Patent application title: METHODS FOR IDENTIFYING COMPOUNDS OF INTEREST USING ENCODED LIBRARIES
Inventors:
Barry Morgan (Franklin, MA, US)
Barry Morgan (Franklin, MA, US)
Stephen Hale (Belmont, MA, US)
Christopher C. Arico-Muendel (West Roxbury, MA, US)
Matthew Clark (Cambridge, MA, US)
Richard Wagner (Cambridge, MA, US)
David I. Israel (Concord, MA, US)
Malcolm L. Gefter (Lincoln, MA, US)
Malcolm L. Gefter (Lincoln, MA, US)
Dennis Benjamin (Redmond, WA, US)
Dennis Benjamin (Redmond, WA, US)
Nils Jakob Vest Hansen (Copenhagen V, DK)
Malcolm J. Kavarana (Burlington, MA, US)
Steffen Phillip Creaser (Cambridge, MA, US)
Steffen Phillip Creaser (Cambridge, MA, US)
George J. Franklin (Auburn, MA, US)
Paolo A. Centrella (Acton, MA, US)
Raksha A. Acharya (Bedford, MA, US)
Assignees:
GLAXOSMITHKLINE LLC
IPC8 Class: AC40B2004FI
USPC Class:
506 4
Class name: Combinatorial chemistry technology: method, library, apparatus method specially adapted for identifying a library member identifying a library member by means of a tag, label, or other readable or detectable entity associated with the library member (e.g., decoding process, etc.)
Publication date: 2012-03-22
Patent application number: 20120071329
Abstract:
The present invention provides a method for identifying a compound of
interest by screening libraries of molecules which include an encoding
oligonucleotide tag.Claims:
1. A method for identifying one or more compounds which bind to a
biological target, said method comprising: (A) synthesizing a library of
compounds, wherein the compounds comprise a functional moiety comprising
two or more building blocks which is operatively linked to an initial
oligonucleotide which identifies the structure of the functional moiety
by: (i) providing a solution comprising m initiator compounds, wherein m
is an integer of 1 or greater, where the initiator compounds consist of a
functional moiety comprising n building blocks, where n is an integer of
1 or greater, which is operatively linked to an initial oligonucleotide
which identifies the n building blocks; (ii) dividing the solution of
step (i) into r reaction vessels, wherein r is an integer of 2 or
greater, thereby producing r aliquots of the solution; (iii) reacting the
initiator compounds in each reaction vessel with one of r building
blocks, thereby producing r aliquots comprising compounds consisting of a
functional moiety comprising n+1 building blocks operatively linked to
the initial oligonucleotide; and (iv) reacting the initial
oligonucleotide in each aliquot with one of a set of r distinct incoming
oligonucleotides in the presence of an enzyme which catalyzes the
ligation of the incoming oligonucleotide and the initial oligonucleotide,
under conditions suitable for enzymatic ligation of the incoming
oligonucleotide and the initial oligonucleotide; thereby producing r
aliquots of molecules consisting of a functional moiety comprising n+1
building blocks operatively linked to an elongated oligonucleotide which
encodes the n+1 building blocks; (B) contacting the biological target
with the library of compounds, or a portion thereof, under conditions
suitable for at least one member of the library of compounds to bind to
the target; (C) removing library members that do not bind to the target;
(D) sequencing the encoding oligonucleotides of the at least one member
of the library of compounds which binds to the target, and (E) using the
sequences determined in step (D) to determine the structure of the
functional moieties of the members of the library of compounds which bind
to the biological target, thereby identifying one or more compounds which
bind to the biological target.
2. The method of claim 1, further comprising amplifying the encoding oligonucleotides of the at least one member of the library of compounds which binds to the target.
3. The method of claim 2, wherein said amplifying step comprises: (i) forming a water-in-oil emulsion to create a plurality of aqueous microreactors, wherein at least one of the microreactors comprises the at least one member of the library of compounds that binds to the target, a single bead capable of binding to the encoding oligonucleotide of the at least one member of the library of compounds that binds to the target, and amplification reaction solution containing reagents necessary to perform nucleic acid amplification; (ii) amplifying the encoding oligonucleotide in the microreactors to form amplified copies of said encoding oligonucleotide; and (iii) binding the amplified copies of the encoding oligonucleotide to the beads in the microreactors.
4. The method of claim 1, wherein said sequencing step (D) comprises: (i) annealing an effective amount of a sequencing primer to the amplified copies of the encoding oligonucleotide and extending the sequencing primer with a polymerase and a predetermined nucleotide triphosphate to yield a sequencing product and, if the predetermined nucleotide triphosphate is incorporated onto a 3' end of said sequencing primer, a sequencing reaction byproduct; and (ii) identifying the sequencing reaction byproduct, thereby determining the sequence of the encoding oligonucleotide.
5. A method for identifying one or more compounds which bind to a biological target, said method comprising: (A) synthesizing a library of compounds, wherein the compounds comprise a functional moiety comprising two or more building blocks which is operatively linked to an initial oligonucleotide which identifies the structure of the functional moiety by: (i) providing a solution comprising m initiator compounds, wherein m is an integer of 1 or greater, where the initiator compounds consist of a functional moiety comprising n building blocks, where n is an integer of 1 or greater, which is operatively linked to an initial oligonucleotide which identifies the n building blocks; (ii) dividing the solution of step (i) into r reaction vessels, wherein r is an integer of 2 or greater, thereby producing r aliquots of the solution; (iii) reacting the initiator compounds in each reaction vessel with one of r building blocks, thereby producing r aliquots comprising compounds consisting of a functional moiety comprising n+1 building blocks operatively linked to the initial oligonucleotide; and (iv) reacting the initial oligonucleotide in each aliquot with one of a set of r distinct incoming oligonucleotides in the presence of an enzyme which catalyzes the ligation of the incoming oligonucleotide and the initial oligonucleotide, under conditions suitable for enzymatic ligation of the incoming oligonucleotide and the initial oligonucleotide; thereby producing r aliquots of molecules consisting of a functional moiety comprising n+1 building blocks operatively linked to an elongated oligonucleotide which encodes the n+1 building blocks; (B) contacting the biological target with the library of compounds, or a portion thereof, under conditions suitable for at least one member of the library of compounds to bind to the target; (C) removing library members that do not bind to the target; (D) sequencing the encoding oligonucleotides of the at least one member of the library of compounds which binds to the target, wherein said sequencing comprises: (i) annealing an effective amount of a sequencing primer to the amplified copies of the encoding oligonucleotide and extending the sequencing primer with a polymerase and a predetermined nucleotide triphosphate to yield a sequencing product and, if the predetermined nucleotide triphosphate is incorporated onto a 3' end of said sequencing primer, a sequencing reaction byproduct; and (ii) identifying the sequencing reaction byproduct, thereby determining the sequence of the encoding oligonucleotide; and (E) using the sequence of the encoding oligonucleotide determined in step (D) to determine the structure of the functional moieties of the members of the library of compounds which bind to the biological target, thereby identifying one or more compounds which bind to the biological target.
6. The method of claim 5, further comprising amplifying the encoding oligonucleotides of the at least one member of the library of compounds which binds to the target.
7. The method of claim 6, wherein said amplification of the encoding oligonucleotides is carried out by a method selected from the group consisting of: the polymerase chain reaction (PCR); transcription-based amplification, rapid amplification of cDNA ends, continuous flow amplification, and rolling circle amplification.
8. The method of any one of claim 1, 4, or 5, wherein said sequencing of the encoding oligonucleotides is carried out by a pyrophosphate-based sequencing reaction or a single molecule sequencing by synthesis method.
9. The method of claim 8, wherein the sequencing reaction byproduct is PPi and a coupled sulfurylase/luciferase reaction is used to generate light for detection.
10. The method of any one of claim 1 or 5, further comprising the step of enriching for beads which bind amplified copies of the encoding oligonucleotide away from beads to which no encoding oligonucleotide is bound.
11. The method of claim 10, wherein the method for said enrichment step is selected from the group consisting of affinity purification, and electrophoresis.
12. The method of claim 3, further comprising breaking the emulsion to retrieve one or more of the amplified copies of the encoding oligonucleotide.
13. The method of claim 1 or 5, further comprising the step of (A)(v) combining two or more of the r aliquots, thereby producing a solution comprising molecules consisting of a functional moiety comprising n+1 building blocks, which is operatively linked to an elongated oligonucleotide which encodes the n+1 building blocks.
14. The method of claim 13, wherein r aliquots are combined.
15. The method of claim 13, wherein the steps (A)(i) to (A)(v) are conducted one or more times to yield cycles 1 to i, where i is an integer of 2 or greater, wherein in cycle s+1, where s is an integer of i-1 or less, the solution comprising m initiator compounds of step (a) is the solution of step (e) of cycle s.
16. The method of claim 1 or 5, wherein at least one of building blocks is an amino acid.
17. The method of claim 1 or 5, wherein the initial oligonucleotide is a covalently coupled double-stranded oligonucleotide.
18. The method of claim 17, wherein the incoming oligonucleotide is a double-stranded oligonucleotide.
19. The method of claim 1 or 5, wherein the initiator compounds comprise a linker moiety comprising a first functional group adapted to bond with a building block, a second functional group adapted to bond to the 5' end of an oligonucleotide, and a third functional group adapted to bond to the 3'-end of an oligonucleotide.
20. The method of claim 19, wherein the linker moiety is of the structure ##STR00115## wherein A is a functional group adapted to bond to a building block; B is a functional group adapted to bond to the 5'-end of an oligonucleotide; C is a functional group adapted to bond to the 3'-end of an oligonucleotide; S is an atom or a scaffold; D is a chemical structure that connects A to S; E is a chemical structure that connects B to S; and F is a chemical structure that connects C to S.
21. The method of claim 20, wherein: A is an amino group; B is a phosphate group; and C is a phosphate group.
22. The method of claim 20, wherein D, E and F are each, independently, an alkylene group or an oligo(ethylene glycol) group.
23. The method of claim 20, wherein S is a carbon atom, a nitrogen atom, a phosphorus atom, a boron atom, a phosphate group, a cyclic group or a polycyclic group.
24. The method of claim 23, wherein the linker moiety is of the structure ##STR00116## wherein each of n, m and p is, independently, an integer from 1 to about 20.
25. The method of claim 24, wherein each of n, m and p is independently an integer from 2 to eight.
26. The method of claim 25, wherein each of n, m and p is independently an integer from 3 to 6.
27. The method of claim 24, wherein the linker moiety has the structure ##STR00117##
28. The method of claim 1 or 5, wherein each of said initiator compounds comprises a reactive group and wherein each of said r building blocks comprises a complementary reactive group which is complementary to said reactive group.
29. The method of claim 28, wherein the reactive group and the complementary reactive group are selected from the group consisting of an amino group; a carboxyl group; a sulfonyl group; a phosphonyl group; an epoxide group; an aziridine group; and an isocyanate group.
30. The method of claim 28, wherein reactive group and the complementary reactive group are selected from the group consisting of a hydroxyl group; a carboxyl group; a sulfonyl group; a phosphonyl group; an epoxide group; an aziridine group; and an isocyanate group.
31. The method of claim 28, wherein the reactive group and the complementary reactive group are selected from the group consisting of an amino group and an aldehyde or ketone group.
32. The method of claim 28, wherein the reaction between the reactive group and the complementary reactive group is conducted under reducing conditions.
33. The method of claim 28, wherein the reactive group and the complementary reactive group are selected from the group consisting of a phosphorous ylide group and an aldehyde or ketone group.
34. The method of claim 28, wherein the reactive group and the complementary reactive group react via cycloaddition to form a cyclic structure.
35. The method of claim 34, wherein the reactive group and the complementary reactive group are selected from the group consisting of an alkyne and an azide.
36. The method of claim 28, wherein the reactive group and the complementary functional group are selected from the group consisting of a halogenated heteroaromatic group and a nucleophile.
37. The method of claim 36, wherein the halogenated heteroaromatic group is selected from the group consisting of chlorinated pyrimidines, chlorinated triazines and chlorinated purines.
38. The method of claim 36, wherein the nucleophile is an amino group.
39. The method of claim 13, further comprising following cycle i, the step of: (A)(vi) cyclizing one or more of the functional moieties.
40. The method of claim 39, wherein a functional moiety of step (A)(vi) comprises an azido group and an alkynyl group.
41. The method of claim 40, wherein the functional moiety is maintained under conditions suitable for cycloaddition of the azido group and the alkynyl group to form a triazole group, thereby forming a cyclic functional moiety.
42. The method of claim 41, wherein the cycloaddition reaction is conducted in the presence of a copper catalyst.
43. The method of claim 42, wherein at least one of the one or more functional moieties of step (f) comprises at least two sulfhydryl groups, and said functional moiety is maintained under conditions suitable for reaction of the two sulfhydryl groups to form a disulfide group, thereby cyclicizing the functional moiety.
44. The method of claim 1 or 5, wherein the initial oligonucleotide comprises a PCR primer sequence.
45. The method of claim 13, wherein the incoming oligonucleotide of cycle i comprises a PCR closing primer.
46. The method of claim 13, further comprising following cycle i, the step of (d) ligating an oligonucleotide comprising a closing PCR primer sequence to the encoding oligonucleotide.
47. The method of claim 46, wherein the oligonucleotide comprising a closing PCR primer sequence is ligated to the encoding oligonucleotide in the presence of an enzyme which catalyzes said ligation.
Description:
RELATED APPLICATIONS
[0001] This application is a continuation of U.S. patent application Ser. No. 11/584,880, filed Oct. 23, 2006, which claims priority to U.S. Provisional Application No. 60/731,464, filed Oct. 28, 2005. This application is related to U.S. Patent Application No. 60/689,466, filed Jun. 9, 2005, pending, and U.S. patent application Ser. No. 11/015,458 filed Dec. 17, 2004. This application is also related to U.S. Provisional Patent Application Ser. No. 60/530,854, filed on Dec. 17, 2003; U.S. Provisional Patent Application Ser. No. 60/540,681, filed on Jan. 30, 2004; U.S. Provisional Patent Application Ser. No. 60/553,715 filed Mar. 15, 2004; and U.S. Provisional Patent Application Ser. No. 60/588,672 filed Jul. 16, 2004. The entire contents of each of the foregoing applications are incorporated herein by reference.
SEQUENCE LISTING
[0002] The instant application contains a Sequence Listing which has been submitted via EFS-Web and is hereby incorporated by reference in its entirety. The ASCII copy of the Sequence Listing, created on Mar. 15, 2011, is named SeqList.txt, and is 219,888 bytes in size.
BACKGROUND OF THE INVENTION
[0003] The search for more efficient methods of identifying compounds having useful biological activities has led to the development of methods for screening vast numbers of distinct compounds, present in collections referred to as combinatorial libraries. Such libraries can include 105 or more distinct compounds. A variety of methods exist for producing combinatorial libraries, and combinatorial syntheses of peptides, peptidomimetics and small organic molecules have been reported.
[0004] The two major challenges in the use of combinatorial approaches in drug discovery are the synthesis of libraries of sufficient complexity and the identification of molecules which are active in the screens used. It is generally acknowledged that greater the degree of complexity of a library, i.e., the number of distinct structures present in the library, the greater the probability that the library contains molecules with the activity of interest. Therefore, the chemistry employed in library synthesis must be capable of producing vast numbers of compounds within a reasonable time frame. However, for a given formal or overall concentration, increasing the number of distinct members within the library lowers the concentration of any particular library member. This complicates the identification of active molecules from high complexity libraries.
[0005] One approach to overcoming these obstacles has been the development of encoded libraries, and particularly libraries in which each compound includes an amplifiable tag. Such libraries include DNA-encoded libraries, in which a DNA tag identifying a library member can be amplified using techniques of molecular biology, such as the polymerase chain reaction. However, the use of such methods for producing very large libraries is yet to be demonstrated, and it is clear that improved methods for producing such libraries are required for the realization of the potential of this approach to drug discovery.
SUMMARY OF THE INVENTION
[0006] Traditional drug discovery methods have relied on multi-step selection processes, often involving the amplification (e.g., PCR amplification) of nucleic acid molecules, and the sequencing of up to 1,000 or more of the top clones. This multi-step selection process and the nucleic acid amplification often lead to the introduction of many biases (as discussed in, for example, Holt, L. J., et al. (2000) Nucleic Acids Res. 28(15):E72). The presence of these biases typically leads to the selection of compounds that lack the desired biological activity.
[0007] The present invention provides improved methods as compared to the prior art methods in that it provides methods which eliminate the foregoing biases. For example, the present invention provides methods of identifying a compound of interest using a massively parallel sequencing approach which leads to the accurate identification of a compound with a desired biological activity using fewer selection steps. Moreover, as described herein, a unique tagging system has been developed that eliminates biases introduced by nucleic acid amplification, e.g., PCR amplification. In addition, the methods described herein allow for an expansive and extensive analysis of the selected compounds having a desired biological property, which, in turn, allows for related compounds with familial structural relationships to be identified (structure activity relationships). In summary, using the methods of the invention, a single step selection/enrichment cycle can be performed and then sequencing can be performed at the single molecule level, preferably without the need for any nucleic acid amplification.
[0008] Accordingly, in one aspect, the invention provides a method for identifying one or more compounds which bind to a biological target. The method comprises synthesizing a library of compounds, wherein the compounds comprise a functional moiety comprising two or more building blocks which is operatively linked to an initial oligonucleotide which identifies the structure of the functional moiety by providing a solution comprising m initiator compounds, wherein m is an integer of 1 or greater, where the initiator compounds consist of a functional moiety comprising n building blocks, where n is an integer of 1 or greater, which is operatively linked to an initial oligonucleotide which identifies the n building blocks, dividing the solution described above into r reaction vessels, wherein r is an integer of 2 or greater, thereby producing r aliquots of the solution, reacting the initiator compounds in each reaction vessel with one of r building blocks, thereby producing r aliquots comprising compounds consisting of a functional moiety comprising n+1 building blocks operatively linked to the initial oligonucleotide, and reacting the initial oligonucleotide in each aliquot with one of a set of r distinct incoming oligonucleotides in the presence of an enzyme which catalyzes the ligation of the incoming oligonucleotide and the initial oligonucleotide, under conditions suitable for enzymatic ligation of the incoming oligonucleotide and the initial oligonucleotide; thereby producing r aliquots of molecules consisting of a functional moiety comprising n+1 building blocks operatively linked to an elongated oligonucleotide which encodes the n+1 building blocks; contacting the biological target with the library of compounds, or a portion thereof, under conditions suitable for at least one member of the library of compounds to bind to the target, removing library members that do not bind to the target, sequencing the encoding oligonucleotides of the at least one member of the library of compounds which binds to the target, and using the foregoing sequences to determine the structure of the functional moieties of the members of the library of compounds which bind to the biological target, thereby identifying one or more compounds which bind to the biological target.
[0009] In one embodiment, the methods of the invention may further comprise amplifying the encoding oligonucleotide of the at least one member of the library of compounds which binds to the target prior to sequencing.
[0010] In one embodiment, the method of amplifying comprises forming a water-in-oil emulsion to create a plurality of aqueous microreactors, wherein at least one of the microreactors comprises the at least one member of the library of compounds that binds to the target, a single bead capable of binding to the encoding oligonucleotide of the at least one member of the library of compounds that binds to the target, and amplification reaction solution containing reagents necessary to perform nucleic acid amplification, amplifying the encoding oligonucleotide in the microreactors to form amplified copies of the encoding oligonucleotide, and binding the amplified copies of the encoding oligonucleotide to the beads in the microreactors.
[0011] In one embodiment, the method of sequencing comprises annealing an effective amount of a sequencing primer to the amplified copies of the encoding oligonucleotide and extending the sequencing primer with a polymerase and a predetermined nucleotide triphosphate to yield a sequencing product and, if the predetermined nucleotide triphosphate is incorporated onto a 3' end of the sequencing primer, a sequencing reaction byproduct, and identifying the sequencing reaction byproduct, thereby determining the sequence of the encoding oligonucleotide.
[0012] In one embodiment, sequencing is performed using the polymerase chain reaction. In another embodiment, sequencing is performed using a pyrophosphate sequencing method or using a single molecule sequencing by synthesis method.
BRIEF DESCRIPTION OF THE DRAWINGS
[0013] FIG. 1 is a schematic representation of ligation of double stranded oligonucleotides (SEQ ID NOS 921-926, respectively, in order of appearance), in which the initial oligonucleotide has an overhang which is complementary to the overhang of the incoming oligonucleotide. The initial strand is represented as either free, conjugated to an aminohexyl linker or conjugated to a phenylalanine residue via an aminohexyl linker.
[0014] FIG. 2 is a schematic representation of oligonucleotide ligation using a splint strand. In this embodiment, the splint is a 12-mer oligonucleotide with sequences complementary to the single-stranded initial oligonucleotide and the single-stranded incoming oligonucleotide.
[0015] FIG. 3 is a schematic representation of ligation of an initial oligonucleotide and an incoming oligonucleotide, when the initial oligonucleotide is double-stranded with covalently linked strands, and the incoming oligonucleotide is double-stranded.
[0016] FIG. 4 is a schematic representation of oligonucleotide elongation using a polymerase (SEQ ID NOS 921 & 927-929, respectively, in order of appearance). The initial strand is represented as either free, conjugated to an aminohexyl linker or conjugated to a phenylalanine residue via an aminohexyl linker.
[0017] FIG. 5 is a schematic representation of the synthesis cycle of one embodiment of the invention.
[0018] FIG. 6 is a schematic representation of a multiple round selection process using the libraries of the invention.
[0019] FIG. 7 is a gel resulting from electrophoresis of the products of each of cycles 1 to 5 described in Example 1 and following ligation of the closing primer. Molecular weight standards are shown in lane 1, and the indicated quantities of a hyperladder, for DNA quantitation, are shown in lanes 9 to 12.
[0020] FIG. 8 is a schematic depiction of the coupling of building blocks using azide-alkyne cycloaddition.
[0021] FIGS. 9 and 10 illustrate the coupling of building blocks via nucleophilic aromatic substitution on a chlorinated triazine.
[0022] FIG. 11 shows representative chlorinated heteroaromatic structures suitable for use in the synthesis of functional moieties.
[0023] FIG. 12 illustrates the cyclization of a linear peptide using the azide/alkyne cycloaddition reaction.
[0024] FIG. 13a is a chromatogram of the library produced as described in Example 2 following Cycle 4.
[0025] FIG. 13b is a mass spectrum of the library produced as described in Example 2 following Cycle 4.
DETAILED DESCRIPTION OF THE INVENTION
[0026] The present invention relates to methods of producing compounds and combinatorial compound libraries, the compounds and libraries produced via the methods of the invention, and methods of using the libraries to identify compounds having a desired property, such as a desired biological activity. The invention further relates to the compounds identified using these methods.
[0027] A variety of approaches have been taken to produce and screen combinatorial chemical libraries. Examples include methods in which the individual members of the library are physically separated from each other, such as when a single compound is synthesized in each of a multitude of reaction vessels. However, these libraries are typically screened one compound at a time, or at most, several compounds at a time and do not, therefore, result in the most efficient screening process. In other methods, compounds are synthesized on solid supports. Such solid supports include chips in which specific compounds occupy specific regions of the chip or membrane ("position addressable"). In other methods, compounds are synthesized on beads, with each bead containing a different chemical structure.
[0028] Two difficulties that arise in screening large libraries are (1) the number of distinct compounds that can be screened; and (2) the identification of compounds which are active in the screen. In one method, the compounds which are active in the screen are identified by narrowing the original library into ever smaller fractions and subfractions, in each case selecting the fraction or subfraction which contains active compounds and further subdividing until attaining an active subfraction which contains a set of compounds which is sufficiently small that all members of the subset can be individually synthesized and assessed for the desired activity. This is a tedious and time consuming activity.
[0029] Another method of deconvoluting the results of a combinatorial library screen is to utilize libraries in which the library members are tagged with an identifying label, that is, each label present in the library is associated with a discreet compound structure present in the library, such that identification of the label tells the structure of the tagged molecule. One approach to tagged libraries utilizes oligonucleotide tags, as described, for example, in U.S. Pat. Nos. 5,573,905; 5,708,153; 5,723,598, 6,060,596 published PCT applications WO 93/06121; WO 93/20242; WO 94/13623; WO 00/23458; WO 02/074929 and WO 02/103008, and by Brenner and Lerner (Proc. Natl. Acad. Sci. USA 89, 5381-5383 (1992); Nielsen and Janda (Methods: A Companion to Methods in Enzymology 6, 361-371 (1994); and Nielsen, Brenner and Janda (J. Am. Chem. Soc. 115, 9812-9813 (1993)), each of which is incorporated herein by reference in its entirety. Such tags can be amplified, using for example, polymerase chain reaction, to produce many copies of the tag and identify the tag by sequencing. The sequence of the tag then identifies the structure of the binding molecule, which can be synthesized in pure form and tested. To date, there has been no report of the use of the methodology disclosed by Lerner et al. to prepare large libraries. The present invention provides an improvement in methods to produce DNA-encoded libraries, as well as the first examples of large (105 members or greater) libraries of DNA-encoded molecules in which the functional moiety is synthesized using solution phase synthetic methods.
[0030] The present invention provides methods which enable facile synthesis of oligonucleotide-encoded combinatorial libraries, and permit an efficient, high-fidelity means of adding such an oligonucleotide tag to each member of a vast collection of molecules.
[0031] The methods of the invention include methods for synthesizing bifunctional molecules which comprise a first moiety ("functional moiety") which is made up of building blocks, and a second moiety operatively linked to the first moiety, comprising an oligonucleotide tag which identifies the structure of the first moiety, i.e., the oligonucleotide tag indicates which building blocks were used in the construction of the first moiety, as well as the order in which the building blocks were linked. Generally, the information provided by the oligonucleotide tag is sufficient to determine the building blocks used to construct the active moiety. In certain embodiments, the sequence of the oligonucleotide tag is sufficient to determine the arrangement of the building blocks in the functional moiety, for example, for peptidic moieties, the amino acid sequence.
[0032] The term "functional moiety" as used herein, refers to a chemical moiety comprising one or more building blocks. Preferably, the building blocks in the functional moiety are not nucleic acids. The functional moiety can be a linear or branched or cyclic polymer or oligomer or a small organic molecule.
[0033] The term "building block", as used herein, is a chemical structural unit which is linked to other chemical structural units or can be linked to other such units. When the functional moiety is polymeric or oligomeric, the building blocks are the monomeric units of the polymer or oligomer. Building blocks can also include a scaffold structure ("scaffold building block") to which is, or can be, attached one or more additional structures ("peripheral building blocks").
[0034] It is to be understood that the term "building block" is used herein to refer to a chemical structural unit as it exists in a functional moiety and also in the reactive form used for the synthesis of the functional moiety. Within the functional moiety, a building block will exist without any portion of the building block which is lost as a consequence of incorporating the building block into the functional moiety. For example, in cases in which the bond-forming reaction releases a small molecule (see below), the building block as it exists in the functional moiety is a "building block residue", that is, the remainder of the building block used in the synthesis following loss of the atoms that it contributes to the released molecule.
[0035] The building blocks can be any chemical compounds which are complementary, that is the building blocks must be able to react together to form a, structure comprising two or more building blocks. Typically, all of the building blocks used will have at least two reactive groups, although it is possible that some of the building blocks (for example the last building block in an oligomeric functional moiety) used will have only one reactive group each. Reactive groups on two different building blocks should be complementary, i.e., capable of reacting together to form a covalent bond, optionally with the concomitant loss of a small molecule, such as water, HCl, HF, and so forth.
[0036] For the present purposes, two reactive groups are complementary if they are capable of reacting together to form a covalent bond. In a preferred embodiment, the bond forming reactions occur rapidly under ambient conditions without substantial formation of side products. Preferably, a given reactive group will react with a given complementary reactive group exactly once. In one embodiment, complementary reactive groups of two building blocks react, for example, via nucleophilic substitution, to form a covalent bond. In one embodiment, one member of a pair of complementary reactive groups is an electrophilic group and the other member of the pair is a nucleophilic group.
[0037] Complementary electrophilic and nucleophilic groups include any two groups which react via nucleophilic substitution under suitable conditions to form a covalent bond. A variety of suitable bond-forming reactions are known in the art. See, for example, March, Advanced Organic Chemistry, fourth edition, New York: John Wiley and Sons (1992), Chapters 10 to 16; Carey and Sundberg, Advanced Organic Chemistry, Part B, Plenum (1990), Chapters 1-11; and Collman et al., Principles and Applications of Organotransition Metal Chemistry, University Science Books, Mill Valley, Calif. (1987), Chapters 13 to 20; each of which is incorporated herein by reference in its entirety. Examples of suitable electrophilic groups include reactive carbonyl groups, such as acyl chloride groups, ester groups, including carbonyl pentafluorophenyl esters and succinimide esters, ketone groups and aldehyde groups; reactive sulfonyl groups, such as sulfonyl chloride groups, and reactive phosphonyl groups. Other electrophilic groups include terminal epoxide groups, isocyanate groups and alkyl halide groups. Suitable nucleophilic groups include primary and secondary amino groups and hydroxyl groups and carboxyl groups.
[0038] Suitable complementary reactive groups are set forth below. One of skill in the art can readily determine other reactive group pairs that can be used in the present method, and the examples provided herein are not intended to be limiting.
[0039] In a first embodiment, the complementary reactive groups include activated carboxyl groups, reactive sulfonyl groups or reactive phosphonyl groups, or a combination thereof, and primary or secondary amino groups. In this embodiment, the complementary reactive groups react under suitable conditions to form an amide, sulfonamide or phosphonamidate bond.
[0040] In a second embodiment, the complementary reactive groups include epoxide groups and primary or secondary amino groups. An epoxide-containing building block reacts with an amine-containing building block under suitable conditions to form a carbon-nitrogen bond, resulting in a β-amino alcohol.
[0041] In another embodiment, the complementary reactive groups include aziridine groups and primary or secondary amino groups. Under suitable conditions, an aziridine-containing building block reacts with an amine-containing building block to form a carbon-nitrogen bond, resulting in a 1,2-diamine. In a third embodiment, the complementary reactive groups include isocyanate groups and primary or secondary amino groups. An isocyanate-containing building block will react with an amino-containing building block under suitable conditions to form a carbon-nitrogen bond, resulting in a urea group.
[0042] In a fourth embodiment, the complementary reactive groups include isocyanate groups and hydroxyl groups. An isocyanate-containing building block will react with an hydroxyl-containing building block under suitable conditions to form a carbon-oxygen bond, resulting in a carbamate group.
[0043] In a fifth embodiment, the complementary reactive groups include amino groups and carbonyl-containing groups, such as aldehyde or ketone groups. Amines react with such groups via reductive amination to form a new carbon-nitrogen bond.
[0044] In a sixth embodiment, the complementary reactive groups include phosphorous ylide groups and aldehyde or ketone groups. A phosphorus-ylide-containing building block will react with an aldehyde or ketone-containing building block under suitable conditions to form a carbon-carbon double bond, resulting in an alkene.
[0045] In a seventh embodiment, the complementary reactive groups react via cycloaddition to form a cyclic structure. One example of such complementary reactive groups are alkynes and organic azides, which react under suitable conditions to form a triazole ring structure. An example of the use of this reaction to link two building blocks is illustrated in FIG. 8. Suitable conditions for such reactions are known in the art and include those disclosed in WO 03/101972, the entire contents of which are incorporated by reference herein.
[0046] In an eighth embodiment, the complementary reactive groups are an alkyl halide and a nucleophile, such as an amino group, a hydroxyl group or a carboxyl group. Such groups react under suitable conditions to form a carbon-nitrogen (alkyl halide plus amine) or carbon oxygen (alkyl halide plus hydroxyl or carboxyl group).
[0047] In a ninth embodiment, the complementary functional groups are a halogenated heteroaromatic group and a nucleophile, and the building blocks are linked under suitable conditions via aromatic nucleophilic substitution. Suitable halogenated heteroaromatic groups include chlorinated pyrimidines, triazines and purines, which react with nucleophiles, such as amines, under mild conditions in aqueous solution. Representative examples of the reaction of an oligonucleotide-tagged trichlorotriazine with amines are shown in FIGS. 9 and 10. Examples of suitable chlorinated heteroaromatic groups are shown in FIG. 11.
[0048] Additional bond-forming reactions that can be used to join building blocks in the synthesis of the molecules and libraries of the invention include those shown below. The reactions shown below emphasize the reactive functional groups. Various substituents can be present in the reactants, including those labeled R1, R2, R3 and R4. The possible positions which can be substituted include, but are not limited, to those indicated by R1, R2, R3 and R4. These substituents can include any suitable chemical moieties, but are preferably limited to those which will not interfere with or significantly inhibit the indicated reaction, and, unless otherwise specified, can include hydrogen, alkyl, substituted alkyl, aryl, substituted aryl, heteroaryl, substituted heteroaryl, alkoxy, aryloxy, arylalkyl, substituted arylalkyl, amino, substituted amino and others as are known in the art. Suitable substituents on these groups include alkyl, aryl, heteroaryl, cyano, halogen, hydroxyl, nitro, amino, mercapto, carboxyl, and carboxamide. Where specified, suitable electron-withdrawing groups include nitro, carboxyl, haloalkyl, such as trifluoromethyl and others as are known in the art. Examples of suitable electron-donating groups include alkyl, alkoxy, hydroxyl, amino, halogen, acetamido and others as are known in the art.
Addition of a Primary Amine to an Alkene:
##STR00001##
[0049] Nucleophilic Substitution:
##STR00002##
[0050] Reductive Alkylation of an Amine:
##STR00003##
[0051] Palladium Catalyzed Carbon-Carbon Bond Forming Reactions:
##STR00004##
[0052] Ugi Condensation Reactions:
##STR00005##
[0053] Electrophilic Aromatic Substitution Reactions:
##STR00006##
[0054] X is an electron-donating group.
Imine/Iminium/Enamine Forming Reactions:
##STR00007##
[0055] Cycloaddition Reactions:
##STR00008##
[0057] Diels-Alder Cycloaddition
##STR00009##
[0058] 1,3-dipolar cycloaddition, X--Y--Z═C--N--O, C--N--S, N3.
Nucleophilic Aromatic Substitution Reactions:
##STR00010##
[0059] W is an electron withdrawing group
##STR00011##
[0060] Examples of suitable substituents X and Y include substituted or unsubstituted amino, substituted or unsubstituted alkoxy, substituted or unsubstituted thioalkoxy, substituted or unsubstituted aryloxy and substituted and unsubstituted thioaryloxy.
##STR00012##
Heck Reaction:
##STR00013##
[0061] Acetal Formation:
##STR00014##
[0063] Examples of suitable substituents X and Y include substituted and unsubstituted amino, hydroxyl and sulhydryl; Y is a linker that connects X and Y and is suitable for forming the ring structure found in the product of the reaction.
Aldol Reactions:
##STR00015##
[0064] Examples of suitable substituents X include O, S and NR3.
[0065] Scaffold building blocks which can be used to form the molecules and libraries of the invention include those which have two or more functional groups which can participate in bond forming reactions with peripheral building block precursors, for example, using one or more of the bond forming reactions discussed above. Scaffold moieties may also be synthesized during construction of the libraries and molecules of the invention, for example, using building block precursors which can react in specific ways to form molecules comprising a central molecular moiety to which are appended peripheral functional groups. In one embodiment, a library of the invention comprises molecules comprising a constant scaffold moiety, but different peripheral moieties or different arrangements of peripheral moieties. In certain libraries, all library members comprise a constant scaffold moiety; other libraries can comprise molecules having two or more different scaffold moieties. Examples of scaffold moiety-forming reactions that can be used in the construction of the molecules and libraries of the invention are set forth in the Table. The references cited in the table are incorporated herein by reference in their entirety. The groups R1, R2, R3 and R4 are limited only in that they should not interfere with, or significantly inhibit, the indicated reaction, and can include hydrogen, alkyl, substituted alkyl, heteroalkyl, substituted heteroalkyl, cycloalkyl, heterocycloalkyl, substituted cycloalkyl, substituted heterocycloalkyl, aryl, substituted aryl, arylalkyl, heteroarylalkyl, substituted arylalkyl, substituted heteroarylalkyl, heteroaryl, substituted heteroaryl, halogen, alkoxy, aryloxy, amino, substituted amino and others as are known in the art. Suitable substituents include, but are not limited to, alkyl, alkoxy, thioalkoxy, nitro, hydroxyl, sulfhydryl, aryloxy, aryl-S--, halogen, carboxy, amino, alkylamino, dialkylamino, arylamino, cyano, cyanate, nitrile, isocyanate, thiocyanate, carbamyl, and substituted carbamyl.
[0066] It is to be understood that the synthesis of a functional moiety can proceed via one particular type of coupling reaction, such as, but not limited to, one of the reactions discussed above, or via a combination of two or more coupling reactions, such as two or more of the coupling reactions discussed above. For example, in one embodiment, the building blocks are joined by a combination of amide bond formation (amino and carboxylic acid complementary groups) and reductive amination (amino and aldehyde or ketone complementary groups). Any coupling chemistry can be used, provided that it is compatible with the presence of an oligonucleotide. Double stranded (duplex) oligonucleotide tags, as used in certain embodiments of the present invention, are chemically more robust than single stranded tags, and, therefore, tolerate a broader range of reaction conditions and enable the use of bond-forming reactions that would not be possible with single-stranded tags.
[0067] A building block can include one or more functional groups in addition to the reactive m group or groups employed to form the functional moiety. One or more of these additional functional groups can be protected to prevent undesired reactions of these functional groups. Suitable protecting groups are known in the art for a variety of functional groups (Greene and Wuts, Protective Groups in Organic Synthesis, second edition, New York: John Wiley and Sons (1991), incorporated herein by reference). Particularly useful protecting groups include t-butyl esters and ethers, acetals, trityl ethers and amines, acetyl esters, trimethylsilyl ethers, trichloroethyl ethers and esters and carbamates.
[0068] In one embodiment, each building block comprises two reactive groups, which can be the same or different. For example, each building block added in cycle s can comprise two reactive groups which are the same, but which are both complementary to the reactive groups of the building blocks added at steps s-1 and s+1. In another embodiment, each building block comprises two reactive groups which are themselves complementary. For example, a library comprising polyamide molecules can be produced via reactions between building blocks comprising two primary amino groups and building blocks comprising two activated carboxyl groups. In the resulting compounds there is no N- or C-terminus, as alternate amide groups have opposite directionality. Alternatively, a polyamide library can be produced using building blocks that each comprise an amino group and an activated carboxyl group. In this embodiment, the building blocks added in step n of the cycle will have a free reactive group which is complementary to the available reactive group on the n-1 building block, while, preferably, the other reactive group on the nth building block is protected. For example, if the members of the library are synthesized from the C to N direction, the building blocks added will comprise an activated carboxyl group and a protected amino group.
[0069] The functional moieties can be polymeric or oligomeric moieties, such as peptides, peptidomimetics, peptide nucleic acids or peptoids, or they can be small non-polymeric molecules, for example, molecules having a structure comprising a central scaffold and structures arranged about the periphery of the scaffold. Linear polymeric or oligomeric libraries will result from the use of building blocks having two reactive groups, while branched polymeric or oligomeric libraries will result from the use of building blocks having three or more reactive groups, optionally in combination with building blocks having only two reactive groups. Such molecules can be represented by the general formula X1X2 . . . Xn, where each X is a monomeric unit of a polymer comprising n monomeric units, where n is an integer greater than 1 In the case of oligomeric or polymeric compounds, the terminal building blocks need not comprise two functional groups. For example, in the case of a polyamide library, the C-terminal building block can comprise an amino group, but the presence of a carboxyl group is optional. Similarly, the building block at the N-terminus can comprise a carboxyl group, but need not contain an amino group.
[0070] Branched oligomeric or polymeric compounds can also be synthesized provided that at least one building block comprises three functional groups which are reactive with other building blocks. A library of the invention can comprise linear molecules, branched molecules or a combination thereof.
[0071] Libraries can also be constructed using, for example, a scaffold building block having two or more reactive groups, in combination with other building blocks having only one available reactive group, for example, where any additional reactive groups are either protected or not reactive with the other reactive groups present in the scaffold building block. In one embodiment, for example, the molecules synthesized can be represented by the general formula X(Y)n, where X is a scaffold building block; each Y is a building block linked to X and n is an integer of at least two, and preferably an integer from 2 to about 6. In one preferred embodiment, the initial building block of cycle 1 is a scaffold building block. In molecules of the formula X(Y)n, each Y can be the same or different, but in most members of a typical library, each Y will be different.
[0072] In one embodiment, the libraries of the invention comprise polyamide compounds. The polyamide compounds can be composed of building blocks derived from any amino acids, including the twenty naturally occurring α-amino acids, such as alanine (Ala; A), glycine (Gly; G), asparagine (Asn; N), aspartic acid (Asp; D), glutamic acid (Glu; E), histidine (His; H), leucine (Leu; L), lysine (Lys; K), phenylalanine (Phe; F), tyrosine (Tyr; Y), threonine (Thr; T), serine (Ser; S), arginine (Arg; R), valine (Val; V), glutamine (Gln; Q), isoleucine (Ile; I), cysteine (Cys; C), methionine (Met; M), proline (Pro; P) and tryptophan (Trp; W), where the three-letter and one-letter codes for each amino acid are given. In their naturally occurring form, each of the foregoing amino acids exists in the L-configuration, which is to be assumed herein unless otherwise noted. In the present method, however, the D-configuration forms of these amino acids can also be used. These D-amino acids are indicated herein by lower case three- or one-letter code, i.e., ala (a), gly (g), leu (I), gln (q), thr (t), ser (s), and so forth. The building blocks can also be derived from other α-amino acids, including, but not limited to, 3-arylalanines, such as naphthylalanine, phenyl-substituted phenylalanines, including 4-fluoro-, 4-chloro, 4-bromo and 4-methylphenylalanine; 3-heteroarylalanines, such as 3-pyridylalanine, 3-thienylalanine, 3-quinolylalanine, and 3-imidazolylalanine; ornithine; citrulline; homocitrulline; sarcosine; homoproline; homocysteine; substituted proline, such as hydroxyproline and fluoroproline; dehydroproline; norleucine; O-methyltyrosine; O-methylserine; O-methylthreonine and 3-cyclohexylalanine. Each of the preceding amino acids can be utilized in either the D- or L-configuration.
[0073] The building blocks can also be amino acids which are not α-amino acids, such as α-azamino acids; β, γ, δ, ε,-amino acids, and N-substituted amino acids, such as N-substituted glycine, where the N-substituent can be, for example, a substituted or unsubstituted alkyl, aryl, heteroaryl, arylalkyl or heteroarylalkyl group. In one embodiment, the N-substituent is a side chain from a naturally-occurring or non-naturally occurring α-amino acid.
[0074] The building block can also be a peptidomimetic structure, such as a dipeptide, tripeptide, tetrapeptide or pentapeptide mimetic. Such peptidomimetic building blocks are preferably derived from amino acyl compounds, such that the chemistry of addition of these building blocks to the growing poly(aminoacyl) group is the same as, or similar to, the chemistry used for the other building blocks. The building blocks can also be molecules which are capable of forming bonds which are isosteric with a peptide bond, to form peptidomimetic functional moieties comprising a peptide backbone modification, such as ψ[CH2S], ψ[CH2NH], ψ[CSNH2], ψ[NHCO], ψ[COCH2], and ψ[(E) or (Z) CH═CH]. In the nomenclature used above, ψ indicates the absence of an amide bond. The structure that replaces the amide group is specified within the brackets.
[0075] In one embodiment, the invention provides a method of synthesizing a compound comprising or consisting of a functional moiety which is operatively linked to an encoding oligonucleotide. The method includes the steps of: (1) providing an initiator compound consisting of an initial functional moiety comprising n building blocks, where n is an integer of 1 or greater, wherein the initial functional moiety comprises at least one reactive group, and wherein the initial functional moiety is operatively linked to an initial oligonucleotide which encodes the n building blocks; (2) reacting the initiator compound with a building block comprising at least one complementary reactive group, wherein the at least one complementary reactive group is complementary to the reactive group of step (1), under suitable conditions for reaction of the reactive group and the complementary reactive group to form a covalent bond; (3) reacting the initial oligonucleotide with an incoming oligonucleotide in the presence of an enzyme which catalyzes ligation of the initial oligonucleotide and the incoming oligonucleotide, under conditions suitable for ligation of the incoming oligonucleotide and the initial oligonucleotide, thereby producing a molecule which comprises or consists of a functional moiety comprising n+1 building blocks which is operatively linked to an encoding oligonucleotide. If the functional moiety of step (3) comprises a reactive group, steps 1-3 can be repeated one or more times, thereby forming cycles 1 to i, where i is an integer of 2 or greater, with the product of step (3) of a cycle s-1, where s is an integer of i or less, becoming the initiator compound of step (1) of cycle s. In each cycle, one building block is added to the growing functional moiety and one oligonucleotide sequence, which encodes the new building block, is added to the growing encoding oligonucleotide.
[0076] In one embodiment, the initial initiator compound(s) is generated by reacting a first building block with an oligonucleotide (e.g., an oligonucleotide which includes PCR primer sequences or an initial oligonucleotide) or with a linker to which such an oligonucleotide is attached. In the embodiment set forth in FIG. 5, the linker comprises a reactive group for attachment of a first building block and is attached to an initial oligonucleotide. In this embodiment, reaction of a building block, or in each of multiple aliquots, one of a collection of building blocks, with the reactive group of the linker and addition of an oligonucleotide encoding the building block to the initial oligonucleotide produces the one or more initial initiator compounds of the process set forth above.
[0077] In a preferred embodiment, each individual building block is associated with a distinct oligonucleotide, such that the sequence of nucleotides in the oligonucleotide added in a given cycle identifies the building block added in the same cycle.
[0078] The coupling of building blocks and ligation of oligonucleotides will generally occur at similar concentrations of starting materials and reagents. For example, concentrations of reactants on the order of micromolar to millimolar, for example from about 10 μM to about 10 mM, are preferred in order to have efficient coupling of building blocks.
[0079] In certain embodiments, the method further comprises, following step (2), the step of scavenging any unreacted initial functional moiety. Scavenging any unreacted initial functional moiety in a particular cycle prevents the initial functional moiety of the cycle from reacting with a building block added in a later cycle. Such reactions could lead to the generation of functional moieties missing one or more building blocks, potentially leading to a range of functional moiety structures which correspond to a particular oligonucleotide sequence. Such scavenging can be accomplished by reacting any remaining initial functional moiety with a compound which reacts with the reactive group of step (2). Preferably, the scavenger compound reacts rapidly with the reactive group of step (2) and includes no additional reactive groups that can react with building blocks added in later cycles. For example, in the synthesis of a compound where the reactive group of step (2) is an amino group, a suitable scavenger compound is an N-hydroxysuccinimide ester, such as acetic acid N-hydroxysuccinimide ester.
[0080] In another embodiment, the invention provides a method of producing a library of compounds, wherein each compound comprises a functional moiety comprising two or more building block residues which is operatively linked to an oligonucleotide. In a preferred embodiment, the oligonucleotide present in each molecule provides sufficient information to identify the building blocks within the molecule and, optionally, the order of addition of the building blocks. In this embodiment, the method of the invention comprises a method of synthesizing a library of compounds, wherein the compounds comprise a functional moiety comprising two or more building blocks which is operatively linked to an oligonucleotide which identifies the structure of the functional moiety. The method comprises the steps of (1) providing a solution comprising m initiator compounds, wherein m is an integer of 1 or greater, where the initiator compounds consist of a functional moiety comprising n building blocks, where n is an integer of 1 or greater, which is operatively linked to an initial oligonucleotide which identifies the n building blocks; (2) dividing the solution of step (1) into at least r fractions, wherein r is an integer of 2 or greater; (3) reacting each fraction with one of r building blocks, thereby producing r fractions comprising compounds consisting of a functional moiety comprising n+1 building blocks operatively linked to the initial oligonucleotide; (4) reacting each of the r fractions of step (3) with one of a set of r distinct incoming oligonucleotides under conditions suitable for enzymatic ligation of the incoming oligonucleotide to the initial oligonucleotide, thereby producing r fractions comprising molecules consisting of a functional moiety comprising n+1 building blocks operatively linked to an elongated oligonucleotide which encodes the n+1 building blocks. Optionally, the method can further include the step of (5) recombining the r fractions, produced in step (4), thereby producing a solution comprising molecules consisting of a functional moiety comprising n+1 building blocks, which is operatively linked to an elongated oligonucleotide which encodes the n+1 building blocks. Steps (1) to (5) can be conducted one or more times to yield cycles 1 to i, where i is an integer of 2 or greater. In cycle s+1, where s is an integer of i-1 or less, the solution comprising m initiator compounds of step (1) is the solution of step (5) of cycle s. Likewise, the initiator compounds of step (1) of cycle s+1 are the products of step (4) in cycle s.
[0081] Preferably the solution of step (2) is divided into r fractions in each cycle of the library synthesis. In this embodiment, each fract is reated with a unique building block.
[0082] In the methods of the invention, the order of addition of the building block and the incoming oligonucleotide is not critical, and steps (2) and (3) of the synthesis of a molecule, and steps (3) and (4) in the library synthesis can be reversed, i.e., the incoming oligonucleotide can be ligated to the initial oligonucleotide before the new building block is added. In certain embodiments, it may be possible to conduct these two steps simultaneously.
[0083] In certain embodiments, the method further comprises, following step (2), the step of scavenging any unreacted initial functional moiety. Scavenging any unreacted initial functional moiety in a particular cycle prevents the initial functional moiety of a the cycle from reacting with a building block added in a later cycle. Such reactions could lead to the generation of functional moieties missing one or more building blocks, potentially leading to a range of functional moiety structures which correspond to a particular oligonucleotide sequence. Such scavenging can be accomplished by reacting any remaining initial functional moiety with a compound which reacts with the reactive group of step (2). Preferably, the scavenger compound reacts rapidly with the reactive group of step (2) and includes no additional reactive groups that can react with building blocks added in later cycles. For example, in the synthesis of a compound where the reactive group of step (2) is an amino group, a suitable scavenger compound is an N-hydroxysuccinimide ester, such as acetic acid N-hydroxysuccinimide ester.
[0084] In one embodiment, the building blocks used in the library synthesis are selected from a set of candidate building blocks by evaluating the ability of the candidate building blocks to react with appropriate complementary functional groups under the conditions used for synthesis of the library. Building blocks which are shown to be suitably reactive under such conditions can then be selected for incorporation into the library. The products of a given cycle can, optionally, be purified. When the cycle is an intermediate cycle, i.e., any cycle prior to the final cycle, these products are intermediates and can be purified prior to initiation of the next cycle. If the cycle is the final cycle, the products of the cycle are the final products, and can be purified prior to any use of the compounds. This purification step can, for example, remove unreacted or excess reactants and the enzyme employed for oligonucleotide ligation. Any methods which are suitable for separating the products from other species present in solution can be used, including liquid chromatography, such as high performance liquid chromatography (HPLC) and precipitation with a suitable co-solvent, such as ethanol. Suitable methods for purification will depend upon the nature of the products and the solvent system used for synthesis.
[0085] The reactions are, preferably, conducted in aqueous solution, such as a buffered aqueous solution, but can also be conducted in mixed aqueous/organic media consistent with the solubility properties of the building blocks, the oligonucleotides, the intermediates and final products and the enzyme used to catalyze the oligonucleotide ligation.
[0086] It is to be understood that the theoretical number of compounds produced by a given cycle in the method described above is the product of the number of different initiator compounds, m, used in the cycle and the number of distinct building blocks added in the cycle, r. The actual number of distinct compounds produced in the cycle can be as high as the product of r and m (r×m), but could be lower, given differences in reactivity of certain building blocks with certain other building blocks. For example, the kinetics of addition of a particular building block to a particular initiator compound may be such that on the time scale of the synthetic cycle, little to none of the product of that reaction may be produced.
[0087] In certain embodiments, a common building block is added prior to cycle 1, following the last cycle or in between any two cycles. For example, when the functional moiety is a polyamide, a common N-terminal capping building block can be added after the final cycle. A common building block can also be introduced between any two cycles, for example, to add a functional group, such as an alkyne or azide group, which can be utilized to modify the functional moieties, for example by cyclization, following library synthesis.
[0088] The term "operatively linked", as used herein, means that two chemical structures are linked together in such a way as to remain linked through the various manipulations they are expected to undergo. Typically the functional moiety and the encoding oligonucleotide are linked covalently via an appropriate linking group. The linking group is a bivalent moiety with a site of attachment for the oligonucleotide and a site of attachment for the functional moiety. For example, when the functional moiety is a polyamide compound, the polyamide compound can be attached to the linking group at its N-terminus, its C-terminus or via a functional group on one of the side chains. The linking group is sufficient to separate the polyamide compound and the oligonucleotide by at least one atom, and preferably, by more than one atom, such as at least two, at least three, at least four, at least five or at least six atoms. Preferably, the linking group is sufficiently flexible to allow the polyamide compound to bind target molecules in a manner which is independent of the oligonucleotide.
[0089] In one embodiment, the linking group is attached to the N-terminus of the polyamide compound and the 5'-phosphate group of the oligonucleotide. For example, the linking group can be derived from a linking group precursor comprising an activated carboxyl group on one end and an activated ester on the other end. Reaction of the linking group precursor with the N-terminal nitrogen atom will form an amide bond connecting the linking group to the polyamide compound or N-terminal building block, while reaction of the linking group precursor with the 5'-hydroxy group of the oligonucleotide will result in attachment of the oligonucleotide to the linking group via an ester linkage. The linking group can comprise, for example, a polymethylene chain, such as a --(CH2)n-- chain or a poly(ethylene glycol) chain, such as a --(CH2CH2O)n chain, where in both cases n is an integer from 1 to about 20. Preferably, n is from 2 to about 12, more preferably from about 4 to about 10. In one embodiment, the linking group comprises a hexamethylene (--(CH2)6--) group.
[0090] When the building blocks are amino acid residues, the resulting functional moiety is a polyamide. The amino acids can be coupled using any suitable chemistry for the formation of amide bonds. Preferably, the coupling of the amino acid building blocks is conducted under conditions which are compatible with enzymatic ligation of oligonucleotides, for example, at neutral or near-neutral pH and in aqueous solution. In one embodiment, the polyamide compound is synthesized from the C-terminal to N-terminal direction. In this embodiment, the first, or C-terminal, building block is coupled at its carboxyl group to an oligonucleotide via a suitable linking group. The first building block is reacted with the second building block, which preferably has an activated carboxyl group and a protected amino group. Any activating/protecting group strategy which is suitable for solution phase amide bond formation can be used. For example, suitable activated carboxyl species include acyl fluorides (U.S. Pat. No. 5,360,928, incorporated herein by reference in its entirety), symmetrical anhydrides and N-hydroxysuccinimide esters. The acyl groups can also be activated in situ, as is known in the art, by reaction with a suitable activating compound. Suitable activating compounds include dicyclohexylcarbodiimide (DCC), diisopropylcarbodiimide (DIC), 1-ethoxycarbonyl-2-ethoxy-1,2-dihydroquinoline (EEDQ), 1-ethyl-3-(3-dimethylaminopropyl)carbodiimide hydrochloride (EDC), n-propane-phosphonic anhydride (PPA), N,N-bis(2-oxo-3-oxazolidinyl)imido-phosphoryl chloride (BOP-Cl), bromo-tris-pyrrolidinophosphonium hexafluorophosphate (PyBrop), diphenylphosphoryl azide (DPPA), Castro's reagent (BOP, PyBop), O-benzotriazolyl-N,N,N',N'-tetramethyluronium salts (HBTU), diethylphosphoryl cyanide (DEPCN), 2,5-diphenyl-2,3-dihydro-3-oxo-4-hydroxy-thiophene dioxide (Steglich's reagent; HOTDO), 1,1'-carbonyl-diimidazole (CDI), and 4-(4,6-dimethoxy-1,3,5-triazin-2-yl)-4-methylmorpholinium chloride (DMT-MM). The coupling reagents can be employed alone or in combination with additives such as N,N-dimethyl-4-aminopyridine (DMAP), N-hydroxy-benzotriazole (HOBt), N-hydroxybenzotriazine (HOOBt), N-hydroxysuccinimide (HOSu) N-hydroxyazabenzotriazole (HOAt), azabenzotriazolyl-tetramethyluronium salts (HATU, HAPyU) or 2-hydroxypyridine. In certain embodiments, synthesis of a library requires the use of two or more activation strategies, to enable the use of a structurally diverse set of building blocks. For each building block, one skilled in the art can determine the appropriate activation strategy.
[0091] The N-terminal protecting group can be any protecting group which is compatible with the conditions of the process, for example, protecting groups which are suitable for solution phase synthesis conditions. A preferred protecting group is the fluorenylmethoxycarbonyl ("Fmoc") group. Any potentially reactive functional groups on the side chain of the aminoacyl building block may also need to be suitably protected. Preferably the side chain protecting group is orthogonal to the N-terminal protecting group, that is, the side chain protecting group is removed under conditions which are different than those required for removal of the N-terminal protecting group. Suitable side chain protecting groups include the nitroveratryl group, which can be used to protect both side chain carboxyl groups and side chain amino groups. Another suitable side chain amine protecting group is the N-pent-4-enoyl group.
[0092] The building blocks can be modified following incorporation into the functional moiety, for example, by a suitable reaction involving a functional group on one or more of the building blocks. Building block modification can take place following addition of the final building block or at any intermediate point in the synthesis of the functional moiety, for example, after any cycle of the synthetic process. When a library of bifunctional molecules of the invention is synthesized, building block modification can be carried out on the entire library or on a portion of the library, thereby increasing the degree of complexity of the library. Suitable building block modifying reactions include those reactions that can be performed under conditions compatible with the functional moiety and the encoding oligonucleotide. Examples of such reactions include acylation and sulfonation of amino groups or hydroxyl groups, alkylation of amino groups, esterification or thioesterification of carboxyl groups, amidation of carboxyl groups, epoxidation of alkenes, and other reactions as are known the art. When the functional moiety includes a building block having an alkyne or an azide functional group, the azide/alkyne cycloaddition reaction can be used to derivatize the building block. For example, a building block including an alkyne can be reacted with an organic azide, or a building block including an azide can be reacted with an alkyne, in either case forming a triazole. Building block modification reactions can take place after addition of the final building block or at an intermediate point in the synthetic process, and can be used to append a variety of chemical structures to the functional moiety, including carbohydrates, metal binding moieties and structures for targeting certain biomolecules or tissue types.
[0093] In another embodiment, the functional moiety comprises a linear series of building blocks and this linear series is cyclized using a suitable reaction. For example, if at least two building blocks in the linear array include sulfhydryl groups, the sulfhydryl groups can be oxidized to form a disulfide linkage, thereby cyclizing the linear array. For example, the functional moieties can be oligopeptides which include two or more L or D-cysteine and/or L or D-homocysteine moieties. The building blocks can also include other functional groups capable of reacting together to cyclize the linear array, such as carboxyl groups and amino or hydroxyl groups.
[0094] In a preferred embodiment, one of the building blocks in the linear array comprises an alkyne group and another building block in the linear array comprises an azide group. The azide and alkyne groups can be induced to react via cycloaddition, resulting in the formation of a macrocyclic structure. In the example illustrated in FIG. 9, the functional moiety is a polypeptide comprising a propargylglycine building block at its C-terminus and an azidoacetyl group at its N-terminus. Reaction of the alkyne and the azide group under suitable conditions results in formation of a cyclic compound, which includes a triazole structure within the macrocycle. In the case of a library, in one embodiment, each member of the library comprises alkyne- and azide-containing building blocks and can be cyclized in this way. In a second embodiment, all members of the library comprises alkyne- and azide-containing building blocks, but only a portion of the library is cyclized. In a third embodiment, only certain functional moieties include alkyne- and azide-containing building blocks, and only these molecules are cyclized. In the forgoing second and third embodiments, the library, following the cycloaddition reaction, will include both cyclic and linear functional moieties.
[0095] In some embodiments of the invention in which the same functional moiety, e.g., triazine, is added to each and all of the fractions of the library during a particular synthesis step, it may not be necessary to add an oligonucleotide tag encoding that function moiety.
[0096] Oligonucleotides may be ligated by chemical or enzymatic methods. In one embodiment, oligonucleotides are ligated by chemical means. Chemical ligation of DNA and RNA may be performed using reagents such as water soluble carbodiimide and cyanogen bromide as taught by, for example, Shabarova, et al. (1991) Nucleic Acids Research, 19, 4247-4251), Federova, et al. (1996) Nucleosides and Nucleotides, 15, 1137-1147, and Carriero and Damha (2003) Journal of Organic Chemistry, 68, 8328-8338. In one embodiment, chemical ligation is performed using cyanogen bromide, 5 M in acetonitrile, in a 1:10 v/v ratio with 5' phosphorylated oligonucleotide in a pH 7.6 buffer (1 M MES+20 mM MgCl2) at 0 degrees for 1-5 minutes. The oligonucleotides may be double stranded, preferably with an overhang of about 5 to about 14 bases. The oligonucleotide may also be single stranded, in which case a splint with an overlap of about 6 bases with each of the oligonucleotides to be ligated is employed to position the reactive 5' and 3' moieties in proximity with each other.
[0097] In another embodiment, the oligonucleotides are ligated using enzymatic methods. In one embodiment, the initial building block is operatively linked to an initial oligonucleotide. Prior to or following coupling of a second building block to the initial building block, a second oligonucleotide sequence which identifies the second building block is ligated to the initial oligonucleotide. Methods for ligating the initial oligonucleotide sequence and the incoming oligonucleotide sequence are set forth in FIGS. 1 and 2. In FIG. 1, the initial oligonucleotide is double-stranded, and one strand includes an overhang sequence which is complementary to one end of the second oligonucleotide and brings the second oligonucleotide into contact with the initial oligonucleotide. Preferably the overhanging sequence of the initial oligonucleotide and the complementary sequence of the second oligonucleotide are both at least about 4 bases; more preferably both sequences are both the same length. The initial oligonucleotide and the second oligonucleotide can be ligated using a suitable enzyme. If the initial oligonucleotide is linked to the first building block at the 5' end of one of the strands (the "top strand"), then the strand which is complementary to the top strand (the "bottom strand") will include the overhang sequence at its 5' end, and the second oligonucleotide will include a complementary sequence at its 5' end. Following ligation of the second oligonucleotide, a strand can be added which is complementary to the sequence of the second oligonucleotide which is 3' to the overhang complementary sequence, and which includes additional overhang sequence.
[0098] In one embodiment, the oligonucleotide is elongated as set forth in FIG. 2. The oligonucleotide bound to the growing functional moiety and the incoming oligonucleotide are positioned for ligation by the use of a "splint" sequence, which includes a region which is complementary to the 3' end of the initial oligonucleotide and a region which is complementary to the 5' end of the incoming oligonucleotide. The splint brings the 5' end of the oligonucleotide into proximity with the 3' end of the incoming oligo and ligation is accomplished using enzymatic ligation. In the example illustrated in FIG. 2, the initial oligonucleotide consists of 16 nucleobases and the splint is complementary to the 6 bases at the 3' end. The incoming oligonucleotide consists of 12 nucleobases, and the splint is complementary to the 6 bases at the 5' terminus. The length of the splint and the lengths of the complementary regions are not critical. However, the complementary regions should be sufficiently long to enable stable dimer formation under the conditions of the ligation, but not so long as to yield an excessively large encoding nucleotide in the final molecules. It is preferred that the complementary regions are from about 4 bases to about 12 bases, more preferably from about 5 bases to about 10 bases, and most preferably from about 5 bases to about 8 bases in length.
[0099] The split-and-pool methods used for the methods for library synthesis set forth herein assure that each unique functional moiety is operatively linked to at least one unique oligonucleotide sequence which identifies the functional moiety. If 2 or more different oligonucleotide tags are used for at least one building bock in at least one of the synthetic cycles, each distinct functional moiety comprising that building block will be encoded by multiple oligonucleotides. For example, if 2 oligonucleotide tags are used for each building block during the synthesis of a 4 cycle library, there will be 16 DNA sequences (24) that encode each unique functional moiety. There are several potential advantages for encoding each unique functional moiety with multiple sequences. First, selection of a different combination of tag sequences encoding the same functional moiety assures that those molecules were independently selected. Second, selection of a different combination of tag sequences encoding the same functional moiety eliminates the possibility that the selection was based on the sequence of the oligonucleotide. Third, technical artifact can be recognized if sequence analysis suggests that a particular functional moiety is highly enriched, but only one sequence combination out of many possibilities appears. Multiple tagging can be accomplished by having independent split reactions with the same building block but a different oligonucleotide tag. Alternatively, multiple tagging can be accomplished by mixing an appropriate ratio of each tag in a single tagging reaction with an individual building block.
[0100] In one embodiment, the initial oligonucleotide is double-stranded and the two strands are covalently joined. One means of covalently joining the two strands is shown in FIG. 3, in which a linking moiety is used to link the two strands and the functional moiety. The linking moiety can be any chemical structure which comprises a first functional group which is adapted to react with a building block, a second functional group which is adapted to react with the 3'-end of an oligonucleotide, and a third functional group which is adapted to react with the 5'-end of an oligonucleotide. Preferably, the second and third functional groups are oriented so as to position the two oligonucleotide strands in a relative orientation that permits hybridization of the two strands. For example, the linking moiety can have the general structure (I):
##STR00016##
where A, is a functional group that can form a covalent bond with a building block, B is a functional group that can form a bond with the 5'-end of an oligonucleotide, and C is a functional group that can form a bond with the 3'-end of an oligonucleotide. D, F and E are chemical groups that link functional groups A, C and B toS, which is a core atom or scaffold. Preferably, D, E and F are each independently a chain of atoms, such as an alkylene chain or an oligo(ethylene glycol) chain, and D, E and F can be the same or different, and are preferably effective to allow hybridization of the two oligonucleotides and synthesis of the functional moiety. In one embodiment, the trivalent linker has the structure
##STR00017##
In this embodiment, the NH group is available for attachment to a building block, while the terminal phosphate groups are available for attachment to an oligonucleotide.
[0101] In embodiments in which the initial oligonucleotide is double-stranded, the incoming oligonucleotides are also double-stranded. As shown in FIG. 3, the initial oligonucleotide can have one strand which is longer than the other, providing an overhang sequence. In this embodiment, the incoming oligonucleotide includes an overhang sequence which is complementary to the overhang sequence of the initial oligonucleotide. Hybridization of the two complementary overhang sequences brings the incoming oligonucleotide into position for ligation to the initial oligonucleotide. This ligation can be performed enzymatically using a DNA or RNA ligase. The overhang sequences of the incoming oligonucleotide and the initial oligonucleotide are preferably the same length and consist of two or more nucleotides, preferably from 2 to about 10 nucleotides, more preferably from 2 to about 6 nucleotides. In one preferred embodiment, the incoming oligonucleotide is a double-stranded oligonucleotide having an overhang sequence at each end. The overhang sequence at one end is complementary to the overhang sequence of the initial oligonucleotide, while, after ligation of the incoming oligonucleotide and the initial oligonucleotide, the overhang sequence at the other end becomes the overhang sequence of initial oligonucleotide of the next cycle. In one embodiment, the three overhang sequences are all 2 to 6 nucleotides in length, and the encoding sequence of the incoming oligonucleotide is from 3 to 10 nucleotides in length, preferably 3 to 6 nucleotides in length. In a particular embodiment, the overhang sequences are all 2 nucleotides in length and the encoding sequence is 5 nucleotides in length.
[0102] In the embodiment illustrated in FIG. 4, the incoming strand has a region at its 3' end which is complementary to the 3' end of the initial oligonucleotide, leaving overhangs at the 5' ends of both strands. The 5' ends can be filled in using, for example, a DNA polymerase, such as vent polymerase, resulting in a double-stranded elongated oligonucleotide. The bottom strand of this oligonucleotide can be removed, and additional sequence added to the 3' end of the top strand using the same method.
[0103] The encoding oligonucleotide tag is formed as the result of the successive addition of oligonucleotides that identify each successive building block. In one embodiment of the methods of the invention, the successive oligonucleotide tags may be coupled by enzymatic ligation to produce an encoding oligonucleotide.
[0104] Enzyme-catalyzed ligation of oligonucleotides can be performed using any enzyme that has the ability to ligate nucleic acid fragments. Exemplary enzymes include ligases, polymerases, and topoisomerases. In specific embodiments of the invention, DNA ligase (EC 6.5.1.1), DNA polymerase (EC 2.7.7.7), RNA polymerase (EC 2.7.7.6) or topoisomerase (EC 5.99.1.2) are used to ligate the oligonucleotides. Enzymes contained in each EC class can be found, for example, as described in Bairoch (2000) Nucleic Acids Research 28:304-5.
[0105] In a preferred embodiment, the oligonucleotides used in the methods of the invention are oligodeoxynucleotides and the enzyme used to catalyze the oligonucleotide ligation is DNA ligase. In order for ligation to occur in the presence of the ligase, i.e., for a phosphodiester bond to be formed between two oligonucleotides, one oligonucleotide must have a free 5' phosphate group and the other oligonucleotide must have a free 3' hydroxyl group. Exemplary DNA ligases that may be used in the methods of the invention include T4 DNA ligase, Taq DNA ligase, T4 RNA ligase, DNA ligase (E. coli) (all available from, for example, New England Biolabs, MA).
[0106] One of skill in the art will understand that each enzyme used for ligation has optimal activity under specific conditions, e.g., temperature, buffer concentration, pH and time. Each of these conditions can be adjusted, for example, according to the manufacturer's instructions, to obtain optimal ligation of the oligonucleotide tags.
[0107] The incoming oligonucleotide can be of any desirable length, but is preferably at least three nucleobases in length. More preferably, the incoming oligonucleotide is 4 or more nucleobases in length. In one embodiment, the incoming oligonucleotide is from 3 to about 12 nucleobases in length. It is preferred that the oligonucleotides of the molecules in the libraries of the invention have a common terminal sequence which can serve as a primer for PCR, as is known in the art. Such a common terminal sequence can be incorporated as the terminal end of the incoming oligonucleotide added in the final cycle of the library synthesis, or it can be added following library synthesis, for example, using the enzymatic ligation methods disclosed herein.
[0108] A preferred embodiment of the method of the invention is set forth in FIG. 5. The process begins with a synthesized DNA sequence which is attached at its 5' end to a linker which terminates in an amino group. In step 1, this starting DNA sequence is ligated to an incoming DNA sequence in the presence of a splint DNA strand, DNA ligase and dithiothreitol in Tris buffer. This yields a tagged DNA sequence which can then be used directly in the next step or purified, for example, using HPLC or ethanol precipitation, before proceeding to the next step. In step 2 the tagged DNA is reacted with a protected activated amino acid, in this example, an Fmoc-protected amino acid fluoride, yielding a protected amino acid-DNA conjugate. In step 3, the protected amino acid-DNA conjugate is deprotected, for example, in the presence of piperidine, and the resulting deprotected conjugate is, optionally, purified, for example, by HPLC or ethanol precipitation. The deprotected conjugate is the product of the first synthesis cycle, and becomes the starting material for the second cycle, which adds a second amino acid residue to the free amino group of the deprotected conjugate.
[0109] In embodiments in which PCR is to be used to amplify and/or sequence the encoding oligonucleotides of selected molecules, the encoding oligonucleotides may include, for example, PCR primer sequences and/or sequencing primers (e.g., primers such as, for example, 3'-GACTACCGCGCTCCCTCCG-5' (SEQ ID NO: 891) and 3'-GACTCGCCCGACCGTTCCG-5' (SEQ ID NO: 892)). A PCR primer sequence can be included, for example, in the initial oligonucleotide prior to the first cycle of synthesis, and/or it can be included with the first incoming oligonucleotide, and/or it can be ligated to the encoding oligonucleotide following the final cycle of library synthesis, and/or it can be included in the incoming oligonucleotide of the final cycle. The PCR primer sequences added following the final cycle of library synthesis and/or in the incoming oligonucleotide of the final cycle are referred to herein as "capping sequences".
[0110] In one embodiment, the PCR primer sequence is designed into the encoding oligonucleotide tag. For example, a PCR primer sequence may be incorporated into the initial oligonucleotide tag and/or it may be incorporated into the final oligonucleotide tag. In one embodiment the same PCR primer sequence is incorporated into the initial and final oligonucleotide tag. In another embodiment, a first PCR sequence is incorporated into the initial oligonucleotide tag and a second PCR primer sequence is incorporated in the final oligonucleotide tag. Alternatively, the second PCR primer sequence may be incorporated into the capping sequence as described herein. In preferred embodiments, the PCR primer sequence is at least about 5, 7, 10, 13, 15, 17, 20, 22, or 25 nucleotides in length.
[0111] PCR primer sequences suitable for use in the libraries of the invention are known in the art; suitable primers and methods are set forth, for example, in Innis, et al., eds., PCR Protocols: A Guide to Methods and Applications, San Diego: Academic Press (1990), the contents of which are incorporated herein by reference in their entirety. Other suitable primers for use in the construction of the libraries described herein are those primers described in PCT Publications WO 2004/069849 and WO 2005/003375, the contents of which are expressly incorporated herein by reference.
[0112] The term "polynucleotide" as used herein in reference to primers, probes and nucleic acid fragments or segments to be synthesized by primer extension is defined as a molecule comprised of two or more deoxyribonucleotides, preferably more than three.
[0113] The term "primer" as used herein refers to a polynucleotide whether purified from a nucleic acid restriction digest or produced synthetically, which is capable of acting as a point of initiation of nucleic acid synthesis when placed under conditions in which synthesis of a primer extension product which is complementary to a nucleic acid strand is induced, i.e., in the presence of nucleotides and an agent for polymerization such as DNA polymerase, reverse transcriptase and the like, and at a suitable temperature and pH. The primer is preferably single stranded for maximum efficiency, but may alternatively be in double stranded form. If double stranded, the primer is first treated to separate it from its complementary strand before being used to prepare extension products. Preferably, the primer is a polydeoxyribonucleotide. The primer must be sufficiently long to prime the synthesis of extension products in the presence of the agents for polymerization. The exact lengths of the primers will depend on many factors, including temperature and the source of primer.
[0114] The primers used herein are selected to be "substantially" complementary to the different strands of each specific sequence to be amplified. This means that the primer must be sufficiently complementary so as to non-randomly hybridize with its respective template strand. Therefore, the primer sequence may or may not reflect the exact sequence of the template.
[0115] The polynucleotide primers can be prepared using any suitable method, such as, for example, the phosphotriester or phosphodiester methods described in Narang et al., (1979) Meth. Enzymol., 68:90; U.S. Pat. No. 4,356,270, U.S. Pat. No. 4,458,066, U.S. Pat. No. 4,416,988, U.S. Pat. No. 4,293,652; and Brown et al., (1979) Meth. Enzymol., 68:109. The contents of all the foregoing documents are incorporated herein by reference.
[0116] In cases in which the PCR primer sequences are included in an incoming oligonucleotide, these incoming oligonucleotides will preferably be significantly longer than the incoming oligonucleotides added in the other cycles, because they will include both an encoding sequence and a PCR primer sequence.
[0117] In one embodiment, the capping sequence is added after the addition of the final building block and final incoming oligonucleotide, and the synthesis of a library as set forth herein includes the step of ligating the capping sequence to the encoding oligonucleotide, such that the oligonucleotide portion of substantially all of the library members terminates in a sequence that includes a PCR primer sequence. Preferably, the capping sequence is added by ligation to the pooled fractions which are products of the final synthetic cycle. The capping sequence can be added using the enzymatic process used in the construction of the library.
[0118] In one embodiment, the same capping sequence is ligated to every member of the library. In another embodiment, a plurality of capping sequences are used. In this embodiment, oligonucleotide capping sequences containing variable bases are, for example, ligated onto library members following the final synthetic cycle. In one embodiment, following the final synthetic cycle, the fractions are pooled and then split into fractions again, with each fraction having a different capping sequence added. Alternatively, multiple capping sequences can be added to the pooled library following the final synthesis cycle. In both embodiments, the final library members will include molecules comprising specific functional moieties linked to identifying oligonucleotides including two or more different capping sequences.
[0119] In one embodiment, the capping primer comprises an oligonucleotide sequence containing variable, i.e., degenerate, nucleotides. Such degenerate bases within the capping primers permit the identification of library molecules of interest by determining whether a combination of building blocks is the consequence of PCR duplication (identical sequence) or independent occurrences of the molecule (different sequence). For example, such degenerate bases may reduce the potential number of false positives identified during the biological screening of the encoded library.
[0120] In one embodiment, a degenerate capping primer comprises or has the following sequence:
##STR00018##
where N can be any of the 4 bases, permitting 1024 different sequences (45). The primer has the following sequence after its ligation onto the library and primer-extension:
TABLE-US-00001 (SEQ ID NO: 895) 5'-CAGCGTTCGA N'N'N'N'N'CAGACAAGCTTCACCTGC-3' (SEQ ID NO: 896) 3'-AA GTCGCAAGCT N N N N N GTCTGTTCGAAGTGGACG-5'
[0121] In another embodiment, the capping primer comprises or has the following sequence:
##STR00019##
[0122] where B can be any of C, G or T, permitting 19,683 different sequences (39). The design of the degenerate region in this primer improves DNA sequence analysis, as the A bases that flank and punctuate the degenerate B bases prevent homopolymeric stretches of greater than 3 bases, and facilitate sequence alignment.
[0123] In one embodiment, the degenerate capping oligonucleotide is ligated to the members of the library using a suitable enzyme and the upper strand of the degenerate capping oligonucleotide is subsequently polymerized using a suitable enzyme, such as a DNA polymerase.
[0124] In another embodiment, the PCR priming sequence is a "universal adaptor" or "universal primer". As used herein, a "universal adaptor" or "universal primer" is an oligonucleotide that contains a unique PCR priming region, that is, for example, about 5, 7, 10, 13, 15, 17, 20, 22, or 25 nucleotides in length, and is located adjacent to a unique sequencing priming region that is, for example, about 5, 7, 10, 13, 15, 17, 20, 22, or 25 nucleotides in length, and is optionally followed by a unique discriminating key sequence (or sample identifier sequence) consisting of at least one of each of the four deoxyribonucleotides (i.e., A, C, G, T).
[0125] As used herein, the term "discriminating key sequence" or "sample identifier sequence" refers to a sequence that may be used to uniquely tag a population of molecules from a sample. Multiple samples, each containing a unique sample identifier sequence, can be mixed, sequenced and re-sorted after DNA sequencing for analysis of individual samples. The same discriminating sequence can be used for an entire library or, alternatively, different discriminating key sequences can be used to track different libraries. In one embodiment, the discriminating key sequence is on either the 5' PCR primer, the 3' PCR primer, or on both primers. If both PCR primers contain a sample identifier sequence, the number of different samples that can be pooled with unique sample identifier sequences is the product of the number of sample identifier sequences on each primer. Thus, 10 different 5' sample identifier sequence primers can be combined with 10 different 3' sample identifier sequence primers to yield 100 different sample identifier sequence combinations.
[0126] Non-limiting examples of 5' and 3' unique PCR primers containing discriminating key sequences include the following:
TABLE-US-00002 5' primers (variable positions bold and italicized): (SEQ ID NO: 898) 5' A-GCCTTGCCAGCCCGCTCAG TGACTCCCAAATCGATGTG; (SEQ ID NO: 899) 5' C-GCCTTGCCAGCCCGCTCAG TGACTCCCAAATCGATGTG; (SEQ ID NO: 900) 5' G-GCCTTGCCAGCCCGCTCAG TGACTCCCAAATCGATGTG; (SEQ ID NO: 901) 5' T-GCCTTGCCAGCCCGCTCAG TGACTCCCAAATCGATGTG; (SEQ ID NO: 902) 5' AA-GCCTTGCCAGCCCGCTCAG TGACTCCCAAATCGATGTG; (SEQ ID NO: 903) 5' AC-GCCTTGCCAGCCCGCTCAG TGACTCCCAAATCGATGTG; (SEQ ID NO: 904) 5' AG-GCCTTGCCAGCCCGCTCAG TGACTCCCAAATCGATGTG; (SEQ ID NO: 905) 5' AT-GCCTTGCCAGCCCGCTCAG TGACTCCCAAATCGATGTG; and (SEQ ID NO: 906) 5' CA-GCCTTGCCAGCCCGCTCAG TGACTCCCAAATCGATGTG. 3' SID primers (variable positions bold and italicized): (SEQ ID NO: 907) 3' A-GCCTCCCTCGCGCCATCAG GCAGGTGAAGCTTGTCTG; (SEQ ID NO: 908) 3' C-GCCTCCCTCGCGCCATCAG GCAGGTGAAGCTTGTCTG; (SEQ ID NO: 909) 3' G-GCCTCCCTCGCGCCATCAG GCAGGTGAAGCTTGTCTG; (SEQ ID NO: 910) 3' T-GCCTCCCTCGCGCCATCAG GCAGGTGAAGCTTGTCTG; (SEQ ID NO: 911) 3' AA-GCCTCCCTCGCGCCATCAG GCAGGTGAAGCTTGTCTG; (SEQ ID NO: 912) 3' AC-GCCTCCCTCGCGCCATCAG GCAGGTGAAGCTTGTCTG; (SEQ ID NO: 913) 3' AG-GCCTCCCTCGCGCCATCAG GCAGGTGAAGCTTGTCTG; (SEQ ID NO: 914) 3' AT-GCCTCCCTCGCGCCATCAG GCAGGTGAAGCTTGTCTG; and (SEQ ID NO: 915) 3' CA-GCCTCCCTCGCGCCATCAG GCAGGTGAAGCTTGTCTG
[0127] In one embodiment, the discriminating key sequence is about 4, 5, 6, 7, 8, 9, or nucleotides in length. In another embodiment, the discriminating key sequence is a combination of about 1-4 nucleotides. In yet another embodiment, each universal adaptor is about forty-four nucleotides in length. In one embodiment the universal adaptors are ligated, using T4 DNA ligase, onto the end of the encoding oligonucleotide. Different universal adaptors may be designed specifically for each library preparation and will, therefore, provide a unique identifier for each library. The size and sequence of the universal adaptors may be modified as deemed necessary by one of skill in the art.
[0128] In one embodiment, the universal adaptor added as a capping sequence is linked to a support binding moiety. For example, a 5'-biotin is added to the universal adaptor to allow, for example, isolation of single-stranded DNA template as well as non-covalent coupling of the universal adaptor to the surface of a solid support that is saturated with a biotin-binding protein (i.e., streptavidin, neutravidin or avidin). Other linkages are well known in the art and may be used in place of biotin-streptavidin (for example antibody/antigen-epitope, receptor/ligand and oligonucleotide pairing or complimentarity).
[0129] In another embodiment, the capping sequence contains anchor primer sequences such that the members of the library may be attached to a solid substrate. In one embodiment, the anchor primer sequences are annealed to the capping sequences using recognized techniques (see, e.g., Hatch, et al. (1999) Genet. Anal Biomol Engineer 15: 35-40; U.S. Pat. No. 5,714,320, and U.S. Pat. No. 5,854,033). In general, any procedure for annealing the anchor primers to the capping sequences is suitable as long as it results in formation of specific, i.e., perfect or nearly perfect, complementarity between the adapter region or regions in the anchor primer sequence and a sequence present in the capping sequences. The anchoring of the encoding oligonucleotide to the solid surface may be reversible or irreversible, e.g., the anchor to the solid surface may be cleavable or non-cleavable.
[0130] In one embodiment, the universal primer, is annealed to a solid support that contains oligonucleotide capture primers that are complementary to the PCR priming regions of the universal adaptor ends.
[0131] In one embodiment, the solid support is a bead, for example, a sepharose bead. The beads may be of any convenient size and fabricated from any number of known materials. Example of such materials include: inorganics, natural polymers, and synthetic polymers. Specific examples of these materials include: cellulose, cellulose derivatives, acrylic resins, glass; silica gels, polystyrene, gelatin, polyvinyl pyrrolidone, co-polymers of vinyl and acrylamide, polystyrene cross-linked with divinylbenzene or the like (see, Merrifield (1964) Biochemistry 3:1385-1390), polyacrylamides, latex gels, polystyrene, dextran, rubber, silicon, plastics, nitrocellulose, celluloses, natural sponges, silica gels, glass, metals plastic, cellulose, cross-linked dextrans (e.g., Sephadex®) and agarose gel (Sepharose®) and solid phase supports known to those of skill in the art.
[0132] The encoding oligonucleotides may be attached to the solid support capture bead ("DNA capture bead") in any manner known in the art. Any suitable coupling agent known in the art can be used, such as, for example, water-soluble carbodiimide, to link the 5'-phosphate on the DNA to amine-coated capture beads through a phosphoamidate bond, coupling specific oligonucleotide linkers to the bead using similar chemistry, and using DNA ligase to link the DNA to the linker on the bead, joining the oligonucleotide to the beads using N-hydroxysuccinamide (NHS) and its derivatives, such that one end of the oligonucleotide may contain a reactive group (such as an amide group) which forms a covalent bond with the solid support, while the other end of the linker contains a second reactive group that can bond with the oligonucleotide to be immobilized.
[0133] In another embodiment, the oligonucleotide is bound to the DNA capture bead by non-covalent linkage, such as chelation or antigen-antibody complexes, may also be used to join the oligonucleotide to the bead. Oligonucleotide linkers can be employed which specifically hybridize to unique sequences at the end of the DNA fragment, such as the overlapping end from a restriction enzyme site or the "sticky ends" of bacteriophage lambda based cloning vectors, but blunt-end ligations can also be used beneficially. These methods are described in detail in U.S. Pat. No. 5,674,743. It is preferred that any method used to immobilize the beads will continue to bind the immobilized oligonucleotide throughout the steps in the methods of the invention.
[0134] In one embodiment, the oligonucleotide is attached to a solid support manufactured from, for example, glass, plastic, a nylon membrane, a gel matrix, ceramics, silica, silicon, or any other non-reactive material as described in U.S. Pat. No. 6,787,308, the entire contents of which are incorporated by reference. The supports generally comprise a flat, i.e., planar, surface, or at least an array in which the molecules to be analysed are in the same plane. The oligonucleotide may be attached by specific covalent or non-covalent interactions. In one embodiment of the invention, the surface of a solid support is coated with streptavidin or avidin. In another embodiment of the invention, the solid surface is coated with an epoxide and the molecules are coupled via an amine linkage. In yet another embodiment, the encoding oligonucleotide may be attached to a solid support via hybridization to a complementary nucleic acid molecule previously attached to the solid support.
[0135] In one embodiment, the solid support is pretreated to create surface chemistry that facilitates oligonucleotide attachment and subsequent sequence analysis. In one embodiment, the solid support is coated with a polyelectrolyte multilayer (PEM). In another embodiment, the encoding oligonucleotide is attached to the surface of a microfabricated channel or to the surface of reaction chambers that are disposed along a microfabricated flow channel, optionally with streptavidin-biotin links. The methods of each of these attachment methods are described in PCT Publication No. WO 2005/080605, the entire contents of which are incorporated by reference.
[0136] In one embodiment, the encoding oligonucleotide is attached to a solid surface at high density and at single molecule resolution. In one embodiment, the encoding oligonucleotide is attached to a solid surface at an individually-addressable location (see, e.g., PCT Publication No. WO 2005/080605).
[0137] Attachment of the encoding oligonucleotide to any suitable solid surface can occur prior to the hybridization of a primer for amplification and/or sequencing or alternatively, the encoding oligonucleotide can be attached to any suitable solid surface after the hybridization of a primer for amplification and/or sequencing.
[0138] In another embodiment, the oligonucleotide is attached to a particle, such as a microsphere, which is itself attached to a solid support. The microspheres may be of any suitable size, typically in the range of from 10 nm to 100 nm in diameter.
[0139] In one embodiment, the universal adaptors are not 5'-phosphorylated. Accordingly, "gaps" or "nicks" can be filled in by using a DNA polymerase enzyme that can bind to, strand displace and extend the nicked DNA fragments according to techniques recognized in the art. DNA polymerases that lack 3'->5' exonuclease activity but exhibit 5'->3' exonuclease activity have the ability to recognize nicks, displace the nicked strands, and extend the strand in a manner that results in the repair of the nicks and in the formation of non-nicked double-stranded DNA (Hamilton, et al. (2001) BioTechniques 31:370).
[0140] Several modifying enzymes are utilized for the nick repair step, including but not limited to polymerase, ligase and kinase. DNA polymerases that can be used for this application include, for example, E. coli DNA pol I, Thermoanaerobacter thermohydrosulfuricus pol I, and bacteriophage phi 29. In one embodiment, the strand displacing enzyme Bacillus stearothermophilus pol I (Bst DNA polymerase I) is used to repair the nicked dsDNA and results in non-nicked dsDNA. In another embodiment, the ligase is T4 and the kinase is polynucleotide kinase.
[0141] The invention further relates to the compounds which can be produced using the methods of the invention, and collections of such compounds, either as isolated species or pooled to form a library of chemical structures. Compounds of the invention include compounds of the formula
##STR00020##
where X is a functional moiety comprising one or more building blocks, Z is an oligonucleotide attached at its 3' terminus to B and Y is an oligonucleotide which is attached to C at its 5' terminus. A is a functional group that forms a covalent bond with X, B is a functional group that forms a bond with the 3'-end of Z and C is a functional group that forms a bond with the 5'-end of Y. D, F and E are chemical groups that link functional groups A, C and B to S, which is a core atom or scaffold. Preferably, D, E and F are each independently a chain of atoms, such as an alkylene chain or an oligo(ethylene glycol) chain, and D, E and F can be the same or different, and are preferably effective to allow hybridization of the two oligonucleotides and synthesis of the functional moiety.
[0142] Preferably, Y and Z are substantially complementary and are oriented in the compound so as to enable Watson-Crick base pairing and duplex formation under suitable conditions. Y and Z are the same length or different lengths. Preferably, Y and Z are the same length, or one of Y and Z is from 1 to 10 bases longer than the other. In a preferred embodiment, Y and Z are each 10 or more bases in length and have complementary regions of ten or more base pairs. More preferably, Y and Z are substantially complementary throughout their length, i.e., they have no more than one mismatch per every ten base pairs. Most preferably, Y and Z are complementary throughout their length, i.e., except for any overhang region on Y or Z, the strands hybridize via Watson-Crick base pairing with no mismatches throughout their entire length.
[0143] S can be a single atom or a molecular scaffold. For example, S can be a carbon atom, a boron atom, a nitrogen atom or a phosphorus atom, or a polyatomic scaffold, such as a phosphate group or a cyclic group, such as a cycloalkyl, cycloalkenyl, heterocycloalkyl, heterocycloalkenyl, aryl or heteroaryl group. In one embodiment, the linker is a group of the structure
##STR00021##
where each of n, m and p is, independently, an integer from 1 to about 20, preferably from 2 to eight, and more preferably from 3 to 6. In one particular embodiment, the linker has the structure shown below.
##STR00022##
[0144] In one embodiment, the libraries of the invention include molecules consisting of a functional moiety composed of building blocks, where each functional moiety is operatively linked to an encoding oligonucleotide. The nucleotide sequence of the encoding oligonucleotide is indicative of the building blocks present in the functional moiety, and in some embodiments, the connectivity or arrangement of the building blocks. The invention provides the advantage that the methodology used to construct the functional moiety and that used to construct the oligonucleotide tag can be performed in the same reaction medium, preferably an aqueous medium, thus simplifying the method of preparing the library compared to methods in the prior art. In certain embodiments in which the oligonucleotide ligation steps and the building block addition steps can both be conducted in aqueous media, each reaction will have a different pH optimum. In these embodiments, the building block addition reaction can be conducted at a suitable pH and temperature in a suitable aqueous buffer. The buffer can then be exchanged for an aqueous buffer which provides a suitable pH for oligonucleotide ligation.
[0145] In another embodiment, the invention provides compounds, and libraries comprising such compounds, of Formula II
Z-L-At-X(Y)n (II)
where X is a molecular scaffold, each Y is independently, a peripheral moiety, and n is an integer from 1 to 6. Each A is independently, a building block and n is an integer from 0 to about 5. L is a linking moiety and Z is a single-stranded or double-stranded oligonucleotide which identifies the structure -At-X(Y)n. The structure X(Y)n can be, for example, one of the scaffold structures set forth in Table 8 (see below). In one embodiment, the invention provides compounds, and libraries comprising such compounds, of Formula III:
##STR00023##
where t is an integer from 0 to about 5, preferably from 0 to 3, and each A is, independently, a building block. L is a linking moiety and Z is a single-stranded or double-stranded oligonucleotide which identifies each A and R1, R2, R3 and R4. R1, R2, R3 and R4 are each independently a substituent selected from hydrogen, alkyl, substituted alkyl, heteroalkyl, substituted heteroalkyl, cycloalkyl, heterocycloalkyl, substituted cycloalkyl, substituted heterocycloalkyl, aryl, substituted aryl, arylalkyl, heteroarylalkyl, substituted arylalkyl, substituted heteroarylalkyl, heteroaryl, substituted heteroaryl, alkoxy, aryloxy, amino, and substituted amino. In one embodiment, each A is an amino acid residue.
[0146] Libraries which include compounds of Formula II or Formula III can comprise at least about 100; 1000; 10,000; 100,000; 1,000,000 or 10,000,000 compounds of Formula II or Formula III. In one embodiment, the library is prepared via a method designed to produce a library comprising at least about 100; 1000; 10,000; 100,000; 1,000,000 or 10,000,000 compounds of Formula II or Formula III.
TABLE-US-00003 TABLE 8 Scaffolds Amine Aldehyde/Ketone Carboxylic acid Other Reference ##STR00024## ##STR00025## ##STR00026## ##STR00027## Carranco, I., et al. (2005) J. Comb. Chem. 7: 33-41 ##STR00028## amines benzaldehydes and furfural ##STR00029## Rosamilia, A. E., et al. (2005) Organic Letters 7: 1525-1528 ##STR00030## ##STR00031## ##STR00032## ##STR00033## ##STR00034## Syeda Huma, H. Z., et al. (2002) Tet Lett 43: 6485- 6488 ##STR00035## ##STR00036## R2--CHO ##STR00037## ≡N--R3 Tempest, P., et al. (2001) Tet Lett 42: 4959-4962 ##STR00038## ##STR00039## ##STR00040## ##STR00041## ##STR00042## Paulvannan, K. (1999) Tet Lett 40: 1851- 1854 ##STR00043## R1--CHO ##STR00044## ≡N--R4 Tempest, P., et al. (2001) Tet Lett 42: 4963-4968 ##STR00045## R2--NH2 ##STR00046## ##STR00047## ≡N--R3 Tempest, P., et al. (2003) Tet Lett 44: 1947-1950 ##STR00048## R1--CHO R2--COOH ##STR00049## Nefzi, A., et al. (1999) Tet Lett 40: 4939- 4942 ##STR00050## ##STR00051## ##STR00052## ##STR00053## ##STR00054## Bose, A. K., et al. (2005) Tet Lett 46: 1901- 1903 ##STR00055## ##STR00056## R1--CHO ##STR00057## Stadler, A. and Kappe, C. O. (2001) J. Comb. Chem. 3: 624-630; Lengar, A. and Kappe, C. O. (2004) Organic Letters 6: 771- 774 ##STR00058## wide range of primary aliphatic amines ##STR00059## ##STR00060## Ivachtchenko, A. V., et al. (2003) J. Comb. Chem. 5: 775-788 ##STR00061## ##STR00062## ##STR00063## ##STR00064## Micheli, F., et al. (2001) J. Comb. Chem. 3: 224- 228 ##STR00065## R1--HS R1--NH2 ##STR00066## ##STR00067## ##STR00068## Sternson, S. M., et al. (2001) Org. Lett. 3: 4239- 4242 ##STR00069## ##STR00070## ##STR00071## Cheng, W. -C., et al. (2002) J. Org. Chem. 67: 5673- 5677; Park, K. -H., et al. (2001) J Comb Chem 3: 171-176 ##STR00072## ##STR00073## ##STR00074## Brown, B. J., et al. (2000) Synlett 1: 131- 133 ##STR00075## R1--NH2 ##STR00076## ##STR00077## ##STR00078## Kilburn, J. P., et al. (2001) Tet Lett 42: 2583-2586 ##STR00079## amino acid amino acid ester del Fresno, M., et al. (1998) Tet Lett 39: 2639- 2642 ##STR00080## amino acid carboxylic acids Alvarez- Gutierrez, J. M., et al. (2000) Tet Lett 41: 609- 612 ##STR00081## R2--CHO ##STR00082## ##STR00083## Rinnova, M., et al. (2002) J. Comb. Chem 4: 209-213 ##STR00084## R1--NH2 ##STR00085## ##STR00086## Makara, G. M., et al. (2002) Organic Lett 4: 1751-1754 ##STR00087## ##STR00088## Schell, P., et al. (2005) J. Comb. Chem 7: 96-98 ##STR00089## amino acids Feliu, L., et al. (2003) J. Comb. Chem. 5: 356-361 ##STR00090## Amines Aldehydes ##STR00091## amino acids Hiroshige, M., et al. (1995) J. Am. Chem. Soc. 117: 11590- 11591 ##STR00092## amino acids Bose, A. K., et al. (2005) Tet Lett 46: 1901- 1903
[0147] One advantage of the methods of the invention is that they can be used to prepare libraries comprising vast numbers of compounds. The ability to amplify encoding oligonucleotide sequences using known methods such as polymerase chain reaction ("PCR") means that selected molecules can be identified even if relatively few copies are recovered. This allows the practical use of very large libraries, which, as a consequence of their high degree of complexity, either comprise relatively few copies of any given library member, or require the use of very large volumes. For example, a library consisting of 108 unique structures in which each structure has 1×1012 copies (about 1 picomole), requires about 100 L of solution at 1 μM effective concentration. For the same library, if each member is represented by 1,000,000 copies, the volume required is 100 μL at 1 μM effective concentration.
[0148] In a preferred embodiment, the library comprises from about 103 to about 1015 copies of each library member. Given differences in efficiency of synthesis among the library members, it is possible that different library members will have different numbers of copies in any given library. Therefore, although the number of copies of each member theoretically present in the library may be the same, the actual number of copies of any given library member is independent of, the number of copies of any other member. More preferably, the compound libraries of the invention include at least about 105, 106 or 107 copies of each library member, or of substantially all library members. By "substantially all" library members is meant at least about 85% of the members of the library, preferably at least about 90%, and more preferably at least about 95% of the members of the library.
[0149] Preferably, the library includes a sufficient number of copies of each member that multiple rounds (i.e., two or more) of selection against a biological target can be performed, with sufficient quantities of binding molecules remaining following the final round of selection to enable amplification of the oligonucleotide tags of the remaining molecules and, therefore, identification of the functional moieties of the binding molecules. A schematic representation of such a selection process is illustrated in FIG. 6, in which 1 and 2 represent library members, B is a target molecule and X is a moiety operatively linked to B that enables the removal of B from the selection medium. In this example, compound 1 binds to B, while compound 2 does not bind to B. The selection process, as depicted in Round 1, comprises (I) contacting a library comprising compounds 1 and 2 with B--X under conditions suitable for binding of compound 1 to B; (II) removing unbound compound 2, (III) dissociating compound 1 from B and removing BX from the reaction medium. The result of Round 1 is a collection of molecules that is enriched in compound 1 relative to compound 2. Subsequent rounds employing steps I-III result in further enrichment of compound 1 relative to compound 2. Although three rounds of selection are shown in FIG. 6, in practice any number of rounds may be employed, for example from one round to ten rounds, to achieve the desired enrichment of binding molecules relative to non-binding molecules.
[0150] In the embodiment shown in FIG. 6, there is no amplification (synthesis of more copies) of the compounds remaining after any of the rounds of selection. Such amplification can lead to a mixture of compounds which is not consistent with the relative amounts of the compounds remaining after the selection. This inconsistency is due to the fact that certain compounds may be more readily synthesized that other compounds, and thus may be amplified in a manner which is not proportional to their presence following selection. For example, if compound 2 is more readily synthesized than compound 1, the amplification of the molecules remaining after Round 2 would result in a disproportionate amplification of compound 2 relative to compound 1, and a resulting mixture of compounds with a much lower (if any) enrichment of compound 1 relative to compound 2.
[0151] In one embodiment, the target is immobilized on a solid support by any known immobilization technique. The solid support can be, for example, a water-insoluble matrix contained within a chromatography column or a membrane. The encoded library can be applied to a water-insoluble matrix contained within a chromatography column. The column is then washed to remove non-specific binders. Target-bound compounds can then be dissociated by changing the pH, salt concentration, organic solvent concentration, or other methods, such as competition with a known ligand to the target.
[0152] In another embodiment, the target is free in solution and is incubated with the encoded library. Compounds which bind to the target (also referred to herein as "ligands") are selectively isolated by a size separation step such as gel filtration or ultrafiltration. In one embodiment, the mixture of encoded compounds and the target biomolecule are passed through a size exclusion chromatography column (gel filtration), which separates any ligand-target complexes from the unbound compounds. The ligand-target complexes are transferred to a reverse-phase chromatography column, which dissociates the ligands from the target. The dissociated ligands are then analyzed by PCR amplification and sequence analysis of the encoding oligonucleotides. This approach is particularly advantageous in situations where immobilization of the target may result in a loss of activity.
[0153] Accordingly, in one aspect of the invention, methods are provided for identifying one or more compounds in a library of compounds, produced as described herein, that bind to a biological target and subsequently determining the structure of the functional moieties of the member(s) of the library of compounds that bind to the biological target.
[0154] For example, in one embodiment, one or more compounds which bind to a biological target can be identified by a method comprising the steps of:
[0155] (A) synthesizing a library of compounds, wherein the compounds comprise a functional moiety comprising two or more building blocks which is operatively linked to an initial oligonucleotide which identifies the structure of the functional moiety by: [0156] (i) providing a solution comprising m initiator compounds, wherein m is an integer of 1 or greater, where the initiator compounds consist of a functional moiety comprising n building blocks, where n is an integer of 1 or greater, which is operatively linked to an initial oligonucleotide which identifies the n building blocks; [0157] (ii) dividing the solution of step (i) into r reaction vessels, wherein r is an integer of 2 or greater, thereby producing r aliquots of the solution; [0158] (iii) reacting the initiator compounds in each reaction vessel with one of r building blocks, thereby producing r aliquots comprising compounds consisting of a functional moiety comprising n+1 building blocks operatively linked to the initial oligonucleotide; and [0159] (iv) reacting the initial oligonucleotide in each aliquot with one of a set of r distinct incoming oligonucleotides in the presence of an enzyme which catalyzes the ligation of the incoming oligonucleotide and the initial oligonucleotide, under conditions suitable for enzymatic ligation of the incoming oligonucleotide and the initial oligonucleotide; thereby producing r aliquots of molecules consisting of a functional moiety comprising n+1 building blocks operatively linked to an elongated oligonucleotide which encodes the n+1 building blocks;
[0160] (B) contacting the biological target with the library of compounds, or a portion thereof, under conditions suitable for at least one member of the library of compounds to bind to the target;
[0161] (C) removing library members that do not bind to the target;
[0162] (D) sequencing the encoding oligonucleotides of the at least one member of the library of compounds which binds to the target, and
[0163] (E) using the sequences determined in step (D) to determine the structure of the functional moieties of the members of the library of compounds which bind to the biological target, thereby identifying one or more compounds which bind to the biological target.
[0164] In one embodiment, the method further comprises ligating a degenerate capping oligonucleotide to the members of the library of compounds in the presence of an enzyme which catalyzes the ligation and polymerizing the degenerate capping oligonucleotide with an enzyme that catalyzes the polymerization of DNA.
[0165] In one embodiment, the method may further comprise amplifying the encoding oligonucleotide of the at least one member of the library of compounds which binds to the target prior to sequencing.
[0166] In one embodiment of the invention, the selection and enrichment of the library is monitored using an oligonucleotide array. For example, a library of compounds may be hybridized to a solid surface, such as a chip comprising oligonucleotides, e.g., an Affymetrix oligonucleotide chip, which is subsequently flouresced to detect the oligonucleotide tags bound to the surface. This hybridization can be repeated at each successive step of the screening process for identifying a compound with a desired biological activity.
[0167] In one embodiment, the library of compounds comprising encoding oligonucleotides which are optionally attached to capture beads as described above are emulsified as a heat stable water-in-oil emulsion to form a microcapsule according to the methods described in PCT Publications WO 2004/069849, WO 2005/003375, and WO 2005/073410. In one embodiment, the emulsion can be generated by suspending the oligonucleotide tag, with or without attached beads, in amplification solution, e.g., forming a "microreactor." As used herein, the term "amplification solution" means the sufficient mixture of reagents that is necessary to perform amplification of template DNA. One example of an amplification solution, is a PCR amplification solution, that one of skill in the art can readily prepare.
[0168] In one embodiment of the invention, the library of compounds comprising encoding oligonucleotides are amplified to increase the copy number of encoding oligonucleotide molecules prior to sequencing. Encoding oligonucleotides may be amplified by any suitable method of DNA amplification including, for example, temperature cycling-polymerase chain reaction (PCR) (see, e.g., Saiki, et al. (1995) Science 230:1350-1354; Gingeras, et al. WO 88/10315; Davey, et al. European Patent Application Publication No. 329,822; Miller, et al. WO 89/06700), ligase chain reaction (see, e.g., Barany (1991) Proc. Natl Acad. Sci. USA 88:189-193; Barringer, et al. (1990) Gene 89:117-122), transcription-based amplification (see, e.g., Kwoh, et al. (1989) Proc. Natl. Acad. Sci. USA 86:1173-1177) isothermal amplification systems--self-sustaining, sequence replication (see, e.g., Guatelli, et al. (1990) Proc. Natl. Acad. Sci. USA 87:1874-1878); the Qp replicase system (see, e.g., Lizardi, et al. (1988) BioTechnology 6: 1197-1202); strand displacement amplification (Walker, et al. (1992) Nucleic Acids Res 20(7):1691-6; the methods described by Walker, et al. (Proc. Natl. Acad. Sci. USA (1992) 1:89(1):392-6; the methods described by Kievits, et al. (J Virol Methods (1991) 35(3):273-86; "race" (Frohman, In: PCR Protocols: A Guide to Methods and Applications, Academic Press, NY (1990)); "one-sided PCR" (Ohara, et al. (1989) Proc. Natl. Acad. Sci. U.S.A. 86.5673-5677); "di-oligonucleotide" amplification, isothermal amplification (Walker, et al. (1992) Proc. Natl. Acad. Sci. U.S.A. 89:392-396), and rolling circle amplification (reviewed in U.S. Pat. No. 5,714,320).
[0169] In one embodiment, the library of compounds comprising encoding oligonucleotides is amplified prior to sequence analysis in order to minimize any potential skew in the population distribution of DNA molecules present in the selected library mix. For example, only a small amount of library is recovered after a selection step and is typically amplified using PCR prior to sequence analysis. PCR has the potential to produce a skew in the population distribution of DNA molecules present in the selected library mix. This is especially problematic when the number of input molecules is small and the input molecules are poor PCR templates. PCR products produced at early cycles are more efficient templates than covalent duplex library, and therefore the frequency of these molecules in the final amplified population may be much higher than in original input template.
[0170] Accordingly, in order to minimize this potential PCR skew, in one embodiment of the invention, a population of single-stranded oligonucleotides corresponding to the individual library members is produced by, for example, using one primer in a reaction, followed by PCR amplification using two primers. By doing so, there is a linear accumulation of single-stranded primer-extension product prior to exponential amplification using PCR, and the diversity and distribution of molecules in the accumulated primer-extension product more accurately reflect the diversity and distribution of molecules present in the original input template, since the exponential phase of amplification occurs only after much of the original molecular diversity present is represented in the population of molecules produced during the primer-extension reaction.
[0171] Preferably, DNA amplification is performed by PCR. PCR amplification methods are described in detail in U.S. Pat. Nos. 4,683,192, 4,683,202, 4,800,159, and 4,965,188, and at least in PCR Technology: Principles and Applications for DNA Amplification, H. Erlich, ed., Stockton Press, New York (1989); and PCR Protocols: A Guide to Methods and Applications, Innis et al., eds., Academic Press, San Diego, Calif. (1990). The contents of all the foregoing documents are incorporated herein by reference. In one embodiment of the invention, PCR amplification of the template is performed on an oligonucleotide tag bound to a bead, and encapsulated with a PCR solution comprising all the necessary reagents for a PCR reaction. In another embodiment of the invention, PCR amplification of the template is performed on a soluble oligonucleotide tag (i.e., not bound to a bead) which is encapsulated with a PCR solution comprising all the necessary reagents for a PCR reaction. PCR is subsequently performed by exposing the emulsion to any suitable thermocycling regimen known in the art. In one embodiment, between 30 and 50 cycles, preferably about 40 cycles, of amplification are performed. It is desirable, bin not necessary, that following the amplification procedure there be one or more hybridization and extension cycles following the cycles of amplification. In a another embodiment, between 10 and 30 cycles, or about 25 cycles, of hybridization and extension are performed. In one embodiment, the template DNA is amplified until about at least two million to fifty million copies or about ten million to thirty million copies of the template DNA are immobilized per bead.
[0172] Following amplification of the encoding oligonucleotide tag, the emulsion is "broken" (also referred to as "demulsification" in the art). There are many well known methods of breaking an emulsion (see, e.g., U.S. Pat. No. 5,989,892 and references cited therein) and one of skill in the art would be able to select the proper method. For example, the emulsion may be broken by adding additional oil to cause the emulsion to separate into two phases. The oil phase is then removed, and a suitable organic solvent (e.g., hexanes) is added. After mixing, the oil/organic solvent phase is removed. This step may be repeated several times. Finally, the aqueous layers is removed. If the encoding oligonucleotides are attached to beads, the beads are then washed with an organic solvent/annealing buffer mixture, and then washed again in annealing buffer. Suitable organic solvents include alcohols such as methanol, ethanol and the like.
[0173] The amplified encoding oligonucleotides may then be resuspended in aqueous solution for use, for example, in a sequencing reaction according to known technologies. (See, e.g., Sanger, F. et al. (1977) Proc. Natl. Acad. Sci. U.S.A. 75:5463-5467; Maxam & Gilbert (1977) Proc Natl Acad Sci USA 74:560-564; Ronaghi, et al. (1998) Science 281:363, 365; Lysov, et al. (1988) Dokl Akad Nauk SSSR 303:1508-1511; Bains & Smith (1988) J TheorBiol 135:303-307; Drnanac, R. et al. (1989) Genomics 4:114-128; Khrapko, et al. (1989) FEBS Lett 256:118-122; Pevzner (1989) J Biomol Struct Dyn 7:63-73; Southern, et al. (1992) Genomics 13:1008-1017).
[0174] If the encoding oligonucleotide attached to a bead is to be used in a pyrophosphate-based sequencing reaction (described, e.g., in U.S. Pat. Nos. 6,274,320, 6,258,568 and 6,210,891, and incorporated herein by reference), then it is necessary to remove the second strand of the PCR product and anneal a sequencing primer to the single stranded template that is bound to the bead.
[0175] Briefly, the second strand is melted away using any number of commonly known methods such as NaOH, low ionic (e.g., salt) strength, or heat processing. Following this melting step, the beads are pelleted and the supernatant is discarded. The beads are resuspended in an annealing buffer, the sequencing primer added, and annealed to the bead-attached single stranded template using a standard annealing cycle.
[0176] The amplified encoding oligonucleotide, optionally on a bead, may be sequenced either directly or in a different reaction vessel. In one embodiment of the present invention, the encoding oligonucleotide is sequenced directly on the bead by transferring the bead to a reaction vessel and subjecting the DNA to a sequencing reaction (e.g., pyrophosphate or Sanger sequencing). Alternatively, the beads may be isolated and the encoding oligonucleotide may be removed from each bead and sequenced. Nonetheless, the sequencing steps may be performed on each individual bead and/or the beads that contain no nucleic acid template may be removed prior to distribution to a reaction vessel by, for example, biotin-streptavidin magnetic beads. Other suitable methods to separate beads are described in, for example, Bauer, J. (1999) J. Chromatography B, 722:55-69 and in Brody et al. (1999) Applied Physics Lett. 74:144-146.
[0177] Once the encoding oligonucleotide tag has been amplified, the sequence of the tag, and ultimately the composition of the selected molecule, can be determined using nucleic acid sequence analysis, a well known procedure for determining the sequence of nucleotide sequences. Nucleic acid sequence analysis is approached by a combination of (a) physiochemical techniques, based on the hybridization or denaturation of a probe strand plus its complementary target, and (b) enzymatic reactions with polymerases.
[0178] The nucleotide sequence of the oligonucleotide tag comprised of polynucleotides that identify the building blocks that make up the functional moiety as described herein, may be determined by the use of any sequencing method known to one of skill in the art. Suitable methods are described in, for example, Sanger, F. et al. (1977) Proc. Natl. Acad. Sci. U.S.A. 75:5463-5467; Maxam & Gilbert (1977) Proc Natl Acad Sci USA 74:560-564; Ronaghi, et al. (1998) Science 281:363, 365; Lysov, et al. (1988) Dokl Akad Nauk SSSR 303:1508-1511; Bains & Smith (1988) J TheorBiol 135:303-307; Drnanac, R. et al. (1989) Genomics 4:114-128; Khrapko, et al. (1989) FEBS Lett 256:118-122; Pevzner (1989) J Biomol Struct Dyn 7:63-73; Southern, et al. (1992) Genomics 13:1008-1017).
[0179] In a preferred embodiment, the oligonucleotide tags are sequenced using the apparati and methods described in PCT publications WO 2004/069849, WO 2005/003375, WO 2005/073410, and WO 2005/054431, the entire contents of each of which are incorporated herein by this reference.
[0180] In one embodiment, a region of the sequence product is determined by annealing a sequencing primer to a region of the template nucleic acid, and then contacting the sequencing primer with a DNA polymerase and a known nucleotide triphosphate, i.e., dATP, dCTP, dGTP, dTTP, or an analog of one of these nucleotides, such as, for example, α-thio-dATP. The sequence can be determined by detecting a sequence reaction byproduct, using methods known in the art.
[0181] In some embodiments, the nucleotide is modified to contain a disulfide-derivative of a hapten, such as biotin. The addition of the modified nucleotide to the nascent primer annealed to an anchored substrate is analyzed by a suitable post-polymerization method. Such methods enable a nucleotide to be identified in a given target position, and the DNA to be sequenced simply and rapidly while avoiding the need for electrophoresis and the use of potentially dangerous radiolabels.
[0182] Examples of suitable haptens include, for example, biotin, digoxygenin, the fluorescent dye molecules cy3 and cy5, and fluorescein. The attachment of the hapten can occur through linkages via the sugar, the base, and/or via the phosphate moiety on the nucleotide. Exemplary means for signal amplification following polymerization and extension of the encoding oligonucleotide include fluorescent, electrochemical and enzymatic means. In one embodiment using enzymatic amplification, the enzyme is one for which light-generating substrates are known, such as, for example, alkaline phosphatase (AP), horse-radish peroxidase (HRP), beta-galactosidase, or luciferase, and the means for the detection of these light-generating (chemiluminescent) substrates can include a CCD camera.
[0183] A sequencing primer can be of any length or base composition, as long as it is capable of specifically annealing to a region of the nucleic acid template (i.e., the oligonucleotide tag). The oligonucleotide primers of the present invention may be synthesized by conventional technology, e.g., with a commercial oligonucleotide synthesizer and/or by ligating together subfragments that have been so synthesized. No particular structure for the sequencing primer is required so long as it is able to specifically prime a region on the template nucleic acid. The sequencing primer is extended with the DNA polymerase to form a sequence product. The extension is performed in the presence of one or more types of nucleotide triphosphates, and if desired, auxiliary binding proteins. Incorporation of the dNTP is determined by, for example, assaying for the presence of a sequencing byproduct.
[0184] In one embodiment, the nucleic acid sequence of the oligonucleotide tag is determined by the use of the polymerase chain reaction (PCR). Briefly, the oligonucleotide tag (optionally attached to a bead) is subjected to a PCR reaction as follows. The appropriate sample is contacted with a PCR primer pair, each member of the pair having a pre-selected nucleotide sequence. The PCR primer pair is capable of initiating primer extension reactions by hybridizing to a PCR primer binding site on the encoding oligonucleotide tag.
[0185] The PCR reaction is performed by mixing the PCR primer pair, preferably a predetermined amount thereof, with the nucleic acids of the encoding oligonucleotide tag, preferably a predetermined amount thereof, in a PCR buffer to form a PCR reaction admixture. The admixture is thermocycled for a number of cycles, which is typically predetermined, sufficient for the formation of a PCR reaction product. A sufficient amount of product is one that can be isolated in a sufficient amount to allow for DNA sequence determination.
[0186] PCR is typically carried out by thermocycling i.e., repeatedly increasing and decreasing the temperature of a PCR reaction admixture within a temperature range whose lower limit is about 30° C. to about 55° C. and whose upper limit is about 90° C. to about 100° C. The increasing and decreasing can be continuous, but is preferably phasic with time periods of relative temperature stability at each of temperatures favoring polynucleotide synthesis, denaturation and hybridization.
[0187] The PCR reaction is performed using any suitable method. Generally it occurs in a buffered aqueous solution, i.e., a PCR buffer, preferably at a pH of 7-9. Preferably, a molar excess of the primer is present. A large molar excess is preferred to improve the efficiency of the process.
[0188] The PCR buffer also contains the deoxyribonucleotide triphosphates (polynucleotide synthesis substrates) dATP, dCTP, dGTP, and dTTP and a polymerase, typically thermostable, all in adequate amounts for primer extension (polynucleotide synthesis) reaction. The resulting solution (PCR admixture) is heated to about 90° C.-100° C. for about 1 to 10 minutes, preferably from 1 to 4 minutes. After this heating period the solution is allowed to cool to 54° C., which is preferable for primer hybridization. The synthesis reaction may occur at a temperature ranging from room temperature up to a temperature above which the polymerase (inducing agent) no longer functions efficiently. Thus, for example, if DNA polymerase is used, the temperature is generally no greater than about 40° C. The thermocycling is repeated until the desired amount of PCR product is produced. An exemplary PCR buffer comprises the following reagents: 50 mM KCl; 10 mM Tris-HCl at pH 8.3; 1.5 mM MgCl2; 0.001% (wt/vol) gelatin, 200 μM dATP; 200 μM dTTP; 200 dCTP; 200 μM dGTP; and 2.5 units Thermus aquaticus (Taq) DNA polymerase I per 100 microliters of buffer.
[0189] Suitable enzymes for elongating the primer sequences include, for example, E. coli DNA polymerase I, Taq DNA polymerase, Klenow fragment of E. coli DNA polymerase I, T4 DNA polymerase, other available DNA polymerases, reverse transcriptase, and other enzymes, including heat-stable enzymes, which will facilitate combination of the nucleotides in the proper manner to form the primer extension products which are complementary to each nucleic acid strand. Generally, the synthesis will be initiated at the 3' end of each primer and proceed in the 5' direction along the template strand, until synthesis terminates, producing molecules of different lengths. The newly synthesized DNA strand and its complementary strand form a double-stranded molecule which can be used in the succeeding steps of the analysis process.
[0190] In one embodiment, the nucleotide sequence of the oligonucleotide tag is determined by measuring inorganic pyrophosphate (PPi) liberated from a nucleotide triphosphate (dNTP) as the dNMP is incorporated into an extended sequence primer. This method of sequencing, termed Pyrosequencing® technology (PyroSequencing AB, Stockholm, Sweden) can be performed in solution (liquid phase) or as a solid phase technique. PPi-based sequencing methods are described in, e.g., U.S. Pat. Nos. 6,274,320, 6,258,568 and 6,210,891, WO9813523A1, Ronaghi, et al. (1996) Anal Biochem. 242:84-89, Ronaghi, et al. (1998) Science 281:363-365, and USSN 2001/0024790. These disclosures of PPi sequencing are incorporated herein in their entirety, by reference. See also, e.g., U.S. Pat. Nos. 6,210,891 and 6,258,568, each of which are fully incorporated herein by this reference.
[0191] Pyrophosphate can be detected by a number of different methodologies, and various enzymatic methods have been previously described (see e.g., Reeves, et al. (1969) Anal Biochem. 28:282-287; Guillory, et al. (1971) Anal Biochem. 39:170-180; Johnson, et al. (1968) Anal Biochem. 15:273; Cook, et al. 1978. Anal Biochem. 91:557-565; and Drake, et al. (1979) Anal Biochem. 94: 117-120).
[0192] In one embodiment, PPi is detected enzymatically (e.g., by the generation of light). Such methods enable a nucleotide to be identified in a given target position, and the DNA to be sequenced simply and rapidly while avoiding the need for electrophoresis and the use of potentially dangerous radiolabels.
[0193] In one embodiment, the PPi and a coupled luciferase-luciferin reaction is used to generate light for detection. In another embodiment, the PPi and a coupled sulfurylase/luciferase reaction is used to generate light for detection as described in U.S. Pat. No. 6,902,921, the contents of which are hereby expressly incorporated herein by reference. In one embodiment, the sulfurylase is thermostable. In some embodiments, either or both the sulfurylase and luciferase are immobilized on one or more mobile solid supports disposed at each reaction site.
[0194] In another embodiment, the nucleotide sequence of the oligonucleotide tag may be determined according to the methods described in PCT Publication No. WO 01/23610, the contents of which are incorporated herein by reference. Briefly, a target nucleotide sequence can be determined by generating its complement using the polymerase reaction to extend a suitable primer, and characterizing the successive incorporation of bases that generate the complement sequence. The target sequence is, typically, immobilized on a solid support. Each of the different bases A, T, G, or C is then brought, by sequential addition, into contact with the target, and any incorporation events are detected via a suitable label attached to the base.
[0195] A labeled base is incorporated into the complementary sequence by the use of a polymerase, e.g., a polymerase with a 3' to 5' exonuclease activity (e.g., DNA polymerase I, the Klenow fragment, DNA polymerase III, T4 DNA polymerase, and T7 DNA polymerase). Following detection of the incorporated labeled base, the polymerase replaces the terminally labeled base with a corresponding unlabelled base, thus permitting further sequencing to occur.
[0196] In yet another embodiment, the nucleotide sequence of the oligonucleotide tag is determined by the use of single molecule sequencing by synthesis methods described in, for example, PCT Publication No. WO 2005/080605, the entire contents of which are expressly incorporated by reference. The benefit of using this technology is that it eliminates the need for DNA amplification prior to sequencing, thus, abolishing the introduction of amplification errors and bias. Briefly, the encoding oligonucleotide is hybridized to a universal primer immobilized on a solid surface. The oligonucleotide:primer duplexes are visualized by, e.g., illuminating the surface with a laser and imaging with a digital TV camera connected to a microscope, and the positions of all the duplexes on the surface are recorded. DNA polymerase and one type of fluorescently labeled nucleotide, e.g., A, is added to the surface and incorporated into the appropriate primer. Subsequently, the polymerase and the unincorporated nucleotides are washed from the surface and the incorporated nucleotide is visualized by, e.g., illuminating the surface with a laser and imaging with a camera as before to record the positions of the incorporated nucleotides. The fluorescent label is removed from each incorporated nucleotide and the process is repeated with the next nucleotide, e.g., G, stepping through A, C, G, T, until the desired read-length is achieved.
[0197] One group of fluorescent dyes suitable for this method of sequencing is fluorescence resonance energy transfer (FRET) dyes, including donor and acceptor energy fluorescent dyes and linkers such as, for example, Cy3 and Cy5. FRET is a phenomenon described in, for example, Selvin (1995) Methods in Enzym. 246:300. FRET can detect the incorporation of multiple nucleotides into a single oligonucleotide molecule and is, thus, useful for sequencing the encoding oligonucleotides of the invention. Sequencing methods using FRET are described in, for example, PCT Publication No. WO 2005/080605, the entire contents of which are expressly incorporated by reference. Alternatively, quantum dots can be used as a labeling moiety on the different types of nucleotides for use in sequencing reactions.
[0198] Once single ligands are identified by the above-described process, various levels of analysis can be applied to yield structure-activity relationship information and to guide further optimization of the affinity, specificity and bioactivity of the ligand. For ligands derived from the same scaffold, three-dimensional molecular modeling can be employed to identify significant structural features common to the ligands, thereby generating families of small-molecule ligands that presumably bind at a common site on the target biomolecule.
[0199] A variety of screening approaches can be used to obtain ligands that possess high affinity for one target but significantly weaker affinity for another closely related target. One screening strategy is to identify ligands for both biomolecules in parallel experiments and to subsequently eliminate common ligands by a cross-referencing comparison. In this method, ligands for each biomolecule can be separately identified as disclosed above. This method is compatible with both immobilized target biomolecules and target biomolecules free in solution.
[0200] For immobilized target biomolecules, another strategy is to add a preselection step that eliminates all ligands that bind to the non-target biomolecule from the library. For example, a first biomolecule can be contacted with an encoded library as described above. Compounds which do not bind to the first biomolecule are then separated from any first biomolecule-ligand complexes which form. The second biomolecule is then contacted with the compounds which did not bind to the first biomolecule. Compounds which bind to the second biomolecule can be identified as described above and have significantly greater affinity for the second biomolecule than to the first biomolecule.
[0201] A ligand for a biomolecule of unknown function which is identified by the method disclosed above can also be used to determine the biological function of the biomolecule. This is advantageous because although new gene sequences continue to be identified, the functions of the proteins encoded by these sequences and the validity of these proteins as targets for new drug discovery and development are difficult to determine and represent perhaps the most significant obstacle to applying genomic information to the treatment of disease. Target-specific ligands obtained through the process described in this invention can be effectively employed in whole cell biological assays or in appropriate animal models to understand both the function of the target protein and the validity of the target protein for therapeutic intervention. This approach can also confirm that the target is specifically amenable to small molecule drug discovery.
[0202] In one embodiment, one or more compounds within a library of the invention are identified as ligands for a particular biomolecule. These compounds can then be assessed in an in vitro assay for the ability to bind to the biomolecule. Preferably, the functional moieties of the binding compounds are synthesized without the oligonucleotide tag or linker moiety, and these functional moieties are assessed for the ability to bind to the biomolecule.
[0203] The effect of the binding of the functional moieties to the biomolecule on the function of the biomolecule can also be assessed using in vitro cell-free or cell-based assays. For a biomolecule having a known function, the assay can include a comparison of the activity of the biomolecule in the presence and absence of the ligand, for example, by direct measurement of the activity, such as enzymatic activity, or by an indirect measure, such as a cellular function that is influenced by the biomolecule. If the biomolecule is of unknown function, a cell which expresses the biomolecule can be contacted with the ligand and the effect of the ligand on the viability, function, phenotype, and/or gene expression of the cell is assessed. The in vitro assay can be, for example, a cell death assay, a cell proliferation assay or a viral replication assay. For example, if the biomolecule is a protein expressed by a virus, a cell infected with the virus can be contacted with a ligand for the protein. The affect of the binding of the ligand to the protein on viral viability can then be assessed.
[0204] A ligand identified by the method of the invention can also be assessed in an in vivo model or in a human. For example, the ligand can be evaluated in an animal or organism which produces the biomolecule. Any resulting change in the health status (e.g., disease progression) of the animal or organism can be determined.
[0205] For a biomolecule, such as a protein or a nucleic acid molecule, of unknown function, the effect of a ligand which binds to the biomolecule on a cell or organism which produces the biomolecule can provide information regarding the biological function of the biomolecule. For example, the observation that a particular cellular process is inhibited in the presence of the ligand indicates that the process depends, at least in part, on the function of the biomolecule.
[0206] Ligands identified using the methods of the invention can also be used as affinity reagents for the biomolecule to which they bind. In one embodiment, such ligands are used to effect affinity purification of the biomolecule, for example, via chromatography of a solution comprising the biomolecule using a solid phase to which one or more such ligands are attached.
[0207] In addition to the screening of encoded libraries as described herein, other traditional drug discovery methods, such as phage display, differential display (mRNA display), and aptamer/SELEX, could benefit from the methods of the invention which eliminate the introduction of amplification errors and biases. For example, multiple rounds of selection using phage display (described in, for example, PCT Publication Nos. WO91/18980, WO91/19818, and WO92/18619, and U.S. Pat. No. 5,223,409, the entire contents of each of which are incorporated herein by reference) can cause host toxicity and, consequently, loss or under-representation of desired library members (see, e.g., Daugherty, P. S., et al. (1999) Protein Engineering 12(7):613-621 and Holt, L. J., et al. (2000) Nucleic Acids Res. 28(15):E72). Moreover, methods such as Systematic Evolution of Ligands by EXponential enrichment (also known as SELEX which is described in, for example, U.S. Pat. Nos. 5,654,151, 5,503,978, 5,567,588 and 5270163, as well as PCT Publication Nos. WO 96/38579 and WO9927133A1, the entire contents of each of which are incorporated herein by reference) introduce biases due to the need for multiple rounds of selection, i.e., partitioning unbound nucleic acids from those nucleic acids which have bound specifically to a target molecule, and multiple rounds of amplification of the nucleic acids that have bound to the target by reverse transcription and PCR. Similarly, methods of selection like differential display (described in, for example, U.S. Pat. Nos. 5,580,726 and 5,700,644, the entire contents of each of which are incorporated herein by reference) rely on multiple rounds of PCR amplification which also leads to unequal representation of the clones in the library. Thus, the foregoing multi-step selection processes may benefit from the methods described herein which employ massively parallel sequencing approaches (such as, for example, a pyrophosphate-based sequencing method or a single molecule sequencing by synthesis method) which leads to the accurate identification of a compound with a desired biological activity without the need for any nucleic acid amplification.
[0208] This invention is further illustrated by the following examples which should not be construed as limiting. The contents of all references, patents and published patent applications cited throughout this application, as well as the Figures and the Sequence Listing, are hereby incorporated in reference.
EXAMPLES
Example 1
Synthesis and Characterization of a Library on the Order of 105 Members
[0209] The synthesis of a library comprising on the order of 105 distinct members was accomplished using the following reagents:
Compound 1 (SEQ ID NOS 916-917, Respectively, in Order of Appearance):
##STR00093##
[0210] Single Letter Codes for Deoxyribonucleotides:
[0211] A=adenosine C=cytidine G=guanosine T=thymidine
Building Block Precursors:
##STR00094## ##STR00095##
[0212] Oligonucleotide Tags:
TABLE-US-00004 [0213] Tag Sequence number 5'-PO4-GCAACGAAG (SEQ ID NO: 1) 1.1 ACCGTTGCT-PO3-5' (SEQ ID NO: 2) 5'-PO3-GCGTACAAG (SEQ ID NO: 3) 1.2 ACCGCATGT-PO3-5' (SEQ ID NO: 4) 5'-PO3-GCTCTGTAG (SEQ ID NO: 5) 1.3 ACCGAGACA-PO3-5' (SEQ ID NO: 6) 5'-PO3-GTGCCATAG (SEQ ID NO: 7) 1.4 ACCACGGTA-PO3-5' (SEQ ID NO: 8) 5'-PO3-GTTGACCAG (SEQ ID NO: 9) 1.5 ACCAACTGG-PO3-5' (SEQ ID NO: 10) 5'-PO3-CGACTTGAC (SEQ ID NO: 11) 1.6 CAAGTCGCA-PO3-5' (SEQ ID NO: 12) 5'-PO3-CGTAGTCAG (SEQ ID NO: 13) 1.7 ACGCATCAG-PO3-5' (SEQ ID NO: 14) 5'-PO3-CCAGCATAG (SEQ ID NO: 15) 1.8 ACGGTCGTA-PO3-5' (SEQ ID NO: 16) 5'-PO3-CCTACAGAG (SEQ ID NO: 17) 1.9 ACGGATGTC-PO3-5' (SEQ ID NO: 18) 5'-PO3-CTGAACGAG (SEQ ID NO: 19) 1.10 CGTTCAGCA-PO3-5' (SEQ ID NO: 20) 5'-PO3-CTCCAGTAG (SEQ ID NO: 21) 1.11 ACGAGGTCA-PO3-5' (SEQ ID NO: 22) 5'-PO3-TAGGTCCAG (SEQ ID NO: 23) 1.12 ACATCCAGG-PO3-5' (SEQ ID NO: 24) 5'-PO3-GCGTGTTGT (SEQ ID NO: 25) 2.1 TCCGCACAA-PO3-5' (SEQ ID NO: 26) 5'-PO3-GCTTGGAGT (SEQ ID NO: 27) 2.2 TCCGAACCT-PO3-5' (SEQ ID NO: 28) 5'-PO3-GTCAAGCGT (SEQ ID NO: 29) 2.3 TCCAGTTCG-PO3-5' (SEQ ID NO: 30) 5'-PO3-CAAGAGCGT (SEQ ID NO: 31) 2.4 TCGTTCTCG-PO3-5' (SEQ ID NO: 32) 5'-PO3-CAGTTCGGT (SEQ ID NO: 33) 2.5 TCGTCAAGC-PO3-5' (SEQ ID NO: 34) 5'-PO3-CGAAGGAGT (SEQ ID NO: 35) 2.6 TCGCTTCCT-PO3-5' (SEQ ID NO: 36) 5'-PO3-CGGTGTTGT (SEQ ID NO: 37) 2.7 TCGCCACAA-PO3-5' (SEQ ID NO: 38) 5'-PO3-CGTTGCTGT (SEQ ID NO: 39) 2.8 TCGCAACGA-PO3-5' (SEQ ID NO: 40) 5'-PO3-CCGATCTGT (SEQ ID NO: 41) 2.9 TCGGCTAGA-PO3-5' (SEQ ID NO: 42) 5'-PO3-CCTTCTCGT (SEQ ID NO: 43) 2.10 TCGGAAGAG-PO3-5' (SEQ ID NO: 44) 5'-PO3-TGAGTCCGT (SEQ ID NO: 45) 2.11 TCACTCAGG-PO3-5' (SEQ ID NO: 46) 5'-PO3-TGCTACGGT (SEQ ID NO: 47) 2.12 TCAGATTGC-PO3-5' (SEQ ID NO: 48) 5'-PO3-GTGCGTTGA (SEQ ID NO: 49) 3.1 CACACGCAA-PO3-5' (SEQ ID NO: 50) 5'-PO3-GTTGGCAGA (SEQ ID NO: 51) 3.2 CACAACCGT-PO3-5' (SEQ ID NO: 52) 5'-PO3-CCTGTAGGA (SEQ ID NO: 53) 3.3 CAGGACATC-PO3-5' (SEQ ID NO: 54) 5'-PO3-CTGCGTAGA (SEQ ID NO: 55) 3.4 CAGACGCAT-PO3-5' (SEQ ID NO: 56) 5'-PO3-CTTACGCGA (SEQ ID NO: 57) 3.5 CAGAATGCG-PO3-5' (SEQ ID NO: 58) 5'-PO3-TGGTCACGA (SEQ ID NO: 59) 3.6 CAACCAGTG-PO3-5' (SEQ ID NO: 60) 5'-PO3-TCAGAGCGA (SEQ ID NO: 61) 3.7 CAAGTCTCG-PO3-5' (SEQ ID NO: 62) 5'-PO3-TTGCTCGGA (SEQ ID NO: 63) 3.8 CAAACGAGC-PO3-5' (SEQ ID NO: 64) 5'-PO3-GCAGTTGGA (SEQ ID NO: 65) 3.9 CACGTCAAC-PO3-5' (SEQ ID NO: 66) 5'-PO3-GCCTGAAGA (SEQ ID NO: 67) 3.10 CACGGACTT-PO3-5' (SEQ ID NO: 68) 5'-PO3-GTAGCCAGA (SEQ ID NO: 69) 3.11 CACATCGGT-PO3-5' (SEQ ID NO: 70) 5'-PO3-GTCGCTTGA (SEQ ID NO: 71) 3.12 CACAGCGAA-PO3-5' (SEQ ID NO: 72) 5'-PO3-GCCTAAGTT (SEQ ID NO: 73) 4.1 CTCGGATTC-PO3-5' (SEQ ID NO: 74) 5'-PO3-GTAGTGCTT (SEQ ID NO: 75) 4.2 CTCATCACG-PO3-5' (SEQ ID NO: 76) 5'-PO3-GTCGAAGTT (SEQ ID NO: 77) 4.3 CTCAGCTTC-PO3-5' (SEQ ID NO: 78) 5'-PO3-GTTTCGGTT (SEQ ID NO: 79) 4.4 CTCAAAGCC-PO3-5' (SEQ ID NO: 80) 5'-PO3-CAGCGTTTT (SEQ ID NO: 81) 4.5 CTGTCGCAA-PO3-5' (SEQ ID NO: 82) 5'-PO3-CATACGCTT (SEQ ID NO: 83) 4.6 CTGTATGCG-PO3-5' (SEQ ID NO: 84) 5'-PO3-CGATCTGTT (SEQ ID NO: 85) 4.7 CTGCTAGAC-PO3-5' (SEQ ID NO: 86) 5'-PO3-CGCTTTGTT (SEQ ID NO: 87) 4.8 CTGCGAAAC-PO3-5' (SEQ ID NO: 88) 5'-PO3-CCACAGTTT (SEQ ID NO: 89) 4.9 CTGGTGTCA-PO3-5' (SEQ ID NO: 90) 5'-PO3-CCTGAAGTT (SEQ ID NO: 91) 4.10 CTGGACTTC-PO3-5' (SEQ ID NO: 92) 5'-PO3-CTGACGATT (SEQ ID NO: 93) 4.11 CTGACTGCT-PO3-5' (SEQ ID NO: 94) 5'-PO3-CTCCACTTT (SEQ ID NO: 95) 4.12 CTGAGGTGA-PO3-5' (SEQ ID NO: 96) 5'-PO3-ACCAGAGCC (SEQ ID NO: 97) 5.1 AATGGTCTC-PO3-5' (SEQ ID NO: 98) 5'-PO3-ATCCGCACC (SEQ ID NO: 99) 5.2 AATAGGCGT-PO3-5' (SEQ ID NO: 100) 5'-PO3-GACGACACC (SEQ ID NO: 101) 5.3 AACTGCTGT-PO3-5' (SEQ ID NO: 102) 5'-PO3-GGATGGACC (SEQ ID NO: 103) 5.4 AACCTACCT-PO3-5' (SEQ ID NO: 104) 5'-PO3-GCAGAAGCC (SEQ ID NO: 105) 5.5 AACGTCTTC-PO3-5' (SEQ ID NO: 106) 5'-PO3-GCCATGTCC (SEQ ID NO: 107) 5.6 AACGGTACA-PO3-5' (SEQ ID NO: 108) 5'-PO3-GTCTGCTCC (SEQ ID NO: 109) 5.7 AACAGACGA-PO3-5' (SEQ ID NO: 110) 5'-PO3-CGACAGACC (SEQ ID NO: 111) 5.8 AAGCTGTCT-PO3-5' (SEQ ID NO: 112) 5'-PO3-CGCTACTCC (SEQ ID NO: 113) 5.9 AAGCGATGA-PO3-5' (SEQ ID NO: 114) 5'-PO3-CCACAGACC (SEQ ID NO: 115) 5.10 AAGGTGTCT-PO3-5' (SEQ ID NO: 116) 5'-PO3-CCTCTCTCC (SEQ ID NO: 117) 5.11 AAGGAGAGA-PO3-5' (SEQ ID NO: 118) 5'-PO3-CTCGTAGCC (SEQ ID NO: 119) 5.12 AAGAGCATC-PO3-5' (SEQ ID NO: 120)
1× ligase buffer: 50 mM Tris, pH 7.5; 10 mM dithiothreitol; 10 mM MgCl2; 2.5 mM ATP; 50 mM NaCl. 10× ligase buffer: 500 mM Tris, pH 7.5; 100 mM dithiothreitol; 100 mM MgCl2; 25 mM ATP; 500 mM NaCl
Cycle 1
[0214] To each of twelve PCR tubes was added 50 μL of a 1 mM solution of Compound 1 in water; 75 μL of a 0.80 mM solution of one of Tags 1.1-1.12; 15 μL 10× ligase buffer and 10 μL deionized water. The tubes were heated to 95° C. for 1 minute and then cooled to 16° C. over 10 minutes. To each tube was added 5,000 units T4 DNA ligase (2.5 μL of a 2,000,000 unit/mL solution (New England Biolabs, Cat. No. M0202)) in 50 μl 1× ligase buffer and the resulting solutions were incubated at 16° C. for 16 hours.
[0215] Following ligation, samples were transferred to 1.5 ml Eppendorf tubes and treated with 20 μL 5 M aqueous NaCl and 500 μL cold (-20° C.) ethanol, and held at -20° C. for 1 hour. Following centrifugation, the supernatant was removed and the pellet was washed with 70% aqueous ethanol at -20° C. Each of the pellets was then dissolved in 150 μL of 150 mM sodium borate buffer, pH 9.4.
[0216] Stock solutions comprising one each of building block precursors BB1 to BB12, N,N-diisopropylethanolamine and O-(7-azabenzotriazol-1-yl)-1,1,3,3-tetramethyluronium hexafluorophosphate, each at a concentration of 0.25 M, were prepared in DMF and stirred at room temperature for 20 minutes. The building block precursor solutions were added to each of the pellet solutions described above to provide a 10-fold excess of building block precursor relative to linker. The resulting solutions were stirred. An additional 10 equivalents of building block precursor was added to the reaction mixture after 20 minute, and another 10 equivalents after 40 minutes. The final concentration of DMF in the reaction mixture was 22%. The reaction solutions were then stirred overnight at 4° C. The reaction progress was monitored by RP-HPLC using 50 mM aqueous tetraethylammonium acetate (pH=7.5) and acetonitrile, and a gradient of 2-46% acetonitrile over 14 min. Reaction was stopped when ˜95% of starting material (linker) is acylated. Following acylation the reaction mixtures were pooled and lyophilized to dryness. The lyophilized material was then purified by HPLC, and the fractions corresponding to the library (acylated product) were pooled and lyophilized.
[0217] The library was dissolved in 2.5 ml of 0.01M sodium phosphate buffer (pH=8.2) and 0.1 ml of piperidine (4% v/v) was added to it. The addition of piperidine results in turbidity which does not dissolve on mixing. The reaction mixtures were stirred at room temperature for 50 minutes, and then the turbid solution was centrifuged (14,000 rpm), the supernatant was removed using a 200 μl pipette, and the pellet was resuspended in 0.1 ml of water. The aqueous wash was combined with the supernatant and the pellet was discarded. The deprotected library was precipitated from solution by addition of excess ice-cold ethanol so as to bring the final concentration of ethanol in the reaction to 70% v/v. Centrifugation of the aqueous ethanol mixture gave a white pellet comprising the library. The pellet was washed once with cold 70% aq. ethanol. After removal of solvent the pellet was dried in air (˜5 min.) to remove traces of ethanol and then used in cycle 2. The tags and corresponding building block precursors used in Round 1 are set forth in Table 1, below.
TABLE-US-00005 TABLE 1 Building Block Precursor Tag BB1 1.11 BB2 1.6 BB3 1.2 BB4 1.8 BB5 1.1 BB6 1.10 BB7 1.12 BB8 1.5 BB9 1.4 BB10 1.3 BB11 1.7 BB12 1.9
Cycles 2-5
[0218] For each of these cycles, the combined solution resulting from the previous cycle was divided into 12 equal aliquots of 50 ul each and placed in PCR tubes. To each tube was added a solution comprising a different tag, and ligation, purification and acylation were performed as described for Cycle 1, except that for Cycles 3-5, the HPLC purification step described for Cycle 1 was omitted. The correspondence between tags and building block precursors for Cycles 2-5 is presented in Table 2.
[0219] The products of Cycle 5 were ligated with the closing primer shown below, using the method described above for ligation of tags.
TABLE-US-00006 5'-PO3-GGCACATTGATTTGGGAGTCA (SEQ ID NO: 918) GTGTAACTAAACCCTCAGT-PO3-5' (SEQ ID NO: 919)
TABLE-US-00007 TABLE 2 Building Block Cycle 2 Cycle 3 Cycle 4 Cycle 5 Precursor Tag Tag Tag Tag BB1 2.7 3.7 4.7 5.7 BB2 2.8 3.8 4.8 5.8 BB3 2.2 3.2 4.2 5.2 BB4 2.10 3.10 4.10 5.10 BB5 2.1 3.1 4.1 5.1 BB6 2.12 3.12 4.12 5.12 BB7 2.5 3.5 4.5 5.5 BB8 2.6 3.6 4.6 5.6 BB9 2.4 3.4 4.4 5.4 BB10 2.3 3.3 4.3 5.3 BB11 2.9 3.9 4.9 5.9 BB12 2.11 3.11 4.11 5.11
Results:
[0220] The synthetic procedure described above has the capability of producing a library comprising 125 (about 249,000) different structures. The synthesis of the library was monitored via gel electrophoresis of the product of each cycle. The results of each of the five cycles and the final library following ligation of the closing primer are illustrated in FIG. 7. The compound labeled "head piece" is Compound 1. The figure shows that each cycle results in the expected molecular weight increase and that the products of each cycle are substantially homogeneous with regard to molecular weight.
Example 2
Synthesis and Characterization of a Library on the Order of 108 Members
[0221] The synthesis of a library comprising on the order of 108 distinct members was accomplished using the following reagents:
Compound 2: (Nucleotides 1-8 of SEQ ID NO:916 and Nucleotides 12-17 of SEQ ID NO:917, Respectively, in Order of Appearance):
##STR00096##
[0222] Single Letter Codes for Deoxyribonucleotides:
[0223] A=adenosine C=cytidine G=guanosine T=thymidine
Building Block Precursors:
##STR00097## ##STR00098## ##STR00099## ##STR00100## ##STR00101## ##STR00102## ##STR00103## ##STR00104## ##STR00105## ##STR00106## ##STR00107## ##STR00108## ##STR00109##
TABLE-US-00008 [0224] TABLE 3 Oligonucleotide tags used in cycle 1: Tag Number Top Strand Sequence Bottom Strand Sequence 1.1 5'-PO3- 5'-PO3- AAATCGATGTGGTCACTCAG GAGTGACCACATCGATTTGG (SEQ ID NO: 121) (SEQ ID NO: 122) 1.2 5'-PO3- 5'-PO3- AAATCGATGTGGACTAGGAG CCTAGTCCACATCGATTTGG (SEQ ID NO: 123) (SEQ ID NO: 124) 1.3 5'-PO3- 5'-PO3- AAATCGATGTGCCGTATGAG CATACGGCACATCGATTTGG (SEQ ID NO: 125) (SEQ ID NO: 126) 1.4 5'-PO3- 5'-PO3- AAATCGATGTGCTGAAGGAG CCTTCAGCACATCGATTTGG (SEQ ID NO: 127) (SEQ ID NO: 128) 1.5 5'-PO3- 5'-PO3- AAATCGATGTGGACTAGCAG GCTAGTCCACATCGATTTGG (SEQ ID NO: 129) (SEQ ID NO: 130) 1.6 5'-PO3- 5'-PO3- AAATCGATGTGCGCTAAGAG CTTAGCGCACATCGATTTGG (SEQ ID NO: 131) (SEQ ID NO: 132) 1.7 5'-PO3- 5'-PO3- AAATCGATGTGAGCCGAGAG CTCGGCTCACATCGATTTGG (SEQ ID NO: 133) (SEQ ID NO: 134) 1.8 5'-PO3- 5'-PO3- AAATCGATGTGCCGTATCAG GATACGGCACATCGATTTGG (SEQ ID NO: 135) (SEQ ID NO: 136) 1.9 5'-PO3- 5'-PO3- AAATCGATGTGCTGAAGCAG GCTTCAGCACATCGATTTGG (SEQ ID NO: 137) (SEQ ID NO: 138) 1.10 5'-PO3- 5'-PO3- AAATCGATGTGTGCGAGTAG ACTCGCACACATCGATTTGG (SEQ ID NO: 139) (SEQ ID NO: 140) 1.11 5'-PO3- 5'-PO3- AAATCGATGTGTTTGGCGAG CGCCAAACACATCGATTTGG (SEQ ID NO: 141) (SEQ ID NO: 142) 1.12 5'-PO3- 5'-PO3- AAATCGATGTGCGCTAACAG GTTAGCGCACATCGATTTGG (SEQ ID NO: 143) (SEQ ID NO: 144) 1.13 5'-PO3- 5'-PO3- AAATCGATGTGAGCCGACAG GTCGGCTCACATCGATTTGG (SEQ ID NO: 145) (SEQ ID NO: 146) 1.14 5'-PO3- 5'-PO3- AAATCGATGTGAGCCGAAAG TTCGGCTCACATCGATTTGG (SEQ ID NO: 147) (SEQ ID NO: 148) 1.15 5'-PO3- 5'-PO3- AAATCGATGTGTCGGTAGAG CTACCGACACATCGATTTGG (SEQ ID NO: 149) (SEQ ID NO: 150) 1.16 5'-PO3- 5'-PO3- AAATCGATGTGGTTGCCGAG CGGCAACCACATCGATTTGG (SEQ ID NO: 151) (SEQ ID NO: 152) 1.17 5'-PO3- 5'-PO3- AAATCGATGTGAGTGCGTAG ACGCACTCACATCGATTTGG (SEQ ID NO: 153) (SEQ ID NO: 154) 1.18 5'-PO3- 5'-PO3- AAATCGATGTGGTTGCCAAG TGGCAACCACATCGATTTGG (SEQ ID NO: 155) (SEQ ID NO: 156) 1.19 5'-PO3- 5'-PO3- AAATCGATGTGTGCGAGGAG CCTCGCACACATCGATTTGG (SEQ ID NO: 157) (SEQ ID NO: 158) 1.20 5'-PO3- 5'-PO3- AAATCGATGTGGAACACGAG CGTGTTCCACATCGATTTGG (SEQ ID NO: 159) (SEQ ID NO: 160) 1.21 5'-PO3- 5'-PO3- AAATCGATGTGCTTGTCGAG CGACAAGCACATCGATTTGG (SEQ ID NO: 161) (SEQ ID NO: 162) 1.22 5'-PO3- 5'-PO3- AAATCGATGTGTTCCGGTAG A0CCGGAACACATCGATTTGG (SEQ ID NO: 163) (SEQ ID NO: 164) 1.23 5'-PO3- 5'-PO3- AAATCGATGTGTGCGAGCAG GCTCGCACACATCGATTTGG (SEQ ID NO: 165) (SEQ ID NO: 166) 1.24 5'-PO3- 5'-PO3- AAATCGATGTGGTCAGGTAG ACCTGACCACATCGATTTGG (SEQ ID NO: 167) (SEQ ID NO: 168) 1.25 5'-PO3- 5'-PO3- AAATCGATGTGGCCTGTTAG AACAGGCCACATCGATTTGG (SEQ ID NO: 169) (SEQ ID NO: 170) 1.26 5'-PO3- 5'-PO3- AAATCGATGTGGAACACCAG GGTGTTCCACATCGATTTGG (SEQ ID NO: 171) (SEQ ID NO: 172) 1.27 5'-PO3-AAATCGATGTGCTTGTCCAG 5'-PO3- (SEQ ID NO: 173) GGACAAGCACATCGATTTGG (SEQ ID NO: 174) 1.28 5'-PO3- 5'-PO3- AAATCGATGTGTGCGAGAAG TCTCGCACACATCGATTTGG (SEQ ID NO: 175) (SEQ ID NO: 176) 1.29 5'-PO3- 5'-PO3- AAATCGATGTGAGTGCGGAG CCGCACTCACATCGATTTGG (SEQ ID NO: 177) (SEQ ID NO: 178) 1.30 5'-PO3- 5'-PO3- AAATCGATGTGTTGTCCGAG CGGACAACACATCGATTTGG (SEQ ID NO: 179) (SEQ ID NO: 180) 1.31 5'-PO3- 5'-PO3- AAATCGATGTGTGGAACGAG CGTTCCACACATCGATTTGG (SEQ ID NO: 181) (SEQ ID NO: 182) 1.32 5'-PO3- 5'-PO3- AAATCGATGTGAGTGCGAAG TCGCACTCACATCGATTTGG (SEQ ID NO: 183) (SEQ ID NO: 184) 1.33 5'-PO3- 5'-PO3- AAATCGATGTGTGGAACCAG GGTTCCACACATCGATTTGG (SEQ ID NO: 185) (SEQ ID NO: 186) 1.34 5'-PO3- 5'-PO3- AAATCGATGTGTTAGGCGAG CGCCTAACACATCGATTTGG (SEQ ID NO: 187) (SEQ ID NO: 188) 1.35 5'-PO3- 5'-PO3- AAATCGATGTGGCCTGTGAG CACAGGCCACATCGATTTGG (SEQ ID NO: 189) (SEQ ID NO: 190) 1.36 5'-PO3-AAATCGATGTGCTCCTGTAG 5'-PO3- (SEQ ID NO: 191) ACAGGAGCACATCGATTTGG (SEQ ID NO: 192) 1.37 5'-PO3- 5'-PO3- AAATCGATGTGGTCAGGCAG GCCTGACCACATCGATTTGG (SEQ ID NO: 193) (SEQ ID NO: 194) 1.38 5'-PO3- 5'-PO3- AAATCGATGTGGTCAGGAAG TCCTGACCACATCGATTTGG (SEQ ID NO: 195) (SEQ ID NO: 196) 1.39 5'-PO3- 5'-PO3- AAATCGATGTGGTAGCCGAG CGGCTACCACATCGATTTGG (SEQ ID NO: 197) (SEQ ID NO: 198) 1.40 5'-PO3- 5'-PO3- AAATCGATGTGGCCTGTAAG TACAGGCCACATCGATTTGG (SEQ ID NO: 199) (SEQ ID NO: 200) 1.41 5'-PO3- 5'-PO3- AAATCGATGTGCTTTCGGAG CCGAAAGCACATCGATTTGG (SEQ ID NO: 201) (SEQ ID NO: 202) 1.42 5'-PO3- 5'-PO3- AAATCGATGTGCGTAAGGAG CCTTACGCACATCGATTTGG (SEQ ID NO: 203) (SEQ ID NO: 204) 1.43 5'-PO3- 5'-PO3- AAATCGATGTGAGAGCGTAG ACGCTCTCACATCGATTTGG (SEQ ID NO: 205) (SEQ ID NO: 206) 1.44 5'-PO3- 5'-PO3- AAATCGATGTGGACGGCAAG TGCCGTCCACATCGATTTGG (SEQ ID NO: 207) (SEQ ID NO: 208) 1.45 5'-PO3-AAATCGATGTGCTTTCGCAG 5'-PO3- (SEQ ID NO: 209) GCGAAAGCACATCGATTTGG (SEQ ID NO: 210) 1.46 5'-PO3- 5'-PO3- AAATCGATGTGCGTAAGCAG GCTTACGCACATCGATTTGG (SEQ ID NO: 211) (SEQ ID NO: 212) 1.47 5'-PO3- 5'-PO3- AAATCGATGTGGCTATGGAG CCATAGCCACATCGATTTGG (SEQ ID NO: 213) (SEQ ID NO: 214) 1.48 5'-PO3- 5'-PO3- AAATCGATGTGACTCTGGAG CCAGAGTCACATCGATTTGG (SEQ ID NO: 215) (SEQ ID NO: 216) 1.49 5'-PO3-AAATCGATGTGCTGGAAAG 5'-PO3- (SEQ ID NO: 217) TTCCAGCACATCGATTTGG (SEQ ID NO: 218) 1.50 5'-PO3- 5'-PO3- AAATCGATGTGCCGAAGTAG ACTTCGGCACATCGATTTGG (SEQ ID NO: 219) (SEQ ID NO: 220) 1.51 5'-PO3- 5'-PO3- AAATCGATGTGCTCCTGAAG TCAGGAGCACATCGATTTGG (SEQ ID NO: 221) (SEQ ID NO: 222) 1.52 5'-PO3- 5'-PO3- AAATCGATGTGTCCAGTCAG GACTGGACACATCGATTTGG (SEQ ID NO: 223) (SEQ ID NO: 224) 1.53 5'-PO3- 5'-PO3- AAATCGATGTGAGAGCGGAG CCGCTCTCACATCGATTTGG (SEQ ID NO: 225) (SEQ ID NO: 226) 1.54 5'-PO3- 5'-PO3- AAATCGATGTGAGAGCGAAG TCGCTCTCACATCGATTTGG (SEQ ID NO: 227) (SEQ ID NO: 228) 1.55 5'-PO3- 5'-PO3- AAATCGATGTGCCGAAGGAG CCTTCGGCACATCGATTTGG (SEQ ID NO: 229) (SEQ ID NO: 230) 1.56 5'-PO3- 5'-PO3- AAATCGATGTGCCGAAGCAG GCTTCGGCACATCGATTTGG (SEQ ID NO: 231) (SEQ ID NO: 232) 1.57 5'-PO3- 5'-PO3- AAATCGATGTGTGTTCCGAG CGGAACACACATCGATTTGG (SEQ ID NO: 233) (SEQ ID NO: 234) 1.58 5'-PO3- 5'-PO3- AAATCGATGTGTCTGGCGAG CGCCAGACACATCGATTTGG (SEQ ID NO: 235) (SEQ ID NO: 236) 1.59 5'-PO3- 5'-PO3- AAATCGATGTGCTATCGGAG CCGATAGCACATCGATTTGG (SEQ ID NO: 237) (SEQ ID NO: 238) 1.60 5'-PO3- 5'-PO3- AAATCGATGTGCGAAAGGAG CCTTTCGCACATCGATTTGG (SEQ ID NO: 239) (SEQ ID NO: 240) 1.61 5'-PO3- 5'-PO3- AAATCGATGTGCCGAAGAAG TCTTCGGCACATCGATTTGG (SEQ ID NO: 241) (SEQ ID NO: 242)
1.62 5'-PO3- 5'-PO3- AAATCGATGTGGTTGCAGAG CTGCAACCACATCGATTTGG (SEQ ID NO: 243) (SEQ ID NO: 244) 1.63 5'-PO3- 5'-PO3- AAATCGATGTGGATGGTGAG- CACCATCCACATCGATTTGG (SEQ ID NO: 245) (SEQ ID NO: 246) 1.64 5'-PO3- 5'-PO3- AAATCGATGTGCTATCGCAG GCGATAGCACATCGATTTGG (SEQ ID NO: 247) (SEQ ID NO: 248) 1.65 5'-PO3- 5'-PO3- AAATCGATGTGCGAAAGCAG GCTTTCGCACATCGATTTGG (SEQ ID NO: 249) (SEQ ID NO: 250) 1.66 5'-PO3- 5'-PO3- AAATCGATGTGACACTGGAG CCAGTGTCACATCGATTTGG (SEQ ID NO: 251) (SEQ ID NO: 252) 1.67 5'-PO3- 5'-PO3- AAATCGATGTGTCTGGCAAG TGCCAGACACATCGATTTGG (SEQ ID NO: 253) (SEQ ID NO: 254) 1.68 5'-PO3- 5'-PO3- AAATCGATGTGGATGGTCAG GACCATCCACATCGATTTGG (SEQ ID NO: 255) (SEQ ID NO: 256) 1.69 5'-PO3- 5'-PO3- AAATCGATGTGGTTGCACAG GTGCAACCACATCGATTTGG (SEQ ID NO: 257) (SEQ ID NO: 258) 1.70 5'-PO3- 5'-PO3-CGATGCCCCATCCGA AAATCGATGTGGGCATCGAG TTT GG (SEQ ID NO: 259) (SEQ ID NO: 260) 1.71 5'-PO3- 5'-PO3- AAATCGATGTGTGCCTCCAG GGAGGCACACATCGATTTGG (SEQ ID NO: 261) (SEQ ID NO: 262) 1.72 5'-PO3- 5'-PO3- AAATCGATGTGTGCCTCAAG TGAGGCACACATCGATTTGG (SEQ ID NO: 263) (SEQ ID NO: 264) 1.73 5'-PO3- 5'-PO3- AAATCGATGTGGGCATCCAG GGATGCCCACATCGATTTGG (SEQ ID NO: 265) (SEQ ID NO: 266) 1.74 5'-PO3- 5'-PO3-TGATGCCCA CAT CGA AAATCGATGTGGGCATCAAG TTT GG (SEQ ID NO: 267) (SEQ ID NO: 268) 1.75 5'-PO3- 5'-PO3-CGA CAG GCA CAT AAATCGATGTGCCTGTCGAG CGA TTT GG (SEQ ID NO: 269) (SEQ ID NO: 270) 1.76 5'-PO3- 5'-PO3-ATC CGT CCA CAT AAATCGATGTGGACGGATAG CGA TTT GG (SEQ ID NO: 271) (SEQ ID NO: 272) 1.77 5'-PO3- 5'-PO3-GGA CAG GCA CAT AAATCGATGTGCCTGTCCAG CGA TTT GG (SEQ ID NO: 273) (SEQ ID NO: 274) 1.78 5'-PO3- 5'-PO3-CGT GCT TCA CAT AAATCGATGTGAAGCACGAG CGA TTT GG (SEQ ID NO: 275) (SEQ ID NO: 276) 1.79 5'-PO3- 5'-PO3-TGA CAG GCA CAT AAATCGATGTGCCTGTCAAG CGA TTT GG (SEQ ID NO: 277) (SEQ ID NO: 278) 1.80 5'-PO3- 5'-PO3-GGT GCT TCA CAT AAATCGATGTGAAGCACCAG CGA TTT GG (SEQ ID NO: 279) (SEQ ID NO: 280) 1.81 5'-PO3-AAATCGATGTGCCTTCGTAG 5'-PO3-ACG AAG GCA CAT (SEQ ID NO: 281) CGA TTT GG (SEQ ID NO: 282) 1.82 5'-PO3- 5'-PO3-CGG ACG ACA CAT AAATCGATGTGTCGTCCGAG CGA TTT GG (SEQ ID NO: 283) (SEQ ID NO: 284) 1.83 5'-PO3- 5'-PO3-CAG ACT CCA CAT AAATCGATGTGGAGTCTGAG CGA TTT GG (SEQ ID NO: 285) (SEQ ID NO: 286) 1.84 5'-PO3- 5'-PO3-CGG ATC ACA CAT AAATCGATGTGTGATCCGAG CGA TTT GG (SEQ ID NO: 287) (SEQ ID NO: 288) 1.85 5'-PO3- 5'-PO3-CGC CTG ACA CAT AAATCGATGTGTCAGGCGAG CGA TTT GG (SEQ ID NO: 289) (SEQ ID NO: 290) 1.86 5'-PO3- 5'-PO3-TGG ACG ACA CAT AAATCGATGTGTCGTCCAAG CGA TTT GG (SEQ ID NO: 291) (SEQ ID NO: 292) 1.87 5'-PO3- 5'-PO3-CTC CGT CCA CAT AAATCGATGTGGACGGAGAG CGA TTT GG (SEQ ID NO: 293) (SEQ ID NO: 294) 1.88 5'-PO3- 5'-PO3-CTG CTA CCA CAT AAATCGATGTGGTAGCAGAG CGA TTT GG (SEQ ID NO: 295) (SEQ ID NO: 296) 1.89 5'-PO3- 5'-PO3- AAATCGATGTGGCTGTGTAG ACACAGCCACATCGATTTGG (SEQ ID NO: 297) (SEQ ID NO: 298) 1.90 5'-PO3- 5'-PO3-GTC CGT CCA CAT AAATCGATGTGGACGGACAG CGA TTT GG (SEQ ID NO: 299) (SEQ ID NO: 300) 1.91 5'-PO3- 5'-PO3-TGC CTG ACA CAT AAATCGATGTGTCAGGCAAG CGA TTT GG (SEQ ID NO: 301) (SEQ ID NO: 302) 1.92 5'-PO3- 5'-PO3- AAATCGATGTGGCTCGAAAG TTCGAGCCACATCGATTTGG (SEQ ID NO: 303) (SEQ ID NO: 304) 1.93 5'-PO3- 5'-PO3-CCG AAG GCA CAT AAATCGATGTGCCTTCGGAG CGA TTT GG (SEQ ID NO: 305) (SEQ ID NO: 306) 1.94 5'-PO3- 5'-PO3-GTG CTA CCA CAT AAATCGATGTGGTAGCACAG CGA TTT GG (SEQ ID NO: 307) (SEQ ID NO: 308) 1.95 5'-PO3- 5'-PO3-GAC CTT CCA CAT AAATCGATGTGGAAGGTCAG CGA TTT GG (SEQ ID NO: 309) (SEQ ID NO: 310) 1.96 5'-PO3- 5'-PO3-ACA GCA CCA CAT AAATCGATGTGGTGCTGTAG CGA TTT GG (SEQ ID NO: 311) (SEQ ID NO: 312)
TABLE-US-00009 TABLE 4 Oligonucleotide tags used in cycle 2: Tag Number Top strand sequence Bottom strand sequence 2.1 5'-PO3-GTT GCC TGT 5'-PO3-AGG CAA CCT (SEQ ID NO: 313) (SEQ ID NO: 314) 2.2 5'-PO3-CAG GAC GGT 5'-PO3-CGT CCT GCT (SEQ ID NO: 315) (SEQ ID NO: 316) 2.3 5'-PO3-AGA CGT GGT 5'-PO3-CAC GTC TCT (SEQ ID NO: 317) (SEQ ID NO: 318) 2.4 5'-PO3-CAG GAC CGT 5'-PO3-GGT CCT GCT (SEQ ID NO: 319) (SEQ ID NO: 320) 2.5 5'-PO3-CAG GAC AGT 5'-PO3-TGT CCT GCT (SEQ ID NO: 321) (SEQ ID NO: 322) 2.6 5'-PO3-CAC TCT GGT 5'-PO3-CAG AGT GCT (SEQ ID NO: 323) (SEQ ID NO: 324) 2.7 5'-PO3-GAC GGC TGT 5'-PO3-AGC CGT CCT (SEQ ID NO: 325) (SEQ ID NO: 326) 2.8 5'-PO3-CAC TCT CGT 5'-PO3-GAG AGT GCT (SEQ ID NO: 327) (SEQ ID NO: 328) 2.9 5'-PO3-GTA GCC TGT 5'-PO3-AGG CTA CCT (SEQ ID NO: 329) (SEQ ID NO: 330) 2.10 5'-PO3-GCC ACT TGT 5'-PO3-AAG TGG CCT (SEQ ID NO: 331) (SEQ ID NO: 332) 2.11 5'-PO3-CAT CGC TGT 5'-PO3-AGC GAT GCT (SEQ ID NO: 333) (SEQ ID NO: 334) 2.12 5'-PO3-CAC TGG TGT 5'-PO3-ACC AGT GCT (SEQ ID NO: 335) (SEQ ID NO: 336) 2.13 5'-PO3-GCC ACT GGT 5'-PO3-CAG TGG CCT (SEQ ID NO: 337) (SEQ ID NO: 338) 2.14 5'-PO3-TCT GGC TGT 5'-PO3-AGC CAG ACT (SEQ ID NO: 339) (SEQ ID NO: 340) 2.15 5'-PO3-GCC ACT CGT 5'-PO3-GAG TGG CCT (SEQ ID NO: 341) (SEQ ID NO: 342) 2.16 5'-PO3-TGC CTC TGT 5'-PO3-AGA GGC ACT (SEQ ID NO: 343) (SEQ ID NO: 344) 2.17 5'-PO3-CAT CGC AGT 5'-PO3-TGC GAT GCT (SEQ ID NO: 345) (SEQ ID NO: 346) 2.18 5'-PO3-CAG GAA GGT 5'-PO3-CTT CCT GCT (SEQ ID NO: 347) (SEQ ID NO: 348) 2.19 5'-PO3-GGC ATC TGT 5'-PO3-AGA TGC CCT (SEQ ID NO: 349) (SEQ ID NO: 350) 2.20 5'-PO3-CGG TGC TGT 5'-PO3-AGC ACC GCT (SEQ ID NO: 351) (SEQ ID NO: 352) 2.21 5'-PO3-CAC TGG CGT 5'-PO3-GCC AGT GCT (SEQ ID NO: 353) (SEQ ID NO: 354) 2.22 5'-PO3-TCTCCTCGT 5'-PO3-GAGGAGACT (SEQ ID NO: 355) (SEQ ID NO: 356) 2.23 5'-PO3-CCT GTC TGT 5'-PO3-AGA CAG GCT (SEQ ID NO: 357) (SEQ ID NO: 358) 2.24 5'-PO3-CAA CGC TGT 5'-PO3-AGC GTT GCT (SEQ ID NO: 359) (SEQ ID NO: 360) 2.25 5'-PO3-TGC CTC GGT 5'-PO3-CGA GGC ACT (SEQ ID NO: 361) (SEQ ID NO: 362) 2.26 5'-PO3-ACA CTG CGT 5'-PO3-GCA GTG TCT (SEQ ID NO: 363) (SEQ ID NO: 364) 2.27 5'-PO3-TCG TCC TGT 5'-PO3-AGG ACG ACT (SEQ ID NO: 365) (SEQ ID NO: 366) 2.28 5'-PO3-GCT GCC AGT 5'-PO3-TGG CAG CCT (SEQ ID NO: 367) (SEQ ID NO: 368) 2.29 5'-PO3-TCA GGC TGT 5'-PO3-AGC CTG ACT (SEQ ID NO: 369) (SEQ ID NO: 370) 2.30 5'-PO3-GCC AGG TGT 5'-PO3-ACC TGG CCT (SEQ ID NO: 371) (SEQ ID NO: 372) 2.31 5'-PO3-CGG ACC TGT 5'-PO3-AGG TCC GCT (SEQ ID NO: 373) (SEQ ID NO: 374) 2.32 5'-PO3-CAA CGC AGT 5'-PO3-TGC GTT GCT (SEQ ID NO: 375) (SEQ ID NO: 376) 2.33 5'-PO3-CAC ACG AGT 5'-PO3-TCG TGT GCT (SEQ ID NO: 377) (SEQ ID NO: 378) 2.34 5'-PO3-ATG GCC TGT 5'-PO3-AGG CCA TCT (SEQ ID NO: 379) (SEQ ID NO: 380) 2.35 5'-PO3-CCA GTC TGT 5'-PO3-AGA CTG GCT (SEQ ID NO: 381) (SEQ ID NO: 382) 2.36 5'-PO3-GCC AGG AGT 5'-PO3-TCC TGG CCT (SEQ ID NO: 383) (SEQ ID NO: 384) 2.37 5'-PO3-CGG ACC AGT 5'-PO3-TGG TCC GCT (SEQ ID NO: 385) (SEQ ID NO: 386) 2.38 5'-PO3-CCT TCG CGT 5'-PO3-GCG AAG GCT (SEQ ID NO: 387) (SEQ ID NO: 388) 2.39 5'-PO3-GCA GCC AGT 5'-PO3-TGG CTG CCT (SEQ ID NO: 389) (SEQ ID NO: 390) 2.40 5'-PO3-CCA GTC GGT 5'-PO3-CGA CTG GCT (SEQ ID NO: 391) (SEQ ID NO: 392) 2.41 5'-PO3-ACT GAG CGT 5'-PO3-GCT CAG TCT (SEQ ID NO: 393) (SEQ ID NO: 394) 2.42 5'-PO3-CCA GTC CGT 5'-PO3-GGA CTG GCT (SEQ ID NO: 395) (SEQ ID NO: 396) 2.43 5'-PO3-CCA GTC AGT 5'-PO3-TGA CTG GCT (SEQ ID NO: 397) (SEQ ID NO: 398) 2.44 5'-PO3-CAT CGA GGT 5'-PO3-CTC GAT GCT (SEQ ID NO: 399) (SEQ ID NO: 400) 2.45 5'-PO3-CCA TCG TGT 5'-PO3-ACG ATG GCT (SEQ ID NO: 401) (SEQ ID NO: 402) 2.46 5'-PO3-GTG CTG CGT 5'-PO3-GCA GCA CCT (SEQ ID NO: 403) (SEQ ID NO: 404) 2.47 5'-PO3-GAC TAC GGT 5'-PO3-CGT AGT CCT (SEQ ID NO: 405) (SEQ ID NO: 406) 2.48 5'-PO3-GTG CTG AGT 5'-PO3-TCA GCA CCT (SEQ ID NO: 407) (SEQ ID NO: 408) 2.49 5'-PO3-GCTGCATGT 5'-PO3-ATGCAGCCT (SEQ ID NO: 409) (SEQ ID NO: 410) 2.50 5'-PO3-GAGTGGTGT 5'-PO3-ACCACTCCT (SEQ ID NO: 411) (SEQ ID NO: 412) 2.51 5'-PO3-GACTACCGT 5'-PO3-GGTAGTCCT (SEQ ID NO: 413) (SEQ ID NO: 414) 2.52 5'-PO3-CGGTGATGT 5'-PO3-ATCACCGCT (SEQ ID NO: 415) (SEQ ID NO: 416) 2.53 5'-PO3-TGCGACTGT 5'-PO3-AGTCGCACT (SEQ ID NO: 417) (SEQ ID NO: 418) 2.54 5'-PO3-TCTGGAGGT 5'-PO3-CTCCAGACT (SEQ ID NO: 419) (SEQ ID NO: 420) 2.55 5'-PO3-AGCACTGGT 5'-PO3-CAGTGCTCT (SEQ ID NO: 421) (SEQ ID NO: 422) 2.56 5'-PO3-TCGCTTGGT 5'-PO3-CAAGCGACT (SEQ ID NO: 423) (SEQ ID NO: 424) 2.57 5'-PO3-AGCACTCGT 5'-PO3-GAGTGCTCT (SEQ ID NO: 425) (SEQ ID NO: 426) 2.58 5'-PO3-GCGATTGGT 5'-PO3-CAATCGCCT (SEQ ID NO: 427) (SEQ ID NO: 428) 2.59 5'-PO3-CCATCGCGT 5'-PO3-GCGATGGCT (SEQ ID NO: 429) (SEQ ID NO: 430) 2.60 5'-PO3-TCGCTTCGT 5'-PO3-GAAGCGACT (SEQ ID NO: 431) (SEQ ID NO: 432) 2.61 5'-PO3-AGTGCCTGT 5'-PO3-AGGCACTCT (SEQ ID NO: 433) (SEQ ID NO: 434) 2.62 5'-PO3-GGCATAGGT 5'-PO3-CTATGCCCT (SEQ ID NO: 435) (SEQ ID NO: 436) 2.63 5'-PO3-GCGATTCGT 5'-PO3-GAATCGCCT (SEQ ID NO: 437) (SEQ ID NO: 438) 2.64 5'-PO3-TGCGACGGT 5'-PO3-CGTCGCACT (SEQ ID NO: 439) (SEQ ID NO: 440) 2.65 5'-PO3-GAGTGGCGT 5'-PO3-GCCACTCCT (SEQ ID NO: 441) (SEQ ID NO: 442) 2.66 5'-PO3-CGGTGAGGT 5'-PO3-CTCACCGCT (SEQ ID NO: 443) (SEQ ID NO: 444) 2.67 5'-PO3-GCTGCAAGT 5'-PO3-TTGCAGCCT (SEQ ID NO: 445) (SEQ ID NO: 446) 2.68 5'-PO3-TTCCGCTGT 5'-PO3-AGCGGAACT (SEQ ID NO: 447) (SEQ ID NO: 448) 2.69 5'-PO3-GAGTGGAGT 5'-PO3-TCCACTCCT (SEQ ID NO: 449) (SEQ ID NO: 450) 2.70 5'-PO3-ACAGAGCGT 5'-PO3-GCTCTGTCT (SEQ ID NO: 451) (SEQ ID NO: 452) 2.71 5'-PO3-TGCGACCGT 5'-PO3-GGTCGCACT (SEQ ID NO: 453) (SEQ ID NO: 454) 2.72 5'-PO3-CCTGTAGGT 5'-PO3-CTACAGGCT (SEQ ID NO: 455) (SEQ ID NO: 456) 2.73 5'-PO3-TAGCCGTGT 5'-PO3-ACGGCTACT (SEQ ID NO: 457) (SEQ ID NO: 458) 2.74 5'-PO3-TGCGACAGT 5'-PO3-TGTCGCACT (SEQ ID NO: 459) (SEQ ID NO: 460) 2.75 5'-PO3-GGTCTGTGT 5'-PO3-ACAGACCCT (SEQ ID NO: 461) (SEQ ID NO: 462) 2.76 5'-PO3-CGGTGAAGT 5'-PO3-TTCACCGCT (SEQ ID NO: 463) (SEQ ID NO: 464) 2.77 5'-PO3-CAACGAGGT 5'-PO3-CTCGTTGCT (SEQ ID NO: 465) (SEQ ID NO: 466) 2.78 5'-PO3-GCAGCATGT 5'-PO3-ATGCTGCCT (SEQ ID NO: 467) (SEQ ID NO: 468) 2.79 5'-PO3-TCGTCAGGT 5'-PO3-CTGACGACT (SEQ ID NO: 469) (SEQ ID NO: 470) 2.80 5'-PO3-AGTGCCAGT 5'-PO3-TGGCACTCT (SEQ ID NO: 471) (SEQ ID NO: 472) 2.81 5'-PO3-TAGAGGCGT 5'-PO3-GCCTCTACT (SEQ ID NO: 473) (SEQ ID NO: 474) 2.82 5'-PO3-GTCAGCGGT 5'-PO3-CGCTGACCT
(SEQ ID NO: 475) (SEQ ID NO: 476) 2.83 5'-PO3-TCAGGAGGT 5'-PO3-CTCCTGACT (SEQ ID NO: 477) (SEQ ID NO: 478) 2.84 5'-PO3-AGCAGGTGT 5'-PO3-ACCTGCTCT (SEQ ID NO: 479 (SEQ ID NO: 480) 2.85 5'-PO3-TTCCGCAGT 5'-PO3-TGCGGAACT (SEQ ID NO: 481) (SEQ ID NO: 482) 2.86 5'-PO3-GTCAGCCGT 5'-PO3-GGCTGACCT (SEQ ID NO: 483) (SEQ ID NO: 484) 2.87 5'-PO3-GGTCTGCGT 5'-PO3-GCAGACCCT (SEQ ID NO: 485) (SEQ ID NO: 486) 2.88 5'-PO3-TAGCCGAGT 5'-PO3-TCGGCTACT (SEQ ID NO: 487) (SEQ ID NO: 488) 2.89 5'-PO3-GTCAGCAGT 5'-PO3-TGCTGACCT (SEQ ID NO: 489) (SEQ ID NO: 490) 2.90 5'-PO3-GGTCTGAGT 5'-PO3-TCAGACCCT (SEQ ID NO: 491) (SEQ ID NO: 492) 2.91 5'-PO3-CGGACAGGT 5'-PO3-CTGTCCGCT (SEQ ID NO: 493) (SEQ ID NO: 494) 2.92 5'-PO3-TTAGCCGGT5'- 5'-PO3-CGGCTAACT5'-PO3- PO3-3' 3' (SEQ ID NO: 495) (SEQ ID NO: 496) 2.93 5'-PO3-GAGACGAGT 5'-PO3-TCGTCTCCT (SEQ ID NO: 497) (SEQ ID NO: 498) 2.94 5'-PO3-CGTAACCGT 5'-PO3-GGTTACGCT (SEQ ID NO: 499) (SEQ ID NO: 500) 2.95 5'-PO3-TTGGCGTGT5'- 5'-PO3-ACGCCAACT5'-PO3- PO3-3' 3' (SEQ ID NO: 501) (SEQ ID NO: 502) 2.96 5'-PO3-ATGGCAGGT 5'-PO3-CTGCCATCT (SEQ ID NO: 503) (SEQ ID NO: 504)
TABLE-US-00010 TABLE 5 Oligonucleotide tags used in cycle 3 Tag Bottom strand number Top strand sequence sequence 3.1 5'-PO3-CAG CTA CGA 5'-PO3-GTA GCT GAC (SEQ ID NO: 505) (SEQ ID NO: 506) 3.2 5'-PO3-CTC CTG CGA 5'-PO3-GCA GGA GAC (SEQ ID NO: 507) (SEQ ID NO: 508) 3.3 5'-PO3-GCT GCC TGA 5'-PO3-AGG CAG CAC (SEQ ID NO: 509) (SEQ ID NO: 510) 3.4 5'-PO3-CAG GAA CGA 5'-PO3-GTT CCT GAC (SEQ ID NO: 511) (SEQ ID NO: 512) 3.5 5'-PO3-CAC ACG CGA 5'-PO3-GCG TGT GAC (SEQ ID NO: 513) (SEQ ID NO: 514) 3.6 5'-PO3-GCA GCC TGA 5'-PO3-AGG CTG CAC (SEQ ID NO: 515) (SEQ ID NO: 516) 3.7 5'-PO3-CTG AAC GGA 5'-PO3-CGT TCA GAC (SEQ ID NO: 517) (SEQ ID NO: 518) 3.8 5'-PO3-CTG AAC CGA 5'-PO3-GGT TCA GAC (SEQ ID NO: 519) (SEQ ID NO: 520) 3.9 5'-PO3-TCT GGA CGA 5'-PO3-GTC CAG AAC (SEQ ID NO: 521) (SEQ ID NO: 522) 3.10 5'-PO3-TGC CTA CGA 5'-PO3-GTA GGC AAC (SEQ ID NO: 523) (SEQ ID NO: 524) 3.11 5'-PO3-GGC ATA CGA 5'-PO3-GTA TGC CAC (SEQ ID NO: 525) (SEQ ID NO: 526) 3.12 5'-PO3-CGG TGA CGA 5'-PO3-GTC ACC GAC (SEQ ID NO: 527) (SEQ ID NO: 528) 3.13 5'-PO3-CAA CGA CGA 5'-PO3-GTC GTT GAC (SEQ ID NO: 529) (SEQ ID NO: 530) 3.14 5'-PO3-CTC CTC TGA 5'-PO3-AGA GGA GAC (SEQ ID NO: 531) (SEQ ID NO: 532) 3.15 5'-PO3-TCA GGA CGA 5'-PO3-GTC CTG AAC (SEQ ID NO: 533) (SEQ ID NO: 534) 3.16 5'-PO3-AAA GGC GGA 5'-PO3-CGC CTT TAC (SEQ ID NO: 535) (SEQ ID NO: 536) 3.17 5'-PO3-CTC CTC GGA 5'-PO3-CGA GGA GAC (SEQ ID NO: 537) (SEQ ID NO: 538) 3.18 5'-PO3-CAG ATG CGA 5'-PO3-GCA TCT GAC (SEQ ID NO: 539) (SEQ ID NO: 540) 3.19 5'-PO3-GCA GCA AGA 5'-PO3-TTG CTG CAC (SEQ ID NO: 541) (SEQ ID NO: 542) 3.20 5'-PO3-GTG GAG TGA 5'-PO3-ACT CCA CAC (SEQ ID NO: 543) (SEQ ID NO: 544) 3.21 5'-PO3-CCA GTA GGA 5'-PO3-CTA CTG GAC (SEQ ID NO: 545) (SEQ ID NO: 546) 3.22 5'-PO3-ATG GCA CGA 5'-PO3-GTG CCA TAC (SEQ ID NO: 547) (SEQ ID NO: 548) 3.23 5'-PO3-GGA CTG TGA 5'-PO3-ACA GTC CAC (SEQ ID NO: 549) (SEQ ID NO: 550) 3.24 5'-PO3-CCG AAC TGA 5'-PO3-AGT TCG GAC (SEQ ID NO: 551) (SEQ ID NO: 552) 3.25 5'-PO3-CTC CTC AGA 5'-PO3-TGA GGA GAC (SEQ ID NO: 553) (SEQ ID NO: 554) 3.26 5'-PO3-CAC TGC TGA 5'-PO3-AGC AGT GAC (SEQ ID NO: 555) (SEQ ID NO: 556) 3.27 5'-PO3-AGC AGG CGA 5'-PO3-GCC TGC TAC (SEQ ID NO: 557) (SEQ ID NO: 558) 3.28 5'-PO3-AGC AGG AGA 5'-PO3-TCC TGC TAC (SEQ ID NO: 559) (SEQ ID NO: 560) 3.29 5'-PO3-AGA GCC AGA 5'-PO3-TGG CTC TAC (SEQ ID NO: 561) (SEQ ID NO: 562) 3.30 5'-PO3-GTC GTT GGA 5'-PO3-CAA CGA CAC (SEQ ID NO: 563) (SEQ ID NO: 564) 3.31 5'-PO3-CCG AAC GGA 5'-PO3-CGT TCG GAC (SEQ ID NO: 565) (SEQ ID NO: 566) 3.32 5'-PO3-CAC TGC GGA 5'-PO3-CGC AGT GAC (SEQ ID NO: 567) (SEQ ID NO: 568) 3.33 5'-PO3-GTG GAG CGA 5'-PO3-GCT CCA CAC (SEQ ID NO: 569) (SEQ ID NO: 570) 3.34 5'-PO3-GTG GAG AGA 5'-PO3-TCT CCA CAC (SEQ ID NO: 571) (SEQ ID NO: 572) 3.35 5'-PO3-GGA CTG CGA 5'-PO3-GCA GTC CAC (SEQ ID NO: 573) (SEQ ID NO: 574) 3.36 5'-PO3-CCG AAC CGA 5'-PO3-GGT TCG GAC (SEQ ID NO: 575) (SEQ ID NO: 576) 3.37 5'-PO3-CAC TGC CGA 5'-PO3-GGC AGT GAC (SEQ ID NO: 577) (SEQ ID NO: 578) 3.38 5'-PO3-CGA AAC GGA 5'-PO3-CGT TTC GAC (SEQ ID NO: 579) (SEQ ID NO: 580) 3.39 5'-PO3-GGA CTG AGA 5'-PO3-TCA GTC CAC (SEQ ID NO: 581) (SEQ ID NO: 582) 3.40 5'-PO3-CCG AAC AGA 5'-PO3-TGT TCG GAC (SEQ ID NO: 583) (SEQ ID NO: 584) 3.41 5'-PO3-CGA AAC CGA 5'-PO3-GGT TTC GAC (SEQ ID NO: 585) (SEQ ID NO: 586) 3.42 5'-PO3-CTG GCT TGA 5'-PO3-AAG CCA GAC (SEQ ID NO: 587) (SEQ ID NO: 588) 3.43 5'-PO3-CAC ACC TGA 5'-PO3-AGG TGT GAC (SEQ ID NO: 589) (SEQ ID NO: 590) 3.44 5'-PO3-AAC GAC CGA 5'-PO3-GGT CGT TAC (SEQ ID NO: 591) (SEQ ID NO: 592) 3.45 5'-PO3-ATC CAG CGA 5'-PO3-GCT GGA TAC (SEQ ID NO: 593) (SEQ ID NO: 594) 3.46 5'-PO3-TGC GAA GGA 5'-PO3-CTT CGC AAC (SEQ ID NO: 595) (SEQ ID NO: 596) 3.47 5'-PO3-TGC GAA CGA 5'-PO3-GTT CGC AAC (SEQ ID NO: 597) (SEQ ID NO: 598) 3.48 5'-PO3-CTG GCT GGA 5'-PO3-CAG CCA GAC (SEQ ID NO: 599) (SEQ ID NO: 600) 3.49 5'-PO3-CAC ACC GGA 5'-PO3-CGG TGT GAC (SEQ ID NO: 601) (SEQ ID NO: 602) 3.50 5'-PO3-AGT GCA GGA 5'-PO3-CTG CAC TAC (SEQ ID NO: 603) (SEQ ID NO: 604) 3.51 5'-PO3-GAC CGT TGA 5'-PO3-AAC GGT CAC (SEQ ID NO: 605) (SEQ ID NO: 606) 3.52 5'-PO3-GGT GAG TGA 5'-PO3-ACT CAC CAC (SEQ ID NO: 607) (SEQ ID NO: 608) 3.53 5'-PO3-CCT TCC TGA 5'-PO3-AGG AAG GAC (SEQ ID NO: 609) (SEQ ID NO: 610) 3.54 5'-PO3-CTG GCT AGA 5'-PO3-TAG CCA GAC (SEQ ID NO: 611) (SEQ ID NO: 612) 3.55 5'-PO3-CAC ACC AGA 5'-PO3-TGG TGT GAC (SEQ ID NO: 613) (SEQ ID NO: 614) 3.56 5'-PO3-AGC GGT AGA 5'-PO3-TAC CGC TAC (SEQ ID NO: 615) (SEQ ID NO: 616) 3.57 5'-PO3-GTC AGA GGA 5'-PO3-CTC TGA CAC (SEQ ID NO: 617) (SEQ ID NO: 618) 3.58 5'-PO3-TTC CGA CGA 5'-PO3-GTC GGA AAC (SEQ ID NO: 619) (SEQ ID NO: 620) 3.59 5'-PO3-AGG CGT AGA 5'-PO3-TAC GCC TAC (SEQ ID NO: 621) (SEQ ID NO: 622) 3.60 5'-PO3-CTC GAC TGA 5'-PO3-AGT CGA GAC (SEQ ID NO: 623) (SEQ ID NO: 624) 3.61 5'-PO3-TAC GCT GGA 5'-PO3-CAG CGT AAC (SEQ ID NO: 625) (SEQ ID NO: 626) 3.62 5'-PO3-GTT CGG TGA 5'-PO3-ACC GAA CAC (SEQ ID NO: 627) (SEQ ID NO: 628) 3.63 5'-PO3-GCC AGC AGA 5'-PO3-TGC TGG CAC (SEQ ID NO: 629) (SEQ ID NO: 630) 3.64 5'-PO3-GAC CGT AGA 5'-PO3-TAC GGT CAC (SEQ ID NO: 631) (SEQ ID NO: 632) 3.65 5'-PO3-GTG CTC TGA 5'-PO3-AGA GCA CAC (SEQ ID NO: 633) (SEQ ID NO: 634) 3.66 5'-PO3-GGT GAG CGA 5'-PO3-GCT CAC CAC (SEQ ID NO: 635) (SEQ ID NO: 636) 3.67 5'-PO3-GGT GAG AGA 5'-PO3-TCT CAC CAC (SEQ ID NO: 637) (SEQ ID NO: 638) 3.68 5'-PO3-CCT TCC AGA 5'-PO3-TGG AAG GAC (SEQ ID NO: 639) (SEQ ID NO: 640) 3.69 5'-PO3-CTC CTA CGA 5'-PO3-GTA GGA GAC (SEQ ID NO: 641) (SEQ ID NO: 642) 3.70 5'-PO3-CTC GAC GGA 5'-PO3-CGT CGA GAC (SEQ ID NO: 643) (SEQ ID NO: 644) 3.71 5'-PO3-GCC GTT TGA 5'-PO3-AAA CGG CAC (SEQ ID NO: 645) (SEQ ID NO: 646) 3.72 5'-PO3-GCG GAG TGA 5'-PO3-ACT CCG CAC (SEQ ID NO: 647) (SEQ ID NO: 648) 3.73 5'-PO3-CGT GCT TGA 5'-PO3-AAG CAC GAC (SEQ ID NO: 649) (SEQ ID NO: 650) 3.74 5'-PO3-CTC GAC CGA 5'-PO3-GGT CGA GAC (SEQ ID NO: 651) (SEQ ID NO: 652) 3.75 5'-PO3-AGA GCA GGA 5'-PO3-CTG CTC TAC (SEQ ID NO: 653) (SEQ ID NO: 654) 3.76 5'-PO3-GTG CTC GGA 5'-PO3-CGA GCA CAC (SEQ ID NO: 655) (SEQ ID NO: 656) 3.77 5'-PO3-CTC GAC AGA 5'-PO3-TGT CGA GAC (SEQ ID NO: 657) (SEQ ID NO: 658) 3.78 5'-PO3-GGA GAG TGA 5'-PO3-ACT CTC CAC (SEQ ID NO: 659) (SEQ ID NO: 660) 3.79 5'-PO3-AGG CTG TGA 5'-PO3-ACA GCC TAC (SEQ ID NO: 661) (SEQ ID NO: 662) 3.80 5'-PO3-AGA GCA CGA 5'-PO3-GTG CTC TAC (SEQ ID NO: 663) (SEQ ID NO: 664) 3.81 5'-PO3-CCA TCC TGA 5'-PO3-AGG ATG GAC (SEQ ID NO: 665) (SEQ ID NO: 666) 3.82 5'-PO3-GTT CGG AGA 5'-PO3-TCC GAA CAC
(SEQ ID NO: 667) (SEQ ID NO: 668) 3.83 5'-PO3-TGG TAG CGA 5'-PO3-GCT ACC AAC (SEQ ID NO: 669) (SEQ ID NO: 670) 3.84 5'-PO3-GTG CTC CGA 5'-PO3-GGA GCA CAC (SEQ ID NO: 671) (SEQ ID NO: 672) 3.85 5'-PO3-GTG CTC AGA 5'-PO3-TGA GCA CAC (SEQ ID NO: 673) (SEQ ID NO: 674) 3.86 5'-PO3-GCC GTT GGA 5'-PO3-CAA CGG CAC (SEQ ID NO: 675) (SEQ ID NO: 676) 3.87 5'-PO3-GAG TGC TGA 5'-PO3-AGC ACT CAC (SEQ ID NO: 677) (SEQ ID NO: 678) 3.88 5'-PO3-GCT CCT TGA 5'-PO3-AAG GAG CAC (SEQ ID NO: 679) (SEQ ID NO: 680) 3.89 5'-PO3-CCG AAA GGA 5'-PO3-CTT TCG GAC (SEQ ID NO: 681) (SEQ ID NO: 682) 3.90 5'-PO3-CAC TGA GGA 5'-PO3-CTC AGT GAC (SEQ ID NO: 683) (SEQ ID NO: 684) 3.91 5'-PO3-CGT GCT GGA 5'-PO3-CAG CAC GAC (SEQ ID NO: 685) (SEQ ID NO: 686) 3.92 5'-PO3-CCG AAA CGA 5'-PO3-GTT TCG GAC (SEQ ID NO: 687) (SEQ ID NO: 688) 3.93 5'-PO3-GCG GAG AGA 5'-PO3-TCT CCG CAC (SEQ ID NO: 689) (SEQ ID NO: 690) 3.94 5'-PO3-GCC GTT AGA 5'-PO3-TAA CGG CAC (SEQ ID NO: 691) (SEQ ID NO: 692) 3.95 5'-PO3-TCT CGT GGA 5'-PO3-CAC GAG AAC (SEQ ID NO: 693) (SEQ ID NO: 694) 3.96 5'-PO3-CGT GCT AGA 5'-PO3-TAG CAC GAC (SEQ ID NO: 695) (SEQ ID NO: 696)
TABLE-US-00011 TABLE 6 Oligonucleotide tags used in cycle 4 Tag Bottom strand number Top strand sequence sequence 4.1 5'-PO3-GCCTGTCTT 5'-PO3-GAC AGG CTC (SEQ ID NO: 697) (SEQ ID NO: 698) 4.2 5'-PO3-CTCCTGGTT 5'-PO3-CCA GGA GTC (SEQ ID NO: 699) (SEQ ID NO: 700) 4.3 5'-PO3-ACTCTGCTT 5'-PO3-GCA GAG TTC (SEQ ID NO: 701) (SEQ ID NO: 702) 4.4 5'-PO3-CATCGCCTT 5'-PO3-GGC GAT GTC (SEQ ID NO: 703) (SEQ ID NO: 704) 4.5 5'-PO3-GCCACTATT 5'-PO3-TAG TGG CTC (SEQ ID NO: 705) (SEQ ID NO: 706) 4.6 5'-PO3-CACACGGTT 5'-PO3-CCG TGT GTC (SEQ ID NO: 707) (SEQ ID NO: 708) 4.7 5'-PO3-CAACGCCTT 5'-PO3-GGC GTT GTC (SEQ ID NO: 709) (SEQ ID NO: 710) 4.8 5'-PO3-ACTGAGGTT 5'-PO3-CCT CAG TTC (SEQ ID NO: 711) (SEQ ID NO: 712) 4.9 5'-PO3-GTGCTGGTT 5'-PO3-CCA GCA CTC (SEQ ID NO: 713) (SEQ ID NO: 714) 4.10 5'-PO3-CATCGACTT 5'-PO3-GTC GAT GTC (SEQ ID NO: 715) (SEQ ID NO: 716) 4.11 5'-PO3-CCATCGGTT 5'-PO3-CCG ATG GTC (SEQ ID NO: 717) (SEQ ID NO: 718) 4.12 5'-PO3-GCTGCACTT 5'-PO3-GTG CAG CTC (SEQ ID NO: 719) (SEQ ID NO: 720) 4.13 5'-PO3-ACAGAGGTT 5'-PO3-CCT CTG TTC (SEQ ID NO: 721) (SEQ ID NO: 722) 4.14 5'-PO3-AGTGCCGTT 5'-PO3-CGG CAC TTC (SEQ ID NO: 723) (SEQ ID NO: 724) 4.15 5'-PO3-CGGACATTT 5'-PO3-ATG TCC GTC (SEQ ID NO: 725) (SEQ ID NO: 726) 4.16 5'-PO3-GGTCTGGTT 5'-PO3-CCA GAC CTC (SEQ ID NO: 727) (SEQ ID NO: 728) 4.17 5'-PO3-GAGACGGTT 5'-PO3-CCG TCT CTC (SEQ ID NO: 729) (SEQ ID NO: 730) 4.18 5'-PO3-CTTTCCGTT 5'-PO3-CGG AAA GTC (SEQ ID NO: 731) (SEQ ID NO: 732) 4.19 5'-PO3-CAGATGGTT 5'-PO3-CCA TCT GTC (SEQ ID NO: 733) (SEQ ID NO: 734) 4.20 5'-PO3-CGGACACTT 5'-PO3-GTG TCC GTC (SEQ ID NO: 735) (SEQ ID NO: 736) 4.21 5'-PO3-ACTCTCGTT 5'-PO3-CGA GAG TTC (SEQ ID NO: 737) (SEQ ID NO: 738) 4.22 5'-PO3-GCAGCACTT 5'-PO3-GTG CTG CTC (SEQ ID NO: 739) (SEQ ID NO: 740) 4.23 5'-PO3-ACTCTCCTT 5'-PO3-GGA GAG TTC (SEQ ID NO: 741) (SEQ ID NO: 742) 4.24 5'-PO3-ACCTTGGTT 5'-PO3-CCA AGG TTC (SEQ ID NO: 743) (SEQ ID NO: 744) 4.25 5'-PO3-AGAGCCGTT 5'-PO3-CGG CTC TTC (SEQ ID NO: 745) (SEQ ID NO: 746) 4.26 5'-PO3-ACCTTGCTT 5'-PO3-GCA AGG TTC (SEQ ID NO: 747) (SEQ ID NO: 748) 4.27 5'-PO3-AAGTCCGTT 5'-PO3-CGG ACT TTC (SEQ ID NO: 749) (SEQ ID NO: 750) 4.28 5'-PO3-GGA CTG GTT 5'-PO3-CCA GTC CTC (SEQ ID NO: 751) (SEQ ID NO: 752) 4.29 5'-PO3-GTCGTTCTT 5'-PO3-GAA CGA CTC (SEQ ID NO: 753) (SEQ ID NO: 754) 4.30 5'-PO3-CAGCATCTT 5'-PO3-GAT GCT GTC (SEQ ID NO: 755) (SEQ ID NO: 756) 4.31 5'-PO3-CTATCCGTT 5'-PO3-CGG ATA GTC (SEQ ID NO: 757) (SEQ ID NO: 758) 4.32 5'-PO3-ACACTCGTT 5'-PO3-CGA GTG TTC (SEQ ID NO: 759) (SEQ ID NO: 760) 4.33 5'-PO3-ATCCAGGTT 5'-PO3-CCT GGA TTC (SEQ ID NO: 761) (SEQ ID NO: 762) 4.34 5'-PO3-GTTCCTGTT 5'-PO3-CAG GAA CTC (SEQ ID NO: 763) (SEQ ID NO: 764) 4.35 5'-PO3-ACACTCCTT 5'-PO3-GGA GTG TTC (SEQ ID NO: 765) (SEQ ID NO: 766) 4.36 5'-PO3-GTTCCTCTT 5'-PO3-GAG GAA CTC (SEQ ID NO: 767) (SEQ ID NO: 768) 4.37 5'-PO3-CTGGCTCTT 5'-PO3-GAG CCA GTC (SEQ ID NO: 769) (SEQ ID NO: 770) 4.38 5'-PO3-ACGGCATTT 5'-PO3-ATG CCG TTC (SEQ ID NO: 771) (SEQ ID NO: 772) 4.39 5'-PO3-GGTGAGGTT 5'-PO3-CCT CAC CTC (SEQ ID NO: 773) (SEQ ID NO: 774) 4.40 5'-PO3-CCTTCCGTT 5'-PO3-CGG AAG GTC (SEQ ID NO: 775) (SEQ ID NO: 776) 4.41 5'-PO3 -TACGCTCTT 5'-PO3 -GAG CGT ATC (SEQ ID NO: 777) (SEQ ID NO: 778) 4.42 5'-PO3-ACGGCAGTT 5'-PO3-CTG CCG TTC (SEQ ID NO: 779) (SEQ ID NO: 780 4.43 5'-PO3-ACTGACGTT 5'-PO3-CGT CAG TTC (SEQ ID NO: 781) (SEQ ID NO: 782) 4.44 5'-PO3-ACGGCACTT 5'-PO3-GTG CCG TTC (SEQ ID NO: 783) (SEQ ID NO: 784) 4.45 5'-PO3-ACTGACCTT 5'-PO3-GGT CAG TTC (SEQ ID NO: 785) (SEQ ID NO: 786) 4.46 5'-PO3-TTTGCGGTT 5'-PO3-CCG CAA ATC (SEQ ID NO: 787) (SEQ ID NO: 788) 4.47 5'-PO3-TGGTAGGTT 5'-PO3-CCT ACC ATC (SEQ ID NO: 789) (SEQ ID NO: 790) 4.48 5'-PO3-GTTCGGCTT 5'-PO3-GCC GAA CTC (SEQ ID NO: 791) (SEQ ID NO: 792) 4.49 5'-PO3-GCC GTT CTT 5'-PO3-GAA CGG CTC (SEQ ID NO: 793) (SEQ ID NO: 794) 4.50 5'-PO3-GGAGAGGTT 5'-PO3-CCT CTC CTC (SEQ ID NO: 795) (SEQ ID NO: 796) 4.51 5'-PO3-CACTGACTT 5'-PO3-GTC AGT GTC (SEQ ID NO: 797) (SEQ ID NO: 798) 4.52 5'-PO3-CGTGCTCTT 5'-PO3-GAG CAC GTC (SEQ ID NO: 799) (SEQ ID NO: 800) 4.53 5'-PO3-AATCCGCTT 5'-PO3 -GCGGATTTC (SEQ ID NO: 801) (SEQ ID NO: 802) 4.54 5'-PO3-AGGCTGGTT 5'-PO3-CCA GCC TTC (SEQ ID NO: 803) (SEQ ID NO: 804) 4.55 5'-PO3-GCTAGTGTT 5'-PO3-CAC TAG CTC (SEQ ID NO: 805) (SEQ ID NO: 806) 4.56 5'-PO3-GGAGAGCTT 5'-PO3-GCT CTC CTC (SEQ ID NO: 807) (SEQ ID NO: 808) 4.57 5'-PO3-GGAGAGATT 5'-PO3-TCT CTC CTC (SEQ ID NO: 809) (SEQ ID NO: 810) 4.58 5'-PO3-AGGCTGCTT 5'-PO3-GCA GCC TTC (SEQ ID NO: 811) (SEQ ID NO: 812) 4.59 5'-PO3-GAGTGCGTT 5'-PO3-CGC ACT CTC (SEQ ID NO: 813) (SEQ ID NO: 814) 4.60 5'-PO3-CCATCCATT 5'-PO3-TGG ATG GTC (SEQ ID NO: 815) (SEQ ID NO: 816) 4.61 5'-PO3-GCTAGTCTT 5'-PO3-GAC TAG CTC (SEQ ID NO: 817) (SEQ ID NO: 818) 4.62 5'-PO3-AGGCTGATT 5'-PO3-TCA GCC TTC (SEQ ID NO: 819) (SEQ ID NO: 820) 4.63 5'-PO3-ACAGACGTT 5'-PO3-CGT CTG TTC (SEQ ID NO: 821) (SEQ ID NO: 822) 4.64 5'-PO3-GAGTGCCTT 5'-PO3-GGC ACT CTC (SEQ ID NO: 823) (SEQ ID NO: 824) 4.65 5'-PO3-ACAGACCTT 5'-PO3-GGT CTG TTC (SEQ ID NO: 825) (SEQ ID NO: 826) 4.66 5'-PO3-CGAGCTTTT 5'-PO3-AAG CTC GTC (SEQ ID NO: 827) (SEQ ID NO: 828) 4.67 5'-PO3-TTAGCGGTT 5'-PO3-CCG CTA ATC (SEQ ID NO: 829) (SEQ ID NO: 830) 4.68 5'-PO3-CCTCTTGTT 5'-PO3-CAA GAG GTC (SEQ ID NO: 831) (SEQ ID NO: 832) 4.69 5'-PO3-GGTCTCTTT 5'-PO3-AGA GAC CTC (SEQ ID NO: 833) (SEQ ID NO: 834) 4.70 5'-PO3-GCCAGATTT 5'-PO3-ATC TGG CTC (SEQ ID NO: 835) (SEQ ID NO: 836) 4.71 5'-PO3-GAGACCTTT 5'-PO3-AGG TCT CTC (SEQ ID NO: 837) (SEQ ID NO: 838) 4.72 5'-PO3-CACACAGTT 5'-PO3-CTG TGT GTC (SEQ ID NO: 839) (SEQ ID NO: 840) 4.73 5'-PO3-CCTCTTCTT 5'-PO3-GAA GAG GTC (SEQ ID NO: 841) (SEQ ID NO: 842) 4.74 5'-PO3-TAGAGCGTT 5'-PO3-CGC TCT ATC (SEQ ID NO: 843) (SEQ ID NO: 844) 4.75 5'-PO3-GCACCTTTT 5'-PO3-AAG GTG CTC (SEQ ID NO: 845) (SEQ ID NO: 846) 4.76 5'-PO3-GGCTTGTTT 5'-PO3-ACA AGC CTC (SEQ ID NO: 847) (SEQ ID NO: 848) 4.77 5'-PO3-GACGCGATT 5'-PO3-TCG CGT CTC (SEQ ID NO: 849) (SEQ ID NO: 850) 4.78 5'-PO3-CGAGCTGTT 5'-PO3-CAG CTC GTC (SEQ ID NO: 851) (SEQ ID NO: 852) 4.79 5'-PO3-TAGAGCCTT 5'-PO3-GGC TCT ATC (SEQ ID NO: 853) (SEQ ID NO: 854) 4.80 5'-PO3-CATCCGTTT 5'-PO3-ACG GAT GTC (SEQ ID NO: 855) (SEQ ID NO: 856) 4.81 5'-PO3-GGTCTCGTT 5'-PO3-CGA GAC CTC (SEQ ID NO: 857) (SEQ ID NO: 858) 4.82 5'-PO3-GCCAGAGTT 5'-PO3-CTC TGG CTC
(SEQ ID NO: 859) (SEQ ID NO: 860) 4.83 5'-PO3-GAGACCGTT 5'-PO3-CGG TCT CTC (SEQ ID NO: 861) (SEQ ID NO: 862) 4.84 5'-PO3-CGAGCTATT 5'-PO3-TAG CTC GTC (SEQ ID NO: 863) (SEQ ID NO: 864) 4.85 5'-PO3-GCAAGTGTT 5'-PO3-CAC TTG CTC (SEQ ID NO: 865) (SEQ ID NO: 866) 4.86 5'-PO3-GGTCTCCTT 5'-PO3-GGA GAC CTC (SEQ ID NO: 867) (SEQ ID NO: 868) 4.87 5'-PO3-GCCAGACTT 5'-PO3-GTC TGG CTC (SEQ ID NO: 869) (SEQ ID NO: 870) 4.88 5'-PO3-GGTCTCATT 5'-PO3-TGA GAC CTC (SEQ ID NO: 871) (SEQ ID NO: 872) 4.89 5'-PO3-GAGACCATT 5'-PO3-TGG TCT CTC (SEQ ID NO: 873) (SEQ ID NO: 874) 4.90 5'-PO3-CCTTCAGTT 5'-PO3-CTG AAG GTC (SEQ ID NO: 875) (SEQ ID NO: 876) 4.91 5'-PO3-GCACCTGTT 5'-PO3-CAG GTG CTC (SEQ ID NO: 877) (SEQ ID NO: 878) 4.92 5'-PO3-AAAGGCGTT 5'-PO3-CGC CTT TTC (SEQ ID NO: 879) (SEQ ID NO: 880) 4.93 5'-PO3-CAGATCGTT 5'-PO3-CGA TCT GTC (SEQ ID NO: 881) (SEQ ID NO: 882) 4.94 5'-PO3-CATAGGCTT 5'-PO3-GCC TAT GTC (SEQ ID NO: 883) (SEQ ID NO: 884) 4.95 5'-PO3-CCTTCACTT 5'-PO3-GTG AAG GTC (SEQ ID NO: 885) (SEQ ID NO: 886) 4.96 5'-PO3-GCACCTCTT 5'-PO3-GAG GTG CTC (SEQ ID NO: 887) (SEQ ID NO: 888)
TABLE-US-00012 TABLE 7 Correspondence between building blocks and oligonucleotide tags for Cycles 1-4. Building block Cycle 1 Cycle 2 Cycle 3 Cycle 4 BB1 1.1 2.1 3.1 4.1 BB2 1.2 2.2 3.2 4.2 BB3 1.3 2.3 3.3 4.3 BB4 1.4 2.4 3.4 4.4 BB5 1.5 2.5 3.5 4.5 BB6 1.6 2.6 3.6 4.6 BB7 1.7 2.7 3.7 4.7 BB8 1.8 2.8 3.8 4.8 BB9 1.9 2.9 3.9 4.9 BB10 1.10 2.10 3.10 4.10 BB11 1.11 2.11 3.11 4.11 BB12 1.12 2.12 3.12 4.12 BB13 1.13 2.13 3.13 4.13 BB14 1.14 2.14 3.14 4.14 BB15 1.15 2.15 3.15 4.15 BB16 1.16 2.16 3.16 4.16 BB17 1.17 2.17 3.17 4.17 BB18 1.18 2.18 3.18 4.18 BB19 1.19 2.19 3.19 4.19 BB20 1.20 2.20 3.20 4.20 BB21 1.21 2.21 3.21 4.21 BB22 1.22 2.22 3.22 4.22 BB23 1.23 2.23 3.23 4.23 BB24 1.24 2.24 3.24 4.24 BB25 1.25 2.25 3.25 4.25 BB26 1.26 2.26 3.26 4.26 BB27 1.27 2.27 3.27 4.27 BB28 1.28 2.28 3.28 4.28 BB29 1.29 2.29 3.29 4.29 BB30 1.30 2.30 3.30 4.30 BB31 1.31 2.31 3.31 4.31 BB32 1.32 2.32 3.32 4.32 BB33 1.33 2.33 3.33 4.33 BB34 1.34 2.34 3.34 4.34 BB35 1.35 2.35 3.35 4.35 BB36 1.36 2.36 3.36 4.36 BB37 1.37 2.37 3.37 4.37 BB38 1.38 2.38 3.38 4.38 BB39 1.39 2.39 3.39 4.39 BB40 1.44 2.44 3.44 4.44 BB41 1.41 2.41 3.41 4.41 BB42 1.42 2.42 3.42 4.42 BB43 1.43 2.43 3.43 4.43 BB44 1.40 2.40 3.40 4.40 BB45 1.45 2.45 3.45 4.45 BB46 1.46 2.46 3.46 4.46 BB47 1.47 2.47 3.47 4.47 BB48 1.48 2.48 3.48 4.48 BB49 1.49 2.49 3.49 4.49 BB50 1.50 2.50 3.50 4.50 BB51 1.51 2.51 3.51 4.51 BB52 1.52 2.52 3.52 4.52 BB53 1.53 2.53 3.53 4.53 BB54 1.54 2.54 3.54 4.54 BB55 1.55 2.55 3.55 4.55 BB56 1.56 2.56 3.56 4.56 BB57 1.57 2.57 3.57 4.57 BB58 1.58 2.58 3.58 4.58 BB59 1.59 2.59 3.59 4.59 BB60 1.60 2.60 3.60 4.60 BB61 1.61 2.61 3.61 4.61 BB62 1.62 2.62 3.62 4.62 BB63 1.63 2.63 3.63 4.63 BB64 1.64 2.64 3.64 4.64 BB65 1.65 2.65 3.65 4.65 BB66 1.66 2.66 3.66 4.66 BB67 1.67 2.67 3.67 4.67 BB68 1.68 2.68 3.68 4.68 BB69 1.69 2.69 3.69 4.69 BB70 1.70 2.70 3.70 4.70 BB71 1.71 2.71 3.71 4.71 BB72 1.72 2.72 3.72 4.72 BB73 1.73 2.73 3.73 4.73 BB74 1.74 2.74 3.74 4.74 BB75 1.75 2.75 3.75 4.75 BB76 1.76 2.76 3.76 4.76 BB77 1.77 2.77 3.77 4.77 BB78 1.78 2.78 3.78 4.78 BB79 1.79 2.79 3.79 4.79 BB80 1.80 2.80 3.80 4.80 BB81 1.81 2.81 3.81 4.81 BB82 1.82 2.82 3.82 4.82 BB83 1.96 2.96 3.96 4.96 BB84 1.83 2.83 3.83 4.83 BB85 1.84 2.84 3.84 4.84 BB86 1.85 2.85 3.85 4.85 BB87 1.86 2.86 3.86 4.86 BB88 1.87 2.87 3.87 4.87 BB89 1.88 2.88 3.88 4.88 BB90 1.89 2.89 3.89 4.89 BB91 1.90 2.90 3.90 4.90 BB92 1.91 2.91 3.91 4.91 BB93 1.92 2.92 3.92 4.92 BB94 1.93 2.93 3.93 4.93 BB95 1.94 2.94 3.94 4.94 BB96 1.95 2.95 3.95 4.95
1× ligase buffer: 50 mM Tris, pH 7.5; 10 mM dithiothreitol; 10 mM MgCl2; 2 mM ATP; 50 mM NaCl. 10× ligase buffer: 500 mM Tris, pH 7.5; 100 mM dithiothreitol; 100 mM MgCl2; 20 mM ATP; 500 mM NaCl
Attachment of Water Soluble Spacer to Compound 2
[0225] To a solution of Compound 2 (60 mL, 1 mM) in sodium borate buffer (150 mM, pH 9.4) that was chilled to 4° C. was added 40 equivalents of N-Fmoc-15-amino-4,7,10,13-tetraoxaoctadecanoic acid (S-Ado) in N,N-dimethylformamide (DMF) (16 mL, 0.15 M) followed by 40 equivalents of 4-(4,6-dimethoxy[1.3.5]triazin-2-yl)-4-methylmorpholinium chloride hydrate (DMTMM) in water (9.6 mL, 0.25 M). The mixture was gently shaken for 2 hours at 4° C. before an additional 40 equivalents of S-Ado and DMTMM were added and shaken for a further 16 hours at 4° C.
[0226] Following acylation, a 0.1× volume of 5 M aqueous NaCl and a 2.5× volume of cold (-20° C.) ethanol was added and the mixture was allowed to stand at -20° C. for at least one hour. The mixture was then centrifuged for 15 minutes at 14,000 rpm in a 4° C. centrifuge to give a white pellet which was washed with cold EtOH and then dried in a lyophilizer at room temperature for 30 minutes. The solid was dissolved in 40 mL of water and purified by Reverse Phase HPLC with a Waters Xterra RP18 column. A binary mobile phase gradient profile was used to elute the product using a 50 mM aqueous triethylammonium acetate buffer at pH 7.5 and 99% acetonitrile/1% water solution. The purified material was concentrated by lyophilization and the resulting residue was dissolved in 5 mL of water. A 0.1× volume of piperidine was added to the solution and the mixture was gently shaken for 45 minutes at room temperature. The product was then purified by ethanol precipitation as described above and isolated by centrifugation. The resulting pellet was washed twice with cold EtOH and dried by lyophilization to give purified Compound 3.
Cycle 1
[0227] To each well in a 96 well plate was added 12.5 of a 4 mM solution of Compound 3 in water; 100 μL of a 1 mM solution of one of oligonucleotide tags 1.1 to 1.96, as shown in Table 3 (the molar ratio of Compound 3 to tags was 1:2). The plates were heated to 95° C. for 1 minute and then cooled to 16° C. over 10 minutes. To each well was added 10 μL of 10× ligase buffer, 30 units T4 DNA ligase (1 μL of a 30 unit/μL solution (FermentasLife Science, Cat. No. EL0013)), 76.5 μl of water and the resulting solutions were incubated at 16° C. for 16 hours.
[0228] After the ligation reaction, 20 μL of 5 M aqueous NaCl was added directly to each well, followed by 500 μL cold (-20° C.) ethanol, and held at -20° C. for 1 hour. The plates were centrifugated for 1 hour at 3200 g in a Beckman Coulter Allegra 6R centrifuge using Beckman Microplus Carriers. The supernatant was carefully removed by inverting the plate and the pellet was washed with 70% aqueous cold ethanol at -20° C. Each of the pellets was then dissolved in sodium borate buffer (50 μL, 150 mM, pH 9.4) to a concentration of 1 mM and chilled to 4° C.
[0229] To each solution was added 40 equivalents of one of the 96 building block precursors in DMF (13 μL, 0.15 M) followed by 40 equivalents of DMT-MM in water (8 μL, 0.25M), and the solutions were gently shaken at 4° C. After 2 hours, an additional 40 equivalents of one of each building block precursor and DMTMM were added and the solutions were gently shaken for 16 hours at 4° C. Following acylation, 10 equivalents of acetic acid-N-hydroxy-succinimide ester in DMF (2 μL, 0.25M) was added to each solution and gently shaken for 10 minutes.
[0230] Following acylation, the 96 reaction mixtures were pooled and 0.1 volume of 5M aqueous NaCl and 2.5 volumes of cold absolute ethanol were added and the solution was allowed to stand at -20° C. for at least one hour. The mixture was then centrifuged. Following centrifugation, as much supernatant as possible was removed with a micropipette, the pellet was washed with cold ethanol and centrifuged again. The supernatant was removed with a 200 μL pipet. Cold 70% ethanol was added to the tube, and the resulting mixture was centrifuged for 5 min at 4° C.
[0231] The supernatant was removed and the remaining ethanol was removed by lyophilization at room temperature for 10 minutes. The pellet was then dissolved in 2 mL of water and purified by Reverse Phase HPLC with a Waters Xterra RP18 column. A binary mobile phase gradient profile was used to elute the library using a 50 mM aqueous triethylammonium acetate buffer at pH 7.5 and 99% acetonitrile/1% water solution. The fractions containing the library were collected, pooled, and lyophilized. The resulting residue was dissolved in 2.5 mL of water and 250 μL of piperidine was added. The solution was shaken gently for 45 minutes and then precipitated with ethanol as previously described. The resulting pellet was dried by lyophilization and then dissolved in sodium borate buffer (4.8 mL, 150 mM, pH 9.4) to a concentration of 1 mM.
[0232] The solution was chilled to 4° C. and 40 equivalents each of N-Fmoc-propargylglycine in DMF (1.2 mL, 0.15 M) and DMT-MM in water (7.7 mL, 0.25 M) were added. The mixture was gently shaken for 2 hours at 4° C. before an additional 40 equivalents of N-Fmoc-propargylglycine and DMT-MM were added and the solution was shaken for a further 16 hours. The mixture was later purified by EtOH precipitation and Reverse Phase HPLC as described above and the N-Fmoc group was removed by treatment with piperidine as previously described. Upon final purification by EtOH precipitation, the resulting pellet was dried by lyophilization and carried into the next cycle of synthesis
Cycles 2-4
[0233] For each of these cycles, the dried pellet from the previous cycle was dissolved in water and the concentration of library was determined by spectrophotometry based on the extinction coefficient of the DNA component of the library, where the initial extinction coefficient of Compound 2 is 131,500 L/(molecm). The concentration of the library was adjusted with water such that the final concentration in the subsequent ligation reactions was 0.25 mM. The library was then divided into 96 equal aliquots in a 96 well plate. To each well was added a solution comprising a different tag (molar ratio of the library to tag was 1:2), and ligations were performed as described for Cycle 1. Oligonucleotide tags used in Cycles 2, 3 and 4 are set forth in Tables 4, 5 and 6, respectively. Correspondence between the tags and the building block precursors for each of Cycles 1 to 4 is provided in Table 7. The library was precipitated by the addition of ethanol as described above for Cycle 1, and dissolved in sodium borate buffer (150 mM, pH 9.4) to a concentration of 1 mM. Subsequent acylations and purifications were performed as described for Cycle 1, except HPLC purification was omitted during Cycle 3.
[0234] The products of Cycle 4 were ligated with the closing primer shown below, using the method described above for ligation of tags.
TABLE-US-00013 (SEQ ID NO: 889) 5'-PO3-CAG AAG ACA GAC AAG CTT CAC CTG C (SEQ ID NO: 890) 5'-PO3-GCA GGT GAA GCT TGT CTG TCT TCT GAA
Results:
[0235] The synthetic procedure described above has the capability of producing a library comprising 964 (about 108) different structures. The synthesis of the library was monitored via gel electrophoresis and LC/MS of the product of each cycle. Upon completion, the library was analyzed using several techniques. FIG. 13a is a chromatogram of the library following Cycle 4, but before ligation of the closing primer; FIG. 13b is a mass spectrum of the library at the same synthetic stage. The average molecular weight was determined by negative ion LC/MS analysis. The ion signal was deconvoluted using ProMass software. This result is consistent with the predicted average mass of the library.
[0236] The DNA component of the library was analyzed by agarose gel electrophoresis, which showed that the majority of library material corresponds to ligated product of the correct size. DNA sequence analysis of molecular clones of PCR product derived from a sampling of the library shows that DNA ligation occurred with high fidelity and to near completion.
Library Cyclization
[0237] At the completion of Cycle 4, a portion of the library was capped at the N-terminus using azidoacetic acid under the usual acylation conditions. The product, after purification by EtOH precipitation, was dissolved in sodium phosphate buffer (150 mM, pH 8) to a concentration of 1 mM and 4 equivalents each of CuSO4 in water (200 mM), ascorbic acid in water (200 mM), and a solution of the compound shown below in DMF (200 mM) were added. The reaction mixture was then gently shaken for 2 hours at room temperature.
##STR00110##
[0238] To assay the extent of cyclization, 5 μL aliquots from the library cyclization reaction were removed and treated with a fluorescently-labeled azide or alkyne (14 of 100 mM DMF stocks) prepared as described in Example 4. After 16 hours, neither the alkyne or azide labels had been incorporated into the library by HPLC analysis at 500 nm. This result indicated that the library no longer contained azide or alkyne groups capable of cycloaddition and that the library must therefore have reacted with itself, either through cyclization or intermolecular reactions. The cyclized library was purified by Reverse Phase HPLC as previously described. Control experiments using uncyclized library showed complete incorporation of the fluorescent tags mentioned above.
Example 4
Preparation of Fluorescent Tags for Cyclization Assay
[0239] In separate tubes, propargyl glycine or 2-amino-3-phenylpropylazide (8 μmol each) was combined with FAM-OSu (Molecular Probes Inc.) (1.2 equiv.) in pH 9.4 borate buffer (250 μL). The reactions were allowed to proceed for 3 h at room temperature, and were then lyophilized overnight. Purification by HPLC afforded the desired fluorescent alkyne and azide in quantitative yield.
##STR00111##
Example 5
Cyclization of Individual Compounds Using the Azide/Alkyne Cycloaddition Reaction
Preparation of Azidoacetyl-Gly-Pro-Phe-Pra-NH2 (SEQ ID NO: 920):
[0240] Using 0.3 mmol of Rink-amide resin, the indicated sequence was synthesized using standard solid phase synthesis techniques with Fmoc-protected amino acids and HATU as activating agent (Pra=C-propargylglycine). Azidoacetic acid was used to cap the tetrapeptide. The peptide was cleaved from the resin with 20% TFA/DCM for 4 h. Purification by RP HPLC afforded product as a white solid (75 mg, 51%). 1H NMR (DMSO-d6, 400 MHz): 8.4-7.8 (m, 3H), 7.4-7.1 (m, 7H), 4.6-4.4 (m, 1H), 4.4-4.2 (m, 2H), 4.0-3.9 (m, 2H), 3.74 (dd, 1H, J=6 Hz, 17 Hz), 3.5-3.3 (m, 2H), 3.07 (dt, 1H, J=5 Hz, 14 Hz), 2.92 (dd, 1H, J=5 Hz, 16 Hz), 2.86 (t, 1H, J=2 Hz), 2.85-2.75 (m, 1H), 2.6-2.4 (m, 2H), 2.2-1.6 (m, 4H). IR (mull) 2900, 2100, 1450, 1300 cm-1. ESIMS 497.4 ([M+H], 100%), 993.4 ([2M+H], 50%). ESIMS with ion-source fragmentation: 519.3 ([M+Na], 100%), 491.3 (100%), 480.1 ([M-NH2], 90%), 452.2 ([M-NH2--CO], 20%), 424.2 (20%), 385.1 ([M-Pra], 50%), 357.1 ([M-Pra-CO], 40%), 238.0 ([M-Pra-Phe], 100%).
Cyclization of Azidoacetyl-Gly-Pro-Phe-Pra-NH2 (SEQ ID NO: 920):
##STR00112##
[0242] The azidoacetyl peptide (31 mg, 0.62 mmol) was dissolved in MeCN (30 mL). Diisopropylethylamine (DIEA, 1 mL) and Cu(MeCN)4PF6 (1 mg) were added. After stirring for 1.5 h, the solution was evaporated and the resulting residue was taken up in 20% MeCN/H2O. After centrifugation to remove insoluble salts, the solution was subjected to preparative reverse phase HPLC. The desired cyclic peptide was isolated as a white solid (10 mg, 32%). 1H NMR (DMSO-d6, 400 MHz): 8.28 (t, 1H, J=5 Hz), 7.77 (s, 1H), 7.2-6.9 (m, 9H), 4.98 (m, 2H), 4.48 (m, 1H), 4.28 (m, 1H), 4.1-3.9 (m, 2H), 3.63 (dd, 1H, J=5 Hz, 16 Hz), 3.33 (m, 2H), 3.0 (m, 3H), 2.48 (dd, 1H, J=11 Hz, 14 Hz), 1.75 (m, 1H0, 1.55 (m, 1H), 1.32 (m, 1H), 1.05 (m, 1H). IR (mull) 2900, 1475, 1400 cm-1. ESIMS 497.2 ([M+H], 100%), 993.2 ([2M+H], 30%), 1015.2 ([2M+Na], 15%). ESIMS with ion-source fragmentation: 535.2 (70%), 519.3 ([M+Na], 100%), 497.2 ([M+H], 80%), 480.1 ([M-NH2], 30%), 452.2 ([M-NH2--CO], 40%), 208.1 (60%).
Preparation of Azidoacetyl-Gly-Pro-Phe-Pra-Gly-OH (SEQ ID NO: 920):
[0243] Using 0.3 mmol of Glycine-Wang resin, the indicated sequence was synthesized using Fmoc-protected amino acids and HATU as the activating agent. Azidoacetic acid was used in the last coupling step to cap the pentapeptide. Cleavage of the peptide was achieved using 50% TFA/DCM for 2 h. Purification by RP HPLC afforded the peptide as a white solid (83 mg; 50%). 1H NMR (DMSO-d6, 400 MHz): 8.4-7.9 (m, 4H), 7.2 (m, 5H), 4.7-4.2 (m, 3H), 4.0-3.7 (m, 4H), 3.5-3.3 (m, 2H), 3.1 (m, 1H), 2.91 (dd, 1H, J=4 Hz, 16 Hz), 2.84 (t, 1H, J=2.5 Hz), 2.78 (m, 1H), 2.6-2.4 (m, 2H), 2.2-1.6 (m, 4H). IR (mull) 2900, 2100, 1450, 1350 cm-1. ESIMS 555.3 ([M+H], 100%). ESIMS with ion-source fragmentation: 577.1 ([M+Na], 90%), 555.3 ([M+H], 80%), 480.1 ([M-Gly], 100%), 385.1 ([M-Gly-Pra], 70%), 357.1 ([M-Gly-Pra-CO], 40%), 238.0 ([M-Gly-Pra-Phe], 80%).
Cyclization of Azidoacetyl-Gly-Pro-Phe-Pra-Gly-OH (SEQ ID NO: 920):
[0244] The peptide (32 mg, 0.058 mmol) was dissolved in MeCN (60 mL). Diisopropylethylamine (1 mL) and Cu(MeCN)4 PF6 (1 mg) were added and the solution was stirred for 2 h. The solvent was evaporated and the crude product was subjected to RP HPLC to remove dimers and trimers. The cyclic monomer was isolated as a colorless glass (6 mg, 20%). ESIMS 555.6 ([M+H], 100%), 1109.3 ([2M+H], 20%), 1131.2 ([2M+Na], 15%).
[0245] ESIMS with ion source fragmentation: 555.3 ([M+H], 100%), 480.4 ([M-Gly], 30%), 452.2 ([M-Gly-CO], 25%), 424.5 ([M-Gly-2CO], 10%, only possible in a cyclic structure).
Conjugation of Linear Peptide to DNA:
[0246] Compound 2 (45 nmol) was dissolved in 45 μL sodium borate buffer (pH 9.4; 150 mM). At 4° C., linear peptide (18 μL of a 100 mM stock in DMF; 180 nmol; 40 equiv.) was added, followed by DMT-MM (3.6 μL of a 500 mM stock in water; 180 nmol; 40 equiv.). After agitating for 2 h, LCMS showed complete reaction, and product was isolated by ethanol precipitation. ESIMS 1823.0 ([M-3H]/3, 20%), 1367.2 ([M-4H]/4, 20%), 1093.7 ([M-5H]/5, 40%), 911.4 ([M-6H]/6, 100%).
Conjugation of Cyclic Peptide to DNA:
[0247] Compound 2 (20 nmol) was dissolved in 20 μL sodium borate buffer (pH 9.4, 150 mM). At 4° C., linear peptide (8 μL of a 100 mM stock in DMF; 80 nmol; 40 equiv.) was added, followed by DMT-MM (1.6 μL of a 500 mM stock in water; 80 nmol; 40 equiv.). After agitating for 2 h, LCMS showed complete reaction, and product was isolated by ethanol precipitation. ESIMS 1823.0 ([M-3H]/3, 20%), 1367.2 ([M-4H]/4, 20%), 1093.7 ([M-5H]/5, 40%), 911.4 ([M-6H]/6, 100%).
Cyclization of DNA-Linked Peptide:
[0248] Linear peptide-DNA conjugate (10 nmol) was dissolved in pH 8 sodium phosphate buffer (10 μL, 150 mm). At room temperature, 4 equivalents each of CuSO4, ascorbic acid, and the Sharpless ligand were all added (0.2 μL of 200 mM stocks). The reaction was allowed to proceed overnight. RP HPLC showed that no linear peptide-DNA was present, and that the product co-eluted with authentic cyclic peptide-DNA. No traces of dimers or other oligomers were observed.
##STR00113##
Example 6
Application of Aromatic Nucleophilic Substitution Reactions to Functional Moiety Synthesis
[0249] General Procedure for Arylation of Compound 3 with Cyanuric Chloride:
[0250] Compound 2 is dissolved in pH 9.4 sodium borate buffer at a concentration of 1 mM. The solution is cooled to 4° C. and 20 equivalents of cyanuric chloride is then added as a 500 mM solution in MeCN. After 2 h, complete reaction is confirmed by LCMS and the resulting dichlorotriazine-DNA conjugate is isolated by ethanol precipitation.
Procedure for Amine Substitution of Dichlorotriazine-DNA:
[0251] The dichlorotriazine-DNA conjugate is dissolved in pH 9.5 borate buffer at a concentration of 1 mM. At room temperature, 40 equivalents of an aliphatic amine is added as a DMF solution. The reaction is followed by LCMS and is usually complete after 2 h. The resulting alkylamino-monochlorotriazine-DNA conjugate is isolated by ethanol precipitation.
Procedure for Amine Substitution of Monochlorotriazine-DNA:
[0252] The alkylamino-monochlorotriazine-DNA conjugate is dissolved in pH 9.5 borate buffer at a concentration of 1 mM. At 42° C., 40 equivalents of a second aliphatic amine is added as a DMF solution. The reaction is followed by LCMS and is usually complete after 2 h. The resulting diaminotriazine-DNA conjugate is isolated by ethanol precipitation.
Example 7
Application of Reductive Amination Reactions to Functional Moiety Synthesis
[0253] General Procedure for Reductive Amination of DNA-Linker Containing a Secondary Amine with an Aldehyde Building Block:
[0254] Compound 2 was coupled to an N-terminal proline residue. The resulting compound was dissolved in sodium phosphate buffer (50 μL, 150 mM, pH 5.5) at a concentration of 1 mM. To this solution was added 40 equivalents each of an aldehyde building block in DMF (8 μL, 0.25M) and sodium cyanoborohydride in DMF (8 μL, 0.25M) and the solution was heated at 80° C. for 2 hours. Following alkylation, the solution was purified by ethanol precipitation.
General Procedure for Reductive Aminations of DNA-Linker Containing an Aldehyde with Amine Building Blocks:
[0255] Compound 2 coupled to a building block comprising an aldehyde group was dissolved in sodium phosphate buffer (50 μL, 250 mM, pH 5.5) at a concentration of 1 mM. To this solution was added 40 equivalents each of an amine building block in DMF (8 μL, 0.25M) and sodium cyanoborohydride in DMF (8 μL, 0.25M) and the solution was heated at 80° C. for 2 hours. Following alkylation, the solution was purified by ethanol precipitation.
Example 8
Application of Peptoid Building Reactions to Functional Moiety Synthesis
General Procedure for Peptoid Synthesis on DNA-Linker:
##STR00114##
[0257] Compound 2 was dissolved in sodium borate buffer (50 μL, 150 mM, pH 9.4) at a concentration of 1 mM and chilled to 4° C. To this solution was added 40 equivalents of N-hydroxysuccinimidyl bromoacetate in DMF (13 μL, 0.15 M) and the solution was gently shaken at 4° C. for 2 hours. Following acylation, the DNA-Linker was purified by ethanol precipitation and redissolved in sodium borate buffer (50 μL, 150 mM, pH 9.4) at a concentration of 1 mM and chilled to 4° C. To this solution was added 40 equivalents of an amine building block in DMF (13 μL, 0.15 M) and the solution was gently shaken at 4° C. for 16 hours. Following alkylation, the DNA-linker was purified by ethanol precipitation and redissolved in sodium borate buffer (50 μL, 150 mM, pH 9.4) at a concentration of 1 mM and chilled to 4° C. Peptoid synthesis is continued by the stepwise addition of N-hydroxysuccinimidyl bromoacetate followed by the addition of an amine building block.
Example 9
Application of the Azide-Alkyne Cycloaddition Reaction to Functional Moiety Synthesis
General Procedure
[0258] An alkyne-containing DNA conjugate is dissolved in pH 8.0 phosphate buffer at a concentration of ca. 1 mM. To this mixture is added 10 equivalents of an organic azide and 5 equivalents each of copper (II) sulfate, ascorbic acid, and the ligand (tris-((1-benzyltriazol-4-yl)methyl)amine all at room temperature. The reaction is followed by LCMS, and is usually complete after 1-2 h. The resulting triazole-DNA conjugate can be isolated by ethanol precipitation.
Example 10
Identification of a Ligand to Abl Kinase from Within an Encoded Library
[0259] The ability to enrich molecules of interest in a DNA-encoded library above undesirable library members is paramount to identifying single compounds with defined properties against therapeutic targets of interest. To demonstrate this enrichment ability a known binding molecule (described by Shah et al., Science 305, 399-401 (2004), incorporated herein by reference) to rhAbl kinase (GenBank U07563) was synthesized. This compound was attached to a double stranded DNA oligonucleotide via the linker described in the preceding examples using standard chemistry methods to produce a molecule similar (functional moiety linked to an oligonucleotide) to those produced via the methods described in Examples 1 and 2. A library generally produced as described in Example 2 and the DNA-linked Abl kinase binder were designed with unique DNA sequences that allowed qPCR analysis of both species. The DNA-linked Abl kinase binder was mixed with the library at a ratio of 1:1000. This mixture was equilibrated with to rhAble kinase, and the enzyme was captured on a solid phase, washed to remove non-binding library members and binding molecules were eluted. The ratio of library molecules to the DNA-linked Abl kinase inhibitor in the eluate was 1:1, indicating a greater than 500-fold enrichment of the DNA-linked Abl-kinase binder in a 1000-fold excess of library molecules.
EQUIVALENTS
[0260] Those skilled in the art will recognize, or be able to ascertain using no more than routine experimentation, many equivalents to the specific embodiments of the invention described herein. Such equivalents are intended to be encompassed by the following claims.
Sequence CWU
1
92919DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 1gcaacgaag
929DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 2tcgttgcca
939DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
3gcgtacaag
949DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 4tgtacgcca
959DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 5gctctgtag
969DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
6acagagcca
979DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 7gtgccatag
989DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 8atggcacca
999DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
9gttgaccag
9109DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 10ggtcaacca
9119DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 11cgacttgac
9129DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
12acgctgaac
9139DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 13cgtagtcag
9149DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 14gactacgca
9159DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
15ccagcatag
9169DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 16atgctggca
9179DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 17cctacagag
9189DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
18ctgtaggca
9199DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 19ctgaacgag
9209DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 20acgacttgc
9219DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
21ctccagtag
9229DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 22actggagca
9239DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 23taggtccag
9249DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
24ggacctaca
9259DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 25gcgtgttgt
9269DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 26aacacgcct
9279DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
27gcttggagt
9289DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 28tccaagcct
9299DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 29gtcaagcgt
9309DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
30gcttgacct
9319DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 31caagagcgt
9329DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 32gctcttgct
9339DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
33cagttcggt
9349DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 34cgaactgct
9359DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 35cgaaggagt
9369DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
36tccttcgct
9379DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 37cggtgttgt
9389DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 38aacaccgct
9399DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
39cgttgctgt
9409DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 40agcaacgct
9419DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 41ccgatctgt
9429DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
42agatcggct
9439DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 43ccttctcgt
9449DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 44gagaaggct
9459DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
45tgagtccgt
9469DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 46ggactcact
9479DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 47tgctacggt
9489DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
48cgttagact
9499DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 49gtgcgttga
9509DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 50aacgcacac
9519DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
51gttggcaga
9529DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 52tgccaacac
9539DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 53cctgtagga
9549DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
54ctacaggac
9559DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 55ctgcgtaga
9569DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 56tacgcagac
9579DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
57cttacgcga
9589DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 58gcgtaagac
9599DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 59tggtcacga
9609DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
60gtgaccaac
9619DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 61tcagagcga
9629DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 62gctctgaac
9639DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
63ttgctcgga
9649DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 64cgagcaaac
9659DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 65gcagttgga
9669DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
66caactgcac
9679DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 67gcctgaaga
9689DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 68ttcaggcac
9699DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
69gtagccaga
9709DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 70tggctacac
9719DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 71gtcgcttga
9729DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
72aagcgacac
9739DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 73gcctaagtt
9749DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 74cttaggctc
9759DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
75gtagtgctt
9769DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 76gcactactc
9779DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 77gtcgaagtt
9789DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
78cttcgactc
9799DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 79gtttcggtt
9809DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 80ccgaaactc
9819DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
81cagcgtttt
9829DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 82aacgctgtc
9839DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 83catacgctt
9849DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
84gcgtatgtc
9859DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 85cgatctgtt
9869DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 86cagatcgtc
9879DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
87cgctttgtt
9889DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 88caaagcgtc
9899DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 89ccacagttt
9909DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
90actgtggtc
9919DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 91cctgaagtt
9929DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 92cttcaggtc
9939DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
93ctgacgatt
9949DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 94tcgtcagtc
9959DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 95ctccacttt
9969DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
96agtggagtc
9979DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 97accagagcc
9989DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 98ctctggtaa
9999DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
99atccgcacc
91009DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 100tgcggataa
91019DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 101gacgacacc
91029DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
102tgtcgtcaa
91039DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 103ggatggacc
91049DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 104tccatccaa
91059DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
105gcagaagcc
91069DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 106cttctgcaa
91079DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 107gccatgtcc
91089DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
108acatggcaa
91099DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 109gtctgctcc
91109DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 110agcagacaa
91119DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
111cgacagacc
91129DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 112tctgtcgaa
91139DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 113cgctactcc
91149DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
114agtagcgaa
91159DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 115ccacagacc
91169DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 116tctgtggaa
91179DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
117cctctctcc
91189DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 118agagaggaa
91199DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 119ctcgtagcc
91209DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
120ctacgagaa
912120DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 121aaatcgatgt ggtcactcag
2012220DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 122gagtgaccac atcgatttgg
2012320DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
123aaatcgatgt ggactaggag
2012420DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 124cctagtccac atcgatttgg
2012520DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 125aaatcgatgt
gccgtatgag
2012620DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 126catacggcac atcgatttgg
2012720DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 127aaatcgatgt
gctgaaggag
2012820DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 128ccttcagcac atcgatttgg
2012920DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 129aaatcgatgt
ggactagcag
2013020DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 130gctagtccac atcgatttgg
2013120DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 131aaatcgatgt
gcgctaagag
2013220DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 132cttagcgcac atcgatttgg
2013320DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 133aaatcgatgt
gagccgagag
2013420DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 134ctcggctcac atcgatttgg
2013520DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 135aaatcgatgt
gccgtatcag
2013620DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 136gatacggcac atcgatttgg
2013720DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 137aaatcgatgt
gctgaagcag
2013820DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 138gcttcagcac atcgatttgg
2013920DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 139aaatcgatgt
gtgcgagtag
2014020DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 140actcgcacac atcgatttgg
2014120DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 141aaatcgatgt
gtttggcgag
2014220DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 142cgccaaacac atcgatttgg
2014320DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 143aaatcgatgt
gcgctaacag
2014420DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 144gttagcgcac atcgatttgg
2014520DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 145aaatcgatgt
gagccgacag
2014620DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 146gtcggctcac atcgatttgg
2014720DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 147aaatcgatgt
gagccgaaag
2014820DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 148ttcggctcac atcgatttgg
2014920DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 149aaatcgatgt
gtcggtagag
2015020DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 150ctaccgacac atcgatttgg
2015120DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 151aaatcgatgt
ggttgccgag
2015220DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 152cggcaaccac atcgatttgg
2015320DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 153aaatcgatgt
gagtgcgtag
2015420DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 154acgcactcac atcgatttgg
2015520DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 155aaatcgatgt
ggttgccaag
2015620DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 156tggcaaccac atcgatttgg
2015720DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 157aaatcgatgt
gtgcgaggag
2015820DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 158cctcgcacac atcgatttgg
2015920DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 159aaatcgatgt
ggaacacgag
2016020DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 160cgtgttccac atcgatttgg
2016120DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 161aaatcgatgt
gcttgtcgag
2016220DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 162cgacaagcac atcgatttgg
2016320DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 163aaatcgatgt
gttccggtag
2016420DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 164accggaacac atcgatttgg
2016520DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 165aaatcgatgt
gtgcgagcag
2016620DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 166gctcgcacac atcgatttgg
2016720DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 167aaatcgatgt
ggtcaggtag
2016820DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 168acctgaccac atcgatttgg
2016920DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 169aaatcgatgt
ggcctgttag
2017020DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 170aacaggccac atcgatttgg
2017120DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 171aaatcgatgt
ggaacaccag
2017220DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 172ggtgttccac atcgatttgg
2017320DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 173aaatcgatgt
gcttgtccag
2017420DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 174ggacaagcac atcgatttgg
2017520DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 175aaatcgatgt
gtgcgagaag
2017620DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 176tctcgcacac atcgatttgg
2017720DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 177aaatcgatgt
gagtgcggag
2017820DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 178ccgcactcac atcgatttgg
2017920DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 179aaatcgatgt
gttgtccgag
2018020DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 180cggacaacac atcgatttgg
2018120DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 181aaatcgatgt
gtggaacgag
2018220DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 182cgttccacac atcgatttgg
2018320DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 183aaatcgatgt
gagtgcgaag
2018420DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 184tcgcactcac atcgatttgg
2018520DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 185aaatcgatgt
gtggaaccag
2018620DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 186ggttccacac atcgatttgg
2018720DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 187aaatcgatgt
gttaggcgag
2018820DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 188cgcctaacac atcgatttgg
2018920DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 189aaatcgatgt
ggcctgtgag
2019020DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 190cacaggccac atcgatttgg
2019120DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 191aaatcgatgt
gctcctgtag
2019220DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 192acaggagcac atcgatttgg
2019320DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 193aaatcgatgt
ggtcaggcag
2019420DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 194gcctgaccac atcgatttgg
2019520DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 195aaatcgatgt
ggtcaggaag
2019620DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 196tcctgaccac atcgatttgg
2019720DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 197aaatcgatgt
ggtagccgag
2019820DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 198cggctaccac atcgatttgg
2019920DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 199aaatcgatgt
ggcctgtaag
2020020DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 200tacaggccac atcgatttgg
2020120DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 201aaatcgatgt
gctttcggag
2020220DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 202ccgaaagcac atcgatttgg
2020320DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 203aaatcgatgt
gcgtaaggag
2020420DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 204ccttacgcac atcgatttgg
2020520DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 205aaatcgatgt
gagagcgtag
2020620DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 206acgctctcac atcgatttgg
2020720DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 207aaatcgatgt
ggacggcaag
2020820DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 208tgccgtccac atcgatttgg
2020920DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 209aaatcgatgt
gctttcgcag
2021020DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 210gcgaaagcac atcgatttgg
2021120DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 211aaatcgatgt
gcgtaagcag
2021220DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 212gcttacgcac atcgatttgg
2021320DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 213aaatcgatgt
ggctatggag
2021420DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 214ccatagccac atcgatttgg
2021520DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 215aaatcgatgt
gactctggag
2021620DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 216ccagagtcac atcgatttgg
2021719DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 217aaatcgatgt
gctggaaag
1921819DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 218ttccagcaca tcgatttgg
1921920DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 219aaatcgatgt
gccgaagtag
2022020DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 220acttcggcac atcgatttgg
2022120DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 221aaatcgatgt
gctcctgaag
2022220DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 222tcaggagcac atcgatttgg
2022320DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 223aaatcgatgt
gtccagtcag
2022420DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 224gactggacac atcgatttgg
2022520DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 225aaatcgatgt
gagagcggag
2022620DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 226ccgctctcac atcgatttgg
2022720DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 227aaatcgatgt
gagagcgaag
2022820DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 228tcgctctcac atcgatttgg
2022920DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 229aaatcgatgt
gccgaaggag
2023020DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 230ccttcggcac atcgatttgg
2023120DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 231aaatcgatgt
gccgaagcag
2023220DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 232gcttcggcac atcgatttgg
2023320DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 233aaatcgatgt
gtgttccgag
2023420DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 234cggaacacac atcgatttgg
2023520DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 235aaatcgatgt
gtctggcgag
2023620DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 236cgccagacac atcgatttgg
2023720DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 237aaatcgatgt
gctatcggag
2023820DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 238ccgatagcac atcgatttgg
2023920DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 239aaatcgatgt
gcgaaaggag
2024020DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 240cctttcgcac atcgatttgg
2024120DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 241aaatcgatgt
gccgaagaag
2024220DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 242tcttcggcac atcgatttgg
2024320DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 243aaatcgatgt
ggttgcagag
2024420DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 244ctgcaaccac atcgatttgg
2024520DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 245aaatcgatgt
ggatggtgag
2024620DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 246caccatccac atcgatttgg
2024720DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 247aaatcgatgt
gctatcgcag
2024820DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 248gcgatagcac atcgatttgg
2024920DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 249aaatcgatgt
gcgaaagcag
2025020DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 250gctttcgcac atcgatttgg
2025120DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 251aaatcgatgt
gacactggag
2025220DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 252ccagtgtcac atcgatttgg
2025320DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 253aaatcgatgt
gtctggcaag
2025420DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 254tgccagacac atcgatttgg
2025520DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 255aaatcgatgt
ggatggtcag
2025620DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 256gaccatccac atcgatttgg
2025720DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 257aaatcgatgt
ggttgcacag
2025820DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 258gtgcaaccac atcgatttgg
2025920DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 259aaatcgatgt
gggcatcgag
2026020DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 260cgatgcccca tccgatttgg
2026120DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 261aaatcgatgt
gtgcctccag
2026220DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 262ggaggcacac atcgatttgg
2026320DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 263aaatcgatgt
gtgcctcaag
2026420DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 264tgaggcacac atcgatttgg
2026520DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 265aaatcgatgt
gggcatccag
2026620DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 266ggatgcccac atcgatttgg
2026720DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 267aaatcgatgt
gggcatcaag
2026820DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 268tgatgcccac atcgatttgg
2026920DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 269aaatcgatgt
gcctgtcgag
2027020DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 270cgacaggcac atcgatttgg
2027120DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 271aaatcgatgt
ggacggatag
2027220DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 272atccgtccac atcgatttgg
2027320DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 273aaatcgatgt
gcctgtccag
2027420DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 274ggacaggcac atcgatttgg
2027520DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 275aaatcgatgt
gaagcacgag
2027620DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 276cgtgcttcac atcgatttgg
2027720DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 277aaatcgatgt
gcctgtcaag
2027820DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 278tgacaggcac atcgatttgg
2027920DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 279aaatcgatgt
gaagcaccag
2028020DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 280ggtgcttcac atcgatttgg
2028120DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 281aaatcgatgt
gccttcgtag
2028220DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 282acgaaggcac atcgatttgg
2028320DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 283aaatcgatgt
gtcgtccgag
2028420DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 284cggacgacac atcgatttgg
2028520DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 285aaatcgatgt
ggagtctgag
2028620DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 286cagactccac atcgatttgg
2028720DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 287aaatcgatgt
gtgatccgag
2028820DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 288cggatcacac atcgatttgg
2028920DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 289aaatcgatgt
gtcaggcgag
2029020DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 290cgcctgacac atcgatttgg
2029120DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 291aaatcgatgt
gtcgtccaag
2029220DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 292tggacgacac atcgatttgg
2029320DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 293aaatcgatgt
ggacggagag
2029420DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 294ctccgtccac atcgatttgg
2029520DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 295aaatcgatgt
ggtagcagag
2029620DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 296ctgctaccac atcgatttgg
2029720DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 297aaatcgatgt
ggctgtgtag
2029820DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 298acacagccac atcgatttgg
2029920DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 299aaatcgatgt
ggacggacag
2030020DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 300gtccgtccac atcgatttgg
2030120DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 301aaatcgatgt
gtcaggcaag
2030220DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 302tgcctgacac atcgatttgg
2030320DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 303aaatcgatgt
ggctcgaaag
2030420DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 304ttcgagccac atcgatttgg
2030520DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 305aaatcgatgt
gccttcggag
2030620DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 306ccgaaggcac atcgatttgg
2030720DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 307aaatcgatgt
ggtagcacag
2030820DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 308gtgctaccac atcgatttgg
2030920DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 309aaatcgatgt
ggaaggtcag
2031020DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 310gaccttccac atcgatttgg
2031120DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 311aaatcgatgt
ggtgctgtag
2031220DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 312acagcaccac atcgatttgg
203139DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 313gttgcctgt
93149DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
314aggcaacct
93159DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 315caggacggt
93169DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 316cgtcctgct
93179DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
317agacgtggt
93189DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 318cacgtctct
93199DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 319caggaccgt
93209DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
320ggtcctgct
93219DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 321caggacagt
93229DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 322tgtcctgct
93239DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
323cactctggt
93249DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 324cagagtgct
93259DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 325gacggctgt
93269DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
326agccgtcct
93279DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 327cactctcgt
93289DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 328gagagtgct
93299DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
329gtagcctgt
93309DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 330aggctacct
93319DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 331gccacttgt
93329DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
332aagtggcct
93339DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 333catcgctgt
93349DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 334agcgatgct
93359DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
335cactggtgt
93369DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 336accagtgct
93379DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 337gccactggt
93389DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
338cagtggcct
93399DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 339tctggctgt
93409DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 340agccagact
93419DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
341gccactcgt
93429DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 342gagtggcct
93439DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 343tgcctctgt
93449DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
344agaggcact
93459DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 345catcgcagt
93469DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 346tgcgatgct
93479DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
347caggaaggt
93489DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 348cttcctgct
93499DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 349ggcatctgt
93509DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
350agatgccct
93519DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 351cggtgctgt
93529DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 352agcaccgct
93539DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
353cactggcgt
93549DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 354gccagtgct
93559DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 355tctcctcgt
93569DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
356gaggagact
93579DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 357cctgtctgt
93589DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 358agacaggct
93599DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
359caacgctgt
93609DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 360agcgttgct
93619DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 361tgcctcggt
93629DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
362cgaggcact
93639DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 363acactgcgt
93649DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 364gcagtgtct
93659DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
365tcgtcctgt
93669DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 366aggacgact
93679DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 367gctgccagt
93689DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
368tggcagcct
93699DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 369tcaggctgt
93709DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 370agcctgact
93719DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
371gccaggtgt
93729DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 372acctggcct
93739DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 373cggacctgt
93749DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
374aggtccgct
93759DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 375caacgcagt
93769DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 376tgcgttgct
93779DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
377cacacgagt
93789DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 378tcgtgtgct
93799DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 379atggcctgt
93809DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
380aggccatct
93819DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 381ccagtctgt
93829DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 382agactggct
93839DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
383gccaggagt
93849DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 384tcctggcct
93859DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 385cggaccagt
93869DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
386tggtccgct
93879DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 387ccttcgcgt
93889DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 388gcgaaggct
93899DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
389gcagccagt
93909DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 390tggctgcct
93919DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 391ccagtcggt
93929DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
392cgactggct
93939DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 393actgagcgt
93949DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 394gctcagtct
93959DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
395ccagtccgt
93969DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 396ggactggct
93979DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 397ccagtcagt
93989DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
398tgactggct
93999DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 399catcgaggt
94009DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 400ctcgatgct
94019DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
401ccatcgtgt
94029DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 402acgatggct
94039DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 403gtgctgcgt
94049DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
404gcagcacct
94059DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 405gactacggt
94069DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 406cgtagtcct
94079DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
407gtgctgagt
94089DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 408tcagcacct
94099DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 409gctgcatgt
94109DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
410atgcagcct
94119DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 411gagtggtgt
94129DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 412accactcct
94139DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
413gactaccgt
94149DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 414ggtagtcct
94159DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 415cggtgatgt
94169DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
416atcaccgct
94179DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 417tgcgactgt
94189DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 418agtcgcact
94199DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
419tctggaggt
94209DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 420ctccagact
94219DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 421agcactggt
94229DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
422cagtgctct
94239DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 423tcgcttggt
94249DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 424caagcgact
94259DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
425agcactcgt
94269DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 426gagtgctct
94279DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 427gcgattggt
94289DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
428caatcgcct
94299DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 429ccatcgcgt
94309DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 430gcgatggct
94319DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
431tcgcttcgt
94329DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 432gaagcgact
94339DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 433agtgcctgt
94349DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
434aggcactct
94359DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 435ggcataggt
94369DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 436ctatgccct
94379DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
437gcgattcgt
94389DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 438gaatcgcct
94399DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 439tgcgacggt
94409DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
440cgtcgcact
94419DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 441gagtggcgt
94429DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 442gccactcct
94439DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
443cggtgaggt
94449DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 444ctcaccgct
94459DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 445gctgcaagt
94469DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
446ttgcagcct
94479DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 447ttccgctgt
94489DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 448agcggaact
94499DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
449gagtggagt
94509DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 450tccactcct
94519DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 451acagagcgt
94529DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
452gctctgtct
94539DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 453tgcgaccgt
94549DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 454ggtcgcact
94559DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
455cctgtaggt
94569DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 456ctacaggct
94579DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 457tagccgtgt
94589DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
458acggctact
94599DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 459tgcgacagt
94609DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 460tgtcgcact
94619DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
461ggtctgtgt
94629DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 462acagaccct
94639DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 463cggtgaagt
94649DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
464ttcaccgct
94659DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 465caacgaggt
94669DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 466ctcgttgct
94679DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
467gcagcatgt
94689DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 468atgctgcct
94699DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 469tcgtcaggt
94709DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
470ctgacgact
94719DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 471agtgccagt
94729DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 472tggcactct
94739DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
473tagaggcgt
94749DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 474gcctctact
94759DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 475gtcagcggt
94769DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
476cgctgacct
94779DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 477tcaggaggt
94789DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 478ctcctgact
94799DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
479agcaggtgt
94809DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 480acctgctct
94819DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 481ttccgcagt
94829DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
482tgcggaact
94839DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 483gtcagccgt
94849DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 484ggctgacct
94859DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
485ggtctgcgt
94869DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 486gcagaccct
94879DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 487tagccgagt
94889DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
488tcggctact
94899DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 489gtcagcagt
94909DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 490tgctgacct
94919DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
491ggtctgagt
94929DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 492tcagaccct
94939DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 493cggacaggt
94949DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
494ctgtccgct
94959DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 495ttagccggt
94969DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 496cggctaact
94979DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
497gagacgagt
94989DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 498tcgtctcct
94999DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 499cgtaaccgt
95009DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
500ggttacgct
95019DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 501ttggcgtgt
95029DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 502acgccaact
95039DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
503atggcaggt
95049DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 504ctgccatct
95059DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 505cagctacga
95069DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
506gtagctgac
95079DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 507ctcctgcga
95089DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 508gcaggagac
95099DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
509gctgcctga
95109DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 510aggcagcac
95119DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 511caggaacga
95129DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
512gttcctgac
95139DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 513cacacgcga
95149DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 514gcgtgtgac
95159DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
515gcagcctga
95169DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 516aggctgcac
95179DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 517ctgaacgga
95189DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
518cgttcagac
95199DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 519ctgaaccga
95209DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 520ggttcagac
95219DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
521tctggacga
95229DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 522gtccagaac
95239DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 523tgcctacga
95249DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
524gtaggcaac
95259DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 525ggcatacga
95269DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 526gtatgccac
95279DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
527cggtgacga
95289DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 528gtcaccgac
95299DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 529caacgacga
95309DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
530gtcgttgac
95319DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 531ctcctctga
95329DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 532agaggagac
95339DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
533tcaggacga
95349DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 534gtcctgaac
95359DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 535aaaggcgga
95369DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
536cgcctttac
95379DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 537ctcctcgga
95389DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 538cgaggagac
95399DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
539cagatgcga
95409DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 540gcatctgac
95419DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 541gcagcaaga
95429DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
542ttgctgcac
95439DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 543gtggagtga
95449DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 544actccacac
95459DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
545ccagtagga
95469DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 546ctactggac
95479DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 547atggcacga
95489DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
548gtgccatac
95499DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 549ggactgtga
95509DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 550acagtccac
95519DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
551ccgaactga
95529DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 552agttcggac
95539DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 553ctcctcaga
95549DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
554tgaggagac
95559DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 555cactgctga
95569DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 556agcagtgac
95579DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
557agcaggcga
95589DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 558gcctgctac
95599DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 559agcaggaga
95609DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
560tcctgctac
95619DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 561agagccaga
95629DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 562tggctctac
95639DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
563gtcgttgga
95649DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 564caacgacac
95659DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 565ccgaacgga
95669DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
566cgttcggac
95679DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 567cactgcgga
95689DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 568cgcagtgac
95699DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
569gtggagcga
95709DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 570gctccacac
95719DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 571gtggagaga
95729DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
572tctccacac
95739DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 573ggactgcga
95749DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 574gcagtccac
95759DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
575ccgaaccga
95769DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 576ggttcggac
95779DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 577cactgccga
95789DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
578ggcagtgac
95799DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 579cgaaacgga
95809DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 580cgtttcgac
95819DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
581ggactgaga
95829DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 582tcagtccac
95839DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 583ccgaacaga
95849DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
584tgttcggac
95859DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 585cgaaaccga
95869DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 586ggtttcgac
95879DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
587ctggcttga
95889DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 588aagccagac
95899DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 589cacacctga
95909DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
590aggtgtgac
95919DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 591aacgaccga
95929DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 592ggtcgttac
95939DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
593atccagcga
95949DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 594gctggatac
95959DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 595tgcgaagga
95969DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
596cttcgcaac
95979DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 597tgcgaacga
95989DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 598gttcgcaac
95999DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
599ctggctgga
96009DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 600cagccagac
96019DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 601cacaccgga
96029DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
602cggtgtgac
96039DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 603agtgcagga
96049DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 604ctgcactac
96059DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
605gaccgttga
96069DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 606aacggtcac
96079DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 607ggtgagtga
96089DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
608actcaccac
96099DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 609ccttcctga
96109DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 610aggaaggac
96119DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
611ctggctaga
96129DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 612tagccagac
96139DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 613cacaccaga
96149DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
614tggtgtgac
96159DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 615agcggtaga
96169DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 616taccgctac
96179DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
617gtcagagga
96189DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 618ctctgacac
96199DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 619ttccgacga
96209DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
620gtcggaaac
96219DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 621aggcgtaga
96229DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 622tacgcctac
96239DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
623ctcgactga
96249DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 624agtcgagac
96259DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 625tacgctgga
96269DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
626cagcgtaac
96279DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 627gttcggtga
96289DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 628accgaacac
96299DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
629gccagcaga
96309DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 630tgctggcac
96319DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 631gaccgtaga
96329DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
632tacggtcac
96339DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 633gtgctctga
96349DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 634agagcacac
96359DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
635ggtgagcga
96369DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 636gctcaccac
96379DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 637ggtgagaga
96389DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
638tctcaccac
96399DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 639ccttccaga
96409DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 640tggaaggac
96419DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
641ctcctacga
96429DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 642gtaggagac
96439DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 643ctcgacgga
96449DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
644cgtcgagac
96459DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 645gccgtttga
96469DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 646aaacggcac
96479DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
647gcggagtga
96489DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 648actccgcac
96499DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 649cgtgcttga
96509DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
650aagcacgac
96519DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 651ctcgaccga
96529DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 652ggtcgagac
96539DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
653agagcagga
96549DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 654ctgctctac
96559DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 655gtgctcgga
96569DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
656cgagcacac
96579DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 657ctcgacaga
96589DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 658tgtcgagac
96599DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
659ggagagtga
96609DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 660actctccac
96619DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 661aggctgtga
96629DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
662acagcctac
96639DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 663agagcacga
96649DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 664gtgctctac
96659DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
665ccatcctga
96669DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 666aggatggac
96679DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 667gttcggaga
96689DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
668tccgaacac
96699DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 669tggtagcga
96709DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 670gctaccaac
96719DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
671gtgctccga
96729DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 672ggagcacac
96739DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 673gtgctcaga
96749DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
674tgagcacac
96759DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 675gccgttgga
96769DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 676caacggcac
96779DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
677gagtgctga
96789DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 678agcactcac
96799DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 679gctccttga
96809DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
680aaggagcac
96819DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 681ccgaaagga
96829DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 682ctttcggac
96839DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
683cactgagga
96849DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 684ctcagtgac
96859DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 685cgtgctgga
96869DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
686cagcacgac
96879DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 687ccgaaacga
96889DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 688gtttcggac
96899DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
689gcggagaga
96909DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 690tctccgcac
96919DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 691gccgttaga
96929DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
692taacggcac
96939DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 693tctcgtgga
96949DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 694cacgagaac
96959DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
695cgtgctaga
96969DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 696tagcacgac
96979DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 697gcctgtctt
96989DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
698gacaggctc
96999DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 699ctcctggtt
97009DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 700ccaggagtc
97019DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
701actctgctt
97029DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 702gcagagttc
97039DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 703catcgcctt
97049DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
704ggcgatgtc
97059DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 705gccactatt
97069DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 706tagtggctc
97079DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
707cacacggtt
97089DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 708ccgtgtgtc
97099DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 709caacgcctt
97109DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
710ggcgttgtc
97119DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 711actgaggtt
97129DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 712cctcagttc
97139DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
713gtgctggtt
97149DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 714ccagcactc
97159DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 715catcgactt
97169DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
716gtcgatgtc
97179DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 717ccatcggtt
97189DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 718ccgatggtc
97199DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
719gctgcactt
97209DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 720gtgcagctc
97219DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 721acagaggtt
97229DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
722cctctgttc
97239DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 723agtgccgtt
97249DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 724cggcacttc
97259DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
725cggacattt
97269DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 726atgtccgtc
97279DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 727ggtctggtt
97289DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
728ccagacctc
97299DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 729gagacggtt
97309DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 730ccgtctctc
97319DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
731ctttccgtt
97329DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 732cggaaagtc
97339DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 733cagatggtt
97349DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
734ccatctgtc
97359DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 735cggacactt
97369DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 736gtgtccgtc
97379DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
737actctcgtt
97389DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 738cgagagttc
97399DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 739gcagcactt
97409DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
740gtgctgctc
97419DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 741actctcctt
97429DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 742ggagagttc
97439DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
743accttggtt
97449DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 744ccaaggttc
97459DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 745agagccgtt
97469DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
746cggctcttc
97479DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 747accttgctt
97489DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 748gcaaggttc
97499DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
749aagtccgtt
97509DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 750cggactttc
97519DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 751ggactggtt
97529DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
752ccagtcctc
97539DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 753gtcgttctt
97549DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 754gaacgactc
97559DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
755cagcatctt
97569DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 756gatgctgtc
97579DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 757ctatccgtt
97589DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
758cggatagtc
97599DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 759acactcgtt
97609DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 760cgagtgttc
97619DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
761atccaggtt
97629DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 762cctggattc
97639DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 763gttcctgtt
97649DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
764caggaactc
97659DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 765acactcctt
97669DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 766ggagtgttc
97679DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
767gttcctctt
97689DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 768gaggaactc
97699DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 769ctggctctt
97709DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
770gagccagtc
97719DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 771acggcattt
97729DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 772atgccgttc
97739DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
773ggtgaggtt
97749DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 774cctcacctc
97759DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 775ccttccgtt
97769DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
776cggaaggtc
97779DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 777tacgctctt
97789DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 778gagcgtatc
97799DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
779acggcagtt
97809DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 780ctgccgttc
97819DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 781actgacgtt
97829DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
782cgtcagttc
97839DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 783acggcactt
97849DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 784gtgccgttc
97859DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
785actgacctt
97869DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 786ggtcagttc
97879DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 787tttgcggtt
97889DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
788ccgcaaatc
97899DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 789tggtaggtt
97909DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 790cctaccatc
97919DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
791gttcggctt
97929DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 792gccgaactc
97939DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 793gccgttctt
97949DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
794gaacggctc
97959DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 795ggagaggtt
97969DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 796cctctcctc
97979DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
797cactgactt
97989DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 798gtcagtgtc
97999DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 799cgtgctctt
98009DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
800gagcacgtc
98019DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 801aatccgctt
98029DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 802gcggatttc
98039DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
803aggctggtt
98049DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 804ccagccttc
98059DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 805gctagtgtt
98069DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
806cactagctc
98079DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 807ggagagctt
98089DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 808gctctcctc
98099DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
809ggagagatt
98109DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 810tctctcctc
98119DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 811aggctgctt
98129DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
812gcagccttc
98139DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 813gagtgcgtt
98149DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 814cgcactctc
98159DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
815ccatccatt
98169DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 816tggatggtc
98179DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 817gctagtctt
98189DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
818gactagctc
98199DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 819aggctgatt
98209DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 820tcagccttc
98219DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
821acagacgtt
98229DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 822cgtctgttc
98239DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 823gagtgcctt
98249DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
824ggcactctc
98259DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 825acagacctt
98269DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 826ggtctgttc
98279DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
827cgagctttt
98289DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 828aagctcgtc
98299DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 829ttagcggtt
98309DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
830ccgctaatc
98319DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 831cctcttgtt
98329DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 832caagaggtc
98339DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
833ggtctcttt
98349DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 834agagacctc
98359DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 835gccagattt
98369DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
836atctggctc
98379DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 837gagaccttt
98389DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 838aggtctctc
98399DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
839cacacagtt
98409DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 840ctgtgtgtc
98419DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 841cctcttctt
98429DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
842gaagaggtc
98439DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 843tagagcgtt
98449DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 844cgctctatc
98459DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
845gcacctttt
98469DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 846aaggtgctc
98479DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 847ggcttgttt
98489DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
848acaagcctc
98499DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 849gacgcgatt
98509DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 850tcgcgtctc
98519DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
851cgagctgtt
98529DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 852cagctcgtc
98539DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 853tagagcctt
98549DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
854ggctctatc
98559DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 855catccgttt
98569DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 856acggatgtc
98579DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
857ggtctcgtt
98589DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 858cgagacctc
98599DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 859gccagagtt
98609DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
860ctctggctc
98619DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 861gagaccgtt
98629DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 862cggtctctc
98639DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
863cgagctatt
98649DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 864tagctcgtc
98659DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 865gcaagtgtt
98669DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
866cacttgctc
98679DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 867ggtctcctt
98689DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 868ggagacctc
98699DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
869gccagactt
98709DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 870gtctggctc
98719DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 871ggtctcatt
98729DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
872tgagacctc
98739DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 873gagaccatt
98749DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 874tggtctctc
98759DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
875ccttcagtt
98769DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 876ctgaaggtc
98779DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 877gcacctgtt
98789DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
878caggtgctc
98799DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 879aaaggcgtt
98809DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 880cgccttttc
98819DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
881cagatcgtt
98829DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 882cgatctgtc
98839DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 883cataggctt
98849DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
884gcctatgtc
98859DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 885ccttcactt
98869DNAArtificial SequenceDescription of Artificial
Sequence Synthetic oligonucleotide 886gtgaaggtc
98879DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
887gcacctctt
98889DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 888gaggtgctc
988925DNAArtificial SequenceDescription of Artificial
Sequence Synthetic primer 889cagaagacag acaagcttca cctgc
2589027DNAArtificial SequenceDescription of
Artificial Sequence Synthetic primer 890gcaggtgaag cttgtctgtc
ttctgaa 2789119DNAArtificial
SequenceDescription of Artificial Sequence Synthetic primer
891gcctccctcg cgccatcag
1989219DNAArtificial SequenceDescription of Artificial Sequence Synthetic
primer 892gccttgccag cccgctcag
1989310DNAArtificial SequenceDescription of Artificial
Sequence Synthetic primer 893cagcgttcga
1089435DNAArtificial SequenceDescription of
Artificial Sequence Synthetic primer 894gcaggtgaag cttgtctgnn
nnntcgaacg ctgaa 3589533DNAArtificial
SequenceDescription of Artificial Sequence Synthetic primer
895cagcgttcga nnnnncagac aagcttcacc tgc
3389635DNAArtificial SequenceDescription of Artificial Sequence Synthetic
primer 896gcaggtgaag cttgtctgnn nnntcgaacg ctgaa
3589747DNAArtificial SequenceDescription of Artificial
Sequence Synthetic primer 897gcctccctcg cgccatcaga bbbabbbabb
bagcatcgaa cgctgaa 4789839DNAArtificial
SequenceDescription of Artificial Sequence Synthetic primer
898gccttgccag cccgctcaga tgactcccaa atcgatgtg
3989939DNAArtificial SequenceDescription of Artificial Sequence Synthetic
primer 899gccttgccag cccgctcagc tgactcccaa atcgatgtg
3990039DNAArtificial SequenceDescription of Artificial
Sequence Synthetic primer 900gccttgccag cccgctcagg tgactcccaa
atcgatgtg 3990139DNAArtificial
SequenceDescription of Artificial Sequence Synthetic primer
901gccttgccag cccgctcagt tgactcccaa atcgatgtg
3990240DNAArtificial SequenceDescription of Artificial Sequence Synthetic
primer 902gccttgccag cccgctcaga atgactccca aatcgatgtg
4090340DNAArtificial SequenceDescription of Artificial
Sequence Synthetic primer 903gccttgccag cccgctcaga ctgactccca
aatcgatgtg 4090440DNAArtificial
SequenceDescription of Artificial Sequence Synthetic primer
904gccttgccag cccgctcaga gtgactccca aatcgatgtg
4090540DNAArtificial SequenceDescription of Artificial Sequence Synthetic
primer 905gccttgccag cccgctcaga ttgactccca aatcgatgtg
4090640DNAArtificial SequenceDescription of Artificial
Sequence Synthetic primer 906gccttgccag cccgctcagc atgactccca
aatcgatgtg 4090738DNAArtificial
SequenceDescription of Artificial Sequence Synthetic primer
907gtctgttcga agtggacgag actaccgcgc tccctccg
3890838DNAArtificial SequenceDescription of Artificial Sequence Synthetic
primer 908gtctgttcga agtggacgcg actaccgcgc tccctccg
3890938DNAArtificial SequenceDescription of Artificial
Sequence Synthetic primer 909gtctgttcga agtggacggg actaccgcgc
tccctccg 3891038DNAArtificial
SequenceDescription of Artificial Sequence Synthetic primer
910gtctgttcga agtggacgtg actaccgcgc tccctccg
3891139DNAArtificial SequenceDescription of Artificial Sequence Synthetic
primer 911gtctgttcga agtggacgaa gactaccgcg ctccctccg
3991239DNAArtificial SequenceDescription of Artificial
Sequence Synthetic primer 912gtctgttcga agtggacgca gactaccgcg
ctccctccg 3991339DNAArtificial
SequenceDescription of Artificial Sequence Synthetic primer
913gtctgttcga agtggacgga gactaccgcg ctccctccg
3991439DNAArtificial SequenceDescription of Artificial Sequence Synthetic
primer 914gtctgttcga agtggacgta gactaccgcg ctccctccg
3991539DNAArtificial SequenceDescription of Artificial
Sequence Synthetic primer 915gtctgttcga agtggacgac gactaccgcg
ctccctccg 3991619DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
916tgactcccaa atcaatgtg
1991717DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 917cattgatttg ggagtca
1791821DNAArtificial SequenceDescription of
Artificial Sequence Synthetic primer 918ggcacattga tttgggagtc a
2191919DNAArtificial
SequenceDescription of Artificial Sequence Synthetic primer
919tgactcccaa atcaatgtg
199205PRTArtificial SequenceDescription of Artificial Sequence Synthetic
peptide 920Gly Pro Phe Xaa Gly1 592125DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
921agtctggtac agggtgttct tttta
2592229DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 922accgtaaaaa gaacaccctg taccagact
2992312DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 923cggtggctgg ag
1292412DNAArtificial
SequenceDescription of Artificial Sequence Synthetic oligonucleotide
924aaggctccag cc
1292537DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 925agtctggtac agggtgttct ttttacggtg gctggag
3792641DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 926aaggctccag
ccaccgtaaa aagaacaccc tgtaccagac t
4192731DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 927cggaaacggg taccctaaaa agaacaccct g
3192840DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 928agtctggtac
agggtgttct ttttagggta cccgtttccg
4092940DNAArtificial SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 929cggaaacggg taccctaaaa agaacaccct gtaccagact
40
User Contributions:
Comment about this patent or add new information about this topic:
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
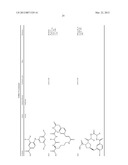 |  |
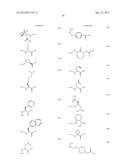 | 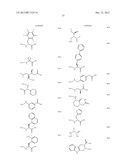 |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 | 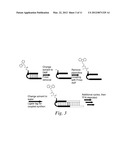 |
 |  |
 |  |
 |  |
 |  |
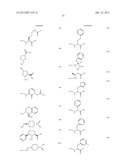 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 | 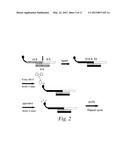 |
 |  |
 |  |
 |  |
 |  |
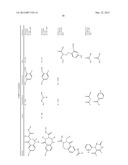 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 | 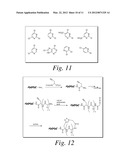 |
 |  |
 |  |
 |  |
 |  |
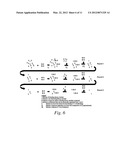 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 | 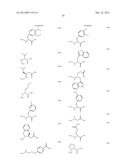 |
 | 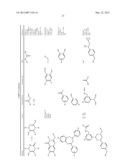 |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
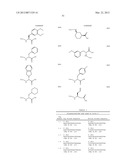 |  |
 |  |
 |
| Similar patent applications: | |
| Date | Title |
|---|---|
| 2013-03-21 | Methods for synthesizing pools of probes |
| 2012-11-08 | Method for identifying lineage-related antibodies |
| 2012-12-20 | Methods for screening antibodies |
| 2013-04-04 | Methods for haplotyping single cells |
| 2013-05-23 | Method for identifying lineage-related antibodies |
| New patent applications in this class: | |
| Date | Title |
|---|---|
| 2022-05-05 | Libraries for next generation sequencing |
| 2019-05-16 | Strategies for high throughput identification and detection of polymorphisms |
| 2019-05-16 | Method for high-throughput aflp-based polymorphism detection |
| 2019-05-16 | Semi-permeable arrays for analyzing biological systems and methods of using same |
| 2019-05-16 | Methods and systems for performing single cell analysis of molecules and molecular complexes |
| New patent applications from these inventors: | |
| Date | Title |
|---|---|
| 2015-10-08 | Cd19 binding agents and uses thereof |
| 2014-10-23 | Methods for tagging dna-encoded libraries |
| 2014-04-17 | Structural support scheme for the replacement of trailing portions of sails |
| 2013-05-30 | Antibody drug conjugates (adc) that bind to 24p4c12 proteins |
| 2013-05-23 | Methods of inhibition of protein fucosylation in vivo using fucose analogs |
| Top Inventors for class "Combinatorial chemistry technology: method, library, apparatus" | |
| Rank | Inventor's name |
|---|---|
| 1 | Mehdi Azimi |
| 2 | Kia Silverbrook |
| 3 | Geoffrey Richard Facer |
| 4 | Alireza Moini |
| 5 | William Marshall |