Patent application title: TIE-BREAKING IN SHORTEST PATH DETERMINATION
Inventors:
Jerome Chiabaut (Ottawa, CA)
Assignees:
ROCKSTAR CONSORTIUM US LP
IPC8 Class: AH04L12721FI
USPC Class:
370238
Class name: Data flow congestion prevention or control flow control of data transmission through a network least cost or minimum delay routing
Publication date: 2014-10-16
Patent application number: 20140307559
Abstract:
A consistent tie-breaking decision between equal-cost shortest (lowest
cost) paths is achieved by comparing an ordered set of node identifiers
for each of a plurality of end-to-end paths. Alternatively, the same
results can be achieved, on-the-fly, as a shortest path tree is
constructed, by making a selection of an equal-cost path using the node
identifiers of the diverging branches of the tree. Both variants allow a
consistent selection to be made of equal-cost paths, regardless of where
in the network the shortest paths are calculated. This ensures that
traffic flow between any two nodes, in both the forward and reverse
directions, will always follow the same path through the network.Claims:
1-20. (canceled)
21. A method of determining forwarding information for use in forwarding packets at a forwarding node of a packet-forwarding network, each node of the network having a unique node identifier, the method comprising: determining lowest cost paths between a first node and a second node of the network; determining that a plurality of lowest cost path have substantially equal cost, at least one of the lowest cost paths traversing a largest number of nodes and at least one other of the lowest cost paths traversing fewer than the largest number of nodes; and selecting a lowest cost path that satisfies a condition that: processing the plurality of lowest cost paths according to the steps of: for each lowest cost path, sorting respective node identifiers assigned to nodes traversed by the lowest cost path according to a first ordering criterion to derive a respective path identifier; for each lowest cost path traversing fewer nodes than the largest number of nodes, adding at least one additional identifier to the corresponding path identifier, the adding being consistent with the first ordering criterion; and ordering the path identifiers according to a second ordering criterion; would put the path identifier of the selected lowest cost path at one extreme of the ordered path identifiers.
22. The method of claim 21, further comprising selecting the lowest cost path that satisfies the condition by: for each lowest cost path, sorting respective node identifiers assigned to nodes traversed by the lowest cost path according to a first ordering criterion to derive a respective path identifier; for each lowest cost path traversing fewer nodes than the largest number of nodes, adding at least one additional identifier to the corresponding path identifier, the adding being consistent with the first ordering criterion; ordering the path identifiers according to a second ordering criterion; and selecting a lowest cost path having a path identifier at one extreme of the ordered path identifiers.
23. The method of claim 22, wherein adding at least one additional identifier comprises: when the first ordering criterion is increasing ordering, adding at least one additional identifier, each additional identifier being deemed to be higher than all node identifiers; and when the first ordering criterion is decreasing ordering, adding at least one additional identifier, each additional identifier being deemed to be lower than all node identifiers.
24. The method of claim 23, wherein adding at least one additional identifier comprises adding additional identifiers to each path identifier for each lowest cost path traversing fewer nodes than the largest number of nodes until each path identifier has a number of identifiers not less than the largest number of nodes.
25. The method of claim 23, wherein adding at least one additional identifier comprises adding additional identifiers to each path identifier for each lowest cost path traversing fewer nodes than the largest number of nodes until each path identifier has a common number of identifiers.
26. The method of claim 22, wherein: the first ordering criterion is an increasing ordering criterion; and adding at least one identifier comprises adding at least one additional identifier having a value deemed to be greater than any node identifier to a trailing end of the respective path identifier for each lowest cost path traversing fewer nodes than the largest number of nodes.
27. The method of claim 22, wherein: the first ordering criterion is a decreasing ordering criterion; and adding at least one identifier comprises adding at least one additional identifier having a value deemed to be lower than any node identifier to a trailing end of the respective path identifier for each lowest cost path traversing fewer nodes than the largest number of nodes.
28. The method of claim 22, wherein: the first ordering criterion is an increasing ordering criterion; and adding at least one identifier comprises adding additional identifiers having a value deemed to be lower than any node identifier to a leading end of the respective path identifier for each lowest cost path traversing fewer nodes than the largest number of nodes until all path identifiers have a common number of identifiers.
29. The method of claim 22, wherein: the first ordering criterion is a decreasing ordering criterion; and adding at least one identifier comprises adding additional identifiers having a value deemed to be greater than any node identifier to a leading end of the respective path identifier for each lowest cost path traversing fewer nodes than the largest number of nodes until all path identifiers have a common number of identifiers.
30. The method of claim 22, wherein adding at least one additional identifier comprises adding additional identifiers to each path identifier for each lowest cost path traversing fewer nodes than the largest number of nodes until each path identifier has a number of identifiers equal to the largest number of nodes.
31. The method of claim 22, wherein the first ordering criterion is a lexicographic ordering criterion.
32. A network node comprising at least one processor and at least one processor-readable storage medium storing instructions for execution by the at least on processor to determine forwarding information for use in forwarding packets at a forwarding node of a packet-forwarding network in which each node of the network has a unique node identifier, the instructions comprising: instructions executable to determine lowest cost paths between a first node and a second node of the network; instructions executable to determine that a plurality of lowest cost path have substantially equal cost, at least one of the lowest cost paths traversing a largest number of nodes and at least one other of the lowest cost paths traversing fewer than the largest number of nodes; and instructions executable to select a lowest cost path that satisfies a condition that: processing the plurality of lowest cost paths according to the steps of: for each lowest cost path, sorting respective node identifiers assigned to nodes traversed by the lowest cost path according to a first ordering criterion to derive a respective path identifier; for each lowest cost path traversing fewer nodes than the largest number of nodes, adding at least one additional identifier to the corresponding path identifier, the adding being consistent with the first ordering criterion; and ordering the path identifiers according to a second ordering criterion; would put the path identifier of the selected lowest cost path at one extreme of the ordered path identifiers.
33. The network node of claim 32, further comprising instructions executable to select the lowest cost path meeting the condition, comprising: instructions executable to sort, for each lowest cost path, respective node identifiers assigned to nodes traversed by the lowest cost path according to a first ordering criterion to derive a respective path identifier; instructions executable to add, for each lowest cost path traversing fewer nodes than the largest number of nodes, at least one additional identifier to the corresponding path identifier, the adding being consistent with the first ordering criterion; instructions executable to order the path identifiers according to a second ordering criterion; and instructions executable to select a lowest cost path having a path identifier at one extreme of the ordered path identifiers.
34. The network node of claim 33, wherein the instructions executable to add at least one additional identifier comprise instructions executable: when the first ordering criterion is increasing ordering, to add at least one additional identifier, each additional identifier being deemed to be higher than all node identifiers; and when the first ordering criterion is decreasing ordering, to add at least one additional identifier, each additional identifier being deemed to be lower than all node identifiers.
35. The network node of claim 33, wherein the instructions executable to add at least one additional identifier comprises instructions executable to add additional identifiers to each path identifier for each lowest cost path traversing fewer nodes than the largest number of nodes until each path identifier has a number of identifiers not less than the largest number of nodes.
36. The network node of claim 33, wherein the instructions executable to add at least one additional identifier comprises instructions executable to add additional identifiers to each path identifier for each lowest cost path traversing fewer nodes than the largest number of nodes until each path identifier has a common number of identifiers.
37. The network node of claim 33, wherein: the first ordering criterion is an increasing ordering criterion; and the instructions executable to add at least one identifier comprise instructions executable to add at least one additional identifier having a value deemed to be greater than any node identifier to a trailing end of the respective path identifier for each lowest cost path traversing fewer nodes than the largest number of nodes.
38. The network node of claim 33, wherein: the first ordering criterion is a decreasing ordering criterion; and the instructions executable to add at least one identifier comprise instructions executable to add at least one additional identifier having a value deemed to be lower than any node identifier to a trailing end of the respective path identifier for each lowest cost path traversing fewer nodes than the largest number of nodes.
39. The network node of claim 33, wherein: the first ordering criterion is an increasing ordering criterion; and the instructions executable to add at least one identifier comprise instructions executable to add at least one additional identifier having a value deemed to be lower than any node identifier to a leading end of the respective path identifier for each lowest cost path traversing fewer nodes than the largest number of nodes.
40. The network node of claim 33, wherein: the first ordering criterion is a decreasing ordering criterion; and the instructions executable to add at least one identifier comprise instructions executable to add additional identifiers having a value deemed to be greater than any node identifier to a leading end of the respective path identifier for each lowest cost path traversing fewer nodes than the largest number of nodes until all path identifiers have a common number of identifiers.
41. The network node of claim 33, wherein the instructions executable to add at least one additional identifier comprise instructions executable to add additional identifiers to each path identifier for each lowest cost path traversing fewer nodes than the largest number of nodes until each path identifier has a number of identifiers equal to the largest number of nodes.
42. The network node of claim 33, wherein the first ordering criterion is a lexicographic ordering criterion.
Description:
RELATED APPLICATIONS
[0001] This application is a Continuation of U.S. patent application Ser. No. 13/477,366 filed May 22, 2012, which is a Continuation-In-Part of U.S. patent application Ser. No. 13/023,823 filed Feb. 9, 2011, which is a continuation of U.S. patent application Ser. No. 11/964,478 filed Dec. 26, 2007, issued Mar. 22, 2011 as U.S. Pat. No. 7,911,944.
FIELD OF THE INVENTION
[0002] This invention relates to consistently selecting paths among multiple possibilities, such as equal-cost shortest paths, in a packet-forwarding communications network, such as an Ethernet network.
BACKGROUND TO THE INVENTION
[0003] In packet-forwarding communications networks, a node can learn about the topology of the network and can decide, on the basis of the knowledge it acquires of the topology, how it will route traffic to each of the other network nodes. The main basis for selecting a path is path cost, which can be specified in terms of a number of hops between nodes, or by some other metric such as bandwidth of links connecting nodes, or both. Open Shortest Path First (OSPF) and Intermediate System-to-Intermediate System (IS-IS) are widely used link-state protocols which establish shortest paths based on each node's advertisements of path cost. These protocols typically do not attempt to tie-break between multiple, equal-cost, paths. Instead, they typically spread traffic across several equal-cost paths. The spreading algorithms are not specified and can vary from router to router. Alternatively, they may make a local selection of a single path, but without consideration of consistency with the selection made by other routers. Consequently, in either case the reverse direction of a flow is not guaranteed to use the path used by the forward direction.
[0004] Multicast routing protocols such as Multicast Open Shortest Path First (MOSPF) depend on each router in a network constructing the same shortest path tree. For this reason, MOSPF implements a tie-breaking scheme based on link type, LAN vs. point-to-point, and router identifier to ensure that identical trees are produced. However, basing the tie-breaking decision on the parent with the largest identifier implies that, in general, the paths used by the reverse flows will not be the same as the paths used by the forward flows.
[0005] Spanning Tree Protocols (Spanning Tree Protocol (STP), Rapid Spanning Tree Protocol (RSTP), Multiple Spanning Tree Protocol (MSTP) are ways of creating loop-free spanning trees in an arbitrary topology. The Spanning Tree Protocol is performed by each node in the network. All of the Spanning Tree Protocols use a local tie-breaking decision based on (bridge identifier, port identifier) to select between equal-cost paths. In Spanning tree a root node is elected first, and then the tree is constructed with respect to that root by all nodes. So, although all paths are symmetrical for go and return traffic (by definition, a simple tree makes this the only possible construct), the election process is slow and the simple tree structure cannot use any redundant capacity. Similarly, Radia Perlman's Rbridges proposal uses the identifier of the parent node as tie-breaker.
[0006] Mick Seaman in his Shortest Path Bridging proposal to the IEEE 802.1 Working Group (http://www.ieee802.org/1/files/public/docs2005/new-seaman-shortest-path-- 0305-02.pdf) describes a simple protocol enhancement to the Rapid Spanning Tree Protocol which enforces consistent tie-breaking decisions, by adding a `cut vector`. The proposal uses a VID per node, to identify a Spanning Tree per node. In order to fit all the information that needs to be transmitted by a bridge in a single legal Ethernet frame, this technique currently limits the size of the Ethernet network to 32 bridges.
[0007] FIG. 1 illustrates how, even for a trivial network example, a tie-breaking method based on the parent node identifier fails to produce symmetric paths. In this example, the links are considered as having equal-cost and so the determination of path cost simply considers the number of hops. Consider first computing the path from A to B. When the computation reaches node 2, the existence of equal-cost paths will be discovered. There is a first path (A-1-3-6) and a second path (A-1-4-5). If the tie-breaking algorithm selects a path based on the parent node with the smallest identifier, it will select the second path (A-1-4-5) because node identifier 5 is smaller than node identifier 6. However, now consider computing the path from B to A. When the computation reaches node 1, the existence of equal-cost paths will be discovered. There is a first path (B-2-6-3) and a second path (B-2-5-4). Using the same tie-breaking criterion, the tie-breaking algorithm selects the first path (B-2-6-3) because node identifier 3 is smaller than node identifier 4. So, it can be seen that the shortest path computations made by nodes A and B provide inconsistent results.
[0008] There is a requirement in some emerging protocols, such as Provider Link State Bridging (PLSB), a proposal to IEEE 802.laq, to preserve congruency of forwarding across the network for both unicast and unknown/multicast traffic and to use a common path in both forward and reverse directions of flow. Accordingly, it is important that nodes can consistently arrive at the same decision when tie-breaking between equal-cost paths. Furthermore, it is desirable that a node can perform the tie-breaking with the minimum amount of processing effort.
SUMMARY OF THE INVENTION
[0009] A first aspect of the invention provides a method of determining forwarding information for use in forwarding packets at a first node of a packet-forwarding network. The method determines the shortest paths between the first node and a second node of the network and determines when a plurality of shortest paths have substantially equal-cost. The method forms, for each substantially equal-cost path, a set of node identifiers which define the set of nodes in the path and then orders each set of node identifiers using a first ordering criterion to form a path identifier. The first ordering criterion is independent of the order in which node identifiers appear in the path. The method then selects between the plurality of equal-cost paths by comparing the path identifiers. Each node of the network has a unique node identifier.
[0010] Advantageously, the first ordering criterion is increasing lexicographic order or decreasing lexicographic order, although any ordering criterion can be used which creates a totally ordered set of node identifiers.
[0011] Preferably, the method further comprises ordering the plurality of path identifiers into an ordered list using a second ordering criterion. Similarly, the second ordering criterion can be increasing lexicographic order, decreasing lexicographic order or any ordering criterion which creates a totally ordered set of path identifiers.
[0012] Another aspect of the invention provides a method of determining forwarding information for use in forwarding packets at a first node of a packet-forwarding network. The method comprises determining shortest paths between the first node and a second node of the network by iteratively forming a shortest path tree and determines, while forming the shortest path tree, when a plurality of paths have equal-cost, each equal-cost path comprising a branch which diverges from a divergence node common to the equal-cost paths. The method identifies, in each diverging branch, a node identifier using a first selection criterion to form a branch identifier and selects between the plurality of branches by comparing the branch identifiers.
[0013] Advantageously, the method uses a total ordering criterion to compare and select a node identifier in each branch, such as lexicographic order.
[0014] Advantageously, the method records the node identifier which meets the first selection criterion in each of the diverging branches while backtracking to the divergence node. This has an advantage in further simplifying computation and reducing storage requirements.
[0015] Both aspects of the invention can be used to select two equal-cost paths by using different first ordering/selection criteria and a common second ordering/selection criterion or by using a common first ordering criterion/selection and different second ordering/selection criteria. Three or four equal-cost paths can be selected in a similar manner by consistently applying the first and second ordering/selection criteria at nodes and selecting identifiers at a particular position in the ordered lists.
[0016] The invention can be used as a tie-breaker to select between equal-cost paths by comparing an ordered set of node identifiers for each of a plurality of end-to-end paths. Alternatively, it has been found that the same results can be achieved, on-the-fly, as a shortest path tree is constructed, by making a selection of an equal-cost path using the node identifiers of the diverging branches of the tree, local to where the selection decision needs to be made. This has advantages of reducing the amount of computation, and reducing the amount of data which needs to be stored. Branches can be compared on a pair-wise basis to further reduce the amount of computation. This becomes particularly important as the size and complexity of the network increases. Both variants of the invention have the important property of allowing a consistent selection to be made of equal-cost paths, regardless of where in the network the shortest paths are calculated. This ensures that traffic flow between any two nodes, in both the forward and reverse directions, will always follow the same path through the network.
[0017] The invention is not intended to be restricted to any particular way of determining a shortest path: Dijkstra's algorithm, Floyd's algorithm, or any other suitable alternative can be used.
[0018] The invention can be used as a tie-breaker between equal-cost paths having exactly the same value, or paths which are within a desired offset of one another both in terms of link metric or number of hops. This may be desirable in real life situation to increase the diversity between the set of eligible paths. For example, it may not always be cost-effective to deploy nodes and links in the symmetrical fashion in general required to achieve exactly equal-cost between any two end-points. By relaxing the constraint to requiring that the hop count on different routes be within one hop of each other, modest asymmetry can still result in eligible routes, and loop-free topology is still guaranteed because a difference of two hops is the minimum necessary to achieve a looping path.
[0019] It will be understood that the term "shortest path" is not limited to determining paths based only on distance, and is intended to encompass any metric, or combination of metrics, which can be used to specify the "cost" of a link. A non-exhaustive list of metrics is: distance, number of hops, capacity, speed, usage, availability.
[0020] The method is stable in the sense that the selection of an equal-cost shortest path is not affected by the removal of parts of the network that are not on the selected paths, such as failed nodes or links.
[0021] Advantageously, the network is an Ethernet network although the invention can be applied to other types of packet-forwarding networks, especially those that have a requirement for symmetrical traffic-routing paths.
[0022] The functionality described here can be implemented in software, hardware or a combination of these. The invention can be implemented by means of a suitably programmed computer or any form of processing apparatus. Accordingly, another aspect of the invention provides software for implementing any of the described methods. The software may be stored on an electronic memory device, hard disk, optical disk or other machine-readable storage medium. The software may be delivered as a computer program product on a machine-readable carrier or it may be downloaded to a node via a network connection.
[0023] A further aspect of the invention provides a network node comprising a processor which is configured to perform any of the described methods.
[0024] A further aspect of the invention provides a network of nodes which each consistently apply the described methods to select between equal-cost paths.
BRIEF DESCRIPTION OF THE DRAWINGS
[0025] Embodiments of the invention will be described, by way of example only, with reference to the accompanying drawings in which:
[0026] FIG. 1 shows a network topology having equal-cost paths;
[0027] FIG. 2 shows an example of a packet-forwarding network in which the invention can be implemented;
[0028] FIG. 3 schematically shows apparatus at one of the bridging nodes of FIG. 2;
[0029] FIG. 4 shows the locality of shortest paths;
[0030] FIG. 5 shows the locality of tie-breaking decisions;
[0031] FIGS. 6 to 8 show example network topologies for illustrating calculation of shortest paths;
[0032] FIG. 9 shows a further example network topology for illustrating calculation of shortest paths;
[0033] FIGS. 10 to 12 show tie-breaking steps of a shortest path calculation of the network topology shown in FIG. 9;
[0034] FIGS. 13A and 13B illustrate an example of nodes dual-homed onto a mesh network; and
[0035] FIG. 14 shows an example of equal cost paths for which an enhanced tie-breaking technique may be needed to provide results which are consistent from node to node.
DESCRIPTION OF PREFERRED EMBODIMENTS
[0036] FIG. 2 shows an example of a link state protocol controlled Ethernet network 10 in which the invention can be implemented and FIG. 3 schematically shows apparatus at one of the nodes 41-48. Nodes (also called bridges, or bridging nodes) 41-48 forming the mesh network exchange link state advertisements 56 with one another. This is achieved via the well understood mechanism of a link state routing system. A routing system module 51 exchanges information 56 with peer nodes in the network regarding the network topology using a link state routing protocol. This exchange of information allows the nodes to generate a synchronized view of the network topology. At each node, a Shortest Path Determination module 52 calculates a shortest path tree, which determines the shortest path to each other node. The shortest paths determined by module 52 are used to populate a Forwarding Information Base 54 with entries for directing traffic through the network. As will be described in greater detail below, situations will arise when module 52 will encounter multiple equal-cost paths. A tie-breaking module 53 selects one (or more) of the equal-cost paths in a consistent manner. In normal operation, packets are received 57 at the node and a destination lookup module 55 determines, using the FIB 54, the port (or multiple ports in the case of multicast distribution) over which the received packet should be forwarded 58. If there is not a valid entry in the FIB 54 then the packet may then be discarded. It will be appreciated that the modules shown in FIG. 3 are for illustrative purposes only and may be implemented by combining or distributing functions among the modules of a node as would be understood by a person of skill in the art.
[0037] Various shortest path algorithms can be used to determine if a given node is on the shortest path between a given pair of bridges. An all-pairs shortest path algorithm such as Floyd's algorithm [R. Floyd: Algorithm 97 (shortest path), Communications of the ACM, 7:345, 1962] or Dijkstra's single-source shortest path algorithm (E. W. Dijkstra: A note on two problems in connection with graphs, Numerical Mathematics, 1:269-271, 1959] can be implemented in the node 41-48 to compute the shortest path between pairs of nodes. It should be understood that any suitable shortest path algorithm could also be utilized. The link metric used by the shortest path algorithm can be static or dynamically modified to take into account traffic engineering information. For example, the link metric can include a measure of cost such as capacity, speed, usage and availability.
[0038] By way of introduction to the problem, the requirements of a tie-breaking algorithm which can make consistent decisions between equal-cost paths will firstly be described. The list of requirements is set out in Table 1 below:
TABLE-US-00001 TABLE 1 # Requirement Description 1 Complete The tie-breaking algorithm must always be able to choose between two paths 2 Commutative tiebreak(a, b) = tiebreak(b, a) 3 Associative tiebreak(a, tiebreak(b, c)) = tiebreak(tiebreak(a, b), c) 4 Symmetric tiebreak(reverse(a), reverse(b)) = reverse(tiebreak(a, b)) 5 Local tiebreak(concat(a, c), concat(b, c)) = concat(tiebreak(a, b), c)
[0039] The essence of a tie-breaking algorithm is to always `work`. No matter what set of paths the algorithm is presented with, the algorithm should always be able to choose one and only one path. First and foremost, the tie-breaking algorithm should therefore be complete (1). For consistent tie-breaking, the algorithm must produce the same results regardless of the order in which equal-cost paths are discovered and tie-breaking is performed. That is, the tie-breaking algorithm should be commutative (2) and associative (3). The requirement that tie-breaking between three paths must produce the same results regardless of the order in which pairs of paths are considered (3) is not so obvious and yet it is absolutely necessary for consistent results as equal-cost paths are discovered in a different order depending on the direction of the computation through the network The tie-breaking algorithm must be symmetric (4), i.e. the tie-breaking algorithm must produce the same result regardless of the direction of the path: the shortest path between two nodes A and B must be the reverse of the shortest path between B and A. Finally, locality is a very important property of shortest paths that is exploited by routing systems (5). The locality property simply says that: a sub-path of a shortest path is also a shortest path. This seemingly trivial property of shortest paths has an important application in packet networks that use destination-based forwarding. In these networks, the forwarding decision at intermediate nodes along a path is based solely on the destination address of the packet, not its source address. Consequently, in order to generate its forwarding information, a node needs only compute the shortest path from itself to all the other nodes and the amount of forwarding information produced grows linearly, not quadratically, with the number of nodes in the network. In order to enable destination-based forwarding, the tie-breaking algorithm must therefore preserve the locality property of shortest paths: a sub-path of the shortest path selected by the tie-breaking algorithm must be the shortest path selected by the tie-breaking algorithm.
[0040] Considerations of computational efficiency put another seemingly different requirement on the tie-breaking algorithm: the algorithm should be able to make a tie-breaking decision as soon as equal-cost paths are discovered. FIG. 5 illustrates this point. An intermediate node I is connected by two equal-cost paths, p and q, to node A and by another pair of equal-cost paths, r and s, to node B. There are therefore four equal-cost paths between nodes A and B, all going through node I: p+r, p+s, q+r, q+s. As the computation of the shortest path from A to B progresses, the existence of equal-cost sub-paths between A and I will be discovered first. To avoid having to carry forward knowledge of these two paths, the tie-breaking algorithm should be able to choose between them as soon as the existence of the second equal-cost shortest sub-path is discovered. The tie-breaking decisions made at intermediate nodes will ultimately affect the outcome of the computation. By eliminating one of the two sub-paths, p and q, between nodes A and I, the algorithm removes two of the four shortest paths between nodes A and B from further consideration. Similarly, in the reverse direction, the tie-breaking algorithm will choose between sub-paths r and s before making a final determination. These local decisions must be consistent with one another and, in particular, the choice between two equal-cost paths should remain the same if the paths were to be extended in the same way. For instance, in the case depicted in FIG. 3, the tie-breaking algorithm should verify the following four identities:
[0041] tiebreak(concat(p, r), concat(q, r))=concat(tiebreak(p, q), r)
[0042] tiebreak(concat(p, s), concat(q, s))=concat(tiebreak(p, q), s)
[0043] concat(p, tiebreak(r, s))=tiebreak(concat(p, r), concat(p, s))
[0044] concat(q, tiebreak(r, s))=tiebreak(concat(q, r), concat(q, s))
[0045] It turns out that the symmetry (4) and locality (5) conditions are both necessary and sufficient to guarantee that the tie-breaking algorithm will make consistent local decisions, a fact that can be exploited to produce very efficient implementations of the single-source shortest path algorithm in the presence of equal-cost shortest paths.
[0046] The list of requirements set out in Table 1 is not intended to be exhaustive, and there are other properties of shortest paths that could have been included in Table 1. For example, if a link which is not part of a shortest path is removed from the graph, the shortest path is not affected. Likewise, the tie-breaking algorithm's selection between multiple equal-cost paths should not be affected if a link which is not part of the selected path is removed from the graph, and that even if this link is part of some of the equal-cost paths that were rejected by the algorithm.
[0047] A first embodiment of a consistent tie-breaking algorithm will now be described. This algorithm begins by forming a path identifier for each path. The path identifier is an ordered list of the identifiers of each node traversed by the path through the network. The node identifiers are sorted in lexicographic order. The path identifier is the resulting concatenation of the ordered node identifiers. FIG. 6 shows an example network, with end nodes A, B and intermediate nodes 0-9. A first path (along the top of FIG. 6) between nodes A and B traverses nodes having the node identifiers A-0-5-6-1-4-8-B. After ordering the list of node identifiers in ascending lexicographic order, the path can be represented by the path identifier 014568AB. This construction ensures that a path and its reverse will have the same path identifier. Furthermore, because the algorithm is only dealing with shortest paths or nearly shortest paths, only two paths--the direct path and the corresponding reverse path--can share an identifier. Finally, the tie-breaking algorithm simply selects the path with the smallest (or largest) path identifier. The algorithm can be summarised as:
[0048] 1) Sort the set of identifiers of the nodes in the path according to a first ordering criterion which achieves a total ordering of the set of node identifiers. A preferred first ordering criterion is increasing or decreasing lexicographic order;
[0049] 2) Concatenate the set of ordered node identifiers to create a path identifier;
[0050] 3) Sort the path identifiers according to a second ordering criterion which achieves a total ordering of the set of path identifiers. A preferred second ordering criterion is increasing or decreasing lexicographic order;
[0051] 4) Select the path whose path identifier appears at one end (first or last) of the sorted set of path identifiers. Advantageously, this step selects the path identifier appearing first in the ordered set of path identifiers.
[0052] Each node in the network that performs this algorithm consistently uses the same ordering criteria and selects a path at the same agreed position in the set of path identifiers, in order to select the same path.
[0053] The term "lexicographic order" means the set of node identifiers are arranged in order of size of identifier. So, if node identifiers are alphabetic, the set of node identifiers are arranged in alphabetic order A, B, C, D . . . etc.; if node identifiers are numerical, the set of node identifiers are arranged in numerical order. Clearly, this scheme can accommodate any way of labelling nodes, and any combination of types of identifier. For example, a mix of numbers and letters could be ordered by agreeing an order for numbers with respect to letters (e.g. order numbers first, then letters). Alternatively, each character can be given its American Standard Code for Information Interchange (ASCII) code and the ASCII codes can be sorted in increasing (decreasing) order. Each node uses the same convention to order the node identifiers of paths in the same manner. This algorithm will produce consistent results because: there is a one-to-one mapping between a path (strictly speaking between the pair made up of a path and its reverse) and its identifier, and there is a strict ordering of the path identifiers.
[0054] Referring again to FIG. 6, the top path between nodes A and B is represented, after ordering, by the path identifier 014568AB. Similarly, a second path between nodes A and B traverses nodes A-0-7-9-1-4-8-B and this can be represented, after ordering, by the path identifier 014789AB. Finally, a third path (along the bottom of FIG. 6) between nodes A and B traverses nodes A-0-7-9-2-3-8-B and this can be represented, after ordering, by the path identifier 023789AB. The tie-breaking algorithm compares each element of the ordered path identifier, in an agreed direction. In this example, the convention that will be used is that each node selects the lowest of the ordered path identifiers, when the path identifiers are compared in a particular direction (e.g. left-to-right). The ordered path identifiers, for the three equal-cost paths are:
[0055] 014568AB
[0056] 014789AB
[0057] 023789AB
[0058] Starting with the left-hand element of the identifiers, all three path identifiers begin with `0`. The next elements are `1` or `2`, so only the top two identifiers need to be considered any further. Reaching the fourth element, "0145 . . . " is smaller than "0147 . . . " and so the top path is selected. Real node identifiers in IS-IS and Ethernet are composed of six 8-bit bytes and are usually written as an hexadecimal string such as: 00-e0-7b-c1-a8-c2. Nicknames of nodes can also be used, providing they are used consistently.
[0059] FIG. 7 shows a simple network topology to illustrate the effects of different ordering criteria. Two nodes, X, Y, are connected by four equal-cost paths having the node identifiers 1-8. Four possible options will now be described:
[0060] sort node IDs by ascending order; sort path IDs by ascending order; select first (smallest) path ID. If the node identifiers in each path are ordered in ascending order of size (e.g. the top path with nodes 1, 7 becomes 17), that gives the path identifiers 17, 28, 35, 46. Arranging these path identifiers in ascending order of size, and selecting the first path identifier in the ordered list, has the result of selecting the first (top) path, with the nodes 1 and 7.
[0061] sort node IDs by ascending order; sort path IDs by ascending order; select last (largest) path ID. This option has the result of selecting the last (bottom) path, with the nodes 4 and 6.
[0062] sort node IDs by descending order; sort path IDs by ascending order; select first (smallest) path ID. Sorting the node identifiers in each path in descending order of size gives path identifiers (71, 82, 53, 64). Arranging these path identifiers in ascending order of size gives (53, 64, 71, 82) and selecting the first (smallest) path identifier in the ordered list, has the result of selecting the third path, with the nodes 3 and 5.
[0063] sort node IDs by descending order; sort path IDs by ascending order; select last (largest) path ID. This option has the result of selecting the second path, with the nodes 8 and 2.
[0064] As will be described in more detail below, there are situations in which it is desirable for nodes to apply multiple, different, ordering and/or selection criteria to select multiple equal-cost paths.
[0065] So far this description assumes that the algorithm is non-local and that tie-breaking is performed after all the equal-cost paths have been found. However, it has been found that a local version of this algorithm can produce the same results by considering only the nodes on the diverging branches. Indeed, the tie-breaking result depends only on the relative positions of the smallest node identifier in the diverging branches. A second embodiment of a consistent tie-breaking algorithm can be summarised as:
[0066] 1) Find the node identifier in the diverging branch of the first path which meets a first selection criterion. This can be considered a branch identifier for the first path;
[0067] 2) Find the node identifier in the diverging branch of the second path which meets the first selection criterion. This can be considered a branch identifier for the second path;
[0068] 3) Select one of the paths using a second selection criterion, which operates on the branch identifiers selected by steps (1) and (2).
[0069] Preferred options for the first selection criterion are to find the node identifier which is the first (or last) when the node identifiers are arranged using a total ordering scheme, such as lexicographic order (increasing or decreasing lexicographic order). As will be explained below, it is not necessary for the scheme to compile the total set of node identifiers in a branch and then order the set. Instead, the scheme can iteratively compare pairs of node identifiers using an awareness of lexicographic order. Similarly, preferred options for the second selection criterion are to find the branch identifier which is the first (or last) when the branch identifiers are arranged using a total ordering scheme, such as lexicographic order (increasing or decreasing lexicographic order).
[0070] Referring again to the topology of FIG. 7, the four equal-cost paths between nodes X and Y can represent four equal-cost diverging branches from a parent node X. The tie-breaking algorithm needs to select one of the four branches. There are four possible options:
[0071] identify the smallest node ID in each branch. This results in (1, 2, 3, 4) as the branch identifiers. Then, identify the smallest of the branch identifiers. This has the result of selecting the first (top) path, with the nodes 1 and 7.
[0072] identify the smallest node ID in each branch. Then, identify the largest of the branch identifiers. This option has the result of selecting the last (bottom) path, with the nodes 4 and 6.
[0073] identify the largest node ID in each branch. This results in (5, 6, 7, 8) as the branch identifiers. Then, identify the smallest of the branch identifiers. This has the result of selecting the path with the nodes 3 and 5.
[0074] identify the largest node ID in each branch. Then, identify the largest of the branch identifiers. This option has the result of selecting the path with the nodes 2 and 8.
[0075] As will be described in more detail below, there are situations in which it is desirable for nodes to apply multiple, different, ordering and/or selection criteria to select multiple equal-cost paths.
[0076] This algorithm can be implemented very easily and efficiently with simple comparisons. FIG. 8 shows another network topology. The local version of the method, will start at node 13, and proceed to find two diverging paths leading from node 15. The method explores the two separate paths as far as node 16, where the two paths converge again. At this point, the method examines the node identifiers for each of the two paths. For the first path, the node identifiers are: 10, 14, 17, 21 and for the second path the node identifiers are: 11, 12, 19, 20. The path with the lowest identifier (10) is the top path. Two ways of comparing the paths will be described. Firstly, the method can maintain a list of node identifiers for each of the diverging paths and can compare the elements of these lists. Alternatively, the method can simply backtrack from node 16 towards node 15, keeping track of the lowest node identifier found in each branch. At each backward step, the method compares the lowest node identifier found so far, with the new node identifier encountered at that step. The lowest node identifier is stored. When the method has backtracked as far as node 15, the two lowest values (10 in the top branch, 11 in the lower branch) can simply be compared to one another to find the path having the lowest node identifier. Accordingly, the top path is selected.
[0077] One of the most common algorithms for finding shortest cost paths in a network is Dijkstra's algorithm [Dijkstra 59]. It solves the problem of finding the shortest paths from a point in a graph (the source or root node) to all possible destinations when the length of a path is defined as the sum of the positive hop-by-hop link costs. This problem is sometimes called the single-source shortest paths problem. For a graph, G=(N, L) where N is a set of nodes and L is a set of links connecting them, Dijkstra's algorithm uses a priority queue, usually called TENT, to visit the nodes in order of increasing distance from the source node. The other data structures needed to implement Dijkstra's algorithm are:
[0078] Distance: an array of best estimates of the shortest distance from the source node to each node
[0079] Parent: an array of predecessors for each node
[0080] The following text describes the known Dijkstra's algorithm, and describes how it can be modified to perform a tie-break when multiple equal-cost paths are discovered. Dijkstra's algorithm is described here because it is one of the most commonly used shortest path finding algorithms. However, it will be appreciated that other algorithms could equally be used. The initialization phase sets the Distance of each node, except the source node itself, to Infinity. The Distance of the source node is set to zero and its Parent is set to Null as it is the root of the tree. At the start of the computation, the priority queue contains only the source node. As the algorithm progresses, nodes are added to the priority queue when a path from the source node to them is found. Nodes are pulled out of the priority queue in order of increasing distance from the source node, after the shortest path between them and the source node has been found. The algorithm stops when all the nodes reachable from the source node have been cycled through the priority queue. While the priority queue TENT is not empty, the algorithm performs the following steps:
[0081] 1) Find the node N in TENT which is closest to the source node and remove it from TENT
[0082] 2) For each node connected to N, if the node's distance to the source would be reduced by making N its parent, then change the node's parent to N, set the node's distance to the new distance, and add the node to TENT.
[0083] Upon completion of the algorithm, Distance(node) contains the shortest distance from the source node to the node (or Infinity if the node is not reachable from the source node) and Parent(node) contains the predecessor of the node in the spanning tree (except for the source node and the nodes which are not reachable from the source node). The parent of a node is updated only if changing parents actually reduces the node's distance. This means that, if multiple equal-cost shortest paths exist between the source node and some other node, only the first one encountered during the execution of the algorithm will be considered.
[0084] The above steps are conventional steps of Dijkstra's algorithm. At this point Dijkstra is modified to add a consistent tie-breaking step. Step 2 above is modified as follows:
[0085] 2) For each node connected to node N do the following:
[0086] 2a) if the node's distance to the source would be reduced by making N its parent, then change the node's parent to N, set the node's distance to the new distance, and add the node to TENT.
[0087] 2b) if the node's distance to the source node would remain the same after making N its parent, then invoke the tie-breaking algorithm to determine if the node's parent should be changed.
[0088] The tie-breaking algorithm is invoked when a convergence point of two diverging branches is reached. For example, considering the topology shown in FIG. 8, if Dijkstra's algorithm is started from node 13, diverging branches are discovered leading from node 15 (an upper branch with nodes 10, 14, 17, 21 and a lower branch with nodes 11, 12, 19, 20) and these diverging branches converge at node 16. It is at node 16 that the tie-breaking algorithm would be invoked to select between the two branches.
[0089] The pseudo-code below shows an implementation of the modified Dijkstra's algorithm with consistent tie-breaking using a priority queue implementation of the TENT set. The Enqueue operation takes two arguments, a queue and a node, and puts the node in the proper queue position according to its distance from the source node. The Dequeue operation removes from the queue the node at the head of the queue i.e. the node with the smallest distance from the source node.
TABLE-US-00002 for each Node in Network do Distance(Node) = Infinity; Empty(Tent); Distance(Source) = 0; Parent(Source) = Null; Node = Source; do for each Link in OutgoingLinks(Node) do newDistance = Distance(Node) + Cost(Link); Child = EndNode(Link); if (newDistance < Distance(Child) do Distance(Child) = newDistance; Parent(Child) = Node; Enqueue(Tent, Child); else if (newDistance == Distance(Child) do Parent(Child) = TieBreak(Node, Parent(Child)); while (Node = Dequeue(Tent));
[0090] The tie-breaking algorithm operates by back-tracking the two equal-cost paths, starting from the current parent and the new candidate parent of the node respectively, all the way back to the divergence point. The fact that the two diverging paths may have a different number of hops complicates matters slightly as the two paths must be backtracked by an unknown, un-equal number of hops. This problem can be resolved by always back-tracking the longer of the two paths first or both simultaneously when they have equal-cost. Alternatively, this difficulty can be eliminated altogether by ensuring that two paths will only be considered to be of equal-cost if, and only if, they have the same number of hops. This is easily accomplished by either incorporating a hop count in the path cost or by using the hop count as a first order tie-breaker.
[0091] The following pseudo-code shows an implementation of the tie-breaking algorithm that assumes that the two paths have the same number of hops (and therefore so do their diverging branches). The tie-breaking function takes the two nodes at the end of two equal paths and returns one of them to indicate which of the two paths it selected.
TABLE-US-00003 old = oldParent; new = newParent; oldMinld = Sysld(old); newMinld = Sysld(new); while ((old=Parent(old)) != (new=Parent(new))) do tmp = Sysld(old); if (tmp < oldMinld) do oldMinld = tmp; tmp = Sysld(new); if (tmp < newMinld) do newMinld = tmp; if (newMinld < oldMinld) return newParent; else return oldParent;
[0092] The frequency with which the algorithm needs to be performed depends on the application. PLSB essentially needs to compute the all-pairs shortest paths (sometimes a subset thereof). In this case Dijkstra's algorithm needs to be run for all the nodes in the network (all but one to be precise). Floyd's algorithm computes the all-pairs shortest paths so it would need to be run only once. Other applications may only require the computation of a smaller number of paths (e.g. if only one shortest path is required then Dijkstra's algorithm would have to be run only once with one of the path's endpoints as the source).
[0093] FIG. 9 shows an example network of nodes A-H, J interconnected by links. For each link, a metric associated with that link is shown as an integer value on the link. There are six different, equal-cost, shortest paths between node A and node B in this network. These are shown in the table below with their respective length and path identifier:
TABLE-US-00004 Path AGDHB AGCHB AGCJB AFCHB AFCJB AFEJB Length 10 10 10 10 10 10 Identifier ABDGH ABCGH ABCGJ ABCFH ABCFJ ABEFJ
[0094] All of these six paths have the same length, 10. The non-local version of the tie-breaking algorithm will select the one with the smallest path identifier (ABCFH), i.e. path AFCHB. The remainder of this section shows how the local version of the tie-breaking algorithm arrives at the same result by making only local tie-breaking decisions as equal-cost paths and sub-paths are discovered during the execution of Dijkstra's algorithm. Dijsktra's algorithm initializes a table of distances and parents (or predecessors) for the nodes in the network. All the distances are initially set to infinity except for the source node whose distance is set to zero. The parents are undefined at this stage:
TABLE-US-00005 Node A B C D E F G H J Distance 0 ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞ Parent -- -- -- -- -- -- -- -- --
[0095] Dijkstra's algorithm also initializes its priority queue to contain only the source node, A: TENT=[(A, 0)].
[0096] The first iteration of the Dijkstra loop selects the first and only node in TENT, node A. Then for each of node A's neighbours, namely nodes F and G, it updates their distance to the source and makes node A their parent. Finally these two nodes are added to the TENT priority queue.
[0097] During this first iteration of Dijkstra's algorithm the table of distances and parents becomes:
TABLE-US-00006 Node A B C D E F G H J Distance 0 ∞ ∞ ∞ ∞ 2 1 ∞ ∞ Parent -- -- -- -- -- A A -- --
[0098] At the end of this first iteration the priority queue is: TENT=[G, 1), (F, 2)].
[0099] The second iteration of the Dijkstra loop removes the node with the smallest distance, node G, from the priority queue. It updates two of G's neighbours that have not been processed yet, nodes C and D, and adds them to the priority queue:
TABLE-US-00007 Node A B C D E F G H J Distance 0 ∞ 5 4 ∞ 2 1 ∞ ∞ Parent -- -- G G -- A A -- --
[0100] At the end of the second iteration, the priority queue is: TENT=[F, 2), (D, 4), (C, 5)].
[0101] The third iteration of the Dijkstra loop removes node F from the priority queue. It updates two neighbours of node F, nodes C and E, and adds node E to the priority queue (node C is there already). The distance of node C does not change but there is a new candidate equal path between node A and node C going through node F. The tie-breaking algorithm must therefore be invoked to choose between this new path going through node F and the old one going through node G. This is shown in FIG. 10. The tie-breaking algorithm is invoked with the new candidate parent of node C, node F, and its old parent, node G. oldMin is set to the identifier of the old parent, G, and newMin is set to the identifier of the new parent, F. Because nodes F and G share the same parent (node A), the backtracking loop is not executed. The tiebreaking simply compares oldMin and newMin and because newMin=F<G=oldMin, node F is selected as the new parent of node C:
TABLE-US-00008 Node A B C D E F G H J Distance 0 ∞ 5 4 4 2 1 ∞ ∞ Parent -- -- F G F A A -- --
[0102] At the end of the third iteration, the priority queue is: TENT=[D, 4), (E, 4), (C, 5)]. The fourth iteration of the Dijkstra loop removes one of the two nodes with distance 4, node D 10 for instance, from the priority queue. Of D's two neighbours only one, node H, is updated and added to the priority queue:
TABLE-US-00009 Node A B C D E F G H J Distance 0 ∞ 5 4 4 2 1 6 ∞ Parent -- -- F G F A A D --
[0103] At the end of the fourth iteration, the priority queue is: TENT=[E, 4), (C, 5), (H, 6)].
[0104] The fifth iteration of the Dijkstra loop removes node E from the priority queue. Of E's two neighbours only one, node J, is updated and added to the priority queue.
TABLE-US-00010 Node A B C D E F G H J Distance 0 ∞ 5 4 4 2 1 6 6 Parent -- -- F G F A A D E
[0105] At the end of the fifth iteration, the priority queue is: TENT=[C, 5), (H, 6), (J, 6)].
[0106] The sixth iteration of the Dijkstra's loop removes node C from the priority queue. Two of C's neighbours, nodes J and H, have equal-cost paths to node A through node C. The tie-breaking algorithm must therefore be invoked twice for nodes J and H respectively.
[0107] For node J, the tie-breaking algorithm is invoked with the new potential parent, node C, and the old parent, node E. oldMin is set to the identifier of the old parent, E, and newMin is set to the identifier of the new parent, C. Because these two nodes, E and C, share the same parent (node F), the backtracking loop is not executed. The tiebreaking simply compares oldMin and newMin and because newMin=C<E=oldMin, the new parent is selected. Node J's parent is therefore replaced by node C. This is shown in FIG. 11.
[0108] For node H, the tie-breaking algorithm is invoked with the new potential parent, node C, and the old parent, node D. oldMin is set to the identifier of the old parent, D, and newMin is set to the identifier of the new parent, C. Because these two nodes have different parents, both paths must be backtracked one hop further. D's parent is G and because G>oldMin (=D), oldMin does not change. C's parent is F and because F>newMin (=C), newMin does not change either. Because F and G share the same parent, node A, the backtracking loop stops. The tiebreaking algorithm then compares oldMin and newMin and because newMin=C<D=oldMin, node C is selected to become node H's new parent. This is shown in FIG. 12.
TABLE-US-00011 Node A B C D E F G H J Distance 0 ∞ 5 4 4 2 1 6 6 Parent -- -- F G F A A C C
[0109] At the end of the sixth iteration, the priority queue is: TENT=[H, 6), (J, 6)].
[0110] The seventh iteration of the Dijkstra's loop removes one of the two nodes with distance 6, node H for instance, from the priority queue. Only one of H's neighbours, node B, is updated and added to the priority queue:
TABLE-US-00012 Node A B C D E F G H J Distance 0 10 5 4 4 2 1 6 6 Parent -- H F G F A A C C
[0111] At the end of the seventh iteration, the priority queue is: TENT=[J, 6), (B, 10)].
[0112] The eighth iteration of the Dijkstra's loop removes node J from the priority queue. Of J's neighbours, only node B needs to be updated. Its distance does not change but there is a new candidate equal path between node A and node B going through node J.
[0113] The tie-breaking algorithm is invoked with the new potential parent of node B, node J, and the old parent, node H. oldMin is set to the identifier of the old parent, H, and newMin is set to the identifier of the new parent, J. Because these two nodes, H and J, share the same parent (node C), the backtracking loop is not executed. The tiebreaking simply compares oldMin and newMin and because oldMin=H<J=newMin, the old parent is selected and node B's parent remains the same.
TABLE-US-00013 Node A B C D E F G H J Distance 0 10 5 4 4 2 1 6 6 Parent -- H F G F A A C C
[0114] At the end of the eighth iteration, the priority queue is: TENT=[B, 10)].
[0115] Finally the last iteration of the Dijkstra's loop removes node B from the queue and the algorithm terminates because none of B's neighbours can be updated (node B is the node that is the furthest away from the source node A).
[0116] The reverse of the shortest path from node A to node B can be read directly from the parent table starting at node B and following the parents until node A is reached: BHCFA. The shortest path from node A to node B selected by the local tie-breaking algorithm is therefore its reverse path: AFCHB.
[0117] Although there are 6 equal-cost paths between nodes A and B, the local tie-breaking was only invoked a total of 4 times during the execution of Dijkstra's algorithm. At its first invocation, the tie-breaking algorithm had to choose between sub-paths AFC and AGC. It selected sub-path AFC, thereby eliminating two paths, AGCJB and AGCHB, from further consideration. At its second invocation, the tie-breaking algorithm had to choose between sub-paths AFCJ and AFEJ. It selected sub-path AFCJ, thereby eliminating a third path, AFEJB, from further consideration. At its third invocation, the tie-breaking algorithm had to choose between sub-paths AGDH and AGCH. It selected sub-path AGCH, thereby eliminating a fourth path, AGDHB, from further consideration. Finally, at its fourth invocation, the tie-breaking algorithm had to choose between paths AFCHB and AFCJB. It eliminated a fifth path, AFCJB, and selected path AFCHB as the final solution.
Selection of Equal-Cost Multi-Paths for Load Spreading
[0118] In many networking applications it is often advantageous to use several equal-cost paths, especially if this can be achieved in a consistent fashion. By using two variants of the tie-breaking algorithm, it is possible to use two equal-cost paths between a pair of nodes when they exist. FIG. 13 shows a common networking scenario in which edge nodes X and Y are each dual-homed on a full mesh of core nodes A, B, C, D. For redundancy, each edge node is connected to two core nodes, with node X connected to core nodes A and B and node Y connected to nodes C and D. Each core node is connected to all of the other core nodes, e.g. node A is connected to B, C, and D. The problem with this topology is that if only one shortest path is used between a pair of nodes, a lot of access capacity will be wasted under normal circumstances. When multiple equal-cost shortest paths exist between two nodes, two variants of the tie-breaking algorithm can be used to consistently select exactly two paths. Any convention, agreed by all nodes, can be used to make the selection between equal-cost paths. One particularly convenient convention is to select a first path having the smallest identifier and a second path having the largest identifier. In FIG. 13, since the core nodes are fully meshed, four equal-cost paths exist between the edge nodes X and Y: (X, A, C, Y), (X, A, D, Y), (X, B, C, Y), (X, B, D, Y). The two variants of the tie-breaking algorithm will select these two paths:
[0119] (X, min(A, B), min(C, D), Y) and,
[0120] (X, max(A, B), max(C, D), Y).
[0121] Because the node identifiers are unique, min(A, B) !=max(A, B) and min(C, D) !=max(C, D): these two paths are maximally diverse: they have only their endpoints in common. In FIGS. 13A and 13B, the two selected paths are (X, A, C, Y) and (X, B, D, Y).
Tie-Breaking for Equal-Cost Shortest-Paths with Different Hop Counts
[0122] The 4 variants of the local tie breaking technique described above as the second embodiment are defined by the following rules--
[0123] 1. Select the branch that contains the smallest node identifier.
[0124] 2. Select the branch that does not contain the smallest node identifier.
[0125] 3. Select the branch that contains the largest node identifier.
[0126] 4. Select the branch that does not contain the largest node identifier.
[0127] As defined above, all 4 variants are effective for equal cost paths traversing unequal numbers of nodes. However, the global tie breaking technique described above as the first embodiment may not be effective where equal cost paths traverse different numbers of nodes. One such situation is illustrated in FIG. 14. Each of the links A-C, C-B and B-D are assigned a cost of 1, and link A-B is assigned a cost of 2. Consequently paths A-C-B and A-B each have a cost of 2 and are equal cost paths. Using the techniques described above, the identifier of path A-B, AB is lexicographically ordered ahead of ABC, the identifier of path A-C-B. However, adding the link B-D, paths A-C-B-D and A-B-D each have a cost of 3 and are also equal cost paths. Using the techniques described above, the identifier of path A-C-B-D, ABCD is lexicographically ordered ahead of ABD, the identifier of path A-B-D. So a tie breaking algorithm that selects path A-B over path A-C-B would also select path A-C-B-D over path A-B-D, a result which is not consistent with the locality property discussed above.
[0128] The 4 variants of the global tie breaking technique described above as the first embodiment are defined by the following rules--
[0129] 1. Sort the node identifiers in increasing order to form path identifiers, sort the path identifiers lexicographically and select the path whose identifier is first among the sorted path identifiers.
[0130] 2. Sort the node identifiers in increasing order to form path identifiers, sort the path identifiers lexicographically and select the path whose identifier is last among the sorted path identifiers.
[0131] 3. Sort the node identifiers in decreasing order to form path identifiers, sort the path identifiers lexicographically and select the path whose identifier is first among the sorted path identifiers.
[0132] 4. Sort the node identifiers in decreasing order to form path identifiers, sort the path identifiers lexicographically and select the path whose identifier is last among the sorted path identifiers.
[0133] As defined above, the variants 3 and 4 of the global tie breaking algorithm are effective for equal cost paths traversing unequal numbers of nodes, but variants 1 and 2 do not always provide consistent results.
[0134] Variants 1 and 2 of the global tie breaking technique do not work properly when a path identifier for one of the equal cost paths is a prefix of a path identifier for another of the equal cost paths. The problem arises because the shorter path identifier runs out of node identifiers before a path selection can be made.
[0135] To address this problem, shorter path identifiers may be padded out by adding dummy node identifiers so that the path identifiers for all of the equal cost paths to be compared have the same number of node identifiers. However, the padding should be consistent with the ordering criterion that is used to form the path identifiers.
[0136] For example, it may seem natural to add null identifiers that are accorded a lower value than any node identifier to the trailing end of identifiers of paths having fewer nodes than other equal cost paths until all equal cost path identifiers have the same length. This is the convention adopted, for instance, when ordering words in a dictionary. However, this is not consistent with sorting the identifiers of the nodes in each path in order of increasing value.
[0137] If the node identifiers in each path are sorted in order of increasing value to derive the path identifiers, special identifiers that are accorded a higher value than any node identifier should be added to the trailing end of path identifiers having fewer node identifiers than other equal cost path identifiers until all equal cost path identifiers have the same length. Alternatively, null identifiers that are accorded a lower value than any node identifier may be added to the leading end of path identifiers having fewer node identifiers than other equal cost path identifiers until all equal cost path identifiers have the same length.
[0138] Similarly, if the node identifiers in each path are sorted in order of decreasing value to derive the path identifiers, null identifiers that are accorded a lower value than any node identifier should be added to the trailing end of path identifiers having fewer node identifiers than other equal cost path identifiers until all equal cost path identifiers have the same length. This is the conventional lexicographic ordering. Alternatively, special identifiers that are accorded a higher value than any node identifier may be added to the leading end of path identifiers having fewer node identifiers than other equal cost path identifiers until all equal cost path identifiers have the same length.
[0139] In summary, there are 8 variants of the global tie breaking technique generalized to handle equal cost paths traversing different nodes--
TABLE-US-00014 TABLE 2 End of Path Value of Ordering Criterion ID Used for Added Dummy Path ID Variant for Node IDs Additions IDs Selection 1 Increasing Trailing End Maximum First 2 Increasing Trailing End Maximum Last 3 Decreasing Trailing End Minimum First 4 Decreasing Trailing End Minimum Last 5 Increasing Leading End Minimum First 6 Increasing Leading End Minimum Last 7 Decreasing Leading End Maximum First 8 Decreasing Leading End Maximum Last
[0140] There are several ways of achieving the desired results when the node identifiers in each path are sorted in order of increasing value to derive path identifiers. For instance, instead 5 of padding out path identifiers having fewer node identifiers by adding special identifiers to their trailing end until all equal cost path identifiers have the same length, it is sufficient to add a single special identifier that is accorded a higher value than any node identifier to the trailing end of the shorter path identifiers prior to ordering the path identifiers lexicographically. Yet another way to achieve the same result is to perform a lexicographic comparison of the path identifiers as a first ordering criterion but to use the number of hops as a secondary ordering criterion if, and only if, one of the path identifiers runs out before a determination can be made by the lexicographic comparison. In other words, when one of the path identifiers is a prefix of the other path identifier, the path with the longer identifier is deemed to come before the path with the shorter identifier. Lexicographic ordering of equal length strings is used as the primary ordering criterion and the length of the path identifiers (i.e. the number of hops in the path) is used as a secondary ordering criterion when one of the path identifiers run out before the lexicographic comparison can make a determination. In this case, the path with the larger number of hops is deemed to come before the path with the smaller number of hops.
[0141] Conversely, instead of padding out path identifiers having fewer node identifiers by adding null identifiers to their leading end until all equal cost path identifiers have the same length, one may simply chose to order paths with a smaller number of hops ahead of paths with a larger number of hops. Lexicographic ordering of path identifiers is then used as a secondary ordering criterion for paths with a same number of hops. In this case, paths with a smaller number of hops are deemed to come before paths with a larger number of hops. The length of the path identifiers is used as the primary ordering criterion--paths with fewer hops are always before paths with more hops--and lexicographic ordering is used as a secondary ordering criterion for paths with a same number of hops.
[0142] Similarly, there are several ways of achieving the desired results when the node identifiers in each path are sorted in order of decreasing value to derive path identifiers. For instance, instead of padding out path identifiers having fewer node identifiers by adding null identifiers to their trailing end until all equal cost path identifiers have the same length, it is sufficient to add a single null identifier that is accorded a lower value than any node identifier to the trailing end of the shorter path identifiers prior to ordering the path identifiers lexicographically. Yet another way to achieve the same result is to perform a lexicographic comparison of the path identifiers as a first ordering criterion but to use the number of hops as a secondary ordering criterion if, and only if, one of the path identifiers runs out before a determination can be made by the lexicographic comparison. In other words, when one of the path identifiers is a prefix of the other path identifier, the path with the shorter identifier is deemed to come before the path with the longer identifier. Lexicographic ordering of equal length strings is used as the primary ordering criterion and the length of the path identifiers (i.e. the number of hops in the path) is used as a secondary ordering criterion when one of the path identifiers run out before the lexicographic comparison can make a determination. In this case, the path with the smaller number of hops is deemed to come before the path with the larger number of hops.
[0143] Conversely, instead of padding out path identifiers having fewer node identifiers by adding special identifiers to their leading end until all equal cost path identifiers have the same length, one may simply chose to order paths with a larger number of hops ahead of paths with a smaller number of hops. Lexicographic ordering of path identifiers is then used as a secondary ordering criterion for paths with a same number of hops. In this case, paths with a larger number of hops are deemed to come before paths with a smaller number of hops. The length of the path identifiers is used as the primary ordering criterion--paths with more hops are always before paths with fewer hops--and lexicographic ordering is used as a secondary ordering criterion for paths with a same number of hops.
[0144] The 8 variants of the global tie breaking technique generalized to handle equal cost paths traversing different numbers of nodes can be expressed in terms of several modified lexicographic ordering in which the length of the path identifiers as well as the path identifiers themselves are used to establish a complete ordering of the path identifiers. In Table 3 below, the lexicographic ordering used as a primary ordering criterion is a limited version of the traditional lexicographic ordering: it does not make a determination if one path identifier is a prefix of the other path identifier--
TABLE-US-00015 TABLE 3 Primary Secondary Ordering Ordering Ordering Criterion Criterion for Criterion for Path ID Variant for Node IDs Path IDs Path IDs Selection 1 Increasing Lexicographic Decreasing First Length 2 Increasing Lexicographic Decreasing Last Length 3 Decreasing Lexicographic Increasing First Length 4 Decreasing Lexicographic Increasing Last Length 5 Increasing Increasing Lexicographic First Length 6 Increasing Increasing Lexicographic Last Length 7 Decreasing Decreasing Lexicographic First Length 8 Decreasing Decreasing Lexicographic Last Length
[0145] The traditional lexicographic ordering in which the primary ordering criterion is the lexicographic order and strings that share a common prefix are sorted in order of increasing lengths corresponds to variants 3&4. Variants 1&2 correspond to a modified lexicographic order in which strings that share a common prefix are sorted in order of decreasing lengths. Variants 5-8 correspond to methods of ordering strings in which the length of the strings is the primary ordering criterion and lexicographic ordering is used as the secondary ordering criterion for strings of equal length.
Hop Count as a Primary Tie-Breaking Method
[0146] Having established a framework for producing a complete ordering of path identifiers of different lengths, the effect of using the hop count--the length of the path identifiers--as a first-level tie-breaker can be elucidated. In some cases, a first tie-breaking performed using the length of the path identifiers does not eliminate from consideration the path that would have been ultimately selected--i.e. the first tie-breaking based on the hop count does not affect the end result. If, however, the first level tie-breaking prunes the path that would normally have been selected, a new tie-breaking variant is obtained.
[0147] If a first level of tie-breaking is performed by only considering equal cost paths with a minimum--or maximum--number of hops then variants 1 to 4 produce the same result as variants 5-8 as lexicographic ordering is the only ordering criterion for path identifiers: the secondary criteria of variants 1-4 and the primary criteria of variants 5-8 all become inoperative since the identifiers of the equal-cost paths input to the tie-breaking all share a same--maximal or minima--length. Variants 5&8 always select paths with a minimum number of hops and therefore are not affected by a first level of tie-breaking that selects equal cost paths with a minimum number of hops. These correspond to two variants of the first embodiment above. Conversely, if a first level of tie-breaking is performed by selecting equal cost paths with a minimum number of hops followed by either one of variants 6&7, the other two variants of the first embodiment are obtained. Similarly variants 6&7 always select paths with a maximum number of hops and therefore are not affected by a first level of tie-breaking that selects equal cost paths with a maximum number of hops.
[0148] In summary, the first 2 of the 8 variants above are not variants of the first embodiment described above. Variants 3&4 correspond to variants of the first embodiment where traditional lexicographic ordering is applied to path identifiers of unequal length. The last 4 variants are mathematically equivalent to variants of the first embodiment where a first level of tie-breaking is performed by selecting only paths with a maximal number of hops. The following 12 global tie-breaking variants can be expressed in terms of ordering criteria for the node identifiers and the path identifiers--
TABLE-US-00016 TABLE 4 Secondary Ordering Primary Ordering Criterion Criterion for Criterion for Path ID Variant for Node IDs Path IDs Path IDs Selection 1 Increasing Lexicographic Decreasing First Length 2 Increasing Lexicographic Decreasing Last Length 3 Decreasing Lexicographic Increasing First Length 4 Decreasing Lexicographic Increasing Last Length 5 Increasing Minimum Lexicographic First Length 6 Increasing Minimum Lexicographic Last Length 7 Decreasing Minimum Lexicographic First Length 8 Decreasing Minimum Lexicographic Last Length 9 Increasing Maximum Lexicographic First Length 10 Increasing Maximum Lexicographic Last Length 11 Decreasing Maximum Lexicographic First Length 12 Decreasing Maximum Lexicographic Last Length
[0149] In Table 4 above, the lexicographic ordering used as a primary ordering criterion is a limited version of the traditional lexicographic ordering: it does not make a determination if one path identifier is a prefix of the other path identifier. In this case, a secondary ordering criterion based on the length of the path identifiers must be invoked.
[0150] Each group of four global tie-breaking variants corresponds to the four local tie-breaking variants. Global tie-breaking variants 1-4 correspond to the case where all equal-cost shortest paths are considered regardless of their hop count. Variants 5-8 correspond to the case where only equal-cost shortest paths with a minimal number of hops are considered to be shortest paths. Variants 9-12 correspond to the case where only equal-cost shortest paths with a maximal number of hops are considered to be shortest paths.
[0151] For clarity of exposition, the above description is based on lexicographic ordering of the path identifiers and variations thereof in which string comparisons are performed from left to right. The same tie-breaking variants can also be described, mutatis mutandis, in terms of reverse lexicographic ordering in which string comparisons are performed from right to left. Indeed, any method of ordering path identifiers that provides an unambiguous ordering of all possible path identifiers could be used without departing from the spirit of the invention.
[0152] The invention is not limited to the embodiments described herein, which may be modified or varied without departing from the scope of the invention.
User Contributions:
Comment about this patent or add new information about this topic:
Images included with this patent application:
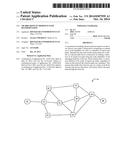 | 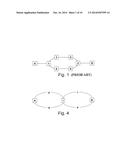 |
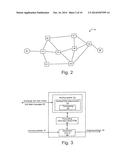 | 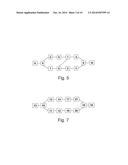 |
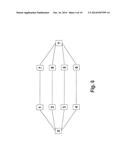 |  |
 | 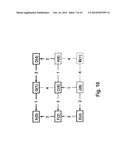 |
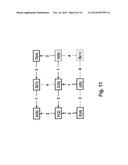 | 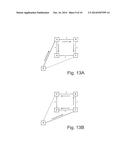 |
 |  |
| New patent applications in this class: | |
| Date | Title |
|---|---|
| 2018-01-25 | Distributed constrained tree formation for deterministic multicast |
| 2017-08-17 | Adjusted spanning tree protocol path cost values in a software defined network |
| 2016-12-29 | System and method of routing calls on a packet network |
| 2016-09-01 | Adaptive software defined networking controller |
| 2016-07-14 | Transmission and reception devices |
| New patent applications from these inventors: | |
| Date | Title |
|---|---|
| 2016-12-29 | Method and apparatus for multicast implementation in a network |
| 2014-09-25 | Method and apparatus for selecting between multiple equal cost paths |
| 2014-06-26 | Resilient attachment to provider link state bridging (plsb) networks |
| 2014-05-22 | Tie-breaking in shortest path determination |
| 2014-05-08 | Break before make forwarding information base (fib) population for multicast |
| Top Inventors for class "Multiplex communications" | |
| Rank | Inventor's name |
|---|---|
| 1 | Peter Gaal |
| 2 | Wanshi Chen |
| 3 | Tao Luo |
| 4 | Hanbyul Seo |
| 5 | Jae Hoon Chung |