Patent application title: Spectrum Searching Method That Uses Non-Chemical Qualities of the Measurement
Inventors:
Christopher D. Brown (Albuquerque, NM, US)
Gregory H. Vander Rhodes (Melrose, MA, US)
Gregory H. Vander Rhodes (Melrose, MA, US)
IPC8 Class: AG01J328FI
USPC Class:
702 76
Class name: Waveform analysis frequency frequency spectrum
Publication date: 2010-07-29
Patent application number: 20100191493
Inventors list |
Agents list |
Assignees list |
List by place |
Classification tree browser |
Top 100 Inventors |
Top 100 Agents |
Top 100 Assignees |
Usenet FAQ Index |
Documents |
Other FAQs |
Patent application title: Spectrum Searching Method That Uses Non-Chemical Qualities of the Measurement
Inventors:
Christopher D. Brown
Gregory H. Vander Rhodes
Agents:
FISH & RICHARDSON PC
Assignees:
Origin: MINNEAPOLIS, MN US
IPC8 Class: AG01J328FI
USPC Class:
702 76
Publication date: 07/29/2010
Patent application number: 20100191493
Abstract:
Methods and systems for determining information about a sample are
disclosed. The methods can include measuring spectral information for the
sample and determining a quantity related to a signal-to-noise ratio for
the spectral information, repeating the measuring and determining until a
value of the quantity is beyond a threshold value, and comparing the
spectral information to reference information to determine the
information about the sample.Claims:
1-39. (canceled)
40. A method, comprising:measuring spectral information for a sample and determining a quantity related to a signal-to-noise ratio for the spectral information;determining whether the quantity is beyond a threshold value of the quantity;if the quantity is not beyond the threshold value:measuring additional spectral information for the sample;combining the additional measured spectral information with previously measured spectral information;determining a new value of the quantity based on the combined spectral information;determining whether the new value of the quantity is beyond the threshold value; andrepeating the measuring additional spectral information, combining the additional measured spectral information with previously measured spectral information, determining a new value of the quantity, and determining whether the new value of the quantity is beyond the threshold value, until the new value of the quantity is beyond the threshold value; andcomparing the combined spectral information to reference information to determine information about the sample.
41. The method of claim 40, wherein the quantity is the signal-to-noise ratio of the measured spectral information.
42. The method of claim 40, further comprising, if an elapsed measurement time exceeds a threshold measurement time, halting further measurement of spectral information.
43. The method of claim 40, further comprising adjusting an operating characteristic of a detection system used to measure the spectral information prior to measuring at least some of the additional spectral information.
44. The method of claim 43, wherein the operating characteristic is a temperature of the detection system.
45. The method of claim 43, wherein the operating characteristic is an aperture of the detection system.
46. The method of claim 43, wherein the operating characteristic is a gain of the detection system.
47. The method of claim 43, wherein adjusting the operating characteristic comprises adjusting an optical configuration of the detection system.
48. The method of claim 47, wherein adjusting the optical configuration comprises adjusting a position of one or more optical components in the detection system.
49. The method of claim 40, further comprising adjusting an amount of ambient light detected by a detection system used to measure the spectral information prior to measuring at least some of the additional spectral information.
50. The method of claim 40, further comprising adjusting a position of a detection system used to measure the spectral information prior to measuring at least some of the additional spectral information.
51. The method of claim 40, further comprising adjusting a detection system used to measure the spectral information to increase an intensity of Raman scattered light emitted by the sample.
52. The method of claim 51, wherein adjusting the detection system comprises increasing an intensity of illumination radiation incident on the sample and generated by a radiation source.
53. The method of claim 40, further comprising adjusting a detection system used to measure the spectral information to increase an intensity of reflected or transmitted infrared radiation from the sample.
54. The method of claim 53, wherein adjusting the detection system comprises increasing an intensity of illumination radiation incident on the sample and generated by a radiation source.
55. The method of claim 40, wherein the reference information comprises information about a plurality of candidates in a library.
56. The method of claim 40, wherein determining information about the sample comprises determining an identity of the sample.
57. The method of claim 40, wherein determining information about the sample comprises determining that the sample comprises a mixture of two or more components.
58. The method of claim 40, wherein determining information about the sample comprises determining that the sample does not comprise any of a plurality of candidates in the reference information.
59. The method of claim 40, wherein determining information about the sample comprises determining information about a hazardousness of the sample.
60. The method of claim 40, wherein determining information about the sample comprises determining whether an identity of the sample can be determined based on the measured spectral information.
61. The method of claim 40, wherein the measured spectral information comprises at least one of Raman scattering information, infrared absorption information, infrared reflectance information, and fluorescence information for the sample.
62. The method of claim 40, wherein determining the quantity related to the signal-to-noise ratio comprises determining a distribution of measured values of the spectral information.
63. The method of claim 62, wherein measuring the spectral information comprises measuring information in a plurality of spectral channels, and determining the quantity related to the signal-to-noise ratio comprises determining a variance for each of the spectral channels, and determining the quantity based on the variances.
64. The method of claim 40, wherein determining the quantity related to the signal-to-noise ratio comprises determining one or more uncertainties associated with measured values of the spectral information.
65. The method of claim 40, wherein determining the quantity related to the signal-to-noise ratio comprises determining a probability of identifying the sample based on the reference information.
66. The method of claim 40, wherein determining the quantity related to the signal-to-noise ratio comprises determining a probability that the sample corresponds to a portion of the reference information associated with one or more pure compounds.
67. The method of claim 40, wherein comparing the combined spectral information to reference information comprises determining an extent of overlap between the measured spectral information and reference information corresponding to each of a plurality of candidates.
68. The method of claim 67, wherein the reference information corresponding to each of the candidates comprises an expected distribution of values of the measured spectral information for each candidate.
69. The method of claim 68, further comprising determining the expected distribution of values for each of the candidates based on an expected noise or error level in a detection system used to measure the spectral information.
70. The method of claim 69, wherein the expected noise or error level comprises at least one of a dark current noise level in the detection system, a read noise level in the detection system, a quantization error in the detection system, a defect error level in the detection system, a gain error level in the detection system, a viability error level in the detection system, and a shot noise level in the detection system.
71. The method of claim 68, further comprising determining the expected distribution of values for each of the candidates based on a temperature of a detection system or a humidity of an environment around the detection system used to measure the spectral information.
72. The method of claim 68, further comprising determining the expected distribution of values based on a selected distribution.
73. The method of claim 72, wherein the selected distribution comprises at least one of a multivariate normal distribution, a log-normal distribution, a Poisson distribution, an inverse Gaussian distribution, a Wishart distribution, and a Snedecor's F-distribution.
74. The method of claim 68, wherein determining the extent of overlap comprises determining, for at least some measured values of spectral information displaced from a center of the expected distribution of values by a first distance, a probability that additional measured values of spectral information would be displaced from the center by an amount greater than the first distance.
75. The method of claim 40, further comprising not combining all of the additional spectral information with the previously measured spectral information.
76. A method, comprising:measuring spectral information for a sample and determining a quantity related to a signal-to-noise ratio for the spectral information;repeating the measuring and determining until a value of the quantity is beyond a threshold value; andcomparing the spectral information to reference information to determine information about the sample.
77. The method of claim 76, wherein the quantity is a signal-to-noise ratio for the spectral information.
78. The method of claim 76, further comprising combining the measured spectral information with previously measured spectral information prior to determining the quantity.
79. The method of claim 76, further comprising, if an elapsed measurement time exceeds a threshold measurement time, halting further measurement of spectral information.
80. The method of claim 76, further comprising adjusting an operating characteristic of a detection system used to measure the spectral information prior to measuring at least some of the spectral information.
81. The method of claim 76, wherein determining information about the sample comprises at least one of determining an identity of the sample, determining that the sample comprises a mixture of two or more components, and determining that the sample does not comprise any of a plurality of candidates in the reference information.
82. The method of claim 76, wherein comparing the spectral information to reference information comprises determining an extent of overlap between the measured spectral information and reference information corresponding to each of a plurality of candidates.
83. The method of claim 82, wherein the reference information corresponding to each of the candidates comprises an expected distribution of values of the measured spectral information for each candidate.
84. The method of claim 83, further comprising determining the expected distribution of values for each of the candidates based on at least one of an expected noise or error level in a detection system used to measure the spectral information, a temperature of the detection system, a humidity of an environment around the detection system, and a selected distribution.
85. The method of claim 83, wherein determining the extent of overlap comprises determining, for at least some measured values of spectral information displaced from a center of the expected distribution of values by a first distance, a probability that additional measured values of spectral information would be displaced from the center by an amount greater than the first distance.
86. The method of claim 78, further comprising combining only a portion of the measured spectral information with previously measured spectral information prior to determining the quantity.
87. The method of claim 76, wherein determining the quantity related to the signal-to-noise ratio comprises determining one or more uncertainties associated with measured values of the spectral information.
88. The method of claim 76, wherein determining the quantity related to the signal-to-noise ratio comprises determining a probability of identifying the sample based on the reference information.
89. The method of claim 76, wherein determining the quantity related to the signal-to-noise ratio comprises determining a probability that the sample corresponds to a portion of the reference information associated with one or more pure compounds.
90. A system, comprising:a radiation source configured to direct incident radiation to a sample;a detector configured to measure radiation from the sample; andan electronic processor configured to:determine spectral information for a sample based on the measured radiation;determine a quantity related to a signal-to-noise ratio for the spectral information;repeat the measuring radiation, determining spectral information, and determining the quantity until a value of the quantity is beyond a threshold value; andcompare the spectral information to reference information to determine information about the sample.
91. The system of claim 90, wherein the electronic processor is configured to combine the spectral information with previously determined spectral information prior to determining the quantity.
92. The system of claim 91, wherein the electronic processor is configured to selectively combine only some of the spectral information with previously determined information prior to determining the quantity.
93. The system of claim 90, wherein the electronic processor is configured to halt further measurement of radiation if an elapsed measurement time exceeds a threshold measurement time.
94. The system of claim 90, wherein the electronic processor is configured to adjust an operating characteristic of the detector prior to measuring at least some of the radiation.
95. The system of claim 90, wherein determining information about the sample comprises at least one of determining an identity of the sample, determining that the sample comprises a mixture of two or more components, and determining that the sample does not comprise any of a plurality of candidates in the reference information.
96. The system of claim 90, wherein determining the quantity related to a signal-to-noise ratio comprises at least one of determining one or more uncertainties associated with measured values of the spectral information, determining a probability of identifying the sample based on the reference information, and determining a probability that the sample corresponds to a portion of the reference information associated with one or more pure compounds.
97. The system of claim 90, wherein the electronic processor is configured to compare the spectral information to reference information by determining an extent of overlap between the spectral information and reference information corresponding to each of a plurality of candidates.
98. The system of claim 97, wherein the reference information corresponding to each of the candidates comprises an expected distribution of values of the spectral information for each candidate.
99. The system of claim 98, wherein the electronic processor is configured to determine the expected distribution of values for each of the candidates based on at least one of an expected noise or error level in the detector, a temperature of the detector, a humidity of an environment around the detector, and a selected distribution.
100. The system of claim 98, wherein the electronic processor is configured to determine the extent of overlap by determining, for at least some values of the spectral information displaced from a center of the expected distribution of values by a first distance, a probability that additional determined values of spectral information would be displaced from the center by an amount greater than the first distance.
Description:
REFERENCE TO PENDING PRIOR PATENT APPLICATIONS
[0001]This patent application claims benefit of pending prior U.S. Provisional Patent Application Ser. No. 60/635,410, filed Dec. 10, 2004 by Christopher D. Brown et al. for SPECTRUM SEARCHING METHOD THAT USES NON-CHEMICAL QUALITIES OF THE MEASUREMENT (Attorney's Docket No. AHURA-33 PROV).
[0002]The above-identified patent application is hereby incorporated herein by reference.
BACKGROUND OF THE INVENTION
[0003]The identification and quantification of chemical entities is largely the domain of analytical chemistry. Both the identification and quantification tasks are made easier with the use of multi-element analytical instrumentation since more analytical information is available to aid the analysis. Examples of contemporary analytical instrumentation capable of producing multi-element (vector) data include multiwavelength infrared and Raman spectrometers, mass spectrometers, nuclear magnetic resonance (NMR) spectrometers, and chromatographic separation-detection systems. Conveniently, as these techniques became more prevalent in the analytical laboratory, computational power also became more affordable and available, and analysts were quick to recognize that computer-aided methods could dramatically speed up the identification and quantification tasks.
[0004]In the computer-aided identification task, which is the focus of this patent, the analytical data is submitted to a system (the search appliance) which scours a library of known materials looking for similarities in the instrument response of the unknown material to the stored responses for known materials. Typically, the search appliance returns to the user a list of materials in the library along with their associated similarity to the submitted data. This entire process is usually termed "spectral library searching". The vast majority of proposed similarity measures cannot be interpreted absolutely, but the relative similarity of the measured data to the various library records is deemed meaningful for ranking purposes. This is akin to today's web search utilities that return to the user a list of sites, ordered by a similarity measure of site-to-query. As with web search utilities, the critical differentiation among competing methods is usually the definition of the similarity measure.
[0005]The most common similarity measure in use today for spectral library searching is correlation based (see S. R. Lowry, "Automated Spectral Searching In Infrared, Raman And Near-infrared Spectroscopy", J. Wiley & Sons, pp. 1948-1961). This approach exploits a linear instrument response, assuming that a chemical species and its spectrum (InfraRed, Raman, mass spectrum, etc.) are immutably tied, and the vector orientation of the spectrum does not depend on the concentration of the species. Other well-known measures of similarly include Euclidean distance and least-squares methodologies (see S. R. Lowry, "Automated Spectral Searching In Infrared, Raman And Near-Infrared Spectroscopy", J. Wiley & Sons, pp. 1948-1961), which are equivalent to the correlation similarity within elementary scalar manipulations. These similarity measures are implemented in many commercial spectral library search software packages.
[0006]In web searching, there are minimal end-user consequences (other than wasted time and frustration) if a page is suggested that does not actually pertain to the query (a "false-positive"). However, many applications of spectral library searching are used to guide actions, such as how chemicals are to be treated in hazardous materials situations, so it is critical to know when an evidence-based decision can be made, and when it cannot. The correlation similarity measure does not suffice to guide actions, as we will illustrate by way example.
[0007]FIGS. 1a and 1b illustrate the challenges posed by spectral library search methods using non-absolute similarity measures such as correlation. In both FIGS. 1a and 1b, the measured material is in fact kerosene, a mixture of petroleum distillates in the C12 to C15 range, but due to different measurement conditions, it is apparent that the precision-states of the two measurements are quite different. In FIG. 1a, the measured kerosene is compared to a library record spectrum of kerosene, yielding a correlation similarity measure of 0.950. In FIG. 1B, the measured kersosene spectrum is compared to a library record spectrum of Japan Drier, a common solvent for painting (a mixture of lighter petroleum distillates), yielding a correlation similarity measure of 0.945. Recall that for any case at hand, the analyst needs to make one of the following judgments based on the similarity measure:
[0008](i) the measured material is likely the top-ranked library material;
[0009](ii) the measured material is likely one of several top-ranked library materials; or
[0010](iii) the measured material is not any of the top-ranked materials (i.e., there is no library match).
[0011]FIGS. 1a and 1b illustrate the complication in such a decision based on the correlation similarity measure. The different precision states of the two measurements mean that even though the similarity measure is the same in the two cases, one is a valid match (i.e., FIG. 1A), while the other is an invalid match (i.e., FIG. 1B). A simple rule cannot be formulated based on correlation that allows one to reliably decide between judgments (i), (ii) and (iii) above. This is because the correlation similarity measure (and equivalently, least-squares or Euclidean distance measures) does not account for the precision state of the measurement, and therefore does not consistently reflect the amount of scientific evidence favoring a judgment.
[0012]Counter-intuitively, when the signal-to-noise ratio is poor, similarity measures in the art tend to more emphatically suggest that the measured material is not in the library; in reality, the evidence provided by the data in such a circumstance is weak--little can be said about whether the material is or is not in the library. Furthermore, when the signal-to-noise ratio increases, the similarity measure tends to increase for all records in the library, when the analyst knows intuitively that with higher quality data, it should be easier to distinguish one library component from another. Indeed, even in FIG. 1B with a very high correlation similarity measure, several obvious mismatched spectral features can be identified (indicated by the arrows in the figure).
[0013]What is needed, and to date lacking, in spectral library search algorithms, are similarity measures that are directly interpretable in terms of the scientific evidence supporting one library "hit" over another.
PRIOR ART
[0014]Scientific evidence favoring one hypothesis over another is most succinctly quantified in terms of probabilities. Probabilistic inference is an old and well-explored field, and some allusions to probability-based spectral library searching have been made in the literature.
[0015]McLafferty et al. proposed what they termed a probability-based similarity measure for mass spectrum library searching, wherein a small set of features are extracted from the mass spectrum of the query data (such as a list of major peaks and their mass/charge values), they are compared to analogous lists of features in library spectra, and the similarity is made relative to the chance of finding a similar number of matching features at random (see J. R. Chapman, "Computers In Mass Spectrometry", Academic Press, 1978).
[0016]Cleij et al. discussed probabilistic similarity measures, wherein selected features of the query spectrum are compared to related features with known uncertainty in the library (see P. Cleij, H. A. Van 'T Klooster, J. C. Van Houwelingen, "Reproducibility As The Basis Of A Similarity Index For Continuous Variables In Straightforward Library Search Methods", Analytica Chimica Acta 150, 23-36, 1983). Their examples include library searches for chemical shift data (NMR spectroscopy), where the uncertainty in the library chemical shift values was determined from measurements at multiple laboratory sites, and chromatographic retention indices where, again, the uncertainty in library retention indices was determined from inter-laboratory variation. There were, however, several critical shortcomings of these investigations.
[0017]Neither McLafferty or Cleij discussed methods for comparing complete spectra against alternative library records (often called "full spectrum library searching"), which is the approach of choice today because no information is discarded in the process; neither approach appropriately controls for the increased probability of false-positives associated with multiple tests of hypothesis (typically requiring a Bonferroni-type correction), and, finally, neither approach actually produces posterior probabilities--probabilities of the form, for example, "P is the probability that the material under study is library material A". The McLafferty approach does not account for the uncertainty in the instrumental measurement conditions, and in Cleij's method, the uncertainty in the library record dominates over the uncertainty in the measurement state, which is presumed to be of indisputable quality.
[0018]A recent journal article by Li et al. (see J. Li, D. B. Hibbert, S. Fuller, J. Cattle, C. Pang Way, "Comparison Of Spectra Using A Bayesian Approach. An Argument Using Oil Spills As An Example", Anal. Chem. 77, 639-644, 2005) (which in turn claims to build on the work of Killeen and Chien--see T. J. Killeen, Y. T. Chien, "Proc. Workshop Pattern Recognition Appl. Oil Identif.", 1977, pp. 66-72) discussed this general shortfall in spectral library searching, and proposed what they termed a Bayesian approach for spectral matching based on the correlation similarity measure. Their method amounts to a naive Bayes classifier which has been well-known in the art for some time but, unfortunately, requires measuring many (large multiples of the entire spectral library) specimens, and recording the calculated correlation similarity measures. The distributions of matching and non-matching correlation similarity measures are then used to determine the probability of a match by traditional methods. Even with this procedure, however, the probabilistic assessment is not accurate because the distribution of correlation similarity measures under "no match" criteria only encompasses known species in the library; all other possible species are not represented--so unless the library encompassed "all possible chemical species" (which is practically precluded), the probabilities will be inaccurate. The method they discussed (i.e., a naive Bayes classifier) also does not adapt to varying measurement conditions.
SUMMARY OF THE INVENTION
[0019]The invention disclosed herein resolves these problems, and several related situations that have not be considered in the prior art, for spectral library searching.
[0020]In one form of the invention, there is provided a method for determining the most likely composition of a sample, comprising:
[0021]obtaining data from a sample, wherein the data comprises a representation of a measured spectrum;
[0022]determining the precision state of the representation of the measured spectrum;
[0023]providing a plurality of library candidates and, for each library candidate, providing data representing the same, wherein the data comprises a representation of a library spectrum;
[0024]determining a representation of the similarity of the sample to each library candidate using (i) the representation of the measured spectrum; (ii) the precision state of the representation of the measured spectrum; and (iii) the representation of the library spectrum for that library candidate; and
[0025]determining the most likely composition of the sample based upon the determined representations of similarity of the sample to each library candidate.
[0026]In another form of the invention, there is provided a method for determining the most likely composition of a sample, comprising:
[0027]obtaining data from a sample, wherein the data comprises a representation of a measured spectrum;
[0028]determining the precision state of the representation of the measured spectrum;
[0029]providing a plurality of library candidates and, for each library candidate, providing data representing the same, wherein the data comprises a representation of a library spectrum;
[0030]determining a representation of the similarity of the sample to a mixture of library candidates using (i) the representation of the measured spectrum; (ii) the precision state of the representation of the measured spectrum; and (iii) the representation of the library spectrum for that library candidate; and
[0031]determining the most likely composition of the sample based upon the determined representations of similarity of the sample to a mixture of library candidates.
[0032]In another form of the invention, there is provided a method for determining the most likely classification of a sample, comprising:
[0033]obtaining data from a sample, wherein the data comprises a representation of a measured spectrum;
[0034]determining the precision state of the representation of the measured spectrum;
[0035]providing a plurality of library candidates and, for each library candidate, providing data representing the same, wherein the data comprises a representation of a library spectrum;
[0036]wherein the data for each of at least some of the library candidates further comprises the identification of a class to which the library candidate belongs;
[0037]determining a representation of the similarity of the sample to each library candidate using (i) the representation of the measured spectrum; (ii) the precision state of the representation of the measured spectrum; and (iii) the representation of the library spectrum for that library candidate; and
[0038]determining the most likely classification of the sample based upon the determined representations of similarity of the sample to each library candidate.
[0039]In another form of the invention, there is provided a method for determining the most likely classification of a sample, comprising:
[0040]obtaining data from a sample, wherein the data comprises a representation of a measured spectrum;
[0041]determining the precision state of the representation of the measured spectrum;
[0042]providing a plurality of library candidates and, for each library candidate, providing data representing the same, wherein the data comprises a representation of a library spectrum;
[0043]wherein the data for each of at least some of the library candidates further comprises the identification of a class to which the library candidate belongs;
[0044]determining a representation of the similarity of the sample to a mixture of library candidates using (i) the representation of the measured spectrum; (ii) the precision state of the representation of the measured spectrum; and (iii) the representation of the library spectrum for that library candidate; and
[0045]determining the most likely classification of the sample based upon the determined representations of similarity of the sample to a mixture of library candidates.
[0046]In another form of the invention, there is provided a system for determining the most likely composition of a sample, comprising:
[0047]apparatus for obtaining data from a sample, wherein the data comprises a representation of a measured spectrum;
[0048]apparatus for determining the precision state of the representation of the measured spectrum;
[0049]apparatus for providing a plurality of library candidates and, for each library candidate, providing data representing the same, wherein the data comprises a representation of a library spectrum;
[0050]apparatus for determining a representation of the similarity of the sample to each library candidate using (i) the representation of the measured spectrum; (ii) the precision state of the representation of the measured spectrum; and (iii) the representation of the library spectrum for that library candidate; and
[0051]apparatus for determining the most likely composition of the sample based upon the determined representations of similarity of the sample to each library candidate.
[0052]In another form of the invention, there is provided a system for determining the most likely composition of a sample, comprising:
[0053]apparatus for obtaining data from a sample, wherein the data comprises a representation of a measured spectrum;
[0054]apparatus for determining the precision state of the representation of the measured spectrum;
[0055]apparatus for providing a plurality of library candidates and, for each library candidate, providing data representing the same, wherein the data comprises a representation of a library spectrum;
[0056]apparatus for determining a representation of the similarity of the sample to a mixture of library candidates using (i) the representation of the measured spectrum; (ii) the precision state of the representation of the measured spectrum; and (iii) the representation of the library spectrum for that library candidate; and
[0057]apparatus for determining the most likely composition of the sample based upon the determined representations of similarity of the sample to a mixture of library candidates.
[0058]In another form of the invention, there is provided a system for determining the most likely classification of a sample, comprising:
[0059]apparatus for obtaining data from a sample, wherein the data comprises a representation of a measured spectrum;
[0060]apparatus for determining the precision state of the representation of the measured spectrum;
[0061]apparatus for providing a plurality of library candidates and, for each library candidate, providing data representing the same, wherein the data comprises a representation of a library spectrum;
[0062]wherein the data for each of at least some of the library candidates further comprises the identification of a class to which the library candidate belongs;
[0063]apparatus for determining a representation of the similarity of the sample to a mixture of library candidates using (i) the representation of the measured spectrum; (ii) the precision state of the representation of the measured spectrum; and (iii) the representation of the library spectrum for that library candidate; and
[0064]apparatus for determining the most likely classification of the sample based upon the determined representations of similarity of the sample to a mixture of library candidates.
BRIEF DESCRIPTION OF THE DRAWINGS
[0065]These and other objects and features of the present invention will be more fully disclosed or rendered obvious by the following detailed description of the preferred embodiments of the invention, which are to be considered together with the accompanying drawings wherein like numbers refer to like parts, and further wherein:
[0066]FIG. 1A is a view showing a spectral comparison between a kerosene measurement and a kerosene library record;
[0067]FIG. 1B is a view showing a spectral comparison between a kerosene measurement and a Japan Drier library record;
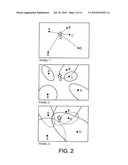
[0068]FIG. 2: panel 1 is a view showing the similarity measure for a query Q and library records A-E, where both the query and library records are treated as points;
[0069]FIG. 2: panel 2 is a view showing the similarity measure for a query Q and library records A-E, where the query is treated as a point and the candidate library records are treated as ellipses to represent the expected variability in measurement of the materials A-E;
[0070]FIG. 2: panel 3 is a view like that of FIG. 2: panel 2 except that there is considerable uncertainty in the expected variability in measurement of the materials A-E;
[0071]FIG. 3A is the dark field count, bright field count and Raman spectrum for acetaminophen where there is substantial broadband background flux;
[0072]FIG. 3B is the dark field count, bright field count and Raman spectrum for acetaminophen where there is little background flux;
[0073]FIGS. 4a and 4b are the analytically estimated standard deviation for each measurement channel for the Raman spectrum for acetaminophen;
[0074]FIG. 5 provides a comparative example of the present invention for two measurements of polystyrene;
[0075]FIG. 6A illustrates the methodology used to determine (i) the discrepancies between a sample measurement and various library records, and (ii) the probability of observing that discrepancy for a particular library record;
[0076]FIG. 6B illustrates the methodology to determine posterior probabilities of library record matches using (i) the calculated probabilities of observing the determined discrepancy for a particular library record, and (ii) the collection of prior probabilities;
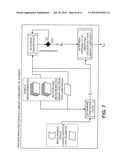
[0077]FIG. 7 illustrates the methodology used to determine (i) the discrepancies between a sample measurement and various library records, and (ii) the probability of observing that discrepancy for a particular library record, using a test for convergence;
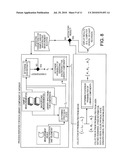
[0078]FIG. 8 is a composite of FIGS. 7 and 6B, further modified to show adjustment of operating parameters so as to improve the result;
[0079]FIG. 9 is a schematic diagram showing one preferred form of apparatus embodying the present invention;
[0080]FIG. 10 is a schematic diagram showing another preferred form of apparatus embodying the present invention;
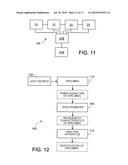
[0081]FIG. 11 is a schematic diagram showing another preferred form of apparatus embodying the present invention; and
[0082]FIG. 12 is a schematic view showing a novel Raman analyzer formed in accordance with the present invention.
DETAILED DESCRIPTION OF THE PREFERRED EMBODIMENTS
[0083]The critical question to be answered by the spectral library search appliance is: given the instrumental measurement of the specimen, and the conditions under which it was measured, (1) is it probable that any of the library records are a match?, and (2) what are the probabilities PA, PB . . . that the measured material is in fact pure A, B, etc.? These probabilities must be directly dependent on the measurement data, and its quality. Generally speaking, the measurement quality is a function of the accuracy of the measurement and its precision (or variability). It can often be assumed that, if the instrument has been designed appropriately and/or appropriate signal conditioning methods have been used, the measurement will be reasonably accurate, but inevitably suffers from imprecision to a degree dependent on the measurement conditions.
[0084]The inventiveness of the new approach discussed herein, relative to prior art, is most generally described as:
Si=f(ylib,i, ymeas, Σi, Σmeas, Ψ) (1)
where Si is the similarity measure between (i) the ith library spectrum, ylib,i, for a given library material I, and (ii) the measured spectrum ymeas. For the new approach of the present invention, the similarity metric is conditional on Σi, Σmeas, which are representations of the "precision state" of the library (Σi) and the measured spectrum (Σmeas) under the circumstances, and Ψ codifies other information available at the time of the similarity analysis.
[0085]By direct comparison, conventional spectral library search methods of the sort known to those skilled in the art are best described as:
Si=f(ylib,i, ymeas) (2)
Certainly ymeas will be a consequence of the measurement circumstances--for example, if the circumstance leads to either particularly low signal, or high noise conditions, ymeas will "look noisy"--and for this reason, it is sometimes (falsely) suggested that the conventional method of Equation (2) automatically accounts for the precision state. The difference between the new method of Equation (1) and the conventional method of Equation (2) is that the new method of Equation (1) separately quantifies the degree of imprecision in the data to provide the similarity measure that is a direct measure of probabilistic evidence.
[0086]The contrast between an evidence-based similarity measure and what is conventionally used in the art is illustrated in FIG. 2. In panel 1 the measurement, treated as a query (Q) for the search appliance, is assessed for similarity to 5 candidate library records (A-E). In panel 1, both the query and library records are treated as points (like the method of equation 2 above), and their similarity (Q to A, Q to B, etc.) is usually a simple function of the distance between points. By this rule, the similarity metrics of Q to A, B, and C are comparable. In panel 2, the measurement query is assumed to be imprecise, and the ellipses around the candidate library records A-E represent the expected variability (e.g., 99%) in measurements of the various materials (A-E) under the precision state of the query. In this case, library record B is the only library record that has a reasonable likelihood of generating the query data given the precision state (although even this is somewhat improbable given the ellipse). Panel 3 reflects a measurement condition in which there is considerable uncertainty (e.g., strong sample fluorescence, which contributes substantial noise to the measurement). The precision state of the query is such that library records B, C and D are all reasonably plausible, although records A and E are less likely. The precision-state-based similarity metric is higher for all 5 library records in panel 3 compared to panel 2, because there is greater uncertainty in the measurement. In the limit, if the imprecision was near infinite (that is, there is very little signal relative to the noise), all library records would be plausible matches, because there is very little (if any) evidence from the measurement to favor one over the other.
[0087]One skilled in the art will recognize that there are many possible embodiments of a precision-state-based similarity measure, but all of these embodiments will be critically reliant on a method of characterizing the precision-state of the measurement. For a dispersive Raman spectrometer measurement using charge coupled device (CCD) detection, as an example, many distinct sources of variability contribute to the precision state of the measurement:
Σmeas=f(IRal, IRam, Ifl, Iambient, Idark, σread, Q, DCCD, GCCD, C, T, H, t, L) (3)
[0088]IRal is the Raleigh scatter intensity, hRam is the Raman scatter intensity, Ifl is the fluorescence intensity, and Iambient is the ambient light intensity. All of these terms affect the uncertainty of the analytical measurement because they each contribute photon shot noise. Idark is the dark current intensity in the CCD, the spontaneous accumulation of detector counts without impinging photons, which also contributes shot noise. σread is the read noise (imprecision in reading out the CCD response), Q is quantization error (a consequence of the analog-to-digital conversion ADC), DCCD is a term relating to variability that is a consequence of defects in the CCD construction, GCCD is the gain on the CCD (the conversion factor from electrons to counts), T and H are the temperature and humidity conditions of the measurement, t is the time spent integrating the signals, C is physicochemical effects that can alter the exact Raman intensities of the sample (note that each of these effects has a potential wavelength dependence), and L is a "long-term" variability term that reflects changes in the system performance over a time period greater than that of any individual sample measurement, e.g., calibration related variability. As is apparent from the above discussion, some sources of imprecision are determined by the measurement conditions (e.g., photon shot noise, dark noise), some are determined by the unit taking the measurements (e.g., system gain, read noise, quantization noise), and some are determined by the overall design of the platform (e.g., wavelength axis and linewidth stability, temperature/humidity sensitivity).
[0089]Many of the sources of variability in library spectra are similar, although since library spectra are often desired to be of very high quality, signal averaging can effectively reduce the magnitude of these variances.
[0090]There are at least two routes for determining the functional relationship between the measurement parameters and the corresponding precision state: empirical observation and analytical estimation. There are also foreseeable circumstances in which the precision state of the measurement can be inferred from experience, e.g., a measurement being made under very bright ambient lighting conditions will be less precise than a measurement of the same material made in a dark room.
[0091]Furthermore, the precision state may be determined by a combination of two or more of empirical observation, analytical estimation and experience.
[0092]In empirical observation, many measurements are acquired under a set of conditions, and the imprecision observed over the measurements is characterized using, for example, a variance-covariance matrix. Further, the dependence of such a variance-covariance matrix on other factors can be discerned by focused studies. However, this is rather cumbersome and time-consuming, particularly if rapid similarity judgments are desired and the precision state can vary (as in Raman spectroscopy, FTIR and similar techniques). In many measurement modalities (including Raman, FTIR and other spectroscopies), much about the precision state can often be inferred directly from the properties of the device and/or the environment in which the measurement was acquired. In Raman spectroscopy, for example, read noise and quantization noise are solely functions of the instrument electronics, which are usually fixed for a given spectrometer, and constant across CCD pixels. The total shot noise at a given pixel is dependent on the total counts from all sources registered at that pixel, the gain on the CCD electronics, and a defect factor of that pixel. The temperature and humidity conditions can be determined by on-board transducers, the integration time is known, and the L term can be predetermined from the statistical properties of the system calibration, and its behavior over accelerated life testing. The precision state can change dramatically, however, if the measurement is acquired under different circumstances. For example, a measurement acquired outdoors in bright diffuse sunlight versus a dimly lit room; a meat-storage freezer versus an uncooled storage building; a 0.5 second measurement versus a 5 second measurement.
[0093]In FTIR spectroscopy the precision state is also contingent on the measurement conditions, and instrumental aspects such as the detector attributes, data acquisition/signal processing electronics and software, and source flux and flicker.
[0094]To give an example of the analytical determination of precision state under two different measurement conditions, we show data from a Raman spectrometer in FIGS. 3a and 3b. Both measurements are of acetaminophen in a Raman inactive container for similar exposure times (8 seconds). In FIG. 3A there is sizable broadband background flux from outdoor light pollution evident in both the dark and bright field spectra, while in FIG. 3B there is little background flux. So-called "hot-pixels" are evident in both FIG. 3A and FIG. 3B. The net result, after the usual elementary signal processing operations, are the Raman spectra at the bottom of FIG. 3A and FIG. 3B. The precision-state of these two measurements can be determined at each individual channel as:
σshot2=(total count dark+total counts bright)/G
{G is the effective gain in counts/e-, which is impacted by the ADC as well as defects in the pixel}
σtotal2=σshot2+2*σread2+2*- σjn2
{read, Johnson and flicker noise}Thus a variance can be determined for each channel of measurement data. There is an excess of shot noise in FIG. 3A because of the background flux, so while the Raman measurements in FIG. 3A and FIG. 3B look similar in terms of signal, FIG. 3A has higher noise due to the ambient shot noise. The precision states are markedly different in these two common cases, as shown in FIGS. 4a and 4b, where the analytically estimated standard deviation at each measurement channel is plotted.
[0095]The two cases above were measured on the same system under different ambient conditions, but a similar comparison could have been made on two different systems under the same conditions. The differences in precision states in such a case will be a consequence of the system collection efficiencies, filter/detector responses, as well as the characteristics of the electronics, and ADC. Moreover, in comparing multiple systems under the same measurement conditions, other sources of imprecision will be evident, such as subtle variations in lineshape between systems, wavelength calibration settings, system throughput detector and responsivities. Staying with the variance-covariance representation, these effects generally manifest as covariance terms (off-diagonal non-zero elements in the variance covariance matrix).
[0096]Finally, there are physical effects in analytical measurements that can cause distortions in measured data. For example, the Raman scattering intensity at a particular Raman shift value can vary slightly over varying excitation laser wavelengths (leading to slightly different Raman cross-sections), and changes in local polarizability due to solvent and surface effects. In attenuated total reflectance FTIR spectroscopy the refractive index and alignment of the ATR crystal can distort the measured reflectance data. These effects which lead to imprecision across instruments can all be approximated with varying degrees of success using analytic means.
[0097]There are other means of representing the precision state of the measurement, for example, Fourier and wavelet-domain representations and reduced-rank representations. The choice of precision-state representation is in large part coupled with a chosen representation of similarity.
[0098]Given a representation of the precision state, there are several possible similarity measures that implicitly relate to the scientific evidence favoring library records. For example, in a least-squares formulation, one could assume the model for the system is
y meas = β 0 + β 1 y lib , j + e = [ 1 y lib , i ] [ β 0 β 1 ] + e = y i β + e ( 4 ) ##EQU00001##
where β0 and β1 are constant and multiplicative parameters (assembled into a vector β), and e is a realization of the variability in the measurement of ylib,i with distribution e˜N(0,Σi). One precision-state-based similarity measure can be determined by estimating the generalized lack of fit from the normal equation
i=(In-Y(YTΣi-1Y)-1YTΣi-1)ymeas (5)
and then comparing the residual to the expected distribution of e. If i is not anticipated from the expected distribution of e, then a match is highly improbable. The probability itself is dependent on the distribution of e. If it is multivariate normal, as is the assumption in the case illustrated above, the probability (L) of e given e˜N(0,Σi) is
L i = exp ( - 1 2 e ^ i T Σ i - 1 e ^ i ) ( 2 π ) n Σ i ( 6 ) ##EQU00002##
where n is the number of elements in e, and the enclosure |h| indicates the determinant. For very large n, this formula can be challenging to evaluate, so any of a number of numerically efficient alternatives can be exploited. For instance, one can take advantage of the fact that part of the numerator, iTΣiT i, is χ2 with n degrees of freedom. To determine the precision-state-based similarity metric, then, one could determine the probability of seeing instantiations of e more extreme than the measurement at hand, the cumulative probability from iTΣiT i to ∞ on the χ2 distribution. If the cumulative probability is very low, then if the material represented by the query data is really the same material represented by the library record, it is a very unusual occurrence. Higher probabilities are indicative of much more likely measurements. One skilled in the art will recognize that the precision of various types of instrumentation may be more appropriately characterized by different density functions, such as log-normal, Poisson, or inverse-Gaussian. In these cases the appropriate density function is used to determine the Li values.
[0099]In situations in which the exact distribution of e is approximated empirically rather than being analytically determined, other well-known statistical approximations can be used. For example, empirically estimated normal densities are often characterized using the Wishart distribution, and the chi-squared analog is represented by Snedecor's F-distribution. If the distributional form of e is not known, or cannot be easily parametrically described, empirical cumulative density functions (estimated by, for example, the Kaplan-Meier method--see Cox, D. R. and D. Oakes, "Analysis Of Survival Data", Chapman & Hall, London, 1984) can be used to determine Li. Non-parametric analogs can also be used.
[0100]The least-squares formulation above provides a convenient route to a precision-based similarity metric in some circumstances, but other preferred embodiments include a correlation-based similarity measure, where the correlation measure is explicitly adjusted for the precision-state. Discriminant functional representations, neural network architectures, and support vector machines are also all capable of being modified to produce similarity measures that are conditional on the precision-state of the measurement.
[0101]In one embodiment, the Li values are used as measures of precision-state-based similarity. Alternatively, or as a continuation of this embodiment, with a series of Li's calculated for multiple library spectra, one can determine the exclusive probability that the measured material is a pure representation of one library entry versus another, often termed the "posterior probability". Bayes theorem gives the posterior probability, Pi, (exclusive) for a given library component:
P i = θ i L i j = 1 k θ j L j ( 7 ) ##EQU00003##
where there are k elements in the library, or k elements under consideration. The symbol θ codifies other information regarding a given library component independent of the instrument measurement under the constraint that the sum of all θ values must equal 1 (an aspect of Ψ discussed above). For a simple example, consider the case where the analyst knows the unknown specimen of interest is a white powder. Some of the library records may be associated with materials that are white powders in pure form. Therefore, the θ values for each library entry can be chosen to reflect the fact that white-powder library materials are more probabilistically likely than non-white-powder materials. There is an important distinction between what is commonly done by those practicing the art--which is to exclude from the search library records which do not correspond to white powders--and the above approach, which quantitatively reflects probabilities and comprises the other novel aspect of the disclosed spectral library search method. We detail this aspect and its utility next.
[0102]If no extra (i.e., non-instrument measurement) information is available at the time of the measurement, each θ is set to 1/k, indicating that no prior preference exists for any particular library component, a condition usually termed a "flat prior" in the probability literature. The evidence-based similarity measure of this embodiment allows for "scenarios" that do make some library species more likely than others, but never with θ=0 or 1. For example, if a white powder is being analyzed (a characterization which is an input from the user), then all library components that could be in white powder form are given preferred prior probability, for example, θ might favor white-powders over organic liquids 4:1. This is preferred over setting θ equal to zero for non-white powder substances, because users cannot be completely relied upon for perfect input, and phase changes of materials are possible in different measurement conditions. Further, prior probabilities can never be 0 or 1 in any circumstance (except, perhaps for some pathological cases), because these states convey absolute certainty about the as yet unknown outcome.
[0103]Other attributes that can be used to determine the prior probability include, but are not limited to, odor, appearance, texture, crystallinity, color, etc. In these cases, a user can either be prompted for other information (e.g., "What is the color of the substance? Is it solid, liquid?" etc.), or they may choose one or more predefined scenarios that represent one attribute, or a combination of attributes. For example, hazardous materials and drug enforcement personnel often refer to "white powder" scenarios. In this case, the prior probabilities can be automatically set to reflect pre-measurement odds favoring materials in the library that meet these criteria. Therefore, the user could either be presented with the probability Li, which represents the probability that library material i and precision state could lead to the observed measurement, or Pi which is the probability that the material under study is library material i given the precision state and other prior information encoded in the various θ values.
[0104]In one embodiment of this invention, the θi values are determined by a multinomial logistic model on physicochemical properties of samples including color, odor, form (e.g., solid, liquid, gas), while in another embodiment the θ values are determined from text searches of a database of material properties with correspondences to the spectral library. In yet another embodiment, the θ's are modified according the "hazardousness" of the library material, which is advantageous in preventing false-negative search results when such errors could be highly dangerous, a risk-based prior probability.
[0105]FIG. 5 gives a comparative example of this entire process for two measurements of polystyrene. Case A has a relatively low signal-to-noise ratio (SNR), and case B has a slightly better SNR. The tables below the graphs compare (i) a correlation-based search to (ii) an evidence-based approach contingent on the precision state. For the evidence-based search, we also compare search under a flat prior to search using a state-based prior (solid, liquid, gas). Correlation similarities for the top 6 hits are all in excess of 0.7. Use of the precision-state in Case A, however, reveals that a match for polystyrene is probabilistically favored approximately 3:1 over the next best match, and when the state-based prior is used, polystyrene is favored 20:1 over benzyl alcohol. With the SNR improved slightly in Case B, the correlation similarities all increase (although the differences between similarity measures is essentially the same). The evidence-based search is emphatic that polystyrene is favored almost 10:1 over benzyl alcohol, and, with the state-based prior included, this increases to almost 50:1 odds.
[0106]FIGS. 6A and 6B illustrate a general embodiment of this novel process.
[0107]In some situations it is advantageous to use manipulations of the measurement or library data to improve signal-to-noise ratio, favorably alter the signal character, or compress the data for ease of calculation and storage. Further, for some applications of spectral library searching parametric similarity functions may be difficult to formulate, and instead non-parametric alternatives are advantageously employed, and the measurement data and library data must be represented in a form that is amenable for the non-parametric similarity analysis. Common examples of signal manipulations/compression include Fourier and wavelet filtering, compression by principal components, polynomial smoothing and derivative filters, and spline-based manipulations. Non-parametric manipulations include binary representations of spectrum band positions/heights, tabulated functional values, etc. One skilled in the art will recognize that, in these cases, the representation of the precision-state (e.g., the variance-covariance matrix) must also be manipulated so that it is representative of the precision state of the representation of the measurement data.
[0108]Some variability terms depend on the magnitude of the library spectrum that most closely matches the measured spectrum. For example, one might examine the probability that a particular library spectrum could give rise to the measurement (the measurement is a random observation from a distribution around the library spectrum), in which case the Raman shot noise will depend on the magnitude of the library spectrum that best describes the measurement. Therefore, the Raman shot term of Σ and the best fit parameters β must be determined simultaneously. This can solved by any number of means well known in the art, including alternating least-squares (ALS) (see Young, F. W., "Quantitative Analysis Of Qualitative Data", Psychometrika 46, 357-388, 1981), iterative majorization, or nonlinear optimization methods such as Levenberg-Marquardt (see Levenberg, K., "A Method For The Solution Of Certain Problems In Least Squares", Quart. Appl. Math. 2, 164-168, 1944, and Marquardt, D., "An Algorithm For Least-Squares Estimation Of Nonlinear Parameters", SIAM J. Appl. Math. 11, 431-441, 1963), or the simplex method (see J. A. Nelder and R. Mead, "A Simplex Method For Function Minimization", Computer Journal 7, 308-313, 1965). We have used the ALS and iterative majorization approaches and found that convergence is usually achieved in less than 20 iterations. FIG. 7 illustrates an embodiment of this novel sub-process.
Variability in the Measured and Library Spectra
[0109]Ideally, the information in the library is known to infinite or extremely high precision, and one assumes that the imprecision of the measurement condition results in a distribution of potential observations around the library spectrum. But, in practice, library spectra are never perfectly determined. This can be problematic for contemporary library search methods, because all presently used approaches assume the library spectrum is known to infinite accuracy. If the signal-to-noise in the measured spectrum is high enough, part of the dissimilarity between a measurement and the library record may in fact be due to the inaccuracy of the library spectrum itself. The remedy for this problem is to define the variability of the library spectrum itself, again either by measurement or first principles or both, and determine the similarity measures under the constraint that some imprecision is expected in the library spectrum itself. One general approach to this is the extension of Equation 5 by Tikhonov regularization:
i=(In-Y(YtΣi-Y-Σlib)-1Y.su- p.TΣi-1)ymeas (10)
which constrains the solution according to the variability in the library record Σlib. One skilled in the art will recognize that a constraint of this form could be implemented by any number of insubstantially different means (such as further correction of a correlation-based measure for the imprecision of the library spectrum), but the critical aspect is that the similarity measures depend on Σlib.
Non-Linear Discrepancy Approaches
[0110]One skilled in the art will recognize that, while we have illustrated a linear discrepancy analysis approach, the use of variability information in the derivation of a similarity metric for the user could equally apply to non-linear discrepancy estimating methods such as neural networks, support vector machines, nearest-neighbor methods, etc.
Use of Variability to Direct Operation of Measurement Device
[0111]An aspect of the described invention is to control the operation of a measurement device such that a precision state is achieved that allows for a more definitive assessment of the probable matches, that is, the measurement device is operated such that substantial evidence favors only one or two possibilities. This can be thought of as occurring by forcing non-similar candidates have an even lower similarity measure by altering the conditions of the measurement. Provided that the variability term Σ can be influenced by controllable device operating parameters, such as source intensity, integration time, aperture, resolution, etc., such a device could make a measurement with known operating parameters, determine the precision state of such a measurement, and if the evidence is insufficient to make a sound determination of the composition of the sample in question, alter the device operating parameters in such a way that the precision state is more favorable. FIG. 8 illustrates an embodiment of this approach. Additionally or alternatively, the device could instruct in the user to alter the measurement characteristics in a way that is favorable for the precision state, e.g., `shield the sample from impinging light pollution`, `reposition the measurement device for more efficient collection`, `change the device operating characteristics.`
Mixture Extension
[0112]The use of variability information to assess the similarity of a measurement to a library component, extends seamlessly to the assessment of the similarity of a measurement to a mixture of library components. Instead of
Y=.left brkt-bot.1 ylib,i.right brkt-bot. (11)
as in Equations 4, 5 and 10 above, Y is expanded to include possible mixture library components
Y=.left brkt-bot.1 ylib,i ylib,j . . . ylib,q.right brkt-bot. (12)
[0113]The procedures discussed above all apply by simple extension, although now the discrepancy, e, is distributed with terms that depend on the precision of the measurement state contributed by each possible library component. Nonetheless, similarity measures can still be derived that depend on the precision state, and many are simple extensions of the non-mixture similarity measures. For example, the probability determinations discussed above remain valid for mixtures of library records, and the method can provide the user with the probability that the measured sample is a mixture of q library components, rather than the probability the measured sample is a pure library component.
Classification
[0114]The use of precision-state information can also be useful if the desire is to identify the class of chemical materials that is similar to the measured sample. One could, for instance, determine the precision-based similarity of the measurement to a number of candidates, and the joint probability for the class of compounds can be used for classification purposes, e.g., "explosives", "non-steroidal anti-inflammatory drugs", "narcotics", etc. This is generally termed classification, rather than identification, as the class of compounds is believed to be indicated by the aggregate similarity of the query to collections of library records with similar properties.
Utility
[0115]The above invention is extremely useful for materials identification or classification, as it provides the user with a similarity, or similarities measures, that directly quantify the amount of knowledge that exists at the time of the analysis. Actions that follow the analysis are then directly dependent on the knowledge provided by the method, for example, evacuate the immediate area, clean up material using hazard suits, etc. In many instances the knowledge provided by this approach over current methods is expected to yield dramatic savings in money, time, and human lives.
Various Systems for Analyzing a Specimen
[0116]It is possible to embody the present invention in many different constructions. Such constructions will be apparent to those skilled in the art in view of the present disclosure.
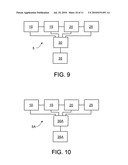
[0117]Thus, for example, and looking now at FIG. 9, there is shown a system 5 for determining the most likely composition of a sample, comprising: apparatus 10 for obtaining data from a sample, wherein the data comprises a representation of a measured spectrum; apparatus 15 for determining the precision state of the representation of the measured spectrum; apparatus 20 for providing a plurality of library candidates and, for each library candidate, providing data representing the same, wherein the data comprises a representation of a library spectrum; apparatus 25 for determining the precision state of the representation of each library spectrum; apparatus 30 for determining a representation of the similarity of the sample to each library candidate using (i) the representation of the measured spectrum, (ii) the precision state of the representation of the measured spectrum, (iii) the representation of the library spectrum for that library candidate, and (iv) the precision state of the representation of the library spectrum for that library candidate; and apparatus 35 for determining the most likely composition of the sample based upon the determined representations of similarity of the sample to each library candidate.
[0118]Furthermore, and looking now at FIG. 10, there is shown a system 5A for determining the most likely composition of a sample, comprising:
[0119]apparatus 10 for obtaining data from a sample, wherein the data comprises a representation of a measured spectrum; apparatus 15 for determining the precision state of the representation of the measured spectrum; apparatus 20 for providing a plurality of library candidates and, for each library candidate, providing data representing the same, wherein the data comprises a representation of a library spectrum; apparatus 25 for determining the precision state of the representation of each library spectrum; apparatus 30A for determining a representation of the similarity of the sample to a mixture of library candidates using (i) the representation of the measured spectrum, (ii) the precision state of the representation of the measured spectrum, (iii) the representation of the library spectrum for the library candidates, and (iv) the precision state of the representation of the library spectrum for the library candidates; and apparatus 35A for determining the most likely composition of the sample based upon the determined representations of similarity of the sample to a mixture of library candidates.
[0120]Furthermore, and looking now at FIG. 11, there is shown a system 5B for determining the most likely classification of a sample, comprising: apparatus 10 for obtaining data from a sample, wherein the data comprises a representation of a measured spectrum; apparatus 15 for determining the precision state of the representation of the measured spectrum; apparatus 20 for providing a plurality of library candidates and, for each library candidate, providing data representing the same, wherein the data comprises a representation of a library spectrum; apparatus 25 for determining the precision state of the representation of each library spectrum; wherein the data for each of at least some of the library candidates further comprises the identification of a class to which the library candidate belongs; apparatus 30B for determining a representation of the similarity of the sample to a mixture of library candidates using (i) the representation of the measured spectrum, (ii) the precision state of the representation of the measured spectrum, and (iii) the representation of the library spectrum for that library candidate; and apparatus 35B for determining the most likely classification of the sample based upon the determined representations of similarity of the sample to a mixture of library candidates.
Raman Spectroscopy Applications
[0121]It is possible to utilize the present invention in many applications.
[0122]It is particularly useful in applications involving Raman spectroscopy.
[0123]Thus, for example, in FIG. 12 there is shown (in schematic form) a novel Raman analyzer 100 formed in accordance with the present invention. Raman analyzer 100 generally comprises an appropriate light source 105 (e.g., a laser) for delivering excitation light to a specimen 110 so as to generate the Raman signature for the specimen being analyzed, a spectrometer 105 for receiving the Raman signature of the specimen and determining the wavelength characteristics of that Raman signature, and analysis apparatus 115 formed in accordance with the present invention for receiving the wavelength information from spectrometer 105 and, using the same, identifying specimen 110.
Further Modifications
[0124]It will be appreciated that still further embodiments of the present invention will be apparent to those skilled in the art in view of the present disclosure. It is to be understood that the present invention is by no means limited to the particular constructions herein disclosed and/or shown in the drawings, but also comprises any modifications or equivalents within the scope of the invention.
User Contributions:
comments("1"); ?> comment_form("1"); ?>Inventors list |
Agents list |
Assignees list |
List by place |
Classification tree browser |
Top 100 Inventors |
Top 100 Agents |
Top 100 Assignees |
Usenet FAQ Index |
Documents |
Other FAQs |
User Contributions:
Comment about this patent or add new information about this topic:
Images included with this patent application:
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
| Similar patent applications: | |
| Date | Title |
|---|---|
| 2011-10-06 | Filtering method for improving the data quality of geometric tire measurements |
| 2012-06-28 | Impulse response measuring method and impulse response measuring device |
| 2011-12-08 | Systems and methods for radiance efficiency measurement |
| 2012-03-22 | Systems and methods for quality control of computer-based tests |
| 2012-07-26 | Systems and methods for improved coordinate acquisition member comprising calibration information |
| New patent applications in this class: | |
| Date | Title |
|---|---|
| 2015-11-12 | Classification and identification of solid propellant rocket motors |
| 2015-03-26 | Method and apparatus for a parallel frequency-mask trigger |
| 2015-03-05 | Occupancy measurement and triggering in frequency domain bitmaps |
| 2014-05-22 | Combinatorial mask triggering in time or frequency domain |
| 2013-12-05 | Monitoring and analysis of power system components |
| New patent applications from these inventors: | |
| Date | Title |
|---|---|
| 2016-01-28 | Adaptation of field use spectroscopy equipment |
| 2015-02-05 | Optical scanning |
| 2014-12-25 | Method and apparatus for the application of force to a sample for detection using an electromechanical means |
| 2012-03-15 | Determination of a measure of a glycation end-product or disease state using tissue fluorescence |
| 2011-12-22 | Handheld infrared and raman measurement devices and methods |
| Top Inventors for class "Data processing: measuring, calibrating, or testing" | |
| Rank | Inventor's name |
|---|---|
| 1 | Lowell L. Wood, Jr. |
| 2 | Roderick A. Hyde |
| 3 | Shelten Gee Jao Yuen |
| 4 | James Park |
| 5 | Chih-Kuang Chang |