Patent application title: Processing Search Queries Using A Data Structure
Inventors:
Konstantin Tretjakov (Tallinn, EE)
Luciano García-Bañuelos (Tartu, EE)
Luciano Garcia-Bañuelos (Tartu, EE)
Abel Armas-Cervantes (Tartu, EE)
Jaak Vilo (Tartu, EE)
Marlon G. Dumas
IPC8 Class: AG06F1730FI
USPC Class:
707723
Class name: Database and file access post processing of search results ranking search results
Publication date: 2013-04-25
Patent application number: 20130103678
Abstract:
According to an embodiment, there is provided a method of generating a
data structure stored in computer memory for processing a search query in
a network of interconnected nodes, wherein the method comprises selecting
landmark nodes by the following steps and storing the selected landmark
nodes in the data structure: sampling from the network nodes a first
sample of vertex pairs, computing the shortest path for each vertex pair,
each shortest path comprising a set of vertices between each vertex in
the vertex pair; identifying a first landmark node which occurs in more
of the shortest paths more often than any other vertex; removing from the
network vertices shortest paths including the first landmark node and
identifying a second landmark node which occurs in more of the remaining
shortest paths than any other remaining vertex.Claims:
1. A method of generating a data structure stored in a computer memory
for use in performing a search query in a network of interconnected
nodes, wherein the method comprises selecting landmark nodes by the
following steps and showing the selected landmark nodes in the data
structure: sampling from the network nodes a first sample of vertex
pairs; computing the shortest path for each vertex pair, each shortest
path comprising a set of vertices between each vertex in the vertex pair;
identifying a first landmark node which occurs in more of the shortest
paths more often than any other vertex; removing from the network
vertices shortest paths including the first landmark node; and
identifying a second landmark node which occurs in more of the remaining
shortest paths than any other remaining vertex.
2. A method according to claim 1, comprising storing in the data structure in association with each landmark node vertex data for each vertex in the network.
3. A method according to claim 2, wherein the vertex data comprises a distance from each vertex to the landmark node.
4. A method according to claim 2 wherein the vertex data comprises a shortest path tree.
5. A method according to claim 4 wherein the shortest path tree is in the form of a set of parent links wherein each parent link identifies an adjacent vertex node in the shortest path between the vertex and the landmark node.
6. A data structure, recorded on an electronic storage medium, generated by the method of claim 1 when used in a computer implemented method of processing a search query.
7. A method of processing a search query to provide a search result, the method comprising receiving at a computer device a search query in the form of a digital message, the query identifying a source node and a target node; and executing at the computer device an application for generating a search result, the application performing the following steps: accessing the data structure, in which each landmark has stored therewith a shortest path tree in the form of a set of parent links wherein each parent link identifies an adjacent vertex node; for each landmark identifying the location of the source node and the target node in the shortest path trees to the landmark node; for each landmark node using the identified locations of the target node and source node to generate a measure of distance between the source node and the target node; determining the landmark with the shortest distance; and providing a search result related to the shortest path tree of that landmark.
8. A method according to claim 7, wherein the measure of distance is generated by: computing a first distance over the shortest path between the source node and the landmark node; computing a second distance over the shortest path between the landmark node and the target node; and summing the first and second distances.
9. A method according to claim 7, wherein generating the measure of distance includes: identifying a common ancestor node in the shortest path trees from the source node and the target node to the landmark node.
10. A method according to claim 9, comprising: summing a first distance from the source node to the common ancestor node and a second distance from the common ancestor node to the target nodes to generate the measure of distance.
11. A method according to claim 9 wherein the measure of distance is generated by: identifying in all pairs of nodes in a first paths between the source node and the common ancestor node and a second path between the common ancestor node and the target node; locating any of said pairs which are edges; identifying the edge of the shortest distance; and using the edge to determine measure of distance between the source node and the target node.
12. A method according to claim 7 wherein the measure of distance is generated by: for each landmark recording nodes in common between the shortest path trees from the source node and the target node to the landmark node; executing a graph traversal from the source node, traversing only commonly recorded nodes, to update shortest path from the source node to the target node and using the updated shortest path to determine the measure of distance.
13. A method according to claim 12 wherein the measure of distance is generated using the updated shortest path.
14. A method according to claim 7 wherein the step of providing a search result comprises displaying the search result to a user.
15. A method according to claim 7 wherein the step of providing a search result comprises providing the search result to a search function which generates a comparison between a plurality of search results to provide a set of outputs in ranked order.
16. A method according to claim 7 wherein the search result comprises a list of node identifiers in the shortest path tree of the landmark with the shortest distance.
17. A method according to claim 7 wherein the search result comprises the number of nodes in the shortest path tree of the landmark for the shortest distance.
18. A computer device for processing a search query to provide a search result, the computer device comprising: a first component comprising a data structure, each landmark node having stored therewith a shortest path tree in the form of a set of parent links wherein each parent link identifies an adjacent vertex node in the shortest path between each node in the data structure and the landmark node: and a second component comprising a processor configured to execute an application for generating a search result, the application performing the following steps: accessing the data structure; for each landmark identifying the location of the source node and the target node in shortest path trees to the landmark node; for each landmark using the identified locations of the target node and source node to generate a measure of distance between the source node and the target node; determining the landmark with the shortest distance; and providing a search result related to the shortest path tree of that landmark.
19. A computer program product comprising a non-transitory computer readable medium storing thereon computer readable instructions configured so as when executed on one or more processors to perform the operations of generating a data structure stored in a computer memory for use in performing a search query in a network of interconnected nodes including selecting landmark nodes by: sampling from the network nodes a first sample of vertex pairs; computing the shortest path for each vertex pair, each shortest path comprising a set of vertices between each vertex in the vertex pair; identifying a first landmark node which occurs in more of the shortest paths more often than any other vertex; removing from the network vertices shortest paths including the first landmark node; and identifying a second landmark node which occurs in more of the remaining shortest paths than any other remaining vertex.
Description:
RELATED APPLICATION
[0001] This application claims priority under 35 U.S.C. §119 or 365 to Great Britain, Application No. GB 1118333.2, filed Oct. 24, 2011.
[0002] The entire teachings of the above application(s) are incorporated herein by reference.
TECHNICAL FIELD
[0003] The present invention relates to processing search queries, and in particular to generating a data structure for processing a query in a network of interconnected nodes.
BACKGROUND
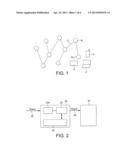
[0004] There exist many situations where computer networks comprise a typically very large number of interconnected nodes. For example, the communication network of Skype represents a large social network for peer to peer communication. FIG. 1 is a schematic diagram of a small part of a typical computer network. The network is shown to comprise a plurality of nodes Ni. Each node can be associated with one or more physical computer devices as shown for example in the case of node Ni which is shown to be associated with a mobile device 2, a PC 4 and a tablet 6. Each node is associated with a single user, who in this case can register or log in with a particular network using any one of the computer devices. The nodes are shown interconnected by connections Ci. In the context of the physical network, the connections Ci can be implemented in any known way, wired or wireless. In the context of users associated with nodes, the connections do not necessarily pertain to a single physical connection in a network, but represent a relationship between users associated with the nodes at either end of the connection. As an example, in the case of Skype, two users are considered to be connected if they are in each other's contact lists. A common challenge with such networks is to allow a user to search for another user by name for example and to see the results of a search ranked in the order of their shortest path distance to him. Similarly, a user may wish to know what chain of contacts allows him to reach another user in the network. Attempts to solve the problem have used analytic techniques for finding the shortest paths between a given pair of nodes in a graph.
[0005] There exists a large body of methods to address this problem. Existing methods can be broadly classified into exact and approximate. Exact methods, such as those based on Dijkstra's traversal, are prohibitively slow for performing online queries on graphs with hundreds of millions of vertices, which is a typical size for a contemporary social network. Among the approximate methods, a family of scalable algorithms for this problem are the so-called landmark-based (or sketch-based) approaches. In this family of techniques, a fixed set of landmark nodes is selected and distances are precomputed from each vertex to some or all of the landmarks. Knowledge of the distances to the landmarks, together with the triangle inequality, typically allows one to compute approximate distance between any two vertices in O(k) time, where k is the number of landmarks, and O(kn) space, where n is the number of vertices in the network. Those estimates can then be used as-is, or exploited further as a component of a graph traversal or routing strategy in order to obtain an exact shortest path.
[0006] An important aspect of landmark based methods is the way landmarks are selected--a careful selection strategy can have a significant positive effect. Strategies which rely on selecting landmarks with high degree, betweeness--and closeness--centrality as well as ensuring proper dispersion of landmarks over the graph and its paths have been suggested.
[0007] Reference is made to a paper by Potamias et al entitled "Fast Shortest Path Distance Estimation in Large networks" in CIKM '09: Proceedings of the 18th International Conference on Information and Knowledge Management, pages 867-878 NY, USA 2009. In that paper, a landmark based distance estimation algorithm is evaluated under different landmark selection strategies. According to this paper, the highest degree and closeness centrality techniques have been shown to typically yield highest accuracy.
[0008] Although landmark-based algorithms do not provide strong theoretical guarantees on approximation quality, they have been shown to perform well in practice, scaling up to graphs with millions or even billions of edges with acceptable accuracy and response times of under one second per query.
[0009] It is an objective of the present invention to improve the accuracy over existing techniques, with acceptable computation times for generating a data structure for use in processing a search query.
SUMMARY
[0010] According to an aspect of the present invention there is provided a method of generating a data structure stored in computer memory for processing a search query in a network of interconnected nodes, wherein the method comprises selecting landmark nodes by the following steps and storing the selected landmark nodes in the data structure: sampling from the network nodes a first sample of vertex pairs, computing the shortest path for each vertex pair, each shortest path comprising a set of vertices between each vertex in the vertex pair; identifying a first landmark node which occurs in more of the shortest paths more often than any other vertex; removing from the network vertices shortest paths including the first landmark node and identifying a second landmark node which occurs in more of the remaining shortest paths than any other remaining vertex.
[0011] The invention also provides a computer program product comprising a non-transitory computer readable medium storing thereon computer readable instructions which when executed by a computer carry out the steps of the above-defined methods.
[0012] The data structure has applicability when recorded on an electronic storage medium and used in processing a search query. Another aspect of the invention provides a method of processing a search query to provide a search result, the method comprising receiving at a computer device a search query in the form of a digital message, the query identifying a source node and a target node, and executing at the computer device an application for generating a search result, the application performing the following steps: accessing the data structure generated by the above method, in which each landmark has stored therewith a shortest path tree in the form of a set of parent links wherein each parent link identifies an adjacent vertex node, for each landmark identifying the location of the source node and the target node in the shortest path trees to the landmark node, for each landmark node using the identified locations of the target node and source node to generate a measure of distance between the source node and the target node, determining the landmark with the shortest distance and providing a search result related to the shortest path tree of that landmark.
[0013] According to a first technique the measure of distance is generated by computing a first distance over the shortest path between the source node and the landmark node; computing a second distance over the shortest path between the landmark node and the target node; and summing the first and second distances.
[0014] According to a second technique, the measure of distance is generated by identifying a common ancestor node in the shortest path trees from the source node and the target node to the landmark node. In one version, this is followed by the step of summing a first distance from the source node to the common ancestor node and a second distance from the common ancestor node to the target node.
[0015] In another version, this is followed by the steps of identifying all pairs of nodes in a first path between the source node and the common parent node and a second path between the common parent node and the target node; locating any of said pairs which are edges; identifying the edge of the shortest distance; and using the edge to determine the measure of using the edge to determine measure of distance between the source node and the target node.
[0016] According to a third technique the measure of distance is generated by recording nodes in common between the shortest path trees from the source node and the target node to each landmark node; executing a graph traversal from the source node, traversing only commonly recorded nodes, to update a shortest path from the source node to the target node; and using the updated shortest path to determine the measure of distance.
[0017] Embodiments of the invention described in the following provide improvements relating to a new landmark selection strategy that seeks to maximise the coverage of all shortest paths by the selected landmarks.
[0018] Embodiments of the invention discussed in the following allow for a significantly improved execution time, for example more than four seconds on a graph with ten times less edges and one hundred times less vertexes than a Skype graph snapshot of February 2010.
[0019] For a better understanding of the present invention and to show how the same may be carried into effect reference will now be made by way of example to the accompanying drawings:
BRIEF DESCRIPTION OF THE DRAWINGS
[0020] FIG. 1 is a diagram of part of a network.
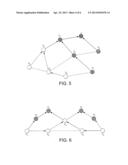
[0021] FIG. 2 is a block diagram of a system for performing a search query.
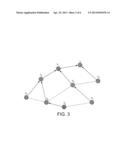
[0022] FIG. 3 illustrates a shortest path tree for one landmark.
[0023] FIG. 4 illustrates a data set for one landmark.
[0024] FIG. 5 illustrates a shortest path tree with a lower common ancestor.
[0025] FIG. 6 illustrates a shortest path tree with edge insertion.
[0026] FIG. 7 is a flow chart of a landmark selection method.
[0027] FIG. 8 is a table of experimental results.
DETAILED DESCRIPTION
[0028] FIG. 2 is a schematic block diagram of a system for processing a search query. The system comprises a computer device 20 which implements two components. A first component 22 is a data structure which is a memory or other form of computer store holding data in the form of a graph as described further herein. The second component is a processing function 24 which accesses the data structure 22 and uses it to process a search query. In operation, a query 26 in the form of a digital message is received by the computer device 20 and the computer device 20 operates to generate a result 28. The result can be utilised in a number of different ways by a user result function 30. For example the user result function 30 can be a search function which receives other inputs along with the result 28 and generates a search result to a user. Alternatively, the user result function 30 can be a display which displays a result 28 directly to a user.
[0029] Each component 22, 24 can be implemented by a processor and a memory. It will readily be appreciated that a single processor and single memory can be used to provide both components, or the components can be provided by separate processes and separate memories. In the first component, code executed by a processor 22a generates and maintains the data structure 22, and in the second component code executed by the processor processes the search query as will be described more fully later.
[0030] The query 26 is received by the computer device 20 from a user. A user can input the query into one of the physical devices with which he is associated by any known input means. The query is supplied to the computer device 20 in the form of a digital message over any transmission mechanism. For example, where the user is associated with a client terminal, the query can be supplied through the internet to a server at which the computer device 20 is implemented. Alternatively, the query could be handled locally at a client terminal. As will become clearer in the following, the query includes an identifier of a source node, generally being a node associated with the user inputting the query, and a target node which will be the subject of the search.
[0031] An improvement over existing techniques derives from the selection of landmarks. A "greedy" approach is proposed to select these landmarks that provide the best coverage of all shortest paths in a random sample of vertex pairs.
[0032] Before describing the invention, landmark-based distance estimates techniques will first be described.
[0033] Basic Definitions
[0034] Let G=(V,E) denote a graph with n=|V| vertices and m=|E| edges. For simplicity of exposition, we shall consider an undirected, unweighted graph, although the approach can be easily generalized to accommodate weighted directed graphs as well.
[0035] A path πs,t of length l between two vertices s,t.di-elect cons.V is defined as a sequence πs,t=(s,u1,u2, . . . , ul-1,t), where {u1,u2, . . . , ul-1}.OR right.V and {(s,u1),(u1,u2), . . . , (ul-1,t)}.OR right.E. We denote the length l of a path πs,t as |πs,t|. The concatenation of two paths πs,t=(s, . . . , t) and πt,v=(t, . . . , v) is the combined path πs,v=πs,t+πt,v=(s, . . . , t, . . . , v).
[0036] The distance d(s,t) between vertices s and t is defined as the length of the shortest path between s and t. The shortest path distance in a graph is a metric and satisfies the triangle inequality: for any s,t,u.di-elect cons.V
d(s,t)≦d(s,u)+d(u,t). (1)
[0037] The upper bound becomes an equality if there exists a shortest path ps,t which passes through u.
[0038] The diameter of a graph is the maximal length of a shortest path in the graph. An important property of social networks in this respect is that their diameter is small. Centrality of a vertex is a general term used to refer to a number of metrics of importance of a vertex within a graph. Betweenness centrality corresponds to the mean proportion of shortest paths passing through a given vertex. Closeness centrality measures the average distance of a vertex to all other vertices in the graph.
[0039] Landmark-Based Distance Estimation
[0040] Before describing the improved landmark selection process, the basic landmark-based distance estimation technique will be explained.
[0041] As noted in Equation 1, if we fix a single landmark node u and precompute the distance d(u,v) from this node to each other vertex v in the graph, we can get an upper bound approximation for the distance d(s,t) between any two vertices s and t:
dUapprox. (s, t)=d (s, u)+d (u, t)
[0042] If we now select a set U={u1,u2, . . . , uk} of k landmarks, a potentially better approximation can be computed:
d approx . U ( s , t ) = min u ε U d approx . u ( s , t ) ##EQU00001##
[0043] In principle, the triangle inequality also allows to compute a lower bound on the distance, but previous work indicates that lower-bound estimates are not as accurate as the upper-bound ones.
[0044] In the following we refer to this algorithm as LANDMARKS-BASIC (Algorithm 1)
[0045] For unweighted graph, the algorithm requires O(km) time to precompute distances using k BFS traversals and O(kn) space to store the distances. Each query is answered in O(k) time. Note that this approach only allows us to compute an approximate distance, but does not provide a way to retrieve the path itself.
[0046] Improved Landmark-Based Algorithms
[0047] Shortest Path Trees
[0048] An improvement to the above algorithm is the idea of maintaining an explicit shortest path tree (SPT) for each landmark, instead of simply storing the distances to landmarks as numbers. More precisely, let pu[v] be the next vertex on an arbitrarily chosen shortest path from a vertex v to a landmark u. We shall refer to pu[v] as the parent link of v in the SPT of u (see FIG. 3). Similarly to distances, parent links can be computed in a straightforward manner during a BFS traversal of the graph in O(m) time per landmark.
[0049] In FIG. 3 black arrows denote parent links. Dashed lines are graph edges that are not part of the tree.
[0050] The availability of parent links enables us to recover an exact shortest path from each vertex v to each landmark u by simply following the corresponding links. For example, if the source node is V5, the data set indicates pu[V5]=V3; pu[V3]=V1; pu[V2]=u. Consequently, it also allows to compute the shortest path distance d(u,v) (in that case 3) and thus directly apply the ideas of the LANDMARKS-BASIC algorithm, with the only difference that each distance computation now requires O(D) steps, where D is the diameter of the graph. As the diameters of social network graphs tend to be small, the overhead of such a computation is minor.
[0051] Note that this approach allows to retrieve an actual path between any two vertices in addition to the distance approximation. FIG. 4 shows the data set for landmark u in the data structure 22. It will be appreciated that a similar data set is held for each landmark.
[0052] Lowest Common Ancestor Method
[0053] Besides performing basic landmark-based approximation, the availability of the SPT allows us to significantly improve the upper bound estimates on distances for many vertex pairs. Consider the situation depicted in FIG. 5 and suppose we wish to approximate the distance between v5 and v8. By applying the basic technique we obtain an upper bound estimate of d(v5,v8)≦d(v5,u)+d(u,v8)=3+4=7. Observe, however, that once we have the explicit shortest paths:
πv5.sub.,u=(v5,v3,v1,u), πv8.sub.,u=(v8,v6,v3,v1,u),
[0054] we can note that both of them pass through v3 and thus the estimate
d(v5,v8)≦d(v5,v3)+d(v3,v8)=1+2=3.
[0055] will result in a better upper bound. In general, whenever two shortest paths πs,u and πt,u have a common vertex v≠u, we have
d(s,t)≦d(s,v)+d(v,t)<d(s,u)+d(u,t), (2)
[0056] and thus if we use v instead of u to approximate d(s,t) we obtain a tighter bound. Naturally, it makes sense to select the vertex v providing the best such approximation. It can be seen that this vertex is the lowest common ancestor (LCA) of s and t in the SPT of u. When approximating distance between v5 and v8 we use their lowest common ancestor v3 instead of the landmark u as a reference.
[0057] This observation provides the basis of an LCA approximation method (DISTANCE-LCA, Algorithm 2). By substituting this distance estimate into Equation 3, we obtain a new algorithm LANDMARKS-LCA with increased accuracy. Note that this algorithm can also be trivially extended to return the actual path.
[0058] One way to understand the extent of improvement is to note that the basic algorithm will provide exact estimates only for shortest paths that pass through the landmark vertex. In FIG. 5 those are only the paths connecting v2 with v1 and v3. The LCA algorithm, however, will provide exact answers for all shortest paths that lie along the SPT, and there will be typically considerably more of those.
[0059] Landmarks-BFS
[0060] The algorithms LANDMARKS-BASIC and LANDMARKS-LCA use each landmark for distance approximation independently of the other landmarks. This is not the best possible use of all available landmark data. Consider FIG. 6, for example. When approximating distance between vertices v1 and v5, we would obtain a path of length 5 if we used the two landmarks independently. By combining the two subtrees we can find a better path of length 4.
[0061] This suggests a powerful improvement over the previous approaches. In order to approximate distance between two vertices, collect all paths from those vertices to all landmarks, and perform a usual BFS (or, in the case of weighted graphs, Dijkstra) traversal on the subgraph, induced by the union of those paths. We refer to this algorithm as LANDMARKS-BFS (Algorithm 3).
[0062] For k landmarks, the size of the subgraph will be less than 2 kD. Consequently, the memory complexity of LANDMARKS-BFS is O(kD) and the time complexity is at most O(k2D2).
[0063] By taking other graph edges (i.e., "shortcuts") into account, in LANDMARKS-BFS we further improve the distance approximation to 3.
[0064] Shortcutting
[0065] Denote the lowest common ancestor of s and t by v. The LCA algorithm approximates πs,t by a concatenation of πs,v with πv,t. However, it may happen that a vertex w.di-elect cons.πs,v is connected directly by an edge with a vertex w'.di-elect cons.πv,t. In this case, an even shorter approximation to πs,t can be obtained by concatenating the paths πs,w, πw,w' and πw',t. For example, in FIG. 5, the edge (v5,v6) acts as a shortcut from πv5.sub.,v3 to πv3.sub.,v8. If we account for this edge, we may further improve the LCA distance estimate to the true shortest path d(v5,v8)=2.
[0066] In order to locate shortcuts we can simply examine all pairs of vertices in πs,v×πt,v and if some of them are connected by an edge, find the edge providing the best distance estimate. This can be done in |πs,v|×|πt,v|, i.e., at most O(D2) steps. We refer to the resulting distance approximation method as DISTANCE-SC (Algorithm 4. By using this upper bound estimate in Equation 3 we obtain the landmark-based algorithm LANDMARKS-SC.
[0067] Landmark Selection Techniques
[0068] Although landmarks can be selected uniformly at random, it has been shown by experiment that selecting landmarks with the highest degree or lowest closeness centrality typically ensures better distance estimates, whereas it is shown that the two methods provide similar accuracy. A novel landmark selection technique with improved accuracy is now described.
[0069] Best Coverage
[0070] When a landmark u lies on the shortest path between s and t, its upper bound distance estimate is exact. We say that such a landmark covers the pair (s,t). Consequently, the most desirable set of landmarks would be the one that covers as many vertex pairs as possible. A simple greedy strategy based on sampling is explained with reference to Algorithm 4, and FIG. 7. A graph G with V vertices representing the network is supplied (702). We sample (704) a set of M vertex pairs, and compute (706, 708) exact shortest path for each pair. This computation can be carried out by any known method, e.g. BSF graph traversal. As the first landmark we select (710) the vertex that is present in the greatest number of paths of the sample, i.e. the most popular vertex. We remove (712) the paths covered by that first landmark from the sample and proceed to select (by returning to 710 for i<k) the second landmark as the vertex, which covers most of the remaining paths. Subsequent landmarks in the returned (714) set {ul-uh} are determined in a similar way. The landmarks are stored in the data structure 22.
[0071] Incremental Updates
[0072] If the graph is subject to intensive edge insertion and deletion, landmarks that have been computed originally become outdated and the approximation performance deteriorates. Therefore, landmarks have to be maintained up to date. Although this can be achieved by means of daily or hourly full recomputation, such a solution is computationally expensive. Moreover, for certain applications, such as the abovementioned social search, it can be particularly important to maintain landmarks up to date at all times. Indeed, if the social search feature is relied upon by new users to establish their first list of contacts, it is important that adding a new contact would be immediately reflected in the consequent search orderings.
[0073] Fortunately, when landmarks are maintained in the form of shortest path trees with single pointers (parent links), they can be updated incrementally to accommodate edge insertions or deletions. The procedures for maintaining SPTs under insertions and deletions are known, for example see D. Frigori et al, "Fully dynamic algorithms for maintaining shortest path trees" Journal of Algorithms, Vol 34, November 2, pages 251-281 2000. In the particular case of unweighted graphs with a small diameter, they are fairly straightforward.
[0074] As an informal example, consider the SPT presented on FIG. 3. Suppose that an edge {u,v8} has just been inserted into the graph. The SPT update algorithm would proceed as follows. Firstly, note that the newly added edge provides a shorter path from v8 to the landmark than what was previously available. Therefore, the parent pointer of v8 has to be changed to make use of the new edge: pu[v8]:=u. Now that the path to the landmark from v8 has improved, we have to recursively examine all neighbours of v8 (i.e., v6 and v7) and check, whether switching their parent pointer to v8 would improve their previously known path to the landmark. This is true both for v6 and v7, hence we set pu[v6]:=v8, pu[v7]:=v8. We repeat this again for all neighbours of v6 and v7. Having found no new path improvements, we complete the update.
[0075] The deletion of an edge involves two passes. Consider again FIG. 3 and suppose the edge {v1,v3} was deleted from the graph. In order to find a new path to the landmark (and a new parent pointer) for v3, we first examine its neighbours (v5 and v6). Unfortunately, both of them relied on v3 for reaching the landmark, hence they provide no immediate fix. We record v3 temporarily in a priority queue, using the best available new path length (∞ so far) as the key. We then recursively descend to process the children of v3 in the SPT. Vertex v5 has no immediate fix and gets recorded in the priority queue with key ∞. Vertex v6, however, can be connected to v4, retaining a path to the landmark of length 3. Consequently, there is no need to process children of v6. After reconnecting v6 we must update the keys of its neighbours (v3 and v5) in the priority queue--the new potential path of length 4 is better than the previously recorded ∞. This completes the first pass. In the second pass we empty the priority queue, rebuilding the rest of the SPT.
[0076] We provide a more formal description of the update procedures in Algorithms 5 and 6.
[0077] In theory, a single update may trigger the SPT recomputation for the whole graph (e.g. deleting an edge that was a bridge between the landmark and all the other nodes). In practice, however, such situations are rare and, according to our experiments, the amortized time necessary to process a single update in a real Skype network is in the order of milliseconds.
[0078] Networks
[0079] The following are examples of real-world social network graphs, representing four different orders of magnitude in terms of network size.
[0080] DBLP. The DBLP dataset contains bibliographic information of computer science publications. Every vertex corresponds to an author. Two authors are connected by an edge if they have co-authored at least one publication.
[0081] Orkut. Orkut is a large social networking website. It is a graph, where each user corresponds to a vertex and each user-to-user connection is an edge.
[0082] Twitter. Twitter is a microblogging site, which allows users to follow each other, thus forming a network.
[0083] Skype. Skype is a large social network for peer-to-peer communication. We say that two users are connected by an edge if they are in each other's contact list.
[0084] The properties of these datasets are summarized in Table 1. The table shows the number of vertices |V|, number of edges |E|, average distance between vertices d (computed on a sample vertex pairs), approximate diameter Δ, fraction of vertices in the largest connected component |S|/|V|, and average time to perform a BFS traversal over the graph tBFS.
TABLE-US-00001 TABLE 1 Datasets. Dataset |V| |E| d Δ |S|/|V| tBFS DBLP 770K 2.6M 6.3 25 85% 345 ms Orkut 3.1M 117M 5.7 10 100% 8 sec Twitter 41.7M 1.2B 4.2 25 100% 9 min Skype 454M 3.1B 6.7 60 85% 20 min
[0085] Comparative statements made herein concerning accuracy are stored as experiments using a random sample of SV vertex pair from each graph of the above datasets, and a parameter.
[0086] Approximation error is computed as (l'-l)/l, where l' is the approximation and l is the actual distance.
[0087] Suitable hardware is a server with 32×Quad-core AMD Opteron 64 bit 2.2 GHz processors, 256 G of RAM, accessing IBM DS 3400 FC SAN disk array, running Red Hat Enterprise Linux 5 operating system.
[0088] According to the above description, two improvements to existing approaches for landmark based estimation of shortest paths are described. The improvements strike a trade off between accuracy, query execution time and disc usage for pre-computed data. The pre-computed data refers to the data structure 22 which has to be generated and maintained for ready access in the search query. Improvements of up to 25% have been obtained with respect to previous related work, while maintaining the response time per query to a few miliseconds--even for a graph with billions of edges--and a space consumption of memory comparable to previous methods.
[0089] Moreover, an exclusive property of the methods described above is a support for dynamic updates.
[0090] The algorithms are being presented for the case of an undirected unweighted graph. The techniques can be generalised to weighted graphs by replacing the BFS in the SPT pre-computation phase and in the landmark-BFS algorithm with a Dijkstra traversal. The generalisation to directed graphs requires computing two shortest path trees for each landmark--the first one holding distances to the landmark, and the second one with distances from the landmark. The algorithms then need to be updated slightly to use both trees appropriately (for examples lines 4 and 5 of algorithm 3 will refer to two different trees rather than one).
[0091] Being a distance approximation scheme a landmark based algorithm can be used as a heuristic in a unidirectional or bidirectional A* search, as described for example in a paper by Goldberg et al published in 16th ACM--SIAM Symposium of Discrete Algorithms pages 156-165, 2005. In particular, this ability to efficiently estimate exact shortest paths allows us to take larger samples for best coverage landmark selection. Note that due to the incremental update capabilities of the above approach, the result is a fast fully dynamic exact shortest path algorithm.
[0092] In the approach described above, all landmarks are selected ex ante and the selection of landmarks is never revised. A further improvement can be obtained by using information collected during the processing of queries in order to add or remove landmarks. Each time a query is answered using the landmark-LCA algorithm, we can identify which landmarks are used and which specify vertices are used as LCAs. Based on the frequency of use of LCA's certain vertices can be promoted to become landmarks, or landmarks that are infrequently used can be dropped.
[0093] While this invention has been particularly shown and described with references to example embodiments thereof, it will be understood by those skilled in the art that various changes in form and details may be made therein without departing from the scope of the invention encompassed by the appended claims.
User Contributions:
Comment about this patent or add new information about this topic:
Images included with this patent application:
 |  |
 |  |
 |  |
 |
| Similar patent applications: | |
| Date | Title |
|---|---|
| 2014-05-29 | Accelerating time series data base queries using dictionary based representations |
| 2014-05-29 | Keyword-based search engine results using enhanced query strategies |
| 2014-01-02 | Processing structured and unstructured data |
| 2014-01-09 | Optimizing sparse schema-less data in data stores |
| 2013-02-28 | Apparatus and method for processing partitioned data for securing content |
| New patent applications in this class: | |
| Date | Title |
|---|---|
| 2022-05-05 | Ranking of documents belonging to different domains based on comparison of descriptors thereof |
| 2019-05-16 | Smart agent services using machine learning technology |
| 2019-05-16 | Searching method and system based on multi-round inputs, and terminal |
| 2019-05-16 | Personalized content sharing |
| 2019-05-16 | Browsing methods, computer program products, servers and systems |
| New patent applications from these inventors: | |
| Date | Title |
|---|---|
| 2013-04-25 | Processing search queries in a network of interconnected nodes |
| Top Inventors for class "Data processing: database and file management or data structures" | |
| Rank | Inventor's name |
|---|---|
| 1 | International Business Machines Corporation |
| 2 | International Business Machines Corporation |
| 3 | John M. Santosuosso |
| 4 | Robert R. Friedlander |
| 5 | James R. Kraemer |