Patent application title: Handwritten Character Recognition System
Inventors:
Jonathon Leigh Napper (Balmain, AU)
Assignees:
Silverbrook Research Pty Ltd
IPC8 Class: AG06K934FI
USPC Class:
382179
Class name: Image segmentation segmenting individual characters or words segmenting hand-printed characters
Publication date: 2012-12-27
Patent application number: 20120328195
Abstract:
A handwritten character recognition system is disclosed. The system has
an input device for receiving handwritten strokes, and a processor for
classifying the handwritten strokes as an output character. The processor
does so by calculating a degree of membership of the handwritten strokes
to each of a plurality of character models. The character model that
produces the highest degree of membership is selected and the handwritten
strokes ate classified as the output character associated with the
character model that produces the highest degree of membership.Claims:
1. A handwritten character recognition system comprising: an input device
for receiving one or more handwritten strokes; and a processor for:
calculating a degree of membership of the one or more handwritten strokes
to each of a plurality of character models; selecting the character model
that produces the highest degree of membership; and classify the one or
more handwritten strokes as an output character associated with the
character model that produces the highest degree of membership, wherein
the degree of membership of the one or more handwritten strokes to each
respective character model is calculated by: segmenting the one or more
handwritten strokes into sub-strokes according to a model specific
segmentation scheme defined for the respective character model;
calculating a degree of conformity of each sub-stroke to a set of generic
shapes defined for the respective character model; calculating the degree
of membership of the one or more handwritten strokes to the respective
character model based on a set of rules specific for the respective
character model and defining the positioning of the set of generic
shapes.
2. The handwritten character recognition system of claim 1 wherein the input device is a graphics tablet.
3. The handwritten character recognition system of claim 1 wherein, upon failure of the segmentation of the one or more handwritten strokes into sub-strokes according to the model specific segmentation scheme defined for the respective character model, the degree of membership of the one or more handwritten strokes to the respective character model is given a low value.
4. The handwritten character recognition system of claim 1 wherein each model specific segmentation scheme defines a minimum sub-stroke length.
5. The handwritten character recognition system of claim 4 wherein the minimum sub-stroke length is based upon the length of the segment being segmented.
6. The handwritten character recognition system of claim 1, wherein at least one character model has a plurality of associated model specific segmentation schemes.
7. The handwritten character recognition system of claim 6, wherein the processor, for each character model having a plurality of associated model specific segmentation schemes, determines whether the one or more strokes is capable of being segmented with one of the model specific segmentation schemes, and if the one or more strokes are incapable of be segmented, the processor changes the model specific segmentation schemes.
6. The handwritten character recognition system of claim 1, wherein fuzzy logic rules are used in calculating the degree of conformity and the degree of membership.
Description:
CROSS REFERENCE TO RELATED APPLICATION
[0001] This application is a continuation application of U.S. application Ser. No. 13/204,703 filed Aug. 7, 2011, which is a continuation application of U.S. application Ser. No. 12/941,807 filed Nov. 8, 2010 now issued U.S. Pat. No. 8,009,914, which is a continuation application of U.S. application Ser. No. 12/750,587 filed Mar. 30, 2010, now issued U.S. Pat. No. 7,848,574, which is a continuation application of U.S. application Ser. No. 12/031,615 filed Feb. 14, 2008, now issued U.S. Pat. No. 7,697,761, which is a continuation application of U.S. application Ser. No. 10/492,168 filed Apr. 9, 2004, now issued U.S. Pat. No. 7,359,551, which is a 371 of PCT/AU02/01393 filed Oct. 15, 2002 all of which are herein incorporated by reference.
TECHNICAL FIELD
[0002] The present invention relates to a method of interpreting and decoding handwritten data entry into a computer or other processing device, and in particular, to a method of handwriting recognition which involves decomposing individual characters into one or more primitive sub-strokes, where applicable.
BACKGROUND ART
[0003] The reference to any prior art in this specification is not, and should not be taken as, an acknowledgement or any form of suggestion that the prior art forms part of the common general knowledge.
[0004] Prior art processing devices, such as handheld computers, are available which decode user instructions based on handwritten data inputs. Other devices force the user to enter data using a pseudo-handwritten format. One example of such a device is produced by Palm Computers and use a proprietary input format known as Graffiti. This input format allows the user of a handheld computer to enter data into the device by moving a plastic stylus in predefined motions over a touchscreen area, where each character has an associated `stroke`, which in many cases resembles the actual character.
[0005] Such systems offer advantages where the portable device is too small to have a usefully sized keyboard, but they require the user to learn an artificial `language` in order to enter data.
[0006] The range of handwriting styles possessed by individual users is vast, and therefore, the provision of automated computer recognition of different user's handwriting is problematic. This has resulted in minimal use of commercially viable handwriting recognition systems in computing devices. It is desirable to provide a system which is able to interpret handwriting without forcing the user to adapt his or her writing style to conform with the expected input style of a particular device.
[0007] Most pattern or character recognition systems perform some kind of segmentation of an input signal to identify the fundamental primitives of the data and to minimize the level of noise in the input. Segmentation is also performed to reduce the amount of information used during feature extraction, and allows pattern recognition to occur on more abstract features of the input signal.
[0008] In handwriting recognition systems, individual strokes are often segmented into a number of sub-stroke primitives during preprocessing. These primitives are then passed to a feature extraction module or used directly for pattern classification. In cursive or connected print recognition systems, a single stroke may represent more than one letter, so segmentation is used to identify potential letter segmentation points.
[0009] Many segmentation techniques have been described by the research community, including simple approaches based on the properties of the human motor system Examples include segmenting at curvature maxima, critical points, and velocity extrema, or a combination of these techniques (e.g. looking for points where curvature extrema and velocity minima coincide). Other research has proposed using ballistic gesture detection, independent component analysis of the strokes, and regularity and singularity concepts for the segmentation of strokes.
[0010] While the above procedures use handwriting generation as the foundation for segmentation, other techniques are based on the perception process. Key to the visual decoding of letters is the perception of the local relative positions of primitives thus positional extrema play an important role in the recognition of letter shapes. Perception based criteria for segmentation include X and Y extrema, cusps, and stroke intersections.
[0011] While stroke segmentation can improve the accuracy of a handwriting recognition system under certain conditions, it can also be a major source of recognition errors. Most motor-based stroke segmentation algorithms apply some kind of numeric threshold when selecting segmentation points, resulting in the possibly inconsistent splitting of strokes that are poorly formed. FIG. 2b) shows the incorrect segmentation based on curvature extrema of a badly written letter `a`.
[0012] In this example, stroke segmentation is being used to partition or segment the circular body of the `a` from the more linear stem using the extreme curvature at the top of the stem as a segmentation point. FIG. 2a) shows the correct segmentation point (as indicated by the cross). However, FIG. 2b) has a curvature extremum inside the circular body, and is missing the expected cusp that marks the beginning of the letter stem, resulting in the incorrect segmentation of the stroke.
[0013] Velocity is also used for segmentation, since handwriting is generated by a series of ballistic movements (i.e. accelerating from the start to a peak velocity, then decelerating at the target point). Sections of high velocity are generally straight, while low velocity usually occurs at the extrema of curvature. However, velocity is also subject to thresholding problems, and additionally, the user may pause while writing a stroke, leading to an invalid segmentation point. In FIG. 3, the sampled points, indicated by squares, for a letter `a` are shown. The velocity of the pen can be derived from the spacing between the samples (assuming a constant sampling rate), so a large spacing indicates high velocity, while samples that are close together indicate lower velocity. In the example, the low velocity (and high curvature) regions can be seen as clusters of samples in the cusp at the top of the stem, as well as in the small hook at the bottom of the stem. However, there is another region of low velocity (on the left of the circular region) that was caused by the writer hesitating during the down-stroke. So while the letter `a` is clearly well written, the velocity-based segmentation may produce an inconsistent result.
[0014] Perceptual segmentation techniques, such as using Y-extrema as segmentation points, generally do not suffer from thresholding problems, since no numeric value is required to determine if a point is a local extremum. However, these techniques also suffer from inconsistent segmentation. In FIG. 4a), the letter `a` is segmented, indicated by a cross, at a Y-extremum located near the start of the stroke. However, the second letter `a`, shown in FIG. 4b) while clearly the same letter as the first, does not contain a Y-extremum at this position, as the stroke tends to level off.
[0015] Most other segmentation algorithms suffer from these problems, and are particularly affected by poorly written letters. Due to the difficult and error-prone nature of stroke segmentation, many systems do not attempt any kind of stroke segmentation and simply work directly on the raw, un-segmented strokes provided by the user. Those systems that do perform stroke segmentation usually implement some kind of elastic matching procedure to minimize the effect of inconsistent segmentation.
[0016] "Elastic Structural Matching For Recognizing Online Handwritten Alphanumeric Characters," Technical Report HKUST-CS98-07, Department Of Computer Science, Hong Kong University, March 1998 discloses the use of extrema of curvature to segment strokes into multiple line segments. However, they note that "a smooth stroke may be broken into parts due to poor quality writing" thus causing incorrect segmentation to occur. To counter this, they implement a set of rules that attempt to detect invalid segmentation, combining incorrectly segmented sub-strokes to form a new stroke.
[0017] "Handwritten Word Recognition--The Approach Proved By Practice", Advances In Handwriting Recognition, Series in Machine Perception and Artificial Intelligence, Vol. 34, pp. 153-162, World Scientific Publishing Co. 1999 discloses the use of zero crossing points in vertical velocity to segment handwritten cursive strokes in a commercial optical check-reading system. The sub-strokes are then matched against a set of primitive elements to be used in an elastic-matching recognizer.
[0018] "Global Methods for Stroke-segmentation", Advances In Handwriting Recognition, Series in Machine Perception and Artificial Intelligence, Vol. 34, pp. 225-234, World Scientific Publishing Co. 1999 discloses stroke segmentation of offline images based on contour curve fitting. In their method, curves are first approximated using cubic B-splines, with segmentation cuts made at the extreme points of curvature.
[0019] "A Fuzzy Online Handwriting Recognition System: FOHRES," Proceedings of the 2nd International Conference on Fuzzy Theory and Technology, 13-16 Oct., 1993, Durham, NC teaches the use of fuzzy-logic representations of pen velocity and direction together with a group of linguistic variables to form a set of fuzzy-logic rules for stroke segmentation. Their segmented strokes are used as the primitives for fuzzy feature extraction.
[0020] "Recognizing Letters in Online Handwriting Using Hierarchical Fuzzy Inference", 4th International Conference Document Analysis and Recognition (ICDAR), Aug. 18-20, 1997, Ulm, Germany discloses the segmentation of strokes at cusps and points with horizontal tangents into sets of PStrokes (partial strokes). The disclosed algorithm uses a system of angular smoothing (rather than the point-position smoothing that is often performed) that does not distort discontinuous parts of the pen trajectory (i.e. cusps).
[0021] "Detection Of Extreme Points of Online Handwritten Scripts", Progress In Handwriting Recognition, pp. 169-176, 2-5 Sep., 1996, Colchester, UK. World Scientific Publishing Co. discloses a robust local extrema of curvature detection algorithm that is based on the delta log-normal theory of handwriting recognition, which is disclosed in "A Delta Lognormal Model for Handwriting Generation," Proceedings of the 7th Biennial Conference of the International Graphonomics Society, 126-127, 1995. To segment strokes into primitive components, they disclose the use of calculations of angular signal intensity and first order crossing points.
[0022] "Perceptual Model of Handwriting Drawing Application to the Handwriting Segmentation Problem", 4th International Conference Document Analysis and Recognition (ICDAR), Aug. 18-20, 1997, Ulm, Germany discloses a modeling and segmentation approach based on the detection of a set of "perceptual anchor points". Basically, they search for `catastrophe` points, which are defined as points of discontinuity such as pen-ups, sharp turns, and cusps, and `perceptual` points, which include points of inflection, X- and Y-extrema, and stroke intersection points.
[0023] U.S. Pat. No. 6,275,611 describes a character recognition system that segments strokes at points where "local angle change is a maxima and exceeds a set threshold". See also "Handwriting Recognition Device, Method and Alphabet, With Strokes Grouped Into Stroke Sub-Structures", Aug. 14, 2001. A full description of the segmentation algorithm is given in U.S. Pat. No. 5,740,273. Similarly, U.S. Pat. No. 5,889,889 discloses the performance of stroke segmentation in a handwritten character recognizer by detecting points that "are identified by such criteria as abruptness of direction changes, as well as by pen lifts". This discloses the same segmentation procedure in a system designed to represent handwritten input in a parametric form for compression and reconstruction, segmenting strokes at "corners and cusps, where direction changes abruptly". See also U.S. Pat. No. 6,044,174.
[0024] The process described in U.S. Pat. No. 6,137,908 identifies Y-extrema as part of the preprocessing of strokes for recognition. Intermediate points between these extremum are also extracted and stored as a "frame" for use in the recognition system.
[0025] Similarly, U.S. Pat. No. 5,610,996 discloses the use of a series of arcs as primitives for recognition, where "the arcs begin and end at Y-extrema points on the sample text." This document also discloses the use of alternative segmentation schemes, such as X-extrema, and combined X-Y extrema.
[0026] U.S. Pat. No. 4,024,500 discloses the use of X- and Y-extrema to segment cursive strokes in to characters (rather than ballistic sub-stroke primitives).
[0027] U.S. Pat. No. 5,854,855 teaches the use of a velocity profile to segment strokes, and "associates sub-stroke boundaries with selected velocity minima in the handwriting input."
[0028] U.S. Pat. No. 5,577,135 discloses the segmentation of strokes at Y-extrema, resulting in a series of up- and down-strokes that are used in a Hidden Markov Model (HMM) recognition system. In another HMM recognition system described in U.S. Pat. No. 5,878,164, strokes are "segmented into letters or sub-character primitives according to defined boundary conditions such as pen ups and cusps".
[0029] The prior art references each attempt to introduce new techniques to address the problems of recognising handwritten input text. Each may offer an improvement, but none offers a robust system which addresses all the previously described problems.
DISCLOSURE OF INVENTION
[0030] In accordance with an aspect of the present invention there is provided a handwritten character recognition system comprising: [0031] an input device for receiving one or more handwritten strokes; and [0032] a processor for: [0033] calculating a degree of membership of the one or more handwritten strokes to each of a plurality of character models; [0034] selecting the character model that produced the highest degree of membership; and [0035] classify the one or more handwritten strokes as an output character associated with the character model that produced the highest degree of membership, [0036] wherein the degree of membership of the one or more handwritten strokes to each respective character model is calculated by: [0037] segmenting the one or more handwritten strokes into sub-strokes according to a model specific segmentation scheme defined for the respective character model; [0038] calculating a degree of conformity of each sub-stroke to a set of generic shapes defined for the respective character model; [0039] calculating the degree of membership of the one or more handwritten strokes to the respective character model based on a set of rules specific for the respective character model and defining the positioning of the set of generic shapes.
[0040] Other aspects are also disclosed.
BRIEF DESCRIPTION OF FIGURES
[0041] The present invention should become apparent from the following description, which is given by way of example only, of a preferred but non-limiting embodiment thereof, described in connection with the accompanying figures, wherein:
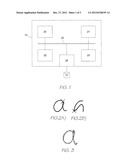
[0042] FIG. 1 illustrates an embodiment of the present invention wherein, the figure shows a processing system arranged to receive user inputs and process them according to further embodiments of the invention;
[0043] FIGS. 2a) and 2b) show well-formed and poorly-formed versions of the letter `a`;
[0044] FIG. 3 shows how velocity segmentation may be used to interpret a letter `a`, and the problems associated therewith;
[0045] FIGS. 4a) and 4b) illustrate the problem of using y-extrema to decode the letter `a`;
[0046] FIG. 5 shows the segmentation of the letter `a`;
[0047] FIG. 6 shows the segmentation of the letter `b`;
[0048] FIG. 7 shows the segmentation of the letter `B`;
[0049] FIGS. 8a), 8b) and 8c) show the three individual segments of the letter `B`;
[0050] FIG. 9 shows the segmentation of the letter `E`;
[0051] FIG. 10 shows the fuzzy group memberships based on line orientation in degrees; and
[0052] FIGS. 11a)-d) show a selection of generic stroke primitives used in character recognition.
MODES FOR CARRYING OUT THE INVENTION
[0053] The following modes are described as applied to the written description and appended claims in order to provide a more precise understanding of the subject matter of the present invention.
[0054] The following examples provide a more detailed outline of one embodiment of the present invention. These examples are intended to be merely illustrative and not limiting of the scope of the present invention.
[0055] The present invention provides a method for performing handwritten character recognition. Also provided is an apparatus for performing the method. In the figures, incorporated to illustrate the features of the present invention, like reference numerals are used to identify like parts throughout the figures.
[0056] Methods according to embodiments of the invention can be performed using a processing system an example of which is shown in FIG. 1.
[0057] In particular, the processing system 10 generally includes at least a processor 20, a memory 21, and an input device 22, such as a graphics tablet and/or touchscreen, an output device 23, such as a display, coupled together via a bus 24 as shown. An external interface is also provided as shown at 25, for coupling the processing system to a store 11, such as a database. Additionally, a stylus may be used to allow a user to input text to the system 10.
[0058] In use, the processing system is adapted to allow model and rule data to be stored in and/or retrieved from the database 11. This allows the processor to receive handwriting data via the input 22, process the handwriting data and compare this to the data stored in the store. This in turn allows the processing system to recognise the characters included in the handwritten text. From this, it will be appreciated that the processing system 10 may be any form of processing system such as a computer, a laptop, server, specialised hardware, or the like.
[0059] The operation of the processing system 10 will now be described in more detail.
[0060] Herein is described a model-specific approach to stroke segmentation for handwritten character recognition, including examples of model-specific algorithms. Techniques for the optimization of the procedure are also given.
[0061] It is clear that the stroke segmentation heuristics described above in relation to prior art techniques do not always produce consistent segmentation points due to the extreme variability in handwritten input. The problem is caused, in part, by the segmentation procedure operating independently of the letter recognition. This means that degenerative situations will produce incorrect results, and these segmentation failures will be hard to detect and correct in the classifier which attempts to correlate the segments with a single character.
[0062] Due to the ambiguity of handwriting, a graphic symbol may have a different meanings depending on local context; for example, ambiguous letter formations may be interpreted differently based on syntactic or semantic information (such as a dictionary or character grammar). Similarly, the individual strokes and sub-strokes that comprise an individual letter need to be interpreted in terms of the local context to ensure the correct interpretation is made.
[0063] Embodiments of the invention which use model-specific stroke segmentation, delay the segmentation of handwritten strokes, allowing it to be integrated with the classification procedure. This results in more information about the type of segmentation points expected by the letter model to be used by the segmentation process. The metric used to segment the strokes is based on the expected structure of the current character from a series that is being recognized, thus a single global segmentation procedure is not used.
[0064] As each letter prototype, allograph or character model is compared to the input, the input strokes are segmented based on whatever technique will identify the critical points, resulting in a more consistent decomposition of the strokes into primitives. Additionally, the failure of the segmentation process to find the expected segmentation points for a particular letter model means that further analysis of that model is not required, allowing efficient culling of models that do not match the general structure of the input.
[0065] In practice, the user enters a character using a stylus, and the processor, executing a program to perform an embodiment of the invention, first checks whether the input letter is an `a`, and will attempt to segment the input according to what is expected for an `a`. It then continues to check the input against some or all possible data entries, for example, `b`-`z`, scoring each attempt. In this way, the result having the closest match is classified as the input letter. A suitable scoring scheme is disclosed later.
[0066] There may be several models for each letter to take account of the various ways in which a particular letter may be written. For instance, some people write the letter `z` to look like an upper case `N` on its side, while others write it to so that it resembles the number `3`.
[0067] It is noted that while each letter model potentially requires a segmentation procedure to be performed, many models will use the same or similar segmentation points, meaning that these points can be cached to reduce the segmentation processing overhead. For instance, the letters `y` and `g` have similar depending tail segments which may be cached as described.
[0068] Recognition begins with some simple preprocessing to remove noise from the signal. This may include techniques such as smoothing of the sampled points (if the sampling process is noisy) and removing hooks from the beginning and end of the strokes, which would otherwise confuse the recognition process. The points may also be normalized by removing duplicate points or re-sampling to enforce a minimum distance between samples.
[0069] Each letter model defined in the handwriting classifier defines a segmentation procedure that will be performed on the input strokes. The segmentation produces a set of segmentation points that will be used to partition the stroke into a series of sub-strokes. The algorithm works on a single stroke at a time. To avoid creating stroke sub-segments that are too small to be structurally relevant, a minimum sub-stroke length is calculated based on the overall length of the stroke:
l m i n = λ i = 2 n p i - p i - 1 ##EQU00001## [0070] where [0071] pi=coordinates of point i [0072] n=number of points in the stroke [0073] λ minimum length threshold (empirically set to 0.05)
[0074] Segmentation proceeds with the algorithm iterating through the samples until it has identified a potential segmentation point as defined by the current letter model. If the correct point cannot be found, the algorithm returns a failure, indicating that the input does not conform to the structure expected by the letter model. Otherwise, if the two sub-strokes created by splitting the stroke at this point will be larger than lmin, the stroke is split at that point and processing continues with the remainder of the stroke. If either sub-stroke is smaller than lmin, the segmentation point is ignored, and processing continues. When all segmentation points have been correctly identified, the procedure ends and indicates to the recognizer that segmentation was successful.
[0075] It is noted that letter models can use any arbitrary segmentation technique as indicated by the expected structure of the handwritten letter, and some models may not require any stroke segmentation. For example, simple models for `c` and `o` may simply match the input directly, without attempting to reduce the strokes to sub-stroke primitives. Generally, there is no information to be derived from the segmentation of these single ballistic gestures, and allowing matching against the un-segmented strokes can avoid the problems that can be generated by traditional segmentation techniques (e.g. the smooth velocity-curvature profile can cause segmentation to occur at an arbitrary point depending on the style of the writer).
[0076] The following examples illustrate the segmentation procedure for various models. FIG. 5 shows the critical points 30, 32 used for the segmentation of a single-stroke allograph of the letter `a`.
[0077] Assuming that the model expects the stroke to be segmented at the top of the letter stem 32, the segmentation algorithm initially searches for the first Y-minimum 30 then attempts to find a Y-maximum 32 after this point 30. If the Y-maximum is found, the point is marked as a segmentation point. Note that the Y-minimum 30 is not used for segmentation, but simply to ensure that the correct Y-maximum 32 point is found. Without first searching for an initial Y-minimum 30, an incorrect Y-maximum could be located (as show in FIG. 4b)). Also note that this procedure will find the correct segmentation point for all the examples discussed with regard to FIGS. 1 -3 above.
[0078] As a counter-example, assume that a handwritten `c`, as input by the user, is being matched using the `a` model defined above. While the Y-minimum will be found, the search for a subsequent Y-maximum will fail. End-points will not be matched as segmentation points. As a result, the segmentation procedure will fail, indicating that the input does not match the general structure of the model, allowing the model to be removed from the list of potential matches.
[0079] While the above segmentation procedure works well for a number of letter models, other models will require different algorithms. As a simple example, FIG. 6 shows the segmentation for a model of the letter `b`.
[0080] To segment this single-stroke allograph of `b`, the first Y-minimum is found and used as the segmentation point 40, producing a vertical line sub-stroke, and a curved `o` shaped sub-stroke. A more complex segmentation procedure is given in FIG. 7.
[0081] In the single-stroke model of the letter `B` given above, the first segmentation point is found at the first Y-minimum 50. Following this, a Y-maximum 52 is found, followed by an X-minimum 54, which is used as the second segmentation point. FIG. 8 shows the segmented letter.
[0082] The result is an initial vertical line sub-stroke as shown in FIG. 8a), followed by a curved `p` sub-stroke in FIG. 8b), and followed by a "sideways-u" sub-stroke in FIG. 8c). This segmentation approach is robust to variation in curvature and velocity, and produces consistent segmentation for a wide variety of writing styles. On the other hand, the global segmentation procedures used in the prior art can produce very inconsistent segmentation of handwritten letters such as the one given above, being dependent on degrees of curvature and consistent velocity of pen-strokes.
[0083] Not all letter models can be consistently segmented using X- and Y-extrema. For example, FIG. 9 shows the segmentation of a two-stroke allograph of the letter `E`.
[0084] Using X-minima to detect segmentation points 60 and 62 may not be successful, especially if the letter is somewhat rotated or angled. Similarly, using Y-minima will not necessarily produce the correct segmentation. For this allograph, the two points of highest angular change in the first stroke can be used for segmentation. Note that an angular threshold is not required to find these points, since the two highest points of curvature can be easily found by sorting the curvature values at each point. More sophisticated processing is possible; for example, ensuring the segmentation points produce sub-strokes of roughly equal lengths. Overall, arbitrarily complex model-specific segmentation based on any structural feature of the input stroke can be performed to ensure the correct segmentation points are consistently found.
[0085] The segmentation procedure described above for the letter `a` will work for all letter models that follow the basic structure of having a curved region followed by a cusp, followed by a down-stroke (e.g. some allographs of `d`, `g`, `u`, `y`, etc.) As a result, the sub-strokes found can be stored for later use when matching these similarly structured models. Further, if the sub-strokes are converted to a feature representation before classification, the feature vectors can be stored to prevent repeated feature extraction.
[0086] Many of the stroke segmentation techniques that can be used will require sub-stroke distance and curvature information. To avoid recalculating these values every time stroke segmentation is performed, a secondary data-structure can be created to cache the values by storing a distance and curvature value with each point on the stroke.
[0087] The following description illustrates how model-specific stroke segmentation can by used in the recognition of handwritten characters. While the example is based on a fuzzy-logic based classifier, it is apparent to the skilled person that this technique can be used with any classifier type that can utilize stroke segmentation, and the procedure can be easily incorporated into structural (such as elastic-matching) and statistical classifiers.
[0088] One approach to modeling the imprecision and stylistic variation of handwritten characters is to use fuzzy logic, which allows the definition of sets of criteria that are not precisely defined. Fuzzy logic classifiers work by assigning an input signal a degree of membership to a fuzzy model depending on how well the features match the fuzzy rules that describe the model. Suitable Fuzzy logic classifiers for handwritten character recognition are described further in: "A New Fuzzy Geometric Representation for On-Line Isolated Character Recognition", International Conference on Pattern Recognition (ICPR'98), pp. 1121-1123, 1998; and "Fuzzy Feature Description of Handwriting Patterns", Pattern Recognition, Vol. 30, No. 10, pp. 1591-1604, 1997.
[0089] As an example, a fuzzy logic rule for defining straight lines may contain the following sets: vertical lines (VL), horizontal lines (HL), lines of positive slant (PS), and lines negative slant (NS). Clearly, most lines will not fit perfectly within these restricted sets and will usually have a degree of membership to more than one of these sets. Thus, fuzzy logic defines a logical set notation where set membership is gradual rather than discrete. FIG. 10 illustrates a set of possible group membership functions for straight lines, as defined by normalized orientation (in degrees).
[0090] FIG. 10 shows a series of bell-like curves. As an example, the curve labelled VL, meaning Vertical Line, defined a set of lines which, when compared to a true horizontal line, have angles approximately in the range from a little below 45° to a little over 135°, with those closest to 90° having a higher weighting. Similar curves are shown for Horizontal Lines (HL), Negative Sloping Lines (NS) and Positive Slanting Lines (PS).
[0091] The example fuzzy logic classifier consists of a set of rules that define individual letter models. These rules match stroke and sub-stroke primitives against a set of generic stroke shapes. The rules also include relative position information used to distinguish letters that are composed of similar primitives. The linguistic primitives used include an `o`-like curve (OC) shown in FIG. 11a), a `c`-like curve (CC) shown in FIG. 11b), a `d`-like curve (DC) shown in FIG. 11c), and a vertical curve to the right (RVC) shown in FIG. 11d).
[0092] For each sub-stroke, a degree of membership in these primitive sets is calculated based on a simple structural analysis of the strokes using the following information: the absolute stroke curvature, the position of the start and end points in relation to the bounding box of the stroke, and the orientation of the line between the start and end points.
[0093] The positional primitives LEFT, RIGHT, TOP, CENTRE, and BOTTOM indicate stroke position within the bounding box of the letter, and the straight-line primitives described above (VL, HL, PS, NS) are also used. Some typical rule examples are:
RULE a ' ' : ( OC | CC ) & LEFT & CENTRE , ( VL | RVC ) & RIGHT ##EQU00002## RULE b ' ' : VL & LEFT , ( OC | D C ) & RIGHT & BOTTOM ##EQU00002.2## RULE c ' ' : CC ##EQU00002.3## RULE d ' ' : ( OC | CC ) & LEFT & BOTTOM , VL & RIGHT ##EQU00002.4## ##EQU00002.5##
[0094] In the rules above, the `|` symbol indicates a fuzzy OR, the `&` symbol indicates a fuzzy AND, parenthesis indicate logical precedence, and a comma indicates sub-stroke composition using a fuzzy AND (i.e. the expression on the left of the comma is evaluated using the first sub-stroke, the expression on the right is evaluated using the second sub-stroke, with the results combined using a fuzzy AND).
[0095] As an example, the first rule can be read as follows: an `a` letter is an `o`-like curve or a `c`-like curve located to the left and centered vertically in the letter, followed by a vertical line or a vertical curve to the right, located at the right of the letter. It is noted that there may be many alternate rules for each letter, modeling the stylistic variability of handwriting.
[0096] While these rules describe how the primitives are composed for each letter model, they do not indicate how strokes are decomposed into the primitives. To do this, each rule is associated with a model-specific segmentation rule that is executed against the input strokes before the rule is evaluated:
RULE a ' ' : MIN Y -> MAX Y ##EQU00003## RULE b ' ' : MIN Y ##EQU00003.2## RULE c ' ' : ##EQU00003.3## RULE d ' ' : MAX Y -> MIN Y ##EQU00003.4## ##EQU00003.5## RULE k ' ' : MIN Y , MAX Y , MIN X ##EQU00003.6## ##EQU00003.7##
[0097] MAXY represents a search for the next Y-maximum. MINY represents the search for the next Y-minimum. The →symbol indicates that the point defined on the left is found first but not used for segmentation; rather it is found to ensure the subsequent point is correctly located. Note that the classification of the `c` model requires only a single stroke, and thus no segmentation is performed for that model. The `k` model is shown as an example of a rule containing multiple segmentation points, found in the order specified.
[0098] Once the stroke segmentation is performed using the model-specific rules, the sub-strokes are classified by degree of membership in the generic stroke classes. These membership values are then used to evaluate the structure rules, giving an indication of how well the input matches the letter model. Each letter model is similarly evaluated, and the input is classified as the class of the model that gives the highest fuzzy membership value.
[0099] In summary, each input is tested against each rule, and each rule further defines the segmentation approach to be taken in the expectation that the input character is the same as the character being tested for. If the segmentation for a particular character model cannot be performed because the input character does not conform to the character being tested for by the rule, then a zero or low score will be attached to that attempt at classification.
[0100] The invention may also be said broadly to consist in the parts, elements and features referred to or indicated in the specification of the application, individually or collectively, in any or all combinations of two or more of said parts, elements or features, and where specific integers are mentioned herein which have known equivalents in the art to which the invention relates, such known equivalents are deemed to be incorporated herein as if individually set forth.
[0101] Although the preferred embodiment has been described in detail, it should be understood that various changes, substitutions, and alterations can be made herein by one of ordinary skill in the art without departing from the scope of the present invention as hereinbefore described and as hereinafter claimed.
User Contributions:
Comment about this patent or add new information about this topic:
Images included with this patent application:
 |  |
 |  |
| Similar patent applications: | |
| Date | Title |
|---|---|
| 2011-12-01 | Handwritten character recognition system |
| 2011-03-03 | Handwritten character recognition |
| 2010-12-30 | Statistical online character recognition |
| 2012-08-30 | Method and system for preprocessing an image for optical character recognition |
| 2009-12-31 | Method and apparatus for magnetic character recognition |
| New patent applications in this class: | |
| Date | Title |
|---|---|
| 2014-04-24 | Character recognition |
| 2013-11-28 | Handwritten character retrieval apparatus and method |
| 2013-11-28 | Handwritten document retrieval apparatus and method |
| 2012-08-09 | Annotation detection and anchoring on ink notes |
| New patent applications from these inventors: | |
| Date | Title |
|---|---|
| 2012-09-20 | Digital ink database searching using handwriting feature synthesis |
| 2012-06-07 | Method of compressing sequence of strokes |
| 2012-04-19 | System for determining orientation of digital ink |
| 2011-12-08 | Classification scheme and system for modifying character allographs contained therein |
| 2011-12-01 | Classifying a string formed from hand-written characters |
| Top Inventors for class "Image analysis" | |
| Rank | Inventor's name |
|---|---|
| 1 | Geoffrey B. Rhoads |
| 2 | Dorin Comaniciu |
| 3 | Canon Kabushiki Kaisha |
| 4 | Petronel Bigioi |
| 5 | Eran Steinberg |