Patent application title: USING ONTOLOGICAL INFORMATION IN OPEN DOMAIN TYPE COERCION
Inventors:
David A. Ferrucci (Yorktown Heights, NY, US)
David A. Ferrucci (Yorktown Heights, NY, US)
Aditya A. Kalyanpur (Westwood, NJ, US)
Aditya A. Kalyanpur (Westwood, NJ, US)
James W. Murdock, Iv (Millwood, NY, US)
James W. Murdock, Iv (Millwood, NY, US)
Christopher A. Welty (Hawthorne, NY, US)
Wlodek W. Zadrozny (Tarrytown, NY, US)
Wlodek W. Zadrozny (Tarrytown, NY, US)
Assignees:
International Business Machines Corporation
IPC8 Class: AG06F1730FI
USPC Class:
707706
Class name: Data processing: database and file management or data structures database and file access search engines
Publication date: 2012-12-27
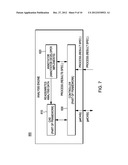
Patent application number: 20120330921
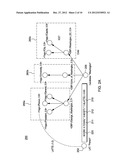
Abstract:
A computer-implemented system, method and program product generates
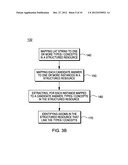
answers to questions in an input query text string. The method includes
determining, by a programmed processor unit, a lexical answer type (LAT)
string associated with an input query; automatically obtaining a
candidate answer string to the input query from a data corpus; mapping
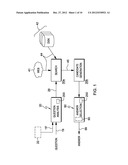
the query LAT string to a first type string in a structured resource;
mapping the candidate answer string to a second type string in the
structured resource; and determining if the first type string and the
second type string are disjointed; and scoring the candidate answer
string based on the determination of the types being disjointed wherein
the structured resource includes a semantic database providing
ontological content.Claims:
1. A computer-implemented method of generating answers to questions
comprising the steps of: receiving an input query text string;
determining, by a programmed processor unit, a lexical answer type (LAT)
string associated with an input query; automatically obtaining a
candidate answer string to the input query from a data corpus; mapping
said query LAT string to a first type string in a structured resource;
mapping said candidate answer string to a second type string in the
structured resource; and determining if said first type string and said
second type string are disjointed; and scoring said candidate answer
string based on said determination of said types being disjointed wherein
said structured resource includes a semantic database providing
ontological content.
2. The computer-implement method of claim 1, wherein said determining step is carried out by identifying an axiom in the structured resource that relates the first type string to the second type string as being a disjointed.
3. The computer-implemented method of claim 2 wherein said ontological content further provides associated senses of said word concepts.
4. The computer-implemented method of claim 1 wherein said mapping said candidate answer string to said second type string is carried out by mapping said candidate answer string to an instance in a structured resource and mapping said instance to said second type string in a structured resource.
5. The computer-implemented method of claim 2 wherein an axiom between type strings comprise one or more of: equivalence axiom, subsumption axiom, and axioms of siblings.
6. The computer-implemented method of claim 1, wherein mapping said query LAT string to said first type string in a structured resource comprises one or more of: accessing said semantic database and obtaining type entities that match the query LAT string; obtaining, from said semantic database, a sense rank of the obtained type entities; accessing a data corpus and obtaining, from said data corpus, a ranked list of types based on detected number of instances of the type therein; detecting a similarity between contextual data of the input query and contextual data associated with a type from the ontological content, and outputting a similarity measure; generating a confidence score based on a weighted combination of the sense rank, ranked list of type and said similarity measure.
7. The computer-implemented method of claim 6, wherein said detecting a similarity comprises: aligning the context using a BOW (bag of words) approach; or, applying a vector model to compute said similarity.
8. The computer-implemented method of claim 1 wherein mapping said candidate answer to said second type string comprises: accessing a data resource and obtaining instance entities that match said candidate answer; accessing, using a search engine, a data corpus and obtaining, from said data corpus, a ranked list of said instances based on a frequency of occurrence; computing a similarity measure between contextual data of said input query and contextual data associated with an instance; and, generating a confidence score based on a weighted combination of the ranked list of instances and said similarity measure.
Description:
CROSS-REFERENCE TO RELATED APPLICATIONS
[0001] The present invention relates to and claims the benefit of the filing date of commonly-owned, co-pending U.S. patent application Ser. No. 13/244,348 filed Sep. 24, 2011 which further claims the benefit of U.S. Provisional Patent Application No. 61/386,019, filed Sep. 24, 2010, the entire contents and disclosure of which is incorporated by reference as if fully set forth herein.
BACKGROUND
[0002] An introduction to the current issues and approaches of question answering (QA) can be found in the web-based reference http://en.wikipedia.org/wiki/Question_answering. Generally, QA is a type of information retrieval. Given a collection of documents (such as the World Wide Web or a local collection) the system should be able to retrieve answers to questions posed in natural language. QA is regarded as requiring more complex natural language processing (NLP) techniques than other types of information retrieval such as document retrieval, and it is sometimes regarded as the next step beyond search engines.
[0003] QA research attempts to deal with a wide range of question types including: fact, list, definition, How, Why, hypothetical, semantically-constrained, and cross-lingual questions. Search collections vary from small local document collections, to internal organization documents, to compiled newswire reports, to the World Wide Web.
[0004] Closed-domain QA deals with questions under a specific domain, for example medicine or automotive maintenance, and can be seen as an easier task because NLP systems can exploit domain-specific knowledge frequently formalized in ontologies. Open-domain QA deals with questions about nearly everything, and can only rely on general ontologies and world knowledge. On the other hand, these systems usually have much more data available from which to extract the answer.
[0005] Alternatively, closed-domain QA might refer to a situation where only a limited type of questions are accepted, such as questions asking for descriptive rather than procedural information.
[0006] Access to information is currently dominated by two paradigms. First, a database query that answers questions about what is in a collection of structured records. Second, a search that delivers a collection of document links in response to a query against a collection of unstructured data, for example, text or html.
[0007] A major unsolved problem in such information query paradigms is the lack of a computer program capable of accurately answering factual questions based on information included in a collection of documents that can be either structured, unstructured, or both. Such factual questions can be either broad, such as "what are the risks of vitamin K deficiency?", or narrow, such as "when and where was Hillary Clinton's father born?"
[0008] It is a challenge to understand the query, to find appropriate documents that might contain the answer, and to extract the correct answer to be delivered to the user. There is a need to further advance the methodologies for answering open-domain questions.
SUMMARY
[0009] In one aspect there is provided a computing infrastructure and methodology that conducts question and answering and performs automatic candidate answer evaluation using a candidate answer scoring technique that maps candidate answer lexical types (LT) to query LAT instances (types) to produce a final TyCor score that additionally obtains and uses one or more ontologies for type matching and uses axioms/reasoning for considering type inclusion/exclusion
[0010] Thus, in one aspect, there is provided a. computer-implemented system, method and program product for generating answers to questions comprising: receiving an input query text string; determining, by a programmed processor unit, a lexical answer type (LAT) string associated with an input query; automatically obtaining a candidate answer string to the input query from a data corpus; mapping the query LAT string to a first type string in a structured resource; mapping the candidate answer string to a second type string in the structured resource; and determining if the first type string and the second type string are disjointed; and scoring the candidate answer string based on the determination of the types being disjointed wherein the structured resource includes a semantic database providing ontological content.
[0011] Further to this aspect, the determining is carried out by identifying an axiom in the structured resource that relates the first type string to the second type string as being a disjointed.
[0012] In this further aspect, one or more axioms between types comprise: one or more of: equivalence axiom, subsumption axiom, and axioms of siblings between types.
[0013] In a further aspect, there is provided a system for generating answers to questions comprising: a memory; a processor device in communication with the memory that performs a method comprising: receiving an input query text string; determining, by a programmed processor unit, a lexical answer type (LAT) string associated with an input query; automatically obtaining a candidate answer string to the input query from a data corpus; mapping the query LAT string to a first type string in a structured resource; mapping the candidate answer string to a second type string in the structured resource; and determining if the first type string and the second type string are disjointed; and scoring the candidate answer string based on the determination of the types being disjointed wherein the structured resource includes a semantic database providing ontological content
[0014] In this further aspect, the determining is carried out by identifying an axiom in the structured resource that relates the first type string to the second type string as being a disjointed.
[0015] In this further aspect, one or more axioms between types comprise: one or more of: equivalence axiom, subsumption axiom, and axioms of siblings between types.
[0016] A computer program product is provided for performing operations. The computer program product includes a storage medium readable by a processing circuit and storing instructions run by the processing circuit for running a method(s). The method(s) are the same as listed above.
BRIEF DESCRIPTION OF THE DRAWINGS
[0017] The objects, features and advantages of the invention are understood within the context of the Detailed Description, as set forth below. The Detailed Description is understood within the context of the accompanying drawings, which form a material part of this disclosure, wherein:
[0018] FIG. 1 shows a high level logical architecture 10 of a question/answering method in which the present invention may be employed;
[0019] FIG. 2A depicts a candidate answer score process 250 that takes as input two strings: a determined LAT, and a candidate answer, and ascertains the degree of type match;
[0020] FIG. 2B shows an additional candidate answer score process 275 that performs mapping of a LAT string to Types utilizing ontological information from an ontological resource, according to one embodiment;
[0021] FIG. 3A is a flow diagram illustrating a computer programmed candidate answer generation process 100 for conducting questions and answers with deferred type evaluation;
[0022] FIG. 3B depicts a flow diagram illustrating score production performed at step 132 of FIG. 3A according to one embodiment;
[0023] FIG. 4 depicts a flow diagram illustrating mapping of a LAT string to Types using an ontological resource as performed at step 140 of FIG. 3B;
[0024] FIG. 5 depicts a flow diagram illustrating mapping of a candidate answer to Instances in a data resource using as performed at step 150 of FIG. 3B;
[0025] FIG. 6 depicts an excerpt of a structured knowledge base such as a DBpedia page that is tightly interlinked with a YAGO type;
[0026] FIG. 7 depicts an aspect of a UIMA framework implementation for providing one type of analysis engine for processing CAS data structures; and
[0027] FIG. 8 illustrates an exemplary hardware configuration to run method steps described in FIGS. 2A-5 in one embodiment.
DETAILED DESCRIPTION
[0028] FIG. 1 illustrates the major components that comprise a canonical question answering system 10 and their workflow. The question analysis component 20 receives a natural language question 19 (for example "Who is the 42nd president of the United States?") and analyzes the question to produce, via functionality 200, the semantic type of the expected answer (in this example, "president"), and optionally other analysis results for downstream processing. A lexical answer type (LAT) block 200 in the query analysis module implements functions and programming interfaces to determine the LAT(s) of a query to be later used for candidate answer type matching. The search component 30a formulates queries 29 from the output of question analysis and consults various resources such as the World Wide Web 41 or one or more knowledge resources, e.g., databases, knowledge bases 42, to retrieve supporting evidence 44 including, e.g., whole documents or document portions, web-pages, database tuples, etc., that are relevant to answering the query/question. The candidate answer generation component 30b then extracts from the search results 45 potential (candidate) answers to the question, which are then scored and ranked by the answer selection component 50 to produce a final ranked list of answers with associated confidence scores.
[0029] In one type of question and answer system with deferred type evaluation, after the extracting of correct answers (i.e., candidate answer instances to queries obtained from a data corpus, a knowledge base, or open domain sources like the Internet), answer-typing is performed, i.e., a determination of associations between searched entities (i.e. candidate answers), and lexical types (LT). The determined candidate answer lexical type (LT) is compared against a computed lexical answer type ("LAT") string of the query which is detected prior by question analysis block 20, and an evaluation is made in determining the correctness of the answer.
[0030] That is, as part of the answer selection component 50, QA systems may utilize a type coercion (TyCor) process in which a lexical type of a candidate answer is "coerced" to the question LAT based on several techniques. The coercion process may involve candidate answer to instance matching, instance to type association extraction, and LAT to type matching. The results of the "coercion" are referred to as a TyCor score that reflects the degree to which the candidate may be "coerced" to the LAT, where higher scores indicate a better coercion.
[0031] The present invention provides a candidate answer type scoring process that maps candidate answer LT to query LAT instances to produce a final score that uses one or more ontologies for type matching; and further, uses axioms/reasoning for considering type inclusion/exclusion.
[0032] Commonly-owned, co-pending U.S. patent application Ser. No. 12/126,642, titled "SYSTEM AND METHOD FOR PROVIDING QUESTION AND ANSWERS WITH DEFERRED TYPE EVALUATION", incorporated by reference herein, describes a QA system and method in which answers are automatically generated for questions that involves comparing the query LAT to the candidate answer LTs associated with each candidate answer.
[0033] The present disclosure extends and complements the effectiveness of the system and method described in co-pending U.S. patent application Ser. No. 12/126,642 by implementing a modified TyCor process to evaluate candidate answers to produce a final candidate answer score using one or more ontologies from an ontological resource. An ontological resource may include a semantic knowledgebase (KB), or any database that contains instances along with some concepts or types associated with it. The semantic KB is linked to the structured resource for type matching, and axioms/reasoning are identified in the ontological resource for considering type inclusion/exclusion. As will be described herein, ontological information is accessed during the TyCor scoring process by automatically accessing the semantic knowledgebase (KB).
[0034] For purposes of illustration, in one embodiment, a semantic KB including ontological information that is automatically accessed during the TyCor scoring process described herein below is a semantic database such as the web-based resource YAGO ("Yet Another Great Ontology") providing an interface that allows users to pose questions (to YAGO) in the form of queries on the YAGO homepage (http://www.mpi-inf.mpg.de/yago-naga/yago/) incorporated by reference herein. YAGO's semantic knowledge-base includes content automatically extracted from Wikipedia® (at http://www.wikipedia.org/) a registered trademark of Wikimedia Foundation, Inc., San Francisco Calif.) and WordNet® (http://wordnet.princeton.edu/) a registered trademark of Trustees of Princeton University, The Princeton University, Princeton, N.J., to provides structured ontological information. A further semantic database includes the web-based resource DBpedia (www.DBpedia.org) which is a web-based resource that provides structured information automatically extracted from the knowledgebase, Wikipedia®.
[0035] Moreover, ontological information maybe further automatically accessed using the web-site WordNet® that enumerates all senses of concepts (words). For example, a concept in Wordnet® may have multiple senses, e.g., the concept (word) "star" in Wordnet® can mean an astronomical object or a movie "star". In one embodiment, YAGO concepts are automatically linked to the web-site WordNet®. A type coercion process that uses ontological information accesses such as DBpedia/YAGO and/or WordNet® may improve both the quality and coverage of TyCor scoring.
[0036] In one embodiment, the use of "ontologies" in a TyCor scoring process includes the identification and use of "axioms". One axiom is referred to as a disjointness axiom that can be used to generate a negative TyCor score (referred to as "AnTyCor" score) and used to eliminate incorrect candidate answers to a question. An "axiom" is alternately referred to herein as a "logical rule" (represents, for example, a subclass rule, or an equivalent-class rule).
[0037] Reference is had to FIG. 3A that depicts a flow diagram of a computer programmed method 100 for conducting questions and answers with deferred type evaluation leading to generation of a candidate answer TyCor score such as described in co-pending U.S. patent application Ser. No. 12/126,642.
[0038] Generally, in the method of "deferred type evaluation" depicted in FIG. 3A, a first processing 112 represents the step of receiving, at a processing device, an input query, and generating a data structure including a question string and context for input to a Lexical Answer Type (LAT) processing unit block 200 (of FIG. 1) where, as indicated at 115, the Query is analyzed and lexical answer type (LAT) is computed. As a result of processing in the LAT processing component, as run at 115, there is generated an output data structure including the computed LAT and possibly additional terms from the original question.
[0039] As result of processing in the LAT block 200 then, as typified at 120, there is generated an output data structure including the computed original query (terms and assigned weights) in a manner such as described in co-pending U.S. patent application Ser. No. 12/152,441 the whole contents and disclosure of which is incorporated by reference as if fully set forth herein.
[0040] Returning to FIG. 3A, then, at processing 122, there is performed searching for candidate answer documents in a data corpus having structured and semi-structured content, and returning the results.
[0041] As a result of processing in a candidate answer generation module, as typified at 122, there is generated an output data structure including all of the documents found from the data corpus (e.g., primary sources and knowledge base).
[0042] Then, at 128, there is depicted the step of analyzing, using the generated LAT (the lexical answer type), each document for a candidate answer to produce a set of candidate answers.
[0043] Then, at 132, there is performed evaluating each candidate answer and producing a score for each candidate answer using ontological information in the embodiment described herein. The result of the modified TyCor processing in accordance with the embodiments described herein, produces candidate answer scores, and the answer(s) are returned at step 133 (based on their scores).
[0044] FIG. 3B depicts a flow diagram illustrating candidate answer evaluation and score production performed at step 132 of FIG. 3A according to one embodiment. The evaluating performed for a candidate answer received includes TyCor score processes as shown in FIG. 3B that includes: mapping the LAT string to one or more lexical types or concepts in a structured resource at 140; mapping each candidate answer to one or more instances in a structured resource at 150; extracting, for each candidate answer or instance mapped to a candidate answer, one or more lexical types or concepts in a structured resource at 160; and identifying one or more axioms in said structured resource that links the lexical type mapped to the LAT string to the lexical type mapped to the instance which in turn is mapped to the candidate answer at 170.
[0045] Thus, as shown at 140, FIG. 3B, there is performed the mapping of the LAT string derived from the query to one or more lexical types or concepts in a structured resource by accessing a resource having ontological content, for example a semantic database such as YAGO and/or Wordnet®, and finding the types or concepts based on the LAT.
[0046] In one embodiment, there is performed accessing the semantic database and obtaining type or concept entities that match the LAT string. A matching function is invoked that returns a ranked list of mappings associated with some confidence. A word sense disambiguation function may be used to perform the mapping step that maps a word to a correct sense. A word sense disambiguation function may be used as described in Agirre, Eneko & Philip Edmonds (eds.), 2006., Word Sense Disambiguation: Algorithms and Applications. Dordrecht: Springer. www.wsdbook.org; or Yarowsky, David. 2000, "Word sense disambiguation. Handbook of Natural Language Processing", ed. by Dale et al., 629-654. New York: Marcel Dekker. or Ide, Nancy & Jean Veronis, 1998, "Word sense disambiguation: The state of the art. Computational Linguistics", 24(1):1-40. For example, a LAT "star" could be used in the "astronomical object" sense, or it could be in the "movie actor" sense, which is automatically inferred using context to obtain the mapping. As different words have different senses corresponding to different concepts, the mapping will provide the different interpretations with a confidence score. The context, i.e., a prior knowledge, or a bias, is input to the matching function to discern the senses.
[0047] FIG. 4 shows a detailed score generation process of the mapping of the LAT string to the types from the structured database at 140 of FIG. 3B that utilizes ontological information in one embodiment. There is first performed at 142 obtaining, e.g., from conducting a search in an ontological resource, e.g., YAGO and/or WordNet®, a set of identified/searchable concepts having labels or IDs that explicitly match the LAT string. Then, starting at 145, there is obtained three pieces of information, a processing component performs obtaining the LATs "sense" rank, such as provided by WordNet®. Then, at 146, a processing component, such as a search engine, conducts a search of a structured data resource knowledge base, database, a data corpus or the Web, to obtain the number of instances of the concept. For example, a knowledge base Wikipedia® pages include categories having links (e.g., categories) which are treated as a "type", however a link is provided between Wikipedia® and DBpedia (e.g. via use of a 1:1 mapping between URLs) as DBpedia provides a more structured view of Wkipedia® page content. Step 146 produces a ranked list of types based on detected number of instances (i.e., frequency) of the concepts, e.g., in information available on the Web.
[0048] As mentioned, when mapping the question LAT to a typing system, there may be further performed a word sense disambiguation by taking into account the entity and the context in which it appears in the question (context is needed to disambiguate the entity). Thus, at 147, a processing component implements functions to compute a similarity measure (score) between the text surrounding the query LAT string and contextual data associated with concept in the ontological resource (or ontology). This includes, via a processing search engine: 1) identifying context in the question and obtaining a representation/model of the context; and 2) implementing function to measure and score the similarity between the contexts based on the representation.
[0049] As an example, a type "film" can refer to a "photographic film", or "a movie". In one embodiment, for the mapping, the context of the question is used in addition to information from various sources such as Wordnet® (e.g., to get sense information for nouns ("types"), type popularity scores from a domain corpus (e.g., "gem" as a precious stone is more popular than "gem" as a person), a background knowledge resource about relations that inform which are the typical relations/predicates associated with the noun (e.g., "sold this gem" lends more evidence to gem as a precious stone rather than person).
[0050] Then, at 149, the process generates a first confidence score based on a weighted combination of sense rank, ranked list and similarity measure scores obtained at steps 145, 146 and 147. Alternatively, a confidence score may be based on an un-weighted combination. In the case of a weighted combination, a weighting is applied to each of the scores to provide an overall confidence score based on a weighted combination of these outputs. This can be done for example using a machine-learning algorithm such as a Logistic Regression as described in David W. Hosmer, Stanley Lemeshow. "Applied logistic regression". John Wiley and Sons, 2000, incorporated by reference herein. The raw scores obtained may be input to the machine learning process that generates weights that are applied to the individual scores; e.g., a context similarity score may be given a higher weight due it its importance in ascertaining the sense. It should be understood that one or more of the steps 145-147 may be performed to provide the mapping LAT string to lexical type scores with one or more of the generated outputs utilized in the final score generation with the mappings and associated confidence scores maintained in a memory storage device.
[0051] In one embodiment, the raw scores (145, 146 and 147) may be simply combined in an applied combination function, i.e., summed, into a final score and these can be added without weights applied.
[0052] Returning to FIG. 3B, at 150 there is performed mapping each candidate answer against instances found in a structured resource such as Wikipedia® and DBpedia. For example, the candidate answer is mapped to instances in a Wikipedia (DBpedia) page resulting in generating an output data structure, including the mapped instances.
[0053] FIG. 5 shows a detailed score generation process of the mapping of the candidate answer string to instances in a structured database at 150 of FIG. 3B that utilizes a data resource having structured content or information in one embodiment. There is first performed at 152 obtaining, e.g., from conducting a search in a structured resource, e.g., Wikipedia® and DBpedia, a set of commercially identified/searchable instances having labels or IDs that explicitly match the candidate answer string. Then, at 154, a processing component, such as a search engine, conducts a search of the structured data resource knowledge base, database, a data corpus or the Web, to obtain the number of instances of the candidate answer. Step 154 produces a ranked list of instances based on detected number of instances (i.e., frequency) of the instances, e.g., in information available on the Web or a corpus. Then, at 157, a processing component implements functions to compute a similarity measure (score) between the text in the question/query string and contextual data associated with the instance in the ontological resource (ontology). Then, at 159, the process generates a confidence score based on a weighted (or unweighted in an alternate embodiment) combination of the ranked instance list and similarity measure scores obtained at 154 and 157. This step may include applying a weighting to each of the scores to provide an overall confidence score based on a weighted combination of these outputs. It should be understood that one or both of the steps 154 and 157 may be performed to provide the mapping of candidate answer string to instances in the structured resource with one or more of the generated outputs utilized in the final score generation with corresponding mappings and associated confidence scores maintained in a memory storage device.
[0054] In one embodiment, the use of context, e.g., particularly, at step 147 in FIG. 4 and step 157 in FIG. 5, involves obtaining the text in the query or relating to the query as surrounding context for use in determining the similarity. In the case of the LAT string, at 147, FIG. 4, the question LAT context is used in the matching to concepts or types in the ontological resource to obtain corresponding matching scores; and in the case of the candidate answer string, at 157, FIG. 5, the question context is used in the matching to instances in the structured resource to obtain corresponding matching scores. For example, the entity "Washington" is ambiguous in that it can refer to a person (George Washington), a city (Washington D.C.), an institution (Univ. of Washington), a state (Washington), etc. Thus, there is performed a determining of the correct sense of an entity dependent upon the context in which it appears. Thus, in one embodiment, similarity measure scores includes applying functions such as: aligning the context using BOW (bag of words) model such as described in http://en.wikipedia.org/wiki/Bag_of_words_model, or applying a vector similarity model approach such as described in http://en.wikipedia.org/wiki/Vector_space_model. A variety of information in encyclopedic and the structured resources such as Wikipedia®, and DBpedia may be used to obtain, e.g., alternate names, possible disambiguations, etc. Further, the discerning of types or instances from among noisy types or instances may require disambiguation. For example, given mappings of candidates to two different type systems, obtaining types from each type system may require disambiguation or type alignment, e.g., such as described in Agirre, Eneko & Philip Edmonds (eds.), 2006 entitled "Word Sense Disambiguation: Algorithms and Applications", Dordrecht: Springer. www.wsdbook.org.
[0055] For the context similarity measuring, there is accessed in Wordnet® the association(s) with every concept that includes a description of what concept means and examples of where the word appears in text. These descriptions provide a concept. In accessing YAGO, associated with every concept, there is included context in the form of a comment as opposed to a description.
[0056] Returning to FIG. 3B, at 160, there is provided identifying, for each candidate answer, one or more types or concepts in the structured resource. In one embodiment, the identifying may be performed using the one or more instances obtained at 150, however, it not necessary. Further to this step, there may be additionally performed extracting the one or more types of concepts for storage in a memory storage device.
[0057] Thus, at 160, once a candidate string has been mapped to an instance in a structured KB, there is performed obtaining the types for the entity involved, checking its type assertions (instance types or ITs), and navigating the type taxonomy to pull out all relevant types. Techniques to seek and find popular types associated with the entity in a large domain corpus are performed.
[0058] For example, in the case of a relative ambiguous candidate string, e.g., "JFK"--meaning a person, an airport, or a movie, there is first discerned the context to disambiguate the entity. Any disambiguation using context of the question including the entity, is performed at the time of mapping the entity to some knowledge base (e.g., Wikipedia® or DBpedia that may include type information) at 150. In an example candidate string "JFK", from the context it is inferred that JFK refers to a president type. This may be mapped to a JFK entry in a Wikipedia® page to obtain types ("U.S. president", "politician", "senator", "writer", etc.) for example that may be extracted from a "category" section of the Wikipedia page which may include type words or phrases. This may be performed a search engine in conjunction with a parser to extract the types. In one embodiment, the parser includes intelligence that looks for head noun of a phrase, for example to extract the relevant type.
[0059] Finally, as indicated at 170, there is identified from the structured ontological resource (e.g., YAGO/Wordnet®) one or more axioms in the structured resource that links the one or more LTs to ITs, i.e., specifies a relationship between the LTs to ITs, to produce candidate answer and LAT string score. An identified axiom(s), for example, a sub-class or sub-type links are identified among candidate instance (/types) and LAT instance (/types) and used to modify the final TyCor score. A Type alignment function may first be implemented as described in Aditya Kalyanpur, J. William Murdock, James Fan and Christopher Welty, in "Leveraging Community-built Knowledge for Type Coercion in Question Answering", Proceedings of ISWC 2011, incorporated by reference herein.
[0060] In one embodiment, an example "disjointness" axiom(s) may be provided in the ontological resource and used to generate an AnTyCor score as now described:
[0061] As a non-limiting illustrative example, suppose a question LAT is "country" and the candidate answer is "Albert Einstein", which has a type of Person in the structured resource. The presence of a "disjointness" axiom between the types Person and Country will produce a negative TyCor score for the candidate (i.e., AnTyCor score having a -1 value, for example). Even when no explicit disjointness axioms are defined in the ontology, disjointness may be statistically inferred from the instance data and used to generate the AnTycor score as described in the incorporated by reference: Aditya Kalyanpur, J. William Murdock, James Fan and Christopher Welty, in "Leveraging Community-built Knowledge for Type Coercion in Question Answering", Proceedings of ISWC 2011.
[0062] Further to this example, if the types Country and Person have no common instances in a very large structured source, it is inferred that they are statistically disjoint with a certain degree of confidence. The "completeness" of a type may be estimated and used to define an AnTyCore score.
[0063] As mentioned above, ontological axioms (i.e., axioms defined in the ontology) are either factual assertions or rules of inference.
[0064] Example: 1) "Albert Einstein is-a Scientist"--is a factual assertion;
[0065] Example 2) "Scientist is-a Person" is a simple subclass axiom/rule, which states that every instance of the concept Scientist is also an instance of the concept Person (i.e., a collection of such sub-class axioms forms a taxonomy).
[0066] Example 3) "Person is-disjoint-with Country" is a disjointness axiom which states that an instance of the concept Person cannot be an instance of Country (i.e. the two concepts are mutually exclusive).
[0067] Such rules/axioms are either defined manually by domain experts and/or acquired (semi-) automatically using knowledge mining techniques from a large corpus. Thus, for example, given a question that asks for a Country, a candidate answer "Albert Einstein" is computed from Wikipedia®. Using above Examples (1)-(3) processing, a record for "Albert Einstein" is accessed from a structured knowledge base such as DBpedia which obtains "types" (as types are assigned to instances in DBpedia records) or, accessed from the ontology from YAGO or Wordnet® (that provides on-line an ontology of many concepts) and in which it is inferred that since Einstein is a scientist, he is also a "type" person, and hence is not a "type" country. Hence, this candidate answer will be assigned an AnTyCor score (negative TyCore score).
[0068] For example, FIG. 6 shows an excerpt of a structured knowledge base such as a DBpedia page that defines, and being tightly interlinked with YAGO resource, a YAGO type. In FIG. 6, the DBpedia page 300 provides a list of properties 302, and corresponding property values 305. One searchable property is a label 310 having a value indicating the type, e.g., "Scientist" 315. Further instance values of type "scientist" are shown as a list of instances 320, e.g., Alfred_Russel_Wallace, Antoine_Lavoisier, etc. Thus, a search of the corresponding DBpedia page source code will automatically obtain an instance "type" for a candidate answer instance. Further shown is a list of sub-types 345 of the given type--in this example, sub-types of type Scientist 315, such as "Canadian Computer Scientist", "Welsh Space Scientist" etc. As indicated in FIG. 6, the page 300 further includes an additional entry indicating a property of type "scientist" as a subclass 325 of the type "Person" 330, e.g., indicated by the entry: yago:Person100007846. That is, the DBpedia page 300 specifies a subclass axiom 325 which indicates that type "Scientist" is a subclass of "Person". The corresponding identifier 340 at the end of the type name refers to a searchable WordNet® sense for this type. In one embodiment, for the case of disjointness axioms, these are added to YAGO between YAGO types. For example, Type "Person is disjoint with Location".
[0069] The way this axiom is used in AnTyCor is the following: Considering the query LAT: "Country" and Candidate: "Albert Einstein". 1. CHAI processing is used on the above candidate answer to obtain http://dbpedia.org/page/Albert_Einstein; 2. The type strings for the candidate answer are obtained by accessing http://dbpedia.org/class/yago/Scientist110560637 (from 1); 3. LATTE processing is used to obtain type strings for the query LAT by accessing: http://dbpedia.org/class/yago/Countryl08544813; and 4. TATA processing compares the type string (from 2) and the type string (from 3) which produces a score of -1, for example, because the two types are disjoint. This disjointness is found by a reasoner because Scientist is a sub-type of Person, and Country is a sub-type of Location, and there has been added an axiom or rule that Person is disjoint-with Country. Hence, the final TyCor score produced at the end of step 4 is the -1 AnTyCor score.
[0070] As a further example, assuming it is known a priori that the coverage for a particular type in the structured resource is very high, then under a closed world assumption, any instance that is not of the concerned type may be assigned a (negative) AnTyCor score.
[0071] In a further embodiment, a logical reasoner component such as described in A. Riazanov and A. Voronkov entitled "The Design and Implementation of Vampire. AI Communications", 15(2-3):91-110, 2002, may be implemented to infer connections between instances and LAT types (when no explicit links exist), and thus improve TyCor coverage.
[0072] As an example, supposing the question LAT is "Canadian" and the candidate answer string is "Wayne Gretzky", and it is known from a structured text resource (e.g., DBPedia) that "Wayne Gretzky" was born in Ontario, Canada. Using a logical reasoner and axioms about nationality, it is inferred that he is a Canadian, even without the presence of explicit type information, and thus produce a meaningful TyCor score.
[0073] In further embodiments, axioms about equivalence, subsumption, and siblings between types are treated differently to produce finer grained TyCor scores based on the type of match. This information may be further be used as features in the TyCor model.
[0074] Further, sibling axioms show type relatedness without disjointness, e.g., a painter type and musician type are both sub-types of person, and these may be found in the Wordnet®, for example. These may be assigned a very small score in the computing the candidate answer score. This score can be manually assigned based on empirical analysis of the data or be automatically learned using machine learning techniques such as Logistic Regression.
[0075] Further, subsumption axioms indicate types in sub-type relationships, e.g., "president" is a sub-type of "person", so a relatively higher score may be assigned in the computing the candidate answer score.
[0076] Further, equivalence axioms indicate a synonymous type relationship, e.g., a type "man" and a type "male" person are synonymous, so a relatively higher score may be assigned in the computing the candidate answer score.
[0077] FIG. 2A shows an example TyCor processing component 250 takes as input two strings: the determined LAT 202, and candidate answer 205, and ascertains the degree of type match (whether the candidate answer type matches the query LAT or not). Thus, for a LAT 202 "person" and a candidate answer 205 of "Washington", having a possible lexical type "person", there is agreement and potentially a high value TyCor (confidence) score. As shown in FIG. 2A, the TyCor processing 250 performs one or more parallel processing functions that produce individual scores as described herein. A process known as LATTE is invoked to produce a LATTE score 210. The LATTE score represents a degree of match between the query LAT 202 and a type in a structured database, in this example, YAGO. In the example, the LAT is "person" and matches perfectly with the type "person" in the structured database (i.e. YAGO). In this example, a value of 1.0 indicates an exact type match. Additionally, a process known as CHAI is invoked to produce a CHAI score 211. The CHAI score represents a degree of match between the candidate answer string 205 to instances in a knowledge base, such as DBpedia. Additionally, a process known as ICET is invoked that produces an ICET score 212. The ICET score represents a degree of match between an instance in a knowledge base mapped to the candidate answer and a type in a structured database, in this example, YAGO. In FIG. 2A, three examples of the ICET process are shown at 260a, 260b and 260c. As shown, a TyCor score 225 is produced as a combination, e.g., summation or product, of the individual LATTE 210, CHAI 211 and ICET 212 scores.
[0078] FIG. 2B shows an example TyCor processing component 250 with the additional process 270 in accordance with the additional process step 170 of FIG. 3B. Generally, as shown in FIG. 2B, example inputs to the TyCor processing component 250 are LAT input string 202 of "state" and a candidate answer string 205 of "Washington". Again, the TyCor processing component 250 performs parallel processing functions that produce individual scores. The process includes accessing an ontological resource, such as YAGO or Wordnet®, where all word senses are enumerated. That is, the knowledge base or information source is automatically linked to the ontological resources (YAGO or Wordnet®).
[0079] In the example shown, the LATTE processing 280 of input string "state" 202 produces LATTE scores by matching the input string "state" to instance strings, for example "PoliticalState" and "PhysicalState", in a ontology database such as in YAGO. In this example, a higher score (0.9) is obtained when matched against a political state and a lower score (0.1) when matched against a physical state. This score is computed based on the context of the question and background prior knowledge using machine learning techniques. Details of how this is done are explained in U.S. patent application Ser. No. 12/126,642, incorporated herein by reference.
[0080] Further, in the example shown, the CHAI processing of input candidate string 205 "Washington" will yield a ranked list of instances from a structured knowledge base that match the string "Washington", such as "George Washington (President)", "Washington (State)", or "Washington D.C. (city)". Each instance is associated with a corresponding score based on the context of the input string and background prior knowledge. In the example shown, two instances are shown "George_Washington" receiving a CHAI score of (0.7) and "G_Thomas_Washinton" receiving a CHAI score of (0.2). Again, details of how the scores are computed are explained in U.S. patent application Ser. No. 12/126,642, incorporated herein by reference.
[0081] Further, ICET processing 260a and 260b computes ICET scores for each of the types for the instances produced in the CHAI step. For example, the instance of "George Washington" has mapped types Person, President and General each receiving a different ICET scores. Again, details of how the scores are computed are explained in U.S. patent application Ser. No. 12/126,642, incorporated herein by reference.
[0082] The new processing step introduced in FIG. 2B is referred to as TATA (type to type alignment) processing 270. The TATA processing 270 compares the types mapped to the LAT 202 with the types mapped to the instances which were mapped to the candidate answer 205. Again, a TATA score 213 is produced representing whether there is a match between the types. At this step 270, one embodiment of the invention uses axioms or logical rules in the ontology to ascertain a measure of disjointedness referred to as an AnTyCor score or negative TyCor score. Thus, as shown in FIG. 2B, a TATA score 213 (i.e. AnTyCor or negative TyCor) is produced representing that the type "Political State" mapped to the LAT is found to be disjoint with the type "Person" mapped to the instance "George Washington" which in turn was mapped to the candidate answer. In other embodiments, even when no explicit axioms are defined in an ontology, it is possible to statistically infer disjointedness from the type date and use it to generate an AnTyCor score. For example, if the types, such as "Country" and "Person", have no common instances in a large structure source then a statistical disjointedness can be inferred. In another embodiment, it is possible to estimate the "completeness" of a type and use this estimate to determine an AnTyCor score. For example, suppose it is known a priori that the coverage for a particular type in the structure resource is very high, then, under a closed world assumption, any instance that is not of the concerned type can be assigned a AnTyCor score or negative TyCor score. In yet another embodiment, using a logical reasoner, it is possible to infer connection between types, even when no explicit links exist, and thus improve the TyCor score. For example, if the query LAT is "Canadian" and the candidate answer string is "Wayne Gretzky", and it is known from the structured resource that "Wayne Gretzky" was "born in Ontario, Canada", then using a logical reasoner and axioms about nationality, it is possible to infer that "Wayne Gretzky" is "Canadian" without the explicit type information, and thus a better TyCor score can be calculated. In yet another embodiment, axioms about equivalence, subsumption, siblings, etc. between types can be treated differently to produce finer grained TyCor scores and this information can also be used as features in a TyCor model.
[0083] As mentioned, FIG. 1 shows a system diagram described in U.S. patent application Ser. No. 12/126,642 depicting a high-level logical architecture 10 and methodology in which the system and method for deferred type evaluation using text with limited structure is employed in one embodiment.
[0084] Generally, as shown in FIG. 1, the high level logical architecture 10 includes the Query Analysis module 20 implementing functions for receiving and analyzing a user query or question. The term "user" may refer to a person or persons interacting with the system, or refers to a computer system 22 generating a query by mechanical means, and where the term "user query" refers to such a mechanically generated query and context 19'. A candidate answer generation module 30 is provided to implement a search for candidate answers by traversing structured, semi structured and unstructured sources contained in a Primary Sources module 11 and in an Answer Source Knowledge Base (KB) module 21 containing collections of relations and lists extracted from primary sources. All the sources of information can be locally stored or distributed over a network, including the Internet.
[0085] The Candidate Answer generation module 30 of architecture 10 generates a plurality of output data structures containing candidate answers based upon the analysis of retrieved data. In FIG. 1, an Evidence Gathering module 50 interfaces with the primary data sources and knowledge bases for concurrently analyzing the evidence based on passages having candidate answers, and scores each of candidate answers, in one embodiment, as parallel processing operations. In one embodiment, the architecture may be employed utilizing the Common Analysis System (CAS) candidate answer structures as is described in commonly-owned, issued U.S. Pat. No. 7,139,752, the whole contents and disclosure of which is incorporated by reference as if fully set forth herein.
[0086] As depicted in FIG. 1, the Evidence Gathering module 50 comprises a Candidate Answer Scoring module 250 for analyzing a retrieved passage and scoring each of candidate answers of a retrieved passage. The Answer Source Knowledge Base (KB) 21 may comprise one or more databases of structured or semi-structured sources (pre-computed or otherwise) comprising collections of relations (e.g., Typed Lists). In an example implementation, the Answer Source knowledge base may comprise a database stored in a memory storage system, e.g., a hard drive.
[0087] An Answer Ranking module 60 may be invoked to provide functionality for ranking candidate answers and determining a response 99 returned to a user via a user's computer display interface (not shown) or a computer system 22, where the response may be an answer, or an elaboration of a prior answer or request for clarification in response to a question--when a high quality answer to the question is not found. A machine learning implementation is further provided where the "answer ranking" module 60 includes a trained model component (not shown) produced using a machine learning techniques from prior data.
[0088] The processing depicted in FIG. 1, may be local, on a server, or server cluster, within an enterprise, or alternately, may be distributed with or integral with or otherwise operate in conjunction with a public or privately available search engine in order to enhance the question answer functionality in the manner as described. Thus, the method may be provided as a computer program product comprising instructions executable by a processing device, or as a service deploying the computer program product. The architecture employs a search engine (e.g., a document retrieval system) as a part of Candidate Answer Generation module 30 which may be dedicated to searching the Internet, a publicly available database, a web-site (e.g., IMDB.com) or, a privately available database. Databases can be stored in any storage system, non-volatile memory storage systems, e.g., a hard drive or flash memory, and can be distributed over the network or not.
[0089] As mentioned, the system and method of FIG. 1 makes use of the Common Analysis System (CAS), a subsystem of the Unstructured Information Management Architecture (UIMA) that handles data exchanges between the various UIMA components, such as analysis engines and unstructured information management applications. CAS supports data modeling via a type system independent of programming language, provides data access through a powerful indexing mechanism, and provides support for creating annotations on text data, such as described in (http://www.research.ibm.com/journal/sj/433/gotz.html) incorporated by reference as if set forth herein. It should be noted that the CAS allows for multiple definitions of the linkage between a document and its annotations, as is useful for the analysis of images, video, or other non-textual modalities (as taught in the herein incorporated reference U.S. Pat. No. 7,139,752).
[0090] In one embodiment, the UIMA may be provided as middleware for the effective management and interchange of unstructured information over a wide array of information sources. The architecture generally includes a search engine, data storage, analysis engines containing pipelined document annotators and various adapters. The UIMA system, method and computer program may be used to generate answers to input queries. The method includes inputting a document and operating at least one text analysis engine that comprises a plurality of coupled annotators for tokenizing document data and for identifying and annotating a particular type of semantic content. Thus it can be used to analyze a question and to extract entities as possible answers to a question from a collection of documents.
[0091] As further shown in greater detail in the architecture diagram of FIG. 1, the "Query Analysis" module 20 receives an input that comprises the query 19 entered, for example, by a user via their web-based browser device. An input query 19 may comprise a text string. The query analysis block 20 includes additionally a Lexical Answer Type (LAT) block 200 that implements functions and programming interfaces to provide additional constraints on the answer type (LAT). The computation in the block 20 comprises but is not limited to the Lexical Answer Type. The LAT block 200 includes certain functions/sub-functions (not shown) to determine the LAT.
[0092] As mentioned above, a LAT of the question/query is the type (i.e. the descriptor) of the referent of the entity that is a valid answer to the question. In practice, LAT is the descriptor of the answer detected by a natural language understanding module comprising a collection of patterns and/or a parser with a semantic interpreter.
[0093] With reference to the Lexical Answer Type (LAT) block 200, in the query analysis module 20 of FIG. 1, the LAT represents the question terms that identify the semantic type of the correct answer. In one embodiment, as known, a LAT may be detected in a question through pattern LAT detection rules. These rules are implemented and can be encoded manually or learned by machine automatically through association rule learning. In this case, the natural language understanding model can be limited to implementation the rules.
[0094] In one embodiment, the above-described modules of FIG. 1-2 can be represented as functional components in UIMA is preferably embodied as a combination of hardware and software for developing applications that integrate search and analytics over a combination of structured and unstructured information. The software program that employs UIMA components to implement end-user capability is generally referred to as the application, the application program, or the software application.
[0095] The UIMA high-level architecture, one embodiment of which is illustrated in FIG. 1, defines the roles, interfaces and communications of large-grained components that cooperate to implement UIM applications. These include components capable of analyzing unstructured source artifacts, such as documents containing textual data and/or image data, integrating and accessing structured sources and storing, indexing and searching for artifacts based on discovered semantic content.
[0096] Although not shown, a non-limiting embodiment of the UIMA high-level architecture includes a Semantic Search Engine, a Document Store, at least one Text Analysis Engine (TAE), at least one Structured Knowledge Source Adapter, a Collection Processing Manager, at least one Collection Analysis Engine, all interfacing with Application logic. In one example embodiment, the UIMA operates to access both structured information and unstructured information to generate candidate answers and an answer in the manner as discussed herein. The unstructured information may be considered to be a collection of documents, and can be in the form of text, graphics, static and dynamic images, audio and various combinations thereof.
[0097] Aspects of the UIMA are further shown in FIG. 7, where there is illustrated a Analysis Engine (AE) 600 that can be a component part of the Text Analysis Engine (TAE). Included in the AE 600 is a Common Analysis System (CAS) 610, an annotator 620 and a controller 630. A second embodiment of a TAE (not shown) includes an aggregate Analysis Engine composed of two or more component analysis engines as well as the CAS, and implements the same external interface as the AE 600.
Common Analysis System 610
[0098] The Common Analysis System (CAS) 610 is provided as the common facility that all Annotators 620 use for accessing and modifying analysis structures. Thus, the CAS 610 enables coordination between annotators 620 and facilitates annotator 620 reuse within different applications and different types of architectures (e.g. loosely vs. tightly coupled). The CAS 610 can be considered to constrain operation of the various annotators.
[0099] The CAS 610 principally provides for data modeling, data creation and data retrieval functions. Data modeling preferably defines a tree hierarchy of (data) types, as shown in the example Table 1 provided below. The types have attributes or properties referred to as features. In preferred embodiments, there are a small number of built-in (predefined) types, such as integer (int), floating point (float) and string; UIMA also includes the predefined data type "Annotation". The data model is defined in the annotator descriptor, and shared with other annotators. In the Table 1, some "Types" that are considered extended from prior art unstructured information management applications to accommodate question answering in the preferred embodiment of the invention include:
TABLE-US-00001 TABLE 1 TYPE's PARENT TYPE (or feature) (or feature type) Query Record Top Query Query Record Query Context Query Record Candidate Answer Record Annotation Candidate Answer Candidate Answer Record Feature: CandidateAnswerScore Float QueryLexical Answer Type Annotation CandidateAnswer LT Annotation Feature: TyCorScore Float
[0100] In Table 1, for example, all of the question answering types (list in the left column) are new types and extend either another new type or an existing type (shown in the right column). For example, both Query and Query Context are kinds of Query Record, a new type; while Candidate Answer Record extends the UIMA type Annotation, but adds a new feature CandidateAnswerScore which is a Float. In addition, Table 1 describes the query LAT as having a UIMA Annotation type; CandidateAnswerLT is also an Annotation, but with an additional featue TyCorScore of type Float.
[0101] CAS 610 data structures may be referred to as "feature structures." To create a feature structure, the type must be specified (see TABLE 1). Annotations (and -feature structures) are stored in indexes.
[0102] The CAS 610 may be considered to be a collection of methods (implemented as a class, for example, in Java or C++) that implements an expressive object-based data structure as an abstract data type. Preferably, the CAS 610 design is largely based on a TAE Feature-Property Structure, that provides user-defined objects, properties and values for flexibility, a static type hierarchy for efficiency, and methods to access the stored data through the use of one or more iterators.
[0103] The abstract data model implemented through the CAS 610 provides the UIMA 100 with, among other features: platform independence (i.e., the type system is defined declaratively, independently of a programming language); performance advantages (e.g., when coupling annotators 610 written in different programming languages through a common data model); flow composition by input/output specifications for annotators 610 (that includes declarative specifications that allow type checking and error detection, as well as support for annotators (TAE) as services models); and support for third generation searching procedures through semantic indexing, search and retrieval (i.e. semantic types are declarative, not key-word based).
[0104] The CAS 610 provides the annotator 620 with a facility for efficiently building and searching an analysis structure. The analysis structure is a data structure that is mainly composed of meta-data descriptive of sub-sequences of the text of the original document. An exemplary type of meta-data in an analysis structure is the annotation. An annotation is an object, with its own properties, that is used to annotate a sequence of text. There are an arbitrary number of types of annotations. For example, annotations may label sequences of text in terms of their role in the document's structure (e.g., word, sentence, paragraph etc), or to describe them in terms of their grammatical role (e.g., noun, noun phrase, verb, adjective etc.). There is essentially no limit on the number of, or application of, annotations. Other examples include annotating segments of text to identify them as proper names, locations, military targets, times, events, equipment, conditions, temporal conditions, relations, biological relations, family relations or other items of significance or interest.
[0105] Typically an Annotator's 620 function is to analyze text, as well as an existing analysis structure, to discover new instances of the set of annotations that it is designed to recognize, and then to add these annotations to the analysis structure for input to further processing by other annotators 620.
[0106] In addition to the annotations, the CAS 610 of FIG. 7 may store the original document text, as well as related documents that may be produced by the annotators 620 (e.g., translations and/or summaries of the original document). Preferably, the CAS 610 includes extensions that facilitate the export of different aspects of the analysis structure (for example, a set of annotations) in an established format, such as XML.
[0107] More particularly, the CAS 610 is that portion of the TAE that defines and stores annotations of text. The CAS API is used both by the application and the annotators 620 to create and access annotations. The CAS API includes, preferably, at least three distinct interfaces. A Type system controls creation of new types and provides information about the relationship between types (inheritance) and types and features. One non-limiting example of type definitions is provided in TABLE 1. A Structure Access Interface handles the creation of new structures and the accessing and setting of values. A Structure Query Interface deals with the retrieval of existing structures.
[0108] The Type system provides a classification of entities known to the system, similar to a class hierarchy in object-oriented programming. Types correspond to classes, and features correspond to member variables. Preferably, the Type system interface provides the following functionality: add a new type by providing a name for the new type and specifying the place in the hierarchy where it should be attached; add a new feature by providing a name for the new feature and giving the type that the feature should be attached to, as well as the value type; and query existing types and features, and the relations among them, such as "which type(s) inherit from this type".
[0109] Preferably, the Type system provides a small number of built-in types. As was mentioned above, the basic types are int, float and string. In a Java implementation, these correspond to the Java int, float and string types, respectively. Arrays of annotations and basic data types are also supported. The built-in types have special API support in the Structure Access Interface.
[0110] The Structure Access Interface permits the creation of new structures, as well as accessing and setting the values of existing structures. Preferably, this provides for creating a new structure of a given type; getting and setting the value of a feature on a given structure; and accessing methods for built-in types. Feature definitions are provided for domains, each feature having a range.
[0111] In an alternative environment, modules of FIGS. 1, 2 can be represented as functional components in GATE (General Architecture for Text Engineering) (see: http://gate.ac.uk/releases/gate-2.0alpha2-build484/doc/userguide.html). Gate employs components which are reusable software chunks with well-defined interfaces that are conceptually separate from GATE itself. All component sets are user-extensible and together are called CREOLE--a Collection of REusable Objects for Language Engineering. The GATE framework is a backplane into which plug CREOLE components. The user gives the system a list of URLs to search when it starts up, and components at those locations are loaded by the system. In one embodiment, only their configuration data is loaded to begin with; the actual classes are loaded when the user requests the instantiation of a resource.). GATE components are one of three types of specialized Java Beans: 1) Resource: The top-level interface, which describes all components. What all components share in common is that they can be loaded at runtime, and that the set of components is extendable by clients. They have Features, which are represented externally to the system as "meta-data" in a format such as RDF, plain XML, or Java properties. Resources may all be Java beans in one embodiment. 2) ProcessingResource: Is a resource that is runnable, may be invoked remotely (via RMI), and lives in class files. In order to load a PR (Processing Resource) the system knows where to find the class or jar files (which will also include the metadata); 3) LanguageResource: Is a resource that consists of data, accessed via a Java abstraction layer. They live in relational databases; and, VisualResource: Is a visual Java bean, component of GUIs, including of the main GATE gui. Like PRs these components live in .class or .jar files.
[0112] In describing the GATE processing model any resource whose primary characteristics are algorithmic, such as parsers, generators and so on, is modelled as a Processing Resource. A PR is a Resource that implements the Java Runnable interface. The GATE Visualisation Model implements resources whose task is to display and edit other resources are modelled as Visual Resources. The Corpus Model in GATE is a Java Set whose members are documents. Both Corpora and Documents are types of Language Resources (LR) with all LRs having a Feature Map (a Java Map) associated with them that stored attribute/value information about the resource. FeatureMaps are also used to associate arbitrary information with ranges of documents (e.g. pieces of text) via an annotation model. Documents have a DocumentContent which is a text at present (future versions may add support for audiovisual content) and one or more AnnotationSets which are Java Sets.
[0113] As UIMA, GATE can be used as a basis for implementing natural language dialog systems and multimodal dialog systems having the disclosed question answering system as one of the main submodules. The references, incorporated herein by reference above (U.S. Pat. Nos. 6,829,603 and 6,983,252, and 7,136,909) enable one skilled in the art to build such an implementation.
[0114] FIG. 8 illustrates an exemplary hardware configuration of a computing system 401 in which the present system and method may be employed. The hardware configuration preferably has at least one processor or central processing unit (CPU) 411. The CPUs 411 are interconnected via a system bus 412 to a random access memory (RAM) 414, read-only memory (ROM) 416, input/output (I/O) adapter 418 (for connecting peripheral devices such as disk units 421 and tape drives 440 to the bus 412), user interface adapter 422 (for connecting a keyboard 424, mouse 426, speaker 428, microphone 432, and/or other user interface device to the bus 412), a communication adapter 434 for connecting the system 401 to a data processing network, the Internet, an Intranet, a local area network (LAN), etc., and a display adapter 436 for connecting the bus 412 to a display device 438 and/or printer 439 (e.g., a digital printer of the like).
[0115] As will be appreciated by one skilled in the art, aspects of the present invention may be embodied as a system, method or computer program product. Accordingly, aspects of the present invention may take the form of an entirely hardware embodiment, an entirely software embodiment (including firmware, resident software, micro-code, etc.) or an embodiment combining software and hardware aspects that may all generally be referred to herein as a "circuit," "module" or "system." Furthermore, aspects of the present invention may take the form of a computer program product embodied in one or more computer readable medium(s) having computer readable program code embodied thereon.
[0116] Any combination of one or more computer readable medium(s) may be utilized. The computer readable medium may be a computer readable signal medium or a computer readable storage medium. A computer readable storage medium may be, for example, but not limited to, an electronic, magnetic, optical, electromagnetic, infrared, or semiconductor system, apparatus, or device, or any suitable combination of the foregoing. More specific examples (a non-exhaustive list) of the computer readable storage medium would include the following: an electrical connection having one or more wires, a portable computer diskette, a hard disk, a random access memory (RAM), a read-only memory (ROM), an erasable programmable read-only memory (EPROM or Flash memory), an optical fiber, a portable compact disc read-only memory (CD-ROM), an optical storage device, a magnetic storage device, or any suitable combination of the foregoing. In the context of this document, a computer readable storage medium may be any tangible medium that can contain, or store a program for use by or in connection with a system, apparatus, or device running an instruction.
[0117] A computer readable signal medium may include a propagated data signal with computer readable program code embodied therein, for example, in baseband or as part of a carrier wave. Such a propagated signal may take any of a variety of forms, including, but not limited to, electro-magnetic, optical, or any suitable combination thereof. A computer readable signal medium may be any computer readable medium that is not a computer readable storage medium and that can communicate, propagate, or transport a program for use by or in connection with a system, apparatus, or device running an instruction.
[0118] Program code embodied on a computer readable medium may be transmitted using any appropriate medium, including but not limited to wireless, wireline, optical fiber cable, RF, etc., or any suitable combination of the foregoing.
[0119] Computer program code for carrying out operations for aspects of the present invention may be written in any combination of one or more programming languages, including an object oriented programming language such as Java, Smalltalk, C++ or the like and conventional procedural programming languages, such as the "C" programming language or similar programming languages. The program code may run entirely on the user's computer, partly on the user's computer, as a stand-alone software package, partly on the user's computer and partly on a remote computer or entirely on the remote computer or server. In the latter scenario, the remote computer may be connected to the user's computer through any type of network, including a local area network (LAN) or a wide area network (WAN), or the connection may be made to an external computer (for example, through the Internet using an Internet Service Provider).
[0120] Aspects of the present invention are described below with reference to flowchart illustrations and/or block diagrams of methods, apparatus (systems) and computer program products according to embodiments of the invention. It will be understood that each block of the flowchart illustrations and/or block diagrams, and combinations of blocks in the flowchart illustrations and/or block diagrams, can be implemented by computer program instructions. These computer program instructions may be provided to a processor of a general purpose computer, special purpose computer, or other programmable data processing apparatus to produce a machine, such that the instructions, which run via the processor of the computer or other programmable data processing apparatus, create means for implementing the functions/acts specified in the flowchart and/or block diagram block or blocks. These computer program instructions may also be stored in a computer readable medium that can direct a computer, other programmable data processing apparatus, or other devices to function in a particular manner, such that the instructions stored in the computer readable medium produce an article of manufacture including instructions which implement the function/act specified in the flowchart and/or block diagram block or blocks.
[0121] The computer program instructions may also be loaded onto a computer, other programmable data processing apparatus, or other devices to cause a series of operational steps to be performed on the computer, other programmable apparatus or other devices to produce a computer implemented process such that the instructions which run on the computer or other programmable apparatus provide processes for implementing the functions/acts specified in the flowchart and/or block diagram block or blocks.
[0122] The flowchart and block diagrams in the Figures illustrate the architecture, functionality, and operation of possible implementations of systems, methods and computer program products according to various embodiments of the present invention. In this regard, each block in the flowchart or block diagrams may represent a module, segment, or portion of code, which comprises one or more operable instructions for implementing the specified logical function(s). It should also be noted that, in some alternative implementations, the functions noted in the block may occur out of the order noted in the figures. For example, two blocks shown in succession may, in fact, be run substantially concurrently, or the blocks may sometimes be run in the reverse order, depending upon the functionality involved. It will also be noted that each block of the block diagrams and/or flowchart illustration, and combinations of blocks in the block diagrams and/or flowchart illustration, can be implemented by special purpose hardware-based systems that perform the specified functions or acts, or combinations of special purpose hardware and computer instructions.
[0123] The embodiments described above are illustrative examples and it should not be construed that the present invention is limited to these particular embodiments. Thus, various changes and modifications may be effected by one skilled in the art without departing from the spirit or scope of the invention as defined in the appended claims.
User Contributions:
Comment about this patent or add new information about this topic:
Images included with this patent application:
 |  |
 |  |
 |  |
 |  |
 |  |
 |
| Similar patent applications: | |
| Date | Title |
|---|---|
| 2012-12-13 | Caching responses for scoped and non-scoped domain name system queries |
| 2012-12-20 | Method for restoring software applications on desktop computers |
| 2012-12-20 | Systems and methods for using graphical representations to manage query results |
| 2012-12-20 | Systems and methods for using graphical representations to manage query results |
| 2012-12-06 | Customizing language for organization application installation |
| New patent applications in this class: | |
| Date | Title |
|---|---|
| 2019-05-16 | Computer-implemented platform for generating query-answer pairs |
| 2019-05-16 | Internet of things structured query language query formation |
| 2019-05-16 | Method and apparatus for coupling the internet, environment and intrinsic memory to users |
| 2019-05-16 | Extracting structured data from weblogs |
| 2019-05-16 | Dynamic search set creation in a search engine |
| New patent applications from these inventors: | |
| Date | Title |
|---|---|
| 2020-03-19 | Decision-support application and system for medical differential-diagnosis and treatment using a question-answering system |
| 2017-06-01 | Type evaluation in a question-answering system |
| 2017-06-01 | Providing answers to questions including assembling answers from multiple document segments |
| 2017-05-18 | Concept identification in a question answering system |
| 2016-05-26 | Entity-relation based passage scoring in a question answering computer system |
| Top Inventors for class "Data processing: database and file management or data structures" | |
| Rank | Inventor's name |
|---|---|
| 1 | International Business Machines Corporation |
| 2 | International Business Machines Corporation |
| 3 | John M. Santosuosso |
| 4 | Robert R. Friedlander |
| 5 | James R. Kraemer |