Patent application title: METHOD FOR MINIMIZING OVERDRAFT CHARGE-OFF
Inventors:
Steven Wolfson (Scituate, MA, US)
Assignees:
Carreker Corporation
IPC8 Class: AG06Q4000FI
USPC Class:
705 39
Class name: Automated electrical financial or business practice or management arrangement finance (e.g., banking, investment or credit) including funds transfer or credit transaction
Publication date: 2009-12-31
Patent application number: 20090327123
Inventors list |
Agents list |
Assignees list |
List by place |
Classification tree browser |
Top 100 Inventors |
Top 100 Agents |
Top 100 Assignees |
Usenet FAQ Index |
Documents |
Other FAQs |
Patent application title: METHOD FOR MINIMIZING OVERDRAFT CHARGE-OFF
Inventors:
Steven Wolfson
Agents:
SUTHERLAND II
Assignees:
Carreker Corporation
Origin: ATLANTA, GA US
IPC8 Class: AG06Q4000FI
USPC Class:
705 39
Patent application number: 20090327123
Abstract:
A method for minimizing overdraft charge-off in a bank account includes:
(a) identifying a plurality of factors that can result in a bank account
charge-off; (b) building a case history database of bank account holder
information based upon a plurality of data elements associated with each
of the plurality of factors; (c) creating numeric and/or categorical
representations of the bank account holder information for each of the
bank accounts in the case history database; (d) tabulating the numeric
and/or categorical representations and the data elements for the bank
accounts in the case history database; (e) combining certain ones of the
numeric and/or categorical representations to separate the bank accounts
in the case history database into a plurality of risk groups, each risk
group having an associated probability of charge-off; and (f) optimizing,
for each of the plurality of risk groups, a bank profit, by setting
overdraft limits.Claims:
1. A method for minimizing overdraft charge-off in a bank account
comprising:a) identifying a plurality of factors that can result in a
bank account charge-off;b) building a case history account database of
bank account holder information based upon a plurality of data elements
associated with each of the plurality of factors;c) creating numeric
representations of the bank account holder information for each of the
bank accounts in the case history database;d) tabulating the numeric
representations and the data elements for the bank accounts in the case
history database;e) combining certain ones of the numeric representations
to separate the bank accounts in the case history database into a
plurality of risk groups, each risk group having an associated
probability of charge-off; andf) optimizing, for each of the plurality of
risk groups, a bank profit, by setting overdraft limits.
2. The method of claim 1 wherein the overdraft limits are set to generate additional reserve for certain bank accounts.
3. The method of claim 1 wherein the overdraft limits are set to reduce losses for certain bank accounts.
4. The method of claim 1 and further including:monitoring the numeric representations, the overdraft limits and bank profits to determine when changes are necessary to the overdraft limits.
5. A method for minimizing overdraft charge-off in a bank account comprising:a) identifying a plurality of factors that can result in a bank account charge-off;b) building a case history account database of bank account holder information based upon a plurality of data elements associated with each of the plurality of factors;c) creating categorical representations of the bank account holder information for each of the bank accounts in the case history database;d) tabulating the categorical representations and the data elements for the bank accounts in the case history database;e) combining certain ones of the categorical representations to separate the bank accounts in the case history database into a plurality of risk groups, each risk group having an associated probability of charge-off; andf) optimizing, for each of the plurality of risk groups, a bank profit, by setting overdraft limits.
6. The method of claim 5 wherein the overdraft limits are set to generate additional reserve for certain bank accounts.
7. The method of claim 5 wherein the overdraft limits are set to reduce losses for certain bank accounts.
8. The method of claim 5 and further including:monitoring the categorical representations, the overdraft limits and bank profits to determine when changes are necessary to the overdraft limits.
Description:
TECHNICAL FIELD OF THE INVENTION
[0001]The present invention relates to the processing of banking transactions, and more particularly to a method for minimizing overdraft charge-off.
BACKGROUND OF THE INVENTION
[0002]When a bank customer attempts to make a check card purchase, withdraw funds from an ATM or make a teller withdrawal, their bank must determine whether the customer has sufficient balances to cover the item, and, if not, whether to authorize the purchase or withdrawal into an overdrawn position or decline the transaction. Similarly, when one or more bank customer checks (or other returnable items) are processed in the nightly posting batch run, the bank must determine whether to pay or return each item that, if posted, would overdraw the customer's account. Each day any given bank may make millions of such authorization/decline and pay/return decisions. Each day the banking community as a whole makes trillions of such decisions. From a customer service perspective, banks would prefer to authorize and pay such transactions. Declines and returns are embarrassing to customers. Declines often lead to less frequent use of a given check card. Returns can lead additional vendor assessed fees for bounced checks and/or late payment. So customers and banks alike regard it as better customer service when the bank covers an overdraft transaction, but some fraction of the overdrafts thus generated are never repaid. Indeed, at a typical bank, between 4% to 8% of those accounts allowed to overdraw will never fully repay leaving the bank to charge off the negative balance and absorb the loss.
[0003]If a bank knew in advance that a given account was headed for charge-off, the bank could forgo decisions that would take that account's balance into a negative position, and authorize and pay only those items where there was no probability of charge-off. Such precise foreknowledge is, of course, impossible. But it is possible to ascertain the probability that a given account will charge off and, based on that probability, a bank can make better decisions about when to authorize and/or pay transactions into overdraft. While there are a variety of software systems and methodologies on the market that address the "overdraft" problem, none function to ascertain either the probability of charge-off or the probability of cure (i.e. the probability that an account with a negative balance will pay back what is owed returning to a positive balance.
[0004]Current software systems and methodologies are based on either fixed or user-definable scoring systems. The score is used to control overdrafts through a single quantity called the overdraft limit. The overdraft limit for an account is the maximum negative balance into which a bank will either authorize or pay a transaction.
[0005]Overdraft limits are generated by evaluating certain quantities of interest, which though similar among existing approaches, may vary from one approach to the next. Often, these quantities represent values already available in the DDA (Demand Deposit Account) system, which is the system of record for the balances of each account and for other information about the account and how it is to be processed. Based on the value of one of these quantities, the overdraft limit for the associated account may be either incremented or decremented according to the scoring rules for the quantity.
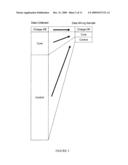
[0006]Few of these software systems and methodologies offer objective justification for the inclusion of a particular quantity; none shows how these quantities relate to charge-off and cure behavior. In fact, demonstrating such a relationship is not easy because of the time spans involved. At the time when an authorization or pay decision is made, it may require 45 days or more (depending on the charge-off process of the bank) before it is clear whether or not an account charged off and, if so, how much money was lost. Since some fraction of charge-offs are eventually recovered, post charge-off history needs to studied to determine net losses. Similarly, the decision itself relies on characteristics of the account gathered over some suitable period of time leading up to the decision. (See FIG. 1.) Thus, an objective analysis of the predictive power of any given characteristic requires data collected over an extended period of time. Without such data, one may appeal to intuition, but one cannot bring the power of data mining to bear to assess whether one's intuition is correct.
[0007]As compared to other situations where banks put principal at risk in order to service customers and assess fees or interest, the overdraft space is very profitable. (Banks do not call overdrafts loans, because they are not committed to extending the overdraft and to make such a commitment would subject the extension to lending regulations which, in many ways, are more stringent than those governing overdrafts.) Overdraft revenue has been made increasingly profitable over the last two decades through a series of marketing, pricing and processing reforms that have significantly enhanced overdraft revenue.
[0008]One side effect of these reforms is that overdraft charge-offs have risen disproportionately with revenue. Since the revenues still far outweigh charge-offs, overdrafts are still a very profitable business, but it is clear that the current software systems and methodologies employed to control losses through the setting of overdraft limits are deficient. For this reason a need exists for better, more robust and responsive approaches to address the overdraft problem.
SUMMARY OF THE INVENTION
[0009]In accordance with the present invention, a method for minimizing overdraft charge-off in a bank account includes:
[0010](a) identifying a plurality of factors that can result in a bank account charge-off;
[0011](b) building a case history database of bank account holder information based upon a plurality of data elements associated with each of the plurality of factors;
[0012](c) creating numeric and/or categorical representations of the bank account holder information for each of the bank accounts in the case history database;
[0013](d) tabulating the numeric and/or categorical representations and the data elements for the bank accounts in the case history database;
[0014](e) combining certain ones of the numeric and/or categorical representations to separate the bank accounts in the case history database into a plurality of risk groups, each risk group having an associated probability of charge-off; and
[0015](f) optimizing, for each of the plurality of risk groups, a bank profit, by setting overdraft limits.
BRIEF DESCRIPTION OF THE DRAWINGS
[0016]For a more complete understanding of the present invention and for further advantages thereof, reference is now made to the following Description of the Preferred Embodiments taken in conjunction with the accompanying Drawings in which:
[0017]FIG. 1 illustrates a timeline for a typical case history including a charge-off;
[0018]FIG. 2 illustrates a set of timelines for six different case histories, some of which cure, some of which charge-off and some of which (control case histories), include no overdraft incidents;
[0019]FIG. 3 illustrates available sets of case histories reduced to more manageable sample sets;
[0020]FIG. 4 illustrates a table of telltales for each case history;
[0021]FIG. 5 illustrates a format in which telltale statistics are gathered to support further analysis;
[0022]FIG. 6; illustrates a typical ROC (Receiver Operating Characterstic) curve used to determine the stand-alone predictive power of a given numeric telltale;
[0023]FIG. 7 illustrates self-similar case histories being partitioned into risk groups;
[0024]FIG. 8 illustrates a simple binary decision tree demonstrating that end nodes need not all lie at the same level (i.e. at the same number of binary decisions away from the root node of the tree);
[0025]FIG. 9 illustrates a multi-modal profit vs. risk curve;
[0026]FIG. 10 illustrates a profit vs. risk curve flattening out in a more realistic multi-modal situation;
[0027]FIG. 11 illustrates the partitioning of large differentiated population into a set of self-similar risk groups, each with a well defined maximum on its profit vs. risk curve;
[0028]FIG. 12 illustrates changes to a profit vs. risk curve for given risk groups as the composition of case histories occupying that risk group change over time;
[0029]FIG. 13 illustrates the "trajectory" of an account as it moves from one risk node to the next on the basis of changes in its telltale values;
[0030]FIG. 14 illustrates one curve from one multi-parameter family of curves that meets the high-level criteria for a family of overdraft-limit vs. probability of charge-off curves;
[0031]FIG. 15 illustrates a table used to summarize modeling results for the profit (or loss) made by a bank by offering a given set of limits over a suitable modeling period;
[0032]FIG. 16 illustrates a bank (local) and central components of a system for practicing the method of the present invention;
[0033]FIG. 17 illustrates a central (hub) component of a system servicing multiple individual bank-local (spokes) components; and
[0034]FIG. 18 illustrates extract files prepared by a bank.
DESCRIPTION OF THE PREFERRED EMBODIMENTS
[0035]Categories of Risk Predicting Factors
[0036]The present invention examines six categories of characteristics in order to ascertain the probability that a given account will charge-off: Balances, Transactions, Exceptions, Account Information, Customer Information, and Relationship Information. Within each category, are identified various "conceptual telltales." As used herein, a conceptual telltale is particular characteristic of the pre-decision case history of an account, hypothesized to have value in predicting charge-off risk.
[0037]For any given conceptual telltale, there will be numerous ways the telltale can be represented as either a number or as categorical information. As an example, consider the account category conceptual telltale "age of the account at the time the overdraft decision is to be made" (or "age of account" for short). One could represent this as a number in days, in (30-day) months, as the logarithm of the number days old or in many other ways. One could also represent age of account as a set of categories: Just Opened (0-29 days), New (30-89 days), Moderate (90-364 days), Mature (1-3 years), Long Lived (≧3 years). Certain representations may lead to greater predictive power, while others lead to less, and often several representations will have essentially in the same predictive power. The problem of identifying the most "powerful" representation of a given conceptual telltale will be further described.
[0038]The present invention identifies representations of distinct conceptual telltales with combined predictive power exceeding that of any single factor. For a variety of reasons, seemingly different conceptual telltales are not always completely independent. Consider for example the transaction category conceptual telltale "annualized average deposits." While not equivalent to an account holder's income, in most cases it is a good proxy for it. One reason people have higher incomes is because their skill set commands a higher wage or salary; another reason is that most people earn more as they get older and more experienced. New accounts are not always young account holders, but there is a positive correlation. Thus, a priori, it is not clear how much additive value can be obtained by using age of account and annualized average deposits together to predict charge-off risk.
[0039]Individual telltales may remain constant, change slowly or change rapidly (sometimes even within the course of a day). One conceptual telltale, for example, deposit pattern interruption, is subject to dramatic swings. Clearly, bank receipt of a new deposit (or, in the case of ACH, receipt of advanced notice that such a deposit is queued up and may posted on a future date) signals that in some sense deposits are no longer interrupted. While it is impractical for banks to be recalculating individual telltale values across their account base on a real time basis throughout the day, it is possible to project the future value of that certain rapidly changing telltales would take should certain transaction types take place or transaction types with certain values materialize.
[0040]Sometimes it is useful to combine two or more telltales from possibly different categories into a single representation. As an example, consider the sex of the account holder. On the surface, this would appear to fall within the Customer Information category of information, but some accounts are held by businesses for which sex is obviously meaningless. Most banks and bankers would regard the type of account as Account Information and therefore be led to think of the distinction as to whether an account is business or personal as being an Account distinction. Sex, on the other hand is a Customer distinction. Therefore, the categorical representation, Male, Female or Business, is actually a hybrid of the Account Information and Customer Information categories.
[0041]Collecting Data and Assembling Case Histories
[0042]As previously stated, in order to explore the predictive power of a given conceptual telltale one must be able to study how accounts with differing values for various representations of that conceptual telltale appear based on all that is known at the time of an overdraft decision with the eventual charge-off/cure behavior of the account. One prepare for such an investigation by either finding institutions with enough retained history to construct the required data set or by arranging to collect the information over a period of months on a go forward basis. The present invention relied on the former method to arrive at its initial design. As will be discussed below, a computer system for implementing one embodiment of the system will rely on the second method.
[0043]A "case history" is defined herein as the totality of tracked balances, transactions and exceptions over a period of time along with the more static information about the account, customer and relationship. There are three types of case histories of interest. FIG. 2 illustrates examples of each:
[0044]Charge-Off--Where an account overdraws due to one or more authorization or pay decisions and later charges-off. (Case histories 2, 5 & 6)
[0045]Cure--Where an account overdraws due to one or more authorization or pay decisions and later restores a non-negative balance. (Case histories 1 & 3)
[0046]Control--Where an account has no overdrafts. (Case history 4)
[0047]To assemble case history data, actual bank data for balance, transaction, exception, account, customer and relationship information was collected for a combination of charge-off, cure and control accounts. Charge-offs are relatively rare events. Cures are more frequent but still rarer than control accounts. In order to have a statistically valid sample of charge-off case histories, one must examine all charge-offs due to overdrafts initiated over an extended period of time (the "critical period"). One must also examine cure case histories, which accounts that overdrew during the critical period and later returned to a positive balance (even if they subsequently charged off due to an even later overdraft that initiated after the critical period.) And, lastly, one must examine control case histories, which are account whose balance never went from positive (or zero) to negative throughout the critical period.
[0048]The bank data comprising the case histories was extracted, transformed and loaded into a case history database containing all the information obtained. Because of the relative frequencies of charge-off, cure and control accounts, this database contained more cure case histories than charge-offs and more control cases histories than cures.
[0049]In order to support the analysis and data mining (described below), a subset of this database was formed with all or nearly all of the charge-off accounts and roughly equal numbers of cure and control accounts selected randomly from the starting database. (See FIG. 3.)
[0050]Finally, a third database, the Data Mining Source Database, is constructed, which includes are row for each case history and columns for each individual telltale. Individual telltales may be one of several representations of a single conceptual telltale. (See FIG. 4).
[0051]Determining the Most Promising Representing of each Conceptual Telltale
[0052]Where there is more than one representation for an individual telltale, it becomes important for to identify the most powerful predictor of charge-off. It is also important to identify the relative predictive power of the conceptual telltales by comparing the "best" representation for each To do this two techniques are required: averages and ROC curves.
[0053]Averages
[0054]For numerical telltales, the average value of the telltale for charge-off, cure and control subsets of the Data Mining Source Database is computed. Categorical telltales must be handled differently. To analyze, for example, the sex of the primary account holder, one could create a representation that included two options, M and F. But one could equally establish two separate representations male and female, each taking values of 1 for yes and 0 for no. One can now computer the average value for male and female respectively, although the second of these is redundant information. For broader categories with n unique options (and nulls, meaning no information available, must be treated as one of the options), n-1 of the averages will be independent and the remaining one holds no new information.
[0055]A second nuance of exploring averages is that typically case history data will include one or several case histories with telltale values far in excess of the norm. Since it is desired to compare the averages of the three groups, charge-off, cure and control, wherever there is danger that a single case history (or small number of case histories) might distort the average value for one of these groups and make it "seem" larger than the others, there is need to eliminate the effect of these case histories from the average analysis. In statistics, this is called the outlier problem and there are several methods available for culling outliers to produce averages (and other statistics) more representative of the population under consideration.
[0056]One embodiment of the present invention uses the relatively simple technique of finding the average for the 95% of case histories in a group (charge-off, cure or control) with lowest values for that telltale. By averaging the vast majority of the case histories in each group and ignoring enough to weed out any outliers, it is possible to obtain a telltale average that, if significantly different across the groups, is indicative of potential predictive power. (See FIG. 5.)
[0057]ROC Curves and Lifts
[0058]ROC stands for Receiver Operating Statistics. ROC curves and their associated lifts are commonly used to identify the potential power of a given predictor such as a given individual telltale which may be one of several representing a conceptual telltale. (See FIG. 6.)
[0059]In ROC analysis, one sorts all charge-off and cure case histories low-to-high according to the individual telltale being analyzed. If more of the charge-off case histories "bubble" to the top of list or "sink" to the bottom, that is an indication that the telltale takes on rather different values for charge-off case histories than it does for cure case histories. If instead, the charge-off and cure case histories are fairly random distributed up and down the list, that is an indication that the telltale does little to distinguish between charge-off and cure.
[0060]If one starts at the low end of the telltale value list and works toward the high end, plotting the fraction of charge-off histories encountered vs. the fraction of cure case histories encountered, one generates a curve similar to that shown in FIG. 6. The area between the telltale curve and the 45° line associated with a random mixing of charge-of and cure case histories gives the lift for that individual telltale. Once calculated, these lifts are added to the table with the full and 95% averages to provide a comprehensive summary of the standalone predictive power of each individual telltale.
[0061]In one embodiment of the invention, where there are multiple individual telltale representations of a single conceptual telltale, the one with the greatest lift is taken as the most likely candidate to carry forward to the next step. Other statistical techniques also serve the same purpose.
[0062]Data Mining for Risk Group Clusters
[0063]At the time an overdraft decision is to be made, one has the values of all the account's telltales based on the behavior of the account up to that time. From other data collected, it is known which of these accounts will charge-off eventually. Now we wish to identify self-similar collections of account histories with respect to their probability of charge-off and likelihood of curing. (See FIG. 7.) In FIG. 7a, an array of account case histories is shown 2-dimensionally for convenience. The position of each dot represents the information available to the system at the time of overdraft decision. From this information, a decision must be made about how much risk to take. In FIG. 7b, the same array is shown with boundary lines identifying the "natural" risk group clusters: G1, G2 . . . , G7. Case histories within a cluster tend to be similar, in an appropriate sense, to others within the same cluster but different from those in other clusters.
[0064]In data mining this identification is called cluster detection, and there are a variety of techniques, including k-means clustering and neural nets for carrying out this step. In one embodiment of the present invention another cluster detection technique called decision trees is used to partition charge-off and cure case histories into risk group clusters. After partitioning, all the case histories in a given risk group will be similar with respect to their combination of telltale values, while all those case histories in different risk groups will tend to have rather different combinations of values. Decision trees have the advantage of generating an "explainable" result that can be readily traced through.
[0065]Decision tree algorithms start with the entire case history population (here just charge-offs and cures) and select the best telltale and the best splitting value (in an appropriate sense) for dividing the population up into the two most significantly different subpopulations. Although the final charge-off/cure result for each case history is carried alone through the splitting, it is not used to generate a split. Since that future in not known at the time of the overdraft decision, its use would not be fair. Instead, the goal is to use only those things known at the time of overdraft decision to predict charge-off and cure outcomes.
[0066]After the initial split, additional splits are made further down the tree. Various data mining algorithms are employed to determine the details of each split and to decide when to stop splitting further so as to avoid over-fitting the data. (See FIG. 8.)
[0067]One standard output of decision tree building tools is a set of statistics telling how well the risk groups (end or leaf nodes of the tree) predict the attributes one is investigating, in this case charge-off and cure. Trees are built with different combinations of telltales and with different combinations of tree-building options. The numbers of potential combinations grows large quickly. Sticking with individual telltales with the highest ROC curve lift for each conceptual telltale helps reduces the combinatorial explosion. The construction of trees using telltales in pairs helps identify hidden dependencies, reducing options still further. Nevertheless, it may be impractical to conduct an exhaustive search of all remaining combinations. Instead, judgment and parsimony are required in settling on a "final" tree to carry forward to the next step in the process.
[0068]There are two distinct outputs of the decision tree building step. First, one has the set of self-similar risk groups. Because the charge-off/cure result for each was "carried along for the ride," one can assign a probability of charge-off to each group. One can also "carry along" information about the amount of the charge-off, the amount of the recovery and the split of each into principal vs. fees. Based on this information on can determine the expectation value for un-recovered principal and fee charge-offs.
[0069]Second, one has the tree itself. The tree is a well defined algorithim for partitioning cases histories into self-similar risk groups. As such, it can be used to partition future case histories into those same risk groups. Once appropriate treatments are determined for each risk group, future case histories can be assigned those treatments based on the risk group they are partitioned into.
[0070]Treatment Optimization and Limits
[0071]Having partitioned case histories into risk groups, the next step is to seek the "best" treatment for each. Treatment optimization is driven by profit and customer service concerns. Where it is profitable to authorize and/or pay an item into overdraft, the service to the customer should be offered. Where, however, the bank is likely to lose money, then the bank should decline or return the associated transactions.
[0072]In one embodiment of the present invention, profit is given by the formula
[0073]Profit=Fees generated [0074]-Fees waived [0075]-Fees charged off [0076]+Charged off fees recovered [0077]-Principal charged off [0078]+Charged off principal recovered [0079]+Interchange fees [0080]+Estimated soft profit [0081]-Estimated soft costs
[0082]where
[0083]Fees generated=Fees assessed by the bank in its batch posting process for items that would post into a negative balance if paid (i.e. insufficient funds items).
[0084]Fees waived=Fees waived or refunded by the bank.
[0085]Fees charged-off=Fees assessed but never collected due to the account charging off with a negative balance.
[0086]Charged off fees recovered=Fees charged off but later recovered as part of the bank's or a third party's post-charge-off collection process.
[0087]Principal charged off=Principal extended by the bank to cover insufficient funds items and later charged off.
[0088]Charged off principal recovered=Principal extended by the bank to cover insufficient funds items, then charged off but later recovered as part of the bank's or a third party's post-charge-off collection process.
[0089]Interchange fees=Fees received by the bank for servicing certain types of electronic transaction (e.g. a point of sale check card transaction)
[0090]Estimated soft profit=Estimated total profit associated with factors like enhanced customer retention.
[0091]Estimated soft cost=Estimated total cost associated with factors like the reduced use of a check card following one or more denials by the bank.
[0092]As with most risk reward situations, if a bank were to forgo all risk, fee generation would fall and profits would be low. Similarly, if a bank were to ignore risk, losses would be high and again profits would be low or even negative. The general situation is indicated in FIG. 9. As one embraces additional risk, in the current case by authorizing and paying more items into an overdraft position, one is rewarded with increasing profits. If all customers behaved in the same way, profit would grow continuously to some maximum and then fall off. As a result of the prior analysis, however, self-similar risk groups which differ in behavior (i.e. their propensity for charge-off) from one group to the next have been identified. Each of these risk groups will have its maximum profit for a different level of risk, leading to a multi-modal profit vs. risk curve. (See again FIG. 9.)
[0093]The number of unique risk groups for decision trees with strong predictive power tends to be 40 or more. Thus, in the combined profit vs. risk curve for an entire population, individual profit maxima tend to merge into a broad plateau masking the existence of individual risk groups. (See FIG. 10.) If, instead, one considers the profit vs. risk curves for each of the individuals risk groups, as illustrated in FIG. 11, the individual profit maxima re-emerge although the actual curves may not be as smooth as those shown.
[0094]Ideally one would like to "park" the risk taken for each risk group at the point of maximum profit. The risk groups defined by a decision tree are not static however. Some telltales change almost daily, but even infrequent changes will lead to a case history moving from one risk group to another with the passage of time. As a result, the precise composition of a risk group will change even though the decision tree rules describing it will not. The effect is for the maxima of the profit vs. risk curves to move about as well. (See FIG. 12.) This affects how the best treatments for each risk group should be determined.
[0095]A given case history will move about the decision tree risk groups as its telltale values change. At each "stop", the fees it generates and principal it puts at risk make additive (possibly negative) contributions to the profit history over for that account. Since the treatments assigned to each node differ, it is the full set of treatments across the entire tree that define a given profit history. (See FIG. 13).
[0096]The treatment for each risk group is comprised of a set of overdraft limits playing slightly different roles. In one embodiment of the present invention there are four such limits.
[0097]Batch Limit: The limit used to make pay/return decisions in batch posting provided that no deposit has been made since the last batch posting and no notice received of any pending ACH deposits.
[0098]Deposit Override Batch Limit: The limit used to make pay/return decisions in batch posting when either a deposit has been made since the last batch posting or notice has been received of a pending ACH deposit.
[0099]Authorization Limit:The limit used to make authorization/decline decisions during the day provided that no deposit has been made since the last batch posting and no notice received of any pending ACH deposits.
[0100]Deposit Override Authorization Limit: The limit used to make authorization/decline decisions during the day when either deposit has been made since the last batch posting or notice has been received of a pending ACH deposit.
[0101]In other embodiments of the present invention, other, fewer or more limits could be used depending on:
[0102]the rapidly changing telltales for which one decides to project the risk group to which a case history might move, and, as a result, require a different limit; and
[0103]the individual debit channels (e.g. checks, tellers, ATM, POS, ACH, etc) for which one decides to offer other than the basic Batch Limit.
[0104]In setting these various limits it is important to keep certain broad rules in mind. These rules are illustrated in FIG. 14.
[0105]First, the Batch Limit assigned to a less risky risk group is always greater than or equal to that assigned to a more risky risk group. Second, in assigning Batch Limits, as one moves from the least risky risk groups toward those of greater risk, there will be a point at which the overdraft limit vs. probability of charge-off curve falls off rather rapidly as the risk of charge-off loss overwhelms the possibility of incremental fee revenue. Third, the overdraft limit vs. probability of charge-off curve may either approach zero or tail off to some small no zero amount where very little principal is put at risk for the opportunity of securing a single fee.
[0106]Various multi-parameter families of smooth curves with these properties can used to generate limits. One embodiment of the present invention uses the 5-parameter family of curves given by the following equation.
L=a(e.sup.(-bpc.sup.)-e.sup.(-b))+c(1-p)+d
[0107]where
[0108]L=The overdraft limit to be assigned to a risk group.
[0109]p=The probability of charge-off for that risk group.
[0110]a, b, c, d, e=The five parameters governing the detailed shape of the curve.
[0111]Other similar equations could be used as well.
[0112]The precise shape of the curve giving the limits (of a given type: Batch, Authorization, etc.) as a function of the probability of charge-off are determined through a multi-step modeling procedure.
[0113]A suitable modeling period is chosen. Eventually modeling results will be normalized to yield annual values. In one embodiment of the present invention, a single calendar month is used.
[0114]The results of using a test limit of zero dollars for each risk group are modeled for the month.
[0115]The Profit Formula is used to determine the profit (or loss) at that limit for each risk group on each day of the modeling period
[0116]The total profit (or loss) for each risk group is obtained by summing the individual daily results.
[0117]The process is repeated with a new test limit. It is helpful to examine fairly closely spaced test limits near zero and more widely spaced test limits as one works toward a suitable maximum. In one embodiment of the present invention, test-limit increments of 5 dollars are used at first and then gradually increased to increments of 500 dollars up to a maximum of 5000 dollars.
[0118]The results of this iterative modeling process are assembled into a Profit Grid, an example of which is shown in FIG. 15.
[0119]For any given Profit Grid and any given multi-parameter set of curves, standard regression techniques are used to find the parameter settings resulting in the maximum total profit for all risk groups. In one embodiment of the present invention, Excel's Solver feature performs this function.
[0120]The models in this procedure examine the what-if profit (or loss) of re-authorizing or re-posting transactions at the current test limit instead of at the limit the account actually had on that day. Because customers will behave differently as they are treated differently, one can not assume that the effects of one day can be carried forward to the next over an extended period of time. In one embodiment of the present invention, no effects are carried forward with each posting day being modeled as a simple change from the way that day had originally posted at the bank. In other embodiments, differences could be allowed to accumulate over a period of days before being discarded. Thus, for example, Wednesday's model might include balance differences resulting from modeled activity on Monday and Tuesday. In this 2-day cumulative approach, Thursday's model includes balance differences resulting from Tuesday and Wednesday, but not from Monday.
[0121]As a result of the methodology and processes describe above, limits can be assigned that vary with probability of charge-off, meet the general criteria highlighted in FIG. 14 and maximize profit over an extended period long enough to be realistically normalized to a year.
[0122]Tuning
[0123]The limits assigned by the methodology describe above will grant "safe" case histories higher limits and risky case histories lower or even zero limits. Changing the limits offered to an account as its case history evolves, will induce further change in the way the account holder manages that account. Thus, however well a given decision tree recognizes and partitions out the unique self-similar risk-groups, the effects of using that tree to assign future limits will induce changes in customer behavior that over time erode the predictive accuracy of the tree. For this reason, some form of tracking and tuning are necessary to insure ongoing fidelity.
[0124]Tracking and tuning are important for other reasons as well. Each year the fraction of debit transactions conducted electronically increases. Many of these are ATM or POS transactions. If declined, an ATM or POS transaction generates no revenue, not even Interchange Fees. By contrast, a returned check generates a returned item fee that is, in most cases, the exact same size as a paid overdraft fee. So future payment migration will further alter the revenue framework, detuning any purely static limit system.
[0125]Two other factors to consider are the joint influences of competition from non-bank financial service providers and of product reforms aimed at expanding and/or reclaiming market share. These factors introduce additional dynamic elements that will render at least some current assumptions invalid in the future.
[0126]The tracking and tuning elements of the present methodology provide a way to respond to the aforementioned challenges, while at the same time providing a way to "turn on" the methodology at a bank that is either unable or chooses not to initiate a study of the type described earlier. (See "Collecting Data and Assembling Case Histories") Indeed, since the study approach leads to considerable delay in implementation, the preferred approach would be to forego a study and "turn on" the methodology as described herein.
[0127]In one embodiment of the present invention, a software system, interfaced with the bank's systems, collects the raw data elements needed to compute values for the set of individual telltales determined to be the most powerful predictors of charge-off and cure. That same system also:
[0128]Runs case histories through the then current decision tree, thereby determining their probability of charge-off;
[0129]calculates from the probability of charge-off, the overdraft limit(s) to be assigned to the case history. (See "Treatment Optimization and Limits");
[0130]collects and assembles tracking information on the limits used, the fees generated and the charge-offs incurred; and
[0131]analyzes these results in view of the decision tree behind the limits, the individual telltales used in that tree, and other individual telltales available at the time but not used by the tree.
[0132]Referring again to FIG. 16, a software system for implementing the methodology of the present invention includes one set of components running locally at each bank using the system and another set of components running at a central location. The components running locally at each installed bank house the logic and data needed to assign overdraft limits for that bank's account base; the central components house the logic and data to perform regular, ongoing performance tuning for all individual bank installations (see FIG. 17).
[0133]The process begins as shown in FIG. 16, with data being extracted from five major systems in the bank.
TABLE-US-00001 TABLE 1 Bank Source System Information to be Acquired DDA (Demand Deposit Account Account, transaction, day-1 exception System) handling, balances, overdraft limits. Exceptions System Day-2 exception handling. Customer Information System Customer information, relationship information. Online Authorization System Authorizations, denials, overdraft limits, intra-day memo-posted items. Charge-Off Collection System Charge-offs, recoveries.
[0134]These systems are fairly standard across a wide spectrum of banks, although the actual names for these systems used within a given bank vary. Often, the interface information required is replicated by the bank in more than one system, and some systems may be easier or more economical to extract from. Thus, in some cases, additional data sources, beyond those listed in Table 1, may be required. In other cases, one Bank Source System may be omitted because the data required from it is replicated in other systems on the list.
[0135]Banks implementing the system are provided with specifications describing how each of several interface files are to be prepared prior to being passed to Local Limit System (see FIG. 16). These specifications define the content, format, file naming conventions, update rules, and update frequency for each such interface file. The specifications also provide for the option of dividing all case history information by "regions." These "regions" should not be thought of as necessarily geographical regions, but instead as any grouping of case histories into subsets convenient for the bank to process separately.
[0136]In order for information from different interface files to be combined so as to either create or extend in a case history, all the information about a given case history needs to share some unique key. The account number (possibly in combination with a bank or organization number) is the natural key for such a purpose, but has the disadvantage of exposing potential identity theft information (the account number itself) to the Local Limit System and Central Performance Optimizer. In contrast, there is no risk of identity theft associated with the other extract fields, even though these fields contain the critical information needed to predict charge-off prediction and tune performance.
[0137]Consequently, it adds a useful layer of security to "mask" account numbers (or the combination of bank number or organization number along with account number) prior to sharing the prepared extract files with the Local Limit System and eventually the Central Performance Optimizer. This process is illustrated in FIG. 18. Because the bank controls the encryption keys used to "mask" account numbers, only they are in a position to "unmask" them. Unmasking is, indeed, an important requirement in support of limit assignment and problem resolution.
[0138]It will be recalled that the present invention assigns one or more overdraft limits to each case history. (See Treat Optimization and Limits.) These limits are passed back from the Local Limit System to the bank using the masked account numbers as identifiers. To make use of these limits in updating their own systems, the bank must unmask the account numbers.
[0139]Similarly, any installation of a new methodology or system normally involves a testing period. During such testing periods, one often encounters apparent data anomalies that must be traced back to source systems involved. Even when a methodology or system has been in place for some time, there is still the need for a trace-back method, should unanticipated data vales materialize. In the current case, in order to trace back one or more case histories, the data in question must be sent back to the bank still keyed by the masked account numbers the bank assigned prior forwarding the raw data on to the Local Limit System. In order to research this case history data on their own systems, the bank must first unmask the account numbers for each.
[0140]Returning now to the extract files shown in FIG. 18, after identity field masking these files would be placed in a designated staging area on the bank's secure storage. This area would have previously been made accessible to the Local Limit System. At this point, one of two things would happen:
[0141]The bank process responsible for moving the files to the staging area would message the Local Limit System (see FIG. 16) notifying it that new extracts were available for import; or
[0142]the Local Limit System would have been previously configured to look periodically (poll) for new files in the staging area and begin import processing whenever they were detected.
[0143]Regardless of whether the Local Limit System becomes aware of new extract files via messaging or polling, the next step is to import all available files. Import processing performs various validity checks on the data, updates case history information in the Local Database attached to the Local Limit System (see FIG. 16), and copies each processed extract to another location to preserve the file, should it be needed further, while preventing redundant processing.
[0144]Telltale Computation
[0145]Once the Local Database (see FIG. 16) has been updated with any additions or changes to the case histories, individual telltale calculation can begin. As explained earlier (see Determining the Most Promising Representation of Each Conceptual Telltale), any given conceptual telltale may have one or more representations. Many of these representations follow similar calculation rules. For example, one frequently repeated rule can be codified in a template of the form:
[0146]Count the total number of transactions of type ______ that have occurred in the last ______ calendar days.
[0147]In the preferred embodiment, each representation of each conceptual telltale to be refreshed across the case histories is listed in a table that indicates the specific imported data and calculation template to use. Working through this table for each case history completes the process of refreshing all telltales. From time to time, table entries may be added, adding a new individual telltale, or marked as disabled, indicating that a given individual telltale will no longer be refreshed (for now).
[0148]Limit Assignment
[0149]At implementation, each bank adopting the preferred embodiment will be assigned an initial decision tree for partitioning their case histories into risk groups. This decision tree will be based on what is known about effective trees previously or currently in use at other institutions that have adopted the system and information gathered during the implementation planning process. This initial tree will be known to partition case histories into risk groups with certain probabilities of charge-off.
[0150]Similarly, based on what is known about effective limit setting functions (see Treatment Optimization and Limits) at other institutions that have adopted the system and information gathered during the implementation planning process, an initial set of limit functions will be assigned. These limit functions assign limits of various types (see the discussion about multiple limits in Treatment Optimization and Limits) to case histories based on their probability of charge-off. Thus, as each case history is passed through the decision tree the result is a risk group with a probability of charge-off and therefore a set of limits.
[0151]Both the initial decision tree and the initial set of limit functions should be regarded as provisional in the following sense: While they serve as conservative starting points, as yet, they do not fully take all bank specific information into account and are, therefore, not fully optimized. We will return to how the preferred embodiment incorporates bank specific information into trees and limit functions in a later section.
[0152]Local Reports
[0153]In order to monitor day-to-day operation, track long term performance, and take advantage of the unique, case history database assembled by the preferred embodiment, it will offer a selection of standard reports and an ad hoc reporting facility. Standard reports may be set to run automatically, on an appropriate schedule, or on an as needed basis. All reports may be both printed or distributed electronically using the preferred electronic distribution channel of the bank.
[0154]Local reports would have access to all the balance, transaction, exception, account, customer and relationship information received from the bank. Local reports would also have access to the limits sent back to the bank and statistical summary information on the effectiveness of those limits in providing customer service, in generating fees and in controlling charge-offs. Other information, like the logic structure of the current tree, the set of telltales it relies on, the calculation of those telltales and the limit functions in use might not be available to the users of the Local Limit System.
[0155]Upload to Central Performance Optimizer
[0156]Periodically, the data accumulated in the Local Database by the Local Limit System would be uploaded to the Central Performance Optimizer and stored in its database, the Central Repository. (See FIG. 16.) Data would be encrypted and transmitted over a secure FTP link, then decrypted for update into the Central Repository. The upload frequency could be as often as once a day or as infrequently as once a month or less, depending on the amounts of data accumulated at a given size bank and the FTP bandwidth available. Other methods of encryption and transmission would be available in other embodiments.
[0157]Note that the decryption referred to in the last paragraph, does not expose privacy information. Account numbers (and any other privacy fields used) are already masked in the extracts forwarded by the bank to the Local Limit System. Only masked values are imported into the Local Database. These masked numbers are then encrypted once again for transmission to the Central Performance Optimizer. The decryption that follows transmission, returns account numbers (and any other privacy fields) to their masked values. Thus identity information is still protected.
[0158]Performance Optimizing
[0159]As discussed earlier (see Collecting Data and Assembling Case Histories), one approach to implementing the methodology employed in the invention is to conduct an up-front study. Such a study would collect information, retained by the bank to establish case histories tracing sufficiently far back in time as to allow for the calculation of those historical telltales based on days and/or months of history. For many banks, this approach is impractical. Even when it is practical, collecting and manipulating the data could lead to implementation delays.
[0160]The preferred embodiment relies instead on forward data collection. When the system is "turned on" the bank sends extract files initializing the case histories to be tracked and awarded limits by the system. However much historical information is available should be included in these extracts. Typically this will be enough to create some historical telltales but not those that span a longer period, ruling out these other telltales for immediate use. After the required longer period of time, these other telltales become eligible for inclusion in decision trees
[0161]It will also be typical for a bank to include in its extracts certain information unique to that institution. For example, a bank might include its own numeric or categorical customer profitability score. In order to determine the predictive value of bank unique information, accounts with differing values must be watched over a period of time to see which overdraft and later cure, and which overdraft and later charge off. After a suitable period has elapsed, the stand-alone predictive value of such bank-specific telltales can be assessed via the techniques described in Determining the Most Promising Representation of Each Conceptual Telltale and the power of such individual telltales to work in concert with others analyzed by testing new decision trees.
[0162]Thus some telltales must first "ripen" before enough is known about them to use them in the case history partitioning process. As they do ripen, the potential exists to take advantage of what they convey about a given case history and improve to overall prediction of charge-off and cure. This is one of three ways in which the Central Performance Optimizer acts to tune performance.
[0163]The second concerns changes in the bank's product mix, account base, geographic footprint, transaction mix and operational procedures, all of which normally evolve slowly over time and any of which may change suddenly with the introduction of a major bank initiative. Such changes can render previously powerful telltales less so. Conversely, such changes can increase the predictive power of a telltale that had not seemed promising earlier.
[0164]The third way in which the Central Performance Optimizer acts to tune performance arises because, in principle, one could define an infinite number of telltales based on the data being collected. In the end, those actually created and tested are a matter of human ingenuity and business sense. Because the Central Repository brings together similar information from many banks and because it houses interesting bank unique data items as well, it provides a workbench where human creativity and business sense can be applied in the search for new predictors of charge-off and cure.
[0165]In summary, therefore, the Central Performance Optimizer provides the following telltale and decision tree capabilities:
[0166]test new trees based on telltales as they "ripen" following implementation;
[0167]test new combinations of telltales in new trees as changes in the bank de-optimize the current set; and
[0168]provide a research platform for the search for even better ways of turning raw extract information into predictive telltales and trees.
[0169]The Central Performance Optimizer also supports limit function tuning. Recall that limit functions map the probability of charge-off associated with a risk group into one or a set of overdraft limits that constitute the treatment for that risk group. (See Treatment Optimization and Limits.) The extent to which these functions optimize the profitability of the ensemble of case histories being tracked and managed by the Local Limit System will change over time with other natural changes as discussed earlier: namely, either evolutionary or sudden changes to product mix, account base, geographic footprint, transaction mix or operational procedures.
[0170]The Central Performance Optimizer, in the preferred embodiment at least, is a combination of software routines to seek improved telltales, trees and limit functions along with a set of tools allowing subject-matter experts to take that same process even further.
[0171]One way the Central Performance Optimizer will seek improved telltales is to examine all meaningful combinations of values that can be plugged into each of the calculation templates in the system. Consider, for example, the calculation template discussed in the section on Telltale Computation.
[0172]Count the total number of transactions of type ______ that have occurred in the last ______ calendar days.
[0173]One transaction type and conceptual telltale of interest that relies on this template is the number of customer initiated debits in the N most recent days. The Central Performance Optimizer would seek the "best" individual representation of this conceptual telltale by trying all values of N from 1 to the maximum numbers of days available in the raw data history provided in a given bank's extract files. The ROC lift for each value of N would be calculated, compared and plotted. (See FIG. 6, ROC Curves and Lift and the section titled Determining the Most Promising Representation of Each Conceptual Telltale.) Such analysis might show that the ROC lift vs. the number of calendar days counted peaks at a single value or has multiple peaks. The former case would lead to a single telltale with the value of N giving the maximum lift; the latter case would lead to multiple telltales.
[0174]Similarly, within the Central Performance Optimizer the decision tree building software would be programmed to look at all possible trees meeting certain reasonability constraints. Because the number possible trees based on T individual telltales chosen from M available telltales grows rapidly (on the order of MT), reasonability constraints are needed to ensure that the Central Performance Optimizer completes this analysis in a reasonable amount of time.
[0175]Once the automated routines of the Central Performance Optimizer (and/or subject-matter experts using the data in the Central Repository and the tools supplied by the Central Performance Optimizer) have found an enhanced configuration of telltales, decision tree and limit functions, a "package" with the code and table modifications needed to effect those enhancements is prepared for download to the bank.
[0176]Enhancement Packages
[0177]Packaged enhancements are encrypted by the Central Performance Optimizer, downloaded to the receiving bank over secure FTP, unencrypted by the Local Limit System at that bank and stored Each time a new enhancement package is forwarded to a bank's Local Limit System, the designated system administrator for that system is notified and provided with a brief description of high-level contents of the package, the reasons for its being sent and the differences it should make.
[0178]The code and table modifications included in the package remain idle until the system administrator turns them on in "test mode," In test mode the new code and tables are run against a suitable sample of the bank's case histories side-by-side with the existing code and tables currently in use at that bank. Various test results are made available via screens and reports. Based on these outputs, the system administrator for the Local Limit System may chose to activated the new code and tables, or leave them idle pending further testing and inquiry.
User Contributions:
comments("1"); ?> comment_form("1"); ?>Inventors list |
Agents list |
Assignees list |
List by place |
Classification tree browser |
Top 100 Inventors |
Top 100 Agents |
Top 100 Assignees |
Usenet FAQ Index |
Documents |
Other FAQs |
User Contributions:
Comment about this patent or add new information about this topic:
Images included with this patent application:
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
| Similar patent applications: | |
| Date | Title |
|---|---|
| 2012-03-15 | Determining commercial share of wallet |
| 2009-08-20 | System and method for minimizing redundant meetings |
| 2012-04-19 | Computer-implemented system and method for offering commercial parking reservations |
| 2012-04-19 | Method of conducting financial transactions where a payer's financial account information is entered only once with a payment system |
| 2008-10-30 | Method and system for managing caselog fraud and chargeback |
| New patent applications in this class: | |
| Date | Title |
|---|---|
| 2022-05-05 | Disposition of transactions after-the-fact |
| 2022-05-05 | Search engine with automated blockchain-based smart contracts |
| 2019-05-16 | Products and processes for revenue sharing and delivery |
| 2019-05-16 | Systems and methods for processing electrical energy-based transactions |
| 2019-05-16 | Item information retrieval system |
| New patent applications from these inventors: | |
| Date | Title |
|---|---|
| 2013-07-18 | Systems and methods for deposit predictions based upon template matching |
| 2010-09-23 | Systems and methods for deposit predictions based upon monte carlo analysis |
| 2010-09-23 | Systems and methods for deposit predictions based upon template matching |
| Top Inventors for class "Data processing: financial, business practice, management, or cost/price determination" | |
| Rank | Inventor's name |
|---|---|
| 1 | Royce A. Levien |
| 2 | Robert W. Lord |
| 3 | Mark A. Malamud |
| 4 | Adam Soroca |
| 5 | Dennis Doughty |