Patent application title: SWEET TASTE RECEPTORS
Inventors:
Jiayu Liao (Carlsbad, CA, US)
Sheng Ding (San Diego, CA, US)
Peter G. Schultz (La Jolla, CA, US)
Assignees:
IRM LLC
The Scripps Research Institute
IPC8 Class: AA61K31711FI
USPC Class:
514 44
Class name: N-glycoside nitrogen containing hetero ring polynucleotide (e.g., rna, dna, etc.)
Publication date: 2009-03-19
Patent application number: 20090075927
Inventors list |
Agents list |
Assignees list |
List by place |
Classification tree browser |
Top 100 Inventors |
Top 100 Agents |
Top 100 Assignees |
Usenet FAQ Index |
Documents |
Other FAQs |
Patent application title: SWEET TASTE RECEPTORS
Inventors:
Peter G. Schultz
Sheng Ding
Jiayu Liao
Agents:
GENOMICS INSTITUTE OF THE;NOVARTIS RESEARCH FOUNDATION
Assignees:
IRM LLC
Origin: SAN DIEGO, CA US
IPC8 Class: AA61K31711FI
USPC Class:
514 44
Abstract:
This invention provides novel genes and polypeptides of the sweet receptor
family, methods for production of the polypeptides, methods for screening
compounds that specifically bind to and/or modulate the activity of these
polypeptides; and antibodies specific for the polypeptides.Claims:
1. An isolated or recombinant polypeptide that comprises one or more of
the following:(a.) an amino acid sequence or subsequence that is at least
75% identical to SEQ ID SEQ ID NO.7 as determined by BLASTP using default
parameters;(b.) an amino acid sequence or subsequence that comprises one
or more domains of an hT1R3 polypeptide, wherein the hT1R3 polypeptide
comprises an amino acid sequence of SEQ ID NO.7;(c.) an amino acid
sequence or subsequence that is at least 75% identical to a domain within
SEQ ID NO.7 as determined by BLASTP using default parameters, wherein the
domain is selected from the group consisting of: an amino-terminal
extracellular domain; an extracellular domain located between TM2 and
TM3, between TM4 and TM5, or between TM6 and TM7; a transmembrane (TM)
domain; an intracellular domain located between TM1 and TM2, between TM3
and TM4, or between TM5 and TM6; and a carboxyl-terminal intracellular
domain;(d.) an amino acid sequence or subsequence that is specifically
bound by an antibody that specifically binds to an amino acid sequence of
SEQ ID NO.7, wherein the antibody is not specifically bound by an amino
acid selected from the group consisting of SEQ ID NO. 2, SEQ ID NO. 3,
SEQ ID NO. 5, SEQ ID NO. 6, SEQ ID NO. 8, and SEQ ID NO. 9;(e.) an amino
acid sequence or subsequence that is encoded by a nucleotide sequence of
SEQ ID NO 12, or a complementary sequence thereof;(f.) an amino acid
sequence or subsequence that is encoded by a first nucleic acid that
specifically hybridizes to a second nucleic acid, wherein the second
nucleic acid comprises a sequence of SEQ ID NO 12, or a complement
thereof, under stringent conditions, wherein the first nucleic acid
hybridizes to the second nucleic acid under said stringent conditions
with at least 5.times. an affinity that the first nucleic acid hybridizes
to a third nucleic acid that is an mT1R3 nucleic acid or an rT1R3 nucleic
acid; or,(g.) an amino acid sequence or subsequence corresponding to a
conservative variation an amino acid sequence or subsequence of any one
of (a.)-(f.).
2. The isolated or recombinant polypeptide of claim 1, wherein the polypeptide comprises an amino acid sequence of SEQ ID NO.7, or a conservative variation thereof.
3. The isolated or recombinant polypeptide of claim 1, wherein the polypeptide comprises a mature hT1R3 protein.
4. The isolated polypeptide of claim 1, wherein the domain of (b.) is selected from the group consisting of:an amino-terminal extracellular domain;an extracellular domain located between TM2 and TM3, between TM4 and TM5, or between TM6 and TM7;a transmembrane (TM) domain;an intracellular domain located between TM1 and TM2, between TM3 and TM4, or between TM5 and TM6; anda carboxyl-terminal intracellular domain.
5. The polypeptide of claim 1, wherein the polypeptide is a heteromer.
6. The polypeptide of claim 1, wherein the polypeptide is a homomultimer.
7. The polypeptide of claim 1, wherein the polypeptide is a heteromer that comprises more than one polypeptide having an amino acid sequence of SEQ ID NO.7, or a conservative variation thereof.
8. An isolated or recombinant nucleic acid that encodes the isolated or recombinant polypeptide of claim 1, wherein the polypeptide is a substantially full-length a polypeptide, or wherein the nucleic acid is capable of rescuing function of a mutant or recombinant cell that is defective with respect to hT1R3.
9. The isolated or recombinant nucleic acid of claim 8, wherein the nucleic acid is a DNA.
10. The isolated or recombinant nucleic acid of claim 8, wherein the nucleic acid is a cDNA.
11. The isolated or recombinant nucleic acid of claim 8, wherein the nucleic acid is an RNA.
12. The isolated or recombinant nucleic acid of claim 8, wherein the nucleic acid is a coding nucleic acid that encodes an amino acid sequence of SEQ ID NO. 7, or a conservative variation thereof; or wherein the isolated or recombinant nucleic acid is a complementary nucleic acid that is complementary to the coding nucleic acid.
13. The isolated or recombinant nucleic acid of claim 8, wherein the nucleic acid comprises a nucleotide sequence of SEQ ID NO. 12, and a complementary sequence thereof.
14. The isolated or recombinant nucleic acid of claim 8, wherein the nucleic acid comprises or is coded within an expression vector.
15. A cDNA or mRNA that encodes the isolated or recombinant polypeptide of claim 1.
16. An expression vector encoding the cDNA or mRNA of claim 15.
17. An antibody or fragment thereof which specifically binds the isolated or recombinant polypeptide of claim 1.
18. An antibody fragment according to claim 17, wherein the antibody fragment is an Fab or F(ab')2 fragment.
19. An antibody according to claim 17 wherein the antibody is a polyclonal antibody.
20. An antibody according to claim 17 which is a monoclonal antibody.
21. An antibody according to claim 17, wherein the antibody does not bind to any protein selected from the group consisting of: mT1R1, mT1R2, mT1R3, rT1R1, rT1R2 and rT1R3.
22. An expression vector that encodes a polypeptide of claim 1.
23. A cell comprising the expression vector of claim 22.
24. A biosensor comprising the polypeptide of claim 1.
25. A method for producing a recombinant or isolated polypeptide, comprising:(a.) culturing a cell comprising an expression vector encoding the recombinant or isolated polypeptide of claim 1, under conditions suitable for expression of the isolated or recombinant polypeptide; and,(b.) purifying the polypeptide such that the polypeptide is enriched at least 5.times. as compared to the polypeptide present in step (a).
26. The method of claim 25, wherein (b.) comprises purifying the polypeptide such that the polypeptide is enriched at least 100.times. as compared to the polypeptide present in step (a.).
27. An isolated or recombinant polypeptide made by the method of claim 25.
28. A method of identifying compounds which bind to and/or modulate an activity of the isolated or recombinant polypeptide of claim 1, the method comprising:(a.) contacting a biological sample comprising the isolated or recombinant polypeptide with a test compound; and,(b.) detecting binding and/or modulation of the activity of the polypeptide by the compound, thereby identifying a compound which binds to and/or modulates the activity of the polypeptide.
29. The method of claim 28, wherein step (b.) includes detecting binding of an antibody to the isolated or recombinant polypeptide.
30. The method of claim 28, wherein step (b.) includes detecting a signal produced by the isolated or recombinant polypeptide.
31. The method of claim 30, wherein the signal is a conformation-dependent signal, wherein a conformation of the isolated or recombinant polypeptide is modified by binding of the test compound to the isolated or recombinant polypeptide.
32. The method of claim 28, wherein the biological sample comprises a cell which expresses the recombinant polypeptide.
33. The method of claim 28, wherein detecting binding comprises one or more of: a Ca2+ flux assay, a cAMP assay, a GTPgammaS binding assay, a melanophore assay, a phospholipase C assay, a beta-arrestin FRET assay, and a transcriptional reporter assay.
34. The method of claim 28, wherein the transcriptional reporter assay comprises detecting an activity of one or response element selected from the group consisting of: a CRE, a SRE, an MRE, a TRE, an NFAT, and an NFkB-response element, wherein the response element directs expression of an operably coupled reporter gene.
35. The method of claim 28, wherein the biological sample comprises a biosensor.
36. The method of claim 35, wherein the biosensor comprises a Chem-FET.
37. A method of identifying compounds which bind to and/or modulate an activity of a polypeptide comprising hT1R3, the method comprising:(a.) contacting a biological sample comprising hT1R3 with a test compound; and,(b.) detecting binding and/or modulation of the activity of the polypeptide by the compound, thereby identifying a compound which binds to and/or modulates the activity of the polypeptide.
38. The method of claim 37, wherein step (b.) includes detecting binding of an antibody to the isolated or recombinant polypeptide.
39. The method of claim 37, wherein step (b.) includes detecting a signal produced by the isolated or recombinant polypeptide.
40. The method of claim 37, wherein the signal is a conformation-dependent signal, wherein a conformation of the isolated or recombinant polypeptide is modified by binding of the test compound to the isolated or recombinant polypeptide.
41. The method of claim 37, wherein the biological sample comprises a cell which expresses the recombinant polypeptide.
42. The method of claim 37, wherein detecting binding comprises one or more of: a Ca2+ flux assay, a cAMP assay, a GTPgammaS binding assay, a melanophore assay, a phospholipase C assay, a beta-arrestin FRET assay, and a transcriptional reporter assay.
43. The method of claim 42, wherein the transcriptional reporter assay comprises detecting an activity of one or response element selected from the group consisting of: a CRE, a SRE, an MRE, a TRE, an NFAT, and an NFkB-response element, wherein the response element directs expression of an operably coupled reporter gene.
44. The method of claim 37, wherein the biological sample comprises a biosensor.
45. The method of claim 44, wherein the biosensor comprises a Chem-FET.
46. A method of rescuing a cell that has altered or missing T1R3 function, comprising introducing a nucleic acid into the cell, wherein the nucleic acid encodes the recombinant polypeptide of claim 1, and expressing recombinant polypeptide, thereby providing hT1R3 function to the cell.
47. The method of claim 46, wherein the cell is in cell culture.
48. The method of claim 46, wherein the cell is in a tissue.
49. The method of claim 46, wherein the cell is in a taste bud.
50. The method of claim 46, wherein the cell is in taste bud in a mammal.
Description:
CROSS-REFERENCE TO RELATED APPLICATIONS
[0001]This application is a divisional of U.S. patent application Ser. No. 10/246,785, filed Sep. 17, 2002, pending, which application is a non-provisional of U.S. Ser. No. 60/323,450, "Sweet Taste Receptors" by Liao and Schultz, filed Sep. 18, 2001, which applications are incorporated herein by reference in their entireties.
FIELD OF THE INVENTION
[0002]This invention relates to novel sweet receptor nucleic acids and polypeptides. In particular, the invention relates to polypeptides that are homologous to other sweet receptors, nucleic acids encoding the polypeptides, vectors and host cells comprising the nucleic acids and antibodies that specifically bind to the polypeptides. The invention also relates to recombinant methods for producing the polypeptides and methods for identifying compounds that bind to and/or modulate the activity of the polypeptides.
BACKGROUND OF THE INVENTION
[0003]In mammals, there are three chemosensory systems (taste, olfactory and vomeronasal perceptions) that function to convert external chemical signals to specific neuronal activities. These neuronal signals are then integrated in different regions of brain and the output of these signals affect the organism's various innate behaviors, ranging from aversion and attraction to food or small volatile chemicals to reproductive actions. Among these chemosensory systems, taste perception provides immediate valuation of nutrients. Although the molecular universe of tastants consists of diverse chemical structures such as ions, small organic molecules, proteins, carbohydrates, amino acids, and lipids, it is generally believed that mammals have five basic taste modalities: sour, salty, bitter, sweet, and umami (glutamate) as described, e.g., in Lindemann, Physiol. Rev. 76:718-766, 1996; Kinnamon et al., Annu. Rev. Physiol. 54:715-731, 1992; and Gilbertson et al., Curr. Opin. Neurobiol. 10: 519-527, 2000.
[0004]The sensation of taste is initiated by the interaction of tastants with their receptors in the taste cells, which are clustered in onion-shape taste buds embedded within the lingual epithelium in tongue and palate as described, e.g., in Lindemann, supra. On the tongue, taste buds are topographically distributed into papillae in different locations of tongue. Fungiform papillae are located at the front of the tongue and contain a small number of taste buds; foliate papillae, containing dozens of taste buds, are localized along the posterior lateral edge of the tongue; and at the back of the tongue, circumvallate papillae contain thousands of taste buds. Classical physiological studies have found that fungiform papillae are sensitive to sweet, foliate papillae are sensitive to sour and bitter, and circumvallate papillae are particularly sensitive to bitter.
[0005]Each taste modality is thought to be mediated by distinct cell surface receptors that are expressed in a subset of taste cells. Electrophysiological and biochemical studies suggest that salty and sour tastants signal through Na+ and H+ membrane channels as described, e.g., in Heck et al. Science 223: 403-405, 1984; Avenet et al., J. Memb. Biol. 105:245-255, 1988, Doolin et al., J. Gen. Physiol. 107:545-554, 1996; Formaker et al., Am. J. Physiol 255:1002-1007, 1988; Kinnamon et al. Proc. Natl. Acad. Sci. USA 85:7023-7027, 1988; and Gilbertson et al., J. Gen. Physiol. 100:803-824, 1992. In contrast, bitter, sweet, and umami taste transduction are believed to involve G protein-coupled receptors (GPCR).
[0006]GPCRs are a class of seven-transmembrane proteins which transduce an extracellular signal, i.e., ligand binding to receptor, into a cellular response. Upon ligand binding to a GPCR, the GPCR activates an intracellular guanine nucleotide protein known as G-protein (guanine nucleotide binding protein), which mediates a response to the extracellular signal. G-proteins are heterotrimeric proteins composed of an alpha, beta and gamma subunit. The activated G protein alters the activity of various cellular effector enzymes (e.g., adenylate cyclase and phosphodiesterase), which in turn alters the levels of various second messengers (e.g., cAMP, cGMP, and inositol triphosphate (IP3)).
[0007]Experiments with the bitter substance, denatonium, have shown that the secondary messages, cAMP and IP3, are induced in response to bitter stimuli as described, e.g., in Spielamn et al., Am. J. Physiol. 270:C926-C931, 1996; and Ruiz-Avila et al., Nature 376:80-85, 1995. Other studies have revealed that gustducin, a G protein expressed in subpopulation of taste buds, can activate phosphodiesterase (PDE) and thereby decrease cNMP levels in response to bitter stimuli as described, e.g., in Ruiz-Avila et al, supra; and Hoon et al., Biochem. J. 309:629-636, 1995. These secondary messages, which are generally involved in G protein signaling, are consistent with the involvement of GPCRs in taste transduction. Sweet substances have also been shown to cause the elevation of the secondary messages, cAMP and IP3, presumably in response to activation of G protein-coupled receptor cascades by Gs protein as described, e.g., in Striem et al., Biochem. J. 260:121-126, 1989; and Bernhardt et al., J. Physiol. 490:325-336, 1996. The involvement of G proteins in bitter and sweet transduction is also supported by the discovery that mice with a null allele of gustducin have an impaired ability to detect bitter and sweet substances as described, e.g., in Wong et al., Nature 381:796-800, 1996.
[0008]The involvement of G-protein coupled receptors in taste transduction has recently been confirmed by the discovery of three families of GPCRs expressed in mammalian taste bud cells, a number of which have been shown to be activated by bitter and glutamate tastants as described, e.g., in Firestein, Nature 404:552-553, 2000. A splice variant of a metabotropic glutamate receptor was cloned from rat taste bud and was shown to respond to monosodium L-glutamate when expressed in heterogonous cells as described, e.g., in Chaudharri et al., Nature Neurosci. 3:113-119, 2000. Two additional candidate taste receptors, T1R1 and T2R2, have been isolated from rat taste bud, and show distant homology with putative pheromone receptor V2Rs and metabotropic glutamate receptors, as described in Hoon et al., Cell 96:541-552, 1999. T1R1 and T2R2 were postulated to function as sweet and bitter receptors, respectively, based on their topographic distribution in the tongue as described, e.g., in Hoon et al., supra, 1999. Searches of the human and mouse genomes have identified another family of taste receptors (T2Rs) containing approximately 25 members as described, e.g., in Adler et al., Cell 100:693-702, 2000; and Matsunami et al., Nature 404:601-603, 2000. One receptor in this family, mT2R5, is specifically activated by the bitter substance cycloheximide, while the human hT2R4 and mouse mT2R8 respond to denatonium as described, e.g., in Chandrashekar et al., Cell 100:703-711, 2000.
[0009]Over the past few years, much effort has been directed toward the development of various sweeteners that interact with taste receptors to mimic natural sweet taste stimulants. See, Robert H. Cagan, Ed., Neural Mechanisms in Taste, Chapter 4, CRC Press, Inc., Boca Raton, Fla., 1989. Examples of sweeteners that have been developed to mimic sweet tastes are saccharin (an anhydride of o-sulfimide benzoic acid), monellin (a protein), aspartame (a peptide composed of aspartic acid and methyl ester of phenylalanine) and the thaumatins (also proteins). Many sweeteners developed to date are not suitable as food additives, however, because they are uneconomical, high in calories, carcinogenic or lose their sweetness when exposed to elevated temperatures for long periods, rendering them unsuitable for use in most baking applications.
[0010]Development of new sweeteners that mimic sweet (and other) tastes has been limited by a lack of knowledge of the taste cell proteins responsible for transducing the sweet taste modalities. Accordingly, the identification of new sweet taste receptors would enable the identification of the natural ligands, i.e., natural sweet tastants, of these proteins and the design of novel sweeteners that mimic sweet taste perception. The present invention fulfills these and other needs.
SUMMARY OF THE INVENTION
[0011]The present invention relates members of the sweet receptor family, in particular human sweet receptor 1 (hT1R1), human sweet receptor 2 (hT1R2) and human sweet receptor 3 (hT1R3) nucleic acids and polypeptides, vectors and host cells comprising the nucleic acids, antibodies to the polypeptides, and methods for producing the polypeptides. In another aspect, the present invention relates to methods for identifying agents that bind to and/or modulate the activity of these polypeptides, e.g., use of the polypeptides (e.g., when present in biological materials) as sensor or assay components to detect molecules that are perceived as sweet and/or that provide for glutamate (umami) detection. The invention also provides for rescue of sweet and/or umami taste function in cells that are defective in expression of hT1R1, hT1R2 or hT1R3, e.g., by expressing the polypeptides of the invention in the cells, e.g., from a recombinant construct. This cell rescue can be performed in vitro (e.g., in cell culture) or in vivo (e.g., in mammalian taste buds).
[0012]Accordingly, in a first aspect, the invention provides isolated or recombinant polypeptides (e.g., that comprises hT1R1, hT1R2 or hT1R3 function). These polypeptides can be characterized in any of a variety of related ways. For example, the polypeptides of the invention can include an amino acid sequence or subsequence that is at least 75% identical to an hT1R1 polypeptide (e.g., SEQ ID NO. 1), an hT1R2 polypeptide (e.g., SEQ ID NO.4), and/or an hT1R3 polypeptide (e.g., SEQ ID NO.7), e.g., as determined by BLASTP using default parameters (or another comparison algorithm or via manual alignment). Similarly, the polypeptides of the invention can include an amino acid sequence or subsequence that comprises one or more domains of an hT1R1 polypeptide, an hT1R2 polypeptide, or an hT1R3 polypeptide, e.g., where the hT1R1 polypeptide, the hT1R2 polypeptide, or the hT1R3 polypeptide comprises an amino acid sequence such as those of hT1R1, hT1R2 and/or hT1R3 (e.g., SEQ ID NO. 1, SEQ ID NO.4 and SEQ ID NO.7, respectively). In a related aspect, the polypeptides of the invention can include an amino acid sequence or subsequence that is at least 75% identical to a domain encoded by hT1R1, hT1R2 and/or hT1R3, (e.g., SEQ ID NO. 1, SEQ ID NO.4 or SEQ ID NO.7, respectively), e.g., as determined by BLASTP using default parameters, where the domain includes: an amino-terminal extracellular domain; an extracellular domain located between TM2 and TM3, between TM4 and TM5, or between TM6 and TM7; a transmembrane (TM) domain; an intracellular domain located between TM1 and TM2, between TM3 and TM4, or between TM5 and TM6; and/or a carboxyl-terminal intracellular domain. Any polypeptide of the invention optionally includes one or more of these domains. The polypeptides of the invention can also be defined by immunoreactivity, e.g., the polypeptides of the invention can include an amino acid sequence or subsequence that is specifically bound by an antibody that specifically binds to an amino acid such as hT1R1, hT1R2 and/or hT1R3 (e.g., SEQ ID NO. 1, SEQ ID NO.4, and/or SEQ ID NO.7, respectively) where the antibody is not specifically bound by an amino acid from the corresponding mouse or rat homologues (e.g., as represented at SEQ ID NO. 2, SEQ ID NO. 3, SEQ ID NO. 5, SEQ ID NO. 6, SEQ ID NO. 8, and/or SEQ ID NO. 9). Examples of polypeptides of the invention include the polypeptides encoded by amino acid sequences or subsequences that are encoded by SEQ ID NO. 10, SEQ ID NO. 11 and/or SEQ ID NO 12, and/or complementary sequences thereof. In general, the polypeptides of the invention can also be defined with respect to the nucleic acids that encode them, e.g., polypeptides of the invention can include an amino acid sequence or subsequence that is encoded by a first nucleic acid that specifically hybridizes to a second nucleic acid, wherein the second nucleic acid is a nucleic acid that encodes hT1R1, hT1R2 and/or hT1R3 (e.g., SEQ ID NO. 10, SEQ ID NO. 11 and/or SEQ ID NO 12), or a complement thereof, under stringent conditions, where the first nucleic acid hybridizes to the second nucleic acid under the stringent conditions with at least 5× an affinity that the first nucleic acid hybridizes to a third nucleic acid that encodes a mouse or rat homologue, e.g., an mT1R1 nucleic acid, an rT1R1 nucleic acid, an mT1R2 nucleic acid, an rT1R2 nucleic acid, an mT1R3 nucleic acid and/or a rT1R3 nucleic acid. Also encompassed within the polypeptides of the invention are any and all amino acid sequences or subsequences corresponding to a conservative variation of any of the amino acid sequences or subsequences noted above, e.g., an amino acid sequence such as SEQ ID NO. 1, SEQ ID NO:4, SEQ ID NO.7, or a conservative variation thereof.
[0013]In one aspect the polypeptide of the invention is a mature polypeptide, e.g., a mature hT1R1 protein, a mature hT1R2 protein, or a mature hT1R3 protein, e.g., a protein having an activity of the hT1R1, hT1R2 or hT1R3 protein. The polypeptide can be, e.g., a monomer, a homomultimer or a heteromer. For example, the polypeptide can be a homomultimer or a heteromer that includes more than one polypeptide, e.g., as shown by SEQ ID NO. 1, SEQ ID NO.4, and/or SEQ ID NO.7 (hT1R1, hT1R2 and hT1R3, respectively), or a conservative variation thereof. Also provided by the invention are isolated polypeptides that include one or more domains of an hT1R1, hT1R2, or hT1R3 polypeptide.
[0014]In addition to the polypeptides noted above, methods for producing a recombinant or isolated polypeptide are also provided. For example, the methods can include growing a cell in culture comprising an expression vector encoding a recombinant or isolated polypeptide as described above, under conditions suitable for expression of the isolated or recombinant polypeptide. The polypeptide is then purified, e.g., such that the polypeptide is enriched at least 5× (and typically 50×, 100×, 1000× or more) as compared to the polypeptide present in the culture. The resulting isolated or recombinant polypeptide made by this method is also a feature of the invention.
[0015]Nucleic acids, e.g., isolated or recombinant nucleic acids, are also a feature of the invention. For example, a nucleic acid that encodes any of the preceding polypeptides (e.g., SEQ ID NO. 1, SEQ ID NO. 4, and SEQ ID NO. 7, or a conservative variation thereof) is optionally a feature of the invention. In one class of embodiments, the nucleic acid encodes a substantially full-length a polypeptide, and/or is capable of rescuing a function of a mutant or recombinant cell that is defective with respect to hT1R1, hT1R2 or hT1R3 (e.g., where the cell is a deletion mutant with respect to hT1R1, hT1R2 and/or hT1R3). Exemplar nucleic acids of the invention include those represented at SEQ ID NO. 10, SEQ ID NO. 11, SEQ ID NO. 12, (hT1R1, hT1R2 and hT1R3 nucleic acids, respectively) and/or complementary sequences thereof. The nucleic acid optionally includes a DNA (e.g., a gDNA, a cDNA or a DNA cloning or expression vector), or an RNA (e.g., an mRNA or RNA cloning or expression vector).
[0016]In one related aspect, the invention includes an hT1R2 nucleic acid that hybridizes under stringent conditions to a first nucleic acid, e.g., that includes the first two exons (e.g., nucleotides 1-483) from nucleotide sequence of SEQ ID NO. 11, or to a complement thereof, wherein the stringent conditions are selected such that the hT1R2 nucleic acid preferentially hybridizes to the first nucleic acid as compared to a mT1R2 nucleic acid or complement thereof, or to an rT1R2 nucleic acid or complement thereof. For example, the hT1R2 nucleic acid can encode a hT1R2 polypeptide comprising the sequence set forth at SEQ ID NO: 4. Here again, the nucleic acid optionally encodes a substantially full length hT1R2 polypeptide and can be a DNA or RNA (e.g., a gDNA, a cDNA or a DNA cloning or expression vector), or an RNA (e.g., an mRNA or RNA cloning or expression vector). For example, the hT1R2 nucleic acid can include or be coded within an expression vector.
[0017]The present invention also provides antibodies, e.g., antibodies or fragments thereof which specifically bind the isolated or recombinant polypeptides described above. For example, the antibody fragment can be an Fab or F(ab')2 fragment, the antibody can be a monoclonal or polyclonal antibody, or the like. Optionally, the antibody can be a discriminatory antibody that specifically hybridizes to a polypeptide as noted above, but which does not specifically bind to a rat or mouse homologue protein, e.g., mT1R1, mT1R2, mT1R3, rT1R1, rT1R2 or rT1R3.
[0018]As noted above, in one aspect, expression vectors that encode the polypeptides noted above are provided. Similarly, cells that include the expression vectors are a feature of the invention. In addition, biosensors comprising the polypeptides are also a feature of the invention.
[0019]In one aspect, the invention includes a database and/or a computer-readable medium comprising a character string that represents any polypeptide, nucleic acid, cell, vector, antibody or other material of the invention that is noted herein. Optionally, the database or computer readable medium is coupled to one or more instruction set, software package, network, internet, intranet, user input, user-viewable output, computer, or other feature or component that transmits, manipulates, reads or otherwise acts upon the database or computer-readable medium.
[0020]The invention also provides methods of identifying compounds which bind to and/or modulate an activity of the isolated or recombinant polypeptides noted above. In the methods, a biological sample comprising the isolated or recombinant polypeptide is contacted with a test compound. binding and/or modulation of the activity of the polypeptide by the compound is then detected, thereby identifying a compound which binds to and/or modulates the activity of the polypeptide. The detection of binding or activity can take any of a wide variety of forms, e.g., detecting binding of an antibody to the isolated or recombinant polypeptide, or detecting a signal produced by the isolated or recombinant polypeptide. In addition to detection of activity of the polypeptides noted above, cells or other biological materials that include endogenous hT1R1, hT1R2 or hT1R3 can be used in the methods (e.g., cultures of cells derived from taste buds, or the like). Optionally, such materials and methods do not include testing cells in a mammal, e.g., in a human.
[0021]Examples of signals that can be detected include conformation-dependent signals, e.g., where a conformation of the isolated or recombinant polypeptide is modified by binding of the test compound to the isolated or recombinant polypeptide. Detecting binding can include, e.g., one or more of: a Ca2+ flux assay, a cAMP assay, a GTPgammaS binding assay, a melanophore assay, a phospholipase C assay, a beta-arrestin FRET assay, and a transcriptional reporter assay. Where detection includes measuring a signal from a transcriptional reporter assay (e.g., detection of a reporter gene (e.g., CAT activity) coupled to a response element that is controlled by a second messanger activated by hT1R1, hT1R2 and/or hT1R3, or a multimer thereof), common response elements that can be detected include: a CRE, a SRE, an MRE, a TRE, an NFAT, and/or an NFkB-response element.
[0022]The biological sample can be in any of a variety of configurations, e.g., cells which express the recombinant polypeptide, biosensors (liquid or solid phase), a Chem-FET, a cell extract; a membrane preparation comprising the protein of interest or another material comprising the proteins noted herein, or the like.
[0023]The invention also provides methods of rescuing cells that have altered or missing T1R1, T1R2, or T1R3 function (e.g., due to deletion or other mutation of genes relevant to such function). In the methods, a nucleic acid that encodes the recombinant polypeptide noted above is introduced into a cell and expressed, thereby providing hT1R1, hT1R2, or hT1R3 function to the cell. The cell can, e.g., be in cell culture, in a tissue, in a taste bud, in a mammal (e.g., a human), or the like.
[0024]The invention also includes kits, e.g., comprising a polypeptide, nucleic acid, vector, cell or antibody as noted above and further including, e.g., instructional materials in the use of the polypeptides or nucleic acids, e.g., in the methods herein, packaging materials, containers for holding other kit elements, and the like.
BRIEF DESCRIPTION OF THE FIGURES
[0025]FIGS. 1A-1C is a sequence alignment between human, mouse and rat sweet receptor sequences. Three putative human sweet receptor proteins (hT1R1, SEQ ID NO:1; hT1R2, SEQ ID NO:4; and hT1R3, SEQ ID NO:7) are aligned with three mouse T1Rs (mT1R1, SEQ ID NO:2; mT1R2, SEQ ID NO:5; and mT1R3, SEQ ID NO:8), and two rat T1Rs (rT1R1, SEQ ID NO:3; and rT1R2 SEQ ID NO:6) using ClustalW. Horizontal bars indicate seven-transmembrane domains for GPCRs as predicted using hT1R1 protein; potential signal peptides for hT1R1-3 are boxed. Identical amino acids are boxed in black, while conserved amino acids are boxed in gray. As shown, the three human sweet receptors are related to mouse and rat T1Rs.
[0026]FIGS. 2A-2C provide nucleotide sequences of hT1R1, hT1R2 and hT1R3 cDNAs. FIG. 2A shows the nucleotide sequence of the hT1R1 cDNA. FIG. 2B shows the nucleotide sequence of the hT1R2 cDNA. FIG. 2C shows the nucleotide sequence of the hT1R3 cDNA.
[0027]FIG. 3 is a schematic showing the structure/location of the three sweet receptor genes (clustered in human chromosome 1). (Top) Chromosome mapping studies were carried out using the NCBI human genome search interface with the distance to the end of the chromosome shown in kilobases (K) (not to scale). The chromosome locations of two genes (T1R2 and T1R3) were determined using two BAC clones (AL080251 and AL391244, respectively) that are located very close to the two genes. The arrow indicates the span and orientation of the gene. The numbers under the arrows indicate the size of the gene, including introns and exons. The number for T1R2 is approximate because the sequence for the transcriptional start region and first two exons is not available. (Bottom) The distal region of mouse chromosome 4 corresponds to the syntenic region of human 1p36.33. The locations of three mouse T1Rs were obtained from The Jackson Laboratory Mouse Informatics Database.
DETAILED DESCRIPTION
Definitions
[0028]A "host cell," as used herein, refers to a prokaryotic or eukaryotic cell that contains heterologous DNA that has been introduced into the cell by any means, e.g., electroporation, calcium phosphate precipitation, microinjection, transformation, viral infection, and/or the like.
[0029]A "vector" is a composition for facilitating introduction, replication and/or expression of a selected nucleic acid in a cell. Vectors include, e.g., plasmids, cosmids, viruses, YACs, bacteria, poly-lysine, etc. A "vector nucleic acid" is a nucleic acid molecule into which heterologous nucleic acid is optionally inserted which can then be introduced into an appropriate host cell. Vectors preferably have one or more origins of replication, and one or more sites into which the recombinant DNA can be inserted. Vectors often have convenient means by which cells with vectors can be selected from those without, e.g., they encode drug resistance genes. Common vectors include plasmids, viral genomes, and (primarily in yeast and bacteria) "artificial chromosomes." "Expression vectors" are vectors that comprise elements that provide for or facilitate transcription of nucleic acids which are cloned into the vectors. Such elements can include, e.g., promoters and/or enhancers operably coupled to a nucleic acid of interest.
[0030]"Plasmids" generally are designated herein by a lower case p preceded and/or followed by capital letters and/or numbers, in accordance with standard naming conventions that are familiar to those of skill in the art. Starting plasmids disclosed herein are either commercially available, publicly available on an unrestricted basis, or can be constructed from available plasmids by routine application of well known, published procedures. Many plasmids and other cloning and expression vectors that can be used in accordance with the present invention are well known and readily available to those of skill in the art. Moreover, those of skill readily may construct any number of other plasmids suitable for use in the invention. The properties, construction and use of such plasmids, as well as other vectors, in the present invention will be readily apparent to those of skill from the present disclosure.
[0031]The term "isolated" means that the material is removed from its original environment (e.g., the natural environment if it is naturally occurring). For example, a naturally-occurring nucleic acid, polypeptide, or cell present in a living animal is not isolated, but the same polynucleotide, polypeptide, or cell separated from some or all of the coexisting materials in the natural system, is isolated, even if subsequently reintroduced into the natural system. Such nucleic acids can be part of a vector and/or such nucleic acids or polypeptides could be part of a composition, and still be isolated in that such vector or composition is not part of its natural environment. A "recombinant nucleic acid" is one that is made by recombining nucleic acids, e.g., during cloning, DNA shuffling or other procedures. A "recombinant polypeptide" is a polypeptide which is produced by expression of a recombinant nucleic acid. An "amino acid sequence" is a polymer of amino acid residues (a protein, polypeptide, etc.) or a character string representing an amino acid polymer, depending on context. Either the given nucleic acid or the complementary nucleic acid can be determined from any specified polynucleotide sequence.
[0032]The terms "nucleic acid," "DNA sequence" or "polynucleotide" refer to a deoxyribonucleotide or ribonucleotide polymer in either single- or double-stranded form, and unless otherwise limited, encompasses known analogues of natural nucleotides that hybridize to nucleic acids in manner similar to naturally occurring nucleotides. A "polynucleotide sequence" is a nucleic acid (which is a polymer of nucleotides (A, C, T, U, G, etc. or naturally occurring or artificial nucleotide analogues) or a character string representing a nucleic acid, depending on context. Either the given nucleic acid or the complementary nucleic acid can be determined from any specified polynucleotide sequence.
[0033]A "subsequence" or "fragment" is any portion of an entire sequence, up to and including the complete sequence. Typically a subsequence or fragment comprises less than the full-length sequence.
[0034]Numbering of a given amino acid or nucleotide polymer "corresponds to numbering" of a selected amino acid polymer or nucleic acid when the position of any given polymer component (amino acid residue, incorporated nucleotide, etc.) is designated by reference to the same residue position in the selected amino acid or nucleotide, rather than by the actual position of the component in the given polymer.
[0035]Proteins and/or protein sequences are "homologous" when they are derived, naturally or artificially, from a common ancestral protein or protein sequence. Similarly, nucleic acids and/or nucleic acid sequences are homologous when they are derived, naturally or artificially, from a common ancestral nucleic acid or nucleic acid sequence. For example, any naturally occurring hT1Rx nucleic acid can be modified by any available mutagenesis method. When expressed, this mutagenized nucleic acid encodes a polypeptide that is homologous to the protein encoded by the original hT1Rx nucleic acid. Homology is generally inferred from sequence similarity between two or more nucleic acids or proteins (or sequences thereof). The precise percentage of similarity between sequences that is useful in establishing homology varies with the nucleic acid and protein at issue, but as little as 25% sequence similarity is routinely used to establish homology. Higher levels of sequence similarity, e.g., 30%, 40%, 50%, 60%, 70%, 80%, 90%, 95% or 99% or more can also be used to establish homology. Methods for determining sequence similarity percentages (e.g., BLASTP and BLASTN using default parameters) are described herein and are generally available.
[0036]The terms "identical", "sequence identical" or "sequence identity" in the context of two nucleic acid sequences or amino acid sequences refers to the residues in the two sequences which are the same when aligned for maximum correspondence over a specified comparison window. A "comparison window", as used herein, refers to a segment of at least about 20 contiguous positions, usually about 50 to about 200, more usually about 100 to about 150 in which a sequence may be compared to a reference sequence of the same number of contiguous positions after the two sequences are aligned optimally. Methods of alignment of sequences for comparison are well-known in the art. Optimal alignment of sequences for comparison may be conducted by the local homology algorithm of Smith and Waterman (1981) Adv. Appl. Math. 2:482; by the alignment algorithm of Needleman and Wunsch (1970) J. Mol. Biol. 48:443; by the search for similarity method of Pearson and Lipman (1988) Proc. Nat. Acad. Sci. U.S.A. 85:2444; by computerized implementations of these algorithms (including, but not limited to CLUSTAL in the PC/Gene program by Intelligentics, Mountain View Calif., GAP, BESTFIT, BLAST, FASTA, and TFASTA in the Wisconsin Genetics Software Package, Genetics Computer Group (GCG), 575 Science Dr., Madison, Wis., U.S.A.); the CLUSTAL program is well described by Higgins and Sharp (1988) Gene 73:237-244 and Higgins and Sharp (1989) CABIOS 5:151-153; Corpet et al. (1988) Nucleic Acids Res. 16:10881-10890; Huang et al (1992) Computer Applications in the Biosciences 8:155-165; and Pearson et al. (1994) Methods in Molecular Biology 24:307-331. Alignment is also often performed by inspection and manual alignment. In one class of embodiments, the polypeptides herein are at least 70%, generally at least 75%, optionally at least 80%, 85%, 90%, 95% or 99% or more identical to a reference polypeptide, e.g., hT1R1, hT1R2 and/or hT1R3, e.g., as set forth at SEQ ID NO: 1, SEQ ID NO: 4 or SEQ ID NO: 7 respectively, e.g., as measured by BLASTP (or CLUSTAL, or any other available alignment software) using default parameters. Similarly, nucleic acids can also be described with reference to a starting nucleic acid, e.g., they can be 50%, 60%, 70%, 75%, 80%, 85%, 90%, 95%, 99% or more identical to a reference nucleic acid, e.g., hT1R1, hT1R2 and/or hT1R3, e.g., as set forth at SEQ ID NO: 10, SEQ ID NO: 11 or SEQ ID NO: 12, respectively, e.g., as measured by BLASTN (or CLUSTAL, or any other available alignment software) using default parameters.
[0037]The terms "substantially identical" nucleic acid or amino acid sequences means that a nucleic acid or amino acid sequence comprises a sequence that has at least 90% sequence identity or more, preferably at least 95%, more preferably at least 98% and most preferably at least 99%, compared to a reference sequence using the programs described above (preferably BLAST) using standard parameters. For example, the BLASTN program (for nucleotide sequences) uses as defaults a wordlength (W) of 11, an expectation (E) of 10, M=5, N=-4, and a comparison of both strands. For amino acid sequences, the BLASTP program uses as defaults a wordlength (W) of 3, an expectation (E) of 10, and the BLOSUM62 scoring matrix (see Henikoff & Henikoff, Proc. Natl. Acad. Sci. USA 89:10915 (1989)). Percentage of sequence identity is determined by comparing two optimally aligned sequences over a comparison window, wherein the portion of the polynucleotide sequence in the comparison window may comprise additions or deletions (i.e., gaps) as compared to the reference sequence (which does not comprise additions or deletions) for optimal alignment of the two sequences. The percentage is calculated by determining the number of positions at which the identical nucleic acid base or amino acid residue occurs in both sequences to yield the number of matched positions, dividing the number of matched positions by the total number of positions in the window of comparison and multiplying the result by 100 to yield the percentage of sequence identity. Preferably, the substantial identity exists over a region of the sequences that is at least about 50 residues in length, more preferably over a region of at least about 100 residues, and most preferably the sequences are substantially identical over at least about 150 residues. In a most preferred embodiment, the sequences are substantially identical over the entire length of the coding regions.
[0038]"Selectively hybridizing" or "selective hybridization" includes hybridization, under stringent hybridization conditions, of a nucleic acid sequence to a specified nucleic acid target sequence to a detectably greater degree that its hybridization to non-target nucleic acid sequences. Selectively hybridizing sequences have at least 50%, or 60% or 70% or 80% or 90% sequence identity or more, e.g., preferably 95% sequence identity, and most preferably 98-100% sequence identity (i.e., complementarity) with each other.
[0039]"Stringent hybridization" conditions or "stringent conditions" in the context of nucleic acid hybridization assay formats are sequence dependent, and are different under different environmental parameters. An extensive guide to hybridization of nucleic acids is found in Tijssen (1993) Laboratory Techniques in Biochemistry and Molecular Biology--Hybridization with Nucleic Acid Probes Part 1, Chapter 2 "Overview of Principles of Hybridization and the Strategy of Nucleic Acid Probe Assays" Elsevier, N.Y. Generally, highly stringent conditions are selected to be about 5° C. lower than the thermal melting point (Tm) for the specific sequence at a defined ionic strength and pH. The Tm is the temperature (under defined ionic strength and pH) at which 50% of the target sequence hybridizes to a perfectly matched probe. Very stringent conditions are selected to be equal to the Tm point for a particular nucleic acid of the present invention, this occurs, e.g., when a copy of a nucleic acid is created using the maximum codon degeneracy permitted by the genetic code. Stringent hybridization conditions are sequence-dependent and will be different in different circumstances. Longer sequences hybridize specifically at higher temperatures.
[0040]An example of stringent hybridization conditions for hybridization of complementary nucleic acids which have more than 100 complementary residues on a filter in a Southern or northern blot is 50% formalin with 1 mg of heparin at 42° C., with the hybridization being carried out overnight. An example of highly stringent wash conditions is 0.15M NaCl at 72° C. for about 15 minutes. An example of stringent wash conditions is a 0.2×SSC wash at 65° C. for 15 minutes (see, Sambrook, supra for a description of SSC buffer). Often, a high stringency wash is preceded by a low stringency wash to remove background probe signal. An example medium stringency wash for a duplex of, e.g., more than 100 nucleotides, is 1×SSC at 45° C. for 15 minutes. An example low stringency wash for a duplex of, e.g., more than 100 nucleotides, is 4-6×SSC at 40° C. for 15 minutes. In general, a signal to noise ratio of 2× (or higher, e.g., 5×, 10×, 20×, 50×, 100× or more) than that observed for control probe in the particular hybridization assay indicates detection of a specific hybridization. For example, the control probe can be a mouse or rate homologue to the relevant nucleic acid, as noted herein. Nucleic acids which do not hybridize to each other under stringent conditions are still substantially identical if the polypeptides which they encode are substantially identical. This occurs, e.g., when a copy of a nucleic acid is created using the maximum codon degeneracy permitted by the genetic code. The term "polypeptide" is used interchangeably herein with the terms "polypeptides" and "protein(s)", and refers to a polymer of amino acid residues, e.g., as typically found in proteins in nature. A "mature protein" is a protein which is full-length and which, optionally, includes glycosylation or other modifications typical for the protein in a given cell membrane.
[0041]The term "modulate" with respect to an hT1R1, hT1R2, and/or hT1R3 proteins refers to a change in the activity of hT1R1, hT1R2, and/or hT1R3 proteins. For example, modulation may cause an increase or a decrease in protein activity (e.g., coupled GTPase activity), binding characteristics, membrane permeability or any other biological, functional, or immunological properties of such proteins. The change in activity can arise from, for example, an increase or decrease in expression of one or more genes that encode these proteins, the stability of an mRNA that encodes the protein, translation efficiency, or from a change in activity of the protein itself. For example, a molecule that binds to one of the receptors can cause an increase or decrease in the biological activity of the receptor.
[0042]The term "variant" with respect to a polypeptide refers to an amino acid sequence that is altered by one or more amino acids with respect to a reference sequence. The variant can have "conservative" changes, wherein a substituted amino acid has similar structural or chemical properties, e.g., replacement of leucine with isoleucine. Alternatively, a variant can have "nonconservative" changes, e.g., replacement of a glycine with a tryptophan. Analogous minor variation can also include amino acid deletion or insertion, or both. Guidance in determining which amino acid residues can be substituted, inserted, or deleted without eliminating biological or immunological activity can be found using computer programs well known in the art, for example, DNASTAR software. Examples of conservative substitutions are also described below.
[0043]As used herein, an "antibody" is a protein comprising one or more polypeptides substantially or partially encoded by immunoglobulin genes or fragments of immunoglobulin genes. The recognized immunoglobulin genes include the kappa, lambda, alpha, gamma, delta, epsilon and mu constant region genes, as well as myriad immunoglobulin variable region genes. Light chains are classified as either kappa or lambda. Heavy chains are classified as gamma, mu, alpha, delta, or epsilon, which in turn define the immunoglobulin classes, IgG, IgM, IgA, IgD and IgE, respectively. A typical immunoglobulin (antibody) structural unit comprises a tetramer. Each tetramer is composed of two identical pairs of polypeptide chains, each pair having one "light" (about 25 kD) and one "heavy" chain (about 50-70 kD). The N-terminus of each chain defines a variable region of about 100 to 110 or more amino acids primarily responsible for antigen recognition. The terms variable light chain (VL) and variable heavy chain (VH) refer to these light and heavy chains respectively. Antibodies exist as intact immunoglobulins or as a number of well characterized fragments produced by digestion with various peptidases. Thus, for example, pepsin digests an antibody below the disulfide linkages in the hinge region to produce F(ab)'2, a dimer of Fab which itself is a light chain joined to VH-CH1 by a disulfide bond. The F(ab)'2 may be reduced under mild conditions to break the disulfide linkage in the hinge region thereby converting the (Fab')2 dimer into an Fab' monomer. The Fab' monomer is essentially an Fab with part of the hinge region (see, Fundamental Immunology, W. E. Paul, ed., Raven Press, N.Y. (1999), for a more detailed description of other antibody fragments). While various antibody fragments are defined in terms of the digestion of an intact antibody, one of skill will appreciate that such Fab' fragments may be synthesized de novo either chemically or by utilizing recombinant DNA methodology. Thus, the term antibody, as used herein, includes antibodies or fragments either produced by the modification of whole antibodies or synthesized de novo using recombinant DNA methodologies. Antibodies include multiple or single chain antibodies, including single chain Fv (sFv) antibodies in which a variable heavy and a variable light chain are joined together (directly or through a peptide linker) to form a continuous polypeptide.
[0044]A variety of additional terms are defined or otherwise characterized herein.
DESCRIPTION OF THE PREFERRED EMBODIMENTS
[0045]The present invention relates to the identification of three novel members of human sweet receptors referred to as hT1R1, hT1R2 and hT1R3 nucleic acids encoding these proteins, vectors and host cells comprising the nucleic acids, methods for producing the proteins and methods for identifying compounds which bind to and/or modulate the activity of these proteins. These genes are specifically expressed in specialized neuroepithelial cells referred to as human taste receptor cells located in the fungiform papillae of the tongue.
[0046]Evidence supports the assignment of hT1R1, hT1R2 and hT1R3 as belonging to the sweet receptor family. The hT1R1, hT1R2 and hT1R3 proteins show homology to their mouse (mT1R1, mT1R2, mT1R3) and rat (rT1R1, rT1R2) counterparts (see, Example 1). All three hT1Rs are predicted to contain seven-transmembrane domains (see, FIG. 1) consistent with previous studies implicating G proteins and their respective GPCRs in sweet taste transduction. In addition, all three ht1Rs are predicted to have long N-terminal extracellular domains which is characteristic of other members of the GPCR subfamily 3, which includes metabotropic glutamate receptors (as described below, the receptors herein can form heteromers that provide glutamate receptor activity as well as sweet receptor activity), extracellular Ca++ sensors and pheromone receptors. Chromosome mapping studies using the NCBI human genome search interface (see, Example 2) have demonstrated that these three genes are clustered in a region of human chromosome 1. The aforementioned region of the human chromosome is syntenous to the distal end of mouse chromosome 4 which contains the Sac locus, which in turn has been implicated in detecting sweet tastants as described, e.g., in Fuller, J. Hered. 65:33-36, 1974; Lush et al., Genet. Res. 66:167-174; and Bachmanov, Mamm. Genome 8:545-548. In situ hybridization studies (see, Example 3) have also confirmed that these genes are specifically expressed in human taste receptor cells in the fungiform papillae of the human tongue which is consistent with their role in taste perception. Based on the amino acid homology between the hT1R proteins and their mouse and rat counterparts, the hT1R genes' expression in the fungiform papillae of the human tongue, and the location of the hT1R proteins on human chromosome 1, a syntenic region of the distal end of mouse chromosome 4 in which the mouse Sac locus maps, it is reasonable to conclude that the new hT1R proteins function as sweet receptors or receptor components. As noted below, various heteromeric versions of the proteins have been shown to respond to glutamate, implicating them as glutamate receptors as well.
[0047]Since the aforementioned genes are expressed in taste cells, these genes and their related polypeptides can serve as specific targets for the identification of sweet tastants and the design of novel sweeteners. Accordingly, the invention also relates to methods for screening compounds that bind to and/or modulate the activity of these receptors, to identify compounds that stimulate sweet taste perception.
Making Compositions of the Invention
[0048]In practicing the present invention, many conventional techniques in molecular biology, microbiology, and recombinant DNA are optioanlly used. These techniques are well known and are explained in, for example, Current Protocols in Molecular Biology, Volumes I, II, and III, 1997 (F. M. Ausubel ed.); Sambrook et al., 2001, Molecular Cloning: A Laboratory Manual, Third Edition, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y.; DNA Cloning: A Practical Approach, Volumes I and II, 1985 (D. N. Glover ed.); Oligonucleotide Synthesis, 1984 (M. L. Gait ed.); Nucleic Acid Hybridization, 1985, (Hames and Higgins); Transcription and Translation, 1984 (Hames and Higgins eds.); Animal Cell Culture, 1986 (R. I. Freshney ed.); Immobilized Cells and Enzymes, 1986 (IRL Press); Perbal, 1984, A Practical Guide to Molecular Cloning; the series, Methods in Enzymology (Academic Press, Inc.); Gene Transfer Vectors for Mammalian Cells, 1987 (J. H. Miller and M. P. Calos eds., Cold Spring Harbor Laboratory); and Methods in Enzymology Vol. 154 and Vol. 155 (Wu and Grossman, and Wu, eds., respectively).
[0049]Nucleic Acids
[0050]In one aspect, the invention provides isolated nucleic acids encoding a hT1R1 protein. These include the isolated nucleic acid molecule encoding hT1R1 protein comprising an amino acid sequence as set forth in SEQ ID NO:1 (FIG. 1) and the isolated nucleic acid molecule encoding a hT1R1 protein comprising a nucleotide sequence as set forth in SEQ ID NO:10 (FIG. 2A) as well as a wide variety of variants as noted herein.
[0051]In another aspect, the invention provides isolated nucleic acids encoding a hT1R2 protein. These include the isolated nucleic acid molecule encoding hT1R2 protein comprising an amino acid sequence as set forth in SEQ ID NO:4 (FIG. 1) and the isolated nucleic acid molecule encoding a hT1R2 protein comprising a nucleotide sequence as set forth in SEQ ID NO:11 (FIG. 2B) as well as a wide variety of variants as noted herein.
[0052]In another aspect, the invention provides isolated nucleic acids encoding a hT1R3 protein. These include the isolated nucleic acid molecule encoding hT1R3 protein comprising an amino acid sequence as set forth in SEQ ID NO:7 (FIG. 1) and the isolated nucleic acid molecule encoding a hT1R3 protein comprising a nucleotide sequence as set forth in SEQ ID NO:12 (FIG. 2C) as well as a wide variety of variants as noted herein.
[0053]Nucleic acid molecules of the present invention also include isolated nucleic acid molecules that have at least 50% identity or more, typically at least 60% identity or more, generally 70% identity or more, often 80% identity or more, e.g., 90% identity or more, preferably at least 95% identity, more preferably at least 98% identity, and most preferably at least 99% identity to a nucleic acid encoding a polypeptide comprising the amino acid sequence of SEQ ID NO:1, SEQ ID NO:4 and/or SEQ ID NO:7, respectively. Such nucleic acid molecules include a nucleic acid encoding a polypeptide of SEQ ID NO:1, SEQ ID NO:4 and SEQ ID NO:7 as set forth above. The identity can be over the entire coding region, or can be over a subsequence, e.g., a subsequence comprising at least about 10%, e.g., at least 25%, e.g., at least 50% or more of the full-length sequence. Nucleic acids of the present invention also include fragments of the aforementioned nucleic acid molecules. For example, the invention provides nucleic acids that encode one or more of the domains of the hT1R receptors. Such domains include the amino terminal extracellular domain, the seven transmembrane (TM) domains, the extracellular domains (located between TM2 and TM3, between TM4 and TM5, and between TM6 and TM7), and the intracellular domains (C-terminal to TM7, and between TM1 and TM2, between TM3 and TM4, and between TM5 and TM6). The amino acid sequences of the transmembrane domains, intracellular domains, and extracellular domains are shown in, for example, FIG. 1.
[0054]Nucleic acids of the present invention include isolated nucleic acid molecules encoding polypeptide variants which comprise the amino acid sequences of SEQ ID NO:1, SEQ ID NO:4 and SEQ ID NO:7 (h1R1, h1R2 and h1R3, respectively). Such nucleotide variants include deletion variants, substitution variants and addition or insertion variants.
[0055]The invention also provides isolated nucleic acid molecules that are fully complementary to all the above described isolated nucleic acid molecules.
[0056]An isolated nucleic acid encoding one of the above polypeptides including homologs from species other than rat, mouse or human, may be obtained by a method which comprises the steps of screening an appropriate library under stringent conditions with a labeled probe having the sequence of SEQ ID NO:2, SEQ ID NO:4 and SEQ ID NO:6, or a fragment thereof; and isolating cDNA and genomic clones containing the nucleotide sequences. Such hybridization techniques are well-known to a skilled artisan. Another typical method for making appropriate sequences includes performing PCR on genomic or cDNA from an appropriate library or nucleic acid preparation.
[0057]Nucleic acid molecules encoding the above hT1R receptors and variants thereof can be obtained from genomic or cDNA, can be amplified via PCR or LCR, or can be synthesized, or made by any combination of conventional techniques. The DNA can then be used to express the hT1R protein, or as a template for preparation of RNA or as a molecular probe which selectively hybridizes to, and thus can detect the presence of, other T1Rx-encoding nucleotide sequences. Naturally occurring sequences can be mutated, e.g., by point mutagenesis or DNA shuffling or other available mutagenesis methods to make variants that are within the scope of the invention. One of skill will also appreciate that essentially any RNA can be converted into a double stranded DNA suitable for restriction digestion, PCR expansion and sequencing using reverse transcriptase and a polymerase. See, Ausubel, Sambrook and Berger, herein. In addition, RNAs of the invention can be made by transcription of DNA sequences.
[0058]When nucleic acid molecules of the present invention are utilized for the recombinant production of hT1R polypeptides of the present invention, the nucleotide sequence can include the coding sequence for the mature polypeptide, by itself; or the coding sequence for the mature polypeptide in reading frame with other coding sequences, such as those encoding a leader or secretory sequence, a pre-, or pro- or prepro-protein sequence, or other fusion peptide portions. For example, a marker sequence which facilitates purification of the fused polypeptide can be encoded, e.g., a hexa-histidine peptide, as provided in the pQE vector (Qiagen, Inc.) and described in Gentz et al., Proc. Nat'l. Acad. Sci. USA (1989) 86:821-824, or is an HA tag. The nucleic acid molecule can also contain noncoding 5' and 3' sequences, such as transcribed, non-translated sequences, splicing and polyadenylation signals, ribosome binding sites and sequences that stabilize mRNA.
[0059]General texts which describe molecular biological techniques for making nucleic acids, including the use of vectors, promoters and many other relevant topics, include Berger and Kimmel, Guide to Molecular Cloning Techniques, Methods in Enzymology volume 152 Academic Press, Inc., San Diego, Calif. (Berger); Sambrook et al., Molecular Cloning--A Laboratory Manual (3nd Ed.), Vol. 1-3, Cold Spring Harbor Laboratory, Cold Spring Harbor, N.Y., 2000 ("Sambrook") and Current Protocols in Molecular Biology, F. M. Ausubel et al., eds., Current Protocols, a joint venture between Greene Publishing Associates, Inc. and John Wiley & Sons, Inc., (supplemented through 2002) ("Ausubel")). Examples of techniques sufficient to direct persons of skill through in vitro amplification methods, including the polymerase chain reaction (PCR) the ligase chain reaction (LCR), Q.E-backward.-replicase amplification and other RNA polymerase mediated techniques (e.g., NASBA), e.g., for the production of the homologous nucleic acids of the invention are found in Berger, Sambrook, and Ausubel, as well as Mullis et al., (1987) U.S. Pat. No. 4,683,202; PCR Protocols A Guide to Methods and Applications (Innis et al. eds) Academic Press Inc. San Diego, Calif. (1990) (Innis); Arnheim & Levinson (Oct. 1, 1990) C&EN 36-47; The Journal Of NIH Research (1991) 3, 81-94; (Kwoh et al. (1989) Proc. Natl. Acad. Sci. USA 86, 1173; Guatelli et al. (1990) Proc. Natl. Acad. Sci. USA 87, 1874; Lomell et al. (1989) J. Clin. Chem 35, 1826; Landegren et al., (1988) Science 241, 1077-1080; Van Brunt (1990) Biotechnology 8, 291-294; Wu and Wallace, (1989) Gene 4, 560; Barringer et al. (1990) Gene 89, 117, and Sooknanan and Malek (1995) Biotechnology 13: 563-564.
[0060]In addition, a plethora of kits are commercially available for the purification of plasmids or other relevant nucleic acids from cells, (see, e.g., EasyPrep®, FlexiPrep®, both from Pharmacia Biotech; StrataClean®, from Stratagene; and, QIAprep® from Qiagen). Any isolated and/or purified nucleic acid can be further manipulated to produce other nucleic acids, used to transfect cells, incorporated into related vectors to infect organisms, or the like. Typical cloning vectors contain transcription and translation terminators, transcription and translation initiation sequences, and promoters useful for regulation of the expression of the particular target nucleic acid. The vectors optionally comprise generic expression cassettes containing at least one independent terminator sequence, sequences permitting replication of the cassette in eukaryotes, or prokaryotes, or both, (e.g., shuttle vectors) and selection markers for both prokaryotic and eukaryotic systems. Vectors are suitable for replication and integration in prokaryotes, eukaryotes, or both. See, Giliman & Smith, Gene 8:81 (1979); Roberts, et al., Nature, 328:731 (1987); Schneider, B., et al., Protein Expr. Purif. 6435:10 (1995); Ausubel, Sambrook, Berger (above). A catalogue of Bacteria and Bacteriophages useful for cloning is provided, e.g., by the ATCC, e.g., The ATCC Catalogue of Bacteria and Bacteriophage published yearly by the ATCC. Additional basic procedures for sequencing, cloning and other aspects of molecular biology and underlying theoretical considerations are also found in Watson et al. (1992) Recombinant DNA Second Edition, Scientific American Books, NY.
[0061]Other useful references, e.g. for cell isolation and culture (e.g., for subsequent nucleic acid isolation) include Freshney (1994) Culture of Animal Cells, a Manual of Basic Technique, third edition, Wiley-Liss, New York and the references cited therein; Payne et al. (1992) Plant Cell and Tissue Culture in Liquid Systems John Wiley & Sons, Inc. New York, N.Y.; Gamborg and Phillips (eds) (1995) Plant Cell, Tissue and Organ Culture; Fundamental Methods Springer Lab Manual, Springer-Verlag (Berlin Heidelberg N.Y.) and Atlas and Parks (eds) The Handbook of Microbiological Media (1993) CRC Press, Boca Raton, Fla.
[0062]In addition, essentially any nucleic acid (and virtually any labeled nucleic acid, whether standard or non-standard) can be custom or standard ordered from any of a variety of commercial sources, such as The Midland Certified Reagent Company (mcrc@oligos.com), The Great American Gene Company (www.genco.com), ExpressGen Inc. (www.expressgen.com), Operon Technologies Inc. (Alameda, Calif.) and many others.
[0063]Various types of mutagenesis are optionally used in the present invention, e.g., to modify hT1R1, hT1R2 or hT1R3 nucleic acids and encoded polypeptides to produce conservative or non-conservative variants. Any available mutagenesis procedure can be used. Such mutagenesis procedures optionally include selection of mutant nucleic acids and polypeptides for one or more activity of interest. Procedures that can be used include, but are not limited to: site-directed point mutatgenesis, random point mutagenesis, in vitro or in vivo homologous recombination (DNA shuffling), mutagenesis using uracil containing templates, oligonucleotide-directed mutagenesis, phosphorothioate-modified DNA mutagenesis, mutagenesis using gapped duplex DNA, point mismatch repair, mutagenesis using repair-deficient host strains, restriction-selection and restriction-purification, deletion mutagenesis, mutagenesis by total gene synthesis, double-strand break repair, and many others known to persons of skill. Mutagenesis, e.g., involving chimeric constructs, are also included in the present invention. In one embodiment, mutagenesis can be guided by known information of the naturally occurring molecule or altered or mutated naturally occurring molecule, e.g., sequence, sequence comparisons, physical properties, crystal structure or the like. In another class of embodiments, modification is essentially random (e.g., as in classical DNA shuffling).
[0064]The above texts describe these procedures. Additional information is found in the following publications and references cited within: Arnold, Protein engineering for unusual environments, Current Opinion in Biotechnology 4:450-455 (1993); Bass et al., Mutant Trp repressors with new DNA-binding specificities, Science 242:240-245 (1988); Botstein & Shortle, Strategies and applications of in vitro mutagenesis, Science 229:1193-1201 (1985); Carter et al., Improved oligonucleotide site-directed mutagenesis using M13 vectors, Nucl. Acids Res. 13: 4431-4443 (1985); Carter, Site-directed mutagenesis, Biochem. J. 237:1-7 (1986); Carter, Improved oligonucleotide-directed mutagenesis using M13 vectors, Methods in Enzymol. 154: 382-403 (1987); Dale et al., Oligonucleotide-directed random mutagenesis using the phosphorothioate method, Methods Mol. Biol. 57:369-374 (1996); Eghtedarzadeh & Henikoff, Use of oligonucleotides to generate large deletions, Nucl. Acids Res. 14: 5115 (1986); Fritz et al., Oligonucleotide-directed construction of mutations: a gapped duplex DNA procedure without enzymatic reactions in vitro, Nucl. Acids Res. 16: 6987-6999 (1988); Grundstrom et al., Oligonucleotide-directed mutagenesis by microscale `shot-gun` gene synthesis, Nucl. Acids Res. 13: 3305-3316 (1985); Kunkel, The efficiency of oligonucleotide directed mutagenesis, in Nucleic Acids & Molecular Biology (Eckstein, F. and Lilley, D. M. J. eds., Springer Verlag, Berlin)) (1987); Kunkel, Rapid and efficient site-specific mutagenesis without phenotypic selection, Proc. Natl. Acad. Sci. USA 82:488-492 (1985); Kunkel et al., Rapid and efficient site-specific mutagenesis without phenotypic selection, Methods in Enzymol. 154, 367-382 (1987); Kramer et al., The gapped duplex DNA approach to oligonucleotide-directed mutation construction, Nucl. Acids Res. 12: 9441-9456 (1984); Kramer & Fritz Oligonucleotide-directed construction of mutations via gapped duplex DNA, Methods in Enzymol. 154:350-367 (1987); Kramer et al., Point Mismatch Repair, Cell 38:879-887 (1984); Kramer et al., Improved enzymatic in vitro reactions in the gapped duplex DNA approach to oligonucleotide-directed construction of mutations, Nucl. Acids Res. 16: 7207 (1988); Ling et al., Approaches to DNA mutagenesis: an overview, Anal Biochem. 254(2): 157-178 (1997); Lorimer and Pastan Nucleic Acids Res. 23, 3067-8 (1995); Mandecki, Oligonucleotide-directed double-strand break repair in plasmids of Escherichia coli: a method for site-specific mutagenesis, Proc. Natl. Acad. Sci. USA, 83:7177-7181 (1986); Nakamaye & Eckstein, Inhibition of restriction endonuclease Nci I cleavage by phosphorothioate groups and its application to oligonucleotide-directed mutagenesis, Nucl. Acids Res. 14: 9679-9698 (1986); Nambiar et al., Total synthesis and cloning of a gene coding for the ribonuclease S protein, Science 223: 1299-1301 (1984); Sakamar and Khorana, Total synthesis and expression of a gene for the a-subunit of bovine rod outer segment guanine nucleotide-binding protein (transducin), Nucl. Acids Res. 14: 6361-6372 (1988); Sayers et al., Y-T Exonucleases in phosphorothioate-based oligonucleotide-directed mutagenesis, Nucl. Acids Res. 16:791-802 (1988); Sayers et al., Strand specific cleavage of phosphorothioate-containing DNA by reaction with restriction endonucleases in the presence of ethidium bromide, (1988) Nucl. Acids Res. 16: 803-814; Sieber, et al., Nature Biotechnology, 19:456-460 (2001); Smith, In vitro mutagenesis, Ann. Rev. Genet. 19:423-462 (1985); Methods in Enzymol. 100: 468-500 (1983); Methods in Enzymol. 154: 329-350 (1987); Stemmer, Nature 370, 389-91 (1994); Taylor et al., The use of phosphorothioate-modified DNA in restriction enzyme reactions to prepare nicked DNA, Nucl. Acids Res. 13: 8749-8764 (1985); Taylor et al., The rapid generation of oligonucleotide-directed mutations at high frequency using phosphorothioate-modified DNA, Nucl. Acids Res. 13: 8765-8787 (1985); Wells et al., Importance of hydrogen-bond formation in stabilizing the transition state of subtilisin, Phil. Trans. R. Soc. Lond. A 317: 415-423 (1986); Wells et al., Cassette mutagenesis: an efficient method for generation of multiple mutations at defined sites, Gene 34:315-323 (1985); Zoller & Smith, Oligonucleotide-directed mutagenesis using M13-derived vectors: an efficient and general procedure for the production of point mutations in any DNA fragment, Nucleic Acids Res. 10:6487-6500 (1982); Zoller & Smith, Oligonucleotide-directed mutagenesis of DNA fragments cloned into M13 vectors, Methods in Enzymol. 100:468-500 (1983); and Zoller & Smith, Oligonucleotide-directed mutagenesis: a simple method using two oligonucleotide primers and a single-stranded DNA template, Methods in Enzymol. 154:329-350 (1987). Additional details on many of the above methods can be found in Methods in Enzymology Volume 154, which also describes useful controls for trouble-shooting problems with various mutagenesis methods.
[0065]Polypeptides
[0066]In another aspect, the present invention relates to hT1R polypeptides. These include the hT1R1 polypeptide comprising an amino acid sequence as set forth in SEQ ID NO:1 (FIG. 1), the hT1R2 polypeptide comprising an amino acid sequence as set forth in SEQ ID:4 (FIG. 1) and the hT1R3 polypeptide comprising an amino acid sequence as set forth in SEQ ID NO:7 (FIG. 1) as well as variants thereof. The polypeptides of the present invention also include fragments of the aforementioned sequences. For example, the invention also provides polypeptides that comprise one or more domains of the hT1R receptor polypeptides. These domains, which include extracellular domains, intracellular domains, and transmembrane domains, are described above and shown in FIG. 1.
[0067]Polypeptides of the present invention include isolated polypeptides, e.g., variants, in which the amino acid sequence has at least 75% identity, preferably at least 80% identity, typically 90% identity, preferably at least 95% identity, more preferably at least 98% identity and most preferably at least 99% identity, to the amino acid sequences as set forth in SEQ ID NO:1, SEQ ID NO:4 and SEQ ID NO:7. Such sequences include the sequences of SEQ ID NO:1, SEQ ID NO:4 and SEQ ID NO:7 as set forth above.
[0068]The aforementioned hT1R polypeptides can be obtained by any of a variety of methods. Smaller peptides (less than 50 amino acids long) are conveniently synthesized by standard chemical techniques and can be chemically or enzymatically ligated to form larger polypeptides. Polypeptides can be purified from biological sources by methods well known in the art (see, e.g., Protein Purification, Principles and Practice, Second Edition (1987) Scopes, Springer Verlag, N.Y.). They are optionally (and preferably) produced in their naturally occurring, truncated, or fusion protein forms by recombinant DNA technology using techniques well known in the art. These methods include, for example, in vitro recombinant DNA techniques, synthetic techniques and in vivo genetic recombination. See, for example, the techniques described in Sambrook et al. (2001) Molecular Cloning, A Laboratory Manual, Third Edition, Cold Spring Harbor Press, N.Y.; and Ausubel et al., eds. (1997) Current Protocols in Molecular Biology, Green Publishing Associates, Inc., and John Wiley & Sons, Inc., N.Y (supplemented through 2002). Alternatively, RNA encoding the proteins can be chemically synthesized. See, for example, the techniques described in Oligonucleotide Synthesis, (1984) Gait ed., IRL Press, Oxford, which is incorporated by reference herein in its entirety. Obtaining large quantities of these polypeptides is preferably by recombinant techniques as further described above under the section entitled "making nucleic acids."
[0069]Another aspect of the present invention relates to a method for producing a hT1R1, ht1R2 or hT1R3 polypeptide, or a polypeptide that comprises one or more domains thereof. These methods involve, e.g.,:
[0070]a) culturing a host cell comprising a nucleic acid of the invention, e.g., a nucleic acid encoding an hT1R1, hT1R2 or hT1R3 polypeptide, or variant or domain thereof, under conditions suitable for expression of the hT1R1, hT1R2 or hT1R3 polypeptide; and
[0071]b) isolating the hT1R1, hT1R2 or hT1R3 polypeptide or domain thereof.
[0072]As described, the nucleic acid molecules described herein can be expressed in a suitable host cell to produce active hT1R1, hT1R2 or hT1R3 protein. Expression occurs by placing a nucleotide sequence encoding these proteins into an appropriate expression vector and introducing the expression vector into a suitable host cell, culturing the transformed host cell under conditions suitable for expression of the hT1R1, hT1R2, hT1R3 protein or variant thereof, or a polypeptide that comprises one or more domains of such proteins, and purifying the recombinant proteins from the host cell to obtain purified, and preferably active, hT1R1, hT1R2 or hT1R3 protein. Appropriate expression vectors are known in the art. For example, pET-14b, pcDNA1Amp, and pVL1392 are available from Novagen and Invitrogen and are suitable vectors for expression in E. coli, COS cells and baculovirus infected insect cells, respectively. These vectors are illustrative of those that are known in the art. Suitable host cells can be any cell capable of growth in a suitable media and allowing purification of the expressed protein. Examples of suitable host cells include bacterial cells, such as E. coli, Streptococci, Staphylococci, Streptomyces and Bacillus subtilis cells; fungal cells such as yeast cells, e.g., Pichia, and Aspergillus cells; insect cells such as Drosophila S2 and Spodoptera Sf9 cells, mammalian cells such as CHO, COS, HeLa; and plant cells.
[0073]Culturing and growth of the transformed host cells can occur under conditions that are known in the art. The conditions will generally depend upon the host cell and the type of vector used. Suitable culturing conditions may be used such as temperature and chemicals and will depend on the type of promoter utilized. In addition to Sambrook, Berger, Ausubel and the other references previously noted, details regarding cell culture can also be found in Freshney (1994) Culture of Animal Cells, a Manual of Basic Technique, third edition, Wiley-Liss, New York Payne et al. (1992) Plant Cell and Tissue Culture in Liquid Systems John Wiley & Sons, Inc. New York, N.Y.; Gamborg and Phillips (eds) (1995) Plant Cell, Tissue and Organ Culture; Fundamental Methods Springer Lab Manual, Springer-Verlag (Berlin Heidelberg N.Y.); and Atlas and Parks (eds) The Handbook of Microbiological Media (1993) CRC Press, Boca Raton, Fla.
[0074]Purification of the hT1R1, hT1R2 or hT1R3 protein, or domains of such proteins, can be accomplished using known techniques without performing undue experimentation. Generally, the transformed cells expressing one of these proteins are broken, crude purification occurs to remove debris and some contaminating proteins, followed by chromatography to further purify the protein to the desired level of purity. Cells can be broken by known techniques such as homogenization, sonication, detergent lysis and freeze-thaw techniques. Crude purification can occur using ammonium sulfate precipitation, centrifugation or other known techniques. Suitable chromatography includes anion exchange, cation exchange, high performance liquid chromatography (HPLC), gel filtration, affinity chromatography, hydrophobic interaction chromatography, etc. Well known techniques for refolding proteins can be used to obtain the active conformation of the protein when the protein is denatured during intracellular synthesis, isolation or purification.
[0075]In general, proteins of the invention, e.g., proteins comprising hT1R1, hT1R2 and/or hT1R3 sequences or domains, or antibodies to such proteins can be purified, either partially (e.g., achieving a 5×, 10×, 100×, 500×, or 1000× or greater purification), or even substantially to homogeneity (e.g., where the protein is the main component of a solution, typically excluding the solvent (e.g., water or DMSO) and buffer components (e.g., salts and stabilizers) that the protein is suspended in, e.g., if the protein is in a liquid phase), according to standard procedures known to and used by those of skill in the art. Accordingly, polypeptides of the invention can be recovered and purified by any of a number of methods well known in the art, including, e.g., ammonium sulfate or ethanol precipitation, acid or base extraction, column chromatography, affinity column chromatography, anion or cation exchange chromatography, phosphocellulose chromatography, hydrophobic interaction chromatography, hydroxylapatite chromatography, lectin chromatography, gel electrophoresis and the like. Protein refolding steps can be used, as desired, in making correctly folded mature proteins. High performance liquid chromatography (HPLC), affinity chromatography or other suitable methods can be employed in final purification steps where high purity is desired. In one embodiment, antibodies made against hT1R1, hT1R2 and/or hT1R3 (or proteins comprising hT1R1, hT1R2 and/or hT1R3 domains) are used as purification reagents, e.g., for affinity-based purification of proteins comprising one or more hT1R1, hT1R2 and/or hT1R3 domains or antibodies thereto. Once purified, partially or to homogeneity, as desired, the polypeptides are optionally used e.g., as assay components, therapeutic reagents or as immunogens for antibody production.
[0076]In addition to other references noted herein, a variety of purification/protein purification methods are well known in the art, including, e.g., those set forth in R. Scopes, Protein Purification, Springer-Verlag, N.Y. (1982); Deutscher, Methods in Enzymology Vol. 182: Guide to Protein Purification, Academic Press, Inc. N.Y. (1990); Sandana (1997) Bioseparation of Proteins, Academic Press, Inc.; Bollag et al. (1996) Protein Methods, 2nd Edition Wiley-Liss, NY; Walker (1996) The Protein Protocols Handbook Humana Press, NJ; Harris and Angal (1990) Protein Purification Applications: A Practical Approach IRL Press at Oxford, Oxford, England; Harris and Angal Protein Purification Methods: A Practical Approach IRL Press at Oxford, Oxford, England; Scopes (1993) Protein Purification Principles and Practice 3rd Edition Springer Verlag, NY; Janson and Ryden (1998) Protein Purification: Principles, High Resolution Methods and Applications, Second Edition Wiley-VCH, NY; and Walker (1998) Protein Protocols on CD-ROM Humana Press, NJ; and the references cited therein.
[0077]Those of skill in the art will recognize that, after synthesis, expression and/or purification, proteins can possess a conformation different from the desired conformations of the relevant polypeptides. For example, polypeptides produced by prokaryotic systems often are optimized by exposure to chaotropic agents to achieve proper folding. During purification from, e.g., lysates derived from E. coli, the expressed protein is optionally denatured and then renatured. This is accomplished, e.g., by solubilizing the proteins in a chaotropic agent such as guanidine HCl. In general, it is occasionally desirable to denature and reduce expressed polypeptides and then to cause the polypeptides to re-fold into the preferred conformation. For example, guanidine, urea, DTT, DTE, and/or a chaperonin can be added to a translation product of interest. Methods of reducing, denaturing and renaturing proteins are well known to those of skill in the art (see, the references above, and Debinski, et al. (1993) J. Biol. Chem., 268: 14065-14070; Kreitman and Pastan (1993) Bioconjug. Chem., 4: 581-585; and Buchner, et al., (1992) Anal. Biochem., 205: 263-270). Debinski, et al., for example, describe the denaturation and reduction of inclusion body proteins in guanidine-DTE. The proteins can be refolded in a redox buffer containing, e.g., oxidized glutathione and L-arginine. Refolding reagents can be flowed or otherwise moved into contact with the one or more polypeptide or other expression product, or vice-versa.
[0078]The polynucleotides of the present invention optionally comprise a coding sequence fused in-frame to a marker sequence which, e.g., facilitates purification of the encoded polypeptide. Such purification facilitating domains include, but are not limited to, metal chelating peptides such as histidine-tryptophan modules that allow purification on immobilized metals, a sequence which binds glutathione (e.g., GST), a hemagglutinin (HA) tag (corresponding to an epitope derived from the influenza hemagglutinin protein; Wilson, I., et al. (1984) Cell 37:767), maltose binding protein sequences, the FLAG epitope utilized in the FLAGS extension/affinity purification system (Immunex Corp, Seattle, Wash.), and the like. The inclusion of a protease-cleavable polypeptide linker sequence between the purification domain and the sequence of the invention is useful to facilitate purification.
[0079]Sequence Variations
[0080]Silent Variations
[0081]Due to the degeneracy of the genetic code, any of a variety of nucleic acids sequences encoding polypeptides of the invention are optionally produced, some which can bear lower levels of sequence identity to the hT1Rx nucleic acid and polypeptide sequences in the figures. The following provides a typical codon table specifying the genetic code, found in many biology and biochemistry texts.
TABLE-US-00001 TABLE 1 Codon Table Amino acids Codon Alanine Ala A GCA GCC GCG GCU Cysteine Cys C UGC UGU Aspartic acid Asp D GAC GAU Glutamic acid Glu E GAA GAG Phenylalanine Phe F UUC UUU Glycine Gly G GGA GGC GGG GGU Histidine His H CAC CAU Isoleucine Ile I AUA AUC AUU Lysine Lys K AAA AAG Leucine Leu L UUA UUG CUA CUC CUG CUU Methionine Met M AUG Asparagine Asn N AAC AAU Proline Pro P CCA CCC CCG CCU Glutamine Gln Q CAA CAG Arginine Arg R AGA AGG CGA CGC CGG CGU Serine Ser S AGC AGU UCA UCC UCG UCU Threonine Thr T ACA ACC ACG ACU Valine Val V GUA GUC GUG GUU Tryptophan Trp W UGG Tyrosine Tyr Y UAC UAU
[0082]The codon table shows that many amino acids are encoded by more than one codon. For example, the codons AGA, AGG, CGA, CGC, CGG, and CGU all encode the amino acid arginine. Thus, at every position in the nucleic acids of the invention where an arginine is specified by a codon, the codon can be altered to any of the corresponding codons described above without altering the encoded polypeptide. It is understood that U in an RNA sequence corresponds to T in a DNA sequence.
[0083]Using, as an example, the nucleic acid sequence corresponding to nucleotides 1-18 of SEQ ID NO: 10 are: ATG CTG CTC TGC ACG GCT (MLLCTA from SEQ ID NO: 1). A silent variation of this sequence includes ATG, TTA TTG TGT, ACC, GCC (also encoding MLLCTA from SEQ ID NO:1).
[0084]Such "silent variations" are one species of "conservatively modified variations", discussed below. One of skill will recognize that each codon in a nucleic acid (except ATG, which is ordinarily the only codon for methionine) can be modified by standard techniques to encode a functionally identical polypeptide. Accordingly, each silent variation of a nucleic acid which encodes a polypeptide is implicit in any described sequence. The invention, therefore, explicitly provides each and every possible variation of a nucleic acid sequence encoding a polypeptide of the invention that could be made by selecting combinations based on possible codon choices. These combinations are made in accordance with the standard triplet genetic code (e.g., as set forth in Table 1, or as is commonly available in the art) as applied to the nucleic acid sequence encoding a T1Rx polypeptide of the invention. All such variations of every nucleic acid herein are specifically provided and described by consideration of the sequence in combination with the genetic code. One of skill is fully able to make these silent substitutions using the methods herein.
[0085]Conservative Variations
[0086]"Conservatively modified variations" or, simply, "conservative variations" of a particular nucleic acid sequence or polypeptide are those which encode identical or essentially identical amino acid sequences. One of skill will recognize that individual substitutions, deletions or additions which alter, add or delete a single amino acid or a small percentage of amino acids (typically less than 5%, more typically less than 4%, 2% or 1%) in an encoded sequence are "conservatively modified variations" where the alterations result in the deletion of an amino acid, addition of an amino acid, or substitution of an amino acid with a chemically similar amino acid.
[0087]Conservative substitution tables providing functionally similar amino acids are well known in the art. Table 2 sets forth six groups which contain amino acids that are "conservative substitutions" for one another.
TABLE-US-00002 TABLE 2 Conservative Substitution Groups 1 Alanine (A) Serine (S) Threonine (T) 2 Aspartic acid (D) Glutamic acid (E) 3 Asparagine (N) Glutamine (Q) 4 Arginine (R) Lysine (K) 5 Isoleucine (I) Leucine (L) Methionine (M) Valine (V) 6 Phenylalanine (F) Tyrosine (Y) Tryptophan (W)
[0088]Thus, "conservatively substituted variations" of a listed polypeptide sequence of the present invention include substitutions of a small percentage, typically less than 5%, more typically less than 2% or 1%, of the amino acids of the polypeptide sequence, with a conservatively selected amino acid of the same conservative substitution group.
[0089]For example, a conservatively substituted variation of the polypeptide identified herein as SEQ ID NO:1 will contain "conservative substitutions", according to the six groups defined above, in up to about 40 residues (i.e., about 5% of the amino acids) in the full-length polypeptide.
[0090]In a further example, if conservative substitutions were localized in the region corresponding to amino acids 5-10 (TARLV), examples of conservatively substituted variations of this region include conservative exchange of conserved amino acids, e.g., substitution of STKMM or TSKVI (or any others that can be made according to Table 2) for TARLV. Listing of a protein sequence herein, in conjunction with the above substitution table, provides an express listing of all conservatively substituted proteins.
[0091]Finally, the addition or deletion of sequences which do not alter the encoded activity of a nucleic acid molecule, such as the addition or deletion of a non-functional sequence, is a conservative variation of the basic nucleic acid or polypeptide.
[0092]One of skill will appreciate that many conservative variations of the nucleic acid constructs which are disclosed yield a functionally identical construct. For example, as discussed above, owing to the degeneracy of the genetic code, "silent substitutions" (i.e., substitutions in a nucleic acid sequence which do not result in an alteration in an encoded polypeptide) are an implied feature of every nucleic acid sequence which encodes an amino acid. Similarly, "conservative amino acid substitutions," in one or a few amino acids in an amino acid sequence are substituted with different amino acids with highly similar properties, are also readily identified as being highly similar to a disclosed construct. Such conservative variations of each disclosed sequence are a feature of the present invention.
[0093]hT1R1, hT1R2 and/or hT1R3 Antibodies
[0094]In another aspect, antibodies to hT1R1, hT1R2 or hT1R3 proteins or fragments thereof can be generated using methods that are well known in the art. The antibodies can be utilized for detecting and/or purifying the hT1Rx proteins, optionally discriminating the proteins from various homologues, and/or in biosensor hT1R1, hT1R2 or hT1R3 activity detection applications. As used herein, the term antibody includes, but is not limited to, polyclonal antibodies, monoclonal antibodies, humanized or chimeric antibodies and biologically functional antibody fragments, which are those fragments sufficient for binding of the antibody fragment to the protein.
[0095]For the production of antibodies to a protein encoded by one of the disclosed genes, various host animals may be immunized by injection with the polypeptide, or a portion thereof. Such host animals may include, but are not limited to, rabbits, mice and rats, to name but a few. Various adjuvants may be used to enhance the immunological response, depending on the host species, including, but not limited to, Freund's (complete and incomplete), mineral gels such as aluminum hydroxide, surface active substances such as lysolecithin, pluronic polyols, polyanions, peptides, oil emulsions, keyhole limpet hemocyanin, dinitrophenol, and potentially useful human adjuvants such as BCG (bacille Calmette-Guerin) and Corynebacterium parvum.
[0096]Polyclonal antibodies are heterogeneous populations of antibody molecules derived from the sera of animals immunized with an antigen, such as target gene product, or an antigenic functional derivative thereof. For the production of polyclonal antibodies, host animals, such as those described above, may be immunized by injection with the encoded protein, or a portion thereof, supplemented with adjuvants as also described above.
[0097]Monoclonal antibodies (mAbs), which are homogeneous populations of antibodies to a particular antigen, may be obtained by any technique which provides for the production of antibody molecules by continuous cell lines in culture. These include, but are not limited to, the hybridoma technique of Kohler and Milstein (Nature 256:495-497, 1975; and U.S. Pat. No. 4,376,110), the human B-cell hybridoma technique (Kosbor et al., Immunology Today 4:72, 1983; Cole et al., Proc. Nat'l. Acad. Sci. USA 80:2026-2030, 1983), and the EBV-hybridoma technique (Cole et al., Monoclonal Antibodies and Cancer Therapy, Alan R. Liss, Inc., pp. 77-96, 1985). Such antibodies may be of any immunoglobulin class, including IgG, IgM, IgE, IgA, IgD, and any subclass thereof. The hybridoma producing the mAb of this invention may be cultivated in vitro or in vivo. Production of high titers of mAbs in vivo makes this the presently preferred method of production.
[0098]In addition, techniques developed for the production of "chimeric antibodies" (Morrison et al., Proc. Nat'l. Acad. Sci. USA 81:6851-6855, 1984; Neuberger et al., Nature 312:604-608, 1984; Takeda et al., Nature 314:452-454, 1985) by splicing the genes from a mouse antibody molecule of appropriate antigen specificity, together with genes from a human antibody molecule of appropriate biological activity, can be used. A chimeric antibody is a molecule in which different portions are derived from different animal species, such as those having a variable or hypervariable region derived from a murine mAb and a human immunoglobulin constant region.
[0099]Alternatively, techniques described for the production of single-chain antibodies (U.S. Pat. No. 4,946,778; Bird, Science 242:423-426, 1988; Huston et al., Proc. Nat'l. Acad. Sci. USA 85:5879-5883, 1988; and Ward et al., Nature 334:544-546, 1989) can be adapted to produce differentially expressed gene-single chain antibodies. Single chain antibodies are formed by linking the heavy and light chain fragments of the Fv region via an amino acid bridge, resulting in a single-chain polypeptide.
[0100]In one aspect, techniques useful for the production of "humanized antibodies" can be adapted to produce antibodies to the proteins, fragments or derivatives thereof. Such techniques are disclosed in U.S. Pat. Nos. 5,932,448; 5,693,762; 5,693,761; 5,585,089; 5,530,101; 5,569,825; 5,625,126; 5,633,425; 5,789,650; 5,661,016; and 5,770,429.
[0101]Antibody fragments which recognize specific epitopes may be generated by known techniques. For example, such fragments include, but are not limited to, the F(ab')2 fragments, which can be produced by pepsin digestion of the antibody molecule, and the Fab fragments, which can be generated by reducing the disulfide bridges of the F(ab')2 fragments. Alternatively, Fab expression libraries may be constructed (Huse et al., Science 246:1275-1281, 1989) to allow rapid and easy identification of monoclonal Fab fragments with the desired specificity.
[0102]The protocols for detecting and measuring the expression of the described hT1R proteins using the above mentioned antibodies are well known in the art. Such methods include, but are not limited to, dot blotting, western blotting, competitive and noncompetitive protein binding assays, enzyme-linked immunosorbant assays (ELISA), immunohistochemistry, fluorescence-activated cell sorting (FACS), and others commonly used and widely described in scientific and patent literature, and many employed commercially.
[0103]Particularly preferred, for ease of detection, is the sandwich ELISA, of which a number of variations exist, all of which are intended to be encompassed by the present invention. For example, in a typical forward assay, unlabeled antibody is immobilized on a solid substrate and the sample to be tested is brought into contact with the bound molecule and incubated for a period of time sufficient to allow formation of an antibody-antigen binary complex. At this point, a second antibody, labeled with a reporter molecule capable of inducing a detectable signal, is then added and incubated, allowing time sufficient for the formation of a ternary complex of antibody-antigen-labeled antibody. Any unreacted material is washed away, and the presence of the antigen is determined by observation of a signal, or may be quantitated by comparing with a control sample containing known amounts of antigen. Variations on the forward assay include the simultaneous assay, in which both sample and antibody are added simultaneously to the bound antibody, or a reverse assay, in which the labeled antibody and sample to be tested are first combined, incubated and added to the unlabeled surface bound antibody. These techniques are well known to those skilled in the art, and the possibility of minor variations will be readily apparent. As used herein, "sandwich assay" is intended to encompass all variations on the basic two-site technique. For the immunoassays of the present invention, the only limiting factor is that the labeled antibody be an antibody which is specific for the protein expressed by the gene of interest.
[0104]The most commonly used reporter molecules in this type of assay are either enzymes, fluorophore- or radionuclide-containing molecules. In the case of an enzyme immunoassay, an enzyme is conjugated to the second antibody, usually by means of glutaraldehyde or periodate. As will be readily recognized, however, a wide variety of different ligation techniques exist which are well-known to the skilled artisan. Commonly used enzymes include horseradish peroxidase, glucose oxidase, beta-galactosidase and alkaline phosphatase, among others. The substrates to be used with the specific enzymes are generally chosen for the production, upon hydrolysis by the corresponding enzyme, of a detectable color change. For example, p-nitrophenyl phosphate is suitable for use with alkaline phosphatase conjugates; for peroxidase conjugates, 1,2-phenylenediamine or toluidine are commonly used. It is also possible to employ fluorogenic substrates, which yield a fluorescent product, rather than the chromogenic substrates noted above. A solution containing the appropriate substrate is then added to the tertiary complex. The substrate reacts with the enzyme linked to the second antibody, giving a qualitative visual signal, which may be further quantitated, usually spectrophotometrically, to give an evaluation of the amount of PLAB which is present in the serum sample.
[0105]Alternately, fluorescent compounds, such as fluorescein and rhodamine, can be chemically coupled to antibodies without altering their binding capacity. When activated by illumination with light of a particular wavelength, the fluorochrome-labeled antibody absorbs the light energy, inducing a state of excitability in the molecule, followed by emission of the light at a characteristic longer wavelength. The emission appears as a characteristic color visually detectable with a light microscope. Immunofluorescence and EIA techniques are both very well established in the art and are particularly preferred for the present method. However, other reporter molecules, such as radioisotopes, chemiluminescent or bioluminescent molecules may also be employed. It will be readily apparent to the skilled artisan how to vary the procedure to suit the required use.
[0106]Defining Proteins and Nucleic Acids by Immunoreactivity
[0107]Because the polypeptides of the invention provide a variety of new polypeptide sequences, the polypeptides also provide new structural features which can be recognized, e.g., in immunological assays. The generation of antisera which specifically bind the polypeptides of the invention, as well as the polypeptides which are bound by such antisera, are a feature of the invention.
[0108]For example, the invention includes hT1R1, hT1R2 and hT1R3 proteins that specifically bind to or that are specifically immunoreactive with an antibody or antisera generated against an immunogen comprising an amino acid sequence selected from SEQ ID NO: 1, SEQ ID NO: 4 or SEQ ID NO: 7 (and/or nucleic acids that encode such hT1R1, hT1R2 and hT1R3 proteins). To eliminate cross-reactivity with other homologues (e.g., the mouse and rat homologues), the antibody or antisera is optionally subtracted with mT1R1, mT1R2, mT1R3, rT1R1, rT1R2, and/or rT1R3 protein(s). In one typical format, the immunoassay uses a polyclonal antiserum which was raised against one or more polypeptide comprising one or more of the sequences corresponding to one or more of SEQ ID NO: 1, SEQ ID NO: 4 or SEQ ID NO: 7 or a substantial subsequence thereof (i.e., at least about 30% of the full length sequence provided, or typically at least about 50%, 75% or more of the sequence). The set of potential polypeptide immunogens derived from SEQ ID NO: 1, SEQ ID NO: 4 or SEQ ID NO: 7 are collectively referred to below as "the immunogenic polypeptides." The resulting antisera is optionally selected to have low cross-reactivity against the control homologues (mT1R1, mT1R2, mT1R3, rT1R1, rT1R2, and/or rT1R3, e.g., as set forth in SEQ ID NO: 2, SEQ ID NO: 3 SEQ ID NO: 5 SEQ ID NO: 6 SEQ ID NO: 8 and SEQ ID NO: 9) and any such cross-reactivity is optionally removed, e.g., by immunoabsorbtion, with one or more of the control homologues, prior to use of the polyclonal antiserum in the immunoassay. In order to produce antisera for use in an immunoassay, one or more of the immunogenic polypeptides is produced and purified as described herein. For example, recombinant protein can be produced in a recombinant cell. An inbred strain of mice (used in this assay because results are more reproducible due to the virtual genetic identity of the mice) is immunized with the immunogenic protein(s) in combination with a standard adjuvant, such as Freund's adjuvant, and a standard mouse immunization protocol (see, e.g., Harlow and Lane (1988) Antibodies, A Laboratory Manual, Cold Spring Harbor Publications, New York, for a standard description of antibody generation, immunoassay formats and conditions that can be used to determine specific immunoreactivity. Additional references and discussion of antibodies is also found herein and can be applied here to defining polypeptides by immunoreactivity). Alternatively, one or more synthetic or recombinant polypeptide derived from the sequences disclosed herein is conjugated to a carrier protein and used as an immunogen.
[0109]Polyclonal sera are collected and titered against the immunogenic polypeptide in an immunoassay, for example, a solid phase immunoassay with one or more of the immunogenic proteins immobilized on a solid support. Polyclonal antisera with a titer of 106 or greater are selected, pooled and subtracted with the control polypeptides to produce subtracted pooled titered polyclonal antisera.
[0110]The subtracted pooled titered polyclonal antisera are tested for cross reactivity against the control homologues (the mouse and or rat T1Rx protein(s)) in a comparative immunoassay. In this comparative assay, discriminatory binding conditions are determined for the subtracted titered polyclonal antisera which result in at least about a 5-10 fold higher signal to noise ratio for binding of the titered polyclonal antisera to the immunogenic polypeptide as compared to binding to the control homologues. That is, the stringency of the binding reaction is adjusted by the addition of non-specific competitors such as albumin or non-fat dry milk, and/or by adjusting salt conditions, temperature, and/or the like. These binding conditions are used in subsequent assays for determining whether a test polypeptide (a polypeptide being compared to the immunogenic polypeptides and/or the control polypeptides) is specifically bound by the pooled subtracted polyclonal antisera. In particular, test polypeptides which show at least a 2-5× higher signal to noise ratio than the control homologues under discriminatory binding conditions, and at least about a 1/2 signal to noise ratio as compared to the immunogenic polypeptide(s), clearly shares substantial structural similarity with the immunogenic polypeptide as compared to the mouse or rat homologues, and is, therefore a polypeptide of the invention.
[0111]In another example, immunoassays in the competitive binding format are used for detection of a test polypeptide. For example, as noted, cross-reacting antibodies are removed from the pooled antisera mixture by immunoabsorbtion with the control polypeptides. The immunogenic polypeptide(s) are then immobilized to a solid support which is exposed to the subtracted pooled antisera. Test proteins are added to the assay to compete for binding to the pooled subtracted antisera. The ability of the test protein(s) to compete for binding to the pooled subtracted antisera as compared to the immobilized protein(s) is compared to the ability of the immunogenic polypeptide(s) added to the assay to compete for binding (the immunogenic polypeptides compete effectively with the immobilized immunogenic polypeptides for binding to the pooled antisera). The percent cross-reactivity for the test proteins is calculated, using standard calculations.
[0112]In a parallel assay, the ability of the control proteins to compete for binding to the pooled subtracted antisera is optionally determined as compared to the ability of the immunogenic polypeptide(s) to compete for binding to the antisera. Again, the percent cross-reactivity for the control polypeptides is calculated, using standard calculations. Where the percent cross-reactivity is at least 5-10× as high for the test polypeptides as compared to the control polypeptides and or where the binding of the test polypeptides is approximately in the range of the binding of the immunogenic polypeptides, the test polypeptides are said to specifically bind the pooled subtracted antisera.
[0113]In general, the immunoabsorbed and pooled antisera can be used in a competitive binding immunoassay as described herein to compare any test polypeptide to the immunogenic and/or control polypeptide(s). In order to make this comparison, the immunogenic, test and control polypeptides are each assayed at a wide range of concentrations and the amount of each polypeptide required to inhibit 50% of the binding of the subtracted antisera to, e.g., an immobilized control, test or immunogenic protein is determined using standard techniques. If the amount of the test polypeptide required for binding in the competitive assay is less than twice the amount of the immunogenic polypeptide that is required, then the test polypeptide is said to specifically bind to an antibody generated to the immunogenic protein, provided the amount is at least about 5-10× as high as for the control polypeptide.
[0114]As an additional determination of specificity, the pooled antisera is optionally fully immunosorbed with the immunogenic polypeptide(s) (rather than the control polypeptides) until little or no binding of the resulting immunogenic polypeptide subtracted pooled antisera to the immunogenic polypeptide(s) used in the immunosorbtion is detectable. This fully immunosorbed antisera is then tested for reactivity with the test polypeptide. If little or no reactivity is observed (i.e., no more than 2× the signal to noise ratio observed for binding of the fully immunosorbed antisera to the immunogenic polypeptide), then the test polypeptide is specifically bound by the antisera elicited by the immunogenic protein.
[0115]Methods of Use/Biosensors
[0116]In another aspect, the present invention relates to the use of the hT1R1, hT1R2 and hT1R3 proteins and/or coding nucleic acids in methods for identifying a compound, i.e., a sweet or umami (glutamate) tastant, that interacts/binds to the protein(s) encoded by these genes. The test compound can be natural or synthetic molecules such as proteins or fragments thereof, carbohydrates, organic or inorganic compounds and/or the like. This can be achieved, e.g., by utilizing the hT1R1, hT1R2 and hT1R3 proteins of the invention, or active fragments thereof, in cell-free or cell-based assays. A variety of formats are applicable, including measurement of second messenger effects (e.g., Ca2+ flux assays, cAMP assays, GTPgammaS binding assays, melanophore assays; phospholipase C assays, beta-arrestin FRET assays, and transcriptional reporter assays, e.g., using CRE, SRE, MRE, TRE, NFAT, and/or NFkB-response elements coupled to appropriate reporters.
[0117]In one embodiment, cell-free assays for identifying such compounds comprise a reaction mixture containing a protein encoded by one of the disclosed genes and a test compound or a library of test compounds. Accordingly, one example of a cell-free method for identifying test compounds that specifically bind to the hT1R1, ht1R2 and hT1R3 proteins comprises contacting a protein or functional fragment thereof with a test compound or library of test compounds and detecting the formation of complexes by conventional methods. In particularly useful embodiments, a library of the test compounds can be synthesized on a solid substrate, e.g., plastic pins or some other surface. The test compounds are reacted with the hT1R protein or fragment thereof and washed to elute unbound protein. Bound hT1R is then detected by methods well known in the art. Purified hT1R can also be applied directly onto plates for use in the aforementioned screening method. Antibody binding to the proteins can also be detected in this format.
[0118]Interaction between molecules can also be assessed by using real-time BIA (Biomolecular Interaction Analysis, Pharmacia Biosensor AB), which detects surface plasmon resonance, an optical phenomenon. Detection depends on changes in the mass concentration of mass macromolecules at the biospecific interface and does not require labeling of the molecules. In one useful embodiment, a library of test compounds can be immobilized on a sensor surface, e.g., a wall of a micro-flow cell. A solution containing the protein or functional fragment thereof is then continuously circulated over the sensor surface. An alteration in the resonance angle, as indicated on a signal recording, indicates the occurrence of an interaction. This technique is described in more detail in the BIAtechnology Handbook by Pharmacia.
[0119]In yet other useful embodiments, the hT1R protein or fragment thereof can be immobilized to facilitate separation of complexes from uncomplexed forms of the protein and automation of the assay. Complexation of the protein can be achieved in any type of vessel, e.g., microtitre plates, micro-centrifuge tubes and test tubes. In particularly preferred embodiments, the protein can be fused to another protein, e.g., glutathione-S-transferase to form a fusion protein which can be adsorbed onto a matrix, e.g., glutathione Sepharose® beads (Sigma Chemical. St. Louis, Mo.), which are then combined with the test compound and incubated under conditions sufficient to form complexes. Subsequently, the beads are washed to remove unbound label, and the matrix is immobilized and the radiolabel is determined.
[0120]Another method for immobilizing proteins on matrices involves utilizing biotin and streptavidin. For example, the protein can be biotinylated using biotin NHS (N-hydroxy-succinimide), using well known techniques and immobilized in the well of streptavidin-coated plates.
[0121]Cell-free assays can also be used to identify agents which specifically bind and/or modulate the activity. In one embodiment, the protein is incubated with a test compound and the catalytic activity of the protein is determined. In another embodiment, the binding affinity of the protein to a target molecule can be determined by methods known in the art.
[0122]In addition to cell-free assays such as those described above, the hT1R proteins can be utilized in cell-based assay for identifying compounds which bind to and/or modulate hT1R activity.
[0123]For example, one method for identifying compounds which bind to these proteins comprises, providing a cell that expresses one of these proteins, e.g., hT1R1, combining a test compound with the cell and measuring the formation of a complex between the test compound and the hT1R protein. The cell can be a mammalian cell, a yeast cell, bacterial cell, insect cell, a human taste cell of the fungiform papillae, or any other cell expressing the hT1R protein.
[0124]In another embodiment, human taste cells or heterologous cells expressing hT1Rs, or plasma membrane preparations of such cells, can be utilized to screen for bioactivity of test compounds or peptides. As stated above, the hT1R proteins described herein are homologous to known GPCR proteins. Accordingly, the hT1R proteins are coupled to G-proteins, which mediate signal transduction. A variety of intracellular effectors have been identified as being G-protein regulated including, but not limited to, adenyl cyclase, cyclic GMP, phospholipase C, phospholipase A2 and phosphodiesterases. G-proteins also interact with a variety of ion channels, e.g., certain voltage-sensitive Ca++ transients. Accordingly, the level of such second messengers produced by the aforementioned intracellular effectors, and thus activity of the hT1R receptors, can be measured by techniques, which are well known to those skilled in the art. For example, the level of cAMP produced by activation of adenyl cyclase, can be measured by competitive assays which quantities {3H}cAMP in the presence of unlabeled cAMP. The GTPase activity by G proteins can be measured, e.g., in plasma membrane preparations by measuring the hydrolysis of gamma 32P GTP. Breakdown of phosphatidylinositol-4,5-bisphosphate to 1,4,5-IP3 and diacylglycerol can be monitored by measuring the amount of diacylglycerol using thin-layer chromatography, or measuring the amount of IP3 using radiolabeling techniques or HPLC. The generation of arachidonic acid by the activation of phospholipase A2 can be readily quantitated by well-known techniques.
[0125]The search for sweet (or glutamate) substances using hT1Rx genes can also be done by cell-based assay. It is known that GPCRs induce Ca++ flux and other signal transduction pathways. Efflux of intracellular calcium or influx of calcium from outside the cell can be measured using conventional techniques, e.g., loading cells with a Ca++ sensitive fluorescent dye such as fura-2 or indol-1, and measuring any change in Ca++ using a fluorometer, such as Fluoskan Ascent Fluorescent Plate Reader or Fluorometric Imaging Plate Reader. The signal pathways initiated by hT1Rs in response to sweet compounds can also be monitored by reporter gene assays. The co-localization of hT1R2 and hT1R3 in the same taste cell of human tongue may indicate the co-expression of hT1R2 and hT1R3 genes in the heterologous cell system is required for their activities. The co-expression of promiscuous G proteins with hT1Rs may help to funnel heterologous signal transduction of hT1Rs through a common pathway involving phospholipase C and Ca++ mobilization.
[0126]As described, other assays such as melanophore assays, Phospholipase C assays, beta-arrestin FRET assays, and Transcriptional reporter assays, e.g., using CRE, SRE, MRE, TRE, NFAT, and/or NFkB-response elements coupled to appropriate reporters can be used. Detection using reporter genes coupled to appropriate response elements are particularly convenient. For example, the coding sequence to chloramphenicol acetyl transferase, beta galactosidase or other convenient markers are coupled to a response element that is activated by a second messenger that is activated by a protein of the invention. Cells expressing the marker in response to application of an appropriate test compound are detected by cell survival, or by expression of a colorimetric marker, or the like, according to well established methods.
[0127]In an alternate embodiment, conformational changes are detected by coupling the polypeptides of the invention to an electrical readout, e.g., to a chemically coupled field effect transistor (a CHEM-FET) or other appropriate system for detecting changes in conductance or other electrical properties brought about by a conformational shift by the protein of the invention.
[0128]In an alternate aspect, potential modulators of hT1R1, hT1R2 and/or hT1R3 activity or expression can be screened for. For example, potential modulators (small molecules, organic molecules, inorganic molecules, proteins, hormones, transcription factors, or the like) can be contacted to a cell and an effect on hT1R1, hT1R2 and/or hT1R3 activity or expression (or both) can be screened for. For example, expression of hT1R1, hT1R2 and/or hT1R3 can be detected, e.g., via northern analysis or quantitative (optionally real time) RT-PCR, before and after application of potential expression modulators. Similarly, promoter regions of the various genes (e.g., generally sequences in the region of the start site of transcription, e.g., within 5 KB of the start site, e.g., 1 KB, or less e.g., within 500 BP or 250 BP or 100 BP of the start site) can be coupled to reporter constructs (CAT, beta-galactosidase, luciferase or any other available reporter) and can be similarly be tested for expression activity modulation by the potential modulator. In either case, the assays can be performed in a high-throughput fashion, e.g., using automated fluid handling and/or detection systems, in serial or parallel fashion. Similarly, activity modulators can be tested by contacting a potential modulator to an appropriate cell using any of the activity detection methods herein, regardless of whether the activity that is detected is the result of activity modulation, expression modulation or both.
[0129]Biosensors of the invention are devices or systems that comprise the proteins of the invention coupled to a readout that measures or displays one or more activity of the protein. Thus, any of the above described assay components can be configured as a biosensor by operably coupling the appropriate assay components to a readout. The readout can be optical (e.g., to detect cell markers or cell survival) electrical (e.g., coupled to a FET, a BIAcore, or any of a variety of others), spectrographic, or the like, and can optionally include a user-viewable display (e.g., a CRT or optical viewing station). The biosensor can be coupled to robotics or other automation, e.g., microfluidic systems, that direct contact of the test compounds to the proteins of the invention, e.g., for automated high-throughput analysis of test compound activity. A large variety of automated systems that can be adapted to use with the biosensors of the invention are commercially available. For example, automated systems have been made to assess a variety of biological phenomena, including, e.g., expression levels of genes in response to selected stimuli (Service (1998) "Microchips Arrays Put DNA on the Spot" Science 282:396-399). Laboratory systems can also perform, e.g., repetitive fluid handling operations (e.g., pipetting) for transferring material to or from reagent storage systems that comprise arrays, such as microtiter trays or other chip trays, which are used as basic container elements for a variety of automated laboratory methods. Similarly, the systems manipulate, e.g., microtiter trays and control a variety of environmental conditions such as temperature, exposure to light or air, and the like. Many such automated systems are commercially available. Examples of automated systems are available from the Zymark Corporation (Zymark Center, Hopkinton, Mass.), which utilize various Zymate systems (see also, www.zymark.com/), which typically include, e.g., robotics and fluid handling modules. Similarly, the common ORCA® robot, which is used in a variety of laboratory systems, e.g., for microtiter tray manipulation, is also commercially available, e.g., from Beckman Coulter, Inc. (Fullerton, Calif.). A number of automated approaches to high-throughput activity screening are provided by the Genomics Institute of the Novartis Foundation (La Jolla, Calif.); See GNF.org on the world-wide web. Microfluidic screening applications are commercially available from Caliper Technologies Corp. (Mountain View, Calif.). For example, (e.g., LabMicrofluidic Device® high throughput screening system (HTS) by Caliper Technologies, Mountain View, Calif. or the HP/Agilent technologies Bioanalyzer using LabChip® technology by Caliper Technologies Corp. can be adapted for use in the present invention.
[0130]Data Systems Comprising hT1R1, hT1R2 and hT1R3 Sequences
[0131]The present invention provides databases, computers, computer readable media and systems comprising character strings corresponding to the sequence information herein for the polypeptides and nucleic acids herein, including, e.g., those sequences listed herein and the various silent substitutions and conservative substitutions thereof.
[0132]Various methods known in the art can be used to detect homology or similarity between different character strings, or can be used to perform other desirable functions such as to control output files, provide the basis for making presentations of information including the sequences and the like. Examples include BLAST, discussed supra.
[0133]Thus, different types of homology and similarity of various stringency and length can be detected, predicted and/or recognized in the data systems herein. For example, many homology determination methods have been designed for comparative analysis of sequences of biopolymers (nucleic acids, proteins, etc.), for spell-checking in word processing, and for data retrieval from various databases. With an understanding of hydrogen bonding between the principal nucleobases in natural polynucleotides, models that simulate annealing of complementary homologous polynucleotide strings can also be used as a foundation of sequence alignment or other operations typically performed on the character strings corresponding to the sequences herein (e.g., word-processing manipulations, construction of figures comprising sequence or subsequence character strings, output tables, etc.). An example of a software package for calculating sequence similarity is BLAST, which can be adapted to the present invention by inputting character strings corresponding to the sequences herein. CLUSTAL provides another appropriate package.
[0134]Similarly, standard desktop applications such as word processing software (e.g., Microsoft Word® or Corel WordPerfect®) and database software (e.g., spreadsheet software such as Microsoft Excel®, Corel Quattro Pro®, or database programs such as Microsoft Access® or Sequel®, Oracle®, Paradox®) can be adapted to the present invention by inputting a character string corresponding to the proteins or nucleic acids of the invention (either nucleic acids or proteins, or both). For example, the integrated systems can include the foregoing software having the appropriate character string information, e.g., used in conjunction with a user interface (e.g., a GUI in a standard operating system such as a Windows, Macintosh or LINUX system) to manipulate strings of characters. As noted, specialized alignment programs such as BLAST can also be incorporated into the systems of the invention for alignment of nucleic acids or proteins (or corresponding character strings).
[0135]Systems for analysis in the present invention typically include a digital computer with an appropriate data base and a sequence of the invention. Software for aligning sequences, as well as data sets entered into the software system comprising any of the sequences herein can be a feature of the invention. The computer can be, e.g., a PC (Intel x86 or Pentium chip-compatible DOS®, OS2® WINDOWS® WINDOWS NT®, WINDOWS95®, WINDOWS98®, WINDOWS2000, WINDOWSME, or LINUX based machine, a MACINTOSH®, Power PC, or a UNIX based (e.g., SUN® work station or LINUX based machine) or other commercially common computer which is known to one of skill. Software for entering and aligning or otherwise manipulating sequences is available, or can easily be constructed by one of skill using a standard programming language such as Visualbasic, Fortran, Basic, Java, or the like.
[0136]Any controller or computer optionally includes a monitor which is often a cathode ray tube ("CRT") display, a flat panel display (e.g., active matrix liquid crystal display, liquid crystal display, etc.), or others. Computer circuitry is often placed in a box which includes numerous integrated circuit chips, such as a microprocessor, memory, interface circuits, and others. The box also optionally includes a hard disk drive, a floppy disk drive, a high capacity removable drive such as a writeable CD-ROM, and other common peripheral elements. Inputting devices such as a keyboard or mouse optionally provide for input from a user and for user selection of sequences to be compared or otherwise manipulated in the relevant computer system.
[0137]The computer typically includes appropriate software for receiving user instructions, either in the form of user input into a set parameter fields, e.g., in a GUI, or in the form of preprogrammed instructions, e.g., preprogrammed for a variety of different specific operations. The software then converts these instructions to appropriate language for instructing the operation of the fluid direction and transport controller to carry out the desired operation.
[0138]The software can also include output elements for controlling nucleic acid synthesis (e.g., based upon a sequence or an alignment of a sequences herein) or other operations which occur downstream from an alignment or other operation performed using a character string corresponding to a sequence herein.
[0139]Cell Rescue--Treatement
[0140]In one aspect, the invention includes rescue of a cell that is defective in function of one or more endogenous hT1Rx genes or polypeptides. This can be accomplished simply by introducing a new copy of the gene (or a heterologous nucleic acid that expresses the relevant protein) into a cell. Other approaches, such as homologous recombination to repair the defective gene (e.g., via chimeraplasty) can also be performed. In any event, rescue of function can be measured, e.g., in any of the in vitro assays noted herein. Indeed, this can be used as a general method of screening cells in vitro for an hT1Rx activity. Accordingly, in vitro rescue of function is useful in this context for the myriad in vitro screening methods noted above, e.g., for the identification of sweet or glutamate tastants in cells. The cells that are rescued can include cells in culture, (including primary or secondary cell culture from patients, as well as cultures of well-established cells). Where the cells are isolated from a patient, this has additional diagnostic utility in establishing which hT1Rx sequence is defective in a patient that presents with a tasting defect.
[0141]In another aspect, the cell rescue occurs in a patient, e.g., a human or veterinary patient, e.g., to remedy a tastant defect (for example, older patients often present with an inability to perceive sweet tastants and there are genetic defects that also present as an inability to taste sweet tastants). Thus, one aspect of the invention is gene therapy to remedy tasting defects (or even simply to enhance tastant discrimination), in human or veterinary applications. In these applications, the nucleic acids of the invention are optionally cloned into appropriate gene therapy vectors (and/or are simply delivered as naked or liposome-conjugated nucleic acids), which are then delivered (generally topically to the taste buds, but optionally systemically), optionally in combination with appropriate carriers or delivery agents. Proteins can also be delivered directly, but delivery of the nucleic acid is typically preferred in applications where stable expression is desired. Compositions for administration, e.g., comprise a therapeutically effective amount of the gene therapy vector or other relevant nucleic acid, and a pharmaceutically acceptable carrier or excipient. Such a carrier or excipient includes, but is not limited to, saline, buffered saline, dextrose, water, glycerol, ethanol, and/or combinations thereof. The formulation is made to suit the mode of administration. In general, methods of administering gene therapy vectors for topical use are well known in the art and can be applied to administration of the nucleic acids of the invention.
[0142]Therapeutic compositions comprising one or more nucleic acid of the invention are optionally tested in one or more appropriate in vitro and/or in vivo animal model of disease, to confirm efficacy, tissue metabolism, and to estimate dosages, according to methods well known in the art. In particular, dosages can initially be determined by activity, stability or other suitable measures of the formulation.
[0143]Administration is by any of the routes normally used for introducing a molecule into ultimate contact with taste bud cells, though topical administration or direct injection into the taste buds is simplest and therefore preferred. The nucleic acids of the invention are administered in any suitable manner, optionally with one or more pharmaceutically acceptable carriers. Suitable methods of administering such nucleic acids in the context of the present invention to a patient are available, and, although more than one route can be used to administer a particular composition, a particular route can often provide a more immediate and more effective action or reaction than another route.
[0144]Pharmaceutically acceptable carriers are determined in part by the particular composition being administered, as well as by the particular method used to administer the composition. Accordingly, there is a wide variety of suitable formulations of pharmaceutical compositions of the present invention. Compositions can be administered by a number of routes including, but not limited to: oral (in this case, topical and oral can be the same or different, e.g., topical delivery to the taste buds can be oral, as can systemic administration by the GI tract), intravenous, intraperitoneal, intramuscular, transdermal, subcutaneous, topical, sublingual, or rectal administration. Compositions can be administered via liposomes (e.g., topically), or via topical delivery of naked DNA or viral vectors. Such administration routes and appropriate formulations are generally known to those of skill in the art.
[0145]The compositions, alone or in combination with other suitable components, can also be made into aerosol formulations (i.e., they can be "nebulized") to be administered via inhalation. Aerosol formulations can be placed into pressurized acceptable propellants, such as dichlorodifluoromethane, propane, nitrogen, and the like. Formulations suitable for parenteral administration, such as, for example, by intraarticular (in the joints), intravenous, intramuscular, intradermal, intraperitoneal, and subcutaneous routes, include aqueous and non-aqueous, isotonic sterile injection solutions, which can contain antioxidants, buffers, bacteriostats, and solutes that render the formulation isotonic with the blood of the intended recipient, and aqueous and non-aqueous sterile suspensions that can include suspending agents, solubilizers, thickening agents, stabilizers, and preservatives. The formulations of packaged nucleic acid can be presented in unit-dose or multi-dose sealed containers, such as ampules and vials.
[0146]The dose administered to a patient, in the context of the present invention, is sufficient to effect a beneficial therapeutic response in the patient over time, or, e.g., to provide sweet or glutamate tastant discrimination as perceived by the patient in an objective sweet or glutamate tastant test. The dose is determined by the efficacy of the particular vector, or other formulation, and the activity, stability or serum half-life of the polypeptide which is expressed, and the condition of the patient, as well as the body weight or surface area of the patient to be treated. The size of the dose is also determined by the existence, nature, and extent of any adverse side-effects that accompany the administration of a particular vector, formulation, or the like in a particular patient. In determining the effective amount of the vector or formulation to be administered in the treatment of disease, the physician evaluates local expression in the taste buds, or circulating plasma levels, formulation toxicities, progression of the relevant disease, and/or where relevant, the production of antibodies to proteins encoded by the polynucleotides. The dose administered, e.g., to a 70 kilogram patient are typically in the range equivalent to dosages of currently-used therapeutic proteins, adjusted for the altered activity or serum half-life of the relevant composition. The vectors of this invention can supplement treatment conditions by any known conventional therapy.
[0147]For administration, formulations of the present invention are administered at a rate determined by the LD-50 of the relevant formulation, and/or observation of any side-effects of the vectors of the invention at various concentrations, e.g., as applied to the mass or topical delivery area and overall health of the patient. Administration can be accomplished via single or divided doses.
[0148]If a patient undergoing treatment develops fevers, chills, or muscle aches, he/she receives the appropriate dose of aspirin, ibuprofen, acetaminophen or other pain/fever controlling drug. Patients who experience reactions to the compositions, such as fever, muscle aches, and chills are premedicated 30 minutes prior to the future infusions with either aspirin, acetaminophen, or, e.g., diphenhydramine. Meperidine is used for more severe chills and muscle aches that do not quickly respond to antipyretics and antihistamines. Treatment is slowed or discontinued depending upon the severity of the reaction.
[0149]Kits
[0150]In an additional aspect, the present invention provides kits embodying the methods, composition, systems or apparatus herein. Kits of the invention optionally comprise one or more of the following: (1) a composition, system, system component as described herein; (2) instructions for practicing the methods described herein, and/or for using the compositions or operating the system or system components herein; (3) one or more hT1Rx composition or component; (4) a container for holding components or compositions, and, (5) packaging materials.
EXAMPLES
[0151]The following examples are offered to illustrate, but not to limit the present invention.
[0152]A search of the human genome database led to the identification of three human candidate taste receptors, hT1R1, hT1R2, and hT1R3, which contain seven transmembrane domains. All three genes map to a region of chromosome 1, which is syntenous to the distal end of chromosome 4 in mouse, which contains the Sac locus that is involved in detecting sweet tastants. A genetic marker, DVL1, which is linked to the Sac locus, is within 1,700 bp of to human T1R3. All three hT1Rs genes are all expressed selectively in human taste receptor cells in the fungiform papillae, consistent with their role in taste perception.
[0153]Accordingly, a family of putative human taste receptors, responsible for detecting sweet tastants are identified. All three hT1Rs sequences are closely related to candidate mammalian sweet taste receptors and sensory receptors (Hoon et al. (1999) Cell 96, 541-551; Montmayeur et al. (2001) Nature Neuroscience, 4, 492-498; Max et al. (2001) Nature Genetics, 28, 58-63; Brown et al. (1993) Nature 366, 575-580; and Matsunami et al. (1997) Cell 90, 775-784); all three hT1Rs contain seven-transmembrane domains, consistent with previous studies implicating G proteins in sweet taste transduction. Furthermore, all three hT1Rs localize in human chromosome 1, in accord with recent studies that show most functionally related chemosensory receptors tend to cluster in the same region of the chromosome. The mouse syntenic locus of hT1R3 is very close to the Sac locus, which has been implicated in sweet taste transduction (Fuller, J. (1974) J. Hered. 65, 33-36; Lush et al. (1995) Genet. Res. 66, 167-174; Bachmanov, A., (1997) Mamm. Genome 8, 545-548). Finally, the hT1Rs are specifically expressed in subsets of taste receptor cells in human tongue.
[0154]The results described here suggest that the T1R3 gene is responsible for the Sac phenotype (See also, Montmayer (2001) and Max (2001), above and Nelson, et al. (2001) Cell 106, 381-390).
[0155]Interestingly, in contrast to observations that shows rat T1R1 and T1R2 are expressed in same taste buds, but in most cases, not in the same cells (Hoon (1999), above), it was found that hT1R2 and hT1R3 are expressed in most of cases in the same taste cells. Thus, a single taste cell may express more than one type of taste receptors (Adler (2000), above), consistent with the experimental observations suggesting that some taste cells may respond to, but not discriminate, multiple taste stimuli (Lindemann, B. (1996) Physiol. Rev. 76, 718-766). This is in striking contrast to olfactory and vomeronasal systems, in which each receptor cell only expresses one receptor gene, providing a cellular mechanism for stimuli discrimination (Buck, L. (2000) Cell 100, 611-6). The co-expression of large subsets of T2Rs and T1Rs in individual taste cells, together with the observation that each sensory fiber innervates multiple taste buds and several taste cells within each taste bud, would result in detection of a large range of distinct tastants, but would not allow discrimination of these substances. The fact that hT1R2 and hT1R3 only share 25% sequence identity suggests distinct ligand specificity. The co-expression of hT1R2 and hT1R3 in the same taste cell reflect the possibility of heterodimer formation, which can lead to different ligand specificity relative to that of each receptor, as is the cases for many GPCR dimers. The results herein show that hT1R1 is expressed in different cells relative to hT1R2 and hT1R3.
[0156]For additional evidence that the mouse T1R2 and T1R3 combine to function as sweet receptor, and mouse T1R3 rescued the Sac phenotype, see (Nelson et al. (2001) Cell 106, 381-390). Further confirming the results herein, it has also recently been shown that the human T1R2/T1R3 recognizes diverse natural and synthetic sweeteners and that human T1R1/T1R3 responds to the umami taste stimulus l-glutamate (Li et al. (2002) Proc. Natl. Acad. Sci. 99, 4692-4696).
Materials and Methods
[0157]hT1R Gene Searching
[0158]The Framesearch program (protein query searches translated protein database) was used to search the Celera human genome database (Release R18 to R25) using rat T1R1 protein as the query. After filtering sequences containing either stop codon(s) or known genes, the contigs containing potential novel genes were submitted to Genescan (http://gnes.mit.edu/GENESCAN.html gnes(dot)mit(dot)edu/GENESCAN(dot)html) for full-length gene prediction. For those exons that were missed by Genescan, TBlastN searches were applied to the same contig using rat T1R1 as the query. All novel protein sequences were subjected to a membrane domain prediction program (TopPhred 2) for verification.
[0159]The 5' end of human T1R2 was obtained by cDNA PCR. The oligonucleotide, 5'-CGCAGCAAAGCCGGGAAGCGCACCTTGTCTC-3' (SEQ ID NO: 7) corresponding to nucleotides 515-545 of hT1R2, was used for cDNA PCR using Marathon-Ready cDNA as template (Clontech). A 600 bp fragment was obtained and cloned into Topo-2.1 vector for sequencing (Invitrogen). The deduced amino acid sequence was then assembled with the Genescan-predicted hT1R2 sequence.
[0160]Chromosome Mapping
[0161]The coding regions of hT1R1 and hT1R3 were used as queries to search the NCBI human genome database (www(dot)ncbi(dot)nlm(dot)nih(dot)gov/genome/seq/page(dot)cgi?F=HsBlast.h- tml &&ORG=Hs) to obtain the chromosome locations relative to telomere. Because the sequence of hT1R2 was not in the NCBI database, a fragment sequence from Celera contig x2HTBKLHUGU that contains the hT1R2 gene was used to search the HTGS database. A BAC clone, AL080251, was found and a search of the human genome database identified its chromosome location. Because one end of the BAC clone AL080251 was about 30 kb away from the hT1R2 gene (the putative third exon), the chromosome location of hT1R2 was deduced from its location relative to the BAC clone AL080251. The genetic marker DVL1 was initially obtained from the NCBI human genome database and used to identify the corresponding location in the mouse syntenic region from the Jackson laboratory Mouse Informatics Database (www(dot)informatics(dot)jax(dot)org/menus/homology menu(dot)shtml). The chromosome locations of mT1Rs were also obtained from the Jackson laboratory Mouse Informatics Database.
[0162]In Situ Hybridization
[0163]Human tongue tissue was obtained from a donor of 70 year old male Caucasian (National Disease Research Interchange). Fresh frozen sections (10 micrometer) of taste papillae were hybridized to digoxigenin-labelled cRNA probes prepared from cloned segments of cDNA encoding the last exons of hT1R1-3. All hybridizations were carried out at high stringency (5×SSC, 50% formamide, 55° C.). For single-label detection, signals were developed using alkaline phosphatase-conjugated antibodies to digoxigenin and NBT/BCIP substrate (Roshe). For two-color fluorescent in situ hybridization, sections of taste papillae were hybridized simultaneously to both digoxigenin-(hT1R2) and fluorescein-(hT1R3) labeled cRNA probes (Roche). Following hybridization, the labeled probes were recognized with peroxidase-anti-digoxigenin and alkaline phosphatase-anti-fluorescein antibodies, respectively (Roche). The tyramide-biotin/streptavidin-Alexa 488 (NEN and Molecular Probe) and HNPP/fast red (Roche) were then used as substrates for fluorescent labeling with peroxidase and alkaline phosphatase, respectively. Sections were mounted in VECTASHIELD Mounting Medium with DAPI (VECTOR Laboratories) to counterstain nuclei.
[0164]In one experiment, expression of the three sweet receptor mRNAs in human taste cells was analyzed. Frozen sections of human fungiform taste papillae were hybridized with digoxigenin-labelled hT1R1, hT1R2, hT1R3 cRNA probes in either anti-sense or sense orientation. The level of expression of hT1R1 was observed to be very low compared to that of hT1R2 and T1R3. The papillae from an adjacent section hybridized to the sense probe and showed no non-specific binding.
[0165]In another experiment, it was determined that hT1R2 colocalizes with hT1R3 in human taste receptor cells. Papillae from human fungiform were hybridized simultaneously with a digoxigenin-labelled hT1R2 and a fluorescein-labelled T1R3 probe. The digoxigenin-labelled T1R2 probe and fluorescein-labeled T1R3 probe were imaged with Alexa 488 (green) and HNPP/fast red (red), respectively. The overlay of the two images shows that some cells coexpress T1R2 and T1R3 (yellow).
Example 1
Identification of Human Sweet Receptor Genes
[0166]A series of search/verification criteria were initially developed as part of the search procedure. The search was carried out using both DNA and protein sequences as queries to increase the possibility of discovering new genes in the human genome. The candidate fragments/genes were evaluated based on existing knowledge of GPCRs and taste receptors, i.e., the sequences of sweet receptors are related to each other; the deduced amino acid sequences should show seven transmembrane domains; and the sweet receptors should be clustered in the same chromosome region. Rat T1R1 (rT1R1) was first utilized as the query to search all public genome and EST databases. No homologous sequences were found initially. The Celera human genome database in an unassembled version was then searched, using the Framesearch program. More than twenty fragments encoding peptides showing similarity to rT1R1 protein were discovered. PCR was used to assess the expression of these fragments. Seven fragments were expressed in testis. Although it is possible that these fragments come from the same gene, the fact that the several different peptides encoded by these fragments show homology to the same region of rT1R1 suggest that there may be several T1R1 homologues in human.
[0167]After the small DNA fragments were assembled into larger fragments, the database was searched again. Based on similarity scores, eleven sequences were chosen for further evaluation. Of these eleven sequences, five fragments were excluded because they contain stop codons in the coding regions, suggesting that they might be pseudogenes. The remaining six fragments were further characterized. Of these, two fragments correspond to two known genes-metabotropic glutamate receptor 3 and Ca2+ sensor 5, and three encode peptides that are homologous to rat T1R1 and are localized in chromosome 1 (see below). The full-length coding region of these three genes was predicted from their corresponding contigs (x8YLHLD for putative hT1R1, x2HTBKLHUGU for putative hT1R2, x2HTBKWRET8 for putative hT1R3) by using the Genscan gene prediction program and tBlastN with rat T1R1 as the query. Two full-length genes encoding proteins with seven transmembrane helices are predicted. The third gene, which encodes a peptide more closely related to rat T1R2, lacks approximately 150 amino acids at the N-terminus due to the fact that the contig x2HTBKLHUGU has several un-sequenced gaps in the putative exon 1 and 2 coding-regions. The EST database was also searched to find any ESTs corresponding to hT1Rs, but none were found, suggesting tissue-specific and/or low-level expressions.
[0168]The PCR method was then utilized to obtain the 5' sequence of the putative human T1R2 cDNA. Using a gene-specific primer, a 600 bp fragment was obtained from human testis cDNA template. Sequencing revealed an in-frame-peptide that is very similar to the N-terminal 150 amino acids of rat T1R2 N-terminus, strongly suggesting this to be 5' sequences of hT1R2 cDNA.
[0169]The deduced amino acid sequences of all three human T1Rs show a high degree of homology to both their mouse and rat counterparts (FIGS. 1A-C). hT1R1 shows much higher sequence identity to its orthologoue, mT1R1 in mouse and rT1R1 in rat (69.8% and 70.0% amino acid identity, respectively) than its homologues, hT1R2 and hT1R3 (30.7% and 26.0%, respectively). The same is true for the other two members: hT1R2 shows 67.9% and 70.4% amino acid identity to mT1R2 and rT1R2, respectively; hT1R3 shows 72% identity to mT1R3. This group of human taste receptors belongs to GPCR subfamily 3, which includes metabotropic glutamate receptors, extracellular Ca2+ sensors, and pheromone receptors. All three hT1Rs have long N-terminal extracellular domains (FIG. 1), similar to other members of this family of GPCRs. This long N-terminal extracellular domain has been suggested to function in dimerization and/or ligand binding as described, e.g., in Kunishima et al., Nature 407: 971-977, 2000. The nucleotide sequences of the hT1R1, hT1R2 and hT1R3 cDNAs are shown in FIGS. 2A, 2B, and 2C, respectively.
[0170]The three hT1Rs are encoded by a similar number of exons, hT1R1 and hT1R3 by 6 exons, and hT1R2 by more than 5 exons. This result is consistent with that of the mouse T1Rs, as described by Montmayeur et al., Nature Neuroscience 4:492-498, 2001. However, the hT1Rs genes span different sizes in the chromosome: the hT1R1 coding region spans 24 kb; hT1R2 occupies more than 15 kb, and hT1R3 is only 4 kb in size (FIG. 3, see below). Interestingly, all the transmembrane domains are encoded by the last and also the largest exon for all three hT1Rs.
Example 2
Mapping of the Human T1Rs Receptor Genes to a Region in Chromosome 1, the Syntenic Region of Mouse Distal Chromosome 4 End Containing the Sac Locus
[0171]We then asked whether the human T1Rs co-localize to the same chromosome, as might be expected for taste receptors having similar properties. Using hT1R1 to search the human genome database in NCBI, the hT1R1 gene was found to be localized in the contig NT--019267, which maps to chromosome 1. The coding region of hT1R1 spans 24 kb from 12433K to 12409K of chromosome 1 (FIG. 3). Unfortunately, hT1R2 was not able to be mapped directly because there is no corresponding clone in the NCBI human genome database. An electronic chromosome walking strategy was used to find overlapping clones. Using a sequence in the region of 2.16 Mp from Celera contig x2HTBKLHUGU, an overlapping BAC clone, AL080251 was found, which has been assigned to chromosome 1p35.2-p36.23. The end of the AL080251 clone, 30 kb from the hT1R2 gene, maps to a position of 13804K in chromosome 1. The location of hT1R was at 13776K to 13761K in chromosome 1 (FIG. 3). Using the same approach for hT1R1, hT1R3 was found to be localized to a region of 4 kb, from 61116K to 61111K in human chromosome 1 (FIG. 3). This region belongs to contig NT--025635. To find the locus information, the human high-throughput genome project database (htgs) was also searched and hT1R3 was found in two BAC clones, AC026283 and AL139287. These two BAC clones, however, have not been assigned to a locus in the chromosome. We then used the electronic chromosome walking strategy again to find a overlapping BAC clone, AL391244.11, which overlaps with AC026283 and is assigned to human chromosome 1p36.31-36.33.
[0172]The above results show that all three human T1Rs indeed form a cluster in chromosome 1. Using The Jackson Laboratory Mouse Informatics database, the corresponding region in mouse was determined to be distal chromosome 4. Interestingly, the Sac locus has been mapped to the same distal region of chromosome 4 at about 83 cM, as described by Fuller, J. Hered. 65:33-36, 1974; Lush et al. Genet. Res. 66:167-174, 1995; and Bachmanov, Mamm. Genome 8:545-548, 1997. Recently, mT1R1 has also been mapped to this region, approximately 5 cM from the Sac locus as described, e.g., in Li et al., Mamm. Genome 12: 13-15, 2001. hT1R1 shows very high sequence similarity to mT1R1 (69.8%, see above). These results suggest that there might be a sweet receptor cluster in this region. To determine whether any of the hT1Rs identified may be an orthologue of Sac locus, several genetic markers closely linked to hT1Rs were examined. One of the markers, DVL1-a human dishevelled homologue, which is tightly linked to the hT1R3 gene only about 1,700 bp away, was found to map to the distal end of chromosome 4 at 82.0 cM. This location is very close to the mapped Sac locus at 83 cM, suggesting the likelihood of T1R3 as a gene of the Sac locus. Recently, two papers have been published which also suggest that T1R3 is the closest GPCR gene to Sac locus (see, e.g., Montmayeur et al., supra; and Max et al., Nature Genetics 28:58-63, 2001.
Example 3
Expression of hT1Rs in Taste Cells
[0173]If hT1Rs are taste receptors, they should be expressed in taste tissues. According to classical models of taste discrimination, fungiform papillae are more sensitive to sweet substances than other regions of the tongue. To examine the expression of the hT1Rs, in situ hybridizations were carried out with sections containing human fungiform taste papillae. All three hT1Rs genes were found to be selectively expressed in a subset of taste receptor cells, but absent from surrounding lingual epithelium. Control sense cRNA probes did not hybridize to the taste cells in the immediate adjacent sections. The hT1R2 and hT1R3 probes hybridize to approximately 10-20% of taste cells. The hybridization signal for hT1R1 was much weaker than those for hT1R2 and hT1R3 in fungiform papillae. The hybridization signals for hT1R1 were also very weak in circumvallate and foliate taste papillae. These results are consistent with those described for the recently published mouse T1Rs as described in Montmayeur et al., supra.
[0174]A preliminary analysis of the expression pattern of the hT1Rs was also carried out. In most cases, T1R1 was expressed in different taste buds from that of hT1R2 and hT1R3, consistent with the previous studies for rat rT1R1 and rT1R2 (see Hoon et al., supra). Surprisingly, hT1R2 and hT1R3 are expressed in the same taste bud in single-labeling in situ experiments. To examine whether hT1R2 and hT1R3 might be expressed in the same taste cells, a fungiform papillae section was hybridized with different labeled-hT1R2 and hT1R3 cRNA probes simultaneously. The results from the hybridization studies show that hT1R2 and hT1R3 are expressed largely in the same taste cells (5 of 5 taste buds examined in the section). However, some T1R2-expressing cells do not express T1R3. These results are in contrast to a recent observation that mouse all T1R2-expressing cells also express T1R3 (see also, Montmayeur et al., supra).
[0175]It is understood that the examples and embodiments described herein are for illustrative purposes only and that various modifications or changes in light thereof will be suggested to persons skilled in the art and are to be included within the spirit and purview of this application and scope of the appended claims. Thus, the above description should not be construed as limiting, but merely as exemplification of preferred embodiments.
[0176]All patent applications, patents and literature references cited herein are hereby incorporated by reference in their entirety for all purposes to the same extent as if every such patent application, patent, or literature reference were indicated to be incorporated by reference in its entirety.
TABLE-US-00003 SEQUENCE TABLE Example T1Rx Nucleic Acids And Polypeptides >hT1R1 (Nucleic Acid; SEQ ID NO:10) ATGCTGCTCTGCACGGCTCGCCTGGTCGGCCTGCAGCTTCTCATTTCCTGCTGCTGGGCCTTTGCCTGCCATAG- CACGGA GTCTTCTCCTGACTTCACCCTCCCCGGAGATTACCTCCTGGCAGGCCTGTTCCCTCTCCATTCTGGCTGTCTGC- AGGTGA GGCACAGACCCGAGGTGACCCTGTGTGACAGGTCTTGTAGCTTCAATGAGCATGGCTACCACCTCTTCCAGGCT- ATGCGG CTTGGGGTTGAGGAGATAAACAACTCCACGGCCCTGCTGCCCAACATCACCCTGGGGTACCAGCTGTATGATGT- GTGTTC TGACTCTGCCAATGTGTATGCCACGCTGAGAGTGCTCTCCCTGCCAGGGCAACACCACATAGAGCTCCAAGGAG- ACCTTC TCCACTATTCCCCTACGGTGCTGGCAGTGATTGGGCCTGACAGCACCAACCGTGCTGCCACCACAGCCGCCCTG- CTGAGC CCTTTCCTGGTGCCCATGCTTATTAGCTATGCGGCCAGCAGCGAGACGCTCAGCGTGAAGCGGCAGTATCCCTC- TTTCCT GCGCACCATCCCCAATGACAAGTACCAGGTGGAGACCATGGTGCTGCTGCTGCAGAAGTTCGGGTGGACCTGGA- TCTCTC TGGTTGGCAGCAGTGACGACTATGGGCAGCTAGGGGTGCAGGCACTGGAGAACCAGGCCACTGGTCAGGGGATC- TGCATT GCTTTCAAGGACATCATGCCCTTCTCTGCCCAGGTGGGCGATGAGAGGATGCAGTGCCTCATGCGCCACCTGGC- CCAGGC CGGGGCCACCGTCGTGGTTGTTTTTTCCAGCCGGCAGTTGGCCAGGGTGTTTTTCGAGTCCGTGGTGCTGACCA- ACCTGA CTGGCAAGGTGTGGGTCGCCTCAGAAGCCTGGGCCCTCTCCAGGCACATCACTGGGGTGCCCGGGATCCAGCGC- ATTGGG ATGGTGCTGGGCGTGGCCATCCAGAAGAGGGCTGTCCCTGGCCTGAAGGCGTTTGAAGAAGCCTATGCCCGGGC- AGACAA GGAGGCCCCTAGGCCTTGCCACAAGGGCTCCTGGTGCAGCAGCAATCAGCTCTGCAGAGAATGCCAAGCTTTCA- TGGCAC ACACGATGCCCAAGCTCAAAGCCTTCTCCATGAGTTCTGCCTACAACGCATACCGGGCTGTGTATGCGGTGGCC- CATGGC CTCCACCAGCTCCTGGGCTGTGCCTCTGGAGCTTGTTCCAGGGGCCGAGTCTACCCCTGGCAGTTGGAGCAGAT- CCACAA GGTGCATTTCCTTCTACACAAGGACACTGTGGCGTTTAATGACAACAGAGATCCCCTCAGTAGCTATAACATAA- TTGCCT GGGACTGGAATGGACCCAAGTGGACCTTCACGGTCCTCGGTTCCTCCACATGGTCTCCAGTTCAGCTAAACATA- AATGAG ACCAAAATCCAGTGGCACGGAAAGGACAACCAGGAACCAAGTCTGTGTGTTCCAGCGACTGTCTTGAAGGGCAC- CAGCGA GTGGTTACGGGTTTCCATCACTGCTGCTTTGAGTGTGTGCCCTGTGGGGGGTTCTTGGCCTTCCCTTTCAGACC- TCTACA GATGCCAGCCTTGTGGGAAAGAAGAGTGGGCACCTGAGGGAAGCCAGACCTGCTTCCCGCGCACTGTGGTGTTT- TTGGCT TTGCGTGAGCACACCTCTTGGGTGCTGCTGGCAGCTAACACGCTGCTGCTGCTGCTGCTGCTTGGGACTGCTGG- CCTGTT TGCCTGGCACCTAGACACCCCTGTGGTGAGGTCAGCAGGGGGCCGCCTGTGCTTTCTTATGCTGGGCTCCCTGG- CAGCAG GTAGTGGCAGCCTCTATGGCTTCTTTGGGGAACCCACAAGGCCTGCGTGCTTGCTACGCCAGGCCCTCTTTGCC- CTTGGT TTCACCATCTTCCTGTCCTGCCTGACAGTTCGCTCATTCCAACTAATCATCATCTTCAAGTTTTCCACCAAGGT- ACCTAC ATTCTACCACGCCTGGGTCCAAAACCACGGTGCTGGCCTGTTTGTGATGATCAGCTCAGCGGCCCAGCTGCTTA- TCTGTC TAACTTGGCTGGTGGTGTGGACCCCACTGCCTGCTAGGGAATACCAGCGCTTCCCCCATCTGGTGATGCTTGAG- TGCACA GAGACCAACTCCCTGGGCTTCATACTGGCCTTCCTCTACAATGGCCTCCTCTCCATCAGTGCCTTTGCCTGCAG- CTACCT GGGTAAGGACTTGCCAGAGAACTACAACGAGGCCAAATGTGTCACCTTCAGCCTGCTCTTCAACTTCGTGTCCT- GGATCG CCTTCTTCACCACGGCCAGCGTCTACGACGGCAAGTACCTGCCTGCGGCCAACATGATGGCTGGGCTGAGCAGC- CTGAGC AGCGGCTTCGGTGGGTATTTTCTGCCTAAGTGCTACGTGATCCTCTGCCGCCCAGACCTCAACAGCACAGAGCA- CTTCCA GGCCTCCATTCAGGACTACACGAGGCGCTGCGGCTCCACCTGA >hT1R1 (amino acid; SEQ ID NO:1) MLLCTARLVGLQLLISCCWAFACHSTESSPDFTLPGDYLLAGLFPLHSGCLQVRHRPEVTLCDRSCSFNEHGYH- LFQAMR LGVEEINNSTALLPNITLGYQLYDVCSDSANVYATLRVLSLPGQHHIELQGDLLHYSPTVLAVIGPDSTNRAAT- TAALLS PFLVPMLISYAASSETLSVKRQYPSFLRTIPNDKYQVETMVLLLQKFGWTWISLVGSSDDYGQLGVQALENQAT- GQGICI AFKDIMPFSAQVGDERMQCLMRHLAQAGATVVVVFSSRQLARVFFESVVLTNLTGKVWVASEAWALSRHITGVP- GIQRIG MVLGVAIQKRAVPGLKAFEEAYARADKEAPRPCHKGSWCSSNQLCRECQAFMAHTMPKLKAFSMSSAYNAYRAV- YAVAHG LHQLLGCASGACSRGRVYPWQLEQIHKVHFLLHKDTVAFNDNRDPLSSYNIIAWDWNGPKWTFTVLGSSTWSPV- QLNINE TKIQWHGKDNQEPSLCVPATVLKGTSEWLRVSITAALSVCPVGGSWPSLSDLYRCQPCGKEEWAPEGSQTCFPR- TVVFLA LREHTSWVLLAANTLLLLLLLGTAGLFAWHLDTPVVRSAGGRLCFLMLGSLAAGSGSLYGFFGEPTRPACLLRQ- ALFALG FTIFLSCLTVRSFQLIIIFKFSTKVPTFYHAWVQNHGAGLFVMISSAAQLLICLTWLVVWTPLPAREYQRFPHL- VMLECT ETNSLGFILAFLYNGLLSISAFACSYLGKDLPENYNEAKCVTFSLLFNFVSWIAFFTTASVYDGKYLPAANMMA- GLSSLS SGFGGYFLPKCYVILCRPDLNSTEHFQASIQDYTRRCGST. >hT1R2 (nucleic acid; SEQ ID NO: 11) ATGGGGCCCAGGGCAAAGACCATCTGCTCCCTGTTCTTCCTCCTATGGGTCCTGGCTGAGCCGGCTGAGAACTC- GGACTT CTACCTGCCTGGGGATTACCTCCTGGGTGGCCTCTTCTCCCTCCATGCCAACATGAAGGGCATTGTTCACCTTA- ACTTCC TGCAGGTGCCCATGTGCAAGGAGTATGAAGTGAAGGTGATAGGCTACAACCTCATGCAGGCCATGCGCTTTGCG- GTGGAG GAGATCAACAATGACAGCAGCCTGCTGCCTGGTGTGCTGCTGGGCTATGAGATCGTGGATGTGTGCTACATCTC- CAACAA TGTCCAGCCGGTGCTCTACTTCCTGGCACACGGGGACAACCTCCTTCCCATCCAAGAGGACTACAGTAACTACA- TTTCCC GTGCGGTGGCTGTCATTGGCCCTGACAACTCCGAGTCTGTCATGACTGTGGCCAACTTCCTCTCCCTATTTCTC- CTTCCA CAGATCACCTACAGCGCCATCAGCGATGAGCTGCGAGACAAGGTGCGCTTCCCGGCTTTGCTGCGTACCACACC- CAGCGC CGACCACCACATCGAGGCCATGGTGCAGCTGATGCTGCACTTCCGCTGGAACTGGATCATTGTGCTGGTGAGCA- GCGACA CCTATGGCCGCGACAATGGCCAGCTGCTTGGCGAGCGCGTGGCCCGGCGCGACATCTGCATCGCCTTCCAGGAG- ACGCTG CCCACACTGCAGCCCAACCAGAACATGACGTCAGAGGAGCGCCAGCGCCTGGTGACCATTGTGGACAAGCTGCA- GCAGAG CACAGCGCGCGTCGTGGTCGTGTTCTCGCCCGACCTGACCCTGTACCACTTCTTCAATGAGGTGCTGCGCCAGA- ACTTCA CTGGCGCCGTGTGGATCGCCTCCGAGTCCTGGGCCATCGACCCGGTCCTGCACAACCTCACGGAGCTGCGCCAC- TTGGGC ACCTTCCTGGGCATCACCATCCAGAGCGTGCCCATCCCGGGCTTCAGTGAGTTCCGCGAGTGGGGCCCACAGGC- TGGGCC GCCACCCCTCAGCAGGACCAGCCAGAGCTATACCTGCAACCAGGAGTGCGACAACTGCCTGAACGCCACCTTGT- CCTTCA ACACCATTCTCAGGCTCTCTGGGGAGCGTGTCGTCTACAGCGTGTACTCTGCGGTCTATGCTGTGGCCCATGCC- CTGCAC AGCCTCCTCGGCTGTGACAAAAGCACCTGCACCAAGAGGGTGGTCTACCCCTGGCAGCTGCTTGAGGAGATCTG- GAAGGT CAACTTCACTCTCCTGGACCACCAAATCTTCTTCGACCCGCAAGGGGACGTGGCTCTGCACTTGGAGATTGTCC- AGTGGC AATGGGACCGGAGCCAGAATCCCTTCCAGAGCGTCGCCTCCTACTACCCCCTGCAGCGACAGCTGAAGAACATC- CAAGAC ATCTCCTGGCACACCATCAACAACACGATCCCTATGTCCATGTGTTCCAAGAGGTGCCAGTCAGGGCAAAAGAA- GAAGCC TGTGGGCATCCACGTCTGCTGCTTCGAGTGCATCGACTGCCTTCCCGGCACCTTCCTCAACCACACTGAAGATG- AATATG AATGCCAGGCCTGCCCGAATAACGAGTGGTCCTACCAGAGTGAGACCTCCTGCTTCAAGCGGCAGCTGGTCTTC- CTGGAA TGGCATGAGGCACCCACCATCGCTGTGGCCCTGCTGGCCGCCCTGGGCTTCCTCAGCACCCTGGCCATCCTGGT- GATATT CTGGAGGCACTTCCAGACACCCATAGTTCGCTCGGCTGGGGGCCCCATGTGCTTCCTGATGCTGACACTGCTGC- TGGTGG CATACATGGTGGTCCCGGTGTACGTGGGGCCGCCCAAGGTCTCCACCTGCCTCTGCCGCCAGGCCCTCTTTCCC- CTCTGC TTCACAATCTGCATCTCCTGTATCGCCGTGCGTTCTTTCCAGATCGTCTGCGCCTTCAAGATGGCCAGCCGCTT- CCCACG CGCCTACAGCTACTGGGTCCGCTACCAGGGGCCCTACGTCTCTATGGCATTTATCACGGTACTCAAAATGGTCA- TTGTGG TAATTGGCATGCTGGCCACGGGCCTCAGTCCCACCACCCGTACTGACCCCGATGACCCCAAGATCACAATTGTC- TCCTGT AACCCCAACTACCGCAACAGCCTGCTGTTCAACACCAGCCTGGACCTGCTGCTCTCAGTGGTGGGTTTCAGCTT- CGCCTA CATGGGCAAAGAGCTGCCCACCAACTACAACGAGGCCAAGTTCATCACCCTCAGCATGACCTTCTATTTCACCT- CATCCG TCTCCCTCTGCACCTTCATGTCTGCCTACAGCGGGGTGCTGGTCACCATCGTGGACCTCTTGGTCACTGTGCTC- AACCTC CTGGCCATCAGCCTGGGCTACTTCGGCCCCAAGTGCTACATGATCCTCTTCTACCCGGAGCGCAACACGCCCGC- CTACTT CAACAGTCATGATCCAGGGCTACACCATGAGGAGGGACTAG >hT1R2 (amino acid; SEQ ID NO: 4) MGPRAKTICSLFFLLWVLAEPAENSDFYLPGDYLLGGLFSLHANMKGIVHLNFLQVPMCKEYEVKVIGYNLMQA- MRFAVE EINNDSSLLPGVLLGYEIVDVCYISNNVQPVLYFLAHGDNLLPIQEDYSNYISRAVAVIGPDNSESVMTVANFL- SLFLLP QITYSAISDELRDKVRFPALLRTTPSADHHIEAMVQLMLHFRWNWIIVLVSSDTYGRDNGQLLGERVARRDICI- AFQETL PTLQPNQNMTSEERQRLVTIVDKLQQSTARVVVVFSPDLTLYHFFNEVLRQNFTGAVWIASESWAIDPVLHNLT- ELRHLG TFLGITIQSVPIPGFSEEREWCPQAGPPPLSRTSQSYTCNQECDNCLNATLSFNTILRLSGERVVYSVYSAVYA- VAHALH SLLGCDKSTCTKRVVYPWQLLEEIWKVNFTLLDHQIFFDPQGDVALHLEIVQWQWDRSQNPFQSVASYYPLQRQ- LKNIQD ISWHTINNTIPMSMCSKRCQSGQKKKPVGIHVCCFECIDCLPGTFLNHTEDEYECQACPNNEWSYQSETSCFKR- QLVFLE WHEAPTIAVALLAALGFLSTLAILVIFWRHFQTPIVRSAGGPMCFLMLTLLLVAYMVVPVYVGPPKVSTCLCRQ- ALFPLC FTICISCIAVRSFQIVCAFKMASRFPRAYSYWVRYQGPYVSMAFITVLKMVIVVIGMLATGLSPTTRTDPDDPK- ITIVSC NPNYRNSLLFNTSLDLLLSVVGFSFAYMGKELPTNYNEAKFITLSMTFYFTSSVSLCTFMSAYSGVLVTIVDLL- VTVLNL LAISLGYEGPKCYMILFYPERNTPAYFNSMIQGYTMRRD. >hT1R3 (nucleic acid; SEQ ID NO: 12) ATGCTGGGCCCTGCTGTCCTGGGCCTCAGCCTCTGGGCTCTCCTGCACCCTGGGACGGGGGCCCCATTGTGCCT- GTCACA GCAACTTAGGATGAAGGGGGACTACGTGCTGGGGGGGCTGTTCCCCCTGGGCGAGGCCGAGGAGGCTGGCCTCC- GCAGCC GGACACGGCCCAGCAGCCCTGTGTGCACCAGGTTCTCCTCAAAGGCCCTGCTCTGGGCACTGGCCATGAAAATG- GCCGTG GAGGAGATCAACAACAAGTCGGATCTGCTGCCCGGGCTGCGCCTGGGCTACGACCTCTTTGATACGTGCTCGGA- GCCTGT GGTGGCCATGAAGCCCAGCCTCATGTTCCTGGCCAAGGCAGGCAGCCGCGACATCGCCGCCTACTGCAACTACA- CGCAGT ACCAGCCCCGTGTGCTGGCTGTCATCGGGCCCCACTCGTCAGAGCTCGCCATGGTCACCGGCAAGTTCTTCAGC- TTCTTC CTCATGCCCCAGGTCAGCTACGGTGCTAGCATGGAGCTGCTGAGCGCCCGGGAGACCTTCCCCTCCTTCTTCCG- CACCGT GCCCAGCGACCGTGTGCAGCTGACGGCCGCCGCGGAGCTGCTGCAGGAGTTCGGCTGGAACTGGGTGGCCGCCC- TGGGCA GCGACGACGAGTACGGCCGGCAGGGCCTGAGCATCTTCTCGGCCCTGGCCGCGGCACGCGGCATCTGCATCGCG- CACGAG GGCCTGGTGCCGCTGCCCCGTGCCGATGACTCGCGGCTGGGGAAGGTGCAGGACGTCCTGCACCAGGTGAACCA- GAGCAG CGTGCAGGTGGTGCTGCTGTTCGCCTCCGTGCACGCCGCCCACGCCCTCTTCAACTACAGCATCAGCAGCAGGC- TCTCGC CCAAGGTGTGGGTGGCCAGCGAGGCCTGGCTGACCTCTGACCTGGTCATGGGGCTGCCCGGCATGGCCCAGATG- GGCACG GTGCTTGGCTTCCTCCAGAGGGGTGCCCAGCTGCACGAGTTCCCCCAGTACGTGAAGACGCACCTGGCCCTGGC- CACCGA CCCGGCCTTCTGCTCTGCCCTGGGCGAGAGGGAGCAGGGTCTGGAGGAGGACGTGGTGGGCCAGCGCTGCCCGC- AGTGTG ACTGCATCACGCTGCAGAACGTGAGCGCAGGGCTAAATCACCACCAGACGTTCTCTGTCTACGCAGCTGTGTAT- AGCGTG GCCCAGGCCCTGCACAACACTCTTCAGTGCAACGCCTCAGGCTGCCCCGCGCAGGACCCCGTGAAGCCCTGGCA- GCTCCT GGAGAACATGTACAACCTGACCTTCCACGTGGGCGGGCTGCCGCTGCGGTTCGACAGCAGCGGAAACGTGGACA- TGGAGT ACGACCTGAAGCTGTGGGTGTGGCAGGGCTCAGTGCCCAGGCTCCACGACGTGGGCAGGTTCAACGGCAGCCTC- AGGACA GAGCGCCTGAAGATCCGCTGGCACACGTCTGACAAGCCCGTGTCCCGGTGCTCGCGGCAGTGCCAGGAGGGCCA- GGTGCG CCGGGTCAAGGGGTTCCACTCCTGCTGCTACGACTGTGTGGACTGCGAGGCGGGCAGCTACCGGCAAAACCCAG- ACGACA TCGCCTGCACCTTTTGTGGCCAGGATGAGTGGTCCCCGGAGCGAAGCACACGCTGCTTCCGCCGCAGGTCTCGG- TTCCTG GCATGGGGCGAGCCGGCTGTGCTGCTGCTGCTCCTGCTGCTGAGCCTGGCGCTGGGCCTTGTGCTGGCTGCTTT- GGGGCT GTTCGTTCACCATCGGGACAGCCCACTGGTTCAGGCCTCGGGGGGGCCCCTGGCCTGCTTTGGCCTGGTGTGCC- TGGGCC TGGTCTGCCTCAGCGTCCTCCTGTTCCCTGGCCAGCCCAGCCCTGCCCGATGCCTGGCCCAGCAGCCCTTGTCC- CACCTC CCGCTCACGGGCTGCCTGAGCACACTCTTCCTGCAGGCGGCCGAGATCTTCGTGGAGTCAGAACTGCCTCTGAG- CTGGGC AGACCGGCTGAGTGGCTGCCTGCGGGGGCCCTGGGCCTGGCTGGTGGTGCTGCTGGCCATGCTGGTGGAGGTCG- CACTGT GCACCTGGTACCTGGTGGCCTTCCCGCCGGAGGTGGTGACGGACTGGCACATGCTGCCCACGGAGGCGCTGGTG- CACTGC CGCACACGCTCCTGGGTCAGCTTCGGCCTAGCGCACGCCACCAATGCCACGCTGGCCTTTCTCTGCTTCCTGGG- CACTTT CCTGGTGCGGAGCCAGCCGGGCCGCTACAACCGTGCCCGTGGCCTCACCTTTGCCATGCTGGCCTACTTCATCA- CCTGGG TCTCCTTTGTGCCCCTCCTGGCCAATGTGCAGGTGGTCCTCAGGCCCGCCGTGCAGATGGGCGCCCTCCTGCTC- TGTGTC CTGGGCATCCTGGCTGCCTTCCACCTGCCCAGGTGTTACCTGCTCATGCGGCAGCCAGGGCTCAACACCCCCGA- GTTCTT CCTGGGAGGGGGCCCTGGGGATGCCCAAGGCCAGAATGACGGGAACACAGGAAATCAGGGGAAACATGAGTGA >hT1R3 (amino acid; SEQ ID NO: 7) MLGPAVLGLSLWALLHPGTGAPLCLSQQLRMKGDYVLGGLFPLGEAEEAGLRSRTRPSSPVCTRFSSNGLLWAL- AMKMAV EEINNKSDLLPGLRLGYDLFDTCSEPVVAMKPSLMFLAKAGSRDIAAYCNYTQYQPRVLAVIGPHSSELAMVTG-
KFFSFF LMPQVSYGASMELLSARETFPSFFRTVPSDRVQLTAAAELLQEFGWNWVAALGSDDEYGRQGLSIFSALAAARG- ICIAHE GLVPLPRADDSRLGKVQDVLHQVNQSSVQVVLLFASVHAAHALFNYSISSRLSPKVWVASEAWLTSDLVMGLPG- MAQMGT VLGFLQRGAQLHEFPQYVKTHLALATDPAFCSALGEREQGLEEDVVGQRCPQCDCITLQNVSAGLNHHQTFSVY- AAVYSV AQALHNTLQCNASGCPAQDPVKPWQLLENMYNLTFHVGGLPLRFDSSGNVDMEYDLKLWVWQGSVPRLHDVGRF- NGSLRT ERLKIRWHTSDKPVSRCSRQCQEGQVRRVKGFHSCCYDCVDCEAGSYRQNPDDIACTFCGQDEWSPERSTRCFR- RRSRFL AWGEPAVLLLLLLLSLALGLVLAALGLFVHHRDSPLVQASGGPLACFGLVCLGLVCLSVLLFPGQPSPARCLAQ- QPLSHL PLTGCLSTLFLQAAEIFVESELPLSWADRLSGCLRCPWAWLVVLLAMLVEVALCTWYLVAFPPEVVTDWHMLPT- EALVHC RTRSWVSFGLAHATNATLAFLCFLGTFLVRSQPGRYNRARGLTFAMLAYFITWVSFVPLLANVQVVLRPAVQMG- ALLLCV LGILAAFHLPRCYLLMRQPGLNTPEFFLGGGPGDAQGQNDGNTGNQGKHE. >mT1R1 (Nucleic Acid; SEQ ID NO. 13) ATGCTTTTCTGGGCAGCTCACCTCCTGCTCAGCCTGCACGTGGCCGTTGCTTACTGCTGGGCTTTCAGCTGCCA- AAGGAC AGAATCCTCTCCAGGTTTCAGCCTCCCTGGGGACTTCCTCCTGGCAGGCCTGTTCTCCCTCCATGCTGACTGTC- TGCAGG TGAGACACAGACCTCTGGTGACAAGTTGTGACAGGTCTGACAGCTTCAACGGCCATGGCTATCACCTCTTCCAA- GCCATG CGGTTCACCGTTGAGGAGATAAACAACTCCACAGCTCTGCTTCCCAACATCACCCTGGGGTATGAACTGTATGA- CGTGTG CTCAGAGTCTTCCAATGTCTATGCCACCCTGAGGGTGCCCGCCCAGCAAGGGACAGGCCACCTAGAGATGCAGA- GAGATC TTCGCAACCACTCCTCCAAGGTGGTGGCACTCATTGGGCCTGATAACACTGACCACGCTGTCACCACTGCTGCC- CTGCTG AGCCCTTTTCTGATGCCCCTGGTCAGCTATGAGGCGAGCAGCGTGATCCTCAGTGGGAAGCGCAAGTTCCCGTC- CTTCTT GCGCACCATCCCCAGCGATAAGTACCAGGTGGAAGTCATAGTGCGGCTGCTGCAGAGCTTCGGCTGGGTCTGGA- TCTCGC TCGTTGGCAGCTATGGTGACTACGGGCAGCTGGGCGTACAGGCGCTGGAGGAGCTGGCCACTCCACGGGGCATC- TGCGTC GCCTTCAAGGACGTGGTGCCTCTCTCCGCCCAGGCGGGTGACCCAAGGATGCAGCGCATGATGCTGCGTCTGGC- TCGAGC CAGGACCACCGTGGTCGTGGTCTTCTCTAACCGGCACCTGGCTGGAGTGTTCTTCAGGTCTGTGGTGCTGGCCA- ACCTGA CTGGCAAAGTGTGGATCGCCTCCGAAGACTGGGCCATCTCCACGTACATCACCAATGTGCCCGGGATCCAGGGC- ATTGGG ACGGTGCTGGGGGTGGCCATCCAGCAGAGACAAGTCCCTGGCCTGAAGGAGTTTGAAGAGTCCTATGTCCAGGC- AGTGAT GGGTGCTCCCAGAACTTGCCCAGAGGGGTCCTGGTGCGGCACTAACCAGCTGTGCAGGGAGTGTCACGCTTTCA- CGACAT GGAACATGCCCGAGCTTGGAGCCTTCTCCATGAGCGCTGCCTACAATGTGTATGAGGCTGTGTATGCTGTGGCC- CACGGC CTCCACCAGCTCCTGGGATGTACCTCTGGGACCTGTGCCAGAGGCCCAGTCTACCCCTGGCAGCTTCTTCAGCA- GATCTA CAAGGTGAATTTCCTTCTACATAAGAAGACTGTAGCATTCGATGACAAGGGGGACCCTCTAGGTTATTATGACA- TCATCG CCTGGGACTGGAATGGACCTGAATGGACCTTTGAGGTCATTGGTTCTGCCTCACTGTCTCCAGTTCATCTAGAC- ATAAAT AAGACAAAAATCCAGTGGCACGGGAAGAACAATCAGGTGCCTGTGTCAGTGTGTACCAGGGACTGTCTCGAAGG- GCACCA CAGGTTGGTCATGGGTTCCCACCACTGCTGCTTCGAGTGCATGCCCTGTGAAGCTGGGACATTTCTCAACACGA- GTGAGC TTCACACCTGCCAGCCTTGTGGAACAGAAGAATGGGCCCCTGAGGGGAGCTCAGCCTGCTTCTCACGCACCGTG- GAGTTC TTGGGGTGGCATGAACCCATCTCTTTGGTGCTATTAGCAGCTAACACGCTATTGCTGCTGCTGCTGATTGGGAC- TGCTGG CCTGTTTGCCTGGCGTCTTCACACGCCTGTTGTGAGGTCAGCTGGGGGTAGGCTGTGCTTCCTCATGCTGGGTT- CCTTGG TAGCTGGGAGTTGCAGCCTCTACAGCTTCTTCGGGAAGCCCACGGTGCCCGCGTGCTTGCTGCGTCAGCCCCTC- TTTTCT CTCGGGTTTGCCATTTTCCTCTCCTGTCTGACAATCCGCTCCTTCCAACTGGTCATCATCTTCAAGTTTTCTAC- CAAGGT ACCCACATTCTACCACACTTGGGCCCAAAACCATGGTGCCGGAATATTCGTCATTGTCAGCTCCACGGTCCATT- TGTTCC TCTGTCTCACGTGGCTTGCAATGTGGACCCCACGGCCCACCAGGGAGTACCAGCGCTTCCCCCATCTGGTGATT- CTTGAG TGCACAGAGGTCAACTCTGTGGGCTTCCTGGTGGCTTTCGCACACAACATCCTCCTCTCCATCAGCACCTTTGT- CTGCAG CTACCTGGGTAAGGAACTGCCGGAGAACTATAACGAAGCCAAATGTGTCACCTTCAGCCTGCTCCTCCACTTCG- TATCCT GGATCGCTTTCTTCACCATGTCCAGCATTTACCAGGGCAGCTACCTACCCGCGGTCAATGTGCTGGCAGGGCTG- GCCACT CTGAGTGGCGGCTTCAGCGGCTATTTCCTCCCTAAATGCTACGTGATTCTCTGCCGTCCAGAACTCAACAACAC- AGAACA CTTTCAGGCCTCCATCCAGGACTACACGAGGCGCTGCGGCACTACCTGA >mT1R1 (Amino Acid; SEQ ID NO: 2) MLFWAAHLLLSLQLAVAYCWAFSCQRTESSPGFSLPGDFLLAGLFSLHADCLQVRHRPLVTSCDRSDSFNGHGY- HLFQAM RFTVEEINNSTALLPNITLGYELYDVCSESSNVYATLRVPAQQGTGHLEMQRDLRNHSSKVVALIGPDNTDHAV- TTAALL SPFLMPLVSYEASSVILSGKRKFPSFLRTIPSDKYQVEVIVRLLQSFGWVWISLVGSYGDYGQLGVQALEELAT- PRGICV AFKDVVPLSAQAGDPRMQRMMLRLARARTTVVVVFSNRHLAGVFFRSVVLANLTGKVWIASEDWAISTYITNVP- GIQGIG TVLGVAIQQRQVPGLKEFEESYVQAVMGAPRTCPEGSWCGTNQLCRECHAFTTWNMPELGAFSMSAAYNVYEAV- YAVAHG LHQLLGCTSGTCARGPVYPWQLLQQIYKVNFLLHKKTVAPDDKGDPLGYYDIIAWDWNGPEWTFEVIGSASLSP- VHLDIN KTKIQWHGKNNQVPVSVCTRDCLEGHHRLVMGSHHCCFECMPCEAGTFLNTSELHTCQPCGTEEWAPEGSSACF- SRTVEF LGWHEPISLVLLAANTLLLLLLIGTAGLFAWRLHTPVVRSAGGRLCFLMLGSLVAGSCSLYSFFGKPTVPACLL- RQPLFS LGFAIFLSCLTIRSFQLVIIFKFSTKVPTFYHTWAQNHGAGIFVIVSSTVHLFLCLTWLAMWTPRPTREYQRFP- HLVILE CTEVNSVGFLVAFAHNILLSISTFVCSYLGKELPENYNEAKCVTPSLLLHFVSWIAFFTMSSIYQGSYLPAVNV- LAGLAT LSGGFSGYFLPKCYVILCRPELNNTEHFQASIQDYTRRCGTT. >mT1R2 (Nucleic Acid; SEQ ID NO: 14) ATGCTGCGCACTGTGCCCAGCGCCACCCACCACATCGAGGCCATGGTGCAACTGATGGTTCACTTCCAGTGGAA- CTGGAT CGTGGTGCTGGTGAGCGATGACGATTATGGCCGAGAGAACAGCCACCTGCTGAGCCAGCGTCTGACCAACACTG- GCGATA TCTGCATTGCCTTCCAGGAGGTTCTGCCTGTACCAGAACCCAACCAGGCCGTGAGGCCTGAGGAGCAGGACCAA- CTGGAC AACATCCTGGACAAGCTGCGGCGGACCTCGGCGCGTGTGGTGGTGATATTCTCGCCAGAGCTGAGCCTGCACAA- CTTCTT CCGCGAGGTGCTGCGCTGGAACTTCACAGGCTTTGTGTGGATTGCCTCTGAGTCCTGGGCCATCGACCCTGTTC- TACACA ACCTCACAGAGCTGCGCCACACGGGCACTTTCCTGGGCGTCACCATCCAGAGGGTGTCCATCCCTGGCTTCAGC- CAGTTC CGAGTGCGCCACGACAAGCCAGAGTATCCCATGCCTAACGAGACCAGCCTGAGGACTACCTGTAACCAGGACTG- TGACGC CTGCATGAACATCACCGAGTCCTTTAACAACGTTCTCATGCTTTCGGGGGAGCGTGTGGTCTACAGTGTGTACT- CGGCCG TCTACGCGGTAGCCCACACCCTCCACAGACTCCTCCACTGCAACCAGGTCCGCTGCACCAAGCAAATCGTCTAT- CCATGG CAGCTACTCAGGGAGATCTGGCATGTCAACTTCACGCTCCTGGGCAACCAGCTCTTCTTCGACGAACAAGGGGA- CATGCC GATGCTCCTGGACATCATCCAGTGGCAATGGGGCCTGAGCCAGAACCCCTTCCAAAGCATCGCCTCCTACTCCC- CCACCG AGACGAGGCTGACCTACATTAGCAATGTGTCCTGGTACACCCCCAACAACACGGTCCCCATATCCATGTGTTCT- AAGAGT TGCCAGCCTGGGCAAATGAAAAAACCCATAGGCCTCCACCCGTGCTGCTTCGAGTGTGTGGACTGTCCGCCGGG- CACCTA CCTCAACCGATCAGTAGATGAGTTTAACTGTCTGTCCTGCCCGGGTTCCATGTGGTCTTACAAGAACAACATCG- CTTGCT TCAAGCGGCGGCTGGCCTTCCTGGAGTGGCACGAAGTGCCCACTATCGTGGTGACCATCCTGGCCGCCCTGGGC- TTCATC AGTACGCTGGCCATTCTGCTCATCTTCTGGAGACATTTCCAGACGCCCATGGTGCGCTCGGCGGGCGGCCCCAT- GTGCTT CCTGATGCTGGTGCCCCTGCTGCTGGCGTTCGGGATGGTCCCCGTGTATGTGGGCCCCCCCACGGTCTTCTCCT- GTTTCT GCCGCCAGGCTTTCTTCACCGTTTGCTTCTCCGTCTGCCTCTCCTGCATCACGGTGCGCTCCTTCCAGATTGTG- TGCGTC TTCAAGATGGCCAGACGCCTGCCAAGCGCCTACGGTTTCTGGATGCGTTACCACGGGCCCTACGTCTTTGTGGC- CTTCAT CACGGCCGTCAAGGTGGCCCTGGTGGCAGGCAACATGCTGGCCACCACCATCAACCCCATTGGCCGGACCGACC- CCGATG ACCCCAATATCATAATCCTCTCCTGCCACCCTAACTACCGCAACGGGCTACTCTTCAACACCAGCATGGACTTG- CTGCTG TCCGTGCTGGGTTTCAGCTTCGCGTACGTGGGCAAGGAACTGCCCACCAACTACAACGAAGCCAAGTTCATCAC- CCTCAG CATGACCTTCTCCTTCACCTCCTCCATCTCCCTCTGCACGTTCATGTCTGTCCACGATGGCGTGCTGGTCACCA- TCATGG ATCTCCTGGTCACTGTGCTCAACTTTCTGGCCATCGGCTTGGGGTACTTTGGCCCCAAGTGTTACATGATCCTT- TTCTAC CCGGAGCGCAACACTTCAGCTTATTTCAATAGCATGATTCAGGGCTACACGATGAGGAAGAGCTAG >mT1R2 (amino acid; SEQ ID NO: 5) MLRTVPSATHHIEAMVQLMVHPQWNWIVVLVSDDDYGRENSHLLSQRLTNTGDICIAFQEVLPVPEPNQAVRPE- EQDQLD NILDKLRRTSARVVVIFSPELSLHNFFREVLRWNFTGFVWIASESWAIDPVLHNLTELRHTGTPLGVTIQRVSI- PGFSQF RVRHDKPEYPMPNETSLRTTCNQDCDACMNITESPNNVLMLSGERVVYSVYSAVYAVAHTLHRLLHCNQVRCTK- QIVYPW QLLREIWHVNFTLLGNQLFFDEQGDMPMLLDIIQWQWGLSQNPFQSIASYSPTETRLTYISNVSWYTPNNTVPI- SMCSKS CQPGQMKKPIGLHPCCFECVDCPPGTYLNRSVDEFNCLSCPGSMWSYKNNIACFKRRLAFLEWHEVPTIVVTIL- AALGFI STLAILLIFWRHFQTPMVRSAGGPMCFLMLVPLLLAFGMVPVYVGPPTVPFCFCRQAFFTVCFSVCLSCITVRS- FQIVCV FKMARRLPSAYGFWMRYHGPYVFVAFITAVKVALVAGNMLATTINPIGRTDPDDPNIIILSCHPNYRNGLLFNT- SMDLLL SVLGFSFAYVGKELPTNYNEAKFITLSMTFSFTSSISLCTFMSVHDGVLVTIMDLLVTVLNFLAIGLGYFGPKC- YMILFY PERNTSAYFNSMIQGYTMRKS. >mT1R3 (nucleic acid; SEQ ID NO: 15) ATGCCAGCTTTGGCTATCATGGGTCTCAGCCTGGCTGCTTTCCTGGAGCTTGGGATGGGGGCCTCTTTGTGTCT- GTCACA GCAATTCAAGGCACAAGGGGACTACATACTGGGCGGGCTATTTCCCCTGGGCTCAACCGAGGAGGCCACTCTCA- ACCAGA GAACACAACCCAACAGCATCCCGTGCAACAGGTTCTCACCCCTTGGTTTGTTCCTGGCCATGGCTATGAAGATG- GCTGTG GAGGAGATCAACAATGGATCTGCCTTGCTCCCTGGGCTGCGGCTGGGCTATGACCTATTTGACACATGCTCCGA- GCCAGT GGTCACCATGAAATCCAGTCTCATGTTCCTGGCCAAGGTGGGCAGTCAAAGCATTGCTGCCTACTGCAACTACA- CACAGT ACCAACCCCGTGTGCTGGCTGTCATCGGCCCCCACTCATCAGAGCTTGCCCTCATTACAGGCAAGTTCTTCAGC- TTCTTC CTCATGCCACAGGTCAGCTATAGTGCCAGCATGGATCGGCTAAGTGACCGGGAAACGTTTCCATCCTTCTTCCG- CACAGT GCCCAGTGACCGGGTGCAGCTGCAGGCAGTTGTGACTCTGTTGCAGAACTTCAGCTGGAACTGGGTGGCCGCCT- TAGGGA GTGATGATGACTATGGCCGGGAAGGTCTGAGCATCTTTTCTAGTCTGGCCAATGCACGAGGTATCTGCATCGCA- CATGAG GGCCTGGTGCCACAACATGACACTAGTGGCCAACAGTTGGGCAAGGTGCTGGATGTACTACGCCAAGTGAACCA- AAGTAA AGTACAAGTGGTGGTGCTGTTTGCCTCTGCCCGTGCTGTCTACTCCCTTTTTAGTTACAGCATCCATCATGGCC- TCTCAC CCAAGGTATGGGTGGCCAGTGAGTCTTGGCTGACATCTGACCTGGTCATGACACTTCCCAATATTGCCCGTGTG- GGCACT GTGCTTGGGTTTTTGCAGCGGGGTGCCCTACTGCCTGAATTTTCCCATTATGTGGAGACTCACCTTGCCCTGGC- CGCTGA CCCAGCATTCTGTGCCTCACTGAATGCGGAGTTGGATCTGGAGGAACATGTGATGGGGCAACGCTGTCCACGGT- GTGACG ACATCATGCTGCAGAACCTATCATCTGGGCTGTTGCAGAACCTATCAGCTGGGCAATTGCACCACCAAATATTT- GCAACC TATGCAGCTGTGTACAGTGTGGCTCAAGCCCTTCACAACACCCTACAGTGCAATGTCTCACATTGCCACGTATC- AGAACA TGTTCTACCCTGGCAGCTCCTGGAGAACATGTACAATATGAGTTTCCATGCTCGAGACTTGACACTACAGTTTG- ATGCTG AAGGGAATGTAGACATGGAATATGACCTGAAGATGTGGGTGTGGCACAGCCCTACACCTGTATTACATACTGTG- GGCACC TTCAACGGCACCCTTCAGCTGCAGCAGTCTAAAATGTACTGGCCAGGCAACCAGGTGCCAGTCTCCCAGTGTTC- CCGCCA GTGCAAAGATGGCCAGGTTCGCCGAGTAAAGGGCTTTCATTCCTGCTGCTATGACTGCGTGGACTGCAAGGCGG- GCAGCT ACCGGAAGCATCCAGATGACTTCACCTGTACTCCATGTAACCAGGACCAGTGGTCCCCAGAGAAAAGCACAGCC- TGCTTA CCTCGCAGGCCCAAGTTTCTGGCTTGGGGGGAGCCAGTTGTGCTGTCACTCCTCCTGCTGCTTTGCCTGGTGCT- GGGTCT AGCACTGGCTGCTCTGGGGCTCTCTGTCCACCACTGGGACAGCCCTCTTGTCCAGGCCTCAGGTGGCTCACAGT- TCTGCT TTGGCCTGATCTGCCTAGGCCTCTTCTGCCTCAGTGTCCTTCTGTTCCCAGGGCGGCCAAGCTCTGCCAGCTGC- CTTGCA CAACAACCAATGGCTCACCTCCCTCTCACAGGCTGCCTGAGCACACTCTTCCTGCAAGCAGCTGAGACCTTTGT- GGAGTC TGAGCTGCCACTGAGCTGGGCAAACTGGCTATGCAGCTACCTTCGGGGACTCTGGGCCTGGCTAGTGGTACTGT- TGGCCA CTTTTGTGGAGGCAGCACTATGTGCCTGGTATTTGATCGCTTTCCCACCAGAGGTGGTGACAGACTGGTCAGTG- CTGCCC ACAGAGGTACTGGAGCACTGCCACGTGCGTTCCTGGGTCAGCCTGGGCTTGGTGCACATCACCAATGCAATGTT- AGCTTT CCTCTGCTTTCTGGGCACTTTCCTGGTACAGAGCCAGCCTGGCCGCTACAACCGTGCCCGTGGTCTCACCTTCG- CCATGC TAGCTTATTTCATCACCTGGGTCTCTTTTGTGCCCCTCCTGGCCAATGTGCAGGTGGCCTACCAGCCAGCTGTG- CAGATG GGTGCTATCCTAGTCTGTGCCCTGGGCATCCTGGTCACCTTCCACCTGCCCAAGTGCTATGTGCTTCTTTGGCT- GCCAAA GCTCAACACCCAGGAGTTCTTCCTGGGAAGGAATGCCAAGAAAGCAGCAGATGAGAACAGTGGCGGTGGTGAGG- CAGCTC AGGGACACAATGAATGA >mT1R3 (amino acid; SEQ ID NO: 8) MPALAIMGLSLAAFLELGMGASLCLSQQFKAQGDYTLGGLFPLGSTEEATLNQRTQPNSIPCNRFSPLGLFLAM- AMKMAV EEINNGSALLPGLRLGYDLFDTCSEPVVTMKSSLMFLAKVGSQSIAAYCNYTQYQPRVLAVIGPHSSELALITG- KFFSFF LMPQVSYSASMDRLSDRETFPSFFRTVPSDRVQLQAVVTLLQNFSWNWVAALGSDDDYGREGLSIFSSLANARG- ICIAHE
GLVPQHDTSGQQLGKVLDVLRQVNQSKVQVVVLFASARAVYSLFSYSIHHGLSPKVWVASESWLTSDLVMTLPN- IARVGT VLGFLQRGALLPEFSHYVETHLALAADPAFCASLNAELDLEEHVMGQRCPRCDDIMLQNLSSGLLQNLSAGQLH- HQIFAT YAAVYSVAQALHNTLQCNVSHCHVSEHVLPWQLLENMYNMSFHARDLTLQFDAEGNVDMEYDLKMWVWQSPTPV- LHTVGT FNGTLQLQQSKMYWPGNQVPVSQCSRQCKDGQVRRVKGFHSCCYDCVDCKAGSYRKHPDDFTCTPCNQDQWSPE- KSTACL PRRPKFLAWGEPVVLSLLLLLCLVLGLALAALGLSVHHWDSPLVQASCCSQFCFGLICLGLFCLSVLLFPCRPS- SASCLA QQPMAHLPLTGCLSTLFLQAAETFVESELPLSWANWLCSYLRGLWAWLVVLLATFVEAALCAWYLIAFPPEVVT- DWSVLP TEVLEHCHVRSWVSLGLVHITNAMLAFLCFLGTFLVQSQPGRYNRARGLTFAMLAYFITWVSFVPLLANVQVAY- QPAVQM GAILVCALGILVTFHLPKCYVLLWLPKLNTQEFFLGRNAKKAADENSGGGEAAQGHNE. >rT1R1 (nucleic acid; SEQ ID NO: 16) ATGCTCTTCTGGGCTGCTCACCTGCTGCTCAGCCTGCAGTTGGTCTACTGCTGGGCTTTCAGCTGCCAAAGGAC- AGAGTC CTCTCCAGGCTTCAGCCTTCCTGGGGACTTCCTCCTTGCAGGTCTGTTCTCCCTCCATGGTGACTGTCTGCAGG- TGAGAC ACAGACCTCTGGTGACAAGTTGTGACAGGCCCGACAGCTTCAACGGCCATGGCTACCACCTCTTCCAAGCCATG- CGGTTC ACTGTTGAGGAGATAAACAACTCCTCGGCCCTGCTTCCCAACATCACCCTGGGGTATGAGCTGTACGACGTGTG- CTCAGA ATCTGCCAATGTGTATGCCACCCTGAGGGTGCTTGCCCTGCAAGGGCCCCGCCACATAGAGATACAGAAAGACC- TTCGCA ACCACTCCTCCAAGGTGGTGGCCTTCATCGGGCCTGACAACACTGACCACGCTGTCACTACCGCTGCCTTGCTG- GGTCCT TTCCTGATGCCCCTGGTCAGCTATGAGGCAAGCAGCGTGGTACTCAGTGCCAAGCGCAAGTTCCCGTCTTTCCT- TCGTAC CGTCCCCAGTGACCGGCACCAGGTGGAGGTCATGGTGCAGCTGCTGCAGAGTTTTGGGTGGGTGTGGATCTCGC- TCATTG GCAGCTACGGTGATTACGGGCAGCTGGGTGTGCAGGCGCTGGAGGAGCTGGCCGTGCCCCGGGGCATCTGCGTC- GCCTTC AAGGACATCGTGCCTTTCTCTGCCCGGGTGGGTGACCCGAGGATGCAGAGCATGATGCAGCATCTGGCTCAGGC- CAGGAC CACCGTGGTTGTGGTCTTCTCTAACGGCCACCTGGCTAGAGTGTTCTTCAGGTCCGTGGTGCTGGCCAACCTGA- CTGGCA AAGTGTGGGTCGCCTCAGAAGACTGGGCCATCTCCACGTACATCACCAGCGTGACTGGGATCCAAGGCATTGGG- ACGGTG CTCGGTGTGGCCGTCCAGCAGAGACAAGTCCCTGGGCTGAAGGAGTTTGAGGAGTCTTATGTCAGGGCTGTAAC- AGCTGC TCCCAGCGCTTGCCCGGAGGGGTCCTGGTGCAGCACTAACCAGCTGTGCCGGGAGTGCCACACGTTCACGACTC- GTAACA TGCCCACGCTTGGAGCCTTCTCCATGAGTGCCGCCTACGCAGTGTATGAGGCTGTGTACGCTGTGGCCCACGGC- CTCCAC CAGCTCCTGGGATGTACTTCTGAGATCTGTTCCAGAGGCCCAGTCTACCCCTGGCAGCTTCTTCAGCAGATCTA- CAAGGT GAATTTTCTTCTACATGAGAATACTGTGGCATTTGATGACAACGGGGACACTCTAGGTTACTACGACATCATCG- CCTGGG ACTGGAATGGACCTGAATGGACCTTTGAGATCATTGGCTCTGCCTCACTGTCTCCAGTTCATCTGGACATAAAT- AAGACA AAAATCCAGTGGCACGGGAAGAACAATCAGGTGCCTGTGTCAGTGTGTACCACGGACTGTCTGGCAGGGCACCA- CAGGGT GGTTGTGGGTTCCCACCACTGCTGCTTTGAGTGTGTGCCCTGCGAAGCTGGGACCTTTCTCAACATGAGTGAGC- TTCACA TCTGCCAGCCTTGTGGAACAGAAGAATGGGCACCCAAGGAGAGCACTACTTGCTTCCCACGCACGGTGGAGTTC- TTGGCT TGGCATGAACCCATCTCTTTGGTGCTAATAGCAGCTAACACGCTATTGCTGCTGCTGCTGGTTGGGACTGCTGG- CCTGTT TGCCTGGCATTTTCACACACCTGTAGTGAGGTCAGCTGGGGGTAGGCTGTGCTTCCTCATGCTGGGTTCCCTGG- TGGCCG GAAGTTGCAGCTTCTATAGCTTCTTCGGGGAGCCCACGGTGCCCGCGTGCTTGCTGCGTCAGCCCCTCTTTTCT- CTCGGG TTTGCCATCTTCCTCTCCTGCCTGACAATCCGCTCCTTCCAACTGGTCATCATCTTCAAGTTTTCTACCAAGGT- GCCCAC ATTCTACGCTACCTGGGCCCAAAACCATGGTGCAGGTCTATTCGTCATTGTCAGCTCCACGGTCCATTTGCTCA- TCTGTC TCACATGGCTTGTAATGTGGACCCCACGACCCACCAGGGAATACCAGCGCTTCCCCCATCTGGTGATTCTCGAG- TGCACA GAGGTCAACTCTGTAGGCTTCCTGTTGGCTTTCACCCACAACATTCTCCTCTCCATCAGTACCTTCGTCTGCAG- CTACCT GGGTAAGGAACTGCCAGAGAACTATAATGAAGCCAAATGTGTCACCTTCAGCCTGCTCCTCAACTTCGTATCCT- GGATCG CCTTCTTCACCATGGCCAGCATTTACCAGGGCAGCTACCTGCCTGCGGTCAATGTGCTGGCAGGGCTGACCACA- CTGAGC GGCGGCTTCAGCGGTTACTTCCTCCCCAAGTGCTATGTGATTCTCTGCCGTCCAGAACTCAACAATACAGAACA- CTTTCA GGCCTCCATCCAGGACTACACGAGGCGCTGCGGCACTACCTGA >rT1R1 (amino acid; SEQ ID NO: 3) MLFWAAHLLLSLQLVYCWAFSCQRTESSPGFSLPGDFLLAGLFSLHGDCLQVRHRPLVTSCDRPDSFNGHGYHL- FQAMRF TVEEINNSSALLPNITLGYELYDVCSESANVYATLRVLALQCPRHIEIQKDLRNHSSKVVAFIGPDNTDHAVTT- AALLGP FLMPLVSYEASSVVLSAKRKFPSFLRTVPSDRHQVEVMVQLLQSFCWVWISLIGSYGDYGQLGVQALEELAVPR- GICVAF KDIVPFSARVGDPRMQSMMQHLAQARTTVVVVFSNRHLARVFFRSVVLANLTGKVWVASEDWAISTYITSVTGI- QGIGTV LGVAVQQRQVPGLKEFEESYVRAVTAAPSACPEGSWCSTNQLCRECHTFTTRNMPTLGAFSMSAAYRVYEAVYA- VAHGLH QLLGCTSEICSRGPVYPWQLLQQIYKVNFLLHENTVAFDDNGDTLGYYDIIAWDWNGPEWTFEIIGSASLSPVH- LDINKT KIQWHGKNNQVPVSVCTTDCLAGHHRVVVGSHHCCFECVPCEAGTFLNMSELHICQPCGTEEWAPKESTTCFPR- TVEFLA WHEPISLVLIAANTLLLLLLVGTACLFAWHFHTPVVRSAGGRLCFLMLGSLVAGSCSFYSFFGEPTVPACLLRQ- PLFSLG FAIFLSCLTIRSFQLVIIFKFSTKVPTFYRTWAQNHGAGLFVIVSSTVHLLICLTWLVMWTPRPTREYQRFPHL- VILECT EVNSVGFLLAFTHNILLSISTFVCSYLGKELPENYNEAKCVTFSLLLNFVSWIAFFTMASIYQGSYLPAVNVLA- GLTTLS GGFSGYFLPKCYVILCRPELNNTEHFQASIQDYTRRCGTT. >rT1R2 (Nucleic Acid; SEQ ID NO: 17) ATGGGTCCCCAGGCAAGGACACTCTGCTTGCTGTCTCTCCTGCTGCATGTTCTGCCTAAGCCAGGCAAGCTGGT- AGAGAA CTCTGACTTCCACCTGGCCGGGGACTACCTCCTGGGTGGCCTCTTTACCCTCCATGCCAACGTGAAGAGCATCT- CCCACC TCAGCTACCTGCAGGTGCCCAAGTGCAATGAGTTCACCATGAAGGTGTTGGGCTACAACCTCATGCAGGCCATG- CGTTTC GCTGTGGAGGAGATCAACAACTGTAGCTCCCTGCTACCCGGCGTGCTGCTCGGCTACGAGATGGTGGATGTCTG- TTACCT CTCCAACAATATCCACCCTGGGCTCTACTTCCTGGCACAGGACGACGACCTCCTGCCCATCCTCAAAGACTACA- GCCAGT ACATGCCCCACGTGGTGGCTGTCATTGGCCCCGACAACTCTGAGTCCGCCATTACCGTGTCCAACATTCTCTCT- CATTTC CTCATCCCACAGATCACATACAGCGCCATCTCCGACAAGCTGCGGGACAAGCGGCACTTCCCTAGCATGCTACG- CACAGT GCCCAGCGCCACCCACCACATCGAGGCCATGGTGCAGCTGATGGTTCACTTCCAATGGAACTGGATTGTGGTGC- TGGTGA GCGACGACGATTACGGCCGCGAGAACAGCCACCTGTTGAGCCAGCGTCTGACCAAAACGAGCGACATCTGCATT- GCCTTC CAGGAGGTTCTGCCCATACCTGAGTCCAGCCAGGTCATGAGGTCCGAGGAGCAGAGACAACTGGACAACATCCT- GGACAA GCTGCGGCGGACCTCGGCGCGCGTCGTGGTGGTGTTCTCGCCCGAGCTGAGCCTGTATAGCTTCTTTCACGAGG- TGCTCC GCTGGAACTTCACGGGTTTTGTGTGGATCGCCTCTGAGTCCTGGGCTATCGACCCAGTTCTGCATAACCTCACG- GAGCTG CGCCACACGGGTACTTTTCTGGGCGTCACCATCCAGAGGGTGTCCATCCCTGGCTTCAGTCAGTTCCGAGTGCG- CCGTGA CAAGCCAGGGTATCCCGTGCCTAACACGACCAACCTGCGGACGACCTGCAACCAGGACTGTGACGCCTGCTTGA- ACACCA CCAAGTCCTTCAACAACATCCTTATACTTTCGGGGCAGCGCGTGGTCTACAGCGTGTACTCGGCAGTTTACGCG- GTGGCC CATGCCCTCCACAGACTCCTCGGCTGTAACCGGGTCCGCTGCACCAAGCAAAAGGTCTACCCGTGGCAGCTACT- CAGGGA GATCTGGCACGTCAACTTCACGCTCCTGGGTAACCGGCTCTTCTTTGACCAACAAGGGGACATGCCGATGCTCT- TGGACA TCATCCAGTGGCAGTGGGACCTGAGCCAGAATCCCTTCCAAAGCATCGCCTCCTATTCTCCCACCAGCAAGAGG- CTAACC TACATTAACAATGTGTCCTGGTACACCCCCAACAACACGGTCCCTGTCTCCATGTGTTCCAAGAGCTGCCAGCC- AGGGCA AATGAAAAAGTCTGTGGGCCTCCACCCTTGTTGCTTCGAGTGCTTGGATTGTATGCCAGGCACCTACCTCAACC- GCTCAG CAGATGAGTTTAACTGTCTGTCCTGCCCGGGTTCCATGTGGTCCTACAAGAACGACATCACTTGCTTCCAGCGG- CGGCCT ACCTTCCTGGAGTGGCACGAAGTGCCCACCATCGTGGTGGCCATACTGGCTGCCCTGGGCTTCTTCAGTACACT- GGCCAT TCTTTTCATCTTCTGGAGACATTTCCAGACACCCATGGTGCGCTCGGCCGGTGGCCCCATGTGCTTCCTGATGC- TCGTGC CCCTGCTGCTGGCGTTTGGGATGGTGCCCGTGTATGTGGGGCCCCCCACGGTCTTCTCATGCTTCTGCCGACAG- GCTTTC TTCACCGTCTGCTTCTCCATCTGCCTATCCTGCATCACCGTGCGCTCCTTCCAGATCGTGTGTCTCTTCAAGAT- GGCCAG ACGCCTGCCAAGTGCCTACAGTTTTTGGATGCGTTACCACGGGCCCTATGTCTTCGTGGCCTTCATCACGGCCA- TCAAGG TGGCCCTGGTGGTGGGCAACATGCTGGCCACCACCATCAACCCCATTGGCCGGACCGACCCGGATGACCCCAAC- ATCATG ATCCTCTCGTGCCACCCTAACTACCGCAACGGGCTACTGTTCAACACCAGCATGGACTTGCTGCTGTCTGTGCT- GGGTTT CAGCTTCGCTTACATGGGCAAGGAGCTGCCCACCAACTACAACGAAGCCAAGTTCATCACTCTCAGCATGACCT- TCTCCT TCACCTCCTCCATCTCCCTCTGCACCTTCATGTCTGTGCACGACGGCGTGCTGGTCACCATCATGGACCTCCTG- GTCACT GTGCTCAACTTCCTGGCCATCGGCTTGGGATACTTTGGCCCCAAGTGTTACATGATCCTTTTCTACCCGGAGCG- CAACAC CTCAGCCTATTTCAATAGCATGATCCAGGGCTACACCATGAGGAAGAGC >rT1R2 (Amino Acid; SEQ ID NO: 6) MGPQARTLCLLSLLLHVLPKPGKLVENSDFHLAGDYLLGGLFTLHANVKSISHLSYLQVPKCNEFTMKVLGYNL- MQAMRF AVEEINNCSSLLPGVLLGYEMVDVCYLSNNIHPGLYFLAQDDDLLPILKDYSQYMPHVVAVIGPDNSESAITVS- NILSHF LIPQITYSAISDKLRDKRHFPSMLRTVPSATHHIEAMVQLMVHFQWNWIVVLVSDDDYGRENSHLLSQRLTKTS- DICIAF QEVLPIPESSQVMRSEEQRQLDNILDKLRRTSARVVVVFSPELSLYSFFHEVLRWNFTGFVWIASESWAIDPVL- HNLTEL RHTGTFLGVTIQRVSIPGFSQFRVRRDKPGYPVPNTTNLRTTCNQDCDACLNTTKSFNNILILSGERVVYSVYS- AVYAVA HALHRLLGCNRVRCTKQKVYPWQLLREIWHVNFTLLGNRLFFDQQGDMPMLLDIIQWQWDLSQNPFQSIASYSP- TSKRLT YINNVSWYTPNNTVPVSMCSKSCQPGQMKKSVGLHPCCFECLDCMPGTYLNRSADEFNCLSCPGSMWSYKNDIT- CFQRRP TFLEWHEVPTIVVAILAALGFFSTLAILFIFWRHFQTPMVRSAGGPMCFLMLVPLLLAFGMVPVYVGPPTVFSC- FCRQAF FTVCFSICLSCITVRSFQIVCVFKMARRLPSAYSFWMRYHGPYVFVAFITAIKVALVVGNMLATTINPIGRTDP- DDPNIM ILSCHPNYRNGLLFNTSMDLLLSVLGFSFAYMGKELPTNYNEAKFITLSMTFSFTSSISLCTFMSVHDGVLVTI- MDLLVT VLNFLAIGLGYFGPKCYMILFYPERNTSAYFNSMIQGYTMRKS >rT1R3 (Nucleic Acid; SEQ ID NO: 18) ATGCCGGGTTTGGCTATCTTGGGCCTCAGTCTGGCTGCTTTCCTGGAGCTTGGGATGGGGTCCTCTTTGTGTCT- GTCACA GCAATTCAAGGCACAAGGGGACTATATATTGGGTGGACTATTTCCCCTGGGCACAACTGAGGAGGCCACTCTCA- ACCAGA GAACACAGCCCAACGGCATCCTATGTACCAGGTTCTCGCCCCTTGGTTTGTTCCTGGCCATGGCTATGAAGATG- GCTGTA GAGGAGATCAACAATGGATCTGCCTTGCTCCCTGGGCTGCGACTGGGCTATGACCTGTTTGACACATGCTCAGA- GCCAGT GGTCACCATGAAGCCCAGCCTCATGTTCATGGCCAAGGTGGGAAGTCAAAGCATTGCTGCCTACTGCAACTACA- CACAGT ACCAACCCCGTGTGCTGGCTGTCATTGGTCCCCACTCATCAGAGCTTGCCCTCATTACAGGCAAGTTCTTCAGC- TTCTTC CTCATGCCACAGGTCAGCTATAGTGCCAGCATGGATCGGCTAAGTGACCGGGAAACATTTCCATCCTTCTTCCG- CACAGT GCCCAGTGACCGGGTGCAGCTGCAGGCCGTTGTGACACTGTTGCAGAATTTCAGCTGGAACTGGGTGGCTGCCT- TAGGTA GTGATGATGACTATGGCCGGGAAGGTCTGAGCATCTTTTCTGGTCTGGCCAACTCACGAGGTATCTGCATTGCA- CACGAG GGCCTGGTGCCACAACATGACACTAGTGGCCAACAATTGGGCAAGGTGGTGGATGTGCTACGCCAAGTGAACCA- AAGCAA AGTACAGGTGGTGGTGCTGTTTGCATCTGCCCGTGCTGTCTACTCCCTTTTTAGCTACAGCATCCTTCATGACC- TCTCAC CCAAGGTATGGGTGGCCAGTGAGTCCTGGCTGACCTCTGACCTGGTCATGACACTTCCCAATATTGCCCGTGTG- GGGACT GTTCTTGGGTTTCTGCAGCGCGGTGCCCTACTGCCTGAATTTTCCCATTATGTGGAGACTCGCCTTGCCCTAGC- TGCTGA CCCAACATTCTGTGCCTCCCTGAAAGCTGAGTTGGATCTGGAGGAGCGCGTGATGGGGCCACGCTGTTCACAAT- GTGACT ACATCATGCTACAGAACCTGTCATCTGGGCTGATGCAGAACCTATCAGCTGGGCAGTTGCACCACCAAATATTT- GCAACC TATGCAGCTGTGTACAGTGTGGCTCAGGCCCTTCACAACACCCTGCAGTGCAATGTCTCACATTGCCACACATC- AGAGCC TGTTCAACCCTGGCAGCTCCTGGAGAACATGTACAATATGAGTTTCCGTGCTCGAGACTTGACACTGCAGTTTG- ATGCCA AAGGGAGTGTAGACATGGAATATGACCTCAAGATGTGGGTGTGGCAGAGCCCTACACCTGTACTACATACTGTA- GGCACC TTCAACGGCACCCTTCAGCTGCAGCACTCGAAAATGTATTGGCCAGGCAACCAGGTGCCAGTCTCCCAGTGCTC- CCGGCA GTGCAAAGATGGCCAGGTGCGCAGAGTAAAGGGCTTTCATTCCTGCTGCTATGACTGTGTGGACTGCAAGGCAG- GGAGCT ACCGGAAGCATCCAGATGACTTCACCTGTACTCCATGTGGCAAGGATCAGTGGTCCCCAGAAAAAAGCACAACC- TGCTTA CCTCGCAGGCCCAAGTTTCTGGCTTGGGGGGAGCCAGCTGTGCTGTCACTTCTCCTGCTGCTTTGCCTGGTGCT- GGGCCT GACACTGGCTGCCCTGGGGCTCTTTGTCCACTACTGGGACAGCCCTCTTGTTCAGGCCTCAGGTGGGTCACTGT- TCTGCT TTGGCCTGATCTGCCTAGGCCTCTTCTGCCTCAGTGTCCTTCTGTTCCCAGGACGACCACGCTCTGCCAGCTGC- CTTGCC CAACAACCAATGGCTCACCTCCCTCTCACAGGCTGCCTGAGCACACTCTTCCTGCAAGCAGCCGAGATCTTTGT- GGAGTC TGAGCTGCCACTGAGTTGGGCAAACTGGCTCTGCAGCTACCTTCGGGGCCCCTGGGCTTGGCTGGTGGTACTGC- TGGCCA CTCTTGTGGAGGCTGCACTATGTGCCTGGTACTTGATGGCTTTCCCTCCGCAGGTGGTGACAGATTGGCAGGTG- CTGCCC ACGGAGGTACTGGAACACTGCCGCATGCGTTCCTGGGTCAGCCTGGGCTTGGTGCACATCACCAATGCAGTGTT- AGCTTT CCTCTGCTTTCTGGGCACTTTCCTGGTACAGAGCCAGCCTGGTCGCTATAACCGTGCCCGTGGCCTCACCTTCG- CCATGC
TAGCTTATTTCATCATCTGGGTCTCTTTTGTGCCCCTCCTGGCTAATGTGCAGGTGGCCTACCAGCCAGCTGTG- CAGATG GGTGCTATCTTATTCTGTGCCCTGGGCATCCTGGCCACCTTCCACCTGCCCAAATGCTATGTACTTCTGTGGCT- GCCAGA GCTCAACACCCAGGAGTTCTTCCTGGGAAGGAGCCCCAAGGAAGCATCAGATGGGAATAGTGGTAGTAGTGAGG- CAACTC GGGGACACAGTGAATGA >rT1R3 (Amino Acid; SEQ ID NO: 9) MPGLAILGLSLAAFLELGMGSSLCLSQQFKAQGDYILGGLFPLGTTEEATLNQRTQPNGILCTRFSPLCLFLAM- AMKMAV EEINNGSALLPGLRLGYDLFDTCSEPVVTMKPSLMFMAKVGSQSIAAYCNYTQYQPRVLAVIGPHSSELALITG- KFFSFF LMPQVSYSASMDRLSDRETFPSFFRTVPSDRVQLQAVVTLLQNFSWNWVAALGSDDDYGREGLSIFSGLANSRG- ICIAHE GLVPQHDTSGQQLGKVVDVLRQVNQSKVQVVVLFASARAVYSLFSYSILHDLSPKVWVASESWLTSDLVMTLPN- IARVGT VLGFLQRGALLPEFSHYVETRLALAADPTFCASLKAELDLEERVMGPRCSQCDYIMLQNLSSGLMQNLSAGQLH- HQIFAT YAAVYSVAQALHNTLQCNVSHCHTSEPVQPWQLLENMYNMSFRARDLTLQFDAKGSVDMEYDLKMWVWQSPTPV- LHTVGT FNGTLQLQHSKMYWPGNQVPVSQCSRQCKDGQVRRVKGFHSCCYDCVDCKAGSYRKHPDDFTCTPCGKDQWSPE- KSTTCL PRRPKFLAWGEPAVLSLLLLLCLVLGLTLAALGLFVHYWDSPLVQASGGSLFCFGLICLGLFCLSVLLFPGRPR- SASCLA QQPMAHLPLTGCLSTLFLQAAEIFVESELPLSWANWLCSYLRGPWAWLVVLLATLVEAALCAWYLMAFPPEVVT- DWQVLP TEVLEHCRMRSWVSLGLVHITNAVLAFLCFLGTFLVQSQPGRYNRARGLTFAMLAYFIIWVSFVPLLANVQVAY- QPAVQM GAILFCALGILATFHLPKCYVLLWLPELNTQEFFLGRSPKEASDGNSGSSEATRGHSE.
Sequence CWU
1
221840PRTHomo sapiens 1Met Leu Leu Cys Thr Ala Arg Leu Val Gly Leu Gln Leu
Leu Ile Ser1 5 10 15Cys
Cys Trp Ala Phe Ala Cys His Ser Thr Glu Ser Ser Pro Asp Phe 20
25 30Thr Leu Pro Gly Asp Tyr Leu Leu
Ala Gly Leu Phe Pro Leu His Ser 35 40
45Gly Cys Leu Gln Val Arg His Arg Pro Glu Val Thr Leu Cys Asp Arg
50 55 60Ser Cys Ser Phe Asn Glu His Gly
Tyr His Leu Phe Gln Ala Met Arg65 70 75
80Leu Gly Val Glu Glu Ile Asn Asn Ser Thr Ala Leu Leu
Pro Asn Ile 85 90 95Thr
Leu Gly Tyr Gln Leu Tyr Asp Val Cys Ser Asp Ser Ala Asn Val
100 105 110Tyr Ala Thr Leu Arg Val Leu
Ser Leu Pro Gly Gln His His Ile Glu 115 120
125Leu Gln Gly Asp Leu Leu His Tyr Ser Pro Thr Val Leu Ala Val
Ile 130 135 140Gly Pro Asp Ser Thr Asn
Arg Ala Ala Thr Thr Ala Ala Leu Leu Ser145 150
155 160Pro Phe Leu Val Pro Met Leu Ile Ser Tyr Ala
Ala Ser Ser Glu Thr 165 170
175Leu Ser Val Lys Arg Gln Tyr Pro Ser Phe Leu Arg Thr Ile Pro Asn
180 185 190Asp Lys Tyr Gln Val Glu
Thr Met Val Leu Leu Leu Gln Lys Phe Gly 195 200
205Trp Thr Trp Ile Ser Leu Val Gly Ser Ser Asp Asp Tyr Gly
Gln Leu 210 215 220Gly Val Gln Ala Leu
Glu Asn Gln Ala Thr Gly Gln Gly Ile Cys Ile225 230
235 240Ala Phe Lys Asp Ile Met Pro Phe Ser Ala
Gln Val Gly Asp Glu Arg 245 250
255Met Gln Cys Leu Met Arg His Leu Ala Gln Ala Gly Ala Thr Val Val
260 265 270Val Val Phe Ser Ser
Arg Gln Leu Ala Arg Val Phe Phe Glu Ser Val 275
280 285Val Leu Thr Asn Leu Thr Gly Lys Val Trp Val Ala
Ser Glu Ala Trp 290 295 300Ala Leu Ser
Arg His Ile Thr Gly Val Pro Gly Ile Gln Arg Ile Gly305
310 315 320Met Val Leu Gly Val Ala Ile
Gln Lys Arg Ala Val Pro Gly Leu Lys 325
330 335Ala Phe Glu Glu Ala Tyr Ala Arg Ala Asp Lys Glu
Ala Pro Arg Pro 340 345 350Cys
His Lys Gly Ser Trp Cys Ser Ser Asn Gln Leu Cys Arg Glu Cys 355
360 365Gln Ala Phe Met Ala His Thr Met Pro
Lys Leu Lys Ala Phe Ser Met 370 375
380Ser Ser Ala Tyr Asn Ala Tyr Arg Ala Val Tyr Ala Val Ala His Gly385
390 395 400Leu His Gln Leu
Leu Gly Cys Ala Ser Gly Ala Cys Ser Arg Gly Arg 405
410 415Val Tyr Pro Trp Gln Leu Glu Gln Ile His
Lys Val His Phe Leu Leu 420 425
430His Lys Asp Thr Val Ala Phe Asn Asp Asn Arg Asp Pro Leu Ser Ser
435 440 445Tyr Asn Ile Ile Ala Trp Asp
Trp Asn Gly Pro Lys Trp Thr Phe Thr 450 455
460Val Leu Gly Ser Ser Thr Trp Ser Pro Val Gln Leu Asn Ile Asn
Glu465 470 475 480Thr Lys
Ile Gln Trp His Gly Lys Asp Asn Gln Glu Pro Ser Leu Cys
485 490 495Val Pro Ala Thr Val Leu Lys
Gly Thr Ser Glu Trp Leu Arg Val Ser 500 505
510Ile Thr Ala Ala Leu Ser Val Cys Pro Val Gly Gly Ser Trp
Pro Ser 515 520 525Leu Ser Asp Leu
Tyr Arg Cys Gln Pro Cys Gly Lys Glu Glu Trp Ala 530
535 540Pro Glu Gly Ser Gln Thr Cys Phe Pro Arg Thr Val
Val Phe Leu Ala545 550 555
560Leu Arg Glu His Thr Ser Trp Val Leu Leu Ala Ala Asn Thr Leu Leu
565 570 575Leu Leu Leu Leu Leu
Gly Thr Ala Gly Leu Phe Ala Trp His Leu Asp 580
585 590Thr Pro Val Val Arg Ser Ala Gly Gly Arg Leu Cys
Phe Leu Met Leu 595 600 605Gly Ser
Leu Ala Ala Gly Ser Gly Ser Leu Tyr Gly Phe Phe Gly Glu 610
615 620Pro Thr Arg Pro Ala Cys Leu Leu Arg Gln Ala
Leu Phe Ala Leu Gly625 630 635
640Phe Thr Ile Phe Leu Ser Cys Leu Thr Val Arg Ser Phe Gln Leu Ile
645 650 655Ile Ile Phe Lys
Phe Ser Thr Lys Val Pro Thr Phe Tyr His Ala Trp 660
665 670Val Gln Asn His Gly Ala Gly Leu Phe Val Met
Ile Ser Ser Ala Ala 675 680 685Gln
Leu Leu Ile Cys Leu Thr Trp Leu Val Val Trp Thr Pro Leu Pro 690
695 700Ala Arg Glu Tyr Gln Arg Phe Pro His Leu
Val Met Leu Glu Cys Thr705 710 715
720Glu Thr Asn Ser Leu Gly Phe Ile Leu Ala Phe Leu Tyr Asn Gly
Leu 725 730 735Leu Ser Ile
Ser Ala Phe Ala Cys Ser Tyr Leu Gly Lys Asp Leu Pro 740
745 750Glu Asn Tyr Asn Glu Ala Lys Cys Val Thr
Phe Ser Leu Leu Phe Asn 755 760
765Phe Val Ser Trp Ile Ala Phe Phe Thr Thr Ala Ser Val Tyr Asp Gly 770
775 780Lys Tyr Leu Pro Ala Ala Asn Met
Met Ala Gly Leu Ser Ser Leu Ser785 790
795 800Ser Gly Phe Gly Gly Tyr Phe Leu Pro Lys Cys Tyr
Val Ile Leu Cys 805 810
815Arg Pro Asp Leu Asn Ser Thr Glu His Phe Gln Ala Ser Ile Gln Asp
820 825 830Tyr Thr Arg Arg Cys Gly
Ser Thr 835 8402842PRTMus musculus 2Met Leu Phe
Trp Ala Ala His Leu Leu Leu Ser Leu Gln Leu Ala Val1 5
10 15Ala Tyr Cys Trp Ala Phe Ser Cys Gln
Arg Thr Glu Ser Ser Pro Gly 20 25
30Phe Ser Leu Pro Gly Asp Phe Leu Leu Ala Gly Leu Phe Ser Leu His
35 40 45Ala Asp Cys Leu Gln Val Arg
His Arg Pro Leu Val Thr Ser Cys Asp 50 55
60Arg Ser Asp Ser Phe Asn Gly His Gly Tyr His Leu Phe Gln Ala Met65
70 75 80Arg Phe Thr Val
Glu Glu Ile Asn Asn Ser Thr Ala Leu Leu Pro Asn 85
90 95Ile Thr Leu Gly Tyr Glu Leu Tyr Asp Val
Cys Ser Glu Ser Ser Asn 100 105
110Val Tyr Ala Thr Leu Arg Val Pro Ala Gln Gln Gly Thr Gly His Leu
115 120 125Glu Met Gln Arg Asp Leu Arg
Asn His Ser Ser Lys Val Val Ala Leu 130 135
140Ile Gly Pro Asp Asn Thr Asp His Ala Val Thr Thr Ala Ala Leu
Leu145 150 155 160Ser Pro
Phe Leu Met Pro Leu Val Ser Tyr Glu Ala Ser Ser Val Ile
165 170 175Leu Ser Gly Lys Arg Lys Phe
Pro Ser Phe Leu Arg Thr Ile Pro Ser 180 185
190Asp Lys Tyr Gln Val Glu Val Ile Val Arg Leu Leu Gln Ser
Phe Gly 195 200 205Trp Val Trp Ile
Ser Leu Val Gly Ser Tyr Gly Asp Tyr Gly Gln Leu 210
215 220Gly Val Gln Ala Leu Glu Glu Leu Ala Thr Pro Arg
Gly Ile Cys Val225 230 235
240Ala Phe Lys Asp Val Val Pro Leu Ser Ala Gln Ala Gly Asp Pro Arg
245 250 255Met Gln Arg Met Met
Leu Arg Leu Ala Arg Ala Arg Thr Thr Val Val 260
265 270Val Val Phe Ser Asn Arg His Leu Ala Gly Val Phe
Phe Arg Ser Val 275 280 285Val Leu
Ala Asn Leu Thr Gly Lys Val Trp Ile Ala Ser Glu Asp Trp 290
295 300Ala Ile Ser Thr Tyr Ile Thr Asn Val Pro Gly
Ile Gln Gly Ile Gly305 310 315
320Thr Val Leu Gly Val Ala Ile Gln Gln Arg Gln Val Pro Gly Leu Lys
325 330 335Glu Phe Glu Glu
Ser Tyr Val Gln Ala Val Met Gly Ala Pro Arg Thr 340
345 350Cys Pro Glu Gly Ser Trp Cys Gly Thr Asn Gln
Leu Cys Arg Glu Cys 355 360 365His
Ala Phe Thr Thr Trp Asn Met Pro Glu Leu Gly Ala Phe Ser Met 370
375 380Ser Ala Ala Tyr Asn Val Tyr Glu Ala Val
Tyr Ala Val Ala His Gly385 390 395
400Leu His Gln Leu Leu Gly Cys Thr Ser Gly Thr Cys Ala Arg Gly
Pro 405 410 415Val Tyr Pro
Trp Gln Leu Leu Gln Gln Ile Tyr Lys Val Asn Phe Leu 420
425 430Leu His Lys Lys Thr Val Ala Phe Asp Asp
Lys Gly Asp Pro Leu Gly 435 440
445Tyr Tyr Asp Ile Ile Ala Trp Asp Trp Asn Gly Pro Glu Trp Thr Phe 450
455 460Glu Val Ile Gly Ser Ala Ser Leu
Ser Pro Val His Leu Asp Ile Asn465 470
475 480Lys Thr Lys Ile Gln Trp His Gly Lys Asn Asn Gln
Val Pro Val Ser 485 490
495Val Cys Thr Arg Asp Cys Leu Glu Gly His His Arg Leu Val Met Gly
500 505 510Ser His His Cys Cys Phe
Glu Cys Met Pro Cys Glu Ala Gly Thr Phe 515 520
525Leu Asn Thr Ser Glu Leu His Thr Cys Gln Pro Cys Gly Thr
Glu Glu 530 535 540Trp Ala Pro Glu Gly
Ser Ser Ala Cys Phe Ser Arg Thr Val Glu Phe545 550
555 560Leu Gly Trp His Glu Pro Ile Ser Leu Val
Leu Leu Ala Ala Asn Thr 565 570
575Leu Leu Leu Leu Leu Leu Ile Gly Thr Ala Gly Leu Phe Ala Trp Arg
580 585 590Leu His Thr Pro Val
Val Arg Ser Ala Gly Gly Arg Leu Cys Phe Leu 595
600 605Met Leu Gly Ser Leu Val Ala Gly Ser Cys Ser Leu
Tyr Ser Phe Phe 610 615 620Gly Lys Pro
Thr Val Pro Ala Cys Leu Leu Arg Gln Pro Leu Phe Ser625
630 635 640Leu Gly Phe Ala Ile Phe Leu
Ser Cys Leu Thr Ile Arg Ser Phe Gln 645
650 655Leu Val Ile Ile Phe Lys Phe Ser Thr Lys Val Pro
Thr Phe Tyr His 660 665 670Thr
Trp Ala Gln Asn His Gly Ala Gly Ile Phe Val Ile Val Ser Ser 675
680 685Thr Val His Leu Phe Leu Cys Leu Thr
Trp Leu Ala Met Trp Thr Pro 690 695
700Arg Pro Thr Arg Glu Tyr Gln Arg Phe Pro His Leu Val Ile Leu Glu705
710 715 720Cys Thr Glu Val
Asn Ser Val Gly Phe Leu Val Ala Phe Ala His Asn 725
730 735Ile Leu Leu Ser Ile Ser Thr Phe Val Cys
Ser Tyr Leu Gly Lys Glu 740 745
750Leu Pro Glu Asn Tyr Asn Glu Ala Lys Cys Val Thr Phe Ser Leu Leu
755 760 765Leu His Phe Val Ser Trp Ile
Ala Phe Phe Thr Met Ser Ser Ile Tyr 770 775
780Gln Gly Ser Tyr Leu Pro Ala Val Asn Val Leu Ala Gly Leu Ala
Thr785 790 795 800Leu Ser
Gly Gly Phe Ser Gly Tyr Phe Leu Pro Lys Cys Tyr Val Ile
805 810 815Leu Cys Arg Pro Glu Leu Asn
Asn Thr Glu His Phe Gln Ala Ser Ile 820 825
830Gln Asp Tyr Thr Arg Arg Cys Gly Thr Thr 835
8403840PRTRattus norvegicus 3Met Leu Phe Trp Ala Ala His Leu Leu
Leu Ser Leu Gln Leu Val Tyr1 5 10
15Cys Trp Ala Phe Ser Cys Gln Arg Thr Glu Ser Ser Pro Gly Phe
Ser 20 25 30Leu Pro Gly Asp
Phe Leu Leu Ala Gly Leu Phe Ser Leu His Gly Asp 35
40 45Cys Leu Gln Val Arg His Arg Pro Leu Val Thr Ser
Cys Asp Arg Pro 50 55 60Asp Ser Phe
Asn Gly His Gly Tyr His Leu Phe Gln Ala Met Arg Phe65 70
75 80Thr Val Glu Glu Ile Asn Asn Ser
Ser Ala Leu Leu Pro Asn Ile Thr 85 90
95Leu Gly Tyr Glu Leu Tyr Asp Val Cys Ser Glu Ser Ala Asn
Val Tyr 100 105 110Ala Thr Leu
Arg Val Leu Ala Leu Gln Gly Pro Arg His Ile Glu Ile 115
120 125Gln Lys Asp Leu Arg Asn His Ser Ser Lys Val
Val Ala Phe Ile Gly 130 135 140Pro Asp
Asn Thr Asp His Ala Val Thr Thr Ala Ala Leu Leu Gly Pro145
150 155 160Phe Leu Met Pro Leu Val Ser
Tyr Glu Ala Ser Ser Val Val Leu Ser 165
170 175Ala Lys Arg Lys Phe Pro Ser Phe Leu Arg Thr Val
Pro Ser Asp Arg 180 185 190His
Gln Val Glu Val Met Val Gln Leu Leu Gln Ser Phe Gly Trp Val 195
200 205Trp Ile Ser Leu Ile Gly Ser Tyr Gly
Asp Tyr Gly Gln Leu Gly Val 210 215
220Gln Ala Leu Glu Glu Leu Ala Val Pro Arg Gly Ile Cys Val Ala Phe225
230 235 240Lys Asp Ile Val
Pro Phe Ser Ala Arg Val Gly Asp Pro Arg Met Gln 245
250 255Ser Met Met Gln His Leu Ala Gln Ala Arg
Thr Thr Val Val Val Val 260 265
270Phe Ser Asn Arg His Leu Ala Arg Val Phe Phe Arg Ser Val Val Leu
275 280 285Ala Asn Leu Thr Gly Lys Val
Trp Val Ala Ser Glu Asp Trp Ala Ile 290 295
300Ser Thr Tyr Ile Thr Ser Val Thr Gly Ile Gln Gly Ile Gly Thr
Val305 310 315 320Leu Gly
Val Ala Val Gln Gln Arg Gln Val Pro Gly Leu Lys Glu Phe
325 330 335Glu Glu Ser Tyr Val Arg Ala
Val Thr Ala Ala Pro Ser Ala Cys Pro 340 345
350Glu Gly Ser Trp Cys Ser Thr Asn Gln Leu Cys Arg Glu Cys
His Thr 355 360 365Phe Thr Thr Arg
Asn Met Pro Thr Leu Gly Ala Phe Ser Met Ser Ala 370
375 380Ala Tyr Arg Val Tyr Glu Ala Val Tyr Ala Val Ala
His Gly Leu His385 390 395
400Gln Leu Leu Gly Cys Thr Ser Glu Ile Cys Ser Arg Gly Pro Val Tyr
405 410 415Pro Trp Gln Leu Leu
Gln Gln Ile Tyr Lys Val Asn Phe Leu Leu His 420
425 430Glu Asn Thr Val Ala Phe Asp Asp Asn Gly Asp Thr
Leu Gly Tyr Tyr 435 440 445Asp Ile
Ile Ala Trp Asp Trp Asn Gly Pro Glu Trp Thr Phe Glu Ile 450
455 460Ile Gly Ser Ala Ser Leu Ser Pro Val His Leu
Asp Ile Asn Lys Thr465 470 475
480Lys Ile Gln Trp His Gly Lys Asn Asn Gln Val Pro Val Ser Val Cys
485 490 495Thr Thr Asp Cys
Leu Ala Gly His His Arg Val Val Val Gly Ser His 500
505 510His Cys Cys Phe Glu Cys Val Pro Cys Glu Ala
Gly Thr Phe Leu Asn 515 520 525Met
Ser Glu Leu His Ile Cys Gln Pro Cys Gly Thr Glu Glu Trp Ala 530
535 540Pro Lys Glu Ser Thr Thr Cys Phe Pro Arg
Thr Val Glu Phe Leu Ala545 550 555
560Trp His Glu Pro Ile Ser Leu Val Leu Ile Ala Ala Asn Thr Leu
Leu 565 570 575Leu Leu Leu
Leu Val Gly Thr Ala Gly Leu Phe Ala Trp His Phe His 580
585 590Thr Pro Val Val Arg Ser Ala Gly Gly Arg
Leu Cys Phe Leu Met Leu 595 600
605Gly Ser Leu Val Ala Gly Ser Cys Ser Phe Tyr Ser Phe Phe Gly Glu 610
615 620Pro Thr Val Pro Ala Cys Leu Leu
Arg Gln Pro Leu Phe Ser Leu Gly625 630
635 640Phe Ala Ile Phe Leu Ser Cys Leu Thr Ile Arg Ser
Phe Gln Leu Val 645 650
655Ile Ile Phe Lys Phe Ser Thr Lys Val Pro Thr Phe Tyr Arg Thr Trp
660 665 670Ala Gln Asn His Gly Ala
Gly Leu Phe Val Ile Val Ser Ser Thr Val 675 680
685His Leu Leu Ile Cys Leu Thr Trp Leu Val Met Trp Thr Pro
Arg Pro 690 695 700Thr Arg Glu Tyr Gln
Arg Phe Pro His Leu Val Ile Leu Glu Cys Thr705 710
715 720Glu Val Asn Ser Val Gly Phe Leu Leu Ala
Phe Thr His Asn Ile Leu 725 730
735Leu Ser Ile Ser Thr Phe Val Cys Ser Tyr Leu Gly Lys Glu Leu Pro
740 745 750Glu Asn Tyr Asn Glu
Ala Lys Cys Val Thr Phe Ser Leu Leu Leu Asn 755
760 765Phe Val Ser Trp Ile Ala Phe Phe Thr Met Ala Ser
Ile Tyr Gln Gly 770 775 780Ser Tyr Leu
Pro Ala Val Asn Val Leu Ala Gly Leu Thr Thr Leu Ser785
790 795 800Gly Gly Phe Ser Gly Tyr Phe
Leu Pro Lys Cys Tyr Val Ile Leu Cys 805
810 815Arg Pro Glu Leu Asn Asn Thr Glu His Phe Gln Ala
Ser Ile Gln Asp 820 825 830Tyr
Thr Arg Arg Cys Gly Thr Thr 835 8404839PRTHomo
sapiens 4Met Gly Pro Arg Ala Lys Thr Ile Cys Ser Leu Phe Phe Leu Leu Trp1
5 10 15Val Leu Ala Glu
Pro Ala Glu Asn Ser Asp Phe Tyr Leu Pro Gly Asp 20
25 30Tyr Leu Leu Gly Gly Leu Phe Ser Leu His Ala
Asn Met Lys Gly Ile 35 40 45Val
His Leu Asn Phe Leu Gln Val Pro Met Cys Lys Glu Tyr Glu Val 50
55 60Lys Val Ile Gly Tyr Asn Leu Met Gln Ala
Met Arg Phe Ala Val Glu65 70 75
80Glu Ile Asn Asn Asp Ser Ser Leu Leu Pro Gly Val Leu Leu Gly
Tyr 85 90 95Glu Ile Val
Asp Val Cys Tyr Ile Ser Asn Asn Val Gln Pro Val Leu 100
105 110Tyr Phe Leu Ala His Gly Asp Asn Leu Leu
Pro Ile Gln Glu Asp Tyr 115 120
125Ser Asn Tyr Ile Ser Arg Ala Val Ala Val Ile Gly Pro Asp Asn Ser 130
135 140Glu Ser Val Met Thr Val Ala Asn
Phe Leu Ser Leu Phe Leu Leu Pro145 150
155 160Gln Ile Thr Tyr Ser Ala Ile Ser Asp Glu Leu Arg
Asp Lys Val Arg 165 170
175Phe Pro Ala Leu Leu Arg Thr Thr Pro Ser Ala Asp His His Ile Glu
180 185 190Ala Met Val Gln Leu Met
Leu His Phe Arg Trp Asn Trp Ile Ile Val 195 200
205Leu Val Ser Ser Asp Thr Tyr Gly Arg Asp Asn Gly Gln Leu
Leu Gly 210 215 220Glu Arg Val Ala Arg
Arg Asp Ile Cys Ile Ala Phe Gln Glu Thr Leu225 230
235 240Pro Thr Leu Gln Pro Asn Gln Asn Met Thr
Ser Glu Glu Arg Gln Arg 245 250
255Leu Val Thr Ile Val Asp Lys Leu Gln Gln Ser Thr Ala Arg Val Val
260 265 270Val Val Phe Ser Pro
Asp Leu Thr Leu Tyr His Phe Phe Asn Glu Val 275
280 285Leu Arg Gln Asn Phe Thr Gly Ala Val Trp Ile Ala
Ser Glu Ser Trp 290 295 300Ala Ile Asp
Pro Val Leu His Asn Leu Thr Glu Leu Arg His Leu Gly305
310 315 320Thr Phe Leu Gly Ile Thr Ile
Gln Ser Val Pro Ile Pro Gly Phe Ser 325
330 335Glu Phe Arg Glu Trp Gly Pro Gln Ala Gly Pro Pro
Pro Leu Ser Arg 340 345 350Thr
Ser Gln Ser Tyr Thr Cys Asn Gln Glu Cys Asp Asn Cys Leu Asn 355
360 365Ala Thr Leu Ser Phe Asn Thr Ile Leu
Arg Leu Ser Gly Glu Arg Val 370 375
380Val Tyr Ser Val Tyr Ser Ala Val Tyr Ala Val Ala His Ala Leu His385
390 395 400Ser Leu Leu Gly
Cys Asp Lys Ser Thr Cys Thr Lys Arg Val Val Tyr 405
410 415Pro Trp Gln Leu Leu Glu Glu Ile Trp Lys
Val Asn Phe Thr Leu Leu 420 425
430Asp His Gln Ile Phe Phe Asp Pro Gln Gly Asp Val Ala Leu His Leu
435 440 445Glu Ile Val Gln Trp Gln Trp
Asp Arg Ser Gln Asn Pro Phe Gln Ser 450 455
460Val Ala Ser Tyr Tyr Pro Leu Gln Arg Gln Leu Lys Asn Ile Gln
Asp465 470 475 480Ile Ser
Trp His Thr Ile Asn Asn Thr Ile Pro Met Ser Met Cys Ser
485 490 495Lys Arg Cys Gln Ser Gly Gln
Lys Lys Lys Pro Val Gly Ile His Val 500 505
510Cys Cys Phe Glu Cys Ile Asp Cys Leu Pro Gly Thr Phe Leu
Asn His 515 520 525Thr Glu Asp Glu
Tyr Glu Cys Gln Ala Cys Pro Asn Asn Glu Trp Ser 530
535 540Tyr Gln Ser Glu Thr Ser Cys Phe Lys Arg Gln Leu
Val Phe Leu Glu545 550 555
560Trp His Glu Ala Pro Thr Ile Ala Val Ala Leu Leu Ala Ala Leu Gly
565 570 575Phe Leu Ser Thr Leu
Ala Ile Leu Val Ile Phe Trp Arg His Phe Gln 580
585 590Thr Pro Ile Val Arg Ser Ala Gly Gly Pro Met Cys
Phe Leu Met Leu 595 600 605Thr Leu
Leu Leu Val Ala Tyr Met Val Val Pro Val Tyr Val Gly Pro 610
615 620Pro Lys Val Ser Thr Cys Leu Cys Arg Gln Ala
Leu Phe Pro Leu Cys625 630 635
640Phe Thr Ile Cys Ile Ser Cys Ile Ala Val Arg Ser Phe Gln Ile Val
645 650 655Cys Ala Phe Lys
Met Ala Ser Arg Phe Pro Arg Ala Tyr Ser Tyr Trp 660
665 670Val Arg Tyr Gln Gly Pro Tyr Val Ser Met Ala
Phe Ile Thr Val Leu 675 680 685Lys
Met Val Ile Val Val Ile Gly Met Leu Ala Thr Gly Leu Ser Pro 690
695 700Thr Thr Arg Thr Asp Pro Asp Asp Pro Lys
Ile Thr Ile Val Ser Cys705 710 715
720Asn Pro Asn Tyr Arg Asn Ser Leu Leu Phe Asn Thr Ser Leu Asp
Leu 725 730 735Leu Leu Ser
Val Val Gly Phe Ser Phe Ala Tyr Met Gly Lys Glu Leu 740
745 750Pro Thr Asn Tyr Asn Glu Ala Lys Phe Ile
Thr Leu Ser Met Thr Phe 755 760
765Tyr Phe Thr Ser Ser Val Ser Leu Cys Thr Phe Met Ser Ala Tyr Ser 770
775 780Gly Val Leu Val Thr Ile Val Asp
Leu Leu Val Thr Val Leu Asn Leu785 790
795 800Leu Ala Ile Ser Leu Gly Tyr Phe Gly Pro Lys Cys
Tyr Met Ile Leu 805 810
815Phe Tyr Pro Glu Arg Asn Thr Pro Ala Tyr Phe Asn Ser Met Ile Gln
820 825 830Gly Tyr Thr Met Arg Arg
Asp 8355661PRTMus musculus 5Met Leu Arg Thr Val Pro Ser Ala Thr
His His Ile Glu Ala Met Val1 5 10
15Gln Leu Met Val His Phe Gln Trp Asn Trp Ile Val Val Leu Val
Ser 20 25 30Asp Asp Asp Tyr
Gly Arg Glu Asn Ser His Leu Leu Ser Gln Arg Leu 35
40 45Thr Asn Thr Gly Asp Ile Cys Ile Ala Phe Gln Glu
Val Leu Pro Val 50 55 60Pro Glu Pro
Asn Gln Ala Val Arg Pro Glu Glu Gln Asp Gln Leu Asp65 70
75 80Asn Ile Leu Asp Lys Leu Arg Arg
Thr Ser Ala Arg Val Val Val Ile 85 90
95Phe Ser Pro Glu Leu Ser Leu His Asn Phe Phe Arg Glu Val
Leu Arg 100 105 110Trp Asn Phe
Thr Gly Phe Val Trp Ile Ala Ser Glu Ser Trp Ala Ile 115
120 125Asp Pro Val Leu His Asn Leu Thr Glu Leu Arg
His Thr Gly Thr Phe 130 135 140Leu Gly
Val Thr Ile Gln Arg Val Ser Ile Pro Gly Phe Ser Gln Phe145
150 155 160Arg Val Arg His Asp Lys Pro
Glu Tyr Pro Met Pro Asn Glu Thr Ser 165
170 175Leu Arg Thr Thr Cys Asn Gln Asp Cys Asp Ala Cys
Met Asn Ile Thr 180 185 190Glu
Ser Phe Asn Asn Val Leu Met Leu Ser Gly Glu Arg Val Val Tyr 195
200 205Ser Val Tyr Ser Ala Val Tyr Ala Val
Ala His Thr Leu His Arg Leu 210 215
220Leu His Cys Asn Gln Val Arg Cys Thr Lys Gln Ile Val Tyr Pro Trp225
230 235 240Gln Leu Leu Arg
Glu Ile Trp His Val Asn Phe Thr Leu Leu Gly Asn 245
250 255Gln Leu Phe Phe Asp Glu Gln Gly Asp Met
Pro Met Leu Leu Asp Ile 260 265
270Ile Gln Trp Gln Trp Gly Leu Ser Gln Asn Pro Phe Gln Ser Ile Ala
275 280 285Ser Tyr Ser Pro Thr Glu Thr
Arg Leu Thr Tyr Ile Ser Asn Val Ser 290 295
300Trp Tyr Thr Pro Asn Asn Thr Val Pro Ile Ser Met Cys Ser Lys
Ser305 310 315 320Cys Gln
Pro Gly Gln Met Lys Lys Pro Ile Gly Leu His Pro Cys Cys
325 330 335Phe Glu Cys Val Asp Cys Pro
Pro Gly Thr Tyr Leu Asn Arg Ser Val 340 345
350Asp Glu Phe Asn Cys Leu Ser Cys Pro Gly Ser Met Trp Ser
Tyr Lys 355 360 365Asn Asn Ile Ala
Cys Phe Lys Arg Arg Leu Ala Phe Leu Glu Trp His 370
375 380Glu Val Pro Thr Ile Val Val Thr Ile Leu Ala Ala
Leu Gly Phe Ile385 390 395
400Ser Thr Leu Ala Ile Leu Leu Ile Phe Trp Arg His Phe Gln Thr Pro
405 410 415Met Val Arg Ser Ala
Gly Gly Pro Met Cys Phe Leu Met Leu Val Pro 420
425 430Leu Leu Leu Ala Phe Gly Met Val Pro Val Tyr Val
Gly Pro Pro Thr 435 440 445Val Phe
Ser Cys Phe Cys Arg Gln Ala Phe Phe Thr Val Cys Phe Ser 450
455 460Val Cys Leu Ser Cys Ile Thr Val Arg Ser Phe
Gln Ile Val Cys Val465 470 475
480Phe Lys Met Ala Arg Arg Leu Pro Ser Ala Tyr Gly Phe Trp Met Arg
485 490 495Tyr His Gly Pro
Tyr Val Phe Val Ala Phe Ile Thr Ala Val Lys Val 500
505 510Ala Leu Val Ala Gly Asn Met Leu Ala Thr Thr
Ile Asn Pro Ile Gly 515 520 525Arg
Thr Asp Pro Asp Asp Pro Asn Ile Ile Ile Leu Ser Cys His Pro 530
535 540Asn Tyr Arg Asn Gly Leu Leu Phe Asn Thr
Ser Met Asp Leu Leu Leu545 550 555
560Ser Val Leu Gly Phe Ser Phe Ala Tyr Val Gly Lys Glu Leu Pro
Thr 565 570 575Asn Tyr Asn
Glu Ala Lys Phe Ile Thr Leu Ser Met Thr Phe Ser Phe 580
585 590Thr Ser Ser Ile Ser Leu Cys Thr Phe Met
Ser Val His Asp Gly Val 595 600
605Leu Val Thr Ile Met Asp Leu Leu Val Thr Val Leu Asn Phe Leu Ala 610
615 620Ile Gly Leu Gly Tyr Phe Gly Pro
Lys Cys Tyr Met Ile Leu Phe Tyr625 630
635 640Pro Glu Arg Asn Thr Ser Ala Tyr Phe Asn Ser Met
Ile Gln Gly Tyr 645 650
655Thr Met Arg Lys Ser 6606843PRTRattus norvegicus 6Met Gly
Pro Gln Ala Arg Thr Leu Cys Leu Leu Ser Leu Leu Leu His1 5
10 15Val Leu Pro Lys Pro Gly Lys Leu
Val Glu Asn Ser Asp Phe His Leu 20 25
30Ala Gly Asp Tyr Leu Leu Gly Gly Leu Phe Thr Leu His Ala Asn
Val 35 40 45Lys Ser Ile Ser His
Leu Ser Tyr Leu Gln Val Pro Lys Cys Asn Glu 50 55
60Phe Thr Met Lys Val Leu Gly Tyr Asn Leu Met Gln Ala Met
Arg Phe65 70 75 80Ala
Val Glu Glu Ile Asn Asn Cys Ser Ser Leu Leu Pro Gly Val Leu
85 90 95Leu Gly Tyr Glu Met Val Asp
Val Cys Tyr Leu Ser Asn Asn Ile His 100 105
110Pro Gly Leu Tyr Phe Leu Ala Gln Asp Asp Asp Leu Leu Pro
Ile Leu 115 120 125Lys Asp Tyr Ser
Gln Tyr Met Pro His Val Val Ala Val Ile Gly Pro 130
135 140Asp Asn Ser Glu Ser Ala Ile Thr Val Ser Asn Ile
Leu Ser His Phe145 150 155
160Leu Ile Pro Gln Ile Thr Tyr Ser Ala Ile Ser Asp Lys Leu Arg Asp
165 170 175Lys Arg His Phe Pro
Ser Met Leu Arg Thr Val Pro Ser Ala Thr His 180
185 190His Ile Glu Ala Met Val Gln Leu Met Val His Phe
Gln Trp Asn Trp 195 200 205Ile Val
Val Leu Val Ser Asp Asp Asp Tyr Gly Arg Glu Asn Ser His 210
215 220Leu Leu Ser Gln Arg Leu Thr Lys Thr Ser Asp
Ile Cys Ile Ala Phe225 230 235
240Gln Glu Val Leu Pro Ile Pro Glu Ser Ser Gln Val Met Arg Ser Glu
245 250 255Glu Gln Arg Gln
Leu Asp Asn Ile Leu Asp Lys Leu Arg Arg Thr Ser 260
265 270Ala Arg Val Val Val Val Phe Ser Pro Glu Leu
Ser Leu Tyr Ser Phe 275 280 285Phe
His Glu Val Leu Arg Trp Asn Phe Thr Gly Phe Val Trp Ile Ala 290
295 300Ser Glu Ser Trp Ala Ile Asp Pro Val Leu
His Asn Leu Thr Glu Leu305 310 315
320Arg His Thr Gly Thr Phe Leu Gly Val Thr Ile Gln Arg Val Ser
Ile 325 330 335Pro Gly Phe
Ser Gln Phe Arg Val Arg Arg Asp Lys Pro Gly Tyr Pro 340
345 350Val Pro Asn Thr Thr Asn Leu Arg Thr Thr
Cys Asn Gln Asp Cys Asp 355 360
365Ala Cys Leu Asn Thr Thr Lys Ser Phe Asn Asn Ile Leu Ile Leu Ser 370
375 380Gly Glu Arg Val Val Tyr Ser Val
Tyr Ser Ala Val Tyr Ala Val Ala385 390
395 400His Ala Leu His Arg Leu Leu Gly Cys Asn Arg Val
Arg Cys Thr Lys 405 410
415Gln Lys Val Tyr Pro Trp Gln Leu Leu Arg Glu Ile Trp His Val Asn
420 425 430Phe Thr Leu Leu Gly Asn
Arg Leu Phe Phe Asp Gln Gln Gly Asp Met 435 440
445Pro Met Leu Leu Asp Ile Ile Gln Trp Gln Trp Asp Leu Ser
Gln Asn 450 455 460Pro Phe Gln Ser Ile
Ala Ser Tyr Ser Pro Thr Ser Lys Arg Leu Thr465 470
475 480Tyr Ile Asn Asn Val Ser Trp Tyr Thr Pro
Asn Asn Thr Val Pro Val 485 490
495Ser Met Cys Ser Lys Ser Cys Gln Pro Gly Gln Met Lys Lys Ser Val
500 505 510Gly Leu His Pro Cys
Cys Phe Glu Cys Leu Asp Cys Met Pro Gly Thr 515
520 525Tyr Leu Asn Arg Ser Ala Asp Glu Phe Asn Cys Leu
Ser Cys Pro Gly 530 535 540Ser Met Trp
Ser Tyr Lys Asn Asp Ile Thr Cys Phe Gln Arg Arg Pro545
550 555 560Thr Phe Leu Glu Trp His Glu
Val Pro Thr Ile Val Val Ala Ile Leu 565
570 575Ala Ala Leu Gly Phe Phe Ser Thr Leu Ala Ile Leu
Phe Ile Phe Trp 580 585 590Arg
His Phe Gln Thr Pro Met Val Arg Ser Ala Gly Gly Pro Met Cys 595
600 605Phe Leu Met Leu Val Pro Leu Leu Leu
Ala Phe Gly Met Val Pro Val 610 615
620Tyr Val Gly Pro Pro Thr Val Phe Ser Cys Phe Cys Arg Gln Ala Phe625
630 635 640Phe Thr Val Cys
Phe Ser Ile Cys Leu Ser Cys Ile Thr Val Arg Ser 645
650 655Phe Gln Ile Val Cys Val Phe Lys Met Ala
Arg Arg Leu Pro Ser Ala 660 665
670Tyr Ser Phe Trp Met Arg Tyr His Gly Pro Tyr Val Phe Val Ala Phe
675 680 685Ile Thr Ala Ile Lys Val Ala
Leu Val Val Gly Asn Met Leu Ala Thr 690 695
700Thr Ile Asn Pro Ile Gly Arg Thr Asp Pro Asp Asp Pro Asn Ile
Met705 710 715 720Ile Leu
Ser Cys His Pro Asn Tyr Arg Asn Gly Leu Leu Phe Asn Thr
725 730 735Ser Met Asp Leu Leu Leu Ser
Val Leu Gly Phe Ser Phe Ala Tyr Met 740 745
750Gly Lys Glu Leu Pro Thr Asn Tyr Asn Glu Ala Lys Phe Ile
Thr Leu 755 760 765Ser Met Thr Phe
Ser Phe Thr Ser Ser Ile Ser Leu Cys Thr Phe Met 770
775 780Ser Val His Asp Gly Val Leu Val Thr Ile Met Asp
Leu Leu Val Thr785 790 795
800Val Leu Asn Phe Leu Ala Ile Gly Leu Gly Tyr Phe Gly Pro Lys Cys
805 810 815Tyr Met Ile Leu Phe
Tyr Pro Glu Arg Asn Thr Ser Ala Tyr Phe Asn 820
825 830Ser Met Ile Gln Gly Tyr Thr Met Arg Lys Ser
835 8407850PRTHomo sapiens 7Met Leu Gly Pro Ala Val Leu
Gly Leu Ser Leu Trp Ala Leu Leu His1 5 10
15Pro Gly Thr Gly Ala Pro Leu Cys Leu Ser Gln Gln Leu
Arg Met Lys 20 25 30Gly Asp
Tyr Val Leu Gly Gly Leu Phe Pro Leu Gly Glu Ala Glu Glu 35
40 45Ala Gly Leu Arg Ser Arg Thr Arg Pro Ser
Ser Pro Val Cys Thr Arg 50 55 60Phe
Ser Ser Asn Gly Leu Leu Trp Ala Leu Ala Met Lys Met Ala Val65
70 75 80Glu Glu Ile Asn Asn Lys
Ser Asp Leu Leu Pro Gly Leu Arg Leu Gly 85
90 95Tyr Asp Leu Phe Asp Thr Cys Ser Glu Pro Val Val
Ala Met Lys Pro 100 105 110Ser
Leu Met Phe Leu Ala Lys Ala Gly Ser Arg Asp Ile Ala Ala Tyr 115
120 125Cys Asn Tyr Thr Gln Tyr Gln Pro Arg
Val Leu Ala Val Ile Gly Pro 130 135
140His Ser Ser Glu Leu Ala Met Val Thr Gly Lys Phe Phe Ser Phe Phe145
150 155 160Leu Met Pro Gln
Val Ser Tyr Gly Ala Ser Met Glu Leu Leu Ser Ala 165
170 175Arg Glu Thr Phe Pro Ser Phe Phe Arg Thr
Val Pro Ser Asp Arg Val 180 185
190Gln Leu Thr Ala Ala Ala Glu Leu Leu Gln Glu Phe Gly Trp Asn Trp
195 200 205Val Ala Ala Leu Gly Ser Asp
Asp Glu Tyr Gly Arg Gln Gly Leu Ser 210 215
220Ile Phe Ser Ala Leu Ala Ala Ala Arg Gly Ile Cys Ile Ala His
Glu225 230 235 240Gly Leu
Val Pro Leu Pro Arg Ala Asp Asp Ser Arg Leu Gly Lys Val
245 250 255Gln Asp Val Leu His Gln Val
Asn Gln Ser Ser Val Gln Val Val Leu 260 265
270Leu Phe Ala Ser Val His Ala Ala His Ala Leu Phe Asn Tyr
Ser Ile 275 280 285Ser Ser Arg Leu
Ser Pro Lys Val Trp Val Ala Ser Glu Ala Trp Leu 290
295 300Thr Ser Asp Leu Val Met Gly Leu Pro Gly Met Ala
Gln Met Gly Thr305 310 315
320Val Leu Gly Phe Leu Gln Arg Gly Ala Gln Leu His Glu Phe Pro Gln
325 330 335Tyr Val Lys Thr His
Leu Ala Leu Ala Thr Asp Pro Ala Phe Cys Ser 340
345 350Ala Leu Gly Glu Arg Glu Gln Gly Leu Glu Glu Asp
Val Val Gly Gln 355 360 365Arg Cys
Pro Gln Cys Asp Cys Ile Thr Leu Gln Asn Val Ser Ala Gly 370
375 380Leu Asn His His Gln Thr Phe Ser Val Tyr Ala
Ala Val Tyr Ser Val385 390 395
400Ala Gln Ala Leu His Asn Thr Leu Gln Cys Asn Ala Ser Gly Cys Pro
405 410 415Ala Gln Asp Pro
Val Lys Pro Trp Gln Leu Leu Glu Asn Met Tyr Asn 420
425 430Leu Thr Phe His Val Gly Gly Leu Pro Leu Arg
Phe Asp Ser Ser Gly 435 440 445Asn
Val Asp Met Glu Tyr Asp Leu Lys Leu Trp Val Trp Gln Gly Ser 450
455 460Val Pro Arg Leu His Asp Val Gly Arg Phe
Asn Gly Ser Leu Arg Thr465 470 475
480Glu Arg Leu Lys Ile Arg Trp His Thr Ser Asp Lys Pro Val Ser
Arg 485 490 495Cys Ser Arg
Gln Cys Gln Glu Gly Gln Val Arg Arg Val Lys Gly Phe 500
505 510His Ser Cys Cys Tyr Asp Cys Val Asp Cys
Glu Ala Gly Ser Tyr Arg 515 520
525Gln Asn Pro Asp Asp Ile Ala Cys Thr Phe Cys Gly Gln Asp Glu Trp 530
535 540Ser Pro Glu Arg Ser Thr Arg Cys
Phe Arg Arg Arg Ser Arg Phe Leu545 550
555 560Ala Trp Gly Glu Pro Ala Val Leu Leu Leu Leu Leu
Leu Leu Ser Leu 565 570
575Ala Leu Gly Leu Val Leu Ala Ala Leu Gly Leu Phe Val His His Arg
580 585 590Asp Ser Pro Leu Val Gln
Ala Ser Gly Gly Pro Leu Ala Cys Phe Gly 595 600
605Leu Val Cys Leu Gly Leu Val Cys Leu Ser Val Leu Leu Phe
Pro Gly 610 615 620Gln Pro Ser Pro Ala
Arg Cys Leu Ala Gln Gln Pro Leu Ser His Leu625 630
635 640Pro Leu Thr Gly Cys Leu Ser Thr Leu Phe
Leu Gln Ala Ala Glu Ile 645 650
655Phe Val Glu Ser Glu Leu Pro Leu Ser Trp Ala Asp Arg Leu Ser Gly
660 665 670Cys Leu Arg Gly Pro
Trp Ala Trp Leu Val Val Leu Leu Ala Met Leu 675
680 685Val Glu Val Ala Leu Cys Thr Trp Tyr Leu Val Ala
Phe Pro Pro Glu 690 695 700Val Val Thr
Asp Trp His Met Leu Pro Thr Glu Ala Leu Val His Cys705
710 715 720Arg Thr Arg Ser Trp Val Ser
Phe Gly Leu Ala His Ala Thr Asn Ala 725
730 735Thr Leu Ala Phe Leu Cys Phe Leu Gly Thr Phe Leu
Val Arg Ser Gln 740 745 750Pro
Gly Arg Tyr Asn Arg Ala Arg Gly Leu Thr Phe Ala Met Leu Ala 755
760 765Tyr Phe Ile Thr Trp Val Ser Phe Val
Pro Leu Leu Ala Asn Val Gln 770 775
780Val Val Leu Arg Pro Ala Val Gln Met Gly Ala Leu Leu Leu Cys Val785
790 795 800Leu Gly Ile Leu
Ala Ala Phe His Leu Pro Arg Cys Tyr Leu Leu Met 805
810 815Arg Gln Pro Gly Leu Asn Thr Pro Glu Phe
Phe Leu Gly Gly Gly Pro 820 825
830Gly Asp Ala Gln Gly Gln Asn Asp Gly Asn Thr Gly Asn Gln Gly Lys
835 840 845His Glu 8508858PRTMus
musculus 8Met Pro Ala Leu Ala Ile Met Gly Leu Ser Leu Ala Ala Phe Leu
Glu1 5 10 15Leu Gly Met
Gly Ala Ser Leu Cys Leu Ser Gln Gln Phe Lys Ala Gln 20
25 30Gly Asp Tyr Ile Leu Gly Gly Leu Phe Pro
Leu Gly Ser Thr Glu Glu 35 40
45Ala Thr Leu Asn Gln Arg Thr Gln Pro Asn Ser Ile Pro Cys Asn Arg 50
55 60Phe Ser Pro Leu Gly Leu Phe Leu Ala
Met Ala Met Lys Met Ala Val65 70 75
80Glu Glu Ile Asn Asn Gly Ser Ala Leu Leu Pro Gly Leu Arg
Leu Gly 85 90 95Tyr Asp
Leu Phe Asp Thr Cys Ser Glu Pro Val Val Thr Met Lys Ser 100
105 110Ser Leu Met Phe Leu Ala Lys Val Gly
Ser Gln Ser Ile Ala Ala Tyr 115 120
125Cys Asn Tyr Thr Gln Tyr Gln Pro Arg Val Leu Ala Val Ile Gly Pro
130 135 140His Ser Ser Glu Leu Ala Leu
Ile Thr Gly Lys Phe Phe Ser Phe Phe145 150
155 160Leu Met Pro Gln Val Ser Tyr Ser Ala Ser Met Asp
Arg Leu Ser Asp 165 170
175Arg Glu Thr Phe Pro Ser Phe Phe Arg Thr Val Pro Ser Asp Arg Val
180 185 190Gln Leu Gln Ala Val Val
Thr Leu Leu Gln Asn Phe Ser Trp Asn Trp 195 200
205Val Ala Ala Leu Gly Ser Asp Asp Asp Tyr Gly Arg Glu Gly
Leu Ser 210 215 220Ile Phe Ser Ser Leu
Ala Asn Ala Arg Gly Ile Cys Ile Ala His Glu225 230
235 240Gly Leu Val Pro Gln His Asp Thr Ser Gly
Gln Gln Leu Gly Lys Val 245 250
255Leu Asp Val Leu Arg Gln Val Asn Gln Ser Lys Val Gln Val Val Val
260 265 270Leu Phe Ala Ser Ala
Arg Ala Val Tyr Ser Leu Phe Ser Tyr Ser Ile 275
280 285His His Gly Leu Ser Pro Lys Val Trp Val Ala Ser
Glu Ser Trp Leu 290 295 300Thr Ser Asp
Leu Val Met Thr Leu Pro Asn Ile Ala Arg Val Gly Thr305
310 315 320Val Leu Gly Phe Leu Gln Arg
Gly Ala Leu Leu Pro Glu Phe Ser His 325
330 335Tyr Val Glu Thr His Leu Ala Leu Ala Ala Asp Pro
Ala Phe Cys Ala 340 345 350Ser
Leu Asn Ala Glu Leu Asp Leu Glu Glu His Val Met Gly Gln Arg 355
360 365Cys Pro Arg Cys Asp Asp Ile Met Leu
Gln Asn Leu Ser Ser Gly Leu 370 375
380Leu Gln Asn Leu Ser Ala Gly Gln Leu His His Gln Ile Phe Ala Thr385
390 395 400Tyr Ala Ala Val
Tyr Ser Val Ala Gln Ala Leu His Asn Thr Leu Gln 405
410 415Cys Asn Val Ser His Cys His Val Ser Glu
His Val Leu Pro Trp Gln 420 425
430Leu Leu Glu Asn Met Tyr Asn Met Ser Phe His Ala Arg Asp Leu Thr
435 440 445Leu Gln Phe Asp Ala Glu Gly
Asn Val Asp Met Glu Tyr Asp Leu Lys 450 455
460Met Trp Val Trp Gln Ser Pro Thr Pro Val Leu His Thr Val Gly
Thr465 470 475 480Phe Asn
Gly Thr Leu Gln Leu Gln Gln Ser Lys Met Tyr Trp Pro Gly
485 490 495Asn Gln Val Pro Val Ser Gln
Cys Ser Arg Gln Cys Lys Asp Gly Gln 500 505
510Val Arg Arg Val Lys Gly Phe His Ser Cys Cys Tyr Asp Cys
Val Asp 515 520 525Cys Lys Ala Gly
Ser Tyr Arg Lys His Pro Asp Asp Phe Thr Cys Thr 530
535 540Pro Cys Asn Gln Asp Gln Trp Ser Pro Glu Lys Ser
Thr Ala Cys Leu545 550 555
560Pro Arg Arg Pro Lys Phe Leu Ala Trp Gly Glu Pro Val Val Leu Ser
565 570 575Leu Leu Leu Leu Leu
Cys Leu Val Leu Gly Leu Ala Leu Ala Ala Leu 580
585 590Gly Leu Ser Val His His Trp Asp Ser Pro Leu Val
Gln Ala Ser Gly 595 600 605Gly Ser
Gln Phe Cys Phe Gly Leu Ile Cys Leu Gly Leu Phe Cys Leu 610
615 620Ser Val Leu Leu Phe Pro Gly Arg Pro Ser Ser
Ala Ser Cys Leu Ala625 630 635
640Gln Gln Pro Met Ala His Leu Pro Leu Thr Gly Cys Leu Ser Thr Leu
645 650 655Phe Leu Gln Ala
Ala Glu Thr Phe Val Glu Ser Glu Leu Pro Leu Ser 660
665 670Trp Ala Asn Trp Leu Cys Ser Tyr Leu Arg Gly
Leu Trp Ala Trp Leu 675 680 685Val
Val Leu Leu Ala Thr Phe Val Glu Ala Ala Leu Cys Ala Trp Tyr 690
695 700Leu Ile Ala Phe Pro Pro Glu Val Val Thr
Asp Trp Ser Val Leu Pro705 710 715
720Thr Glu Val Leu Glu His Cys His Val Arg Ser Trp Val Ser Leu
Gly 725 730 735Leu Val His
Ile Thr Asn Ala Met Leu Ala Phe Leu Cys Phe Leu Gly 740
745 750Thr Phe Leu Val Gln Ser Gln Pro Gly Arg
Tyr Asn Arg Ala Arg Gly 755 760
765Leu Thr Phe Ala Met Leu Ala Tyr Phe Ile Thr Trp Val Ser Phe Val 770
775 780Pro Leu Leu Ala Asn Val Gln Val
Ala Tyr Gln Pro Ala Val Gln Met785 790
795 800Gly Ala Ile Leu Val Cys Ala Leu Gly Ile Leu Val
Thr Phe His Leu 805 810
815Pro Lys Cys Tyr Val Leu Leu Trp Leu Pro Lys Leu Asn Thr Gln Glu
820 825 830Phe Phe Leu Gly Arg Asn
Ala Lys Lys Ala Ala Asp Glu Asn Ser Gly 835 840
845Gly Gly Glu Ala Ala Gln Gly His Asn Glu 850
8559858PRTRattus norvegicus 9Met Pro Gly Leu Ala Ile Leu Gly Leu Ser
Leu Ala Ala Phe Leu Glu1 5 10
15Leu Gly Met Gly Ser Ser Leu Cys Leu Ser Gln Gln Phe Lys Ala Gln
20 25 30Gly Asp Tyr Ile Leu Gly
Gly Leu Phe Pro Leu Gly Thr Thr Glu Glu 35 40
45Ala Thr Leu Asn Gln Arg Thr Gln Pro Asn Gly Ile Leu Cys
Thr Arg 50 55 60Phe Ser Pro Leu Gly
Leu Phe Leu Ala Met Ala Met Lys Met Ala Val65 70
75 80Glu Glu Ile Asn Asn Gly Ser Ala Leu Leu
Pro Gly Leu Arg Leu Gly 85 90
95Tyr Asp Leu Phe Asp Thr Cys Ser Glu Pro Val Val Thr Met Lys Pro
100 105 110Ser Leu Met Phe Met
Ala Lys Val Gly Ser Gln Ser Ile Ala Ala Tyr 115
120 125Cys Asn Tyr Thr Gln Tyr Gln Pro Arg Val Leu Ala
Val Ile Gly Pro 130 135 140His Ser Ser
Glu Leu Ala Leu Ile Thr Gly Lys Phe Phe Ser Phe Phe145
150 155 160Leu Met Pro Gln Val Ser Tyr
Ser Ala Ser Met Asp Arg Leu Ser Asp 165
170 175Arg Glu Thr Phe Pro Ser Phe Phe Arg Thr Val Pro
Ser Asp Arg Val 180 185 190Gln
Leu Gln Ala Val Val Thr Leu Leu Gln Asn Phe Ser Trp Asn Trp 195
200 205Val Ala Ala Leu Gly Ser Asp Asp Asp
Tyr Gly Arg Glu Gly Leu Ser 210 215
220Ile Phe Ser Gly Leu Ala Asn Ser Arg Gly Ile Cys Ile Ala His Glu225
230 235 240Gly Leu Val Pro
Gln His Asp Thr Ser Gly Gln Gln Leu Gly Lys Val 245
250 255Val Asp Val Leu Arg Gln Val Asn Gln Ser
Lys Val Gln Val Val Val 260 265
270Leu Phe Ala Ser Ala Arg Ala Val Tyr Ser Leu Phe Ser Tyr Ser Ile
275 280 285Leu His Asp Leu Ser Pro Lys
Val Trp Val Ala Ser Glu Ser Trp Leu 290 295
300Thr Ser Asp Leu Val Met Thr Leu Pro Asn Ile Ala Arg Val Gly
Thr305 310 315 320Val Leu
Gly Phe Leu Gln Arg Gly Ala Leu Leu Pro Glu Phe Ser His
325 330 335Tyr Val Glu Thr Arg Leu Ala
Leu Ala Ala Asp Pro Thr Phe Cys Ala 340 345
350Ser Leu Lys Ala Glu Leu Asp Leu Glu Glu Arg Val Met Gly
Pro Arg 355 360 365Cys Ser Gln Cys
Asp Tyr Ile Met Leu Gln Asn Leu Ser Ser Gly Leu 370
375 380Met Gln Asn Leu Ser Ala Gly Gln Leu His His Gln
Ile Phe Ala Thr385 390 395
400Tyr Ala Ala Val Tyr Ser Val Ala Gln Ala Leu His Asn Thr Leu Gln
405 410 415Cys Asn Val Ser His
Cys His Thr Ser Glu Pro Val Gln Pro Trp Gln 420
425 430Leu Leu Glu Asn Met Tyr Asn Met Ser Phe Arg Ala
Arg Asp Leu Thr 435 440 445Leu Gln
Phe Asp Ala Lys Gly Ser Val Asp Met Glu Tyr Asp Leu Lys 450
455 460Met Trp Val Trp Gln Ser Pro Thr Pro Val Leu
His Thr Val Gly Thr465 470 475
480Phe Asn Gly Thr Leu Gln Leu Gln His Ser Lys Met Tyr Trp Pro Gly
485 490 495Asn Gln Val Pro
Val Ser Gln Cys Ser Arg Gln Cys Lys Asp Gly Gln 500
505 510Val Arg Arg Val Lys Gly Phe His Ser Cys Cys
Tyr Asp Cys Val Asp 515 520 525Cys
Lys Ala Gly Ser Tyr Arg Lys His Pro Asp Asp Phe Thr Cys Thr 530
535 540Pro Cys Gly Lys Asp Gln Trp Ser Pro Glu
Lys Ser Thr Thr Cys Leu545 550 555
560Pro Arg Arg Pro Lys Phe Leu Ala Trp Gly Glu Pro Ala Val Leu
Ser 565 570 575Leu Leu Leu
Leu Leu Cys Leu Val Leu Gly Leu Thr Leu Ala Ala Leu 580
585 590Gly Leu Phe Val His Tyr Trp Asp Ser Pro
Leu Val Gln Ala Ser Gly 595 600
605Gly Ser Leu Phe Cys Phe Gly Leu Ile Cys Leu Gly Leu Phe Cys Leu 610
615 620Ser Val Leu Leu Phe Pro Gly Arg
Pro Arg Ser Ala Ser Cys Leu Ala625 630
635 640Gln Gln Pro Met Ala His Leu Pro Leu Thr Gly Cys
Leu Ser Thr Leu 645 650
655Phe Leu Gln Ala Ala Glu Ile Phe Val Glu Ser Glu Leu Pro Leu Ser
660 665 670Trp Ala Asn Trp Leu Cys
Ser Tyr Leu Arg Gly Pro Trp Ala Trp Leu 675 680
685Val Val Leu Leu Ala Thr Leu Val Glu Ala Ala Leu Cys Ala
Trp Tyr 690 695 700Leu Met Ala Phe Pro
Pro Glu Val Val Thr Asp Trp Gln Val Leu Pro705 710
715 720Thr Glu Val Leu Glu His Cys Arg Met Arg
Ser Trp Val Ser Leu Gly 725 730
735Leu Val His Ile Thr Asn Ala Val Leu Ala Phe Leu Cys Phe Leu Gly
740 745 750Thr Phe Leu Val Gln
Ser Gln Pro Gly Arg Tyr Asn Arg Ala Arg Gly 755
760 765Leu Thr Phe Ala Met Leu Ala Tyr Phe Ile Ile Trp
Val Ser Phe Val 770 775 780Pro Leu Leu
Ala Asn Val Gln Val Ala Tyr Gln Pro Ala Val Gln Met785
790 795 800Gly Ala Ile Leu Phe Cys Ala
Leu Gly Ile Leu Ala Thr Phe His Leu 805
810 815Pro Lys Cys Tyr Val Leu Leu Trp Leu Pro Glu Leu
Asn Thr Gln Glu 820 825 830Phe
Phe Leu Gly Arg Ser Pro Lys Glu Ala Ser Asp Gly Asn Ser Gly 835
840 845Ser Ser Glu Ala Thr Arg Gly His Ser
Glu 850 855102523DNAHomo sapiens 10atgctgctct
gcacggctcg cctggtcggc ctgcagcttc tcatttcctg ctgctgggcc 60tttgcctgcc
atagcacgga gtcttctcct gacttcaccc tccccggaga ttacctcctg 120gcaggcctgt
tccctctcca ttctggctgt ctgcaggtga ggcacagacc cgaggtgacc 180ctgtgtgaca
ggtcttgtag cttcaatgag catggctacc acctcttcca ggctatgcgg 240cttggggttg
aggagataaa caactccacg gccctgctgc ccaacatcac cctggggtac 300cagctgtatg
atgtgtgttc tgactctgcc aatgtgtatg ccacgctgag agtgctctcc 360ctgccagggc
aacaccacat agagctccaa ggagaccttc tccactattc ccctacggtg 420ctggcagtga
ttgggcctga cagcaccaac cgtgctgcca ccacagccgc cctgctgagc 480cctttcctgg
tgcccatgct tattagctat gcggccagca gcgagacgct cagcgtgaag 540cggcagtatc
cctctttcct gcgcaccatc cccaatgaca agtaccaggt ggagaccatg 600gtgctgctgc
tgcagaagtt cgggtggacc tggatctctc tggttggcag cagtgacgac 660tatgggcagc
taggggtgca ggcactggag aaccaggcca ctggtcaggg gatctgcatt 720gctttcaagg
acatcatgcc cttctctgcc caggtgggcg atgagaggat gcagtgcctc 780atgcgccacc
tggcccaggc cggggccacc gtcgtggttg ttttttccag ccggcagttg 840gccagggtgt
ttttcgagtc cgtggtgctg accaacctga ctggcaaggt gtgggtcgcc 900tcagaagcct
gggccctctc caggcacatc actggggtgc ccgggatcca gcgcattggg 960atggtgctgg
gcgtggccat ccagaagagg gctgtccctg gcctgaaggc gtttgaagaa 1020gcctatgccc
gggcagacaa ggaggcccct aggccttgcc acaagggctc ctggtgcagc 1080agcaatcagc
tctgcagaga atgccaagct ttcatggcac acacgatgcc caagctcaaa 1140gccttctcca
tgagttctgc ctacaacgca taccgggctg tgtatgcggt ggcccatggc 1200ctccaccagc
tcctgggctg tgcctctgga gcttgttcca ggggccgagt ctacccctgg 1260cagttggagc
agatccacaa ggtgcatttc cttctacaca aggacactgt ggcgtttaat 1320gacaacagag
atcccctcag tagctataac ataattgcct gggactggaa tggacccaag 1380tggaccttca
cggtcctcgg ttcctccaca tggtctccag ttcagctaaa cataaatgag 1440accaaaatcc
agtggcacgg aaaggacaac caggaaccaa gtctgtgtgt tccagcgact 1500gtcttgaagg
gcaccagcga gtggttacgg gtttccatca ctgctgcttt gagtgtgtgc 1560cctgtggggg
gttcttggcc ttccctttca gacctctaca gatgccagcc ttgtgggaaa 1620gaagagtggg
cacctgaggg aagccagacc tgcttcccgc gcactgtggt gtttttggct 1680ttgcgtgagc
acacctcttg ggtgctgctg gcagctaaca cgctgctgct gctgctgctg 1740cttgggactg
ctggcctgtt tgcctggcac ctagacaccc ctgtggtgag gtcagcaggg 1800ggccgcctgt
gctttcttat gctgggctcc ctggcagcag gtagtggcag cctctatggc 1860ttctttgggg
aacccacaag gcctgcgtgc ttgctacgcc aggccctctt tgcccttggt 1920ttcaccatct
tcctgtcctg cctgacagtt cgctcattcc aactaatcat catcttcaag 1980ttttccacca
aggtacctac attctaccac gcctgggtcc aaaaccacgg tgctggcctg 2040tttgtgatga
tcagctcagc ggcccagctg cttatctgtc taacttggct ggtggtgtgg 2100accccactgc
ctgctaggga ataccagcgc ttcccccatc tggtgatgct tgagtgcaca 2160gagaccaact
ccctgggctt catactggcc ttcctctaca atggcctcct ctccatcagt 2220gcctttgcct
gcagctacct gggtaaggac ttgccagaga actacaacga ggccaaatgt 2280gtcaccttca
gcctgctctt caacttcgtg tcctggatcg ccttcttcac cacggccagc 2340gtctacgacg
gcaagtacct gcctgcggcc aacatgatgg ctgggctgag cagcctgagc 2400agcggcttcg
gtgggtattt tctgcctaag tgctacgtga tcctctgccg cccagacctc 2460aacagcacag
agcacttcca ggcctccatt caggactaca cgaggcgctg cggctccacc 2520tga
2523112520DNAHomo
sapiens 11atggggccca gggcaaagac catctgctcc ctgttcttcc tcctatgggt
cctggctgag 60ccggctgaga actcggactt ctacctgcct ggggattacc tcctgggtgg
cctcttctcc 120ctccatgcca acatgaaggg cattgttcac cttaacttcc tgcaggtgcc
catgtgcaag 180gagtatgaag tgaaggtgat aggctacaac ctcatgcagg ccatgcgctt
tgcggtggag 240gagatcaaca atgacagcag cctgctgcct ggtgtgctgc tgggctatga
gatcgtggat 300gtgtgctaca tctccaacaa tgtccagccg gtgctctact tcctggcaca
cggggacaac 360ctccttccca tccaagagga ctacagtaac tacatttccc gtgcggtggc
tgtcattggc 420cctgacaact ccgagtctgt catgactgtg gccaacttcc tctccctatt
tctccttcca 480cagatcacct acagcgccat cagcgatgag ctgcgagaca aggtgcgctt
cccggctttg 540ctgcgtacca cacccagcgc cgaccaccac atcgaggcca tggtgcagct
gatgctgcac 600ttccgctgga actggatcat tgtgctggtg agcagcgaca cctatggccg
cgacaatggc 660cagctgcttg gcgagcgcgt ggcccggcgc gacatctgca tcgccttcca
ggagacgctg 720cccacactgc agcccaacca gaacatgacg tcagaggagc gccagcgcct
ggtgaccatt 780gtggacaagc tgcagcagag cacagcgcgc gtcgtggtcg tgttctcgcc
cgacctgacc 840ctgtaccact tcttcaatga ggtgctgcgc cagaacttca ctggcgccgt
gtggatcgcc 900tccgagtcct gggccatcga cccggtcctg cacaacctca cggagctgcg
ccacttgggc 960accttcctgg gcatcaccat ccagagcgtg cccatcccgg gcttcagtga
gttccgcgag 1020tggggcccac aggctgggcc gccacccctc agcaggacca gccagagcta
tacctgcaac 1080caggagtgcg acaactgcct gaacgccacc ttgtccttca acaccattct
caggctctct 1140ggggagcgtg tcgtctacag cgtgtactct gcggtctatg ctgtggccca
tgccctgcac 1200agcctcctcg gctgtgacaa aagcacctgc accaagaggg tggtctaccc
ctggcagctg 1260cttgaggaga tctggaaggt caacttcact ctcctggacc accaaatctt
cttcgacccg 1320caaggggacg tggctctgca cttggagatt gtccagtggc aatgggaccg
gagccagaat 1380cccttccaga gcgtcgcctc ctactacccc ctgcagcgac agctgaagaa
catccaagac 1440atctcctggc acaccatcaa caacacgatc cctatgtcca tgtgttccaa
gaggtgccag 1500tcagggcaaa agaagaagcc tgtgggcatc cacgtctgct gcttcgagtg
catcgactgc 1560cttcccggca ccttcctcaa ccacactgaa gatgaatatg aatgccaggc
ctgcccgaat 1620aacgagtggt cctaccagag tgagacctcc tgcttcaagc ggcagctggt
cttcctggaa 1680tggcatgagg cacccaccat cgctgtggcc ctgctggccg ccctgggctt
cctcagcacc 1740ctggccatcc tggtgatatt ctggaggcac ttccagacac ccatagttcg
ctcggctggg 1800ggccccatgt gcttcctgat gctgacactg ctgctggtgg catacatggt
ggtcccggtg 1860tacgtggggc cgcccaaggt ctccacctgc ctctgccgcc aggccctctt
tcccctctgc 1920ttcacaatct gcatctcctg tatcgccgtg cgttctttcc agatcgtctg
cgccttcaag 1980atggccagcc gcttcccacg cgcctacagc tactgggtcc gctaccaggg
gccctacgtc 2040tctatggcat ttatcacggt actcaaaatg gtcattgtgg taattggcat
gctggccacg 2100ggcctcagtc ccaccacccg tactgacccc gatgacccca agatcacaat
tgtctcctgt 2160aaccccaact accgcaacag cctgctgttc aacaccagcc tggacctgct
gctctcagtg 2220gtgggtttca gcttcgccta catgggcaaa gagctgccca ccaactacaa
cgaggccaag 2280ttcatcaccc tcagcatgac cttctatttc acctcatccg tctccctctg
caccttcatg 2340tctgcctaca gcggggtgct ggtcaccatc gtggacctct tggtcactgt
gctcaacctc 2400ctggccatca gcctgggcta cttcggcccc aagtgctaca tgatcctctt
ctacccggag 2460cgcaacacgc ccgcctactt caacagcatg atccagggct acaccatgag
gagggactag 2520122553DNAHomo sapiens 12atgctgggcc ctgctgtcct gggcctcagc
ctctgggctc tcctgcaccc tgggacgggg 60gccccattgt gcctgtcaca gcaacttagg
atgaaggggg actacgtgct gggggggctg 120ttccccctgg gcgaggccga ggaggctggc
ctccgcagcc ggacacggcc cagcagccct 180gtgtgcacca ggttctcctc aaacggcctg
ctctgggcac tggccatgaa aatggccgtg 240gaggagatca acaacaagtc ggatctgctg
cccgggctgc gcctgggcta cgacctcttt 300gatacgtgct cggagcctgt ggtggccatg
aagcccagcc tcatgttcct ggccaaggca 360ggcagccgcg acatcgccgc ctactgcaac
tacacgcagt accagccccg tgtgctggct 420gtcatcgggc cccactcgtc agagctcgcc
atggtcaccg gcaagttctt cagcttcttc 480ctcatgcccc aggtcagcta cggtgctagc
atggagctgc tgagcgcccg ggagaccttc 540ccctccttct tccgcaccgt gcccagcgac
cgtgtgcagc tgacggccgc cgcggagctg 600ctgcaggagt tcggctggaa ctgggtggcc
gccctgggca gcgacgacga gtacggccgg 660cagggcctga gcatcttctc ggccctggcc
gcggcacgcg gcatctgcat cgcgcacgag 720ggcctggtgc cgctgccccg tgccgatgac
tcgcggctgg ggaaggtgca ggacgtcctg 780caccaggtga accagagcag cgtgcaggtg
gtgctgctgt tcgcctccgt gcacgccgcc 840cacgccctct tcaactacag catcagcagc
aggctctcgc ccaaggtgtg ggtggccagc 900gaggcctggc tgacctctga cctggtcatg
gggctgcccg gcatggccca gatgggcacg 960gtgcttggct tcctccagag gggtgcccag
ctgcacgagt tcccccagta cgtgaagacg 1020cacctggccc tggccaccga cccggccttc
tgctctgccc tgggcgagag ggagcagggt 1080ctggaggagg acgtggtggg ccagcgctgc
ccgcagtgtg actgcatcac gctgcagaac 1140gtgagcgcag ggctaaatca ccaccagacg
ttctctgtct acgcagctgt gtatagcgtg 1200gcccaggccc tgcacaacac tcttcagtgc
aacgcctcag gctgccccgc gcaggacccc 1260gtgaagccct ggcagctcct ggagaacatg
tacaacctga ccttccacgt gggcgggctg 1320ccgctgcggt tcgacagcag cggaaacgtg
gacatggagt acgacctgaa gctgtgggtg 1380tggcagggct cagtgcccag gctccacgac
gtgggcaggt tcaacggcag cctcaggaca 1440gagcgcctga agatccgctg gcacacgtct
gacaagcccg tgtcccggtg ctcgcggcag 1500tgccaggagg gccaggtgcg ccgggtcaag
gggttccact cctgctgcta cgactgtgtg 1560gactgcgagg cgggcagcta ccggcaaaac
ccagacgaca tcgcctgcac cttttgtggc 1620caggatgagt ggtccccgga gcgaagcaca
cgctgcttcc gccgcaggtc tcggttcctg 1680gcatggggcg agccggctgt gctgctgctg
ctcctgctgc tgagcctggc gctgggcctt 1740gtgctggctg ctttggggct gttcgttcac
catcgggaca gcccactggt tcaggcctcg 1800ggggggcccc tggcctgctt tggcctggtg
tgcctgggcc tggtctgcct cagcgtcctc 1860ctgttccctg gccagcccag ccctgcccga
tgcctggccc agcagccctt gtcccacctc 1920ccgctcacgg gctgcctgag cacactcttc
ctgcaggcgg ccgagatctt cgtggagtca 1980gaactgcctc tgagctgggc agaccggctg
agtggctgcc tgcgggggcc ctgggcctgg 2040ctggtggtgc tgctggccat gctggtggag
gtcgcactgt gcacctggta cctggtggcc 2100ttcccgccgg aggtggtgac ggactggcac
atgctgccca cggaggcgct ggtgcactgc 2160cgcacacgct cctgggtcag cttcggccta
gcgcacgcca ccaatgccac gctggccttt 2220ctctgcttcc tgggcacttt cctggtgcgg
agccagccgg gccgctacaa ccgtgcccgt 2280ggcctcacct ttgccatgct ggcctacttc
atcacctggg tctcctttgt gcccctcctg 2340gccaatgtgc aggtggtcct caggcccgcc
gtgcagatgg gcgccctcct gctctgtgtc 2400ctgggcatcc tggctgcctt ccacctgccc
aggtgttacc tgctcatgcg gcagccaggg 2460ctcaacaccc ccgagttctt cctgggaggg
ggccctgggg atgcccaagg ccagaatgac 2520gggaacacag gaaatcaggg gaaacatgag
tga 2553132529DNAMus musculus 13atgcttttct
gggcagctca cctgctgctc agcctgcagc tggccgttgc ttactgctgg 60gctttcagct
gccaaaggac agaatcctct ccaggtttca gcctccctgg ggacttcctc 120ctggcaggcc
tgttctccct ccatgctgac tgtctgcagg tgagacacag acctctggtg 180acaagttgtg
acaggtctga cagcttcaac ggccatggct atcacctctt ccaagccatg 240cggttcaccg
ttgaggagat aaacaactcc acagctctgc ttcccaacat caccctgggg 300tatgaactgt
atgacgtgtg ctcagagtct tccaatgtct atgccaccct gagggtgccc 360gcccagcaag
ggacaggcca cctagagatg cagagagatc ttcgcaacca ctcctccaag 420gtggtggcac
tcattgggcc tgataacact gaccacgctg tcaccactgc tgccctgctg 480agcccttttc
tgatgcccct ggtcagctat gaggcgagca gcgtgatcct cagtgggaag 540cgcaagttcc
cgtccttctt gcgcaccatc cccagcgata agtaccaggt ggaagtcata 600gtgcggctgc
tgcagagctt cggctgggtc tggatctcgc tcgttggcag ctatggtgac 660tacgggcagc
tgggcgtaca ggcgctggag gagctggcca ctccacgggg catctgcgtc 720gccttcaagg
acgtggtgcc tctctccgcc caggcgggtg acccaaggat gcagcgcatg 780atgctgcgtc
tggctcgagc caggaccacc gtggtcgtgg tcttctctaa ccggcacctg 840gctggagtgt
tcttcaggtc tgtggtgctg gccaacctga ctggcaaagt gtggatcgcc 900tccgaagact
gggccatctc cacgtacatc accaatgtgc ccgggatcca gggcattggg 960acggtgctgg
gggtggccat ccagcagaga caagtccctg gcctgaagga gtttgaagag 1020tcctatgtcc
aggcagtgat gggtgctccc agaacttgcc cagaggggtc ctggtgcggc 1080actaaccagc
tgtgcaggga gtgtcacgct ttcacgacat ggaacatgcc cgagcttgga 1140gccttctcca
tgagcgctgc ctacaatgtg tatgaggctg tgtatgctgt ggcccacggc 1200ctccaccagc
tcctgggatg tacctctggg acctgtgcca gaggcccagt ctacccctgg 1260cagcttcttc
agcagatcta caaggtgaat ttccttctac ataagaagac tgtagcattc 1320gatgacaagg
gggaccctct aggttattat gacatcatcg cctgggactg gaatggacct 1380gaatggacct
ttgaggtcat tggttctgcc tcactgtctc cagttcatct agacataaat 1440aagacaaaaa
tccagtggca cgggaagaac aatcaggtgc ctgtgtcagt gtgtaccagg 1500gactgtctcg
aagggcacca caggttggtc atgggttccc accactgctg cttcgagtgc 1560atgccctgtg
aagctgggac atttctcaac acgagtgagc ttcacacctg ccagccttgt 1620ggaacagaag
aatgggcccc tgaggggagc tcagcctgct tctcacgcac cgtggagttc 1680ttggggtggc
atgaacccat ctctttggtg ctattagcag ctaacacgct attgctgctg 1740ctgctgattg
ggactgctgg cctgtttgcc tggcgtcttc acacgcctgt tgtgaggtca 1800gctgggggta
ggctgtgctt cctcatgctg ggttccttgg tagctgggag ttgcagcctc 1860tacagcttct
tcgggaagcc cacggtgccc gcgtgcttgc tgcgtcagcc cctcttttct 1920ctcgggtttg
ccattttcct ctcctgtctg acaatccgct ccttccaact ggtcatcatc 1980ttcaagtttt
ctaccaaggt acccacattc taccacactt gggcccaaaa ccatggtgcc 2040ggaatattcg
tcattgtcag ctccacggtc catttgttcc tctgtctcac gtggcttgca 2100atgtggaccc
cacggcccac cagggagtac cagcgcttcc cccatctggt gattcttgag 2160tgcacagagg
tcaactctgt gggcttcctg gtggctttcg cacacaacat cctcctctcc 2220atcagcacct
ttgtctgcag ctacctgggt aaggaactgc cggagaacta taacgaagcc 2280aaatgtgtca
ccttcagcct gctcctccac ttcgtatcct ggatcgcttt cttcaccatg 2340tccagcattt
accagggcag ctacctaccc gcggtcaatg tgctggcagg gctggccact 2400ctgagtggcg
gcttcagcgg ctatttcctc cctaaatgct acgtgattct ctgccgtcca 2460gaactcaaca
acacagaaca ctttcaggcc tccatccagg actacacgag gcgctgcggc 2520actacctga
2529141986DNAMus
musculus 14atgctgcgca ctgtgcccag cgccacccac cacatcgagg ccatggtgca
actgatggtt 60cacttccagt ggaactggat cgtggtgctg gtgagcgatg acgattatgg
ccgagagaac 120agccacctgc tgagccagcg tctgaccaac actggcgata tctgcattgc
cttccaggag 180gttctgcctg taccagaacc caaccaggcc gtgaggcctg aggagcagga
ccaactggac 240aacatcctgg acaagctgcg gcggacctcg gcgcgtgtgg tggtgatatt
ctcgccagag 300ctgagcctgc acaacttctt ccgcgaggtg ctgcgctgga acttcacagg
ctttgtgtgg 360attgcctctg agtcctgggc catcgaccct gttctacaca acctcacaga
gctgcgccac 420acgggcactt tcctgggcgt caccatccag agggtgtcca tccctggctt
cagccagttc 480cgagtgcgcc acgacaagcc agagtatccc atgcctaacg agaccagcct
gaggactacc 540tgtaaccagg actgtgacgc ctgcatgaac atcaccgagt cctttaacaa
cgttctcatg 600ctttcggggg agcgtgtggt ctacagtgtg tactcggccg tctacgcggt
agcccacacc 660ctccacagac tcctccactg caaccaggtc cgctgcacca agcaaatcgt
ctatccatgg 720cagctactca gggagatctg gcatgtcaac ttcacgctcc tgggcaacca
gctcttcttc 780gacgaacaag gggacatgcc gatgctcctg gacatcatcc agtggcaatg
gggcctgagc 840cagaacccct tccaaagcat cgcctcctac tcccccaccg agacgaggct
gacctacatt 900agcaatgtgt cctggtacac ccccaacaac acggtcccca tatccatgtg
ttctaagagt 960tgccagcctg ggcaaatgaa aaaacccata ggcctccacc cgtgctgctt
cgagtgtgtg 1020gactgtccgc cgggcaccta cctcaaccga tcagtagatg agtttaactg
tctgtcctgc 1080ccgggttcca tgtggtctta caagaacaac atcgcttgct tcaagcggcg
gctggccttc 1140ctggagtggc acgaagtgcc cactatcgtg gtgaccatcc tggccgccct
gggcttcatc 1200agtacgctgg ccattctgct catcttctgg agacatttcc agacgcccat
ggtgcgctcg 1260gcgggcggcc ccatgtgctt cctgatgctg gtgcccctgc tgctggcgtt
cgggatggtc 1320cccgtgtatg tgggcccccc cacggtcttc tcctgtttct gccgccaggc
tttcttcacc 1380gtttgcttct ccgtctgcct ctcctgcatc acggtgcgct ccttccagat
tgtgtgcgtc 1440ttcaagatgg ccagacgcct gccaagcgcc tacggtttct ggatgcgtta
ccacgggccc 1500tacgtctttg tggccttcat cacggccgtc aaggtggccc tggtggcagg
caacatgctg 1560gccaccacca tcaaccccat tggccggacc gaccccgatg accccaatat
cataatcctc 1620tcctgccacc ctaactaccg caacgggcta ctcttcaaca ccagcatgga
cttgctgctg 1680tccgtgctgg gtttcagctt cgcgtacgtg ggcaaggaac tgcccaccaa
ctacaacgaa 1740gccaagttca tcaccctcag catgaccttc tccttcacct cctccatctc
cctctgcacg 1800ttcatgtctg tccacgatgg cgtgctggtc accatcatgg atctcctggt
cactgtgctc 1860aactttctgg ccatcggctt ggggtacttt ggccccaagt gttacatgat
ccttttctac 1920ccggagcgca acacttcagc ttatttcaat agcatgattc agggctacac
gatgaggaag 1980agctag
1986152577DNAMus musculus 15atgccagctt tggctatcat gggtctcagc
ctggctgctt tcctggagct tgggatgggg 60gcctctttgt gtctgtcaca gcaattcaag
gcacaagggg actacatact gggcgggcta 120tttcccctgg gctcaaccga ggaggccact
ctcaaccaga gaacacaacc caacagcatc 180ccgtgcaaca ggttctcacc ccttggtttg
ttcctggcca tggctatgaa gatggctgtg 240gaggagatca acaatggatc tgccttgctc
cctgggctgc ggctgggcta tgacctattt 300gacacatgct ccgagccagt ggtcaccatg
aaatccagtc tcatgttcct ggccaaggtg 360ggcagtcaaa gcattgctgc ctactgcaac
tacacacagt accaaccccg tgtgctggct 420gtcatcggcc cccactcatc agagcttgcc
ctcattacag gcaagttctt cagcttcttc 480ctcatgccac aggtcagcta tagtgccagc
atggatcggc taagtgaccg ggaaacgttt 540ccatccttct tccgcacagt gcccagtgac
cgggtgcagc tgcaggcagt tgtgactctg 600ttgcagaact tcagctggaa ctgggtggcc
gccttaggga gtgatgatga ctatggccgg 660gaaggtctga gcatcttttc tagtctggcc
aatgcacgag gtatctgcat cgcacatgag 720ggcctggtgc cacaacatga cactagtggc
caacagttgg gcaaggtgct ggatgtacta 780cgccaagtga accaaagtaa agtacaagtg
gtggtgctgt ttgcctctgc ccgtgctgtc 840tactcccttt ttagttacag catccatcat
ggcctctcac ccaaggtatg ggtggccagt 900gagtcttggc tgacatctga cctggtcatg
acacttccca atattgcccg tgtgggcact 960gtgcttgggt ttttgcagcg gggtgcccta
ctgcctgaat tttcccatta tgtggagact 1020caccttgccc tggccgctga cccagcattc
tgtgcctcac tgaatgcgga gttggatctg 1080gaggaacatg tgatggggca acgctgtcca
cggtgtgacg acatcatgct gcagaaccta 1140tcatctgggc tgttgcagaa cctatcagct
gggcaattgc accaccaaat atttgcaacc 1200tatgcagctg tgtacagtgt ggctcaagcc
cttcacaaca ccctacagtg caatgtctca 1260cattgccacg tatcagaaca tgttctaccc
tggcagctcc tggagaacat gtacaatatg 1320agtttccatg ctcgagactt gacactacag
tttgatgctg aagggaatgt agacatggaa 1380tatgacctga agatgtgggt gtggcagagc
cctacacctg tattacatac tgtgggcacc 1440ttcaacggca cccttcagct gcagcagtct
aaaatgtact ggccaggcaa ccaggtgcca 1500gtctcccagt gttcccgcca gtgcaaagat
ggccaggttc gccgagtaaa gggctttcat 1560tcctgctgct atgactgcgt ggactgcaag
gcgggcagct accggaagca tccagatgac 1620ttcacctgta ctccatgtaa ccaggaccag
tggtccccag agaaaagcac agcctgctta 1680cctcgcaggc ccaagtttct ggcttggggg
gagccagttg tgctgtcact cctcctgctg 1740ctttgcctgg tgctgggtct agcactggct
gctctggggc tctctgtcca ccactgggac 1800agccctcttg tccaggcctc aggtggctca
cagttctgct ttggcctgat ctgcctaggc 1860ctcttctgcc tcagtgtcct tctgttccca
gggcggccaa gctctgccag ctgccttgca 1920caacaaccaa tggctcacct ccctctcaca
ggctgcctga gcacactctt cctgcaagca 1980gctgagacct ttgtggagtc tgagctgcca
ctgagctggg caaactggct atgcagctac 2040cttcggggac tctgggcctg gctagtggta
ctgttggcca cttttgtgga ggcagcacta 2100tgtgcctggt atttgatcgc tttcccacca
gaggtggtga cagactggtc agtgctgccc 2160acagaggtac tggagcactg ccacgtgcgt
tcctgggtca gcctgggctt ggtgcacatc 2220accaatgcaa tgttagcttt cctctgcttt
ctgggcactt tcctggtaca gagccagcct 2280ggccgctaca accgtgcccg tggtctcacc
ttcgccatgc tagcttattt catcacctgg 2340gtctcttttg tgcccctcct ggccaatgtg
caggtggcct accagccagc tgtgcagatg 2400ggtgctatcc tagtctgtgc cctgggcatc
ctggtcacct tccacctgcc caagtgctat 2460gtgcttcttt ggctgccaaa gctcaacacc
caggagttct tcctgggaag gaatgccaag 2520aaagcagcag atgagaacag tggcggtggt
gaggcagctc agggacacaa tgaatga 2577162523DNARattus norvegicus
16atgctcttct gggctgctca cctgctgctc agcctgcagt tggtctactg ctgggctttc
60agctgccaaa ggacagagtc ctctccaggc ttcagccttc ctggggactt cctccttgca
120ggtctgttct ccctccatgg tgactgtctg caggtgagac acagacctct ggtgacaagt
180tgtgacaggc ccgacagctt caacggccat ggctaccacc tcttccaagc catgcggttc
240actgttgagg agataaacaa ctcctcggcc ctgcttccca acatcaccct ggggtatgag
300ctgtacgacg tgtgctcaga atctgccaat gtgtatgcca ccctgagggt gcttgccctg
360caagggcccc gccacataga gatacagaaa gaccttcgca accactcctc caaggtggtg
420gccttcatcg ggcctgacaa cactgaccac gctgtcacta ccgctgcctt gctgggtcct
480ttcctgatgc ccctggtcag ctatgaggca agcagcgtgg tactcagtgc caagcgcaag
540ttcccgtctt tccttcgtac cgtccccagt gaccggcacc aggtggaggt catggtgcag
600ctgctgcaga gttttgggtg ggtgtggatc tcgctcattg gcagctacgg tgattacggg
660cagctgggtg tgcaggcgct ggaggagctg gccgtgcccc ggggcatctg cgtcgccttc
720aaggacatcg tgcctttctc tgcccgggtg ggtgacccga ggatgcagag catgatgcag
780catctggctc aggccaggac caccgtggtt gtggtcttct ctaaccggca cctggctaga
840gtgttcttca ggtccgtggt gctggccaac ctgactggca aagtgtgggt cgcctcagaa
900gactgggcca tctccacgta catcaccagc gtgactggga tccaaggcat tgggacggtg
960ctcggtgtgg ccgtccagca gagacaagtc cctgggctga aggagtttga ggagtcttat
1020gtcagggctg taacagctgc tcccagcgct tgcccggagg ggtcctggtg cagcactaac
1080cagctgtgcc gggagtgcca cacgttcacg actcgtaaca tgcccacgct tggagccttc
1140tccatgagtg ccgcctacag agtgtatgag gctgtgtacg ctgtggccca cggcctccac
1200cagctcctgg gatgtacttc tgagatctgt tccagaggcc cagtctaccc ctggcagctt
1260cttcagcaga tctacaaggt gaattttctt ctacatgaga atactgtggc atttgatgac
1320aacggggaca ctctaggtta ctacgacatc atcgcctggg actggaatgg acctgaatgg
1380acctttgaga tcattggctc tgcctcactg tctccagttc atctggacat aaataagaca
1440aaaatccagt ggcacgggaa gaacaatcag gtgcctgtgt cagtgtgtac cacggactgt
1500ctggcagggc accacagggt ggttgtgggt tcccaccact gctgctttga gtgtgtgccc
1560tgcgaagctg ggacctttct caacatgagt gagcttcaca tctgccagcc ttgtggaaca
1620gaagaatggg cacccaagga gagcactact tgcttcccac gcacggtgga gttcttggct
1680tggcatgaac ccatctcttt ggtgctaata gcagctaaca cgctattgct gctgctgctg
1740gttgggactg ctggcctgtt tgcctggcat tttcacacac ctgtagtgag gtcagctggg
1800ggtaggctgt gcttcctcat gctgggttcc ctggtggccg gaagttgcag cttctatagc
1860ttcttcgggg agcccacggt gcccgcgtgc ttgctgcgtc agcccctctt ttctctcggg
1920tttgccatct tcctctcctg cctgacaatc cgctccttcc aactggtcat catcttcaag
1980ttttctacca aggtgcccac attctaccgt acctgggccc aaaaccatgg tgcaggtcta
2040ttcgtcattg tcagctccac ggtccatttg ctcatctgtc tcacatggct tgtaatgtgg
2100accccacgac ccaccaggga ataccagcgc ttcccccatc tggtgattct cgagtgcaca
2160gaggtcaact ctgtaggctt cctgttggct ttcacccaca acattctcct ctccatcagt
2220accttcgtct gcagctacct gggtaaggaa ctgccagaga actataatga agccaaatgt
2280gtcaccttca gcctgctcct caacttcgta tcctggatcg ccttcttcac catggccagc
2340atttaccagg gcagctacct gcctgcggtc aatgtgctgg cagggctgac cacactgagc
2400ggcggcttca gcggttactt cctccccaag tgctatgtga ttctctgccg tccagaactc
2460aacaatacag aacactttca ggcctccatc caggactaca cgaggcgctg cggcactacc
2520tga
2523172529DNARattus norvegicus 17atgggtcccc aggcaaggac actctgcttg
ctgtctctcc tgctgcatgt tctgcctaag 60ccaggcaagc tggtagagaa ctctgacttc
cacctggccg gggactacct cctgggtggc 120ctctttaccc tccatgccaa cgtgaagagc
atctcccacc tcagctacct gcaggtgccc 180aagtgcaatg agttcaccat gaaggtgttg
ggctacaacc tcatgcaggc catgcgtttc 240gctgtggagg agatcaacaa ctgtagctcc
ctgctacccg gcgtgctgct cggctacgag 300atggtggatg tctgttacct ctccaacaat
atccaccctg ggctctactt cctggcacag 360gacgacgacc tcctgcccat cctcaaagac
tacagccagt acatgcccca cgtggtggct 420gtcattggcc ccgacaactc tgagtccgcc
attaccgtgt ccaacattct ctctcatttc 480ctcatcccac agatcacata cagcgccatc
tccgacaagc tgcgggacaa gcggcacttc 540cctagcatgc tacgcacagt gcccagcgcc
acccaccaca tcgaggccat ggtgcagctg 600atggttcact tccaatggaa ctggattgtg
gtgctggtga gcgacgacga ttacggccgc 660gagaacagcc acctgttgag ccagcgtctg
accaaaacga gcgacatctg cattgccttc 720caggaggttc tgcccatacc tgagtccagc
caggtcatga ggtccgagga gcagagacaa 780ctggacaaca tcctggacaa gctgcggcgg
acctcggcgc gcgtcgtggt ggtgttctcg 840cccgagctga gcctgtatag cttctttcac
gaggtgctcc gctggaactt cacgggtttt 900gtgtggatcg cctctgagtc ctgggctatc
gacccagttc tgcataacct cacggagctg 960cgccacacgg gtacttttct gggcgtcacc
atccagaggg tgtccatccc tggcttcagt 1020cagttccgag tgcgccgtga caagccaggg
tatcccgtgc ctaacacgac caacctgcgg 1080acgacctgca accaggactg tgacgcctgc
ttgaacacca ccaagtcctt caacaacatc 1140cttatacttt cgggggagcg cgtggtctac
agcgtgtact cggcagttta cgcggtggcc 1200catgccctcc acagactcct cggctgtaac
cgggtccgct gcaccaagca aaaggtctac 1260ccgtggcagc tactcaggga gatctggcac
gtcaacttca cgctcctggg taaccggctc 1320ttctttgacc aacaagggga catgccgatg
ctcttggaca tcatccagtg gcagtgggac 1380ctgagccaga atcccttcca aagcatcgcc
tcctattctc ccaccagcaa gaggctaacc 1440tacattaaca atgtgtcctg gtacaccccc
aacaacacgg tccctgtctc catgtgttcc 1500aagagctgcc agccagggca aatgaaaaag
tctgtgggcc tccacccttg ttgcttcgag 1560tgcttggatt gtatgccagg cacctacctc
aaccgctcag cagatgagtt taactgtctg 1620tcctgcccgg gttccatgtg gtcctacaag
aacgacatca cttgcttcca gcggcggcct 1680accttcctgg agtggcacga agtgcccacc
atcgtggtgg ccatactggc tgccctgggc 1740ttcttcagta cactggccat tcttttcatc
ttctggagac atttccagac acccatggtg 1800cgctcggccg gtggccccat gtgcttcctg
atgctcgtgc ccctgctgct ggcgtttggg 1860atggtgcccg tgtatgtggg gccccccacg
gtcttctcat gcttctgccg acaggctttc 1920ttcaccgtct gcttctccat ctgcctatcc
tgcatcaccg tgcgctcctt ccagatcgtg 1980tgtgtcttca agatggccag acgcctgcca
agtgcctaca gtttttggat gcgttaccac 2040gggccctatg tcttcgtggc cttcatcacg
gccatcaagg tggccctggt ggtgggcaac 2100atgctggcca ccaccatcaa ccccattggc
cggaccgacc cggatgaccc caacatcatg 2160atcctctcgt gccaccctaa ctaccgcaac
gggctactgt tcaacaccag catggacttg 2220ctgctgtctg tgctgggttt cagcttcgct
tacatgggca aggagctgcc caccaactac 2280aacgaagcca agttcatcac tctcagcatg
accttctcct tcacctcctc catctccctc 2340tgcaccttca tgtctgtgca cgacggcgtg
ctggtcacca tcatggacct cctggtcact 2400gtgctcaact tcctggccat cggcttggga
tactttggcc ccaagtgtta catgatcctt 2460ttctacccgg agcgcaacac ctcagcctat
ttcaatagca tgatccaggg ctacaccatg 2520aggaagagc
2529182577DNARattus norvegicus
18atgccgggtt tggctatctt gggcctcagt ctggctgctt tcctggagct tgggatgggg
60tcctctttgt gtctgtcaca gcaattcaag gcacaagggg actatatatt gggtggacta
120tttcccctgg gcacaactga ggaggccact ctcaaccaga gaacacagcc caacggcatc
180ctatgtacca ggttctcgcc ccttggtttg ttcctggcca tggctatgaa gatggctgta
240gaggagatca acaatggatc tgccttgctc cctgggctgc gactgggcta tgacctgttt
300gacacatgct cagagccagt ggtcaccatg aagcccagcc tcatgttcat ggccaaggtg
360ggaagtcaaa gcattgctgc ctactgcaac tacacacagt accaaccccg tgtgctggct
420gtcattggtc cccactcatc agagcttgcc ctcattacag gcaagttctt cagcttcttc
480ctcatgccac aggtcagcta tagtgccagc atggatcggc taagtgaccg ggaaacattt
540ccatccttct tccgcacagt gcccagtgac cgggtgcagc tgcaggccgt tgtgacactg
600ttgcagaatt tcagctggaa ctgggtggct gccttaggta gtgatgatga ctatggccgg
660gaaggtctga gcatcttttc tggtctggcc aactcacgag gtatctgcat tgcacacgag
720ggcctggtgc cacaacatga cactagtggc caacaattgg gcaaggtggt ggatgtgcta
780cgccaagtga accaaagcaa agtacaggtg gtggtgctgt ttgcatctgc ccgtgctgtc
840tactcccttt ttagctacag catccttcat gacctctcac ccaaggtatg ggtggccagt
900gagtcctggc tgacctctga cctggtcatg acacttccca atattgcccg tgtgggcact
960gttcttgggt ttctgcagcg cggtgcccta ctgcctgaat tttcccatta tgtggagact
1020cgccttgccc tagctgctga cccaacattc tgtgcctccc tgaaagctga gttggatctg
1080gaggagcgcg tgatggggcc acgctgttca caatgtgact acatcatgct acagaacctg
1140tcatctgggc tgatgcagaa cctatcagct gggcagttgc accaccaaat atttgcaacc
1200tatgcagctg tgtacagtgt ggctcaggcc cttcacaaca ccctgcagtg caatgtctca
1260cattgccaca catcagagcc tgttcaaccc tggcagctcc tggagaacat gtacaatatg
1320agtttccgtg ctcgagactt gacactgcag tttgatgcca aagggagtgt agacatggaa
1380tatgacctga agatgtgggt gtggcagagc cctacacctg tactacatac tgtaggcacc
1440ttcaacggca cccttcagct gcagcactcg aaaatgtatt ggccaggcaa ccaggtgcca
1500gtctcccagt gctcccggca gtgcaaagat ggccaggtgc gcagagtaaa gggctttcat
1560tcctgctgct atgactgtgt ggactgcaag gcagggagct accggaagca tccagatgac
1620ttcacctgta ctccatgtgg caaggatcag tggtccccag aaaaaagcac aacctgctta
1680cctcgcaggc ccaagtttct ggcttggggg gagccagctg tgctgtcact tctcctgctg
1740ctttgcctgg tgctgggcct gacactggct gccctggggc tctttgtcca ctactgggac
1800agccctcttg ttcaggcctc aggtgggtca ctgttctgct ttggcctgat ctgcctaggc
1860ctcttctgcc tcagtgtcct tctgttccca ggacgaccac gctctgccag ctgccttgcc
1920caacaaccaa tggctcacct ccctctcaca ggctgcctga gcacactctt cctgcaagca
1980gccgagatct ttgtggagtc tgagctgcca ctgagttggg caaactggct ctgcagctac
2040cttcggggcc cctgggcttg gctggtggta ctgctggcca ctcttgtgga ggctgcacta
2100tgtgcctggt acttgatggc tttccctcca gaggtggtga cagattggca ggtgctgccc
2160acggaggtac tggaacactg ccgcatgcgt tcctgggtca gcctgggctt ggtgcacatc
2220accaatgcag tgttagcttt cctctgcttt ctgggcactt tcctggtaca gagccagcct
2280ggtcgctata accgtgcccg tggcctcacc ttcgccatgc tagcttattt catcatctgg
2340gtctcttttg tgcccctcct ggctaatgtg caggtggcct accagccagc tgtgcagatg
2400ggtgctatct tattctgtgc cctgggcatc ctggccacct tccacctgcc caaatgctat
2460gtacttctgt ggctgccaga gctcaacacc caggagttct tcctgggaag gagccccaag
2520gaagcatcag atgggaatag tggtagtagt gaggcaactc ggggacacag tgaatga
25771918DNAartificialexample of silent variation of nucleotides 1-18
of SEQ ID NO10 19atgttattgt gtaccgcc
18205PRTartificialexample of conservative substitution of
amino acids 5-10 of hT1R1 20Ser Thr Lys Met Met1
5215PRTartificialexample of conservative substitution of amino
acids 5-10 of hT1R1 21Thr Ser Lys Val Ile1
52231DNAArtificialsynthetic oligonucleotide used to obtain 5' end of
hT1R2 22cgcagcaaag ccgggaagcg caccttgtct c
31
User Contributions:
comments("1"); ?> comment_form("1"); ?>Inventors list |
Agents list |
Assignees list |
List by place |
Classification tree browser |
Top 100 Inventors |
Top 100 Agents |
Top 100 Assignees |
Usenet FAQ Index |
Documents |
Other FAQs |
User Contributions:
Comment about this patent or add new information about this topic:
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
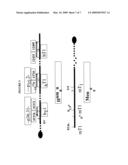 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
| Similar patent applications: | |
| Date | Title |
|---|---|
| 2013-05-09 | Selective androgen receptor modulators |
| 2013-04-25 | Selective sigma-1 receptor ligands |
| 2009-11-12 | Soluble heterodimeric receptors and uses thereof |
| 2012-10-04 | Human single-chain t cell receptors |
| 2013-05-16 | Use of fts and analogs to treat non-autoimmune-allergic and non-allergic inflammatory conditions |
| New patent applications in this class: | |
| Date | Title |
|---|---|
| 2009-12-10 | Compounds and methods for modulating expression of pcsk9 |
| 2009-12-03 | Dsrna as insect control agent |
| 2009-11-26 | Oligomeric compounds and compositions for use in modulation of small non-coding rnas |
| 2009-11-26 | Oligomeric compounds and compositions for use in modulation of small non-coding rnas |
| 2009-11-19 | Novel oligonucleotide compositions and probe sequences useful for detection and analysis of micrornas and their target mrnas |
| New patent applications from these inventors: | |
| Date | Title |
|---|---|
| 2022-09-15 | Monocyclic agonists of stimulator of interferon genes sting |
| 2022-03-10 | Chimeric antigen receptor effector cell switches with humanized targeting moieties and/or optimized chimeric antigen receptor interacting domains and uses thereof |
| 2022-03-10 | Modified therapeutic agents and compositions thereof |
| 2022-01-06 | Modified therapeutic agents, stapled peptide lipid conjugates, and compositions thereof |
| 2021-11-25 | Methods for inducing chondrogenesis |
| Top Inventors for class "Drug, bio-affecting and body treating compositions" | |
| Rank | Inventor's name |
|---|---|
| 1 | Anthony W. Czarnik |
| 2 | Ulrike Wachendorff-Neumann |
| 3 | Ken Chow |
| 4 | John E. Donello |
| 5 | Rajinder Singh |