Patent application title: DATA REDISTRIBUTION IN SHARED NOTHING ARCHITECTURE
Inventors:
Philip Shawn Cox (Toronto, CA)
Leo T.m. Lau (Thornhill, CA)
Adil Mohammad Sardar (Markham, CA)
David Tremaine (Thornhill, CA)
Assignees:
International Business Machines Corporation
IPC8 Class: AG06F1202FI
USPC Class:
711173
Class name: Storage accessing and control memory configuring memory partitioning
Publication date: 2009-03-05
Patent application number: 20090063807
Inventors list |
Agents list |
Assignees list |
List by place |
Classification tree browser |
Top 100 Inventors |
Top 100 Agents |
Top 100 Assignees |
Usenet FAQ Index |
Documents |
Other FAQs |
Patent application title: DATA REDISTRIBUTION IN SHARED NOTHING ARCHITECTURE
Inventors:
Leo T.M. Lau
Adil Mohammad Sardar
Philip Shawn COX
David Tremaine
Agents:
IBM ST-SVL;SAWYER LAW GROUP LLP
Assignees:
International Business Machines Corporation
Origin: PALO ALTO, CA US
IPC8 Class: AG06F1202FI
USPC Class:
711173
Abstract:
A system and method for data redistribution. In one embodiment, the method
includes dividing data into batches at a sending partition; populating a
first data structure with the first pages and the first control
information in a first data structure; storing the first data structure
in a cache at the sending partition; sending the changes over the network
to the receiving partition; receiving a notification that the changes
have been successfully stored in the second hard disk at the receiving
partition; and storing, in response to the notification, the changes on
the first hard disk at the sending partition.Claims:
1. A method comprising:dividing data into batches at a sending partition,
wherein the data is to be redistributed to a receiving partition, wherein
each batch comprises a plurality of first pages and first control
information, wherein the plurality of first pages includes changes to a
memory, and wherein the control information is used to restart a
distribution process in the event of a failure;populating a first data
structure with the first pages and the first control information in a
first data structure;storing the first data structure in a cache at the
sending partition, wherein the changes are not stored to a first hard
disk at the sending partition until after the changes are successfully
stored at the receiving partition;sending the changes over the network to
the receiving partition, wherein the receiving partition populates a
second data structure with second pages and second control information,
where the plurality of second pages includes the changes, and wherein the
changes are subsequently stored in a second hard disk at the receiving
partition;receiving a notification that the changes have been
successfully stored in the second hard disk at the receiving partition;
andstoring, in response to the notification, the changes on the first
hard disk at the sending partition.
2. The method of claim 1 further comprising removing the control information from the data structure to free up memory space.
3. The method of claim 1 further comprising:restarting the populating, storing, and sending steps in response to a failure during redistribution of data; andcausing an undo operation at the receiving partition in response to the failure.
4. A system comprising:a processor; anda memory for storing an application; anda first hard disk coupled to the processor, wherein the application is operable to cause the processor to:divide data into batches at a sending partition, wherein the data is to be redistributed to a receiving partition, wherein each batch comprises a plurality of first pages and first control information, wherein the plurality of first page includes changes to a memory, and wherein the control information is used to restart a distribution process in the event of a failure;populate a first data structure with the first pages and the first control information in a first data structure;store the first data structure in a cache at the sending partition, wherein the changes are not stored to the first hard disk at the sending partition until after the changes are successfully stored at the receiving partition;send the changes over the network to the receiving partition, wherein the receiving partition populates a second data structure with second pages and second control information, where the plurality of second pages includes the changes, and wherein the changes are subsequently stored in a second hard disk at the receiving partition;receive a notification that the changes have been successfully stored in the second hard disk at the receiving partition; andstore, in response to the notification, the changes on the first hard disk at the sending partition.
5. The system of claim 1 wherein the application is operable to cause the processor to:restart the populating, storing, and sending steps in response to a failure during redistribution of data; andcause an undo operation at the receiving partition in response to the failure.
Description:
FIELD OF THE INVENTION
[0001]The present invention relates to computer systems, and more particularly to a method and system for data redistribution.
BACKGROUND OF THE INVENTION
[0002]In data warehouse growth scenarios involving the addition of new database partitions to an existing database, it is necessary to redistribute the data in the database to achieve an even balance of data among all the database partitions (i.e., both existing partitions and newly added partitions). Such redistribution scenarios typically involve movement of a significant amount of data, and require downtime while the system is offline.
[0003]When database manager capacity does not meet present or projected future needs, business can expand its capacity by adding more physical machines. Adding more physical machines can increase both data-storage space and processing power by adding separate single-processor or multiple-processor physical machines. The memory and storage system resources on each machine are typically not shared with the other machines. Although adding machines might result in communication and task-coordination issues, this choice provides the advantage of balancing data and user access across more than one system in shared nothing architecture. When new machines are added to a shared-nothing architecture, existing data needs to be redistributed. This operation is called data redistribution. This data redistribution operation is far more common in data warehouse customers as the amount of data accumulates over time. In addition, as merges and acquisitions become more popular, the need for more capacity also increases.
[0004]One problem with this operation is that requirement of logging data movement requires a substantial amount of memory space to store the logged data. For example, if one machine is added to a two-machine cluster, 33% of the data of the entire database will need to be deleted on the existing machines and 33% will need to be added on the new machine. This significant amount of data logging not only impacts performance, but also introduces a significant burden on setting up the active logging space and its corresponding backup/restore system.
[0005]Accordingly, what is needed is an improved method and system for data redistribution. The present invention addresses such a need.
SUMMARY OF THE INVENTION
[0006]A method and system for data redistribution is disclosed. In one embodiment, the method includes dividing data into batches at a sending partition, wherein the data is to be redistributed to a receiving partition, wherein each batch comprises a plurality of first pages and first control information, wherein the plurality of first pages includes changes to a memory, and wherein the control information is used to restart a distribution process in the event of a failure. The method further includes populating a first data structure with the first pages and the first control information in a first data structure. The method further includes storing the first data structure in a cache at the sending partition, wherein the changes are not stored to a first hard disk at the sending partition until after the changes are successfully stored at the receiving partition. The method further includes sending the changes over the network to the receiving partition, wherein the receiving partition populates a second data structure with second pages and second control information, where the plurality of second pages includes the changes, and wherein the changes are subsequently stored in a second hard disk at the receiving partition. The method further includes receiving a notification that the changes have been successfully stored in the second hard disk at the receiving partition. The method further includes storing, in response to the notification, the changes on the first hard disk at the sending partition. According to the system and method disclosed herein, unnecessary logging is avoided and required memory space is minimized.
BRIEF DESCRIPTION OF THE DRAWINGS
[0007]FIG. 1 is a block diagram of a redistribution system in accordance with one embodiment of the present invention.
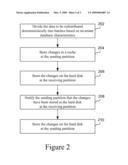
[0008]FIG. 2 is a flow chart showing a method for redistributing data in accordance with one embodiment of the present invention.
[0009]FIG. 3 is a block diagram of a redistribution system in accordance with one embodiment of the present invention.
DETAILED DESCRIPTION OF THE INVENTION
[0010]The present invention relates to computer systems, and more particularly to a method and system for data redistribution. The following description is presented to enable one of ordinary skill in the art to make and use the invention, and is provided in the context of a patent application and its requirements. Various modifications to the preferred embodiment and the generic principles and features described herein will be readily apparent to those skilled in the art. Thus, the present invention is not intended to be limited to the embodiments shown, but is to be accorded the widest scope consistent with the principles and features described herein.
[0011]A system and method in accordance with the present invention for redistributing data have been disclosed. The method includes dividing data that is to be redistributed to batches, where each batch includes pages that include changes to memory and corresponding control information. The batches are stored in a cache at a sending partition until the batches are stored in a hard disk at a receiving partition. After the batches are successfully stored in the hard disk at the receiving partition, the batches are stored in a hard disk at the sending partition. If there is a failure in the process, the process may restart by reprocessing the batch that was being processed during the failure. As a result, unnecessary logging is avoided, and required memory space is minimized. To more particularly describe the features of the present invention, refer now to the following description in conjunction with the accompanying figures.
[0012]FIG. 1 is a block diagram of a redistribution system 100 in accordance with one embodiment of the present invention. FIG. 1 shows a sending system or sending partition 102 and a receiving system or receiving partition 104. The sending partition 102 includes a processor 106, a redistribution application 108 that is executed by the processor 106 and stored in a memory. The sending partition 102 also includes a database management hard disk 110, consistency points 114, pages 116, control information 118, and a memory cache 120. Similarly, the receiving partition 104 includes a processor 126, a redistribution application 128 that is executed by the processor 126 and stored in a memory. The receiving partition also includes a database management hard disk 130, a file system hard disk 132, one or more consistency points 134, pages 136, and control information 138. For ease of illustration, only one consistency point 114 is shown at the sending partition 102, and only one consistency point 134 is shown at the sending partition 104. In operation, the redistribution applications 108 and 128 are operable to divide data into multiple consistency points 114 and 134, as described below.
[0013]FIG. 2 is a flow chart showing a method for redistributing data in accordance with one embodiment of the present invention. Referring to both FIGS. 1 and 2, in step 202, at the sending partition 102, the redistribution application 108 divides the data that is to be redistributed deterministically into batches, also referred to as consistency points 114, based on invariant database characteristics. The data is divided deterministically into batches, because redo operations may require the same batch size and pages. In particular implementations, the database structure may imply the type of table. In one implementation, the redistribution application 108 may select different batch sizes based on how the table which stored the data was created. In one embodiment, a consistency point is data structure that ties together a series of changes in memory (e.g., pages 116) and corresponding logical structure changes (e.g., control information 118). The consistency point 114 shown in FIG. 1 is the very first consistency point and includes modified or "dirty" pages 116 and corresponding control information 118. As the redistribution application 108 works on the table data stored on the database management hard disk 110, the redistribution application 108 populates the consistency point 114 with the pages and control information (numbered circle 1). In one embodiment, while data is being redistributed, multiple consistency points 114 may exist at any given time. Also, in one embodiment, the redistribution application 108 may store each consistency point 114 in separate consistency point files.
[0014]In step 204, for each consistency point, the redistribution application 108 stores the changes (e.g., pages 116) on the sending machine in the memory cache 120 at the sending partition 102. In one embodiment, the redistribution application does not store the pages (i.e., changes) to the database management hard disk 110 until after the redistribution application 128 at the receiving partition 104 has successfully stored all its changes (e.g., pages 136) for consistency point 134 to a database management hard disk 130.
[0015]The redistribution application 108 sends the changes over the network to the receiving partition 104 (numbered circle 2), and the redistribution application 128 populates the consistency point 134 with pages 136 which include the changes, and with control information 128 (numbered circle 3). This process continues until the redistribution application 108 at the sending partition 102 determines that enough data has been processed. Once enough data has been processed, in step 206, the redistribution application 128 at the receiving partition 104 initiates a procedure to commit or store the changes to the database management hard disk 130. In one embodiment, control information 128 is first written to the file system hard disk 132. This ensures that the control information has been written for the undo operation in the event of a failure. Once the control information has been written out, there is no need for caching at the receiver partition 104. As such, the redistribution application 108 may immediately begin writing the changed pages to disk. In one embodiment, before the sending partition 102 sends data, the sending partition needs to update the control information 118, and ensure that the control information 118 is written to file system hard disk 112.
[0016]In step 206, redistribution application 128 at the receiving partition 104 stores the changes on database management hard disk 130 at the receiving partition 104. In one embodiment, the receiving partition 104 may receive and process data from multiple consistency points (e.g., current consistency points being processed on different sending partitions) in parallel so that the logging scheme is minimized and does not impede concurrency or performance. In the step 208, the redistribution application 128 at the receiving partition 104 notifies the redistribution application 108 at the sending partition 102 that the receiving partition 104 has successfully stored the changes on the database management hard disk 130 at the receiving partition 104. In step 210, in response to the notification, the redistribution application 108 stores the changes on the database management hard disk 110 via the memory cache 120 at the sending partition 102. The redistribution application 108 may then empty the memory cache 120.
[0017]In one embodiment, there is one control file per consistency point, and once the consistency point is complete (e.g., all of the changes to the data in the consistency point are written to the database management hard disk 110 at the sending partition 102 and to the database management hard disk 130 at the receiving partition 104), the corresponding control files with the control information 118 and 128 may be removed from the consistency point 114 so that the control information does not accumulate and thus freeing up memory space.
[0018]In one embodiment, the data redistribute operation is restartable in that if the redistribute operation fails due to a problem such as a resource error (e.g., not enough hard disk space, memory, log space, etc.), the redistribution application 108 may simply restart the data redistribution process where it left off without needing to restore the database from the beginning. For example, the redistribution application 108 may restart at the batch after the batch that was last successfully stored at the receiving partition 104. In one embodiment, for each data page being processed, the redistribution application stores a relatively small amount of control information in a control file (CF) at both the sending and receiving partitions 102 and 104 during runtime. In one embodiment, the control information includes the page ID and the number of rows changed in each page. The page ID and the number of rows changed in each page provide a reference point that the redistribution application 108 may use to restart the data redistribution process where it left off before the failure. As such, there is no need to store user data from the control file. Storing only the control information in the control file minimizes the amount of information saved on both the sending and receiving partitions 102 and 104, while still being able to recover from an unplanned failure.
[0019]FIG. 3 is a block diagram of a redistribution system 100 in accordance with one embodiment of the present invention. The redistribution system 100 of FIG. 3 is the same as that of FIG. 1, except that the redistribution system 100 of FIG. 3 includes second consistency points 150 and 160, pages 152 and 162, and control information 154 and 164. As FIG. 3 shows, in one embodiment, the redistribution application 108 simultaneously executes two sequences of events. As described in more detail below, the numbered triangles 1-6 indicate how a consistency point is committed (i.e. stored to hard disks). In one embodiment, the numbered circles 1-3 indicate the same sequence of events shown in FIG. 1 above.
[0020]When the consistency point 114 is being committed, the redistribution application 102 will continue to operate on the second consistency point 150. In one embodiment, when the redistribution application 108 first commits consistency point 114, the control information 118 is stored in a control file on the file system hard disk 112 via the memory cache 120 (numbered triangle 1). The redistribution application 108 then sends a message containing the changes over the network to the receiving partition 104 (numbered triangle 2). Upon receiving the message, the redistribution application 128 at the receiving partition 104 begins writing the control information 128 and then the pages 136 to the file system hard disk 132 at the receiving partition 104 (numbered triangle 3). In one embodiment, the redistribution application 108 does not write pages 116 to the database management hard disk 110 at the sending partition for a particular consistency point until after the redistribution application 128 writes the corresponding control information 128 and pages 136 to the database management hard disk 130 at the receiving partition 104. As such, if an error occurs, the redistribution application 108 may reprocess that consistency point at the sending partition. In one embodiment, after the redistribution application 128 at the receiving partition 104 writes the pages 136 to the file system hard disk 132 at the receiving partition 104, the redistribution application 128 writes the corresponding control information to the database management hard disk 130 (numbered triangle 4). The redistribution application 128 at the receiving partition 104 then sends back a notification to the redistribution application 108 at the sending partition 102 to indicate that the redistribution application 108 has successfully stored the changes on the database management hard disk 130 at the receiving partition 104 (numbered triangle 5). In response to the notification, the redistribution application 108 then writes its pages 116 the database management hard disk 110, which completes the processing of consistency point 114.
[0021]In one embodiment, Table 1 shows example content in a status table. On either the sending or receiving partitions 102 and 104, each consistency point may be in either a "Done" state or a "Not Done" state. The Table 1 shows the corresponding recovery actions for all combinations:
TABLE-US-00001 TABLE 1 Sending Partition Receiving Partition Sending Partition Receiving Partition CP state CP state Recovery Action Recovery Action Not Done Not Done Redo CP Undo CP Not Done Done Redo CP Nothing Done Not Done Error Error Done Done Nothing Nothing
[0022]In one embodiment, after a failure, the redistribution applications 108 and 128 only need to perform a redo operation at the sending partition 102 and perform an undo operation the receiving partition 104 for any of the above-described processing steps associated with any batches of changes that were not successfully stored at the hard disk of the receiving partition 104 before the failure occurred. The information stored in the control file for each consistency point will then be used to redo the operations on the sending partition and undo the operations on the receiving partition.
[0023]According to the system and method disclosed herein, the present invention provides numerous benefits. For example, embodiments of the present invention avoid unnecessary logging by avoiding having to log the actual content of each row being moved thereby saving storage space. As such, the sending partition stores enough information to redo the consistency point in case of a failure. Also, the receiving partition stores enough information to undo the consistency point in case of a failure. The value of "minimal logging" is that it minimizes the log space requirement so that the system need not reserve inordinate amounts of log space for the operation. At the same time, minimal logging allows for the redistribution operation to be restartable. Minimal logging also helps to increase performance because fewer system resources are consumed by logging operations.
[0024]A method and system for redistributing data has been disclosed. The method includes dividing data that is to be redistributed in to batches, where each batch includes pages of changes to memory and corresponding control information. The batches are stored in a cache at a sending partition until the batches are stored in a hard disk at a receiving partition. After the batches are successfully stored in the hard disk at the receiving partition, the batches are stored in a hard disk at the sending partition. As a result, unnecessary logging is avoided and required memory space is minimized.
[0025]The present invention has been described in accordance with the embodiments shown. One of ordinary skill in the art will readily recognize that there could be variations to the embodiments, and that any variations would be within the spirit and scope of the present invention. For example, embodiments of the present invention may be implemented using hardware, software, a computer-readable medium containing program instructions, or a combination thereof. Software written according to the present invention or results of the present invention may be stored in some form of computer-readable medium such as memory, hard disk, CD-ROM, DVD, or other media for subsequent purposes such as being executed or processed by a processor, being displayed to a user, etc. Also, software written according to the present invention or results of the present invention may be transmitted in a signal over a network. In some embodiments, a computer-readable medium may include a computer-readable signal that may be transmitted over a network. Accordingly, many modifications may be made by one of ordinary skill in the art without departing from the spirit and scope of the appended claims.
User Contributions:
comments("1"); ?> comment_form("1"); ?>Inventors list |
Agents list |
Assignees list |
List by place |
Classification tree browser |
Top 100 Inventors |
Top 100 Agents |
Top 100 Assignees |
Usenet FAQ Index |
Documents |
Other FAQs |
User Contributions:
Comment about this patent or add new information about this topic:
Images included with this patent application:
 |  |
 |  |
| Similar patent applications: | |
| Date | Title |
|---|---|
| 2012-05-10 | Spatial extent migration for tiered storage architecture |
| 2012-09-06 | Method for managing hierarchical storage during detection of sensitive information, computer readable storage media and system utilizing same |
| 2012-09-06 | Spatial extent migration for tiered storage architecture |
| 2010-10-28 | Hybrid distributed and cloud backup architecture |
| 2011-01-27 | Data reliability in storage architectures |
| New patent applications in this class: | |
| Date | Title |
|---|---|
| 2019-05-16 | Configuration state registers grouped based on functional affinity |
| 2018-01-25 | Disaggregated compute resources and storage resources in a storage system |
| 2016-12-29 | Byte addressable storing system |
| 2016-06-30 | Memory management in presence of asymmetrical memory transfer cost |
| 2016-06-02 | Apparatus and method for processing data samples with different bit widths |
| New patent applications from these inventors: | |
| Date | Title |
|---|---|
| 2010-05-20 | Efficient undo-processing during data redistribution |
| 2009-03-05 | Method for maintaining parallelism in database processing using record identifier substitution assignment |
| 2009-03-05 | Dynamic data compaction for data redistribution |
| Top Inventors for class "Electrical computers and digital processing systems: memory" | |
| Rank | Inventor's name |
|---|---|
| 1 | Lokesh M. Gupta |
| 2 | Michael T. Benhase |
| 3 | Yoshiaki Eguchi |
| 4 | International Business Machines Corporation |
| 5 | Chih-Kang Yeh |