness of each gene identified in (A) is color coded and identified in the chorismate superpathway.
[0022] FIG. 5A This figure depicts the natural metabolic pathways utilize by E. coli during bio-production which results in the natural products lactate, formate and acetate FIG. 5B. The proposed metabolic pathway to produce 3-HP as a bio-production product. Arrows represent enzymatic activities. The non natural enzymatic function to be evolved in this Phase I project is colored in red. Enzyme activities are as follows [i] glucokinase, [ii] phosphoglucose isomerase, [iii] 6-phosphofructose kinase, [iv] fructose bisphosphate aldolase, [v] triose-phosphate isomerase, [vi] glyceraldehydes 3-phosphate dehydrogenase, [vii] phosphoglycerate kinase, [viii] phosphoglycerate mutase, [ix] enolase, [xi] pyruvate kinase, [xi] lactate dehydrogenase, [xii] pyruvate oxidase, [xiii] pyruvate-formate lyase, [xiv] phosphate acetyltransferase, [xv] acetate kinase, [xvi] phosphoenolpyruvate carboxykinase [xvii] the proposed oxaloacetate alpha-oxo decarboxylase, [xviii] 3-hydropxypropionate dehydrogenase and [xix] malonate semialdehyde dehydrogenase
[0023] FIG. 6 This figure depicts the chemical reaction performed by 2-oxo acid decarboxylases. R can be any group.
[0024] FIG. 7A This figure depicts the chemical reaction performed by alpha-ketoglutarate decarboxylase encoded by the kgd gene from M. tuberculosis. FIG. 7B depicts the proposed reaction performed by the newly evolved enzyme, oxaloacetate alpha-oxo-decarboxylase. The proposed enzyme will be encoded by the oad-2 gene which will be evolved by mutation from the kgd gene.
[0025] FIG. 8 This figure depicts an overview of the methods to select a diverse library of 2-oxo acid decarboxylases for oxaloacetate alpha-oxo-decarboxylase activity. [i] A natural 2-oxo acid decarboxylase is mutated to create a variant library, [ii] this library is introduced into a microbial host that will not survive in a given environment without the presence of the product of the alpha-oxo-decarboxylase, malonate semialdehyde. [iii]. Positive mutants are identified by growth under selective conditions.
[0026] FIG. 9A depicts the proposed selection of the metabolism of E. coli strain NZN111 is shown in the left box. The pflB gene is disrupted blocking the formation of acetyl-coA in anaerobic conditions. The lack of acetyl-coA formation severely inhibits growth. The proposed additional enzymatic path to acetyl-coA is outlined in the right box. The characterized mmsA gene can supply acetyl-coA under anaerobic conditions if it is supplied with malonate semialdehyde by an oxaloacetate alpha-oxo decarboxylase. Kgd mutants with this activity will allow the strain to grow under anaerobic conditions.
[0027] FIG. 9B depicts the proposed selection of the relevant metabolism of E. coli strain AB354 is summarized in the left box. The panD gene is mutated blocking the synthesis of beta-alanine, an essential precursor for pantothenate (coA). The lack of pantothenate formation abolishes growth on minimal media. The proposed additional enzymatic path to beta-alanine is outlined in the right box. The characterized R. norvegicus beta-alanine aminotransferase gene (gabT) can supply beta-alanine if it is supplied with malonate semialdehyde as a substrate. An active oxaloacetate alpha-decarboxylase will supply this substrate and enable growth on minimal media. Kgd mutants with this activity will allow the strain to grow on minimal media.
[0028] FIG. 10A depicts the anticipated Selection Results of mutant colonies expressing the desired oxaloacetate alpha-oxo-decarboxylase will grow under anaerobic conditions when expressed in E. coli NZN111 expressing mmsA. No growth will be observed under these conditions in the E. coli NZN111, E. coli NZN111+mmsA controls. Or in mutants not expressing the desired activity.
[0029] FIG. 10B depicts the anticipated Selection Results of mutant colonies expressing the desired oxaloacetate alpha-decarboxylase will grow on minimal media when expressed in E. coli AB354 expressing gabT. No growth will be observed under these conditions in the E. coli AB354, E. coli AB354+gabT controls, or in kgd mutants not expressing the desired activity.
[0030] FIG. 11 depicts the screening Protocol. Purified enzyme will be mixed in vitro with the appropriate substrate and reagents. A) The control reaction for the native alpha-ketoglutarate decarboxylase. B) Predicted results for the native alpha-ketoglutarate decarboxylase with oxaloacetate as a substrate. C) Predicted results for kgd mutants, both positive and negative, for oxaloacetate alpha-decarboxylase activity.
[0031] FIG. 12 Expression and Purification results of pKK223-Cterm-5×His-kgd. Lane 1=marker; lane 2=uninduced culture; lane 3=induced culture; lane 4=native lysate; lane 5=flowthrough; lane 6=first wash (wash 1); lane 7=last wash (wash 3); lane 8=first elution; lane 9=second elution, purified kg; lane 10=pelleted cell debris. The arrow points to the band comprising purified alpha-ketoglutarate decarboxylase.
DETAILED DESCRIPTION OF EMBODIMENTS OF THE INVENTION
[0032] Generally the invention is directed to compositions and methods for production of target chemical compounds in an organism. Various aspects of the invention are directed to providing altered/modified proteins having different enzymatic activity/function as compared to the unaltered protein. Further aspects, of the invention are directed to recombinant organisms comprising altered/modified pathways which are enhanced for production of a target compound (e.g., 3-HP). In some embodiments, a recombinant organism of the invention is a microorganism or algae. In further embodiments, a recombinant organism is a bacterium (e.g., E. coli).
[0033] In one aspect of the invention, an organism is modified to include one or more genes encoding a protein involved in biosynthesis to enhance production of a target chemical compound (e.g., 3-HP). In further embodiments, such one or more genes encode one or more proteins which enhance the capability of the organism to produce a target chemical compound in culture. In one embodiment, such a chemical compound is 3-HP. In yet a further embodiment, the organism comprises at least one recombinant gene resulting in pyruvate, oxalocetate and acetyl-coA production without committed formate production.
[0034] In another embodiment, the recombinant organism comprises acetyl-coA that is produced via the intermediate malonate semialdehyde. In yet another embodiment, acetyl-coA is produced via the intermediate pyruvate through pyruvate synthase.
[0035] Another aspect of the invention is directed to a method for producing 3-HP comprising growing a recombinant organism of the invention, where the organism comprises an enzyme which converts oxaloacetate to malonate semialdehyde. In further embodiments, the recombinant organism is engineered to delete or substantially reduce activity of one or more genes, where the gene(s) include but are not limited to pfkA, pfkB, ldhA, pta, poxB, pflB or a combination thereof. In yet a further embodiment, the recombinant organism is modified to enhance the activity (such as by increasing expression or improving the relevant functioning) of one or more enzymes including but not limited to pck, mmsA, mmsB, oad-2, homologs thereof, or any combination thereof.
[0036] In one embodiment, a method is provided for producing 3-HP comprising growing an organism under a condition which enhance said 3-HP production, wherein said condition is selected from acetyl-coA production via malonate semialdehyde, acetyal-coA production via pyruvate by pyrvuate synthase, without committed production of formate, homologs thereof and any combination thereof.
[0037] In a further aspect of the invention a recombinant microorganism is provided capable of producing 3-HP at quantities greater than about 10, 15, 20, 30, 40, 50, 60, 65, 70, 75, 80, 85, 90, 95, 100, 105, 110, 115, 120, 125, 130, 135, 140 145 or 150 g/L. In one embodiment, the recombinant organism is capable of producing 3-HP from about 30 to about 100 g/L of biomass/culture.
[0038] In a further aspect of the invention, a bio-production mixture is provided for producing 3HP, said mixture comprising a recombinant microorganism; one or more products selected from a group consisting tyrosine, phenylalanine, para-aminobenzoate, para-hydroxy-benzoate, 2,3,-dihydrobenzoate and shikimate.
[0039] In further embodiments, the mixture comprises a microorganism which is engineered to produce pck, mmsA, mmsB, oad-2, homologs thereof, or a combination thereof. In further embodiments, the microorganism does not produce enzymes selected from a group consisting of pfkA, pfkB, ldhA, pta, poxB, pflB, homologs thereof and a combination thereof. In various embodiments, the microorganism is E. coli.
[0040] In one aspect of the invention, an isolated polypeptide is provided possessing oxaloacetate alpha oxo-decarboxylase activity, converting oxaloacetate to malonate semialdehyde. Furthermore, a nucleic acid encoding the polypeptide is provided. In yet a further embodiments, a functional variant for the polypeptide or nucleic acid sequence is provided which is homologous to the reference polypeptide and/or nucleic acid and functions as an oxaloacetate alpha oxo-decarboxylase. In some embodiments such a functional variant has at least about 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96, 97, 98, or 99% identity with alpha-ketoglutarate decarboxylase.
[0041] Accordingly, in various aspects of the invention improved methods for biomass production of 3-HP at higher concentrations are disclosed. With this development, it is feasible to construct E. coli strains that are highly tolerant to 3-HP and that will maintain robust metabolic activity in the presence of higher concentrations of 3-HP. In various embodiments, metabolic pathways which support the bio-production of 3-HP are manipulated to increase 3-HP production. In some embodiments, such metabolic pathways do not rely upon or are not affected by metabolic processes that are themselves inhibited by 3-HP.
[0042] Utilizing processes for identification of a 3-HP insensitive bio-production pathway (infra, under "Metabolic Toxicity of 3-HP"), in various embodiments of the invention a bio-production pathway is characterized for the synthesis of 3-HP in E. coli. In a further embodiment, an altered 2-oxo acid decarboxylase is utilized in a bio-production pathway to produce 3-HP. In yet further embodiments, a bio-production pathway is utilized incorporating previously characterized and sequenced enzymes that have been reported in the literature, as discussed below under "Previously Characterized Enzymes".
[0043] In various embodiments, a bio-production pathway (shown in FIG. 6) relies directly or indirectly on the metabolite oxaloacetate through the intermediate malonate semialdehyde. The desired enzymatic activity carries out the conversion of oxaloacetate to malonate semialdehyde. This can be accomplished via a decarboxylation reaction not previously reported by a particular enzyme. More specifically, the decarboxylation of 2-oxo acids, such as oxaloacetate, is accomplished by a well understood set of thiamine pyrophosphate dependant decarboxylases, including pyruvate decarboxylases and branched chain 2-oxo acid decarboxylases. A more recently characterized enzyme from M. tuberculosis, alpha ketoglutarate decarboxylase, coded by the kgd gene, possesses catalytic activity with a primary substrate very similar to oxaloacetate, decarboxylating the metabolite alpha-ketoglutarate to succinate semialdehyde. As described in greater detail below, an alpha-ketoglutarate decarboxylase from M. tuberculosis is modified into an oxaloacetate alpha-oxo-decarboxylase or a functional variant thereof. In various embodiments, any 2-oxo acid decarboxylase including but not limited to pyruvate decarboxylases form various sources or branched chain 2-oxo acid decarboxylases are modified into an oxaloacetate alpha-oxo decarboxylase or a functional variant thereof. In various embodiments, a "functional variant" is a protein encoded by a sequence having about 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 96, 97, 98, or 99 percent identity with the nucleic acid sequence encoding the modified/altered oxaloacetate alpha-oxo-decarboxylase. In further embodiments, sequence identity can be on the amino acid sequence level, where a functional variant has a sequence identity with the reference sequence of about 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 96, 97, 98, or 99. For example, a functional variant can have sequence identity that is 90 percent, or 95 percent, but where the enzyme still functions as an oxaloacetate alpha-oxo-decarboxylase when expressed in an organism (e.g., microorganism, algae, plant), such as E. coli.
[0044] In other embodiments, a microorganism or algae is engineered to follow a preferred 3-HP bio-production pathway and also to enhance tolerance to 3-HP production at commercially viable levels. In some such embodiments, the microorganism is a bacterium, such as E. coli. Thus, as one example an E. coli strain is constructed and optimized for a desired pathway as discussed herein, wherein enhanced tolerance to 3-HP also is established so as to produce commercially viable titers of product. Accordingly, it is within the conception of the present invention that its teachings, methods and compositions may be combined with other teachings, methods and compositions more specifically directed to 3-HP tolerance improvement, including co-owned and/or licensed inventions.
[0045] Metabolic Toxicity of 3-HP
[0046] Severe growth inhibition has been observed for extracellular 3-HP levels as low as 10 g/L in minimal media (pH 7.0), which limits the economic feasibility of 3-HP production as a platform chemical. FIG. 2 demonstrates the toxic affects of 3-HP on E. coli when grown in minimal media. These toxic effects have been observed to be far greater when the strains are grown in minimal media as compared to growth in rich media (containing a mixture of all nutrients, amino acids and vitamins). However toxicity at levels below required titers (100 g/L) are still observed in rich media. These data alone indicate that 3-HP may be exerting toxic effects by suppressing central metabolic pathways essential to amino acid metabolism.
[0047] Diagnosis of 3-HP Toxicity Mechanisms
[0048] To better understand the toxic effects of 3-HP on E. coli, a genome-wide technology is used (multi-Scale Analysis of Library Enrichments (SCALEs)), such as disclosed in U.S. Patent Application Publication No. 20060084098, with related inventions described in U.S. Patent Application Publication Nos. 20080103060 and 200702185333 (the latter entitled "Enhanced Alcohol Tolerant Microorganism and Methods of Use Thereof,) published Sep. 20, 2007), which are incorporated by reference herein in their entirety for their respective teachings of methods that provide important information which may be analyzed to make a discovery of previously unappreciated metabolic relationships. An overview of the SCALES approach as well as sample data are depicted in FIG. 3.
[0049] This genome-wide approach allows identification of numerous genetic changes that can reduce the toxic effects of 3-HP. The results of our studies (shown in FIG. 4) identified hundreds of genes and other genetic elements that when at increased copy confer varying levels of tolerance to the presence of 3-HP in E. coli. When applied alone, these genetic changes may allow for small increases in tolerance; but when applied together they allow for insight into the 3-HP toxicity mechanisms. By grouping genetic elements that confer tolerance by their metabolic roles key metabolic pathways that are inhibited by 3-HP were identified.
[0050] The data shown in FIG. 4 depict identification of the chorismate superpathway as a target of 3-HP toxicity. In some embodiments, toxicity is alleviated by several processes. For example, the addition of the downstream products of branches of the chorismate superpathway, tyrosine, phenylalanine, para-aminobenzoate (a tetrahydrofolate precursor), para-hydroxy-benzoate (a precursor of ubiquinone) and 2,3-dihydroxybenzoate (an enterobactin precursor) all alleviate toxicity to a degree.
[0051] A 3-HP Bio Production Pathway
[0052] The genetic modifications conferring a 3-HP tolerant phenotype can enhance a 3-HP bio-production process utilizing E. coli. In addition, the mechanisms identified indicate that several current pathways under consideration for the production of 3-HP may not be viable routes at high levels of production
[0053] In various embodiments, a bio-production pathway is utilized which uses one or more metabolic pathways not negatively affected by 3-HP. Therefore, in some embodiments one or more traditional fermentation pathways in E. coli as well as pathways involving amino acid intermediates that are currently being explored by others [9,10] are bypassed in order to enhance production. In certain embodiments, a pathway to produce 3-HP is that depicted in FIG. 5. Also, one or more gene deletions in E. coli are effectuated as well as the expression of several enzymatic functions new to E. coli. In some embodiments, the one or more gene deletions are selected genes including but not limited to gene(s) encoding pyruvate kinase (pfkA and pfkB), lactate dehydrogenase (ldhA), phosphate acetyltransferase (pta), pyruvate oxidase (poxB) and pyruvate-formate lyase (pflB) enzymes. In further embodiments, any of the one or more deletions in the preceding are combined with one or more enzyme modifications, where the enzymes include but are not limited to phosphoenolpyruvate carboxykinase (pck), malonate semialdehyde dehydrogenase A (mmsA), malonate semialdehyde dehydrogenase B (mmsB) and oxaloacetate alpha-oxo-decarboxylase (oad-2) enzymes are expressed. It should be understood that the term "deletion" in this context does not necessarily require an entire gene deletion, but rather, a modification sufficient to knock out or effectively reduce function.
[0054] The enzymatic activity (oxaloacetate alpha-oxo-decarboxylase) utilized in the proposed pathway has not been reported in the known scientific literature. The enzyme oxaloacetate alpha-oxo-decarboxylase enhances 3-HP production.
[0055] In various embodiments, a pathway having features valuable for bio-production of organic acids in general and can be viewed as a metabolic starting point for numerous other products and in various different organisms (e.g., bacteria, yeast, algae). In various embodiments, such a pathway enhancer allows intracellular production of the key intermediate acetyl-coA without the committed production of the fermentative byproduct formate normally produced in microorganisms (e.g., E. coli) with acetyl-coA under fermentative conditions.
[0056] Previously Characterized Enzymes
[0057] In various embodiments, an engineered pathway of the invention comprises several genetic modifications to wild type microorganisms (e.g., E. coli), in addition to the expression of the oxaloacetate alpha-oxo decarboxylase. For example, one or more mutations in a microorganism (e.g., E. coli) can include but not limited to genes: pykA, pykF, ldhA, pflB, pta and poxB genes. Standard methodologies can be used to generate these gene deletions and such methods are routine in the art (See, for example, Sambrook and Russell, Molecular Cloning: A Laboratory Manual, Third Edition 2001 (volumes 1-3), Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y., hereinafter "Sambrook and Russell").
[0058] In addition to these one or more genetic deletions, the following enzymatic activities can be expressed to enhance 3-HP production (e.g., in E. coli): phosphoenolpyruvate carboxykinase and malonate semialdehyde dehydrogenase. In a further embodiment, the mmsA gene is expressed (e.g., mmsA from Rattus norvegicus which has been shown to possess malonate semialdehyde dehydrogenase activity and converts malonate semialdehyde to acetyl-coA). In yet a further embodiment, the mmsB gene is expressed (e.g., mmsB gene from Pseudomonas aeruginosa which has been shown to have 3-hydropxypropionate dehydrogenase activity). In another further embodiment, a GDP dependant phosphoenolpyruvate carboxykinase is expressed (e.g., gene from Alcaligenes eutrophus which has been characterized with kinetics favoring the desired direction producing oxaloacetate). Any genes disclosed herein can be readily synthesized using standard methodologies.
[0059] 2-oxo Acid Decarboxylases.
[0060] Several 2-oxo decarboxylases (also referred to as 2-keto acid decarboxylases, alpha-oxo decarboxylases, or alpha-keto acid decarboxylases) with a broad substrate range have been previously characterized, including several pyruvate and branched chain 2-keto-acid decarboxylases. In various embodiments, enzymes from this class of decarboxylases are utilized. The reaction carried out by these enzymes is depicted in FIG. 6. Of additional interest is that a convenient colorimetric method has been developed to assay this enzymatic activity by detection of the products of this enzyme class which are all aldehydes. In one embodiment, a previously characterized enzyme, alpha ketoglutarate decarboxylase, encoded by the kgd gene from Mycobacterium tuberculosis is used. The enzymatic reaction performed by this enzyme is depicted in FIG. 7A, which is very similar to the desired enzymatic activity, the decarboxylation of oxaloacetate to malonate semialdehyde depicted in FIG. 7B.
[0061] Altered Enzyme Activity
[0062] In one embodiment, clones comprising enhanced oxaloacetate alpha-oxo-decarboxylase activity are obtained by mutation of a gene encoding an enzyme having a similar catalytic activity, namely 2-oxo acid decarboxylases. For example, mutant libraries of a 2-oxo acid decarboxylase gene are constructed. Oxaloacetate alpha-oxo-decarboxylase activity is selected from a mutant library of a 2-oxo acid decarboxylase genes and in one embodiment from a mutant library of the kgd gene encoding an alpha-ketoglutarate decarboxylase. In further embodiments, mutant genes encoding enzymes that modulate or enhance the desired activity are identified.
[0063] Overview
[0064] To obtain the desired altered enzyme, a mutant library of a 2-oxo acid decarboxylase gene is constructed, which will be used for selections. In various embodiments, various 2-oxo acid decarboxylase genes are cloned into an appropriate expression system for E. coli. Several 2-keto acid decarboxylases with a broad substrate range have been previously characterized (Pohl, M., Sprenger, G. A., Muller, M., A new perspective on thiamine catalysis. Current Opinion in Biotechnology, 15(4), 335-342 (2004)). Of particular interest is an enzyme from M. tuberculosis, alpha-ketoglutarate decarboxylase, kgd, which has been purified and characterized (Tian, J., Bryk, R. Itoh, M., Suematsu, M., and Carl Nathan, C. Variant tricarboxylic acid cycle in Mycobacterium tuberculosis: Identification of alpha-ketoglutarate decarboxylase. PNAS. Jul. 26, 2005 vol. 102(30): 10670-10677; Stephanopoulos, G., Challenges in engineering microbes for biofuels production. Science, 2007. 315(5813):801-804). Numerous 2-oxo acid decarboxylase genes are known in the art, including but limited to pyruvate decarboxylases from several sources, branched-chain 2-keto acid decarboxylases from various sources, benzylformate decarboxylases from various sources and phenylpyruvate decarboxylases from several sources (refer to www.metacyc.org for a more complete list). In one embodiment, the kgd gene, encoding and alpha-ketoglutarate decarboxylase from M. tuberculosis is cloned into an appropriate expression system for E. coli. Subsequently, this expression clone is mutated to create a library of mutant clones.
[0065] Cloning an 2-oxo Acid Decarboxylase Gene
[0066] Cloning and expression of any 2 oxo-acid decarboxylase gene including but limited to the kgd gene is performed via gene synthesis supplied from a commercial supplier using standard or conventional techniques. Therefore, no culturing or manipulating of M. tuberculosis is required in the case of kgd. In addition, gene synthesis allows for codon optimization for a particular host. Once obtained using standard methodology, the gene is cloned into an expression system using standard techniques.
[0067] Construction of a 2-oxo Acid Decarboxylase Gene Library
[0068] The plasmid containing the cloned 2-oxo acid decarboxylase gene, including but limited to the kgd gene is mutated by standard methods resulting in a large library of mutants. Generally, any of a number of well-known standard methods may be used (See, for example, chapters 1-19 of Directed Evolution Library Creation Methods and Protocols, F. H. Arnold & G. Georgiou, Eds., Methods in Molecular Biology, Vol. 231, Humana Press (2003)). The mutant sequences are introduced into a new host cell line, generating a final library for subsequent selection.
[0069] Selection of Altered Activity
[0070] A selection based approach such as described herein can result in the rapid identification of a t-oxo acid decarboxylase mutant with oxaloacetate alpha-oxo-decarboxylase activity. In one example, an available strain of E. coli, strain NZN111 is utilized as a host for the selection. This E. coli strain has deletions in both the ldhA and pflB genes resulting in severely limited growth (˜10 hr doubling time) under anaerobic conditions (See right side of FIG. 5). This growth limitation is due in part to the inability to produce the necessary metabolite acetyl-coA under these conditions. (See FIG. 9A below.) A strain of E. coli NZN111 expressing mmsA (E. coli NZN111+mmsA) in addition to a mutant 2-oxo acid decarboxylase gene, including but limited to the kgd gene, having oxaloacetate alpha-oxo-decarboxylase activity is capable of producing the metabolite acetyl-coA from the metabolic intermediate malonate semialdehyde in media supplemented with tartrate (tartate can be used as a supplement and is readily converted to oxaloacetate in E. coli.). This proposed strain has increased growth under anaerobic conditions when compared to both E. coli NZN111 and E. coli NZN11+mmsA, controls. For example, such a selection is depicted in FIG. 10A. In one embodiment, E. coli NZN111 is constructed to express an acetylating malonate semialdehyde dehydrogenase.
[0071] Similar to the 2-oxo acid decarboxylase gene, an acetylating malonate semialdehyde dehydrogenase gene, including but not limited to mmsA, from Pseudomonas aeruginosa PAO1, is obtained via gene synthesis from the commercial provider. It is subsequently be cloned into an expression plasmid.
[0072] In another example, an available strain of E. coli, strain AB354 is utilized as a host for the selection. This E. coli strain has a mutation in the panD genes resulting in severely limited growth in minimal media conditions, without the supplementation of beta-alanine (See right side of FIG. 5). This growth limitation is due to the inability to produce beta-alanine under these conditions. (See FIG. 9B below.) A strain of E. coli AB354 expressing a beta alanine aminotransferase (E. coli AB354+beta alanine aminotransferase) in addition to a mutant 2-oxo acid decarboxylase gene, including but limited to the kgd gene, having oxaloacetate alpha-oxo-decarboxylase activity is capable of producing the metabolite beta-alanine from the metabolic intermediate malonate semialdehyde in minimal media. This proposed strain has a recovered ability to grow in minimal media with supplementation of beta-alanine. For example, such a selection is depicted in FIG. 10B. In one embodiment, E. coli AB354 is constructed to express a beta-alanine pyruvate aminotransferase.
[0073] Similar to the 2-oxo acid decarboxylase gene, a beta-alanine pyruvate aminotransferase gene, including but not limited to PAO132 from Pseudomonas aeruginosa PAO1, is obtained via gene synthesis from the commercial provider. It is subsequently be cloned into an expression plasmid.
[0074] Selection of Oxaloacetate alpha-oxo-decarboxylase Activity
[0075] The mutant library of kgd genes is introduced into E. coli strain NZN111 expressing the mmsA gene. This population is grown under anaerobic conditions in media supplemented with oxaloacetate. Individual mutants expressing the desired oxaloacetate alpha-oxo-decarboxylase activity show increased growth rates compared to the control strains. These clones are isolated and the mutant protein they express subsequently screened for oxaloacetate alpha-oxo-decarboxylase activity as described above.
[0076] Colorimetric Confirmation of Decarboxylase Activity
[0077] A colorimetric approach is taken from current standard methodologies. This approach necessitates the expression and purification of the mutant enzymes and reaction with the purified enzyme, its cofactor (thiamin pyrophosphate) and the appropriate substrate. Protein expression and purification are performed with standard methodologies.
[0078] The above description of an approach using NZN111 is meant to be exemplary and not limiting. Its teachings may be applied to other microorganism systems to achieve the desired results. For example, and also not meant to be limiting, use of metabolic features of another E. coli strain, AB354, is explained in some of the examples below.
EXAMPLES SECTION
[0079] The following examples disclose specific methods for providing an E. coli cell with heterologous nucleic acid sequences that encode for enzymes or other polypeptides that confer increased tolerance to 3-HP. Where there is a method to achieve a certain result that is commonly practiced in two or more specific examples (or for other reasons), that method may be provided in a separate Common Methods section that follows the examples. Each such common method is incorporated by reference into the respective specific example that so refers to it. Also, where supplier information is not complete in a particular example, additional manufacturer information may be found in a separate Summary of Suppliers section that may also include product code, catalog number, or other information. This information is intended to be incorporated in respective specific examples that refer to such supplier and/or product. In the following examples, efforts have been made to ensure accuracy with respect to numbers used (e.g., amounts, temperatures, etc.), but some experimental error and deviation should be accounted for. Unless indicated otherwise, temperature is in degrees Celsius and pressure is at or near atmospheric pressure at approximately 5340 feet (1628 meters) above sea level. It is noted that work done at external analytical and synthetic facilities was not conducted at or near atmospheric pressure at approximately 5340 feet (1628 meters) above sea level. All reagents, unless otherwise indicated, were obtained commercially.
[0080] The meaning of abbreviations is as follows: "C" means Celsius or degrees Celsius, as is clear from its usage, "s" means second(s), "min" means minute(s), "h," "hr," or "hrs" means hour(s), "psi" means pounds per square inch, "nm" means nanometers, "d" means day(s), "μL" or "uL" or "ul" means microliter(s), "mL" means milliliter(s), "L" means liter(s), "mm" means millimeter(s), "nm" means nanometers, "mM" means millimolar, "μM" or "uM" means micromolar, "M" means molar, "mmol" means millimole(s), "μmol" or "uMol" means micromole(s)", "g" means gram(s), "μg" or "ug" means microgram(s) and "ng" means nanogram(s), "PCR" means polymerase chain reaction, "OD" means optical density, "OD600" means the optical density measured at a wavelength of 600 nm, "kDa" means kilodaltons, "g" means the gravitation constant, "bp" means base pair(s), "kbp" means kilobase pair(s), "% w/v" means weight/volume percent, % v/v" means volume/volume percent, "IPTG" means isopropyl-β-D-thiogalactopyranoiside, "RBS" means ribosome binding site, "rpm" means revolutions per minute, "HPLC" means high performance liquid chromatography, and "GC" means gas chromatography. Also, 10 5 and the like are taken to mean 105 and the like.
Example 1
Development of a Plasmid Comprising kgd
[0081] The nucleic acid sequence for the alpha-ketoglutarate decarboxylase (kgd) from M. tuberculosis was codon optimized for E. coli according to a service from DNA 2.0 (Menlo Park, Calif. USA), a commercial DNA gene synthesis provider. The nucleic acid sequence was synthesized with an eight amino acid N-terminal tag to enable affinity based protein purification. This nucleic acid sequence incorporated an NcoI restriction site overlapping the gene start codon and was followed by a HindIII restriction site. In addition a Shine Delgarno sequence (i.e., a ribosomal binding site) was placed in front of the start codon preceded by an Ecor1 restriction site. This codon optimized kgd nucleic acid sequence construct (SEQ ID NO:001), which is designed to encode for the native kgd protein (SEQ ID NO:002) was synthesized by DNA 2.0 and then provided in a pJ206 vector backbone (SEQ ID NO:003).
[0082] A circular plasmid based cloning vector termed pKK223-kgd for expression of the alpha-ketoglutarate decarboxylase in E. coli was constructed as follows. The kgd gene in the pJ206 vector was amplified via a polymerase chain reaction with the forward primer being TTTTTTTGTATACCATGGATCGTAAATTTCGTGATGATC (SEQ ID NO:004) containing a NcoI site that incorporates the start methionine for the protein sequence, and the reverse primer being CCCGGTGAGATCTAGATCCGAACGCTTCGTCCAAGATTTCTT (SEQ ID NO:005) containing a XbaI site and a BglII site that replaces the stop codon of the kgd gene with an in-frame protein linker sequence SRS. Also, these primers effectively removed the eight amino acid N-terminal tag. The amplified kgd nucleic acid sequence was subjected to enzymatic restriction digestion with the enzymes NcoI and BglII obtained from New England BioLabs (Ipswich, Mass. USA) according to manufacturer's instructions. The digestion mixture was separated by agarose gel electrophoresis, and visualized under UV transillumination as described in Subsection II of the Common Methods Section. An agarose gel slice containing a DNA piece corresponding to the amplified kgd nucleic acid sequence was cut from the gel and the DNA recovered with a standard gel extraction protocol and components from Qiagen according to manufacturer's instructions.
[0083] An E. coli cloning strain bearing pKK223-3 was grown by standard methodologies and plasmid DNA was prepared by a commercial miniprep column from Qiagen.
[0084] A new DNA vector was created by amplifying a pKK223-3 template by polymerase chain reaction with a forward primer being CGGATCTAGATCTCACCATCACCACCATTAGTCGACCTGCAGCCAAG (SEQ ID NO:006) and a reverse primer being TGAGATCTAGATCCGTTATGTCCCATGGTTCTGTTTCCTGTGTG (SEQ ID NO:007). The product was prepared by a commercial PCR-purification column from Qiagen. Both primers contain XbaI restriction sites that allowed for the linear polymerase chain reaction product to be circularized after restriction digestion with XbaI with enzymes obtained from New England BioLabs (Ipswich, Mass. USA) according to manufacturer's instructions, and subsequent self-ligation. The new vector, named pKK223-ct-his (SEQ ID NO:008), contained a multiple cloning region containing the a protein coding cassette under control of a IPTG-inducible promoter with an NcoI site that incorporate the start methionine and with a XbaI site and a BglII site that code for the in-frame protein sequence SRSHHHHH (SEQ ID NO:009), a multi-histidine tag that allows for metal-affinity protein purification of the expressed protein.
[0085] To insert the gene of interest, kgd, this vector was prepared by restriction digestion with the enzymes NcoI and BglII obtained from New England BioLabs (Ipswich, Mass. USA) according to manufacturer's instructions. The digestion mixture was separated by agarose gel electrophoresis, and visualized under UV transillumination as described under Subsection II of the Common Methods Section. An agarose gel slice containing a DNA piece corresponding to the amplified kgd gene product was cut from the gel and the DNA recovered with a standard gel extraction protocol and components from Qiagen according to manufacturer's instructions.
[0086] Pieces of purified DNA corresponding to the amplified kgd gene product and the pKK223-cterm-5×his vector backbone were ligated and the ligation product was transformed and electroporated according to manufacturer's instructions. The sequence of the resulting vector, termed pKK223-cterm-5×his-kgd (SEQ ID NO:010, and simply pKK223-kgd such as in the electronic sequence listing), was confirmed by routine sequencing performed by the commercial service provided by Macrogen (USA). pKK223-cterm-5×his-kgd confers resistance to beta-lactamase and contains the kgd gene of M. tuberculosis under control of a ptac promoter inducible in E. coli hosts by IPTG.
Example 2
Development of a Plasmid Comprising mcr (Partial Prophetic)
[0087] The nucleic acid sequence for the malonyl-coA reductase gene (mcr) from Chloroflexus auranticus was codon optimized for E. coli according to a service from DNA 2.0 (Menlo Park, Calif. USA), a commercial DNA gene synthesis provider. Attached and extending beyond the ends of this codon optimized mcr nucleic acid sequence (SEQ ID NO:011) were an EcoRI restriction site before the start codon and a HindIII restriction site. In addition a Shine Delgarno sequence (i.e., a ribosomal binding site) was placed in front of the start codon preceded by an EcoRI restriction site. This gene construct was synthesized by DNA 2.0 and provided in a pJ206 vector backbone.
[0088] A circular plasmid based cloning vector termed pKK223-mcr for expression of the malonyl-CoA reductase in E. coli was constructed as follows. The mcr gene in the pJ206 vector was amplified via a polymerase chain reaction with the forward primer being TCGTACCAACCATGGCCGGTACGGGTCGTTTGGCTGGTAAAATTG (SEQ ID NO:012) containing a NcoI site that incorporates the start methionine for the protein sequence, and the reverse primer being CGGTGTGAGATCTAGATCCGACGGTAATCGCACGACCGCGGT (SEQ ID NO:013) containing a XbaI site and a BglII site that replaces the stop codon of the mcr gene with an in-frame protein linker sequence SRS. The amplified mcr nucleic acid sequence was subjected to enzymatic restriction digestion with the enzymes NcoI and XbaI obtained from New England BioLabs (Ipswich, Mass. USA) according to manufacturer's instructions. The digestion mixture was separated by agarose gel electrophoresis, and visualized under UV transillumination as described under Subsection II of the Common Methods Section. An agarose gel slice containing a DNA piece corresponding to the amplified mcr nucleic acid sequence was cut from the gel and the DNA recovered with a standard gel extraction protocol and components from Qiagen according to manufacturer's instructions.
[0089] An E. coli cloning strain bearing pKK223-3 was grown by standard methodologies and plasmid DNA was prepared by a commercial miniprep column from Qiagen.
[0090] As described in Example 1 above, a new DNA vector was created by amplifying a pKK223-3 template by polymerase chain reaction with a forward primer being CGGATCTAGATCTCACCATCACCACCATTAGTCGACCTGCAGCCAAG (SEQ ID NO:006) and a reverse primer being TGAGATCTAGATCCGTTATGTCCCATGGTTCTGTTTCCTGTGTG (SEQ ID NO:007). The product was prepared by a commercial PCR-purification column from Qiagen. Both primers contain XbaI restriction sites that allowed for the linear polymerase chain reaction product to be circularized after restriction digestion with XbaI and subsequent self-ligation with enzymes obtained from New England BioLabs (Ipswich, Mass. USA) according to manufacturer's instructions. The vector, named pKK223-ct-his (SEQ ID NO:008), contained a multiple cloning region containing the a protein coding cassette under control of a IPTG-inducible promoter with an NcoI site that incorporates the start methionine and with a XbaI site and a BglII site that codes for the in-frame protein sequence SRSHHHHH (SEQ ID NO:009). The latter multi-histidine sequence allows for metal-affinity protein purification of the expressed protein.
[0091] To insert the gene of interest, mcr, this vector was prepared by restriction digestion with the enzymes NcoI and XbaI obtained from New England BioLabs (Ipswich, Mass. USA) according to manufacturer's instructions. The digestion mixture was separated by agarose gel electrophoresis, and visualized under UV transillumination as described under Subsection II of the Common Methods Section.
[0092] Pieces of purified DNA corresponding to the amplified codon optimized mcr nucleic acid sequence and the pKK223-ct-his vector backbone were ligated and the ligation product was transformed and electroporated according to manufacturer's instructions. The sequence of the resulting vector termed pKK223-mcr (SEQ ID NO:014) is confirmed by routine sequencing performed by the commercial service provided by Macrogen(USA). pKK223-mer confers resistance to beta-lactamase and contains the mcr gene of M. tuberculosis under control of a ptac promoter inducible in E. coli hosts by IPTG.
Example 3
Development of a Plasmid Comprising a Beta Alanine-Pyruvate Aminotransferase Gene. (Prophetic)
[0093] Introduction of a gene, such as the beta alanine pyruvate aminotransferase gene, into bacterial cells requires the addition of transcriptional (promoters) and translational (ribosome binding site) elements for controlled expression and production of proteins encoded by the gene. A nucleic acid sequence for a gene, whether obtained by gene synthesis or by amplification by polymerase chain reaction from genomic sources, can be ligated to nucleic acid sequences defining these transcriptional and translational elements. The present example discloses the addition of an E. coli minimal promoter and ribosome binding site properly oriented in the nucleic acid sequence before a gene of interest.
[0094] The beta alanine pyruvate aminotransferase gene from Pseudomonas aeruginosa PAO1 (locus_tag="PA0132") is amplified by polymerase chain reaction from a genomic DNA template with the forward primer being GGGTTTCCATGGACCAGCCGCTCAACGTGG (SEQ ID NO:015) and the reverse primer being GGGTTTTCAGGCGATGCCGTTGAGCGCTTCGCC (SEQ ID NO:016). The forward primer incorporates an NcoI restriction site at the start methionine codon of the gene and the reverse primer includes a stop codon for the gene. The amplified nucleic acid sequence is subjected to enzymatic restriction digestion with the restriction enzyme NcoI from New England BioLabs (Ipswich, Mass. USA) according to manufacturer's instructions. The digestion mixture is separated by agarose gel electrophoresis, and is visualized under UV transillumination as described under Subsection II of the Common Methods Section. An agarose gel slice containing a DNA piece corresponding to the restricted nucleic acid sequence is cut from the gel and the DNA is recovered with a standard gel extraction protocol and components from Qiagen according to manufacturer's instructions. An E. coli tpiA promoter and ribosome binding site is produced by polymerase chain reaction using a forward primer GGGAACGGCGGGGAAAAACAAACGTT (SEQ ID NO:017) and a reverse primer GGTCCATGGTAATTCTCCACGCTTATAAGC (SEQ ID NO:018). Using genomic E. Coli K12 DNA as the template, a PCR reaction was conducted using these primers.
[0095] The forward primer is complimentary to the nucleic acid sequence upstream of the minimal tpiA promoter region (SEQ ID NO:019), which is the minimal promoter sequence of the E. coli K12 tpi gene. The reverse primer is located just downstream of the minimal promoter region and includes an NcoI restriction site at the location of the start methionine and also includes a ribosome binding site. The PCR-amplified nucleic acid sequence is subjected to enzymatic restriction digestion with the restriction enzyme NcoI from New England BioLabs (Ipswich, Mass. USA) according to manufacturer's instructions. The digestion mixture is separated by agarose gel electrophoresis, and is visualized under UV transillumination as described in Subsection II of the Common Methods Section. An agarose gel slice containing a DNA piece corresponding to the restricted nucleic acid sequence is cut from the gel and the DNA is recovered with a standard gel extraction protocol and components from Qiagen according to manufacturer's instructions. The restricted, purified nucleic acid piece containing the transcriptional and translational elements is ligated to the recovered DNA containing the gene of interest. The ligation product is used as a template for a subsequent polymerase chain reaction using the forward primer GGGAACGGCGGGGAAAAACAAACGTT (SEQ ID NO:020). Alternatively, any other forward primer may be use so long as it includes sufficient nucleic acid sequences upstream of the minimal tpiA promoter sequence (SEQ ID NO:019). In the present specific example, the reverse primer is GGGTTTTCAGGCGATGCCGTTGAGCGCTTCGCC (SEQ ID NO:021). The amplified nucleic acid product is separated by agarose gel electrophoresis, and is visualized under UV transillumination as described in Subsection II of the Common Methods Section. An agarose gel slice containing a DNA piece corresponding to the restricted nucleic acid sequence is cut from the gel and the DNA is recovered with a standard gel extraction protocol and components from Qiagen according to manufacturer's instructions.
[0096] The resulting nucleic acid piece then is ligated into a suitable plasmid or other vector or transposon or other system, for example pSMART (Lucigen Corp, Middleton, Wis., USA), StrataClone (Stratagene, La Jolla, Calif., USA) or pCR2.1-TOPO TA (Invitrogen Corp, Carlsbad, Calif., USA) according to manufacturer's instructions. These methods also are described in the Subsection II of the Common Methods Section. Accordingly, the resulting nucleic acid piece can be restriction digested and purified and re-ligated into any other vector as is standard in the art. A similar method can be used to combine any gene with any transcriptional and translational elements with variation of restriction sites and primers.
[0097] The resulting nucleic acid is cloned using standard methodologies into the multiple cloning site of plasmid pBT-3, resulting in pBT-3-BAAT. This plasmid expresses the beta-alanine aminotransferase has a replicon compatible with pKK223 based vectors and confers chloramphenicol resistance.
Example 4
Development of a Plasmid Comprising an Acetylating Malonate Semialdehyde Dehydrogenase (Prophetic)
[0098] Introduction of a gene, such as an acetylating malonate semialdehyde dehydrogenase gene, into bacterial cells requires the addition of transcriptional (promoters) and translational (ribosome binding site) elements for controlled expression and production of proteins encoded by the gene. A nucleic acid sequence for a gene, whether obtained by gene synthesis or by amplification by polymerase chain reaction from genomic sources, can be ligated to nucleic acid sequences defining these transcriptional and translational elements. The present example discloses the addition of an E. coli minimal promoter and ribosome binding site properly oriented in the nucleic acid sequence before a gene of interest.
[0099] The acetylating malonate semialdehyde dehydrogenase gene, such as is readily available from several sources (e.g., http://ca.expasy.org/cgi-bin/nicezyme.pl?1.2.1.18) is amplified by polymerase chain reaction from a genomic DNA template by standard PCR methodology. The forward primer incorporates an NcoI restriction site at the start methionine codon of the gene and the reverse primer includes a stop codon for the gene. The amplified nucleic acid sequence is subjected to enzymatic restriction digestion with the restriction enzyme NcoI from New England BioLabs (Ipswich, Mass. USA) according to manufacturer's instructions. The digestion mixture is separated by agarose gel electrophoresis, and is visualized under UV transillumination as described under Subsection II of the Common Methods Section. An agarose gel slice containing a DNA piece corresponding to the restricted nucleic acid sequence is cut from the gel and the DNA is recovered with a standard gel extraction protocol and components from Qiagen according to manufacturer's instructions.
[0100] An E. coli tpiA promoter and ribosome binding site is produced by polymerase chain reaction using a forward primer GGGAACGGCGGGGAAAAACAAACGTT (SEQ ID NO:017) and a reverse primer GGTCCATGGTAATTCTCCACGCTTATAAGC (SEQ ID NO:018). Using genomic E. Coli K12 DNA as the template, a PCR reaction was conducted using these primers. The forward primer is complimentary to the nucleic acid sequence upstream of the minimal tpiA promoter region (SEQ ID NO:019). The reverse primer is located just downstream of the minimal promoter region and includes an NcoI restriction site at the location of the start methionine and also includes a ribosome binding site. The PCR-amplified nucleic acid sequence is subjected to enzymatic restriction digestion with the restriction enzyme NcoI from New England BioLabs (Ipswich, Mass. USA) according to manufacturer's instructions. The digestion mixture is separated by agarose gel electrophoresis, and is visualized under UV transillumination as described in Subsection II of the Common Methods Section. An agarose gel slice containing a DNA piece corresponding to the restricted nucleic acid sequence is cut from the gel and the DNA is recovered with a standard gel extraction protocol and components from Qiagen according to manufacturer's instructions.
[0101] The restricted, purified nucleic acid piece containing the transcriptional and translational elements is ligated to the recovered DNA containing the gene of interest. The ligation product is used as a template for a subsequent polymerase chain reaction using the forward primer GGGAACGGCGGGGAAAAACAAACGTT (SEQ ID NO:017). Alternatively, any other forward primer may be use so long as it includes sufficient nucleic acid sequences upstream of the minimal tpiA promoter sequence (SEQ ID NO:019). In the present specific example, the reverse primer is GGGTTTTCAGGCGATGCCGTTGAGCGCTTCGCC (SEQ ID NO:021). The amplified nucleic acid product is separated by agarose gel electrophoresis, and is visualized under UV transillumination as described in Subsection II of the Common Methods Section. An agarose gel slice containing a DNA piece corresponding to the restricted nucleic acid sequence is cut from the gel and the DNA is recovered with a standard gel extraction protocol and components from Qiagen according to manufacturer's instructions.
[0102] The resulting nucleic acid piece then is ligated into a suitable plasmid or other vector or transposon or other system, for example pSMART (Lucigen Corp, Middleton, Wis., USA), StrataClone (Stratagene, La Jolla, Calif., USA) or pCR2.1-TOPO TA (Invitrogen Corp, Carlsbad, Calif., USA) according to manufacturer's instructions. These methods also are described in the Subsection II of the Common Methods Section. Accordingly, the resulting nucleic acid piece can be restriction digested and purified and re-ligated into any other vector as is standard in the art. A similar method can be used to combine any gene with any transcriptional and translational elements with variation of restriction sites and primers.
[0103] The resulting nucleic acid is cloned using standard methodologies into the multiple cloning site of plasmid pBT-3, resulting in pBT-3-mmsA. This plasmid expresses an acetylating malonate semialdehyde dehydrogenase has a replicon compatible with pKK223 based vectors and confers chloramphenicol resistance.
Example 5
Development of a Plasmid Comprising a Pyruvate Decarboxylase. Evolution of Pyruvate Decarboxylase Enzymes for the Enzymatic Conversion of Oxaloacetate to Malonate Semialdehyde (Prophetic)
[0104] Similarly to alpha-ketoglutarate dehydrogenase from Mycobacterium tuberculosis, the pyruvate decarboxylase from Zymomonas mobilis can be evolved to perform the conversion of oxaloacetate to malonate semialdehyde. The pyruvate decarboxylase enzyme is a thiamine diphosphate-dependent enzyme that decarboxylates 2-keto acids and has been shown to prefer short aliphatic substrates (Siegert P et al. (2005). Exchanging the substrate specificities of pyruvate decarboxylase from Zymomonas mobilis and benzoylformate decarboxylase from Pseudomonas putida. Protein Eng Des Sel 18, 345-357). Additionally, this enzyme does not require substrate activation by pyruvamide (Hoppner, T. C. & Doelle, H. W. (1983). Purification and kinetic characteristics of pyruvate decarboxylase and ethanol dehydrogenase from Zymomonas mobilis in relation to ethanol production. Eur J Appl Microbiol Biotechnol 17, 152-157), and a structure of the protein characterized by x-ray crystallography shows the residues responsible for formation of the substrate and cofactor binding pockets (Dobritzsch D et al. (1998). High resolution crystal structure of pyruvate decarboxylase from Zymomonas mobilis. Implications for substrate activation in pyruvate decarboxylases. J Biol Chem 273, 20196-20204). Furthermore, alteration of the substrate specificity of this enzyme by specific amino acid changes have previously been reported (Siegert P et al. (2005). Exchanging the substrate specificities of pyruvate decarboxylase from Zymomonas mobilis and benzoylformate decarboxylase from Pseudomonas putida. Protein Eng Des Sel 18, 345-357). An example of a process for randomly mutating specific amino acid regions of this protein follows.
[0105] To evolve the binding pocket of the protein for performing the oxaloacetate to malonate semialdehyde conversion, specific regions of the nucleic acid sequence comprising regions of the protein's amino acid sequence will be mutated. Identification of specific amino acid regions within the protein that are involved in the binding pocket interactions is performed by examining the previously determined crystal structure and also by comparing the protein sequence of the Zymomonas mobilis pyruvate decarboxylase with pyruvate decarboxylase from other species showing strong sequence similarity. Using this information, the nucleotide sequence of the gene is examined in order to place restriction sites within the nucleotide sequence at the boundaries of the corresponding amino acid regions identified previously. Form this nucleotide sequence, the Zymomonas mobilis pyruvate decarboxylase gene with these restrictions sites is codon optimized for E. coli according to a service from DNA 2.0 (Menlo Park, Calif. USA), a commercial DNA gene synthesis provider (SEQ ID NO:022). This gene construct is synthesized by DNA 2.0 and provided in a pJ206 vector backbone. Additionally, the protein sequence includes the addition of a hepta-histidine purification tag (SEQ ID NO:009), which can be easily removed by restriction digestion of the plasmid with HindIII followed by self-ligation. The protein for which SEQ ID NO:022 encodes is provided as SEQ ID NO:023.
[0106] To specifically mutate amino acids in the pyruvate decarboxylase protein, the plasmid containing the codon-optimized sequence is cut at regions of interest via the incorporated restriction sites. Nucleotide sequences is synthesized or produced by polymerase chain reaction with oligonucleotides designed to incorporate specific or random changes at these regions of interest.
[0107] These nucleotide sequences will incorporate restriction sites or overhanging ends complimentary to the restriction sites used to cut the plasmid such that the new sequences are ligated into the plasmid to create the desired changes in the protein. These changes can be performed singly or multiply. If these changes are performed multiply, the resulting plasmids are transformed into a panD deleted E. coli strain and screened in a manner such as depicted in FIGS. 10A and 10B. Additionally, the protein produced by these changes may be assayed in a manner such as depicted in FIG. 11.
Example 6
Development of a Nucleic Acid Sequence Encoding a Protein Sequence Demonstrating Elevated Oxaloacetate Alpha-Decarboxylase Activity (Partial Prophetic)
[0108] Oxaloacetate alpha-decarboxylase activity is selected from a pool of alpha-ketoglutarate decarboxylase (kgd) mutants by selection in an E. coli AB354 host expressing a beta-alanine pyruvate aminotransferase. pKK223-cterm-5×his-kgd encoding the kgd gene was constructed as described above. Confirmation of alpha-ketoglutarate decarboxylase protein expression and enzymatic activity with appropriate controls were as follows. E. Cloni 10GF' electrocompetent cells (Lucigen, Cat. #60061-1) were transformed with the pKK223-Cterm-5×His-kgd, plasmid containing sequence for 5× HIS-tagged kgd protein behind a pTAC promoter. Transformants were confirmed using restriction digest and DNA sequencing (Macrogen, Korea). Expression and purification of his-tagged-kgd was performed as described in Subsection III of the Common Methods Section. SDS-PAGE results of expression and purification are show in FIG. 12. E. coli AB354 (ΔpanD) was transformed with the vector controls, pKK223, pKK223-Cterm-5×His, as well as the test vectors pKK223-mcr and pKK223-Cterm-5×His-kgd, according to standard methods described below. Each of the strains were grown overnight in LB rich media supplemented with 200 mg/L ampicillin (according to standard protocols). Following overnight growth, cells twice were harvested by centrifugation and washed by resuspension in M9 minimal media (standard protocol), diluted 1:10,000 and plated on M9 minimal media plates with 0.05 g/L threonine, 0.1 g/L leucine, 0.067 g/L thiamine, with the additional appropriate supplements, where indicated at the following concentrations (10 g/L beta-alanine (Sigma Aldrich, St. Louis, Mo.), 1 mM Isopropyl β-D-1-thiogalactopyranoside (Thermo Fisher Scientific, Fairlawn, N.J.), 0.2 g/L putrescine (MPBiomedicals, Santa Ana, Calif.), 200 mg/L ampicillin (Research Products International Corp., Mt. Prospect, Ill.) After plating, agarose plates were incubated at 37 C overnight by standard methods. Table 1 depicts the results of these selection controls. A plus (+) indicates growth on a plate, minus (-) indicates no growth. These data confirm the absence of growth in the selection hosts. Putrescine is known to induce the expression of gamma-aminobutyrate transaminase in E. coli. This enzyme has been shown in some species including Rattus norvegicus to also have beta-alanine aminotransferase activity. The mcr gene encoding the malonyl-coA reductase, has been shown to produce malonate semialdehyde. The lack of growth on the strain expressing malonyl-coA reductase in the presence of putrescine indicates the need for the co-expression of a beta-alanine aminotransferase in E. coli AB354 for the selection.
TABLE-US-00001 TABLE 1 Supplements β- Amp + Amp + ala- β-ala- IPTG + AMP + IPTG + Strain None nine Amp nine Amp Put Put K12 + + - - - - - AB354 - + - - - - - (Δ panD) AB354 - + - + - - - (Δ panD) + pKK223 AB354 - + - + - - - (Δ panD) + pKK223-mcr AB354 - + - + - - - (Δ panD) + pKK223-kgd
[0109] Mutant libraries of pKK223-cterm-5×his-kgd were constructed as follows. Plasmid DNA of pKK223-cterm-5×his-kgd was purified by standard methods and transformed in the mutator strain E. coli XL1-Red (Stratagene, La Jolla, Calif.) according to manufacturer's protocols. Cells were harvested according to manufacturer's protocols and mutated plasmid DNA purified by standard methods.
[0110] Mutant pKK223-cterm-5×his-kgd DNA is used to transform an E. coli host, AB354+pBT-3-BAAT, described above. Greater than 10 5 transformants are collected from LB ampicillin (200 g/L) , Chloramphenicol (40 g/L) agarose plates. Cells are washed in M9 minimal media, diluted 1:10,000 and plated on M9 minimal media plates with 0.05 g/L threonine, 0.1 g/L leucine, 0.067 g/L thiamine, with 1 mM Isopropyl β-D-1-thiogalactopyranoside (Thermo Fisher Scientific, Fairlawn, N.J.), 200 g/L ampicillin and 40 g/L chloramphenicol. Plates are incubated at 37 C for several days. Colonies that grow are individually collected as positives clones bearing oxaloacetate alpha-decarboxylase activity.
Example 7
Development of a Nucleic Acid Sequence Encoding a Protein Sequence Demonstrating Elevated Oxaloacetate Alpha-Decarboxylase Activity (Prophetic)
[0111] Oxaloacetate alpha-decarboxylase activity is selected from a pool of pyruvate decarboxylase (pdc) mutants by selection in an E. coli AB354 host expressing a beta-alanine pyruvate aminotransferase. pKK223-cterm-5×his-pdc encoding the pdc gene is constructed as described above. Confirmation of pyruvate decarboxylase protein expression and enzymatic activity with appropriate controls are as follows. E. Cloni 10GF' electrocompetent cells (Lucigen, Cat. #60061-1) are transformed with the pKK223-Cterm-5×His-pdc, plasmid containing sequence for 5× HIS-tagged pdc protein behind a pTAC promoter. Transformants are confirmed using restriction digest and DNA sequencing (Macrogen, Korea). Expression and purification of his-tagged-pdc are performed as described in Subsection III of the Common Methods Section. E. coli AB354 (ΔpanD) is transformed with the vector controls, pKK223, pKK223-Cterm-5×His, as well as the test vectors pKK223-mcr and pKK223-Cterm-5×His-pdc, according to standard methods described below. Each of the strains is grown overnight in LB rich media supplemented with 200 mg/L ampicillin (according to standard protocols). Following overnight growth, cells twice are harvested by centrifugation and washed by resuspension in M9 minimal media (standard protocol), diluted 1:10,000 and plated on M9 minimal media plates with 0.05 g/L threonine, 0.1 g/L leucine, 0.067 g/L thiamine, with the additional appropriate supplements, where indicated at the following concentrations (10 g/L beta-alanine (Sigma Aldrich, St. Louis, Mo.), 1 mM Isopropyl β-D-1-thiogalactopyranoside (Thermo Fisher Scientific, Fairlawn, N.J.), 0.2 g/L putrescine (MPBiomedicals, Santa Ana, Calif.), 200mg/L ampicillin (Research Products International Corp., Mt. Prospect, Ill.) After plating, agarose plates were incubated at 37 C overnight by standard methods. Putrescine is known to induce the expression of gamma-aminobutyrate transaminase in E. coli. This enzyme has been shown in some species including Rattus norvegicus to also have beta-alanine aminotransferase activity. The mcr gene encoding the malonyl-coA reductase, has been shown to produce malonate semialdehyde. The lack of growth on the strain expressing malonyl-coA reductase in the presence of putrescine indicates the need for the co-expression of a beta-alanine aminotransferase in E. coli AB354 for the selection.
[0112] Mutant libraries of pKK223-cterm-5×his-pdc are constructed as follows. Plasmid DNA of pKK223-cterm-5×his-pdc are purified by standard methods and transformed in the mutator strain E. coli XL1-Red (Stratagene, La Jolla, Calif.) according to manufacturer's protocols. Cells are harvested according to manufacturer's protocols and mutated plasmid DNA purified by standard methods.
[0113] Mutant pKK223-cterm-5×his-pdc DNA is used to transform an E. coli host, AB354+pBT-3-BAAT, described above. Greater than 10 5 transformants are collected from LB ampicillin (200 g/L), Chloramphenicol (40 g/L) agarose plates. Cells are washed in M9 minimal media, diluted 1:10,000 and plated on M9 minimal media plates with 0.05 g/L threonine, 0.1 g/L leucine, 0.067 g/L thiamine, with 1 mM Isopropyl β-D-1-thiogalactopyranoside (Thermo Fisher Scientific, Fairlawn, N.J.), 200 g/L ampicillin and 40 g/L chloramphenicol. Plates are incubated at 37 C for several days. Colonies that grow are individually collected as positives clones bearing oxaloacetate alpha-decarboxylase activity.
Example 8
Development of a Nucleic Acid Sequence Encoding a Protein Sequence Demonstrating Elevated Oxaloacetate Alpha-Decarboxylase Activity (Partial Prophetic)
[0114] Oxaloacetate alpha-decarboxylase activity is selected from a pool of alpha-ketoglutarate decarboxylase (kgd) mutants by selection in an E. coli NZN111 host expressing an acetylating malonate semialdehyde dehydrogenase. pKK223-cterm-5×his-kgd encoding the kgd gene was constructed as described above. Confirmation of alpha-ketoglutarate decarboxylase protein expression and enzymatic activity with appropriate controls were as follows. E. Cloni 10GF' electrocompetent cells (Lucigen, Cat. #60061-1) were transformed with the pKK223-Cterm-5×His-kgd, plasmid containing sequence for 5× HIS-tagged kgd protein behind a pTAC promoter. Transformants were confirmed using restriction digest and DNA sequencing (Macrogen, Korea). Expression and purification of his-tagged-kgd were performed as described in Subsection III of the Common Methods Section.
[0115] E. coli NZN111 is transformed with the vector controls, pKK223, pKK223-Cterm-5×His, as well as the test vectors pKK223-mcr and pKK223-Cterm-5×His-kgd, according to standard methods described below. Each of the strains is grown overnight in LB rich media supplemented with 200 mg/L ampicillin (according to standard protocols). Following overnight growth, cells twice are harvested by centrifugation and washed by resuspension in LB media (standard protocol), diluted 1:10,000 and plated on LB media plates with the additional appropriate supplements, where indicated at the following concentrations 1 mM Isopropyl β-D-1-thiogalactopyranoside (Thermo Fisher Scientific, Fairlawn, N.J.), 200mg/L ampicillin (Research Products International Corp., Mt. Prospect, Ill.) After plating, agarose plates are incubated at 37 C overnight anaerobically in BD type A Bio-Bags according to manufacturer's instructions (BD Biosciences, Franklin Lakes, N.J., Catalog #261214). The mcr gene encoding the malonyl-coA reductase, has been shown to produce malonate semialdehyde. The presence of growth of the strain expressing malonyl-coA reductase in the presence of the co expressed acetylating malonate semialdehyde dehydrogenase in E. coli NZN111 serves as a positive control for the selection.
[0116] Mutant libraries of pKK223-cterm-5×his-kgd were constructed as follows. Plasmid DNA of pKK223-cterm-5×his-kgd were purified by standard methods and transformed into the mutator strain E. coli XL1-Red (Stratagene, La Jolla, Calif.) according to manufacturer's protocols. Cells were harvested according to manufacturer's protocols and mutated plasmid DNA purified by standard methods.
[0117] Mutant pKK223-cterm-5×his-kgd DNA is used to transform an E. coli host, NZN111+pBT-3-mmsA, described above. Greater than 10 5 transformants are collected from LB ampicillin (200 g/L), Chloramphenicol (40 g/L) agarose plates. Cells are washed in LB media, diluted 1:10,000 and plated on LB media plates with 1 mM Isopropyl β-D-1-thiogalactopyranoside (Thermo Fisher Scientific, Fairlawn, N.J.), 200 g/L ampicillin and 40 g/L chloramphenicol. Plates are incubated at 37 C for several days anaerobically in BD type A Bio-Bags according to manufacturer's instructions (BD Biosciences, Franklin Lakes, N.J., Catalog #261214). Colonies that grow are individually collected as positives clones bearing oxaloacetate alpha-decarboxylase activity.
Example 9
Development of a Nucleic Acid Sequence Encoding a Protein Sequence Demonstrating Elevated Oxaloacetate Alpha-Decarboxylase Activity (Prophetic)
[0118] Oxaloacetate alpha-decarboxylase activity is selected from a pool of pyruvate decarboxylase (pdc) mutants by selection in an E. coli NZN111 host expressing an acetylating malonate semialdehyde dehydrogenase. pKK223-cterm-5×his-pdc encoding the pdc gene is constructed as described above. Confirmation of pyruvate decarboxylase protein expression and enzymatic activity with appropriate controls are as follows. E. Cloni 10GF' electrocompetent cells (Lucigen, Cat. #60061-1) are transformed with the pKK223-Cterm-5×His-pdc, plasmid containing sequence for 5× HIS-tagged pdc protein behind a pTAC promoter. Transformants are confirmed using restriction digest and DNA sequencing (Macrogen, Korea). Expression and purification of his-tagged-pdc are performed as described in Subsection III of the Common Methods Section.
[0119] E. coli NZN111 and E. coli NZN111+pBT3-mmsA is transformed with the vector controls, pKK223, pKK223-Cterm-5×His, as well as the test vectors pKK223-mcr and pKK223-Cterm-5×His-pdc, according to standard methods described below. Each of the strains is grown overnight in LB rich media supplemented with 200 mg/L ampicillin (according to standard protocols). Following overnight growth, cells twice are harvested by centrifugation and washed by resuspension in LB media (standard protocol), diluted 1:10,000 and plated on LB media plates with the additional appropriate supplements, where indicated at the following concentrations 1 mM Isopropyl β-D-1-thiogalactopyranoside (Thermo Fisher Scientific, Fairlawn, N.J.), 200 mg/L ampicillin (Research Products International Corp., Mt. Prospect, Ill.) After plating, agarose plates were incubated at 37 C overnight anaerobically in BD type A Bio-Bags according to manufacturer's instructions (BD Biosciences, Franklin Lakes, N.J., Catalog #261214). The mcr gene encoding the malonyl-coA reductase, has been shown to produce malonate semialdehyde. The presence of growth of the strain expressing malonyl-coA reductase in the presence of the co-expressed acetylating malonate semialdehyde in E. coli NZN111 serves as a positive control for the selection.
[0120] Mutant libraries of pKK223-cterm-5×his-pdc are constructed as follows. Plasmid DNA of pKK223-cterm-5×his-pdc are purified by standard methods and transformed into the mutator strain E. coli XL1-Red (Stratagene, La Jolla, Calif.) according to manufacturer's protocols. Cells are harvested according to manufacturer's protocols and mutated plasmid DNA purified by standard methods.
[0121] Mutant pKK223-cterm-5×his-pdc DNA is used to transform an E. coli host, NZN111+pBT-3-mmsA, described above. Greater than 10 5 transformants are collected from LB ampicillin (200 g/L), chloramphenicol (40 g/L) agarose plates. Cells are washed in LB media, diluted 1:10,000 and plated on LB media plates with 1 mM Isopropyl β-D-1-thiogalactopyranoside (Thermo Fisher Scientific, Fairlawn, N.J.), 200 g/L ampicillin and 40 g/L chloramphenicol. Plates are incubated at 37 C for several days anaerobically in BD type A Bio-Bags according to manufacturer's instructions (BD Biosciences, Franklin Lakes, N.J., Catalog #261214). Colonies that grow are individually collected as positives clones bearing oxaloacetate alpha-decarboxylase activity.
Example 10
Confirmation of Oxaloacetate Alpha-Decarboxylase Activity (Partial Prophetic)
[0122] The colorimetric to confirm enzymatic decarboxylation of 2-oxo-acid substrates is adapted from current standard methodologies and is illustrated below in FIG. 11. This approach necessitates the expression and purification of the mutant enzymes and reaction with the purified enzyme, its cofactor (thiamin pyrophosphate) and the appropriate substrate. Protein expression and purification are performed with standard methodologies. This colorimetric screening method will be used both to conduct broad screening for positive oxaloacetate alpha-decarboxylase mutants, and also to conduct confirmatory testing of the positive clones identified in a selection method described above.
[0123] Transformants containing a gene cloned into the pKK223-Cterm-5×his expression vector are grown overnight in LB+0.2% glucose+200 ug/mL Ampicillin, diluted 1:20 and grown (LB+0.2% glucose+200 ug/mL Ampicillin) to OD600 of 0.4. IPTG is added at 1 mM final concentration to induce protein expression. Cultures are then allowed to grow at 37 degrees C. for four hours. Cells were harvested by centrifugation at 4 degrees C. for 10 minutes at 4000 rpm. Pellets are resuspended and concentrated 50× (e.g. 500 mL culture resuspended in 10 mL buffer) in Qiagen Ni-NTA Lysis Buffer (50 mM Na2HPO4, 300 mM NaCl, 10 mM imidazole, pH 8.0)+1 mM PMSF. Lysozyme is added to a final concentration of 1 mg/mL; cells are incubated on ice for 30 minutes. Cells are lysed using a French Press (cell pressure=2000 psi) three times. Lysates are cleared by centrifugation at 4 degrees C. for 20 minutes, applied to Qiagen Ni-NTA columns, washed and eluted as specified by Qiagen (cat. #31314). Samples are analyzed by SDS-PAGE by routine protocols.
[0124] 100 uL reaction mixtures contain 50 mM Potassium phosphate (pH 7.0), 0.2 mM TPP, 1 mM MgCl2, 10 mM of the appropriate substrate. 300 pg of purified enzyme is added to the reaction and incubated 16 hours at 37 degrees C. After 16 hours at 37 degrees C., 100 uL of Purpald colorimetric indicator (as per Sigma-Aldrich, cat. #162892) is added to each well in order to detect formation of corresponding aldehyde product. After addition of the Purpald, reactions are incubated at room temperature for 1 hour and read at a wavelength of 540 nm in a Thermomax Microplate Reader (Molecular Devices) using SOFTMax Pro Microplate Reader software, Ver. 4.0. Absorbances greater than control reactions without substrate are used to determine the presence of decarboxylation.
[0125] Common Methods Section
[0126] All methods in this Section are provided for incorporation into the above methods where so referenced therein and/or below.
[0127] Subsection I. Bacterial Growth Methods: Bacterial growth culture methods, and associated materials and conditions, are disclosed for respective species that may be utilized as needed, as follows:
[0128] Escherichia coli K12 is a gift from the Gill lab (University of Colorado at Boulder) and is obtained as an actively growing culture. Serial dilutions of the actively growing E. coli K12 culture are made into Luria Broth (RPI Corp, Mt. Prospect, Ill., USA) and are allowed to grow for aerobically for 24 hours at 37° C. at 250 rpm until saturated.
[0129] Pseudomonas aeruginosa genomic DNA is a gift from the Gill lab (University of Colorado at Boulder).
[0130] Subsection II: Gel Preparation, DNA Separation, Extraction, Ligation, and Transformation Methods:
[0131] Molecular biology grade agarose (RPI Corp, Mt. Prospect, Ill., USA) is added to 1× TAE to make a 1% Agarose: TAE solution. To obtain 50× TAE add the following to 900 mL of distilled water: add the following to 900 ml distilled H2O: 242 g Tris base (RPI Corp, Mt. Prospect, Ill., USA), 57.1 ml Glacial Acetic Acid (Sigma-Aldrich, St. Louis, Mo., USA) and 18.6 g EDTA (Fisher Scientific, Pittsburgh, Pa. USA) and adjust volume to 1L with additional distilled water. To obtain 1× TAE, add 20 mL of 50× TAE to 980 mL of distilled water. The agarose-TAE solution is then heated until boiling occurred and the agarose is fully dissolved. The solution is allowed to cool to 50° C. before 10 mg/mL ethidium bromide (Acros Organics, Morris Plains, N.J., USA) is added at a concentration of 5 ul per 100 mL of 1% agarose solution. Once the ethidium bromide is added, the solution is briefly mixed and poured into a gel casting tray with the appropriate number of combs (Idea Scientific Co., Minneapolis, Minn., USA) per sample analysis. DNA samples are then mixed accordingly with 5× TAE loading buffer. 5× TAE loading buffer consists of 5× TAE (diluted from 50× TAE as described above), 20% glycerol (Acros Organics, Morris Plains, N.J., USA), 0.125% Bromophenol Blue (Alfa Aesar, Ward Hill, Mass., USA), and adjust volume to 50 mL with distilled water. Loaded gels are then run in gel rigs (Idea Scientific Co., Minneapolis, Minn., USA) filled with 1× TAE at a constant voltage of 125 volts for 25-30 minutes. At this point, the gels are removed from the gel boxes with voltage and visualized under a UV transilluminator (FOTODYNE Inc., Hartland, Wis., USA).
[0132] The DNA isolated through gel extraction is then extracted using the QIAquick Gel Extraction Kit following manufacturer's instructions (Qiagen (Valencia Calif. USA)). Similar methods are known to those skilled in the art.
[0133] The thus-extracted DNA then may be ligated into pSMART (Lucigen Corp, Middleton, Wis., USA), StrataClone (Stratagene, La Jolla, Calif., USA) or pCR2.1-TOPO TA (Invitrogen Corp, Carlsbad, Calif., USA) according to manufacturer's instructions. These methods are described in the next subsection of Common Methods.
[0134] Ligation Methods:
[0135] For Ligations into pSMART Vectors:
[0136] Gel extracted DNA is blunted using PCRTerminator (Lucigen Corp, Middleton, Wis., USA) according to manufacturer's instructions. Then 500 ng of DNA is added to 2.5 uL 4× CloneSmart vector premix, 1 ul CloneSmart DNA ligase (Lucigen Corp, Middleton, Wis., USA) and distilled water is added for a total volume of 10 ul. The reaction is then allowed to sit at room temperature for 30 minutes and then heat inactivated at 70° C. for 15 minutes and then placed on ice. E. cloni 10G Chemically Competent cells (Lucigen Corp, Middleton, Wis., USA) are thawed for 20 minutes on ice. 40 ul of chemically competent cells are placed into a microcentrifuge tube and 1 ul of heat inactivated CloneSmart Ligation is added to the tube. The whole reaction is stirred briefly with a pipette tip. The ligation and cells are incubated on ice for 30 minutes and then the cells are heat shocked for 45 seconds at 42° C. and then put back onto ice for 2 minutes. 960 ul of room temperature Recovery media (Lucigen Corp, Middleton, Wis., USA) and places into microcentrifuge tubes. Shake tubes at 250 rpm for 1 hour at 37° C. Plate 100 ul of transformed cells on Luria Broth plates (RPI Corp, Mt. Prospect, Ill., USA) plus appropriate antibiotics depending on the pSMART vector used. Incubate plates overnight at 37° C.
[0137] For Ligations into StrataClone:
[0138] Gel extracted DNA is blunted using PCRTerminator (Lucigen Corp, Middleton, Wis., USA) according to manufacturer's instructions. Then 2 ul of DNA is added to 3 ul StrataClone Blunt Cloning buffer and 1 ul StrataClone Blunt vector mix amp/kan (Stratagene, La Jolla, Calif., USA) for a total of 6 ul. Mix the reaction by gently pipeting up at down and incubate the reaction at room temperature for 30 minutes then place onto ice. Thaw a tube of StrataClone chemically competent cells (Stratagene, La Jolla, Calif., USA) on ice for 20 minutes. Add 1 ul of the cloning reaction to the tube of chemically competent cells and gently mix with a pipette tip and incubate on ice for 20 minutes. Heat shock the transformation at 42° C. for 45 seconds then put on ice for 2 minutes. Add 250 ul pre-warmed Luria Broth (RPI Corp, Mt. Prospect, Ill., USA) and shake at 250 rpm for 37° C. for 2 hour. Plate 100 ul of the transformation mixture onto Luria Broth plates (RPI Corp, Mt. Prospect, Ill., USA) plus appropriate antibiotics. Incubate plates overnight at 37° C.
[0139] For Ligations into pCR2.1-TOPO TA:
[0140] Add 1 ul TOPO vector, 1 ul Salt Solution (Invitrogen Corp, Carlsbad, Calif., USA) and 3 ul gel extracted DNA into a microcentrifuge tube. Allow the tube to incubate at room temperature for 30 minutes then place the reaction on ice. Thaw one tube of TOP10F' chemically competent cells (Invitrogen Corp, Carlsbad, Calif., USA) per reaction. Add 1 ul of reaction mixture into the thawed TOP10F' cells and mix gently by swirling the cells with a pipette tip and incubate on ice for 20 minutes. Heat shock the transformation at 42° C. for 45 seconds then put on ice for 2 minutes. Add 250 ul pre-warmed SOC media (Invitrogen Corp, Carlsbad, Calif., USA) and shake at 250 rpm for 37° C. for 1 hour. Plate 100 ul of the transformation mixture onto Luria Broth plates (RPI Corp, Mt. Prospect, Ill., USA) plus appropriate antibiotics. Incubate plates overnight at 37° C.
[0141] General Transformation and Related Culture Methodologies:
[0142] Chemically competent transformation protocols are carried out according to the manufactures instructions or according to the literature contained in Molecular Cloning (Sambrook and Russell). Generally, plasmid DNA or ligation products are chilled on ice for 5 to 30 min. in solution with chemically competent cells. Chemically competent cells are a widely used product in the field of biotechnology and are available from multiple vendors, such as those indicated above in this Subsection. Following the chilling period cells generally are heat-shocked for 30 seconds at 42° C. without shaking, re-chilled and combined with 250 microliters of rich media, such as S.O.C. Cells are then incubated at 37° C. while shaking at 250 rpm for 1 hour. Finally, the cells are screened for successful transformations by plating on media containing the appropriate antibiotics.
[0143] The choice of an E. coli host strain for plasmid transformation is determined by considering factors such as plasmid stability, plasmid compatibility, plasmid screening methods and protein expression. Strain backgrounds can be changed by simply purifying plasmid DNA as described above and transforming the plasmid into a desired or otherwise appropriate E. coli host strain such as determined by experimental necessities, such as any commonly used cloning strain (e.g., DH5α, Top10F', E. cloni 10G, etc.).
[0144] To make 1L M9 minimal media:
[0145] M9 minimal media was made by combining 5× M9 salts, 1M MgSO4, 20% glucose, 1M CaCl2 and sterile deionized water. The 5× M9 salts are made by dissolving the following salts in deionized water to a final volume of 1L: 64 g Na2HPO4.7H2O, 15 g KH2PO4, 2.5 g NaCl, 5.0 g NH4Cl. The salt solution was divided into 200 mL aliquots and sterilized by autoclaving for 15 minutes at 15 psi on the liquid cycle. A 1M solution of MgSO4 and 1M CaCl2 were made separately, then sterilized by autoclaving. The glucose was filter sterilized by passing it thought a 0.22 μm filter. All of the components are combined as follows to make 1L of M9: 750 mL sterile water, 200 mL 5× M9 salts, 2 mL of 1M MgSO4, 20 mL 20% glucose, 0.1 mL CaCl2, Q.S. to a final volume of 1L.
[0146] To Make EZ Rich Media:
[0147] All media components were obtained from TEKnova (Hollister Calif. USA) and combined in the following volumes. 100 mL 10× MOPS mixture, 10 mL 0.132M K2 HPO4, 100 mL 10× ACGU, 200 mL 5× Supplement EZ, 10 mL 20% glucose, 580 mL sterile water.
[0148] Subsection III. Additional Methods Related to Enzyme Evaluation Expression and Purification of proteins expressed in pKK223-Cterm-5×his by Expression Plasmids
[0149] Transformants containing a gene cloned into the pKK223-Cterm-5×his expression vector were grown overnight in LB+0.2% glucose+200 ug/mL Ampicillin, diluted 1:20 and grown (LB+0.2% glucose+200 ug/mL Ampicillin) to OD600 of 0.4. IPTG was added at 1 mM final concentration to induce protein expression. Cultures were then allowed to grow at 37 degrees C. for four hours. Cells were harvested by centrifugation at 4 degrees C. for 10 minutes at 4000 rpm. Pellets were resuspended and concentrated 50× (e.g. pellet from 500 mL culture resuspended in 10 mL buffer) in Qiagen Ni-NTA Lysis Buffer (50 mM Na2HPO4, 300 mM NaCl, 10 mM imidazole, pH 8.0)+1 mM PMSF. Lysozyme was added to a final concentration of 1 mg/mL; cells were incubated on ice for 30 minutes. Cells were lysed using a French Press (cell pressure=2000 psi) three times. Lysates were cleared by centrifugation at 4 degrees C. for 20 minutes, applied to Qiagen Ni-NTA columns, washed and eluted as specified by Qiagen (cat. #31314). Samples were analyzed by SDS-PAGE by routine protocols.
[0150] Decarboxylation Enzyme Reactions:
[0151] 100 uL reaction mixtures were added to microwells. Each 100 uL of reaction mixture contained 50 mM Potassium Phosphate (pH 7.0), 0.2 mM TPP, 1 mM MgCl2, and 10 mM of the appropriate substrate. 300 pg of purified enzyme was added to a respective microwell and incubated 16 hours at 37 degrees C. After 16 hours at 37 degrees C., 100 uL of Purpald® colorimetric indicator (Sigma-Aldrich, cat. #162892), prepared per manufacturer's instructions, was added to each microwell in order to detect formation of corresponding aldehyde product. After addition of the Purpald®, the microwells were incubated at room temperature for 1 hour and read at a wavelength of 540 nm in a Thermomax Microplate Reader (Molecular Devices) using SOFTMax Pro Microplate Reader software, Ver. 4.0.
[0152] Summary of Suppliers Section
[0153] The names and city addresses of major suppliers are provided in the methods above. In addition, as to Qiagen products, the DNeasy® Blood and Tissue Kit, Cat. No. 69506, is used in the methods for genomic DNA preparation; the QIAprep® Spin ("mini prep"), Cat. No. 27106, is used for plasmid DNA purification, and the QIAquick® Gel Extraction Kit, Cat. No. 28706, is used for gel extractions as described above.
[0154] Bio-production Media
[0155] Bio-production media, which is used in the present invention with recombinant microorganisms having a biosynthetic pathway for 3-HP (and optionally products further downstream of 3-HP), must contain suitable carbon substrates. Suitable substrates may include, but are not limited to, monosaccharides such as glucose and fructose, oligosaccharides such as lactose or sucrose, polysaccharides such as starch or cellulose or mixtures thereof and unpurified mixtures from renewable feed stocks such as cheese whey permeate, cornsteep liquor, sugar beet molasses, and barley malt. Additionally the carbon substrate may also be one-carbon substrates such as carbon dioxide, or methanol for which metabolic conversion into key biochemical intermediates has been demonstrated. In addition to one and two carbon substrates methylotrophic organisms are also known to utilize a number of other carbon containing compounds such as methylamine, glucosamine and a variety of amino acids for metabolic activity. For example, methylotrophic yeast are known to utilize the carbon from methylamine to form trehalose or glycerol (Bellion et al., Microb. Growth C1 Compd., [Int. Symp.], 7th (1993), 415-32. Editor(s): Murrell, J. Collin; Kelly, Don P. Publisher: Intercept, Andover, UK). Similarly, various species of Candida will metabolize alanine or oleic acid (Sulter et al., Arch. Microbiol. 153:485-489 (1990)). Hence it is contemplated that the source of carbon utilized in the present invention may encompass a wide variety of carbon containing substrates and will only be limited by the choice of organism. Although it is contemplated that all of the above mentioned carbon substrates and mixtures thereof are suitable in the present invention as a carbon source, common carbon substrates used as carbon sources are glucose, fructose, and sucrose, as well as mixtures of any of these sugars. Sucrose may be obtained from feed stocks such as sugar cane, sugar beets, cassava, and sweet sorghum. Glucose and dextrose may be obtained through saccharification of starch based feed stocks including grains such as corn, wheat, rye, barley, and oats.
[0156] In addition,sugars may be obtained from cellulosic and lignocellulosic biomass through processes of pretreatment and saccharification, as described, for example, in US patent application US20070031918A1, which is herein incorporated by reference. Biomass refers to any cellulosic or lignocellulosic material and includes materials comprising cellulose, and optionally further comprising hemicellulose, lignin, starch, oligosaccharides and/or monosaccharides. Biomass may also comprise additional components, such as protein and/or lipid. Biomass may be derived from a single source, or biomass can comprise a mixture derived from more than one source; for example, biomass could comprise a mixture of corn cobs and corn stover, or a mixture of grass and leaves. Biomass includes, but is not limited to, bioenergy crops, agricultural residues, municipal solid waste, industrial solid waste, sludge from paper manufacture, yard waste, wood and forestry waste. Examples of biomass include, but are not limited to, corn grain, corn cobs, crop residues such as corn husks, corn stover, grasses, wheat, wheat straw, barley, barley straw, hay, rice straw, switchgrass, waste paper, sugar cane bagasse, sorghum, soy, components obtained from milling of grains, trees, branches, roots, leaves, wood chips, sawdust, shrubs and bushes, vegetables, fruits, flowers and animal manure. Any such biomass may be used in a bio-production method or system to provide a carbon source. In addition to an appropriate carbon source, such as selected from one of the above-disclosed types, bio-production media must contain suitable minerals, salts, cofactors, buffers and other components, known to those skilled in the art, suitable for the growth of the cultures and promotion of the enzymatic pathway necessary for 3-HP (and optionally products further downstream of 3-HP) production.
[0157] Culture Conditions
[0158] Typically cells are grown at a temperature in the range of about 25° C. to about 40° C. in an appropriate medium. Suitable growth media in the present invention are common commercially prepared media such as Luria Bertani (LB) broth, M9 minimal media, Sabouraud Dextrose (SD) broth, Yeast medium (YM) broth or (Ymin) yeast synthetic minimal media. Other defined or synthetic growth media may also be used, and the appropriate medium for growth of the particular microorganism will be known by one skilled in the art of microbiology or bio-production science.
[0159] Suitable pH ranges for the bio-production are between pH 5.0 to pH 9.0, where pH 6.0 to pH 8.0 is a typical pH range for the initial condition.
[0160] Bio-productions may be performed under aerobic, microaerobic, or anaerobic conditions, with or without agitation.
[0161] The amount of 3-HP (and optionally products further downstream of 3-HP) produced in a bio-production media generally can be determined using a number of methods known in the art, for example, high performance liquid chromatography (HPLC) or gas chromatography (GC). Specific HPLC methods for the specific examples are provided herein.
[0162] Bio-production Reactors and Systems:
[0163] Any of the recombinant microorganisms as described and/or referred to above may be introduced into an industrial bio-production system where the microorganisms convert a carbon source into 3-HP (and optionally products further downstream of 3-HP) in a commercially viable operation. The bio-production system includes the introduction of such a recombinant microorganism into a bioreactor vessel, with a carbon source substrate and bio-production media suitable for growing the recombinant microorganism, and maintaining the bio-production system within a suitable temperature range (and dissolved oxygen concentration range if the reaction is aerobic or microaerobic) for a suitable time to obtain a desired conversion of a portion of the substrate molecules to 3-HP (and optionally products further downstream of 3-HP). Industrial bio-production systems and their operation are well-known to those skilled in the arts of chemical engineering and bioprocess engineering. The following paragraphs provide an overview of the methods and aspects of industrial systems that may be used for the bio-production of 3-HP (and optionally products further downstream of 3-HP).
[0164] In various embodiments, any of a wide range of sugars, including, but not limited to sucrose, glucose, xylose, cellulose or hemicellulose, are provided to a microorganism, such as in an industrial system comprising a reactor vessel in which a defined media (such as a minimal salts media including but not limited to M9 minimal media, potassium sulfate minimal media, yeast synthetic minimal media and many others or variations of these), an inoculum of a microorganism providing one or more of the 3-HP (and optionally products further downstream of 3-HP) biosynthetic pathway alternatives, and the a carbon source may be combined. The carbon source enters the cell and is cataboliized by well-known and common metabolic pathways to yield common metabolic intermediates, including phosphoenolpyruvate (PEP). (See Molecular Biology of the Cell, 3rd Ed., B. Alberts et al. Garland Publishing, New York, 1994, pp. 42-45, 66-74, incorporated by reference for the teachings of basic metabolic catabolic pathways for sugars; Principles of Biochemistry, 3rd Ed., D. L. Nelson & M. M. Cox, Worth Publishers, New York, 2000, pp 527-658, incorporated by reference for the teachings of major metabolic pathways; and Biochemistry, 4th Ed., L. Stryer, W. H. Freeman and Co., New York, 1995, pp. 463-650, also incorporated by reference for the teachings of major metabolic pathways.). Further to types of industrial bio-production, various embodiments of the present invention may employ a batch type of industrial bioreactor. A classical batch bioreactor system is considered "closed" meaning that the composition of the medium is established at the beginning of a respective bio-production event and not subject to artificial alterations and additions during the time period ending substantially with the end of the bio-production event. Thus, at the beginning of the bio-production event the medium is inoculated with the desired organism or organisms, and bio-production is permitted to occur without adding anything to the system. Typically, however, a "batch" type of bio-production event is batch with respect to the addition of carbon source and attempts are often made at controlling factors such as pH and oxygen concentration. In batch systems the metabolite and biomass compositions of the system change constantly up to the time the bio-production event is stopped. Within batch cultures cells moderate through a static lag phase to a high growth log phase and finally to a stationary phase where growth rate is diminished or halted. If untreated, cells in the stationary phase will eventually die. Cells in log phase generally are responsible for the bulk of production of a desired end product or intermediate.
[0165] A variation on the standard batch system is the Fed-Batch system. Fed-Batch bio-production processes are also suitable in the present invention and comprise a typical batch system with the exception that the substrate is added in increments as the bio-production progresses. Fed-Batch systems are useful when catabolite repression is apt to inhibit the metabolism of the cells and where it is desirable to have limited amounts of substrate in the media. Measurement of the actual substrate concentration in Fed-Batch systems may be measured directly, such as by sample analysis at different times, or estimated on the basis of the changes of measurable factors such as pH, dissolved oxygen and the partial pressure of waste gases such as CO2. Batch and Fed-Batch approaches are common and well known in the art and examples may be found in Thomas D. Brock in Biotechnology: A Textbook of Industrial Microbiology, Second Edition (1989) Sinauer Associates, Inc., Sunderland, Mass., Deshpande, Mukund V., Appl. Biochem. Biotechnol., 36:227, (1992), and Biochemical Engineering Fundamentals, 2nd Ed. J. E. Bailey and D. F. Ollis, McGraw Hill, New York, 1986, herein incorporated by reference for general instruction on bio-production, which as used herein may be aerobic, microaerobic, or anaerobic.
[0166] Although the present invention may be performed in batch mode, as provided in Example 8, or in fed-batch mode, it is contemplated that the method would be adaptable to continuous bio-production methods. Continuous bio-production is considered an "open" system where a defined bio-production medium is added continuously to a bioreactor and an equal amount of conditioned media is removed simultaneously for processing. Continuous bio-production generally maintains the cultures within a controlled density range where cells are primarily in log phase growth. Two types of continuous bioreactor operation include: 1) Chemostat--where fresh media is fed to the vessel while simultaneously removing an equal rate of the vessel contents. The limitation of this approach is that cells are lost and high cell density generally is not achievable. In fact, typically one can obtain much higher cell density with a fed-batch process. 2) Perfusion culture, which is similar to the chemostat approach except that the stream that is removed from the vessel is subjected to a separation technique which recycles viable cells back to the vessel. This type of continuous bioreactor operation has been shown to yield significantly higher cell densities than fed-batch and can be operated continuously. Continuous bio-production is particularly advantageous for industrial operations because it has less down time associated with draining, cleaning and preparing the equipment for the next bio-production event. Furthermore, it is typically more economical to continuously operate downstream unit operations, such as distillation, than to run them in batch mode.
[0167] Continuous bio-production allows for the modulation of one factor or any number of factors that affect cell growth or end product concentration. For example, one method will maintain a limiting nutrient such as the carbon source or nitrogen level at a fixed rate and allow all other parameters to moderate. In other systems a number of factors affecting growth can be altered continuously while the cell concentration, measured by media turbidity, is kept constant. Continuous systems strive to maintain steady state growth conditions and thus the cell loss due to the medium being drawn off must be balanced against the cell growth rate in the bio-production. Methods of modulating nutrients and growth factors for continuous bio-production processes as well as techniques for maximizing the rate of product formation are well known in the art of industrial microbiology and a variety of methods are detailed by Brock, supra.
[0168] It is contemplated that embodiments of the present invention may be practiced using either batch, fed-batch or continuous processes and that any known mode of bio-production would be suitable. Additionally, it is contemplated that cells may be immobilized on an inert scaffold as whole cell catalysts and subjected to suitable bio-production conditions for 3-HP (and optionally products further downstream of 3-HP) production.
[0169] The following published resources are incorporated by reference herein for their respective teachings to indicate the level of skill in these relevant arts, and as needed to support a disclosure that teaches how to make and use methods of industrial bio-production of 3-HP (and optionally products further downstream of 3-HP) from sugar sources, and also industrial systems that may be used to achieve such conversion with any of the recombinant microorganisms of the present invention (Biochemical Engineering Fundamentals, 2nd Ed. J. E. Bailey and D. F. Ollis, McGraw Hill, New York, 1986, entire book for purposes indicated and Chapter 9, pages 533-657 in particular for biological reactor design; Unit Operations of Chemical Engineering, 5th Ed., W. L. McCabe et al., McGraw Hill, New York 1993, entire book for purposes indicated, and particularly for process and separation technologies analyses; Equilibrium Staged Separations, P. C. Wankat, Prentice Hall, Englewood Cliffs, N.J. USA, 1988, entire book for separation technologies teachings).
[0170] The scope of the present invention is not meant to be limited to the exact sequences provided herein. It is appreciated that a range of modifications to nucleic acid and to amino acid sequences may be made and still provide a desired functionality. The following discussion is provided to more clearly define ranges of variation that may be practiced and still remain within the scope of the present invention.
[0171] It is recognized in the art that some amino acid sequences of the present invention can be varied without significant effect of the structure or function of the proteins disclosed herein. Variants included can constitute deletions, insertions, inversions, repeats, and type substitutions so long as the indicated enzyme activity is not significantly affected. Guidance concerning which amino acid changes are likely to be phenotypically silent can be found in Bowie, J. U., et Al., "Deciphering the Message in Protein Sequences: Tolerance to Amino Acid Substitutions," Science 247:1306-1310 (1990).
[0172] In various embodiments polypeptides obtained by the expression of the polynucleotide molecules of the present invention may have at least approximately 80%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identity to one or more amino acid sequences encoded by the genes and/or nucleic acid sequences described herein for the 3-HP (and optionally products further downstream of 3-HP) biosynthesis pathways. A truncated respective polypeptide has at least about 90% of the full length of a polypeptide encoded by a nucleic acid sequence encoding the respective native enzyme, and more particularly at least 95% of the full length of a polypeptide encoded by a nucleic acid sequence encoding the respective native enzyme. By a polypeptide having an amino acid sequence at least, for example, 95% "identical" to a reference amino acid sequence of a polypeptide is intended that the amino acid sequence of the claimed polypeptide is identical to the reference sequence except that the claimed polypeptide sequence can include up to five amino acid alterations per each 100 amino acids of the reference amino acid of the polypeptide. In other words, to obtain a polypeptide having an amino acid sequence at least 95% identical to a reference amino acid sequence, up to 5% of the amino acid residues in the reference sequence can be deleted or substituted with another amino acid, or a number of amino acids up to 5% of the total amino acid residues in the reference sequence can be inserted into the reference sequence. These alterations of the reference sequence can occur at the amino or carboxy terminal positions of the reference amino acid sequence or anywhere between those terminal positions, interspersed either individually among residues in the reference sequence or in one or more contiguous groups within the reference sequence.
[0173] As a practical matter, whether any particular polypeptide is at least 80%, 85%, 90%, 92%, 95%, 96%, 97%, 98% or 99% identical to any reference amino acid sequence of any polypeptide described herein (which may correspond with a particular nucleic acid sequence described herein), such particular polypeptide sequence can be determined conventionally using known computer programs such the Bestfit program (Wisconsin Sequence Analysis Package, Version 8 for Unix, Genetics Computer Group, University Research Park, 575 Science Drive, Madison, Wis. 53711). When using Bestfit or any other sequence alignment program to determine whether a particular sequence is, for instance, 95% identical to a reference sequence according to the present invention, the parameters are set, of course, such that the percentage of identity is calculated over the full length of the reference amino acid sequence and that gaps in homology of up to 5% of the total number of amino acid residues in the reference sequence are allowed. For example, in a specific embodiment the identity between a reference sequence (query sequence, a sequence of the present invention) and a subject sequence, also referred to as a global sequence alignment, may be determined using the FASTDB computer program based on the algorithm of Brutlag et al. (Comp. App. Biosci. 6:237-245 (1990)). Preferred parameters used in a FASTDB amino acid alignment are: Matrix=PAM 0, k-tuple=2, Mismatch Penalty=1, Joining Penalty=20, Randomization Group Length=0, Cutoff Score=1, Window Size=sequence length, Gap Penalty=5, Gap Size Penalty=0.05, Window Size=500 or the length of the subject amino acid sequence, whichever is shorter. According to this embodiment, if the subject sequence is shorter than the query sequence due to N- or C-terminal deletions, not because of internal deletions, a manual correction is made to the results to take into consideration the fact that the FASTDB program does not account for N- and C-terminal truncations of the subject sequence when calculating global percent identity. For subject sequences truncated at the N- and C-termini, relative to the query sequence, the percent identity is corrected by calculating the number of residues of the query sequence that are N- and C-terminal of the subject sequence, which are not matched/aligned with a corresponding subject residue, as a percent of the total bases of the query sequence. A determination of whether a residue is matched/aligned is determined by results of the FASTDB sequence alignment. This percentage is then subtracted from the percent identity, calculated by the above FASTDB program using the specified parameters, to arrive at a final percent identity score. This final percent identity score is what is used for the purposes of this embodiment. Only residues to the N- and C-termini of the subject sequence, which are not matched/aligned with the query sequence, are considered for the purposes of manually adjusting the percent identity score. That is, only query residue positions outside the farthest N- and C-terminal residues of the subject sequence. For example, a 90 amino acid residue subject sequence is aligned with a 100 residue query sequence to determine percent identity. The deletion occurs at the N-terminus of the subject sequence and therefore, the FASTDB alignment does not show a matching/alignment of the first 10 residues at the N-terminus. The 10 unpaired residues represent 10% of the sequence (number of residues at the N- and C-termini not matched/total number of residues in the query sequence) so 10% is subtracted from the percent identity score calculated by the FASTDB program. If the remaining 90 residues were perfectly matched the final percent identity would be 90%. In another example, a 90 residue subject sequence is compared with a 100 residue query sequence. This time the deletions are internal deletions so there are no residues at the N- or C-termini of the subject sequence which are not matched/aligned with the query. In this case the percent identity calculated by FASTDB is not manually corrected. Once again, only residue positions outside the N- and C-terminal ends of the subject sequence, as displayed in the FASTDB alignment, which are not matched/aligned with the query sequence are manually corrected for.
[0174] The above descriptions and methods for sequence homology are intended to be exemplary and it is recognized that this concept is well-understood in the art. Further, it is appreciated that nucleic acid sequences may be varied and still provide a functional enzyme, and such variations are within the scope of the present invention. Nucleic acid sequences that encode polypeptides that provide the indicated functions for 3-HP (and optionally products further downstream of 3-HP) that increase tolerance or production are considered within the scope of the present invention. These may be further defined by the stringency of hybridization, described below, but this is not meant to be limiting when a function of an encoded polypeptide matches a specified 3-HP (and optionally products further downstream of 3-HP) tolerance-related or biosynthesis pathway enzyme activity.
[0175] Further to nucleic acid sequences, "hybridization" refers to the process in which two single-stranded polynucleotides bind non-covalently to form a stable double-stranded polynucleotide. The term "hybridization" may also refer to triple-stranded hybridization. The resulting (usually) double-stranded polynucleotide is a "hybrid" or "duplex." "Hybridization conditions" will typically include salt concentrations of less than about 1M, more usually less than about 500 mM and less than about 200 mM. Hybridization temperatures can be as low as 5° C., but are typically greater than 22° C., more typically greater than about 30° C., and often are in excess of about 37° C. Hybridizations are usually performed under stringent conditions, i.e. conditions under which a probe will hybridize to its target subsequence. Stringent conditions are sequence-dependent and are different in different circumstances. Longer fragments may require higher hybridization temperatures for specific hybridization. As other factors may affect the stringency of hybridization, including base composition and length of the complementary strands, presence of organic solvents and extent of base mismatching, the combination of parameters is more important than the absolute measure of any one alone. Generally, stringent conditions are selected to be about 5° C. lower than the Tm for the specific sequence at a defined ionic strength and pH. Exemplary stringent conditions include salt concentration of at least 0.01 M to no more than 1 M Na ion concentration (or other salts) at a pH 7.0 to 8.3 and a temperature of at least 25° C. For example, conditions of 5×SSPE (750 mM NaCl, 50 mM NaPhosphate, 5 mM EDTA, pH 7.4) and a temperature of 25-30° C. are suitable for allele-specific probe hybridizations. For stringent conditions, see for example, Sambrook and Russell and Anderson "Nucleic Acid Hybridization" 1st Ed., BIOS Scientific Publishers Limited (1999), which are hereby incorporated by reference for hybridization protocols. "Hybridizing specifically to" or "specifically hybridizing to" or like expressions refer to the binding, duplexing, or hybridizing of a molecule substantially to or only to a particular nucleotide sequence or sequences under stringent conditions when that sequence is present in a complex mixture (e.g., total cellular) DNA or RNA.
[0176] Having so described the present invention and provided examples, and further discussion, and in view of the above paragraphs, it is appreciated that various non-limiting aspects of the present invention may include:
[0177] A genetically modified (recombinant) microorganism comprising a nucleic acid sequence that encodes a polypeptide with at least 85% amino acid sequence identity to any of the enzymes of any of 3-HP tolerance-related or biosynthetic pathways, wherein the polypeptide has enzymatic activity effective to perform the enzymatic reaction of the respective 3-HP biosynthetic pathway enzyme, and the recombinant microorganism exhibits greater 3-H tolerance and/or 3-HP bio-production.
[0178] A genetically modified (recombinant) microorganism comprising a nucleic acid sequence that encodes a polypeptide with at least 90% amino acid sequence identity to any of the enzymes of any of 3-HP tolerance-related or biosynthetic pathways, wherein the polypeptide has enzymatic activity effective to perform the enzymatic reaction of the respective 3-HP tolerance-related or biosynthetic pathway enzyme, and the recombinant microorganism exhibits greater 3-HP tolerance and/or 3-HPbio-production.
[0179] A genetically modified (recombinant) microorganism comprising a nucleic acid sequence that encodes a polypeptide with at least 95% amino acid sequence identity to any of the enzymes of any of 3-HP tolerance-related or biosynthetic pathways, wherein the polypeptide has enzymatic activity effective to perform the enzymatic reaction of the respective 3-HP tolerance-related or biosynthetic pathway enzyme, and the recombinant microorganism exhibits greater 3-HPtolerance and/or 3-HP bio-production.
[0180] The above paragraphs are meant to indicate modifications in the nucleic acid sequences may be made and a respective polypeptide encoded there from remains functional so as to perform an enzymatic catalysis along one of the 3-HP tolerance-related and/or biosynthetic pathways described above.
[0181] The term "heterologous DNA," "heterologous nucleic acid sequence," and the like as used herein refers to a nucleic acid sequence wherein at least one of the following is true: (a) the sequence of nucleic acids is foreign to (i.e., not naturally found in) a given host microorganism; (b) the sequence may be naturally found in a given host microorganism, but in an unnatural (e.g., greater than expected) amount; or (c) the sequence of nucleic acids comprises two or more subsequences that are not found in the same relationship to each other in nature. For example, regarding instance (c), a heterologous nucleic acid sequence that is recombinantly produced will have two or more sequences from unrelated genes arranged to make a new functional nucleic acid. Embodiments of the present invention may result from introduction of an expression vector into a host microorganism, wherein the expression vector contains a nucleic acid sequence coding for an enzyme that is, or is not, normally found in a host microorganism. With reference to the host microorganism's genome, then, the nucleic acid sequence that codes for the enzyme is heterologous.
[0182] Also, and more generally, in accordance with examples and embodiments herein, there may be employed conventional molecular biology, cellular biology, microbiology, and recombinant DNA techniques within the skill of the art. Such techniques are explained fully in the literature. (See, e.g., Sambrook and Russell, Molecular Cloning: A Laboratory Manual, Third Edition 2001 (volumes 1-3), Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y.; Animal Cell Culture, R. I. Freshney, ed., 1986). These published resources are incorporated by reference herein for their respective teachings of standard laboratory methods found therein. Further, all patents, patent applications, patent publications, and other publications referenced herein (collectively, "published resource(s)") are hereby incorporated by reference in this application. Such incorporation, at a minimum, is for the specific teaching and/or other purpose that may be noted when citing the reference herein. If a specific teaching and/or other purpose is not so noted, then the published resource is specifically incorporated for the teaching(s) indicated by one or more of the title, abstract, and/or summary of the reference. If no such specifically identified teaching and/or other purpose may be so relevant, then the published resource is incorporated in order to more fully describe the state of the art to which the present invention pertains, and/or to provide such teachings as are generally known to those skilled in the art, as may be applicable. However, it is specifically stated that a citation of a published resource herein shall not be construed as an admission that such is prior art to the present invention.
[0183] Thus, based on the above disclosure, it is appreciated that within the scope of the present invention are methods for selection and identification of mutant polynucleotides comprising nucleic acid sequences that encode mutant polypeptides that demonstrate elevated activity of oxaloacetate alpha-oxo decarboxylase activity (also referred to herein as oxaloacetate alpha-decarboxylase activity). Also within the scope of the present invention may be compositions that comprise such identified mutant polynucleotides and polypeptides. In various embodiments, these methods are directed for the specific purpose of obtaining recombinant microorganisms that have capacity for increased bio-production of 3-HP. Although specific genes, enzymes, plasmids and other constructs are described in the above examples, these are not meant to limit the scope of the invention, particularly in view of the level of skill in the art.
[0184] Thus, while various embodiments of the present invention have been shown and described herein, it will be obvious that such embodiments are provided by way of example only. Numerous variations, changes and substitutions may be made without departing from the invention herein in its various embodiments. Specifically, and for whatever reason, for any grouping of compounds, nucleic acid sequences, polypeptides including specific proteins including functional enzymes, metabolic pathway enzymes or intermediates, elements, or other compositions, or concentrations stated or otherwise presented herein in a list, table, or other grouping (such as metabolic pathway enzymes shown in a figure), unless clearly stated otherwise, it is intended that each such grouping provides the basis for and serves to identify various subset embodiments, the subset embodiments in their broadest scope comprising every subset of such grouping by exclusion of one or more members (or subsets) of the respective stated grouping. Moreover, when any range is described herein, unless clearly stated otherwise, that range includes all values therein and all sub-ranges therein. Accordingly, it is intended that the invention be limited only by the spirit and scope of appended claims, and of later claims, and of either such claims as they may be amended during prosecution of this or a later application claiming priority hereto.
Sequence CWU
1
2313736DNAArtificial SequenceCodon optimized kgd gene sequence with
customized ends 1ttgacggata tcaagcttct attaaccgaa cgcttcgtcc aagatttctt
gctgctccac 60ggcatgaacc ttcgaggaac cgctgctcgg cgcagacatc gcgcgacggg
agatacgctt 120gatgcccgcc aacttgtccg gcagcaactc cggcaactcc aaaccgaaac
gcggccaggc 180gccctggttc gctggttcct cctggaccca aaagaactct ttgacatttt
cgtaacgatc 240cagggtttca cgcagacgac gacgcggcaa cggcgccagt tgctccagac
gcacaattgc 300cagatcatta cggttgtctt tcgccttgcg tgccgccaat tcataataca
acttaccgga 360ggtcaacaga atacggctaa ctttattgcg gtcgccgata ccatcctcgt
aggtcggttc 420ctccaggacg ctacggaatt taatctcggt aaaatcctta atctccgaaa
ccgccgcctt 480gtggcgcagc atggatttcg gggtaaacac gatcaacgga cgttggatgc
cgtccaacgc 540gtggcggcgc agcaagtgaa agtaattgga cggggtgctc ggcatcgcga
tcgtcatgct 600accctcagcc cacagctgca aaaagcgctc aatgcgcgcc gacgtgtggt
ccgggccctg 660accctcgtgg ccgtgtggca gcaacagaac aacgttggac agctgacccc
atttcgcttc 720gcccgagctg atgaactcgt caatgatcga ctgggcacca ttaacaaagt
cgccgaattg 780cgcctcccac agcacaaccg cgtctggatt gccaacggta taaccgtact
caaaacccac 840agccgcgtat tccgacaacg gcgaatcata aaccaggaac ttaccaccgg
tcgggctgcc 900gtcgctgtta gtcgccagca gctgcagcgg ggtgaactcc tcgccggtgt
gacggtcgat 960cagcacagaa tgacgctggc taaaggtgcc acgacgagag tcttgaccgc
tcagacggac 1020cagcttgccc tcagcaacca ggctgcccag cgccagcaac tcaccaaacg
cccagtcaat 1080cttaccctca tacgccatct cacgacgctt ttccagcacc ggctgaacgc
gcgggtgtgc 1140cgtgaaaccg ttaggcagcg ccaggaaggc atcaccgata cgtgccagca
gggatttgtc 1200aacagcggtc gccaggcccg ctgggatcat ttggtccgac tcgacgctct
ccgacggttg 1260gacgccgtgc ttctccagtt cgcgcacttc gttgaacaca cgctccagtt
ggccctggta 1320atcgcgcagc gcatcctccg cctctttcat gctgatgtcg ccacgaccga
tcagagcctc 1380ggtgtaggat ttacgggcgc cacgcttggt gtccacgacg tcatagacat
acggattggt 1440catagatgga tcgtcaccct cattatgacc acgacgacga tagcacagca
tgtcaataac 1500aacgtccttt ttaaagcgtt ggcggaagtc aactgccaaa cgcgcaaccc
agacacacgc 1560ttctggatcg tcgccgttca cgtggaagat tggcgcaccg atcatcttcg
ccacatccgt 1620gcagtactcg ctcgaacgag agtattccgg agcggtggtg aagccgattt
ggttgttcac 1680aatgatgtga atcgtaccac ccacacgata gccaggcaga tttgccagat
tcagcgtctc 1740cgcaacaacg ccttgacccg cgaaggccgc atcaccgtgc agcatcaacg
gaacgacgga 1800gaatgcacgt tggccgtcgg agtcaatgga accgtggtcc agcaggtctt
gcttcgcacg 1860caccaaacct tccagcactg gatcgaccgc ttccaaatgg gacggatttg
ccgtcaggga 1920aacctgaata tcgttatcgc caaacatttg cagatacaga cccgtcgcac
ccaggtggta 1980cttgacatcg ccggaaccgt gagcctggga cgggttcaga ttgccttcaa
actccgtaaa 2040gatttgcgaa tacggtttgc ccacgatgtt cgccaggaca ttcaagcgac
cacggtgcgg 2100catgccaatg accacttcat ccaaaccatg ctcggcacat tggtcaatcg
ccgcgtccat 2160cattggaata acagattccg caccctccag gctaaaacgc ttttggccca
catacttggt 2220ttgcaggaag gtttcaaacg cctccgctgc gttcagtttc gacaagatgt
acttttgttg 2280agcaacggtc ggtttgacgt gcttcgtctc gacacgctgc tccagccact
ccttttgttc 2340cgggtccaga atgtgcgcgt actcaacacc gatgtgacgg cagtacgcgt
cgcgcagcaa 2400acccagcacg tcacgcagct ttttgtattg agcacccgcg aaaccgtcaa
ccttaaagac 2460gcggtccagg tcccacagag tcaggccatg cgtcaacacc tccaaatccg
gatgcgaacg 2520aaagcgcgcc ttatccaagc gcaacgggtc ggtgtccgcc atcagatggc
cgcggttgcg 2580ataggccgcg atcaggttca tcacacgtgc gttcttgtca acgatcgagt
ccggattatc 2640ggtgctccaa cgcactggca ggtacgggat gctcagctcg cggaagacct
catcccagaa 2700gccatcagac aacagcagtt catgaatggt acgcaggaag tcaccgcttt
ccgcaccttg 2760aatgatacgg tggtcgtagg tagaagtcag ggtaatcagt ttgccaatac
ccagctcagc 2820gatgcgttcc tcggacgcgc cttggaactc cgccggatat tccatcgcac
cgacaccgat 2880gatagcacct tgacctggca tcaggcgtgg cacagagtgc accgtgccaa
tcgtgcccgg 2940attcgtcagc gaaatcgtaa cgccagcgaa gtcctcggtg gtcagtttac
catcacgagc 3000acgacggacg atgtcctcgt acgcggtaac gaactgcgcg aagcgcatcg
tctcgcaacg 3060tttgataccg gccaccacca gagagcgctt gccatcttta ccttgcaggt
caatagccag 3120acccagattg gtgtgcgcag gagtaaccgc cgtcggctta ccgtccacct
ccgtgtagtg 3180gcgattcata ttcgggaact tcttaaccgc ctgaaccaga gcataaccca
gcaaatgggt 3240aaagctgatt ttaccaccac gcgtgcgttt caactgatta ttgatcacga
tacgattatc 3300gatcaacaat ttcgctggca cagcacgcac cgaggtcgcc gtaggcactt
ccagcgacgc 3360gctcatgttc ttcacgacag cagccgccgc accacgcagg acagcaactt
catcgccttc 3420ggctggcgga ggcaccgcgg tcttggcggc cagagccgcc acgacaccgt
tgcccgctgc 3480ggccgtgtcg gccggtttcg gcggcgcttg cggagccgcc gctgccgcac
gctcagcgac 3540caaagggctg gtcacacgag tcggctcagc agccggttgg gaagtcggct
ccgggctata 3600gtccaccaga aactcatgcc agcttgggtc aacggaagac ggatcatcac
gaaatttacg 3660atacatacca acacgagacg ggtcctgagt caccatggat atatctcctt
cttaaagaat 3720tcgatatctc agcgac
373621224PRTMycobacterium tuberculosis 2Met Val Thr Gln Asp
Pro Ser Arg Val Gly Met Tyr Arg Lys Phe Arg1 5
10 15Asp Asp Pro Ser Ser Val Asp Pro Ser Trp His
Glu Phe Leu Val Asp 20 25
30Tyr Ser Pro Glu Pro Thr Ser Gln Pro Ala Ala Glu Pro Thr Arg Val
35 40 45Thr Ser Pro Leu Val Ala Glu Arg
Ala Ala Ala Ala Ala Pro Gln Ala 50 55
60Pro Pro Lys Pro Ala Asp Thr Ala Ala Ala Gly Asn Gly Val Val Ala65
70 75 80Ala Leu Ala Ala Lys
Thr Ala Val Pro Pro Pro Ala Glu Gly Asp Glu 85
90 95Val Ala Val Leu Arg Gly Ala Ala Ala Ala Val
Val Lys Asn Met Ser 100 105
110Ala Ser Leu Glu Val Pro Thr Ala Thr Ser Val Arg Ala Val Pro Ala
115 120 125Lys Leu Leu Ile Asp Asn Arg
Ile Val Ile Asn Asn Gln Leu Lys Arg 130 135
140Thr Arg Gly Gly Lys Ile Ser Phe Thr His Leu Leu Gly Tyr Ala
Leu145 150 155 160Val Gln
Ala Val Lys Lys Phe Pro Asn Met Asn Arg His Tyr Thr Glu
165 170 175Val Asp Gly Lys Pro Thr Ala
Val Thr Pro Ala His Thr Asn Leu Gly 180 185
190Leu Ala Ile Asp Leu Gln Gly Lys Asp Gly Lys Arg Ser Leu
Val Val 195 200 205Ala Gly Ile Lys
Arg Cys Glu Thr Met Arg Phe Ala Gln Phe Val Thr 210
215 220Ala Tyr Glu Asp Ile Val Arg Arg Ala Arg Asp Gly
Lys Leu Thr Thr225 230 235
240Glu Asp Phe Ala Gly Val Thr Ile Ser Leu Thr Asn Pro Gly Thr Ile
245 250 255Gly Thr Val His Ser
Val Pro Arg Leu Met Pro Gly Gln Gly Ala Ile 260
265 270Ile Gly Val Gly Ala Met Glu Tyr Pro Ala Glu Phe
Gln Gly Ala Ser 275 280 285Glu Glu
Arg Ile Ala Glu Leu Gly Ile Gly Lys Leu Ile Thr Leu Thr 290
295 300Ser Thr Tyr Asp His Arg Ile Ile Gln Gly Ala
Glu Ser Gly Asp Phe305 310 315
320Leu Arg Thr Ile His Glu Leu Leu Leu Ser Asp Gly Phe Trp Asp Glu
325 330 335Val Phe Arg Glu
Leu Ser Ile Pro Tyr Leu Pro Val Arg Trp Ser Thr 340
345 350Asp Asn Pro Asp Ser Ile Val Asp Lys Asn Ala
Arg Val Met Asn Leu 355 360 365Ile
Ala Ala Tyr Arg Asn Arg Gly His Leu Met Ala Asp Thr Asp Pro 370
375 380Leu Arg Leu Asp Lys Ala Arg Phe Arg Ser
His Pro Asp Leu Glu Val385 390 395
400Leu Thr His Gly Leu Thr Leu Trp Asp Leu Asp Arg Val Phe Lys
Val 405 410 415Asp Gly Phe
Ala Gly Ala Gln Tyr Lys Lys Leu Arg Asp Val Leu Gly 420
425 430Leu Leu Arg Asp Ala Tyr Cys Arg His Ile
Gly Val Glu Tyr Ala His 435 440
445Ile Leu Asp Pro Glu Gln Lys Glu Trp Leu Glu Gln Arg Val Glu Thr 450
455 460Lys His Val Lys Pro Thr Val Ala
Gln Gln Lys Tyr Ile Leu Ser Lys465 470
475 480Leu Asn Ala Ala Glu Ala Phe Glu Thr Phe Leu Gln
Thr Lys Tyr Val 485 490
495Gly Gln Lys Arg Phe Ser Leu Glu Gly Ala Glu Ser Val Ile Pro Met
500 505 510Met Asp Ala Ala Ile Asp
Gln Cys Ala Glu His Gly Leu Asp Glu Val 515 520
525Val Ile Gly Met Pro His Arg Gly Arg Leu Asn Val Leu Ala
Asn Ile 530 535 540Val Gly Lys Pro Tyr
Ser Gln Ile Phe Thr Glu Phe Glu Gly Asn Leu545 550
555 560Asn Pro Ser Gln Ala His Gly Ser Gly Asp
Val Lys Tyr His Leu Gly 565 570
575Ala Thr Gly Leu Tyr Leu Gln Met Phe Gly Asp Asn Asp Ile Gln Val
580 585 590Ser Leu Thr Ala Asn
Pro Ser His Leu Glu Ala Val Asp Pro Val Leu 595
600 605Glu Gly Leu Val Arg Ala Lys Gln Asp Leu Leu Asp
His Gly Ser Ile 610 615 620Asp Ser Asp
Gly Gln Arg Ala Phe Ser Val Val Pro Leu Met Leu His625
630 635 640Gly Asp Ala Ala Phe Ala Gly
Gln Gly Val Val Ala Glu Thr Leu Asn 645
650 655Leu Ala Asn Leu Pro Gly Tyr Arg Val Gly Gly Thr
Ile His Ile Ile 660 665 670Val
Asn Asn Gln Ile Gly Phe Thr Thr Ala Pro Glu Tyr Ser Arg Ser 675
680 685Ser Glu Tyr Cys Thr Asp Val Ala Lys
Met Ile Gly Ala Pro Ile Phe 690 695
700His Val Asn Gly Asp Asp Pro Glu Ala Cys Val Trp Val Ala Arg Leu705
710 715 720Ala Val Asp Phe
Arg Gln Arg Phe Lys Lys Asp Val Val Ile Asp Met 725
730 735Leu Cys Tyr Arg Arg Arg Gly His Asn Glu
Gly Asp Asp Pro Ser Met 740 745
750Thr Asn Pro Tyr Val Tyr Asp Val Val Asp Thr Lys Arg Gly Ala Arg
755 760 765Lys Ser Tyr Thr Glu Ala Leu
Ile Gly Arg Gly Asp Ile Ser Met Lys 770 775
780Glu Ala Glu Asp Ala Leu Arg Asp Tyr Gln Gly Gln Leu Glu Arg
Val785 790 795 800Phe Asn
Glu Val Arg Glu Leu Glu Lys His Gly Val Gln Pro Ser Glu
805 810 815Ser Val Glu Ser Asp Gln Met
Ile Pro Ala Gly Leu Ala Thr Ala Val 820 825
830Asp Lys Ser Leu Leu Ala Arg Ile Gly Asp Ala Phe Leu Ala
Leu Pro 835 840 845Asn Gly Phe Thr
Ala His Pro Arg Val Gln Pro Val Leu Glu Lys Arg 850
855 860Arg Glu Met Ala Tyr Glu Gly Lys Ile Asp Trp Ala
Phe Gly Glu Leu865 870 875
880Leu Ala Leu Gly Ser Leu Val Ala Glu Gly Lys Leu Val Arg Leu Ser
885 890 895Gly Gln Asp Ser Arg
Arg Gly Thr Phe Ser Gln Arg His Ser Val Leu 900
905 910Ile Asp Arg His Thr Gly Glu Glu Phe Thr Pro Leu
Gln Leu Leu Ala 915 920 925Thr Asn
Ser Asp Gly Ser Pro Thr Gly Gly Lys Phe Leu Val Tyr Asp 930
935 940Ser Pro Leu Ser Glu Tyr Ala Ala Val Gly Phe
Glu Tyr Gly Tyr Thr945 950 955
960Val Gly Asn Pro Asp Ala Val Val Leu Trp Glu Ala Gln Phe Gly Asp
965 970 975Phe Val Asn Gly
Ala Gln Ser Ile Ile Asp Glu Phe Ile Ser Ser Gly 980
985 990Glu Ala Lys Trp Gly Gln Leu Ser Asn Val Val
Leu Leu Leu Pro His 995 1000
1005Gly His Glu Gly Gln Gly Pro Asp His Thr Ser Ala Arg Ile Glu
1010 1015 1020Arg Phe Leu Gln Leu Trp
Ala Glu Gly Ser Met Thr Ile Ala Met 1025 1030
1035Pro Ser Thr Pro Ser Asn Tyr Phe His Leu Leu Arg Arg His
Ala 1040 1045 1050Leu Asp Gly Ile Gln
Arg Pro Leu Ile Val Phe Thr Pro Lys Ser 1055 1060
1065Met Leu Arg His Lys Ala Ala Val Ser Glu Ile Lys Asp
Phe Thr 1070 1075 1080Glu Ile Lys Phe
Arg Ser Val Leu Glu Glu Pro Thr Tyr Glu Asp 1085
1090 1095Gly Ile Gly Asp Arg Asn Lys Val Ser Arg Ile
Leu Leu Thr Ser 1100 1105 1110Gly Lys
Leu Tyr Tyr Glu Leu Ala Ala Arg Lys Ala Lys Asp Asn 1115
1120 1125Arg Asn Asp Leu Ala Ile Val Arg Leu Glu
Gln Leu Ala Pro Leu 1130 1135 1140Pro
Arg Arg Arg Leu Arg Glu Thr Leu Asp Arg Tyr Glu Asn Val 1145
1150 1155Lys Glu Phe Phe Trp Val Gln Glu Glu
Pro Ala Asn Gln Gly Ala 1160 1165
1170Trp Pro Arg Phe Gly Leu Glu Leu Pro Glu Leu Leu Pro Asp Lys
1175 1180 1185Leu Ala Gly Ile Lys Arg
Ile Ser Arg Arg Ala Met Ser Ala Pro 1190 1195
1200Ser Ser Gly Ser Ser Lys Val His Ala Val Glu Gln Gln Glu
Ile 1205 1210 1215Leu Asp Glu Ala Phe
Gly 122038621DNAArtificial Sequencep206 plasmid with codon optimized
kgd gene nucleic acid sequence and softag 3ggtggcggta cttgggtcga
tatcaaagtg catcacttct tcccgtatgc ccaactttgt 60atagagagcc actgcgggat
cgtcaccgta atctgcttgc acgtagatca cataagcacc 120aagcgcgttg gcctcatgct
tgaggagatt gatgagcgcg gtggcaatgc cctgcctccg 180gtgctcgccg gagactgcga
gatcatagat atagatctca ctacgcggct gctcaaactt 240gggcagaacg taagccgcga
gagcgccaac aaccgcttct tggtcgaagg cagcaagcgc 300gatgaatgtc ttactacgga
gcaagttccc gaggtaatcg gagtccggct gatgttggga 360gtaggtggct acgtcaccga
actcacgacc gaaaagatca agagcagccc gcatggattt 420gacttggtca gggccgagcc
tacatgtgcg aatgatgccc atacttgagc cacctaactt 480tgttttaggg cgactgccct
gctgcgtaac atcgttgctg ctccataaca tcaaacatcg 540acccacggcg taacgcgctt
gctgcttgga tgcccgaggc atagactgta caaaaaaaca 600gtcataacaa gccatgaaaa
ccgccactgc gccgttacca ccgctgcgtt cggtcaaggt 660tctggaccag ttgcgtgagc
gcattttttt ttcctcctcg gcgtttacgc cccgccctgc 720cactcatcgc agtactgttg
taattcatta agcattctgc cgacatggaa gccatcacag 780acggcatgat gaacctgaat
cgccagcggc atcagcacct tgtcgccttg cgtataatat 840ttgcccatag tgaaaacggg
ggcgaagaag ttgtccatat tggccacgtt taaatcaaaa 900ctggtgaaac tcacccaggg
attggcgctg acgaaaaaca tattctcaat aaacccttta 960gggaaatagg ccaggttttc
accgtaacac gccacatctt gcgaatatat gtgtagaaac 1020tgccggaaat cgtcgtggta
ttcactccag agcgatgaaa acgtttcagt ttgctcatgg 1080aaaacggtgt aacaagggtg
aacactatcc catatcacca gctcaccgtc tttcattgcc 1140atacggaact ccggatgagc
attcatcagg cgggcaagaa tgtgaataaa ggccggataa 1200aacttgtgct tatttttctt
tacggtcttt aaaaaggccg taatatccag ctgaacggtc 1260tggttatagg tacattgagc
aactgactga aatgcctcaa aatgttcttt acgatgccat 1320tgggatatat caacggtggt
atatccagtg atttttttct ccattttttt ttcctccttt 1380agaaaaactc atcgagcatc
aaatgaaact gcaatttatt catatcagga ttatcaatac 1440catatttttg aaaaagccgt
ttctgtaatg aaggagaaaa ctcaccgagg cagttccata 1500ggatggcaag atcctggtat
cggtctgcga ttccgactcg tccaacatca atacaaccta 1560ttaatttccc ctcgtcaaaa
ataaggttat caagtgagaa atcaccatga gtgacgactg 1620aatccggtga gaatggcaaa
agtttatgca tttctttcca gacttgttca acaggccagc 1680cattacgctc gtcatcaaaa
tcactcgcat caaccaaacc gttattcatt cgtgattgcg 1740cctgagcgag gcgaaatacg
cgatcgctgt taaaaggaca attacaaaca ggaatcgagt 1800gcaaccggcg caggaacact
gccagcgcat caacaatatt ttcacctgaa tcaggatatt 1860cttctaatac ctggaacgct
gtttttccgg ggatcgcagt ggtgagtaac catgcatcat 1920caggagtacg gataaaatgc
ttgatggtcg gaagtggcat aaattccgtc agccagttta 1980gtctgaccat ctcatctgta
acatcattgg caacgctacc tttgccatgt ttcagaaaca 2040actctggcgc atcgggcttc
ccatacaagc gatagattgt cgcacctgat tgcccgacat 2100tatcgcgagc ccatttatac
ccatataaat cagcatccat gttggaattt aatcgcggcc 2160tcgacgtttc ccgttgaata
tggctcattt ttttttcctc ctttaccaat gcttaatcag 2220tgaggcacct atctcagcga
tctgtctatt tcgttcatcc atagttgcct gactccccgt 2280cgtgtagata actacgatac
gggagggctt accatctggc cccagcgctg cgatgatacc 2340gcgagaacca cgctcaccgg
ctccggattt atcagcaata aaccagccag ccggaagggc 2400cgagcgcaga agtggtcctg
caactttatc cgcctccatc cagtctatta attgttgccg 2460ggaagctaga gtaagtagtt
cgccagttaa tagtttgcgc aacgttgttg ccatcgctac 2520aggcatcgtg gtgtcacgct
cgtcgtttgg tatggcttca ttcagctccg gttcccaacg 2580atcaaggcga gttacatgat
cccccatgtt gtgcaaaaaa gcggttagct ccttcggtcc 2640tccgatcgtt gtcagaagta
agttggccgc agtgttatca ctcatggtta tggcagcact 2700gcataattct cttactgtca
tgccatccgt aagatgcttt tctgtgactg gtgagtactc 2760aaccaagtca ttctgagaat
agtgtatgcg gcgaccgagt tgctcttgcc cggcgtcaat 2820acgggataat accgcgccac
atagcagaac tttaaaagtg ctcatcattg gaaaacgttc 2880ttcggggcga aaactctcaa
ggatcttacc gctgttgaga tccagttcga tgtaacccac 2940tcgtgcaccc aactgatctt
cagcatcttt tactttcacc agcgtttctg ggtgagcaaa 3000aacaggaagg caaaatgccg
caaaaaaggg aataagggcg acacggaaat gttgaatact 3060catattcttc ctttttcaat
attattgaag catttatcag ggttattgtc tcatgagcgg 3120atacatattt gaatgtattt
agaaaaataa acaaataggg gtcagtgtta caaccaatta 3180accaattctg aacattatcg
cgagcccatt tatacctgaa tatggctcat aacacccctt 3240gtttgcctgg cggcagtagc
gcggtggtcc cacctgaccc catgccgaac tcagaagtga 3300aacgccgtag cgccgatggt
agtgtgggga ctccccatgc gagagtaggg aactgccagg 3360catcaaataa aacgaaaggc
tcagtcgaaa gactgggcct ttcgcccggg ctaattgagg 3420ggtgtcgccc ttttgacgga
tatcaagctt ctattaaccg aacgcttcgt ccaagatttc 3480ttgctgctcc acggcatgaa
ccttcgagga accgctgctc ggcgcagaca tcgcgcgacg 3540ggagatacgc ttgatgcccg
ccaacttgtc cggcagcaac tccggcaact ccaaaccgaa 3600acgcggccag gcgccctggt
tcgctggttc ctcctggacc caaaagaact ctttgacatt 3660ttcgtaacga tccagggttt
cacgcagacg acgacgcggc aacggcgcca gttgctccag 3720acgcacaatt gccagatcat
tacggttgtc tttcgccttg cgtgccgcca attcataata 3780caacttaccg gaggtcaaca
gaatacggct aactttattg cggtcgccga taccatcctc 3840gtaggtcggt tcctccagga
cgctacggaa tttaatctcg gtaaaatcct taatctccga 3900aaccgccgcc ttgtggcgca
gcatggattt cggggtaaac acgatcaacg gacgttggat 3960gccgtccaac gcgtggcggc
gcagcaagtg aaagtaattg gacggggtgc tcggcatcgc 4020gatcgtcatg ctaccctcag
cccacagctg caaaaagcgc tcaatgcgcg ccgacgtgtg 4080gtccgggccc tgaccctcgt
ggccgtgtgg cagcaacaga acaacgttgg acagctgacc 4140ccatttcgct tcgcccgagc
tgatgaactc gtcaatgatc gactgggcac cattaacaaa 4200gtcgccgaat tgcgcctccc
acagcacaac cgcgtctgga ttgccaacgg tataaccgta 4260ctcaaaaccc acagccgcgt
attccgacaa cggcgaatca taaaccagga acttaccacc 4320ggtcgggctg ccgtcgctgt
tagtcgccag cagctgcagc ggggtgaact cctcgccggt 4380gtgacggtcg atcagcacag
aatgacgctg gctaaaggtg ccacgacgag agtcttgacc 4440gctcagacgg accagcttgc
cctcagcaac caggctgccc agcgccagca actcaccaaa 4500cgcccagtca atcttaccct
catacgccat ctcacgacgc ttttccagca ccggctgaac 4560gcgcgggtgt gccgtgaaac
cgttaggcag cgccaggaag gcatcaccga tacgtgccag 4620cagggatttg tcaacagcgg
tcgccaggcc cgctgggatc atttggtccg actcgacgct 4680ctccgacggt tggacgccgt
gcttctccag ttcgcgcact tcgttgaaca cacgctccag 4740ttggccctgg taatcgcgca
gcgcatcctc cgcctctttc atgctgatgt cgccacgacc 4800gatcagagcc tcggtgtagg
atttacgggc gccacgcttg gtgtccacga cgtcatagac 4860atacggattg gtcatagatg
gatcgtcacc ctcattatga ccacgacgac gatagcacag 4920catgtcaata acaacgtcct
ttttaaagcg ttggcggaag tcaactgcca aacgcgcaac 4980ccagacacac gcttctggat
cgtcgccgtt cacgtggaag attggcgcac cgatcatctt 5040cgccacatcc gtgcagtact
cgctcgaacg agagtattcc ggagcggtgg tgaagccgat 5100ttggttgttc acaatgatgt
gaatcgtacc acccacacga tagccaggca gatttgccag 5160attcagcgtc tccgcaacaa
cgccttgacc cgcgaaggcc gcatcaccgt gcagcatcaa 5220cggaacgacg gagaatgcac
gttggccgtc ggagtcaatg gaaccgtggt ccagcaggtc 5280ttgcttcgca cgcaccaaac
cttccagcac tggatcgacc gcttccaaat gggacggatt 5340tgccgtcagg gaaacctgaa
tatcgttatc gccaaacatt tgcagataca gacccgtcgc 5400acccaggtgg tacttgacat
cgccggaacc gtgagcctgg gacgggttca gattgccttc 5460aaactccgta aagatttgcg
aatacggttt gcccacgatg ttcgccagga cattcaagcg 5520accacggtgc ggcatgccaa
tgaccacttc atccaaacca tgctcggcac attggtcaat 5580cgccgcgtcc atcattggaa
taacagattc cgcaccctcc aggctaaaac gcttttggcc 5640cacatacttg gtttgcagga
aggtttcaaa cgcctccgct gcgttcagtt tcgacaagat 5700gtacttttgt tgagcaacgg
tcggtttgac gtgcttcgtc tcgacacgct gctccagcca 5760ctccttttgt tccgggtcca
gaatgtgcgc gtactcaaca ccgatgtgac ggcagtacgc 5820gtcgcgcagc aaacccagca
cgtcacgcag ctttttgtat tgagcacccg cgaaaccgtc 5880aaccttaaag acgcggtcca
ggtcccacag agtcaggcca tgcgtcaaca cctccaaatc 5940cggatgcgaa cgaaagcgcg
ccttatccaa gcgcaacggg tcggtgtccg ccatcagatg 6000gccgcggttg cgataggccg
cgatcaggtt catcacacgt gcgttcttgt caacgatcga 6060gtccggatta tcggtgctcc
aacgcactgg caggtacggg atgctcagct cgcggaagac 6120ctcatcccag aagccatcag
acaacagcag ttcatgaatg gtacgcagga agtcaccgct 6180ttccgcacct tgaatgatac
ggtggtcgta ggtagaagtc agggtaatca gtttgccaat 6240acccagctca gcgatgcgtt
cctcggacgc gccttggaac tccgccggat attccatcgc 6300accgacaccg atgatagcac
cttgacctgg catcaggcgt ggcacagagt gcaccgtgcc 6360aatcgtgccc ggattcgtca
gcgaaatcgt aacgccagcg aagtcctcgg tggtcagttt 6420accatcacga gcacgacgga
cgatgtcctc gtacgcggta acgaactgcg cgaagcgcat 6480cgtctcgcaa cgtttgatac
cggccaccac cagagagcgc ttgccatctt taccttgcag 6540gtcaatagcc agacccagat
tggtgtgcgc aggagtaacc gccgtcggct taccgtccac 6600ctccgtgtag tggcgattca
tattcgggaa cttcttaacc gcctgaacca gagcataacc 6660cagcaaatgg gtaaagctga
ttttaccacc acgcgtgcgt ttcaactgat tattgatcac 6720gatacgatta tcgatcaaca
atttcgctgg cacagcacgc accgaggtcg ccgtaggcac 6780ttccagcgac gcgctcatgt
tcttcacgac agcagccgcc gcaccacgca ggacagcaac 6840ttcatcgcct tcggctggcg
gaggcaccgc ggtcttggcg gccagagccg ccacgacacc 6900gttgcccgct gcggccgtgt
cggccggttt cggcggcgct tgcggagccg ccgctgccgc 6960acgctcagcg accaaagggc
tggtcacacg agtcggctca gcagccggtt gggaagtcgg 7020ctccgggcta tagtccacca
gaaactcatg ccagcttggg tcaacggaag acggatcatc 7080acgaaattta cgatacatac
caacacgaga cgggtcctga gtcaccatgg atatatctcc 7140ttcttaaaga attcgatatc
tcagcgacaa gggcgacaca aaatttattc taaatgcata 7200ataaatactg ataacatctt
atagtttgta ttatattttg tattatcgtt gacatgtata 7260attttgatat caaaaactga
ttttcccttt attattttcg agatttattt tcttaattct 7320ctttaacaaa ctagaaatat
tgtatataca aaaaatcata aataatagat gaatagttta 7380attataggtg ttcatcaatc
gaaaaagcaa cgtatcttat ttaaagtgcg ttgctttttt 7440ctcatttata aggttaaata
attctcatat atcaagcaaa gtgacaggcg cccttaaata 7500ttctgacaaa tgctctttcc
ctaaactccc cccataaaaa aacccgccga agcgggtttt 7560tacgttattt gcggattaac
gattactcgt tatcagaacc gcccaggggg cccgagctta 7620agactggccg tcgttttaca
acacagaaag agtttgtaga aacgcaaaaa ggccatccgt 7680caggggcctt ctgcttagtt
tgatgcctgg cagttcccta ctctcgcctt ccgcttcctc 7740gctcactgac tcgctgcgct
cggtcgttcg gctgcggcga gcggtatcag ctcactcaaa 7800ggcggtaata cggttatcca
cagaatcagg ggataacgca ggaaagaaca tgtgagcaaa 7860aggccagcaa aaggccagga
accgtaaaaa ggccgcgttg ctggcgtttt tccataggct 7920ccgcccccct gacgagcatc
acaaaaatcg acgctcaagt cagaggtggc gaaacccgac 7980aggactataa agataccagg
cgtttccccc tggaagctcc ctcgtgcgct ctcctgttcc 8040gaccctgccg cttaccggat
acctgtccgc ctttctccct tcgggaagcg tggcgctttc 8100tcatagctca cgctgtaggt
atctcagttc ggtgtaggtc gttcgctcca agctgggctg 8160tgtgcacgaa ccccccgttc
agcccgaccg ctgcgcctta tccggtaact atcgtcttga 8220gtccaacccg gtaagacacg
acttatcgcc actggcagca gccactggta acaggattag 8280cagagcgagg tatgtaggcg
gtgctacaga gttcttgaag tggtgggcta actacggcta 8340cactagaaga acagtatttg
gtatctgcgc tctgctgaag ccagttacct tcggaaaaag 8400agttggtagc tcttgatccg
gcaaacaaac caccgctggt agcggtggtt tttttgtttg 8460caagcagcag attacgcgca
gaaaaaaagg atctcaagaa gatcctttga tcttttctac 8520ggggtctgac gctcagtgga
acgacgcgcg cgtaactcac gttaagggat tttggtcatg 8580agcttgcgcc gtcccgtcaa
gtcagcgtaa tgctctgctt a 8621439DNAArtificial
SequenceForward primer for PCR amplification of codon optimized kgd
nucleic acid sequence 4tttttttgta taccatggat cgtaaatttc gtgatgatc
39542DNAArtificial SequenceReverse primer for PCR
amplification of codon optimized kgd nucleic acid sequence
5cccggtgaga tctagatccg aacgcttcgt ccaagatttc tt
42647DNAArtificial SequenceForward primer for PCR amplification of
pKK223-3 template 6cggatctaga tctcaccatc accaccatta gtcgacctgc agccaag
47744DNAArtificial SequenceReverse primer for PCR
amplification of pKK223-3 template 7tgagatctag atccgttatg tcccatggtt
ctgtttcctg tgtg 4484614DNAArtificial
SequencepKK223-ct-his vector 8ttgacaatta atcatcggct cgtataatgt gtggaattgt
gagcggataa caatttcaca 60caggaaacag aaccatggga cataacggat ctagatctca
ccatcaccac cattagtcga 120cctgcagcca agcttggctg ttttggcgga tgagagaaga
ttttcagcct gatacagatt 180aaatcagaac gcagaagcgg tctgataaaa cagaatttgc
ctggcggcag tagcgcggtg 240gtcccacctg accccatgcc gaactcagaa gtgaaacgcc
gtagcgccga tggtagtgtg 300gggtctcccc atgcgagagt agggaactgc caggcatcaa
ataaaacgaa aggctcagtc 360gaaagactgg gcctttcgtt ttatctgttg tttgtcggtg
aacgctctcc tgagtaggac 420aaatccgccg ggagcggatt tgaacgttgc gaagcaacgg
cccggagggt ggcgggcagg 480acgcccgcca taaactgcca ggcatcaaat taagcagaag
gccatcctga cggatggcct 540ttttgcgttt ctacaaactc ttttgtttat ttttctaaat
acattcaaat atgtatccgc 600tcatgagaca ataaccctga taaatgcttc aataatattg
aaaaaggaag agtatgagta 660ttcaacattt ccgtgtcgcc cttattccct tttttgcggc
attttgcctt cctgtttttg 720ctcacccaga aacgctggtg aaagtaaaag atgctgaaga
tcagttgggt gcacgagtgg 780gttacatcga actggatctc aacagcggta agatccttga
gagttttcgc cccgaagaac 840gttttccaat gatgagcact tttaaagttc tgctatgtgg
cgcggtatta tcccgtgttg 900acgccgggca agagcaactc ggtcgccgca tacactattc
tcagaatgac ttggttgagt 960actcaccagt cacagaaaag catcttacgg atggcatgac
agtaagagaa ttatgcagtg 1020ctgccataac catgagtgat aacactgcgg ccaacttact
tctgacaacg atcggaggac 1080cgaaggagct aaccgctttt ttgcacaaca tgggggatca
tgtaactcgc cttgatcgtt 1140gggaaccgga gctgaatgaa gccataccaa acgacgagcg
tgacaccacg atgctgtagc 1200aatggcaaca acgttgcgca aactattaac tggcgaacta
cttactctag cttcccggca 1260acaattaata gactggatgg aggcggataa agttgcagga
ccacttctgc gctcggccct 1320tccggctggc tggtttattg ctgataaatc tggagccggt
gagcgtgggt ctcgcggtat 1380cattgcagca ctggggccag atggtaagcc ctcccgtatc
gtagttatct acacgacggg 1440gagtcaggca actatggatg aacgaaatag acagatcgct
gagataggtg cctcactgat 1500taagcattgg taactgtcag accaagttta ctcatatata
ctttagattg atttaaaact 1560tcatttttaa tttaaaagga tctaggtgaa gatccttttt
gataatctca tgaccaaaat 1620cccttaacgt gagttttcgt tccactgagc gtcagacccc
gtagaaaaga tcaaaggatc 1680ttcttgagat cctttttttc tgcgcgtaat ctgctgcttg
caaacaaaaa aaccaccgct 1740accagcggtg gtttgtttgc cggatcaaga gctaccaact
ctttttccga aggtaactgg 1800cttcagcaga gcgcagatac caaatactgt ccttctagtg
tagccgtagt taggccacca 1860cttcaagaac tctgtagcac cgcctacata cctcgctctg
ctaatcctgt taccagtggc 1920tgctgccagt ggcgataagt cgtgtcttac cgggttggac
tcaagacgat agttaccgga 1980taaggcgcag cggtcgggct gaacgggggg ttcgtgcaca
cagcccagct tggagcgaac 2040gacctacacc gaactgagat acctacagcg tgagcattga
gaaagcgcca cgcttcccga 2100agggagaaag gcggacaggt atccggtaag cggcagggtc
ggaacaggag agcgcacgag 2160ggagcttcca gggggaaacg cctggtatct ttatagtcct
gtcgggtttc gccacctctg 2220acttgagcgt cgatttttgt gatgctcgtc aggggggcgg
agcctatgga aaaacgccag 2280caacgcggcc tttttacggt tcctggcctt ttgctggcct
tttgctcaca tgttctttcc 2340tgcgttatcc cctgattctg tggataaccg tattaccgcc
tttgagtgag ctgataccgc 2400tcgccgcagc cgaacgaccg agcgcagcga gtcagtgagc
gaggaagcgg aagagcgcct 2460gatgcggtat tttctcctta cgcatctgtg cggtatttca
caccgcatat ggtgcactct 2520cagtacaatc tgctctgatg ccgcatagtt aagccagtat
acactccgct atcgctacgt 2580gactgggtca tggctgcgcc ccgacacccg ccaacacccg
ctgacgcgcc ctgacgggct 2640tgtctgctcc cggcatccgc ttacagacaa gctgtgaccg
tctccgggag ctgcatgtgt 2700cagaggtttt caccgtcatc accgaaacgc gcgaggcagc
tgcggtaaag ctcatcagcg 2760tggtcgtgaa gcgattcaca gatgtctgcc tgttcatccg
cgtccagctc gttgagtttc 2820tccagaagcg ttaatgtctg gcttctgata aagcgggcca
tgttaagggc ggttttttcc 2880tgtttggtca ctgatgcctc cgtgtaaggg ggatttctgt
tcatgggggt aatgataccg 2940atgaaacgag agaggatgct cacgatacgg gttactgatg
atgaacatgc ccggttactg 3000gaacgttgtg agggtaaaca actggcggta tggatgcggc
gggaccagag aaaaatcact 3060cagggtcaat gccagcgctt cgttaataca gatgtaggtg
ttccacaggg tagccagcag 3120catcctgcga tgcagatccg gaacataatg gtgcagggcg
ctgacttccg cgtttccaga 3180ctttacgaaa cacggaaacc gaagaccatt catgttgttg
ctcaggtcgc agacgttttg 3240cagcagcagt cgcttcacgt tcgctcgcgt atcggtgatt
cattctgcta accagtaagg 3300caaccccgcc agcctagccg ggtcctcaac gacaggagca
cgatcatgcg cacccgtggc 3360caggacccaa cgctgcccga gatgcgccgc gtgcggctgc
tggagatggc ggacgcgatg 3420gatatgttct gccaagggtt ggtttgcgca ttcacagttc
tccgcaagaa ttgattggct 3480ccaattcttg gagtggtgaa tccgttagcg aggtgccgcc
ggcttccatt caggtcgagg 3540tggcccggct ccatgcaccg cgacgcaacg cggggaggca
gacaaggtat agggcggcgc 3600ctacaatcca tgccaacccg ttccatgtgc tcgccgaggc
ggcataaatc gccgtgacga 3660tcagcggtcc agtgatcgaa gttaggctgg taagagccgc
gagcgatcct tgaagctgtc 3720cctgatggtc gtcatctacc tgcctggaca gcatggcctg
caacgcgggc atcccgatgc 3780cgccggaagc gagaagaatc ataatgggga aggccatcca
gcctcgcgtc gcgaacgcca 3840gcaagacgta gcccagcgcg tcggccgcca tgccggcgat
aatggcctgc ttctcgccga 3900aacgtttggt ggcgggacca gtgacgaagg cttgagcgag
ggcgtgcaag attccgaata 3960ccgcaagcga caggccgatc atcgtcgcgc tccagcgaaa
gcggtcctcg ccgaaaatga 4020cccagagcgc tgccggcacc tgtcctacga gttgcatgat
aaagaagaca gtcataagtg 4080cggcgacgat agtcatgccc cgcgcccacc ggaaggagct
gactgggttg aaggctctca 4140agggcatcgg tcgacgctct cccttatgcg actcctgcat
taggaagcag cccagtagta 4200ggttgaggcc gttgagcacc gccgccgcaa ggaatggtgc
atgcaaggag atggcgccca 4260acagtccccc ggccacgggg cctgccacca tacccacgcc
gaaacaagcg ctcatgagcc 4320cgaagtggcg agcccgatct tccccatcgg tgatgtcggc
gatataggcg ccagcaaccg 4380cacctgtggc gccggtgatg ccggccacga tgcgtccggc
gtagaggatc cgggcttatc 4440gactgcacgg tgcaccaatg cttctggcgt caggcagcca
tcggaagctg tggtatggct 4500gtgcaggtcg taaatcactg cataattcgt gtcgctcaag
gcgcactccc gttctggata 4560atgttttttg cgccgacatc ataacggttc tggcaaatat
tctgaaatga gctg 461498PRTArtificial SequenceHistidine tag
polypeptide sequence 9Ser Arg Ser His His His His His1
5108241DNAArtificial SequencepKK223-kgd plasmid with codon optimized kgd
gene nucleic acid sequence 10ttgacaatta atcatcggct cgtataatgt
gtggaattgt gagcggataa caatttcaca 60caggaaacag aaccatggat cgtaaatttc
gtgatgatcc gtcttccgtt gacccaagct 120ggcatgagtt tctggtggac tatagcccgg
agccgacttc ccaaccggct gctgagccga 180ctcgtgtgac cagccctttg gtcgctgagc
gtgcggcagc ggcggctccg caagcgccgc 240cgaaaccggc cgacacggcc gcagcgggca
acggtgtcgt ggcggctctg gccgccaaga 300ccgcggtgcc tccgccagcc gaaggcgatg
aagttgctgt cctgcgtggt gcggcggctg 360ctgtcgtgaa gaacatgagc gcgtcgctgg
aagtgcctac ggcgacctcg gtgcgtgctg 420tgccagcgaa attgttgatc gataatcgta
tcgtgatcaa taatcagttg aaacgcacgc 480gtggtggtaa aatcagcttt acccatttgc
tgggttatgc tctggttcag gcggttaaga 540agttcccgaa tatgaatcgc cactacacgg
aggtggacgg taagccgacg gcggttactc 600ctgcgcacac caatctgggt ctggctattg
acctgcaagg taaagatggc aagcgctctc 660tggtggtggc cggtatcaaa cgttgcgaga
cgatgcgctt cgcgcagttc gttaccgcgt 720acgaggacat cgtccgtcgt gctcgtgatg
gtaaactgac caccgaggac ttcgctggcg 780ttacgatttc gctgacgaat ccgggcacga
ttggcacggt gcactctgtg ccacgcctga 840tgccaggtca aggtgctatc atcggtgtcg
gtgcgatgga atatccggcg gagttccaag 900gcgcgtccga ggaacgcatc gctgagctgg
gtattggcaa actgattacc ctgacttcta 960cctacgacca ccgtatcatt caaggtgcgg
aaagcggtga cttcctgcgt accattcatg 1020aactgctgtt gtctgatggc ttctgggatg
aggtcttccg cgagctgagc atcccgtacc 1080tgccagtgcg ttggagcacc gataatccgg
actcgatcgt tgacaagaac gcacgtgtga 1140tgaacctgat cgcggcctat cgcaaccgcg
gccatctgat ggcggacacc gacccgttgc 1200gcttggataa ggcgcgcttt cgttcgcatc
cggatttgga ggtgttgacg catggcctga 1260ctctgtggga cctggaccgc gtctttaagg
ttgacggttt cgcgggtgct caatacaaaa 1320agctgcgtga cgtgctgggt ttgctgcgcg
acgcgtactg ccgtcacatc ggtgttgagt 1380acgcgcacat tctggacccg gaacaaaagg
agtggctgga gcagcgtgtc gagacgaagc 1440acgtcaaacc gaccgttgct caacaaaagt
acatcttgtc gaaactgaac gcagcggagg 1500cgtttgaaac cttcctgcaa accaagtatg
tgggccaaaa gcgttttagc ctggagggtg 1560cggaatctgt tattccaatg atggacgcgg
cgattgacca atgtgccgag catggtttgg 1620atgaagtggt cattggcatg ccgcaccgtg
gtcgcttgaa tgtcctggcg aacatcgtgg 1680gcaaaccgta ttcgcaaatc tttacggagt
ttgaaggcaa tctgaacccg tcccaggctc 1740acggttccgg cgatgtcaag taccacctgg
gtgcgacggg tctgtatctg caaatgtttg 1800gcgataacga tattcaggtt tccctgacgg
caaatccgtc ccatttggaa gcggtcgatc 1860cagtgctgga aggtttggtg cgtgcgaagc
aagacctgct ggaccacggt tccattgact 1920ccgacggcca acgtgcattc tccgtcgttc
cgttgatgct gcacggtgat gcggccttcg 1980cgggtcaagg cgttgttgcg gagacgctga
atctggcaaa tctgcctggc tatcgtgtgg 2040gtggtacgat tcacatcatt gtgaacaacc
aaatcggctt caccaccgct ccggaatact 2100ctcgttcgag cgagtactgc acggatgtgg
cgaagatgat cggtgcgcca atcttccacg 2160tgaacggcga cgatccagaa gcgtgtgtct
gggttgcgcg tttggcagtt gacttccgcc 2220aacgctttaa aaaggacgtt gttattgaca
tgctgtgcta tcgtcgtcgt ggtcataatg 2280agggtgacga tccatctatg accaatccgt
atgtctatga cgtcgtggac accaagcgtg 2340gcgcccgtaa atcctacacc gaggctctga
tcggtcgtgg cgacatcagc atgaaagagg 2400cggaggatgc gctgcgcgat taccagggcc
aactggagcg tgtgttcaac gaagtgcgcg 2460aactggagaa gcacggcgtc caaccgtcgg
agagcgtcga gtcggaccaa atgatcccag 2520cgggcctggc gaccgctgtt gacaaatccc
tgctggcacg tatcggtgat gccttcctgg 2580cgctgcctaa cggtttcacg gcacacccgc
gcgttcagcc ggtgctggaa aagcgtcgtg 2640agatggcgta tgagggtaag attgactggg
cgtttggtga gttgctggcg ctgggcagcc 2700tggttgctga gggcaagctg gtccgtctga
gcggtcaaga ctctcgtcgt ggcaccttta 2760gccagcgtca ttctgtgctg atcgaccgtc
acaccggcga ggagttcacc ccgctgcagc 2820tgctggcgac taacagcgac ggcagcccga
ccggtggtaa gttcctggtt tatgattcgc 2880cgttgtcgga atacgcggct gtgggttttg
agtacggtta taccgttggc aatccagacg 2940cggttgtgct gtgggaggcg caattcggcg
actttgttaa tggtgcccag tcgatcattg 3000acgagttcat cagctcgggc gaagcgaaat
ggggtcagct gtccaacgtt gttctgttgc 3060tgccacacgg ccacgagggt cagggcccgg
accacacgtc ggcgcgcatt gagcgctttt 3120tgcagctgtg ggctgagggt agcatgacga
tcgcgatgcc gagcaccccg tccaattact 3180ttcacttgct gcgccgccac gcgttggacg
gcatccaacg tccgttgatc gtgtttaccc 3240cgaaatccat gctgcgccac aaggcggcgg
tttcggagat taaggatttt accgagatta 3300aattccgtag cgtcctggag gaaccgacct
acgaggatgg tatcggcgac cgcaataaag 3360ttagccgtat tctgttgacc tccggtaagt
tgtattatga attggcggca cgcaaggcga 3420aagacaaccg taatgatctg gcaattgtgc
gtctggagca actggcgccg ttgccgcgtc 3480gtcgtctgcg tgaaaccctg gatcgttacg
aaaatgtcaa agagttcttt tgggtccagg 3540aggaaccagc gaaccagggc gcctggccgc
gtttcggttt ggagttgccg gagttgctgc 3600cggacaagtt ggcgggcatc aagcgtatct
cccgtcgcgc gatgtctgcg ccgagcagcg 3660gttcctcgaa ggttcatgcc gtggagcagc
aagaaatctt ggacgaagcg ttcggatcta 3720gatctcacca tcaccaccat tagtcgacct
gcagccaagc ttggctgttt tggcggatga 3780gagaagattt tcagcctgat acagattaaa
tcagaacgca gaagcggtct gataaaacag 3840aatttgcctg gcggcagtag cgcggtggtc
ccacctgacc ccatgccgaa ctcagaagtg 3900aaacgccgta gcgccgatgg tagtgtgggg
tctccccatg cgagagtagg gaactgccag 3960gcatcaaata aaacgaaagg ctcagtcgaa
agactgggcc tttcgtttta tctgttgttt 4020gtcggtgaac gctctcctga gtaggacaaa
tccgccggga gcggatttga acgttgcgaa 4080gcaacggccc ggagggtggc gggcaggacg
cccgccataa actgccaggc atcaaattaa 4140gcagaaggcc atcctgacgg atggcctttt
tgcgtttcta caaactcttt tgtttatttt 4200tctaaataca ttcaaatatg tatccgctca
tgagacaata accctgataa atgcttcaat 4260aatattgaaa aaggaagagt atgagtattc
aacatttccg tgtcgccctt attccctttt 4320ttgcggcatt ttgccttcct gtttttgctc
acccagaaac gctggtgaaa gtaaaagatg 4380ctgaagatca gttgggtgca cgagtgggtt
acatcgaact ggatctcaac agcggtaaga 4440tccttgagag ttttcgcccc gaagaacgtt
ttccaatgat gagcactttt aaagttctgc 4500tatgtggcgc ggtattatcc cgtgttgacg
ccgggcaaga gcaactcggt cgccgcatac 4560actattctca gaatgacttg gttgagtact
caccagtcac agaaaagcat cttacggatg 4620gcatgacagt aagagaatta tgcagtgctg
ccataaccat gagtgataac actgcggcca 4680acttacttct gacaacgatc ggaggaccga
aggagctaac cgcttttttg cacaacatgg 4740gggatcatgt aactcgcctt gatcgttggg
aaccggagct gaatgaagcc ataccaaacg 4800acgagcgtga caccacgatg ctgtagcaat
ggcaacaacg ttgcgcaaac tattaactgg 4860cgaactactt actctagctt cccggcaaca
attaatagac tggatggagg cggataaagt 4920tgcaggacca cttctgcgct cggcccttcc
ggctggctgg tttattgctg ataaatctgg 4980agccggtgag cgtgggtctc gcggtatcat
tgcagcactg gggccagatg gtaagccctc 5040ccgtatcgta gttatctaca cgacggggag
tcaggcaact atggatgaac gaaatagaca 5100gatcgctgag ataggtgcct cactgattaa
gcattggtaa ctgtcagacc aagtttactc 5160atatatactt tagattgatt taaaacttca
tttttaattt aaaaggatct aggtgaagat 5220cctttttgat aatctcatga ccaaaatccc
ttaacgtgag ttttcgttcc actgagcgtc 5280agaccccgta gaaaagatca aaggatcttc
ttgagatcct ttttttctgc gcgtaatctg 5340ctgcttgcaa acaaaaaaac caccgctacc
agcggtggtt tgtttgccgg atcaagagct 5400accaactctt tttccgaagg taactggctt
cagcagagcg cagataccaa atactgtcct 5460tctagtgtag ccgtagttag gccaccactt
caagaactct gtagcaccgc ctacatacct 5520cgctctgcta atcctgttac cagtggctgc
tgccagtggc gataagtcgt gtcttaccgg 5580gttggactca agacgatagt taccggataa
ggcgcagcgg tcgggctgaa cggggggttc 5640gtgcacacag cccagcttgg agcgaacgac
ctacaccgaa ctgagatacc tacagcgtga 5700gcattgagaa agcgccacgc ttcccgaagg
gagaaaggcg gacaggtatc cggtaagcgg 5760cagggtcgga acaggagagc gcacgaggga
gcttccaggg ggaaacgcct ggtatcttta 5820tagtcctgtc gggtttcgcc acctctgact
tgagcgtcga tttttgtgat gctcgtcagg 5880ggggcggagc ctatggaaaa acgccagcaa
cgcggccttt ttacggttcc tggccttttg 5940ctggcctttt gctcacatgt tctttcctgc
gttatcccct gattctgtgg ataaccgtat 6000taccgccttt gagtgagctg ataccgctcg
ccgcagccga acgaccgagc gcagcgagtc 6060agtgagcgag gaagcggaag agcgcctgat
gcggtatttt ctccttacgc atctgtgcgg 6120tatttcacac cgcatatggt gcactctcag
tacaatctgc tctgatgccg catagttaag 6180ccagtataca ctccgctatc gctacgtgac
tgggtcatgg ctgcgccccg acacccgcca 6240acacccgctg acgcgccctg acgggcttgt
ctgctcccgg catccgctta cagacaagct 6300gtgaccgtct ccgggagctg catgtgtcag
aggttttcac cgtcatcacc gaaacgcgcg 6360aggcagctgc ggtaaagctc atcagcgtgg
tcgtgaagcg attcacagat gtctgcctgt 6420tcatccgcgt ccagctcgtt gagtttctcc
agaagcgtta atgtctggct tctgataaag 6480cgggccatgt taagggcggt tttttcctgt
ttggtcactg atgcctccgt gtaaggggga 6540tttctgttca tgggggtaat gataccgatg
aaacgagaga ggatgctcac gatacgggtt 6600actgatgatg aacatgcccg gttactggaa
cgttgtgagg gtaaacaact ggcggtatgg 6660atgcggcggg accagagaaa aatcactcag
ggtcaatgcc agcgcttcgt taatacagat 6720gtaggtgttc cacagggtag ccagcagcat
cctgcgatgc agatccggaa cataatggtg 6780cagggcgctg acttccgcgt ttccagactt
tacgaaacac ggaaaccgaa gaccattcat 6840gttgttgctc aggtcgcaga cgttttgcag
cagcagtcgc ttcacgttcg ctcgcgtatc 6900ggtgattcat tctgctaacc agtaaggcaa
ccccgccagc ctagccgggt cctcaacgac 6960aggagcacga tcatgcgcac ccgtggccag
gacccaacgc tgcccgagat gcgccgcgtg 7020cggctgctgg agatggcgga cgcgatggat
atgttctgcc aagggttggt ttgcgcattc 7080acagttctcc gcaagaattg attggctcca
attcttggag tggtgaatcc gttagcgagg 7140tgccgccggc ttccattcag gtcgaggtgg
cccggctcca tgcaccgcga cgcaacgcgg 7200ggaggcagac aaggtatagg gcggcgccta
caatccatgc caacccgttc catgtgctcg 7260ccgaggcggc ataaatcgcc gtgacgatca
gcggtccagt gatcgaagtt aggctggtaa 7320gagccgcgag cgatccttga agctgtccct
gatggtcgtc atctacctgc ctggacagca 7380tggcctgcaa cgcgggcatc ccgatgccgc
cggaagcgag aagaatcata atggggaagg 7440ccatccagcc tcgcgtcgcg aacgccagca
agacgtagcc cagcgcgtcg gccgccatgc 7500cggcgataat ggcctgcttc tcgccgaaac
gtttggtggc gggaccagtg acgaaggctt 7560gagcgagggc gtgcaagatt ccgaataccg
caagcgacag gccgatcatc gtcgcgctcc 7620agcgaaagcg gtcctcgccg aaaatgaccc
agagcgctgc cggcacctgt cctacgagtt 7680gcatgataaa gaagacagtc ataagtgcgg
cgacgatagt catgccccgc gcccaccgga 7740aggagctgac tgggttgaag gctctcaagg
gcatcggtcg acgctctccc ttatgcgact 7800cctgcattag gaagcagccc agtagtaggt
tgaggccgtt gagcaccgcc gccgcaagga 7860atggtgcatg caaggagatg gcgcccaaca
gtcccccggc cacggggcct gccaccatac 7920ccacgccgaa acaagcgctc atgagcccga
agtggcgagc ccgatcttcc ccatcggtga 7980tgtcggcgat ataggcgcca gcaaccgcac
ctgtggcgcc ggtgatgccg gccacgatgc 8040gtccggcgta gaggatccgg gcttatcgac
tgcacggtgc accaatgctt ctggcgtcag 8100gcagccatcg gaagctgtgg tatggctgtg
caggtcgtaa atcactgcat aattcgtgtc 8160gctcaaggcg cactcccgtt ctggataatg
ttttttgcgc cgacatcata acggttctgg 8220caaatattct gaaatgagct g
8241113716DNAArtificial
SequenceCodon-optimized mcr nucleic acid sequence 11gatatcgaat tccgctagca
ggagctaagg aagctaaaat gtccggtacg ggtcgtttgg 60ctggtaaaat tgcattgatc
accggtggtg ctggtaacat tggttccgag ctgacccgcc 120gttttctggc cgagggtgcg
acggttatta tcagcggccg taaccgtgcg aagctgaccg 180cgctggccga gcgcatgcaa
gccgaggccg gcgtgccggc caagcgcatt gatttggagg 240tgatggatgg ttccgaccct
gtggctgtcc gtgccggtat cgaggcaatc gtcgctcgcc 300acggtcagat tgacattctg
gttaacaacg cgggctccgc cggtgcccaa cgtcgcttgg 360cggaaattcc gctgacggag
gcagaattgg gtccgggtgc ggaggagact ttgcacgctt 420cgatcgcgaa tctgttgggc
atgggttggc acctgatgcg tattgcggct ccgcacatgc 480cagttggctc cgcagttatc
aacgtttcga ctattttctc gcgcgcagag tactatggtc 540gcattccgta cgttaccccg
aaggcagcgc tgaacgcttt gtcccagctg gctgcccgcg 600agctgggcgc tcgtggcatc
cgcgttaaca ctattttccc aggtcctatt gagtccgacc 660gcatccgtac cgtgtttcaa
cgtatggatc aactgaaggg tcgcccggag ggcgacaccg 720cccatcactt tttgaacacc
atgcgcctgt gccgcgcaaa cgaccaaggc gctttggaac 780gccgctttcc gtccgttggc
gatgttgctg atgcggctgt gtttctggct tctgctgaga 840gcgcggcact gtcgggtgag
acgattgagg tcacccacgg tatggaactg ccggcgtgta 900gcgaaacctc cttgttggcg
cgtaccgatc tgcgtaccat cgacgcgagc ggtcgcacta 960ccctgatttg cgctggcgat
caaattgaag aagttatggc cctgacgggc atgctgcgta 1020cgtgcggtag cgaagtgatt
atcggcttcc gttctgcggc tgccctggcg caatttgagc 1080aggcagtgaa tgaatctcgc
cgtctggcag gtgcggattt caccccgccg atcgctttgc 1140cgttggaccc acgtgacccg
gccaccattg atgcggtttt cgattggggc gcaggcgaga 1200atacgggtgg catccatgcg
gcggtcattc tgccggcaac ctcccacgaa ccggctccgt 1260gcgtgattga agtcgatgac
gaacgcgtcc tgaatttcct ggccgatgaa attaccggca 1320ccatcgttat tgcgagccgt
ttggcgcgct attggcaatc ccaacgcctg accccgggtg 1380cccgtgcccg cggtccgcgt
gttatctttc tgagcaacgg tgccgatcaa aatggtaatg 1440tttacggtcg tattcaatct
gcggcgatcg gtcaattgat tcgcgtttgg cgtcacgagg 1500cggagttgga ctatcaacgt
gcatccgccg caggcgatca cgttctgccg ccggtttggg 1560cgaaccagat tgtccgtttc
gctaaccgct ccctggaagg tctggagttc gcgtgcgcgt 1620ggaccgcaca gctgctgcac
agccaacgtc atattaacga aattacgctg aacattccag 1680ccaatattag cgcgaccacg
ggcgcacgtt ccgccagcgt cggctgggcc gagtccttga 1740ttggtctgca cctgggcaag
gtggctctga ttaccggtgg ttcggcgggc atcggtggtc 1800aaatcggtcg tctgctggcc
ttgtctggcg cgcgtgtgat gctggccgct cgcgatcgcc 1860ataaattgga acagatgcaa
gccatgattc aaagcgaatt ggcggaggtt ggttataccg 1920atgtggagga ccgtgtgcac
atcgctccgg gttgcgatgt gagcagcgag gcgcagctgg 1980cagatctggt ggaacgtacg
ctgtccgcat tcggtaccgt ggattatttg attaataacg 2040ccggtattgc gggcgtggag
gagatggtga tcgacatgcc ggtggaaggc tggcgtcaca 2100ccctgtttgc caacctgatt
tcgaattatt cgctgatgcg caagttggcg ccgctgatga 2160agaagcaagg tagcggttac
atcctgaacg tttcttccta ttttggcggt gagaaggacg 2220cggcgattcc ttatccgaac
cgcgccgact acgccgtctc caaggctggc caacgcgcga 2280tggcggaagt gttcgctcgt
ttcctgggtc cagagattca gatcaatgct attgccccag 2340gtccggttga aggcgaccgc
ctgcgtggta ccggtgagcg tccgggcctg tttgctcgtc 2400gcgcccgtct gatcttggag
aataaacgcc tgaacgaatt gcacgcggct ttgattgctg 2460cggcccgcac cgatgagcgc
tcgatgcacg agttggttga attgttgctg ccgaacgacg 2520tggccgcgtt ggagcagaac
ccagcggccc ctaccgcgct gcgtgagctg gcacgccgct 2580tccgtagcga aggtgatccg
gcggcaagct cctcgtccgc cttgctgaat cgctccatcg 2640ctgccaagct gttggctcgc
ttgcataacg gtggctatgt gctgccggcg gatatttttg 2700caaatctgcc taatccgccg
gacccgttct ttacccgtgc gcaaattgac cgcgaagctc 2760gcaaggtgcg tgatggtatt
atgggtatgc tgtatctgca gcgtatgcca accgagtttg 2820acgtcgctat ggcaaccgtg
tactatctgg ccgatcgtaa cgtgagcggc gaaactttcc 2880atccgtctgg tggtttgcgc
tacgagcgta ccccgaccgg tggcgagctg ttcggcctgc 2940catcgccgga acgtctggcg
gagctggttg gtagcacggt gtacctgatc ggtgaacacc 3000tgaccgagca cctgaacctg
ctggctcgtg cctatttgga gcgctacggt gcccgtcaag 3060tggtgatgat tgttgagacg
gaaaccggtg cggaaaccat gcgtcgtctg ttgcatgatc 3120acgtcgaggc aggtcgcctg
atgactattg tggcaggtga tcagattgag gcagcgattg 3180accaagcgat cacgcgctat
ggccgtccgg gtccggtggt gtgcactcca ttccgtccac 3240tgccaaccgt tccgctggtc
ggtcgtaaag actccgattg gagcaccgtt ttgagcgagg 3300cggaatttgc ggaactgtgt
gagcatcagc tgacccacca tttccgtgtt gctcgtaaga 3360tcgccttgtc ggatggcgcg
tcgctggcgt tggttacccc ggaaacgact gcgactagca 3420ccacggagca atttgctctg
gcgaacttca tcaagaccac cctgcacgcg ttcaccgcga 3480ccatcggtgt tgagtcggag
cgcaccgcgc aacgtattct gattaaccag gttgatctga 3540cgcgccgcgc ccgtgcggaa
gagccgcgtg acccgcacga gcgtcagcag gaattggaac 3600gcttcattga agccgttctg
ctggttaccg ctccgctgcc tcctgaggca gacacgcgct 3660acgcaggccg tattcaccgc
ggtcgtgcga ttaccgtcta atagaagctt gatatc 37161245DNAArtificial
SequencePCR primer 12tcgtaccaac catggccggt acgggtcgtt tggctggtaa aattg
451342DNAArtificial SequencePCR primer 13cggtgtgaga
tctagatccg acggtaatcg cacgaccgcg gt
42148262DNAArtificial Sequencepkk223 plasmid comprising codon-optimized
mcr nucleic acid sequence 14ttgacaatta atcatcggct cgtataatgt
gtggaattgt gagcggataa caatttcaca 60caggaaacag aaccatggcc ggtacgggtc
gtttggctgg taaaattgca ttgatcaccg 120gtggtgctgg taacattggt tccgagctga
cccgccgttt tctggccgag ggtgcgacgg 180ttattatcag cggccgtaac cgtgcgaagc
tgaccgcgct ggccgagcgc atgcaagccg 240aggccggcgt gccggccaag cgcattgatt
tggaggtgat ggatggttcc gaccctgtgg 300ctgtccgtgc cggtatcgag gcaatcgtcg
ctcgccacgg tcagattgac attctggtta 360acaacgcggg ctccgccggt gcccaacgtc
gcttggcgga aattccgctg acggaggcag 420aattgggtcc gggtgcggag gagactttgc
acgcttcgat cgcgaatctg ttgggcatgg 480gttggcacct gatgcgtatt gcggctccgc
acatgccagt tggctccgca gttatcaacg 540tttcgactat tttctcgcgc gcagagtact
atggtcgcat tccgtacgtt accccgaagg 600cagcgctgaa cgctttgtcc cagctggctg
cccgcgagct gggcgctcgt ggcatccgcg 660ttaacactat tttcccaggt cctattgagt
ccgaccgcat ccgtaccgtg tttcaacgta 720tggatcaact gaagggtcgc ccggagggcg
acaccgccca tcactttttg aacaccatgc 780gcctgtgccg cgcaaacgac caaggcgctt
tggaacgccg ctttccgtcc gttggcgatg 840ttgctgatgc ggctgtgttt ctggcttctg
ctgagagcgc ggcactgtcg ggtgagacga 900ttgaggtcac ccacggtatg gaactgccgg
cgtgtagcga aacctccttg ttggcgcgta 960ccgatctgcg taccatcgac gcgagcggtc
gcactaccct gatttgcgct ggcgatcaaa 1020ttgaagaagt tatggccctg acgggcatgc
tgcgtacgtg cggtagcgaa gtgattatcg 1080gcttccgttc tgcggctgcc ctggcgcaat
ttgagcaggc agtgaatgaa tctcgccgtc 1140tggcaggtgc ggatttcacc ccgccgatcg
ctttgccgtt ggacccacgt gacccggcca 1200ccattgatgc ggttttcgat tggggcgcag
gcgagaatac gggtggcatc catgcggcgg 1260tcattctgcc ggcaacctcc cacgaaccgg
ctccgtgcgt gattgaagtc gatgacgaac 1320gcgtcctgaa tttcctggcc gatgaaatta
ccggcaccat cgttattgcg agccgtttgg 1380cgcgctattg gcaatcccaa cgcctgaccc
cgggtgcccg tgcccgcggt ccgcgtgtta 1440tctttctgag caacggtgcc gatcaaaatg
gtaatgttta cggtcgtatt caatctgcgg 1500cgatcggtca attgattcgc gtttggcgtc
acgaggcgga gttggactat caacgtgcat 1560ccgccgcagg cgatcacgtt ctgccgccgg
tttgggcgaa ccagattgtc cgtttcgcta 1620accgctccct ggaaggtctg gagttcgcgt
gcgcgtggac cgcacagctg ctgcacagcc 1680aacgtcatat taacgaaatt acgctgaaca
ttccagccaa tattagcgcg accacgggcg 1740cacgttccgc cagcgtcggc tgggccgagt
ccttgattgg tctgcacctg ggcaaggtgg 1800ctctgattac cggtggttcg gcgggcatcg
gtggtcaaat cggtcgtctg ctggccttgt 1860ctggcgcgcg tgtgatgctg gccgctcgcg
atcgccataa attggaacag atgcaagcca 1920tgattcaaag cgaattggcg gaggttggtt
ataccgatgt ggaggaccgt gtgcacatcg 1980ctccgggttg cgatgtgagc agcgaggcgc
agctggcaga tctggtggaa cgtacgctgt 2040ccgcattcgg taccgtggat tatttgatta
ataacgccgg tattgcgggc gtggaggaga 2100tggtgatcga catgccggtg gaaggctggc
gtcacaccct gtttgccaac ctgatttcga 2160attattcgct gatgcgcaag ttggcgccgc
tgatgaagaa gcaaggtagc ggttacatcc 2220tgaacgtttc ttcctatttt ggcggtgaga
aggacgcggc gattccttat ccgaaccgcg 2280ccgactacgc cgtctccaag gctggccaac
gcgcgatggc ggaagtgttc gctcgtttcc 2340tgggtccaga gattcagatc aatgctattg
ccccaggtcc ggttgaaggc gaccgcctgc 2400gtggtaccgg tgagcgtccg ggcctgtttg
ctcgtcgcgc ccgtctgatc ttggagaata 2460aacgcctgaa cgaattgcac gcggctttga
ttgctgcggc ccgcaccgat gagcgctcga 2520tgcacgagtt ggttgaattg ttgctgccga
acgacgtggc cgcgttggag cagaacccag 2580cggcccctac cgcgctgcgt gagctggcac
gccgcttccg tagcgaaggt gatccggcgg 2640caagctcctc gtccgccttg ctgaatcgct
ccatcgctgc caagctgttg gctcgcttgc 2700ataacggtgg ctatgtgctg ccggcggata
tttttgcaaa tctgcctaat ccgccggacc 2760cgttctttac ccgtgcgcaa attgaccgcg
aagctcgcaa ggtgcgtgat ggtattatgg 2820gtatgctgta tctgcagcgt atgccaaccg
agtttgacgt cgctatggca accgtgtact 2880atctggccga tcgtaacgtg agcggcgaaa
ctttccatcc gtctggtggt ttgcgctacg 2940agcgtacccc gaccggtggc gagctgttcg
gcctgccatc gccggaacgt ctggcggagc 3000tggttggtag cacggtgtac ctgatcggtg
aacacctgac cgagcacctg aacctgctgg 3060ctcgtgccta tttggagcgc tacggtgccc
gtcaagtggt gatgattgtt gagacggaaa 3120ccggtgcgga aaccatgcgt cgtctgttgc
atgatcacgt cgaggcaggt cgcctgatga 3180ctattgtggc aggtgatcag attgaggcag
cgattgacca agcgatcacg cgctatggcc 3240gtccgggtcc ggtggtgtgc actccattcc
gtccactgcc aaccgttccg ctggtcggtc 3300gtaaagactc cgattggagc accgttttga
gcgaggcgga atttgcggaa ctgtgtgagc 3360atcagctgac ccaccatttc cgtgttgctc
gtaagatcgc cttgtcggat ggcgcgtcgc 3420tggcgttggt taccccggaa acgactgcga
ctagcaccac ggagcaattt gctctggcga 3480acttcatcaa gaccaccctg cacgcgttca
ccgcgaccat cggtgttgag tcggagcgca 3540ccgcgcaacg tattctgatt aaccaggttg
atctgacgcg ccgcgcccgt gcggaagagc 3600cgcgtgaccc gcacgagcgt cagcaggaat
tggaacgctt cattgaagcc gttctgctgg 3660ttaccgctcc gctgcctcct gaggcagaca
cgcgctacgc aggccgtatt caccgcggtc 3720gtgcgattac cgtcggatct agatctcacc
atcaccacca ttagtcgacc tgcagccaag 3780cttggctgtt ttggcggatg agagaagatt
ttcagcctga tacagattaa atcagaacgc 3840agaagcggtc tgataaaaca gaatttgcct
ggcggcagta gcgcggtggt cccacctgac 3900cccatgccga actcagaagt gaaacgccgt
agcgccgatg gtagtgtggg gtctccccat 3960gcgagagtag ggaactgcca ggcatcaaat
aaaacgaaag gctcagtcga aagactgggc 4020ctttcgtttt atctgttgtt tgtcggtgaa
cgctctcctg agtaggacaa atccgccggg 4080agcggatttg aacgttgcga agcaacggcc
cggagggtgg cgggcaggac gcccgccata 4140aactgccagg catcaaatta agcagaaggc
catcctgacg gatggccttt ttgcgtttct 4200acaaactctt ttgtttattt ttctaaatac
attcaaatat gtatccgctc atgagacaat 4260aaccctgata aatgcttcaa taatattgaa
aaaggaagag tatgagtatt caacatttcc 4320gtgtcgccct tattcccttt tttgcggcat
tttgccttcc tgtttttgct cacccagaaa 4380cgctggtgaa agtaaaagat gctgaagatc
agttgggtgc acgagtgggt tacatcgaac 4440tggatctcaa cagcggtaag atccttgaga
gttttcgccc cgaagaacgt tttccaatga 4500tgagcacttt taaagttctg ctatgtggcg
cggtattatc ccgtgttgac gccgggcaag 4560agcaactcgg tcgccgcata cactattctc
agaatgactt ggttgagtac tcaccagtca 4620cagaaaagca tcttacggat ggcatgacag
taagagaatt atgcagtgct gccataacca 4680tgagtgataa cactgcggcc aacttacttc
tgacaacgat cggaggaccg aaggagctaa 4740ccgctttttt gcacaacatg ggggatcatg
taactcgcct tgatcgttgg gaaccggagc 4800tgaatgaagc cataccaaac gacgagcgtg
acaccacgat gctgtagcaa tggcaacaac 4860gttgcgcaaa ctattaactg gcgaactact
tactctagct tcccggcaac aattaataga 4920ctggatggag gcggataaag ttgcaggacc
acttctgcgc tcggcccttc cggctggctg 4980gtttattgct gataaatctg gagccggtga
gcgtgggtct cgcggtatca ttgcagcact 5040ggggccagat ggtaagccct cccgtatcgt
agttatctac acgacgggga gtcaggcaac 5100tatggatgaa cgaaatagac agatcgctga
gataggtgcc tcactgatta agcattggta 5160actgtcagac caagtttact catatatact
ttagattgat ttaaaacttc atttttaatt 5220taaaaggatc taggtgaaga tcctttttga
taatctcatg accaaaatcc cttaacgtga 5280gttttcgttc cactgagcgt cagaccccgt
agaaaagatc aaaggatctt cttgagatcc 5340tttttttctg cgcgtaatct gctgcttgca
aacaaaaaaa ccaccgctac cagcggtggt 5400ttgtttgccg gatcaagagc taccaactct
ttttccgaag gtaactggct tcagcagagc 5460gcagatacca aatactgtcc ttctagtgta
gccgtagtta ggccaccact tcaagaactc 5520tgtagcaccg cctacatacc tcgctctgct
aatcctgtta ccagtggctg ctgccagtgg 5580cgataagtcg tgtcttaccg ggttggactc
aagacgatag ttaccggata aggcgcagcg 5640gtcgggctga acggggggtt cgtgcacaca
gcccagcttg gagcgaacga cctacaccga 5700actgagatac ctacagcgtg agcattgaga
aagcgccacg cttcccgaag ggagaaaggc 5760ggacaggtat ccggtaagcg gcagggtcgg
aacaggagag cgcacgaggg agcttccagg 5820gggaaacgcc tggtatcttt atagtcctgt
cgggtttcgc cacctctgac ttgagcgtcg 5880atttttgtga tgctcgtcag gggggcggag
cctatggaaa aacgccagca acgcggcctt 5940tttacggttc ctggcctttt gctggccttt
tgctcacatg ttctttcctg cgttatcccc 6000tgattctgtg gataaccgta ttaccgcctt
tgagtgagct gataccgctc gccgcagccg 6060aacgaccgag cgcagcgagt cagtgagcga
ggaagcggaa gagcgcctga tgcggtattt 6120tctccttacg catctgtgcg gtatttcaca
ccgcatatgg tgcactctca gtacaatctg 6180ctctgatgcc gcatagttaa gccagtatac
actccgctat cgctacgtga ctgggtcatg 6240gctgcgcccc gacacccgcc aacacccgct
gacgcgccct gacgggcttg tctgctcccg 6300gcatccgctt acagacaagc tgtgaccgtc
tccgggagct gcatgtgtca gaggttttca 6360ccgtcatcac cgaaacgcgc gaggcagctg
cggtaaagct catcagcgtg gtcgtgaagc 6420gattcacaga tgtctgcctg ttcatccgcg
tccagctcgt tgagtttctc cagaagcgtt 6480aatgtctggc ttctgataaa gcgggccatg
ttaagggcgg ttttttcctg tttggtcact 6540gatgcctccg tgtaaggggg atttctgttc
atgggggtaa tgataccgat gaaacgagag 6600aggatgctca cgatacgggt tactgatgat
gaacatgccc ggttactgga acgttgtgag 6660ggtaaacaac tggcggtatg gatgcggcgg
gaccagagaa aaatcactca gggtcaatgc 6720cagcgcttcg ttaatacaga tgtaggtgtt
ccacagggta gccagcagca tcctgcgatg 6780cagatccgga acataatggt gcagggcgct
gacttccgcg tttccagact ttacgaaaca 6840cggaaaccga agaccattca tgttgttgct
caggtcgcag acgttttgca gcagcagtcg 6900cttcacgttc gctcgcgtat cggtgattca
ttctgctaac cagtaaggca accccgccag 6960cctagccggg tcctcaacga caggagcacg
atcatgcgca cccgtggcca ggacccaacg 7020ctgcccgaga tgcgccgcgt gcggctgctg
gagatggcgg acgcgatgga tatgttctgc 7080caagggttgg tttgcgcatt cacagttctc
cgcaagaatt gattggctcc aattcttgga 7140gtggtgaatc cgttagcgag gtgccgccgg
cttccattca ggtcgaggtg gcccggctcc 7200atgcaccgcg acgcaacgcg gggaggcaga
caaggtatag ggcggcgcct acaatccatg 7260ccaacccgtt ccatgtgctc gccgaggcgg
cataaatcgc cgtgacgatc agcggtccag 7320tgatcgaagt taggctggta agagccgcga
gcgatccttg aagctgtccc tgatggtcgt 7380catctacctg cctggacagc atggcctgca
acgcgggcat cccgatgccg ccggaagcga 7440gaagaatcat aatggggaag gccatccagc
ctcgcgtcgc gaacgccagc aagacgtagc 7500ccagcgcgtc ggccgccatg ccggcgataa
tggcctgctt ctcgccgaaa cgtttggtgg 7560cgggaccagt gacgaaggct tgagcgaggg
cgtgcaagat tccgaatacc gcaagcgaca 7620ggccgatcat cgtcgcgctc cagcgaaagc
ggtcctcgcc gaaaatgacc cagagcgctg 7680ccggcacctg tcctacgagt tgcatgataa
agaagacagt cataagtgcg gcgacgatag 7740tcatgccccg cgcccaccgg aaggagctga
ctgggttgaa ggctctcaag ggcatcggtc 7800gacgctctcc cttatgcgac tcctgcatta
ggaagcagcc cagtagtagg ttgaggccgt 7860tgagcaccgc cgccgcaagg aatggtgcat
gcaaggagat ggcgcccaac agtcccccgg 7920ccacggggcc tgccaccata cccacgccga
aacaagcgct catgagcccg aagtggcgag 7980cccgatcttc cccatcggtg atgtcggcga
tataggcgcc agcaaccgca cctgtggcgc 8040cggtgatgcc ggccacgatg cgtccggcgt
agaggatccg ggcttatcga ctgcacggtg 8100caccaatgct tctggcgtca ggcagccatc
ggaagctgtg gtatggctgt gcaggtcgta 8160aatcactgca taattcgtgt cgctcaaggc
gcactcccgt tctggataat gttttttgcg 8220ccgacatcat aacggttctg gcaaatattc
tgaaatgagc tg 82621530DNAArtificial SequencePCR
primer 15gggtttccat ggaccagccg ctcaacgtgg
301633DNAArtificial SequencePCR primer 16gggttttcag gcgatgccgt
tgagcgcttc gcc 331726DNAArtificial
SequencePCR primer 17gggaacggcg gggaaaaaca aacgtt
261830DNAArtificial SequencePCR primer 18ggtccatggt
aattctccac gcttataagc 301985DNAE.
coli 19ggtttgaata aatgacaaaa agcaaagcct ttgtgccgat gaatctctat actgtttcac
60agacctgctg ccctgcgggg cggcc
852026DNAArtificial SequencePCR primer 20gggaacggcg gggaaaaaca aacgtt
262133DNAArtificial SequencePCR
primer 21gggttttcag gcgatgccgt tgagcgcttc gcc
33221754DNAArtificial SequenceCodon-optimized pyruvate decarboxylase
DNA sequence based on gene of Zymomonas mobilis. 22catatgtcct
acactgttgg tacttatctg gctgaacgtc tggttcaaat tggtctgaag 60catcactttg
cggtagcggg cgattacaac ctggtgctgc tggataatct gctgctgaac 120aaaaacatgg
aacaggtcta ctgttgtaac gaactgaact gcggcttctc tgctgaaggt 180tatgcccggg
ccaaaggcgc agctgcggcc gtagtgacct actccgttgg tgctctgtcc 240gcatttgatg
caattggtgg cgcctacgca gaaaacctgc cggtaattct gatctctggc 300gctccgaaca
acaacgatca cgcagctggt cacgtgctgc accatgcgct gggcaaaact 360gattatcatt
accagctgga aatggcgaag aacatcactg ccgcagcaga agctatctat 420actccagaag
aagcgccggc aaaaatcgat catgtaatca aaacggccct gcgtgagaag 480aaaccggtgt
atctggaaat tgcttgtaat atcgcgtcta tgccgtgtgc ggccccaggc 540ccagcatctg
ctctgtttaa cgatgaagct agcgatgaag cctctctgaa cgcagctgtg 600gaagaaaccc
tgaaattcat tgcaaaccgt gacaaagttg cggtactggt tggctctaaa 660ctgcgtgccg
cgggtgcaga agaagcggcg gttaaattcg ctgacgccct gggtggtgct 720gtggccacca
tggctgcggc taaatccttt ttcccggaag aaaatccgca ttacatcggt 780acttcctggg
gcgaggtttc ttacccaggt gtcgagaaaa ccatgaagga agctgacgcg 840gtgatcgccc
tggccccggt tttcaatgac tactccacta ctggttggac cgacatcccg 900gacccaaaga
aactggttct ggcagagccg cgctccgttg ttgttaacgg tattcgcttt 960ccgtccgtac
acctgaagga ttatctgact cgtctggcgc agaaagtgag caagaaaacc 1020ggcgctctgg
atttctttaa atctctgaat gcgggtgagc tgaagaaagc cgcaccggcg 1080gacccttctg
ctccgctggt taacgccgaa attgcgcgcc aggtagaagc gctgctgact 1140ccgaatacta
ccgtaattgc ggagactggc gattcctggt tcaacgcaca acgtatgaag 1200ctgcctaacg
gcgctcgagt tgaatacgaa atgcagtggg gccacatcgg ctggtctgtt 1260cctgcagcct
tcggctacgc cgtaggtgct ccggaacgtc gtaacatcct gatggtcggt 1320gacggctctt
tccaactgac cgcgcaggaa gtagcacaga tggttcgtct gaaactgccg 1380gtaatcatct
tcctgattaa caactacggc tataccattg aggtcatgat tcatgatggt 1440ccgtataata
acatcaaaaa ctgggattat gctggtctga tggaagtttt caacggcaac 1500ggcggctacg
attctggtgc tggtaaaggc ctgaaagcaa agacgggtgg cgagctcgca 1560gaagcgatca
aggttgctct ggctaacacc gatggtccga ctctgatcga atgttttatc 1620ggtcgtgaag
attgcactga ggaactggtg aagtggggta agcgtgtggc tgccgcgaat 1680tcccgtaaac
cggtaaataa gcttctcggc catcaccatc accatcacta gaagcttctc 1740tagagaacta
tttc
175423575PRTZymomonas mobilis 23Met Ser Tyr Thr Val Gly Thr Tyr Leu Ala
Glu Arg Leu Val Gln Ile1 5 10
15Gly Leu Lys His His Phe Ala Val Ala Gly Asp Tyr Asn Leu Val Leu
20 25 30Leu Asp Asn Leu Leu Leu
Asn Lys Asn Met Glu Gln Val Tyr Cys Cys 35 40
45Asn Glu Leu Asn Cys Gly Phe Ser Ala Glu Gly Tyr Ala Arg
Ala Lys 50 55 60Gly Ala Ala Ala Ala
Val Val Thr Tyr Ser Val Gly Ala Leu Ser Ala65 70
75 80Phe Asp Ala Ile Gly Gly Ala Tyr Ala Glu
Asn Leu Pro Val Ile Leu 85 90
95Ile Ser Gly Ala Pro Asn Asn Asn Asp His Ala Ala Gly His Val Leu
100 105 110His His Ala Leu Gly
Lys Thr Asp Tyr His Tyr Gln Leu Glu Met Ala 115
120 125Lys Asn Ile Thr Ala Ala Ala Glu Ala Ile Tyr Thr
Pro Glu Glu Ala 130 135 140Pro Ala Lys
Ile Asp His Val Ile Lys Thr Ala Leu Arg Glu Lys Lys145
150 155 160Pro Val Tyr Leu Glu Ile Ala
Cys Asn Ile Ala Ser Met Pro Cys Ala 165
170 175Ala Pro Gly Pro Ala Ser Ala Leu Phe Asn Asp Glu
Ala Ser Asp Glu 180 185 190Ala
Ser Leu Asn Ala Ala Val Glu Glu Thr Leu Lys Phe Ile Ala Asn 195
200 205Arg Asp Lys Val Ala Val Leu Val Gly
Ser Lys Leu Arg Ala Ala Gly 210 215
220Ala Glu Glu Ala Ala Val Lys Phe Ala Asp Ala Leu Gly Gly Ala Val225
230 235 240Ala Thr Met Ala
Ala Ala Lys Ser Phe Phe Pro Glu Glu Asn Pro His 245
250 255Tyr Ile Gly Thr Ser Trp Gly Glu Val Ser
Tyr Pro Gly Val Glu Lys 260 265
270Thr Met Lys Glu Ala Asp Ala Val Ile Ala Leu Ala Pro Val Phe Asn
275 280 285Asp Tyr Ser Thr Thr Gly Trp
Thr Asp Ile Pro Asp Pro Lys Lys Leu 290 295
300Val Leu Ala Glu Pro Arg Ser Val Val Val Asn Gly Ile Arg Phe
Pro305 310 315 320Ser Val
His Leu Lys Asp Tyr Leu Thr Arg Leu Ala Gln Lys Val Ser
325 330 335Lys Lys Thr Gly Ala Leu Asp
Phe Phe Lys Ser Leu Asn Ala Gly Glu 340 345
350Leu Lys Lys Ala Ala Pro Ala Asp Pro Ser Ala Pro Leu Val
Asn Ala 355 360 365Glu Ile Ala Arg
Gln Val Glu Ala Leu Leu Thr Pro Asn Thr Thr Val 370
375 380Ile Ala Glu Thr Gly Asp Ser Trp Phe Asn Ala Gln
Arg Met Lys Leu385 390 395
400Pro Asn Gly Ala Arg Val Glu Tyr Glu Met Gln Trp Gly His Ile Gly
405 410 415Trp Ser Val Pro Ala
Ala Phe Gly Tyr Ala Val Gly Ala Pro Glu Arg 420
425 430Arg Asn Ile Leu Met Val Gly Asp Gly Ser Phe Gln
Leu Thr Ala Gln 435 440 445Glu Val
Ala Gln Met Val Arg Leu Lys Leu Pro Val Ile Ile Phe Leu 450
455 460Ile Asn Asn Tyr Gly Tyr Thr Ile Glu Val Met
Ile His Asp Gly Pro465 470 475
480Tyr Asn Asn Ile Lys Asn Trp Asp Tyr Ala Gly Leu Met Glu Val Phe
485 490 495Asn Gly Asn Gly
Gly Tyr Asp Ser Gly Ala Gly Lys Gly Leu Lys Ala 500
505 510Lys Thr Gly Gly Glu Leu Ala Glu Ala Ile Lys
Val Ala Leu Ala Asn 515 520 525Thr
Asp Gly Pro Thr Leu Ile Glu Cys Phe Ile Gly Arg Glu Asp Cys 530
535 540Thr Glu Glu Leu Val Lys Trp Gly Lys Arg
Val Ala Ala Ala Asn Ser545 550 555
560Arg Lys Pro Val Asn Lys Leu Leu Gly His His His His His His
565 570 575
User Contributions:
Comment about this patent or add new information about this topic:
 | 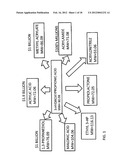 |
 |  |
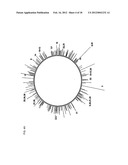 |  |
 | 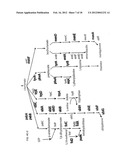 |
 |  |
 |  |
 |  |
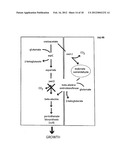 |  |
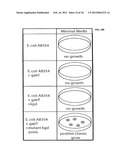 | 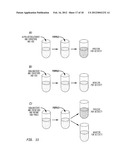 |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
| New patent applications in this class: | |
| Date | Title |
|---|---|
| 2016-05-19 | Thermal conversion vessel used in a process for amidification of acetone cyanohydrin |
| 2016-03-31 | Process and plant for recovering acrylic acid |
| 2016-02-04 | Process for preparing acrylic acid from methanol and acetic acid |
| 2015-12-10 | Process for the preparation of 4-methylpent-3-en-1-ol derivatives |
| 2015-11-19 | Purification of bio based acrylic acid to crude and glacial acrylic acid |
| Top Inventors for class "Organic compounds -- part of the class 532-570 series" | |
| Rank | Inventor's name |
|---|---|
| 1 | Mark O. Scates |
| 2 | Alakananda Bhattacharyya |
| 3 | Josefina T. Chapman |
| 4 | Craig J. Peterson |
| 5 | Dick Nagaki |