Patent application title: DNA POLYMERASE
Inventors:
Philipp Holliger (Cambridge, GB)
Philipp Holliger (Cambridge, GB)
Farid Ghadessy (Singapore, SG)
Marc D'Abbadie (Cambridge, GB)
Assignees:
MEDICAL RESEARCH COUNCIL
IPC8 Class: AC12Q168FI
USPC Class:
435 6
Class name: Chemistry: molecular biology and microbiology measuring or testing process involving enzymes or micro-organisms; composition or test strip therefore; processes of forming such composition or test strip involving nucleic acid
Publication date: 2009-12-10
Patent application number: 20090305292
Inventors list |
Agents list |
Assignees list |
List by place |
Classification tree browser |
Top 100 Inventors |
Top 100 Agents |
Top 100 Assignees |
Usenet FAQ Index |
Documents |
Other FAQs |
Patent application title: DNA POLYMERASE
Inventors:
Farid Ghadessy
Philipp Holliger
Marc d'Abbadie
Agents:
EDWARDS ANGELL PALMER & DODGE LLP
Assignees:
MEDICAL RESEARCH COUNCIL
Origin: BOSTON, MA US
IPC8 Class: AC12Q168FI
USPC Class:
435 6
Patent application number: 20090305292
Abstract:
The present invention relates to DNA polymerases. In particular the
invention relates to a method for the generation of DNA polymerases
exhibiting a relaxed substrate specificity. Uses of mutant polymerases
produced using the methods of the invention are also described.Claims:
1. A pol A DNA polymerase possessing an expanded substrate range, which is
capable of abasic site bypass, wherein the polymerase exhibits at least
95% identity to an amino acid sequence selected from the group consisting
of 3A10, 3B6 and 3B11, and which comprises a mutation (with respect to
any of the three parent genes Taq, Tth and Tfl) or gene segment found in
a clone selected from the group consisting of 3A10, 3B6 and 3B11.
2. The pol A DNA polymerase of claim 1, wherein said DNA polymerase comprises the amino acid sequence of a clone selected from the group consisting of 3A10, 3B6 and 3B11.
3. The pol A DNA polymerase of claim 2, wherein said DNA polymerase consists essentially of the amino acid sequence of any one or more of clones selected from the group consisting of 3A10, 3B6 and 3B11.
4. A nucleic acid construct encoding a pol A DNA polymerase of claim 1.
5. A vector comprising the nucleic acid construct of claim 4.
6. Use of a pol A DNA polymerase of claim 1 in an application selected from the group consisting of PCR amplification, sequencing of damaged DNA templates, the incorporation of unnatural base analogues into DNA and the creation of novel polymerase activities.
7. The use of claim 6, wherein said pol A DNA polymerase is selected from the group consisting of 3A10, 3B6 and 3B11.
8. Use of a blend of pol A DNA polymerases of claim 1 in an application selected from the group consisting of PCR amplification, sequencing of damaged DNA templates, the incorporation of unnatural base analogues into DNA and the creation of novel polymerase activities.
9. The use of claim 8, wherein said blend of pol A DNA polymerases is selected from the group consisting of 3A10, 3B6 and 3B11.
Description:
RELATED APPLICATIONS
[0001]This application is a divisional of U.S. application Ser. No. 11/417,403, which was filed on May 3, 2006, which is a continuation of Application No. PCT/GB04/004643, which was filed on 3 Nov. 2004, which designated the United States and was published in English, and which claims the benefit of United Kingdom Applications GB041087.8, filed 14 May 2004, and GB0325650.0, filed 3 Nov. 2003. The entire teachings of the above applications are incorporated herein by reference.
FIELD OF INVENTION
[0002]The present invention relates to DNA polymerases. In particular the invention relates to a method for the generation of DNA polymerases which exhibit a relaxed substrate specificity. Uses of engineered polymerases produced using the methods of the invention are also described.
BACKGROUND
[0003]Accurate DNA replication is of fundamental importance to all life ensuring the maintenance and transmission of the genome and limiting tumorigenesis in higher organisms. High-fidelity DNA polymerases perform an astonishing feat of molecular recognition, incorporating the correct nucleotide triphosphate (dNTP) substrate molecules as specified by the template base with minimal error rates. For example, even without exonucleolytic proofreading, the replicative DNA polymerase III from E. coli on average only makes one error in ˜105 base pairs (Schaaper JBC 1993).
[0004]As energetic differences between correctly and mispaired nucleotides per se are much too small to give rise to a 105 fold discrimination, the structure of the polymerase active site in high-fidelity polymerases has evolved to enhance those differences. Recent structural studies of the A-family (Pol I-like) DNA polymerases from Thermus aquaticus (Taq) (Li 98), phage T7 (Ellenberger) and B. stearothermophilus (Bst) (Beese) in particular have revealed how conformational changes during the catalytic cycle may exclude non-cognate base-pairing geometries because of steric clashes within the closed active site. As a result of these tight steric constraints, not only are mismatched nucleotides excluded but catalysis becomes exquisitely sensitive to even slight distortions in the primer-template duplex. This precludes or greatly diminishes the replication of modified or damaged DNA templates, the incorporation of modified or unnatural deoxinucleotide triphosphates (dNTP) and the extension of mismatched or unnatural 3' termini.
[0005]While desirable in nature, such stringent substrate discrimination is limiting for many applications in biotechnology. Specifically, it restricts the use of unnatural or modified nucleotide bases and the applications they enable. It also precludes the efficient PCR amplification of damaged DNA templates.
[0006]Some other naturally occurring polymerases are less stringent with regard to their substrate specificity. For example, viral reverse transcriptases like HIV-1 reverse transcriptase or AMV reverse transcriptase and polymerases capable of translesion synthesis such as poly-family polymerases, pol X (Vaisman et al, 2001, JBC) or pol X (Washington (2002), PNAS; or the unusual polB-family polymerase pol X (Johnson, Nature), all extend 3' mismatches with elevated efficiency compared to high fidelity polymerases. The disadvantage of the use of translesion synthesis polymerases for biotechnological uses is that they depend on cellular processivity factors for their activity, such as PCNA. Moreover such polymerases are not stable at the temperatures at which certain biotechnological techniques are performed, such as PCR. Furthermore most Translesion synthesis polymerases have a much reduced fidelity, which would severely compromise their utility for cloning.
[0007]Using another approach, the availability of high-resolution structures has guided efforts to rationally alter the substrate specificity of high fidelity DNA polymerases by site-directed mutagenesis e.g. to increase acceptance of dideoxi-(ddNTPs) (Li 99) or ribonucleotides (rNTPs) (Astatke 98). In vivo complementation followed by screening has also yielded polymerase variants with increased rNTP incorporation and limited bypass of template lesions (Patel 01). Recently, two different in vitro strategies for selection of polymerase activity have been described (Jestin 00, Ghadessy 01, Xia 02). One is based on the proximal attachment of polymerase and template-primer duplex on the same phage particle and has allowed the isolation mutants of Taq polymerase, which incorporate rNTPs and dNTPs with comparable efficiency (Xia 02). However, such methods are complex, prone to error and are laborious.
[0008]Recently, the technique of compartmentalized self-replication (CSR) (Ghadessy 01), which is based on the self-replication of polymerase genes by the encoded polymerases within discrete, non-communicating compartments has allowed the selection of mutants of Taq polymerase with increased thermostability and/or resistance to the potent inhibitor heparin (Ghadessy et al 01).
[0009]However, there still remains a need in the art for an efficient and simple method for relaxing the substrate specificity of high fidelity DNA polymerases whilst maintaining high catalytic turnover and processivity of DNA fragments up to several tens of kb. Such polymerases will be of particular use in applications such as PCR amplification and sequencing of damaged DNA templates, for the incorporation of unnatural base analogues into DNA (such as is required for sequencing or array labelling) and as a starting point for the creation of novel polymerase activities using compartmentalised self replication or other methods.
SUMMARY OF THE INVENTION
[0010]The present inventors modified the principles of directed evolution, (in particular compartmentalised self replication) described in GB97143002, 986063936 and GB 01275643 in the name of the present inventors, to relax the steric control of high fidelity DNA polymerases and consequently to expand the substrate range of such polymerases. All of the documents listed above are herein incorporated by reference.
[0011]They surprisingly found that by performing the technique of compartmentalised self replication referenced above, using repertoires of randomly mutated Taq genes, and flanking primers bearing the mismatches A*G and C*C at their 3' terminus/end, then mutants were generated which not only exhibited the ability to extend the A*G and C*C tranversion mismatches used in the CSR selection, but also surprisingly exhibited a generic ability to extend mispaired 3' termini. This finding is especially significant since Taq polymerase is not able to extend 3' mismatches (Kwok wt al, (1990), Huang (1992).
[0012]The mutant polymerases generated also exhibit high catalytic turnover, concomitant with other high fidelity polymerases and are capable of efficient amplification of DNA fragments up to 26 kb.
[0013]Thus in a first aspect the present invention provides a method for the generation of an engineered DNA polymerase with an expanded substrate range which comprises the step of preparing and expressing nucleic acid encoding an engineered DNA polymerase utilising template nucleic acid and flanking primers which bear one or more distorting 3' termini/ends.
[0014]As herein defined `flanking primers which bear a 3' distorting terminus/end` refer to those primers which possess at their 3' ends one or more group/s, preferably nucleotide group/s which deviate from cognate base-pairing geometry. Such deviations from cognate base-pairing geometry includes but is not limited to: nucleotide mismatches, base lesions (i.e. modified or damaged bases) or entirely unnatural, synthetic base substitutes. According to the above aspects of the invention, advantageously, the flanking primer/s bear one or more nucleotide mismatches at their 3' end/terminus.
[0015]Advantageously, according to the above aspects of the invention the flanking primers may have one, two, three, four, or five or more nucleotide mismatches at the 3' primer end. More advantageously, the one or more nucleotide mismatches are consecutive mismatches. More advantageously, according to the above aspects of the invention, the flanking primers have one or two nucleotide mismatches at the 3' primer end. Most preferably according to the above aspects of the invention, the flanking primers have one nucleotide mismatch at their 3' primer end.
[0016]More specifically the term `distorting 3' termini/ends` includes within its scope the phenomenon whereby, for example, either the 3' terminal base (1-mismatch) or the 3' terminal and upstream base (2-mismatch, 3-mismatch, 4-mismatch and so on) are not complementary to the template base. Preferably mismatches are transversion mismatches i.e. apposing purines with purines and pyrimidines with pyrimidines. Preferably transversion mismatches are G.A and C.C. This type of primer terminus distortion is referred to herein as `primer mismatch distortion`.
[0017]In addition, and as eluded to above, the term `flanking primers bearing distorting 3' termini/ends` includes within its scope flanking primers bearing one or more unatural base analogues at the 3' termini/end of the one or more flanking primers so that distortion of the cognate DNA duplex geometry is created.
[0018]The method of the invention may be used to expand the substrate range of any DNA polymerase which lacks an intrinsic 3-5' exonuclease proofreading activity or where a 3-5' exonuclease proofreading activity has been disabled, e.g. through mutation. Suitable DNA polymerases include polA, polB (see e.g. Patrel & Loeb, Nature Struc Biol 2001) polC, polD, poly, polX and reverse transcriptases (RT) but preferably are processive, high-fidelity polymerases.
[0019]Advantageously, an engineered DNA polymerase with an expanded substrate range according to the invention is generated from a pol A-family DNA polymerase. Advantageously, the DNA polymerase is generated from a repertoire of pol A DNA polymerase nucleic acid as template nucleic acid. Preferably the pol A polymerase is Taq polymerase and the flanking primers used in the generation of the polymerase are one or more of those primers selected from the group consisting of the following: 5'-CAG GAA ACA GCT ATG ACA AAA ATC TAG ATA ACG AGG GA-3'; A•G mismatch; SEQ ID NO: 3); 5'GTA AAA CGA CGG CCA GTA CCA CCG AAC TGC GGG TGA CGC CAA GCC-3' C*C mismatch (SEQ ID NO: 4).
[0020]More advantageously, according to the above aspect of the invention, the nucleic acid encoding the engineered polymerase according to the invention is generated using PCR using one or more flanking primers listed herein.
[0021]Advantageously, the method of the present invention involves the use of compartmentalised self replication, and consists of the steps listed below: [0022](a) preparing nucleic acid encoding a engineered DNA polymerase, wherein the polymerase is generated using a repertoire of nucleic acid molecules encoding one or more DNA polymerases and flanking primers which bears a 3'distorting end. [0023](b) compartmentalising the nucleic acid of step (a) into microcapsules; [0024](c) expressing the nucleic acid to produce their respective DNA polymerase within the microcapsules; [0025](d) sorting the nucleic acid encoding the engineered DNA polymerase which exhibits an expanded substrate range; and [0026](e) expressing the engineered DNA polymerase which exhibits an expanded substrate range.
[0027]Most advantageously, the method of the invention comprises the use of one or more DNA polymerases and flanking primers which bears one or more nucleotide mismatches at their 3'primer ends.
[0028]According to the above aspects of the invention, the term `engineered DNA polymerase` refers to a DNA polymerase which has a nucleic acid sequence which is not 100% identical at the nucleic acid level to the one or more DNA polymerase/s or fragments thereof, from which it is derived, and which is synthetic. According to the invention, an engineered DNA polymerase may belong to any family of DNA polymerase.
[0029]Advantageously, an engineered DNA polymerase according to the invention is a pol A DNA polymerase. As referred to above the term `engineered DNA polymerase` also includes within its scope fragments, derivatives and homologues of an `engineered DNA polymerase` as herein defined so long as it exhibits the requisite property of possessing an expanded substrate range as defined herein. In addition, it is an essential feature of the present invention that an engineered DNA polymerase according to the invention does not include a polymerase with a 3-5' exonuclease activity under the conditions used for the polymerisation reaction. (This definition includes polymerases in which the 3-5' exonuclease is not part of the polymerase polypeptide chain but is associated non-covalently with the active polymerase). Such a proofreading activity would remove any 3' mismatches incorporated according to the method of the invention, and thus would prevent a polymerase according to the invention possessing an expanded substrate range as defined herein.
[0030]As defined herein the term `expanded substrate range` (of an engineered DNA polymerase) means that substrate range of an engineered DNA polymerase according to the present invention is broader than that of the one or more DNA polymerases, or fragments thereof from which it is derived. The term `a broader substrate range` refers to the ability of an engineered polymerase according to the present invention to extend one or more 3'distorting ends, advantageously transversion mismatches (purine*purine, pyrimidine*pyrimidine) for example A*A, C*C, G*G, T*T and G*A, which the one or more polymerase/s from which it is derived cannot extend. That is, essentially, a DNA polymerase which exhibits a relaxed substrate range as herein defined has the ability not only to extend the 3' distorting endsused in its generation, IE those of the flanking primers) but also exhibits a generic ability to extend 3' distorting ends (for example A*G, A*A, G*G mismatches). Preferably, `expanded substrate range` (of an engineered DNA polymerase) includes a wider spectrum of unnatural nucleotide substrates including αS dNTPs, dye-labelled nucleotides, damaged DNA templates and so on. More details are given in the Examples.
[0031]According to the above aspect of the invention advantageously the DNA polymerase generated using CSR technology is a pol A polymerase and it is generated using flanking primers selected from the group consisting of the following: 5'-CAG GAA ACA GCT ATG ACA AAA ATC TAG ATA ACG AGG GA-3'; A•G mismatch; SEQ ID NO: 3); 5'GTA AAA CGA CGG CCA GTA CCA CCG AAC TGC GGG TGA CGC CAA GCC-3' C*C mismatch (SEQ ID NO: 4).
[0032]One skilled in the art will appreciate that in essence, any DNA polymerase flanking primer which incorporates a 3' mismatch will work with any suitable repertoire. The process of mismatch extension will vary in characteristics from polymerase to polymerase, and will also vary according to the experimental conditions. For example, G*A and C*C are the most disfavoured mismatches for extension by Taq polymerase (Huang et al, 92). Other mismatches are favoured for extension by other polymerases and this can be routinely determined by the skilled person.
[0033]One skilled in the art will also appreciate that it is an essential feature of the present invention that the methods described herein will only work for polymerases which are devoid of 3-5' exonuclease activity proofreading under the conditions used for the polymerisation reaction, as such activity would result in the removal of the incorporated mismatches.
[0034]Using the method of the invention, the present inventors generated a number of pol A polymerase mutants. Two of the mutants named M1 and M4 not only exhibit the ability to extend the G*A and C*C transversion mismatches used in the CSR selection, but also surprisingly exhibit a generically enhanced ability to extend 3' mismatched termini.
[0035]Thus in a further aspect the present invention provides an engineered DNA polymerase which exhibits an expanded substrate range. Preferably such an engineered polymerase is obtainable using one or more method/s of the present invention.
[0036]According to the above aspect of the invention, preferably the DNA polymerase is a pol A polymerase.
[0037]According to the above aspect of the invention, preferably the engineered DNA polymerase is obtained using the method of the invention.
[0038]In a further aspect still, the present invention provides a pol A DNA polymerase with an expanded substrate range, or the nucleic acid encoding it, wherein the DNA polymerase is designated M1 or M4 as shown in FIG. 1 and FIG. 2 respectively and depicted as SEQ No 1 and SEQ No 2 respectively.
[0039]According to the above aspect of the invention, preferably the engineered DNA polymerase as herein defined is that polymerase designated M1 in FIG. 1 and depicted SEQ No 1.
[0040]In yet a further aspect the invention provides a pol A DNA polymerase with an expanded substrate range, wherein the polymerase exhibits at least 95% identity to one or more of the amino acid sequences designated M1 and M4 as shown in FIG. 1 and FIG. 2 respectively and depicted SEQ No 1 and SEQ No 2 respectively and which comprises any one or more of the following mutations: E520G, D144G, L254P, E520G, E524G, N583S, 1.1-D144G, L254P, E520G, E524G, N583S, V1131, A129V, L245R, E315K, G364D, G403R, E432D, P481A, 1614M, R704W, D144G, G370D, E742G, K56E, 163T, K127R, M3171, Q680R, R343G, G370D, E520G, G12A, A109T, D251E, P387L, A608V, R617K, D655E, T710N, E742G, A109T, D144G, V155I, P298L, G370D, 1614M, E694K, R795G, E39K, R343G, G370D, E520G, T539A, M747V, K767R, G84A, D144G, K314R, E520G, F598L, A608V, E742G, D58G, R74P, A109T, L245R, R343G, G370D, E520G, N583S, E694K, A743P.
[0041]Advantageously, the invention provides a pol A DNA polymerase with an expanded substrate range, or the nucleic acid encoding it, wherein the polymerase exhibits at least 95% identity to one or more of the amino acid sequences designated M1 and M4 as shown in FIG. 1 and FIG. 2 respectively and depicted SEQ 1 and 2 respectively and which comprises any one or more of the following mutations: G84A, D144G, K314R, E520G, F598L, A608V, E742G, D58G, R74P, A109T, L245R, R343G, G370D, E520G, N583S, E694K, A743P.
[0042]Most advantageously, the invention provides a pol A DNA polymerase with an expanded substrate range, or the nucleic acid encoding it, wherein the polymerase exhibits at least 95% identity to one or more of the amino acid sequences designated M1 and M4 as shown in FIG. 1 and FIG. 2 respectively and depicted SEQ 1 and 2 respectively and which comprises any one or more of the following mutations: G84A, D144G, K314R, E520G, F598L, A608V, E742G.
[0043]According to the above aspect of the invention the mutation `E520G` describes a DNA polymerase according to the invention in which glycine is present at position 520 of the amino acid sequence. The present inventors were surprised to find that E520, which is located at the tip of the thumb domain at a distance 20A from the 3'OH of the mismatched primer terminus, would be involved in mismatch recognition or extension. The mutation of E520 to G520 is clearly important in such roles however as the present inventors have demonstrated. This aspect of the invention is described further in the detailed description of the invention.
[0044]The present inventors consider that the method of the invention is applicable to the generation of `blends` of engineered DNA polymerases with an expanded substrate range. According to the present invention the term a `blend` of more than one polymerase refers to a mixture of 2 or more, 3 or more 4 or more, 5 or more engineered polymerases. Preferably the term `blends` refers to a mixture of 6, 7, 8, 9 or 10 or more `engineered polymerases`.
[0045]It is important to note that the extension of mismatched 3' primer termini is a feature of naturally occurring polymerases. Viral reverse transcriptases (RT) like HIV-1 RT or AMV RT and polymerases capable of translesion synthesis (TLS) such as the poly-family polymerases pol t (Vaisman 2001JBC) or pol κ (Washington 2002 PNAS) or the unusual poIB-family polymerase polζ (Johnson Nature), all extend 3' mismatches with elevated efficiency compared to high-fidelity polymerases. Thus, the mutant polA polymerases according to the present invention share significant functional similarities with other polymerases found in nature but so far represent, the only known member of the polA-family polymerases that are proficient in mismatch extension (ME) and translesion synthesis (TLS).
[0046]In contrast to TLS polymerases, which are distributive and depend on cellular processivity factors such as PCNA, M1 and M4 combine mismatch extension (ME) and translesion synthesis (TLS) with high processivity and in the case of M1 are capable of efficient amplification of DNA fragments of up to 26 kb.
[0047]In a further aspect still the present invention provides a nucleic acid construct which is capable of encoding a pol A DNA polymerase which exhibits an expanded substrate range, wherein said pol A DNA polymerase is depicted in FIG. 1 and FIG. 2 as SEQ No 1 or SEQ No 2 and is designated M1 and M4 respectively.
[0048]According to the above aspect of the invention, preferably the nucleic acid construct encodes the M1 pol A polymerase as described herein.
[0049]In a further aspects the invention provides a pol A DNA polymerase with an expanded substrate range, in particular which is capable of mismatch extension, wherein the DNA polymerase comprises, preferably consists of the amino acid sequence of any one or more of the clones designated herein as 3B5, 3B8, 3C12 and 3D1.
[0050]In yet a further aspect the invention provides a pol A DNA polymerase with an expanded substrate range, in particular which is capable of abasic site bypass, wherein the DNA polymerase comprises, preferably consists of the amino acid sequence of any one or more of the clones designated herein as 3A10, 3B6 and 3B11.
[0051]In a further aspect still the invention provides a pol A DNA polymerase with an expanded substrate range, in particular which is capable of DNA replication involving the incorporation of unatural base analogues into the newly replicated DNA, wherein the pol A DNA polymerase comprises, preferably consists of the amino acid sequence of any one or more of the clones designated herein as 4D11 and 5D4.
[0052]In a further aspect the present invention provides a pol A DNA polymerase with an expanded substrate range, wherein the polymerase exhibits at least 95% identity to one or more of the amino acid sequences designated 3B5, 3B8, 3C12, 3D1, 3A10, 3B6, 3B11, 4D 11 and 5D4. which comprises any one or more of the mutations (with respect to either of the three parent genes Taq, Tth, Tfl) or gene segments found in clones 3B5, 3B8, 3C12, 3D1, 3A10, 3B6, 3B11, 4D11 and 5D4.
[0053]In a further aspect still, the present invention provides a vector comprising a nucleic acid construct according to the present invention.
[0054]In a further aspect still the present invention provides the use of a DNA polymerase according to the present invention in any one or more of the following applications selected from the group consisting of the following: PCR amplification, sequencing of damaged DNA templates, the incorporation of unnatural base analogues into DNA and the creation of novel polymerase activities.
[0055]According to the above aspect of the invention, preferably the use is of a `blend` of DNA polymerases according to the invention or selected according to the method of the invention. The use of blends of polymerases will be familiar to those skilled in the art and is described in Barnes, W. M. (1994) Proc. Natl. Acad. Sci. USA 91, 2216-2220 which is herein incorporated by reference.
[0056]According to the above aspect of the invention, preferably the DNA polymerase is a pol A DNA polymerase. Advantageously, it is generated using CSR technology using flanking primers bearing one or more 3' mismatch pairs of interest as described herein. Other suitable methods include screening after activity preselection (see Patel & Loeb 01) and phage display with proximity coupled template-primer duplex substrate (Jestin 01, Xue, 02. CST is also ideally suited as the present inventors have demonstrated.
[0057]According to the above aspect of the invention, preferably the use of a polymerase according to the invention is in PCR amplification and the polymerase is M1 as herein described.
[0058]According to the above aspect of the invention, advantageously, the creation of novel polymerase activities is produced using the technique of compartmentalised self replication as described herein.
DEFINITIONS
[0059]The term `engineered DNA polymerase` refers to a DNA polymerase which has a nucleic acid sequence which is not 100% identical at the nucleic acid level to the one or more DNA polymerase/s or fragments thereof, from which it is derived, and which has been generated using one or more biotechnological methods. Advantageously, an engineered DNA polymerase according to the invention is a pol-A family DNA polymerase or a pol-B family DNA polymerase. More advantageously, an engineered DNA polymerase according to the invention is a pol-A family DNA polymerase. As referred to above the term `engineered DNA polymerase` also includes within its scope fragments, derivatives and homologues of an `engineered DNA polymerase` as herein defined so long as it exhibits the requisite property of possessing an expanded substrate range as defined herein. In addition, it is an essential feature of the present invention that an engineered DNA polymerase according to the invention does not include a polymerase with a 3-5' exonuclease activity under the conditions used for the polymerisation reaction. Such a proofreading activity would remove any 3' mismatches incorporated according to the method of the invention, and thus would prevent a polymerase according to the invention possessing an expanded substrate range as defined herein.
[0060]As herein defined `flanking primers which bear a 3'distorting terminus` refer to those DNA polymerase primers which possess at their 3' ends one or more group/s, preferably nucleotide group/s which deviate from cognate base-pairing geometry. Such deviations from cognate base-pairing geometry includes but is not limited to: nucleotide mismatches, base lesions (i.e. modified or damaged bases) or entirely unnatural, synthetic base substitutes at the 3 end of a flanking primer used according to the methods of the invention. According to the above aspects of the invention, advantageously, the flanking primer/s bear one or more nucleotide mismatches at their 3' end. Advantageously, according to the above aspects of the invention the flanking primers may have one, two, three, four, or five or more nucleotide mismatches at the 3' primer end. Preferably according to the above aspects of the invention, the flanking primers have one or two nucleotide mismatches at the 3' primer end. Most preferably according to the above aspects of the invention, the flanking primers have one nucleotide mismatch at their 3' primer end.
[0061]As defined herein the term `expanded substrate range` (of an engineered DNA polymerase) means that substrate range of an engineered DNA polymerase according to the present invention is broader than that of the one or more DNA polymerases, or fragments thereof from which it is derived. The term `a broader substrate range` refers to the ability of an engineered polymerase according to the present invention to extend one or more 3'distorting ends, advantageously transversion mismatches (purine*purine, pyrimidine*pyrimidine) for example A*A, C*C, G*G, T*T and G*A, which the one or more polymerase/s from which it is derived cannot extend. That is, essentially, a DNA polymerase which exhibits a relaxed substrate range as herein defined has the ability not only to extend the 3' distorting ends used in its generation, IE those of the flanking primers) but also exhibits a generic ability to extend 3' distorting ends (for example A*G, A*A, G*G mismatches).
BRIEF DESCRIPTION OF THE FIGURES
[0062]FIG. 1 shows the M1 nucleic acid (a; SEQ ID NO: 5) and amino acid sequence (b; SEQ ID NO: 1).
[0063]FIG. 2 shows the M4 nucleic acid (a; SEQ ID NO: 6) amino acid sequence (b; SEQ ID NO 2).
[0064]FIG. 3 shows the general scheme of mismatch extension CSR selection. Self-replication of the pol gene by the encoded polymerase requires extension of flanking primers bearing GA and CC 3' mismatches. Polymerases capable of mismatch extension (Pol*) replicate their own encoding gene (pol*), while Polx cannot extend mismatches and fails to self-replicate. Black bars denote incorporation of the mismatch into replication products.
[0065]FIG. 4. Mismatch extension properties of selected polymerases. (a) Polymerase activity in PCR for matched 3' ends and mismatches. Only mutant polymerases M4 and M1 (not shown) generate amplification products using primers with 3' transversion mismatches. (b) Mismatch extension PCR assay. Mismatch extension capability is expressed as arbitrary mismatch extension units (ratio of polymerase activity in PCR with matched vs. mismatched flanking primers). Different polymerases (black diamonds) and derivatives (open squares, triangles) are shown in separate columns.
[0066]FIG. 5. Lesion bypass activity (A) wtTaq, (B) M1, (C) M4. Each polymerase was assayed over time for its ability to extend a radiolabeled primer annealed to either an undamaged template, or a template containing an abasic site or a cis-syn cyclobutane thymine-thymine dimer (CPD). Template sequence was identical except for three bases located immediately downstream of the primer (N1-3). The local sequence context in the N1-3 region is given on the right hand side of each respective panel. X=abasic site; T-T=CPD.
[0067]FIG. 6. Polymerase activity on unnatural substrates. (A) Polymerase activity in PCR using all αS dNTPs. αS DNA amplification products of 0.4 kb, 0.8 kb and 2 kb, are obtained with M1 but not with wtTaq (wt). φX, HaeIII-digested phage φX174 DNA marker. λH, HindIII-digested phage X DNA marker. (B) Polymerase activity in PCR with complete replacement of dATP with FITC-12-dATP (left) or dTTP with Biotin-16-dUTP (right). Only M1 yields amplification products. M, 1 kb DNA ladder (Invitrogen). (C) Bypass of a 5-nitroindol template (5NI) base. Polymerase activity was assayed over time for its ability to extend a radiolabeled primer annealed to a template containing a 5NI template base.
[0068]FIG. 7. Long range PCR. PCR amplification of fragments of increasing length from a phage X DNA template. WtTaq (wt) fails to generate amplification products larger than 8.8 kb while M1 is able to amplify fragments of >25 kb. λH, HindIII-digested phage λ DNA marker.
[0069]FIG. 8. Hairpin-ELISAs to test nucleotide analogue incorporation by mismatch extension clones. (a) shows assay using primer FITC4 (SEQ ID NO: 7); (b) shows assay using primer FITC102 (SEQ ID NO: 8); (c) shows assay using primer ELISAC4P (SEQ ID NO: 9); (d) shows assay using primer ELISAT3P (SEQ ID NO: 10); (e) shows assay using hairpin primer bearing an abasic site (SEQ ID NO: 11).
[0070]FIG. 9. Clones 3B5, 3B8, 3C12 and 3D1 (where 3 indicates that these are third round clones) were able to extend primers containing four mismatches. The 292 base pair product is indicated with an arrow and was produced after 50 cycles of PCR. It is noteworthy that significant amount of non-specific products are produced in all cases, although the amount of non-specific product varies from polymerase to polymerase. The C12 lane has been appended from another gel. Lane M: markers, Hae III digest of ΦX174.
[0071]FIG. 10. A list of polymerases selected to extend four mismatches were assayed for their ability to extend abasic sites in PCR. Primers with an abasic site seven bases from their 3' end were designed. Such primers will prevent exponential amplification of the target sequence, restriciting it to geometric amplification, unless the abasic site is bypassed. 20 cycles of PCR were sufficient to produce the 176 bp product with the selected polymerases but not with the wild type. (A) Screen which identified clone A10. (B) A further 4 polymerases that display good abasic site bypass. Lane M: markers, Hae III digest of ΦX174.
[0072]FIG. 11. Seven polymerases were assayed for their ability to bypass abasic sites in a primer extension assay. Translesion synthesis activity on an undamaged template, on a template containing an abasic site or a cis-syn cyclobutane thymine-thymine dimer (CPD) tend a radiolabelled primer (pr) annealed to template. The c site or a CPD located immediately downstream of the primer.
[0073](A) On the template containing an abasic site, wtTaq efficiently inserted a base opposite the lesion, but further extension was negligible. In contrast, M1 is capable of both insertion opposite the abasic site and lesion bypass. Of the four mismatch extension polymerases, polymerases A10 and D1 clearly display better abasic site bypass than either wtTaq or M1, with a number of other polymerases displaying improved abasic site activity (notably C12).
[0074](B) The Polymerase A10 was chosen for further investigation and displays superior elongation and bypass when compared to wild type for both the abasic site and the CPD.
[0075]FIG. 12. Several samples of cave hyena (Crocuta spelaea) were extracted and analysed. The seven samples were from Teufelslucke cave (Austria, 40 000 years old), Aufhausener Hohle (Germany, no date determined (2 samples)); Irpfelhohle (Germany, no date determined); Kiskevelyi (Romania 48 500 years old); Miskolc III (Hungary, 44 000 years old); Mala ladnica (Slovakia, no date determined). The target was a 215 bp fragment from the cytochrome B gene in the mitochondrial genome. The amplification was only successful in the presence of sspDNA.
[0076]FIG. 13. Appropriate primers for use in the method of the invention. See example 15 for details.
[0077](A) Schematic representation of two step nested PCR. In the first round a pair of outer primers (represented in green) are used; in the second step a pair of nested inner primers (red) are used.
[0078](B) Target sequences in the cave bear mitochondrial D loop (SEQ ID NO: 12). Outer primer sequences are underlined, Inner primer sequences are in red.
[0079]FIG. 14. Polymerases selected for replication of 5NI were tested for activity with a range of substrates using the hairpin ELISA assay described in example 8. See example 16 for details. Sample 366 is from the Herdengel cave (Austria) and is 60 000 years old. Sample GS 3-7 is from the Gamsulzen cave (Austria) and is between 25 000 and 45 000 years old.
[0080]In eight out of a total of nine uncontaminated experiments, the blend of mismatch polymerases produced more successful (positive) amplifications than SuperTaq. The odds of this occurring by chance are (9!/(8!1!))*(0.5)8(0.5)1=1.76%, as determined by binomial distribution analysis. Given the heterogenity of aDNA samples, it is not surprising that in one case SuperTaq performed better than the blend. Experiment 5 is depicted in FIG. 35.
[0081]The experiments are listed in chronological order and it is noteworthy that the difference in performance between SuperTaq and the blend became less pronounced as time passed. This may be due to freeze/thawing further damaging the aDNA as well as to loss of activity in the blend which less pure than SuperTaq.
[0082]FIG. 15. Polymerases selected for replication of 5NI were tested for activity with a range of substrates. Polymerase 4D11. P is primer, Ch is the chase reaction. Reaction times in minutes. See example 16 for details.
[0083]FIG. 16. Polymerases selected for replication of 5NI were tested for activity with a range of substrates Polymerase 5D4. P is primer, Ch is the chase reaction. Reaction times in minutes. See example 16 for details.
[0084]FIG. 17. Polymerases selected for replication of 5NI were tested for activity with a range of substrates Polymerase 4D11. P is primer, Ch is the chase reaction. Reaction times in minutes. See example 16 for details.
[0085]FIG. 18. Polymerases selected for replication of 5NI were tested for activity with a range of substrates Polymerase 5D4. P is primer, Ch is the chase reaction. Reaction times in minutes. See example 16 for details.
[0086]FIG. 19. Microarray hybridisations of FITC-labelled probes. Microarrays contained replicate features of serial dilutions of Taq, RT and genomic salmon sperm DNA target sequences, as indicated. Labelled randomers were used to visualise the microarray and assess the availability of target sequences for hybridisation. Array co-hybridisations were performed with a Cy5-labelled Taq probe (Cy5Taq), as a reference, and equivalent unlabelled or FITC-labelled probes (FITC10Taq, FITC10M1, FITC100M1). Single examples from 3 replicate experiments are displayed for each co-hybridisation.
[0087]FIG. 20, FIG. 21. Microarray signals from FITC-labelled probes. Mean FITC fluorescence signal of FITC-labelled probes (FITC10Taq, FITC10M1, FITC100M1) for each co-hybridisation is plotted against the Cy5 fluorescence signal of the reference probe (Cy5Taq) for A) Taq, B) RT and C) genomic salmon sperm DNA target sequences, as indicated. D) Microarray background signals from FITC-labelled probes are determined using 3 replicate microarrays for each co-hybridisation experiment of a Cy5-labelled Taq probe (Cy5Taq), as a reference, and unlabeled or FITC-labelled probes (FITC10Taq, FITC10M1, FTTC100M1). Background information was generated by measuring fluorescence signal from 12 non-feature areas of each microarray. Mean pixel intensities were generated and used to derive a ratiometric value for each non-feature area. A mean of the mean ratio +/-1 standard deviation is displayed for each co-hybridisation experiment.
[0088]FIG. 22. Fidelity. (A) MutS ELISA. Relative replication fidelity of wtTaq, M1 and M4 was determined using mutS ELISA of two different DNA fragments (either a 0.4 kb or 2.5 kb region of the cloned Taq gene) obtained by PCR and probed at two different concentrations. (B) Spectra of nucleotide substitutions observed in PCR fragments amplified with either wtTaq or M1. Types of substitutions are given as % of total substitutions (wtTaq: 48, M1: 74). Equivalent substitutions on either strand (e.g. G->A, C->T) were added together (GC->AT). Observed -1 detections (wtTaq: 3, M1: 1) are not shown.
[0089]FIG. 23. Processivity of wtTaq, M1 and M4 was measured at three different polymerase concentrations in the absence (A) or presence (B) of trap DNA. The processivity for nucleotide incorporation at each position was variable but essentially identical for all three polymerases. For example, the probability of enzyme dissociation is higher at positions 2-5 compared to positions 6 and 7 for all three polymerases. In the presence of trap DNA (to ensure all primer extension is the result of a single DNA binding event) 13% of bound wtTaq, 28% of M1 and 15% of M4 extended primers to the end of the template. The termination probabilities for positions 2 through 5 varied from 15-25% for wtTaq and M1 and from 13-35% for M4, while at positions 6 and 7 the termination probability was 5% for wtTaq, 1% for M1, and 2-4% for M4. DNA replication has been characterized as low processive when the termination probability reaches 40-80%15. Our results suggest that M1 and M4 are both processive polymerases, with processivity equal or higher than wtTaq, arguing against a mechanistic interdependence of low processivity and translesion synthesis.
DETAILED DESCRIPTION OF THE INVENTION
(A) Principles Underlying CST Technology According to the Invention
[0090]In a preferred embodiment the present invention provides a method for the generation of an engineered DNA polymerase with an expanded substrate range which comprises the steps of: [0091](a) preparing nucleic acid encoding a mutant DNA polymerase, wherein the polymerase is generated using flanking primers which bear a 3' distorting end [0092](b) compartmentalising the nucleic acid of step (a) into microcapsules; [0093](c) expressing the nucleic acid to produce their respective DNA polymerase within the microcapsules; [0094](d) sorting the nucleic acid encoding the mutant DNA polymerase which exhibits an expanded substrate range; and [0095](e) expressing the mutant DNA polymerase which exhibits an expanded substrate range.
[0096]The techniques of directed evolution and compartmentalised self replication are detailed in GB 97143002 and GB 98063936 and GB 01275643, in the name of the present inventors. These documents are herein incorporated by reference.
[0097]The inventors modified the methods of compartmentalised self replication and surprisingly generated DNA polymerases which exhibited an expanded substrate range as herein defined.
[0098]In particular, the inventors realised that for self-replication of Taq polymerase, compartments must remain stable at the high temperatures of PCR thermocycling. Encapsulation of PCRs has been described previously for lipid vesicles (Oberholzer, T., Albrizio, M. & Luisi, P. L. (1995) Chem. Biol. 2, 677-82 and fixed cells and tissues (Haase, A. T., Retzel, E. F. & Staskus, K. A. (1990) Proc. Natl. Acad. Sci. USA 87, 4971-5; Embleton, M. J., Gorochov, G., Jones, P. T. & Winter, G. (1992) Nucleic Acids) but with low efficiencies.
[0099]The present inventors used recently developed oil in water emulsions but modified the composition of the surfactant as well as the oil to water ratio. Details are given in Example 1. These modifications greatly increased the heat stability of the compartments and allowed PCR yields in the emulsion to approach those of PCR in solution. Further details of the method of compartmentalised self replication are given below.
Microcapsules
[0100]The microcapsules used according to the method of the invention require appropriate physical properties to allow the working of the invention.
[0101]First, to ensure that the nucleic acids and gene products may not diffuse between microcapsules, the contents of each microcapsule must be isolated from the contents of the surrounding microcapsules, so that there is no or little exchange of the nucleic acids and gene products between the microcapsules over the timescale of the experiment.
[0102]Second, the method of the present invention requires that there are only a limited number of nucleic acids per microcapsule. This ensures that the gene product of an individual nucleic acid will be isolated from other nucleic acids. Thus, coupling between nucleic acid and gene product will be highly specific. The enrichment factor is greatest with on average one or fewer nucleic acids per microcapsule, the linkage between nucleic acid and the activity of the encoded gene product being as tight as is possible, since the gene product of an individual nucleic acid will be isolated from the products of all other nucleic acids. However, even if the theoretically optimal situation of, on average, a single nucleic acid or less per microcapsule is not used, a ratio of 5, 10, 50, 100 or 1000 or more nucleic acids per microcapsule may prove beneficial in sorting a large library. Subsequent rounds of sorting, including renewed encapsulation with differing nucleic acid distribution, will permit more stringent sorting of the nucleic acids. Preferably, there is a single nucleic acid, or fewer, per microcapsule.
[0103]Third, the formation and the composition of the microcapsules must not abolish the function of the machinery the expression of the nucleic acids and the activity of the gene products.
[0104]Consequently, any microencapsulation system used must fulfil these three requirements. The appropriate system(s) may vary depending on the precise nature of the requirements in each application of the invention, as will be apparent to the skilled person.
[0105]A wide variety of microencapsulation procedures are available (see Benita, 1996) and may be used to create the microcapsules used in accordance with the present invention. Indeed, more than 200 microencapsulation methods have been identified in the literature (Finch, 1993).
[0106]These include membrane enveloped aqueous vesicles such as lipid vesicles (liposomes) (New, 1990) and non-ionic surfactant vesicles (van Hal et al., 1996). These are closed-membranous capsules of single or multiple bilayers of non-covalently assembled molecules, with each bilayer separated from its neighbour by an aqueous compartment. In the case of liposomes the membrane is composed of lipid molecules; these are usually phospholipids but sterols such as cholesterol may also be incorporated into the membranes (New, 1990). A variety of enzyme-catalysed biochemical reactions, including RNA and DNA polymerisation, can be performed within liposomes (Chakrabarti et al., 1994; Oberholzer et al., 1995a; Oberholzer et al., 1995b; Walde et al., 1994; Wick & Luisi, 1996).
[0107]With a membrane-enveloped vesicle system much of the aqueous phase is outside the vesicles and is therefore non-compartmentalised. This continuous, aqueous phase should be removed or the biological systems in it inhibited or destroyed (for example, by digestion of nucleic acids with DNase or RNase) in order that the reactions are limited to the microcapsules (Luisi et al., 1987).
[0108]Enzyme-catalysed biochemical reactions have also been demonstrated in microcapsules generated by a variety of other methods. Many enzymes are active in reverse micellar solutions (Bru & Walde, 1991; Bru & Walde, 1993; Creagh et al., 1993; Haber et al., 1993; Kumar et al., 1989; Luisi & B., 1987; Mao & Walde, 1991; Mao et al., 1992; Perez et al., 1992; Walde et al., 1994; Walde et al., 1993; Walde et al., 1988) such as the AOT-isooctane-water system (Menger & Yamada, 1979).
[0109]Microcapsules can also be generated by interfacial polymerisation and interfacial complexation (Whateley, 1996). Microcapsules of this sort can have rigid, nonpermeable membranes, or semipermeable membranes. Semipermeable microcapsules bordered by cellulose nitrate membranes, polyamide membranes and lipid-polyamide membranes can all support biochemical reactions, including multienzyme systems (Chang, 1987; Chang, 1992; Lim, 1984). Alginate/polylysine microcapsules (Lim & Sun, 1980), which can be formed under very mild conditions, have also proven to be very biocompatible, providing, for example, an effective method of encapsulating living cells and tissues (Chang, 1992; Sun et al., 1992).
[0110]Non-membranous microencapsulation systems based on phase partitioning of an aqueous environment in a colloidal system, such as an emulsion, may also be used.
[0111]Preferably, the microcapsules of the present invention are formed from emulsions; heterogeneous systems of two immiscible liquid phases with one of the phases dispersed in the other as droplets of microscopic or colloidal size (Becher, 1957; Sherman, 1968; Lissant, 1974; Lissant, 1984).
Emulsions
[0112]Emulsions may be produced from any suitable combination of immiscible liquids. Preferably the emulsion of the present invention has water (containing the biochemical components) as the phase present in the form of finely divided droplets (the disperse, internal or discontinuous phase) and a hydrophobic, immiscible liquid (an `oil`) as the matrix in which these droplets are suspended (the nondisperse, continuous or external phase). Such emulsions are termed `water-in-oil` (W/O). This has the advantage that the entire aqueous phase containing the biochemical components is compartmentalised in discreet droplets (the internal phase). The external phase, being a hydrophobic oil, generally contains none of the biochemical components and hence is inert.
[0113]The emulsion may be stabilised by addition of one or more surface-active agents (surfactants). These surfactants are termed emulsifying agents and act at the water/oil interface to prevent (or at least delay) separation of the phases. Many oils and many emulsifiers can be used for the generation of water-in-oil emulsions; a recent compilation listed over 16,000 surfactants, many of which are used as emulsifying agents (Ash and Ash, 1993). Suitable oils include light white mineral oil and non-ionic surfactants (Schick, 1966) such as sorbitan monooleate (Span®80; ICI) and polyoxyethylenesorbitan monooleate (Tween® 80; ICI) and Triton-X-100.
[0114]The use of anionic surfactants may also be beneficial. Suitable surfactants include sodium cholate and sodium taurocholate. Particularly preferred is sodium deoxycholate, preferably at a concentration of 0.5% w/v, or below. Inclusion of such surfactants can in some cases increase the expression of the nucleic acids and/or the activity of the gene products. Addition of some anionic surfactants to a non-emulsified reaction mixture completely abolishes translation. During emulsification, however, the surfactant is transferred from the aqueous phase into the interface and activity is restored. Addition of an anionic surfactant to the mixtures to be emulsified ensures that reactions proceed only after compartmentalisation.
[0115]Creation of an emulsion generally requires the application of mechanical energy to force the phases together. There are a variety of ways of doing this which utilise a variety of mechanical devices, including stirrers (such as magnetic stir-bars, propeller and turbine stirrers, paddle devices and whisks), homogenisers (including rotor-stator homogenisers, high-pressure valve homogenisers and jet homogenisers), colloid mills, ultrasound and `membrane emulsification` devices (Becher, 1957; Dickinson, 1994).
[0116]Aqueous microcapsules formed in water-in-oil emulsions are generally stable with little if any exchange of nucleic acids or gene products between microcapsules. Additionally, we have demonstrated that several biochemical reactions proceed in emulsion microcapsules. Moreover, complicated biochemical processes, notably gene transcription and translation are also active in emulsion microcapsules. The technology exists to create emulsions with volumes all the way up to industrial scales of thousands of litres (Becher, 1957; Sherman, 1968; Lissant, 1974; Lissant, 1984).
[0117]The preferred microcapsule size will vary depending upon the precise requirements of any individual selection process that is to be performed according to the present invention. In all cases, there will be an optimal balance between gene library size, the required enrichment and the required concentration of components in the individual microcapsules to achieve efficient expression and reactivity of the gene products.
[0118]Details of one example of an emulsion used when performing the method of the present invention are given in Example 1.
Expression within Microcapsules
[0119]The processes of expression must occur within each individual microcapsule provided by the present invention. Both in vitro transcription and coupled transcription-translation become less efficient at sub-nanomolar DNA concentrations. Because of the requirement for only a limited number of DNA molecules to be present in each microcapsule, this therefore sets a practical upper limit on the possible microcapsule size. Preferably, the mean volume of the microcapsules is less that 5.2×10-16 m3, (corresponding to a spherical microcapsule of diameter less than 10 μm, more preferably less than 6.5×10-17 m3 (5 μm), more preferably about 4.2×10-18 m3 (2 μm) and ideally about 9×10-18 m3 (2.6 μm).
[0120]The effective DNA or RNA concentration in the microcapsules may be artificially increased by various methods that will be well-known to those versed in the art. These include, for example, the addition of volume excluding chemicals such as polyethylene glycols (PEG) and a variety of gene amplification techniques, including transcription using RNA polymerases including those from bacteria such as E. coli (Roberts, 1969; Blattner and Dahlberg, 1972; Roberts et al., 1975; Rosenberg et al., 1975), eukaryotes e.g. (Weil et al., 1979; Manley et al., 1983) and bacteriophage such as T7, T3 and SP6 (Melton et al., 1984); the polymerase chain reaction (PCR) (Saiki et al., 1988); Qβ replicase amplification (Miele et al., 1983; Cahill et al., 1991; Chetverin and Spirin, 1995; Katanaev et al., 1995); the ligase chain reaction (LCR) (Landegren et al., 1988; Barany, 1991); and self-sustained sequence replication system (Fahy et al., 1991) and strand displacement amplification (Walker et al., 1992). Even gene amplification techniques requiring thermal cycling such as PCR and LCR could be used if the emulsions and the in vitro transcription or coupled transcription-translation systems are thermostable (for example, the coupled transcription-translation systems could be made from a thermostable organism such as Thermus aquaticus).
[0121]Increasing the effective local nucleic acid concentration enables larger microcapsules to be used effectively. This allows a preferred practical upper limit to the microcapsule volume of about 5.2×10-16 m3 (corresponding to a sphere of diameter 10 um).
[0122]The microcapsule size must be sufficiently large to accommodate all of the required components of the biochemical reactions that are needed to occur within the microcapsule. For example, in vitro, both transcription reactions and coupled transcription-translation reactions require a total nucleoside triphosphate concentration of about 2 mM.
[0123]For example, in order to transcribe a gene to a single short RNA molecule of 500 bases in length, this would require a minimum of 500 molecules of nucleoside triphosphate per microcapsule (8.33×10-22 moles). In order to constitute a 2 mM solution, this number of molecules must be contained within a microcapsule of volume 4.17×10-19 litres (4.17×10-22 m3 which if spherical would have a diameter of 93 nm.
[0124]Furthermore, particularly in the case of reactions involving translation, it is to be noted that the ribosomes necessary for the translation to occur are themselves approximately 20 nm in diameter. Hence, the preferred lower limit for microcapsules is a diameter of approximately 100 nm.
[0125]Therefore, the microcapsule volume is preferably of the order of between 5.2×10-22 m3 and 5.2×10-16 m3 corresponding to a sphere of diameter between 0.1 um and 10 um, more preferably of between about 5.2×10-19 m3 and 6.5×10-17 m3 (1 um and 5 um). Sphere diameters of about 2.6 um are most advantageous.
[0126]It is no coincidence that the preferred dimensions of the compartments (droplets of 2.6 um mean diameter) closely resemble those of bacteria, for example, Escherichia are 1.1-1.5×2.0-6.0 um rods and Azotobacter are 1.5-2.0 um diameter ovoid cells. In its simplest form, Darwinian evolution is based on a `one genotype one phenotype` mechanism. The concentration of a single compartmentalised gene, or genome, drops from 0.4 nM in a compartment of 2 um diameter, to 25 pM in a compartment of 5 um diameter. The prokaryotic transcription/translation machinery has evolved to operate in compartments of ˜1-2 um diameter, where single genes are at approximately nanomolar concentrations. A single gene, in a compartment of 2.6 um diameter is at a concentration of 0.2 nM. This gene concentration is high enough for efficient translation. Compartmentalisation in such a volume also ensures that even if only a single molecule of the gene product is formed it is present at about 0.2 nM, which is important if the gene product is to have a modifying activity of the nucleic acid itself. The volume of the microcapsule should thus be selected bearing in mind not only the requirements for transcription and translation of the nucleic acid/nucleic acid, but also the modifying activity required of the gene product in the method of the invention.
[0127]The size of emulsion microcapsules may be varied simply by tailoring the emulsion conditions used to form the emulsion according to requirements of the selection system. The larger the microcapsule size, the larger is the volume that will be required to encapsulate a given nucleic acid/nucleic acid library, since the ultimately limiting factor will be the size of the microcapsule and thus the number of microcapsules possible per unit volume.
[0128]The size of the microcapsules is selected not only having regard to the requirements of the transcription/translation system, but also those of the selection system employed for the nucleic acid/nucleic acid construct. Thus, the components of the selection system, such as a chemical modification system, may require reaction volumes and/or reagent concentrations which are not optimal for transcription/translation. As set forth herein, such requirements may be accommodated by a secondary re-encapsulation step; moreover, they may be accommodated by selecting the microcapsule size in order to maximise transcription/translation and selection as a whole. Empirical determination of optimal microcapsule volume and reagent concentration, for example as set forth herein, is preferred.
[0129]A "nucleic acid/nucleic acid" in accordance with the present invention is as described above. Preferably, a nucleic acid is a molecule or construct selected from the group consisting of a DNA molecule, an RNA molecule, a partially or wholly artificial nucleic acid molecule consisting of exclusively synthetic or a mixture of naturally-occurring and synthetic bases, any one of the foregoing linked to a polypeptide, and any one of the foregoing linked to any other molecular group or construct. Advantageously, the other molecular group or construct may be selected from the group consisting of nucleic acids, polymeric substances, particularly beads, for example polystyrene beads, magnetic substances such as magnetic beads, labels, such as fluorophores or isotopic labels, chemical reagents, binding agents such as macrocycles and the like.
[0130]The nucleic acid portion of the nucleic acid may comprise suitable regulatory sequences, such as those required for efficient expression of the gene product, for example promoters, enhancers, translational initiation sequences, polyadenylation sequences, splice sites and the like.
Product Selection
[0131]Details of a preferred method of performing the method of the invention are given in Example 1. However, those skilled in the art will appreciate that the examples given are non-limiting and methods for product selection are discussed in more general terms below.
[0132]A ligand or substrate can be connected to the nucleic acid by a variety of means that will be apparent to those skilled in the art (see, for example, Hermanson, 1996). Any tag will suffice that allows for the subsequent selection of the nucleic acid. Sorting can be by any method which allows the preferential separation, amplification or survival of the tagged nucleic acid. Examples include selection by binding (including techniques based on magnetic separation, for example using Dynabeads®), and by resistance to degradation (for example by nucleases, including restriction endonucleases).
[0133]One way in which the nucleic acid molecule may be linked to a ligand or substrate is through biotinylation. This can be done by PCR amplification with a 5'-biotinylation primer such that the biotin and nucleic acid are covalently linked.
[0134]The ligand or substrate to be selected can be attached to the modified nucleic acid by a variety of means that will be apparent to those of skill in the art. A biotinylated nucleic acid may be coupled to a polystyrene microbead (0.035 to 0.2 um in diameter) that is coated with avidin or streptavidin, that will therefore bind the nucleic acid with very high affinity. This bead can be derivatised with substrate or ligand by any suitable method such as by adding biotinylated substrate or by covalent coupling.
[0135]Alternatively, a biotinylated nucleic acid may be coupled to avidin or streptavidin complexed to a large protein molecule such as thyroglobulin (669 Kd) or ferritin (440 Kd). This complex can be derivatised with substrate or ligand, for example by covalent coupling to the alpha-amino group of lysines or through a non-covalent interaction such as biotin-avidin. The substrate may be present in a form unlinked to the nucleic acid but containing an inactive "tag" that requires a further step to activate it such as photoactivation (e.g. of a "caged" biotin analogue, (Sundberg et al., 1995; Pirrung and Huang, 1996)). The catalyst to be selected then converts the substrate to product. The "tag" could then be activated and the "tagged" substrate and/or product bound by a tag-binding molecule (e.g. avidin or streptavidin) complexed with the nucleic acid. The ratio of substrate to product attached to the nucleic acid via the "tag" will therefore reflect the ratio of the substrate and product in solution.
[0136]When all reactions are stopped and the microcapsules are combined, the nucleic acids encoding active enzymes can be enriched using an antibody or other molecule which binds, or reacts specifically with the "tag". Although both substrates and product have the molecular tag, only the nucleic acids encoding active gene product will co-purify.
[0137]The terms "isolating", "sorting" and "selecting", as well as variations thereof, are used herein. Isolation, according to the present invention, refers to the process of separating an entity from a heterogeneous population, for example a mixture, such that it is free of at least one substance with which it was associated before the isolation process. In a preferred embodiment, isolation refers to purification of an entity essentially to homogeneity. Sorting of an entity refers to the process of preferentially isolating desired entities over undesired entities. In as far as this relates to isolation of the desired entities, the terms "isolating" and sorting are equivalent. The method of the present invention permits the sorting of desired nucleic acids from pools (libraries or repertoires) of nucleic acids which contain the desired nucleic acid. Selecting is used to refer to the process (including the sorting process) of isolating an entity according to a particular property thereof.
[0138]Initial selection of a nucleic acid/nucleic acid from a nucleic acid library (for example a mutant taq library) using the present invention will in most cases require the screening of a large number of variant nucleic acids. Libraries of nucleic acids can be created in a variety of different ways, including the following.
[0139]Pools of naturally occurring nucleic acids can be cloned from genomic DNA or cDNA (Sambrook et al., 1989); for example, mutant Taq libraries or other DNA polymerase libraries, made by PCR amplification repertoires of taq or other DNA polymerase genes have proved very effective sources of DNA polymerase fragments. Further details are given in the examples.
[0140]Libraries of genes can also be made by encoding all (see for example Smith, 1985; Parmley and Smith, 1988) or part of genes (see for example Lowman et al., 1991) or pools of genes (see for example Nissim et al., 1994) by a randomised or doped synthetic oligonucleotide. Libraries can also be made by introducing mutations into a nucleic acid or pool of nucleic acids `randomly` by a variety of techniques in vivo, including; using `mutator strains`, of bacteria such as E. coli mutD5 (Liao et al., 1986; Yamagishi et al., 1990; Low et al., 1996). Random mutations can also be introduced both in vivo and in vitro by chemical mutagens, and ionising or UV irradiation (see Friedberg et al., 1995), or incorporation of mutagenic base analogues (Freese, 1959; Zaccolo et al., 1996). `Random` mutations can also be introduced into genes in vitro during polymerisation for example by using error-prone polymerases (Leung et al., 1989). In a preferred embodiment of the method of the invention, the repertoire of nucleic fragments used is a mutant Taq repertoire which has been mutated using error prone PCR. Details are given in Examples 1. According to the method of the invention, the term `random` may be in terms of random positions with random repertoire of amino acids at those positions or it may be selected (predetermined) positions with random repertoire of amino acids at those selected positions.
[0141]Further diversification can be introduced by using homologous recombination either in vivo (see Kowalczykowski et al., 1994 or in vitro (Stemmer, 1994a; Stemmer, 1994b)).
Microcapsules/Sorting
[0142]In addition to the nucleic acids described above, the microcapsules according to the invention will comprise further components required for the sorting process to take place. Other components of the system will for example comprise those necessary for transcription and/or translation of the nucleic acid. These are selected for the requirements of a specific system from the following; a suitable buffer, an in vitro transcription/replication system and/or an in vitro translation system containing all the necessary ingredients, enzymes and cofactors, RNA polymerase, nucleotides, nucleic acids (natural or synthetic), transfer RNAs, ribosomes and amino acids, and the substrates of the reaction of interest in order to allow selection of the modified gene product.
[0143]A suitable buffer will be one in which all of the desired components of the biological system are active and will therefore depend upon the requirements of each specific reaction system. Buffers suitable for biological and/or chemical reactions are known in the art and recipes provided in various laboratory texts, such as Sambrook et al., 1989.
[0144]The in vitro translation system will usually comprise a cell extract, typically from bacteria (Zubay, 1973; Zubay, 1980; Lesley et al., 1991; Lesley, 1995), rabbit reticulocytes (Pelham and Jackson, 1976), or wheat germ (Anderson et al., 1983). Many suitable systems are commercially available (for example from Promega) including some which will allow coupled transcription/translation (all the bacterial systems and the reticulocyte and wheat germ TNT® extract systems from Promega). The mixture of amino acids used may include synthetic amino acids if desired, to increase the possible number or variety of proteins produced in the library. This can be accomplished by charging tRNAs with artificial amino acids and using these tRNAs for the in vitro translation of the proteins to be selected (Ellman et al., 1991; Benner, 1994; Mendel et al., 1995).
[0145]After each round of selection the enrichment of the pool of nucleic acids for those encoding the molecules of interest can be assayed by non-compartmentalised in vitro transcription/replication or coupled transcription-translation reactions. The selected pool is cloned into a suitable plasmid vector and RNA or recombinant protein is produced from the individual clones for further purification and assay.
Microcapsule Identification
[0146]Microcapsules may be identified by virtue of a change induced by the desired gene product which either occurs or manifests itself at the surface of the microcapsule or is detectable from the outside as described in section iii (Microcapsule Sorting). This change, when identified, is used to trigger the modification of the gene within the compartment. In a preferred aspect of the invention, microcapsule identification relies on a change in the optical properties of the microcapsule resulting from a reaction leading to luminescence, phosphorescence or fluorescence within the microcapsule. Modification of the gene within the microcapsules would be triggered by identification of luminescence, phosphorescence or fluorescence. For example, identification of luminescence, phosphorescence or fluorescence can trigger bombardment of the compartment with photons (or other particles or waves) which leads to modification of the nucleic acid. A similar procedure has been described previously for the rapid sorting of cells (Keij et al., 1994). Modification of the nucleic acid may result, for example, from coupling a molecular "tag", caged by a photolabile protecting group to the nucleic acids: bombardment with photons of an appropriate wavelength leads to the removal of the cage. Afterwards, all microcapsules are combined and the nucleic acids pooled together in one environment. Nucleic acids encoding gene products exhibiting the desired activity can be selected by affinity purification using a molecule that specifically binds to, or reacts specifically with, the "tag".
Multi Step Procedure
[0147]It will be also be appreciated that according to the present invention, it is not necessary for all the processes of transcription/replication and/or translation, and selection to proceed in one single step, with all reactions taking place in one microcapsule. The selection procedure may comprise two or more steps. First, transcription/replication and/or translation of each nucleic acid of a nucleic acid library may take place in a first microcapsule. Each gene product is then linked to the nucleic acid which encoded it (which resides in the same microcapsule). The microcapsules are then broken, and the nucleic acids attached to their respective gene products optionally purified. Alternatively, nucleic acids can be attached to their respective gene products using methods which do not rely on encapsulation. For example phage display (Smith, G. P., 1985), polysome display (Mattheakkis et al., 1994), RNA-peptide fusion (Roberts and Szostak, 1997) or lac repressor peptide fusion (Cull, et al., 1992).
[0148]In the second step of the procedure, each purified nucleic acid attached to its gene product is put into a second microcapsule containing components of the reaction to be selected. This reaction is then initiated. After completion of the reactions, the microcapsules are again broken and the modified nucleic acids are selected. In the case of complicated multistep reactions in which many individual components and reaction steps are involved, one or more intervening steps may be performed between the initial step of creation and linking of gene product to nucleic acid, and the final step of generating the selectable change in the nucleic acid.
Amplification
[0149]In all the above configurations, genetic material comprised in the nucleic acids may be amplified and the process repeated in iterative steps. Amplification may be by the polymerase chain reaction (Saiki et al., 1988) or by using one of a variety of other gene amplification techniques including; Qβ replicase amplification (Cahill, Foster and Mahan, 1991; Chetverin and Spirin, 1995; Katanaev, Kumasov and Spirin, 1995); the ligase chain reaction (LCR) (Landegren et al., 1988; Barany, 1991); the self-sustained sequence replication system (Fahy, Kwoh and Gingeras, 1991) and strand displacement amplification (Walker et al., 1992).
(B) DNA Polymerases According to the Invention
(i) General
[0150]High fidelity DNA polymerases such as Pol A (like Taq polymerase) and Pol-B family polymerases which lack a 3'-5' exonuclease proofreading capability show a strict blockage to the extension of distorted or mismatched 3' primer termini to avoid propagation of misincorporations. While the degree of blockage varies considerably depending on the nature of the mismatch, some transversion (purine•purine/pyrimidine•pyrimidine) mismatches are extended up to 106-fold less efficiently than matched termini (Huang 92). Likewise, many unnatural base analogues, while incorporated efficiently, act as strong terminators (Kool, Loakes).
[0151]The present inventors have modified the principles described in Ghadessy, F. G et al (2001) Proc. Nat. Acad. Sci, USA, 93, 4552-4557 (compartmentalised self replication) and Ghadessy 2003, and outlined above. Both these documents are herein incorporated by reference. The present inventors have used these modified techniques to develop a method by which the substrates specificity of high fidelity DNA polymerases may be expanded in a generic way.
[0152]The inventors have exemplified the technique by expanding the substrate specificity of the high-fidelity pol-A family polymerases. In particular, the present inventors created two repertoires of randomly mutated Taq genes, as described in Ghadessy, F. G et al (2001) referred to above. Three cycles of mismatch extension CSR was performed using flanking primers bearing the mismatches A*G and C*C at their 3' ends. Selected clones were ranked using a PCR extension assay described herein.
[0153]Selected mutants exhibited the ability to extend the G*A and C*C transversion mismatches used in the CSR selection, but also exhibited a generic ability to extend mispaired 3' termini. These results are surprising, especially since Taq polymerase is unable to extend such mismatches (Kwok et al, (1990); Huang (1992).
[0154]Thus, using this approach, the inventors have generated DNA polymerases which exhibit a relaxed substrate specificity/expanded substrate range.
[0155]According to the present invention, the term `expanded substrate range` (of an engineered DNA polymerase) means that substrate range of an engineered DNA polymerase according to the present invention is broader than that of the one or more DNA polymerases, or fragments thereof from which it is derived. The term `a broader substrate range` refers to the ability of an engineered polymerase according to the present invention to extend one or more 3' mismatches, for example A*A, G*A, G*G, T*T, C*C, which the one or more polymerase/s from which it is derived cannot extend. That is, essentially, a DNA polymerase which exhibits a relaxed substrate range as herein defined has the ability not only to extend the 3' mismatches used in its generation, (IE those of the flanking primers), but also exhibits a generic ability to extend 3' mismatches (for example A*G, A*A, G*G).
[0156]The two best mutants M1 (G84A, D144G, K314R, E520G, F598L, A608V, E742G) and M4 (D58G, R74P, A109T, L245R, R343G, G370D, E520G, N583S, E694K, A743P) were chosen for further investigation.
[0157]M1 and M4 not only had greatly increased ability to extend the GA and CC transversion mismatches used in the CSR selection, but appeared to have acquired a more generic ability to extend 3' mispaired termini, including other strongly disfavoured transversion mismatches (such as AG, AA, GG) (FIG. 1b), which wtTaq polymerase was unable to extend, as previously reported (Kwok et al 1990, Huang 92).
(ii) M1 and M4 Mutants According to the Invention.
[0158]Nucleic acid sequences encoding M1 and M4 pol A DNA polymerase mutants are depicted SEQ No 1 and SEQ No 2 respectively and are shown in FIG. 1 and FIG. 2 respectively.
[0159]Despite very similar properties, M1 and M4 (and indeed other selected clones) have few mutations in common, suggesting there are multiple molecular solutions to the mismatch extension phenotype. One exception was E520G, a mutation that is shared by all but one of the four best clones of the final selection. Curiously, E520 is located at the very tip of the thumb domain at a distance of 20A from the 3' OH of the mismatched primer terminus and its involvement in mismatch recognition or extension is unclear. However, E520G is clearly important for mismatch extension as backmutation reduces mismatch extension in both M1 and M4 to near wt levels (FIG. 2).
[0160]The only other feature clearly shared by both M1 and M4 are mutations targeting residues, which may be involved in flipping out the +1 template base. Residue E742 mutated in M1 (E742G) forms a direct contact with the flipped out +1 base on the template strand (Li et al), while in M4 the adjacent residue A743 is mutated to proline (A743P), which may disrupt interactions by distorting local backbone conformation. Back mutation of E742G in M1 reduced mismatch extension, but only by ca. 20% indicating that it does not contribute decisively to mismatch extension.
[0161]Surprisingly, mutations in the N-terminal 5'-3' exonuclease domain (53exoD) also appear to be contributing to mismatch extension as suggested by the 2-4 fold increased mismatch extension ability of chimeras of the 53exoD of M1, M4 and polD of wtTaq (FIG. 4). How they promote mismatch extension is unclear but given the apparent distance of the 53exoD from the active site (Utz 99, Eom 96) is unlikely to involve direct effects on extension catalysis. Increased affinity for primer-template duplex could also increase mismatch extension (Huang 92) but dissociation constants of wtTaq, M1 and M4 for matched and mismatched primer-template duplex were indistinguishable as judged by an equilibrium binding assay (Huang 92) (not shown).
The Relationship of M1 and M4 with Other Naturally Occurring DNA Polymerases
[0162]Extension of mismatched 3' primer termini is a feature of naturally occurring polymerases. Viral reverse transcriptases (RT) like HIV-1 RT or AMV RT and polymerases capable of translesion synthesis (TLS) such as the poly-family polymerases pol t (Vaisman 2001JBC) or pol κ (Washington 2002 PNAS) or the unusual polB-family polymerase polζ (Johnson Nature), all extend 3' mismatches with elevated efficiency compared to high-fidelity polymerases. Thus, the selected polymerases share significant functional similarities with preexisting polymerases but represent, to our knowledge, the only known polA-family polymerases that are proficient in mismatch extension (ME) and translesion synthesis (TLS). In contrast to TLS polymerases, which are distributive and depend on cellular processivity factors such as PCNA (Prakash refs for eta/kappa and iota), M1 and M4 combine ME and TLS with high processivity and in the case of M1 are capable of efficient amplification of DNA fragments of up to 26 kb.
[0163]In the case of viral RTs, ME may play a crucial role in allowing error-prone yet processive replication of a multi-kb viral genome. For TLS polymerases, proficient mismatch extension is also a necessary prerequisite for their biological function as unpaired and distorted primer termini necessarily occur opposite lesions in the DNA template strand. The ability of TLS polymerases to traverse replication blocking lesions in DNA is thought to arise from a relaxed geometric selection in the active site (Goodman 02). The ability of M1 and M4 to process both bulky mispairs and a distorting CPD (cys-syn thymidine-thymidine dimer) dimer makes it plausible that, in analogy to TLS polymerases, they also have acquired a more open active site. Indeed, modelling showed that a CPD dimer can not be accommodated in the wtTaq polymerase active site without mayor steric clashes (Trincao01).
[0164]M1 (and to a lesser degree M4) also display a much increased ability to incorporate extend and replicate different types of unnatural nucleotide substrates that deviate to varying degrees from the canonical nucleobase structure. Of these the αS substitution is the most conservative. However, the sulfur anion is significantly larger than oxygen anion and coordinates cations poorly, which may be among the reasons why the wt enzyme will not tolerate full αS substitution. Fluorescently-labelled nucleotides like aS nucleotides retain base-pairing potential but include a bulky and hydrophobic substituent that must be accommodated by the polymerase active site. Steric clashes in the active site are allievated by the presence of a long, flexible linker. Indeed, we find biotin-16-dUTP a much better substrate for M1 than biotin-11-dUTP, while wtTaq cannot utilize either. The hydrophobic analogue 5NI represents the most drastic departure from standard nucleotide chemistry we investigated. Comparable in size to a purine base, 5NI competely lacks any hydrogen bonding potential but like the natural bases, favours the anti-position with respect to the ribose sugar as judged by NMR (J. Gallego, D. L. and P. H., unpublished results). Therefore, a 5NIA or 5NIG basepair would closely resemble a purine-purine transversion mismatch and may cause similar distortions to the canonical DNA duplex geometry. Elegant experiments using isosteric non-hydrogen bonding base analogues have shown that Watson-Crick hydrogen bonding per se is not required for efficient insertion or replication (reviewed by Kool 02). However, while many non-hydrogen-bonding hydrophobic base analogues are efficiently incorporated, they subsequently lead to termination, both at the 3' end and as a template base (Kool, Romesberg).
[0165]Structural and biochemical studies have previously identified regions of the polymerase structure that are important for mismatch discrimination such as motif A (involved in binding the incoming dNTP), the O-helix (motif B) and residues involved in minor groove hydrogen bonding (24, 25). Inspection of the sequence of M1 and M4 reveals a conspicuous absence of mutations in these regions. Rather mutations in M1 and M4 implicate regions of the polymerase not previously associated with substrate recognition such as the tip of the thumb subdomain (E520), the +1 template base-flipping function (E742, A743) in the finger subdomain and the 5-3' exonuclease domain (53exoD).
[0166]The 53exoD is too distant from the active site to have direct effects on mismatch extension. It is, however, thought to be crucial for polymerase processivity and may thus influence mismatch extension (24). Indeed, the Stoffel fragment of Taq polymerase (26), which lacks the 53exoD, displays both reduced processivity and more stringent mismatch discrimination (27). Mutations in the 53exoD of M1 and M4 may therefore contribute to mismatch extension by enhancing polymerase processivity. Together with the ability to bypass abasic sites (generated in large DNA fragments during thermocycling) this may also contribute to the proficiency of M1 at long PCR (FIG. 5). E520 is located at the very tip of the thumb domain at the end of the H2 helix at a distance of 20A from the 3' OH of the mismatched primer terminal base (P1) (2). Mechanistic aspects of the involvement of the E520G mutation in mismatch recognition or extension are therefore not obvious either. It is worth noting though that adjacent regions, especially the preceding loop connecting helices H1 and H2 and parts of helix I, make extensive contacts with the template-primer duplex between P3-P7 (2). It has previously been observed that mismatch incorporation affects extension kinetics up to the P4 position (24). E520G may modify the structure of these regions to ease passage of mismatches and increase elongation efficiency post incorporation. Base flipping, i.e. rotation of the designated base out of the DNA helix axis is a common mechanism among DNA modifying enzymes (e.g. glycosylases) but its precise role for polymerase function is less clear. It has been speculated that flipping out of the +1 template base may contribute to polymerase fidelity by preventing out-of-register base-pairing (25) of the 3' nucleotide to cognate upstream template bases. Interference with this mechanism therefore might promote apparent mismatch extension but would produce -1 base deletions. However, neither primer extensions nor sequencing of PCR products generated with M1 or M4 using primers with 3' GA and CC mismatches revealed any template slippage but on the contrary, confirmed in-register extension of the mismatches (not shown). The utility of reduced base-flipping in the context of the TLS capability of M1 and M4 is easier to understand, especially on the CPD dimer, as the two covalently linked thymine template bases would be refractory to flipping out. Indeed, TLS polymerases, which are naturally able to bypass CPD dimers, appear to lack a base-flipping function (28).
Extension and Incorporation Kinetics of Polymerases According to the Invention.
[0167]Examination of the extension and incorporation kinetics of the mutant polymerases suggests that they have a significantly increased propensity to not only extend but also incorporate transversion mispairs and consequently should have a significantly increased mutation rate compared to the wt enzyme. More relaxed geometric selection in the active site might also be expected to come at the price of significantly reduced fidelity as indeed is the case for TLS polymerases (23). However, measurement of the overall mutation rate using the MutS assay (not shown) and sequencing of PCR products generated by M1 indicated only a modest (<2-fold) increase in the mutation rate (Table 1) mostly due to an increased propensity for transversions. As discussed previously (10), CSR should select for optimal self-mutation rates within the error threshold (31). A change in the mutation spectrum towards a more even distribution of transition and transversion mutations may be an effective solution to accelerate adaptation, while maintaining a healthy distance from the error threshold. This may also make M1 a useful tool for protein engineering as the bias of Taq (and other DNA polymerases) for transition mutations limits the regions of sequence space that can be accessed effectively using PCR mutagenesis
TABLE-US-00001 TABLE 1 Mutation spectrum of wtTaq and M1 in PCR Transitions Transversions AT -> GC GC -> AT AT -> TA AT -> CG GC -> TA GC -> CG Deletions WtTaq* 25 9 8 2 3 1 3 M1* 25 16 15 4 5 10 1 *Mutations derived from sequencing of 40 clones (800 bp) each.
[0168]In summary DNA polymerases according to the present invention, in particular M1 and M4 respectively as depicted in SEQ No 1 and SEQ No 2 possess the following properties:
(1) DNA Translesion synthesis(2) A generic ability to incorporate unnatural base analogues into DNA.(3) M1 has the ability to efficiently amplify DNA targets up to 26 kb.
Uses of DNA Polymerases According to the Invention.
[0169]Directed evolution towards extension of distorting transversion mismatches like GA or CC by CSR yields novel, "unfussy" polymerases with an ability to perform not only efficient mismatch extension and TLS but also accept a range of unnatural nucleotide substrates. The present inventors have shown that the evolution of TLS from a high-fidelity, polA-family, pol B family or other polymerases requires but few mutations, suggesting that TLS and relaxed substrate recognition are functionally connected and may represent a default state of polymerase function rather than a specialization.
[0170]The unusual properties of the DNA polymerases according to the present invention, in particular M1 and M4 may have immediate uses for example for the improved incorporation of dye-modified nucleotides in sequencing and array labelling and/or the amplification of ultra-long DNA targets. They may prove useful in the amplification of damaged DNA templates in forensics or paelobiology, may permit an expansion of the chemical repertoire of aptamers or deoxi-ribozymes (Benner, Barbas, ribozyme review) and may aid efforts to expand the genetic alphabet (Benner, Schultz). The altered mutation spectrum of M1 may make a useful tool in random mutagenesis experiments as the strong bias of Taq and other polymerases towards (A->G, T->C) transitions limits the combinatorial diversity accessible through PCR mutagenesis. Furthermore, the ability of M1 & M4 to extend 3' ends in which the last base is mismatched with the template strand and the ability of H10 (see example 6) to extend 3' ends in which the last two bases are mismatched with the template strand may extend the scope of DNA shuffling methods (Stemmer) by allowing to recombine more distantly related sequences.
[0171]In addition, DNA polymerases according to the invention, in particular pol A polymerases, for example M1 and M4 pol A polymerases as herein described may serve as a useful framework for mutagenesis and evolution towards polymerases capable of utilizing an ever wider array of modified nucleotide substrates. The inventors anticipate that directed evolution may ultimately permit modification of polymerase chemistry itself, allowing the creation of amplifiable DNA-like polymers of defined sequence thus extending molecular evolution to material science.
[0172]The invention will now be described by the following examples which are in no way limiting of the invention claimed herein.
Example 1
General Methods
List of Primers:
TABLE-US-00002 [0173] 1: 5'-CAG GAA ACA GCT ATG ACA AAA ATC TAG ATA ACG AGG GA-3'; (SEQ ID NO: 3) A•G mismatch 2: 5'-GTA AAA CGA CGG CCA GTA CCA CCG AAC TGC GGG TGA CGC (SEQ ID NO: 4) CAA GCC-3'; C•C mismatch 3: 5'-AAA AAT CTA GAT AAC GAG GGC AA-3' (SEQ ID NO: 13) 4: 5'-ACC ACC GAA CTG CGG GTG ACG CCA AGC G-3' (SEQ ID NO: 14) 5: 5'-GAA CTG CGG GTG ACG CCA AGC GCA 3'; A•A mismatch (SEQ ID NO: 15) 6: 5'-CC GAA CTG CGG GTG ACG CCA AGC GG 3'; G•G mismatch (SEQ ID NO: 16) 7: 5'-GAA CTG CGG GTG ACG CCA AGC GCG-3'; G•A mismatch (SEQ ID NO: 17) 8: 5'-AAA AAT CTA GAT AAC GAG GGC AA-3' (SEQ ID NO: 18) 9: 5'-CCG ACT GGC CAA GAT TAG AGA GTA TGG-3' (SEQ ID NO: 19) 10: 5'-GAT TTC CAC GGA TAA GAC TCC GCA TCC-3' (SEQ ID NO: 20) 11: 5'-GGC AGA CGA TGA TGC AGA TAA CCA GAG C-3' (SEQ ID NO: 21) 12: 5'-GCC GAT AGA TAG CCA CGG ACT TCG TAG-3' (SEQ ID NO: 22) 13: 5'-GGA GTA GAT GCT TGC TTT TCT GAG CC-3' (SEQ ID NO: 23) 14: 5'-GAG TTC GTG CTT ACC GCA GAA TGC AG-3' (SEQ ID NO: 24) 15: 5'-ACC GAA CTG CGG GTG ACG CCA AGC G 3' (SEQ ID NO: 25) 16: 5'-ACC GAA CTG CGG GTG ACG CCA AGC C 3' (SEQ ID NO: 26) 17: 5'-ACC GAA CTG CGG GTG ACG CCA AGC A 3' (SEQ ID NO: 27) 18: 5'-AAA CAG CGC TTG GCG TCA CCC GCA GTT CGG T-3' (SEQ ID NO: 28) 19: 5'-AAA CAG GGC TTG GCG TCA CCC GCA GTT CGG T-3' (SEQ ID NO: 29) 20: 5'-AAA CAG AGC TTG GCG TCA CCC GCA GTT CGG T-3' (SEQ ID NO: 30) 21: 5'-AAA CAC CGC TTG GCG TCA CCC GCA GTT CGG T-3' (SEQ ID NO: 31) 22: 5'-AGC TAC CAT GCC TGC ACG AAT TCG GCA TCC GTC GCG ACC ACG (SEQ ID NO: 32) GTC GCA GCG-3' (undamaged) 23: 5'-AGC TAC CAT GCC TGC ACG ACA XCG GCA TCC GTC GCG ACC ACG (SEQ ID NO: 33) GTC GCA GCG-3'; X = abasic site 24: 5'-AGC TAC CAT GCC TGC ACG AAX XCG GCA TCC GTC GCG ACC ACG (SEQ ID NO: 34) GTC GCA GCG-3, XX = CPD dimer 25: 5'-CGT GGT CGC GAC GGA TGC CG-3' (SEQ ID NO: 35) 26: 5'-TAA TAC GAC TCA CTA TAG GGA GA-3' (SEQ ID NO: 36) 27: 5'-ACT GXT CTC CCT ATA GTG AGT CGT ATT A-3'; X = 5NI (SEQ ID NO: 37)
Materials and Methods
[0174]DNA manipulation and protein expression. Expression of Taq clones for screening and CSR selection was as described (10). For kinetic measurements and gel extension assays, polymerases were purified as described (32) using a Biorex70 ion exchange resin (BioRad). All PCR and primer extensions were performed in 1×Taq buffer (50 mM KCl/10 mM Tris.HCl (pH 9.0)/0.1% Triton X-100/1.5 mM MgCl2), with dNTPs (0.25 mM (Amersham Pharmacia Biotech, NJ)) and appropriate primers unless specified otherwise. Primer sequences are provided in Supplementary information. Primer extension reactions were terminated by addition of 95% formamide/10 mM EDTA and analysed on 20% polyacrylamide/7 M Urea gels.
[0175]CSR selection. Activity preselected libraries L1* and L2* (10) were combined and 3 rounds of CSR selection carried out as described (10) except using primers 1: (AG mismatch) and 2: (CC mismatch) and 15 cycles of (94° C. 1 min, 55° C. 1 min, 72° C. 8 min). Round 2 clones were recombined by staggered extension process (StEP) PCR shuffling (33) as described. For round 3, CSR cycles were reduced to 10 and annealing times to 30 sec.
[0176]PCR. A PCR assay was used to screen and rank clones. Briefly, clones were normalized for activity in PCR with matched primers 3, 4 and activity with mismatched primers 1 and 2 (1 μM each) determined at minimal cycle number (15-25 cycles). Extension capability for different mismatches was determined by the same assay using mismatch primers 2 (CC mismatch), 5 (AA mismatch), 6 (GG mismatch), 7 (GA mismatch) with matched primer 3 or primer 1 (AG mismatch) with matched primer 4. Incorporation of unnatural substrates in 50 cycle PCR was carried out using standard conditions and 50 μM αS dNTPs (Promega) or 50 μM FITC-12-dATP (Perkin-Elmer), Rhodamine-5-dUTP (Perkin-Elmer) or Biotin-16-dUTP (Roche) with equivalent amounts of the other 3 dNTPs (all 50 μM). Long PCR was carried out using a two-step cycling protocol as described (22) 94° C. for 2 minutes, followed by 20 cycles of (94° C. 15 sec, 68° C. 30 min) using 5 ng of phage λ DNA (New England Biolabs) template and either primers 9, 10, 11 with primer 12 or primer 13 with primers 10, 14.
[0177]Single nucleotide incorporation/extension kinetics. Kinetic parameters were determined using a gel-based assay essentially as described (16). Primers 15, 16, 17 (3' base=G, C, A respectively) were 32P-labeled and annealed to one of template strands 18, 19, 20 (template base=C, G, A respectively) or 21 (template base C different context). Duplex substrates were used at 50 nM final concentration in 1×Taq buffer with various concentrations of enzyme and dNTP. Reactions were carried out at 60° C. for times whereby <20% of primer-template was utilized at the highest concentration of dNTP.
[0178]Template affinity assays. An equilibrium binding assay (12) was used to determine relative affinity of polymerases for the mismatched primer-templates used in the kinetics assays. Polymerases were preincubated at 60° C. in 1×Taq buffer with 50 nM 32P-labeled matched primer-template and 50 nM unlabeled mismatched competitor primer-templates. Reactions were initiated by simultaneous addition of dCTP (200 μM) and trap DNA (XbaI/SalI-restricted sheared salmon sperm DNA, 4.5 mg/ml). Prior experiments demonstrated trap-effectiveness over the time period used (15 seconds).
[0179]Translesion Replication Assay. Template primers 22 (undamaged) or 23 (containing a synthetic abasic site) were synthesized by Lofstrand Laboratories (Gaithersburg, Md.). Template primer 24 (containing a single cis-syn thymine dimer), was synthesized as described (34). Primer 25 was 32P-labeled and annealed to one of the three templates 22, 23, 24 (at a primer template ratio of molar 1:1.5) and extended in 40 mM Tris.HCl at pH 8.0, 5 mM MgCl2, 100 μM of each dNTP, 10 mM DTT, 250 μg/ml BSA, 2.5% glycerol, 10 nM primer-template DNA and 0.1 Unit of polymerase at 60° C. for various times.
[0180]5NI replication assay. Primer 26 was 32P-labeled and annealed to template primer 27 (containing a single 5-nitroindole) in 1×Taq buffer, 0.1 or 0.5U of the polymerase was added and reactions incubated at 60° C. for 15 mins, after which 40 μM of each dNTP were added and incubation at 60° C. continued for various times.
[0181]Fidelity assays. Mutation rates were determined using the mutS ELISA assay (Genecheck, Ft. Collins, Colo.) or by performing 2×50 cycles of PCR on three different templates and sequencing the cloned products.
Example 2
[0182]Kinetic analysis. Extension and incorporation kinetics of M1 and M4 for a selection of mismatches were measured using a gel-based steady-state kinetic assay (Goodman) (Tables 1 & 2). M1 and M4 respectively extend a CC mispair 390 and 75-fold more efficiently than wtTaq. Examination of the other most disfavored mismatches (GA, AG, AA, GG) reveals generic, although less pronounced, increases of extension efficiencies, as suggested by the PCR assay (FIG. 4, FIG. 5). The gain in extension efficiency derives predominantly from increased relative Vmax values for the mutant polymerases, while Km for nucleotide substrates remains largely unchanged. For most DNA polymerases the relative efficiency of extending a given mispair (f0ext) is similar to the relative efficiency of forming it (finc) (Goodman 1993, Goodman 1990, Washington 2001). Indeed, M1 and M4 respectively incorporate dCTP opposite template base C 206- and 29-fold more efficiently than wtTaq (Table 2).
TABLE-US-00003 TABLE 2 Steady-state kinetic parameters for extension kinetics by wtTaq and mutant polymerases. 3'-Terminal Ratio Base pair* Polymerase Vmax (% Min-1) Km (μM) f.sup.† fext.sup..dagger-dbl. of fext.sup.§ CG WtTaq 1477.0 0.016 92312.5 -- -- M1 308.0 0.02 15400 -- -- M4 817.0 0.012 68083 -- -- CC WtTaq 0.2 39.9 0.00546 5.9 × 10-8 1.0 M1 9.2 25.8 0.356 2.3 × 10-5 390.0 M4 11.1 36.6 0.303 4.5 × 10-6 75.3 GA WtTaq 1.6 32.8 0.05 5.4 × 10-7 1.0 M1 2.4 22.0 0.111 7.2 × 10-6 13.3 M4 7.5 29.0 0.26 3.8 × 10-6 7.0 AG WtTaq 28.0 45.2 0.02 2.1 × 10-7 1.0 M1 44.6 280.2 0.02 1.3 × 10-6 6.2 M4 50.0 259.0 0.1 1.5 × 10-6 7.0 AA WtTaq 1.7 27.3 0.062 6.7 × 10-7 1.0 M1 1.5 40.9 0.037 2.4 × 10-6 3.6 M4 8.5 32.9 0.259 3.8 × 10-6 5.7 GG WtTaq 20.4 174.0 0.117 1.3 × 10-6 1.0 M1 29.6 67.0 0.44 2.9 × 10-5 22.5 M4 70.6 107.0 0.66 9.7 × 10-6 7.6 *Template base: 3' primer base; Incorporated base is dCTP .sup.†f, enzyme efficiency = Vmax/Km .sup..dagger-dbl.fext, f(mismatched 3'terminus)/f(matched terminus) .sup.§fext(mutant polymerase)/fext(wtTaq)
TABLE-US-00004 TABLE 2 Steady-state kinetic parameters for incorporation kinetics by wtTaq and mutant polymerases. Vmax Km Ratio of Base pair* Polymerase (% Min-1) (μM) f.sup.† finc.sup..dagger-dbl. finc.sup.§ G: dCTP WtTaq 1477 0.016 92312.5 -- -- M1 308 0.02 15400 -- -- M4 817 0.012 68083 -- -- G: dGTP WtTaq 57.47 365.27 0.157 1.7 × 10-6 1 M1 215.98 377.1 0.573 3.72 × 10-5 21.88 M4 656.46 82.34 7.97 1.17 × 10-4 68.82 G: dATP WtTaq 1973.68 258.53 7.63 8.27 × 10-5 1 M1 681.82 257.2 2.65 1.72 × 10-4 2.08 M4 1935.48 157.77 12.27 1.80 × 10-4 2.18 G: dTTP WtTaq 25.08 1.64 15.29 1.65 × 10-4 1 M1 10.19 1.65 6.18 4.01 × 10-4 2.43 M4 63.20 5.10 12.39 1.82 × 10-4 1.1 C: dGTP WtTaq 2356.02 0.0366 64285.69 -- M1 111.66 0.0387 2884.55 -- M4 335.42 0.01 33542 -- C: dCTP WtTaq 3.3 1330.89 0.0025 3.86 × 10-8 1 M1 6.08 264.14 0.023 7.97 × 10-6 206.74 M4 52.63 1390.63 0.0378 1.13 × 10-6 29.22 *Template base: incoming nucleotide .sup.†f, enzyme efficiency = Vmax/Km .sup..dagger-dbl.finc, f(incorrect dNTP)/f(correct dNTP) .sup.§finc(mutant polymerase)/finc(wtTaq)
Example 3
[0183]Translesion synthesis. Transversion mispairs represent distorting deviations from the cognate duplex structure. We therefore investigated if M1 and M4 were capable of processing other deviations of the DNA structure such as lesions in the template strand. Using a gel-extension assay we investigated their ability to traverse an abasic site and a cis-syn thymine pyrimidine dimer (CPD) template strand lesion. In control assays using an undamaged template, wtTaq, M1 and M4 efficiently and rapidly extended primers to the end of the template (FIG. 5). On the template containing an abasic site, wtTaq efficiently inserts a base opposite the lesion but, further extension is largely abolished. In contrast, both M1 and M4 are able to extend past the lesion and to the end of the template. The size of the final product is similar to that observed on the undamaged template indicating that bypass occurred without deletions. Perhaps the most striking example of the proficiency of M1 and M4 to bypass template lesions is observed on the CPD-containing template (FIG. 5). Under the assay conditions, wtTaq utilizes a fraction of the available template and is only able to insert a base opposite the 3'T of the dimer after prolonged reaction conditions. In contrast, both M1 and M4 are able to readily extend all of the primer to the 3'T of the dimer. In addition, there is also considerable extension of these primers to the 5'T of the CPD. As with the abasic template, a significant fraction of these primers are subsequently fully extended to the end of the template in an error-free manner without deletions. We estimate that trans-lesion synthesis (TLS) by M1 and M4 may only be 2-5 fold less efficient than that observed with a naturally occurring TLS polymerase, Dpo4 from S. solfataricus (Boudsocq et al (2001), Nucleic Acid Res, 29, 46072001) on the same template.
Example 4
[0184]Unnatural substrates. We reasoned that relaxed geometric selection might also aid the incorporation of unnatural base analogues, some of which inhibit or arrest polymerase activity due to poor geometric fit or lack of interaction with either polymerase or template strand. A first, conservative example are phosphothioate nucleotide triphosphates (αS dNTPs), in which one of the oxygen atoms in the α phosphate group is replaced by sulfur. As part of a dNTP mixture, αS dNTPs are generally well accepted as substrates by DNA polymerases but when we replaced all four dNTPs with their αS counterparts in PCR wtTaq failed to generate any amplification products, while M1 (and to lesser extent M4) were able to generate PCR products of up to 2 kbp, indicating that they could utilize αS dNTPs with much increased efficiency compared to the wt enzyme (FIG. 6). As expected, the resulting αS DNA was completely resistant to cleavage by DNA endonucleases (not shown). Nucleotides bearing bulky adducts such as fluorescent dyes are widely used in applications such as dye terminator sequencing or array labelling. Although generally well tolerated they are incorporated considerably less efficiently than the natural dNTP substrates and can cause permature termination in homopolymeric runs, presumably because of steric crowding due to the bulky dye molecules. In PCR the effect is potentiated because both template and product strands are labelled. When we replaced dUTP with Biotin-16-dUTP or dATP with FITC-12-dATP in PCR, wtTaq was unable to generate any amplification products, while M1 was able to generate 2.7 kb amplification products fully labelled with Biotin-16-dUTP or a 0.4 kb fully labelled with FITC-12-dATP (FIG. 6). Recently, there has been significant interest in hydrophobic, non-hydrogen bonding base-analogues and the applications they may enable. One of these is the candiate "universal base" 5-nitroindole (5NI) (Loakes & Brown 96), which, like other hydrophobic, strongly stacking base analogues, is readily accepted as a substrate, but once incorporated, acts as a strong terminator both at the 3' end and as a template base. In contrast, M4 and in particular M1 efficiently bypass template strand 5NI (FIG. 6) and to a lesser degree, extend 5NI at the 3' end (not shown).
Example 5
[0185]Long PCR. Amplification product size with wtTaq is generally limited to fragments a few kb long but can be extended to much longer targets by inclusion of a proofreading polymerase (Barnes 92). We found that the selected polymerases, in particular M1 was able to efficiently amplify of targets up to 26 kb (FIG. 7), using standard PCR conditions in the absence of auxiliary polymerases or other processivity factors. Under the same conditions wtTaq enzyme failed to amplify targets >9 kb. The molecular basis for the product size limitation in the wt enzyme is thought to be premature termination due to an inability to extend mismatches following nucleotide misincorporation. These are thought to be removed by the proofreading polymerase allowing extension to resume. Our results that a generic mismatch extension ability to results in a similarly extended amplification range supports this concept.
Example 6
Libraries of Polymerase Chimeras
[0186]Libraries of chimeric polymerase gene variants were constructed using a gene shuffling technique called Staggered extension protocol (StEP, (Zhao, Giver et al. 1998)). This technique allows two or more genes of interest from different species to be randomly recombined to produce chimeras, the sequence of which contains parts of the original input parent genes.
[0187]Thermus aquaticus (Taq) wild type and T8 (a previously selected 11 fold more thermostable Taq variant (Ghadessy, Ong et al. 2001)), Thermus thermophilus (Tth) and Thermus flavus (Tfl) polymerases had previously been amplified from genomic DNA and cloned into pASK75 (Skerra 1994) and tested for activity. These genes were then shuffled using the staggered extension protocol (StEP) as described (Zhao, Giver et al. 1998) with (CAG GAA ACA GCT ATG ACA AAA ATC TAG ATA ACG AGG GCA A (SEQ ID NO: 38) and GTA AAA CGA CG G CCA GTA CCA CCG AAC TGC GGG TGA CGC CAA GCG (SEQ ID NO: 39)), recloned into pASK75 and transformed into E. coli TG1. The library size was scored by dilution assays and determining the ratio of clones containing insert using PCR screening and was approximately 108. A diagnostic restriction digest of 20 clones produced 20 unique restriction patterns, indicating that the library was diverse. Subsequent sequencing of selected chimeras showed an average of 4 to 6 crossovers per gene.
Example 7
Selection of Two Mismatch Extension Polymerase
[0188]CSR emulsification and selection was performed on the StEP Taq, Tth and Tfl library essentially as described (Ghadessy, Ong et al. 2001). Mismatch primers with two mismatches at their 3' end (5'-GTA AAA CGA CGG CCA GTT TAT TAA CCA CCG AAC TGC-3' (SEQ ID NO: 40), 5'-CAG GAA ACA GCT ATG ACT CGA CAA AAA TCT AGA TAA CGA CC-3' (SEQ ID NO: 41)) were in the emulsion as the source of selective pressure. The aqueous phase was ether extracted, PCR purified (Qiagen, Chatsworth, Calif.) with an additional 35% GnHCl, digested with DpnI to remove methylated plasmid DNA, treated with ExoSAP (USB) to remove residual primers, reamplified with outnested primers and recloned and transformed into E. coli as above.
[0189]The resultant clones were screened and ranked by PCR assay. Briefly, 2 μL of induced cells were added to 20 μL of PCR mix with the relevant mismatch primers. Clones that produced a band were then subjected to further analysis and the most active clones were sequenced.
[0190]In particular, clone H10 has significant activity on the primers with two mismatches. H10 is a chimera of T. aquaticus wild type (residues 4 to 20 and 221 to 640), T8 (residues 1 to 3 and 641 to 834) and T. thermophilus (residues 21 to 220). H10 has five detectable crossover sites and 13 point mutations, of which 4 are silent (F74ΠI, F28Π0L, P300ΠS, T387ΠA, A441ΠV, A519ΠV Q536ΠR, R679ΠG, F699ΠL).
Example 8
Selecting for a 4 Mismatch Extension Polymerase
[0191]CSR emulsification and selection was performed on the StEP Taq, Tth and Tfl library essentially as described (Ghadessy, Ong et al. 2001). The library had previously been cloned into pASK75 (see example 6). The aqueous phase was ether extracted and replication products were purified using a PCR purification kit (Qiagen, Chatsworth, Calif.) including a wash with an 35% GnHCl. 7 μl of purified replication products (from 48) were digested with 1 μl DpnI (20 Units) to remove plasmid DNA and treated with 2 μl ExoSAP (USB) to remove residual primers for 1 h at 37° C. and reamplified with outnested primers (GTAAAACGACGGCCAGT (SEQ ID NO: 42) and CAGGAAACAGCTATGAC (SEQ ID NO: 43), 94° C. 2 minutes, and then 30 cycles of 94° C. 30 seconds, 50° C. for 30 seconds and 72° C. for 5 minutes with a final 65° C. for 10 minutes). Reamplification products were digested with XbaI and SalI, recloned into pASK75 and transformed into E. coli as above.
[0192]In parallel an alternative selection approach was used: the induced library was emulsified as above with the additional presence of biotinylated dUTP and incubated at 94° C. 5 minutes, 50° C. 1 minute and 72° C. 1 minute. The aqueous phase was ether extracted, the DNA in the aqueous phase was precipitated by addition of 1/10 volume of 3M NaAc, 1 μl glycogen and 2.5 volumes of 100% ethanol. This was then incubated for 1 hour at -20° C., spun for at 13000 rpm for 30 minutes in a benchtop microcentrifuge, washed with 70% ethanol and resuspended in 50 μl buffer EB (Qiagen). 20 ul of Dynabeads (DynaL Biotech) were washed twice and resuspended in 20 μl of bead buffer (10 mM Tris pH 7.5, 1 mM EDTA, 0.2M NaCl) The washed beads were then mixed with the selection in a total volume of 0.5 ml bead buffer and then incubated overnight under constant agitation at room temperature to capture biotinylated products. Beads were washed twice in bead buffer, twice in buffer EB and finally resuspended in 50 μl bead buffer. The resuspended beads were reamplified with outnested primers (sequences and programme as above) and recloned and transformed into E. coli as above.
[0193]Two sets of mismatch primers with four mismatches at their 3' end (underlined) (5'-CAG GAA ACA GCT ATG ACA AAA GTG AAA TGA ATA GTT CGA CTTTT-3' (SEQ ID NO: 44) and 5'-GTA AAA CGA CGG CCA GTC TTC ACA GGT CAA GCT TAT TAA GGTG-3' (SEQ ID NO: 45) as the first set and 5'-CAG GAA ACA GCT ATG ACC ATT GAT AGA GTT ATT TTA CCA CAGGG-3' (SEQ ID NO: 46) and 5'-GTA AAA CGA CGG CCA GTC TTC ACA GGT CAA GCT TAT TAA GGTG-3' (SEQ ID NO: 47) as the second set) were used in the emulsion as two separate sources source of selective pressure.
[0194]The resultant clones from both CSR and CST were screened and ranked by PCR assay. Briefly, 2 μl of induced cells were added to 20 μl of PCR mix with the relevant 4 mismatch primers. Clones that produced a band were then subjected to further analysis and their activity on single, double and quadruple mismatch primers (single mismatch primers: 5'-CAG GAA ACA GCT ATG ACA AAA ATC TAG ATA ACG AGG GA-3' (SEQ ID NO: 48) and 5'-GTA AAA CGA CGG CCA GTA CCA CCG AAC TGC GGG TGA CGC CAA GCC 3' (SEQ ID NO: 49); double mismatch primers: CAG GAA ACA GCT ATG ACT CGA CAA AAA TCT AGA TAA CGA CC (SEQ ID NO: 50) and GTA AAA CGA CGG CCA GTT TAT TAA CCA CCG AAC TGC (SEQ ID NO: 51); four mismatch primers above.) was investigated. Polymerases that could extend all of these mismatches were found, though many polymerases could do only one of the mismatches and none could do all.
[0195]The plasmid DNA of the ten best clones was then purified and shuffled as described above (StEP, (Zhao, Giver et al. 1998)). This was then purified, cut and cloned and the resultant library was subjected to another round of CSR as described (Ghadessy, Ong et al. 2001). The same two sets of mismatch primers with four mismatches at their 3' end were used in the emulsion as two separate sources source of selective pressure. This was then dealt with as above and the resultant clones were screened and ranked by PCR assay (as above). Once again, polymerases that could extend all of these mismatches were found (see Table), though many polymerases could do only one of the mismatches and none could do all. There was a notable increase in clones displaying mismatch activity over the first round.
[0196]The best clones from the second round were combined with the best clones from the first round on a 96 well plate and were subjected to further screening.
[0197]The following table is a summary of the results.
TABLE-US-00005 ##STR00001## A1 is Tth polymerase A2 Tfl; A3 Taq; A4 M1; A5 M4; A6 H10 (see previous example 1A7 to 1D12 are first round clones (where 1 indicates that these are first round clones), 2E1 to 2H12 are second round clones (where 2 indicates that these are second round clones)
[0198]The best first and second round clones were shuffled as described above and subjected to another round of CSR. The same two sets of mismatch primers with four mismatches at their 3' end were used in the emulsion as two separate sources of selective pressure. This was then dealt with as above and the resultant clones were screened and ranked by PCR assay (as above). Once again, polymerases that could extend all of these mismatches were found. In particular, clones 3B5, 3B8, 3C12 and 3D1 (where 3 indicates that these are third round clones) were able to extend primers containing four mismatches. See FIG. 9
[0199]Some promising clones were sequenced. All of the polymerases displayed a similar composition: the first part of the protein, roughly corresponding to the 5-3 exonuclease domain of the polymerase, was derived from Tth, whilst the remaining part of the protein was derived from Taq. Four point mutations (L33→P, E78→K, D145→G and E822→K) re-occurred in the majority of sequenced mutants and one (B10) had acquired an extra 16 amino acids at its C terminus through a frame shift at position 2499. Tfl was highly underrepresented, although some of its sequence was present.
Example 9
Hairpin ELISA to Measure Polymerase Activity
[0200]The below protocol is a sensitive method to measure polymerase activity both for the incorporation of unnatural nucleotide substrates (added to the reaction mixture) or the extension or replication of unnatural nucleotide substrates (incorporated as part of the hairpin oligo).
[0201]The assay comprises a hairpin oligonucleotide which constitutes both primer and template in one. In contains as part of the hairpin a biotinylated dU residue, which allows capture of the hairpin oligonucleotide on streptavidin-coated surfaces.
[0202]The oligonucleotide folds up into a hairpin with a 5' overhang, which serves as the template strand for the polymerase (typical sequence: 5'-AGC TAC CAT GCC TGC ACG CAG TCG GCA TCC GTC GCG ACC ACG TT5 TTC GTG GTC GCG ACG GAT GCC G-3' (SEQ ID NO: 52), bases involved in hairpin formation are underlined, 3' base is in bold, 5=dU-biotin).
[0203]Extension reactions are carried out in the presence of small amounts of a labelled nucleotide typically DIG-16-dUTP. Product is captured (for example on a streptavidin coated ELISA plate) and incorporation of labelled nucleotide into the product strand is measured (using for example an anti-DIG antibody) and taken as a measure of polymerase activity.
Method:
[0204]Extension reactions are carried out in 1×Taq buffer including 1-100 nM of hairpin primer and 100 μM dNTP mixture (comprising 0.3-30% dUTP-DIG), typically incubated at 94° C. for 1-5 min, followed by incubation at 50° C. for 1-5 min, followed by incubation at 72° C. for 1-5 min. (1-10 μl) Reaction products are added to Streptavidin coated ELISA plates (Streptawell, Roche) in 200 μl PBS, 0.2% Tween20 (PBST) and incubated at room temperature for 10 min to 1 h. ELISA plates are washed 3× in PBST and 200 μl of anti-DIG-POD Fab2 fragment (Roche) diluted 1/2000 in PBST is added and the plate is incubated at room temperature for 10 min to 1 h. The plate is washed 3-4× in PBST and developed with an appropriate POD substrate.
Example 10
Hairpin-ELISAs to Test Nucleotide Analogue Incorporation by Mismatch Extension Clones
[0205]Clones previously selected for their ability to extend from a 4 basepair mismatch were assayed for their ability to incorporate a variety of nucleotide analogues.
[0206]Clones were grown at 30° C. overnight in 200 μl 2×TY+ampicillin (100 μg/ml).
[0207]A 150 μl (2×TY+ampicillin 100 μg/ml) overday culture was started from the overnight and grown for 3 hours at 37° C. After 3 hours protein expression was induced by the addition of 50 μl of 2×TY+anhydrous tetracycline (8 ng/ml) to the culture which was then allowed to grow for a further 3 h at 37° C. The cells were pelleted at 2254×g for 5 minutes and the growth medium removed by aspiration after which the cell pellet was resuspended in 100 μl 1×Taq buffer (10 mM Tris-HCl, pH 9.0, 1.5 mM MgCl2, 50 mM KCl, 0.1% Triton X-100, 0.01% (w/v) stabiliser; HT Biotechnology Ltd). Resuspended cells were lysed by incubation at 85° C. for 10 minutes and the cell debris was pelleted at 2254×g for 5 minutes.
ELISA Protocol:
Extension Reaction.
[0208]Reactions were performed in a final volume of 12.5 μl comprising: [0209]1×Taq buffer (10 mM Tris-HCl, pH 9.0, 1.5 mM MgCl2, 50 mM KCl, 0.1% Triton X-100, 0.01% (w/v) stabiliser; HT Biotechnology Ltd). [0210]50 pmoles of primer. [0211]25 μM of each dNTP (minus the nucleotide analogue) of which 10% (2.5 μM) of the dTTP is digoxigenin-11-dUTP and 90% (22.5 μM) is dTTP. [0212]25 μM the nucleotide analogue. [0213]2.5 μl of cell lysate.
[0214]The reaction conditions were: [0215]95° C. 5 minutes; 50° C. 5 minutes; 72° C. 5 minutes.
Detection Reaction:
[0216]5 μl of the extension reaction was added to 200 μl of PBS-Tween (1×PBS; 0.2% Tween 20) in StreptaWell high bind plates (Roche) and allowed to bind for 30 minutes at room temperature. The plate was washed 3× in PBS-Tween after which was added 200 μl PBS-Tween+anti-digioxigenin-POD Fab fragments (antibody diluted 1/2000; Roche). The antibody was allowed to bind for 30 minutes at room temperature.
[0217]The plate was washed 3× in PBS-Tween and 200 μl of the substrate added (per ml 100 μl of 1M NaAc pH 6.0, 10 μl of DAB, 1 μl of H2O2, the reaction was allowed to develop after which it was stopped by adding 100 μl of 1M H2SO4.
Experiment I. ELISA with Fluorescein 12-dATP:
[0218]The ability of clones selected for 4-mismatch extension to incorporate Fluorescein 12-dATP (Perkin Elmer) was assayed using the primer FITC4. The lysates used were concentrated 4-fold.
Experiment II. ELISA with Biotin 11-dATP:
[0219]The ability of clones selected for 4-mismatch extension to incorporate Biotin 11-dATP (Perkin Elmer) was assayed using the primer FITC10. The lysates used were concentrated 4-fold.
Experiment III. ELISA with CyDye 5-dCTP:
[0220]The ability of clones selected for 4-mismatch extension to incorporate Cy5-dCTP (Amersham Biosciences) was assayed using the primer ELISAC4P. The lysates used were concentrated 4-fold.
Experiment IV. ELISA with CyDye 3-dUTP:
[0221]The ability of clones selected for 4-mismatch extension to incorporate CyDye 3-dUTP (Amersham Biosciences) was assayed using the primer ELISAT3P. The lysates used were concentrated 4-fold. The DIG labelled dUTP in the extension reaction was replaced with Fluorescein 12-dATP and the incorporation of Fluorescein 12-dATP was detected by anti-Fluorescein-POD Fab fragments (Roche).
Experiment V. Abasic site ELISA
[0222]The ability of clones selected for 4-mismatch extension to bypass abasic sites was assayed using the primer Pscreen1Abas (AGC TAC CAT GCC TGC ACG CAG 1CG GCA TCC GTC GCG ACC ACG TT5 TTC GTG GTC GCG ACG GAT GCCG (SEQ ID NO: 53), 1=abasic site
5=dU biotin). The lysates used were concentrated 4-fold.
[0223]Clones selected for 4-mismatch extension were assayed for activity with different substrates using an ELISA assay.
A1=Tth Wild-type
A2=Tfl Wild-type
A3=Taq Wild-type
[0224]A4=Taq mutant M1A5=Taq mutant M4A6=Taq mutant H10Rows A-D Clones isolated after 1 round of 4-mismatch selectionRows E-H Clones Isolated After 2 Rounds of 4-mismatch Selection
[0225]The results are shown in FIG. 8.
Experiment V. Abasic Site and 5-hydroxyhydantoin Bypass
[0226]Polymerases 3A10 and 3D1 were investigated further for their ability to bypass abasic sites and 5-hydroxy hydantoins, which are both known to exist in damaged DNA such as found in ancient samples, using the ELISA based activity screen as described above. Both polymerases were more proficient at lesion bypass than wild type Taq by up to two orders of magnitude.
[0227]The hydantion phosphoramidite was synthesised by standard procedures starting from the hydantoin free base. Glycosylation of the silylated hydantoin base in the presence of tin(IV) chloride with the ditoluoyl(alpha) chlorosugar gave rise to two N-glycosylated products which were separated and characterised by 2D-NMR experiments. The tolyl groups were removed with ammonia to yield the free nucleoside which was dimethoxytritylated and phosphytylated in the usual manner. The hairpin primer to assay hydantoin bypass was: 5'-AGC TAC CAT GCC TGC ACG CAG XCG GCA TCC GTC GCG ACC ACG TTY TTC GTG GTC GCG ACG GAT GCC G-3' (SEQ ID NO: 54), X=hydantoin, Y=Biotin-dU.
[0228]The sequences of the clones referred to in Examples are shown below: For the avoidance of any doubt, the first sequence provided in each section is the nucleic acid sequence. The second sequence provided is the corresponding amino acid sequence of the clone.
TABLE-US-00006 2F3: ATGGCGATGCTTCCCCTCTTTGAGCCCAAGGGCCGCGTCCTCCTGGTGGACGGCCACCACCTGGCCTACCGCAC- CTTCTT (SEQ ID NO: 55) CGCCCTGAAGGGCCCCACCACGAGCCGGGGCGAACCGGTGCAGGTGGTCTACGGCTTCGCCAAGAGCCTCCTCA- AGGCC CTGAAGGAGGACGGGTACAAGGCCGTCTTCGTGGTCTTTGACGCCAAGGCCCCCTCATTCCGCCACAAGGCCTA- CGAGG CCTACAGGGCGGGGAGGGCCCCGACCCCCGAGGACTTCCCCCGGCAGCTCGCCCTCATCAAGGAGCTGGTGGAC- CTCCT GGGGTTTACCCGCCTCGAGGTCCCCGGCTACGAGGCGGACGACGTTCTCGCCACCGTGGCCAAGAAGGCGGAAA- AGGA GGGGTACGAGGTGGGCATCCTCACCGCCGACCGCGGCCTCTACCAACTCGTCTCTGACCGCGTCGCCGTCCTCC- ACCCCG AGGGCCACCTCATCACCCCGGAGTGGCTTTGGGAGAAGTACGGCCTCAGGCCGGAGCAGTGGGTGGACTTCCGC- GCCCT CGTGGGGGACCCCTCCGACAACCTCCCCGGGGTCAAGGGCATCGGGGAGAAGACCGCCCTCAAGCTCCTCAAGG- AGTG GGGAAGCCTGGAAAACCTCCTCAAGAACCTGGACCGGGTAAAGCCAGAAAACGTCCGGGAGAAGATCAAGGCCC- ACCT GGAAGACCTCAGGCTCTCCTTGGAGCTCTCCCGGGTGCGCACCGACCTCCCCCTGGAGGTGGACCTCGCCCAGG- GGCGG GAGCCCGACCGGGAGGGGCTTAGGGCCTTTCTGGAGAGGCTTGAGTTTGGCAGCCTCCTCCACGAGTTCGGCCT- TCTGG AAAGCCCCAAGGCCCTGGAGGAGGCCCCCTGGCCCCCGCCGGAAGGGGCCTTCGTGGGCTTTGTGCTTTCCCGC- AAGGA GCCCATGTGGGCCGATCTTCTGGCCCTGGCCGCCGCCAGGGGGGGCCGGGTCCACCGGGCCCCCGAGCCTTATA- AAGCC CTCAGAGACCTGAAGGAGGCGCGGGGGCTTCTCGCCAAAGACCTGAGCGTTCTGGCCCTGAGGGAAGGCCTTGG- CCTCC CGCCCGGCGACGACCCCATGCTCCTCGCCTACCTCCTGGACCCTTCCAACACCACCCCCGAGGGGGTGGCCCGG- CGCTA CGGCGGGGAGTGGACGGAGGAGGCGGGGGAGCGGGCCGCCCTTTCCGAGAGGCTCTTCGCCAACCTGTGGGGGA- GGCT TGAGGGGGAGGAGAGGCTCCTTTGGCTTTACCGGGAGGTGGAGAGGCCCCTTTCCGTTGTCCTGGCCCACATGG- AGGCC ACAGGGGTGCGCCTGGACGTGGCCTATCTCAGGGCCTTGTCCCTGGAGGTGGCCGAGGAGATCGCCCGCCTCGA- GGCCG AGGTCTTCCGCCTGGCCGGCCACCCCTTCAACCTCAACTCCCGGGACCAGCTGGAAAGGGTCCTCTTTGACGAG- CTAGG GCTTCCCGCCATCGGCAAGACGGAGAAGACCGGCAAGCGCTCCACCGGCGCCGCCGTCCTGGAGGCCCTCCACG- AGGC CCACCCCATCGTGGAGAAGATCCTGCAGTACCGGGAGCTCACCAAGCTGAAGAGCACCTACATTGACCCCTTGC- CGGAC CTCATCCACCCCAGGACGGGCCGCCTCCACACCCGCTTCAACCAGACGGCCACGGCCACGGGCAGGCTAAGTAG- CTCCG ATCCCAACCTCCAGAACATCCCCGTCCGCACCCAGCTTGGGCAGAGGATCCGCCGGGCCTTCATCGCCGAGGAG- GGGTG GCTATTGGTGGTCCTGGACTATAGCCAGATAGAGCTCAGGGTGCTGGCCCACCTCTCCGGCGACGAGAACCTGA- TCCGG GTCTTCCAGGAGGGGCGGGACATCCACACGGAAACCGCCAGCTGGATGTTCGGCGTCCCCCAGGAGGCCGTGGA- CCCCC TGATGCGCCGGGCGGCCAAGACCATCAACTTCGGGGTTCTCTACGGCATGTCGGCCTACCGCCTCTCCCAGGAG- CTAGC CATCCCTTACGAGGAGGCCCAGGCCTTCATTGAGCGCTACTTTCAGAGCTTCCCCAAGGTGCGGGCCTGGATTG- GGAAG ACCCTGGAGGAGGGCAGGAGGCGGGGGTACGTGGAGACCCTCTTCGGCCGCCGCCGCTACGTGCCAGACCTAGA- GGCC CGGGTGAAGAGCGTGCGGGAGGCGGCCGAGCGCATGGCCTTCAACACGCCCGTCCAGGGCACCGCCGCCGACCT- CATG AAGCTAGCTATGGTGAAGCTCTTCCCCAGGCTGGAGGAAATGGGGGCCAGGATGCTCCTTCAGGTCCACGACGA- GCTGG TCCTCGAGGCCCCAAAAGAGAGGGCGGAGGCCGTGGCCCGGCTGGCCAAGGAGGTCATGGAGGGGGTGTATCCC- CTGG CCGTGCCCCTGGAGGTGGAGGTGGGGATAGGGGAGGACTGGCTCTCCGCCAAGGAGTGA MAMLPLFEPKGRVLLVDGHHLAYRTFFALKGPTTSRGEPVQVVYGFAKSLLKALKEDGYKAVFVVFDAKAPSFR- HKAYEAY (SEQ ID NO: 56) RAGRAPTPEDFPRQLALIKELVDLLGFTRLEVPGYEADDVLATVAKKAEKEGYEVGILTADRGLYQLVSDRVAV- LHPEGHLIT PEWLWEKYGLRPEQWVDFRALVGDPSDNIPGVKGIGEKTALKLLKEWGSLENLLKNLDRVKPENVREKIKAHLE- DLRLSLE LSRVRTDLPLEVDLAQGREPDREGLRAFLERLEFGSLLHEFGLLESPKALEEAPWPPPEGAFVGFVLSRKEPMW- ADLLALAAA RGGRVHRAPEPYKALRDLKEARGLLAKDLSVLALREGLGLPPGDDPMLLAYLLDPSNTTPEGVARRYGGEWTEE- AGERAAL SERLFANLWGRLEGEERLLWLYREVERPLSVVLAHMEATGVRLDVAYLRALSLEVAEEIARLEAEVFRLAGHPF- NLNSRDQL ERVLFDELGLPAIGKTEKTGKRSTGAAVLEALHEAHPIVEKILQYRELTKLKSTYIDPLPDLIHPRTGRLHTRF- NQTATATGRLS SSDPNIQNIPVRTQLGQRIRRAFIAEEGWLLVVLDYSQIELRVLAHLSGDENIRVFQEGRDIHTETASWMFGVP- QEAVDPLMR RAAKTINFGVLYGMSAYRLSQELAIPYEEAQAFIERYFQSFPKVRAWIGKTLEEGRRRGYVETLFGRRRYVPDL- EARVKSVRE AAERMAFNTPVQGTAADLMKLAMVKLFPRLEEMGARMLLQVHDELVLEAPKERAEAVARLAKEVMEGVYPLAVP- LEVEV GIGEDWLSAKE* 1A10: ATGCGTGGTATGCCTCCTCTTTTTGAGCCCAAGGGCCGCGTCCTCCTGGTGGACGGCCACCTGGCCTACCGCAC- CTTCTT (SEQ ID NO: 57) CGCCCTGAAGGGCCCCACCACGAGCCGGGGCGAACCGGTGCAGGCGGTCTACGGCTTCGCCAAGAGCCTCCTCA- AGGC CCTGAAGGAGGACGGGTACAAGGCCGTCTTCGTGGTCTTTGACGCCAAGGCCCCCTCCCTCCGCCACGAGGCCT- ACGAG GCCTACAAGGCGGGGAGGGCCCCGACCCCCGAGGACTTCCCCCGGCAGCTCGCCCTCATCAAGGAGCTGGTGGA- CCTCC TGGGGTTTACCCGCCTCGAGGTCCCCGGCTACGAGGCGGACGACGTTCTCGCCACCCTGGCCAAGAAGGCGGAA- AAGGA GGGGTACGAGGTGCGCATCCTCACCGCCGACCGCGACCTCTACCAACTCGTCTCCGACCGCGTCGCCGTCCTCC- ACCCCG AGGGCCACCTCATCACCCCGGAGTGGCTTTGGGAGAAGTACGGCCTCAGGCCGGAGCAGTGGGTGGACTTCCGC- GCCCT CGTGGGGGACCCCTCCGACAACCTCCCCGGGGTCAAGGGCATCGGGGAGAGGACCGCCCTCAAGCTCCTCAAGG- AGTG GGGAAGCCTGGAAAACCTCCTCAAGAACCTGGACCGGGTAAAGCCAGAAAACGTCCGGGAGAAGATCAAGGCCC- ACCT GGAAGACCTCAGGCTCTCCTTGGAGCTCTCCCGGGTGCGCACCGACCTCCCCCTGGAGGTGGACCTCGCCCAGG- GGCGG GAGCCCGACCGGGAGAGGCTTAGGGCCTTTCTGGAGAGGCTTGAGTTTGGCAGCCTCCTCCACGAGTTCGGCCT- TCTGG AAAGCCCCAAGGCCCTGGAGGAGGCCCCCTGGCCCCCGCCGGAAGGGGCCTTCGTGGGCTTTGTGCTTTCCCGC- AAGGA GCCCATGTGGGCCGATCTTCTGGCCCTGGCCGCCGCCAGGGGTGGTCGGGTCCACCGGGCCCCCGAGCCTTATA- AAGCC CTCAGGGACTTGAAGGAGGCGCGGGGGCTTCTCGCCAAAGACCTGAGCGTTCTGGCCCTAAGGGAAGGCCTTGG- CCTCC CGCCCGGCGACGACCCCATGCTCCTCGCCTACCTCCTGGACCCTTCCAACACCACCCCCGAGGGGGTGGCCCGG- CGCTA CGGCGGGGAGTGGACGGAGGAGGCGGGGGAGCGGGCCGCCCTTTCCGAGAGGCTCTTCGCCAACCTGTGGGGGA- AGCT TGAGGGGGAGGAGAGGCTCCTTTGGCTTTACCGGGAGGTGGATAGGCCCCTTTCCGCTGTCCTGGCCCACATGG- AGGCC ACAGGGGTGCGCCTGGACGTGGCCTATCTCAGGGCCTCGTCCCTGGAGGTGGCCGAGGAGATCGCCCGCCTCGA- GGCCG AGGTCTTCCGCCTGGCCGGCCACCCCTTCAACCTCAACTCCCGGGACCAGCTGGAAAGGGTCCTCTTTGACGAG- CTAGG GCTTCCCGCCATCGGCAAGACGGAGAAGACCGGCAAGCGCTCCACCAGCGCCGCCGTCCTGGAGGCCCTCCGCG- AGGC CCACCCCATCGTGGAGAAGATCCTGCAGTACCGGGAGCTCACCAAGCTGAAGAGCACCTACATTGACCCCTTGC- CGGAC CTCATCCACCCCAGGACGGGCCGCCTCCACACCCGCTTCAACCAGACGGCCACGGCCACAGGCAGGCTAAGTAG- CTCCG ATCCCAACCTCCAGAACATCCCCGTCCGCACCCCGCTTGGGCAGAGGATCCGCCGGGCCTTCATCGCCGAGGAG- GGGTG GCTATTGGTGGCCCTGGACTATAGCCAGATAGAGCTCAGGGTGCTGGCCCACCTCTCCGGCGACGAGAACCTGA- TCCGG GTCTTCCAGGAGGGGCGGGACATCCACACGGAGACCGCCAGTTGGATGTTCGGCGTCCCCCGGGAGGCCGTGGA- CCCCC TGATGCGCCGGGCGGCCAAGACCATCAACTTCGGGGTCCTCTACGGCATGTCGGCCCGCCGCCTCTCCCAGGAG- CTAGC CATCCCTTACGAGGAGGCCCAGGCCTTCATTGAGCGCTACTTTCAGAGCTTCCCCAAGGTGCGGGCCTGGATTG- AGAAG ACCCTGGAGGAGGGCAGGAGGCGGGGGTACGTGGAGACCCTCTTCGGCCGCCGCCGCTACGTGCCAGACCTAGA- GGCC CGGGTGAAGAGCGTGCGGGAGGCGGCCGAGCGCATGGCCTTCAACATGCCCGTCCAGGGCACCGCCGCCGACCT- CATG AAGCTGGCTATGGTGAAGCTCTTCCCCAGGCTGGAGGAAATGGGGGCCAGGATGCTCCTTCAGGTCCACGACGA- GCTGG TCCTCGAGGCCCCAAAAGAGAGGGCGGAGGCCGTGGCCCGGCTGGCCAAGGAGGTCATGGAGGGGGTGTATCCC- CTGG CCGTGCCCCTGGAGGTGGAGGTGGGGATAGGGGAGGACTGGCTCTCCGCCAAGGAGTGA MRGMPPLFEPKGRVLLVDGHLAYRTFFALKGPTTSRGEPVQAVYGFAKSLLKALKEDGYKAVFVVFDAKAPSLR- HEAYEAY (SEQ ID NO: 58) KAGRAPTPEDFPRQLALIKELVDLLGFTRLEVPGYEADDVLATLAKKAEKEGYEVRILTADRDLYQLVSDRVAV- LHPEGHLIT PEWLWEKYGLRPEQWVDFRALVGDPSDNLPGVKGIGERTALKLLKEWGSLENLLKNLDRVKPENVREKIKAHLE- DLRLSLE LSRVRTDLPLEVDLAQGREPDRERLRAFLERLEFGSLLHEFGLLESPKALEEAPWPPPEGAFVGFVLSRKEPMW- ADLLALAAA RGGRVHRAPEPYKALRDLKEARGLLAKDLSVLALREGLGLPPGDDPMLLAYLLDPSNTTPEGVARRYGGEWTEE- AGERAAL SERLFANLWGKLEGEERLLWLYREVDRPLSAVLAHMEATGVRLDVAYLRASSLEVAEEIARLEAEVFRLAGHPF- NLNSRDQL ERVLFDELGLPAIGKTEKTGKRSTSAAVLEALREAHPIVEKILQYRELTKLKSTYIDPLPDLIHPRTGRLHTRF- NQTATATGRLS SSDPNLQNIPVRTPLGQRIRRAFIAEEGWLLVALDYSQIELRVLAHLSGDENLIRVFQEGRDIHTETASWMFGV- PREAVDPLMR RAAKTINFGVLYGMSARRLSQELAIPYEEAQAFIERYFQSFPKVRAWIEKTLEEGRRRGYVETLFGRRRYVPDL- EARVKSVRE
AAERMAFNMPVQGTAADLMKLAMVKLFPRLEEMGARMLLQVHDELVLEAPKERAEAVARLAKEVMEGVYPLAVP- LEVEV GIGEDWLSAKE* 1A9: ATGCGTGGTATGCATCCTCTTTTTGAGCCCAAGGGCCGCGTCCTCCTGGTGGACGGCCACCACCTGGCCTACCG- CACCTT (SEQ ID NO: 59) CCACGCCCTGAAGGGGCTCACCACCAGCCGGGGGGAGCCGGTGCGGGCGGTCCACGGCTTCGCCAAGAGCCTCC- TCAA GGCCCTGAAGGAGGACGGGTACAAGGCCGTCTTCGTGGTCTTTGACGCCAAGGCCCCCTCCTTCCGCCACGAGG- CCTAC GAGGCCTACAAGGCGGGGAGGGCCCCGACCCCCGAGGACTTCCCCCGGCAGCTCGCCCTCATCAAGGAGCTGGT- GGAC CTCCTGGGGTTTACCCGCCTCGAGGTCCCCGGCTACGAGGCGGACGACGTTCTCGCCACCCTGGCCAAGAAGGC- GGAAA AGGAGGGGTACGAGGTGCGCATCCTCACCGCCGACCGCGACCTCTACCAACTCGTCTCCGACCGCGTCGCCGTC- CTCCA CCCCGAGGGCCACCTCATCACCCCGGAGTGGCTTTGGGAGAAGTACGGCCTCAGGCCGGAGCAGTGGGTGGACT- TCCGC GCCCTCGTGGGGGACCCCTCCGACAACCTCCCCGGGGTCAAGGGCATCGGGGAGAAGACCGCCCTCAAGCTCCT- CAAGG AGTGGGGAAGCCTGGAAAACCTCCTCAAGAACCTGGACCGGCTGAAGCCCGCCATCCGGGAGAAGATCCTGEiC- CCACA TGGACGATCTGAAGCTCTCCTGGGACCTGGCCAAGGTGCGCACCGACCTGCCCCTAGAGGTGGACTTCGCCAAA- AGGCG GGAGCCCGACCGGGAGAGGCTTAGGGCCTTTCTGGAGAGGCTTGAGCTTGGCAGCCTCCTCCACGAGTTCGGCC- TTCTG GAAAGCCCCAAGACCCTGGAGGAGGCCTCCTGGCCCCCGCCGGAAGGGGCCTTCGTGGGCTTTGTGCTTTCCCG- CAAGG AGCCCATGTGGGCCGATCTTCTGGCCCTGGCCGCCGCCAGGGGGGGCCGGGTCCACCGGGCCCCCGAGCCTTAT- AAAGC CCTCAGAGACCTGAAGGAGGCGCGGGGGCTTCTCGCCAAAGACCTGAGCGTTCTGGCCCTGAGGGAAGGCCTTG- GCCTC CCGCCCGGCGACGACCCCATGCTCCTCGCCTACCTCCTGGACCCTTCCAACACCACCCCCGAGGGGGTGGCCCG- GCGCT ACGGCGGGGAGTGGACGGAGGAGGCGGGGGAGCGGGCCGCCCTTTCCGAGAGGCTCTTCGCCAACCTGTGGGGG- AGGC TTGAGGGGGAGGAGAGGCTCCTTTGGCTTTACCGGGAGGTGGAGAGGCCCCTTTCCGTTGTCCTGGCCCACATG- GAGGC CACAGGGGTGCGCCTGGACGTGGCCTATCTCAGGGCCTTGTCCCTGGAGGTGGCCGAGGAGATCGCCCGCCTCG- AGGCC GAGGTCTTCCGCCTGGCCGGCCACCCCTTCAACCTCAACTCCCGGGACCAGCTGGAAAGGGTCCTCTTTGACGA- GCTAG GGCTTCCCGCCATCGGCAAGACGGAGAAGACCGGCAAGCGCTCCACCGGCGCCGCCGTCCTGGAGGCCCTCCGC- GAGG CCCACCCCATCGTGGAGAAGATCCTGCAGTACCGGGAGCTCACCAAGCTGAAGAGCACCTACATTGACCCCTTG- CCGGA CCTCATCCACCCCAGGACGGGCCGCCTCCACACCCGCTTCAACCAGACGGCCACGGCCACGGGCAGGCTAAGTA- GCTCC GATCCCAACCTCCAGAACATCCCCGTCCGCACCCAGCTTGGGCAGAGGATCCGCCGGGCCTTCATCGCCGAGGA- GGGGT GGCTATTGGTGGTCCTGGACTATAGCCAGATAGAGCTCAGGGTGCTGGCCCACCTCTCCGGCGACGAGAACCTG- ATCCG GGTCTTCCAGGAGGGGCGGGACATCCACACGGAAACCGCCAGCTGGATGTTCGGCGTCCCCCAGGAGGCCGTGG- ACCCC CTGATGCGCCGGGCGGCCAAGACCATCAACTTCGGGGTTCTCTACGGCATGTCGGCCTACCGCCTCTCCCAGGA- GCTAG CCATCCCTTACGAGGAGGCCCAGGCCTTCATTGAGCGCTACTTTCAGAGCTTCCCCAAGGTGCGGGCCTGGATT- GGGAA GACCCTGGAGGAGGGCAGGAGGCGGGGGTACGTGGAGACCCTCTTCGGCCGCCGCCGCTACGTGCCAGACCTAG- AGGC CCGGGTGAAGAGCGTGCGGGAGGCGGCCGAGCGCATGGCCTTCAACACGCCCGTCCAGGGCACCGCCGCCGACC- TCAT GAAGCTGGCTATGGTGAAGCTCTTCCCCAGGCTGGAGGAAATGGGGGCCAGGATGCTCCTTCAGGTCCACGACG- AGCTA GTCCTCGAGGCCCCAAAAGAGAGGGCGGAGGCCGTGGCCCGGCTGGCCAAGGAGGTCATGGAGGGGGTGTATCC- CCTG GCCGTGCCCCTGGAGGTGGAGGTGGGGATAGGGGAGGACTGGCTCTCCGCCAAGGAGTGA MRGMHPLFEPKGRVLLVDGHHLAYRTFHALKGLTTSRGEPVRAVHGFAKSLLKALKEDGYKAVFVVFDAKAPSF- RHEAYEA (SEQ ID NO: 60) YKAGRAPTPEDFPRQLALIKELVDLLGFTRLEVPGYEADDVLATLAKKAEKEGYEVRILTADRDLYQLVSDRVA- VLHPEGHLI TPEWLWEKYGLRPEQWVDFRALVGDPSDNLPGVKGIGEKTALKLLKEWGSLENLLKNLDRLKPAIREKILAHMD- DLKLSWD LAKVRTDLPLEVDFAKRREPDRERLRAFLERLELGSLLHEFGLLESPKTLEEASWPPPEGAFVGFVLSRKEPMW- ADLLALAAA RGGRVHRAPEPYKALRDLKEARGLLAKDLSVLALREGLGLPPGDDPMLLAYLLDPSNTTPEGVARRYGGEWTEE- AGERAAL SERLFANLWGRLEGEERLLWLYREVERPLSVVLAHMEATGVRLDVAYLRALSLEVAEEIARLEAEVFRLAGHPF- NLNSRDQL ERVLFDELGLPAIGKTEKTGKRSTGAAVLEALREAHPIVEKILQYRELTKLKSTYIDPLPDLIHPRTGRLHTRF- NQTATATGRLS SSDPNLQNIPVRTQLGQRIRRAFIAEEGWLLVVLDYSQIELRVLAHLSGDENLIRVFQEGRDIHTETASWMFGV- PQEAVDPLMR RAAKTINFGVLYGMSAYRLSQELAIPYEEAQAFIERYFQSFPKVRAWIGKTLEEGRRRGYVETLFGRRRYVPDL- EARVKSVRE AAERMAFNTPVQGTAADLMKLAMVKLFPRLEEMGARMLLQVHDELVLEAPKERAEAVARLAKEVMEGVYPLAVP- LEVEV GIGEDWLSAKE* 2F12: ATGCGTGGTATGCTTCCTCTTTTTGAGCCCAAGGGCCGCGTCCTCCTGGTGGACGGCCACCACCTGGCCTACCG- CACCTT (SEQ ID NO: 61) CTTCGCCCTGAAGGGCCTCACCACGAGCCGGGGCGAACCGGTGCAGGCGGTCTACGGCTTCGCCAAGAGCCTCC- TCAAG GCCCTGAAGGAGGACGGGTACAAGGCCGTCTTCGTGGTCTTTGACGCCAAGGCCCCCTCCCTCCGCCACGAGGC- CTACG AGGCCTACAAGGCGGGGAGGGCCCCGACCCCCGAGGACTTCCCCCGGCAGCTCGCCCTCATCAAGGAGCTGGTG- GACCT CCTGGGGTTTACCCGCCTCGAGGTCCCCGGCTACGAGGCGGACGACGTTCTCGCCACCCTGGCCAAGAAGGCGG- AAAAG GAGGGGTACGAGGTGCGCATCCTCACCGCCGACCGCGACCTCTACCAACTCGTCTCCGACCGCGTCGCCGTCCT- CCACC CCGAGGGCCACCTCATCACCCCGGAGTGGCTTTGGGAGAAGTACGGCCTCAGGCCGGAGCAGTGGGTGGACTTC- CGCGC CCTCGTGGGGGACCCCTCCGACAACCTCCCCGGGGTCAAGGGCATCGGGGAGAAGACCGCCCTCAAGCTCCTCA- AGGAG TGGGGAAGCCTGGAAAACCTCCTCAAGAACCTGGACCGGCTGAAGCCCGCCATCCGGGAGAAGATCCTGGCCCA- CATG GACGATCTGAAGCTCTCCTGGGACCTGGCCAAGGTGCGCACCGACCTGCCCCTGGAGGTGGACTTCGCCAAAAG- GCGGG AGCCCGACCGGGAGAGGCTTAGGGCCTTTCTGGAGAGGCTTGAGCTTGGCAGCCTCCTCCACGAGTTCGGCCTT- CTGGA AAGCCCCAAGGCCCTGGAGGAGGCCTCCTGGCCCCCGCCGGAAGGGGCCTTCGTGGGCTTTGTGCTTACCCGCA- AGGAG CCCATGTGGGCCGATCTTCTGGCCCTGGCCGCCGCCAGGGGGGGCCGGGTCCACCGGGCCCCCGAGCCTTATAA- AGCCC TCAGGGACCTGAAGGAGGCGCGGGGGCTTCTCGCCAAAGACCTGAGCGTTCTGGCCCTGAGGGAAGGCCTTGGC- CTCCC GCCCGGCGACGACCCCATGCTCCTCGCCTACCTCCTGGACCCTTCCAACACCACCCCCGAGGGGGTGGCCCGGC- GCTAC GGCGGGGAGTGGACGGAGGAGGCGGGGGAGCGGGCCGCCCTTTCCGAGAGGCTCTTCGCCAACCTGTGGGGGAG- GCTT GAGGGGGAGGAGAGGCTCCTTTGGCTTTACCGGGAGGTGGAGAGACCCCTTTCCGCTGTCCTGGCCCACATGGA- GGCCA CGGGGGTGCGCCTGGACGTGGCCTATCTCAGGGCCTTGTCCCTGGAGGTGGCCGAGGAGATCGCCCGCCTCGAG- GCCGA GGTCTTCCGCCTGGCCGGCCACCCCTTCAACCTCAACTCCCGAGACCAGCTGGAAAGGGTCCTCTTTGACGAGC- TAGGGC TTCCCGCCATCGGCAAGACGGAGAAGACCGGCAAGCGCTCCACCAGCGCCGCCGTCCTGGAGGCCCTCCGCGAG- GCCC ACCCCATCGTGGAGAAGATCCTGCAGTACCGGGAGCTCACCAAGCTGAAGAGCACCTACATTGACCCCTTGCCG- GACCT CATCCACCCCAGGACGGGCCGCCTCCACACCCGCTTCAACCAGACGGCCACGGCCACGGGCAGGCTAAGTAGCT- CCGAT CCCAACCTCCAGAACATCCCCGTCCGCACCCCGCTTGGGCAGAGGATCCGCCGGGCCTTCATCGCCGAGGAGGG- GTGGC TATTGGTGGCCCTGGACTATAGCCAGATAGAGCTCAGGGTGCTGGCCCACCTCTCCGGCGACGAGAACCTGATC- CGGGT CTTCCAGGAGGGGCGGGACATCCACACGGAGACCGCCAGCTGGATGTTCGGCGTCCCCCEiGGAGGCCGTGGAC- CCCCTG ATGCGCCGGGCGGCCAAGACCATCAACTTCGGGGTCCTCTACGGCATGTCGGCCCACCGCCTCTCCCAGGAGCT- AGCCA TCCCTTACGAGGAGGCCCAGGCCTTCATTGAGCGCTACTTTCAGAGCTTCCCCAAGGTGCGGGCCTGGATTGAG- AAGAC CCTGGAGGAGGGCAGGAGGCGGGGGTACGTGGAGACCCTCTTCGGCCGCCGCCGCTACGTGCCAGACCTAGAGG- CCCG GGTGAAGAGCGTGCGGGAGGCGGCCGAGCGCATGGCCTTCAACATGCCCGTCCAGGGCACCGCCGCCGACCTTA- TGAA GCTCGCCATGGTGAAGCTCTTCCCCCGCCTCCGGGAGATGGGGGCCCGCATGCTCCTCCAGGTCCACGACGAGC- TCCTCC TGGAGGCCCCCCAAGCGCGGGCCGAGGAGGTGGCGGCTTTGGCCAAGGAGGCCATGGAGAAGGCCTATCCCCTC- GCCG TACCCCTGGAGGTGAAGGTGGGGATCGGGGAGGACTGGCTCTCCGCCAAGGAGTGA MRGMLPLFEPKGRVLLVDGHHLAYRTFFALKGLTTSRGEPVQAVYGFAKSLLKALKEDGYKAVFVVFDAKAPSL- RHEAYEA (SEQ ID NO: 62) YKAGRAPTPEDFPRQLALIKELVDLLGFTRLEVPGYEADDVLATLAKKAEKEGYEVRILTADRDLYQLVSDRVA- VLHPEGHLI TPEWLWEKYGLRPEQWVDFRALVGDPSDNIPGVKGIGEKTALKLLKEWGSLENLLKNLDRLKPAIREKILAHMD- DLKLSWD LAKVRTDLPLEVDFAKRREPDRERLRAFLERLELGSLLHEFGLLESPKALEEASWPPPEGAFVGFVLTRKEPMW- ADLLALAAA RGGRVHRAPEPYKALRDLKEARGLLAKDLSVLALREGLGLPPGDDPMLLAYLLDPSNTTPEGVARRYGGEWTEE- AGERAAL SERLFANLWGRLEGEERLLWLYREVERPLSAVLAHMEATGVRLDVAYLRALSLEVAEEIARLEAEVFRLAGHPF- NLNSRDQL ERVLFDELGLPAIGKTEKTGKRSTSAAVLEALREAHPIVEKILQYRELTKLKSTYIDPLPDLIHPRTGRLHTRF- NQTATATGRLS
SSDPNLQNIPVRTPLGQRIRRAFIAEEGWLLVALDYSQIELRVLAHLSGDENLIRVFQEGRDIHTETASWMFGV- PREAVDPLMR RAAKTINFGVLYGMSAHRLSQELAIPYEEAQAFIERYFQSFPKVRAWIEKTLEEGRRRGYVETLFGRRRYVPDL- EARVKSVRE AAERMAFNMPVQGTAADLMKLAMVKLFPRLREMGARMLLQVHDELLLEAPQARAEEVAALAKEAMEKAYPLAVP- LEVKV GIGEDWLSAKE* 1C2: ATGGCGATGCTTCCCCTCTTTGAGCCCAAGGGCCGCGTCCTCCTGGTGGACGGCCACCACCTGGCCTACCGCAC- CTTCTT (SEQ ID NO: 63) CGCCCTGAAGGGCCCCACCACGAGCCGGGGCGAACCGGTGCAGGTGGTCTACGGCTTCGCCAAGAGCCTCCTCA- AGGCC CTGAAGGAGGACGGGTACAAGGCCGTCTTCGTGGTCTTTGACGCCAAGGCCCCCTCATTCCGCCACAAGGCCTA- CGAGG CCTACAGGGCGGGGAGGGCCCCGACCCCCGAGGACTTCCCCCGGCAGCTCGCCCTCATCAAGGAGCTGGTGGAC- CTCCT GGGGTTTACCCGCCTCGAGGTCCCCGGCTACGAGGCGGACGACGTTCTCGCCACCCTGGCCAAGAAGGCGGAAA- AGGA GGGGTACGAGGTGCGCATCCTCACCGCCGACCGCGGCCTATACCAACTCGTCTATGACCGCGTCGCCGTCCTCC- ACCCC GAGGGCCACCTCATCACCCCGGAGTGGCTTTGGGAGAAGTACGGCCTCAGGCCGGAGCAGTGGGTGGACTTCCG- CGCCC TCGTGGGGGACCCCTCCGACAACCTCCCCGGGGTCAAGGGCATCGGGGAGAAGACCGCCCTCAAGCTCCTCAAG- GAGTG GGGAAGCCTGGAAAACCTCCTCAAGAACCTGGACCGGGTAAAGCCAGAAAACGTCCGGGAGAAGATCAAGGCCC- ACCT GGAAGACCTCAGGCTCTCCTTGGAGCTCTCCCGGGTGCGCACCGACCTCCCCCTGGAGGTGGACCTCGCCCAGG- GGCGG GAGCCCGACCGGGAGGGGCTTAGGGCCTTTCTGGAGAGGCTTGAGTTTGGCAGCCTCCTCCACGAGTTCGGCCT- TCTGG AAAGCCCCAAGGCCCTGGAGGAGGCCCCCTGGCCCCCGCCGGAAGGGGCCTTCGTGGGCTTTGTGCTTTCCCGC- AAGGA GCCCATGTGGGCCGATCTTCTGGCCCTGGCCGCCGCCAGGGGTGGTCGAGTCCACCGGGCCCCCGAGCCTTATA- AAGCC CTCAGGGACCTGAAGGAGGCGCGGGGGCTTCTCGCCAAAGACCTGAGCGTTCTGGCCCTAAGGGAAGGCCTTGG- CCTCC CGCCCGGCGACGACCCCATGCTCCTCGCCTACCTCCTGGACCCTTCCAACACCACCCCCGAGGGGGTGGCCCGG- CGCTA CGGCGGGGAGTGGACGGAGGAGGCGGGGGAGCGGGCCGCCCTTTCCGAGAGGCTCTTCGCCAACCTGTGGGGGA- GGCT TGAGGGGGAGGAGAGGCTCCTTTGGCTTTACCGGGAGGTGGAGAGGCCCCTTTCCGCTGTCCTGGCCCACATGG- AGGCC ACGGGGGTGCGCCTGGACGTGGCCTATCTCAGGGCCTTGTCCCTGGAGGTGGCCGAGGAGATCGCCCGCCTCGA- GGCCG AGGTCTTCCGCCTGGCCGGCCACCCCTTCAACCTCAACTCCCGGGACCAGCTGGAAATGGTGCTCTTTGACGAG- CTTAGG CTTCCCGCCTTGGGGAAGACGCAAAAGACGGGCAAGCGCTCCACCAGCGCCGCCGTCCTGGAGGCCCTCCGCGA- GGCCC ACCCCATCGTGGAGAAGATCCTGCAGTACCGGGAGCTCACCAAGCTGAAGAGCACCTACATTGACCCCTTGTCG- GACCT CATCCACCCCAGGACGGGCCGCCTCCACACCCGCTTCAACCAGACGGCCACGGCCACGGGCAGGCTAAGTAGCT- CCGAT CCCAACCTCCAGAACATCCCCGTCCGCACCCCGCTTGGGCAGAGGATCCGCCGGGCCTTCATCGCCGAGGAGGG- GTGGC TACTGGTGGTCCTGGACTATAGCCAGATAGAGCTCAGGGTGCTGGCCCACCTCTCCGGCGACGAAAACCTGATC- AGGGT CTTCCAGGAGGGGCGGGACATCCACACGGAGACCGCCAGCTGGATGTTCGGCGTCCCCCGGGAGGCCGTGGACC- CCCTG ATGCGCCGGGCGGCCAAGACCATCAACTTCGGGGTCCTCTACGGCATGTCGGCCCACCGCCTCTCCCAGGAGCT- AGCCA TCCCTTACGAGGAGGCCCAGGCCTTCATTGAGCGCTACTTTCAGAGCTTCCCCAAGGTGCGGGCCTGGATTGAG- AAGAC CCTGGAGGAGGGCAGGAGGCGGGGGTACGTGGAGACCCTCTTCGGCCGCCGCCGCTACGTGCCAGACCTAGAGG- CCCG GGTGAAGAGCGTGCGGGAGGCGGCCGAGCGCATGGCCTTCAACATGCCCGTCCAGGGCACCGCCGCCGACCTCA- TGAA GCTGGCTATGGTGAAGCTCTTCCCCAGGCTGGAGGAAATGGGGGCCAGGATGCTCCTTCAGGTCCACGACGAGC- TGGTC CTCGAGGCCCCAAAAGAGAGGGCGGAGGCCGTGGCCCGGCTGGCCAAGGAGGTCATGGAGGGGGTGTATCCCCT- GGCC GTGCCCCTGGAGGTGGAGGTGGGGATAGGGGAGGACTGGCTCTCCGCCAAGGAGTGA MAMLPLFEPKGRVLLVDGHHLAYRTFFALKGPTTSRGEPVQVVYGFAKSLLKALKEDGYKAVFVVFDAKAPSFR- HKAYEAY (SEQ ID NO: 64) RAGRAPTPEDFPRQLALIKELVDLLGFTRLEVPGYEADDVLATLAKKAEKEGYEVRILTADRGLYQLVYDRVAV- LHPEGHLIT PEWLWEKYGLRPEQWVDFRALVGDPSDNLPGVKGIGEKTALKLLKEWGSLENLLKNLDRVKPENVREKIKAHLE- DLRLSLE LSRVRTDLPLEVDLAQGREPDREGLRAFLERLEFGSLLHEFGLLESPKALEEAPWPPPEGAFVGFVLSRKEPMW- ADLLALAAA RGGRVHRAPEPYKALRDLKEARGLLAKDLSVLALREGLGLPPGDDPMLLAYLLDPSNTTPEGVARRYGGEWTEE- AGERAAL SERLFANLWGRLEGEERLLWLYREVERPLSAVLAHMEATGVRLDVAYLRALSLEVAEEIARLEAEVFRLAGHPF- NLNSRDQL EMVLFDELRLPALGKTQKTGKRSTSAAVLEALREAHPIVEKILQYRELTKLKSTYIDPLSDLHPRTGRLHTRFN- QTATATGRL SSSDPNLQNIPVRTPLGQRIRRAFIAEEGWLLVVLDYSQIELRVLAHLSGDENLIRVFQEGRDIHTETASWMFG- VPREAVDPLM RRAAKTINFGVLYGMSAHRLSQELAIPYEEAQAFIERYFQSFPKVRAWIEKTLEEGRRRGYVETLFGRRRYVPD- LEARVKSVR EAAERMAFNMPVQGTAADLMKLAMVKLFPRLEEMGARMLLQVHDELVLEAPKERAEAVARLAKEVMEGVYPLAV- PLEVE VGIGEDWLSAKE* 2G6: ATGGCGATGCTTCCCCTCTTTGAGCCCAAGGGCCGCGTCCTCCTGGTGGACGGCCACCACCTGGCCTACCGCAC- CTTCTT (SEQ ID NO: 65) CGCCCTGAAGGGCCCCACCACGAGCCGGGGCGAACCGGTGCAGGTGGTCTACGGCTTCGCCAAGAGCCTCCTCA- AGGCC CTGAAGGAGGACGGGTACAAGGCCGTCTTCGTGGTCTTTGACGCCAAGGCCCCCTCATTCCGCCACAAGGCCTA- CGAGG CCTACAGGGCGGGGAGGGCCCCGACCCCCGAGGACTTCCCCCGGCAGCTCGCCCTCATCAAGGAGCTGGTGGAC- CTCCT GGGGTTTACCCGCCTCGAGGTCCCCGGCTACGAGGCGGACGACGTTCTCGCCACCTTCGCCAAGAAGGCGGAAA- AGGAG GGGTACGAGGTGCGCATCCTCACCGCCGACCGCGGCCTCTACCAACTCGTCTCTGACCGCGTCGCCGTCCTCCA- CCCCGA GGGCCACCTCATCACCCCGGAGTGGCTTTGGGAGAAGTACGGCCTCAGGCCGGAGCAGTGGGTGGACTTCCGCG- CCCTC GTGGGGAACCCCTCCGACAACCTCCCCGGGGTCAAGGGCATCGGGGAGAAGACCGCCCTCAAGCTCCTCAAGGA- GTGG GGAAGCCTGGAAAACCTCCTCAAGAACCTGGACCGGGTAAAGCCAGAAAACGTCCGGGAGAAGATCAAGGCCCA- CCTG GAAGACCTCAGGCTCTCCTTGGAGCTCTCCCGGGTGCGCACCGACCTCCCCCTGGAGGTGGACCTCGCCCAGGG- GCGGG AGCCCGACCGGGAGGGGCTTAGGGCCTTTCTGGAGAGGCTTGAGTTTGGCAGCCTCCTCCACGAGTTCGGCCTT- CTGGA AAGCCCCAAGGCCCTGGAGGAGGCCCCCTGGCCCCCGCCGGAAGGGGCCTTCGTGGGCTTTGTGCTTTCCCGCA- AGGAG CCCATGTGGGCCGATCTTCTGGCCCTGGCCGCCGCCAGGGGTGGTCGAGTCCACCGGGCCCCCGAGCCTTATAA- AGCCC TCAGGGACCTGAAGGAGGCGCGGGGGCTTCTCGCCAAAGACCTGAGCGTTCTGGCCCTAAGGGAAGGCCTTGGC- CTCCC GCCCGGCGACGACCCCATGCTCCTCGCCTACCTCCTGGACCCTTCCAACACCACCCCCGAGGGGGTGGCCCGGC- GCTAC GGCGGGGAGTGGACGGAGGAGGCGGGGGAGCGGGCCGCCCTTTCCGAGAGGCTCTTCGCCAACCTGTGGGGGAG- GCTT GAGGGGGAGGAGAGGCTCCTTTGGCTTTACCGGGAGGTGGAGAGGCCCCTTTCCGCTGTCCTGGCCCACATGGA- GGCCA CGGGGGTGCGCCTGGACGTGGCCTATCTCAGGGCCTTGTCCCTGGAGGTGGCCGAGGAGATCGCCCGCCTCGAG- GCCGA GGTCTTCCGCCTGGCCGGCCACCCCTTCAACCTCAACTCCCGGGACCAGCTGGAAAGGGTCCTCTTTGACGAGC- TAGGGC TTCCCGCCATCGGCAAGACGGAGAAGACCGGCAAGCGCTCCACCAGCGCCGCCGTCCTGGAGGCCCTCCGCGAG- GCCC ACCCCATCGTGGAGAAGATCCTGCAGTACCGGGAGCTCACCAAGCTGAAGAGCACCTACATTGACCCCTTGCCG- GACCT CATCCACCCCAGGACGGGCCGCCTCCACACCCGCTTCAACCAGACGGCCACGGCCACGGGCAGGCTAAGTAGCT- CCGAT CCCAACCTCCAGAACATCCCCGTCCGCACCCCGCTCGGGCAGAGGATCCGCCGGGCCTTCATCGCCGAGGAGGG- GTGGC TATTGGTGGTCCTGGACTATAGCCAGATAGAGCTCAGGGTGCTGGCCCACCTCTCCGGCGACGAGAACCTGATC- CGGGT CTTCCAGGAGGGGCGGGACATCCACACGGAAACCGCCAGCTGGATGTTCGGCGTCCCCCGGGAGGCCGTGGACC- CCCTA ATGCGCCGGGCGGCCAAGACCATCAACTTCGGGGTCCTCTACGGCATGTCGGCCCGCCGCCTCTCCCAGGAGCT- AGCCA TCCCTTACGAGGAGGCCCAGGCCTTCATTGAGCGCTACTTTCAGAGCTTCCCCAAGGTGCGGGCCTGGATTGAG- AAGAC CCTGGAGGAGGGCAGGAGGCGGGGGTACGTGGAGACCCTCTTCGGCCGCCGCCGCTACGTGCCAGACCTAGAGG- CCCG GGTGAAGAGCGTGCGGGAGGCGGCCGAGCGCATGGCCTTCAACATGCCCGTCCAGGGCACCGCCGCCGACCTCA- TGAA GCTGGCTATGGTGAAGCTCTTCCCCAGGCTGGAGGAAATGGGGGCCAGGATGCTCCTTCAGGTCCACGACGAGC- TGGTC CTCGAGGCCCCAAAAGAGAGGGCGGAGGCCGTGGCCCGGCTGGCCAAGGAGGTCATGGAGGGGGTGTATCCCCT- GGCC GTGCCCCTGGAGGTGGAGGTGGGGATAGGGGAGGACTGGCTTTCCGCCAAGGGTTAG Above: nucleic acid sequence of the clone MAMLPLFEPKGRVLLVDGHHLAYRTFFALKGPTTSRGEPVQVVYGFAKSLLKALKEDGYKAVFVVFDAKAPSFR- HKAYEAY (SEQ ID NO: 66) RAGRAPTPEDFPRQLALIKELVDLLGFTRLEVPGYEADDVLATFAKKAEKEGYEVRILTADRGLYQLVSDRVAV- LHPEGHLIT PEWLWEKYGLRPEQWVDFRALVGNPSDNLPGVKGIGEKTALKLLKEWGSLENLLKNLDRVKPENVREKIKAHLE- DLRLSLE LSRVRTDLPLEVDLAQGREPDREGLRAFLERLEFGSLLHEFGLLESPKALEEAPWPPPEGAFVGFVLSRKEPMW- ADLLALAAA RGGRVHRAPEPYKALRDLKEARGLLAKDLSVLALREGLGLPPGDDPMLLAYLLDPSNTTPEGVARRYGGEWTEE- AGERAAL
SERLFANLWGRLEGEERLLWLYREVERPLSAVLAHMEATGVRLDVAYLRALSLEVAEEIARLEAEVFRLAGHPF- NLNSRDQL ERVLFDELGLPAIGKTEKTGKRSTSAAVLEALREAHPIVEKILQYRELTKLKSTYIDPLPDLIHPRTGRLHTRF- NQTATATGRLS SSDPNLQNIPVRTPLGQRIRRAFIAEEGWLLVVLDYSQIELRVLAHLSGDENLIRVFQEGRDIHTETASWMFGV- PREAVDPLMR RAAKTINFGVLYGMSARRLSQELAIPYEEAQAFIERYFQSFPKVRAWIEKTLEEGRRRGYVETLFGRRRYVPDL- EARVKSVRE AAERMAFNMPVQGTAADLMKLAMVKLFPRLEEMGARMLLQVHDELVLEAPKERAEAVARLAKEVMEGVYPLAVP- LEVEV GIGEDWLSAKG*
Above is the Amino Acid Sequence of the Clone
TABLE-US-00007 [0229]1A8: (SEQ ID NO: 67) ATGGTGATGCTTCCCCTCTTTGAGCCCAAGGGCCGCGTCCTCCTGGTGGACGGCCACCACCTGGCCTACCGCAC- CTTCTT CGCCCTGAAGGGCCTCACCACGAGCCGGGGCGAACCGGTGCAGGCGGTCTACGGCTTCGCCAAGAGCCTCCTCA- AGGCC CTGAAGGAGGACGGGTACAAGGCCGTCTTCGTGGTCTTTGACGCCAAGGCCTCCTCCTTCCGCCACGAGGCCTA- CGAGG CCTACAAGGCGGGGAGGGCCCCGACCCCCGAGGACTTCCCCCGGCAGCTCGCCCTCATCAAGGAGCTGGTGGAC- CTCCT GGGGTTTACCCGCCTCGAGGTCCCCGGCTACGAGGTGGACGACGTCCTGGCCAGCCTGGCCAAGAAGGTGGAAA- AGGA GGGGTACGAGGTGCGCATCCTCACCGCCGACCGCGACCTCTACCAACTCGTCTCCGACCGCGTCGCCGTCCTCC- ACCCCG AGGGCCACCTCATCACCCCGGAGTGGCTTTGGGAGAAGTACGGCCTCAGGCCGGAGCAGTGGGTGGACTTCCGC- GCCCT CGTGGGGGACCCCTCCGACAACCTCCCCGGGGTCAAGGGCATCGGGGAGAAGACCGCCCTCAAGCTCCTCAAGG- AGTG GGGAGGCCTGGAAAACCTCCTCAAGAACCTGGACCGGGTAAAGCCAGAAAACGTCCGGGAGAAGATCAAGGCCC- ACCT GGAAGACCTCAGGCTCTCCTTGGAGCTCTCCCGGGTGCGCACCGACCTCCCCCTGGAGGTGGACCTCGCCCAGG- GGCGG GAACCCGACCGGGAGAGGCTTAGGGCCTTTCTGGAGAGGCTTGAGTTTGGCAGCCTCCTCCACGAGTTCGGCCT- TCTGG AAAGCCCCAAGGCCCTGGAGGAGGCCCCCTGGCCCCCGCCGGAAGGGGCCTTCGTGGGCTTTGTGCTTTCCCGC- AAGGA GCCCATGTGGGCCGATCTTCTGGCCCTGGCCGCCGCCAGGGGTGGTCGGGTCCACCGGACCCCCGAGCCTTATA- AAGCC CTCAGGGACTTGAAGGAGGCGCGGGGGCTTCTCGCCAAAGACCTGAGCGTTCTGGCCCTAAGGGAAGGCCTTGG- CCTCC CGCCCGGCGACGACCCCATGCTCCTCGCCTACCTCCTGGACCCTTCCAACACCACCCCCGAGGGGGTGGCCCGG- CGCTA CGGCGGGGAGTGGACGGAGGAGGCGGGGGAGCGGGCCGCCCTTTCCGAGAGGCTCTTCGCCAACCTGTGGGGGA- GGCT TGAGGGGGAGGAGAGGCTCCTTTGGCTTTACCGGGAGGTGGATAGGCCCCTTTCCGCTGTCCTGGCCCACATGG- AGGCC ACAGGGGTGCGCCTGGACGTGGCCTACCTCAGGGCCTTGTCCCTGGAGGTGGCCGAGGAGATCGCCCGCCTCGA- GGCCG AGGTCTTCCGCCTGGCCGGCCACCCCTTCAACCTCAACTCCCGGGACCAGCTGGAAAGGGTCCTCTTTGACGAG- CTAGG GCTTCCCGCCATCGGCAAGACGGAGAAGACCGGCAAGCGCTCCACCAGCGCCGCCGTCCTGGAGGCCCTCCGCG- AGGC CCACCCCATCGTGGAGAAGATCCTGCAGTACCGGGAGCTCACCAAGCTGAAGAGCACCTACATTGACCCCTTGC- CGGAC CTCATCCACCCCAGGACGGGCCGCCTCCACACCCGCTTCAACCAGACGGCCACGGCCACGGGCAGGCTAAGTAG- CTCCG ATCCCAACCTCCAGAACATCCCCGTCCGCACCCCGCTCGGGCAGAGGATCCGCCGGGCCTTCATCGCCGAGGAG- GGGTG GCTATTGGTGGTCCTGGACTATAGCCAGATAGAGCTCAGGGTGCTGGCCCACCTCTCCGGCGACGAGAACCTGA- TCCGG GTCTTCCAGGAGGGGCGGGACATCCACACGGAAACCGCCAGCTGGATGTTCGGCGTCCCCCGGGAGGCCGTGGA- CCCCC TAATGCGCCGGGCGGCCAAGACCATCAACTTCGGGGTTCTCTACGGCATGTCGGCCCACCGCCTCTCCCAGGAG- CTAGC CATCCCTTACGAGGAGGCCCAGGCCTTCATTGAGCGCTACTTTCAGAGCTTCCCCAAGGTGCGGGCCTGGATTG- AGAAG ACCCTGGAGGAGGGCAGGAGGCGGGGGTACGTGGAGACCCTCTTCGGCCGCCGTCGCTACGTGCCAGACCTAGA- GGCC CGGGTGAAGAGCGTGCGGGAGGCGGCCGAGCGCATGGCCTTCAACATGCCCGTCCAGGGCACCGCCGCCGACCT- CATG AAGCTGGCTATGGTGAAGCTCTTCCCCAGGCTGGAAGAAACGGGGGCCAGGATGCTCCTTCAGGTCCACGACGA- GCTGG TCCTCGAGGCCCCAAAAGAGAGGGCGGAGGCCGTGGCCCGGCTGGCCAAGGAGGCCATGGAGGGGGTGTATCCC- CTGG CCGTGCCCCTGGAGGTGGAGGTGGGGATAGGGGAGGACTGGCTCTCCGCCAAGGAGTGA (SEQ ID NO: 68) MVMLPLFEPKGRVLLVDGHHLAYRTFFALKGLTTSRGEPVQAVYGFAKSLLKALKEDGYKAVFVVFDAKASSFR- HEAYEAY KAGRAPTPEDFPRQLALIKELVDLLGFTRLEVPGYEVDDVLASLAKKVEKEGYEVRILTADRDLYQLVSDRVAV- LHPEGHLIT PEWLWEKYGLRPEQWVDFRALVGDPSDNIPGVKGIGEKTALKLLKEWGGLENLLKNLDRVKPENVREKIKAHLE- DLRLSLE LSRVRTDLPLEVDLAQGREPDRERLRAFLERLEFGSLLHEFGLLESPKALEEAPWPPPEGAFVGFVLSRKEPMW- ADLLALAAA RGGRVHRTPEPYKALRDLKEARGLLAKDLSVLALREGLGLPPGDDPMLLAYLLDPSNTTPEGVARRYGGEWTEE- AGERAAL SERLFANLWGRLEGEERLLWLYREVDRPLSAVLAHMEATGVRLDVAYLRALSLEVAEEIARLEAEVFRLAGHPF- NLNSRDQL ERVLFDELGLPAIGKTEKTGKRSTSAAVLEALREAHPIVEKILQYRELTKLKSTYIDPLPDLIHPRTGRLHTRF- NQTATATGRLS SSDPNLQNIPVRTPLGQRIRRAFIAEEGWLLVVLDYSQIELRVLAHLSGDENLIRVFQEGRDIHTETASWMFGV- PREAVDPLMR RAAKTINFGVLYGMSAHRLSQELAIPYEEAQAFIERYFQSFPKVRAWIEKTLEEGRRRGYVETLFGRRRYVPDL- EARVKSVRE AAERMAFNMPVQGTAADLMKLAMVKLFPRLEETGARMLLQVHDELVLEAPKERAEAVARLAKEAMEGVYPLAVP- LEVEV GIGEDWLSAKE* 2H1: (SEQ ID NO: 69) ATGGTGATGCTTCCCCTCTTTGAGCCCAAGGGCCGCGTCCTCCTGGTGGACGGCCACCACCTGGCCTACCGCAC- CTTCTT CGCCCTGAAGGGCCTCACCACGAGCCGGGGCGAACCGGTGCAGGCGGTCTACGGCTTCGCCAAGAGCCTCCTCA- AGGCC CTGAAGGAGGACGGGTACAAGGCCGTCTTCGTGGTCTTTGACGCCAAGGCCTCCTCCTTCCGCCACGAGGCCTA- CGAGG CCTACAAGGCGGGGAGGGCCCCGACCCCCGAGGACTTCCCCCGGCAGCTCGCCCTCATCAAGGAGCTGGTGGAC- CTCCT GGGGTTTACCCGCCTCGAGGTCCCCGGCTACGAGGTGGACGACGTCCTGGCCAGCCTGGCCAAGAAGGTGGAAA- AGGA GGGGTACGAGGTGCGCATCCTCACCGCCGACCGCGGCCTCTACCAACTCGTCTCTGACCGCGTCGCCGTCCTCC- ACCCCG AGGGCCACCTCATCACCCCGGAGTGGCTTTGGGAGAAGTACGGCCTCAGGCCGGAGCAGTGGGTGGACTTCCGC- GCCCT CGTGGGGGACCCCTCCGACAACCTCCCCGGGGTCAAGGGCATCGGGGAGAAGACCGCCCTCAAGCTCCTCAAGG- AGTG GGGAAGCCTGGAAAACCTCCTCAAGAACCTGGACCGGGTAAAGCCAGAAAACGTCCGGGAGAAGATCAAGGCCC- ACCT GGAAGACCTCAGGCTCTCCTTGGAGCTCTCCCGGGTGCGCACCGACCTCCCCCTGGAGGTGGACCTCGCCCAGG- GGCGG GAGCCCGACCGGGAGAGGCTTAGGGCCTTTCTGGAGAGGCTTGAGTTTGGCAGCCTCCTCCACGAGTTCGGCCT- TCTGG AAAGCCCCAAGGCCCTGGAGGAGGCCCCCTGGCCCCCGCCGGAAGGGGCCTTCGTGGGCTTTGTGCTTTCCCGC- AAGGA GCCCATGTGGGCCGATCTTCTGGCCCTGGCCGCCGCCAGGGGTGGTCGGGTCCACCGGGCCCCCGAGCCTTATA- AAGCC CTCAGGGACTTGAAGGAGGCGCGGGGGCTTCTCGCCAAAGACCTGAGCGTTCTGGCCCTAAGGGAAGGCCTTGG- CCTCC CGCCCGGCGACGACCCCATGCTCCTCGCCTACCTCCTGGACCCTTCCAACACCACCCCCGAGGGGGTGGCCCGG- CGCTA CGGCGGGGAGTGGACGGAGGAGGCGGGGGAGCGGGCCGCCCTTTCCGAGAGGCTCTTCGCCAACCTGTGGGGGA- GGCT TGAGGGGGAGGAGAGGCTCCTTTGGCTTTACCGGGAGGTGGATAGGCCCCTTTCCGCTGTCCTGGCCCACATGG- AGGCC ACAGGGGTGCGCCTGGACGTGGCCTATCTCAGGGCCTTGTCCCTGGAGGTGGCCGAGGAGATCGCCCGCCTCGA- GGCCG AGGTCTTCCGCCTGGCCGGCCACCCCTTCAACCTCAACTCCCGGGACCAGCTGGAAAGGGTCCTCTTTGACGAG- CTAGG GCTTCCCGCCATCGGCAAGACGGAGAAGACCGGCAAGCGCTCCACCAGCGCCGCCATCCTGGAGGCCCTCCGCG- AGGC CCACCCCATCGTGGAGAAGATCCTGCAGTACCGGGAGCTCACCAAGCTGAAGAGCACCTACATTGACCCCTTGC- CGGAC CTCATCCACCCCAGGACGGGCCGCCTCCACACCCGCTTCAACCAGACGGCCACGGCCACGGGCAGGCTAAGTAG- CTCCG ATCCCAACCTCCAGAACATCCCCGTCCGCACCCCGCTCGGGCAGAGGATCCGCCGGGCCTTCATCGCCGAGGAG- GGGTG GCTATTGGTGGTCCTGGACTATAGCCAGATAGAGCTCAGGGTGCTGGCCCACCTCTCCGGCGACGAGAACCTGA- CCCGG GTCTTCCAGGAGGGGCGGGACATCCACACGGAAACCGCCAGCTGGATGTTCGGCGTCCCCCGGGAGGCCGTGGA- CCCCC TGATGCGCCGGGCGGCCAAGACCATCAACTTCGGGGTTCTCTACGGCATGTCGGCCCACCGCCTCTCCCAGGAG- CTGGC CATCCCTTACGAGGAGGCCCAGGCCTTCATAGAGCGCTACTTCCAAAGCTTCCCCAAGGTGCGGGCCTGGATAG- AAAAG ACCCTGGAGGAGGGGAGGAAGCGGGGCTACGTGGAAACCCTCTTCGGAAGAAGGCGCTACGTGCCCGACCTCAA- CGCC CGGGTGAAGAGTGTCAGGGAGGCCGCGGAGCGCATGGCCTTCAACATGCCCGTCCAGGGCACCGCCGCCGACCT- TATGA AGCTCGCCATGGTGAAGCTCTTCCCCCGCCTCCGGGAGATGGGGGCCCGCATGCTCCTCCAGGTCCACGACGAG- CTCCTC CTGGAGGCCCCCCAAGCGCGGGCCGAGGAGGTGGCGGCTTTGGCCAAGGAGGCCATGGAGAAGGCCTATCCCCT- CGCC GTACCCCTGGAGGTGAAGGTGGGGATCGGGGAGGACTGGCTCTCCGCCCAAGGAGTGAGTCGACCTGCAGGCAG- CGCT TGGCGTCACCCGCAGTTCGGTGGTTAA (SEQ ID NO: 70) MVMLPLFEPKGRVLLVDGHHLAYRTFFALKGLTTSRGEPVQAVYGFAKSLLKALKEDGYKAVFVVFDAKASSFR- HEAYEAY KAGRAPTPEDFPRQLALIKELVDLLGFTRLEVPGYEVDDVLASLAKKVEKEGYEVRILTADRGLYQLVSDRVAV- LHPEGHLIT PEWLWEKYGLRPEQWVDFRALVGDPSDNLPGVKGIGEKTALKLLKEWGSLENLLKNLDRVKPENVREKIKAHLE- DLRLSLE LSRVRTDLPLEVDLAQGREPDRERLRAFLERLEFGSLLHEFGLLESPKALEEAPWPPPEGAFVGFVLSRKEPMW- ADLLALAAA RGGRVHRAPEPYKALRDLKEARGLLAKDLSVLALREGLGLPPGDDPMLLAYLLDPSNTTPEGVARRYGGEWTEE- AGERAAL SERLFANLWGRLEGEERLLWLYREVDRPLSAVLAHMEATGVRLDVAYLRALSLEVAEEIARLEAEVFRLAGHPF- NLNSRDQL ERVLFDELGLPAIGKTEKTGKRSTSAAILEALREAHPIVEKILQYRELTKLKSTYIDPLPDLIHPRTGRLHTRF-
NQTATATGRLSS SDPNLQNIPVRTPLGQRIRRAFIAEEGWLLVVLDYSQIELRVLAHLSGDENLTRVFQEGRDIHTETASWMFGVP- REAVDPLMR RAAKTINFGVLYGMSAHRLSQELAIPYEEAQAFIERYFQSFPKVRAWIEKTLEEGRKRGYVETLFGRRRYVPDL- NARVKSVRE AAERMAFNMPVQGTAADLMKLAMVKLFPRLREMGARMLLQVHDELLLEAPQARAEEVAALAKEAMEKAYPLAVP- LEVKV GIGEDWLSAQGVSRPAGSAWRHPQFGG* 2F11: (SEQ ID NO: 71) ATGCGTGGTATGCTTCCTCTTTTTGAGCCCAAGGGCCGCGTCCTCCTGGTGGACGGCCACCACCTGGCCTACCG- CACCTT CTTCGCCCTGAAGGGCCCCACCACGAGCCGGGGCGAACCGGTGCAGGCGGTCTACGGCTTCGCCAAGAGCCTCC- TCAAG GCCCTGAAGGAGGACGGGTACAAGGCCGCCTTCGTGGTCTTTGACGCCAAGGCCCCCTCCTTCCGCCACGAGGC- CTACG AGGCCTACAAGGCGGGGAGGGCCCCGACCCCCGAGGACTTCCCCCGGCAGCTCGCCCTCATCAAGGAGCTGGTG- GACCT CCTGGGGTTTACCCGCCTCGAGGTCCCTGGCTACGAGGCGGACGACGTCCTCGCCACCCTGGCCAAGAAGGCGG- AAAAG GAGGGGTACGAGGTGCGCATCCTCACCGCCGACCGCGACCTCTACCAACTCGTCTCCGACCGCGTCGCCGTCCT- CCACC CCGAGGGCCACCTCATCACCCCGGAGTGGCTTTGGGAGAAGTACGGCCTCAGGCCGGAGCAGTGGGTGGACTTC- CGCGC CCTCGTGGGGGACCCCTCCGACAACCTCCCCGGGGTCAAGGGCATCGGGGAGAAGACCGCCCTCAAGCTCCTCA- AGGAG TGGGGAAGCCTGGAAAACCTCCTCAAGAACCTGGACCGGGTAAAGCCAGAAAACGTCCGGGAGAAGATCAAGGC- CCAC CTGGAAGACCTCAGGCTCTCCTTGGAGCTCTCCCGGGTGCGCACCGACCTCCCCCTGGAGGTGGACCTCGCCCA- GGGGC GGGAGCTCGACCGGGAGAGGCTTAGGGCCTTTCTGGAGAGGCTTGAGTTTGGCGGCCTCCTCCACGAGTTCGGC- CTTCT GGAAAGCCCCAAGGCCCTGGAGGAGGCCCCCTGGCCCCCGCCGGAAGGGGCCTTCGTGGGCTTTGTGCTTTCCC- GCAAG GAGCCCATGTGGGCCGATCTTCTGGCCCTGGCCGCCGCCAGGGGTGGTCGGGTCCACCGGGCCCCCGAGCCTTA- TAAAG CCCTCAGGGACTTGAAGGAGGCGCGGGGGCTTCTCGCCAAAGACCTGAGCGTTCTGGCCCTAAGGGAAGGCCTT- GGCCT CCCGCCCGGCGACGACCCCATGCTCCTCGCCTACCTCCTGGACCCTTCCAACACCGCCCCCGAGGGGGTGGCCC- GGCGC TACGGCGGGGAGTGGACGGAGGAGGCGGGGGAGCGGGCCGCCCTTTCCGAGAGGCTCTTCGCCAACCTGTGGGG- GAGG CTTGAGGGGGAGGAGAGGCTCCTTTGGCTTTACCGGGAGGTGGATAGGCCCCTTTCCGCTGTCCTGGCCCACAT- GGAGG CCACAGGGGTACGGCTGGACGTGGCCTGCCTGCAGGCCCTTTCCCTGGAGCTTGCGGAGGAGATCCGCCGCCTC- GAGGA GGAGGTCTTCCGCTTGGCGGGCCACCCCTTCAACCTCAACTCCCGGGACCAGCTGGAAAGGGTCCTCTTTGACG- AGCTA GGGCTTCCCGCCATCGGCAAGACGGAGAAGACCGGCAAGCGCTCCACCAGCGCCGCCATCCTGGAGGCCCTCCG- CGAG GCCCACCCCATCGTGGAGAAGATCCTGCAGTACCGGGAGCTCACCAAGCTGAAGAGCACCTACATTGACCCCTT- GCCGG ACCTCATCCACCCCAGGACGGGCCGCCTCCACACCCGCTTCAACCAGACGGCCACGGCCACGGGCAGGCTAAGT- AGCTC CGATCCCAACCTCCAGAACATCCCCGTCCGCACCCCGCTCGGGCAGAGGATCCGCCGGGCCTTCGTCGCCGAGG- AGGGG TGGCTATTGGTGGTCCTGGACTATAGCCAGATAGAGCTCAGGGTGCTGGCCCACCTCTCCGGCGACGAGAACCT- GACCC GGGTCTTCCTGGAGGGGCGGGACATCCACACGGAAACCGCCAGCTGGATGTTCGGCGTCCCCCGGGAGGCCGTG- GACCC CCTGATGCGCCGGGCGGCCAAGACCATCAACTTCGGGGTTCTCTACGGCATGTCGGCCCACCGCCTCTCCCAGG- AGCTG GCCATCCCTTACGAGGAGGCCCAGGCCTTCATAGAGCGCTACTTCCAAAGCTTCCCCAAGGTGCGGGCCTGGAT- AGAAA AGACCCTGGAGGAGGGGAGGAAGCGGGGCTACGTGGAAACCCTCTTCGGAAGAAGGCGCTACGTGCCCGACCTC- AACG CCCGGGTGAAGAGTGTCAGGGAGGCCGCGGAGCGCATGGCCTTCAACATGCCCGTCCAGGGCACCGCCGCCGAC- CTTAT GAAGCTCGCCATGGTGAAGCTCTTCCCCCGCCTCCGGGAGATGGGGGCCCGCATGCTCCTCCAGGTCCACGACG- AGCTC CTCCTGGAGGCCCCCCAAGCGCGGGCCGAGGAGGTGGCGGCTTTGGCCAAGGAGGCCATGGAGAAGGCCTATCC- CCTC GCCGTACCCCTGGAGGTGAAGGTGGGGATCGGGGAGGACTGGCTCTCCGCCAAGGAGTGA (SEQ ID NO: 72) MRGMLPLFEPKGRVLLVDGHHLAYRTFFALKGPTTSRGEPVQAVYGFAKSLLKALKEDGYKAAFVVFDAKAPSF- RHEAYEA YKAGRAPTPEDFPRQLALIKELVDLLGFTRLEVPGYEADDVLATLAKKAEKEGYEVRILTADRDLYQLVSDRVA- VLHPEGHLI TPEWLWEKYGLRPEQWVDFRALVGDPSDNLPGVKGIGEKTALKLLKEWGSLENLLKNLDRVKPENVREKIKAHL- EDLRLSL ELSRVRTDLPLEVDLAQGRELDRERLRAFLERLEFGGLLHEFGLLESPKALEEAPWPPPEGAFVGFVLSRKEPM- WADLLALAA ARGGRVHRAPEPYKALRDLKEARGLLAKDLSVLALREGLGLPPGDDPMLLAYLLDPSNTAPEGVARRYGGEWTE- EAGERAA LSERLFANLWGRLEGEERLLWLYREVDRPLSAVLAHMEATGVRLDVACLQALSLELAEEIRRLEEEVFRLAGHP- FNLNSRDQ LERVLFDELGLPAIGKTEKTGKRSTSAAILEALREAHPIVEKILQYRELTKLKSTYIDPLPDLIHPRTGRLHTR- FNQTATATGRLS SSDPNLQNIPVRTPLGQRIRRAFVAEEGWLLVVLDYSQIELRVLAHLSGDENLTRVFLEGRDIHTETASWMFGV- PREAVDPLM RRAAKTINFGVLYGMSAHRLSQELAIPYEEAQAFIERYFQSFPKVRAWIEKTLEEGRKRGYVETLFGRRRYVPD- LNARVKSVR EAAERMAFNMPVQGTAADLMKLAMVKLFPRLREMGARMLLQVHDELLLEAPQARAEEVAALAKEAMEKAYPLAV- PLEVK VGIGEDWLSAKE* 2H4: (SEQ ID NO: 73) ATGGCGATGCTTCCCCTCTTTGAGCCCAAGGGCCGCGTCCTCCTGGTGGACGGCCACCACCTGGCCTACCGCAC- CTTCTT CGCCCTGAAGGGCCCCACCACGAGCCGGGGCGAACCGGTGCAGGTGGTCTACGGCTTCGCCAAGAGCCTCCTCA- AGGCC CTGAAGGAGGACGGGTACAAGGCCGTCTTCGTGGTCTTTGACGCCAAGGCCCCCTCATTCCGCCACAAGGCCTA- CGAGG CCTACAGGGCGGGGAGGGCCCCGACCCCCGAGGACTTCCCCCGGCAGCTCGCCCTCATCAAGGAGCTGGTGGAC- CTCCT GGGGTTTACCCGCCTCGAGGTCCCCGGCTACGAGGCGGACGACGTTCTCGCCACCCTGGCCAAGAAGGCGGAAA- AGGA GGGGTACGAGGTGCGCATCCTCACCGCCGACCGCGGCCTCTACCAACTCGTCTCTGACCGCGTCGCCGTCCTCC- ACCCCG AGGGCCACCTCATCACCCCGGAGTGGCTTTGGGAGAAGTACGGCCTCAGGCCGGAGCAGTGGGTGGACTTCCGC- GCCCT CGTGGGGGACCCCTCCGACAACCTCCCCEiGGGTCAAGGGCATCGGGGAGAAGACCGCCCTCAAGCTCCTCAAG- GAGTG GGGAAGCCTGGAAAACCTCCTCAAGAACCTGGACCGGGTAAAGCCAGAAAACGTCCGGGAGAAGATCAAGGCCC- ACCT GGAAGACCTCAGGCTCTCCTTGGAGCTCTCCCGGGTGCGCACCGACCTCCCCCTGGAGGTGGACCTCGCCCAGG- GGCGG GAGCCCGACCGGGAGGGGCTTAGGGCCTTTCTGGAGAGGCTTGAGTTTGGCAGCCTCCTCCACGAGTTCGGCCT- TCTGG AAAGCCCCAAGGCCCTGGAGGAGGCCCCCTGGCCCCCGCCGGAAGGGGCCTTCGTGGGCTTTGTGCTTTCCCGC- AAGGA GCCCATGTGGGCCGATCTTCTGGCCCTGGCCGCCGCCAGGGGTGGTCGAGTCCACCGGGCCCCCGAGCCTTATA- AAGCC CTCAGGGACCTGAAGGAGGCGCGGGGGCTTCTCGCCAAAGACCTGAGCGTTCTGGCCCTAAGGGAAGGCCTTGG- CCTCC CGCCCGGCGACGACCCCATGCTCCTCGCCTACCTCCTGGACCCTTCCAACACCACCCCCGAGGGGGTGGCCCGG- CGCTA CGGCGGGGAGTGGACGGAGGAGGCGGGGGAGCGGGCCGCCCTTTCCGAGAGGCTCTTCGCCAACCTGTGGGGGA- GGCT TGAGGGGGAGGAGAGGCTCCTTTGGCTTTACCGGGAGGTGGAGAGGCCCCTTTCCGCTGTCCTGGCCCACATGG- AGGCC ACGGGGGTGCGCCTGGACGTGGCCTATCTCAGGGCCTTGTCCCTGGAGGTGGCCGAGGAGATCGCCCGCCTCGA- GGCCG AGGTCTTCCGCCTGGCCGGCCACCCCTTCAACCTCAACTCCCGGGACCAGCTGGAAATGGTGCTCTTTGACGAG- CTTAGG CTTCCCGCCTTGGGGAAGACGCAAAAGACGGGCAAGCGCTCCACCAGCGCCGCCGTCCTGGAGGCCCTCCGCGA- GGCCC ACCCCATCGTGGAGAAGATCCTGCAGTACCGGGAGCTCACCAAGCTGAAGAGCACCTACATTGACCCCTTGTCG- GACCT CATCCACCCCAGGACGGGCCGCCTCCACACCCGCTTCAACCAGACGGCCACGGCCACGGGCAGGCTAAGTAGCT- CCGAT CCCAACCTCCAGAACATCCCCGTCCGCACCCCGCTTGGGCAGAGGATCCGCCGGGCCTTCATCGCCGAGGAGGG- GTGGC TACTGGTGGTCCTGGACTATAGCCAGATAGAGCTCAGGGTGCTGGCCCACCTCTCCGGCGACGAAAACCTGATC- AGGGT CTTCCAGGAGGGGCGGGACATCCACACGGAGACCGCCAGCTGGATGTTCGGCGTCCCCCGGGAGGCCGTGGACC- CCCTG ATGCGCCGGGCGGCCAAGACCATCAACTTCGGGGTCCTCTACGGCATGTCGGCCCACCGCCTCTCCCAGGAGCT- AGCCA TCCCTTACGAGGAGGCCCAGGCCTTCATTGAGCGCTACTTTCAGAGCTTCCCCAAGGTGCGGGCCTGGATTGAG- AAGAC CCTGGAGGAGGGCAGGAGGCGGGGGTACGTGGAGACCCTCTTCGGCCGCCGCCGCTACGTGCCAGACCTAGAGG- CCCG GGTGAAGAGCGTGCGGGAGGCGGCCGAGCGCATGGCCTTCAACATGCCCGTCCAGGGCACCGCCGCCGACCTCA- TGAA GCTGGCTATGGTGAAGCTCTTCCCCAGGCTGGAGGAAACGGGGGCCAGGATGCTCCTTCAGGTCCACGACGAGC- TGGTC CTTGAGGCCCCAAAAGAGAGGGCGGAGGCCGTGGCCCGGCTGGCCAAGGAGGTCATGGAGGGGGTGTATCCCCT- GGCC GTGTCCCTGGAGGTGGAGGTGGGGATAGGGGAGGACTGGCTCTCCGCCAAGGAGTGA (SEQ ID NO: 74) MAMLPLFEPKGRVLLVDGHHLAYRTFFALKGPTTSRGEPVQVVYGFAKSLLKALKEDGYKAVFVVFDAKAPSFR- HKAYEAY RAGRAPTPEDFPRQLALIKELVDLLGFTRLEVPGYEADDVLATLAKKAEKEGYEVRILTADRGLYQLVSDRVAV- LHPEGHLIT PEWLWEKYGLRPEQWVDFRALVGDPSDNLPGVKGIGEKTALKLLKEWGSLENLLKNLDRVKPENVREKIKAHLE- DLRLSLE LSRVRTDLPLEVDLAQGREPDREGLRAFLERLEFGSLLHEFGLLESPKALEEAPWPPPEGAFVGFVLSRKEPMW-
ADLLALAAA RGGRVHRAPEPYKALRDLKEARGLLAKDLSVLALREGLGLPPGDDPMLLAYLLDPSNTTPEGVARRYGGEWTEE- AGERAAL SERLFANLWGRLEGEERLLWLYREVERPLSAVLAHMEATGVRLDVAYLRALSLEVAEEIARLEAEVFRLAGHPF- NLNSRDQL EMVLFDELRLPALGKTQKTGKRSTSAAVLEALREAHPIVEKILQYRELTKLKSTYIDPLSDLIHPRTGRLHTRF- NQTATATGRL SSSDPNLQNIPVRTPLGQRIRRAFIAEEGWLLVVLDYSQIELRVLAHLSGDENLIRVFQEGRDIHTETASWMFG- VPREAVDPLM RRAAKTINFGVLYGMSAHRLSQELAIPYEEAQAFIERYFQSFPKVRAWIEKTLEEGRRRGYVETLFGRRRYVPD- LEARVKSVR EAAERMAFNMPVQGTAADLMKLAMVKLFPRLEETGARMLLQVHDELVLEAPKERAEAVARLAKEVMEGVYPLAV- SLEVE VGIGEDWLSAKE* 2H9: (SEQ ID NO: 75) ATGGCGATGCTTCCCCTCTTTGAGCCCAAGGGCCGCGTCCTCCTGGTGGACGGCCACCACCTGGCCTACCGCAC- CTTCTT CGCCCTGAAGGGCCCCACCGCGAGCCGGGGCGAACCGGTGCAGGTGGTCTACGGCTTCGCCAAGAGCCTCCTCA- AGGCC CTGAAGGAGGACGGGTACAAGGCCGTCTTCGTGGTCTTTGACGCCAAGGCCCCCTCATTCCGCCACAAGGCCTA- CGAGG CCTACAGGGCGGGGAGGGCCCCGACCCCCGAGGACTTCCCCCGGCAGCTCGCCCTCATCAAGGAGCTGGTGGAC- CTCCT GGGGTTTACCCGCCTCGAGGTCCCCGGCTACGAGGCGGACGACGTTCTCGCCCCCCTGGCCAAGAAGGCGGAAA- AGGA GGGGTTCGAGGTGCGCATCCTCCCCGCCGTCCGCGGCCTCTGCCCTCTCGTCTCTGACCGCGTCGCCGTCCTCC- TCCCCG AGGGCCACCTCATCACCCCEiGAGTGGCTTTGGGAGAAGTACGGCCTCAGGCCGGAGCAGTGGGTGGACTTCCG- CGCCCT CGTGGGGGACCCCTCCGACAACCTCCCCGGGGTCAAGGGCATCGGGAAGAAGACCGCCCTCAAGCTCCTCAAGG- AGTG GGGAAGCCTGGAAAACCTCCTCAAGAACCTGGACCGGGTAAAGCCAGAAAACGTCCGGGAGAAGATCAAGGCCC- ACCT GGAAGACCTCAGGCTCTCCTTGGAGCTCTCCCGGGTGCGCACCGACCTCCCCCTGGAGGTGGACCTCGCCCAGG- GGCGG GAGCCCGACCGGGAGGGGCTTAGGGCCTTTCTGGAGAGGCTTGAGTTTGGCAGCCTCCTCCACGAGTTCGGCCT- TCTGG AAAGCCCCAAGGCCCTGGAGGAGGCCCCCTGGCCCCCGCCGGAAGGGGCCTTCGTGGGCTTTGTGCTTTCCCGC- AAGGA GCCCATGTGGGCCGATCTTCTGGCCCTGGCCGCCGCCAGGGGTGGTCGGGTCCACCGGGCCCCCGAGCCTTATA- AAGCC CTCAGGGACTTGAAGGAGGCGCGGGGGCTTCTCGCCAAAGACCTGAGCGTTCTGGCCCTAAGGGAAGGCCTTGG- CCTCC CGCCCGGCGACGACCCCATGCTCCTCGCCTACCTCCTGGACCCTTCCAACACCACCCCCGAGGGGGTGGCCCGG- CGCTA CGGCGGGGAGTGGACGGAGGAGGCGGGGGAGCGGGCCGCCCTTTCCGAGAGGCTCTTCGCCAACCTGTGGGGGA- GGCT TGAGGGGGAGGAGAGGCTCCTGTGGCTTTACCGGGAGGTGGATAGGCCCCTTTCCGCTGTCCTGGCCCACATGG- AGGCC ACAGGGGTACGGCTGGACGTGGCCTGCCTGCAGGCCCTTTCCCTGGAGCTTGCGGAGGAGATCCGCCGCCTCGA- GGAGG AGGTCTTCCGCTTGGCGGGCCACCCCTTCAACCTCAACTCCCGGGACCAGCTGGAAAGGGTCCTCTTTGACGAG- CTAGG GCTTCCCGCCATCGGCAAGACGGAGAAGACCGGCAAGCGCTCCACCAGCGCCGCCATCCTGGAGGCCCTCCGCG- AGGC CCACCCCATCGTGGAGAAGATCCTGCAGTACCGGGAGCTCACCAAGCTGAAGAGCACCTACATTGACCCCTTGC- CGGAC CTCATCCACCCCAGGACGGGCCGCCTCCACACCCGCTTCAACCAGACGGCCACGGCCACGGGCAGGCTAAGTAG- CTCCG ATCCCAACCTCCAGAACATCCCCGTCCGCACCCCGCTCGGGCAGAGGATCCGCCGGGCCTTCATCGCCGAGGAG- GGGTG GCTATTGGTGGTCCTGGACTATAGCCAGATAGAGCTCAGGGTGCTGGCCCACCTCTCCGGCGACGAGAACCTGA- CCCGG GTCTTCCAGGAGGGGCGGGACATCCACACGGAAACCGCCAGCTGGATGTTCGGCGTCCCCCGGGAGGCCGTGGA- CCCCC TGATGCGCCGGGCGGCCAAGACCATCAACTTCGGGGTTCTCTACGGCATGTCGGCCCACCGCCTCTCCCAGGAG- CTGGC CATCCCTTACGAGGAGGCCCAGGCCTTCATAGAGCGCTACTTCCAAAGCTTCCCCAAGGTGCGGGCCTGGATAG- AAAAG ACCCTGGAGGAGGGGAGGAAGCGGGGCTACGTGGAAACCCTCTTCGGAAGAAGGCGCTACGTGCCCGACCTCAA- CGCC CGGGTGAAGAGTGTCAGGGAGGCCGCGGAGCGCATGGCCTTCAACATGCCCGTCCAGGGCACCGCCGCCGACCT- TATGA AGCTCGCCATGGTGAAGCTCTTCCCCCGCCTCCGGGAGATGGGGGCCCGCATGCTCCTCCAGGTCCACGACGAG- CTCCTC CTGGAGGCCCCCCAAGCGCGGGCCGAGGAGGTGGCGGCTTTGGCCAAGGAGGCCATGGAGAAGGCCTATCCCCT- CGCC GTACCCCTGGAGGTGAAGGTGGGGATCGGGGAGGACTGGCTCTCCGCCAAGGAGTGA (SEQ ID NO: 76) MAMLPLFEPKGRVLLVDGHHLAYRTFFALKGPTASRGEPVQVVYGFAKSLLKALKEDGYKAVFVVFDAKAPSFR- HKAYEAY RAGRAPTPEDFPRQLALIKELVDLLGFTRLEVPGYEADDVLAPLAKKAEKEGFEVRILPAVRGLCPLVSDRVAV- LLPEGHLITP EWLWEKYGLRPEQWVDFRALVGDPSDNLPGVKGIGKKTALKLLKEWGSLENLLKNLDRVKPENVREKIKAHLED- LRLSLEL SRVRTDLPLEVDLAQGREPDREGLRAFLERLEFGSLLHEFGLLESPKALEEAPWPPPEGAFVGFVLSRKEPMWA- DLLALAAAR GGRVHRAPEPYKALRDLKEARGLLAKDLSVLALREGLGLPPGDDPMLLAYLLDPSNTTPEGVARRYGGEWTEEA- GERAALS ERLFANLWGRLEGEERLLWLYREVDRPLSAVLAHMEATGVRLDVACLQALSLELAEEIRRLEEEVFRLAGHPFN- LNSRDQLE RVLFDELGLPAIGKTEKTGKRSTSAAILEALREAHPIVEKILQYRELTKLKSTYIDPLPDLIHPRTGRLHTRFN- QTATATGRLSSS DPNLQNIPVRTPLGQRIRRAFIAEEGWLLVVLDYSQIELRVLAHLSGDENLTRVFQEGRDIHTETASWMFGVPR- EAVDPLMRR AAKTINFGVLYGMSAHRLSQELAIPYEEAQAFIERYFQSFPKVRAWIEKTLEEGRKRGYVETLFGRRRYVPDLN- ARVKSVREA AERMAFNMPVQGTAADLMKLAMVKLFPRLREMGARMLLQVHDELLLEAPQARAEEVAALAKEAMEKAYPLAVPL- EVKVG IGEDWLSAKE* 1B12: (SEQ ID NO: 77) ATGGCGATGCTTCCCCTCTTTGAGCCCAAAGGCCGGGTCCTCCTGGTGGACGGCCACCACCTGGCCTACCGCAC- CTTCTT CGCCCTGAAGGGCCTCATCACGAGCCGGGCGAACCGGTGCAGGCGGTCTACGGTTTCGCCAAGAGCCTCCTCAA- GGCC CTGAAGGAGGACGGGTACAAGGCCGTCTTCGTGGTCTTTGACGCCAAGGCCCCCTCCTTCCGCCACGAGGCCTA- CGAGG CCTACAAGGCGGGGAGGGCCCCGACCCCCGAGGACTTCCCCCGGCAGCTCGCCCTCATCAAGGAGCTGGTGGAC- CTCCT GGGGTTTACCCGCCTCGAGGTCCAAGGCTACGAGGCGGACGACGTCCTCGCCACCCTGGCCAAGAAGGCGGAAA- AAGA AGGGTACGAGGTGCGCATCCTCACCGCCGACCGGGACCTCTACCAGCTCGTCTCCGACCGCGTCGCCGTCCTCC- ACCCC GAGGGCCACCTCATCACCCCGGAGTGGCTTTGGGAGAAGTACGGCCTCAGGCCGGAGCAGTGGGTGGACTTCCG- CGCCC TCGTGGGGGACCCCTCCGACAACCTCCCCGGGGTCAAGGGCATCGGGGAGAAGACCGCCCTCAAGCTCCTCAAG- GAGTG GGGAAGCCTGGAAAATCTCCTCAAGAACCTGGATCGGGTAAAGCCGGAAAACGTCCGGGAGAAGATCAAGGCCC- ACCT GGAAGACCTCAGGCTCTCCTTGGAGCTCTCCCGGGTGCGTACCGACCTCCCCCTGGAGGTGGACCTCGCCCAGG- GGCGG GAGCCCGACCGGGAAGGGCTTAGGGCCTTCCTGGAGAGGCTGGAGTTCGGCAGCCTCCTCCATGAGTTCGGCCT- TCTGG AAAGCCCCAAGGCCCTGGAGGAGGCCCCCTGGCCCCCGCCGGAAGGGGCCTTCGTGGGCTTTGTGCTTTCCCGC- AAGGA GCCCATGTGGGCCGATCTTCTGGCCCTGGCCGCCGCCAGGGGTGGTCGGGTCCACCGGGCCCCCGAGCCTTATA- AAGCC CTCAGGGACTTGAAGGAGGCGCGGGGGCTTCTCGCCAAAGACCTGAGCGTTCTGGCCCTAAGGGAAGGCCTTGG- CCTCC CGCCCGGCGACGACCCCATGCTCCTCGCCTACCTCCTGGACCCTTCCAACACCACCCCCGAGGGGGTGGCCCGG- CGCTA CGGCGGGGAGTGGACGGAGGAGGCGGGGGAGCGGGCCGCCCTTTCCGAGAGGCTCTTCGCCAACCTGTGGGGGA- GGCT TGAGGGGGAGGAGAGGCTCCTTTGGCTTTACCGGGAGGTGGATAGGCCCCTTTCCGCTGTCCTGGCCCACATGG- AGGCC ACAGGGGTGCGCCTGGACGTGGCCTATCTCAGGGCCTTGTCCCTGGAGGTGGCCGAGGAGATCGCCCGCCTCGA- GGCCG AGGTCTTCCGCCTGGCCGGCCACCCCTTCAACCTCAACTCCCGGGACCAGCTGGAAAGGGTCCTCTTTGACGAG- TTAGGG CTTCCCGCCATCGGCAAGACGGAGAGGACCGGCAAGCGCTCCACCAGCGCCGCCGTCCTGGAGGCCCTCCGCGA- GGCCC ACCCCATCGTGGAGAAGATCCTGCAGTACCGGGAGCTCACCAAGCTGAAGAGCACCTACATTGACCCCTTGCCG- GACCT CATCCACCCCAGGACGGGCCGCCTCCACACCCGCTTCAACCAGACGGCCACGGCCACGGGCAGGCTAAGTAGCT- CCGAT CCCAACCTCCAGAACATCCCCGTCCGCACCCCGCTTGGGCAGAGGATCCGCCGGGCCTTCATCGCCGAGGAGGG- GTGGC TATTGGTGGCCCTGGACTATAGCCAGATAGAGCTCAGGGTGCTGGCCCACCTCTCCGGCGACGAGAACCTGATC- CGGGT CTTCCAGGAGGGGCGGGACATCCACACGGAGACCGCCAGCTGGATGTTCGGTGTCCCCCCGGAGGCCGTGGACC- CCCTG ATGCGCCGGGCGGCCAAGACGGTGAACTTCGGCGTCCTCTACGGCATGTCCGCCCATAGGCTCTCCCAGGAGCT- TTCCAT CCCCTACGAGGAGGCGGTGGCCTTTATAGAGCGCTACTTCCAAAGCTTCCCCAAGGTGCGGGCCTGGATAGAAA- AGACC CTGGAGGAGGGGAGGAAGCGGGGCTACGTGGAAACCCTCTTCGGAAGAAGGCGCTACGTGCCCGACCTCAACGC- CCGG GTGAAGAGCGTCAGGGAGGCCGCGGAGCGCATGGCCTTCAACATGCCCGTCCAGGGCACCGCCGCCGACCTCAT- GAAG CTCGCCATGGTGAAGCTCTTCCCCCGCCTCCGGGAGATGGGGGCCCGCATGCTCCTCCAGGTCCACGACGAGCT- CCTCCT GGAGGCCCCCCAAGCGCGGGCCGAGGAGGTGGCGGCTTTGGCCAAGGAGGCCATGGAGAAGGCCTATCCCCTCG- CCGT ACCCCTGGAGGTGGAGGTGGGGATCGGGGAGGACTGGCTCTCCGCCAAGGAGTGA (SEQ ID NO: 78) MAMLPLFEPKGRVLLVDGHHLAYRTFFALKGLITSRGEPVQAVYGFAKSLLKALKEDGYKAVFVVFDAKAPSFR-
HEAYEAY KAGRAPTPEDFPRQLALIKELVDLLGFTRLEVQGYEADDVLATLAKKAEKEGYEVRILTADRDLYQLVSDRVAV- LHPEGHLIT PEWLWEKYGLRPEQWVDFRALVGDPSDNIPGVKGIGEKTALKLLKEWGSLENLLKNLDRVKPENVREKIKAHLE- DLRLSLE LSRVRTDLPLEVDLAQGREPDREGLRAFLERLEFGSLLHEFGLLESPKALEEAPWPPPEGAFVGFVLSRKEPMW- ADLLALAAA RGGRVHRAPEPYKALRDLKEARGLLAKDLSVLALREGLGLPPGDDPMLLAYLLDPSNTTPEGVARRYGGEWTEE- AGERAAL SERLFANWGRLEGEERLLWLYREVDRPLSAVLAHMEATGVRLDVAYLRALSLEVAEEIARLEAEVFRLAGHPFN- LNSRDQL ERVLFDELGLPAIGKTERTGKRSTSAAVLEALREAHPIVEKILQYRELTKLKSTYIDPLPDLIHPRTGRLHTRF- NQTATATGRLSS SDPNLQNIPVRTPLGQRIRRAFIAEEGWLLVALDYSQIELRVLAHLSGDENLIRVFQEGRDIHTETASWMFGVP- PEAVDPLMRR AAKTVNFGVLYGMSAHRLSQELSIPYEEAVAFIERYFQSFPKVRAWIEKTLEEGRKRGYVETLFGRRRYVPDLN- ARVKSVREA AERMAFNMPVQGTAADLMKLAMVKLFPRLREMGARMLLQVHDELLLEAPQARAEEVAALAKEAMEKAYPLAVPL- EVEVG IGEDWLSAKE* 2H2: (SEQ ID NO: 79) ATGGCGATGCTTCCCCTCTTTGAGCCCAAGGGCCGCGTCCTCCTGGTGGACGGCCACCACCTGGCCTACCGCAC- CTTCTT CGCCCTGAAGGGCCCCACCACGAGCCGGGGCGAACCGGTGCAGGTGGTCTACGGCTTCGCCAAGAGCCTCCTCA- AGGCC CTGAAGGAGGACGGGTACAAGGCCGTCTTCGTGGTCTTTGACGCCAAGGCCCCCTCATTCCGCCACAAGGCCTA- CGAGG CCTACAGGGCGGGGAGGGCCCCGACCCCCGAGGACTTCCCCCGGCAGCTCGCCCTCATCAAGGAGCTGGTGGAC- CTCCT GGGGTTTACCCGCCTCGAGGTCCCCGGCTACGAGGCGGACGACGTTCTCGCCACCCTGGCCAAGAAGGCGGAAA- AGGA GGGGTACGAGGTGCGCATCCTCACCGCCGACCGCGGCCTCTACCAACTCGTCTCTGACCGCGTCGCCGTCCTCC- ACCCCG AGGGCCACCTCATCACCCCGGAGTGGCTTTGGGAGAAGTACGGCCTCAGGCCGGAGCAGTGGGTGGACTTCCGC- GCCCT CGTGGGGGACCCCTCCGACAACCTCCCCGGGGTCAAGGGCATCGGGGAGAAGACCGCCCTCAAGCTCCTCAAGG- AGTG GGGAAGCCTGGAAAACCTCCTCAAGAACCTGGACCGGGTAAAGCCAGAAAACGTCCGGGAGAAGATCAAGGCCC- ACCT GGAAGACCTCAGGCTCTCCTTGGAGCTCTCCCGGGTGCGCACCGACCTCCCCCTGGAGGTGGACCTCGCCCAGG- GGCGG GAGCCCGACCGGGAGAGGCTTAGGGCCTTTCTGGAGAGGCTTGAGTTTGGCGGCCTCCTCCACGAGTTCGGCCT- TCTGG AAAGCCCCAAGGCCCTGGAGGAGGCCCCCTGGCCCCCGCCGGAAGGGGCCTTCGTGGGCTTTGTGCTTTCCCGC- AAGGA GCCCATGTGGGCCGATCTTCTGGCCCTGGCCGCCGCCAGGGGTGGTCGGGTCCACCGGGCCCCCGAGCCTTATA- AAGCC CTCAGGGACTTGAAGGAGGCGCGGGGGCTTCTCGCCAAAGACCTGAGCGTTCTGGCCCTGAGGGAAGGCCTTGG- CCTCC CGCCCGGCGACGACCCCATGCTCCTCGCCTACCTCCTGGACCCTTCCAACACCACCCCCGAGGGGGTGGCCCGG- CGCTA CGGCGGGGAGTGGACGGAGGAGGCGGGGGAGCGGGCCGCCCTTTCCGAGAGGCTCTTCGCCAACCTGTGGGGGA- GGCT TGAGGGGGAGGAGAGGCTCCTTTGGCTTTACCGGGAGGTGGAGAGGCCCCTTTCCGTTGTCCTGGCCCACATGG- AGGCC ACAGGGGTGCGCCTGGACGTGGCCTATCTCAGGGCCTTGTCCCTGGAGGTGGCCGAGGAGATCGCCCGCCTCGA- GGCCG AGGTCTTCCGCCTGGCCGGCCACCCCTTCAACCTCAACTCCCGGGACCAGCTGGAAAGGGTCCTCTTTGACGAG- CTAGG GCTTCCCGCCATCGGCAAGACGGAGAAGACCGGCAAGCGCTCCACCGGCGCCGCCGTCCTGGAGGCCCTCCGCG- AGGC CCACCCCACCGTGGAGAAGATCCTGCAGTACCGGGAGCTCACCAAGCTGAAGAGCACCTACATTGACCCCTTGC- CGGAC CTCATCCACCCCAGGACGGGCCGCCTCCACACCCGCTTCAACCAGACGGCCACGGCCACGGGCAGGCTAAGTAG- CTCCG ACCCCAACCTCCAGAACATCCCCGTCCGCACCCCGCTCGGGCAGAGGATCCGCCGGGCCTTCATCGCCGAGGAG- GGGTG GCTATTGGTGGTCCTGGACTATAGCCAGATAGAGCTCAGGGTGCTGGCCCACCTCTCCGGCGACGAGAACCTGA- TCCGG GTCTTCCAGGAGGGGCGGGACATCCACACGGAAACCGCCAGCTGGATGTTCGGCGTCCCCCGGGAGGCCGTGGA- CCCCC TAATGCGCCGGGCGGCCAAGACCATCAACTTCGGGGTTCTCTACGGCATGTCGGCCCACCGCCTCTCCCAGGAG- CTAGC CATCCCTTACGAGGAGGCCCAGGCCTTCATTGAGCGCTACATTCAGAGCTTCCCCAAGGTGCGGGCCTGGATTG- AGAAG ACCCTGGAGGAGGGCAGGAGGCGGGGGTACGTGGAGACCCTCTTCGGCCGCCGTCGCTACGTGCCAGACCTAGA- GGCC CGGGTGAAGAGCGTGCGGGAGGCGGCCGAGCGCATGGCCTTCAACATGCCCGTCCAGGGCACCGCCGCCGACCT- CATG AAGCTGGCTATGGTGAAGCTCTTCCCCAGGCTGGAAGAAACGGGGGCCAGGATGCTCCTTCAGGTCCACGACGA- GCTGG TCCTCGAGGCCCCAAAAGAGAGGGCGGAGGCCGTGGCCCGGCTGGCCAAGGAGGCCATGGAGGGGGTGTATCCC- CTGG CCGTGCCCCTGGAGGTGGAGGTGGGGATAGGGGAGGACTGGCTCTCCGCCAAGGAGTGA (SEQ ID NO: 80) MAMLPLFEPKGRVLLVDGHHLAYRTFFALKGPTTSRGEPVQVVYGFAKSLLKALKEDGYKAVFVVFDAKAPSFR- HKAYEAY RAGRAPTPEDFPRQLALIKELVDLLGFTRLEVPGYEADDVLATLAKKAEKEGYEVRILTADRGLYQLVSDRVAV- LHPEGHLIT PEWLWEKYGLRPEQWVDFRALVGDPSDNIPGVKGIGEKTALKLLKEWGSLENLLKNLDRVKPENVREKIKAHLE- DLRLSLE LSRVRTDLPLEVDLAQGREPDRERLRAFLERLEFGGLLHEFGLLESPKALEEAPWPPPEGAFVGFVLSRKEPMW- ADLLALAAA RGGRVHRAPEPYKALRDLKEARGLLAKDLSVLALREGLGLPPGDDPMLLAYLLDPSNTTPEGVARRYGGEWTEE- AGERAAL SERLFANLWGRLEGEERLLWLYREVERPLSVVLAHMEATGVRLDVAYLRALSLEVAEEIARLEAEVFRLAGHPF- NLNSRDQL ERVLFDELGLPAIGKTEKTGKRSTGAAVLEALREAHPTVEKILQYRELTKLKSTYIDPLPDLIHPRTGRLHTRF- NQTATATGRLS SSDPNLQNIPVRTPLGQRIRRAFIAEEGWLLVVLDYSQIELRVLAHLSGDENLIRVFQEGRDIHTETASWMFGV- PREAVDPLMR RAAKTINFGVLYGMSAHRLSQELAIPYEEAQAFIERYIQSFPKVRAWIEKTLEEGRRRGYVETLFGRRRYVPDL- EARVKSVRE AAERMAFNMPVQGTAADLMKLAMVKLFPRLEETGARMLLQVHDELVLEAPKERAEAVARLAKEAMEGVYPLAVP- LEVEV GIGEDWLSAKE* 1C8: (SEQ ID NO: 81) ATGCGTGGTATGCTTCCTCTTTTTGAGCCCAAGGGCCGCGTCCTCCTGGTGGACGGCCACCACCTGGCCTACCG- CACCTT CTTCGCCCTGAAGGGCCCCACCACGAGCCGGGGCGAACCGGTGCAGGCGGTCTACGGCTTCGCCAAGAGCCTCC- TCAAG GCCCTGAAGGAGGACGGGTACAAGGCCGCCTTCGTGGTCTTTGACGCCAAGGCCCCCTCCTTCCGCCACGAGGC- CTACG AGGCCTACAAGGCGGGGAGGGCCCCGACCCCCGAGGACTTCCCCCGGCAGCTCGCCCTCATCAAGGAGCTGGTG- GACCT CCTGGGGTTTACCCGCCTCGAGGTCCCTGGCTACGAGGCGGACGACGTCCTCGCCACCCTGGCCAAGAAGGCGG- AAAAG GAGGGGTACGAGGTGCGCATCCTCACCGCCGACCGCGACCTCTACCAACTCGTCTCCGACCGCGTCGCCGTCCT- CCACC CCGAGGGCCACCTCATCACCCCGGAGTGGCTTTGGGAGAAGTACGGCCTCAGGCCGGAGCAGTGGGTGGACTTC- CGCGC CCTCGTGGGGGACCCCTCCGACAACCTCCCCGGGGTCAAGGGCATCGGGGAGAAGACCGCCCTCAAGCTCCTCA- AGGAG TGGGGAAGCCTGGAAAACCTCCTCAAGAACCTGGACCGGGTAAAGCCAGAAAACGTCCGGGAGAAGATCAAGGC- CCAC CTGGAAGACCTCAGGCTCTCCTTGGAGCTCTCCCGGGTGCGCACCGACCTCCCCCTGGAGGTGGACCTCGCCCA- GGGGC GGGAGCCCGACCGGGAGAGGCTTAGGGCCTTTCTGGAGAGGCTTGAGTTTGEiCGGCCTCCTCCACGAGTTCGG- CCTTCT GGAAAGCCCCAAGGCCCTGGAGGAGGCCCCCTGGCCCCCGCCGGAAGGGGCCTTCGTGGGCTTTGTGCTTTCCC- GCAAG GAGCCCATGTGGGCCGATCTTCTGGCCCTGGCCGCCGCCAGGGGTGGTCGGGTCCACCGGGCCCCCGAGCCTTA- TAAAG CCCTCAGGGACTTGAAGGAGGCGCGGGGGCTTCTCGCCAAAGACCTGAGCGTTCTGGCCCTAAGGGAAGGCCTT- GGCCT CCCGCCCGGCGACGACCCCATGCTCCTCGCCTACCTCCTGGACCCTTCCAACACCACCCCCGAGGGGGTGGCCC- GGCGC TACGGCGGGGAGTGGACGGAGGAGGCGGGGGAGCGGGCCGCCCTTTCCGAGAGGCTCTTCGCCAACCTGTGGGG- GAGG CTTGAGGGGGAGGAGAGGCTCCTTTGGCTTTACCGGGAGGTGGATAGEiCCCCTTTCCGCTGTCCTGGCCCACA- TGGAGG CCACAGGGGTACGGCTGGACGTGGCCTGCCTGCAGGCCCTTTCCCTGGAGCTTGCGGAGGAGATCCGCCGCCTC- GAGGA GGAGGTCTTCCGCTTGGCGGGCCACCCCTTCAACCTCAACTCCCGGGACCAGCTGGAAAGGGTCCTCTTTGACG- AGCTA GGGCTTCCCGCCATCGGCAAGACGGAGAAGACCGGCAAGCGCTCCACCAGCGCCGCCATCCTGGAGGCCCTCCG- CGAG GCCCACCCCATCGTGGAGAAGATCCTGCAGTACCGGGAGCTCACCAAGCTGAAGAGCACCTACATTGACCCCTT- GCCGG ACCTCATCCACCCCAGGACGGGCCGCCTCCACACCCGCTTCAACCAGACGGCCACGGCCACGGGCAGGCTAAGT- AGCTC CGATCCCAACCTCCAGAACATCCCCGTCCGCACCCCGCTCGGGCAGAGGATCCGCCGGGCCTTCATCGCCGAGG- AGGGG TGGCTATTGGTGGTCCTGGACTATAGCCAGATAGAGCTCAGGGTGCTGGCCCACCTCTCCGGCGACGAGAACCT- GACCC GGGTCTTCCAGGAGGGGCGGGACATCCACACGGAAACCGCCAGCTGGATGTTCGGCGTCCCCCGGGAGGCCGTG- GACC CCCTGATGCGCCGGGCGGCCAAGACCATCAACTTCGGGGTTCTCTACGGCATGTCGGCCCACCGCCTCTCCCAG- GAGCT GGCCATCCCTTACGAGGAGGCCCAGGCCTTCATAGAGCGCTACTTCCAAAGCTTCCCCAAGGTGCGGGCCTGGA- TAGAA AAGACCCTGGAGGAGGGGAGGAAGCGGGGCTACGTGGAAACCCTCTTCGGAAGAAGGCGCTACGTGCCCGACCT- CAAC GCCCGGGTGAAGAGTGTCAGGGAGGCCGCGGAGCGCATGGCCTTCAACATGCCCGTCCAGGGCACCGCCGCCGA- CCTTA TGAAGCTCGCCATGGTGAAGCTCTTCCCCCGCCTCCGGGAGATGGGGGCCCGCATGCTCCTCCAGGTCCACGAC-
GAGCT CCTCCTGGAGGCCCCCCAAGCGCGGGCCGAGGAGGTGGCGGCTTTGGCCAAGGAGGCCATGGAGAAGGCCTATC- CCCTC GCCGTACCCCTGGAGGTGAAGGTGGGGATCGGGGAGGACTGGCTCTCCGCCAAGGAGTGA (SEQ ID NO: 82) MRGMLPLFEPKGRVLLVDGHHLAYRTFFALKGPTTSRGEPVQAVYGFAKSLLKALKEDGYKAAFVVFDAKAPSF- RHEAYEA YKAGRAPTPEDFPRQLALIKELVDLLGFTRLEVPGYEADDVLATLAKKAEKEGYEVRILTADRDLYQLVSDRVA- VLHPEGHLI TPEWLWEKYGLRPEQWVDFRALVGDPSDNIPGVKGIGEKTALKLLKEWGSLENLLKNLDRVKPENVREKIKAHL- EDLRLSL ELSRVRTDLPLEVDLAQGREPDRERLRAFLERLEFGGLLHEFGLLESPKALEEAPWPPPEGAFVGFVLSRKEPM- WADLLALAA ARGGRVHRAPEPYKALRDLKEARGLLAKDLSVLALREGLGLPPGDDPMLLAYLLDPSNTTPEGVARRYGGEWTE- EAGERAA LSERLFANLWGRLEGEERLLWLYREVDRPLSAVLAHMEATGVRLDVACLQALSLELAEEIRRLEEEVFRLAGHP- FNLNSRDQ LERVLFDELGLPAIGKTEKTGKRSTSAAILEALREAHPIVEKILQYRELTKLKSTYIDPLPDLIHPRTGRLHTR- FNQTATATGRLS SSDPNLQNIPVRTPLGQRTRRAFIAEEGWLLVVLDYSQIELRVLAHLSGDENLTRVFQEGRDIHTETASWMFGV- PREAVDPLM RRAAKTINFGVLYGMSAHRLSQELAIPYEEAQAFIERYFQSFPKVRAWIEKTLEEGRKRGYVETLFGRRRYVPD- LNARVKSVR EAAERMAFNMPVQGTAADLMKLAMVKLFPRLREMGARMLLQVHDELLLEAPQARAEEVAALAKEAMEKAYPLAV- PLEVK VGIGEDWLSAKE* 2H10X: (SEQ ID NO: 83) ATGGCGATGCTTCCCCTCTTTGAGCCCAAGGGCCGTGTCCTCCTGGTGGACGGCCACCACCTGGCCTACCGCAC- CTTCTT CGCCCTGAAGGGCCCCACCACGAGCCGGGGCGAACCGGTGCAGGTGGTCTACGGCTTCGCCAAGAGCCTCCTCA- AGGCC CTGAAGGAGGACGGGTACAAGGCCGTCTTCGTGGTCTTTGACGCCAAGGCCCCCCCATTCCGCCACAAGGCCTA- CGAGG CCTACAGGGCGGGGAGGGCCCCGACCCCCGAGGACTTCCCCCGGCAGCTCGCCCTCATCAAGGAGCTGGTGGAC- CTCCT GGGGTTTACCCGCCTCGAGGTCCCCGGCTACGAGGCGGACGACGTTCTCGCCACCCTGGCCAAGAAGGCGGAAA- AGGA GGGGTACGAGGTGCGCATCCTCACCGCCGACCGCGGCCTCTACCAACTCGTCTCTGACCGCGTCGCCGTCCTCC- ACCCCG AGGGCCACCTCATCACCCCGGAGTGGCTTTGGGAGAAGTACGGCCTCAGGCCGGAGCAGTGGGTGGACTTCCGC- GCCCT CGTGGGGGACCCCTCCGACAACCTCCCCGGGGTCAAGGGCATCGGGGAGAAGACCGCCCTCAAGCTCCTCAAGG- AGTG GGGAAGCCTGGAAAACCTCCTCAAGAACCTGGACCGGGTAAAGCCAGAAAACGTCCGGGAGAAGATCAAGGCCC- ACCT GGAAGATCTCAGGCTCTCCTTGGAGCTCTCCCGGGTGCGCACCGACCTCCCCCTGGAGGTGGACCTCGCCCAGG- GGCGG GAGCCCGACCGGGAGGGGCTTAGGGCCTTTCTGGAGAGGCTTGAGTTTGGCAGCCTCCTCCACGAGTTCGGCCT- TCTGG AAAGCCCCAAGGCCCTGGAGGAGGCCCCCTGGCCCCCGCCGGAAGGGGCCTTCGTGGGCTTTGTGCTTTCCCGC- AAGGA GCCCATGTGGGCCGATCTTCTGGCCCTGGCCGCCGCCAGGGGTGGTCGAGTCCACCGGGCCCCCGAGCCTTATA- AAGCC CTCAGGGACCTGAAGGAGGCGCGGGGGCTTCTCGCCAAAGACCTGAGCGTTCTGGCCCTAAGGGAAGGCCTTGG- CCTCC CGCCCGGCGACGACCCCATGCTCCTCGCCTACCTCCTGGACCCTTCCAACACCACCCCCGAGGGGGTGGCCCGG- CGCTA CGGCGGGGAGTGGACGGAGGAGGCGGGGGAGCGGGCCGCCCTTTCCGAGAGGCTCTTCGCCAACCTGTGGGGGA- GGCT TGAGGGGGAGGAGAGGCTCCTTTGGCTTTACCGGGAGGTGGAGAGGCCCCTTTCCGCTGTCCTGGCCCACATGG- AGGCC ACGGGGGTGCGCCTGGACGTGGCCTATCTCAGGGCCTTGTCCCTGGAGGTGGCCGAGGAGATCGCCCGCCTCGA- GGCCG AGGTCTTCCGCCTGGCCGGCCACCCCTTCAACCTCAACTCCCGGGACCAGCTGGAAATGGTGCTCTTTGACGAG- CTTAGG CTTCCCGCCTTGGGGAAGACGCAAAAGACGGGCAAGCGCTCCACCAGCGCCGCCGTCCTGGAGGCCCTCCGCGA- GGCCC ACCCCATCGTGGAGAAGATCCTGCAGTACCGGGAGCTCACCAAGCTGAAGAGCACCTACATTGACCCCTTGTCG- GACCT CATCCACCCCAGGACGGGCCGCCTCCACACCCGCTTCAACCAGACGGCCACGGCCACGGGCAGGCTAAGTAGCT- CCGAT CCCAACCTCCAGAACATCCCCGTCCGCACCCCGCTTGGGCAGAGGATCCGCCGGGCCTTCATCGCCGAGGAGGG- GTGGC TACTGGTGGTCCTGGACTATAGCCAGATAGAGCTCAGGGTGCTGGCCCACCTCTCCGGCGACGAAAACCTGATC- AGGGT CTTCCAGGAGGGGCGGGACATCCACACGGAGACCGCCAGCTGGATGTTCGGCGTCCCCCGGGAGGCCGTGGACC- CCCTG ATGCGCCGGGCGGCCAAGACCATCAACTTCGGGGTCCTCTACGGCATGTCGGCCCACCGCCTCTCCCAGGAGCT- AGCCA TCCCTTACGAGGAGGCCCAGGCCTTCATTGAGCGCTACTTTCAGAGCTTCCCCAAGGTGCGGGCCTGGATTGAG- AAGAC CCTGGAGGAGGGCAGGAGGCGGGGGTACGTGGAGACCCTCTTCGGCCGCCGCCGCTACGTGCCAGACCTAGAGG- CCCG GGTGAAGAGCGTGCGGGAGGCGGCCGAGCGCATGGCCTTCAACATGCCCGTCCAGGGCACCGCCGCCGACCTCA- TGAA GCTGGCTATGGTGAAGCTCTTCCCCAGGCTGGAGGAAATGGGGGCCAGGATGCTCCTTCAGGTCCACGACGAGC- TGGTC CTCGAGGCCCCAAAAGAGAGGGCGGAGGCCGTGGCCCGGCTGGCCAAGGAGGTCATGGAGGGGGTGTATCCCCT- GGCC GTGCCCCTGGAGGTGGAGGTGGGGATAGGGGAGGACTGGCTCTCCGCCAAGGAGTGA (SEQ ID NO: 84) MAMLPLFEPKGRVLLVDGHHLAYRTFFALKGPTTSRGEPVQVVYGFAKSLLKALKEDGYKAVFVVFDAKAPPFR- HKAYEAY RAGRAPTPEDFPRQLALIKELVDLLGFTRLEVPGYEADDVLATLAKKAEKEGYEVRILTADRGLYQLVSDRVAV- LHPEGHLIT PEWLWEKYGLRPEQWVDFRALVGDPSDNLPGVKGIGEKTALKLLKEWGSLENLLKNLDRVKPENVREKIKAHLE- DLRLSLE LSRVRTDLPLEVDLAQGREPDREGLRAFLERLEFGSLLHEFGLLESPKALEEAPWPPPEGAFVGFVLSRKEPMW- ADLLALAAA RGGRVHRAPEPYKALRDLKEARGLLAKDLSVLALREGLGLPPGDDPMLLAYLLDPSNTTPEGVARRYGGEWTEE- AGERAAL SERLFANLWGRLEGEERLLWLYREVERPLSAVLAHMEATGVRLDVAYLRALSLEVAEEIARLEAEVFRLAGHPF- NLNSRDQL EMVLFDELRLPALGKTQKTGKRSTSAAVLEALREAHPIVEKILQYRELTKLKSTYIDPLSDLIHPRTGRLHTRF- NQTATATGRL SSSDPNLQNIPVRTPLGQRIRRAFIAEEGWLLVVLDYSQIELRVLAHLSGDENLIRVFQEGRDIHTETASWMFG- VPREAVDPLM RRAAKTINFGVLYGMSAHRLSQELAIPYEEAQAFIERYFQSFPKVRAWIEKTLEEGRRRGYVETLFGRRRYVPD- LEARVKSVR EAAERMAFNMPVQGTAADLMKLAMVKLFPRLEEMGARMLLQVHDELVLEAPKERAEAVARLAKEVMEGVYPLAV- PLEVE VGIGEDWLSAKE* 3A10 (SEQ ID NO: 85) ATGGCGATGCTTCCCCTCTTTGAGCCCAAAGGCCGGGTCCTCCTGGTGGACGGCCACCACCTGGCCTACCGCAC- CTTCTT CGCCCTGAAGGGCCTCACCACGAGCCGGGGCGAACCGGTGCAGGTGGTCTACGGCTTCGCCAAGAGCCTCCTCA- AGGCC CTGAAGGAGGACGGGTACAAGGCCGTCTTCGTGGTCTTTGACGCCAAGGCCCCCTCATTCCGCCACAAGGCCTA- CGAGG CCTACAGGGCGGGGAGGGCCCCGACCCCCCAGGACTTCCCCCGGCAGCTCGCCCTCATCAAGGAGCTGGTGGAC- CTCCT GGGGTTTACCCGCCTCGAGGTCCCCGGCTACGAGGCGGACGACGTTCTCGCCACCCTGGCCAAGAAGGCGGAAA- AGGA GGGGTACGAGGTGCGCATCCTCACCGCCGACCGCGGCCTCTACCAACTCGTCTCCGACCGCGTCGCCGTCCTCC- ACCCCG AGGGCCACCTCATCACCCCGGAGTGGCTTTGGGAGAAGTACGGCCTCAGGCCGGAGCAGTGGGTGGACTTCCGC- GCCCT CGTGGGGGACCCCTCCGACAACCTCCCCGGGGTCAAGGGCATCGGGGAGAAGACCGCCCTCAAGCTCCTCAAGG- AGTG GGGAAGCCTGGAAAACCTCCTCAAGAACCTGGACCGGGTAAAGCCAGAAAACGTCCGGGAGAAGATCAAGGCCC- ACCT GGAAGACCTCAGGCTCTCCTTGGAGCTCTCCCGGGTGCGCACCGACCTCCCCCTGGAGGTGGACCTCGCCCAGG- GGCGG GAGCCCGACCGGGAGGGGCTTAGGGCCTTTCTGGAGAGGCTTGAGTTTGGCAGCCTCCTCCACGAGTTCGGCCT- TCTGG AAAGCCCCAAGGCCCTGGAGGAGGCCCCCTGGCCCCCGCCGGAAGGGGCCTTCGTGGGCTTTGTGCTTTCCCGC- AAGGA GCCCATGTGGGCCGATCTTCTGGCCCTGGCCGCCGCCAGGGGTGGTCGAGTCCACCAGGCCCCCGAGCCTTATA- AAGCC CTCAGGGACCTGAAGGAGGCGCGGGGGCTTCTCGCCAAAGACCTGAGCGTTCTGGCCCTAAGGGAAGGCCTTGG- CCTCC CGCCCGGCGACGACCCCATGCTCCTCGCCTACCTCCTGGACCCTTCCAACACCACCCCCGAGGGGGTGGCCCGG- CGCTA CGGCGGGGAGTGGACGGAGGAGGCGGGGGAGCGGGCCGCCCTTTCCGAGAGGCTCTTCGCCAACCTGTGGGGGA- GGCT TGAGGGGGAGGAGAGGCTCCTTTGGCTTTACCGGGAGGTGGAGAGGCCCCTTTCCGCTGTCCTGGCCCACATGG- AGACC ACGGGGGTGCGCCTGGACGTGGCCTATCTCAGGGCCTTGTCCCTGGAGGTGGCCGAGGAGATCGCCCGCCTCGA- GGCCG AGGTCTTCCGCCTGGCCGGCCGCCCCTTCAACCTCAACTCCCGAGACCAGCTGGAAAGGGTCCTCTTTGACGAG- CTAGG GCTTCCCGCCATCGGCAAGACGGAGAAGACCGGCAAGCGCTCCACCAGCGCCGCCGTCCTGGAGGCCCTCCGCG- AGGC CCACCCCATCGTGGAGAAGATCCTGCAGTACCGGGAGCTCACCAAGCTGAAGAGCACCTACATTGACCCCTTGC- CGGAC CTCATCCACCCCAGGACGGGCCGCCTCCACACCCGCTTCAACCAGACGGCCACGGCCACGGGCAGGCTAAGTAG- CTCCG ATCCCAACCTCCAGAACATCCCCGTCCGCACCCCGCTTGGGCAGAGGATCCGCCGGGCCTTCATCGCCGAGGAG- GGGTG GCTATTGGTGGTCCTGGACTATAGCCAGATGGAGCTCAGGGTGCTGGCCCACCTCTCCGGCGACGAGAACCTGA- TCAGG GTCTTCCAGGAGGGGAAGGACATCCACACCCAGACCGCAAGCTGGATGTTCGGTGTCCCCCCGGAGGCCGTGGA- CCCCC TGATGCGCCGGGCGGCCAAGACGGTGAACTTCGGCGTCCTCTACGGCATGTCCGCCCATAGGCTCTCCCAGGAG- CTTTCC ATCCCCTACGAGGAGGCGGTGGCCTTCATAGAGCGCTACTTCCAAAGCTTCCCCAAGGTGCGGGCCTGGATTGA-
GAAGA CCCTGGAGGAGGGCAGGAGGCGGGGGTACGTGGAGACCCTCTTCGGCCGCCGCCGCTACGTGCCCGACCTCAAC- GCCCG GATGAAGAGCGTCAGGGGGGCCGCGGAGCGCATGGCCTTCAACATGCCCGTCCAGGGCACCGCCGCCGACCTCA- TGAA GCTCGCCATGGTGAAGCTCTTCCCCCGCCTCCGGGAGATGGGGGCCCGCATGCTCCTCCAGGTCCACGACGAGC- TCCTCC TGGAGGCCCCCCAAGCGCGGGCCGAGGAGGTGGCGGCTTTGGCCAAGGAGGCCATGGAGAAGGCCTATCCCCTC- GCCG TACCCCTGGAGGTGGAGGTGGGGATCGGGGAGGACTGGCTCTCCGCCAAGGAGTGA (SEQ ID NO: 86) MAMLPLFEPKGRVLLVDGHHLAYRTFFALKGLTTSRGEPVQVVYGFAKSLLKALKEDGYKAVFVVFDAKAPSFR- HKAYEAY RAGRAPTPQDFPRQLALIKELVDLLGFTRLEVPGYEADDVLATLAKKAEKEGYEVRILTADRGLYQLVSDRVAV- LHPEGHLIT PEWLWEKYGLRPEQWVDFRALVGDPSDNIPGVKGIGEKTALKLLKEWGSLENLLKNLDRVKPENVREKIKAHLE- DLRLSLE LSRVRTDLPLEVDLAQGREPDREGLRAFLERLEFGSLLHEFGLLESPKALEEAPWPPPEGAFVGFVLSRKEPMW- ADLLALAAA RGGRVHQAPEPYKALRDLKEARGLLAKDLSVLALREGLGLPPGDDPMLLAYLLDPSNTTPEGVARRYGGEWTEE- AGERAAL SERLFANLWGRLEGEERLLWLYREVERPLSAVLAHMETTGVRLDVAYLRALSLEVAEEIARLEAEVFRLAGRPF- NINSRDQL ERVLFDELGLPAIGKTEKTGKRSTSAAVLEALREAHPIVEKILQYRELTKLKSTYIDPLPDLIHPRTGRLHTRF- NQTATATGRLS SSDPNLQNIPVRTPLGQRIRRAFIAEEGWLLVVLDYSQMELRVLAHLSGDENLIRVFQEGKDIHTQTASWMFGV- PPEAVDPLM RRAAKTVNFGVLYGMSAHRLSQELSIPYEEAVAFIERYFQSFPKVRAWIEKTLEEGRRRGYVETLFGRRRYVPD- LNARMKSV RGAAERMAFNMPVQGTAADLMKLAMVKLFPRLREMGARMLLQVHDELLLEAPQARAEEVAALAKEAMEKAYPLA- VPLEV EVGIGEDWLSAKE* 3B5 (SEQ ID NO: 87) ATGGCGATGCTTCCCCTCTTTGAGCCCAAGGGCCGTGTCCTCCTGGTGGACGGCCACCACCTGGCCTACCGCAC- CTCCTTCG CCCTGAAGGGCCCCACCACGAGCCGGGGCGAACCGGTGCAGGTGGTCTACGGCTTCGCCAAGAGCCTCCTCAAG- GCCCTGA AGGAGGACGGGTACAAGGCCGTCTTCGTGGTCTTTGACGCCAAGGCCCCCCCATTCCGCCACAAGGCCTACGAG- GCCTACA GGGCGGGGAGGGCCCCGACCCCCGAGGACTTCCCCCGGCAGCTCGCCCTCGTCAAGGAGCTGGTGGACCTCCTG- GGGTTTA CCCGCCTCGAGGTCCCCGGCTACGAGGCGGACGACGTTCTCGCCACCCTGGCCAAGAAGGCGGAAAAGGAGGGG- TACGAG GTGCGCATCCTCACCGCCGACCGCGGCCTCTACCAACTCGTCTCTGACCGCGTCGCCGTCCTCCACCCCGAGGG- CCACCTCA TCACCCCGGAGTGGCTTTGGGAGAAGTACGGCCTCAGGCCGGAGCAGTGGGTGGACTTCCGCGCCCTCGTGGGG- GACCCCT CCGACAACCTCCCCGGGGTCAAGGGCATCGGGGAGAAGACCGCCCTCAAGCTCCTCAAGGAGTGGGGAAGCCTG- GAAAAC CTCCTCAAGAACCTGGACCGGGTAAAGCCAGAAAACGTCCGGGAGAAGATCAAGGCCCACCTGGAAGACCTCAG- GCTCTCC TTGGAGCTCTCCCGGGTGCGCACCGACCTCCCCCTGGAGGTGGACCTCGCCCAGGGGCGGGAGCCCGACCGGGA- AAGGCTT AGGGCCTTTCTGGAGAGGCTTGAGTTTGGCAGCCTCCTCCATGAGTTCGGCCTTCTGGAAAGCCCCAAGGCCCT- GGAGGAGG CCCCCTGGCCCCCGCCGGAAGGGGCCTTCGTGGGCTTTGTGCTTTCCCGCAAGGCGCCCATGTGGGCCGATCTT- CTGGCCCT GGCCGCCGCCAGGGGTGGTCGGGTCTACCGGGCCCCCGAGCCTTATAAAGCCCTCAGGGACTTGAAGGAGGCGC- GGGGGCT TCTCGCCAAAGACCTGAGCGTTCTGGCCCTAAGGGAAGGCCTTGGCCTCCCGCCCGGCGACGACCCCATGCTCC- TCGCCTAC CTCCTGGACCCTTCCAACACCACCCCCGAGGGGGTGGCCCGGCGCTACGGCGGGGAGTGGACGGAGGAGGCGGG- GGAGCG GGCCGCCCTTTCCGAGAGGCTCTTCGCCAACCTGTGGGGGAGGCTTGAGGGGGAGGAGAGGCTCCTTTGGCTTT- ACCGGGA GGTGGATAGGCCCCTTTCCGCTGTCCTGGCCCACATGGAGGCCACAGGGGTACGGCTGGACGTGGCCTGCCTGC- AGGCCCTT TCCCTGGAGCTTGCGGAGGAGATCCGCCGCCTCGAGGAGGAGGTCTTCCGCTTGGCGGGCCACACCTTCAACCT- CAACTCCC GGGACCAGCTGGAAAGGGTCCTCTTTGACGAGCTAGGGCTTCCCGCCATCGGCAAGACGGAGAAGACCGGCAAG- CGCTCCA CCAGCGCCGCCATCCTGGAGGCCCTCCGCGAGGCCCACCCCATCGTGGAGAAGATCCTGCAGTACCGGGAGCTC- ACCAAGC TGAAGAGCACCTACATTGACCCCTTGCCGGACCTCATCCACCCCAGGACGGGCCGCCTCCACACCCGCTTCAAC- CAGACGGC CACGGCCACGGGCAGGCTAAGTAGCTCCGATCCCAACCTCCAGAACATCCCCGTCCGCACCCCGCTTGGGCAGA- GGATCCG CCGGGCCTTCATCGCCGAGGAGGGGTGGCTACTGGTGGTCCTGGACTATAGCCAGATAGAGCTCAGGGTGCTGG- CTCACCT CTCCGGCGACGAAAACCTGATCAGGGTCTTCCAGGAGGGGCGGGACATCCACACGGAGACCGCCAGCTGGATGT- TCGGCGT CCCCCGGGAGGCCGTGGACCCCCTGATGCGCCGGGCGGCCAAGACCATCAACTTCGGGGTCCTCTACGGCATGT- CGGCCCA CCGCCTCTCCCAGGAGCTAGCCATCCCTTACGAGGAGGCCCAGGCCTTCATTGAGCGCTACTTTCAGAGCTTCC- CCAAGGTG CGGGCCTGGATTGAGAAGGCCCTGGAGGAGGGCAGGAGGCGGGGGTACGTGGAGACCCTCTTCGGAAGAAGGCG- CTACGT GCCCGACCTCAACGCCCGGGTGAAGAGTGTCAGGGAGGCCGCGGAGCGCATGGCCTTCAACATGCCCGTCCAGG- GCACCGC CGCCGACCTTATGAAGCTCGCCATGGTGAAGCTCTTCCCCCGCCTCCGGGAGATGGGGGCCCGCATGCTCCTCC- AGGTCCAC GACGAGCTCCTCCTGGAGGCCCCCCAAGCGCGGGCCGAGGAGGTGGCGGCTTTGGCCAAGGAGGCCATGGAGAA- GGCCTA TCCCCTCGCCGTACCCCTGGAGGTGAAGGTGGGGATCGGGGAGGACTGGCTCTCCGCCAAGGAGTGA (SEQ ID NO: 88) MAMLPLFEPKGRVLLVDGHHLAYRTSFALKGPTTSRGEPVQVVYGFAKSLLKALKEDGYKAVFVVFDAKAPPFR- HKAYEAYRA GRAPTPEDFPRQLALVKELVDLLGFTRLEVPGYEADDVLATLAKKAEKEGYEVRILTADRGLYQLVSDRVAVLH- PEGHLITPEWL WEKYGLRPEQWVDFRALVGDPSDNLPGVKGIGEKTALKLLKEWGSLENILKNLDRVKPENVREKIKAHLEDLRL- SLELSRVRTD LPLEVDLAQGREPDRERLRAFLERLEFGSLLHEFGLLESPKALEEAPWPPPEGAFVGFVLSRKAPMWADLLALA- AARGGRVYRAP EPYKALRDLKEARGLLAKDLSVLALREGLGLPPGDDPMLLAYLLDPSNTTPEGVARRYGGEWTEEAGERAALSE- RLFANIWGRL EGEERLLWLYREVDRPLSAVLAHMEATGVRLDVACLQALSLELAEEIRRLEEEVFRLAGHTFNLNSRDQLERVL- FDELGLPAIGK TEKTGKRSTSAAILEALREAHPIVEKILQYRELTKLKSTYIDPLPDLIHPRTGRLHTRFNQTATATGRLSSSDP- NLQNIPVRTPLGQRI RRAFIAEEGWLLVVLDYSQIELRVLAHLSGDENLIRVFQEGRDIHTETASWMFGVPREAVDPLMRRAAKTINFG- VLYGMSAHRLS QELATPYEEAQAFTERYFQSFPKVRAWTEKALEEGRRRGYVETLFGRRRYVPDLNARVKSVREAAERMAFNMPV- QGTAADLMKL AMVKLFPRLREMGARMLLQVHDELLLEAPQARAEEVAALAKEAMEKAYPLAVPLEVKVGIGEDWLSAKE* 3B6 (SEQ ID NO: 89) ATGGCGATGCTTCCCCTCTTTGAGCCCAAGGGCCGCGTCCTCCTGGTGGACGGCCACCACCTGGCCTACCGCGC- CTTCTTCG CCCTGAAGGGCCTCACCACGAGCCEiGGGCGAACCGGTGCAGGCGGTCTACGGCTTCGCCAAGAGCCTCCTCAA- GGCCCTGA AGGAGGACGGGTACAAGGCCGTCTTCGTGGTCTTTGACGCCAAGGCCCCCTCCTTCCGCCACGAGGCCTACGAG- GCCTACA AGGCGGGGAGGGCCCCGACCCCCGAGGACTTCCCCCGGCAGCTCGCCCTCATCAAGGAGCTGGTGGACCTCCTG- GGGTTTA CCCGCCTCGAGGTCCAAGGCTACGAGEiCGGACGACGTCCTCGCCACCCTGGCCAAGAAGGCGGAAAAAGAAGG- GTACGAG GTGCGCATCCTCACCGCCGACCGGGACCTCTACCAGCTCGTCTCCGACCGCGTCGCCGTCCTCCACCCCGAGGG- CCACCTCA TCACCCCGGAGTGGCTTTGGGAGAAGTACGGCCTCAGGCCGGAGCAGTGGGTGGACTTCCGCGCCCTCGTGGGG- GACCCCT CCAACAACCTCCCCGGGGTCAAGGGCATCGGGGAGAAGACCGCCCTCAAGCTCCTCAAGGAGTGGGGAAGCCTG- GAAAAC CTCCTCAAGAACCTGGACCGGGTAAAGCCAGAAAACGTCCGGGAGAAGATCAAGGCCCACCTGGAAGACCTCAG- GCTCTCC TTGGAGCTCTCCCGGGTGCGCACCGACCTCCCCCTGGAGGTGGACCTCGCCCAGGGGCGGGAGCTCGACCGGGA- GAGGCTT AGGGCCTTTCTGGAGAGGCTTGAGTTTGGCGGCCTCCTCCACGAGTTCGGCCTTCTGGAAAGCCCCAAGGCCCT- GGAGGAG GCCCCCTGGCCCCCGCCGGAAGGGGCCTTCGTGGGCTTTGTGCTTTCCCGCAAGGAGCCCATGTGGGCCGATCT- TCTGGCCC TGGCCGCCGCCAGGGGTGGTCGGGTCCACCGGGCCCCCGAGCCTTATAAAGCCCTCAGGGACTTGAAGGAGGCG- CGGGGGC TTCTCGCCAAAGACCTGAGCGTTCTGGCCCTAAGGGAAGGCCTTGGCCTCCCGCCCGGCGACGACCCCATGCTC- CTCGCCTA CCTCCTGGACCCTTCCAACACCGCCCCCGAGGGGGTGGCCCGGCGCTACGGCGGGGAGTGGACGGAGGAGGCGG- GGGAGC GGGCCGCCCTTTCCGAGAGGCTCTTCGCCAACCTGTGGGGGAGGCTTGAGGGGGAGGAGAGGCTCCTTTGGCTT- TACCGGG AGGTGGATAGGCCCCTTTCCGCTGTCCTGGCCCACATGGAGGCCACAGGGGTACGGCTGGACGTGGCCTATCTC- AGGGCCTT GTCCCTGGAGGTGGCCGAGGAGATCGCGCGCCTCGAGGCCGAGGTCTTCCGCCTGGCCGGCCACCCCTTCAACC- TCAACTCC CGAGACCAGCTGGAAAGGGTCCTCTTTGACGAGCTAGGGCTTCCCGCCATCGGCAAGACGGAGAAGACCGGCAA- GCGCTCC ACCAGCGCCGCCGTCCTGGAGGCCCTCCGCGAGGCCCACCCCATCGTGGAGAAGATCCTGCAGTACCGGGAGCT- CACCAAG CTGAAGAGCACCTACATTGACCCCTTGCCGAACCTCATCCATCCCAGGACGGGCCGCCTCCACACCCGCTTCAA- CCAGACGG CCACGGCCACGGGCAGGCTAAGTAGCTCCGATCCCAACCTCCAGAACATCCCCGTCCGCACCCCGCTCGGGCAG- AGGATCC GCCGGGCCTTCATCGCCGAGGAGGGGTGGCTATTGGTGGTCCTGGACTATAGCCAGATAGAGCTCAGGGTGCTG- GCCCACC TCTCCGGCGACGAGAACCTGATCCGGGTCTTCCAGGAGGGGCGGGACATCCACACGGAAACCGCCAGCTGGATG- TTCGGCG TCCCCCGGGAGGCCGTGGACCCCCTGATGCGCCGGGCGGCCAAGACCATCAACTTCGGGGTTCTCTACGGCATG- TCGGCCC ACCGCCTCTCCCAGGAGCTAGCCATCCCTTACGAGGAGGCCCAGGCCTTCATTGAGCGCTACTTTCAGAGCTTC-
CCCAAGGT GCGGGCCTGGATAGAAAAGACCCTGGAGGAGGGGAGGAAGCGGGGCTACGTGGAAACCCTCTTCGGAAGAAGGC- GCTACG TGCCCGACCTCAACGCCCGGGTGAAGGGCGTCAGGGAGGCCGCGGAGCGCATGGCCTTCAACATGCCCGTCCAG- GGCACCG CCGCCGACCTCATGAAGCTCGCCATGGTGAAGCTCTTCCCCCGCCTCCGGGAGATGGGGGCCCGCATGCTCCTC- CAGGTCCA CGACGAGCTCCTCCTGGAGGCCCCCCAAGCGCGGGCCGGGGAGGTGGCGGCTTTGGCCAAGGAGGCCATGGAGA- AGGCCT ATCCCCTCGCCGTACCCCTGGAGGTGAAGGTGGGGATCGGGGAGGACTGGCTCTCCGCCAAGGAGTGA (SEQ ID NO: 90) MAMLPLFEPKGRVLLVDGHHLAYRAFFALKGLTTSRGEPVQAVYGFAKSLLKALKEDGYKAVFVVFDAKAPSFR- HEAYEAYKA GRAPTPEDFPRQLALIKELVDLLGFTRLEVQGYEADDVLATLAKKAEKEGYEVRILTADRDLYQLVSDRVAVLH- PEGHLITPEWL WEKYGLRPEQWVDFRALVGDPSNNLPGVKGIGEKTALKLLKEWGSLENLLKNLDRVKPENVREKIKAHLEDLRL- SLELSRVRTD LPLEVDLAQGRELDRERLRAFLERLEFGGLLHEFGLLESPKALEEAPWPPPEGAFVGFVLSRKEPMWADLLALA- AARGGRVHRAP EPYKALRDLKEARGLLAKDLSVLALREGLGLPPGDDPMLLAYLLDPSNTAPEGVARRYGGEWTEEAGERAALSE- RLFANLWGR LEGEERLLWLYREVDRPLSAVLAHMEATGVRLDVAYLRALSLEVAEEIARLEAEVFRLAGHPFNLNSRDQLERV- LFDELGLPAIG KTEKTGKRSTSAAVLEALREAHPIVEKILQYRELTKLKSTYIDPLPNLIHPRTGRLHTRFNQTATATGRLSSSD- PNLQNIPVRTPLGQ RIRRAFIAEEGWLLVVLDYSQIELRVLAHLSGDENLIRVFQEGRDIHTETASWMFGVPREAVDPLMRRAAKTIN- FGVLYGMSAHR LSQELAIPYEEAQAFIERYFQSFPKVRAWIEKTLEEGRKRGYVETLFGRRRYVPDLNARVKGVREAAERMAFNM- PVQGTAADLM KLAMVKLFPRLREMGARMLLQVHDELLLEAPQARAGEVAALAKEAMEKAYPLAVPLEVKVGIGEDWLSAKE* 3B8 (SEQ ID NO: 91) ATGGCGATGCTTCCCCTCTTTGAGCCCAAAGGCCGGGTCCTCCTGGTGGACGGCCACCACCTGGCCTACCGCAC- CTTCTTCG CCCTGAAGGGCCTCACCACGAGCCGGGGCGAACCGGTGCAGGTGGTCTACGGCTTCGCCAAGAGCCTCCTCAAG- GCCCTGA AGGAGGACGGGTACAAGGCCGTCTTCGTGGTCTTTGACGCCAAGGCCCCCTCCCTCCGCCACGAGGCCTACGAG- GCCTACA AGGCGGGGAGGGCCCCGACCCCCGAGGACTTCCTCCGGCAGCTCGCCCTCATCAAGGAGCTGGTGGACCTCCTG- GGGTTTA CCCGCCTCGAGGTCCAAGGCTACGAGGCGGACGACGTCCTCGCCACCCTGGCCAAGAAGGCGGAAAAAGAAGGG- TACGAG GTGCGCATCCTCACCGCCGACCGGGACCTCTACCAGCTCGTCTCCGACCGCGTCGCCGTCCTCCACCCCGAGGG- CCACCTCA TCACCCCGGAGTGGCTTTGGGAGAAGTACGGCCTCAGGCCGGAGCAGTGGGTGGACTTCCGCGCCCTCGTGGGG- GACCCCT CCGACAACCTCCCCGGGGTCAAGGGCATCGGGGAGAAGACCGCCCTCAAGCTCCTCAAGGAGTGGGGAAGCCTG- GAAAAC CTCCTCAAGAACCTGGACCGGCTGAAGCCCGCCATCCGGGAGAAGATCCTGGCCCACATGGACGATCTGAAGCT- CTCCTGG GACCTGGCCAAGGTGCGCACCGACCTGCCCCTAGAGGTGGACTTCGCCAAAAGGCGGGAGCCCGACCGGGAGAG- GCTTAG GGCCTTTCTGGAGAGGCTTGAGCTTGGCAGCCTCCTCCACGAGTTCGGCCTTCTGGAAAGCCCCAAGACCCTGG- AGGAGGCC TCCTGGCCCCCGCCGGAAGGGGCCTTCGTGGGCTTTGTGCTTTCCCGCAAGGAGCCCATGTGGGCCGATCTTCT- GGCCCTGG CCGCCGCCAGGGGGGGCCGGGTCCACCGGGCCCCCGAGCCTTATAAAGCCCTCAGGGACCTGAAGGAGGCGCGG- GGGCTTC TCGCCAAAGACCTGAGCGTTCTGGCCCTAAGGGAAGGCCTTGGCCTCCCGCCCGGCGACGACCCCATGCTCCTC- GCCTACCT CCTGGACCCTTCCAACACCACCCCCGAGGGGGTGGCCCGGCGCTACGGCGGGGAGTGGACGAAGGAGGCGGGGG- AGCGGG CCGCCCTTTCCGAGAGGCTCTTCGCCAACCTGTGGGGGAGGCTTGAGGGGGAGGAGAGGCTCCTTTGGCTTTAC- CGGGAGG TGGATAGGCCCCTTTCCGCTGTCCTGGCCCACATGGAGGCCACAGGGGTGCGCTTGGACGTGGCCTATCTCAGG- GCCTTGTC CCTGGAGGTGGCCGAGGAGATCGCCCGCCTCGAGGCCGAGGTCTTCCGCCTGGCCGGCCATCCCTTCAACCTCA- ACTCCCGG GACCAGCTGGAAAGGGTCCTCTTTGACGAGCTAGGGCTTCCCGCCATCGGCAAGACGGAGAAGACCGGCAAGCG- CTCCACC AGCGCCGCCGTCCTGGAGGCCCTCCGCGAGGCCCACCCCATCGTGGAGAAGATCCTGCAGTACCGGGAGCTCAC- CAAGCTG AAGAGCACCTACATTGACCCCTTGCCGGACCTCATCCACCCCAGGACGGGCCGCCTCCACACCCGCTTCAACCA- GACGGCC ACGGCCACGGGCAGGCTAAGTAGCTCCGATCCCAACCTCCAGAACATCCCCGTCCGCACCCCGCTCGGGCAGAG- GATCCGC CGGGCCTTCGTCGCCGAGGAGGGGTGGCTATTGGTGGTCCTGGACTATAGCCAGATAGAGCTCAGGGTGCTGGC- CCACCTCT CCGGCGACGAGAACCTGACCCGGGTCTTCCTGGAGGGGCGGGACATCCACACGGAAACCGCCAGCTGGATGTTC- GGCGTCC CCCGGGAGGCCGTGGACCCCCTGATGCGCCGGGCGGCCAAGACCATCAACTTCGGGGTTCTCTACGGCATGTCG- GCCCACC GCCTCTCCCAGGAGCTGGCCATCCCTTACGAGGAGGCCCAGGCCTTCATAGAGCGCTACTTCCAAAGCTTCCCC- AAGGTGCG GGCCTGGATAGAAAAGACCCTGGAGGAGGGGAGGAAGCGGGGCTACGTGGAAACCCTCTTCGGAAGAAGGCGCT- ACGTGC CCGACCTCAACGCCCGGGTGAAGAGTGTCAGGGAGGCCGCGGAGCGCATGGCCTTCAACATGCCCGTCCAGGGC- ACCGCCG CCGACCTTATGAAGCTCGCCATGGTGAAGCTCTTCCCCCGCCTCCGGGAGATGGGGGCCCGCATGCTCCTCCAG- GTCCACGA CGAGCTCCTCCTGGAGGCCCCCCAAGCGCGGGCCGAGGAGGTGGCGGCTTTGGCCAAGGAGGCCATGGAGAAGG- CCTATCC CCTCGCCGTACCCCTGGAGGTGAAGGAGGGGATCGGGGAGGACTGGCTCTCCGCCAAGGAGTGA (SEQ ID NO: 92) MAMLPLFEPKGRVLLVDGHHLAYRTFFALKGLTTSRGEPVQVVYGFAKSLLKALKEDGYKAVFVVFDAKAPSLR- HEAYEAYKA GRAPTPEDFLRQLALIKELVDLLGFTRLEVQGYEADDVLATLAKKAEKEGYEVRILTADRDLYQLVSDRVAVLH- PEGHLITPEWL WEKYGLRPEQWVDFRALVGDPSDNLPGVKGIGEKTALKLLKEWGSLENLLKNLDRLKPAIREKILAHMDDLKLS- WDLAKVRTD LPLEVDFAKRREPDRERLRAFLERLELGSLLHEFGLLESPKTLEEASWPPPEGAFVGFVLSRKEPMWADLLALA- AARGGRVHRAP EPYKALRDLKEARGLLAKDLSVLALREGLGLPPGDDPMLLAYLLDPSNTTPEGVARRYGGEWTKEAGERAALSE- RLFANLWGR LEGEERLLWLYREVDRPLSAVLAHMEATGVRLDVAYLRALSLEVAEEIARLEAEVFRLAGHPFNLNSRDQLERV- LFDELGLPAIG KTEKTGKRSTSAAVLEALREAHPIVEKILQYRELTKLKSTYIDPLPDLIHPRTGRLHTRFNQTATATGRLSSSD- PNLQNIPVRTPLGQ RIRRAFVAEEGWLLVVLDYSQIELRVLAHLSGDENITRVFLEGRDIHTETASWMFGVPREAVDPLMRRAAKTIN- FGVLYGMSAH RLSQELAIPYEEAQAFIERYFQSFPKVRAWIEKTLEEGRKRGYVETLFGRRRYVPDLNARVKSVREAAERMAFN- MPVQGTAADL MKLAMVKLFPRLREMGARMLLQVHDELLLEAPQARAEEVAALAKEAMEKAYPLAVPLEVKEGIGEDWLSAKE* 3B10 (SEQ ID NO: 93) ATGGCGATGCTTCCCCTCTTTGAGCCCAAGGGCCGCGTCCTCCTGGTGGACGGCCACCACCTGGCCTACCGCAC- CTTCTTCG CCCTGAAGGGCCCCACCACGAGCCGGGGCGAACCGGTGCAGGTGGTCTACGGCTTCGCCAAGAGCCTCCTCAAG- GCCCTGA AAGAGGACGGGTACAAGGCCGTCTTCGTGGTCTTTGACGCCAAGGCCCCCTCATTCCGCCACAAGGCCTACGAG- GCCTACA GGGCGGGGAGGGCCCCGACCCCCGAGGACTTCCCCCGGCAGCTCGCCCTCATCAAGGAGCTGGTGGACCTCCTG- GGGTTTA CCCGCCTCGAGGTCCCCGGCTACGAGGCGGACGACGTTCTCGCCACCCTGGCCAAGAAGGCGGAAAAGGAGGGG- TACGAG GTGCGCATCCTCACCGCCGACCGCGGCCTCTACCAACTCGTCTCTGACCGCGTCGCCGTCCTCCACCCCGAGGG- CCACCTCA TCACCCCGGAGTGGCTTTGGGAGAAGTACGGCCTCAGGCCGGAGCAGTGGGTGGACTTCCGCGCCCTCGTGGGG- GACCCCT CCGACAACCTCCCCGGGGTCAAGGGCATCGGGGAGAAGACCGCCCTCAAGCTCCTCAAGGAGTGGGGAAGCCTG- GAAAAC CTCCTCAAGAACCTGGACCGGGTAAAGCCAGAAAACGTCCGGGAGAAGATCAAGGCCCACCTGGAAGACCTCAG- GCTCTCC TTGGAGCTCTCCCGGGTGCGCACCGACCTCCCCCTGGAGGTGGACCTCGCCCAGGGGCGGGAGCCCGACCGGGA- GAGGCTT AGGGCCTTTCTGGAGAGGCTTGAGTTTGGCGGCCTCCTCCACGAGTTCGGCCTTCTGGAAAGCCCCAAGGCCCT- GGAGGAG GCCCCCTGGCCCCCGCCGGAAGGGGCCTTCGTGGGCTTTGTGCTTTCCCGCAAGGAGCCCATGTGGGCCGATCT- TCTGGCCC TGGCCGCCGCCAGGGGTGGTCGGGTCCACCGGGCCCCTGAGCCTTATAAAGCCCTCAGGGACTTGAAGGAGGCG- CGGGGGC TTCTCGCCAAAGACCTGAGCGTTCTGGCCCTGAGGGAAGGCCTTGGCCTCCCGCCCGGCGACGACCCCATGCTC- CTCGCCTA CCTCCTGGACCCTTCCAACACCACCCCCGAGGGGGTGGCCCGGCGCTACGGCGGGGAGTGGACGGAGGAGGCGG- GGGAGC GGGCCGCCCTTTCCGAGAGGCTCTTCGCCAACCTGTGGGGGAGGCTTGAGGGGGAGGAGAGGCTCCTTTGGCTT- TACCGGG AGGTGGAGAGACCCCTTTCCGCTGTCCTGGCCCACATGGAGGCCACGGGGGTGCGCCTGGACGTGGCCTATCTC- AGGGCCTT GTCCCTGGAGGTGGCCGAGGAGATCGCCCGCCTCGAGGCCGAGGTCTTCCGCCTGGCCGGCCACCCCTTCAACC- TCAACTCC CGAGACCAGCTGGAAAGGGTCCTCTTTGACGAGCTAGGGCTTCCCGCCATCGGCAAGACGGAGAAGACCGGCAA- GCGCTCC ACCAGCGCCGCCGTCCTGGAGGCCCTCCGCGAGGCCCACCCCATCGTGGAGAAGATCCTGCAGTACCGGGAGCT- CACCAAG CTGAAGAGCACCTACATTGACCCCTTGCCGGACCACATCCACCCCAGGACGGGCCGCCTCCACACCCGCTTCAA- CCAGACG GCCACGGCCACGGGCAGGCTAAGTAGCTCCGATCCCAACCTCCAGAACATCCCCGTCCGCACCCCGCTCGGGCA- GAGGATC CGCCGGGCCTTCATCGCCGAGGAGGGGTGGCTATTGGTGGTCCTGGACTATAGCCAGATAGAGCTCAGGGTGCT- GGCCCAC CTCTCCGGCGACGAGAACCTGACCCGGGTCTTCCAGGAGGGGCGGGACATCCACACGGAAACCGCCAGCTGGAT- GTTCGGC GTCCCCCGGGAGGCCGTGGACCCCCTGATGCGCCGGGCGGCCAAGACCATCAACTTCGGGGTTCTCTACGGCAT- GTCGGCC CACCGCCTCTCCCAGGAGCTGGCCATCCCTTACGAGGAGGCCCAGGCCTTCATAGAGCGCTACTTCCAAAGCTT- CCCCAAGG TGCGGGCCTGGATAGAAAAGACCCTGGAGGAGGGGAGGAAGCGGGGCTACGTGGAAACCCTCTTCGGAAGAAGG-
CGCTAC GTGCCCGACCTCAACGCCCGGGTGAAGAGTGTCAGGGAGGCCGCGGAGCGCATGGCCTTCAACATGCCCGTCCA- GGGCACC GCCGCCGACCTTATGAAGCTCGCCATGGTGAAGCTCTACCCCCGCCTCCGGGAGATGGGGGCCCGCATGCTCCT- CCAGGTCC ACGACGAGCTCCTCCTGGAGGCCCCCCAAGCGCGGGCCGAGGAGGTGGCGGCTTTGGCCAAGGAGGCCATGGAG- AAGGCC TATCCCCTCGCCGTACCCCTGGAGGTGAAGGTGGGGATCGGGGAGGACTGGCTCTCCGCCCAAGGAGTGAGTCG- ACCTGCA GGCAGCGCTTGGCGTCACCCGCAGTTCGGTGGTTAA (SEQ ID NO: 94) MAMLPLFEPKGRVLLVDGHHLAYRTFFALKGPTTSRGEPVQVVYGFAKSLLKALKEDGYKAVFVVFDAKAPSFR- HKAYEAYRA GRAPTPEDFPRQLALIKELVDLLGFTRLEVPGYEADDVLATLAKKAEKEGYEVRILTADRGLYQLVSDRVAVLH- PEGHLITPEWL WEKYGLRPEQWVDFRALVGDPSDNLPGVKGIGEKTALKLLKEWGSLENLLKNLDRVKPENVREKIKAHLEDLRL- SLELSRVRTD LPLEVDLAQGREPDRERLRAFLERLEFGGLLHEFGLLESPKALEEAPWPPPEGAFVGFVLSRKEPMWADLLALA- AARGGRVHRAP EPYKALRDLKEARGLLAKDLSVLALREGLGLPPGDDPMLLAYLLDPSNTTPEGVARRYGGEWTEEAGERAALSE- RLFANLWGRL EGEERLLWLYREVERPLSAVLAHMEATGVRLDVAYLRALSLEVAEEIARLEAEVFRLAGHPFNLNSRDQLERVL- FDELGLPAIGK TEKTGKRSTSAAVLEALREAHPIVEKILQYRELTKLKSTYIDPLPDHIHPRTGRLHTRFNQTATATGRLSSSDP- NLQNIPVRTPLGQR IRRAFIAEEGWLLVVLDYSQIELRVLAHLSGDENLTRVFQEGRDIHTETASWMFGVPREAVDPLMRRAAKTINF- GVLYGMSAHRL SQELAIPYEEAQAFIERYFQSFPKVRAWIEKTLEEGRKRGYVETLFGRRRYVPDLNARVKSVREAAERMAFNMP- VQGTAADLMK LAMVKLYPRLREMGARMLLQVHDELLLEAPQARAEEVAALAKEAMEKAYPLAVPLEVKVGIGEDWLSAQGVSRP- AGSAWRHP QFGG* 3C12 (SEQ ID NO: 95) ATGGCGATGCTTCCCCTCTTTGAGCCCAAGGGCCGCGTCCTCCTGGTGGACGGCCACCACCTGGCCTACCGCAC- CTTCTTCG CCCTGAAGGGCCCCACCACGAGCCGGGGCGAACCGGTGCAGGTGGTCTACGGCTTCGCCAAGAGCCTCCTCAAG- GCCCTGA AGGAGGACGGGTACAAGGCCGTCTTCGTGGTCTTTGACGCCAAGGCCCCCTCATTCCGCCACAAGGCCTACGAG- GCCTACA GGGCGGGGAGGGCCCCGACCCCCGAGGACTTCCCCCGGCAGCTCGCCCTCATCAAGGAGCTGGTGGACCTCCTG- GGGTTTA CCCGCCTCGAGGTCCCCGGCTACGAGGCGGACGACGTTCTCGCCACCCTGGCCAAGAAGGCGGAAAAGGAGGGG- TACGAG GTGCGCATCCTCACCGCCGACCGCGGCCTCTACCAACTCGTCTCTGACCGCGTCGCCGTCCTCCACCCCGAGGG- CCACCTCA TCACCCCGGAGTGGCTTTGGGAGAAGTACGGCCTCAGGCCGGAGCAGTGGGTAGACTTCCGCGCCCTCGTGGGG- GACCCCT CCGACAACCTCCCCGGGGTCAAGGGCATCGGGGAGAAGACCGCCCTCAAGCTCCTCAAGGAGTGGGGAAGCCTG- GAAAAC CTCCTCAAGAACCTGGACCGGGTAAAGCCAGAAAACGTCCGGGAGAAGATCAAGGCCCACCTGGAAGACCTCAG- GCTCTCC TTGGAGCTCTCCCGGGTGCGCACCGACCTCCCCCTGGAGGTGGACCTCGCCCAGGGGCGGGAGCCCGACCGGGA- GGGGCTT AGGGCCTTTCTGGAGAGGCTTGAGTTTGGCAGCCTCCTCCACGAGTTCGGCCTTCTGGAAAGCCCCAAGGCCCT- GGAGGAG GCCCCCTGGCCCCCGCCGGAAGGGGCCTTCGTGGGCTTTGTGCTTTCACGCAAGGAGCCCATGTGGGCCGATCT- TCTGGCCC TGGCCGCCGCCAGGGGTGGTCGGGTCCACCGGGCCCCCGAGCCTTATAAAGCCCTCAGGGACTTGAAGGAGGCG- CGGGGGC TTCTCGCCAAAGACCTGAGCGTTCTGGCCCTAAGGGAAGGCCTTGGCCTCCCGCCCGGCGACGACCCCATGCTC- CTCGCCTA CCTCCTGGACCCTTCCAACACCGCCCCCGAGGGGGTGGCCCGGCGCTACGGCGGGGAGTGGACGGAGGAGGCGG- GGGAGC GGGCCGCCCTTTCCGAGAGGCTCTTCGCCAACCTGTGGGGGAGGCTTGAGGGGGAGGAGAGGCTCCTTTGGCTT- TACCGGG AGGTGGATAGGCCCCTTTCCGCTGTCCTGGCCCACATGGAGGCCACAGGGGTACGGCTGGACGTGGCCTGCCTG- CAGGCCC TTTCCCTGGAGCTTGCGGAGGAGATCCGCCGCCTCGAGGAGGAGGTCTTCCGCTTGGCGGGCCACCCCTTCAAC- CTCAACTC CCGGGACCAGCTGGAAAGGGTCCTCTTTGACGAGCTAGGGCTTCCCGCCATCGGCAAGACGGAGAAGACCGGCA- AGCGCTC CACCAGCGCCGCCATCCTGGAGGCCCTCCGCGAGGCCCACCCCATCGTGGAGAAGATCCTGCAGTACCGGGAGC- TCACCAA GCTGAAGAGCACCTACATTGACCCCTTGCCGGACCTCATCCACCCCAGGACGGGCCGCCTCCACACCCGCTTCA- ACCAGACG GCCACGGCCACGGGCAGGCTAAGTAGCTCCGGTCCCAACCTCCAGAACATCCCCGTCCGCACCCCGCTCGGGCA- GAGGATC CGCCGGGCCTTCGTCGCCGAGGAGGGGTGGCTATTGGTGGTCCTGGACTATAGCCAGATAGAGCTCAGGGTGCT- GGCCCAC CTCTCCGGCGACGAGAACCTGACCCGGGTCTTCCTGGAGGGGCGGGACATCCACACGGAAACCGCCAGCTGGAT- GTTCGGC GTCCCCCGGGAGGCCGTGGACCCCCTGATGCGCCGGGCGGCCAAGACCATCAACTTCGGGGTTCTCTACGGCAT- GTCGGCC CACCGCCTCTCCCAGGAGCTGGCCATCCCTTACGAGGAGGCCCAGGCCTTCATAGAGCGCTACTTCCAAAGCTT- CCCCAAGG TGCGGGCCTGGATAGAAAAGACCCTGGAGGAGGGGAGGAAGCGGGGCTACGTGGAAACCCTCTTCGGAAGAAGG- CGCTAC GTGCCCGACCTCAACGCCCGGGTGAAGAGTGTCAGGGAGGCCGCGGAGCGCATGGCCTTCAACATGCCCGTCCA- GGGCACC GCCGCCGACCTTATGAAGCTCGCCATGGTGAAGCTCTTCCCCCGCCTCCGGGAGATGGGGGCCCGCATGCTCCT- CCAGGTCC ACGACGAGCTCCTCCTGGAGGCCCCCCAAGCGCGGGCCGAGGAAGTGGCGGCTTTGGCCAAGGAGGCCATGGAG- AAGGCC TATCCCCTCGCCGTACCCCTGGAGGTGAAGGTGGGGATCGGGGAGGACTGGCTCTCCGCCAAGGAGTGA (SEQ ID NO: 96) MAMLPLFEPKGRVLLVDGHHLAYRTFFALKGPTTSRGEPVQVVYGFAKSLLKALKEDGYKAVFVVFDAKAPSFR- HKAYEAYRA GRAPTPEDFPRQLALIKELVDLLGFTRLEVPGYEADDVLATLAKKAEKEGYEVRILTADRGLYQLVSDRVAVLH- PEGHLITPEWL WEKYGLRPEQWVDFRALVGDPSDNLPGVKGIGEKTALKLLKEWGSLENLLKNLDRVKPENVREKIKAHLEDLRL- SLELSRVRTD LPLEVDLAQGREPDREGLRAFLERLEFGSLLHEFGLLESPKALEEAPWPPPEGAFVGFVLSRKEPMWADLLALA- AARGGRVHRAP EPYKALRDLKEARGLLAKDLSVLALREGLGLPPGDDPMLLAYLLDPSNTAPEGVARRYGGEWTEEAGERAALSE- RLFANLWGR LEGEERLLWLYREVDRPLSAVLAHMEATGVRLDVACLQALSLELAEEIRRLEEEVFRLAGHPFNLNSRDQLERV- LFDELGLPAIG KTEKTGKRSTSAAILEALREAHPIVEKILQYRELTKLKSTYIDPLPDLIHPRTGRLHTRFNQTATATGRLSSSG- PNLQNIPVRTPLGQ RIRRAFVAEEGWLLVVLDYSQIELRVLAHLSGDENLTRVFLEGRDIHTETASWMFGVPREAVDPLMRRAAKTIN- FGVLYGMSAH RLSQELAIPYEEAQAFIERYFQSFPKVRAWIEKTLEEGRKRGYVETLFGRRRYVPDLNARVKSVREAAERMAFN- MPVQGTAADL MKLAMVKLFPRLREMGARMLLQVHDELLLEAPQARAEEVAALAKEAMEKAYPLAVPLEVKVGIGEDWLSAKE* 3D1 (SEQ ID NO: 97) ATGGCGATGCTTCCCCTCTTTGAGCCCAAGGGCCGCGTCCTCCTGGTGGACGGCCACCACCTGGCCTACCGCAC- CTTCTTCG CCCTGAAGGGCCCCACCACGAGCCGGGGCGAACCGGTGCAGGTGGTCTACGGCTTCGCCAAGAGCCTCCTCAAG- GCCCTGA AGGAGGACGGGTACAAGGCCGTCTTCGTGGTCTTTGACGCCAAGGCCCCCTCATTCCGCCACAAGGCCTACGAG- GCCTACA GGGCGGGGAGGGCCCCGACCCCCGAGGACTTCCCCCGGCAGCTCGCCCTCATCAAGGAGCTGGTGGACCTCCTG- GGGTTTA CCCGCCTCGAGGTCCCCGGCTACGAGGCGGACGACGTTCTCGCCACCCTGGCCAAGAAGGCGGAAAAGGAGGGG- TACGAG GTGCGCATCCTCACCGCCGACCGCGGCCTCTACCAACTCGTCTCTGACCGCGTCGCCGTCCTCCACCCCGAGGG- CCACCTCA TCACCCCGGAGTGGCTTTGGGAGAAGTACGGCCTCAGGCCGGAGCAGTGGGTGGACTTCCGCGCCCTCGTGGGG- GACCCCT CCGACAACCTCCCCGGGGTCAAGGGCATCGGGGAGAAGACCGCCCTCAAGCTCCTCAAGGAGTGGGGAAGCCTG- GAAAAC CTCCTCAAGAACCTGGACCGGGTAAAGCCAGAAAACGTCCGGGAGAAGATCAAGGCCCACCTGGAAGACCTCAG- GCTCTCC TTGGAGCTCTCCCGGGTGCGCACCGACCTCCCCCTGGAGGTGGACCTCGCCCAGAGGCGGGAGCCCGACCGGGA- GGGGCTT AGGGCCTTTCTGGAGAGGCTTGAGTTTGGCAGCCTCTTCCACGAGTTCGGCCTTCTGGAAAGCCCCAAGGCCCT- GGAGGAGG CCCCCTGGCCCCCGCCGGAAGGGGCCTTCGTGGGCTTTGTGCTTTCCCGCAAGGAGCCCATGTGGGCCGATCTT- CTGGCCCT GGCCGCCGCCAGGGGTGGTCGAGTCCACCGGGCCCCCGAGCCTTATAAAGCCCTCAGGGACCTGAAGGAGGCGC- GGGGGCT TCTCGCCAAAGACCTGAGCGTTCTGGCCCTAAGGGAAGGCCTTGGCCTCCCGCCCGGCGACGACCCCATGCTCC- TCGCCTAC CTCCTGGACCCTTCCAACACCACCCCCGAGGGGGTGGCCCGGCGCTACGGCGGGGAGTGGACGGAGGAGGCGGG- GGAGCG GGCCGCCCTTTCCGAGAGGCTCTTCGCCAACCTGTGGGGGAGGCTTGAGGGGGAGGAGAGGCTCCTTTGGCTTT- ACCGGGA GGTGGAGAGGCCCCTTTCCGCTGTCCTGGCCCACATGGAGGCCACGGGGGTGCGCCTGGACGTGGCCTATCTCA- GGGCCTTG TCCCTGGAGGTGGCCGAGGAGATCGCCCGCCTCGAGGCCGAGGTCTTCCGCCTGGCCGGCCACCCCTTCAACCT- CAACTCCC GGGACCAGCTGGAAATGGTGCTCTTTGACGAGCTTAGGCTTCCCGCCTTGGGGAAGACGCAAAAGACGGGCAAG- CGCTCCA CCAGCGCCGCCGTCCTGGAGGCCCTCCGCGAGGCCCACCCCATCGTGGAGAAGATCCTGCAGTACCGGGAGCTC- ACCAAGC TGAAGAGCACCTACATTGACCCCTTGTCGGACCTCATCCACCCCAGGACGGGCCGCCTCCACACCCGCTTCAAC- CAGACGGC CACGGCCACGGGCAGGCTAAGTAGCTCCGATCCCAACCTCCAGAACATCCCCGTCCGCACCCCGCTTGGGCAGA- GGATCCG CCGGGCCTTCATCGCCGAGGAGGGGTGGCTACTGGTGGTCCTGGACTATAGCCAGATAGAGCTCAGGGTGCTGG- CCCACCT CTCCGGCGACGAAAACCTGATCAGGGTCTTCCAGGAGGGGCGGGACATCCACACGGAGACCGCCAGCTGGATGT- TCGGCGT CCCCCGGGAGGCCGTGGACCCCCTGATGCGCCGGGCGGCCAAGACCATCAACTTCGGGGTCCTCTACGGCATGT- CGGCCCA CCGCCTCTCCCAGGAGCTAGCCATCCCTTACGAGGAGGCCCAGGCCTTCATTGAGCGCTACTTTCAGAGCTTCC-
CCAAGGTG CGGGCCTGGATTGAGAAGACCCTGGAGGAGGGCAGGAGGCGGGGGTACGTGGAGACCCTCTTCGGCCGCCGCCG- CTACGT GCCAGACCTAGAGGCCCGGGTGAAGAGCGTGCGGGAGGCGGCCGAGCGCATGGCCTTCAACATGCCCGTCCAGG- GCACCG CCGCCGACCTCATGAAGCTGGCTATGGTGAAGCTCTTCCCCAGGCTGGGAGAAACGGGGGCCAGGATGCTCCTT- CAGGTCC ACGACGAGCTGGTCCTCGAGGCCCCAAAAGAGAGGGCGGAGGCCGTGGCCCGGCTGGCCAAGGAGGCCATGGAG- GGGGTG TATCCCCTGGCCGTGCCCCTGGAGGTGGAGGTGGGGATAGGGGAGGACTGGCTCTCCGCCAAGGGTTAG (SEQ ID NO: 98) MAMLPLFEPKGRVLLVDGHHLAYRTFFALKGPTTSRGEPVQVVYGFAKSLLKALKEDGYKAVFVVFDAKAPSFR- HKAYEAYRA GRAPTPEDFPRQLALIKELVDLLGFTRLEVPGYEADDVLATLAKKAEKEGYEVRILTADRGLYQLVSDRVAVLH- PEGHLITPEWL WEKYGLRPEQWVDFRALVGDPSDNLPGVKGIGEKTALKLLKEWGSLENLLKNLDRVKPENVREKIKAHLEDLRL- SLELSRVRTD LPLEVDLAQRREPDREGLRAFLERLEFGSLFHEFGLLESPKALEEAPWPPPEGAFVGFVLSRKEPMWADLLALA- AARGGRVHRAP EPYKALRDLKEARGLLAKDLSVLALREGLGLPPGDDPMLLAYLLDPSNTTPEGVARRYGGEWTEEAGERAALSE- RLFANLWGRL EGEERLLWLYREVERPLSAVLAHMEATGVRLDVAYLRALSLEVAEEIARLEAEVFRLAGHPFNLNSRDQLEMVL- FDELRLPALG KTQKTGKRSTSAAVLEALREAHPIVEKILQYRELTKLKSTYIDPLSDLIHPRTGRLHTRFNQTATATGRLSSSD- PNLQNIPVRTPLGQ RIRRAFIAEEGWLLVVLDYSQIELRVLAHLSGDENLIRVFQEGRDIHTETASWMFGVPREAVDPLMRRAAKTIN- FGVLYGMSAHR LSQELAIPYEEAQAFIERYFQSFPKVRAWIEKTLEEGRRRGYVETLFGRRRYVPDLEARVKSVREAAERMAFNM- PVQGTAADLM KLAMVKLFPRLGETGARMLLQVHDELVLEAPKERAEAVARLAKEAMEGVYPLAVPLEVEVGIGEDWLSAKG*
Example 11
Abasic Site Bypass by Mismatch Extension Clone in PCR
[0230]A list of polymerases selected to extend four mismatches were assayed for their ability to extend abasic sites in PCR (FIG. 10). C12 and D1, which can also extend four mismatched primers in PCR, as well as A10, B6 and B8, which cannot, all produced an amplification product.
Example 12
Abasic Site Bypass by Mismatch Extension Clone in PCR
[0231]A list of polymerases selected to extend four mismatches were assayed for their ability to extend abasic sites in PCR (FIG. 10). C12 and D1, which can also extend four mismatched primers in PCR, as well as A10, B6 and B8, which cannot, all produced an amplification product.
Example 13
Translesion Synthesis Activity by Mismatch Extension Clone as Determined by Primer Extension Assays
[0232]Seven polymerases were assayed for their ability to bypass abasic sites in a primer extension assay (FIG. 11).
[0233]Primer extension assays were essentially as described in (Ghadessy et al., 2004). Briefly, undamaged oligonucleotides and a 51mer containing a synthetic abasic site were synthesized by Lofstrand Laboratories (Gaithersburg, Md.) using standard techniques and were gel purified prior to use. A 20 mer primer (LES--20P) with the sequence 5'-CGTGGTCGCGACGGATGCCG-3' (SEQ ID NO: 99) was 5'-labeled with [32P]ATP (5000 Ci/mmole; 1 Ci=37 GBq) (Pharmacia®) using T4 polynucleotide kinase (Invitrogen, Carlsbad Calif.). Radiolabeled primer-template DNAs were prepared by annealing the 5'[32P] labeled 20mer primer to one of the two following 51mer templates (at a primer template ratio of molar 1:1.5). 1) undamaged DNA (UNDT51T); 5'-AGC TAC CAT GCC TGC ACG AAT TCG GCA TCC GTC GCG ACC ACG GTC GCA GCG-3' (SEQ ID NO: 100); 2) an oligo (LABA51T) containing a synthetic abasic site (indicated as an X in bold font); 5'-AGC TAC CAT GCC TGC ACG ACA XCG GCA TCC GTC GCG ACC ACG GTC GCA GCG-3' (SEQ ID NO: 101). Standard replication reactions of 10 μl contained 40 mM Tris.HCl at pH 8.0, 5 mM MgCl2, 100 μM of each ultrapure dNTP (Amersham Pharmacia Biotech, NJ), 10 mM DTT, 250 μg/ml BSA, 2.5% glycerol, 10 nM 5'[32P] primer-template DNA and 0.1 Unit of polymerase. After incubation at 60° C. for various times reactions were terminated by the addition of 10 μl of 95% formamide/10 mM EDTA and the samples heated to 100° C. for 5 min. Reaction mixtures (5 μl) were subjected to 20% polyacrylamide/7 M Urea gel electrophoresis and replication products visualized by PhosphorImager analysis.
[0234]Polymerases A10 was the most active and was chosen for further analysis (FIG. 26JRF nomenclature) on abasic sites and cyclobutane thymine-thymine dimers (CPD). A10 was clearly better at both abasic site and CPD extension and bypass than both wild type and M1.
Example 14
Error Rate Investigation of Mismatch Extension Clones as Determined by MutS ELISA
[0235]Relaxed Specificity Might be Expected to be Achieved at the Cost of Lower Fidelity. We used a MutS ELISa to Investigate this Possibility.
[0236]MutS is an E. coli derived mismatch binding protein that binds single base pair mismatches or small (1-4 base) additions or deletions. It can be used to monitor PCR fidelity in an ELISA based assay (Debbie et al., 1997).
[0237]Immobilised Mismatch Binding protein plates (Genecheck, Ft Collins, USA) were used for fidelity measurements as per manufacturer's instructions, essentially as described in (Debbie et al., 1997).
[0238]The mutation rate of D1 was compared that of wtTaq and M1 M1 was already known to have a modestly increased mutation rate (approximately 2 fold) (Ghadessy et al., 2004). The data presented here suggests that D1 has a 2 fold increased error rate compared to M1 and a four fold increased error rate compared to wtTaq. This corresponds approximately to a 1 in 2500 error ratio and is sufficiently low to not be problematic for many applications.
Example 15
Investigation of Mismatch Extension Clones for the Amplification of Damaged DNA Such as is Found in Ancient Samples
[0239]DNA recovered from ancient samples is invariably damaged, limiting the information it can yield. Polymerases that can bypass damage (such as abasic site or hydantoins) might therefore be useful in increasing the information that can be recovered from ancient samples of DNA.
Experiment 1: A Mismatch Extending Polymerase can Amplify Previously Un-Amplifiable Cave Hyena DNA
[0240]Several samples of cave hyena (Crocuta spelea) were extracted and analysed. Of those, seven samples (see FIG. 12 for the list) failed to ever produce an amplification product.
[0241]These samples were chosen to test the efficacy of the expanded substrate spectrum polymerases.
[0242]M1 has a slightly reduced kcat/Km, 14% of Taq wild type, and is hence slightly less efficient in PCR. Therefore, M1 was blended with a commercial preparation of Taq (SuperTaq (HT biotechnology Ltd)) in a ratio of 1 unit to 10 and compared to Taq in the absence of M1. It was hoped that if M1 could bypass the blocking lesions, then the wild type Taq would amplify the resulting translesion synthesis product. On two separate occasions, the M1/SuperTaq mix was able to produce an amplification product whereas SuperTaq alone did not (see FIG. 12 for one example)
[0243]The DNA was cloned and sequence and found to differ in two positions (A71→G, 77A→G) from the expected sequence. This could either be a miscoding lesion resulting from a deamination of C or a population variant sequence not seen previously in aDNA. Indeed, both mutations exist in modem spotted hyena (Crocuta crocuta), arguing for the second interpretation. Of the 10 sequences obtained from the same successful PCR, two each had a further unique single mutation, an A to G in different places. These are most likely errors incurred during amplification. Such errors are frequently seen in aDNA PCR and are one reason why multiple sequences need to be obtained from the same PCR product.
[0244]Contamination problems prevented an exhaustive analysis of the benefits of M1 polymerase. However, this result strongly suggested that a suitable altered polymerase could be usefully applied to aDNA.
Experiment 2: A blend of Mismatch Extending Polymerase Needs Less Ancient DNA for a Successful PCR.
[0245]Polymerases that displayed interesting properties: B5, B8, C12 and D1, which can extend mismatches as well as A10, B6 and B10 which are proficient at abasic site bypass were purified. In order to keep the number of experiments manageable, they were blended in equal volumes with M1, SuperTaq and heparin purified wild-type Taq. This mix of polymerases was used in almost all subsequent experiments and is referred to as the blend.
[0246]To ensure that no polymerase would negatively affect the PCR through its mutant activity, each one was individually blended with SuperTaq and used to perform an aDNA PCR with an ancient sample known to contain amplifiable DNA. All PCRs were successful (data not shown), indicating that it was unlikely that any of the mutant enzymes would be a liability in the blend.
[0247]The activity of the blend was checked against the activity of SuperTaq by a PCR activity dilution series. By this measure, the blend was less active than SuperTaq, by a factor of two.
[0248]The conditions that are usually used in aDNA PCR did not transfer readily to the blend or to SuperTaq as they had been optimised for AmpliTaqGold (Applied Biosystems), a chemically modified version of Taq that allows a hot start and slow enzyme release through heat activation. Manual hot starts are not advisable in aDNA analysis because opening the PCR tube outside the clean room prior to thermocycling carries a high risk of contamination. Furthermore, alternative hot start techniques could not be utilised either: antibodies used to inactivate wtTaq at low temperatures might not bind to the chimerical proteins selected from the Molecular Breeding library and hot start buffers proved ineffective (data not shown). A new two step nested PCR strategy was used. In the first step, the aDNA is amplified over 28 cycles with either SuperTaq or the blend. In the second step, the first PCR is diluted 20 fold in a secondary clean room and amplified with SuperTaq using in-nested primers. This is the approach subsequently used to compare SuperTaq and the blend
[0249]Briefly, 2 μl of ancient sample were added to a 20 μl PCR in SuperTaq buffer (HT Biotech) with 1 μM of the appropriate primers (see FIG. 13), 2 μM of each deoxyribonucleoside triphosphate (dNTP) as well as 0.1 μl of SuperTaq or an equal volume of mutant polymerases and amplified for 28 cycles. This PCR was set up in a clean room following precautions appropriate for aDNA. The first step PCR was then diluted 1 in 20 in a secondary clean room and thermocycled for a further 32 cycles with the same buffer and dNTPs conditions, using in-nested primers and SuperTaq. No template controls were used to test for contamination.
[0250]A two fold dilution series of aDNA with equal volumes of SuperTaq and the blend (and therefore approximately equal activities, with the blend slightly less active) was performed and repeated this four times
[0251]This experiment showed that the blend was more likely to produce a band at a lower concentration of aDNA than SuperTaq. This therefore represented the second experiment that indicated that the mismatch extension polymerases were more proficient at amplifying aDNA than wild-type Taq.
Experiment 3: The mismatch extension polymerases perform consistently better in ancient DNA PCR.
[0252]Sample heterogeneity and the inherent stochasticity of aDNA analysis make the interpretation of a single positive or negative PCR problematic. To address this, multiple PCRs of a same sample and count the number of successful PCR amplifications at a limiting sample dilution were performed. Comparison of SuperTaq with the blend would allowed a statistical analysis. As the amount of aDNA required for this type of approach is large, samples previously shown to be of high quality were chosen and tested at limiting dilutions to increase the amount of material available for analysis. A short target sequence was chosen to allow maximal dilutions.
[0253]This has the additional advantage that at a sufficiently high dilution, the undamaged DNA will have been diluted out, leaving only damaged template. In such conditions, the difference between a polymerase that can bypass blocking lesions and one that cannot should become clearly apparent.
[0254]A total of nine experiments at limiting amounts of aDNA, where the PCR would only be stochastically successful (FIGS. 14 and 15) were performed. In eight out of nine experiments, the blend resulted in more successful PCRs than SuperTaq. The probability of this occurring by chance is 1.76%, as determined by binomial distribution analysis. It is commonly accepted that chance can be dismissed as an explanation when an event is expected to occur at 5% probability or less.
[0255]We can therefore state that this effect is not due to chance and that the blend is repeatedly performing better than SuperTaq in the conditions of the experiment. This proves beyond reasonable doubt that the mismatch extension polymerases are a more sensitive tool for the recovery of ancient DNA sequences.
Example 16
Selection of a Polymerases Capable of Replicating the Unnatural Base Analogue 5-nitroindol (5NI)
[0256]We selected for extension and bypass of 5NI directly from the polymerase chimera library described in example 8 using an analogous strategy to the mismatch selection using flanking primers (5'-CAG GAA ACA GCT ATG ACA AAA ATC TAG ATA ACG AGG GCA 5NI-3' (SEQ ID NO: 102), 5'-GTA AAA CGA CGG CCA GTA CCA CCG AAC TGC GGG TGA CGC CAA GC5NI-3' (SEQ ID NO: 103)) comprising 5NI (or a derivative) at their 3' ends. After round 3, we used flanking primers (5'-CAG GAA ACA GCT ATG ACA AAA ATC TAG ATA 5NICG AGG GCA 5NI-3' (SEQ ID NO: 104), 5'-GTA AAA CGA CGG CCA GTA CCA C5NIG AAC TGC GGG TGA CGC CAA GC5NI-3' (SEQ ID NO: 105)) comprising internal 5NI (or a derivative) as well as 3' terminal 5NI (or a derivative) to increase selection pressure for 5NI replication.
[0257]Five rounds of selection yielded a number of clones with greatly increased ability to replicate 5NI. Among the best clones were round 4 clone 4D11 and round 5 clone 5D4:
TABLE-US-00008 4D11: 5'- (SEQ ID NO: 106) ATGGCGATGCTTCCCCTCTTTGAGCCCAAAGGCCGGGTCCTCCTGGTGGACGGCCACCACCTGGCCTACCGC ACCTTCTTCGCCCTGAAGGGCCTCACCACGAGCCGGGGCGAACCGGTGCAGGCGGTTTACGGCTTCGCCAAG AGCCTCCTCAAGGCCCTGAAGGAGGACGGGTACAAGGCCGTCTTCGTGGTCTTTGACGCCAAGGCCCCCTCC TTCCGCCACGAGGCCTACGAGGCCTACAAGGCGGGGAGGGCCCCGACCCCCGAGGACTTCCCCCGGCAGCTC GCCCTCATCAAGGAGCTGGTGGACCTCCTGGGGTTTACCCGCCTCGAGGTCCAAGGCTACGAGGCGGACGAC GTCCTCGCCACCCTGGCCAAGAAGGCGGAAAAAGAAGGGTACGAGGTGCGCATCCTCACCGCCGACCGGGAC CTCTACCAGCTCGTCTCCGACCGCGTCGCCGTCCTCCACCCCGAGGGCCACCTCATCACCCCGGAGTGGCTT TGGGAGAAGTACGGCCTCAGGCCGGAGCAGTGGGTGGACTTCCGCGCCCTCGTGGGGGACCCCTCCGACAAC CTCCCCGGGATCAAGGGCATCGGGGAGAAGACCGCCCTCAAGCTCCTCAAGGAGTGGGGAAGCCTGGAAAAC CTCCTCAAGAACCTGGACCGGGTAAAGCCAGAAAATGTCCGGGAGAAGATCAAGGCCCACCTGGAAGACCTC AGGCTCTCCTTGGAGCTCTCCCGGGTGCGCACCGACCTCCCCCTGGAGGTGGACTTCGCCAAAAGGCGGGAG CCCGACCGGGAGAGGCTTAGGGCCTTTCTGGAGAGGCTTGAGTTTGGCAGCCTCCTCCACGAGTTCGGCCTT CTGGAAAGCCCCAAGGCCCTGGAGGAGGCCCCCTGGCCCCCGCCGGAAGGGGCCTTCGTGGGCTTTGTGCTT TCCCGCAAGGAGCCCATGTGGGCCGATCTTCTGGCCCTGGCCGCCGCCAAGGGTGGCCGGGTCCACCGGGCC CCCGAGCCTTATAAAGCCCTCAGGGACTTGAAGGAGGCGCGGGGGCTTCTCGCCAAAGACCTGAGCGTTCTG GCCCTAAGGGAAGGCCTTGGCCTCCCGCCCGGCGACGACCCCATGCTCCTCGCCTACCTCCTGGACCCTTCC AACACCACCCCCGAGGGGGTGGCCCGGCGCTACGGCGGGGAGTGGACGGAGGAGGCGGGGGAGCGGGCCGCC CTTTCCGAGAGGCTCTTCGCCAACCTGTGGGGGAGGCTTGAGGGGGAGGAGAGGCTCCTTTGGCTTTACCGG GAGGTGGAGAGGCCCCTTTCCGCTGTCCTGGCCCACATGGAGGCCACGGGGGTGCGCCTGGACGTGGCCTAT CTCAGGGCCTTGTCCCTGGAGGTGGCCGAGGAGATCGCCCGCCTCGAGGCCGAGGTCTTCCGCCTGGCCGGC CACCCCTTCAACCTCAACTCCCGAGACCAGCTGGAAAGGGTCCTCTTTGACGAGCTAGGGCTTCCCGCCATC GGCAAGACGGAGAAGACCGGCAAGCGCTCCACCAGCGCCGCCGTCCTGGAGGCCCTCCGCGAGGCCCACCCC ATCGTGGAGAAGATCCTGCAGTACCGGGAGCTCACCAAGCTGAAGAGCACCTACATTGACCCCTTGCCGGAC CTCATCCACCCCAGGACGGGCCGCCTCCACACCCGCTTCAACCAGACGGCCACGGCCACGGGCAGGCTAAGT AGCTCCGATCCCAACCTCCAGAACATCCCCGTCCGCACCCCGCTCGGGCAGAGGATCCGCCGGGCCTTCATC GCCGAGGGGGGGTGGCTATTGGTGGTCCTGGACTATAGCCAGATGGAGCTCAGGGTGCTGGCCCACCTCTCC GGCGACGAGAACCTGATCCGGGTCTTCCAGGAGGGGCGGGACATCCACACGGAAACCGCCAGCTGGATGTTC GGCGTCCCCCGGGAGGCCGTGGACCCCCTGATGCGCCGGGCGGCCAAGACCATCAACTTCGGGGTTCTCTAC GGCATGTCGGCCCACCGCCTCTCCCAGGAGCTAGCCATCCCTTACGAGGAGGCCCAGGCCTTCATTGAGCGC TACTTTCAGAGCTTCCCCAAGGTGCGGGCCTGGATTGAGAAGACCCTGGAGGAGGGCAGGAGGCGGGGGTAC GTGGAGACCCTCTTCGGCCGCCGCCGCTACGTGCCAGACCTAGAGGCCCGGGTGAAGAGCGTGCGGGAGGCG GCCGAGCGCATGGCCTTCAACATGCCCGTCCAGGGCACCGCCGCCGACCTCATGAAGCTGGCTATGGTGAAG CTCTTCCCCAGGCTGGAGGAAACGGGGGCCAGGATGCTCCTTCAGGTCCACGACGAGCTGGTCCTCGAGGCC CCAAAAGAGAGGGCGGAGGCCGTGGCCCGGCTGGCCAAGGAGGTCATGGAGGGGGTGTATCCCCTGGCCGTG CCCCTGGAGGTGGAGGTGGGGATAGGGGAGGACTGGCTCTCCGCCAAGGAGTGA-3' 4D11 amino acid sequence: MAMLPLFEPKGRVLLVDGHHLAYRTFFALKGLTTSRGEPVQAVYGFAKSLLKALKEDGYKAVFVVFDAKAPS (SEQ ID NO: 107) FRHEAYEAYKAGRAPTPEDFPRQLALIKELVDLLGFTRLEVQGYEADDVLATLAKKAEKEGYEVRILTADRD LYQLVSDRVAVLHPEGHLITPEWLWEKYGLRPEQWVDFRALVGDPSDNLPGIKGIGEKTALKLLKEWGSLEN LLKNLDRVKPENVREKIKAHLEDLRLSLELSRVRTDLPLEVDFAKRREPDRERLRAFLERLEFGSLLHEFGL LESPKALEEAPWPPPEGAFVGFVLSRKEPMWADLLALAAAKGGRVHRAPEPYKALRDLKEARGLLAKDLSVL ALREGLGLPPGDDPMLLAYLLDPSNTTPEGVARRYGGEWTEEAGERAALSERLFANLWGRLEGEERLLWLYR EVERPLSAVLAHMEATGVRLDVAYLRALSLEVAEEIARLEAEVFRLAGHPFNLNSRDQLERVLFDELGLPAI GKTEKTGKRSTSAAVLEALREAHPIVEKILQYRELTKLKSTYIDPLPDLIHPRTGRLHTRFNQTATATGRLS SSDPNLQNIPVRTPLGQRIRRAFIAEGGWLLVVLDYSQMELRVLAHLSGDENLIRVFQEGRDIHTETASWMF GVPREAVDPLMRRAAKTINFGVLYGMSAHRLSQELAIPYEEAQAFIERYFQSFPKVRAWIEKTLEEGRRRGY VETLFGRRRYVPDLEARVKSVREAAERMAFNMPVQGTAADLMKLAMVKLFPRLEETGARMLLQVHDELVLEA PKERAEAVARLAKEVMEGVYPLAVPLEVEVGIGEDWLSAKE* 5D4: 5'- (SEQ ID NO: 108) ATGGCGATGCTTCCCCTCTTTGAGCCCAAAGGCCGGGTCCTCCTGGTGGACGGCCACCACCTGGCCTACCGC ACCTTCTTCGCCCTGAAGGGCCTCACCACGAGTCGGGGCGAACCGGTGCAGGCGGTCTACGGCTTCGCCAAG AGCCTCCTCAAGGCCCTGAAGGAGGACGGGTACAAGGCCATCTTCGTGGTCTTTGACGCCAAGGCCCCCTCC TTCCGCCACGAGGCCCACGAGGCCTACAAGGCGGGGAGGGCCCCGAGCCCCGAGGACTTCCCCCGGCAGCTC GCCCTCATCAAGGAGCTGGTGGACCTCCTGGGGTTTACCCGCCTCGAGGTCCAAGGCTACGAGGCGGACGAC GTCCTCGCCACCCTGGCCAAGAAGGCGGAAAAAGAAGGGTACGAGGTGCGCATCCTCACCGCCGACCGGGAC CTCTACCAGCTCGTCTCCGACCGCGTCGCCGTCCTCCACCCCGAGGGCCACCTCATCACCCCGGAGTGGCTT TGGGAGAAGTACGGCCTCAGGCCGGAGCAGTGGGTGGACTTCCGCGCCCTCGTGGGGGACCCCTCCGACAAC CTCCCCGGGGTCAAGGGCATCGGGGAGAAGACCGCCCTCAAGCTCCTCAAGGAGTGGGGAAGCCTGGAAAAC CTCCTCAAGAACCTGGACCGGCTGAAGCCCGCCATCCGGGAGAAGATCCTGGCCCACATGGACGATCTGAAG CTCTCCTGGGACCTGGCCAAGGTGCGCACCGACCTGCCCCTGGAGGTGGACTTCGCCAAAAGGCGGGAGTCC GATCGGGAGAGGCTTAGGGCCTTTCTGGAGAGGCTTGAGTTTGGCAGCCTCCTCCACGAGTTCGGCCTTCTG GAAAGCCCCAAGGCCCTGGAGGAGGCCCCCTGGCCCCCGCCGGTAGGGGCCTTCGTGGGCTTTGTGCTTTCC CGCAAGGAGCCCATGTGGGCCGATCTTCTGGCCCTGGCCGCCGCCAGGGGTGGTCGGGTCCACCGGGCCCCC GAGCCTTATAAAGCCCTCAGAGACCTGAAGGAGGCGCGGGGGCTTCTCGCCAAAGACCTGAGCGTTCTGGCC CTGAGGGAAGGCCTTGGCCTCCCGCCCGGCGACGACCCCATGCTCCTCGCCTACCTCCTGGACCCTTCCAAC ACCACCCCCGAGGTGGTGGCCCGGCGCTACGGCGGGGAGTGGACGGAGGAGGCGGGGGAGCGGGCCGCCCTT TCCGAGAGGCTCTTCGCCAACCTGTGGGGGAGGCTTGAGGGGGAGGGGAGGCTCCTTTGGCTTTACCGGGGG GTGGAGAGGCCCCTTTCCGCTGTCCTGGCCCACATGGAGGCCACAGGGGTGCGCCTGGACGTGGCCTATCTC AGGGCCTTGTCCCTGGAGGTGGCCGAGGAGATCGCCCGCCTCGAGGCCGAGGTCTTCCGCCTGGCCGGCCAC CCCTTCAACCTCAACTCCCGGGACCAGCTGGAAAGGGTCCTCTTTGACGAGCTAGGGCTTCCCGCCATCGGC AAGACGGAGAAGACCGGCAAGCGCTCCACCAGCGCCGCCGTCCTGGAGGCCCTCCGCGAGGCCCACCCCATC GTGGAGAAGATCCTGCAGTACCGGGAGCTCACCAAGCTGAAGAGCACTTACATTGACCCCTTGCCGGACCTC ATCCACCCCAGGACGGGCCGCCTCCACACCCGCTTCAACCAGACGGCCACGGCCACGGGCAGGCTAAGTAGC TCCGATCCCAACCTCCAGAACATCCCCGTCCGCACCCCGCTCGGGCAGAGGATCCGCCGGGCCTTCATCGCC GAGGGGGGGTGGCTATTGGTGGTCCTGGACTATAGCCAGATGGAGCTCAGGGTGCTGGCCCACCTCTCCGGC GACGAGAACCTGATCCGGGTCTTCCAGGAGGGGCGGGACATCCACACGGAAACCGCCAGCTGGATGTTCGGC GTCCCCCGGGAGGCCGTGGACCCCCTGATGCGCCGGGCGGCCAAGACCATCAACTTCGGGGTTCTCTACGGC ATGTCGGCCCACCGCCTCTCCCAGGAGCTAGCCATCCCTTACGAGGAGGCCCAGGCCTTCATTGAGCGCTAC TTCCAAAGCTTCCCCAAGGTGCGGGCCTGGATAGAAAAGACCCTGGAGGAGGGGAGGAAGCGGGGCTACGTG GAAACCCTCTTCGGAAGAAGGCGCTACGTGCCCGACCTCAACGCCCGGGTGAAGAGCGTCAGGGAGGCCGCG GAGCGCATGGCCTTCAACATGCCCGTCCAGGGCACCGCCGCCGACCTCACGAAGCTGGCTATGGTGAAGCTC TTCCCCAGGCTGGAGGAAACGGGGGCCAGGATGCTCCTTCAGGTCCACGACGAGCTGGTCCTCGAGGCCCCA AAAGAGAGGGCGGAGGCCGTGGCCCGGCTGGCCAAGGAGGTCATGGAGGGGGTGTATCCCCTGGCCGTGCCC CTGGAGGTGGAGGTGGGGATAGGGGAGGACTGGCTTTCCGCCAAGGGTTAG-3' 5D4 amino acid sequence: MAMLPLFEPKGRVLLVDGHHLAYRTFFALKGLTTSRGEPVQAVYGFAKSLLKALKEDGYK (SEQ ID NO: 109) AIFVVFDAKAPSFRHEAHEAYKAGRAPSPEDFPRQLALIKELVDLLGFTRLEVQGYEADD VLATLAKKAEKEGYEVRILTADRDLYQLVSDRVAVLHPEGHLITPEWLWEKYGLRPEQWV DFRALVGDPSDNLPGVKGIGEKTALKLLKEWGSLENLLKNLDRLKPAIREKILAHMDDLK LSWDLAKVRTDLPLEVDFAKRRESDRERLRAFLERLEFGSLLHEFGLLESEKALEEAPWP PPVGAFVGFVLSRKEPMWADLLALAAARGGRVHRAPEPYKALRDLKEARGLLAKDLSVLA LREGLGLPPGDDPMLLAYLLDPSNTTPEVVARRYGGEWTEEAGERAALSERLFANLWGRL EGEGRLLWLYRGVERPLSAVLAHMEATGVRLDVAYLRALSLEVAEEIARLEAEVFRLAGH PFNLNSRDQLERVLFDELGLPAIGKTEKTGKRSTSAAVLEALREAHPIVEKILQYRELTK LKSTYIDPLPDLIHPRTGRLHTRFNQTATATGRLSSSDPNLQNIPVRTPLGQRIRRAFIA EGGWLLVVLDYSQMELRVLAHLSGDENLIRVFQEGRDIHTETASWMFGVPREAVDPLMRR AAKTINFGVLYGMSAHRLSQELAIPYEEAQAFIERYFQSFPKVRAWIEKTLEEGRKRGYV ETLFGRRRYVPDLNARVKSVREAAERMAFNMPVQGTAADLTKLAMVKLFPRLEETGARML LQVHDELVLEAPKERAEAVARLAKEVMEGVYPLAVPLEVEVGIGEDWLSAKG*
Example 17
Expanded Spectrum of Polymerases Selected for Replication of 5NI
[0258]Round 5 polymerases selected for replication of 5NI were tested for activity with a range of substrates using the hairpin ELISA assay described in example 8. tUTP and ceATP were kind gifts from the laboratory of P. Herdewijin, Rega Institute, Katholieke Universiteit Leuven, Belgium. Results are shown in FIG. 14
1. ELISA with tUTP:
[0259]The ability of round 5 clones selected for 5NI replication extension to sequentially incorporate 2 or 3 of the TNA UTP derivative (3', 2')-beta-L-threonyl-UTP was assayed using the hairpin primers (ELISAT2p: 5'-TAG CTC GGT AA CGC CGG CTT CCG TCG CGA CCA CGT TX TTC GTG GTC GCG ACG GAA GCC G-3' (SEQ ID NO: 110), ELISAT3p: 5'-TAG CTC GGT AAA CGC CGG CTT CCG TCG CGA CCA CGT TX TTC GTG GTC GCG ACG GAA GCC G-3' (SEQ ID NO: 10) (X=dU-biotin (Glen research)). The lysates used were concentrated 4-fold. ELISA protocol was a described except that The DIG labelled dUTP in the extension reaction was replaced with Fluorescein 12-dATP (Perkin-Elmer) (at 3% of dATP) and the incorporation of Fluorescein 12-dATP was detected by anti-Fluorescein-POD Fab fragments (Roche).
2. ELISA with ceATP:
[0260]The ability of round 5 clones selected for 5NI replication extension to sequentially incorporate the cyclohexenyl ATP derivative ceATP was assayed using the hairpin primers (ELISA2p: 5'-TAG CTC GGA TTTT CGC CGG CTT CCG TCG CGA CCA CGT TX TTC GTG GTC GCG ACG GAA GCC G-3' (SEQ ID NO: 111), (X=dU-biotin (Glen research)). The lysates used were concentrated 4-fold.
3. ELISA with CyDye 5-dCTP and CyDye 3-dCTP:
[0261]The ability of round 5 clones selected for 5NI replication extension to sequentially incorporate the fluorescent dye-labelled nucleotides Cy5-dCTP and Cy3-dCTP (Amersham Biosciences) was assayed using the hairpin primers (ELISA2p: 5'-TAG CTA CCA GGG CTC CGG CTT CCG TCG CGA CCA CGT TXT TCG TGG TCG CGA CGG AAG CCG-3' (SEQ ID NO: 112), (X=dU-biotin (Glen research)). The lysates used were concentrated 4-fold.
4. Basic Site Bypass ELISA
[0262]The ability of round 5 clones selected for 5NI replication extension to bypass an abasic site was assayed using the hairpin primer (PScreenlabas: 5'-AGC TAC CAT GCC TGC ACG CAG YCG GCA TCC GTC GCG ACC ACG TTX TTC GTG GTC GCG ACG GAT GCC G-3' (SEQ ID NO: 113), (X=dU-biotin, Y=abasic site (Glen research)). The lysates used were concentrated 4-fold.
Example 18
Primer Extension Reaction with Polymerases 4D11 and 5D4
[0263]1: Extension Opposite 5-nitroindole.
##STR00002##
[0264]Primer extension reactions were carried out as follows:
50 pmol of 32P-labelled primer and 100 pmol of template in a volume of 44 μl were annealed in 1×Taq buffer. 4D11 or 5D4 polymerase as cell lysate (6 μl) was added and reactions were incubated at 50° C. for 15 minutes followed by addition of one dNTP (1 μl in total volume of 50 μl, final dNTP concentration 40 μM). 8 μl samples were taken at various time points and added to 8 μl stop solution (7M urea, 100 mM EDTA containing xylene cyanol F). At the end of the time course the remaining 3 dNTPs were added (final concentration each dNTP 40 μM) and reactions incubated at 50° C. for a further 30 minutes. Reaction samples were electrophoretically separated using 20% polyacrylamide gels at 25W for 4 hours. The resultant gels were dried and scanned using a phosphorimager (Molecular Dynamics). Data was processed using the program ImageQuant (Molecular Dynamics). Results are shown in FIGS. 35, 36:
[0265]Similar reactions using Taq, Tth and Tfl wild-type polymerases under identical conditions leads to almost undetectable extension reactions (data not shown).
2. Incorporation and Extension of 5-nitroindole-5'-triphosphate (5NITP).
##STR00003##
[0266]Primer extension reactions were carried out as follows:
50 pmol of 32P-labelled primer and 100 pmol of template in a volume of 44 μl were annealed in 1×Taq buffer. 4D11 or 5D4 polymerase as cell lysate (6 μl) was added and reactions were incubated at 50° C. for 15 minutes followed by addition of d5NITP (1 μl in total volume of 50 μl, final dNTP concentration 40 μM). 8 μl samples were taken at various time points and added to 8 μl stop solution (7M urea, 100 mM EDTA containing xylene cyanol F). At the end of the time course the 4 native dNTPs were added (final concentration each dNTP 40 μM) and reactions incubated at 50° C. for a further 30 minutes.
[0267]Reaction samples were electrophoretically separated using 20% polyacrylamide gels at 25W for 4 hours. The resultant gels were dried and scanned using a phosphorimager (Molecular Dynamics). Data was processed using the program ImageQuant (Molecular Dynamics). Results are shown in FIGS. 17, 18):
[0268]The NI-NI self-pair is also formed exceptionally well, though further extension is reduced (data not shown). Similar reactions using Taq, Tth and Tfl wild-type polymerases under identical conditions leads to almost undetectable extension reactions (data not shown).
Example 19
Array Manufacture and Hybridization Using M1
[0269]Targets were prepared by PCR amplification of 2.5 kb Taq gene using primers 29, 28 or 2 kb of the HIV pol gene using primers 30, 31. Salmon sperm DNA (Invitrogen) was prepared at 100 ng/ul in 50% DMSO. FITC and Cy5 probes were prepared by PCR amplification of 0.4 kb fragment of Taq using primers 8, 28 with either 100% (FITC100M1) or 10% of dATP (FITC10M1, FITC10Taq) replaced by FITC-12-dATP or 10% of dCTP replaced by Cy5-dCTP (Cy5Taq). Cy5 and Cy3 random 20 mers (MWG) were used at 250 nM. Targets were purified using PCR purification kit (Qiagen) and prepared in 50% DMSO and spotted onto GAPSII aminosilane-coated glass slides (Corning) using a MicroGrid (BioRobotics). Array hybridizations were performed according to standard protocols:
[0270]Printed slides were baked for 2 hr at 80° C., incubated with agitation for 30 min at 42° C. in 5×SSC/0.1% BSA Fraction V (Roche)/0.1% SDS, boiled for 2 min in ultrapure water, washed 20× in ultrapure water at room temperature (RT), rinsed in propan-2-ol and dried in a clean airstream. 50 ng of FITC- and Cy5-labelled probes were prepared in 20 μl of hybridization buffer (1 mM Tris-HCl pH7.4, 50 mM tetrasodium pyrophosphate, 1×Denhardts solution, 40% deionised formamide, 0.1% SDS, 100 μg/ml sheared salmon sperm DNA). Each sample was heated to 95° C. for 5 min, centrifuged for 2 min, applied to the surface of an array and covered with a 22×22 mm HybriSlip (Sigma). Hybridizations were performed at 48° C. for 16 hr in a hybridization chamber (Corning). Arrays were washed once with 2×SSC/0.1% SDS at 65° C. for 5 min once with 0.2×SSC at RT for 5 min and twice with 0.05×SSC at RT for 5 min. Slides were dried in a clean airstream, scanned with an ArrayWoRx autoloader (Applied Precision Instruments) and the array images analysed using SoftWoRx tracker (Molecularware).
[0271]Complete substitution of natural nucleotides with their unnatural counterparts altered the properties of the resulting amplification products. For example, fully alphaS substituted DNA was completely resistant to nuclease digestion (not shown).
[0272]The 0.4 kb fragment, in which all adenines (dA) on both strands had been replaced with FITC-12-dAMP (FITC100M1), displayed extremely bright fluorescence. The frequency of fluorophore incorporation per 1000 nucleotides (FOI) is commonly used to specify the fluorescence intensity of a probe. FOIs of microarray probes commonly range from 10-50, while FITC100M1 has an FOI of 295. To investigate if such a high level of fluorophore substitution would affect hybridisation characteristics we performed a series of microarray experiments. We compared the fluorescent signal generated by FITC100M1 with equivalent probes generated using either wtTaq or M1 and replacing only 10% of dAMP with FITC-12-dAMP (FITC10Taq, FITC10M1 (FOI=30)). In competitive co-hybridisation with a standard Cy5-labelled probe (Cy5Taq), FITC100M1 hybridised specifically only with its cognate Taq polymerase target sequence and not with any non-cognate control DNA. Hybridisation of FITC100M1 generated an up to 20-fold higher specific signal than equimolar amounts of the FITC10 probes (FIG. 20) without showing increased background binding (FIGS. 19, 21).
Example 20
Mutation Rates & Spectra of Selected Polymerases M1 and M4
[0273]Mutation rates were determined using the mutS ELISA assay26 (Genecheck, Ft. Collins, Colo.) according to manufacturers instructions. Alternatively, amplification products derived from 2×50 cycles of PCR of 2 targets with different GC content (HIV pol (38% GC), Taq (68% GC)) were cloned, 40 clones (800 bp each) were sequenced and mutations (wtTaq (51), M1 (75)) analyzed.
[0274]Promiscuous mismatch extension might be expected to come at the price of reduced fidelity, as misincorporation no longer leads to termination. Measurement of the overall mutation rate using both the MutS assay (FIG. 22A) and direct sequencing of amplification products, however, indicated an only modestly (1.6 fold) increased mutation rate in M1 (or M4). However, M1 displays a significantly altered mutation spectrum compared to wtTaq, with a clearly increased propensity for transversions, in particular G/C->C/G transversions (FIG. 22B).
Example 21
Processivity
[0275]Naturally occurring translesion polymerases are mostly poorly processive. We therefore investigated, if processivity of M1 and M4 was similarly reduced but found that, even at the lowest enzyme concentrations, primer extension and termination probabilities by M1 and M4 closely matched those of wtTaq (FIG. 23), indicating that both M1 and M4 exhibit processivity equal (or higher) than wtTaq. This is also reflected in the striking proficiency of M1 in long-range PCR (see example 6).
[0276]Processivity was measured using a primer extension assay the presence and absence of trap DNA. Termination probabilities were calculated according to the method of Kokoska et al.
[0277]Oligonucleotide primer 32 (5'-GCG GTG TAG AGA CGA GTG CGG AG-3') (SEQ ID NO: 117) was 32P-labelled and annealed to the template 33 (5'-CTC TCA CAA GCA GCC AGG CAA GCT CCG CAC TCG TCT CTA CAC CGC TCC GC-3' (SEQ ID NO: 118)) (at a primer/template ratio of molar 1/1.5). wtTaq (0.0025 nM; 0.025 nM; 0.25 nM), M1 (0.05 nM; 0.5 nM; 5 nM), and M4 (0.05 nM; 0.5 nM; 5 nM) were preincubated with the primer-template DNA substrates (10 nM) in 10 mM Tris-HCl at pH 9.0, 5 mM MgCl2, 50 mM KCl, 0.1% Triton X 100 at 25° C. for 15 min. Reactions were initiated by addition of 100 μM dNTPs with or without trap DNA (1000-fold excess of unlabeled primer-templates). Reactions were performed at 60° C. for 2 min. Preincubation of polymerases with the trap DNA substrate and labelled primer-template before the addition of dNTPs completely abolished primer extension (not shown) demonstrating trap effectiveness. Thus, in the presence of trap DNA, all DNA synthesis resulted from a single DNA binding event. Gel band intensities were calculated using a Phosphoimager and ImageQuant (both Molecular Dynamics) software. Percentage of polymerase molecules, which extended primers to the end of the template was calculated using the formula: In×100%/(I1+I2+ . . . +In), where In is the intensity of the band at position 22 or 23; I1, I2 . . . is the intensity of the band at position 1, 2 . . . . Termination probabilities (τ) were calculated according to the method of Kokoska et al1, whereby τ at a particular template position was calculated as the intensity of the band at this position divided by the sum of the intensity of this band and the band intensities of all longer products.
[0278]All publications mentioned in the above specification are herein incorporated by reference. Various modifications and variations of the described methods and system of the present invention will be apparent to those skilled in the art without departing from the scope and spirit of the present invention. Although the present invention has been described in connection with specific preferred embodiments, it should be understood that the invention as claimed should not be unduly limited to such specific embodiments. Indeed, various modifications of the described modes for carrying out the invention which are obvious to those skilled in biochemistry, molecular biology and biotechnology or related fields are intended to be within the scope of the following claims.
REFERENCES
[0279]1. Schaaper, R. M. (1993) J. Bio. Chem. 268, 23762-23765. [0280]2. L1, Y., Korolev, S. & Waksman, G. (1998) Embo J. 17, 7514-7525. [0281]3. Doublie, S., Tabor, S., Long, A. M., Richardson, C. C. & Ellenberger, T. (1998) Nature 391, 251-258. [0282]4. Johnson, S. J., Taylor, J. S. & Beese, L. S. (2003) Proc. Natl. Acad. Sci. USA 100, 38895-38900. [0283]5. Li, Y., Mitaxov, V. & Waksman, G. (1999) Proc. Nat. Acad. Sci. USA 96, 9491-9496. [0284]6. Astatke, M., Ng, K., Grindley, N. D. & Joyce, C. M. (1998) Proc. Natl. Acad. Sci. USA 95, 3402-3407. [0285]7. Patel, P. H. & Loeb, L. A. (2000) J. Biol. Chem. 275, 40266-40272. [0286]8. Jestin, J. L., Kristensen, P. & Winter, G. (1999) Angew. Chem. Int. Ed. 38, 1124-1127. [0287]9. Xia, G., Chen, L., Sera, T., Fa, M., Schultz, P. G. & Romesberg, F. E. (2002) Proc. Natl. Acad. Sci. USA 99, 6597-6602. [0288]10. Ghadessy, F. J., Ong, J. L. & Holliger, P. (2001) Proc. Natl. Acad. Sci. USA 98, 4552-4557. [0289]11. Tawfik, D. S. & Griffiths, A. D. (1998) Nature Biotechnol 16, 652-656. [0290]12. Huang, M.-M., Amheim, N. & Goodman, M. F. (1992) Nucleic Acids Res. 20, 4567-4573. [0291]13. Kool, E. T. (2000) Curr. Op. Chem. Biol. 4, 602-608. [0292]14. Kwok, S., Kellogg, D. E., McKinney, N., Spasic, D., Goda, L., Levenson, C. & Sninsky, J. J. (1990) Nucleic Acids Res 18, 999-1005. [0293]15. Eom, S. H., Wang, J. & Steitz, T. A. (1996) Nature 382, 278-281. [0294]16. Creighton, S., Bloom, L. B. & Goodman, M. F. (1995) Meth. Enzymol. 262, 232-56. [0295]17. Mendelman, L. V., Petruska, J. & Goodman, M. F. (1990) J. Biol. Chem. 265, 2338-2346. [0296]18. Boudsocq, F., Iwai, S., Hanaoka, F. & Woodgate, R. (2001) Nucleic Acids Res 29, 4607-4616. [0297]19. Verma, S. & Eckstein, F. (1998) Annu. Rev. Biochem. 67, 99-134. [0298]20. Loakes, D. (2001) Nucleic Acids Res 29, 2437-2447. [0299]21. Berger, M., Wu, Y., Ogawa, A. K., McMinn, D. L., Schultz, P. G. & Romesberg, F. E. (2000) Nucleic Acids Res, 2911-2914. [0300]22. Barnes, W. M. (1994) Proc. Natl. Acad. Sci. USA 91, 2216-2220. [0301]23. Goodman, M. F. (2002) Annu. Rev. Biochem. 71, 17-50. [0302]24. Kunkel, T. A. & Bebenek, K. (2000) Annu. Rev. Biochem. 69, 497-529. [0303]25. Patel, P. H., Suzuki, M., Adman, E., Shinkai, A. & Loeb, L. A. (2001) J. Mol. Biol. 18, 823-837. [0304]26. Lawyer, F. C., Stoffel, S., Saiki, R. K., Chang, S. Y., Landre, P. A., Abramson, R.
[0305]D. & Gelfand, D. H. (1993) PCR Meth. Appl. 2, 275-87. [0306]27. Tada, M., Omata, M., Kawai, S., Saisho, H., Ohto, M., Saiki, R. K. & Sninsky, J. J. (1993) Cancer Res 53, 2472-2474. [0307]28. Ling, H., Boudsocq, F., Woodgate, R. & Yang, W. (2001) Cell 107, 91-102. [0308]29. Trincao, J., Johnson, R. E., Escalante, C. R., Prakash, S., Prakash, L. & Aggarwal, A. K. (2001) Mol. Cell. 8, 417-426. [0309]30. Cho, Y. S., Zhu, F. C., Luxon, B. A. & Gorenstein, D. G. J Biomol Struct Dyn 11, 685-702. [0310]31. Eigen, M. (1971) Naturwissenschaften 58, 465-523. [0311]32. Engelke, D. R., Krikos, A., Bruck, M. E. & Ginsburg, D. (1990) Anal. Biochem. 191, 396-400. [0312]33. Zhao, H., Giver, L., Shao, Z., Affholter, J. A. & Arnold, F. H. (1998) Nature Biotechnol. 16, 258-61. [0313]34. Murata, T., Iwai, S. & Ohtsuka, E. (1990) Nucleic Acids Res 18, 7279-7286.
Sequence CWU
1
1181832PRTArtificial sequenceMutant Thermus aquaticus DNA polymerase 1Met
Arg Gly Met Leu Pro Leu Phe Glu Pro Lys Gly Arg Val Leu Leu1
5 10 15Val Asp Gly His His Leu Ala
Tyr Arg Thr Phe His Ala Leu Lys Gly 20 25
30Leu Thr Thr Ser Arg Gly Glu Pro Val Gln Ala Val Tyr Gly
Phe Ala 35 40 45Lys Ser Leu Leu
Lys Ala Leu Lys Glu Asp Gly Asp Ala Val Ile Val 50 55
60Val Phe Asp Ala Lys Ala Pro Ser Phe Arg His Glu Ala
Tyr Gly Gly65 70 75
80Tyr Lys Ala Ala Arg Ala Pro Thr Pro Glu Asp Phe Pro Arg Gln Leu
85 90 95Ala Leu Ile Lys Glu Leu
Val Asp Leu Leu Gly Leu Ala Arg Leu Glu 100
105 110Val Pro Gly Tyr Glu Ala Asp Asp Val Leu Ala Ser
Leu Ala Lys Lys 115 120 125Ala Glu
Lys Glu Gly Tyr Glu Val Arg Ile Leu Thr Ala Asp Lys Gly 130
135 140Leu Tyr Gln Leu Leu Ser Asp Arg Ile His Val
Leu His Pro Glu Gly145 150 155
160Tyr Leu Ile Thr Pro Ala Trp Leu Trp Glu Lys Tyr Gly Leu Arg Pro
165 170 175Asp Gln Trp Ala
Asp Tyr Arg Ala Leu Thr Gly Asp Glu Ser Asp Asn 180
185 190Leu Pro Gly Val Lys Gly Ile Gly Glu Lys Thr
Ala Arg Lys Leu Leu 195 200 205Glu
Glu Trp Gly Ser Leu Glu Ala Leu Leu Lys Asn Leu Asp Arg Leu 210
215 220Lys Pro Ala Ile Arg Glu Lys Ile Leu Ala
His Met Asp Asp Leu Lys225 230 235
240Leu Ser Trp Asp Leu Ala Lys Val Arg Thr Asp Leu Pro Leu Glu
Val 245 250 255Asp Phe Ala
Lys Arg Arg Glu Pro Asp Arg Glu Arg Leu Arg Ala Phe 260
265 270Leu Glu Arg Leu Glu Phe Gly Ser Leu Leu
His Glu Phe Gly Leu Leu 275 280
285Glu Ser Pro Lys Ala Leu Glu Glu Ala Pro Trp Pro Pro Pro Glu Gly 290
295 300Ala Phe Val Gly Phe Val Leu Ser
Arg Arg Glu Pro Met Trp Ala Asp305 310
315 320Leu Leu Ala Leu Ala Ala Ala Ala Gly Gly Arg Val
His Arg Ala Pro 325 330
335Glu Pro Tyr Lys Ala Leu Arg Asp Leu Lys Glu Ala Arg Gly Leu Leu
340 345 350Ala Lys Asp Leu Ser Val
Leu Ala Leu Arg Glu Gly Leu Gly Leu Pro 355 360
365Pro Gly Asp Asp Pro Met Leu Leu Ala Tyr Leu Leu Asp Pro
Ser Asn 370 375 380Thr Thr Pro Glu Gly
Val Ala Arg Arg Tyr Gly Gly Glu Trp Thr Glu385 390
395 400Glu Ala Gly Glu Arg Ala Ala Leu Ser Glu
Arg Leu Phe Ala Asn Leu 405 410
415Trp Gly Arg Leu Glu Gly Glu Glu Arg Leu Leu Trp Leu Tyr Arg Glu
420 425 430Val Glu Arg Pro Leu
Ser Ala Val Leu Ala His Met Glu Ala Thr Gly 435
440 445Val Arg Leu Asp Val Ala Tyr Leu Arg Ala Leu Ser
Leu Glu Val Ala 450 455 460Glu Glu Ile
Ala Arg Leu Glu Ala Glu Val Phe Arg Leu Ala Gly His465
470 475 480Pro Phe Asn Leu Asn Ser Arg
Asp Gln Leu Glu Arg Val Leu Phe Asp 485
490 495Glu Leu Gly Leu Pro Ala Ile Gly Lys Thr Glu Lys
Thr Gly Lys Arg 500 505 510Ser
Thr Ser Ala Ala Val Leu Gly Ala Leu Arg Glu Ala His Pro Ile 515
520 525Val Glu Lys Ile Leu Gln Tyr Arg Glu
Leu Thr Lys Leu Lys Ser Thr 530 535
540Tyr Ile Asp Pro Leu Pro Asp Leu Ile His Pro Arg Thr Gly Arg Leu545
550 555 560His Thr Arg Phe
Asn Gln Thr Ala Thr Ala Thr Gly Arg Leu Ser Ser 565
570 575Ser Asp Pro Asn Leu Gln Asn Ile Pro Val
Arg Thr Pro Leu Gly Gln 580 585
590Arg Ile Arg Arg Ala Phe Ile Ala Glu Glu Gly Trp Leu Leu Val Val
595 600 605Leu Asp Tyr Ser Gln Ile Glu
Leu Arg Val Leu Ala His Leu Ser Gly 610 615
620Asp Glu Asn Leu Ile Arg Val Phe Gln Glu Gly Arg Asp Ile His
Thr625 630 635 640Glu Thr
Ala Ser Trp Met Phe Gly Val Pro Arg Glu Ala Val Asp Pro
645 650 655Leu Met Arg Arg Ala Ala Lys
Thr Ile Asn Phe Gly Val Leu Tyr Gly 660 665
670Met Ser Ala His Arg Leu Ser Gln Glu Leu Ala Ile Pro Tyr
Glu Glu 675 680 685Ala Gln Ala Phe
Ile Glu Arg Tyr Phe Gln Ser Phe Pro Lys Val Arg 690
695 700Ala Trp Ile Glu Lys Thr Leu Glu Glu Gly Arg Arg
Arg Gly Tyr Val705 710 715
720Glu Thr Leu Phe Gly Arg Arg Arg Tyr Val Pro Asp Leu Glu Ala Arg
725 730 735Val Lys Ser Val Arg
Gly Ala Ala Glu Arg Met Ala Phe Asn Met Pro 740
745 750Val Gln Gly Thr Ala Ala Asp Leu Met Lys Leu Ala
Met Val Lys Leu 755 760 765Phe Pro
Arg Leu Glu Glu Met Gly Ala Arg Met Leu Leu Gln Val His 770
775 780Asp Glu Leu Val Leu Glu Ala Pro Lys Glu Arg
Ala Glu Ala Val Ala785 790 795
800Arg Leu Ala Lys Glu Val Met Glu Gly Val Tyr Pro Leu Ala Val Pro
805 810 815Leu Glu Val Glu
Val Gly Ile Gly Glu Asp Trp Leu Ser Ala Lys Glu 820
825 8302832PRTArtificial sequenceMutant Thermus
aquaticus DNA polymerase 2Met Arg Gly Met Leu Pro Leu Tyr Glu Pro Lys Gly
Arg Val Leu Leu1 5 10
15Val Asp Gly His His Leu Ala Tyr Arg Thr Phe His Ala Leu Lys Gly
20 25 30Leu Thr Thr Ser Arg Gly Glu
Pro Val Gln Ala Val Tyr Gly Phe Ala 35 40
45Lys Ser Leu Leu Lys Ala Leu Lys Glu Gly Gly Asp Ala Val Ile
Val 50 55 60Val Phe Asp Ala Lys Ala
Pro Ser Phe Pro His Glu Ala Tyr Gly Gly65 70
75 80Tyr Lys Ala Gly Arg Ala Pro Thr Pro Glu Asp
Phe Pro Arg Gln Leu 85 90
95Ala Leu Ile Lys Glu Leu Val Asp Leu Leu Gly Leu Thr Arg Leu Glu
100 105 110Val Pro Gly Tyr Glu Ala
Asp Asp Val Leu Ala Ser Leu Ala Lys Lys 115 120
125Ala Glu Lys Glu Gly Tyr Glu Val Arg Ile Leu Thr Ala Asp
Lys Asp 130 135 140Leu Tyr Gln Leu Leu
Ser Asp Arg Ile His Val Leu His Pro Glu Gly145 150
155 160Tyr Leu Ile Thr Pro Ala Trp Leu Trp Glu
Lys Tyr Gly Leu Arg Pro 165 170
175Asp Gln Trp Ala Asp Tyr Arg Ala Leu Thr Gly Asp Glu Ser Asp Asn
180 185 190Leu Pro Gly Val Lys
Gly Ile Gly Glu Lys Thr Ala Arg Lys Leu Leu 195
200 205Glu Glu Trp Gly Ser Leu Glu Ala Leu Leu Lys Asn
Leu Asp Arg Leu 210 215 220Lys Pro Ala
Ile Arg Glu Lys Ile Leu Ala His Met Asp Asp Leu Lys225
230 235 240Leu Ser Trp Asp Arg Ala Lys
Val Arg Thr Asp Leu Pro Leu Glu Val 245
250 255Asp Phe Ala Lys Arg Arg Glu Pro Asp Arg Glu Arg
Leu Arg Ala Phe 260 265 270Leu
Glu Arg Leu Glu Phe Gly Ser Leu Leu His Glu Phe Gly Leu Leu 275
280 285Glu Ser Pro Lys Ala Leu Glu Glu Ala
Pro Trp Pro Pro Pro Glu Gly 290 295
300Ala Phe Val Gly Phe Val Leu Ser Arg Lys Glu Pro Met Trp Ala Asp305
310 315 320Leu Leu Ala Leu
Ala Ala Ala Arg Gly Gly Arg Val His Arg Ala Pro 325
330 335Glu Pro Tyr Lys Ala Leu Gly Asp Leu Lys
Glu Ala Arg Gly Leu Leu 340 345
350Ala Lys Asp Leu Ser Val Leu Ala Leu Arg Glu Gly Leu Gly Leu Pro
355 360 365Pro Asp Asp Asp Pro Met Leu
Leu Ala Tyr Leu Leu Asp Pro Ser Asn 370 375
380Thr Thr Pro Glu Gly Val Ala Arg Arg Tyr Gly Gly Glu Trp Thr
Glu385 390 395 400Glu Ala
Gly Glu Arg Ala Ala Leu Ser Glu Arg Leu Phe Ala Asn Leu
405 410 415Trp Gly Arg Leu Glu Gly Glu
Glu Arg Leu Leu Trp Leu Tyr Arg Glu 420 425
430Val Glu Arg Pro Leu Ser Ala Val Leu Ala His Met Glu Ala
Thr Gly 435 440 445Val Arg Leu Asp
Val Ala Tyr Leu Arg Ala Leu Ser Leu Glu Val Ala 450
455 460Glu Glu Ile Ala Arg Leu Glu Ala Glu Val Phe Arg
Leu Ala Gly His465 470 475
480Pro Phe Asn Leu Asn Ser Arg Asp Gln Leu Glu Arg Val Leu Phe Asp
485 490 495Glu Leu Gly Leu Pro
Ala Ile Gly Lys Thr Glu Lys Thr Gly Lys Arg 500
505 510Ser Thr Ser Ala Ala Val Leu Gly Ala Leu Arg Glu
Ala His Pro Ile 515 520 525Val Glu
Lys Ile Leu Gln Tyr Arg Glu Leu Thr Lys Leu Lys Ser Thr 530
535 540Tyr Ile Asp Pro Leu Pro Asp Leu Ile His Pro
Arg Thr Gly Arg Leu545 550 555
560His Thr Arg Phe Asn Gln Thr Ala Thr Ala Thr Gly Arg Leu Ser Ser
565 570 575Ser Asp Pro Asn
Leu Gln Ser Ile Pro Val Arg Thr Pro Leu Gly Gln 580
585 590Arg Ile Arg Arg Ala Phe Ile Ala Glu Glu Gly
Trp Leu Leu Val Ala 595 600 605Leu
Asp Tyr Ser Gln Ile Glu Leu Arg Val Leu Ala His Leu Ser Gly 610
615 620Asp Glu Asn Leu Ile Arg Val Phe Gln Glu
Gly Arg Asp Ile His Thr625 630 635
640Glu Thr Ala Ser Trp Met Phe Gly Val Pro Arg Glu Ala Val Asp
Pro 645 650 655Leu Met Arg
Arg Ala Ala Lys Thr Ile Asn Phe Gly Val Leu Tyr Gly 660
665 670Met Ser Ala His Arg Leu Ser Gln Glu Leu
Ala Ile Pro Tyr Glu Glu 675 680
685Ala Gln Ala Phe Ile Lys Arg Tyr Phe Gln Ser Phe Pro Lys Val Arg 690
695 700Ala Trp Ile Glu Lys Thr Leu Glu
Glu Gly Arg Arg Arg Gly Tyr Val705 710
715 720Glu Thr Leu Phe Gly Arg Arg Arg Tyr Val Pro Asp
Leu Glu Ala Arg 725 730
735Val Lys Ser Val Arg Glu Pro Ala Glu Arg Met Ala Phe Asn Met Pro
740 745 750Val Gln Gly Thr Ala Ala
Asp Leu Met Lys Leu Ala Met Val Lys Leu 755 760
765Phe Pro Arg Leu Glu Glu Met Gly Ala Arg Met Leu Leu Gln
Val His 770 775 780Asp Glu Leu Val Leu
Glu Ala Pro Lys Glu Arg Ala Glu Ala Val Ala785 790
795 800Arg Leu Ala Lys Glu Val Met Glu Gly Val
Tyr Pro Leu Ala Val Pro 805 810
815Leu Glu Val Glu Val Gly Ile Gly Glu Asp Trp Leu Ser Ala Lys Glu
820 825 830338DNAArtificial
sequencePCR primer for generating mutant Taq polymerase 3caggaaacag
ctatgacaaa aatctagata acgaggga
38445DNAArtificial sequencePCR primer for generating mutant Taq
polymerase 4gtaaaacgac ggccagtacc accgaactgc gggtgacgcc aagcc
4552490DNAArtificial sequenceDNA encodiong mutant Thermus
aquaticus DNA polymerase 5atgctccctc tttttgagcc caaaggccgc
gtcctcctgg tggacggcca ccacctggcc 60taccgcacct tccacgccct gaagggcctc
accaccagcc ggggggagcc ggtgcaggcg 120gtctacggct tcgccaagag cctcctcaag
gccctcaagg aggacgggga cgcggtgatc 180gtggtctttg acgccaaggc cccctccttc
cgccacgagg cctacggggg gtacaaggcg 240gcccgggccc ccacgccgga ggactttccc
cggcaactcg ccctcatcaa ggagctggtg 300gatctcctgg ggctggcgcg cctcgaggtc
ccgggctacg aggcggacga cgtcctggcc 360agcctggcca agaaggcgga aaaggagggc
tacgaggtcc gcatcctcac cgccgacaaa 420ggcctttacc agctcctttc cgaccgcatc
cacgtcctcc accccgaggg gtacctcatc 480accccggcct ggctttggga aaagtacggc
ctgaggcccg accagtgggc cgactaccgg 540gccctgaccg gggacgagtc cgacaacctt
cccggggtca agggcatcgg ggagaagacg 600gcgaggaagc ttctggagga gtgggggagc
ctggaagccc tcctcaagaa cctggaccgg 660ctgaagcccg ccatccggga gaagatcctg
gcccacatgg acgatctgaa gctctcctgg 720gatctggcca aggtgcgcac cgacctgccc
ctggaggtgg acttcgccaa aaggcgggag 780cccgaccggg agaggcttag ggcctttctg
gagaggcttg agtttggcag cctcctccac 840gagttcggcc ttctggaaag ccccaaggcc
ctggaggagg ccccctggcc cccgccggaa 900ggggccttcg tgggctttgt cctttcccgc
agggagccca tgtgggccga tcttctggcc 960ctggccgccg ccaggggggg ccgggtccac
cgggcccccg agccttataa agccctcagg 1020gacctgaagg aggcgcgggg gcttctcgcc
aaagacctga gcgttctggc cctgagggaa 1080ggccttggcc tcccgcccgg cgacgacccc
atgctcctcg cctacctcct ggacccttcc 1140aacaccaccc ccgagggggt ggcccggcgc
tacggcgggg agtggacgga ggaggcgggg 1200gagcgggccg ccctttccga gaggctcttc
gccaacctgt gggggaggct tgagggggag 1260gagaggctcc tttggcttta ccgggaggtg
gagaggcccc tttccgctgt cctggcccac 1320atggaggcca cgggggtgcg cctggacgtg
gcctatctca gggccttgtc cctggaggtg 1380gccgaggaga tcgcccgcct cgaggccgag
gtcttccgcc tggccggcca ccccttcaac 1440ctcaactccc gggaccagct ggaaagggtc
ctctttgacg agctagggct tcccgccatc 1500ggcaagacgg agaagaccgg caagcgctcc
accagcgccg ccgtcctggg ggccctccgc 1560gaggcccacc ccatcgtgga gaagatcctg
cagtaccggg agctcaccaa gctgaagagc 1620acctacattg accccttacc ggacctcatc
caccccagga cgggccgcct ccacacccgc 1680ttcaaccaga cggccacggc cacgggcagg
ctaagtagct ccgatcccaa cctccagaac 1740atccccgtcc gcaccccgct tgggcagagg
atccgccggg ccttcatcgc cgaggagggg 1800tggctattgg tggtcctgga ctatagccag
atagagctca gggtgctggc ccacctctcc 1860ggcgacgaga acctgatccg ggtcttccag
gaggggcggg acatccacac ggagaccgcc 1920agctggatgt tcggcgtccc ccgggaggcc
gtggaccccc tgatgcgccg ggcggccaag 1980accatcaact tcggggtcct ctacggcatg
tcggcccacc gcctctccca ggagctagcc 2040atcccttacg aggaggccca ggccttcatt
gagcgctact ttcagagctt ccccaaggtg 2100cgggcctgga ttgagaagac cctggaggag
ggcaggaggc gggggtacgt ggagaccctc 2160ttcggccgcc gccgctacgt gccagaccta
gaggcccggg tgaagagcgt gcggggggcg 2220gccgagcgca tggccttcaa catgcccgtc
cagggcaccg ccgccgacct catgaagctg 2280gctatggtga agctcttccc caggctggag
gaaatggggg ccaggatgct ccttcaggtc 2340cacgacgagc tggtcctcga ggccccaaaa
gagagggcgg aggccgtggc ccggctggcc 2400aaggaggtca tggagggggt gtatcccctg
gccgtgcccc tggaggtgga ggtggggata 2460ggggaggact ggctctccgc caaggagtga
249062490DNAArtificial sequenceDNA
encoding mutant Thermus aquaticus DNA polymerase 6atgctccctc
tttatgagcc caagggccgc gtcctcctgg tggacggcca ccacctggcc 60taccgcacct
tccacgccct gaagggcctc accaccagcc ggggggagcc ggtgcaggcg 120gtctacggct
tcgccaagag cctcctcaag gccctcaagg agggcgggga cgcggtgatc 180gtggtctttg
acgccaaggc cccctccttc ccccatgagg cctacggggg gtacaaggcg 240ggccgggccc
ccacgccgga ggactttccc cgacaactcg ccctcatcaa ggagctggtg 300gacctcctgg
ggctgacgcg cctcgaggtc ccgggctacg aggcggacga cgtcctggcc 360agcctggcca
agaaggcgga aaaggagggc tacgaggtcc gcatcctcac cgccgacaaa 420gacctttacc
agctcctttc cgaccgcatc cacgtcctcc accccgaggg gtacctcatc 480accccggcct
ggctttggga aaagtacggc ctgaggcccg accagtgggc cgactaccgg 540gccctgaccg
gggacgagtc cgacaacctt cccggggtca agggcatcgg ggagaagacg 600gcgaggaagc
ttctggagga gtgggggagc ctggaagccc tcctcaagaa cctggaccgg 660ctgaagcccg
ccatccggga gaagatcctg gcccacatgg acgatctgaa gctctcctgg 720gaccgggcca
aggtgcgcac cgacctgccc ctggaggtgg acttcgccaa aaggcgggag 780cccgaccggg
agaggcttag ggcctttctg gagaggcttg agtttggcag cctcctccac 840gagttcggcc
ttctggaaag ccccaaggcc ctggaggagg ccccctggcc cccgccggaa 900ggggccttcg
tgggctttgt gctttcccgc aaggagccca tgtgggccga tcttctagcc 960ctggccgccg
ccaggggggg ccgggtccac cgggcccccg agccttataa agccctcggg 1020gacctgaagg
aggcgcgggg gcttctcgcc aaagacctga gcgttctggc cctgagggaa 1080ggccttggcc
tcccgcccga cgacgacccc atgctcctcg cctacctcct ggacccttcc 1140aacaccaccc
ccgagggggt ggcccggcgc tacggcgggg agtggacgga ggaggcaggg 1200gagcgggccg
ccctttccga gaggctcttc gccaacctgt gggggaggct tgagggggag 1260gaaaggctcc
tttggcttta ccgggaggtg gagaggcccc tttccgctgt cctggcccac 1320atggaggcca
cgggggtgcg cctggacgtg gcctatctca gggccttgtc cctggaggtg 1380gccgaggaga
tcgcccgcct cgaggccgag gtcttccgcc tggccggcca ccccttcaac 1440ctcaactccc
gggaccagct ggaaagggtc ctctttgacg agctagggct tcccgccatc 1500ggcaagacgg
agaagaccgg caagcgctcc accagcgccg ccgtcctggg ggccctccgc 1560gaggcccacc
ccatcgtgga gaagatcctg cagtaccggg agctcaccaa gctgaagagc 1620acctacattg
accccttgcc ggacctcatc caccccagga cgggccgcct ccacacccgc 1680ttcaaccaga
cggccacggc cacgggcagg ctaagtagct ccgatcccaa cctccagagc 1740atccccgtcc
gcaccccgct tgggcagagg atccgccggg ccttcatcgc cgaggagggg 1800tggctattgg
tggccctgga ctatagccag atagagctca gggtgctggc ccacctctcc 1860ggcgacgaga
acctgatccg ggtcttccag gaggggcggg acatccacac ggagaccgcc 1920agctggatgt
tcggcgtccc ccgggaggcc gtggaccccc tgatgcgccg ggcggccaag 1980accatcaact
tcggggtcct ctacggcatg tcggcccacc gcctctccca ggagctagcc 2040atcccttacg
aggaggccca ggccttcatt aagcgctact ttcagagctt ccccaaggtg 2100cgggcctgga
ttgagaagac cctggaggag ggcaggaggc gggggtacgt ggagaccctc 2160ttcggccgcc
gccgctacgt gccagaccta gaggcccggg tgaagagcgt gcgggagccg 2220gccgagcgca
tggccttcaa catgcccgtc cagggtaccg ccgccgacct catgaagctg 2280gctatggtga
agctcttccc caggctggag gaaatggggg ccaggatgct ccttcaggtc 2340cacgacgagc
tggtcctcga ggccccaaaa gagagggcgg aggccgtggc ccggctggcc 2400aaggaggtca
tggagggggt gtatcccctg gccgtgcccc tggaggtgga ggtggggata 2460ggggaggact
ggctctccgc caaggagtga
2490760DNAArtificial sequencePrimer used in mismatch extension assays.
7tagctaccat tttcgccggc ttccgtcgcg accacgtttt cgtggtcgcg acggaagccg
60866DNAArtificial sequencePrimer used in mismatch extension assay
8tagctaccat tttttttttc gccggcttcc gtcgcgacca cgttttcgtg gtcgcgacgg
60aagccg
66960DNAArtificial sequencePrimer used in mismatch extension assay
9tagctaccag gggctccggc ttccgtcgcg accacgtttt cgtggtcgcg acggaagccg
601059DNAArtificial sequencePrimer used in mismatch extension assay
10tagctcggta aacgccggct tccgtcgcga ccacgttttc gtggtcgcga cggaagccg
591165DNAArtificial sequencePrimer used in mismatch extension assay
11agctaccatg cctgcacgca gcggcatccg tcgcgaccac gttttcgtgg tcgcgacgga
60tgccg
6512155DNAArtificial sequenceSequence amplified from Cave bear
mitochondrial D loop 12accccatgca tataggcatg tacatattat gcttgatctt
acatgaggac ttacatctca 60aaagtttatt tcaagtgtat agtctgtaag catgtatttc
acttagtcca ggagcttaat 120caccaggcct cgagaaacca gcaacccttg cgagt
1551323DNAArtificial sequencePrimer used in
generation of mutant polymerase 13aaaaatctag ataacgaggg caa
231428DNAArtificial sequencePrimer used in
generation of mutant polymerase 14accaccgaac tgcgggtgac gccaagcg
281524DNAArtificial sequencePrimer used in
mismatch extension assays 15gaactgcggg tgacgccaag cgca
241625DNAArtificial sequencePrimer used in
mismatch extension assays 16ccgaactgcg ggtgacgcca agcgg
251724DNAArtificial sequencePrimer used in
mismatch extension assays 17gaactgcggg tgacgccaag cgcg
241823DNAArtificial sequencePrimer used in
generating and/or analyzing mutant polymerases 18aaaaatctag
ataacgaggg caa
231927DNAArtificial sequencePrimer used in generating or analyzing
mutant polymerases 19ccgactggcc aagattagag agtatgg
272027DNAArtificial sequencePrimer used in generating or
analyzing mutant polymerases 20gatttccacg gataagactc cgcatcc
272128DNAArtificial sequencePrimer used
in generating and/or analyzing mutant polymerases 21ggcagacgat
gatgcagata accagagc
282227DNAArtificial sequencePrimer used in generating and/or analyzing
mutant polymerases 22gccgatagat agccacggac ttcgtag
272326DNAArtificial sequencePrimer used in generating
and/or analyzing mutant polymerases 23ggagtagatg cttgcttttc tgagcc
262426DNAArtificial
sequencePrimer used in generating and/or analyzing mutant
polymerases 24gagttcgtgc ttaccgcaga atgcag
262525DNAArtificial sequencePrimer used in generating and/or
analyzing mutant polymerases 25accgaactgc gggtgacgcc aagcg
252625DNAArtificial sequencePrimer used
in generating and/or analyzing mutant polymerases 26accgaactgc
gggtgacgcc aagcc
252724DNAArtificial sequencePrimer used in generating and/or analyzing
mutant polymerases 27accgaactgc gggtgacgcc aagc
242831DNAArtificial sequencePrimer used in generating
and/or analyzing mutant polymerases 28aaacagcgct tggcgtcacc
cgcagttcgg t 312928DNAArtificial
sequencePrimer used in generating and/or analyzing mutant
polymerases 29cagggcttgg cgtcacccgc agttcggt
283031DNAArtificial sequencePrimer used in generating and/or
analyzing mutant polymerases 30aaacagagct tggcgtcacc cgcagttcgg t
313131DNAArtificial sequencePrimer used
in generating and/or analyzing mutant polymerases 31aaacaccgct
tggcgtcacc cgcagttcgg t
313251DNAArtificial sequencePrimer used in generating and/or analyzing
mutant polymerases 32agctaccatg cctgcacgaa ttcggcatcc gtcgcgacca
cggtcgcagc g 513351DNAArtificial sequencePrimer used in
generating and/or analyzing mutant polymerases 33agctaccatg
cctgcacgac ancggcatcc gtcgcgacca cggtcgcagc g
513451DNAArtificial sequencePrimer used in generating and/or analyzing
mutant polymerases 34agctaccatg cctgcacgaa nncggcatcc gtcgcgacca
cggtcgcagc g 513520DNAArtificial sequencePrimer used in
generating and/or analyzing mutant polymerases 35cgtggtcgcg
acggatgccg
203623DNAArtificial sequencePrimer used in generating and/or analyzing
mutant polymerases 36taatacgact cactataggg aga
233728DNAArtificial sequencePrimer used in generating
and/or analyzing mutant polymerases 37actgntctcc ctatagtgag
tcgtatta 283840DNAArtificial
sequencePrimer used in staggered extension gene shuffling protocol
38caggaaacag ctatgacaaa aatctagata acgagggcaa
403945DNAArtificial sequencePrimer used in staggered extension gene
shuffling protocol 39gtaaaacgac ggccagtacc accgaactgc gggtgacgcc aagcg
454036DNAArtificial sequenceMismatch extension primer
40gtaaaacgac ggccagttta ttaaccaccg aactgc
364141DNAArtificial sequenceMismatch extension primer 41caggaaacag
ctatgactcg acaaaaatct agataacgac c
414217DNAArtificial sequenceOutnested amplification primer 42gtaaaacgac
ggccagt
174317DNAArtificial sequenceOutnested amplification primer 43caggaaacag
ctatgac
174444DNAArtificial sequenceMismatch extension primer 44caggaaacag
ctatgacaaa agtgaaatga atagttcgac tttt
444543DNAArtificial sequenceMismatch extension primer 45gtaaaacgac
ggccagtctt cacaggtcaa gcttattaag gtg
434644DNAArtificial sequenceMismatch extension primer 46caggaaacag
ctatgaccat tgatagagtt attttaccac aggg
444743DNAArtificial sequenceMismatch extension primer 47gtaaaacgac
ggccagtctt cacaggtcaa gcttattaag gtg
434838DNAArtificial sequenceMismatch extension primer 48caggaaacag
ctatgacaaa aatctagata acgaggga
384945DNAArtificial sequenceMismatch extension primer 49gtaaaacgac
ggccagtacc accgaactgc gggtgacgcc aagcc
455041DNAArtificial sequenceMismatch extension primer 50caggaaacag
ctatgactcg acaaaaatct agataacgac c
415136DNAArtificial sequenceMismatch extension primer 51gtaaaacgac
ggccagttta ttaaccaccg aactgc
365267DNAArtificial sequenceHairpin primer and template for polymerase
assay 52agctaccatg cctgcacgca gtcggcatcc gtcgcgacca cgttnttcgt
ggtcgcgacg 60gatgccg
675367DNAArtificial sequenceMismatch extension primer
53agctaccatg cctgcacgca gncggcatcc gtcgcgacca cgttnttcgt ggtcgcgacg
60gatgccg
675467DNAArtificial sequenceHairpin primer/template for polymerase assay
54agctaccatg cctgcacgca gncggcatcc gtcgcgacca cgttnttcgt ggtcgcgacg
60gatgccg
67552502DNAArtificial sequenceMutant Taq polymerase 55atggcgatgc
ttcccctctt tgagcccaag ggccgcgtcc tcctggtgga cggccaccac 60ctggcctacc
gcaccttctt cgccctgaag ggccccacca cgagccgggg cgaaccggtg 120caggtggtct
acggcttcgc caagagcctc ctcaaggccc tgaaggagga cgggtacaag 180gccgtcttcg
tggtctttga cgccaaggcc ccctcattcc gccacaaggc ctacgaggcc 240tacagggcgg
ggagggcccc gacccccgag gacttccccc ggcagctcgc cctcatcaag 300gagctggtgg
acctcctggg gtttacccgc ctcgaggtcc ccggctacga ggcggacgac 360gttctcgcca
ccgtggccaa gaaggcggaa aaggaggggt acgaggtggg catcctcacc 420gccgaccgcg
gcctctacca actcgtctct gaccgcgtcg ccgtcctcca ccccgagggc 480cacctcatca
ccccggagtg gctttgggag aagtacggcc tcaggccgga gcagtgggtg 540gacttccgcg
ccctcgtggg ggacccctcc gacaacctcc ccggggtcaa gggcatcggg 600gagaagaccg
ccctcaagct cctcaaggag tggggaagcc tggaaaacct cctcaagaac 660ctggaccggg
taaagccaga aaacgtccgg gagaagatca aggcccacct ggaagacctc 720aggctctcct
tggagctctc ccgggtgcgc accgacctcc ccctggaggt ggacctcgcc 780caggggcggg
agcccgaccg ggaggggctt agggcctttc tggagaggct tgagtttggc 840agcctcctcc
acgagttcgg ccttctggaa agccccaagg ccctggagga ggccccctgg 900cccccgccgg
aaggggcctt cgtgggcttt gtgctttccc gcaaggagcc catgtgggcc 960gatcttctgg
ccctggccgc cgccaggggg ggccgggtcc accgggcccc cgagccttat 1020aaagccctca
gagacctgaa ggaggcgcgg gggcttctcg ccaaagacct gagcgttctg 1080gccctgaggg
aaggccttgg cctcccgccc ggcgacgacc ccatgctcct cgcctacctc 1140ctggaccctt
ccaacaccac ccccgagggg gtggcccggc gctacggcgg ggagtggacg 1200gaggaggcgg
gggagcgggc cgccctttcc gagaggctct tcgccaacct gtgggggagg 1260cttgaggggg
aggagaggct cctttggctt taccgggagg tggagaggcc cctttccgtt 1320gtcctggccc
acatggaggc cacaggggtg cgcctggacg tggcctatct cagggccttg 1380tccctggagg
tggccgagga gatcgcccgc ctcgaggccg aggtcttccg cctggccggc 1440caccccttca
acctcaactc ccgggaccag ctggaaaggg tcctctttga cgagctaggg 1500cttcccgcca
tcggcaagac ggagaagacc ggcaagcgct ccaccggcgc cgccgtcctg 1560gaggccctcc
acgaggccca ccccatcgtg gagaagatcc tgcagtaccg ggagctcacc 1620aagctgaaga
gcacctacat tgaccccttg ccggacctca tccaccccag gacgggccgc 1680ctccacaccc
gcttcaacca gacggccacg gccacgggca ggctaagtag ctccgatccc 1740aacctccaga
acatccccgt ccgcacccag cttgggcaga ggatccgccg ggccttcatc 1800gccgaggagg
ggtggctatt ggtggtcctg gactatagcc agatagagct cagggtgctg 1860gcccacctct
ccggcgacga gaacctgatc cgggtcttcc aggaggggcg ggacatccac 1920acggaaaccg
ccagctggat gttcggcgtc ccccaggagg ccgtggaccc cctgatgcgc 1980cgggcggcca
agaccatcaa cttcggggtt ctctacggca tgtcggccta ccgcctctcc 2040caggagctag
ccatccctta cgaggaggcc caggccttca ttgagcgcta ctttcagagc 2100ttccccaagg
tgcgggcctg gattgggaag accctggagg agggcaggag gcgggggtac 2160gtggagaccc
tcttcggccg ccgccgctac gtgccagacc tagaggcccg ggtgaagagc 2220gtgcgggagg
cggccgagcg catggccttc aacacgcccg tccagggcac cgccgccgac 2280ctcatgaagc
tagctatggt gaagctcttc cccaggctgg aggaaatggg ggccaggatg 2340ctccttcagg
tccacgacga gctggtcctc gaggccccaa aagagagggc ggaggccgtg 2400gcccggctgg
ccaaggaggt catggagggg gtgtatcccc tggccgtgcc cctggaggtg 2460gaggtgggga
taggggagga ctggctctcc gccaaggagt ga
250256833PRTArtificial sequenceMutant Taq polymerase 56Met Ala Met Leu
Pro Leu Phe Glu Pro Lys Gly Arg Val Leu Leu Val1 5
10 15Asp Gly His His Leu Ala Tyr Arg Thr Phe
Phe Ala Leu Lys Gly Pro 20 25
30Thr Thr Ser Arg Gly Glu Pro Val Gln Val Val Tyr Gly Phe Ala Lys
35 40 45Ser Leu Leu Lys Ala Leu Lys Glu
Asp Gly Tyr Lys Ala Val Phe Val 50 55
60Val Phe Asp Ala Lys Ala Pro Ser Phe Arg His Lys Ala Tyr Glu Ala65
70 75 80Tyr Arg Ala Gly Arg
Ala Pro Thr Pro Glu Asp Phe Pro Arg Gln Leu 85
90 95Ala Leu Ile Lys Glu Leu Val Asp Leu Leu Gly
Phe Thr Arg Leu Glu 100 105
110Val Pro Gly Tyr Glu Ala Asp Asp Val Leu Ala Thr Val Ala Lys Lys
115 120 125Ala Glu Lys Glu Gly Tyr Glu
Val Gly Ile Leu Thr Ala Asp Arg Gly 130 135
140Leu Tyr Gln Leu Val Ser Asp Arg Val Ala Val Leu His Pro Glu
Gly145 150 155 160His Leu
Ile Thr Pro Glu Trp Leu Trp Glu Lys Tyr Gly Leu Arg Pro
165 170 175Glu Gln Trp Val Asp Phe Arg
Ala Leu Val Gly Asp Pro Ser Asp Asn 180 185
190Leu Pro Gly Val Lys Gly Ile Gly Glu Lys Thr Ala Leu Lys
Leu Leu 195 200 205Lys Glu Trp Gly
Ser Leu Glu Asn Leu Leu Lys Asn Leu Asp Arg Val 210
215 220Lys Pro Glu Asn Val Arg Glu Lys Ile Lys Ala His
Leu Glu Asp Leu225 230 235
240Arg Leu Ser Leu Glu Leu Ser Arg Val Arg Thr Asp Leu Pro Leu Glu
245 250 255Val Asp Leu Ala Gln
Gly Arg Glu Pro Asp Arg Glu Gly Leu Arg Ala 260
265 270Phe Leu Glu Arg Leu Glu Phe Gly Ser Leu Leu His
Glu Phe Gly Leu 275 280 285Leu Glu
Ser Pro Lys Ala Leu Glu Glu Ala Pro Trp Pro Pro Pro Glu 290
295 300Gly Ala Phe Val Gly Phe Val Leu Ser Arg Lys
Glu Pro Met Trp Ala305 310 315
320Asp Leu Leu Ala Leu Ala Ala Ala Arg Gly Gly Arg Val His Arg Ala
325 330 335Pro Glu Pro Tyr
Lys Ala Leu Arg Asp Leu Lys Glu Ala Arg Gly Leu 340
345 350Leu Ala Lys Asp Leu Ser Val Leu Ala Leu Arg
Glu Gly Leu Gly Leu 355 360 365Pro
Pro Gly Asp Asp Pro Met Leu Leu Ala Tyr Leu Leu Asp Pro Ser 370
375 380Asn Thr Thr Pro Glu Gly Val Ala Arg Arg
Tyr Gly Gly Glu Trp Thr385 390 395
400Glu Glu Ala Gly Glu Arg Ala Ala Leu Ser Glu Arg Leu Phe Ala
Asn 405 410 415Leu Trp Gly
Arg Leu Glu Gly Glu Glu Arg Leu Leu Trp Leu Tyr Arg 420
425 430Glu Val Glu Arg Pro Leu Ser Val Val Leu
Ala His Met Glu Ala Thr 435 440
445Gly Val Arg Leu Asp Val Ala Tyr Leu Arg Ala Leu Ser Leu Glu Val 450
455 460Ala Glu Glu Ile Ala Arg Leu Glu
Ala Glu Val Phe Arg Leu Ala Gly465 470
475 480His Pro Phe Asn Leu Asn Ser Arg Asp Gln Leu Glu
Arg Val Leu Phe 485 490
495Asp Glu Leu Gly Leu Pro Ala Ile Gly Lys Thr Glu Lys Thr Gly Lys
500 505 510Arg Ser Thr Gly Ala Ala
Val Leu Glu Ala Leu His Glu Ala His Pro 515 520
525Ile Val Glu Lys Ile Leu Gln Tyr Arg Glu Leu Thr Lys Leu
Lys Ser 530 535 540Thr Tyr Ile Asp Pro
Leu Pro Asp Leu Ile His Pro Arg Thr Gly Arg545 550
555 560Leu His Thr Arg Phe Asn Gln Thr Ala Thr
Ala Thr Gly Arg Leu Ser 565 570
575Ser Ser Asp Pro Asn Leu Gln Asn Ile Pro Val Arg Thr Gln Leu Gly
580 585 590Gln Arg Ile Arg Arg
Ala Phe Ile Ala Glu Glu Gly Trp Leu Leu Val 595
600 605Val Leu Asp Tyr Ser Gln Ile Glu Leu Arg Val Leu
Ala His Leu Ser 610 615 620Gly Asp Glu
Asn Leu Ile Arg Val Phe Gln Glu Gly Arg Asp Ile His625
630 635 640Thr Glu Thr Ala Ser Trp Met
Phe Gly Val Pro Gln Glu Ala Val Asp 645
650 655Pro Leu Met Arg Arg Ala Ala Lys Thr Ile Asn Phe
Gly Val Leu Tyr 660 665 670Gly
Met Ser Ala Tyr Arg Leu Ser Gln Glu Leu Ala Ile Pro Tyr Glu 675
680 685Glu Ala Gln Ala Phe Ile Glu Arg Tyr
Phe Gln Ser Phe Pro Lys Val 690 695
700Arg Ala Trp Ile Gly Lys Thr Leu Glu Glu Gly Arg Arg Arg Gly Tyr705
710 715 720Val Glu Thr Leu
Phe Gly Arg Arg Arg Tyr Val Pro Asp Leu Glu Ala 725
730 735Arg Val Lys Ser Val Arg Glu Ala Ala Glu
Arg Met Ala Phe Asn Thr 740 745
750Pro Val Gln Gly Thr Ala Ala Asp Leu Met Lys Leu Ala Met Val Lys
755 760 765Leu Phe Pro Arg Leu Glu Glu
Met Gly Ala Arg Met Leu Leu Gln Val 770 775
780His Asp Glu Leu Val Leu Glu Ala Pro Lys Glu Arg Ala Glu Ala
Val785 790 795 800Ala Arg
Leu Ala Lys Glu Val Met Glu Gly Val Tyr Pro Leu Ala Val
805 810 815Pro Leu Glu Val Glu Val Gly
Ile Gly Glu Asp Trp Leu Ser Ala Lys 820 825
830Glu572502DNAArtificial sequenceMutant Taq polymerase
57atgcgtggta tgcctcctct ttttgagccc aagggccgcg tcctcctggt ggacggccac
60ctggcctacc gcaccttctt cgccctgaag ggccccacca cgagccgggg cgaaccggtg
120caggcggtct acggcttcgc caagagcctc ctcaaggccc tgaaggagga cgggtacaag
180gccgtcttcg tggtctttga cgccaaggcc ccctccctcc gccacgaggc ctacgaggcc
240tacaaggcgg ggagggcccc gacccccgag gacttccccc ggcagctcgc cctcatcaag
300gagctggtgg acctcctggg gtttacccgc ctcgaggtcc ccggctacga ggcggacgac
360gttctcgcca ccctggccaa gaaggcggaa aaggaggggt acgaggtgcg catcctcacc
420gccgaccgcg acctctacca actcgtctcc gaccgcgtcg ccgtcctcca ccccgagggc
480cacctcatca ccccggagtg gctttgggag aagtacggcc tcaggccgga gcagtgggtg
540gacttccgcg ccctcgtggg ggacccctcc gacaacctcc ccggggtcaa gggcatcggg
600gagaggaccg ccctcaagct cctcaaggag tggggaagcc tggaaaacct cctcaagaac
660ctggaccggg taaagccaga aaacgtccgg gagaagatca aggcccacct ggaagacctc
720aggctctcct tggagctctc ccgggtgcgc accgacctcc ccctggaggt ggacctcgcc
780caggggcggg agcccgaccg ggagaggctt agggcctttc tggagaggct tgagtttggc
840agcctcctcc acgagttcgg ccttctggaa agccccaagg ccctggagga ggccccctgg
900cccccgccgg aaggggcctt cgtgggcttt gtgctttccc gcaaggagcc catgtgggcc
960gatcttctgg ccctggccgc cgccaggggt ggtcgggtcc accgggcccc cgagccttat
1020aaagccctca gggacttgaa ggaggcgcgg gggcttctcg ccaaagacct gagcgttctg
1080gccctaaggg aaggccttgg cctcccgccc ggcgacgacc ccatgctcct cgcctacctc
1140ctggaccctt ccaacaccac ccccgagggg gtggcccggc gctacggcgg ggagtggacg
1200gaggaggcgg gggagcgggc cgccctttcc gagaggctct tcgccaacct gtgggggaag
1260cttgaggggg aggagaggct cctttggctt taccgggagg tggataggcc cctttccgct
1320gtcctggccc acatggaggc cacaggggtg cgcctggacg tggcctatct cagggcctcg
1380tccctggagg tggccgagga gatcgcccgc ctcgaggccg aggtcttccg cctggccggc
1440caccccttca acctcaactc ccgggaccag ctggaaaggg tcctctttga cgagctaggg
1500cttcccgcca tcggcaagac ggagaagacc ggcaagcgct ccaccagcgc cgccgtcctg
1560gaggccctcc gcgaggccca ccccatcgtg gagaagatcc tgcagtaccg ggagctcacc
1620aagctgaaga gcacctacat tgaccccttg ccggacctca tccaccccag gacgggccgc
1680ctccacaccc gcttcaacca gacggccacg gccacaggca ggctaagtag ctccgatccc
1740aacctccaga acatccccgt ccgcaccccg cttgggcaga ggatccgccg ggccttcatc
1800gccgaggagg ggtggctatt ggtggccctg gactatagcc agatagagct cagggtgctg
1860gcccacctct ccggcgacga gaacctgatc cgggtcttcc aggaggggcg ggacatccac
1920acggagaccg ccagttggat gttcggcgtc ccccgggagg ccgtggaccc cctgatgcgc
1980cgggcggcca agaccatcaa cttcggggtc ctctacggca tgtcggcccg ccgcctctcc
2040caggagctag ccatccctta cgaggaggcc caggccttca ttgagcgcta ctttcagagc
2100ttccccaagg tgcgggcctg gattgagaag accctggagg agggcaggag gcgggggtac
2160gtggagaccc tcttcggccg ccgccgctac gtgccagacc tagaggcccg ggtgaagagc
2220gtgcgggagg cggccgagcg catggccttc aacatgcccg tccagggcac cgccgccgac
2280ctcatgaagc tggctatggt gaagctcttc cccaggctgg aggaaatggg ggccaggatg
2340ctccttcagg tccacgacga gctggtcctc gaggccccaa aagagagggc ggaggccgtg
2400gcccggctgg ccaaggaggt catggagggg gtgtatcccc tggccgtgcc cctggaggtg
2460gaggtgggga taggggagga ctggctctcc gccaaggagt ga
250258833PRTArtificial sequenceMutant Taq polymerase 58Met Arg Gly Met
Pro Pro Leu Phe Glu Pro Lys Gly Arg Val Leu Leu1 5
10 15Val Asp Gly His Leu Ala Tyr Arg Thr Phe
Phe Ala Leu Lys Gly Pro 20 25
30Thr Thr Ser Arg Gly Glu Pro Val Gln Ala Val Tyr Gly Phe Ala Lys
35 40 45Ser Leu Leu Lys Ala Leu Lys Glu
Asp Gly Tyr Lys Ala Val Phe Val 50 55
60Val Phe Asp Ala Lys Ala Pro Ser Leu Arg His Glu Ala Tyr Glu Ala65
70 75 80Tyr Lys Ala Gly Arg
Ala Pro Thr Pro Glu Asp Phe Pro Arg Gln Leu 85
90 95Ala Leu Ile Lys Glu Leu Val Asp Leu Leu Gly
Phe Thr Arg Leu Glu 100 105
110Val Pro Gly Tyr Glu Ala Asp Asp Val Leu Ala Thr Leu Ala Lys Lys
115 120 125Ala Glu Lys Glu Gly Tyr Glu
Val Arg Ile Leu Thr Ala Asp Arg Asp 130 135
140Leu Tyr Gln Leu Val Ser Asp Arg Val Ala Val Leu His Pro Glu
Gly145 150 155 160His Leu
Ile Thr Pro Glu Trp Leu Trp Glu Lys Tyr Gly Leu Arg Pro
165 170 175Glu Gln Trp Val Asp Phe Arg
Ala Leu Val Gly Asp Pro Ser Asp Asn 180 185
190Leu Pro Gly Val Lys Gly Ile Gly Glu Arg Thr Ala Leu Lys
Leu Leu 195 200 205Lys Glu Trp Gly
Ser Leu Glu Asn Leu Leu Lys Asn Leu Asp Arg Val 210
215 220Lys Pro Glu Asn Val Arg Glu Lys Ile Lys Ala His
Leu Glu Asp Leu225 230 235
240Arg Leu Ser Leu Glu Leu Ser Arg Val Arg Thr Asp Leu Pro Leu Glu
245 250 255Val Asp Leu Ala Gln
Gly Arg Glu Pro Asp Arg Glu Arg Leu Arg Ala 260
265 270Phe Leu Glu Arg Leu Glu Phe Gly Ser Leu Leu His
Glu Phe Gly Leu 275 280 285Leu Glu
Ser Pro Lys Ala Leu Glu Glu Ala Pro Trp Pro Pro Pro Glu 290
295 300Gly Ala Phe Val Gly Phe Val Leu Ser Arg Lys
Glu Pro Met Trp Ala305 310 315
320Asp Leu Leu Ala Leu Ala Ala Ala Arg Gly Gly Arg Val His Arg Ala
325 330 335Pro Glu Pro Tyr
Lys Ala Leu Arg Asp Leu Lys Glu Ala Arg Gly Leu 340
345 350Leu Ala Lys Asp Leu Ser Val Leu Ala Leu Arg
Glu Gly Leu Gly Leu 355 360 365Pro
Pro Gly Asp Asp Pro Met Leu Leu Ala Tyr Leu Leu Asp Pro Ser 370
375 380Asn Thr Thr Pro Glu Gly Val Ala Arg Arg
Tyr Gly Gly Glu Trp Thr385 390 395
400Glu Glu Ala Gly Glu Arg Ala Ala Leu Ser Glu Arg Leu Phe Ala
Asn 405 410 415Leu Trp Gly
Lys Leu Glu Gly Glu Glu Arg Leu Leu Trp Leu Tyr Arg 420
425 430Glu Val Asp Arg Pro Leu Ser Ala Val Leu
Ala His Met Glu Ala Thr 435 440
445Gly Val Arg Leu Asp Val Ala Tyr Leu Arg Ala Ser Ser Leu Glu Val 450
455 460Ala Glu Glu Ile Ala Arg Leu Glu
Ala Glu Val Phe Arg Leu Ala Gly465 470
475 480His Pro Phe Asn Leu Asn Ser Arg Asp Gln Leu Glu
Arg Val Leu Phe 485 490
495Asp Glu Leu Gly Leu Pro Ala Ile Gly Lys Thr Glu Lys Thr Gly Lys
500 505 510Arg Ser Thr Ser Ala Ala
Val Leu Glu Ala Leu Arg Glu Ala His Pro 515 520
525Ile Val Glu Lys Ile Leu Gln Tyr Arg Glu Leu Thr Lys Leu
Lys Ser 530 535 540Thr Tyr Ile Asp Pro
Leu Pro Asp Leu Ile His Pro Arg Thr Gly Arg545 550
555 560Leu His Thr Arg Phe Asn Gln Thr Ala Thr
Ala Thr Gly Arg Leu Ser 565 570
575Ser Ser Asp Pro Asn Leu Gln Asn Ile Pro Val Arg Thr Pro Leu Gly
580 585 590Gln Arg Ile Arg Arg
Ala Phe Ile Ala Glu Glu Gly Trp Leu Leu Val 595
600 605Ala Leu Asp Tyr Ser Gln Ile Glu Leu Arg Val Leu
Ala His Leu Ser 610 615 620Gly Asp Glu
Asn Leu Ile Arg Val Phe Gln Glu Gly Arg Asp Ile His625
630 635 640Thr Glu Thr Ala Ser Trp Met
Phe Gly Val Pro Arg Glu Ala Val Asp 645
650 655Pro Leu Met Arg Arg Ala Ala Lys Thr Ile Asn Phe
Gly Val Leu Tyr 660 665 670Gly
Met Ser Ala Arg Arg Leu Ser Gln Glu Leu Ala Ile Pro Tyr Glu 675
680 685Glu Ala Gln Ala Phe Ile Glu Arg Tyr
Phe Gln Ser Phe Pro Lys Val 690 695
700Arg Ala Trp Ile Glu Lys Thr Leu Glu Glu Gly Arg Arg Arg Gly Tyr705
710 715 720Val Glu Thr Leu
Phe Gly Arg Arg Arg Tyr Val Pro Asp Leu Glu Ala 725
730 735Arg Val Lys Ser Val Arg Glu Ala Ala Glu
Arg Met Ala Phe Asn Met 740 745
750Pro Val Gln Gly Thr Ala Ala Asp Leu Met Lys Leu Ala Met Val Lys
755 760 765Leu Phe Pro Arg Leu Glu Glu
Met Gly Ala Arg Met Leu Leu Gln Val 770 775
780His Asp Glu Leu Val Leu Glu Ala Pro Lys Glu Arg Ala Glu Ala
Val785 790 795 800Ala Arg
Leu Ala Lys Glu Val Met Glu Gly Val Tyr Pro Leu Ala Val
805 810 815Pro Leu Glu Val Glu Val Gly
Ile Gly Glu Asp Trp Leu Ser Ala Lys 820 825
830Glu592502DNAArtificial sequenceMutant Taq polymerase
coding sequence 59atgcgtggta tgcatcctct ttttgagccc aagggccgcg tcctcctggt
ggacggccac 60cacctggcct accgcacctt ccacgccctg aaggggctca ccaccagccg
gggggagccg 120gtgcgggcgg tccacggctt cgccaagagc ctcctcaagg ccctgaagga
ggacgggtac 180aaggccgtct tcgtggtctt tgacgccaag gccccctcct tccgccacga
ggcctacgag 240gcctacaagg cggggagggc cccgaccccc gaggacttcc cccggcagct
cgccctcatc 300aaggagctgg tggacctcct ggggtttacc cgcctcgagg tccccggcta
cgaggcggac 360gacgttctcg ccaccctggc caagaaggcg gaaaaggagg ggtacgaggt
gcgcatcctc 420accgccgacc gcgacctcta ccaactcgtc tccgaccgcg tcgccgtcct
ccaccccgag 480ggccacctca tcaccccgga gtggctttgg gagaagtacg gcctcaggcc
ggagcagtgg 540gtggacttcc gcgccctcgt gggggacccc tccgacaacc tccccggggt
caagggcatc 600ggggagaaga ccgccctcaa gctcctcaag gagtggggaa gcctggaaaa
cctcctcaag 660aacctggacc ggctgaagcc cgccatccgg gagaagatcc tggcccacat
ggacgatctg 720aagctctcct gggacctggc caaggtgcgc accgacctgc ccctagaggt
ggacttcgcc 780aaaaggcggg agcccgaccg ggagaggctt agggcctttc tggagaggct
tgagcttggc 840agcctcctcc acgagttcgg ccttctggaa agccccaaga ccctggagga
ggcctcctgg 900cccccgccgg aaggggcctt cgtgggcttt gtgctttccc gcaaggagcc
catgtgggcc 960gatcttctgg ccctggccgc cgccaggggg ggccgggtcc accgggcccc
cgagccttat 1020aaagccctca gagacctgaa ggaggcgcgg gggcttctcg ccaaagacct
gagcgttctg 1080gccctgaggg aaggccttgg cctcccgccc ggcgacgacc ccatgctcct
cgcctacctc 1140ctggaccctt ccaacaccac ccccgagggg gtggcccggc gctacggcgg
ggagtggacg 1200gaggaggcgg gggagcgggc cgccctttcc gagaggctct tcgccaacct
gtgggggagg 1260cttgaggggg aggagaggct cctttggctt taccgggagg tggagaggcc
cctttccgtt 1320gtcctggccc acatggaggc cacaggggtg cgcctggacg tggcctatct
cagggccttg 1380tccctggagg tggccgagga gatcgcccgc ctcgaggccg aggtcttccg
cctggccggc 1440caccccttca acctcaactc ccgggaccag ctggaaaggg tcctctttga
cgagctaggg 1500cttcccgcca tcggcaagac ggagaagacc ggcaagcgct ccaccggcgc
cgccgtcctg 1560gaggccctcc gcgaggccca ccccatcgtg gagaagatcc tgcagtaccg
ggagctcacc 1620aagctgaaga gcacctacat tgaccccttg ccggacctca tccaccccag
gacgggccgc 1680ctccacaccc gcttcaacca gacggccacg gccacgggca ggctaagtag
ctccgatccc 1740aacctccaga acatccccgt ccgcacccag cttgggcaga ggatccgccg
ggccttcatc 1800gccgaggagg ggtggctatt ggtggtcctg gactatagcc agatagagct
cagggtgctg 1860gcccacctct ccggcgacga gaacctgatc cgggtcttcc aggaggggcg
ggacatccac 1920acggaaaccg ccagctggat gttcggcgtc ccccaggagg ccgtggaccc
cctgatgcgc 1980cgggcggcca agaccatcaa cttcggggtt ctctacggca tgtcggccta
ccgcctctcc 2040caggagctag ccatccctta cgaggaggcc caggccttca ttgagcgcta
ctttcagagc 2100ttccccaagg tgcgggcctg gattgggaag accctggagg agggcaggag
gcgggggtac 2160gtggagaccc tcttcggccg ccgccgctac gtgccagacc tagaggcccg
ggtgaagagc 2220gtgcgggagg cggccgagcg catggccttc aacacgcccg tccagggcac
cgccgccgac 2280ctcatgaagc tggctatggt gaagctcttc cccaggctgg aggaaatggg
ggccaggatg 2340ctccttcagg tccacgacga gctagtcctc gaggccccaa aagagagggc
ggaggccgtg 2400gcccggctgg ccaaggaggt catggagggg gtgtatcccc tggccgtgcc
cctggaggtg 2460gaggtgggga taggggagga ctggctctcc gccaaggagt ga
250260833PRTArtificial sequenceMutant Taq polymerase 60Met Arg
Gly Met His Pro Leu Phe Glu Pro Lys Gly Arg Val Leu Leu1 5
10 15Val Asp Gly His His Leu Ala Tyr
Arg Thr Phe His Ala Leu Lys Gly 20 25
30Leu Thr Thr Ser Arg Gly Glu Pro Val Arg Ala Val His Gly Phe
Ala 35 40 45Lys Ser Leu Leu Lys
Ala Leu Lys Glu Asp Gly Tyr Lys Ala Val Phe 50 55
60Val Val Phe Asp Ala Lys Ala Pro Ser Phe Arg His Glu Ala
Tyr Glu65 70 75 80Ala
Tyr Lys Ala Gly Arg Ala Pro Thr Pro Glu Asp Phe Pro Arg Gln
85 90 95Leu Ala Leu Ile Lys Glu Leu
Val Asp Leu Leu Gly Phe Thr Arg Leu 100 105
110Glu Val Pro Gly Tyr Glu Ala Asp Asp Val Leu Ala Thr Leu
Ala Lys 115 120 125Lys Ala Glu Lys
Glu Gly Tyr Glu Val Arg Ile Leu Thr Ala Asp Arg 130
135 140Asp Leu Tyr Gln Leu Val Ser Asp Arg Val Ala Val
Leu His Pro Glu145 150 155
160Gly His Leu Ile Thr Pro Glu Trp Leu Trp Glu Lys Tyr Gly Leu Arg
165 170 175Pro Glu Gln Trp Val
Asp Phe Arg Ala Leu Val Gly Asp Pro Ser Asp 180
185 190Asn Leu Pro Gly Val Lys Gly Ile Gly Glu Lys Thr
Ala Leu Lys Leu 195 200 205Leu Lys
Glu Trp Gly Ser Leu Glu Asn Leu Leu Lys Asn Leu Asp Arg 210
215 220Leu Lys Pro Ala Ile Arg Glu Lys Ile Leu Ala
His Met Asp Asp Leu225 230 235
240Lys Leu Ser Trp Asp Leu Ala Lys Val Arg Thr Asp Leu Pro Leu Glu
245 250 255Val Asp Phe Ala
Lys Arg Arg Glu Pro Asp Arg Glu Arg Leu Arg Ala 260
265 270Phe Leu Glu Arg Leu Glu Leu Gly Ser Leu Leu
His Glu Phe Gly Leu 275 280 285Leu
Glu Ser Pro Lys Thr Leu Glu Glu Ala Ser Trp Pro Pro Pro Glu 290
295 300Gly Ala Phe Val Gly Phe Val Leu Ser Arg
Lys Glu Pro Met Trp Ala305 310 315
320Asp Leu Leu Ala Leu Ala Ala Ala Arg Gly Gly Arg Val His Arg
Ala 325 330 335Pro Glu Pro
Tyr Lys Ala Leu Arg Asp Leu Lys Glu Ala Arg Gly Leu 340
345 350Leu Ala Lys Asp Leu Ser Val Leu Ala Leu
Arg Glu Gly Leu Gly Leu 355 360
365Pro Pro Gly Asp Asp Pro Met Leu Leu Ala Tyr Leu Leu Asp Pro Ser 370
375 380Asn Thr Thr Pro Glu Gly Val Ala
Arg Arg Tyr Gly Gly Glu Trp Thr385 390
395 400Glu Glu Ala Gly Glu Arg Ala Ala Leu Ser Glu Arg
Leu Phe Ala Asn 405 410
415Leu Trp Gly Arg Leu Glu Gly Glu Glu Arg Leu Leu Trp Leu Tyr Arg
420 425 430Glu Val Glu Arg Pro Leu
Ser Val Val Leu Ala His Met Glu Ala Thr 435 440
445Gly Val Arg Leu Asp Val Ala Tyr Leu Arg Ala Leu Ser Leu
Glu Val 450 455 460Ala Glu Glu Ile Ala
Arg Leu Glu Ala Glu Val Phe Arg Leu Ala Gly465 470
475 480His Pro Phe Asn Leu Asn Ser Arg Asp Gln
Leu Glu Arg Val Leu Phe 485 490
495Asp Glu Leu Gly Leu Pro Ala Ile Gly Lys Thr Glu Lys Thr Gly Lys
500 505 510Arg Ser Thr Gly Ala
Ala Val Leu Glu Ala Leu Arg Glu Ala His Pro 515
520 525Ile Val Glu Lys Ile Leu Gln Tyr Arg Glu Leu Thr
Lys Leu Lys Ser 530 535 540Thr Tyr Ile
Asp Pro Leu Pro Asp Leu Ile His Pro Arg Thr Gly Arg545
550 555 560Leu His Thr Arg Phe Asn Gln
Thr Ala Thr Ala Thr Gly Arg Leu Ser 565
570 575Ser Ser Asp Pro Asn Leu Gln Asn Ile Pro Val Arg
Thr Gln Leu Gly 580 585 590Gln
Arg Ile Arg Arg Ala Phe Ile Ala Glu Glu Gly Trp Leu Leu Val 595
600 605Val Leu Asp Tyr Ser Gln Ile Glu Leu
Arg Val Leu Ala His Leu Ser 610 615
620Gly Asp Glu Asn Leu Ile Arg Val Phe Gln Glu Gly Arg Asp Ile His625
630 635 640Thr Glu Thr Ala
Ser Trp Met Phe Gly Val Pro Gln Glu Ala Val Asp 645
650 655Pro Leu Met Arg Arg Ala Ala Lys Thr Ile
Asn Phe Gly Val Leu Tyr 660 665
670Gly Met Ser Ala Tyr Arg Leu Ser Gln Glu Leu Ala Ile Pro Tyr Glu
675 680 685Glu Ala Gln Ala Phe Ile Glu
Arg Tyr Phe Gln Ser Phe Pro Lys Val 690 695
700Arg Ala Trp Ile Gly Lys Thr Leu Glu Glu Gly Arg Arg Arg Gly
Tyr705 710 715 720Val Glu
Thr Leu Phe Gly Arg Arg Arg Tyr Val Pro Asp Leu Glu Ala
725 730 735Arg Val Lys Ser Val Arg Glu
Ala Ala Glu Arg Met Ala Phe Asn Thr 740 745
750Pro Val Gln Gly Thr Ala Ala Asp Leu Met Lys Leu Ala Met
Val Lys 755 760 765Leu Phe Pro Arg
Leu Glu Glu Met Gly Ala Arg Met Leu Leu Gln Val 770
775 780His Asp Glu Leu Val Leu Glu Ala Pro Lys Glu Arg
Ala Glu Ala Val785 790 795
800Ala Arg Leu Ala Lys Glu Val Met Glu Gly Val Tyr Pro Leu Ala Val
805 810 815Pro Leu Glu Val Glu
Val Gly Ile Gly Glu Asp Trp Leu Ser Ala Lys 820
825 830Glu612502DNAArtificial sequenceMutant Taq
polymerase coding sequence 61atgcgtggta tgcttcctct ttttgagccc aagggccgcg
tcctcctggt ggacggccac 60cacctggcct accgcacctt cttcgccctg aagggcctca
ccacgagccg gggcgaaccg 120gtgcaggcgg tctacggctt cgccaagagc ctcctcaagg
ccctgaagga ggacgggtac 180aaggccgtct tcgtggtctt tgacgccaag gccccctccc
tccgccacga ggcctacgag 240gcctacaagg cggggagggc cccgaccccc gaggacttcc
cccggcagct cgccctcatc 300aaggagctgg tggacctcct ggggtttacc cgcctcgagg
tccccggcta cgaggcggac 360gacgttctcg ccaccctggc caagaaggcg gaaaaggagg
ggtacgaggt gcgcatcctc 420accgccgacc gcgacctcta ccaactcgtc tccgaccgcg
tcgccgtcct ccaccccgag 480ggccacctca tcaccccgga gtggctttgg gagaagtacg
gcctcaggcc ggagcagtgg 540gtggacttcc gcgccctcgt gggggacccc tccgacaacc
tccccggggt caagggcatc 600ggggagaaga ccgccctcaa gctcctcaag gagtggggaa
gcctggaaaa cctcctcaag 660aacctggacc ggctgaagcc cgccatccgg gagaagatcc
tggcccacat ggacgatctg 720aagctctcct gggacctggc caaggtgcgc accgacctgc
ccctggaggt ggacttcgcc 780aaaaggcggg agcccgaccg ggagaggctt agggcctttc
tggagaggct tgagcttggc 840agcctcctcc acgagttcgg ccttctggaa agccccaagg
ccctggagga ggcctcctgg 900cccccgccgg aaggggcctt cgtgggcttt gtgcttaccc
gcaaggagcc catgtgggcc 960gatcttctgg ccctggccgc cgccaggggg ggccgggtcc
accgggcccc cgagccttat 1020aaagccctca gggacctgaa ggaggcgcgg gggcttctcg
ccaaagacct gagcgttctg 1080gccctgaggg aaggccttgg cctcccgccc ggcgacgacc
ccatgctcct cgcctacctc 1140ctggaccctt ccaacaccac ccccgagggg gtggcccggc
gctacggcgg ggagtggacg 1200gaggaggcgg gggagcgggc cgccctttcc gagaggctct
tcgccaacct gtgggggagg 1260cttgaggggg aggagaggct cctttggctt taccgggagg
tggagagacc cctttccgct 1320gtcctggccc acatggaggc cacgggggtg cgcctggacg
tggcctatct cagggccttg 1380tccctggagg tggccgagga gatcgcccgc ctcgaggccg
aggtcttccg cctggccggc 1440caccccttca acctcaactc ccgagaccag ctggaaaggg
tcctctttga cgagctaggg 1500cttcccgcca tcggcaagac ggagaagacc ggcaagcgct
ccaccagcgc cgccgtcctg 1560gaggccctcc gcgaggccca ccccatcgtg gagaagatcc
tgcagtaccg ggagctcacc 1620aagctgaaga gcacctacat tgaccccttg ccggacctca
tccaccccag gacgggccgc 1680ctccacaccc gcttcaacca gacggccacg gccacgggca
ggctaagtag ctccgatccc 1740aacctccaga acatccccgt ccgcaccccg cttgggcaga
ggatccgccg ggccttcatc 1800gccgaggagg ggtggctatt ggtggccctg gactatagcc
agatagagct cagggtgctg 1860gcccacctct ccggcgacga gaacctgatc cgggtcttcc
aggaggggcg ggacatccac 1920acggagaccg ccagctggat gttcggcgtc ccccgggagg
ccgtggaccc cctgatgcgc 1980cgggcggcca agaccatcaa cttcggggtc ctctacggca
tgtcggccca ccgcctctcc 2040caggagctag ccatccctta cgaggaggcc caggccttca
ttgagcgcta ctttcagagc 2100ttccccaagg tgcgggcctg gattgagaag accctggagg
agggcaggag gcgggggtac 2160gtggagaccc tcttcggccg ccgccgctac gtgccagacc
tagaggcccg ggtgaagagc 2220gtgcgggagg cggccgagcg catggccttc aacatgcccg
tccagggcac cgccgccgac 2280cttatgaagc tcgccatggt gaagctcttc ccccgcctcc
gggagatggg ggcccgcatg 2340ctcctccagg tccacgacga gctcctcctg gaggcccccc
aagcgcgggc cgaggaggtg 2400gcggctttgg ccaaggaggc catggagaag gcctatcccc
tcgccgtacc cctggaggtg 2460aaggtgggga tcggggagga ctggctctcc gccaaggagt
ga 250262833PRTArtificial sequenceMutant Taq
polymerase 62Met Arg Gly Met Leu Pro Leu Phe Glu Pro Lys Gly Arg Val Leu
Leu1 5 10 15Val Asp Gly
His His Leu Ala Tyr Arg Thr Phe Phe Ala Leu Lys Gly 20
25 30Leu Thr Thr Ser Arg Gly Glu Pro Val Gln
Ala Val Tyr Gly Phe Ala 35 40
45Lys Ser Leu Leu Lys Ala Leu Lys Glu Asp Gly Tyr Lys Ala Val Phe 50
55 60Val Val Phe Asp Ala Lys Ala Pro Ser
Leu Arg His Glu Ala Tyr Glu65 70 75
80Ala Tyr Lys Ala Gly Arg Ala Pro Thr Pro Glu Asp Phe Pro
Arg Gln 85 90 95Leu Ala
Leu Ile Lys Glu Leu Val Asp Leu Leu Gly Phe Thr Arg Leu 100
105 110Glu Val Pro Gly Tyr Glu Ala Asp Asp
Val Leu Ala Thr Leu Ala Lys 115 120
125Lys Ala Glu Lys Glu Gly Tyr Glu Val Arg Ile Leu Thr Ala Asp Arg
130 135 140Asp Leu Tyr Gln Leu Val Ser
Asp Arg Val Ala Val Leu His Pro Glu145 150
155 160Gly His Leu Ile Thr Pro Glu Trp Leu Trp Glu Lys
Tyr Gly Leu Arg 165 170
175Pro Glu Gln Trp Val Asp Phe Arg Ala Leu Val Gly Asp Pro Ser Asp
180 185 190Asn Leu Pro Gly Val Lys
Gly Ile Gly Glu Lys Thr Ala Leu Lys Leu 195 200
205Leu Lys Glu Trp Gly Ser Leu Glu Asn Leu Leu Lys Asn Leu
Asp Arg 210 215 220Leu Lys Pro Ala Ile
Arg Glu Lys Ile Leu Ala His Met Asp Asp Leu225 230
235 240Lys Leu Ser Trp Asp Leu Ala Lys Val Arg
Thr Asp Leu Pro Leu Glu 245 250
255Val Asp Phe Ala Lys Arg Arg Glu Pro Asp Arg Glu Arg Leu Arg Ala
260 265 270Phe Leu Glu Arg Leu
Glu Leu Gly Ser Leu Leu His Glu Phe Gly Leu 275
280 285Leu Glu Ser Pro Lys Ala Leu Glu Glu Ala Ser Trp
Pro Pro Pro Glu 290 295 300Gly Ala Phe
Val Gly Phe Val Leu Thr Arg Lys Glu Pro Met Trp Ala305
310 315 320Asp Leu Leu Ala Leu Ala Ala
Ala Arg Gly Gly Arg Val His Arg Ala 325
330 335Pro Glu Pro Tyr Lys Ala Leu Arg Asp Leu Lys Glu
Ala Arg Gly Leu 340 345 350Leu
Ala Lys Asp Leu Ser Val Leu Ala Leu Arg Glu Gly Leu Gly Leu 355
360 365Pro Pro Gly Asp Asp Pro Met Leu Leu
Ala Tyr Leu Leu Asp Pro Ser 370 375
380Asn Thr Thr Pro Glu Gly Val Ala Arg Arg Tyr Gly Gly Glu Trp Thr385
390 395 400Glu Glu Ala Gly
Glu Arg Ala Ala Leu Ser Glu Arg Leu Phe Ala Asn 405
410 415Leu Trp Gly Arg Leu Glu Gly Glu Glu Arg
Leu Leu Trp Leu Tyr Arg 420 425
430Glu Val Glu Arg Pro Leu Ser Ala Val Leu Ala His Met Glu Ala Thr
435 440 445Gly Val Arg Leu Asp Val Ala
Tyr Leu Arg Ala Leu Ser Leu Glu Val 450 455
460Ala Glu Glu Ile Ala Arg Leu Glu Ala Glu Val Phe Arg Leu Ala
Gly465 470 475 480His Pro
Phe Asn Leu Asn Ser Arg Asp Gln Leu Glu Arg Val Leu Phe
485 490 495Asp Glu Leu Gly Leu Pro Ala
Ile Gly Lys Thr Glu Lys Thr Gly Lys 500 505
510Arg Ser Thr Ser Ala Ala Val Leu Glu Ala Leu Arg Glu Ala
His Pro 515 520 525Ile Val Glu Lys
Ile Leu Gln Tyr Arg Glu Leu Thr Lys Leu Lys Ser 530
535 540Thr Tyr Ile Asp Pro Leu Pro Asp Leu Ile His Pro
Arg Thr Gly Arg545 550 555
560Leu His Thr Arg Phe Asn Gln Thr Ala Thr Ala Thr Gly Arg Leu Ser
565 570 575Ser Ser Asp Pro Asn
Leu Gln Asn Ile Pro Val Arg Thr Pro Leu Gly 580
585 590Gln Arg Ile Arg Arg Ala Phe Ile Ala Glu Glu Gly
Trp Leu Leu Val 595 600 605Ala Leu
Asp Tyr Ser Gln Ile Glu Leu Arg Val Leu Ala His Leu Ser 610
615 620Gly Asp Glu Asn Leu Ile Arg Val Phe Gln Glu
Gly Arg Asp Ile His625 630 635
640Thr Glu Thr Ala Ser Trp Met Phe Gly Val Pro Arg Glu Ala Val Asp
645 650 655Pro Leu Met Arg
Arg Ala Ala Lys Thr Ile Asn Phe Gly Val Leu Tyr 660
665 670Gly Met Ser Ala His Arg Leu Ser Gln Glu Leu
Ala Ile Pro Tyr Glu 675 680 685Glu
Ala Gln Ala Phe Ile Glu Arg Tyr Phe Gln Ser Phe Pro Lys Val 690
695 700Arg Ala Trp Ile Glu Lys Thr Leu Glu Glu
Gly Arg Arg Arg Gly Tyr705 710 715
720Val Glu Thr Leu Phe Gly Arg Arg Arg Tyr Val Pro Asp Leu Glu
Ala 725 730 735Arg Val Lys
Ser Val Arg Glu Ala Ala Glu Arg Met Ala Phe Asn Met 740
745 750Pro Val Gln Gly Thr Ala Ala Asp Leu Met
Lys Leu Ala Met Val Lys 755 760
765Leu Phe Pro Arg Leu Arg Glu Met Gly Ala Arg Met Leu Leu Gln Val 770
775 780His Asp Glu Leu Leu Leu Glu Ala
Pro Gln Ala Arg Ala Glu Glu Val785 790
795 800Ala Ala Leu Ala Lys Glu Ala Met Glu Lys Ala Tyr
Pro Leu Ala Val 805 810
815Pro Leu Glu Val Lys Val Gly Ile Gly Glu Asp Trp Leu Ser Ala Lys
820 825 830Glu632502DNAArtificial
sequenceMutant Taq polymerase coding sequence 63atggcgatgc ttcccctctt
tgagcccaag ggccgcgtcc tcctggtgga cggccaccac 60ctggcctacc gcaccttctt
cgccctgaag ggccccacca cgagccgggg cgaaccggtg 120caggtggtct acggcttcgc
caagagcctc ctcaaggccc tgaaggagga cgggtacaag 180gccgtcttcg tggtctttga
cgccaaggcc ccctcattcc gccacaaggc ctacgaggcc 240tacagggcgg ggagggcccc
gacccccgag gacttccccc ggcagctcgc cctcatcaag 300gagctggtgg acctcctggg
gtttacccgc ctcgaggtcc ccggctacga ggcggacgac 360gttctcgcca ccctggccaa
gaaggcggaa aaggaggggt acgaggtgcg catcctcacc 420gccgaccgcg gcctatacca
actcgtctat gaccgcgtcg ccgtcctcca ccccgagggc 480cacctcatca ccccggagtg
gctttgggag aagtacggcc tcaggccgga gcagtgggtg 540gacttccgcg ccctcgtggg
ggacccctcc gacaacctcc ccggggtcaa gggcatcggg 600gagaagaccg ccctcaagct
cctcaaggag tggggaagcc tggaaaacct cctcaagaac 660ctggaccggg taaagccaga
aaacgtccgg gagaagatca aggcccacct ggaagacctc 720aggctctcct tggagctctc
ccgggtgcgc accgacctcc ccctggaggt ggacctcgcc 780caggggcggg agcccgaccg
ggaggggctt agggcctttc tggagaggct tgagtttggc 840agcctcctcc acgagttcgg
ccttctggaa agccccaagg ccctggagga ggccccctgg 900cccccgccgg aaggggcctt
cgtgggcttt gtgctttccc gcaaggagcc catgtgggcc 960gatcttctgg ccctggccgc
cgccaggggt ggtcgagtcc accgggcccc cgagccttat 1020aaagccctca gggacctgaa
ggaggcgcgg gggcttctcg ccaaagacct gagcgttctg 1080gccctaaggg aaggccttgg
cctcccgccc ggcgacgacc ccatgctcct cgcctacctc 1140ctggaccctt ccaacaccac
ccccgagggg gtggcccggc gctacggcgg ggagtggacg 1200gaggaggcgg gggagcgggc
cgccctttcc gagaggctct tcgccaacct gtgggggagg 1260cttgaggggg aggagaggct
cctttggctt taccgggagg tggagaggcc cctttccgct 1320gtcctggccc acatggaggc
cacgggggtg cgcctggacg tggcctatct cagggccttg 1380tccctggagg tggccgagga
gatcgcccgc ctcgaggccg aggtcttccg cctggccggc 1440caccccttca acctcaactc
ccgggaccag ctggaaatgg tgctctttga cgagcttagg 1500cttcccgcct tggggaagac
gcaaaagacg ggcaagcgct ccaccagcgc cgccgtcctg 1560gaggccctcc gcgaggccca
ccccatcgtg gagaagatcc tgcagtaccg ggagctcacc 1620aagctgaaga gcacctacat
tgaccccttg tcggacctca tccaccccag gacgggccgc 1680ctccacaccc gcttcaacca
gacggccacg gccacgggca ggctaagtag ctccgatccc 1740aacctccaga acatccccgt
ccgcaccccg cttgggcaga ggatccgccg ggccttcatc 1800gccgaggagg ggtggctact
ggtggtcctg gactatagcc agatagagct cagggtgctg 1860gcccacctct ccggcgacga
aaacctgatc agggtcttcc aggaggggcg ggacatccac 1920acggagaccg ccagctggat
gttcggcgtc ccccgggagg ccgtggaccc cctgatgcgc 1980cgggcggcca agaccatcaa
cttcggggtc ctctacggca tgtcggccca ccgcctctcc 2040caggagctag ccatccctta
cgaggaggcc caggccttca ttgagcgcta ctttcagagc 2100ttccccaagg tgcgggcctg
gattgagaag accctggagg agggcaggag gcgggggtac 2160gtggagaccc tcttcggccg
ccgccgctac gtgccagacc tagaggcccg ggtgaagagc 2220gtgcgggagg cggccgagcg
catggccttc aacatgcccg tccagggcac cgccgccgac 2280ctcatgaagc tggctatggt
gaagctcttc cccaggctgg aggaaatggg ggccaggatg 2340ctccttcagg tccacgacga
gctggtcctc gaggccccaa aagagagggc ggaggccgtg 2400gcccggctgg ccaaggaggt
catggagggg gtgtatcccc tggccgtgcc cctggaggtg 2460gaggtgggga taggggagga
ctggctctcc gccaaggagt ga 250264833PRTArtificial
sequenceMutant Taq polymerase 64Met Ala Met Leu Pro Leu Phe Glu Pro Lys
Gly Arg Val Leu Leu Val1 5 10
15Asp Gly His His Leu Ala Tyr Arg Thr Phe Phe Ala Leu Lys Gly Pro
20 25 30Thr Thr Ser Arg Gly Glu
Pro Val Gln Val Val Tyr Gly Phe Ala Lys 35 40
45Ser Leu Leu Lys Ala Leu Lys Glu Asp Gly Tyr Lys Ala Val
Phe Val 50 55 60Val Phe Asp Ala Lys
Ala Pro Ser Phe Arg His Lys Ala Tyr Glu Ala65 70
75 80Tyr Arg Ala Gly Arg Ala Pro Thr Pro Glu
Asp Phe Pro Arg Gln Leu 85 90
95Ala Leu Ile Lys Glu Leu Val Asp Leu Leu Gly Phe Thr Arg Leu Glu
100 105 110Val Pro Gly Tyr Glu
Ala Asp Asp Val Leu Ala Thr Leu Ala Lys Lys 115
120 125Ala Glu Lys Glu Gly Tyr Glu Val Arg Ile Leu Thr
Ala Asp Arg Gly 130 135 140Leu Tyr Gln
Leu Val Tyr Asp Arg Val Ala Val Leu His Pro Glu Gly145
150 155 160His Leu Ile Thr Pro Glu Trp
Leu Trp Glu Lys Tyr Gly Leu Arg Pro 165
170 175Glu Gln Trp Val Asp Phe Arg Ala Leu Val Gly Asp
Pro Ser Asp Asn 180 185 190Leu
Pro Gly Val Lys Gly Ile Gly Glu Lys Thr Ala Leu Lys Leu Leu 195
200 205Lys Glu Trp Gly Ser Leu Glu Asn Leu
Leu Lys Asn Leu Asp Arg Val 210 215
220Lys Pro Glu Asn Val Arg Glu Lys Ile Lys Ala His Leu Glu Asp Leu225
230 235 240Arg Leu Ser Leu
Glu Leu Ser Arg Val Arg Thr Asp Leu Pro Leu Glu 245
250 255Val Asp Leu Ala Gln Gly Arg Glu Pro Asp
Arg Glu Gly Leu Arg Ala 260 265
270Phe Leu Glu Arg Leu Glu Phe Gly Ser Leu Leu His Glu Phe Gly Leu
275 280 285Leu Glu Ser Pro Lys Ala Leu
Glu Glu Ala Pro Trp Pro Pro Pro Glu 290 295
300Gly Ala Phe Val Gly Phe Val Leu Ser Arg Lys Glu Pro Met Trp
Ala305 310 315 320Asp Leu
Leu Ala Leu Ala Ala Ala Arg Gly Gly Arg Val His Arg Ala
325 330 335Pro Glu Pro Tyr Lys Ala Leu
Arg Asp Leu Lys Glu Ala Arg Gly Leu 340 345
350Leu Ala Lys Asp Leu Ser Val Leu Ala Leu Arg Glu Gly Leu
Gly Leu 355 360 365Pro Pro Gly Asp
Asp Pro Met Leu Leu Ala Tyr Leu Leu Asp Pro Ser 370
375 380Asn Thr Thr Pro Glu Gly Val Ala Arg Arg Tyr Gly
Gly Glu Trp Thr385 390 395
400Glu Glu Ala Gly Glu Arg Ala Ala Leu Ser Glu Arg Leu Phe Ala Asn
405 410 415Leu Trp Gly Arg Leu
Glu Gly Glu Glu Arg Leu Leu Trp Leu Tyr Arg 420
425 430Glu Val Glu Arg Pro Leu Ser Ala Val Leu Ala His
Met Glu Ala Thr 435 440 445Gly Val
Arg Leu Asp Val Ala Tyr Leu Arg Ala Leu Ser Leu Glu Val 450
455 460Ala Glu Glu Ile Ala Arg Leu Glu Ala Glu Val
Phe Arg Leu Ala Gly465 470 475
480His Pro Phe Asn Leu Asn Ser Arg Asp Gln Leu Glu Met Val Leu Phe
485 490 495Asp Glu Leu Arg
Leu Pro Ala Leu Gly Lys Thr Gln Lys Thr Gly Lys 500
505 510Arg Ser Thr Ser Ala Ala Val Leu Glu Ala Leu
Arg Glu Ala His Pro 515 520 525Ile
Val Glu Lys Ile Leu Gln Tyr Arg Glu Leu Thr Lys Leu Lys Ser 530
535 540Thr Tyr Ile Asp Pro Leu Ser Asp Leu Ile
His Pro Arg Thr Gly Arg545 550 555
560Leu His Thr Arg Phe Asn Gln Thr Ala Thr Ala Thr Gly Arg Leu
Ser 565 570 575Ser Ser Asp
Pro Asn Leu Gln Asn Ile Pro Val Arg Thr Pro Leu Gly 580
585 590Gln Arg Ile Arg Arg Ala Phe Ile Ala Glu
Glu Gly Trp Leu Leu Val 595 600
605Val Leu Asp Tyr Ser Gln Ile Glu Leu Arg Val Leu Ala His Leu Ser 610
615 620Gly Asp Glu Asn Leu Ile Arg Val
Phe Gln Glu Gly Arg Asp Ile His625 630
635 640Thr Glu Thr Ala Ser Trp Met Phe Gly Val Pro Arg
Glu Ala Val Asp 645 650
655Pro Leu Met Arg Arg Ala Ala Lys Thr Ile Asn Phe Gly Val Leu Tyr
660 665 670Gly Met Ser Ala His Arg
Leu Ser Gln Glu Leu Ala Ile Pro Tyr Glu 675 680
685Glu Ala Gln Ala Phe Ile Glu Arg Tyr Phe Gln Ser Phe Pro
Lys Val 690 695 700Arg Ala Trp Ile Glu
Lys Thr Leu Glu Glu Gly Arg Arg Arg Gly Tyr705 710
715 720Val Glu Thr Leu Phe Gly Arg Arg Arg Tyr
Val Pro Asp Leu Glu Ala 725 730
735Arg Val Lys Ser Val Arg Glu Ala Ala Glu Arg Met Ala Phe Asn Met
740 745 750Pro Val Gln Gly Thr
Ala Ala Asp Leu Met Lys Leu Ala Met Val Lys 755
760 765Leu Phe Pro Arg Leu Glu Glu Met Gly Ala Arg Met
Leu Leu Gln Val 770 775 780His Asp Glu
Leu Val Leu Glu Ala Pro Lys Glu Arg Ala Glu Ala Val785
790 795 800Ala Arg Leu Ala Lys Glu Val
Met Glu Gly Val Tyr Pro Leu Ala Val 805
810 815Pro Leu Glu Val Glu Val Gly Ile Gly Glu Asp Trp
Leu Ser Ala Lys 820 825
830Glu652502DNAArtificial sequenceMutant Taq polymerase coding sequence
65atggcgatgc ttcccctctt tgagcccaag ggccgcgtcc tcctggtgga cggccaccac
60ctggcctacc gcaccttctt cgccctgaag ggccccacca cgagccgggg cgaaccggtg
120caggtggtct acggcttcgc caagagcctc ctcaaggccc tgaaggagga cgggtacaag
180gccgtcttcg tggtctttga cgccaaggcc ccctcattcc gccacaaggc ctacgaggcc
240tacagggcgg ggagggcccc gacccccgag gacttccccc ggcagctcgc cctcatcaag
300gagctggtgg acctcctggg gtttacccgc ctcgaggtcc ccggctacga ggcggacgac
360gttctcgcca ccttcgccaa gaaggcggaa aaggaggggt acgaggtgcg catcctcacc
420gccgaccgcg gcctctacca actcgtctct gaccgcgtcg ccgtcctcca ccccgagggc
480cacctcatca ccccggagtg gctttgggag aagtacggcc tcaggccgga gcagtgggtg
540gacttccgcg ccctcgtggg gaacccctcc gacaacctcc ccggggtcaa gggcatcggg
600gagaagaccg ccctcaagct cctcaaggag tggggaagcc tggaaaacct cctcaagaac
660ctggaccggg taaagccaga aaacgtccgg gagaagatca aggcccacct ggaagacctc
720aggctctcct tggagctctc ccgggtgcgc accgacctcc ccctggaggt ggacctcgcc
780caggggcggg agcccgaccg ggaggggctt agggcctttc tggagaggct tgagtttggc
840agcctcctcc acgagttcgg ccttctggaa agccccaagg ccctggagga ggccccctgg
900cccccgccgg aaggggcctt cgtgggcttt gtgctttccc gcaaggagcc catgtgggcc
960gatcttctgg ccctggccgc cgccaggggt ggtcgagtcc accgggcccc cgagccttat
1020aaagccctca gggacctgaa ggaggcgcgg gggcttctcg ccaaagacct gagcgttctg
1080gccctaaggg aaggccttgg cctcccgccc ggcgacgacc ccatgctcct cgcctacctc
1140ctggaccctt ccaacaccac ccccgagggg gtggcccggc gctacggcgg ggagtggacg
1200gaggaggcgg gggagcgggc cgccctttcc gagaggctct tcgccaacct gtgggggagg
1260cttgaggggg aggagaggct cctttggctt taccgggagg tggagaggcc cctttccgct
1320gtcctggccc acatggaggc cacgggggtg cgcctggacg tggcctatct cagggccttg
1380tccctggagg tggccgagga gatcgcccgc ctcgaggccg aggtcttccg cctggccggc
1440caccccttca acctcaactc ccgggaccag ctggaaaggg tcctctttga cgagctaggg
1500cttcccgcca tcggcaagac ggagaagacc ggcaagcgct ccaccagcgc cgccgtcctg
1560gaggccctcc gcgaggccca ccccatcgtg gagaagatcc tgcagtaccg ggagctcacc
1620aagctgaaga gcacctacat tgaccccttg ccggacctca tccaccccag gacgggccgc
1680ctccacaccc gcttcaacca gacggccacg gccacgggca ggctaagtag ctccgatccc
1740aacctccaga acatccccgt ccgcaccccg ctcgggcaga ggatccgccg ggccttcatc
1800gccgaggagg ggtggctatt ggtggtcctg gactatagcc agatagagct cagggtgctg
1860gcccacctct ccggcgacga gaacctgatc cgggtcttcc aggaggggcg ggacatccac
1920acggaaaccg ccagctggat gttcggcgtc ccccgggagg ccgtggaccc cctaatgcgc
1980cgggcggcca agaccatcaa cttcggggtc ctctacggca tgtcggcccg ccgcctctcc
2040caggagctag ccatccctta cgaggaggcc caggccttca ttgagcgcta ctttcagagc
2100ttccccaagg tgcgggcctg gattgagaag accctggagg agggcaggag gcgggggtac
2160gtggagaccc tcttcggccg ccgccgctac gtgccagacc tagaggcccg ggtgaagagc
2220gtgcgggagg cggccgagcg catggccttc aacatgcccg tccagggcac cgccgccgac
2280ctcatgaagc tggctatggt gaagctcttc cccaggctgg aggaaatggg ggccaggatg
2340ctccttcagg tccacgacga gctggtcctc gaggccccaa aagagagggc ggaggccgtg
2400gcccggctgg ccaaggaggt catggagggg gtgtatcccc tggccgtgcc cctggaggtg
2460gaggtgggga taggggagga ctggctttcc gccaagggtt ag
250266833PRTArtificial sequenceMutant Taq polymerase 66Met Ala Met Leu
Pro Leu Phe Glu Pro Lys Gly Arg Val Leu Leu Val1 5
10 15Asp Gly His His Leu Ala Tyr Arg Thr Phe
Phe Ala Leu Lys Gly Pro 20 25
30Thr Thr Ser Arg Gly Glu Pro Val Gln Val Val Tyr Gly Phe Ala Lys
35 40 45Ser Leu Leu Lys Ala Leu Lys Glu
Asp Gly Tyr Lys Ala Val Phe Val 50 55
60Val Phe Asp Ala Lys Ala Pro Ser Phe Arg His Lys Ala Tyr Glu Ala65
70 75 80Tyr Arg Ala Gly Arg
Ala Pro Thr Pro Glu Asp Phe Pro Arg Gln Leu 85
90 95Ala Leu Ile Lys Glu Leu Val Asp Leu Leu Gly
Phe Thr Arg Leu Glu 100 105
110Val Pro Gly Tyr Glu Ala Asp Asp Val Leu Ala Thr Phe Ala Lys Lys
115 120 125Ala Glu Lys Glu Gly Tyr Glu
Val Arg Ile Leu Thr Ala Asp Arg Gly 130 135
140Leu Tyr Gln Leu Val Ser Asp Arg Val Ala Val Leu His Pro Glu
Gly145 150 155 160His Leu
Ile Thr Pro Glu Trp Leu Trp Glu Lys Tyr Gly Leu Arg Pro
165 170 175Glu Gln Trp Val Asp Phe Arg
Ala Leu Val Gly Asn Pro Ser Asp Asn 180 185
190Leu Pro Gly Val Lys Gly Ile Gly Glu Lys Thr Ala Leu Lys
Leu Leu 195 200 205Lys Glu Trp Gly
Ser Leu Glu Asn Leu Leu Lys Asn Leu Asp Arg Val 210
215 220Lys Pro Glu Asn Val Arg Glu Lys Ile Lys Ala His
Leu Glu Asp Leu225 230 235
240Arg Leu Ser Leu Glu Leu Ser Arg Val Arg Thr Asp Leu Pro Leu Glu
245 250 255Val Asp Leu Ala Gln
Gly Arg Glu Pro Asp Arg Glu Gly Leu Arg Ala 260
265 270Phe Leu Glu Arg Leu Glu Phe Gly Ser Leu Leu His
Glu Phe Gly Leu 275 280 285Leu Glu
Ser Pro Lys Ala Leu Glu Glu Ala Pro Trp Pro Pro Pro Glu 290
295 300Gly Ala Phe Val Gly Phe Val Leu Ser Arg Lys
Glu Pro Met Trp Ala305 310 315
320Asp Leu Leu Ala Leu Ala Ala Ala Arg Gly Gly Arg Val His Arg Ala
325 330 335Pro Glu Pro Tyr
Lys Ala Leu Arg Asp Leu Lys Glu Ala Arg Gly Leu 340
345 350Leu Ala Lys Asp Leu Ser Val Leu Ala Leu Arg
Glu Gly Leu Gly Leu 355 360 365Pro
Pro Gly Asp Asp Pro Met Leu Leu Ala Tyr Leu Leu Asp Pro Ser 370
375 380Asn Thr Thr Pro Glu Gly Val Ala Arg Arg
Tyr Gly Gly Glu Trp Thr385 390 395
400Glu Glu Ala Gly Glu Arg Ala Ala Leu Ser Glu Arg Leu Phe Ala
Asn 405 410 415Leu Trp Gly
Arg Leu Glu Gly Glu Glu Arg Leu Leu Trp Leu Tyr Arg 420
425 430Glu Val Glu Arg Pro Leu Ser Ala Val Leu
Ala His Met Glu Ala Thr 435 440
445Gly Val Arg Leu Asp Val Ala Tyr Leu Arg Ala Leu Ser Leu Glu Val 450
455 460Ala Glu Glu Ile Ala Arg Leu Glu
Ala Glu Val Phe Arg Leu Ala Gly465 470
475 480His Pro Phe Asn Leu Asn Ser Arg Asp Gln Leu Glu
Arg Val Leu Phe 485 490
495Asp Glu Leu Gly Leu Pro Ala Ile Gly Lys Thr Glu Lys Thr Gly Lys
500 505 510Arg Ser Thr Ser Ala Ala
Val Leu Glu Ala Leu Arg Glu Ala His Pro 515 520
525Ile Val Glu Lys Ile Leu Gln Tyr Arg Glu Leu Thr Lys Leu
Lys Ser 530 535 540Thr Tyr Ile Asp Pro
Leu Pro Asp Leu Ile His Pro Arg Thr Gly Arg545 550
555 560Leu His Thr Arg Phe Asn Gln Thr Ala Thr
Ala Thr Gly Arg Leu Ser 565 570
575Ser Ser Asp Pro Asn Leu Gln Asn Ile Pro Val Arg Thr Pro Leu Gly
580 585 590Gln Arg Ile Arg Arg
Ala Phe Ile Ala Glu Glu Gly Trp Leu Leu Val 595
600 605Val Leu Asp Tyr Ser Gln Ile Glu Leu Arg Val Leu
Ala His Leu Ser 610 615 620Gly Asp Glu
Asn Leu Ile Arg Val Phe Gln Glu Gly Arg Asp Ile His625
630 635 640Thr Glu Thr Ala Ser Trp Met
Phe Gly Val Pro Arg Glu Ala Val Asp 645
650 655Pro Leu Met Arg Arg Ala Ala Lys Thr Ile Asn Phe
Gly Val Leu Tyr 660 665 670Gly
Met Ser Ala Arg Arg Leu Ser Gln Glu Leu Ala Ile Pro Tyr Glu 675
680 685Glu Ala Gln Ala Phe Ile Glu Arg Tyr
Phe Gln Ser Phe Pro Lys Val 690 695
700Arg Ala Trp Ile Glu Lys Thr Leu Glu Glu Gly Arg Arg Arg Gly Tyr705
710 715 720Val Glu Thr Leu
Phe Gly Arg Arg Arg Tyr Val Pro Asp Leu Glu Ala 725
730 735Arg Val Lys Ser Val Arg Glu Ala Ala Glu
Arg Met Ala Phe Asn Met 740 745
750Pro Val Gln Gly Thr Ala Ala Asp Leu Met Lys Leu Ala Met Val Lys
755 760 765Leu Phe Pro Arg Leu Glu Glu
Met Gly Ala Arg Met Leu Leu Gln Val 770 775
780His Asp Glu Leu Val Leu Glu Ala Pro Lys Glu Arg Ala Glu Ala
Val785 790 795 800Ala Arg
Leu Ala Lys Glu Val Met Glu Gly Val Tyr Pro Leu Ala Val
805 810 815Pro Leu Glu Val Glu Val Gly
Ile Gly Glu Asp Trp Leu Ser Ala Lys 820 825
830Gly672502DNAArtificial sequenceMutant Taq polymerase
coding sequence 67atggtgatgc ttcccctctt tgagcccaag ggccgcgtcc tcctggtgga
cggccaccac 60ctggcctacc gcaccttctt cgccctgaag ggcctcacca cgagccgggg
cgaaccggtg 120caggcggtct acggcttcgc caagagcctc ctcaaggccc tgaaggagga
cgggtacaag 180gccgtcttcg tggtctttga cgccaaggcc tcctccttcc gccacgaggc
ctacgaggcc 240tacaaggcgg ggagggcccc gacccccgag gacttccccc ggcagctcgc
cctcatcaag 300gagctggtgg acctcctggg gtttacccgc ctcgaggtcc ccggctacga
ggtggacgac 360gtcctggcca gcctggccaa gaaggtggaa aaggaggggt acgaggtgcg
catcctcacc 420gccgaccgcg acctctacca actcgtctcc gaccgcgtcg ccgtcctcca
ccccgagggc 480cacctcatca ccccggagtg gctttgggag aagtacggcc tcaggccgga
gcagtgggtg 540gacttccgcg ccctcgtggg ggacccctcc gacaacctcc ccggggtcaa
gggcatcggg 600gagaagaccg ccctcaagct cctcaaggag tggggaggcc tggaaaacct
cctcaagaac 660ctggaccggg taaagccaga aaacgtccgg gagaagatca aggcccacct
ggaagacctc 720aggctctcct tggagctctc ccgggtgcgc accgacctcc ccctggaggt
ggacctcgcc 780caggggcggg aacccgaccg ggagaggctt agggcctttc tggagaggct
tgagtttggc 840agcctcctcc acgagttcgg ccttctggaa agccccaagg ccctggagga
ggccccctgg 900cccccgccgg aaggggcctt cgtgggcttt gtgctttccc gcaaggagcc
catgtgggcc 960gatcttctgg ccctggccgc cgccaggggt ggtcgggtcc accggacccc
cgagccttat 1020aaagccctca gggacttgaa ggaggcgcgg gggcttctcg ccaaagacct
gagcgttctg 1080gccctaaggg aaggccttgg cctcccgccc ggcgacgacc ccatgctcct
cgcctacctc 1140ctggaccctt ccaacaccac ccccgagggg gtggcccggc gctacggcgg
ggagtggacg 1200gaggaggcgg gggagcgggc cgccctttcc gagaggctct tcgccaacct
gtgggggagg 1260cttgaggggg aggagaggct cctttggctt taccgggagg tggataggcc
cctttccgct 1320gtcctggccc acatggaggc cacaggggtg cgcctggacg tggcctacct
cagggccttg 1380tccctggagg tggccgagga gatcgcccgc ctcgaggccg aggtcttccg
cctggccggc 1440caccccttca acctcaactc ccgggaccag ctggaaaggg tcctctttga
cgagctaggg 1500cttcccgcca tcggcaagac ggagaagacc ggcaagcgct ccaccagcgc
cgccgtcctg 1560gaggccctcc gcgaggccca ccccatcgtg gagaagatcc tgcagtaccg
ggagctcacc 1620aagctgaaga gcacctacat tgaccccttg ccggacctca tccaccccag
gacgggccgc 1680ctccacaccc gcttcaacca gacggccacg gccacgggca ggctaagtag
ctccgatccc 1740aacctccaga acatccccgt ccgcaccccg ctcgggcaga ggatccgccg
ggccttcatc 1800gccgaggagg ggtggctatt ggtggtcctg gactatagcc agatagagct
cagggtgctg 1860gcccacctct ccggcgacga gaacctgatc cgggtcttcc aggaggggcg
ggacatccac 1920acggaaaccg ccagctggat gttcggcgtc ccccgggagg ccgtggaccc
cctaatgcgc 1980cgggcggcca agaccatcaa cttcggggtt ctctacggca tgtcggccca
ccgcctctcc 2040caggagctag ccatccctta cgaggaggcc caggccttca ttgagcgcta
ctttcagagc 2100ttccccaagg tgcgggcctg gattgagaag accctggagg agggcaggag
gcgggggtac 2160gtggagaccc tcttcggccg ccgtcgctac gtgccagacc tagaggcccg
ggtgaagagc 2220gtgcgggagg cggccgagcg catggccttc aacatgcccg tccagggcac
cgccgccgac 2280ctcatgaagc tggctatggt gaagctcttc cccaggctgg aagaaacggg
ggccaggatg 2340ctccttcagg tccacgacga gctggtcctc gaggccccaa aagagagggc
ggaggccgtg 2400gcccggctgg ccaaggaggc catggagggg gtgtatcccc tggccgtgcc
cctggaggtg 2460gaggtgggga taggggagga ctggctctcc gccaaggagt ga
250268833PRTArtificial sequenceMutant Taq polymerase 68Met Val
Met Leu Pro Leu Phe Glu Pro Lys Gly Arg Val Leu Leu Val1 5
10 15Asp Gly His His Leu Ala Tyr Arg
Thr Phe Phe Ala Leu Lys Gly Leu 20 25
30Thr Thr Ser Arg Gly Glu Pro Val Gln Ala Val Tyr Gly Phe Ala
Lys 35 40 45Ser Leu Leu Lys Ala
Leu Lys Glu Asp Gly Tyr Lys Ala Val Phe Val 50 55
60Val Phe Asp Ala Lys Ala Ser Ser Phe Arg His Glu Ala Tyr
Glu Ala65 70 75 80Tyr
Lys Ala Gly Arg Ala Pro Thr Pro Glu Asp Phe Pro Arg Gln Leu
85 90 95Ala Leu Ile Lys Glu Leu Val
Asp Leu Leu Gly Phe Thr Arg Leu Glu 100 105
110Val Pro Gly Tyr Glu Val Asp Asp Val Leu Ala Ser Leu Ala
Lys Lys 115 120 125Val Glu Lys Glu
Gly Tyr Glu Val Arg Ile Leu Thr Ala Asp Arg Asp 130
135 140Leu Tyr Gln Leu Val Ser Asp Arg Val Ala Val Leu
His Pro Glu Gly145 150 155
160His Leu Ile Thr Pro Glu Trp Leu Trp Glu Lys Tyr Gly Leu Arg Pro
165 170 175Glu Gln Trp Val Asp
Phe Arg Ala Leu Val Gly Asp Pro Ser Asp Asn 180
185 190Leu Pro Gly Val Lys Gly Ile Gly Glu Lys Thr Ala
Leu Lys Leu Leu 195 200 205Lys Glu
Trp Gly Gly Leu Glu Asn Leu Leu Lys Asn Leu Asp Arg Val 210
215 220Lys Pro Glu Asn Val Arg Glu Lys Ile Lys Ala
His Leu Glu Asp Leu225 230 235
240Arg Leu Ser Leu Glu Leu Ser Arg Val Arg Thr Asp Leu Pro Leu Glu
245 250 255Val Asp Leu Ala
Gln Gly Arg Glu Pro Asp Arg Glu Arg Leu Arg Ala 260
265 270Phe Leu Glu Arg Leu Glu Phe Gly Ser Leu Leu
His Glu Phe Gly Leu 275 280 285Leu
Glu Ser Pro Lys Ala Leu Glu Glu Ala Pro Trp Pro Pro Pro Glu 290
295 300Gly Ala Phe Val Gly Phe Val Leu Ser Arg
Lys Glu Pro Met Trp Ala305 310 315
320Asp Leu Leu Ala Leu Ala Ala Ala Arg Gly Gly Arg Val His Arg
Thr 325 330 335Pro Glu Pro
Tyr Lys Ala Leu Arg Asp Leu Lys Glu Ala Arg Gly Leu 340
345 350Leu Ala Lys Asp Leu Ser Val Leu Ala Leu
Arg Glu Gly Leu Gly Leu 355 360
365Pro Pro Gly Asp Asp Pro Met Leu Leu Ala Tyr Leu Leu Asp Pro Ser 370
375 380Asn Thr Thr Pro Glu Gly Val Ala
Arg Arg Tyr Gly Gly Glu Trp Thr385 390
395 400Glu Glu Ala Gly Glu Arg Ala Ala Leu Ser Glu Arg
Leu Phe Ala Asn 405 410
415Leu Trp Gly Arg Leu Glu Gly Glu Glu Arg Leu Leu Trp Leu Tyr Arg
420 425 430Glu Val Asp Arg Pro Leu
Ser Ala Val Leu Ala His Met Glu Ala Thr 435 440
445Gly Val Arg Leu Asp Val Ala Tyr Leu Arg Ala Leu Ser Leu
Glu Val 450 455 460Ala Glu Glu Ile Ala
Arg Leu Glu Ala Glu Val Phe Arg Leu Ala Gly465 470
475 480His Pro Phe Asn Leu Asn Ser Arg Asp Gln
Leu Glu Arg Val Leu Phe 485 490
495Asp Glu Leu Gly Leu Pro Ala Ile Gly Lys Thr Glu Lys Thr Gly Lys
500 505 510Arg Ser Thr Ser Ala
Ala Val Leu Glu Ala Leu Arg Glu Ala His Pro 515
520 525Ile Val Glu Lys Ile Leu Gln Tyr Arg Glu Leu Thr
Lys Leu Lys Ser 530 535 540Thr Tyr Ile
Asp Pro Leu Pro Asp Leu Ile His Pro Arg Thr Gly Arg545
550 555 560Leu His Thr Arg Phe Asn Gln
Thr Ala Thr Ala Thr Gly Arg Leu Ser 565
570 575Ser Ser Asp Pro Asn Leu Gln Asn Ile Pro Val Arg
Thr Pro Leu Gly 580 585 590Gln
Arg Ile Arg Arg Ala Phe Ile Ala Glu Glu Gly Trp Leu Leu Val 595
600 605Val Leu Asp Tyr Ser Gln Ile Glu Leu
Arg Val Leu Ala His Leu Ser 610 615
620Gly Asp Glu Asn Leu Ile Arg Val Phe Gln Glu Gly Arg Asp Ile His625
630 635 640Thr Glu Thr Ala
Ser Trp Met Phe Gly Val Pro Arg Glu Ala Val Asp 645
650 655Pro Leu Met Arg Arg Ala Ala Lys Thr Ile
Asn Phe Gly Val Leu Tyr 660 665
670Gly Met Ser Ala His Arg Leu Ser Gln Glu Leu Ala Ile Pro Tyr Glu
675 680 685Glu Ala Gln Ala Phe Ile Glu
Arg Tyr Phe Gln Ser Phe Pro Lys Val 690 695
700Arg Ala Trp Ile Glu Lys Thr Leu Glu Glu Gly Arg Arg Arg Gly
Tyr705 710 715 720Val Glu
Thr Leu Phe Gly Arg Arg Arg Tyr Val Pro Asp Leu Glu Ala
725 730 735Arg Val Lys Ser Val Arg Glu
Ala Ala Glu Arg Met Ala Phe Asn Met 740 745
750Pro Val Gln Gly Thr Ala Ala Asp Leu Met Lys Leu Ala Met
Val Lys 755 760 765Leu Phe Pro Arg
Leu Glu Glu Thr Gly Ala Arg Met Leu Leu Gln Val 770
775 780His Asp Glu Leu Val Leu Glu Ala Pro Lys Glu Arg
Ala Glu Ala Val785 790 795
800Ala Arg Leu Ala Lys Glu Ala Met Glu Gly Val Tyr Pro Leu Ala Val
805 810 815Pro Leu Glu Val Glu
Val Gly Ile Gly Glu Asp Trp Leu Ser Ala Lys 820
825 830Glu692550DNAArtificial sequenceMutant Taq
polymerase coding sequence 69atggtgatgc ttcccctctt tgagcccaag ggccgcgtcc
tcctggtgga cggccaccac 60ctggcctacc gcaccttctt cgccctgaag ggcctcacca
cgagccgggg cgaaccggtg 120caggcggtct acggcttcgc caagagcctc ctcaaggccc
tgaaggagga cgggtacaag 180gccgtcttcg tggtctttga cgccaaggcc tcctccttcc
gccacgaggc ctacgaggcc 240tacaaggcgg ggagggcccc gacccccgag gacttccccc
ggcagctcgc cctcatcaag 300gagctggtgg acctcctggg gtttacccgc ctcgaggtcc
ccggctacga ggtggacgac 360gtcctggcca gcctggccaa gaaggtggaa aaggaggggt
acgaggtgcg catcctcacc 420gccgaccgcg gcctctacca actcgtctct gaccgcgtcg
ccgtcctcca ccccgagggc 480cacctcatca ccccggagtg gctttgggag aagtacggcc
tcaggccgga gcagtgggtg 540gacttccgcg ccctcgtggg ggacccctcc gacaacctcc
ccggggtcaa gggcatcggg 600gagaagaccg ccctcaagct cctcaaggag tggggaagcc
tggaaaacct cctcaagaac 660ctggaccggg taaagccaga aaacgtccgg gagaagatca
aggcccacct ggaagacctc 720aggctctcct tggagctctc ccgggtgcgc accgacctcc
ccctggaggt ggacctcgcc 780caggggcggg agcccgaccg ggagaggctt agggcctttc
tggagaggct tgagtttggc 840agcctcctcc acgagttcgg ccttctggaa agccccaagg
ccctggagga ggccccctgg 900cccccgccgg aaggggcctt cgtgggcttt gtgctttccc
gcaaggagcc catgtgggcc 960gatcttctgg ccctggccgc cgccaggggt ggtcgggtcc
accgggcccc cgagccttat 1020aaagccctca gggacttgaa ggaggcgcgg gggcttctcg
ccaaagacct gagcgttctg 1080gccctaaggg aaggccttgg cctcccgccc ggcgacgacc
ccatgctcct cgcctacctc 1140ctggaccctt ccaacaccac ccccgagggg gtggcccggc
gctacggcgg ggagtggacg 1200gaggaggcgg gggagcgggc cgccctttcc gagaggctct
tcgccaacct gtgggggagg 1260cttgaggggg aggagaggct cctttggctt taccgggagg
tggataggcc cctttccgct 1320gtcctggccc acatggaggc cacaggggtg cgcctggacg
tggcctatct cagggccttg 1380tccctggagg tggccgagga gatcgcccgc ctcgaggccg
aggtcttccg cctggccggc 1440caccccttca acctcaactc ccgggaccag ctggaaaggg
tcctctttga cgagctaggg 1500cttcccgcca tcggcaagac ggagaagacc ggcaagcgct
ccaccagcgc cgccatcctg 1560gaggccctcc gcgaggccca ccccatcgtg gagaagatcc
tgcagtaccg ggagctcacc 1620aagctgaaga gcacctacat tgaccccttg ccggacctca
tccaccccag gacgggccgc 1680ctccacaccc gcttcaacca gacggccacg gccacgggca
ggctaagtag ctccgatccc 1740aacctccaga acatccccgt ccgcaccccg ctcgggcaga
ggatccgccg ggccttcatc 1800gccgaggagg ggtggctatt ggtggtcctg gactatagcc
agatagagct cagggtgctg 1860gcccacctct ccggcgacga gaacctgacc cgggtcttcc
aggaggggcg ggacatccac 1920acggaaaccg ccagctggat gttcggcgtc ccccgggagg
ccgtggaccc cctgatgcgc 1980cgggcggcca agaccatcaa cttcggggtt ctctacggca
tgtcggccca ccgcctctcc 2040caggagctgg ccatccctta cgaggaggcc caggccttca
tagagcgcta cttccaaagc 2100ttccccaagg tgcgggcctg gatagaaaag accctggagg
aggggaggaa gcggggctac 2160gtggaaaccc tcttcggaag aaggcgctac gtgcccgacc
tcaacgcccg ggtgaagagt 2220gtcagggagg ccgcggagcg catggccttc aacatgcccg
tccagggcac cgccgccgac 2280cttatgaagc tcgccatggt gaagctcttc ccccgcctcc
gggagatggg ggcccgcatg 2340ctcctccagg tccacgacga gctcctcctg gaggcccccc
aagcgcgggc cgaggaggtg 2400gcggctttgg ccaaggaggc catggagaag gcctatcccc
tcgccgtacc cctggaggtg 2460aaggtgggga tcggggagga ctggctctcc gcccaaggag
tgagtcgacc tgcaggcagc 2520gcttggcgtc acccgcagtt cggtggttaa
255070849PRTArtificial sequenceMutant Taq
polymerase 70Met Val Met Leu Pro Leu Phe Glu Pro Lys Gly Arg Val Leu Leu
Val1 5 10 15Asp Gly His
His Leu Ala Tyr Arg Thr Phe Phe Ala Leu Lys Gly Leu 20
25 30Thr Thr Ser Arg Gly Glu Pro Val Gln Ala
Val Tyr Gly Phe Ala Lys 35 40
45Ser Leu Leu Lys Ala Leu Lys Glu Asp Gly Tyr Lys Ala Val Phe Val 50
55 60Val Phe Asp Ala Lys Ala Ser Ser Phe
Arg His Glu Ala Tyr Glu Ala65 70 75
80Tyr Lys Ala Gly Arg Ala Pro Thr Pro Glu Asp Phe Pro Arg
Gln Leu 85 90 95Ala Leu
Ile Lys Glu Leu Val Asp Leu Leu Gly Phe Thr Arg Leu Glu 100
105 110Val Pro Gly Tyr Glu Val Asp Asp Val
Leu Ala Ser Leu Ala Lys Lys 115 120
125Val Glu Lys Glu Gly Tyr Glu Val Arg Ile Leu Thr Ala Asp Arg Gly
130 135 140Leu Tyr Gln Leu Val Ser Asp
Arg Val Ala Val Leu His Pro Glu Gly145 150
155 160His Leu Ile Thr Pro Glu Trp Leu Trp Glu Lys Tyr
Gly Leu Arg Pro 165 170
175Glu Gln Trp Val Asp Phe Arg Ala Leu Val Gly Asp Pro Ser Asp Asn
180 185 190Leu Pro Gly Val Lys Gly
Ile Gly Glu Lys Thr Ala Leu Lys Leu Leu 195 200
205Lys Glu Trp Gly Ser Leu Glu Asn Leu Leu Lys Asn Leu Asp
Arg Val 210 215 220Lys Pro Glu Asn Val
Arg Glu Lys Ile Lys Ala His Leu Glu Asp Leu225 230
235 240Arg Leu Ser Leu Glu Leu Ser Arg Val Arg
Thr Asp Leu Pro Leu Glu 245 250
255Val Asp Leu Ala Gln Gly Arg Glu Pro Asp Arg Glu Arg Leu Arg Ala
260 265 270Phe Leu Glu Arg Leu
Glu Phe Gly Ser Leu Leu His Glu Phe Gly Leu 275
280 285Leu Glu Ser Pro Lys Ala Leu Glu Glu Ala Pro Trp
Pro Pro Pro Glu 290 295 300Gly Ala Phe
Val Gly Phe Val Leu Ser Arg Lys Glu Pro Met Trp Ala305
310 315 320Asp Leu Leu Ala Leu Ala Ala
Ala Arg Gly Gly Arg Val His Arg Ala 325
330 335Pro Glu Pro Tyr Lys Ala Leu Arg Asp Leu Lys Glu
Ala Arg Gly Leu 340 345 350Leu
Ala Lys Asp Leu Ser Val Leu Ala Leu Arg Glu Gly Leu Gly Leu 355
360 365Pro Pro Gly Asp Asp Pro Met Leu Leu
Ala Tyr Leu Leu Asp Pro Ser 370 375
380Asn Thr Thr Pro Glu Gly Val Ala Arg Arg Tyr Gly Gly Glu Trp Thr385
390 395 400Glu Glu Ala Gly
Glu Arg Ala Ala Leu Ser Glu Arg Leu Phe Ala Asn 405
410 415Leu Trp Gly Arg Leu Glu Gly Glu Glu Arg
Leu Leu Trp Leu Tyr Arg 420 425
430Glu Val Asp Arg Pro Leu Ser Ala Val Leu Ala His Met Glu Ala Thr
435 440 445Gly Val Arg Leu Asp Val Ala
Tyr Leu Arg Ala Leu Ser Leu Glu Val 450 455
460Ala Glu Glu Ile Ala Arg Leu Glu Ala Glu Val Phe Arg Leu Ala
Gly465 470 475 480His Pro
Phe Asn Leu Asn Ser Arg Asp Gln Leu Glu Arg Val Leu Phe
485 490 495Asp Glu Leu Gly Leu Pro Ala
Ile Gly Lys Thr Glu Lys Thr Gly Lys 500 505
510Arg Ser Thr Ser Ala Ala Ile Leu Glu Ala Leu Arg Glu Ala
His Pro 515 520 525Ile Val Glu Lys
Ile Leu Gln Tyr Arg Glu Leu Thr Lys Leu Lys Ser 530
535 540Thr Tyr Ile Asp Pro Leu Pro Asp Leu Ile His Pro
Arg Thr Gly Arg545 550 555
560Leu His Thr Arg Phe Asn Gln Thr Ala Thr Ala Thr Gly Arg Leu Ser
565 570 575Ser Ser Asp Pro Asn
Leu Gln Asn Ile Pro Val Arg Thr Pro Leu Gly 580
585 590Gln Arg Ile Arg Arg Ala Phe Ile Ala Glu Glu Gly
Trp Leu Leu Val 595 600 605Val Leu
Asp Tyr Ser Gln Ile Glu Leu Arg Val Leu Ala His Leu Ser 610
615 620Gly Asp Glu Asn Leu Thr Arg Val Phe Gln Glu
Gly Arg Asp Ile His625 630 635
640Thr Glu Thr Ala Ser Trp Met Phe Gly Val Pro Arg Glu Ala Val Asp
645 650 655Pro Leu Met Arg
Arg Ala Ala Lys Thr Ile Asn Phe Gly Val Leu Tyr 660
665 670Gly Met Ser Ala His Arg Leu Ser Gln Glu Leu
Ala Ile Pro Tyr Glu 675 680 685Glu
Ala Gln Ala Phe Ile Glu Arg Tyr Phe Gln Ser Phe Pro Lys Val 690
695 700Arg Ala Trp Ile Glu Lys Thr Leu Glu Glu
Gly Arg Lys Arg Gly Tyr705 710 715
720Val Glu Thr Leu Phe Gly Arg Arg Arg Tyr Val Pro Asp Leu Asn
Ala 725 730 735Arg Val Lys
Ser Val Arg Glu Ala Ala Glu Arg Met Ala Phe Asn Met 740
745 750Pro Val Gln Gly Thr Ala Ala Asp Leu Met
Lys Leu Ala Met Val Lys 755 760
765Leu Phe Pro Arg Leu Arg Glu Met Gly Ala Arg Met Leu Leu Gln Val 770
775 780His Asp Glu Leu Leu Leu Glu Ala
Pro Gln Ala Arg Ala Glu Glu Val785 790
795 800Ala Ala Leu Ala Lys Glu Ala Met Glu Lys Ala Tyr
Pro Leu Ala Val 805 810
815Pro Leu Glu Val Lys Val Gly Ile Gly Glu Asp Trp Leu Ser Ala Gln
820 825 830Gly Val Ser Arg Pro Ala
Gly Ser Ala Trp Arg His Pro Gln Phe Gly 835 840
845Gly712505DNAArtificial sequenceMutant Taq polymerase
coding sequence 71atgcgtggta tgcttcctct ttttgagccc aagggccgcg tcctcctggt
ggacggccac 60cacctggcct accgcacctt cttcgccctg aagggcccca ccacgagccg
gggcgaaccg 120gtgcaggcgg tctacggctt cgccaagagc ctcctcaagg ccctgaagga
ggacgggtac 180aaggccgcct tcgtggtctt tgacgccaag gccccctcct tccgccacga
ggcctacgag 240gcctacaagg cggggagggc cccgaccccc gaggacttcc cccggcagct
cgccctcatc 300aaggagctgg tggacctcct ggggtttacc cgcctcgagg tccctggcta
cgaggcggac 360gacgtcctcg ccaccctggc caagaaggcg gaaaaggagg ggtacgaggt
gcgcatcctc 420accgccgacc gcgacctcta ccaactcgtc tccgaccgcg tcgccgtcct
ccaccccgag 480ggccacctca tcaccccgga gtggctttgg gagaagtacg gcctcaggcc
ggagcagtgg 540gtggacttcc gcgccctcgt gggggacccc tccgacaacc tccccggggt
caagggcatc 600ggggagaaga ccgccctcaa gctcctcaag gagtggggaa gcctggaaaa
cctcctcaag 660aacctggacc gggtaaagcc agaaaacgtc cgggagaaga tcaaggccca
cctggaagac 720ctcaggctct ccttggagct ctcccgggtg cgcaccgacc tccccctgga
ggtggacctc 780gcccaggggc gggagctcga ccgggagagg cttagggcct ttctggagag
gcttgagttt 840ggcggcctcc tccacgagtt cggccttctg gaaagcccca aggccctgga
ggaggccccc 900tggcccccgc cggaaggggc cttcgtgggc tttgtgcttt cccgcaagga
gcccatgtgg 960gccgatcttc tggccctggc cgccgccagg ggtggtcggg tccaccgggc
ccccgagcct 1020tataaagccc tcagggactt gaaggaggcg cgggggcttc tcgccaaaga
cctgagcgtt 1080ctggccctaa gggaaggcct tggcctcccg cccggcgacg accccatgct
cctcgcctac 1140ctcctggacc cttccaacac cgcccccgag ggggtggccc ggcgctacgg
cggggagtgg 1200acggaggagg cgggggagcg ggccgccctt tccgagaggc tcttcgccaa
cctgtggggg 1260aggcttgagg gggaggagag gctcctttgg ctttaccggg aggtggatag
gcccctttcc 1320gctgtcctgg cccacatgga ggccacaggg gtacggctgg acgtggcctg
cctgcaggcc 1380ctttccctgg agcttgcgga ggagatccgc cgcctcgagg aggaggtctt
ccgcttggcg 1440ggccacccct tcaacctcaa ctcccgggac cagctggaaa gggtcctctt
tgacgagcta 1500gggcttcccg ccatcggcaa gacggagaag accggcaagc gctccaccag
cgccgccatc 1560ctggaggccc tccgcgaggc ccaccccatc gtggagaaga tcctgcagta
ccgggagctc 1620accaagctga agagcaccta cattgacccc ttgccggacc tcatccaccc
caggacgggc 1680cgcctccaca cccgcttcaa ccagacggcc acggccacgg gcaggctaag
tagctccgat 1740cccaacctcc agaacatccc cgtccgcacc ccgctcgggc agaggatccg
ccgggccttc 1800gtcgccgagg aggggtggct attggtggtc ctggactata gccagataga
gctcagggtg 1860ctggcccacc tctccggcga cgagaacctg acccgggtct tcctggaggg
gcgggacatc 1920cacacggaaa ccgccagctg gatgttcggc gtcccccggg aggccgtgga
ccccctgatg 1980cgccgggcgg ccaagaccat caacttcggg gttctctacg gcatgtcggc
ccaccgcctc 2040tcccaggagc tggccatccc ttacgaggag gcccaggcct tcatagagcg
ctacttccaa 2100agcttcccca aggtgcgggc ctggatagaa aagaccctgg aggaggggag
gaagcggggc 2160tacgtggaaa ccctcttcgg aagaaggcgc tacgtgcccg acctcaacgc
ccgggtgaag 2220agtgtcaggg aggccgcgga gcgcatggcc ttcaacatgc ccgtccaggg
caccgccgcc 2280gaccttatga agctcgccat ggtgaagctc ttcccccgcc tccgggagat
gggggcccgc 2340atgctcctcc aggtccacga cgagctcctc ctggaggccc cccaagcgcg
ggccgaggag 2400gtggcggctt tggccaagga ggccatggag aaggcctatc ccctcgccgt
acccctggag 2460gtgaaggtgg ggatcgggga ggactggctc tccgccaagg agtga
250572834PRTArtificial sequenceMutant Taq polymerase 72Met Arg
Gly Met Leu Pro Leu Phe Glu Pro Lys Gly Arg Val Leu Leu1 5
10 15Val Asp Gly His His Leu Ala Tyr
Arg Thr Phe Phe Ala Leu Lys Gly 20 25
30Pro Thr Thr Ser Arg Gly Glu Pro Val Gln Ala Val Tyr Gly Phe
Ala 35 40 45Lys Ser Leu Leu Lys
Ala Leu Lys Glu Asp Gly Tyr Lys Ala Ala Phe 50 55
60Val Val Phe Asp Ala Lys Ala Pro Ser Phe Arg His Glu Ala
Tyr Glu65 70 75 80Ala
Tyr Lys Ala Gly Arg Ala Pro Thr Pro Glu Asp Phe Pro Arg Gln
85 90 95Leu Ala Leu Ile Lys Glu Leu
Val Asp Leu Leu Gly Phe Thr Arg Leu 100 105
110Glu Val Pro Gly Tyr Glu Ala Asp Asp Val Leu Ala Thr Leu
Ala Lys 115 120 125Lys Ala Glu Lys
Glu Gly Tyr Glu Val Arg Ile Leu Thr Ala Asp Arg 130
135 140Asp Leu Tyr Gln Leu Val Ser Asp Arg Val Ala Val
Leu His Pro Glu145 150 155
160Gly His Leu Ile Thr Pro Glu Trp Leu Trp Glu Lys Tyr Gly Leu Arg
165 170 175Pro Glu Gln Trp Val
Asp Phe Arg Ala Leu Val Gly Asp Pro Ser Asp 180
185 190Asn Leu Pro Gly Val Lys Gly Ile Gly Glu Lys Thr
Ala Leu Lys Leu 195 200 205Leu Lys
Glu Trp Gly Ser Leu Glu Asn Leu Leu Lys Asn Leu Asp Arg 210
215 220Val Lys Pro Glu Asn Val Arg Glu Lys Ile Lys
Ala His Leu Glu Asp225 230 235
240Leu Arg Leu Ser Leu Glu Leu Ser Arg Val Arg Thr Asp Leu Pro Leu
245 250 255Glu Val Asp Leu
Ala Gln Gly Arg Glu Leu Asp Arg Glu Arg Leu Arg 260
265 270Ala Phe Leu Glu Arg Leu Glu Phe Gly Gly Leu
Leu His Glu Phe Gly 275 280 285Leu
Leu Glu Ser Pro Lys Ala Leu Glu Glu Ala Pro Trp Pro Pro Pro 290
295 300Glu Gly Ala Phe Val Gly Phe Val Leu Ser
Arg Lys Glu Pro Met Trp305 310 315
320Ala Asp Leu Leu Ala Leu Ala Ala Ala Arg Gly Gly Arg Val His
Arg 325 330 335Ala Pro Glu
Pro Tyr Lys Ala Leu Arg Asp Leu Lys Glu Ala Arg Gly 340
345 350Leu Leu Ala Lys Asp Leu Ser Val Leu Ala
Leu Arg Glu Gly Leu Gly 355 360
365Leu Pro Pro Gly Asp Asp Pro Met Leu Leu Ala Tyr Leu Leu Asp Pro 370
375 380Ser Asn Thr Ala Pro Glu Gly Val
Ala Arg Arg Tyr Gly Gly Glu Trp385 390
395 400Thr Glu Glu Ala Gly Glu Arg Ala Ala Leu Ser Glu
Arg Leu Phe Ala 405 410
415Asn Leu Trp Gly Arg Leu Glu Gly Glu Glu Arg Leu Leu Trp Leu Tyr
420 425 430Arg Glu Val Asp Arg Pro
Leu Ser Ala Val Leu Ala His Met Glu Ala 435 440
445Thr Gly Val Arg Leu Asp Val Ala Cys Leu Gln Ala Leu Ser
Leu Glu 450 455 460Leu Ala Glu Glu Ile
Arg Arg Leu Glu Glu Glu Val Phe Arg Leu Ala465 470
475 480Gly His Pro Phe Asn Leu Asn Ser Arg Asp
Gln Leu Glu Arg Val Leu 485 490
495Phe Asp Glu Leu Gly Leu Pro Ala Ile Gly Lys Thr Glu Lys Thr Gly
500 505 510Lys Arg Ser Thr Ser
Ala Ala Ile Leu Glu Ala Leu Arg Glu Ala His 515
520 525Pro Ile Val Glu Lys Ile Leu Gln Tyr Arg Glu Leu
Thr Lys Leu Lys 530 535 540Ser Thr Tyr
Ile Asp Pro Leu Pro Asp Leu Ile His Pro Arg Thr Gly545
550 555 560Arg Leu His Thr Arg Phe Asn
Gln Thr Ala Thr Ala Thr Gly Arg Leu 565
570 575Ser Ser Ser Asp Pro Asn Leu Gln Asn Ile Pro Val
Arg Thr Pro Leu 580 585 590Gly
Gln Arg Ile Arg Arg Ala Phe Val Ala Glu Glu Gly Trp Leu Leu 595
600 605Val Val Leu Asp Tyr Ser Gln Ile Glu
Leu Arg Val Leu Ala His Leu 610 615
620Ser Gly Asp Glu Asn Leu Thr Arg Val Phe Leu Glu Gly Arg Asp Ile625
630 635 640His Thr Glu Thr
Ala Ser Trp Met Phe Gly Val Pro Arg Glu Ala Val 645
650 655Asp Pro Leu Met Arg Arg Ala Ala Lys Thr
Ile Asn Phe Gly Val Leu 660 665
670Tyr Gly Met Ser Ala His Arg Leu Ser Gln Glu Leu Ala Ile Pro Tyr
675 680 685Glu Glu Ala Gln Ala Phe Ile
Glu Arg Tyr Phe Gln Ser Phe Pro Lys 690 695
700Val Arg Ala Trp Ile Glu Lys Thr Leu Glu Glu Gly Arg Lys Arg
Gly705 710 715 720Tyr Val
Glu Thr Leu Phe Gly Arg Arg Arg Tyr Val Pro Asp Leu Asn
725 730 735Ala Arg Val Lys Ser Val Arg
Glu Ala Ala Glu Arg Met Ala Phe Asn 740 745
750Met Pro Val Gln Gly Thr Ala Ala Asp Leu Met Lys Leu Ala
Met Val 755 760 765Lys Leu Phe Pro
Arg Leu Arg Glu Met Gly Ala Arg Met Leu Leu Gln 770
775 780Val His Asp Glu Leu Leu Leu Glu Ala Pro Gln Ala
Arg Ala Glu Glu785 790 795
800Val Ala Ala Leu Ala Lys Glu Ala Met Glu Lys Ala Tyr Pro Leu Ala
805 810 815Val Pro Leu Glu Val
Lys Val Gly Ile Gly Glu Asp Trp Leu Ser Ala 820
825 830Lys Glu732502DNAArtificial sequenceMutant Taq
polymerase coding sequence 73atggcgatgc ttcccctctt tgagcccaag ggccgcgtcc
tcctggtgga cggccaccac 60ctggcctacc gcaccttctt cgccctgaag ggccccacca
cgagccgggg cgaaccggtg 120caggtggtct acggcttcgc caagagcctc ctcaaggccc
tgaaggagga cgggtacaag 180gccgtcttcg tggtctttga cgccaaggcc ccctcattcc
gccacaaggc ctacgaggcc 240tacagggcgg ggagggcccc gacccccgag gacttccccc
ggcagctcgc cctcatcaag 300gagctggtgg acctcctggg gtttacccgc ctcgaggtcc
ccggctacga ggcggacgac 360gttctcgcca ccctggccaa gaaggcggaa aaggaggggt
acgaggtgcg catcctcacc 420gccgaccgcg gcctctacca actcgtctct gaccgcgtcg
ccgtcctcca ccccgagggc 480cacctcatca ccccggagtg gctttgggag aagtacggcc
tcaggccgga gcagtgggtg 540gacttccgcg ccctcgtggg ggacccctcc gacaacctcc
ccggggtcaa gggcatcggg 600gagaagaccg ccctcaagct cctcaaggag tggggaagcc
tggaaaacct cctcaagaac 660ctggaccggg taaagccaga aaacgtccgg gagaagatca
aggcccacct ggaagacctc 720aggctctcct tggagctctc ccgggtgcgc accgacctcc
ccctggaggt ggacctcgcc 780caggggcggg agcccgaccg ggaggggctt agggcctttc
tggagaggct tgagtttggc 840agcctcctcc acgagttcgg ccttctggaa agccccaagg
ccctggagga ggccccctgg 900cccccgccgg aaggggcctt cgtgggcttt gtgctttccc
gcaaggagcc catgtgggcc 960gatcttctgg ccctggccgc cgccaggggt ggtcgagtcc
accgggcccc cgagccttat 1020aaagccctca gggacctgaa ggaggcgcgg gggcttctcg
ccaaagacct gagcgttctg 1080gccctaaggg aaggccttgg cctcccgccc ggcgacgacc
ccatgctcct cgcctacctc 1140ctggaccctt ccaacaccac ccccgagggg gtggcccggc
gctacggcgg ggagtggacg 1200gaggaggcgg gggagcgggc cgccctttcc gagaggctct
tcgccaacct gtgggggagg 1260cttgaggggg aggagaggct cctttggctt taccgggagg
tggagaggcc cctttccgct 1320gtcctggccc acatggaggc cacgggggtg cgcctggacg
tggcctatct cagggccttg 1380tccctggagg tggccgagga gatcgcccgc ctcgaggccg
aggtcttccg cctggccggc 1440caccccttca acctcaactc ccgggaccag ctggaaatgg
tgctctttga cgagcttagg 1500cttcccgcct tggggaagac gcaaaagacg ggcaagcgct
ccaccagcgc cgccgtcctg 1560gaggccctcc gcgaggccca ccccatcgtg gagaagatcc
tgcagtaccg ggagctcacc 1620aagctgaaga gcacctacat tgaccccttg tcggacctca
tccaccccag gacgggccgc 1680ctccacaccc gcttcaacca gacggccacg gccacgggca
ggctaagtag ctccgatccc 1740aacctccaga acatccccgt ccgcaccccg cttgggcaga
ggatccgccg ggccttcatc 1800gccgaggagg ggtggctact ggtggtcctg gactatagcc
agatagagct cagggtgctg 1860gcccacctct ccggcgacga aaacctgatc agggtcttcc
aggaggggcg ggacatccac 1920acggagaccg ccagctggat gttcggcgtc ccccgggagg
ccgtggaccc cctgatgcgc 1980cgggcggcca agaccatcaa cttcggggtc ctctacggca
tgtcggccca ccgcctctcc 2040caggagctag ccatccctta cgaggaggcc caggccttca
ttgagcgcta ctttcagagc 2100ttccccaagg tgcgggcctg gattgagaag accctggagg
agggcaggag gcgggggtac 2160gtggagaccc tcttcggccg ccgccgctac gtgccagacc
tagaggcccg ggtgaagagc 2220gtgcgggagg cggccgagcg catggccttc aacatgcccg
tccagggcac cgccgccgac 2280ctcatgaagc tggctatggt gaagctcttc cccaggctgg
aggaaacggg ggccaggatg 2340ctccttcagg tccacgacga gctggtcctt gaggccccaa
aagagagggc ggaggccgtg 2400gcccggctgg ccaaggaggt catggagggg gtgtatcccc
tggccgtgtc cctggaggtg 2460gaggtgggga taggggagga ctggctctcc gccaaggagt
ga 250274833PRTArtificial sequenceMutant Taq
polymerase 74Met Ala Met Leu Pro Leu Phe Glu Pro Lys Gly Arg Val Leu Leu
Val1 5 10 15Asp Gly His
His Leu Ala Tyr Arg Thr Phe Phe Ala Leu Lys Gly Pro 20
25 30Thr Thr Ser Arg Gly Glu Pro Val Gln Val
Val Tyr Gly Phe Ala Lys 35 40
45Ser Leu Leu Lys Ala Leu Lys Glu Asp Gly Tyr Lys Ala Val Phe Val 50
55 60Val Phe Asp Ala Lys Ala Pro Ser Phe
Arg His Lys Ala Tyr Glu Ala65 70 75
80Tyr Arg Ala Gly Arg Ala Pro Thr Pro Glu Asp Phe Pro Arg
Gln Leu 85 90 95Ala Leu
Ile Lys Glu Leu Val Asp Leu Leu Gly Phe Thr Arg Leu Glu 100
105 110Val Pro Gly Tyr Glu Ala Asp Asp Val
Leu Ala Thr Leu Ala Lys Lys 115 120
125Ala Glu Lys Glu Gly Tyr Glu Val Arg Ile Leu Thr Ala Asp Arg Gly
130 135 140Leu Tyr Gln Leu Val Ser Asp
Arg Val Ala Val Leu His Pro Glu Gly145 150
155 160His Leu Ile Thr Pro Glu Trp Leu Trp Glu Lys Tyr
Gly Leu Arg Pro 165 170
175Glu Gln Trp Val Asp Phe Arg Ala Leu Val Gly Asp Pro Ser Asp Asn
180 185 190Leu Pro Gly Val Lys Gly
Ile Gly Glu Lys Thr Ala Leu Lys Leu Leu 195 200
205Lys Glu Trp Gly Ser Leu Glu Asn Leu Leu Lys Asn Leu Asp
Arg Val 210 215 220Lys Pro Glu Asn Val
Arg Glu Lys Ile Lys Ala His Leu Glu Asp Leu225 230
235 240Arg Leu Ser Leu Glu Leu Ser Arg Val Arg
Thr Asp Leu Pro Leu Glu 245 250
255Val Asp Leu Ala Gln Gly Arg Glu Pro Asp Arg Glu Gly Leu Arg Ala
260 265 270Phe Leu Glu Arg Leu
Glu Phe Gly Ser Leu Leu His Glu Phe Gly Leu 275
280 285Leu Glu Ser Pro Lys Ala Leu Glu Glu Ala Pro Trp
Pro Pro Pro Glu 290 295 300Gly Ala Phe
Val Gly Phe Val Leu Ser Arg Lys Glu Pro Met Trp Ala305
310 315 320Asp Leu Leu Ala Leu Ala Ala
Ala Arg Gly Gly Arg Val His Arg Ala 325
330 335Pro Glu Pro Tyr Lys Ala Leu Arg Asp Leu Lys Glu
Ala Arg Gly Leu 340 345 350Leu
Ala Lys Asp Leu Ser Val Leu Ala Leu Arg Glu Gly Leu Gly Leu 355
360 365Pro Pro Gly Asp Asp Pro Met Leu Leu
Ala Tyr Leu Leu Asp Pro Ser 370 375
380Asn Thr Thr Pro Glu Gly Val Ala Arg Arg Tyr Gly Gly Glu Trp Thr385
390 395 400Glu Glu Ala Gly
Glu Arg Ala Ala Leu Ser Glu Arg Leu Phe Ala Asn 405
410 415Leu Trp Gly Arg Leu Glu Gly Glu Glu Arg
Leu Leu Trp Leu Tyr Arg 420 425
430Glu Val Glu Arg Pro Leu Ser Ala Val Leu Ala His Met Glu Ala Thr
435 440 445Gly Val Arg Leu Asp Val Ala
Tyr Leu Arg Ala Leu Ser Leu Glu Val 450 455
460Ala Glu Glu Ile Ala Arg Leu Glu Ala Glu Val Phe Arg Leu Ala
Gly465 470 475 480His Pro
Phe Asn Leu Asn Ser Arg Asp Gln Leu Glu Met Val Leu Phe
485 490 495Asp Glu Leu Arg Leu Pro Ala
Leu Gly Lys Thr Gln Lys Thr Gly Lys 500 505
510Arg Ser Thr Ser Ala Ala Val Leu Glu Ala Leu Arg Glu Ala
His Pro 515 520 525Ile Val Glu Lys
Ile Leu Gln Tyr Arg Glu Leu Thr Lys Leu Lys Ser 530
535 540Thr Tyr Ile Asp Pro Leu Ser Asp Leu Ile His Pro
Arg Thr Gly Arg545 550 555
560Leu His Thr Arg Phe Asn Gln Thr Ala Thr Ala Thr Gly Arg Leu Ser
565 570 575Ser Ser Asp Pro Asn
Leu Gln Asn Ile Pro Val Arg Thr Pro Leu Gly 580
585 590Gln Arg Ile Arg Arg Ala Phe Ile Ala Glu Glu Gly
Trp Leu Leu Val 595 600 605Val Leu
Asp Tyr Ser Gln Ile Glu Leu Arg Val Leu Ala His Leu Ser 610
615 620Gly Asp Glu Asn Leu Ile Arg Val Phe Gln Glu
Gly Arg Asp Ile His625 630 635
640Thr Glu Thr Ala Ser Trp Met Phe Gly Val Pro Arg Glu Ala Val Asp
645 650 655Pro Leu Met Arg
Arg Ala Ala Lys Thr Ile Asn Phe Gly Val Leu Tyr 660
665 670Gly Met Ser Ala His Arg Leu Ser Gln Glu Leu
Ala Ile Pro Tyr Glu 675 680 685Glu
Ala Gln Ala Phe Ile Glu Arg Tyr Phe Gln Ser Phe Pro Lys Val 690
695 700Arg Ala Trp Ile Glu Lys Thr Leu Glu Glu
Gly Arg Arg Arg Gly Tyr705 710 715
720Val Glu Thr Leu Phe Gly Arg Arg Arg Tyr Val Pro Asp Leu Glu
Ala 725 730 735Arg Val Lys
Ser Val Arg Glu Ala Ala Glu Arg Met Ala Phe Asn Met 740
745 750Pro Val Gln Gly Thr Ala Ala Asp Leu Met
Lys Leu Ala Met Val Lys 755 760
765Leu Phe Pro Arg Leu Glu Glu Thr Gly Ala Arg Met Leu Leu Gln Val 770
775 780His Asp Glu Leu Val Leu Glu Ala
Pro Lys Glu Arg Ala Glu Ala Val785 790
795 800Ala Arg Leu Ala Lys Glu Val Met Glu Gly Val Tyr
Pro Leu Ala Val 805 810
815Ser Leu Glu Val Glu Val Gly Ile Gly Glu Asp Trp Leu Ser Ala Lys
820 825 830Glu752502DNAArtificial
sequenceMutant Taq polymerase coding sequence 75atggcgatgc ttcccctctt
tgagcccaag ggccgcgtcc tcctggtgga cggccaccac 60ctggcctacc gcaccttctt
cgccctgaag ggccccaccg cgagccgggg cgaaccggtg 120caggtggtct acggcttcgc
caagagcctc ctcaaggccc tgaaggagga cgggtacaag 180gccgtcttcg tggtctttga
cgccaaggcc ccctcattcc gccacaaggc ctacgaggcc 240tacagggcgg ggagggcccc
gacccccgag gacttccccc ggcagctcgc cctcatcaag 300gagctggtgg acctcctggg
gtttacccgc ctcgaggtcc ccggctacga ggcggacgac 360gttctcgccc ccctggccaa
gaaggcggaa aaggaggggt tcgaggtgcg catcctcccc 420gccgtccgcg gcctctgccc
tctcgtctct gaccgcgtcg ccgtcctcct ccccgagggc 480cacctcatca ccccggagtg
gctttgggag aagtacggcc tcaggccgga gcagtgggtg 540gacttccgcg ccctcgtggg
ggacccctcc gacaacctcc ccggggtcaa gggcatcggg 600aagaagaccg ccctcaagct
cctcaaggag tggggaagcc tggaaaacct cctcaagaac 660ctggaccggg taaagccaga
aaacgtccgg gagaagatca aggcccacct ggaagacctc 720aggctctcct tggagctctc
ccgggtgcgc accgacctcc ccctggaggt ggacctcgcc 780caggggcggg agcccgaccg
ggaggggctt agggcctttc tggagaggct tgagtttggc 840agcctcctcc acgagttcgg
ccttctggaa agccccaagg ccctggagga ggccccctgg 900cccccgccgg aaggggcctt
cgtgggcttt gtgctttccc gcaaggagcc catgtgggcc 960gatcttctgg ccctggccgc
cgccaggggt ggtcgggtcc accgggcccc cgagccttat 1020aaagccctca gggacttgaa
ggaggcgcgg gggcttctcg ccaaagacct gagcgttctg 1080gccctaaggg aaggccttgg
cctcccgccc ggcgacgacc ccatgctcct cgcctacctc 1140ctggaccctt ccaacaccac
ccccgagggg gtggcccggc gctacggcgg ggagtggacg 1200gaggaggcgg gggagcgggc
cgccctttcc gagaggctct tcgccaacct gtgggggagg 1260cttgaggggg aggagaggct
cctgtggctt taccgggagg tggataggcc cctttccgct 1320gtcctggccc acatggaggc
cacaggggta cggctggacg tggcctgcct gcaggccctt 1380tccctggagc ttgcggagga
gatccgccgc ctcgaggagg aggtcttccg cttggcgggc 1440caccccttca acctcaactc
ccgggaccag ctggaaaggg tcctctttga cgagctaggg 1500cttcccgcca tcggcaagac
ggagaagacc ggcaagcgct ccaccagcgc cgccatcctg 1560gaggccctcc gcgaggccca
ccccatcgtg gagaagatcc tgcagtaccg ggagctcacc 1620aagctgaaga gcacctacat
tgaccccttg ccggacctca tccaccccag gacgggccgc 1680ctccacaccc gcttcaacca
gacggccacg gccacgggca ggctaagtag ctccgatccc 1740aacctccaga acatccccgt
ccgcaccccg ctcgggcaga ggatccgccg ggccttcatc 1800gccgaggagg ggtggctatt
ggtggtcctg gactatagcc agatagagct cagggtgctg 1860gcccacctct ccggcgacga
gaacctgacc cgggtcttcc aggaggggcg ggacatccac 1920acggaaaccg ccagctggat
gttcggcgtc ccccgggagg ccgtggaccc cctgatgcgc 1980cgggcggcca agaccatcaa
cttcggggtt ctctacggca tgtcggccca ccgcctctcc 2040caggagctgg ccatccctta
cgaggaggcc caggccttca tagagcgcta cttccaaagc 2100ttccccaagg tgcgggcctg
gatagaaaag accctggagg aggggaggaa gcggggctac 2160gtggaaaccc tcttcggaag
aaggcgctac gtgcccgacc tcaacgcccg ggtgaagagt 2220gtcagggagg ccgcggagcg
catggccttc aacatgcccg tccagggcac cgccgccgac 2280cttatgaagc tcgccatggt
gaagctcttc ccccgcctcc gggagatggg ggcccgcatg 2340ctcctccagg tccacgacga
gctcctcctg gaggcccccc aagcgcgggc cgaggaggtg 2400gcggctttgg ccaaggaggc
catggagaag gcctatcccc tcgccgtacc cctggaggtg 2460aaggtgggga tcggggagga
ctggctctcc gccaaggagt ga 250276833PRTArtificial
sequenceMutant Taq polymerase 76Met Ala Met Leu Pro Leu Phe Glu Pro Lys
Gly Arg Val Leu Leu Val1 5 10
15Asp Gly His His Leu Ala Tyr Arg Thr Phe Phe Ala Leu Lys Gly Pro
20 25 30Thr Ala Ser Arg Gly Glu
Pro Val Gln Val Val Tyr Gly Phe Ala Lys 35 40
45Ser Leu Leu Lys Ala Leu Lys Glu Asp Gly Tyr Lys Ala Val
Phe Val 50 55 60Val Phe Asp Ala Lys
Ala Pro Ser Phe Arg His Lys Ala Tyr Glu Ala65 70
75 80Tyr Arg Ala Gly Arg Ala Pro Thr Pro Glu
Asp Phe Pro Arg Gln Leu 85 90
95Ala Leu Ile Lys Glu Leu Val Asp Leu Leu Gly Phe Thr Arg Leu Glu
100 105 110Val Pro Gly Tyr Glu
Ala Asp Asp Val Leu Ala Pro Leu Ala Lys Lys 115
120 125Ala Glu Lys Glu Gly Phe Glu Val Arg Ile Leu Pro
Ala Val Arg Gly 130 135 140Leu Cys Pro
Leu Val Ser Asp Arg Val Ala Val Leu Leu Pro Glu Gly145
150 155 160His Leu Ile Thr Pro Glu Trp
Leu Trp Glu Lys Tyr Gly Leu Arg Pro 165
170 175Glu Gln Trp Val Asp Phe Arg Ala Leu Val Gly Asp
Pro Ser Asp Asn 180 185 190Leu
Pro Gly Val Lys Gly Ile Gly Lys Lys Thr Ala Leu Lys Leu Leu 195
200 205Lys Glu Trp Gly Ser Leu Glu Asn Leu
Leu Lys Asn Leu Asp Arg Val 210 215
220Lys Pro Glu Asn Val Arg Glu Lys Ile Lys Ala His Leu Glu Asp Leu225
230 235 240Arg Leu Ser Leu
Glu Leu Ser Arg Val Arg Thr Asp Leu Pro Leu Glu 245
250 255Val Asp Leu Ala Gln Gly Arg Glu Pro Asp
Arg Glu Gly Leu Arg Ala 260 265
270Phe Leu Glu Arg Leu Glu Phe Gly Ser Leu Leu His Glu Phe Gly Leu
275 280 285Leu Glu Ser Pro Lys Ala Leu
Glu Glu Ala Pro Trp Pro Pro Pro Glu 290 295
300Gly Ala Phe Val Gly Phe Val Leu Ser Arg Lys Glu Pro Met Trp
Ala305 310 315 320Asp Leu
Leu Ala Leu Ala Ala Ala Arg Gly Gly Arg Val His Arg Ala
325 330 335Pro Glu Pro Tyr Lys Ala Leu
Arg Asp Leu Lys Glu Ala Arg Gly Leu 340 345
350Leu Ala Lys Asp Leu Ser Val Leu Ala Leu Arg Glu Gly Leu
Gly Leu 355 360 365Pro Pro Gly Asp
Asp Pro Met Leu Leu Ala Tyr Leu Leu Asp Pro Ser 370
375 380Asn Thr Thr Pro Glu Gly Val Ala Arg Arg Tyr Gly
Gly Glu Trp Thr385 390 395
400Glu Glu Ala Gly Glu Arg Ala Ala Leu Ser Glu Arg Leu Phe Ala Asn
405 410 415Leu Trp Gly Arg Leu
Glu Gly Glu Glu Arg Leu Leu Trp Leu Tyr Arg 420
425 430Glu Val Asp Arg Pro Leu Ser Ala Val Leu Ala His
Met Glu Ala Thr 435 440 445Gly Val
Arg Leu Asp Val Ala Cys Leu Gln Ala Leu Ser Leu Glu Leu 450
455 460Ala Glu Glu Ile Arg Arg Leu Glu Glu Glu Val
Phe Arg Leu Ala Gly465 470 475
480His Pro Phe Asn Leu Asn Ser Arg Asp Gln Leu Glu Arg Val Leu Phe
485 490 495Asp Glu Leu Gly
Leu Pro Ala Ile Gly Lys Thr Glu Lys Thr Gly Lys 500
505 510Arg Ser Thr Ser Ala Ala Ile Leu Glu Ala Leu
Arg Glu Ala His Pro 515 520 525Ile
Val Glu Lys Ile Leu Gln Tyr Arg Glu Leu Thr Lys Leu Lys Ser 530
535 540Thr Tyr Ile Asp Pro Leu Pro Asp Leu Ile
His Pro Arg Thr Gly Arg545 550 555
560Leu His Thr Arg Phe Asn Gln Thr Ala Thr Ala Thr Gly Arg Leu
Ser 565 570 575Ser Ser Asp
Pro Asn Leu Gln Asn Ile Pro Val Arg Thr Pro Leu Gly 580
585 590Gln Arg Ile Arg Arg Ala Phe Ile Ala Glu
Glu Gly Trp Leu Leu Val 595 600
605Val Leu Asp Tyr Ser Gln Ile Glu Leu Arg Val Leu Ala His Leu Ser 610
615 620Gly Asp Glu Asn Leu Thr Arg Val
Phe Gln Glu Gly Arg Asp Ile His625 630
635 640Thr Glu Thr Ala Ser Trp Met Phe Gly Val Pro Arg
Glu Ala Val Asp 645 650
655Pro Leu Met Arg Arg Ala Ala Lys Thr Ile Asn Phe Gly Val Leu Tyr
660 665 670Gly Met Ser Ala His Arg
Leu Ser Gln Glu Leu Ala Ile Pro Tyr Glu 675 680
685Glu Ala Gln Ala Phe Ile Glu Arg Tyr Phe Gln Ser Phe Pro
Lys Val 690 695 700Arg Ala Trp Ile Glu
Lys Thr Leu Glu Glu Gly Arg Lys Arg Gly Tyr705 710
715 720Val Glu Thr Leu Phe Gly Arg Arg Arg Tyr
Val Pro Asp Leu Asn Ala 725 730
735Arg Val Lys Ser Val Arg Glu Ala Ala Glu Arg Met Ala Phe Asn Met
740 745 750Pro Val Gln Gly Thr
Ala Ala Asp Leu Met Lys Leu Ala Met Val Lys 755
760 765Leu Phe Pro Arg Leu Arg Glu Met Gly Ala Arg Met
Leu Leu Gln Val 770 775 780His Asp Glu
Leu Leu Leu Glu Ala Pro Gln Ala Arg Ala Glu Glu Val785
790 795 800Ala Ala Leu Ala Lys Glu Ala
Met Glu Lys Ala Tyr Pro Leu Ala Val 805
810 815Pro Leu Glu Val Lys Val Gly Ile Gly Glu Asp Trp
Leu Ser Ala Lys 820 825
830Glu772502DNAArtificial sequenceMutant Taq polymerase coding sequence
77atggcgatgc ttcccctctt tgagcccaaa ggccgggtcc tcctggtgga cggccaccac
60ctggcctacc gcaccttctt cgccctgaag ggcctcatca cgagccgggg cgaaccggtg
120caggcggtct acggtttcgc caagagcctc ctcaaggccc tgaaggagga cgggtacaag
180gccgtcttcg tggtctttga cgccaaggcc ccctccttcc gccacgaggc ctacgaggcc
240tacaaggcgg ggagggcccc gacccccgag gacttccccc ggcagctcgc cctcatcaag
300gagctggtgg acctcctggg gtttacccgc ctcgaggtcc aaggctacga ggcggacgac
360gtcctcgcca ccctggccaa gaaggcggaa aaagaagggt acgaggtgcg catcctcacc
420gccgaccggg acctctacca gctcgtctcc gaccgcgtcg ccgtcctcca ccccgagggc
480cacctcatca ccccggagtg gctttgggag aagtacggcc tcaggccgga gcagtgggtg
540gacttccgcg ccctcgtggg ggacccctcc gacaacctcc ccggggtcaa gggcatcggg
600gagaagaccg ccctcaagct cctcaaggag tggggaagcc tggaaaatct cctcaagaac
660ctggatcggg taaagccgga aaacgtccgg gagaagatca aggcccacct ggaagacctc
720aggctctcct tggagctctc ccgggtgcgt accgacctcc ccctggaggt ggacctcgcc
780caggggcggg agcccgaccg ggaagggctt agggccttcc tggagaggct ggagttcggc
840agcctcctcc atgagttcgg ccttctggaa agccccaagg ccctggagga ggccccctgg
900cccccgccgg aaggggcctt cgtgggcttt gtgctttccc gcaaggagcc catgtgggcc
960gatcttctgg ccctggccgc cgccaggggt ggtcgggtcc accgggcccc cgagccttat
1020aaagccctca gggacttgaa ggaggcgcgg gggcttctcg ccaaagacct gagcgttctg
1080gccctaaggg aaggccttgg cctcccgccc ggcgacgacc ccatgctcct cgcctacctc
1140ctggaccctt ccaacaccac ccccgagggg gtggcccggc gctacggcgg ggagtggacg
1200gaggaggcgg gggagcgggc cgccctttcc gagaggctct tcgccaacct gtgggggagg
1260cttgaggggg aggagaggct cctttggctt taccgggagg tggataggcc cctttccgct
1320gtcctggccc acatggaggc cacaggggtg cgcctggacg tggcctatct cagggccttg
1380tccctggagg tggccgagga gatcgcccgc ctcgaggccg aggtcttccg cctggccggc
1440caccccttca acctcaactc ccgggaccag ctggaaaggg tcctctttga cgagttaggg
1500cttcccgcca tcggcaagac ggagaggacc ggcaagcgct ccaccagcgc cgccgtcctg
1560gaggccctcc gcgaggccca ccccatcgtg gagaagatcc tgcagtaccg ggagctcacc
1620aagctgaaga gcacctacat tgaccccttg ccggacctca tccaccccag gacgggccgc
1680ctccacaccc gcttcaacca gacggccacg gccacgggca ggctaagtag ctccgatccc
1740aacctccaga acatccccgt ccgcaccccg cttgggcaga ggatccgccg ggccttcatc
1800gccgaggagg ggtggctatt ggtggccctg gactatagcc agatagagct cagggtgctg
1860gcccacctct ccggcgacga gaacctgatc cgggtcttcc aggaggggcg ggacatccac
1920acggagaccg ccagctggat gttcggtgtc cccccggagg ccgtggaccc cctgatgcgc
1980cgggcggcca agacggtgaa cttcggcgtc ctctacggca tgtccgccca taggctctcc
2040caggagcttt ccatccccta cgaggaggcg gtggccttta tagagcgcta cttccaaagc
2100ttccccaagg tgcgggcctg gatagaaaag accctggagg aggggaggaa gcggggctac
2160gtggaaaccc tcttcggaag aaggcgctac gtgcccgacc tcaacgcccg ggtgaagagc
2220gtcagggagg ccgcggagcg catggccttc aacatgcccg tccagggcac cgccgccgac
2280ctcatgaagc tcgccatggt gaagctcttc ccccgcctcc gggagatggg ggcccgcatg
2340ctcctccagg tccacgacga gctcctcctg gaggcccccc aagcgcgggc cgaggaggtg
2400gcggctttgg ccaaggaggc catggagaag gcctatcccc tcgccgtacc cctggaggtg
2460gaggtgggga tcggggagga ctggctctcc gccaaggagt ga
250278833PRTArtificial sequenceMutant taq polymerase 78Met Ala Met Leu
Pro Leu Phe Glu Pro Lys Gly Arg Val Leu Leu Val1 5
10 15Asp Gly His His Leu Ala Tyr Arg Thr Phe
Phe Ala Leu Lys Gly Leu 20 25
30Ile Thr Ser Arg Gly Glu Pro Val Gln Ala Val Tyr Gly Phe Ala Lys
35 40 45Ser Leu Leu Lys Ala Leu Lys Glu
Asp Gly Tyr Lys Ala Val Phe Val 50 55
60Val Phe Asp Ala Lys Ala Pro Ser Phe Arg His Glu Ala Tyr Glu Ala65
70 75 80Tyr Lys Ala Gly Arg
Ala Pro Thr Pro Glu Asp Phe Pro Arg Gln Leu 85
90 95Ala Leu Ile Lys Glu Leu Val Asp Leu Leu Gly
Phe Thr Arg Leu Glu 100 105
110Val Gln Gly Tyr Glu Ala Asp Asp Val Leu Ala Thr Leu Ala Lys Lys
115 120 125Ala Glu Lys Glu Gly Tyr Glu
Val Arg Ile Leu Thr Ala Asp Arg Asp 130 135
140Leu Tyr Gln Leu Val Ser Asp Arg Val Ala Val Leu His Pro Glu
Gly145 150 155 160His Leu
Ile Thr Pro Glu Trp Leu Trp Glu Lys Tyr Gly Leu Arg Pro
165 170 175Glu Gln Trp Val Asp Phe Arg
Ala Leu Val Gly Asp Pro Ser Asp Asn 180 185
190Leu Pro Gly Val Lys Gly Ile Gly Glu Lys Thr Ala Leu Lys
Leu Leu 195 200 205Lys Glu Trp Gly
Ser Leu Glu Asn Leu Leu Lys Asn Leu Asp Arg Val 210
215 220Lys Pro Glu Asn Val Arg Glu Lys Ile Lys Ala His
Leu Glu Asp Leu225 230 235
240Arg Leu Ser Leu Glu Leu Ser Arg Val Arg Thr Asp Leu Pro Leu Glu
245 250 255Val Asp Leu Ala Gln
Gly Arg Glu Pro Asp Arg Glu Gly Leu Arg Ala 260
265 270Phe Leu Glu Arg Leu Glu Phe Gly Ser Leu Leu His
Glu Phe Gly Leu 275 280 285Leu Glu
Ser Pro Lys Ala Leu Glu Glu Ala Pro Trp Pro Pro Pro Glu 290
295 300Gly Ala Phe Val Gly Phe Val Leu Ser Arg Lys
Glu Pro Met Trp Ala305 310 315
320Asp Leu Leu Ala Leu Ala Ala Ala Arg Gly Gly Arg Val His Arg Ala
325 330 335Pro Glu Pro Tyr
Lys Ala Leu Arg Asp Leu Lys Glu Ala Arg Gly Leu 340
345 350Leu Ala Lys Asp Leu Ser Val Leu Ala Leu Arg
Glu Gly Leu Gly Leu 355 360 365Pro
Pro Gly Asp Asp Pro Met Leu Leu Ala Tyr Leu Leu Asp Pro Ser 370
375 380Asn Thr Thr Pro Glu Gly Val Ala Arg Arg
Tyr Gly Gly Glu Trp Thr385 390 395
400Glu Glu Ala Gly Glu Arg Ala Ala Leu Ser Glu Arg Leu Phe Ala
Asn 405 410 415Leu Trp Gly
Arg Leu Glu Gly Glu Glu Arg Leu Leu Trp Leu Tyr Arg 420
425 430Glu Val Asp Arg Pro Leu Ser Ala Val Leu
Ala His Met Glu Ala Thr 435 440
445Gly Val Arg Leu Asp Val Ala Tyr Leu Arg Ala Leu Ser Leu Glu Val 450
455 460Ala Glu Glu Ile Ala Arg Leu Glu
Ala Glu Val Phe Arg Leu Ala Gly465 470
475 480His Pro Phe Asn Leu Asn Ser Arg Asp Gln Leu Glu
Arg Val Leu Phe 485 490
495Asp Glu Leu Gly Leu Pro Ala Ile Gly Lys Thr Glu Arg Thr Gly Lys
500 505 510Arg Ser Thr Ser Ala Ala
Val Leu Glu Ala Leu Arg Glu Ala His Pro 515 520
525Ile Val Glu Lys Ile Leu Gln Tyr Arg Glu Leu Thr Lys Leu
Lys Ser 530 535 540Thr Tyr Ile Asp Pro
Leu Pro Asp Leu Ile His Pro Arg Thr Gly Arg545 550
555 560Leu His Thr Arg Phe Asn Gln Thr Ala Thr
Ala Thr Gly Arg Leu Ser 565 570
575Ser Ser Asp Pro Asn Leu Gln Asn Ile Pro Val Arg Thr Pro Leu Gly
580 585 590Gln Arg Ile Arg Arg
Ala Phe Ile Ala Glu Glu Gly Trp Leu Leu Val 595
600 605Ala Leu Asp Tyr Ser Gln Ile Glu Leu Arg Val Leu
Ala His Leu Ser 610 615 620Gly Asp Glu
Asn Leu Ile Arg Val Phe Gln Glu Gly Arg Asp Ile His625
630 635 640Thr Glu Thr Ala Ser Trp Met
Phe Gly Val Pro Pro Glu Ala Val Asp 645
650 655Pro Leu Met Arg Arg Ala Ala Lys Thr Val Asn Phe
Gly Val Leu Tyr 660 665 670Gly
Met Ser Ala His Arg Leu Ser Gln Glu Leu Ser Ile Pro Tyr Glu 675
680 685Glu Ala Val Ala Phe Ile Glu Arg Tyr
Phe Gln Ser Phe Pro Lys Val 690 695
700Arg Ala Trp Ile Glu Lys Thr Leu Glu Glu Gly Arg Lys Arg Gly Tyr705
710 715 720Val Glu Thr Leu
Phe Gly Arg Arg Arg Tyr Val Pro Asp Leu Asn Ala 725
730 735Arg Val Lys Ser Val Arg Glu Ala Ala Glu
Arg Met Ala Phe Asn Met 740 745
750Pro Val Gln Gly Thr Ala Ala Asp Leu Met Lys Leu Ala Met Val Lys
755 760 765Leu Phe Pro Arg Leu Arg Glu
Met Gly Ala Arg Met Leu Leu Gln Val 770 775
780His Asp Glu Leu Leu Leu Glu Ala Pro Gln Ala Arg Ala Glu Glu
Val785 790 795 800Ala Ala
Leu Ala Lys Glu Ala Met Glu Lys Ala Tyr Pro Leu Ala Val
805 810 815Pro Leu Glu Val Glu Val Gly
Ile Gly Glu Asp Trp Leu Ser Ala Lys 820 825
830Glu792502DNAArtificial sequenceMutant Taq polymerase
coding sequence 79atggcgatgc ttcccctctt tgagcccaag ggccgcgtcc tcctggtgga
cggccaccac 60ctggcctacc gcaccttctt cgccctgaag ggccccacca cgagccgggg
cgaaccggtg 120caggtggtct acggcttcgc caagagcctc ctcaaggccc tgaaggagga
cgggtacaag 180gccgtcttcg tggtctttga cgccaaggcc ccctcattcc gccacaaggc
ctacgaggcc 240tacagggcgg ggagggcccc gacccccgag gacttccccc ggcagctcgc
cctcatcaag 300gagctggtgg acctcctggg gtttacccgc ctcgaggtcc ccggctacga
ggcggacgac 360gttctcgcca ccctggccaa gaaggcggaa aaggaggggt acgaggtgcg
catcctcacc 420gccgaccgcg gcctctacca actcgtctct gaccgcgtcg ccgtcctcca
ccccgagggc 480cacctcatca ccccggagtg gctttgggag aagtacggcc tcaggccgga
gcagtgggtg 540gacttccgcg ccctcgtggg ggacccctcc gacaacctcc ccggggtcaa
gggcatcggg 600gagaagaccg ccctcaagct cctcaaggag tggggaagcc tggaaaacct
cctcaagaac 660ctggaccggg taaagccaga aaacgtccgg gagaagatca aggcccacct
ggaagacctc 720aggctctcct tggagctctc ccgggtgcgc accgacctcc ccctggaggt
ggacctcgcc 780caggggcggg agcccgaccg ggagaggctt agggcctttc tggagaggct
tgagtttggc 840ggcctcctcc acgagttcgg ccttctggaa agccccaagg ccctggagga
ggccccctgg 900cccccgccgg aaggggcctt cgtgggcttt gtgctttccc gcaaggagcc
catgtgggcc 960gatcttctgg ccctggccgc cgccaggggt ggtcgggtcc accgggcccc
cgagccttat 1020aaagccctca gggacttgaa ggaggcgcgg gggcttctcg ccaaagacct
gagcgttctg 1080gccctgaggg aaggccttgg cctcccgccc ggcgacgacc ccatgctcct
cgcctacctc 1140ctggaccctt ccaacaccac ccccgagggg gtggcccggc gctacggcgg
ggagtggacg 1200gaggaggcgg gggagcgggc cgccctttcc gagaggctct tcgccaacct
gtgggggagg 1260cttgaggggg aggagaggct cctttggctt taccgggagg tggagaggcc
cctttccgtt 1320gtcctggccc acatggaggc cacaggggtg cgcctggacg tggcctatct
cagggccttg 1380tccctggagg tggccgagga gatcgcccgc ctcgaggccg aggtcttccg
cctggccggc 1440caccccttca acctcaactc ccgggaccag ctggaaaggg tcctctttga
cgagctaggg 1500cttcccgcca tcggcaagac ggagaagacc ggcaagcgct ccaccggcgc
cgccgtcctg 1560gaggccctcc gcgaggccca ccccaccgtg gagaagatcc tgcagtaccg
ggagctcacc 1620aagctgaaga gcacctacat tgaccccttg ccggacctca tccaccccag
gacgggccgc 1680ctccacaccc gcttcaacca gacggccacg gccacgggca ggctaagtag
ctccgacccc 1740aacctccaga acatccccgt ccgcaccccg ctcgggcaga ggatccgccg
ggccttcatc 1800gccgaggagg ggtggctatt ggtggtcctg gactatagcc agatagagct
cagggtgctg 1860gcccacctct ccggcgacga gaacctgatc cgggtcttcc aggaggggcg
ggacatccac 1920acggaaaccg ccagctggat gttcggcgtc ccccgggagg ccgtggaccc
cctaatgcgc 1980cgggcggcca agaccatcaa cttcggggtt ctctacggca tgtcggccca
ccgcctctcc 2040caggagctag ccatccctta cgaggaggcc caggccttca ttgagcgcta
cattcagagc 2100ttccccaagg tgcgggcctg gattgagaag accctggagg agggcaggag
gcgggggtac 2160gtggagaccc tcttcggccg ccgtcgctac gtgccagacc tagaggcccg
ggtgaagagc 2220gtgcgggagg cggccgagcg catggccttc aacatgcccg tccagggcac
cgccgccgac 2280ctcatgaagc tggctatggt gaagctcttc cccaggctgg aagaaacggg
ggccaggatg 2340ctccttcagg tccacgacga gctggtcctc gaggccccaa aagagagggc
ggaggccgtg 2400gcccggctgg ccaaggaggc catggagggg gtgtatcccc tggccgtgcc
cctggaggtg 2460gaggtgggga taggggagga ctggctctcc gccaaggagt ga
250280833PRTArtificial sequenceMutant Taq polymerase 80Met Ala
Met Leu Pro Leu Phe Glu Pro Lys Gly Arg Val Leu Leu Val1 5
10 15Asp Gly His His Leu Ala Tyr Arg
Thr Phe Phe Ala Leu Lys Gly Pro 20 25
30Thr Thr Ser Arg Gly Glu Pro Val Gln Val Val Tyr Gly Phe Ala
Lys 35 40 45Ser Leu Leu Lys Ala
Leu Lys Glu Asp Gly Tyr Lys Ala Val Phe Val 50 55
60Val Phe Asp Ala Lys Ala Pro Ser Phe Arg His Lys Ala Tyr
Glu Ala65 70 75 80Tyr
Arg Ala Gly Arg Ala Pro Thr Pro Glu Asp Phe Pro Arg Gln Leu
85 90 95Ala Leu Ile Lys Glu Leu Val
Asp Leu Leu Gly Phe Thr Arg Leu Glu 100 105
110Val Pro Gly Tyr Glu Ala Asp Asp Val Leu Ala Thr Leu Ala
Lys Lys 115 120 125Ala Glu Lys Glu
Gly Tyr Glu Val Arg Ile Leu Thr Ala Asp Arg Gly 130
135 140Leu Tyr Gln Leu Val Ser Asp Arg Val Ala Val Leu
His Pro Glu Gly145 150 155
160His Leu Ile Thr Pro Glu Trp Leu Trp Glu Lys Tyr Gly Leu Arg Pro
165 170 175Glu Gln Trp Val Asp
Phe Arg Ala Leu Val Gly Asp Pro Ser Asp Asn 180
185 190Leu Pro Gly Val Lys Gly Ile Gly Glu Lys Thr Ala
Leu Lys Leu Leu 195 200 205Lys Glu
Trp Gly Ser Leu Glu Asn Leu Leu Lys Asn Leu Asp Arg Val 210
215 220Lys Pro Glu Asn Val Arg Glu Lys Ile Lys Ala
His Leu Glu Asp Leu225 230 235
240Arg Leu Ser Leu Glu Leu Ser Arg Val Arg Thr Asp Leu Pro Leu Glu
245 250 255Val Asp Leu Ala
Gln Gly Arg Glu Pro Asp Arg Glu Arg Leu Arg Ala 260
265 270Phe Leu Glu Arg Leu Glu Phe Gly Gly Leu Leu
His Glu Phe Gly Leu 275 280 285Leu
Glu Ser Pro Lys Ala Leu Glu Glu Ala Pro Trp Pro Pro Pro Glu 290
295 300Gly Ala Phe Val Gly Phe Val Leu Ser Arg
Lys Glu Pro Met Trp Ala305 310 315
320Asp Leu Leu Ala Leu Ala Ala Ala Arg Gly Gly Arg Val His Arg
Ala 325 330 335Pro Glu Pro
Tyr Lys Ala Leu Arg Asp Leu Lys Glu Ala Arg Gly Leu 340
345 350Leu Ala Lys Asp Leu Ser Val Leu Ala Leu
Arg Glu Gly Leu Gly Leu 355 360
365Pro Pro Gly Asp Asp Pro Met Leu Leu Ala Tyr Leu Leu Asp Pro Ser 370
375 380Asn Thr Thr Pro Glu Gly Val Ala
Arg Arg Tyr Gly Gly Glu Trp Thr385 390
395 400Glu Glu Ala Gly Glu Arg Ala Ala Leu Ser Glu Arg
Leu Phe Ala Asn 405 410
415Leu Trp Gly Arg Leu Glu Gly Glu Glu Arg Leu Leu Trp Leu Tyr Arg
420 425 430Glu Val Glu Arg Pro Leu
Ser Val Val Leu Ala His Met Glu Ala Thr 435 440
445Gly Val Arg Leu Asp Val Ala Tyr Leu Arg Ala Leu Ser Leu
Glu Val 450 455 460Ala Glu Glu Ile Ala
Arg Leu Glu Ala Glu Val Phe Arg Leu Ala Gly465 470
475 480His Pro Phe Asn Leu Asn Ser Arg Asp Gln
Leu Glu Arg Val Leu Phe 485 490
495Asp Glu Leu Gly Leu Pro Ala Ile Gly Lys Thr Glu Lys Thr Gly Lys
500 505 510Arg Ser Thr Gly Ala
Ala Val Leu Glu Ala Leu Arg Glu Ala His Pro 515
520 525Thr Val Glu Lys Ile Leu Gln Tyr Arg Glu Leu Thr
Lys Leu Lys Ser 530 535 540Thr Tyr Ile
Asp Pro Leu Pro Asp Leu Ile His Pro Arg Thr Gly Arg545
550 555 560Leu His Thr Arg Phe Asn Gln
Thr Ala Thr Ala Thr Gly Arg Leu Ser 565
570 575Ser Ser Asp Pro Asn Leu Gln Asn Ile Pro Val Arg
Thr Pro Leu Gly 580 585 590Gln
Arg Ile Arg Arg Ala Phe Ile Ala Glu Glu Gly Trp Leu Leu Val 595
600 605Val Leu Asp Tyr Ser Gln Ile Glu Leu
Arg Val Leu Ala His Leu Ser 610 615
620Gly Asp Glu Asn Leu Ile Arg Val Phe Gln Glu Gly Arg Asp Ile His625
630 635 640Thr Glu Thr Ala
Ser Trp Met Phe Gly Val Pro Arg Glu Ala Val Asp 645
650 655Pro Leu Met Arg Arg Ala Ala Lys Thr Ile
Asn Phe Gly Val Leu Tyr 660 665
670Gly Met Ser Ala His Arg Leu Ser Gln Glu Leu Ala Ile Pro Tyr Glu
675 680 685Glu Ala Gln Ala Phe Ile Glu
Arg Tyr Ile Gln Ser Phe Pro Lys Val 690 695
700Arg Ala Trp Ile Glu Lys Thr Leu Glu Glu Gly Arg Arg Arg Gly
Tyr705 710 715 720Val Glu
Thr Leu Phe Gly Arg Arg Arg Tyr Val Pro Asp Leu Glu Ala
725 730 735Arg Val Lys Ser Val Arg Glu
Ala Ala Glu Arg Met Ala Phe Asn Met 740 745
750Pro Val Gln Gly Thr Ala Ala Asp Leu Met Lys Leu Ala Met
Val Lys 755 760 765Leu Phe Pro Arg
Leu Glu Glu Thr Gly Ala Arg Met Leu Leu Gln Val 770
775 780His Asp Glu Leu Val Leu Glu Ala Pro Lys Glu Arg
Ala Glu Ala Val785 790 795
800Ala Arg Leu Ala Lys Glu Ala Met Glu Gly Val Tyr Pro Leu Ala Val
805 810 815Pro Leu Glu Val Glu
Val Gly Ile Gly Glu Asp Trp Leu Ser Ala Lys 820
825 830Glu812505DNAArtificial sequenceMutant Taq
polymerase coding sequence 81atgcgtggta tgcttcctct ttttgagccc aagggccgcg
tcctcctggt ggacggccac 60cacctggcct accgcacctt cttcgccctg aagggcccca
ccacgagccg gggcgaaccg 120gtgcaggcgg tctacggctt cgccaagagc ctcctcaagg
ccctgaagga ggacgggtac 180aaggccgcct tcgtggtctt tgacgccaag gccccctcct
tccgccacga ggcctacgag 240gcctacaagg cggggagggc cccgaccccc gaggacttcc
cccggcagct cgccctcatc 300aaggagctgg tggacctcct ggggtttacc cgcctcgagg
tccctggcta cgaggcggac 360gacgtcctcg ccaccctggc caagaaggcg gaaaaggagg
ggtacgaggt gcgcatcctc 420accgccgacc gcgacctcta ccaactcgtc tccgaccgcg
tcgccgtcct ccaccccgag 480ggccacctca tcaccccgga gtggctttgg gagaagtacg
gcctcaggcc ggagcagtgg 540gtggacttcc gcgccctcgt gggggacccc tccgacaacc
tccccggggt caagggcatc 600ggggagaaga ccgccctcaa gctcctcaag gagtggggaa
gcctggaaaa cctcctcaag 660aacctggacc gggtaaagcc agaaaacgtc cgggagaaga
tcaaggccca cctggaagac 720ctcaggctct ccttggagct ctcccgggtg cgcaccgacc
tccccctgga ggtggacctc 780gcccaggggc gggagcccga ccgggagagg cttagggcct
ttctggagag gcttgagttt 840ggcggcctcc tccacgagtt cggccttctg gaaagcccca
aggccctgga ggaggccccc 900tggcccccgc cggaaggggc cttcgtgggc tttgtgcttt
cccgcaagga gcccatgtgg 960gccgatcttc tggccctggc cgccgccagg ggtggtcggg
tccaccgggc ccccgagcct 1020tataaagccc tcagggactt gaaggaggcg cgggggcttc
tcgccaaaga cctgagcgtt 1080ctggccctaa gggaaggcct tggcctcccg cccggcgacg
accccatgct cctcgcctac 1140ctcctggacc cttccaacac cacccccgag ggggtggccc
ggcgctacgg cggggagtgg 1200acggaggagg cgggggagcg ggccgccctt tccgagaggc
tcttcgccaa cctgtggggg 1260aggcttgagg gggaggagag gctcctttgg ctttaccggg
aggtggatag gcccctttcc 1320gctgtcctgg cccacatgga ggccacaggg gtacggctgg
acgtggcctg cctgcaggcc 1380ctttccctgg agcttgcgga ggagatccgc cgcctcgagg
aggaggtctt ccgcttggcg 1440ggccacccct tcaacctcaa ctcccgggac cagctggaaa
gggtcctctt tgacgagcta 1500gggcttcccg ccatcggcaa gacggagaag accggcaagc
gctccaccag cgccgccatc 1560ctggaggccc tccgcgaggc ccaccccatc gtggagaaga
tcctgcagta ccgggagctc 1620accaagctga agagcaccta cattgacccc ttgccggacc
tcatccaccc caggacgggc 1680cgcctccaca cccgcttcaa ccagacggcc acggccacgg
gcaggctaag tagctccgat 1740cccaacctcc agaacatccc cgtccgcacc ccgctcgggc
agaggatccg ccgggccttc 1800atcgccgagg aggggtggct attggtggtc ctggactata
gccagataga gctcagggtg 1860ctggcccacc tctccggcga cgagaacctg acccgggtct
tccaggaggg gcgggacatc 1920cacacggaaa ccgccagctg gatgttcggc gtcccccggg
aggccgtgga ccccctgatg 1980cgccgggcgg ccaagaccat caacttcggg gttctctacg
gcatgtcggc ccaccgcctc 2040tcccaggagc tggccatccc ttacgaggag gcccaggcct
tcatagagcg ctacttccaa 2100agcttcccca aggtgcgggc ctggatagaa aagaccctgg
aggaggggag gaagcggggc 2160tacgtggaaa ccctcttcgg aagaaggcgc tacgtgcccg
acctcaacgc ccgggtgaag 2220agtgtcaggg aggccgcgga gcgcatggcc ttcaacatgc
ccgtccaggg caccgccgcc 2280gaccttatga agctcgccat ggtgaagctc ttcccccgcc
tccgggagat gggggcccgc 2340atgctcctcc aggtccacga cgagctcctc ctggaggccc
cccaagcgcg ggccgaggag 2400gtggcggctt tggccaagga ggccatggag aaggcctatc
ccctcgccgt acccctggag 2460gtgaaggtgg ggatcgggga ggactggctc tccgccaagg
agtga 250582834PRTArtificial sequenceMutant Taq
polymerase 82Met Arg Gly Met Leu Pro Leu Phe Glu Pro Lys Gly Arg Val Leu
Leu1 5 10 15Val Asp Gly
His His Leu Ala Tyr Arg Thr Phe Phe Ala Leu Lys Gly 20
25 30Pro Thr Thr Ser Arg Gly Glu Pro Val Gln
Ala Val Tyr Gly Phe Ala 35 40
45Lys Ser Leu Leu Lys Ala Leu Lys Glu Asp Gly Tyr Lys Ala Ala Phe 50
55 60Val Val Phe Asp Ala Lys Ala Pro Ser
Phe Arg His Glu Ala Tyr Glu65 70 75
80Ala Tyr Lys Ala Gly Arg Ala Pro Thr Pro Glu Asp Phe Pro
Arg Gln 85 90 95Leu Ala
Leu Ile Lys Glu Leu Val Asp Leu Leu Gly Phe Thr Arg Leu 100
105 110Glu Val Pro Gly Tyr Glu Ala Asp Asp
Val Leu Ala Thr Leu Ala Lys 115 120
125Lys Ala Glu Lys Glu Gly Tyr Glu Val Arg Ile Leu Thr Ala Asp Arg
130 135 140Asp Leu Tyr Gln Leu Val Ser
Asp Arg Val Ala Val Leu His Pro Glu145 150
155 160Gly His Leu Ile Thr Pro Glu Trp Leu Trp Glu Lys
Tyr Gly Leu Arg 165 170
175Pro Glu Gln Trp Val Asp Phe Arg Ala Leu Val Gly Asp Pro Ser Asp
180 185 190Asn Leu Pro Gly Val Lys
Gly Ile Gly Glu Lys Thr Ala Leu Lys Leu 195 200
205Leu Lys Glu Trp Gly Ser Leu Glu Asn Leu Leu Lys Asn Leu
Asp Arg 210 215 220Val Lys Pro Glu Asn
Val Arg Glu Lys Ile Lys Ala His Leu Glu Asp225 230
235 240Leu Arg Leu Ser Leu Glu Leu Ser Arg Val
Arg Thr Asp Leu Pro Leu 245 250
255Glu Val Asp Leu Ala Gln Gly Arg Glu Pro Asp Arg Glu Arg Leu Arg
260 265 270Ala Phe Leu Glu Arg
Leu Glu Phe Gly Gly Leu Leu His Glu Phe Gly 275
280 285Leu Leu Glu Ser Pro Lys Ala Leu Glu Glu Ala Pro
Trp Pro Pro Pro 290 295 300Glu Gly Ala
Phe Val Gly Phe Val Leu Ser Arg Lys Glu Pro Met Trp305
310 315 320Ala Asp Leu Leu Ala Leu Ala
Ala Ala Arg Gly Gly Arg Val His Arg 325
330 335Ala Pro Glu Pro Tyr Lys Ala Leu Arg Asp Leu Lys
Glu Ala Arg Gly 340 345 350Leu
Leu Ala Lys Asp Leu Ser Val Leu Ala Leu Arg Glu Gly Leu Gly 355
360 365Leu Pro Pro Gly Asp Asp Pro Met Leu
Leu Ala Tyr Leu Leu Asp Pro 370 375
380Ser Asn Thr Thr Pro Glu Gly Val Ala Arg Arg Tyr Gly Gly Glu Trp385
390 395 400Thr Glu Glu Ala
Gly Glu Arg Ala Ala Leu Ser Glu Arg Leu Phe Ala 405
410 415Asn Leu Trp Gly Arg Leu Glu Gly Glu Glu
Arg Leu Leu Trp Leu Tyr 420 425
430Arg Glu Val Asp Arg Pro Leu Ser Ala Val Leu Ala His Met Glu Ala
435 440 445Thr Gly Val Arg Leu Asp Val
Ala Cys Leu Gln Ala Leu Ser Leu Glu 450 455
460Leu Ala Glu Glu Ile Arg Arg Leu Glu Glu Glu Val Phe Arg Leu
Ala465 470 475 480Gly His
Pro Phe Asn Leu Asn Ser Arg Asp Gln Leu Glu Arg Val Leu
485 490 495Phe Asp Glu Leu Gly Leu Pro
Ala Ile Gly Lys Thr Glu Lys Thr Gly 500 505
510Lys Arg Ser Thr Ser Ala Ala Ile Leu Glu Ala Leu Arg Glu
Ala His 515 520 525Pro Ile Val Glu
Lys Ile Leu Gln Tyr Arg Glu Leu Thr Lys Leu Lys 530
535 540Ser Thr Tyr Ile Asp Pro Leu Pro Asp Leu Ile His
Pro Arg Thr Gly545 550 555
560Arg Leu His Thr Arg Phe Asn Gln Thr Ala Thr Ala Thr Gly Arg Leu
565 570 575Ser Ser Ser Asp Pro
Asn Leu Gln Asn Ile Pro Val Arg Thr Pro Leu 580
585 590Gly Gln Arg Ile Arg Arg Ala Phe Ile Ala Glu Glu
Gly Trp Leu Leu 595 600 605Val Val
Leu Asp Tyr Ser Gln Ile Glu Leu Arg Val Leu Ala His Leu 610
615 620Ser Gly Asp Glu Asn Leu Thr Arg Val Phe Gln
Glu Gly Arg Asp Ile625 630 635
640His Thr Glu Thr Ala Ser Trp Met Phe Gly Val Pro Arg Glu Ala Val
645 650 655Asp Pro Leu Met
Arg Arg Ala Ala Lys Thr Ile Asn Phe Gly Val Leu 660
665 670Tyr Gly Met Ser Ala His Arg Leu Ser Gln Glu
Leu Ala Ile Pro Tyr 675 680 685Glu
Glu Ala Gln Ala Phe Ile Glu Arg Tyr Phe Gln Ser Phe Pro Lys 690
695 700Val Arg Ala Trp Ile Glu Lys Thr Leu Glu
Glu Gly Arg Lys Arg Gly705 710 715
720Tyr Val Glu Thr Leu Phe Gly Arg Arg Arg Tyr Val Pro Asp Leu
Asn 725 730 735Ala Arg Val
Lys Ser Val Arg Glu Ala Ala Glu Arg Met Ala Phe Asn 740
745 750Met Pro Val Gln Gly Thr Ala Ala Asp Leu
Met Lys Leu Ala Met Val 755 760
765Lys Leu Phe Pro Arg Leu Arg Glu Met Gly Ala Arg Met Leu Leu Gln 770
775 780Val His Asp Glu Leu Leu Leu Glu
Ala Pro Gln Ala Arg Ala Glu Glu785 790
795 800Val Ala Ala Leu Ala Lys Glu Ala Met Glu Lys Ala
Tyr Pro Leu Ala 805 810
815Val Pro Leu Glu Val Lys Val Gly Ile Gly Glu Asp Trp Leu Ser Ala
820 825 830Lys Glu
832502DNAArtificial sequenceMutant Taq polymerase coding sequence
83atggcgatgc ttcccctctt tgagcccaag ggccgtgtcc tcctggtgga cggccaccac
60ctggcctacc gcaccttctt cgccctgaag ggccccacca cgagccgggg cgaaccggtg
120caggtggtct acggcttcgc caagagcctc ctcaaggccc tgaaggagga cgggtacaag
180gccgtcttcg tggtctttga cgccaaggcc cccccattcc gccacaaggc ctacgaggcc
240tacagggcgg ggagggcccc gacccccgag gacttccccc ggcagctcgc cctcatcaag
300gagctggtgg acctcctggg gtttacccgc ctcgaggtcc ccggctacga ggcggacgac
360gttctcgcca ccctggccaa gaaggcggaa aaggaggggt acgaggtgcg catcctcacc
420gccgaccgcg gcctctacca actcgtctct gaccgcgtcg ccgtcctcca ccccgagggc
480cacctcatca ccccggagtg gctttgggag aagtacggcc tcaggccgga gcagtgggtg
540gacttccgcg ccctcgtggg ggacccctcc gacaacctcc ccggggtcaa gggcatcggg
600gagaagaccg ccctcaagct cctcaaggag tggggaagcc tggaaaacct cctcaagaac
660ctggaccggg taaagccaga aaacgtccgg gagaagatca aggcccacct ggaagatctc
720aggctctcct tggagctctc ccgggtgcgc accgacctcc ccctggaggt ggacctcgcc
780caggggcggg agcccgaccg ggaggggctt agggcctttc tggagaggct tgagtttggc
840agcctcctcc acgagttcgg ccttctggaa agccccaagg ccctggagga ggccccctgg
900cccccgccgg aaggggcctt cgtgggcttt gtgctttccc gcaaggagcc catgtgggcc
960gatcttctgg ccctggccgc cgccaggggt ggtcgagtcc accgggcccc cgagccttat
1020aaagccctca gggacctgaa ggaggcgcgg gggcttctcg ccaaagacct gagcgttctg
1080gccctaaggg aaggccttgg cctcccgccc ggcgacgacc ccatgctcct cgcctacctc
1140ctggaccctt ccaacaccac ccccgagggg gtggcccggc gctacggcgg ggagtggacg
1200gaggaggcgg gggagcgggc cgccctttcc gagaggctct tcgccaacct gtgggggagg
1260cttgaggggg aggagaggct cctttggctt taccgggagg tggagaggcc cctttccgct
1320gtcctggccc acatggaggc cacgggggtg cgcctggacg tggcctatct cagggccttg
1380tccctggagg tggccgagga gatcgcccgc ctcgaggccg aggtcttccg cctggccggc
1440caccccttca acctcaactc ccgggaccag ctggaaatgg tgctctttga cgagcttagg
1500cttcccgcct tggggaagac gcaaaagacg ggcaagcgct ccaccagcgc cgccgtcctg
1560gaggccctcc gcgaggccca ccccatcgtg gagaagatcc tgcagtaccg ggagctcacc
1620aagctgaaga gcacctacat tgaccccttg tcggacctca tccaccccag gacgggccgc
1680ctccacaccc gcttcaacca gacggccacg gccacgggca ggctaagtag ctccgatccc
1740aacctccaga acatccccgt ccgcaccccg cttgggcaga ggatccgccg ggccttcatc
1800gccgaggagg ggtggctact ggtggtcctg gactatagcc agatagagct cagggtgctg
1860gcccacctct ccggcgacga aaacctgatc agggtcttcc aggaggggcg ggacatccac
1920acggagaccg ccagctggat gttcggcgtc ccccgggagg ccgtggaccc cctgatgcgc
1980cgggcggcca agaccatcaa cttcggggtc ctctacggca tgtcggccca ccgcctctcc
2040caggagctag ccatccctta cgaggaggcc caggccttca ttgagcgcta ctttcagagc
2100ttccccaagg tgcgggcctg gattgagaag accctggagg agggcaggag gcgggggtac
2160gtggagaccc tcttcggccg ccgccgctac gtgccagacc tagaggcccg ggtgaagagc
2220gtgcgggagg cggccgagcg catggccttc aacatgcccg tccagggcac cgccgccgac
2280ctcatgaagc tggctatggt gaagctcttc cccaggctgg aggaaatggg ggccaggatg
2340ctccttcagg tccacgacga gctggtcctc gaggccccaa aagagagggc ggaggccgtg
2400gcccggctgg ccaaggaggt catggagggg gtgtatcccc tggccgtgcc cctggaggtg
2460gaggtgggga taggggagga ctggctctcc gccaaggagt ga
250284833PRTArtificial sequenceMutant Taq polymerase 84Met Ala Met Leu
Pro Leu Phe Glu Pro Lys Gly Arg Val Leu Leu Val1 5
10 15Asp Gly His His Leu Ala Tyr Arg Thr Phe
Phe Ala Leu Lys Gly Pro 20 25
30Thr Thr Ser Arg Gly Glu Pro Val Gln Val Val Tyr Gly Phe Ala Lys
35 40 45Ser Leu Leu Lys Ala Leu Lys Glu
Asp Gly Tyr Lys Ala Val Phe Val 50 55
60Val Phe Asp Ala Lys Ala Pro Pro Phe Arg His Lys Ala Tyr Glu Ala65
70 75 80Tyr Arg Ala Gly Arg
Ala Pro Thr Pro Glu Asp Phe Pro Arg Gln Leu 85
90 95Ala Leu Ile Lys Glu Leu Val Asp Leu Leu Gly
Phe Thr Arg Leu Glu 100 105
110Val Pro Gly Tyr Glu Ala Asp Asp Val Leu Ala Thr Leu Ala Lys Lys
115 120 125Ala Glu Lys Glu Gly Tyr Glu
Val Arg Ile Leu Thr Ala Asp Arg Gly 130 135
140Leu Tyr Gln Leu Val Ser Asp Arg Val Ala Val Leu His Pro Glu
Gly145 150 155 160His Leu
Ile Thr Pro Glu Trp Leu Trp Glu Lys Tyr Gly Leu Arg Pro
165 170 175Glu Gln Trp Val Asp Phe Arg
Ala Leu Val Gly Asp Pro Ser Asp Asn 180 185
190Leu Pro Gly Val Lys Gly Ile Gly Glu Lys Thr Ala Leu Lys
Leu Leu 195 200 205Lys Glu Trp Gly
Ser Leu Glu Asn Leu Leu Lys Asn Leu Asp Arg Val 210
215 220Lys Pro Glu Asn Val Arg Glu Lys Ile Lys Ala His
Leu Glu Asp Leu225 230 235
240Arg Leu Ser Leu Glu Leu Ser Arg Val Arg Thr Asp Leu Pro Leu Glu
245 250 255Val Asp Leu Ala Gln
Gly Arg Glu Pro Asp Arg Glu Gly Leu Arg Ala 260
265 270Phe Leu Glu Arg Leu Glu Phe Gly Ser Leu Leu His
Glu Phe Gly Leu 275 280 285Leu Glu
Ser Pro Lys Ala Leu Glu Glu Ala Pro Trp Pro Pro Pro Glu 290
295 300Gly Ala Phe Val Gly Phe Val Leu Ser Arg Lys
Glu Pro Met Trp Ala305 310 315
320Asp Leu Leu Ala Leu Ala Ala Ala Arg Gly Gly Arg Val His Arg Ala
325 330 335Pro Glu Pro Tyr
Lys Ala Leu Arg Asp Leu Lys Glu Ala Arg Gly Leu 340
345 350Leu Ala Lys Asp Leu Ser Val Leu Ala Leu Arg
Glu Gly Leu Gly Leu 355 360 365Pro
Pro Gly Asp Asp Pro Met Leu Leu Ala Tyr Leu Leu Asp Pro Ser 370
375 380Asn Thr Thr Pro Glu Gly Val Ala Arg Arg
Tyr Gly Gly Glu Trp Thr385 390 395
400Glu Glu Ala Gly Glu Arg Ala Ala Leu Ser Glu Arg Leu Phe Ala
Asn 405 410 415Leu Trp Gly
Arg Leu Glu Gly Glu Glu Arg Leu Leu Trp Leu Tyr Arg 420
425 430Glu Val Glu Arg Pro Leu Ser Ala Val Leu
Ala His Met Glu Ala Thr 435 440
445Gly Val Arg Leu Asp Val Ala Tyr Leu Arg Ala Leu Ser Leu Glu Val 450
455 460Ala Glu Glu Ile Ala Arg Leu Glu
Ala Glu Val Phe Arg Leu Ala Gly465 470
475 480His Pro Phe Asn Leu Asn Ser Arg Asp Gln Leu Glu
Met Val Leu Phe 485 490
495Asp Glu Leu Arg Leu Pro Ala Leu Gly Lys Thr Gln Lys Thr Gly Lys
500 505 510Arg Ser Thr Ser Ala Ala
Val Leu Glu Ala Leu Arg Glu Ala His Pro 515 520
525Ile Val Glu Lys Ile Leu Gln Tyr Arg Glu Leu Thr Lys Leu
Lys Ser 530 535 540Thr Tyr Ile Asp Pro
Leu Ser Asp Leu Ile His Pro Arg Thr Gly Arg545 550
555 560Leu His Thr Arg Phe Asn Gln Thr Ala Thr
Ala Thr Gly Arg Leu Ser 565 570
575Ser Ser Asp Pro Asn Leu Gln Asn Ile Pro Val Arg Thr Pro Leu Gly
580 585 590Gln Arg Ile Arg Arg
Ala Phe Ile Ala Glu Glu Gly Trp Leu Leu Val 595
600 605Val Leu Asp Tyr Ser Gln Ile Glu Leu Arg Val Leu
Ala His Leu Ser 610 615 620Gly Asp Glu
Asn Leu Ile Arg Val Phe Gln Glu Gly Arg Asp Ile His625
630 635 640Thr Glu Thr Ala Ser Trp Met
Phe Gly Val Pro Arg Glu Ala Val Asp 645
650 655Pro Leu Met Arg Arg Ala Ala Lys Thr Ile Asn Phe
Gly Val Leu Tyr 660 665 670Gly
Met Ser Ala His Arg Leu Ser Gln Glu Leu Ala Ile Pro Tyr Glu 675
680 685Glu Ala Gln Ala Phe Ile Glu Arg Tyr
Phe Gln Ser Phe Pro Lys Val 690 695
700Arg Ala Trp Ile Glu Lys Thr Leu Glu Glu Gly Arg Arg Arg Gly Tyr705
710 715 720Val Glu Thr Leu
Phe Gly Arg Arg Arg Tyr Val Pro Asp Leu Glu Ala 725
730 735Arg Val Lys Ser Val Arg Glu Ala Ala Glu
Arg Met Ala Phe Asn Met 740 745
750Pro Val Gln Gly Thr Ala Ala Asp Leu Met Lys Leu Ala Met Val Lys
755 760 765Leu Phe Pro Arg Leu Glu Glu
Met Gly Ala Arg Met Leu Leu Gln Val 770 775
780His Asp Glu Leu Val Leu Glu Ala Pro Lys Glu Arg Ala Glu Ala
Val785 790 795 800Ala Arg
Leu Ala Lys Glu Val Met Glu Gly Val Tyr Pro Leu Ala Val
805 810 815Pro Leu Glu Val Glu Val Gly
Ile Gly Glu Asp Trp Leu Ser Ala Lys 820 825
830Glu852502DNAArtificial sequenceMutant Taq polymerase
coding sequence 85atggcgatgc ttcccctctt tgagcccaaa ggccgggtcc tcctggtgga
cggccaccac 60ctggcctacc gcaccttctt cgccctgaag ggcctcacca cgagccgggg
cgaaccggtg 120caggtggtct acggcttcgc caagagcctc ctcaaggccc tgaaggagga
cgggtacaag 180gccgtcttcg tggtctttga cgccaaggcc ccctcattcc gccacaaggc
ctacgaggcc 240tacagggcgg ggagggcccc gaccccccag gacttccccc ggcagctcgc
cctcatcaag 300gagctggtgg acctcctggg gtttacccgc ctcgaggtcc ccggctacga
ggcggacgac 360gttctcgcca ccctggccaa gaaggcggaa aaggaggggt acgaggtgcg
catcctcacc 420gccgaccgcg gcctctacca actcgtctcc gaccgcgtcg ccgtcctcca
ccccgagggc 480cacctcatca ccccggagtg gctttgggag aagtacggcc tcaggccgga
gcagtgggtg 540gacttccgcg ccctcgtggg ggacccctcc gacaacctcc ccggggtcaa
gggcatcggg 600gagaagaccg ccctcaagct cctcaaggag tggggaagcc tggaaaacct
cctcaagaac 660ctggaccggg taaagccaga aaacgtccgg gagaagatca aggcccacct
ggaagacctc 720aggctctcct tggagctctc ccgggtgcgc accgacctcc ccctggaggt
ggacctcgcc 780caggggcggg agcccgaccg ggaggggctt agggcctttc tggagaggct
tgagtttggc 840agcctcctcc acgagttcgg ccttctggaa agccccaagg ccctggagga
ggccccctgg 900cccccgccgg aaggggcctt cgtgggcttt gtgctttccc gcaaggagcc
catgtgggcc 960gatcttctgg ccctggccgc cgccaggggt ggtcgagtcc accaggcccc
cgagccttat 1020aaagccctca gggacctgaa ggaggcgcgg gggcttctcg ccaaagacct
gagcgttctg 1080gccctaaggg aaggccttgg cctcccgccc ggcgacgacc ccatgctcct
cgcctacctc 1140ctggaccctt ccaacaccac ccccgagggg gtggcccggc gctacggcgg
ggagtggacg 1200gaggaggcgg gggagcgggc cgccctttcc gagaggctct tcgccaacct
gtgggggagg 1260cttgaggggg aggagaggct cctttggctt taccgggagg tggagaggcc
cctttccgct 1320gtcctggccc acatggagac cacgggggtg cgcctggacg tggcctatct
cagggccttg 1380tccctggagg tggccgagga gatcgcccgc ctcgaggccg aggtcttccg
cctggccggc 1440cgccccttca acctcaactc ccgagaccag ctggaaaggg tcctctttga
cgagctaggg 1500cttcccgcca tcggcaagac ggagaagacc ggcaagcgct ccaccagcgc
cgccgtcctg 1560gaggccctcc gcgaggccca ccccatcgtg gagaagatcc tgcagtaccg
ggagctcacc 1620aagctgaaga gcacctacat tgaccccttg ccggacctca tccaccccag
gacgggccgc 1680ctccacaccc gcttcaacca gacggccacg gccacgggca ggctaagtag
ctccgatccc 1740aacctccaga acatccccgt ccgcaccccg cttgggcaga ggatccgccg
ggccttcatc 1800gccgaggagg ggtggctatt ggtggtcctg gactatagcc agatggagct
cagggtgctg 1860gcccacctct ccggcgacga gaacctgatc agggtcttcc aggaggggaa
ggacatccac 1920acccagaccg caagctggat gttcggtgtc cccccggagg ccgtggaccc
cctgatgcgc 1980cgggcggcca agacggtgaa cttcggcgtc ctctacggca tgtccgccca
taggctctcc 2040caggagcttt ccatccccta cgaggaggcg gtggccttca tagagcgcta
cttccaaagc 2100ttccccaagg tgcgggcctg gattgagaag accctggagg agggcaggag
gcgggggtac 2160gtggagaccc tcttcggccg ccgccgctac gtgcccgacc tcaacgcccg
gatgaagagc 2220gtcagggggg ccgcggagcg catggccttc aacatgcccg tccagggcac
cgccgccgac 2280ctcatgaagc tcgccatggt gaagctcttc ccccgcctcc gggagatggg
ggcccgcatg 2340ctcctccagg tccacgacga gctcctcctg gaggcccccc aagcgcgggc
cgaggaggtg 2400gcggctttgg ccaaggaggc catggagaag gcctatcccc tcgccgtacc
cctggaggtg 2460gaggtgggga tcggggagga ctggctctcc gccaaggagt ga
250286833PRTArtificial sequenceMutant Taq polymerase 86Met Ala
Met Leu Pro Leu Phe Glu Pro Lys Gly Arg Val Leu Leu Val1 5
10 15Asp Gly His His Leu Ala Tyr Arg
Thr Phe Phe Ala Leu Lys Gly Leu 20 25
30Thr Thr Ser Arg Gly Glu Pro Val Gln Val Val Tyr Gly Phe Ala
Lys 35 40 45Ser Leu Leu Lys Ala
Leu Lys Glu Asp Gly Tyr Lys Ala Val Phe Val 50 55
60Val Phe Asp Ala Lys Ala Pro Ser Phe Arg His Lys Ala Tyr
Glu Ala65 70 75 80Tyr
Arg Ala Gly Arg Ala Pro Thr Pro Gln Asp Phe Pro Arg Gln Leu
85 90 95Ala Leu Ile Lys Glu Leu Val
Asp Leu Leu Gly Phe Thr Arg Leu Glu 100 105
110Val Pro Gly Tyr Glu Ala Asp Asp Val Leu Ala Thr Leu Ala
Lys Lys 115 120 125Ala Glu Lys Glu
Gly Tyr Glu Val Arg Ile Leu Thr Ala Asp Arg Gly 130
135 140Leu Tyr Gln Leu Val Ser Asp Arg Val Ala Val Leu
His Pro Glu Gly145 150 155
160His Leu Ile Thr Pro Glu Trp Leu Trp Glu Lys Tyr Gly Leu Arg Pro
165 170 175Glu Gln Trp Val Asp
Phe Arg Ala Leu Val Gly Asp Pro Ser Asp Asn 180
185 190Leu Pro Gly Val Lys Gly Ile Gly Glu Lys Thr Ala
Leu Lys Leu Leu 195 200 205Lys Glu
Trp Gly Ser Leu Glu Asn Leu Leu Lys Asn Leu Asp Arg Val 210
215 220Lys Pro Glu Asn Val Arg Glu Lys Ile Lys Ala
His Leu Glu Asp Leu225 230 235
240Arg Leu Ser Leu Glu Leu Ser Arg Val Arg Thr Asp Leu Pro Leu Glu
245 250 255Val Asp Leu Ala
Gln Gly Arg Glu Pro Asp Arg Glu Gly Leu Arg Ala 260
265 270Phe Leu Glu Arg Leu Glu Phe Gly Ser Leu Leu
His Glu Phe Gly Leu 275 280 285Leu
Glu Ser Pro Lys Ala Leu Glu Glu Ala Pro Trp Pro Pro Pro Glu 290
295 300Gly Ala Phe Val Gly Phe Val Leu Ser Arg
Lys Glu Pro Met Trp Ala305 310 315
320Asp Leu Leu Ala Leu Ala Ala Ala Arg Gly Gly Arg Val His Gln
Ala 325 330 335Pro Glu Pro
Tyr Lys Ala Leu Arg Asp Leu Lys Glu Ala Arg Gly Leu 340
345 350Leu Ala Lys Asp Leu Ser Val Leu Ala Leu
Arg Glu Gly Leu Gly Leu 355 360
365Pro Pro Gly Asp Asp Pro Met Leu Leu Ala Tyr Leu Leu Asp Pro Ser 370
375 380Asn Thr Thr Pro Glu Gly Val Ala
Arg Arg Tyr Gly Gly Glu Trp Thr385 390
395 400Glu Glu Ala Gly Glu Arg Ala Ala Leu Ser Glu Arg
Leu Phe Ala Asn 405 410
415Leu Trp Gly Arg Leu Glu Gly Glu Glu Arg Leu Leu Trp Leu Tyr Arg
420 425 430Glu Val Glu Arg Pro Leu
Ser Ala Val Leu Ala His Met Glu Thr Thr 435 440
445Gly Val Arg Leu Asp Val Ala Tyr Leu Arg Ala Leu Ser Leu
Glu Val 450 455 460Ala Glu Glu Ile Ala
Arg Leu Glu Ala Glu Val Phe Arg Leu Ala Gly465 470
475 480Arg Pro Phe Asn Leu Asn Ser Arg Asp Gln
Leu Glu Arg Val Leu Phe 485 490
495Asp Glu Leu Gly Leu Pro Ala Ile Gly Lys Thr Glu Lys Thr Gly Lys
500 505 510Arg Ser Thr Ser Ala
Ala Val Leu Glu Ala Leu Arg Glu Ala His Pro 515
520 525Ile Val Glu Lys Ile Leu Gln Tyr Arg Glu Leu Thr
Lys Leu Lys Ser 530 535 540Thr Tyr Ile
Asp Pro Leu Pro Asp Leu Ile His Pro Arg Thr Gly Arg545
550 555 560Leu His Thr Arg Phe Asn Gln
Thr Ala Thr Ala Thr Gly Arg Leu Ser 565
570 575Ser Ser Asp Pro Asn Leu Gln Asn Ile Pro Val Arg
Thr Pro Leu Gly 580 585 590Gln
Arg Ile Arg Arg Ala Phe Ile Ala Glu Glu Gly Trp Leu Leu Val 595
600 605Val Leu Asp Tyr Ser Gln Met Glu Leu
Arg Val Leu Ala His Leu Ser 610 615
620Gly Asp Glu Asn Leu Ile Arg Val Phe Gln Glu Gly Lys Asp Ile His625
630 635 640Thr Gln Thr Ala
Ser Trp Met Phe Gly Val Pro Pro Glu Ala Val Asp 645
650 655Pro Leu Met Arg Arg Ala Ala Lys Thr Val
Asn Phe Gly Val Leu Tyr 660 665
670Gly Met Ser Ala His Arg Leu Ser Gln Glu Leu Ser Ile Pro Tyr Glu
675 680 685Glu Ala Val Ala Phe Ile Glu
Arg Tyr Phe Gln Ser Phe Pro Lys Val 690 695
700Arg Ala Trp Ile Glu Lys Thr Leu Glu Glu Gly Arg Arg Arg Gly
Tyr705 710 715 720Val Glu
Thr Leu Phe Gly Arg Arg Arg Tyr Val Pro Asp Leu Asn Ala
725 730 735Arg Met Lys Ser Val Arg Gly
Ala Ala Glu Arg Met Ala Phe Asn Met 740 745
750Pro Val Gln Gly Thr Ala Ala Asp Leu Met Lys Leu Ala Met
Val Lys 755 760 765Leu Phe Pro Arg
Leu Arg Glu Met Gly Ala Arg Met Leu Leu Gln Val 770
775 780His Asp Glu Leu Leu Leu Glu Ala Pro Gln Ala Arg
Ala Glu Glu Val785 790 795
800Ala Ala Leu Ala Lys Glu Ala Met Glu Lys Ala Tyr Pro Leu Ala Val
805 810 815Pro Leu Glu Val Glu
Val Gly Ile Gly Glu Asp Trp Leu Ser Ala Lys 820
825 830Glu872502DNAArtificial sequenceMutant Taq
polymerase coding sequence 87atggcgatgc ttcccctctt tgagcccaag ggccgtgtcc
tcctggtgga cggccaccac 60ctggcctacc gcacctcctt cgccctgaag ggccccacca
cgagccgggg cgaaccggtg 120caggtggtct acggcttcgc caagagcctc ctcaaggccc
tgaaggagga cgggtacaag 180gccgtcttcg tggtctttga cgccaaggcc cccccattcc
gccacaaggc ctacgaggcc 240tacagggcgg ggagggcccc gacccccgag gacttccccc
ggcagctcgc cctcgtcaag 300gagctggtgg acctcctggg gtttacccgc ctcgaggtcc
ccggctacga ggcggacgac 360gttctcgcca ccctggccaa gaaggcggaa aaggaggggt
acgaggtgcg catcctcacc 420gccgaccgcg gcctctacca actcgtctct gaccgcgtcg
ccgtcctcca ccccgagggc 480cacctcatca ccccggagtg gctttgggag aagtacggcc
tcaggccgga gcagtgggtg 540gacttccgcg ccctcgtggg ggacccctcc gacaacctcc
ccggggtcaa gggcatcggg 600gagaagaccg ccctcaagct cctcaaggag tggggaagcc
tggaaaacct cctcaagaac 660ctggaccggg taaagccaga aaacgtccgg gagaagatca
aggcccacct ggaagacctc 720aggctctcct tggagctctc ccgggtgcgc accgacctcc
ccctggaggt ggacctcgcc 780caggggcggg agcccgaccg ggaaaggctt agggcctttc
tggagaggct tgagtttggc 840agcctcctcc atgagttcgg ccttctggaa agccccaagg
ccctggagga ggccccctgg 900cccccgccgg aaggggcctt cgtgggcttt gtgctttccc
gcaaggcgcc catgtgggcc 960gatcttctgg ccctggccgc cgccaggggt ggtcgggtct
accgggcccc cgagccttat 1020aaagccctca gggacttgaa ggaggcgcgg gggcttctcg
ccaaagacct gagcgttctg 1080gccctaaggg aaggccttgg cctcccgccc ggcgacgacc
ccatgctcct cgcctacctc 1140ctggaccctt ccaacaccac ccccgagggg gtggcccggc
gctacggcgg ggagtggacg 1200gaggaggcgg gggagcgggc cgccctttcc gagaggctct
tcgccaacct gtgggggagg 1260cttgaggggg aggagaggct cctttggctt taccgggagg
tggataggcc cctttccgct 1320gtcctggccc acatggaggc cacaggggta cggctggacg
tggcctgcct gcaggccctt 1380tccctggagc ttgcggagga gatccgccgc ctcgaggagg
aggtcttccg cttggcgggc 1440cacaccttca acctcaactc ccgggaccag ctggaaaggg
tcctctttga cgagctaggg 1500cttcccgcca tcggcaagac ggagaagacc ggcaagcgct
ccaccagcgc cgccatcctg 1560gaggccctcc gcgaggccca ccccatcgtg gagaagatcc
tgcagtaccg ggagctcacc 1620aagctgaaga gcacctacat tgaccccttg ccggacctca
tccaccccag gacgggccgc 1680ctccacaccc gcttcaacca gacggccacg gccacgggca
ggctaagtag ctccgatccc 1740aacctccaga acatccccgt ccgcaccccg cttgggcaga
ggatccgccg ggccttcatc 1800gccgaggagg ggtggctact ggtggtcctg gactatagcc
agatagagct cagggtgctg 1860gctcacctct ccggcgacga aaacctgatc agggtcttcc
aggaggggcg ggacatccac 1920acggagaccg ccagctggat gttcggcgtc ccccgggagg
ccgtggaccc cctgatgcgc 1980cgggcggcca agaccatcaa cttcggggtc ctctacggca
tgtcggccca ccgcctctcc 2040caggagctag ccatccctta cgaggaggcc caggccttca
ttgagcgcta ctttcagagc 2100ttccccaagg tgcgggcctg gattgagaag gccctggagg
agggcaggag gcgggggtac 2160gtggagaccc tcttcggaag aaggcgctac gtgcccgacc
tcaacgcccg ggtgaagagt 2220gtcagggagg ccgcggagcg catggccttc aacatgcccg
tccagggcac cgccgccgac 2280cttatgaagc tcgccatggt gaagctcttc ccccgcctcc
gggagatggg ggcccgcatg 2340ctcctccagg tccacgacga gctcctcctg gaggcccccc
aagcgcgggc cgaggaggtg 2400gcggctttgg ccaaggaggc catggagaag gcctatcccc
tcgccgtacc cctggaggtg 2460aaggtgggga tcggggagga ctggctctcc gccaaggagt
ga 250288833PRTArtificial sequenceMutant Taq
polymerase 88Met Ala Met Leu Pro Leu Phe Glu Pro Lys Gly Arg Val Leu Leu
Val1 5 10 15Asp Gly His
His Leu Ala Tyr Arg Thr Ser Phe Ala Leu Lys Gly Pro 20
25 30Thr Thr Ser Arg Gly Glu Pro Val Gln Val
Val Tyr Gly Phe Ala Lys 35 40
45Ser Leu Leu Lys Ala Leu Lys Glu Asp Gly Tyr Lys Ala Val Phe Val 50
55 60Val Phe Asp Ala Lys Ala Pro Pro Phe
Arg His Lys Ala Tyr Glu Ala65 70 75
80Tyr Arg Ala Gly Arg Ala Pro Thr Pro Glu Asp Phe Pro Arg
Gln Leu 85 90 95Ala Leu
Val Lys Glu Leu Val Asp Leu Leu Gly Phe Thr Arg Leu Glu 100
105 110Val Pro Gly Tyr Glu Ala Asp Asp Val
Leu Ala Thr Leu Ala Lys Lys 115 120
125Ala Glu Lys Glu Gly Tyr Glu Val Arg Ile Leu Thr Ala Asp Arg Gly
130 135 140Leu Tyr Gln Leu Val Ser Asp
Arg Val Ala Val Leu His Pro Glu Gly145 150
155 160His Leu Ile Thr Pro Glu Trp Leu Trp Glu Lys Tyr
Gly Leu Arg Pro 165 170
175Glu Gln Trp Val Asp Phe Arg Ala Leu Val Gly Asp Pro Ser Asp Asn
180 185 190Leu Pro Gly Val Lys Gly
Ile Gly Glu Lys Thr Ala Leu Lys Leu Leu 195 200
205Lys Glu Trp Gly Ser Leu Glu Asn Leu Leu Lys Asn Leu Asp
Arg Val 210 215 220Lys Pro Glu Asn Val
Arg Glu Lys Ile Lys Ala His Leu Glu Asp Leu225 230
235 240Arg Leu Ser Leu Glu Leu Ser Arg Val Arg
Thr Asp Leu Pro Leu Glu 245 250
255Val Asp Leu Ala Gln Gly Arg Glu Pro Asp Arg Glu Arg Leu Arg Ala
260 265 270Phe Leu Glu Arg Leu
Glu Phe Gly Ser Leu Leu His Glu Phe Gly Leu 275
280 285Leu Glu Ser Pro Lys Ala Leu Glu Glu Ala Pro Trp
Pro Pro Pro Glu 290 295 300Gly Ala Phe
Val Gly Phe Val Leu Ser Arg Lys Ala Pro Met Trp Ala305
310 315 320Asp Leu Leu Ala Leu Ala Ala
Ala Arg Gly Gly Arg Val Tyr Arg Ala 325
330 335Pro Glu Pro Tyr Lys Ala Leu Arg Asp Leu Lys Glu
Ala Arg Gly Leu 340 345 350Leu
Ala Lys Asp Leu Ser Val Leu Ala Leu Arg Glu Gly Leu Gly Leu 355
360 365Pro Pro Gly Asp Asp Pro Met Leu Leu
Ala Tyr Leu Leu Asp Pro Ser 370 375
380Asn Thr Thr Pro Glu Gly Val Ala Arg Arg Tyr Gly Gly Glu Trp Thr385
390 395 400Glu Glu Ala Gly
Glu Arg Ala Ala Leu Ser Glu Arg Leu Phe Ala Asn 405
410 415Leu Trp Gly Arg Leu Glu Gly Glu Glu Arg
Leu Leu Trp Leu Tyr Arg 420 425
430Glu Val Asp Arg Pro Leu Ser Ala Val Leu Ala His Met Glu Ala Thr
435 440 445Gly Val Arg Leu Asp Val Ala
Cys Leu Gln Ala Leu Ser Leu Glu Leu 450 455
460Ala Glu Glu Ile Arg Arg Leu Glu Glu Glu Val Phe Arg Leu Ala
Gly465 470 475 480His Thr
Phe Asn Leu Asn Ser Arg Asp Gln Leu Glu Arg Val Leu Phe
485 490 495Asp Glu Leu Gly Leu Pro Ala
Ile Gly Lys Thr Glu Lys Thr Gly Lys 500 505
510Arg Ser Thr Ser Ala Ala Ile Leu Glu Ala Leu Arg Glu Ala
His Pro 515 520 525Ile Val Glu Lys
Ile Leu Gln Tyr Arg Glu Leu Thr Lys Leu Lys Ser 530
535 540Thr Tyr Ile Asp Pro Leu Pro Asp Leu Ile His Pro
Arg Thr Gly Arg545 550 555
560Leu His Thr Arg Phe Asn Gln Thr Ala Thr Ala Thr Gly Arg Leu Ser
565 570 575Ser Ser Asp Pro Asn
Leu Gln Asn Ile Pro Val Arg Thr Pro Leu Gly 580
585 590Gln Arg Ile Arg Arg Ala Phe Ile Ala Glu Glu Gly
Trp Leu Leu Val 595 600 605Val Leu
Asp Tyr Ser Gln Ile Glu Leu Arg Val Leu Ala His Leu Ser 610
615 620Gly Asp Glu Asn Leu Ile Arg Val Phe Gln Glu
Gly Arg Asp Ile His625 630 635
640Thr Glu Thr Ala Ser Trp Met Phe Gly Val Pro Arg Glu Ala Val Asp
645 650 655Pro Leu Met Arg
Arg Ala Ala Lys Thr Ile Asn Phe Gly Val Leu Tyr 660
665 670Gly Met Ser Ala His Arg Leu Ser Gln Glu Leu
Ala Ile Pro Tyr Glu 675 680 685Glu
Ala Gln Ala Phe Ile Glu Arg Tyr Phe Gln Ser Phe Pro Lys Val 690
695 700Arg Ala Trp Ile Glu Lys Ala Leu Glu Glu
Gly Arg Arg Arg Gly Tyr705 710 715
720Val Glu Thr Leu Phe Gly Arg Arg Arg Tyr Val Pro Asp Leu Asn
Ala 725 730 735Arg Val Lys
Ser Val Arg Glu Ala Ala Glu Arg Met Ala Phe Asn Met 740
745 750Pro Val Gln Gly Thr Ala Ala Asp Leu Met
Lys Leu Ala Met Val Lys 755 760
765Leu Phe Pro Arg Leu Arg Glu Met Gly Ala Arg Met Leu Leu Gln Val 770
775 780His Asp Glu Leu Leu Leu Glu Ala
Pro Gln Ala Arg Ala Glu Glu Val785 790
795 800Ala Ala Leu Ala Lys Glu Ala Met Glu Lys Ala Tyr
Pro Leu Ala Val 805 810
815Pro Leu Glu Val Lys Val Gly Ile Gly Glu Asp Trp Leu Ser Ala Lys
820 825 830Glu892502DNAArtificial
sequenceMutant Taq polymerase coding sequence 89atggcgatgc ttcccctctt
tgagcccaag ggccgcgtcc tcctggtgga cggccaccac 60ctggcctacc gcgccttctt
cgccctgaag ggcctcacca cgagccgggg cgaaccggtg 120caggcggtct acggcttcgc
caagagcctc ctcaaggccc tgaaggagga cgggtacaag 180gccgtcttcg tggtctttga
cgccaaggcc ccctccttcc gccacgaggc ctacgaggcc 240tacaaggcgg ggagggcccc
gacccccgag gacttccccc ggcagctcgc cctcatcaag 300gagctggtgg acctcctggg
gtttacccgc ctcgaggtcc aaggctacga ggcggacgac 360gtcctcgcca ccctggccaa
gaaggcggaa aaagaagggt acgaggtgcg catcctcacc 420gccgaccggg acctctacca
gctcgtctcc gaccgcgtcg ccgtcctcca ccccgagggc 480cacctcatca ccccggagtg
gctttgggag aagtacggcc tcaggccgga gcagtgggtg 540gacttccgcg ccctcgtggg
ggacccctcc aacaacctcc ccggggtcaa gggcatcggg 600gagaagaccg ccctcaagct
cctcaaggag tggggaagcc tggaaaacct cctcaagaac 660ctggaccggg taaagccaga
aaacgtccgg gagaagatca aggcccacct ggaagacctc 720aggctctcct tggagctctc
ccgggtgcgc accgacctcc ccctggaggt ggacctcgcc 780caggggcggg agctcgaccg
ggagaggctt agggcctttc tggagaggct tgagtttggc 840ggcctcctcc acgagttcgg
ccttctggaa agccccaagg ccctggagga ggccccctgg 900cccccgccgg aaggggcctt
cgtgggcttt gtgctttccc gcaaggagcc catgtgggcc 960gatcttctgg ccctggccgc
cgccaggggt ggtcgggtcc accgggcccc cgagccttat 1020aaagccctca gggacttgaa
ggaggcgcgg gggcttctcg ccaaagacct gagcgttctg 1080gccctaaggg aaggccttgg
cctcccgccc ggcgacgacc ccatgctcct cgcctacctc 1140ctggaccctt ccaacaccgc
ccccgagggg gtggcccggc gctacggcgg ggagtggacg 1200gaggaggcgg gggagcgggc
cgccctttcc gagaggctct tcgccaacct gtgggggagg 1260cttgaggggg aggagaggct
cctttggctt taccgggagg tggataggcc cctttccgct 1320gtcctggccc acatggaggc
cacaggggta cggctggacg tggcctatct cagggccttg 1380tccctggagg tggccgagga
gatcgcgcgc ctcgaggccg aggtcttccg cctggccggc 1440caccccttca acctcaactc
ccgagaccag ctggaaaggg tcctctttga cgagctaggg 1500cttcccgcca tcggcaagac
ggagaagacc ggcaagcgct ccaccagcgc cgccgtcctg 1560gaggccctcc gcgaggccca
ccccatcgtg gagaagatcc tgcagtaccg ggagctcacc 1620aagctgaaga gcacctacat
tgaccccttg ccgaacctca tccatcccag gacgggccgc 1680ctccacaccc gcttcaacca
gacggccacg gccacgggca ggctaagtag ctccgatccc 1740aacctccaga acatccccgt
ccgcaccccg ctcgggcaga ggatccgccg ggccttcatc 1800gccgaggagg ggtggctatt
ggtggtcctg gactatagcc agatagagct cagggtgctg 1860gcccacctct ccggcgacga
gaacctgatc cgggtcttcc aggaggggcg ggacatccac 1920acggaaaccg ccagctggat
gttcggcgtc ccccgggagg ccgtggaccc cctgatgcgc 1980cgggcggcca agaccatcaa
cttcggggtt ctctacggca tgtcggccca ccgcctctcc 2040caggagctag ccatccctta
cgaggaggcc caggccttca ttgagcgcta ctttcagagc 2100ttccccaagg tgcgggcctg
gatagaaaag accctggagg aggggaggaa gcggggctac 2160gtggaaaccc tcttcggaag
aaggcgctac gtgcccgacc tcaacgcccg ggtgaagggc 2220gtcagggagg ccgcggagcg
catggccttc aacatgcccg tccagggcac cgccgccgac 2280ctcatgaagc tcgccatggt
gaagctcttc ccccgcctcc gggagatggg ggcccgcatg 2340ctcctccagg tccacgacga
gctcctcctg gaggcccccc aagcgcgggc cggggaggtg 2400gcggctttgg ccaaggaggc
catggagaag gcctatcccc tcgccgtacc cctggaggtg 2460aaggtgggga tcggggagga
ctggctctcc gccaaggagt ga 250290833PRTArtificial
sequenceMutant Taq polymerase 90Met Ala Met Leu Pro Leu Phe Glu Pro Lys
Gly Arg Val Leu Leu Val1 5 10
15Asp Gly His His Leu Ala Tyr Arg Ala Phe Phe Ala Leu Lys Gly Leu
20 25 30Thr Thr Ser Arg Gly Glu
Pro Val Gln Ala Val Tyr Gly Phe Ala Lys 35 40
45Ser Leu Leu Lys Ala Leu Lys Glu Asp Gly Tyr Lys Ala Val
Phe Val 50 55 60Val Phe Asp Ala Lys
Ala Pro Ser Phe Arg His Glu Ala Tyr Glu Ala65 70
75 80Tyr Lys Ala Gly Arg Ala Pro Thr Pro Glu
Asp Phe Pro Arg Gln Leu 85 90
95Ala Leu Ile Lys Glu Leu Val Asp Leu Leu Gly Phe Thr Arg Leu Glu
100 105 110Val Gln Gly Tyr Glu
Ala Asp Asp Val Leu Ala Thr Leu Ala Lys Lys 115
120 125Ala Glu Lys Glu Gly Tyr Glu Val Arg Ile Leu Thr
Ala Asp Arg Asp 130 135 140Leu Tyr Gln
Leu Val Ser Asp Arg Val Ala Val Leu His Pro Glu Gly145
150 155 160His Leu Ile Thr Pro Glu Trp
Leu Trp Glu Lys Tyr Gly Leu Arg Pro 165
170 175Glu Gln Trp Val Asp Phe Arg Ala Leu Val Gly Asp
Pro Ser Asn Asn 180 185 190Leu
Pro Gly Val Lys Gly Ile Gly Glu Lys Thr Ala Leu Lys Leu Leu 195
200 205Lys Glu Trp Gly Ser Leu Glu Asn Leu
Leu Lys Asn Leu Asp Arg Val 210 215
220Lys Pro Glu Asn Val Arg Glu Lys Ile Lys Ala His Leu Glu Asp Leu225
230 235 240Arg Leu Ser Leu
Glu Leu Ser Arg Val Arg Thr Asp Leu Pro Leu Glu 245
250 255Val Asp Leu Ala Gln Gly Arg Glu Leu Asp
Arg Glu Arg Leu Arg Ala 260 265
270Phe Leu Glu Arg Leu Glu Phe Gly Gly Leu Leu His Glu Phe Gly Leu
275 280 285Leu Glu Ser Pro Lys Ala Leu
Glu Glu Ala Pro Trp Pro Pro Pro Glu 290 295
300Gly Ala Phe Val Gly Phe Val Leu Ser Arg Lys Glu Pro Met Trp
Ala305 310 315 320Asp Leu
Leu Ala Leu Ala Ala Ala Arg Gly Gly Arg Val His Arg Ala
325 330 335Pro Glu Pro Tyr Lys Ala Leu
Arg Asp Leu Lys Glu Ala Arg Gly Leu 340 345
350Leu Ala Lys Asp Leu Ser Val Leu Ala Leu Arg Glu Gly Leu
Gly Leu 355 360 365Pro Pro Gly Asp
Asp Pro Met Leu Leu Ala Tyr Leu Leu Asp Pro Ser 370
375 380Asn Thr Ala Pro Glu Gly Val Ala Arg Arg Tyr Gly
Gly Glu Trp Thr385 390 395
400Glu Glu Ala Gly Glu Arg Ala Ala Leu Ser Glu Arg Leu Phe Ala Asn
405 410 415Leu Trp Gly Arg Leu
Glu Gly Glu Glu Arg Leu Leu Trp Leu Tyr Arg 420
425 430Glu Val Asp Arg Pro Leu Ser Ala Val Leu Ala His
Met Glu Ala Thr 435 440 445Gly Val
Arg Leu Asp Val Ala Tyr Leu Arg Ala Leu Ser Leu Glu Val 450
455 460Ala Glu Glu Ile Ala Arg Leu Glu Ala Glu Val
Phe Arg Leu Ala Gly465 470 475
480His Pro Phe Asn Leu Asn Ser Arg Asp Gln Leu Glu Arg Val Leu Phe
485 490 495Asp Glu Leu Gly
Leu Pro Ala Ile Gly Lys Thr Glu Lys Thr Gly Lys 500
505 510Arg Ser Thr Ser Ala Ala Val Leu Glu Ala Leu
Arg Glu Ala His Pro 515 520 525Ile
Val Glu Lys Ile Leu Gln Tyr Arg Glu Leu Thr Lys Leu Lys Ser 530
535 540Thr Tyr Ile Asp Pro Leu Pro Asn Leu Ile
His Pro Arg Thr Gly Arg545 550 555
560Leu His Thr Arg Phe Asn Gln Thr Ala Thr Ala Thr Gly Arg Leu
Ser 565 570 575Ser Ser Asp
Pro Asn Leu Gln Asn Ile Pro Val Arg Thr Pro Leu Gly 580
585 590Gln Arg Ile Arg Arg Ala Phe Ile Ala Glu
Glu Gly Trp Leu Leu Val 595 600
605Val Leu Asp Tyr Ser Gln Ile Glu Leu Arg Val Leu Ala His Leu Ser 610
615 620Gly Asp Glu Asn Leu Ile Arg Val
Phe Gln Glu Gly Arg Asp Ile His625 630
635 640Thr Glu Thr Ala Ser Trp Met Phe Gly Val Pro Arg
Glu Ala Val Asp 645 650
655Pro Leu Met Arg Arg Ala Ala Lys Thr Ile Asn Phe Gly Val Leu Tyr
660 665 670Gly Met Ser Ala His Arg
Leu Ser Gln Glu Leu Ala Ile Pro Tyr Glu 675 680
685Glu Ala Gln Ala Phe Ile Glu Arg Tyr Phe Gln Ser Phe Pro
Lys Val 690 695 700Arg Ala Trp Ile Glu
Lys Thr Leu Glu Glu Gly Arg Lys Arg Gly Tyr705 710
715 720Val Glu Thr Leu Phe Gly Arg Arg Arg Tyr
Val Pro Asp Leu Asn Ala 725 730
735Arg Val Lys Gly Val Arg Glu Ala Ala Glu Arg Met Ala Phe Asn Met
740 745 750Pro Val Gln Gly Thr
Ala Ala Asp Leu Met Lys Leu Ala Met Val Lys 755
760 765Leu Phe Pro Arg Leu Arg Glu Met Gly Ala Arg Met
Leu Leu Gln Val 770 775 780His Asp Glu
Leu Leu Leu Glu Ala Pro Gln Ala Arg Ala Gly Glu Val785
790 795 800Ala Ala Leu Ala Lys Glu Ala
Met Glu Lys Ala Tyr Pro Leu Ala Val 805
810 815Pro Leu Glu Val Lys Val Gly Ile Gly Glu Asp Trp
Leu Ser Ala Lys 820 825
830Glu912499DNAArtificial sequenceMutant Taq polymerase coding sequence
91atggcgatgc ttcccctctt tgagcccaaa ggccgggtcc tcctggtgga cggccaccac
60ctggcctacc gcaccttctt cgccctgaag ggcctcacca cgagccgggg cgaaccggtg
120caggtggtct acggcttcgc caagagcctc ctcaaggccc tgaaggagga cgggtacaag
180gccgtcttcg tggtctttga cgccaaggcc ccctccctcc gccacgaggc ctacgaggcc
240tacaaggcgg ggagggcccc gacccccgag gacttcctcc ggcagctcgc cctcatcaag
300gagctggtgg acctcctggg gtttacccgc ctcgaggtcc aaggctacga ggcggacgac
360gtcctcgcca ccctggccaa gaaggcggaa aaagaagggt acgaggtgcg catcctcacc
420gccgaccggg acctctacca gctcgtctcc gaccgcgtcg ccgtcctcca ccccgagggc
480cacctcatca ccccggagtg gctttgggag aagtacggcc tcaggccgga gcagtgggtg
540gacttccgcg ccctcgtggg ggacccctcc gacaacctcc ccggggtcaa gggcatcggg
600gagaagaccg ccctcaagct cctcaaggag tggggaagcc tggaaaacct cctcaagaac
660ctggaccggc tgaagcccgc catccgggag aagatcctgg cccacatgga cgatctgaag
720ctctcctggg acctggccaa ggtgcgcacc gacctgcccc tagaggtgga cttcgccaaa
780aggcgggagc ccgaccggga gaggcttagg gcctttctgg agaggcttga gcttggcagc
840ctcctccacg agttcggcct tctggaaagc cccaagaccc tggaggaggc ctcctggccc
900ccgccggaag gggccttcgt gggctttgtg ctttcccgca aggagcccat gtgggccgat
960cttctggccc tggccgccgc cagggggggc cgggtccacc gggcccccga gccttataaa
1020gccctcaggg acctgaagga ggcgcggggg cttctcgcca aagacctgag cgttctggcc
1080ctaagggaag gccttggcct cccgcccggc gacgacccca tgctcctcgc ctacctcctg
1140gacccttcca acaccacccc cgagggggtg gcccggcgct acggcgggga gtggacgaag
1200gaggcggggg agcgggccgc cctttccgag aggctcttcg ccaacctgtg ggggaggctt
1260gagggggagg agaggctcct ttggctttac cgggaggtgg ataggcccct ttccgctgtc
1320ctggcccaca tggaggccac aggggtgcgc ttggacgtgg cctatctcag ggccttgtcc
1380ctggaggtgg ccgaggagat cgcccgcctc gaggccgagg tcttccgcct ggccggccat
1440cccttcaacc tcaactcccg ggaccagctg gaaagggtcc tctttgacga gctagggctt
1500cccgccatcg gcaagacgga gaagaccggc aagcgctcca ccagcgccgc cgtcctggag
1560gccctccgcg aggcccaccc catcgtggag aagatcctgc agtaccggga gctcaccaag
1620ctgaagagca cctacattga ccccttgccg gacctcatcc accccaggac gggccgcctc
1680cacacccgct tcaaccagac ggccacggcc acgggcaggc taagtagctc cgatcccaac
1740ctccagaaca tccccgtccg caccccgctc gggcagagga tccgccgggc cttcgtcgcc
1800gaggaggggt ggctattggt ggtcctggac tatagccaga tagagctcag ggtgctggcc
1860cacctctccg gcgacgagaa cctgacccgg gtcttcctgg aggggcggga catccacacg
1920gaaaccgcca gctggatgtt cggcgtcccc cgggaggccg tggaccccct gatgcgccgg
1980gcggccaaga ccatcaactt cggggttctc tacggcatgt cggcccaccg cctctcccag
2040gagctggcca tcccttacga ggaggcccag gccttcatag agcgctactt ccaaagcttc
2100cccaaggtgc gggcctggat agaaaagacc ctggaggagg ggaggaagcg gggctacgtg
2160gaaaccctct tcggaagaag gcgctacgtg cccgacctca acgcccgggt gaagagtgtc
2220agggaggccg cggagcgcat ggccttcaac atgcccgtcc agggcaccgc cgccgacctt
2280atgaagctcg ccatggtgaa gctcttcccc cgcctccggg agatgggggc ccgcatgctc
2340ctccaggtcc acgacgagct cctcctggag gccccccaag cgcgggccga ggaggtggcg
2400gctttggcca aggaggccat ggagaaggcc tatcccctcg ccgtacccct ggaggtgaag
2460gaggggatcg gggaggactg gctctccgcc aaggagtga
249992832PRTArtificial sequenceMutant Taq polymerase 92Met Ala Met Leu
Pro Leu Phe Glu Pro Lys Gly Arg Val Leu Leu Val1 5
10 15Asp Gly His His Leu Ala Tyr Arg Thr Phe
Phe Ala Leu Lys Gly Leu 20 25
30Thr Thr Ser Arg Gly Glu Pro Val Gln Val Val Tyr Gly Phe Ala Lys
35 40 45Ser Leu Leu Lys Ala Leu Lys Glu
Asp Gly Tyr Lys Ala Val Phe Val 50 55
60Val Phe Asp Ala Lys Ala Pro Ser Leu Arg His Glu Ala Tyr Glu Ala65
70 75 80Tyr Lys Ala Gly Arg
Ala Pro Thr Pro Glu Asp Phe Leu Arg Gln Leu 85
90 95Ala Leu Ile Lys Glu Leu Val Asp Leu Leu Gly
Phe Thr Arg Leu Glu 100 105
110Val Gln Gly Tyr Glu Ala Asp Asp Val Leu Ala Thr Leu Ala Lys Lys
115 120 125Ala Glu Lys Glu Gly Tyr Glu
Val Arg Ile Leu Thr Ala Asp Arg Asp 130 135
140Leu Tyr Gln Leu Val Ser Asp Arg Val Ala Val Leu His Pro Glu
Gly145 150 155 160His Leu
Ile Thr Pro Glu Trp Leu Trp Glu Lys Tyr Gly Leu Arg Pro
165 170 175Glu Gln Trp Val Asp Phe Arg
Ala Leu Val Gly Asp Pro Ser Asp Asn 180 185
190Leu Pro Gly Val Lys Gly Ile Gly Glu Lys Thr Ala Leu Lys
Leu Leu 195 200 205Lys Glu Trp Gly
Ser Leu Glu Asn Leu Leu Lys Asn Leu Asp Arg Leu 210
215 220Lys Pro Ala Ile Arg Glu Lys Ile Leu Ala His Met
Asp Asp Leu Lys225 230 235
240Leu Ser Trp Asp Leu Ala Lys Val Arg Thr Asp Leu Pro Leu Glu Val
245 250 255Asp Phe Ala Lys Arg
Arg Glu Pro Asp Arg Glu Arg Leu Arg Ala Phe 260
265 270Leu Glu Arg Leu Glu Leu Gly Ser Leu Leu His Glu
Phe Gly Leu Leu 275 280 285Glu Ser
Pro Lys Thr Leu Glu Glu Ala Ser Trp Pro Pro Pro Glu Gly 290
295 300Ala Phe Val Gly Phe Val Leu Ser Arg Lys Glu
Pro Met Trp Ala Asp305 310 315
320Leu Leu Ala Leu Ala Ala Ala Arg Gly Gly Arg Val His Arg Ala Pro
325 330 335Glu Pro Tyr Lys
Ala Leu Arg Asp Leu Lys Glu Ala Arg Gly Leu Leu 340
345 350Ala Lys Asp Leu Ser Val Leu Ala Leu Arg Glu
Gly Leu Gly Leu Pro 355 360 365Pro
Gly Asp Asp Pro Met Leu Leu Ala Tyr Leu Leu Asp Pro Ser Asn 370
375 380Thr Thr Pro Glu Gly Val Ala Arg Arg Tyr
Gly Gly Glu Trp Thr Lys385 390 395
400Glu Ala Gly Glu Arg Ala Ala Leu Ser Glu Arg Leu Phe Ala Asn
Leu 405 410 415Trp Gly Arg
Leu Glu Gly Glu Glu Arg Leu Leu Trp Leu Tyr Arg Glu 420
425 430Val Asp Arg Pro Leu Ser Ala Val Leu Ala
His Met Glu Ala Thr Gly 435 440
445Val Arg Leu Asp Val Ala Tyr Leu Arg Ala Leu Ser Leu Glu Val Ala 450
455 460Glu Glu Ile Ala Arg Leu Glu Ala
Glu Val Phe Arg Leu Ala Gly His465 470
475 480Pro Phe Asn Leu Asn Ser Arg Asp Gln Leu Glu Arg
Val Leu Phe Asp 485 490
495Glu Leu Gly Leu Pro Ala Ile Gly Lys Thr Glu Lys Thr Gly Lys Arg
500 505 510Ser Thr Ser Ala Ala Val
Leu Glu Ala Leu Arg Glu Ala His Pro Ile 515 520
525Val Glu Lys Ile Leu Gln Tyr Arg Glu Leu Thr Lys Leu Lys
Ser Thr 530 535 540Tyr Ile Asp Pro Leu
Pro Asp Leu Ile His Pro Arg Thr Gly Arg Leu545 550
555 560His Thr Arg Phe Asn Gln Thr Ala Thr Ala
Thr Gly Arg Leu Ser Ser 565 570
575Ser Asp Pro Asn Leu Gln Asn Ile Pro Val Arg Thr Pro Leu Gly Gln
580 585 590Arg Ile Arg Arg Ala
Phe Val Ala Glu Glu Gly Trp Leu Leu Val Val 595
600 605Leu Asp Tyr Ser Gln Ile Glu Leu Arg Val Leu Ala
His Leu Ser Gly 610 615 620Asp Glu Asn
Leu Thr Arg Val Phe Leu Glu Gly Arg Asp Ile His Thr625
630 635 640Glu Thr Ala Ser Trp Met Phe
Gly Val Pro Arg Glu Ala Val Asp Pro 645
650 655Leu Met Arg Arg Ala Ala Lys Thr Ile Asn Phe Gly
Val Leu Tyr Gly 660 665 670Met
Ser Ala His Arg Leu Ser Gln Glu Leu Ala Ile Pro Tyr Glu Glu 675
680 685Ala Gln Ala Phe Ile Glu Arg Tyr Phe
Gln Ser Phe Pro Lys Val Arg 690 695
700Ala Trp Ile Glu Lys Thr Leu Glu Glu Gly Arg Lys Arg Gly Tyr Val705
710 715 720Glu Thr Leu Phe
Gly Arg Arg Arg Tyr Val Pro Asp Leu Asn Ala Arg 725
730 735Val Lys Ser Val Arg Glu Ala Ala Glu Arg
Met Ala Phe Asn Met Pro 740 745
750Val Gln Gly Thr Ala Ala Asp Leu Met Lys Leu Ala Met Val Lys Leu
755 760 765Phe Pro Arg Leu Arg Glu Met
Gly Ala Arg Met Leu Leu Gln Val His 770 775
780Asp Glu Leu Leu Leu Glu Ala Pro Gln Ala Arg Ala Glu Glu Val
Ala785 790 795 800Ala Leu
Ala Lys Glu Ala Met Glu Lys Ala Tyr Pro Leu Ala Val Pro
805 810 815Leu Glu Val Lys Glu Gly Ile
Gly Glu Asp Trp Leu Ser Ala Lys Glu 820 825
830932550DNAArtificial sequenceMutant Taq polymerase coding
sequence 93atggcgatgc ttcccctctt tgagcccaag ggccgcgtcc tcctggtgga
cggccaccac 60ctggcctacc gcaccttctt cgccctgaag ggccccacca cgagccgggg
cgaaccggtg 120caggtggtct acggcttcgc caagagcctc ctcaaggccc tgaaagagga
cgggtacaag 180gccgtcttcg tggtctttga cgccaaggcc ccctcattcc gccacaaggc
ctacgaggcc 240tacagggcgg ggagggcccc gacccccgag gacttccccc ggcagctcgc
cctcatcaag 300gagctggtgg acctcctggg gtttacccgc ctcgaggtcc ccggctacga
ggcggacgac 360gttctcgcca ccctggccaa gaaggcggaa aaggaggggt acgaggtgcg
catcctcacc 420gccgaccgcg gcctctacca actcgtctct gaccgcgtcg ccgtcctcca
ccccgagggc 480cacctcatca ccccggagtg gctttgggag aagtacggcc tcaggccgga
gcagtgggtg 540gacttccgcg ccctcgtggg ggacccctcc gacaacctcc ccggggtcaa
gggcatcggg 600gagaagaccg ccctcaagct cctcaaggag tggggaagcc tggaaaacct
cctcaagaac 660ctggaccggg taaagccaga aaacgtccgg gagaagatca aggcccacct
ggaagacctc 720aggctctcct tggagctctc ccgggtgcgc accgacctcc ccctggaggt
ggacctcgcc 780caggggcggg agcccgaccg ggagaggctt agggcctttc tggagaggct
tgagtttggc 840ggcctcctcc acgagttcgg ccttctggaa agccccaagg ccctggagga
ggccccctgg 900cccccgccgg aaggggcctt cgtgggcttt gtgctttccc gcaaggagcc
catgtgggcc 960gatcttctgg ccctggccgc cgccaggggt ggtcgggtcc accgggcccc
tgagccttat 1020aaagccctca gggacttgaa ggaggcgcgg gggcttctcg ccaaagacct
gagcgttctg 1080gccctgaggg aaggccttgg cctcccgccc ggcgacgacc ccatgctcct
cgcctacctc 1140ctggaccctt ccaacaccac ccccgagggg gtggcccggc gctacggcgg
ggagtggacg 1200gaggaggcgg gggagcgggc cgccctttcc gagaggctct tcgccaacct
gtgggggagg 1260cttgaggggg aggagaggct cctttggctt taccgggagg tggagagacc
cctttccgct 1320gtcctggccc acatggaggc cacgggggtg cgcctggacg tggcctatct
cagggccttg 1380tccctggagg tggccgagga gatcgcccgc ctcgaggccg aggtcttccg
cctggccggc 1440caccccttca acctcaactc ccgagaccag ctggaaaggg tcctctttga
cgagctaggg 1500cttcccgcca tcggcaagac ggagaagacc ggcaagcgct ccaccagcgc
cgccgtcctg 1560gaggccctcc gcgaggccca ccccatcgtg gagaagatcc tgcagtaccg
ggagctcacc 1620aagctgaaga gcacctacat tgaccccttg ccggaccaca tccaccccag
gacgggccgc 1680ctccacaccc gcttcaacca gacggccacg gccacgggca ggctaagtag
ctccgatccc 1740aacctccaga acatccccgt ccgcaccccg ctcgggcaga ggatccgccg
ggccttcatc 1800gccgaggagg ggtggctatt ggtggtcctg gactatagcc agatagagct
cagggtgctg 1860gcccacctct ccggcgacga gaacctgacc cgggtcttcc aggaggggcg
ggacatccac 1920acggaaaccg ccagctggat gttcggcgtc ccccgggagg ccgtggaccc
cctgatgcgc 1980cgggcggcca agaccatcaa cttcggggtt ctctacggca tgtcggccca
ccgcctctcc 2040caggagctgg ccatccctta cgaggaggcc caggccttca tagagcgcta
cttccaaagc 2100ttccccaagg tgcgggcctg gatagaaaag accctggagg aggggaggaa
gcggggctac 2160gtggaaaccc tcttcggaag aaggcgctac gtgcccgacc tcaacgcccg
ggtgaagagt 2220gtcagggagg ccgcggagcg catggccttc aacatgcccg tccagggcac
cgccgccgac 2280cttatgaagc tcgccatggt gaagctctac ccccgcctcc gggagatggg
ggcccgcatg 2340ctcctccagg tccacgacga gctcctcctg gaggcccccc aagcgcgggc
cgaggaggtg 2400gcggctttgg ccaaggaggc catggagaag gcctatcccc tcgccgtacc
cctggaggtg 2460aaggtgggga tcggggagga ctggctctcc gcccaaggag tgagtcgacc
tgcaggcagc 2520gcttggcgtc acccgcagtt cggtggttaa
255094849PRTArtificial sequenceMutant Taq polymerase 94Met Ala
Met Leu Pro Leu Phe Glu Pro Lys Gly Arg Val Leu Leu Val1 5
10 15Asp Gly His His Leu Ala Tyr Arg
Thr Phe Phe Ala Leu Lys Gly Pro 20 25
30Thr Thr Ser Arg Gly Glu Pro Val Gln Val Val Tyr Gly Phe Ala
Lys 35 40 45Ser Leu Leu Lys Ala
Leu Lys Glu Asp Gly Tyr Lys Ala Val Phe Val 50 55
60Val Phe Asp Ala Lys Ala Pro Ser Phe Arg His Lys Ala Tyr
Glu Ala65 70 75 80Tyr
Arg Ala Gly Arg Ala Pro Thr Pro Glu Asp Phe Pro Arg Gln Leu
85 90 95Ala Leu Ile Lys Glu Leu Val
Asp Leu Leu Gly Phe Thr Arg Leu Glu 100 105
110Val Pro Gly Tyr Glu Ala Asp Asp Val Leu Ala Thr Leu Ala
Lys Lys 115 120 125Ala Glu Lys Glu
Gly Tyr Glu Val Arg Ile Leu Thr Ala Asp Arg Gly 130
135 140Leu Tyr Gln Leu Val Ser Asp Arg Val Ala Val Leu
His Pro Glu Gly145 150 155
160His Leu Ile Thr Pro Glu Trp Leu Trp Glu Lys Tyr Gly Leu Arg Pro
165 170 175Glu Gln Trp Val Asp
Phe Arg Ala Leu Val Gly Asp Pro Ser Asp Asn 180
185 190Leu Pro Gly Val Lys Gly Ile Gly Glu Lys Thr Ala
Leu Lys Leu Leu 195 200 205Lys Glu
Trp Gly Ser Leu Glu Asn Leu Leu Lys Asn Leu Asp Arg Val 210
215 220Lys Pro Glu Asn Val Arg Glu Lys Ile Lys Ala
His Leu Glu Asp Leu225 230 235
240Arg Leu Ser Leu Glu Leu Ser Arg Val Arg Thr Asp Leu Pro Leu Glu
245 250 255Val Asp Leu Ala
Gln Gly Arg Glu Pro Asp Arg Glu Arg Leu Arg Ala 260
265 270Phe Leu Glu Arg Leu Glu Phe Gly Gly Leu Leu
His Glu Phe Gly Leu 275 280 285Leu
Glu Ser Pro Lys Ala Leu Glu Glu Ala Pro Trp Pro Pro Pro Glu 290
295 300Gly Ala Phe Val Gly Phe Val Leu Ser Arg
Lys Glu Pro Met Trp Ala305 310 315
320Asp Leu Leu Ala Leu Ala Ala Ala Arg Gly Gly Arg Val His Arg
Ala 325 330 335Pro Glu Pro
Tyr Lys Ala Leu Arg Asp Leu Lys Glu Ala Arg Gly Leu 340
345 350Leu Ala Lys Asp Leu Ser Val Leu Ala Leu
Arg Glu Gly Leu Gly Leu 355 360
365Pro Pro Gly Asp Asp Pro Met Leu Leu Ala Tyr Leu Leu Asp Pro Ser 370
375 380Asn Thr Thr Pro Glu Gly Val Ala
Arg Arg Tyr Gly Gly Glu Trp Thr385 390
395 400Glu Glu Ala Gly Glu Arg Ala Ala Leu Ser Glu Arg
Leu Phe Ala Asn 405 410
415Leu Trp Gly Arg Leu Glu Gly Glu Glu Arg Leu Leu Trp Leu Tyr Arg
420 425 430Glu Val Glu Arg Pro Leu
Ser Ala Val Leu Ala His Met Glu Ala Thr 435 440
445Gly Val Arg Leu Asp Val Ala Tyr Leu Arg Ala Leu Ser Leu
Glu Val 450 455 460Ala Glu Glu Ile Ala
Arg Leu Glu Ala Glu Val Phe Arg Leu Ala Gly465 470
475 480His Pro Phe Asn Leu Asn Ser Arg Asp Gln
Leu Glu Arg Val Leu Phe 485 490
495Asp Glu Leu Gly Leu Pro Ala Ile Gly Lys Thr Glu Lys Thr Gly Lys
500 505 510Arg Ser Thr Ser Ala
Ala Val Leu Glu Ala Leu Arg Glu Ala His Pro 515
520 525Ile Val Glu Lys Ile Leu Gln Tyr Arg Glu Leu Thr
Lys Leu Lys Ser 530 535 540Thr Tyr Ile
Asp Pro Leu Pro Asp His Ile His Pro Arg Thr Gly Arg545
550 555 560Leu His Thr Arg Phe Asn Gln
Thr Ala Thr Ala Thr Gly Arg Leu Ser 565
570 575Ser Ser Asp Pro Asn Leu Gln Asn Ile Pro Val Arg
Thr Pro Leu Gly 580 585 590Gln
Arg Ile Arg Arg Ala Phe Ile Ala Glu Glu Gly Trp Leu Leu Val 595
600 605Val Leu Asp Tyr Ser Gln Ile Glu Leu
Arg Val Leu Ala His Leu Ser 610 615
620Gly Asp Glu Asn Leu Thr Arg Val Phe Gln Glu Gly Arg Asp Ile His625
630 635 640Thr Glu Thr Ala
Ser Trp Met Phe Gly Val Pro Arg Glu Ala Val Asp 645
650 655Pro Leu Met Arg Arg Ala Ala Lys Thr Ile
Asn Phe Gly Val Leu Tyr 660 665
670Gly Met Ser Ala His Arg Leu Ser Gln Glu Leu Ala Ile Pro Tyr Glu
675 680 685Glu Ala Gln Ala Phe Ile Glu
Arg Tyr Phe Gln Ser Phe Pro Lys Val 690 695
700Arg Ala Trp Ile Glu Lys Thr Leu Glu Glu Gly Arg Lys Arg Gly
Tyr705 710 715 720Val Glu
Thr Leu Phe Gly Arg Arg Arg Tyr Val Pro Asp Leu Asn Ala
725 730 735Arg Val Lys Ser Val Arg Glu
Ala Ala Glu Arg Met Ala Phe Asn Met 740 745
750Pro Val Gln Gly Thr Ala Ala Asp Leu Met Lys Leu Ala Met
Val Lys 755 760 765Leu Tyr Pro Arg
Leu Arg Glu Met Gly Ala Arg Met Leu Leu Gln Val 770
775 780His Asp Glu Leu Leu Leu Glu Ala Pro Gln Ala Arg
Ala Glu Glu Val785 790 795
800Ala Ala Leu Ala Lys Glu Ala Met Glu Lys Ala Tyr Pro Leu Ala Val
805 810 815Pro Leu Glu Val Lys
Val Gly Ile Gly Glu Asp Trp Leu Ser Ala Gln 820
825 830Gly Val Ser Arg Pro Ala Gly Ser Ala Trp Arg His
Pro Gln Phe Gly 835 840
845Gly952502DNAArtificial sequenceMutant Taq polymerase coding sequence
95atggcgatgc ttcccctctt tgagcccaag ggccgcgtcc tcctggtgga cggccaccac
60ctggcctacc gcaccttctt cgccctgaag ggccccacca cgagccgggg cgaaccggtg
120caggtggtct acggcttcgc caagagcctc ctcaaggccc tgaaggagga cgggtacaag
180gccgtcttcg tggtctttga cgccaaggcc ccctcattcc gccacaaggc ctacgaggcc
240tacagggcgg ggagggcccc gacccccgag gacttccccc ggcagctcgc cctcatcaag
300gagctggtgg acctcctggg gtttacccgc ctcgaggtcc ccggctacga ggcggacgac
360gttctcgcca ccctggccaa gaaggcggaa aaggaggggt acgaggtgcg catcctcacc
420gccgaccgcg gcctctacca actcgtctct gaccgcgtcg ccgtcctcca ccccgagggc
480cacctcatca ccccggagtg gctttgggag aagtacggcc tcaggccgga gcagtgggta
540gacttccgcg ccctcgtggg ggacccctcc gacaacctcc ccggggtcaa gggcatcggg
600gagaagaccg ccctcaagct cctcaaggag tggggaagcc tggaaaacct cctcaagaac
660ctggaccggg taaagccaga aaacgtccgg gagaagatca aggcccacct ggaagacctc
720aggctctcct tggagctctc ccgggtgcgc accgacctcc ccctggaggt ggacctcgcc
780caggggcggg agcccgaccg ggaggggctt agggcctttc tggagaggct tgagtttggc
840agcctcctcc acgagttcgg ccttctggaa agccccaagg ccctggagga ggccccctgg
900cccccgccgg aaggggcctt cgtgggcttt gtgctttcac gcaaggagcc catgtgggcc
960gatcttctgg ccctggccgc cgccaggggt ggtcgggtcc accgggcccc cgagccttat
1020aaagccctca gggacttgaa ggaggcgcgg gggcttctcg ccaaagacct gagcgttctg
1080gccctaaggg aaggccttgg cctcccgccc ggcgacgacc ccatgctcct cgcctacctc
1140ctggaccctt ccaacaccgc ccccgagggg gtggcccggc gctacggcgg ggagtggacg
1200gaggaggcgg gggagcgggc cgccctttcc gagaggctct tcgccaacct gtgggggagg
1260cttgaggggg aggagaggct cctttggctt taccgggagg tggataggcc cctttccgct
1320gtcctggccc acatggaggc cacaggggta cggctggacg tggcctgcct gcaggccctt
1380tccctggagc ttgcggagga gatccgccgc ctcgaggagg aggtcttccg cttggcgggc
1440caccccttca acctcaactc ccgggaccag ctggaaaggg tcctctttga cgagctaggg
1500cttcccgcca tcggcaagac ggagaagacc ggcaagcgct ccaccagcgc cgccatcctg
1560gaggccctcc gcgaggccca ccccatcgtg gagaagatcc tgcagtaccg ggagctcacc
1620aagctgaaga gcacctacat tgaccccttg ccggacctca tccaccccag gacgggccgc
1680ctccacaccc gcttcaacca gacggccacg gccacgggca ggctaagtag ctccggtccc
1740aacctccaga acatccccgt ccgcaccccg ctcgggcaga ggatccgccg ggccttcgtc
1800gccgaggagg ggtggctatt ggtggtcctg gactatagcc agatagagct cagggtgctg
1860gcccacctct ccggcgacga gaacctgacc cgggtcttcc tggaggggcg ggacatccac
1920acggaaaccg ccagctggat gttcggcgtc ccccgggagg ccgtggaccc cctgatgcgc
1980cgggcggcca agaccatcaa cttcggggtt ctctacggca tgtcggccca ccgcctctcc
2040caggagctgg ccatccctta cgaggaggcc caggccttca tagagcgcta cttccaaagc
2100ttccccaagg tgcgggcctg gatagaaaag accctggagg aggggaggaa gcggggctac
2160gtggaaaccc tcttcggaag aaggcgctac gtgcccgacc tcaacgcccg ggtgaagagt
2220gtcagggagg ccgcggagcg catggccttc aacatgcccg tccagggcac cgccgccgac
2280cttatgaagc tcgccatggt gaagctcttc ccccgcctcc gggagatggg ggcccgcatg
2340ctcctccagg tccacgacga gctcctcctg gaggcccccc aagcgcgggc cgaggaagtg
2400gcggctttgg ccaaggaggc catggagaag gcctatcccc tcgccgtacc cctggaggtg
2460aaggtgggga tcggggagga ctggctctcc gccaaggagt ga
250296833PRTArtificial sequenceMutant Taq polymerase 96Met Ala Met Leu
Pro Leu Phe Glu Pro Lys Gly Arg Val Leu Leu Val1 5
10 15Asp Gly His His Leu Ala Tyr Arg Thr Phe
Phe Ala Leu Lys Gly Pro 20 25
30Thr Thr Ser Arg Gly Glu Pro Val Gln Val Val Tyr Gly Phe Ala Lys
35 40 45Ser Leu Leu Lys Ala Leu Lys Glu
Asp Gly Tyr Lys Ala Val Phe Val 50 55
60Val Phe Asp Ala Lys Ala Pro Ser Phe Arg His Lys Ala Tyr Glu Ala65
70 75 80Tyr Arg Ala Gly Arg
Ala Pro Thr Pro Glu Asp Phe Pro Arg Gln Leu 85
90 95Ala Leu Ile Lys Glu Leu Val Asp Leu Leu Gly
Phe Thr Arg Leu Glu 100 105
110Val Pro Gly Tyr Glu Ala Asp Asp Val Leu Ala Thr Leu Ala Lys Lys
115 120 125Ala Glu Lys Glu Gly Tyr Glu
Val Arg Ile Leu Thr Ala Asp Arg Gly 130 135
140Leu Tyr Gln Leu Val Ser Asp Arg Val Ala Val Leu His Pro Glu
Gly145 150 155 160His Leu
Ile Thr Pro Glu Trp Leu Trp Glu Lys Tyr Gly Leu Arg Pro
165 170 175Glu Gln Trp Val Asp Phe Arg
Ala Leu Val Gly Asp Pro Ser Asp Asn 180 185
190Leu Pro Gly Val Lys Gly Ile Gly Glu Lys Thr Ala Leu Lys
Leu Leu 195 200 205Lys Glu Trp Gly
Ser Leu Glu Asn Leu Leu Lys Asn Leu Asp Arg Val 210
215 220Lys Pro Glu Asn Val Arg Glu Lys Ile Lys Ala His
Leu Glu Asp Leu225 230 235
240Arg Leu Ser Leu Glu Leu Ser Arg Val Arg Thr Asp Leu Pro Leu Glu
245 250 255Val Asp Leu Ala Gln
Gly Arg Glu Pro Asp Arg Glu Gly Leu Arg Ala 260
265 270Phe Leu Glu Arg Leu Glu Phe Gly Ser Leu Leu His
Glu Phe Gly Leu 275 280 285Leu Glu
Ser Pro Lys Ala Leu Glu Glu Ala Pro Trp Pro Pro Pro Glu 290
295 300Gly Ala Phe Val Gly Phe Val Leu Ser Arg Lys
Glu Pro Met Trp Ala305 310 315
320Asp Leu Leu Ala Leu Ala Ala Ala Arg Gly Gly Arg Val His Arg Ala
325 330 335Pro Glu Pro Tyr
Lys Ala Leu Arg Asp Leu Lys Glu Ala Arg Gly Leu 340
345 350Leu Ala Lys Asp Leu Ser Val Leu Ala Leu Arg
Glu Gly Leu Gly Leu 355 360 365Pro
Pro Gly Asp Asp Pro Met Leu Leu Ala Tyr Leu Leu Asp Pro Ser 370
375 380Asn Thr Ala Pro Glu Gly Val Ala Arg Arg
Tyr Gly Gly Glu Trp Thr385 390 395
400Glu Glu Ala Gly Glu Arg Ala Ala Leu Ser Glu Arg Leu Phe Ala
Asn 405 410 415Leu Trp Gly
Arg Leu Glu Gly Glu Glu Arg Leu Leu Trp Leu Tyr Arg 420
425 430Glu Val Asp Arg Pro Leu Ser Ala Val Leu
Ala His Met Glu Ala Thr 435 440
445Gly Val Arg Leu Asp Val Ala Cys Leu Gln Ala Leu Ser Leu Glu Leu 450
455 460Ala Glu Glu Ile Arg Arg Leu Glu
Glu Glu Val Phe Arg Leu Ala Gly465 470
475 480His Pro Phe Asn Leu Asn Ser Arg Asp Gln Leu Glu
Arg Val Leu Phe 485 490
495Asp Glu Leu Gly Leu Pro Ala Ile Gly Lys Thr Glu Lys Thr Gly Lys
500 505 510Arg Ser Thr Ser Ala Ala
Ile Leu Glu Ala Leu Arg Glu Ala His Pro 515 520
525Ile Val Glu Lys Ile Leu Gln Tyr Arg Glu Leu Thr Lys Leu
Lys Ser 530 535 540Thr Tyr Ile Asp Pro
Leu Pro Asp Leu Ile His Pro Arg Thr Gly Arg545 550
555 560Leu His Thr Arg Phe Asn Gln Thr Ala Thr
Ala Thr Gly Arg Leu Ser 565 570
575Ser Ser Gly Pro Asn Leu Gln Asn Ile Pro Val Arg Thr Pro Leu Gly
580 585 590Gln Arg Ile Arg Arg
Ala Phe Val Ala Glu Glu Gly Trp Leu Leu Val 595
600 605Val Leu Asp Tyr Ser Gln Ile Glu Leu Arg Val Leu
Ala His Leu Ser 610 615 620Gly Asp Glu
Asn Leu Thr Arg Val Phe Leu Glu Gly Arg Asp Ile His625
630 635 640Thr Glu Thr Ala Ser Trp Met
Phe Gly Val Pro Arg Glu Ala Val Asp 645
650 655Pro Leu Met Arg Arg Ala Ala Lys Thr Ile Asn Phe
Gly Val Leu Tyr 660 665 670Gly
Met Ser Ala His Arg Leu Ser Gln Glu Leu Ala Ile Pro Tyr Glu 675
680 685Glu Ala Gln Ala Phe Ile Glu Arg Tyr
Phe Gln Ser Phe Pro Lys Val 690 695
700Arg Ala Trp Ile Glu Lys Thr Leu Glu Glu Gly Arg Lys Arg Gly Tyr705
710 715 720Val Glu Thr Leu
Phe Gly Arg Arg Arg Tyr Val Pro Asp Leu Asn Ala 725
730 735Arg Val Lys Ser Val Arg Glu Ala Ala Glu
Arg Met Ala Phe Asn Met 740 745
750Pro Val Gln Gly Thr Ala Ala Asp Leu Met Lys Leu Ala Met Val Lys
755 760 765Leu Phe Pro Arg Leu Arg Glu
Met Gly Ala Arg Met Leu Leu Gln Val 770 775
780His Asp Glu Leu Leu Leu Glu Ala Pro Gln Ala Arg Ala Glu Glu
Val785 790 795 800Ala Ala
Leu Ala Lys Glu Ala Met Glu Lys Ala Tyr Pro Leu Ala Val
805 810 815Pro Leu Glu Val Lys Val Gly
Ile Gly Glu Asp Trp Leu Ser Ala Lys 820 825
830Glu972502DNAArtificial sequenceMutant Taq polymerase
coding sequence 97atggcgatgc ttcccctctt tgagcccaag ggccgcgtcc tcctggtgga
cggccaccac 60ctggcctacc gcaccttctt cgccctgaag ggccccacca cgagccgggg
cgaaccggtg 120caggtggtct acggcttcgc caagagcctc ctcaaggccc tgaaggagga
cgggtacaag 180gccgtcttcg tggtctttga cgccaaggcc ccctcattcc gccacaaggc
ctacgaggcc 240tacagggcgg ggagggcccc gacccccgag gacttccccc ggcagctcgc
cctcatcaag 300gagctggtgg acctcctggg gtttacccgc ctcgaggtcc ccggctacga
ggcggacgac 360gttctcgcca ccctggccaa gaaggcggaa aaggaggggt acgaggtgcg
catcctcacc 420gccgaccgcg gcctctacca actcgtctct gaccgcgtcg ccgtcctcca
ccccgagggc 480cacctcatca ccccggagtg gctttgggag aagtacggcc tcaggccgga
gcagtgggtg 540gacttccgcg ccctcgtggg ggacccctcc gacaacctcc ccggggtcaa
gggcatcggg 600gagaagaccg ccctcaagct cctcaaggag tggggaagcc tggaaaacct
cctcaagaac 660ctggaccggg taaagccaga aaacgtccgg gagaagatca aggcccacct
ggaagacctc 720aggctctcct tggagctctc ccgggtgcgc accgacctcc ccctggaggt
ggacctcgcc 780cagaggcggg agcccgaccg ggaggggctt agggcctttc tggagaggct
tgagtttggc 840agcctcttcc acgagttcgg ccttctggaa agccccaagg ccctggagga
ggccccctgg 900cccccgccgg aaggggcctt cgtgggcttt gtgctttccc gcaaggagcc
catgtgggcc 960gatcttctgg ccctggccgc cgccaggggt ggtcgagtcc accgggcccc
cgagccttat 1020aaagccctca gggacctgaa ggaggcgcgg gggcttctcg ccaaagacct
gagcgttctg 1080gccctaaggg aaggccttgg cctcccgccc ggcgacgacc ccatgctcct
cgcctacctc 1140ctggaccctt ccaacaccac ccccgagggg gtggcccggc gctacggcgg
ggagtggacg 1200gaggaggcgg gggagcgggc cgccctttcc gagaggctct tcgccaacct
gtgggggagg 1260cttgaggggg aggagaggct cctttggctt taccgggagg tggagaggcc
cctttccgct 1320gtcctggccc acatggaggc cacgggggtg cgcctggacg tggcctatct
cagggccttg 1380tccctggagg tggccgagga gatcgcccgc ctcgaggccg aggtcttccg
cctggccggc 1440caccccttca acctcaactc ccgggaccag ctggaaatgg tgctctttga
cgagcttagg 1500cttcccgcct tggggaagac gcaaaagacg ggcaagcgct ccaccagcgc
cgccgtcctg 1560gaggccctcc gcgaggccca ccccatcgtg gagaagatcc tgcagtaccg
ggagctcacc 1620aagctgaaga gcacctacat tgaccccttg tcggacctca tccaccccag
gacgggccgc 1680ctccacaccc gcttcaacca gacggccacg gccacgggca ggctaagtag
ctccgatccc 1740aacctccaga acatccccgt ccgcaccccg cttgggcaga ggatccgccg
ggccttcatc 1800gccgaggagg ggtggctact ggtggtcctg gactatagcc agatagagct
cagggtgctg 1860gcccacctct ccggcgacga aaacctgatc agggtcttcc aggaggggcg
ggacatccac 1920acggagaccg ccagctggat gttcggcgtc ccccgggagg ccgtggaccc
cctgatgcgc 1980cgggcggcca agaccatcaa cttcggggtc ctctacggca tgtcggccca
ccgcctctcc 2040caggagctag ccatccctta cgaggaggcc caggccttca ttgagcgcta
ctttcagagc 2100ttccccaagg tgcgggcctg gattgagaag accctggagg agggcaggag
gcgggggtac 2160gtggagaccc tcttcggccg ccgccgctac gtgccagacc tagaggcccg
ggtgaagagc 2220gtgcgggagg cggccgagcg catggccttc aacatgcccg tccagggcac
cgccgccgac 2280ctcatgaagc tggctatggt gaagctcttc cccaggctgg gagaaacggg
ggccaggatg 2340ctccttcagg tccacgacga gctggtcctc gaggccccaa aagagagggc
ggaggccgtg 2400gcccggctgg ccaaggaggc catggagggg gtgtatcccc tggccgtgcc
cctggaggtg 2460gaggtgggga taggggagga ctggctctcc gccaagggtt ag
250298833PRTArtificial sequenceMutant Taq polymerase 98Met Ala
Met Leu Pro Leu Phe Glu Pro Lys Gly Arg Val Leu Leu Val1 5
10 15Asp Gly His His Leu Ala Tyr Arg
Thr Phe Phe Ala Leu Lys Gly Pro 20 25
30Thr Thr Ser Arg Gly Glu Pro Val Gln Val Val Tyr Gly Phe Ala
Lys 35 40 45Ser Leu Leu Lys Ala
Leu Lys Glu Asp Gly Tyr Lys Ala Val Phe Val 50 55
60Val Phe Asp Ala Lys Ala Pro Ser Phe Arg His Lys Ala Tyr
Glu Ala65 70 75 80Tyr
Arg Ala Gly Arg Ala Pro Thr Pro Glu Asp Phe Pro Arg Gln Leu
85 90 95Ala Leu Ile Lys Glu Leu Val
Asp Leu Leu Gly Phe Thr Arg Leu Glu 100 105
110Val Pro Gly Tyr Glu Ala Asp Asp Val Leu Ala Thr Leu Ala
Lys Lys 115 120 125Ala Glu Lys Glu
Gly Tyr Glu Val Arg Ile Leu Thr Ala Asp Arg Gly 130
135 140Leu Tyr Gln Leu Val Ser Asp Arg Val Ala Val Leu
His Pro Glu Gly145 150 155
160His Leu Ile Thr Pro Glu Trp Leu Trp Glu Lys Tyr Gly Leu Arg Pro
165 170 175Glu Gln Trp Val Asp
Phe Arg Ala Leu Val Gly Asp Pro Ser Asp Asn 180
185 190Leu Pro Gly Val Lys Gly Ile Gly Glu Lys Thr Ala
Leu Lys Leu Leu 195 200 205Lys Glu
Trp Gly Ser Leu Glu Asn Leu Leu Lys Asn Leu Asp Arg Val 210
215 220Lys Pro Glu Asn Val Arg Glu Lys Ile Lys Ala
His Leu Glu Asp Leu225 230 235
240Arg Leu Ser Leu Glu Leu Ser Arg Val Arg Thr Asp Leu Pro Leu Glu
245 250 255Val Asp Leu Ala
Gln Arg Arg Glu Pro Asp Arg Glu Gly Leu Arg Ala 260
265 270Phe Leu Glu Arg Leu Glu Phe Gly Ser Leu Phe
His Glu Phe Gly Leu 275 280 285Leu
Glu Ser Pro Lys Ala Leu Glu Glu Ala Pro Trp Pro Pro Pro Glu 290
295 300Gly Ala Phe Val Gly Phe Val Leu Ser Arg
Lys Glu Pro Met Trp Ala305 310 315
320Asp Leu Leu Ala Leu Ala Ala Ala Arg Gly Gly Arg Val His Arg
Ala 325 330 335Pro Glu Pro
Tyr Lys Ala Leu Arg Asp Leu Lys Glu Ala Arg Gly Leu 340
345 350Leu Ala Lys Asp Leu Ser Val Leu Ala Leu
Arg Glu Gly Leu Gly Leu 355 360
365Pro Pro Gly Asp Asp Pro Met Leu Leu Ala Tyr Leu Leu Asp Pro Ser 370
375 380Asn Thr Thr Pro Glu Gly Val Ala
Arg Arg Tyr Gly Gly Glu Trp Thr385 390
395 400Glu Glu Ala Gly Glu Arg Ala Ala Leu Ser Glu Arg
Leu Phe Ala Asn 405 410
415Leu Trp Gly Arg Leu Glu Gly Glu Glu Arg Leu Leu Trp Leu Tyr Arg
420 425 430Glu Val Glu Arg Pro Leu
Ser Ala Val Leu Ala His Met Glu Ala Thr 435 440
445Gly Val Arg Leu Asp Val Ala Tyr Leu Arg Ala Leu Ser Leu
Glu Val 450 455 460Ala Glu Glu Ile Ala
Arg Leu Glu Ala Glu Val Phe Arg Leu Ala Gly465 470
475 480His Pro Phe Asn Leu Asn Ser Arg Asp Gln
Leu Glu Met Val Leu Phe 485 490
495Asp Glu Leu Arg Leu Pro Ala Leu Gly Lys Thr Gln Lys Thr Gly Lys
500 505 510Arg Ser Thr Ser Ala
Ala Val Leu Glu Ala Leu Arg Glu Ala His Pro 515
520 525Ile Val Glu Lys Ile Leu Gln Tyr Arg Glu Leu Thr
Lys Leu Lys Ser 530 535 540Thr Tyr Ile
Asp Pro Leu Ser Asp Leu Ile His Pro Arg Thr Gly Arg545
550 555 560Leu His Thr Arg Phe Asn Gln
Thr Ala Thr Ala Thr Gly Arg Leu Ser 565
570 575Ser Ser Asp Pro Asn Leu Gln Asn Ile Pro Val Arg
Thr Pro Leu Gly 580 585 590Gln
Arg Ile Arg Arg Ala Phe Ile Ala Glu Glu Gly Trp Leu Leu Val 595
600 605Val Leu Asp Tyr Ser Gln Ile Glu Leu
Arg Val Leu Ala His Leu Ser 610 615
620Gly Asp Glu Asn Leu Ile Arg Val Phe Gln Glu Gly Arg Asp Ile His625
630 635 640Thr Glu Thr Ala
Ser Trp Met Phe Gly Val Pro Arg Glu Ala Val Asp 645
650 655Pro Leu Met Arg Arg Ala Ala Lys Thr Ile
Asn Phe Gly Val Leu Tyr 660 665
670Gly Met Ser Ala His Arg Leu Ser Gln Glu Leu Ala Ile Pro Tyr Glu
675 680 685Glu Ala Gln Ala Phe Ile Glu
Arg Tyr Phe Gln Ser Phe Pro Lys Val 690 695
700Arg Ala Trp Ile Glu Lys Thr Leu Glu Glu Gly Arg Arg Arg Gly
Tyr705 710 715 720Val Glu
Thr Leu Phe Gly Arg Arg Arg Tyr Val Pro Asp Leu Glu Ala
725 730 735Arg Val Lys Ser Val Arg Glu
Ala Ala Glu Arg Met Ala Phe Asn Met 740 745
750Pro Val Gln Gly Thr Ala Ala Asp Leu Met Lys Leu Ala Met
Val Lys 755 760 765Leu Phe Pro Arg
Leu Gly Glu Thr Gly Ala Arg Met Leu Leu Gln Val 770
775 780His Asp Glu Leu Val Leu Glu Ala Pro Lys Glu Arg
Ala Glu Ala Val785 790 795
800Ala Arg Leu Ala Lys Glu Ala Met Glu Gly Val Tyr Pro Leu Ala Val
805 810 815Pro Leu Glu Val Glu
Val Gly Ile Gly Glu Asp Trp Leu Ser Ala Lys 820
825 830Gly9920DNAArtificial sequencePrimer for analysis
of mutant polymerase 99cgtggtcgcg acggatgccg
2010051DNAArtificial sequenceTemplate for mutant
polymerase analysis 100agctaccatg cctgcacgaa ttcggcatcc gtcgcgacca
cggtcgcagc g 5110151DNAArtificial sequenceTemplate for
analysis of mutant polymerases 101agctaccatg cctgcacgac ancggcatcc
gtcgcgacca cggtcgcagc g 5110240DNAArtificial sequencePrimer
for selection of polymerase able to replicate 5-nitroindol
102caggaaacag ctatgacaaa aatctagata acgagggcan
4010345DNAArtificial sequencePrimer for selection of polymerase able to
replicate 5-nitroindol 103gtaaaacgac ggccagtacc accgaactgc gggtgacgcc
aagcn 4510440DNAArtificial sequencePrimer used to
select polymerases able to replicate 5-nitroindol 104caggaaacag
ctatgacaaa aatctagata ncgagggcan
4010545DNAArtificial sequencePrimer used to select polymerase able to
replicate 5-nitroindol 105gtaaaacgac ggccagtacc acngaactgc gggtgacgcc
aagcn 451062502DNAArtificial sequenceMutant Taq
polymerase coding sequence 106atggcgatgc ttcccctctt tgagcccaaa ggccgggtcc
tcctggtgga cggccaccac 60ctggcctacc gcaccttctt cgccctgaag ggcctcacca
cgagccgggg cgaaccggtg 120caggcggttt acggcttcgc caagagcctc ctcaaggccc
tgaaggagga cgggtacaag 180gccgtcttcg tggtctttga cgccaaggcc ccctccttcc
gccacgaggc ctacgaggcc 240tacaaggcgg ggagggcccc gacccccgag gacttccccc
ggcagctcgc cctcatcaag 300gagctggtgg acctcctggg gtttacccgc ctcgaggtcc
aaggctacga ggcggacgac 360gtcctcgcca ccctggccaa gaaggcggaa aaagaagggt
acgaggtgcg catcctcacc 420gccgaccggg acctctacca gctcgtctcc gaccgcgtcg
ccgtcctcca ccccgagggc 480cacctcatca ccccggagtg gctttgggag aagtacggcc
tcaggccgga gcagtgggtg 540gacttccgcg ccctcgtggg ggacccctcc gacaacctcc
ccgggatcaa gggcatcggg 600gagaagaccg ccctcaagct cctcaaggag tggggaagcc
tggaaaacct cctcaagaac 660ctggaccggg taaagccaga aaatgtccgg gagaagatca
aggcccacct ggaagacctc 720aggctctcct tggagctctc ccgggtgcgc accgacctcc
ccctggaggt ggacttcgcc 780aaaaggcggg agcccgaccg ggagaggctt agggcctttc
tggagaggct tgagtttggc 840agcctcctcc acgagttcgg ccttctggaa agccccaagg
ccctggagga ggccccctgg 900cccccgccgg aaggggcctt cgtgggcttt gtgctttccc
gcaaggagcc catgtgggcc 960gatcttctgg ccctggccgc cgccaagggt ggccgggtcc
accgggcccc cgagccttat 1020aaagccctca gggacttgaa ggaggcgcgg gggcttctcg
ccaaagacct gagcgttctg 1080gccctaaggg aaggccttgg cctcccgccc ggcgacgacc
ccatgctcct cgcctacctc 1140ctggaccctt ccaacaccac ccccgagggg gtggcccggc
gctacggcgg ggagtggacg 1200gaggaggcgg gggagcgggc cgccctttcc gagaggctct
tcgccaacct gtgggggagg 1260cttgaggggg aggagaggct cctttggctt taccgggagg
tggagaggcc cctttccgct 1320gtcctggccc acatggaggc cacgggggtg cgcctggacg
tggcctatct cagggccttg 1380tccctggagg tggccgagga gatcgcccgc ctcgaggccg
aggtcttccg cctggccggc 1440caccccttca acctcaactc ccgagaccag ctggaaaggg
tcctctttga cgagctaggg 1500cttcccgcca tcggcaagac ggagaagacc ggcaagcgct
ccaccagcgc cgccgtcctg 1560gaggccctcc gcgaggccca ccccatcgtg gagaagatcc
tgcagtaccg ggagctcacc 1620aagctgaaga gcacctacat tgaccccttg ccggacctca
tccaccccag gacgggccgc 1680ctccacaccc gcttcaacca gacggccacg gccacgggca
ggctaagtag ctccgatccc 1740aacctccaga acatccccgt ccgcaccccg ctcgggcaga
ggatccgccg ggccttcatc 1800gccgaggggg ggtggctatt ggtggtcctg gactatagcc
agatggagct cagggtgctg 1860gcccacctct ccggcgacga gaacctgatc cgggtcttcc
aggaggggcg ggacatccac 1920acggaaaccg ccagctggat gttcggcgtc ccccgggagg
ccgtggaccc cctgatgcgc 1980cgggcggcca agaccatcaa cttcggggtt ctctacggca
tgtcggccca ccgcctctcc 2040caggagctag ccatccctta cgaggaggcc caggccttca
ttgagcgcta ctttcagagc 2100ttccccaagg tgcgggcctg gattgagaag accctggagg
agggcaggag gcgggggtac 2160gtggagaccc tcttcggccg ccgccgctac gtgccagacc
tagaggcccg ggtgaagagc 2220gtgcgggagg cggccgagcg catggccttc aacatgcccg
tccagggcac cgccgccgac 2280ctcatgaagc tggctatggt gaagctcttc cccaggctgg
aggaaacggg ggccaggatg 2340ctccttcagg tccacgacga gctggtcctc gaggccccaa
aagagagggc ggaggccgtg 2400gcccggctgg ccaaggaggt catggagggg gtgtatcccc
tggccgtgcc cctggaggtg 2460gaggtgggga taggggagga ctggctctcc gccaaggagt
ga 2502107833PRTArtificial sequenceMutant Taq
polymerase 107Met Ala Met Leu Pro Leu Phe Glu Pro Lys Gly Arg Val Leu Leu
Val1 5 10 15Asp Gly His
His Leu Ala Tyr Arg Thr Phe Phe Ala Leu Lys Gly Leu 20
25 30Thr Thr Ser Arg Gly Glu Pro Val Gln Ala
Val Tyr Gly Phe Ala Lys 35 40
45Ser Leu Leu Lys Ala Leu Lys Glu Asp Gly Tyr Lys Ala Val Phe Val 50
55 60Val Phe Asp Ala Lys Ala Pro Ser Phe
Arg His Glu Ala Tyr Glu Ala65 70 75
80Tyr Lys Ala Gly Arg Ala Pro Thr Pro Glu Asp Phe Pro Arg
Gln Leu 85 90 95Ala Leu
Ile Lys Glu Leu Val Asp Leu Leu Gly Phe Thr Arg Leu Glu 100
105 110Val Gln Gly Tyr Glu Ala Asp Asp Val
Leu Ala Thr Leu Ala Lys Lys 115 120
125Ala Glu Lys Glu Gly Tyr Glu Val Arg Ile Leu Thr Ala Asp Arg Asp
130 135 140Leu Tyr Gln Leu Val Ser Asp
Arg Val Ala Val Leu His Pro Glu Gly145 150
155 160His Leu Ile Thr Pro Glu Trp Leu Trp Glu Lys Tyr
Gly Leu Arg Pro 165 170
175Glu Gln Trp Val Asp Phe Arg Ala Leu Val Gly Asp Pro Ser Asp Asn
180 185 190Leu Pro Gly Ile Lys Gly
Ile Gly Glu Lys Thr Ala Leu Lys Leu Leu 195 200
205Lys Glu Trp Gly Ser Leu Glu Asn Leu Leu Lys Asn Leu Asp
Arg Val 210 215 220Lys Pro Glu Asn Val
Arg Glu Lys Ile Lys Ala His Leu Glu Asp Leu225 230
235 240Arg Leu Ser Leu Glu Leu Ser Arg Val Arg
Thr Asp Leu Pro Leu Glu 245 250
255Val Asp Phe Ala Lys Arg Arg Glu Pro Asp Arg Glu Arg Leu Arg Ala
260 265 270Phe Leu Glu Arg Leu
Glu Phe Gly Ser Leu Leu His Glu Phe Gly Leu 275
280 285Leu Glu Ser Pro Lys Ala Leu Glu Glu Ala Pro Trp
Pro Pro Pro Glu 290 295 300Gly Ala Phe
Val Gly Phe Val Leu Ser Arg Lys Glu Pro Met Trp Ala305
310 315 320Asp Leu Leu Ala Leu Ala Ala
Ala Lys Gly Gly Arg Val His Arg Ala 325
330 335Pro Glu Pro Tyr Lys Ala Leu Arg Asp Leu Lys Glu
Ala Arg Gly Leu 340 345 350Leu
Ala Lys Asp Leu Ser Val Leu Ala Leu Arg Glu Gly Leu Gly Leu 355
360 365Pro Pro Gly Asp Asp Pro Met Leu Leu
Ala Tyr Leu Leu Asp Pro Ser 370 375
380Asn Thr Thr Pro Glu Gly Val Ala Arg Arg Tyr Gly Gly Glu Trp Thr385
390 395 400Glu Glu Ala Gly
Glu Arg Ala Ala Leu Ser Glu Arg Leu Phe Ala Asn 405
410 415Leu Trp Gly Arg Leu Glu Gly Glu Glu Arg
Leu Leu Trp Leu Tyr Arg 420 425
430Glu Val Glu Arg Pro Leu Ser Ala Val Leu Ala His Met Glu Ala Thr
435 440 445Gly Val Arg Leu Asp Val Ala
Tyr Leu Arg Ala Leu Ser Leu Glu Val 450 455
460Ala Glu Glu Ile Ala Arg Leu Glu Ala Glu Val Phe Arg Leu Ala
Gly465 470 475 480His Pro
Phe Asn Leu Asn Ser Arg Asp Gln Leu Glu Arg Val Leu Phe
485 490 495Asp Glu Leu Gly Leu Pro Ala
Ile Gly Lys Thr Glu Lys Thr Gly Lys 500 505
510Arg Ser Thr Ser Ala Ala Val Leu Glu Ala Leu Arg Glu Ala
His Pro 515 520 525Ile Val Glu Lys
Ile Leu Gln Tyr Arg Glu Leu Thr Lys Leu Lys Ser 530
535 540Thr Tyr Ile Asp Pro Leu Pro Asp Leu Ile His Pro
Arg Thr Gly Arg545 550 555
560Leu His Thr Arg Phe Asn Gln Thr Ala Thr Ala Thr Gly Arg Leu Ser
565 570 575Ser Ser Asp Pro Asn
Leu Gln Asn Ile Pro Val Arg Thr Pro Leu Gly 580
585 590Gln Arg Ile Arg Arg Ala Phe Ile Ala Glu Gly Gly
Trp Leu Leu Val 595 600 605Val Leu
Asp Tyr Ser Gln Met Glu Leu Arg Val Leu Ala His Leu Ser 610
615 620Gly Asp Glu Asn Leu Ile Arg Val Phe Gln Glu
Gly Arg Asp Ile His625 630 635
640Thr Glu Thr Ala Ser Trp Met Phe Gly Val Pro Arg Glu Ala Val Asp
645 650 655Pro Leu Met Arg
Arg Ala Ala Lys Thr Ile Asn Phe Gly Val Leu Tyr 660
665 670Gly Met Ser Ala His Arg Leu Ser Gln Glu Leu
Ala Ile Pro Tyr Glu 675 680 685Glu
Ala Gln Ala Phe Ile Glu Arg Tyr Phe Gln Ser Phe Pro Lys Val 690
695 700Arg Ala Trp Ile Glu Lys Thr Leu Glu Glu
Gly Arg Arg Arg Gly Tyr705 710 715
720Val Glu Thr Leu Phe Gly Arg Arg Arg Tyr Val Pro Asp Leu Glu
Ala 725 730 735Arg Val Lys
Ser Val Arg Glu Ala Ala Glu Arg Met Ala Phe Asn Met 740
745 750Pro Val Gln Gly Thr Ala Ala Asp Leu Met
Lys Leu Ala Met Val Lys 755 760
765Leu Phe Pro Arg Leu Glu Glu Thr Gly Ala Arg Met Leu Leu Gln Val 770
775 780His Asp Glu Leu Val Leu Glu Ala
Pro Lys Glu Arg Ala Glu Ala Val785 790
795 800Ala Arg Leu Ala Lys Glu Val Met Glu Gly Val Tyr
Pro Leu Ala Val 805 810
815Pro Leu Glu Val Glu Val Gly Ile Gly Glu Asp Trp Leu Ser Ala Lys
820 825 830Glu1082499DNAArtificial
sequenceMutant Taq polymerase coding sequence 108atggcgatgc ttcccctctt
tgagcccaaa ggccgggtcc tcctggtgga cggccaccac 60ctggcctacc gcaccttctt
cgccctgaag ggcctcacca cgagtcgggg cgaaccggtg 120caggcggtct acggcttcgc
caagagcctc ctcaaggccc tgaaggagga cgggtacaag 180gccatcttcg tggtctttga
cgccaaggcc ccctccttcc gccacgaggc ccacgaggcc 240tacaaggcgg ggagggcccc
gagccccgag gacttccccc ggcagctcgc cctcatcaag 300gagctggtgg acctcctggg
gtttacccgc ctcgaggtcc aaggctacga ggcggacgac 360gtcctcgcca ccctggccaa
gaaggcggaa aaagaagggt acgaggtgcg catcctcacc 420gccgaccggg acctctacca
gctcgtctcc gaccgcgtcg ccgtcctcca ccccgagggc 480cacctcatca ccccggagtg
gctttgggag aagtacggcc tcaggccgga gcagtgggtg 540gacttccgcg ccctcgtggg
ggacccctcc gacaacctcc ccggggtcaa gggcatcggg 600gagaagaccg ccctcaagct
cctcaaggag tggggaagcc tggaaaacct cctcaagaac 660ctggaccggc tgaagcccgc
catccgggag aagatcctgg cccacatgga cgatctgaag 720ctctcctggg acctggccaa
ggtgcgcacc gacctgcccc tggaggtgga cttcgccaaa 780aggcgggagt ccgatcggga
gaggcttagg gcctttctgg agaggcttga gtttggcagc 840ctcctccacg agttcggcct
tctggaaagc cccaaggccc tggaggaggc cccctggccc 900ccgccggtag gggccttcgt
gggctttgtg ctttcccgca aggagcccat gtgggccgat 960cttctggccc tggccgccgc
caggggtggt cgggtccacc gggcccccga gccttataaa 1020gccctcagag acctgaagga
ggcgcggggg cttctcgcca aagacctgag cgttctggcc 1080ctgagggaag gccttggcct
cccgcccggc gacgacccca tgctcctcgc ctacctcctg 1140gacccttcca acaccacccc
cgaggtggtg gcccggcgct acggcgggga gtggacggag 1200gaggcggggg agcgggccgc
cctttccgag aggctcttcg ccaacctgtg ggggaggctt 1260gagggggagg ggaggctcct
ttggctttac cggggggtgg agaggcccct ttccgctgtc 1320ctggcccaca tggaggccac
aggggtgcgc ctggacgtgg cctatctcag ggccttgtcc 1380ctggaggtgg ccgaggagat
cgcccgcctc gaggccgagg tcttccgcct ggccggccac 1440cccttcaacc tcaactcccg
ggaccagctg gaaagggtcc tctttgacga gctagggctt 1500cccgccatcg gcaagacgga
gaagaccggc aagcgctcca ccagcgccgc cgtcctggag 1560gccctccgcg aggcccaccc
catcgtggag aagatcctgc agtaccggga gctcaccaag 1620ctgaagagca cttacattga
ccccttgccg gacctcatcc accccaggac gggccgcctc 1680cacacccgct tcaaccagac
ggccacggcc acgggcaggc taagtagctc cgatcccaac 1740ctccagaaca tccccgtccg
caccccgctc gggcagagga tccgccgggc cttcatcgcc 1800gagggggggt ggctattggt
ggtcctggac tatagccaga tggagctcag ggtgctggcc 1860cacctctccg gcgacgagaa
cctgatccgg gtcttccagg aggggcggga catccacacg 1920gaaaccgcca gctggatgtt
cggcgtcccc cgggaggccg tggaccccct gatgcgccgg 1980gcggccaaga ccatcaactt
cggggttctc tacggcatgt cggcccaccg cctctcccag 2040gagctagcca tcccttacga
ggaggcccag gccttcattg agcgctactt ccaaagcttc 2100cccaaggtgc gggcctggat
agaaaagacc ctggaggagg ggaggaagcg gggctacgtg 2160gaaaccctct tcggaagaag
gcgctacgtg cccgacctca acgcccgggt gaagagcgtc 2220agggaggccg cggagcgcat
ggccttcaac atgcccgtcc agggcaccgc cgccgacctc 2280acgaagctgg ctatggtgaa
gctcttcccc aggctggagg aaacgggggc caggatgctc 2340cttcaggtcc acgacgagct
ggtcctcgag gccccaaaag agagggcgga ggccgtggcc 2400cggctggcca aggaggtcat
ggagggggtg tatcccctgg ccgtgcccct ggaggtggag 2460gtggggatag gggaggactg
gctttccgcc aagggttag 2499109832PRTArtificial
sequenceMutant Taq polymerase 109Met Ala Met Leu Pro Leu Phe Glu Pro Lys
Gly Arg Val Leu Leu Val1 5 10
15Asp Gly His His Leu Ala Tyr Arg Thr Phe Phe Ala Leu Lys Gly Leu
20 25 30Thr Thr Ser Arg Gly Glu
Pro Val Gln Ala Val Tyr Gly Phe Ala Lys 35 40
45Ser Leu Leu Lys Ala Leu Lys Glu Asp Gly Tyr Lys Ala Ile
Phe Val 50 55 60Val Phe Asp Ala Lys
Ala Pro Ser Phe Arg His Glu Ala His Glu Ala65 70
75 80Tyr Lys Ala Gly Arg Ala Pro Ser Pro Glu
Asp Phe Pro Arg Gln Leu 85 90
95Ala Leu Ile Lys Glu Leu Val Asp Leu Leu Gly Phe Thr Arg Leu Glu
100 105 110Val Gln Gly Tyr Glu
Ala Asp Asp Val Leu Ala Thr Leu Ala Lys Lys 115
120 125Ala Glu Lys Glu Gly Tyr Glu Val Arg Ile Leu Thr
Ala Asp Arg Asp 130 135 140Leu Tyr Gln
Leu Val Ser Asp Arg Val Ala Val Leu His Pro Glu Gly145
150 155 160His Leu Ile Thr Pro Glu Trp
Leu Trp Glu Lys Tyr Gly Leu Arg Pro 165
170 175Glu Gln Trp Val Asp Phe Arg Ala Leu Val Gly Asp
Pro Ser Asp Asn 180 185 190Leu
Pro Gly Val Lys Gly Ile Gly Glu Lys Thr Ala Leu Lys Leu Leu 195
200 205Lys Glu Trp Gly Ser Leu Glu Asn Leu
Leu Lys Asn Leu Asp Arg Leu 210 215
220Lys Pro Ala Ile Arg Glu Lys Ile Leu Ala His Met Asp Asp Leu Lys225
230 235 240Leu Ser Trp Asp
Leu Ala Lys Val Arg Thr Asp Leu Pro Leu Glu Val 245
250 255Asp Phe Ala Lys Arg Arg Glu Ser Asp Arg
Glu Arg Leu Arg Ala Phe 260 265
270Leu Glu Arg Leu Glu Phe Gly Ser Leu Leu His Glu Phe Gly Leu Leu
275 280 285Glu Ser Pro Lys Ala Leu Glu
Glu Ala Pro Trp Pro Pro Pro Val Gly 290 295
300Ala Phe Val Gly Phe Val Leu Ser Arg Lys Glu Pro Met Trp Ala
Asp305 310 315 320Leu Leu
Ala Leu Ala Ala Ala Arg Gly Gly Arg Val His Arg Ala Pro
325 330 335Glu Pro Tyr Lys Ala Leu Arg
Asp Leu Lys Glu Ala Arg Gly Leu Leu 340 345
350Ala Lys Asp Leu Ser Val Leu Ala Leu Arg Glu Gly Leu Gly
Leu Pro 355 360 365Pro Gly Asp Asp
Pro Met Leu Leu Ala Tyr Leu Leu Asp Pro Ser Asn 370
375 380Thr Thr Pro Glu Val Val Ala Arg Arg Tyr Gly Gly
Glu Trp Thr Glu385 390 395
400Glu Ala Gly Glu Arg Ala Ala Leu Ser Glu Arg Leu Phe Ala Asn Leu
405 410 415Trp Gly Arg Leu Glu
Gly Glu Gly Arg Leu Leu Trp Leu Tyr Arg Gly 420
425 430Val Glu Arg Pro Leu Ser Ala Val Leu Ala His Met
Glu Ala Thr Gly 435 440 445Val Arg
Leu Asp Val Ala Tyr Leu Arg Ala Leu Ser Leu Glu Val Ala 450
455 460Glu Glu Ile Ala Arg Leu Glu Ala Glu Val Phe
Arg Leu Ala Gly His465 470 475
480Pro Phe Asn Leu Asn Ser Arg Asp Gln Leu Glu Arg Val Leu Phe Asp
485 490 495Glu Leu Gly Leu
Pro Ala Ile Gly Lys Thr Glu Lys Thr Gly Lys Arg 500
505 510Ser Thr Ser Ala Ala Val Leu Glu Ala Leu Arg
Glu Ala His Pro Ile 515 520 525Val
Glu Lys Ile Leu Gln Tyr Arg Glu Leu Thr Lys Leu Lys Ser Thr 530
535 540Tyr Ile Asp Pro Leu Pro Asp Leu Ile His
Pro Arg Thr Gly Arg Leu545 550 555
560His Thr Arg Phe Asn Gln Thr Ala Thr Ala Thr Gly Arg Leu Ser
Ser 565 570 575Ser Asp Pro
Asn Leu Gln Asn Ile Pro Val Arg Thr Pro Leu Gly Gln 580
585 590Arg Ile Arg Arg Ala Phe Ile Ala Glu Gly
Gly Trp Leu Leu Val Val 595 600
605Leu Asp Tyr Ser Gln Met Glu Leu Arg Val Leu Ala His Leu Ser Gly 610
615 620Asp Glu Asn Leu Ile Arg Val Phe
Gln Glu Gly Arg Asp Ile His Thr625 630
635 640Glu Thr Ala Ser Trp Met Phe Gly Val Pro Arg Glu
Ala Val Asp Pro 645 650
655Leu Met Arg Arg Ala Ala Lys Thr Ile Asn Phe Gly Val Leu Tyr Gly
660 665 670Met Ser Ala His Arg Leu
Ser Gln Glu Leu Ala Ile Pro Tyr Glu Glu 675 680
685Ala Gln Ala Phe Ile Glu Arg Tyr Phe Gln Ser Phe Pro Lys
Val Arg 690 695 700Ala Trp Ile Glu Lys
Thr Leu Glu Glu Gly Arg Lys Arg Gly Tyr Val705 710
715 720Glu Thr Leu Phe Gly Arg Arg Arg Tyr Val
Pro Asp Leu Asn Ala Arg 725 730
735Val Lys Ser Val Arg Glu Ala Ala Glu Arg Met Ala Phe Asn Met Pro
740 745 750Val Gln Gly Thr Ala
Ala Asp Leu Thr Lys Leu Ala Met Val Lys Leu 755
760 765Phe Pro Arg Leu Glu Glu Thr Gly Ala Arg Met Leu
Leu Gln Val His 770 775 780Asp Glu Leu
Val Leu Glu Ala Pro Lys Glu Arg Ala Glu Ala Val Ala785
790 795 800Arg Leu Ala Lys Glu Val Met
Glu Gly Val Tyr Pro Leu Ala Val Pro 805
810 815Leu Glu Val Glu Val Gly Ile Gly Glu Asp Trp Leu
Ser Ala Lys Gly 820 825
83011059DNAArtificial sequenceHairpin primer for polymerase assay
110tagctcggta acgccggctt ccgtcgcgac cacgttnttc gtggtcgcga cggaagccg
5911161DNAArtificial sequenceHairpin primer for polymerase assays
111tagctcggat tttcgccggc ttccgtcgcg accacgttnt tcgtggtcgc gacggaagcc
60g
6111260DNAArtificial sequenceHairpin primer for polymerase assay
112tagctaccag ggctccggct tccgtcgcga ccacgttntt cgtggtcgcg acggaagccg
6011367DNAArtificial sequenceHairpin primer for polymerase assays
113agctaccatg cctgcacgca gncggcatcc gtcgcgacca cgttnttcgt ggtcgcgacg
60gatgccg
6711423DNAArtificial sequencePrimer for polymerase extension assay
114taatacgact cactataggg aga
2311530DNAArtificial sequenceTemplate for polymerase extension assay
115attatgctga gtgatatccc tctnatcgat
3011628DNAArtificial sequenceTemplate for polymerase extension assay
116attatgctga gtgatatccc tctngtca
2811723DNAArtificial sequencePrimer for polymerase extension assay
117gcggtgtaga gacgagtgcg gag
2311850DNAArtificial sequenceTemplate for polymerase extension assay
118ctctcacaag cagccaggca agctccgcac tcgtctctac accgctccgc
50
User Contributions:
comments("1"); ?> comment_form("1"); ?>Inventors list |
Agents list |
Assignees list |
List by place |
Classification tree browser |
Top 100 Inventors |
Top 100 Agents |
Top 100 Assignees |
Usenet FAQ Index |
Documents |
Other FAQs |
User Contributions:
Comment about this patent or add new information about this topic:
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 | 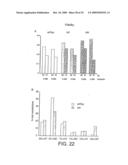 |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
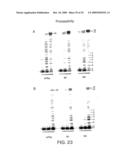 |  |
 |  |
 |  |
 |  |
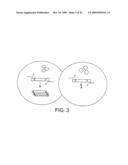 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
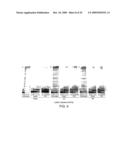 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
| Similar patent applications: | |
| Date | Title |
|---|---|
| 2009-08-13 | Use of dna polymerases |
| 2009-08-20 | Chimeric dna polymerase |
| 2010-02-25 | Novel dna polymerase |
| 2010-07-08 | Dna polymerase fusions and uses thereof |
| 2010-12-09 | Mutant dna polymerases |
| New patent applications in this class: | |
| Date | Title |
|---|---|
| 2011-06-30 | Apparatus and method of authenticating product using polynucleotides |
| 2011-06-30 | Cyanine compounds, compositions including these compounds and their use in cell analysis |
| 2011-06-30 | Method for detecting multiple small nucleic acids |
| 2011-06-30 | Solid-phase chelators and electronic biosensors |
| 2011-06-30 | Cell-based screening assay to identify molecules that stimulate ifn-alpha/beta target genes |
| New patent applications from these inventors: | |
| Date | Title |
|---|---|
| 2016-04-07 | Enzymes |
| 2015-10-01 | Methods for determining resistance against molecules targeting proteins |
| 2015-10-01 | Polymerase capable of producing non-dna nucleotide polymers |
| 2014-05-08 | Dna polymerase |
| Top Inventors for class "Chemistry: molecular biology and microbiology" | |
| Rank | Inventor's name |
|---|---|
| 1 | Marshall Medoff |
| 2 | Anthony P. Burgard |
| 3 | Mark J. Burk |
| 4 | Robin E. Osterhout |
| 5 | Rangarajan Sampath |